
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
It is argued that many-parameter families of loss distributions may work even with limited amounts of historical data. A restriction to unimodality works as a stabilizer, which makes fitted distributions much more stable than their parameters. We propose Box-Cox transformed Gamma and Burr variables. Those are models with three or four parameters with many of the traditional two-parameter families as special cases, and there are well-defined distributions at the boundaries of the parameter space, which is important for stability. The approach is evaluated with model error defined though the theory of misspecification in statistics. It is shown that such error is drastically reduced when a third or fourth parameter is added without increasing the random error more than a little. It is pointed out that the approach may be a suitable starting point for completely automatic procedures.
1. Introduction
Modeling insurance losses from historical observations might have been carried out by the empirical distribution or by non-parametric density estimation (for example Scott Citation1992) if it had not been for future, huge losses not in the data. Indeed, the importance of this extreme right tail has promoted special methods to deal with it; Embrechts et al. (Citation1997) is the standard reference. Yet, in practical insurance, two-parameter models is without doubt still one of the most common approaches (Omari et al. Citation2018). The drawback is that distributions now are tied to a specific shape for which there may be little theoretical justification. Families of distributions with more than two parameters such as the Burr family which goes back to Burr (Citation1942) or the transformed Beta and Gamma distributions in Venter (Citation1985), also treated in Kleiber & Kotz (Citation2003) and Cummins et al. (Citation1990), would be more flexible. It is the aim of the present paper to argue for the use of such multi-parameter families among which we construct a new one with attractive properties. Another tradition in actuarial science is to use slicing or composite distributions with different parametric families imposed on each side of a threshold. The approach has some support in Pickands' theorem, which reveals that tail distributions always become Pareto or exponentially distributed when the threshold tends to infinity. The problem here is that it varies enormously from case to case how large the threshold must be; see Bølviken (Citation2014). This motivates other composite models, and they have in recent years been proposed in large numbers, see for example Cooray & Ananda (Citation2005), Scollnik (Citation2007), Scollnik & Sun (Citation2012), Bakar et al. (Citation2015), Reynkens et al. (Citation2017) and Chan et al. (Citation2018). Composites can be seen as special cases of mixture distributions which have also been used for loss modeling. Some references are Lee & Lin (Citation2010), Verbelen et al. (Citation2015), Miljkovic & Grün (Citation2016) and Gui et al. (Citation2021).
The key issue is how to cope with a lack of knowledge of the shape of the underlying distribution when the experience to go on is limited. One approach, used in Miljkovic & Grün (Citation2016), is to try several families of distributions and select the best-fitting one, another is the so-called Bayesian averaging in Hoeting et al. (Citation1999). Still another, and in our view simpler way, is to start out with multi-parameter models containing the standard two-parameter ones as special cases. There are several possibilities (see above), but our preferred vehicle is the Box-Cox-transformed Gamma and Burr variables constructed in the next section. These models are always unimodal to which we attach great importance. Is such a delimitation too narrow in scope?
Loss data from different populations is common, but their origin would often be known, and we are then in a regression situation outside the realm of this paper. Mixture distributions arise when the underlying populations are unobservable or latent so that it is not known which populations individual losses come from. Whether this violates unimodality depends on how far apart the populations are, but even if multimodality would have been spotted with lots of data, it might not be for smaller amounts. Further, there is a price to be paid for all this flexibility; it is bound to make modeling more vulnerable to random error. This is demonstrated by example in Section 4, and that is where our idea kicks off. By imposing unimodality, fitted distributions might be stable even when there are many parameters and not overwhelmingly much data. The rationale is as follows. Many-parameter, unimodal families will inevitably contain distributions resembling each other, which can only mean uncertain parameter estimates. However, those are not really the target, and the fitted distributions they lead to are much less vulnerable to random error. The transformation families proposed in Section 2 work not only because their distributions are unimodal, but also because they tend to well-defined distributions at the boundary of the parameter space, which is important for their behavior when fitted. This makes it possible to program automatic methods where the computer on its own picks a distribution from the three- or four-parameter family, without human intervention, thus avoiding the whole model selection step, which is particularly useful when data are not abundant.
