
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
As the mussel farming industry expands, particularly in regions such as New Zealand, there is a growing need for advanced monitoring and management solutions to ensure sustainability and operational efficiency. The current reliance on manual infrequent observation of aquaculture structures limits farmers' ability to monitor them in real time. Addressing these challenges, large-scale 3D reconstruction provides a practical solution by facilitating the creation of replicable depictions of mussel farm scenes and floatation buoys derived from recorded video, supporting off-site evaluation and enabling precise decision making. This paper introduces a novel approach to enhance the visualisation and monitoring of mussel farm floatation through a hierarchical reconstruction process. In contrast to earlier studies, we focus on recovering not only the overall environment (background) but also the finer details of key elements such as buoys to create a comprehensive representation of mussel farm geometry and appearance. We propose to segment the scene into the background and granular object instances and reconstruct them separately in a multi-stage process. The initial 3D scene reconstruction is performed using the Structure-from-Motion (SfM) technique, leveraging video footage captured by a vessel-mounted camera. This coarse reconstruction serves as the foundation for subsequent fine-grained enhancements. To recover finer details, object tracking is applied and the trajectories obtained are then conjunct with geometry triangulation to determine the real-world positions of individual buoys. A multiple-scale denoising method, grounded in dominant direction correlation, is implemented to eliminate non-reliable tracking objects and reduce reconstruction artifacts, ensuring the accuracy of the final results. This hierarchical reconstruction approach contributes to the advancement of mussel farm management by offering a powerful technology for comprehensive visualisation, enabling farmers to make informed decisions based on a detailed understanding of the mussel farm's geometry and dynamics.
Introduction
In recent years, the aquaculture industry has experienced substantial growth, with mussel farming playing a pivotal role in this expansion. Regions such as New Zealand have witnessed the emergence of mussel farming as a prominent sector, contributing high-quality seafood for both domestic consumption and international exports. As the industry undergoes significant scaling, the demand for efficient management and monitoring solutions of the mussel farms becomes increasingly paramount (Ferreira et al. Citation2012; Chary et al. Citation2022).
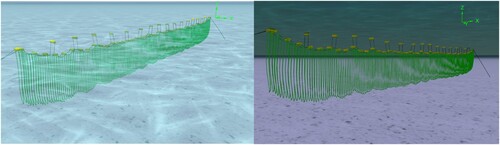
Mussel farming typically involves cultivating mussels on ropes suspended from buoys in coastal waters (See ). Buoys serve as floating platforms to which mussel lines are anchored. Mussel lines, also known as longlines or droplines, consist of ropes or cables with evenly spaced attachments for securing mussel spat (i.e.young mussels) or seedlings. These lines are submerged in the water, allowing the mussels to grow and mature. The arrangement of buoys and mussel lines forms the infrastructure of a mussel farm, providing support and stability for the cultivation process. Monitoring and assessing the structure of buoys and mussel lines is crucial to ensure operational efficiency and assess the environmental impact of mussel farming practices.
Figure 1. This visualisation depicts a mussel farm cultivation platform. The green lines symbolise the ropes where the mussels are cultivated. Suspended beneath the ropes are yellow cylinders representing buoys, which float on the water's surface, supporting the ropes. Two perspectives are visualised: the first provides an aerial view from above the water, while the second offers an underwater perspective.
Traditional manual monitoring approaches rely on labour-intensive on-site procedures, which have been proven to be resource-intensive and provide only sporadic assessments (Aquaculture, Management I Citation2023). To address these challenges, the adoption of 3D reconstruction, especially in large-scale open scenario applications, emerges as a potential solution. Such an approach aims to generate a reproducible representation of scenes using captured video, offering a holistic view of the scene environment (Zhao, Xue, et al. Citation2023). This technology has successfully supported real-world applications, such as precision agriculture (De Castro et al. Citation2018; Torres-Sánchez et al. Citation2018; Ziliani et al. Citation2018) and environment monitoring (Lin et al. Citation2023).
Introducing 3D reconstruction into mussel farm scenarios will yield several benefits. Firstly, it allows for precise spatial mapping and monitoring of the structural integrity of buoys, mussel lines, and other infrastructure components. By accurately capturing the three-dimensional layout of the farm, we can detect mussel population growth and health, and assess any irregularities or damage, which is essential for ensuring the safety and effectiveness of mussel farming operations. Moreover, the 3D reconstruction of mussel farms facilitates advanced data analytics and decision-making processes. By integrating spatial data with environmental parameters, such as water quality and weather conditions, we can optimise farm operations, improve productivity, and mitigate risks.
However, the task of reconstructing an expansive marine scene is notably challenging due to the intricacies arising from complex terrains, reflective water surfaces, and the unpredictable movements of the camera. Existing 3D reconstruction methods, encompassing geometric techniques including structure-from-motion, multi-view stereos, or neural-network-based methods such as Neural Radiance Field (NeRF), face limitations in handling dynamic camera movements within a small range for reliable reconstruction performance. Furthermore, these methods often encounter difficulties in capturing satisfactory representations of open outdoor environments characterised by unconstrained illuminations and variations in object occlusion and scale (Gao et al. Citation2022). The work by Zhao, Xue, et al. (Citation2023) first explored the 3D reconstruction method on mussel farm scenarios. While that approach can deliver satisfactory coarse reconstructions of large open scenes, it faces challenges in capturing crucial details like buoys which are essential for comprehensive monitoring and decision-making in mussel farm management.
The unique ecosystem of mussel farms presents complex spatial and environmental factors that necessitate precise reconstruction techniques. Existing methods have struggled to capture the intricate details of mussel farm structures and environments, leading to limitations in environmental monitoring, resource management, and scientific study objectives. To overcome the limitations of current 3D reconstruction methods and achieve accurate 3D reconstructions of mussel farms, our proposed pipeline introduces novel approaches by leveraging advanced techniques in deep learning-based object detection, multi-object tracking, and geometry triangulation. We aim to enhance the visibility, precision and detail of reconstructed mussel lines while maintaining efficiency and adaptability to overall marine environments. This method effectively segments the scene into the background environment reconstruction and granular object instances reconstruction, specifically targeting buoys, thereby enabling a comprehensive representation of mussel farm geometry and appearance. Initially, the overall environment will be reconstructed utilising both Structure-from-Motion (SfM) and Multiple Visual Stereo (MVS) techniques on video footage captured by a vessel-mounted camera. This process not only establishes a foundational coarse reconstruction but also estimates the intrinsic and extrinsic camera matrices for each image frame.
To further capture finer details, which are more critical for mussel farm monitoring but are mostly elusive in the coarse recovery, we incorporate deep learning-based buoy detection and tracking on the mussel farm video sequences. The obtained trajectories of each detected buoy are subsequently harmonised with geometry triangulation to calculate their real-world coordination. To enhance accuracy and reduce reconstruction artifacts, we introduce a multiple-scale trajectory filtering method rooted in dominant direction correlations to filter the stray buoys.
The results show that the hierarchical coarse-to-refined reconstruction approach can effectively generate a more nuanced 3D reconstruction of mussel farm dynamics, recovering a complete 3D model of buoys and detailing their spatial relations within the scene. By providing such intricate visualisation, our approach can equip mussel farmers to make informed decisions, contributing to enhanced efficiency and sustainability in the burgeoning mussel farming industry. In summary, our contributions are as follows:
We propose a hierarchical 3D reconstruction pipeline to reconstruct not only the overall environment of the mussel farm but also its key elements, such as buoys, ensuring a comprehensive replication of geometry and appearance.
We propose a reconstruction-by-tracking method for recovering object instances for fine-grained reconstruction enhancements. A deep learning-based multiple-object tracking algorithm is designed to effectively achieve buoy detection and trajectory tracking through the image sequence. Following this, a multi-scale trajectory filtering method is proposed to eliminate the tracking anomalies in buoys that stray from the dominant moving direction, ensuring the quality of the reconstructed mussel line.