Then the question is how different methods should be evaluated and compared. What really matters is not the loss model itself, but rather its impact on what it is used for, for example on the projected reserve of a portfolio, which is the chief criterion in the remains of the paper. There are both modeling and sampling error to deal with, and one way to make the distinction between them precise is to draw on the asymptotic theory of likelihood estimates in misspecified models; White (Citation1982) is a much cited reference. Suppose a family of distributions parameterized by θ has been imposed with its likelihood estimate. As the number of historical losses become infinite,
will nearly always converge to some
even if the true loss distribution is outside the family. This
-distribution minimizes the so-called Kullback-Leibler distance to the true one (Section 2.4), and provides a reasonable definition of model error. When we in Section 2.5 compare the projected reserve under these two distributions over a broad range of possibilities, it will emerge that a third parameter often lowers model error drastically and that a fourth one makes it very small indeed.
Model error under our transformation models is thus fairly small, but then there is random error, which we study by both asymptotics and Monte Carlo. One side of that is over-parameterization; how much extra random error is brought in when extra parameters are added, for instance to a two-parameter family? Special weight is placed on log-normal models under which error studies can be carried out by particularly simple mathematics. One thing that must be kept in mind is that errors with scarce data and heavy-tailed distributions might be large in any case, and the real question is how much larger they become when additional parameters are added. Bayesian assumptions if warranted might mitigate error, but that is outside the scope of this paper.
The outline of this paper is as follows. Multi-parameter modeling and model misspecification are introduced in Section 2. Section 3 presents asymptotic results concerning the error that is made using a multi-parameter model when the true model is a simpler one, whereas this is explored in a simulation study in Section 4. An illustrative example involving Norwegian automobile insurance losses is given in Section 5. Finally, Section 6 contains some concluding remarks.
2. A multi-parameter approach
2.1. The Burr model
One way of defining families of loss distributions beyond the two-parameter ones is through ratios of Gamma variables (Venter Citation1985, Kleiber & Kotz Citation2003). Let
(1)
(1) with
and
two independent Gamma variables with mean 1 and shape α and θ. This is the Burr model, also called Beta Prime, Pearson type 6 and extended Pareto, which goes back to Burr (Citation1942). It can also be defined through its density function
(2)
(2) Adding a parameter of scale
leads to a model
for a claim Z. Its moments are
(3)
(3) which are finite when
.
One of the attractive sides of this framework is that it captures under the same roof both heavy-tailed Pareto distributions when and more light-tailed Gamma ones which appear when
. The latter is an immediate consequence of (Equation1
(1)
(1) ) since
as
by virtue of
and sd
, and a similar argument shows that the inverse Gamma
emerges when
.
2.2. Transformation modeling
One way to extend the Burr family is to use parameterized transformations, say
(4)
(4) with
an additional parameter and
some increasing function to be specified. An example of such a construction is the generalized beta distribution of order II (GB2), that uses
which is mentioned in Kleiber & Kotz (Citation2003) (see p. 190), and used for modeling insurance losses in Cummins et al. (Citation1990).
A natural restriction is , making the Burr model a special case. Not all functions
satisfying these conditions lead to the families of unimodal distributions, but one possibility is the Box-Cox transformation
which goes back to Box & Cox (Citation1964). This choice sets up what we shall refer to as the PowerGamma and PowerBurr models
(5)
(5) with parameters θ, η and β for PowerGamma on the left and α, θ, η and β for PowerBurr on the right. The latter collapses to PowerGamma when
. It will emerge in Section 3 that the log-normal is a special case of both, and most other standard loss models are included approximately. The PowerGamma and PowerBurr families are unimodal everywhere; i.e. their density functions are monotonely decreasing when
and have a single maximum otherwise, which follows easily from their mathematical expressions in Appendices C and D.
One of the attractive features of the Box-Cox transformation is its behavior as . It follows from (Equation5
(5)
(5) ) that
on the left and
on the right, in both cases in the limit well-defined models with scale parameter
. We believe this property to have a stabilizing influence when models are fitted. Indeed, it is worth recording what happens with the perhaps superficially equally attractive
. The models for
and
are again unimodal, but now (for example)
as
, and a very small η can only be compensated by extreme variation in X. Such solutions simply are not plausible, yet likelihood fitting for moderate or small amounts of data often came up with them when the transformation was tried out. Does a restriction such as
get rid of them? The problem is that these freak solutions now turn into η-estimates close to 1, and such fitting when examined implied considerable estimation bias, in the sense that the estimated distribution did not fit the data well.
2.3. Illustration
A small example of how such modeling may work is shown in Table where the Gamma, Pareto, Burr, PowerGamma and PowerBurr distributions have been fitted the n = 60 Belgian fire losses from Beirlant et al. (Citation1996), here scaled so their average is one (R-code for fitting the Burr, PowerGamma and PowerBurr is available in https://github.uio.no/ingrihaf/PowerBurr). The parameter values from the five fitted distributions are displayed along with the corresponding means, standard deviations and skewnesses. We have also computed the reserve of a portfolio, i.e. the
percentile of the distribution of the total portfolio loss. We assumed a Poisson distribution for the number of claims with expectation
, and each of the five distributions as the claim size distribution. The resulting reserves are shown in the rightmost column of the Table. Not all modeling based on 60 losses can be expected to be as stable, with standard deviations, skewnesses and reserves that hardly vary with the different loss models. The very large α for Burr and PowerBurr (
was the maximum value allowed) signify that
in (Equation1
(1)
(1) ), so that the Burr and the PowerBurr models obtained are very nearly Gamma and PowerGamma. Standard deviations match the empirical one in the data, which is 1.02, whereas the skewness is substantially higher than the empirical skewness coefficient of 1.46, but which is known to under-estimate the true skewness; see for instance Bølviken (Citation2014).
Table 1. Parameters, mean, sd, skewness and reserve for the Belgian fire data.
2.4. Misspecification
Let be the density function of Z under one of the models above depending on the parameter vector
, and let
be the maximum likelihood estimate of
based on n historical losses. Maximum likelihood is not only the standard method, but also has an appealing error theory. Suppose the true density function
differs from
for all
. Such model error is highly relevant in insurance since there is typically little hard justification for the parametric families imposed. However, even when they do not contain the true distribution, there usually exists some
so that
as
. Indeed, it was shown in Huber (Citation1967) and later in White (Citation1982, Citation1994) under very general conditions that
minimizes the Kullback-Leibler divergence of the family
with respect to the true
, i.e.
(6)
(6) If
for some
, then
, but otherwise
, minimizing (Equation6
(6)
(6) ), deviates from the true
, resulting in model error.
Consider a quantity of interest ψ, for example the reserve of a portfolio in general insurance, i.e. a percentile of the total loss distribution, and write for its value when
is the loss distribution. The value we seek is
under the true density function
, whereas our estimate is
, and its error can be decomposed as
(7)
(7) where the first component on the right reflects the standard error of the estimate. The second component is bias which is the sum of two contributions; i.e.
(8)
(8) with model error on the right which is what remains when
. There is no such error when the PowerGamma or the PowerBurr models from Section 2.1 are fitted Gamma, Pareto or log-normal data.
2.5. Model error
To examine the model error numerically, consider the computation of the reserve in a small Poisson portfolio in general insurance with expected events, meaning a percentile of the total portfolio loss distribution. The true loss models are varied among four different families, notably the log-normal
with
, the log-Gamma
where
is a Gamma-variable with mean 1 and shape θ, the Weibull model
and the logistic distribution defined by
with
. The reserve was computed assuming each of the loss models Pareto, Burr, PowerGamma and PowerBurr in addition to the true one. In the cases where the assumed distribution
did not include the true distribution
as a special case, the best-fitting parameter vector
was found by minimizing the Kullback-Leibler divergence (Equation6
(6)
(6) ) numerically. Finally Monte Carlo with ten million simulations were used to calculate the
reserve under the true
and the approximating one
.