We introduce a triangulation method to determine the 3D points of each buoy based on the tracked centroid and estimated camera matrices across different images. After meshing, these reconstructed buoys are seamlessly integrated with the background environment recoveries, which successfully generates a complete reconstruction.
Related work
3D reconstruction is a fundamental undertaking within the realms of computer vision and computer graphics. Its primary purpose is the precise synthesis of a 3D model from a sequence of 2D images depicting a scene or object. The reconstructed 3D model can authentically replicate the real-world spatial coordinates of the structure points of the scene, providing a comprehensive representation of the scene's geometry and appearance. 3D reconstruction technology often serves as a basis for a spectrum of subsequent applications (Wei et al. Citation2013), ranging from infrastructure assessment (Khaloo and Lattanzi Citation2017; Mlambo et al. Citation2017), comprehending scenes (Chen et al. Citation2020), classifying and segmenting 3D objects (Li, Yang, et al. Citation2022; Song et al. Citation2023), to applications in robotics and augmented reality (Kim et al. Citation2003).
Traditional 3D reconstruction methods
In the domain of 3D reconstruction, traditional methods including stereo vision (Zhang Citation1998; Szeliski Citation2022), structure from motion (Özyeşil et al. Citation2017; Szeliski Citation2022), and depth estimation algorithms (Zhang Citation1998; Eigen et al. Citation2014; Huang et al. Citation2023; Dong, Guo, et al. Citation2024; Dong, Zhang, et al. Citation2024) have played a crucial role. Stereo vision relies on exploiting disparities in corresponding points between images to estimate depth and reconstruct the 3D scene. A key step in stereo vision involves rectifying stereo image pairs to align their epipolar lines. Subsequently, matching algorithms are applied to identify correspondences between image points (Hartley and Zisserman Citation2003; Alcantarilla et al. Citation2013; Li, Barnes, et al. Citation2022).
Multi-view stereo (MVS) techniques (Schönberger et al. Citation2016) complement traditional stereo vision by leveraging information from multiple viewpoints. These methods aim to create a more comprehensive and detailed 3D reconstruction by integrating data from various camera perspectives. MVS involves dense matching algorithms that consider multiple images simultaneously. Notable pioneering work (Seitz et al. Citation2006) showcases a comprehensive analysis of various MVS methods and the improvement in the accuracy and completeness of the 3D scene reconstruction.
The structure from motion method, on the other hand, concentrates on estimating camera poses and 3D point positions from multiple views, particularly adept in scenarios with moving cameras (Wu Citation2011; Wei et al. Citation2020). This method involves three key stages: feature extraction, feature matching for correspondences, and camera pose estimation with 3D structure reconstruction. The camera poses intricately capture both the spatial position and orientation of each camera within the scene. Bundle adjustment is commonly employed to refine camera poses and 3D points, enhancing overall reconstruction accuracy (Engels et al. Citation2006; Agarwal et al. Citation2010; Zach Citation2014). These traditional techniques exhibit computational efficiency, particularly in handling small to medium-sized scenes and scenarios with controlled imaging conditions. However, they face challenges in dynamic scenes and heavily depend on the feature-matching accuracy. Some other efforts have been made to enhance the fundamental SfM for large-scale scenes and robustness, improving its reconstruction capabilities (Wu Citation2011; Chen et al. Citation2023; Cui et al. Citation2023). Notably, VisualSFM (Wu Citation2011) introduced an efficient and scalable system through incremental and distributed techniques. Schonberger and Frahm (Citation2016) introduced a revised SfM method, which presented a comprehensive pipeline aimed at enhancing the robustness, accuracy, completeness, and scalability of reconstructions. This approach has since become one of the most widely utilised methods and software tools for reconstruction purposes. DP-MVS designed a dense 3D reconstruction system for modelling large-scale scenes robustly, combining incremental SfM for sparse reconstruction, a novel detail-preserving PatchMatch approach for depth estimation, and memory-efficient fusion of depth maps for a dense point cloud and surface mesh (Zhou et al. Citation2021). However, this methods also reported oversampled mesh topology issues, which will cause heavy burden for rendering and storage.
Given our scenario in the vast, open, outdoor environment with varying illumination conditions and fluctuating camera movements, we employed the general-purpose revised SfM method proposed by Schonberger and Frahm (Citation2016), along with their developed COLMAP software. These tools demonstrate remarkable adaptability to large-scale and complex environments, making them suitable for our background scene reconstruction. Additionally, to further enhance the reconstruction of individual buoys at the instance level, we leverage deep learning-based tracking and triangulation techniques.
Deep learning-based 3D reconstruction methods
Recent advancements have witnessed the integration of deep learning techniques, predominantly leveraging deep neural networks including Multilayer Perceptrons (MLP) and Convolutional Neural Networks (CNNs), to propel the field of 3D reconstruction (Vijayanarasimhan et al. Citation2017). Some studies have introduced CNNs/MLP and related architectures to augment traditional feature extraction and matching processes (Sarlin et al. Citation2023), striving to enhance the accuracy and level of detail in 3D reconstructions (Jiang et al. Citation2021; Lindenberger et al. Citation2021; Wang, Karaev, et al. Citation2023). In contrast, DeepSFM (Wei et al. Citation2020) employs a deep learning-based approach that enhances bundle adjustment within the SfM pipeline, thereby improving the accuracy of 3D scene reconstruction. In addition, NeuralRecon (Sun et al. Citation2021) employs a strategy progressing from coarse to fine to predict local Truncated Signed Distance Function (TSDF) volumes, ensuring consistency in reconstruction between fragments through a convolutional variant of the Gate Recurrent Unit (GRU).
Furthermore, some recent work embraces the emerging deep learning-based Neural Radiance Fields (NeRF) for 3D reconstruction and novel view synthesis (Tancik et al. Citation2022; Zhang et al. Citation2022; Chen et al. Citation2024; Yuan et al. Citation2024). NeRF, unlike traditional methods relying on discrete surface representations (Mildenhall et al. Citation2020, Citation2021), represents a paradigm shift in 3D reconstruction by utilising neural networks as a continuous volumetric function. This neural network regresses density and colour values along rays (5D coordinates) and computes true colour via numerical integration. The continuous function nature of NeRF enables it to capture intricate details and lighting effects with high fidelity. Despite its ability to generalise to novel viewpoints and synthesise views not present in the training data, NeRF often requires significant computational resources and is sensitive to data sparsity. The NeRF approaches for unbounded scenes (Barron et al. Citation2022; Kulhanek and Sattler Citation2023) typically rely on 360-degree captures of the scene to mitigate data sparsity and ensure successful and high-quality reconstructions. However, in our scenario, the data is captured during vessel navigation, where there is no guarantee of obtaining a full perspective recording of the entire mussel farm area. This limitation poses challenges for applying NeRF methods effectively in our context.
Water/fluid surface reconstruction
Some research focuses specifically on reconstructing water surfaces (Pickup et al. Citation2011; Li et al. Citation2012; Thapa et al. Citation2020) or dynamic fluids. Unlike commonly studied objects such as human faces, bodies, or trees, reconstructing water surfaces presents substantial challenges. Primarily, the absence of visually distinctive features poses a significant hurdle to achieving accurate reconstruction. Additionally, the constant fluctuations in the topology of water pose significant challenges for tracking algorithms due to its dynamic nature. Furthermore, acquiring accurate ground truth data is problematic, as even advanced systems like laser scanners struggle to cope with the complex reflection and refraction conditions present in water environments.
Earlier work attempted to reconstruct water surface geometries based on physical constraints, considering properties such as refraction (Morris and Kutulakos Citation2011) and reflection (Wang et al. Citation2009). However, most of these techniques require specific experimental setups. Li et al. (Citation2012) attempted to relax these constraints by using viewport videos, employing a two-step method involving shape-from-shading surface reconstruction and shallow water flow estimation. However, this approach suffers from low input resolution and requires the camera to be very close to the water surface.