Table reports how much the reserve changes (in per cent) when is replaced by the best-fitting
. In mathematical terms the criterion is
being the reserve, which does not depend on β so that only the shape parameter θ has to be varied. Their values in Table have been chosen with some care to reflect a reasonable range of skewness. The log-Gamma distribution is so heavy-tailed at
or lower that not even the expectation is finite, and both the log-normal with
and the Weibull distribution with
allow very large claims. The results show how well higher-parameter distributions approximate many standard models. Whereas two-parameter Pareto fitting (included for comparison) over-shoots the target enormously, the four-parameter PowerBurr has inconsequential model bias everywhere, and also the three-parameter PowerGamma, except for the exceptionally heavy-tailed log-Gamma case with
. Unlike the other fitted distributions, the PowerGamma does not contain the Pareto family as a special case, but when model bias was calculated as described above, it was again largely minor; i.e.
when the Pareto parameter
,
when
and
when
, the latter so heavy-tailed that the variance is infinite.
Table 2. Model bias in the estimated reserve in
of the true values under Pareto Burr, PowerGamma and PowerBurr fitting.
3. Over-parameterization
3.1. Introduction
Modeling beyond two parameters introduces extra parameter uncertainty if one of the usual two-parameter sub-families is the true one. The size of the degradation can be explored analytically through asymptotics as . Let
be the parameter vector and consider moments
and percentiles
defined as Pr
. Their estimates are
and
where
is the maximum likelihood estimate of
based on n observations of Z.
Under the assumption that the model is the true one, theoretical statistics offer an approximation of
and
through the information matrix
and the gradient vectors
for
and
for
, where
(9)
(9) For moment estimation the result is
(10)
(10) For percentile estimation the results is the same except for
being replaced by
.
A more general form, replacing the information matrix with a sandwich form, covers the situation when the model is misspecified, consult White (Citation1982). Such an extension is relevant for the problems under discussion here, but we shall make no use of it. Our aim in this section is to evaluate under a default, two-parameter model and examine how much it increases when a wider three or four-parameter one is being used.
How large n must be for the asymptotic results to be reasonably accurate approximations in the finite sample case was checked by Monte Carlo and varied with both the skewness of the distribution and with the quantity estimated. In Tables and below, n = 100 observations or even lower (n = 50) are often enough to get rather accurate results with the asymptotic formulas. The convergence is faster for the percentiles than the higher order moments and becomes slower when skewness is high.
Table 3. Relative increase (in ) in the asymptotic standard error of moment and percentile estimates when Burr has been fitted Pareto and Gamma data.
Table 4. Relative increase (in ) in asymptotic standard error of moment and percentile estimates when PowerGamma has been fitted log-normal data.
3.2. Burr against Pareto and Gamma
The first example examines how much Burr fitting inflates uncertainty when the data come from a Pareto or a Gamma distribution. Write the coefficients and
in (Equation10
(10)
(10) ) as
and
under the Burr model and
and
under Pareto. The latter is the special case
, and the ratios
and
indicate extra uncertainty when the Burr family is fitted to Pareto data. We have chosen to report
(11)
(11) the degree of degradation under Burr. Mathematical expressions for the information matrix I and the gradient vector
under the Burr and the Pareto are given in Appendix A.
When the Gamma distribution replaces the Pareto as the true, data generating model, there is the slight complication that the true model now is on the boundary of the parameter space since Burr tends to Gamma as . The degree of degradation thus becomes
(12)
(12) with
and
the coefficients
and
in (Equation10
(10)
(10) ), respectively, under the Gamma model. For how these quantities are calculated, consult Appendix B2.