More recently, researchers have turned to deep neural networks to reconstruct Refractive surfaces. For instance, Zhan et al. (Citation2023) proposed NeRFfrac for novel view synthesis of water surfaces. They trained an MLP-based Refractive Field to accurately estimate the distance from the origin of the ray to the refractive surface. However, this approach requires an orthographic camera positioned to view the fluid surface from above.
These techniques either necessitate specific experimental setups or are designed for low-resolution input requirements. However, the data we captured is in high resolution and comprises single-view viewport navigation videos recorded in a typical outdoor setting (for more details, refer to Section ‘Data capturing and frame sampling’). None of the existing methods can be directly applied to this type of data. Instead, we employ structure-from-motion techniques, known for their robustness in large-scale outdoor reconstructions (Zhao, Xue, et al. Citation2023), to reconstruct both the sea surface and mountain terrain captured by cameras under unconstrained moving conditions.
Instance-level 3D reconstruction
Traditional 3D reconstruction methods, as discussed earlier, primarily focus on scene-level reconstruction. However, when it comes to reconstructing small objects or instances, these methods face precision limitations, particularly with sparse or diminutive structures. The challenge lies in accurately triangulating small or distant objects due to constraints in image information and the limited capabilities of feature-matching techniques. Deep learning-based approaches, while potent, require a substantial volume of training data with considerable computation costs to achieve satisfactory instance reconstruction. Moreover, they might encounter generalisation issues when dealing with novel instances not well-represented in the training dataset.
Several studies have aimed to enhance precision and details in 3D reconstruction more broadly. Works such as COTR (Jiang et al. Citation2021) explore techniques that leverage co-training strategies for improved precision in 3D reconstructions. Additionally, Yu et al. (Citation2021) propose PixelNeRF, a method that utilises neural networks to enhance the fidelity of 3D reconstructions, showcasing advancements in capturing detailed information. However, these methods still impose constraints on data sparsity, movement variations, and object distance, and often come with unsatisfactory object-level reconstruction performance.
Our proposed pipeline stands out from existing 3D reconstruction methods by addressing the distinct challenges encountered in mussel farm environments. Through the integration of advanced object detection, multi-object tracking, and triangulation techniques, our approach aims to deliver accurate and detailed reconstructions of mussel lines, even amidst varying illumination conditions and environmental factors. Unlike conventional methods, our approach takes a unique direction by prioritising the hierarchical reconstruction of specific elements tailored to the needs of mussel farms. This expansion of the existing methodology facilitates the attainment of the desired level of reconstruction detail, especially for small objects or instances that hold particular interest. The proposed approach brings forth efficiency and adaptability, tailored to address the unique challenges posed by marine environments.
Proposed method
In this study, we develop a dense 3D reconstruction method to address the challenges in reconstructing mussel farm environments, with a particular focus on granular key elements reconstruction, such as buoys. Our method is designed to provide a nuanced understanding of the mussel farm dynamics through a hierarchical coarse-to-refined pipeline, leveraging state-of-the-art techniques in computer vision and deep learning. The overall pipeline encompasses stages dedicated to data capturing, background environment reconstruction, and the granular reconstruction of mussel lines achieved by buoy tracking. This hierarchical approach aims to overcome limitations in existing 3D reconstruction methods, especially in dealing with small objects within large-scale marine scenes. By integrating deep learning-based buoy detection and tracking, trajectory filtering, triangulation for instance-wise 3D point reconstruction, and subsequent 3D point smoothing and mesh fusion, our method is to deliver a detailed and accurate representation of mussel farm environments.
Overall pipeline
The proposed method unfolds through a pipeline with four main steps, including data capture, coarse reconstruction, granular reconstruction, and refining a fused mesh of mussel farm (see ). Specifically,
| (1) | In the first step, the video is captured, and frames are selected, with a vessel-mounted camera serving as the eyes capturing the essence of the marine scene. Image sampling methods are employed to ensure an optimal collection of visual data with manageable multi-view consistency in illumination and sufficient visual overlap. | ||||
| (2) | The second step involves the coarse reconstruction of the background environment. The selected video frames undergo an incremental 3D reconstruction process, progressing from sparse to dense, to create a comprehensive canvas of the overall mussel farm appearance. | ||||
| (3) | Since the coarse reconstruction may fall short in recovering small objects due to the limited capability of the feature matching approach, the third step complements this by introducing an explicitly designed granular mussel line reconstruction approach based on deep learning-based multi-object buoy tracking. In this step, the buoy trajectories are first identified and then subjected to triangulation, coordinating the process of generating 3D points for each individual buoy instance. | ||||
| (4) | The last step involves the 3D point smoothing and mesh fusion stage. The acquired 3D points of the mussel line undergo an instance-wise meshing process, elevating precision in heights and orientation. These are then seamlessly combined with the environment reconstruction to present a holistic view. | ||||
Data capturing and frame sampling
The cultivated region within the mussel farm, marked by varying distances and numerous scattered buoys, serves as the primary area of interest for our study. The video, along with other information such as GPS positioning, is captured using a purposefully designed camera for marine environments mounted on a vessel as it navigates through the mussel farm (see the illustration of the device layouts and a navigation route). The data captured in such freestyle drifting deployment presents unique characteristics and challenges in the 3D reconstruction process. The vessel's unpredictable movements, for example, hovering and abrupt changes in speed, can result in irregular visual overlapping variations in the captured scenes, impacting the consistency of the reconstructed 3D model. Additionally, varying illumination conditions, such as capturing against the light or in low light situations introduced by the unconstrained vessel's capture process, further complicate the reconstruction process. The presence of complex terrains, including mountainous areas and reflective water surfaces, adds another layer of complexity. The high reflectance intrinsic to water, such as glistening water areas, can pose challenges in distinguishing and accurately reconstructing objects or surfaces around these areas.
Figure 2. The proposed hierarchical coarse-to-refined reconstruction method for comprehensive mussel farm 3D reconstruction. After adaptive frame sampling, the scenes are divided into the background environment and granular key instances to reconstruct individually. These reconstructed components are then merged seamlessly to produce the final reconstructions.
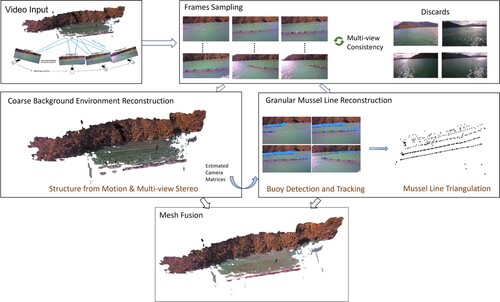
Figure 3. The data capturing device utilised is specifically designed for marine environments. Mounted on a vessel, the camera records video frames and GPS positions simultaneously during the vessel navigation, as illustrated by the red line in the map on the right-hand side.

To mitigate these challenges, the frame selection process becomes crucial for a reliable reconstruction performance. The current 3D reconstruction method benefits from a varied range of perspectives, high image quality, high visual overlap, and a manageable sequence length. Taking this into consideration, we follow the frame sampling method proposed by Zhao, Xue, et al. (Citation2023) to select the frames according to the brightness consistency and the vessel speed provided by the GPS information. Frames with good brightness and illumination consistency are selected, with a high sampling frame rate assigned to swift movement and a low sampling frame rate assigned to slow movement. This frame selection approach will ensure sufficient visual overlap and multi-view consistency in the input for a reliable reconstructed 3D model of the mussel farm.
Coarse environment reconstruction
After selecting frames, we compile a set of overlapping images for the subsequent 3D reconstruction. To reconstruct the overall background environment, we apply the widely recognised COLMAP method (Schonberger and Frahm Citation2016; Schönberger et al. Citation2016), a robust 3D reconstruction tool that is extensively used in various studies (Murez et al. Citation2020; Tancik et al. Citation2022; Zhang et al. Citation2022). The COLMAP method involves two key stages: sparse reconstruction using the SfM method mainly for camera matrices estimation, and dense reconstruction using the MVS method for fine-grained scene geometry. In the SfM phase, the process unfolds through a sequence of key steps: (1) pinpointing and extracting vital features or points of interest from individual images, (2) interlinking these features across images by employing geometric verification techniques for establishing correspondences, ensuring accurate camera pose estimation, and (3) piecing together camera poses and the 3D structure by leveraging the matched feature correspondences along with camera calibration data. The SfM pipeline yields estimated camera intrinsic and extrinsic parameters, including quaternion and translation vectors for each image, while also generating representations of 3D point clouds and dense meshes ().
Figure 4. Coarse background environment 3D reconstruction pipeline. The SfM method is initially applied to estimate a sparse representation of the overall mussel farm environment, including camera poses for each input image. Subsequently, the MVS method is employed for dense reconstruction, and the Poisson surface reconstruction method is utilised to generate the final reconstruction.
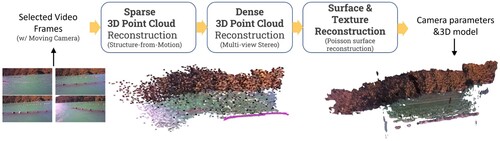
Following SfM (Schönberger et al. Citation2016), the MVS algorithm is incorporated, leveraging information from multiple viewpoints to create a more detailed 3D reconstruction. The MVS step utilises dense matching algorithms, simultaneously considering multiple images, enhancing the overall reconstruction process, especially in scenarios with varying distances and intricate structures often found in marine environments.
Granular mussel line reconstruction with buoy tracking
Deep-learning based buoy detection and tracking
For buoy detection, we employ a customised YOLO model (specifically YOLO-v7 (Wang, Bochkovskiy, et al. Citation2023) in standard architecture in our case, but interchangeable with other YOLO models), fine-tuned using a mussel farm image dataset captured from the same mussel farm and annotated with buoy bounding box as the ground truth (McMillan et al. Citation2023). YOLO, known for its real-time object detection capabilities, serves as a robust foundation for our detection stage. We employed the pre-trained models trained on the Microsoft COCO image dataset for weight initialisation. This dataset encompasses various object categories, such as cars, birds, and traffic lights. Transfer learning was then conducted on these pre-trained models using our mussel farm images, which were meticulously annotated with bounding boxes around buoys of diverse sizes, reflectance, and colour variations. Our mussel farm image dataset comprises images captured by both boat-mounted (489 images total) and buoy-mounted cameras (238 images total). To enhance the robustness of the final model, extensive data augmentation techniques were applied to our labelled dataset. Further details regarding our methodology can be referenced in our prior work (McMillan et al. Citation2023; Zhao, McMillan, et al. Citation2023). For the YOLOv7 implementation, we cloned the official implementation repository. In our adaptation, we preserved all convolutional layers as trainable layers and modified the number of output classes per bounding box anchor to one class, specifically representing buoys.
In the subsequent multi-object tracking stage, we employ the SORT (Simple Online and Realtime Tracking) algorithm (Bewley et al. Citation2016) as the baseline tracking method. Additionally, we explore more advanced algorithms built upon SORT, including OC-SORT (Cao et al. Citation2023) and DeepSORT (Wojke et al. Citation2017), to assess their applicability to our specific task of tracking buoys in the mussel farm environment.
SORT, tailored for online visual tracking, seamlessly processed detections from the video sequence in real time without any training. The algorithm utilises a Kalman Filter (Kalman Citation1960) featuring a linear motion model to estimate the current state of the track and predict the next state through state propagation. The Hungarian Algorithm (Kuhn Citation1955) is employed to associate new detections with existing tracks at each frame and make the Kalman Filter (Kalman Citation1960) make updates or corrections to the state estimate. For SORT implementation and usage, parameters such as maximum unmatched frames, minimum hits, and Intersection over Union (IOU) threshold are key. These parameters dictate the behaviour of the Kalman filter and the assignment of detections to existing tracks. In our implementation, we set the maximum unmatched frames set to 5, determining the maximum number of frames a track can remain unmatched before being considered for deletion. The minimum hits parameter set to 2 specifies the minimum number of hits required for a track to be considered confirmed. Additionally, the IOU threshold was set as 0.2, which governs the minimum IoU score required for a detection to be assigned to an existing track.
While SORT can provide reasonable tracking performance, it tends to be sensitive to tracking state noise, primarily due to the ambiguity caused by object occlusions or movement (Cao et al. Citation2023). OC-SORT (Cao et al. Citation2023) stands out by augmenting SORT's tracking robustness, especially in crowded scenes and instances featuring non-linear motion. This enhancement is achieved through the implementation of a dedicated observation-centric track updating mechanism. By focussing on observations and their specific characteristics, OC-SORT adapts dynamically to challenging tracking scenarios. In OC-SORT implementation and usage, we set the IOU threshold as 0.3, maximum unmatched frames as 30, which represents the maximum number of frames for which a track can remain unmatched before it is considered inactive and removed, and minimum hits as 3 empirically.
On the other hand, DeepSORT (Wojke et al. Citation2017) represents a paradigm shift in tracking algorithms by considering not only the velocity and motion of an object but also incorporating its appearance. This unique approach leverages a deep appearance descriptor, allowing DeepSORT to integrate appearance information in a more nuanced and discriminative manner. The deep appearance descriptor enables the algorithm to distinguish between objects more effectively, particularly in scenarios with varying appearances and challenging conditions. In DeepSORT implementation, the network architecture for appearance embedding comprises a series of convolutional layers organised in blocks, starting with an initial convolutional layer followed by batch normalisation and ReLU activation. Subsequent blocks, labelled from layer1 to layer4, consist of multiple instances of a BasicBlock structure, each containing two convolutional layers with batch normalisation and ReLU activation. These blocks progressively increase the number of channels to capture higher-level representations. The network concludes with an average pooling layer to reduce spatial dimensions. Overall, the architecture aims to learn discriminative features from input data effectively. For data association in the tracking, we set the IOU threshold as 0.7, maximum unmatched frames as 70, which means that all maximum 70 frames of a track can remain unmatched before being considered inactive and removed, and minimum hits as 3 empirically.
The combination of a custom-trained YOLO-v7 model for buoy detection, followed by SORT-based algorithms for multi-object tracking in sequential image frames will provide the trajectory information necessary for the subsequent stages of our 3D reconstruction pipeline.
Trajectory filtering
After the tracking stage, each buoy obtains distinct identity assignments across various frames. While the SORT-based tracking algorithm offers trajectory smoothness, it struggles with maintaining track reliability under challenging conditions posed by occlusion, non-linear motion, and lost objects in the dynamic marine environment. To address these issues, we introduce a robust two-stage direction-based filtering method designed to enhance the reliability of buoy trajectories and, consequently, improve the quality of mussel line reconstruction.
The approach involves filtering out the identities of stray buoys or their frames that deviate significantly from the dominant moving directions. To achieve this, directional analysis is conducted based on 2D trajectory angles, which are calculated using the arctangent of the y-coordinate changes to x-coordinate changes between consecutive points. Dominant directions are determined through histogram analysis, and the top N directions, representing the most frequently occurring directions within a specified range in the histogram, are selected to characterise the dominant directions of mussel lines. Buoys deviating from these dominant directions within a direction margin are identified as stray points and subsequently filtered out. The process can be formulated as follows:
where each
denotes the centroid position of a detected buoy instance in the image plane, and
represents the direction vector of a buoy instance across the frame sequence.
signifies the probabilities of directions within the specified range
for all buoy instances throughout all frames. The set D corresponds to the dominant directions, with the number of candidate dominant directions determined based on the number of mussel lines observed in the captured video, typically falling within the range of [4, 9].