Neither of the criteria (Equation11(11)
(11) ) and (Equation12
(12)
(12) ) depends on β, and only the other parameter (α in the Pareto and θ in the Gamma) needs to be varied. The general picture in the upper half of Table , where the Burr/Pareto and Burr/Gamma comparisons are recorded is that the extra uncertainty in over-specification is limited, especially for the Pareto family in the upper panel. The degradation tends to be higher in models with heavier tails and when estimating moments of higher order or percentiles far out in the right tail, which appears to be a general phenomenon; more on that below.
3.3. PowerGamma against the log-normal
Let with Y Normal
and
are parameters. This widely applied log-normal model (Marlin Citation1984, Zuanetti & Diniz Citation2006) is outside the Burr family, but is a special case of the PowerGamma and PowerBurr, where it is located on the boundary of their parameter spaces. Indeed, in (Equation5
(5)
(5) ), if we take
and
(13)
(13) the log-normal appears in the limit as
. This follows from (Equation5
(5)
(5) ) by elementary linearization manipulations, similar to those in Section 3.4, but is also a consequence of (Equation15
(15)
(15) ) below. The crucial point is that
as
.
There is a useful tilting relationship between the density function of the PowerGamma and the log-normal one
(14)
(14) which is derived in Appendix C1 and reads
(15)
(15) Note that the PowerGamma now has been reparameterized in terms of the parameters
, which are related to the original parameters
as described in (Equation13
(13)
(13) ).
Let and
be the coefficients defining the asymptotic standard deviation of the estimators of
and
under PowerGamma and
and
the analogies under the log-normal. The degradations of the PowerGamma with respect to the log-normal are
(16)
(16) This is similar to (Equation12
(12)
(12) ), but now a simple expression is available though the tilting relationship. It is proved in Appendix C that
(17)
(17) How these quantities vary with σ is shown in Table . The picture is the same as in Table with extra uncertainty for more volatile loss models, for moments of higher order and for percentiles far out into the right tail.
For percentiles the degradation is asymptotically the same for all log-normal distributions in accordance with (Equation17(17)
(17) ) right.
3.4. PowerBurr against the log-normal
The PowerBurr family for log-normal data has the same asymptotic uncertainty as the PowerGamma, as explained below. Such a stability is also manifest in simulations with smaller n in Tables and . One way to address the issue, is to reparametrize once more to (18)
(18)
(19)
(19) so that γ is a the fourth parameter with θ, ξ, and σ as before. Now
with
as
and
as
, and by linearization
with
. Hence when inserting for β and η in
, another round of linearization yields as
and the new parametrization has lead to Z becoming log-normal in the limit.
Table 5. Error (in ) of the true
portfolio reserves, shown in the heading, for the five different fitting regimes and five different loss distributions.
Table 6. Error (in ) in the true reinsurance premia, shown in the heading, for the five different fitting regimes and five different loss distributions.
A more refined version of this argument along the lines in Appendix B would establish a tilting relationship between the PowerBurr density function and the log-normal one. It resembles that in (Equation15
(15)
(15) ) and is now of the form
(20)
(20) It can be established that the function
is an odd polynomial of degree 3, as in (Equation15
(15)
(15) ) right, with coefficients depending on γ. However, the point is that the extra parameter γ in PowerBurr becomes irrelevant as
, i.e. for log-normal data, and the uncertainty under PowerBurr and PowerGamma fitting then must be the same.
4. Simulation study
The asymptotic results become invalid or at least inaccurate when the sample size n is small. In order to explore the performance of the many-parameter distributions in cases with little available data, we have supplemented the asymptotic results with a simulation study. This also enables us to study more complex measures, such as portfolio reserves and reinsurance premia. The test case below assumes a small portfolio with expected incidents, so that the shape of the loss distribution beyond mean and variance is of importance. The claim numbers were assumed to follow a Poisson distribution, and the issue under study is how much many-parameter loss modeling inflates error in two actuarial evaluations, namely the portfolio reserve and a reinsurance premium. When there are only n = 50 historical losses, as in the upper half of Tables and , it is often difficult to determine which family of distributions the data came from.
Claim sizes were drawn from five different loss models, notably a Pareto, a Gamma, a Weibull, a log-Gamma and a log-Normal distribution. Their expectation was always one. Shape parameters were for Pareto,
(Gamma and Weibull),
(log-Gamma) and
(log-Normal), all corresponding to highly skewed distributions. Standard deviations varied from 0.52 (Weibull) up to 1.77 (Pareto); for precise definitions of these distributions, see Section 2.5.
We drew n = 50 or n = 5000 observations from each of the five loss distributions listed above. The former corresponds to a situation with little available data, whereas the latter is close to the asymptotic case. Then, we fitted the true distribution family, as well as the Burr, the PowerGamma and the PowerBurr distributions to each of the simulated datasets. As a reference, we also included an alternative many-parameter distribution, namely the log-Normal-Pareto mixture distribution proposed by Scollnik (Citation2007), with the restrictions that the density and its first derivative should be continuous at the threshold between the log-Normal and the Pareto. This results in a distribution with three free parameters μ and σ from the log-Normal and the threshold parameter θ. All distributions were fitted by maximum likelihood, maximizing the log-likelihood numerically with the R function optim. For the Burr, PowerGamma and PowerBurr, we supplied analytically computed gradients of the log-likelihood in order to speed up the convergence. All of this was repeated m = 1000 times, which gave m different actuarial projections from each of the four fitted distributions for each sample size n. Based on these, we computed the bias (i.e. the average discrepancy from the true value) and the standard deviation.
Table shows the results for the reserve of the Poisson portfolio with
expected incidents, presented as percents of the true assessments. The table should be read columnwise since the point of the exercise is to compare errors when the true family of distributions has been fitted to the data with what we get under the many-parameter fitting regimes. Note that n = 50 historical losses yield huge inaccuracies in any case, but still the biases and standard deviations do not increase by much when many-parameter families have been fitted. Indeed, there are from these assessments no particular reasons to be prefer the projections from the correct two-parameter family as the bias and standard deviation when using the Burr, the PowerGamma or the PowerBurr distributions are either comparable to the ones from using the true distribution family, or even lower. The results in the Gamma column are peculiar. Errors in percent are large, and there is a huge downwards bias even when n = 5000 losses were available, actually substantially smaller with the many-parameter families than with the Gamma family itself. There is no mistake; the results have been checked thoroughly. Note also that the PowerGamma overall gave results that were better than the Burr distribution, and the PowerBurr again slightly better. As for the log-Normal-Pareto mixture, it gives a very low bias and standard deviation when the amount of data is large (n = 5000) and the true claim size model is Log-Normal, as one would expect. Indeed, the fitted distributions in this case are almost the same as the log-Normal, with a very high threshold parameter. It also performs well when the true distribution is log-Gamma, which is quite similar to the log-Normal. In all other cases, and in particular when the amount of data is smaller (n = 50), the log-Normal-Pareto mixture gives rather poor results compared to the Burr, PowerGamma and PowerBurr.
A second experiment recorded in Table confirms the picture. The portfolio was the same as before, but now the target was the pure premium when an layer of the total risk was ceded a reinsurance company. The limits a and b were the
and the
quantiles of the distribution of the total portfolio loss, respectively. The pure premium was then computed as the expectation of the ceded loss. Again, the errors when using the many-parameter distributions to estimate the reinsurance premium are comparable to the ones from using the true distribution family. In fact, the biases tend to be lower for the many-parameter distributions, whereas the standard deviations are more or less the same. One should keep in mind that in practice, the true distribution family is unknown, and so one must expect model error in addition to the random one, which would increase the advantage from using a many-parameter distribution further. Moreover, the performance of the PowerGamma was again overall better than that of the Burr, and the PowerGamma gave all in all the best results of the five loss distributions. The results using the log-Normal-Pareto mixture are similar to the ones for the reserve in Table .