Utilizing the formulation described above, we implement a two-stage filtering strategy. Firstly, at the frame level, the goal is to identify and filter out frames associated with each buoy identity that deviate significantly from the dominant directions. This step is crucial for mitigating the impact of sporadic or unreliable tracking instances that may arise due to occlusion or other transient conditions. Subsequently, at the identity level, a more extensive filtering approach is employed, removing buoy identities with fewer occurrences, low tracking confidence, or those deviating from the dominant direction overall. The final set of stray points, denoted as G, is selected based on a threshold σ, set to 0.2 in both levels in our case. This multi-scale filtering approach ensures the resilience of the trajectory tracking for subsequent 3D reconstruction.
Triangulation for instance-level 3D point reconstruction
In the process of reconstructing instance-level 3D points, we leverage the camera matrices estimated by SfM during the background environment reconstruction. Adopting a pinhole camera model, we employ triangulation to reconstruct the 3D points of each detected buoy, with a focus on the centroid position of the tracked bounding box. For each buoy identity, which corresponds to a variable number of images depending on the camera (vessel) speed, we carefully curate sets of frame pairs with high tracking confidence and sufficient intermediate distance (i.e. frame interval). Triangulation is then executed on the corresponding centroid points of each buoy across these two views, adhering to the epipolar geometry constraint (see for a conceptual illustration).
Figure 5. Granular Instance-Level Reconstruction pipeline involves object detection as the initial step, followed by trajectory filtering, triangulation, and culminating in mesh fusion.
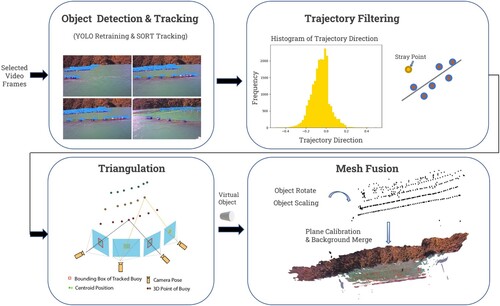
The triangulation process involves the intersection of rays projected from the camera's focal point through the centroid position of a buoy in the image plane of one viewpoint. These rays intersect with rays from another viewpoint capturing the same buoy with an identical identity. Basic linear algebra is applied to determine the intersection point. The averaged 3D points among all these selected view pairs constitute the final 3D coordinates for the buoy in real-world space. The process can be formulated as:
Given two selected viewpoints, R is their camera-to-world rotation project matrix that transformed from the quaternion matrix estimated from SfM. It is transformed to the world-to-camera projection by
. K is the camera intrinsic matrix estimated from SfM with a pinhole camera model and shared between frames.
is the camera centre, and
is the ray from the camera to the centroid position of the detected buoy that is obtained by multi-object tracking algorithm, denoting as
.
is the normalised direction vector from the first camera.
is the normalised direction vector from the second camera.
is the vector from the centre of the first camera to the centre of the second camera. D is the resulting 3D point. · is the dot product, and
is the summation across three axis.
Mesh fusion
In the mesh fusion stage, the obtained 3D points of the mussel line undergo an instance-wise meshing process. To restore the texture and appearance of the buoys, a manually curated cylinder geometry model is employed as the embodiment of the buoy object. The scale and rotation are determined based on the size of the bounding box and its four corner points. All buoys share a uniform orientation direction relative to the camera, reflecting the authentic characteristics of buoys deployed in the mussel farm.
Due to geometric distortion in the images and imprecise camera matrix estimation, some noisy 3D points may be still present in the triangulated 3D points, especially those located far away. To address this, we perform denoising on them based on their distance from the camera with an empirical threshold s = 6 to eliminate far-away outliers.
To ensure the alignment of the plane constituted by the estimated buoy instances with the water surface of the background environment map, and to prevent the coverage of the recovered buoys by the reconstructed water surface in the background environment, we independently estimate planes from the vertices in these two areas using the Random Sample Consensus (RANSAC) plane estimation method (Bolles and Fischler Citation1981). Subsequently, we calculate the transformation matrix between these two independently estimated planes. This transformation matrix is then applied to move the instance-wise plane to the background water surface plane, achieving alignment and avoiding unwanted occlusions.
Experiments
The proposed pipeline is assessed using real-world videos captured from a mussel farm in the Marlborough Sounds of New Zealand. Four distinct videos, each with a frame rate of 25 frames per second, were evaluated. The videos were recorded at different times of the day and in various mussel farm areas, capturing approximately 20 to 60 partially mussel floats at different distances in each frame. The images extracted from these videos have dimensions of 1920*1080 pixels. We evaluate key steps in the proposed pipeline, including multi-object tracking, trajectory filtering, triangulation accuracy, and the final 3D reconstruction performance ().
Table 1. A summary of the videos for performance evaluations.
Background environment reconstruction results
We first evaluate the background environment 3D reconstruction performance on the SfM-MVS pipeline. As suggested by Zhao, Xue, et al. (Citation2023), the mussel farm reconstruction prefers a high-resolution and high frame rate to achieve a reliable reconstruction. So for the evaluation, we chose the 1920*1080 resolution and applied the adaptive frame selection with ratio to vessel speed set to 116 and brightness threshold set to 60 illuminance in LAB colour space. The reconstruction results are illustrated in .
Figure 6. Results of background environment reconstruction. The top row visualises a cluster of frame images from each video.

We observe variations in illumination across these scenes, ranging from favourable weather conditions (see , Scene 1) to overcast weather (see , Scene 3). Additionally, high-reflectance conditions are commonly observed throughout all scenes. The SfM-MVS pipeline demonstrates the ability to reconstruct diverse mussel farm regions with good geometry and texture performance. However, in the absence of explicit guidance information, the SfM-MVS method struggles to properly recover the objects of interest. Notably, most of the buoys remain invisible in the reconstructed water surface which motivates us to improve them for increased practicability in the following stages.
Multi-object detection and tracking performance
For mussel line reconstruction, the accuracy of the instance-wise reconstruction heavily relies on the performance of multi-object detection and tracking. We initially evaluate the buoy detection accuracy of our used YOLO-v7 model retrained with the transfer learning method proposed by McMillan et al. (Citation2023). We extracted 10 consecutive images from each of the four videos and resized them to 549*1028 for performance evaluation. The key metrics include Precision, Recall, mAP at 0.5 Intersection over Union (IoU), and mAP at 0.5:0.95 IoU at 0.05 increasing steps. The detection results for each scenario are presented in . The results demonstrate the robust generalisation of our retrained YOLO-v7 model across various mussel farm environmental conditions, encompassing variations in illumination and high-reflection water surfaces. It attains a peak precision of 0.632, recall of 0.557, and mAP of 0.314 at 0.5:0.95 IoU when evaluated on our data. However, as observed in , we also find the model faces challenges in detecting distant buoys of very small size.
Figure 7. The detection results for buoys in various mussel farm environments are illustrated, with the bounding boxes highlighted in yellow.

Table 2. Buoy detection results on our video data with re-trained YOLO-v7 model.
Building on the detection results, we employed various tracking algorithms, namely SORT, OC-SORT (Cao et al. Citation2023), and DeepSORT (Wojke et al. Citation2017), to reassign identities to individual buoys and associate them across consecutive frames. OC-SORT enhances SORT's tracking robustness in crowded scenes and instances of non-linear motion through a specially designed observation-centric track updating mechanism. In contrast, DeepSORT is characterised as a tracking algorithm that considers not only the velocity and motion of an object but also its appearance. Utilizing a deep appearance descriptor, DeepSORT integrates appearance information in a more discriminative manner. We evaluate these different trackers based on the multiple object tracking accuracy metric, denoted as ‘TA’, expressed as follows:
where
and
represent the number of false negatives and false positives in frame t,
is the count of identity mismatches or switches in tracking frame t, and
denotes the number of ground truth instances in frame t.
As illustrated in , the DeepSORT algorithm exhibits superior tracking accuracy compared with the other algorithms. This underscores the significance of appearance description and feature extraction in the tracking process for ensuring reliable buoy matching across diverse wild environmental conditions. The deep appearance descriptor, introduced by DeepSORT, can effectively discern buoys from the water surface, particularly in challenging scenarios like glittering water surfaces. Further insights are provided in .
Figure 8. Matching results for buoys in two samples from distinct mussel farm environments using the SORT, OC-SORT, and DeepSORT tracking algorithms. The images presented above and below are two consecutive frames, forming a matching pair. The SORT algorithm frequently exhibits an overly dense matching line, attributed to distracting water reflections (e.g. the delineated area within the red box in the first illustration on the top row.). In contrast, OC-SORT and DeepSORT address this issue by incorporating more reliable appearance feature extraction.

Table 3. Comparision of different buoy trackers on our video data.
Analysing the matching results of different trackers on consecutive frame pairs, we observe that the SORT algorithm introduces a notable number of false positives due to misidentifying some water surfaces as reflective buoys (see the excessively dense green matching line in the SORT results column within the ). In contrast, OC-SORT and DeepSORT demonstrate significant improvement by leveraging advanced tracking updating mechanisms and a more powerful appearance descriptor. Compared to OC-SORT, DeepSORT exhibits greater robustness with fewer false negatives. Based on these experimental results, we select DeepSORT as our final tracker for instance-level 3D reconstruction.
Impact of trajectory filtering on triangulation
In assessing the influence of trajectory filtering on triangulation outcomes, we employ a multi-stage filtering approach, with each stage aimed at enhancing the accuracy of the final 3D reconstruction and overcoming challenges inherent in the tracking and triangulation processes. The comparative examination of these filtering stages, illustrated in , highlights the incremental improvements in triangulation results. Initially, triangulation relies on raw trajectories obtained from the multi-object tracking process. However, these raw trajectories may include redundant and irregular points, necessitating further refinement for a more precise reconstruction (See A).
Figure 9. Visualization of triangulation results with filtering at frame and identity level, and denoising for triangulated points.
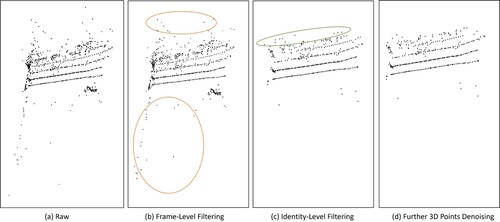
The first filtering stage involves frame-level filtering, where each trajectory for a specific identity is independently filtered. This step is crucial for removing duplicate points that are closely positioned, addressing the potential redundancy introduced by false positives during the tracking process. The frame-level filtering ensures that only distinct and relevant points contribute to the triangulation, enhancing the precision of the 3D reconstruction.
Moving beyond frame-level filtering, identity-level filtering is applied to further refine the triangulation results. This stage is particularly effective in eliminating irregular points, such as those located behind the cameras or associated with identities that only appear sporadically and lack consistent detection across frames (See B areas marked in orange ellipse). By focussing on the reliability and consistency of identity associations, this filtering step contributes to a more accurate and coherent 3D reconstruction.
Additionally, denoising based on the distance to the camera is implemented to mitigate the impact of triangulated points that are too far away and might not be effectively detected by the model (See C the area marked in green ellipse). This denoising step ensures that only points within a relevant distance range contribute to the final 3D reconstruction, enhancing the overall quality and reliability of the reconstructed mussel farm scene.
Instance-level reconstruction performance
To assess the instance-level reconstruction performance, we analyse the relative positions of each triangulated buoy in relation to its neighbouring buoys in four directions: left, right, up (front), and down (behind). The evaluation metrics consider the occurrence of switches between each buoy and its neighbours in these directions, comparing the results with the ground truth provided from images (refer to for a conceptual illustration). The final triangulation accuracy is computed using the following equation:
where
,
,
, and
represent the occurrences of left, right, up, and down-directed switches for buoy instance i, respectively.
is the number of neighbours that buoy i has. Some buoys may have fewer than four neighbours, depending on their original placement in the scene and tracking results. We explicitly factor in the absence of neighbours in specific directions by assigning a value of 0 to the occurrence. Moreover, if a buoy strays in one direction for more than one instance, it is counted as a single occurrence. A higher TriA indicates a more accurate triangulation of instance-wise points. The performance of our triangulation method on this metric is presented in . Moreover, we calculate the misplacement ratio in each direction by dividing the switch occurrences in that direction by the total number of corresponding ground truth instances (denoted as
).
Figure 10. The conceptual illustration depicts the triangulation accuracy metrics. The calculation involves assessing the occurrence of switches in the neighbours of each buoy (red dot), considering the left (orange dot), right (purple dot), up (front) (green dot), and down (behind) (blue dot) directions as four main misplacements.

Table 4. Results of triangulation accuracy on our video data.
As demonstrated in , our proposed triangulation method, which is based on tracking, consistently achieves high accuracy across various scenes. Instances of misplacement in the recovered buoy positions may occur due to imprecise camera distortion or motion estimation, as well as limitations in the accuracy of the detection and tracking algorithm in providing precise buoy centroids. These challenges are general in nature, resulting in misplacements that are similarly distributed across all four directions without exhibiting any specific pattern.
Final reconstruction results
The final reconstruction results exhibit robust performance across diverse illumination conditions, capturing the intricate details of mussel farm environments, as shown in . The method consistently delivers accurate reconstruction results in scene 1, characterised by favourable weather conditions, and scene 2, with high-reflectance conditions, showcasing its resilience to varying environmental factors. The triangulated mussel lines further enhance the reconstruction, with each buoy meticulously positioned in the 3D space, forming coherent and detailed representations. This comprehensive reconstruction not only captures the overall topography of the mussel farm but also preserves the fine-grained details of individual buoys, demonstrating the effectiveness of the proposed methodology in challenging real-world marine scenarios.
Figure 11. Final reconstruction results display both the background environment and instance-level mussel lines, with each reconstructed buoy highlighted in red for enhanced visibility.

Conclusions and future work
In this work, we introduce an innovative hierachical pipeline designed for the comprehensive 3D reconstruction of mussel farms, aiming not only to capture the scene-level background environment but also the intricate details of mussel lines. Departing from conventional 3D reconstruction approaches, our pipeline introduces a novel paradigm by segmenting the scene into background and foreground instances, employing a divide-and-conquer strategy for more nuanced reconstruction. To achieve instance-level reconstruction, we integrate deep learning-based buoy detection and multi-object tracking using the DeepSORT algorithm. This facilitates the association of each buoy across diverse frames, laying the foundation for subsequent triangulation algorithms to pinpoint their precise 3D locations based on corresponding centroids. To ensure the overall precision of the 3D reconstruction, we also propose a trajectory filtering technique that operates at both frame and identity levels. The exhaustive evaluations conducted on real-world mussel farm images demonstrate the efficacy of our pipeline in faithfully reconstructing mussel farms and providing a nuanced understanding of mussel line structures within the marine environment.
While our current pipeline exhibits promising results, we also have identified some areas for further exploration and enhancement. Notably, the current buoy detection method has limitations in reliably identifying distant buoys, impacting the overall completeness of the reconstruction. Future work will concentrate on refining the detection and tracking methods. Moreover, the generalisation of current 3D reconstruction methods is influenced by challenging illumination conditions. Potential future work in this regard may lead to the development of a new pipeline to enhance completeness and accuracy in instance-level reconstruction under challenging outdoor scenarios, especially by resorting to lighting estimation (Chalmers et al. Citation2020; Zhao et al. Citation2021; Xu et al. Citation2022; Zhang et al. Citation2023; Zhao et al. Citation2024) or image/video delighting techniques (Zhang et al. Citation2021; Weir et al. Citation2022, Citation2023). Furthermore, efforts will be directed towards improving the realism of the buoy model used in mesh fusion, aiming for a more accurate representation of mussel farm buoys and the incorporation of sophisticated 3D models for precise texture mapping.
Acknowledgments
We would like to express our thanks to Cawthron Research Institute for providing us with the datasets used in this study.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Agarwal S, Snavely N, Seitz SM, Szeliski R. 2010. Bundle adjustment in the large. In: Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, September 5-11, 2010, Proceedings, Part II 11. Springer. p. 29–42.
- Alcantarilla PF, Beall C, Dellaert F. 2013. Large-scale dense 3D reconstruction from stereo imagery. In: IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan. IEEE.
- Aquaculture, Management I. 2023. Aquaculture and its management (reviewed by 2023-07-13). In: https://www.mpi.govt.nz/fishing-aquaculture/aquaculture-fish-and-shellfish-farming/introduction-to-aquaculture-and-its-management/.
- Barron JT, Mildenhall B, Verbin D, Srinivasan PP, Hedman P. 2022. Mip-nerf 360: unbounded anti-aliased neural radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA. IEEE. p. 5470–5479.
- Bewley A, Ge Z, Ott L, Ramos F, Upcroft B. 2016. Simple online and realtime tracking. In: 2016 IEEE International Conference on Image Processing (ICIP). IEEE. p. 3464–3468.
- Bolles RC, Fischler MA. 1981. A ransac-based approach to model fitting and its application to finding cylinders in range data. In: IJCAI, Vancouver, British Columbia, Canada; vol. 1981. p. 637–643.
- Cao J, Pang J, Weng X, Khirodkar R, Kitani K. 2023. Observation-centric sort: rethinking sort for robust multi-object tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada. IEEE. p. 9686–9696.
- Chalmers A, Zhao J, Medeiros D, Rhee T. 2020. Reconstructing reflection maps using a stacked-CNN for mixed reality rendering. IEEE Transactions on Visualization and Computer Graphics. 27(10).
- Chary K, Brigolin D, Callier MD. 2022. Farm-scale models in fish aquaculture–an overview of methods and applications. Reviews in Aquaculture. 14(4):2122–2157. doi: 10.1111/raq.v14.4
- Chen R, Zhang FL, Rhee T. 2020. Edge-aware convolution for rgb-d image segmentation. In: 2020 35th International Conference on Image and Vision Computing New Zealand (IVCNZ). IEEE. p. 1–6.
- Chen R, Zhao J, Zhang FL, Chalmers A, Rhee T. 2024. Neural radiance fields for dynamic view synthesis using local temporal priors. In: International Conference on Computational Visual Media, Wellington, New Zealand. p. 74–90.
- Chen Y, Yu Z, Song S, Yu T, Li J, Lee GH. 2023. Adasfm: From coarse global to fine incremental adaptive structure from motion. arXiv preprint arXiv:230112135.
- Cui H, Gao X, Shen S. 2023. Mcsfm: multi-camera-based incremental structure-from-motion. IEEE Transactions on Image Processing. 32:6441–6456. doi: 10.1109/TIP.2023.3333547
- De Castro AI, Jiménez-Brenes FM, Torres-Sánchez J, Peña JM, Borra-Serrano I, López-Granados F. 2018. 3-D characterization of vineyards using a novel UAV imagery-based obia procedure for precision viticulture applications. Remote Sensing. 10(4):584. doi: 10.3390/rs10040584
- Dong YJ, Guo YC, Liu YT, Zhang FL, Zhang SH. 2024. Ppea-depth: progressive parameter-efficient adaptation for self-supervised monocular depth estimation. In: Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, Canada; Vol. 38. p. 1609–1617.
- Dong YJ, Zhang FL, Zhang SH. 2024. Mal: motion-aware loss with temporal and distillation hints for self-supervised depth estimation. arXiv preprint arXiv:240211507.
- Eigen D, Puhrsch C, Fergus R. 2014. Depth map prediction from a single image using a multi-scale deep network. Advances in Neural Information Processing Systems. 27.
- Engels C, Stewénius H, Nistér D. 2006. Bundle adjustment rules. Photogrammetric Computer Vision. 2:32.
- Ferreira JG, Aguilar-Manjarrez J, Bacher C, Black K, Dong S, Grant J, Hofmann EE, Kapetsky J, Leung P, Pastres R, et al. 2012. Progressing aquaculture through virtual technology and decision-support tools for novel management. In: Global Conference on Aquaculture 2010, Phuket, Thailand.
- Gao K, Gao Y, He H, Lu D, Xu L, Li J. 2022. Nerf: neural radiance field in 3D vision, a comprehensive review. arXiv preprint arXiv:221000379.
- Hartley R, Zisserman A. 2003. Multiple view geometry in computer vision. Oxford: Cambridge University Press.
- Huang K, Zhang FL, Zhao J, Li Y, Dodgson N. 2023. 360∘ stereo image composition with depth adaption. IEEE Transactions on Visualization and Computer Graphics. p. 1–14.
- Jiang W, Trulls E, Hosang J, Tagliasacchi A, Yi KM. 2021. Cotr: correspondence transformer for matching across images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. p. 6207–6217. Virtual online.
- Kalman RE. 1960. A new approach to linear filtering and prediction problems.
- Khaloo A, Lattanzi D. 2017. Hierarchical dense structure-from-motion reconstructions for infrastructure condition assessment. Journal of Computing in Civil Engineering. 31(1):04016047. doi: 10.1061/(ASCE)CP.1943-5487.0000616
- Kim H, Yang Sj, Sohn K. 2003. 3D reconstruction of stereo images for interaction between real and virtual worlds. In: The Second IEEE and ACM International Symposium on Mixed and Augmented Reality, 2003. Proceedings. IEEE. p. 169–176.
- Kuhn HW. 1955. The hungarian method for the assignment problem. Naval Research Logistics Quarterly. 2(1–2):83–97. doi: 10.1002/nav.v2:1/2
- Kulhanek J, Sattler T. 2023. Tetra-nerf: representing neural radiance fields using tetrahedra. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France. p. 18458–18469.
- Li C, Pickup D, Saunders T, Cosker D, Marshall D, Hall P, Willis P. 2012. Water surface modeling from a single viewpoint video. IEEE Transactions on Visualization and Computer Graphics. 19(7):1242–1251.
- Li XJ, Yang J, Zhang FL. 2022. Laplacian mesh transformer: dual attention and topology aware network for 3D mesh classification and segmentation. In: European Conference on Computer Vision. Springer. p. 541–560.
- Li Y, Barnes C, Huang K, Zhang FL. 2022. Deep 360∘ optical flow estimation based on multi-projection fusion. In: European Conference on Computer Vision. Springer. p. 336–352.
- Lin X, Li A, Bian J, Zhang Z, Lei G, Chen L, Qi J. 2023. Reconstruction of a large-scale realistic three-dimensional (3-d) mountain forest scene for radiative transfer simulations. GIScience & Remote Sensing. 60(1):2261993. doi: 10.1080/15481603.2023.2261993
- Lindenberger P, Sarlin PE, Larsson V, Pollefeys M. 2021. Pixel-perfect structure-from-motion with featuremetric refinement. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. p. 5987–5997. Virtual online.
- McMillan C, Zhao J, Xue B, Vennell R, Zhang M. 2023. Improving buoy detection with deep transfer learning for mussel farm automation. In: 2023 38th International Conference on Image and Vision Computing New Zealand (IVCNZ). IEEE. p. 1–6.
- Mildenhall B, Srinivasan PP, Tancik M, Barron JT, Ramamoorthi R, Ng R. 2020. Nerf: Representing scenes as neural radiance fields for view synthesis. In: ECCV, Glasgow, UK.
- Mildenhall B, Srinivasan PP, Tancik M, Barron JT, Ramamoorthi R, Ng R. 2021. Nerf: representing scenes as neural radiance fields for view synthesis. Communications of the ACM. 65(1):99–106. doi: 10.1145/3503250
- Mlambo R, Woodhouse IH, Gerard F, Anderson K. 2017. Structure from motion (sfm) photogrammetry with drone data: A low cost method for monitoring greenhouse gas emissions from forests in developing countries. Forests. 8(3):68. doi: 10.3390/f8030068
- Morris NJ, Kutulakos KN. 2011. Dynamic refraction stereo. IEEE Transactions on Pattern Analysis and Machine Intelligence. 33(8):1518–1531. doi: 10.1109/TPAMI.2011.24
- Murez Z, Van As T, Bartolozzi J, Sinha A, Badrinarayanan V, Rabinovich A. 2020. Atlas: end-to-end 3D scene reconstruction from posed images. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII 16. Springer. p. 414–431.
- Özyeşil O, Voroninski V, Basri R, Singer A. 2017. A survey of structure from motion*. Acta Numerica. 26:305–364. doi: 10.1017/S096249291700006X
- Pickup D, Li C, Cosker D, Hall P, Willis P. 2011. Reconstructing mass-conserved water surfaces using shape from shading and optical flow. In: Computer Vision–ACCV 2010: 10th Asian Conference on Computer Vision, Queenstown, New Zealand, November 8-12, 2010, Revised Selected Papers, Part IV 10. Springer. p. 189–201.
- Sarlin PE, Lindenberger P, Larsson V, Pollefeys M. 2023. Pixel-perfect structure-from-motion with featuremetric refinement. IEEE Transactions on Pattern Analysis and Machine Intelligence. IEEE. p 5987–5977.
- Schonberger JL, Frahm JM. 2016. Structure-from-motion revisited. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA. IEEE. p. 4104–4113.
- Schönberger JL, Zheng E, Frahm JM, Pollefeys M. 2016. Pixelwise view selection for unstructured multi-view stereo. In: Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part III 14. Springer. p. 501–518.
- Seitz SM, Curless B, Diebel J, Scharstein D, Szeliski R. 2006. A comparison and evaluation of multi-view stereo reconstruction algorithms. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06); Vol. 1. IEEE. p. 519–528.
- Song D, Jiang XJ, Zhang Y, Zhang FL, Jin Y, Zhang Y. 2023. Domain-specific modeling and semantic alignment for image-based 3d model retrieval. Computers & Graphics. 115:25–34. doi: 10.1016/j.cag.2023.06.033
- Sun J, Xie Y, Chen L, Zhou X, Bao H. 2021. Neuralrecon: Real-time coherent 3d reconstruction from monocular video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. p. 15598–15607. Online.
- Szeliski R. 2022. Computer vision: algorithms and applications. Washington, DC: Springer Nature.
- Tancik M, Casser V, Yan X, Pradhan S, Mildenhall B, Srinivasan PP, Barron JT, Kretzschmar H. 2022. Block-nerf: scalable large scene neural view synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA. IEEE. p. 8248–8258.
- Thapa S, Li N, Ye J. 2020. Dynamic fluid surface reconstruction using deep neural network. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE. p. 21–30. Online.
- Torres-Sánchez J, de Castro AI, Pena JM, Jiménez-Brenes FM, Arquero O, Lovera M, López-Granados F. 2018. Mapping the 3D structure of almond trees using uav acquired photogrammetric point clouds and object-based image analysis. Biosystems Engineering. 176:172–184. doi: 10.1016/j.biosystemseng.2018.10.018
- Vijayanarasimhan S, Ricco S, Schmid C, Sukthankar R, Fragkiadaki K. 2017. Sfm-net: learning of structure and motion from video. arXiv preprint arXiv:170407804.
- Wang CY, Bochkovskiy A, Liao HYM. 2023. Yolov7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada. IEEE. p. 7464–7475.
- Wang H, Liao M, Zhang Q, Yang R, Turk G. 2009. Physically guided liquid surface modeling from videos. ACM Transactions on Graphics (TOG). 28(3):1–11.
- Wang J, Karaev N, Rupprecht C, Novotny D. 2023. Visual geometry grounded deep structure from motion. arXiv preprint arXiv:231204563.
- Wei X, Zhang Y, Li Z, Fu Y, Xue X. 2020. Deepsfm: structure from motion via deep bundle adjustment. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16. Springer. p. 230–247.
- Wei YM, Kang L, Yang B, Wu LD. 2013. Applications of structure from motion: a survey. Journal of Zhejiang University SCIENCE C. 14(7):486–494. doi: 10.1631/jzus.CIDE1302
- Weir J, Zhao J, Chalmers A, Rhee T. 2022. Deep portrait delighting. In: European Conference on Computer Vision. Springer. p. 423–439.
- Weir J, Zhao J, Chalmers A, Rhee T. 2023. De-lighting human images using region-specific data augmentation. In: 2023 38th International Conference on Image and Vision Computing New Zealand (IVCNZ). IEEE. p. 1–6.
- Wojke N, Bewley A, Paulus D. 2017. Simple online and realtime tracking with a deep association metric. In: 2017 IEEE International Conference on Image Processing (ICIP). IEEE. p. 3645–3649.
- Wu C. 2011. Visualsfm: a visual structure from motion system. http://www%20cs%20washington%20edu/homes/ccwu/vsfm.
- Xu JP, Zuo C, Zhang FL, Wang M. 2022. Rendering-aware HDR environment map prediction from a single image. In: Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, Canada; vol. 36. AAAI. p. 2857–2865.
- Yu A, Ye V, Tancik M, Kanazawa A. 2021. pixelnerf: neural radiance fields from one or few images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. p. 4578–4587. Online.
- Yuan YJ, Han X, He Y, Zhang FL, Gao L. 2024. Munerf: robust makeup transfer in neural radiance fields. IEEE Transactions on Visualization and Computer Graphics. IEEE. p. 1–12.
- Zach C. 2014. Robust bundle adjustment revisited. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer. p. 772–787.
- Zhan Y, Nobuhara S, Nishino K, Zheng Y. 2023. Nerfrac: neural radiance fields through refractive surface. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France. IEEE. p. 18402–18412.
- Zhang F, Zhao J, Zhang Y, Zollmann S. 2023. A survey on 360 images and videos in mixed reality: algorithms and applications. Journal of Computer Science and Technology. 38(3):473–491. doi: 10.1007/s11390-023-3210-1
- Zhang L, Zhang Q, Wu M, Yu J, Xu L. 2021. Neural video portrait relighting in real-time via consistency modeling. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. p. 802–812. Virtual online.
- Zhang X, Bi S, Sunkavalli K, Su H, Xu Z. 2022. Nerfusion: fusing radiance fields for large-scale scene reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA. IEEE. p. 5449–5458.
- Zhang Z. 1998. Determining the epipolar geometry and its uncertainty: a review. International Journal of Computer Vision. 27:161–195. doi: 10.1023/A:1007941100561
- Zhao J, Chalmers A, Rhee T. 2021. Adaptive light estimation using dynamic filtering for diverse lighting conditions. IEEE Transactions on Visualization and Computer Graphics. 27(11):4097–4106. doi: 10.1109/TVCG.2021.3106497
- Zhao J, McMillan C, Xue B, Vennell R, Zhang M. 2023. Buoy detection under extreme low-light illumination for intelligent mussel farming. In: 2023 38th International Conference on Image and Vision Computing New Zealand (IVCNZ). IEEE. p. 1–6.
- Zhao J, Xue B, Vennell R, Zhang M. 2023. Large-scale mussel farm reconstruction with GPS auxiliary. In: 2023 38th International Conference on Image and Vision Computing New Zealand (IVCNZ). IEEE. p. 1–6.
- Zhao J, Xue B, Zhang M. 2024. Sgformer: boosting transformers for indoor lighting estimation from a single image. In: International Conference on Computational Visual Media, Wellington, New Zealand.
- Zhou L, Zhang Z, Jiang H, Sun H, Bao H, Zhang G. 2021. Dp-mvs: detail preserving multi-view surface reconstruction of large-scale scenes. Remote Sensing. 13(22):4569. doi: 10.3390/rs13224569
- Ziliani MG, Parkes SD, Hoteit I, McCabe MF. 2018. Intra-season crop height variability at commercial farm scales using a fixed-wing uav. Remote Sensing. 10(12):2007. doi: 10.3390/rs10122007