We also ran simulations of the reserve, as well as with
expected claims. The results from these simulations, which are shown in the supplementary material, follow the same patterns as the one presented in the paper. Further, we have also run simulations with the negative binomial as claim frequency distribution, which in practice is a more realistic model. Again, we let the expected number of claims be
and the number of observations be n = 50, but the standard deviation was 3.5. The corresponding results for the
reserve and the reinsurance premium, shown in the supplementary material, are very similar to the ones for Poisson distributed claim numbers.
5. Example: automobile insurance
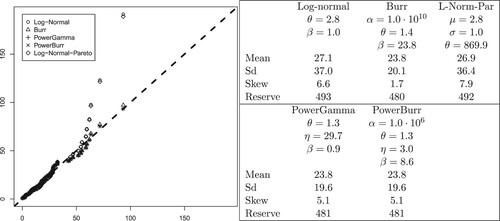
The example is taken from Bølviken (Citation2014) and consists of n = 6446 claims of cost due to personal injuries in motor insurance with the deductible subtracted. This means that the claims are left-truncated at the deductible, but since the deductible is subtracted, the distribution still starts at 0, and we may use the distributions from Section 4 without modifications. The claims include cost due to personal injuries and are heavy-tailed with skewness 5.6 and kurtosis 71.2. The data are around 25 years old with mean and standard deviation 23.9 and 28.9 (in Norwegian kroner, NOK, about ten in one EUR) which would have been higher today. Among the five two-parameter distributions considered in this paper, the log-Normal was the only one providing a reasonable fit to the data, as judged from a Q-Q-plot, though it does not quite capture the largest claims. Its parameters are shown in the right panel of Figure , along with the mean, the standard deviation and the skewness. We also estimated the reserve, assuming a Poisson distributed claim number with
expected incidents, based on ten million simulations This is shown in the same table, and so are corresponding results for the Burr, the PowerGamma and the PowerBurr families. As in the simulations of Section 4, we included the log-Normal-Pareto mixture as a reference. The results from the different distributions are quite similar, except for the skewness. The discrepancy between the smallest and largest projection of the reserve is no more than
.
Figure 1. Five families of distributions fitted the automobile data with Q-Q-plots on the left and parameter estimates and statistical summary on the right.

Q-Q-plots of the five fitted distributions are shown in the left panel of Figure . They suggest that all five distributions fit the automobile insurance data reasonably well, except for the PowerGamma and also the log-Normal far out in the tail. The downward curvatures corresponds to an underestimation of the risk. This is reflected in a lower skewness than for the other families of distributions, and for the PowerGamma also a lower standard deviation. In this case, a Pareto element in the multi-parameter modeling, capturing the heavy tail of the data, seems required for a good fit. This is provided by both the Burr and the PowerBurr distributions, as they both have the Pareto distribution as a special case. For the same reason, the log-Normal-Pareto also gives a better fit to the data than the log-Normal in the tail.
As the Norwegian car insurance dataset is quite large, we also wanted to try the fit to a much smaller one. Therefore, we drew a random sub-sample of 64 claims from automobile insurance data, corresponding to 1/100 of its size. The resulting sample had a mean of 23.8, a standard deviation of 19.7 and a skewness of 1.3. We fitted the same five distributions as to the original data, and the corresponding results are shown in Figure . The Burr, PowerGamma and PowerBurr all provide a rather good fit to the data, also in the tail, as seen from the Q-Q-plot to the left. The fitted log-Normal is now much too heavy-tailed, which is also reflected in the corresponding standard deviation. In this case, the fitted log-Normal-Pareto mixture is essentially the same as the log-Normal, with the same parameters for the log-Normal part and a very high threshold parameter, and therefore does not fit the data particularly well.
Figure 2. Five families of distributions fitted to a random sample of 64 observations from the automobile data with Q-Q-plots on the left and parameter estimates and statistical summary on the right.
6. Concluding remarks
The Box-Cox transformed Gamma and Burr variables lead to models with many of the usual two- parameter families included as special cases, exactly or approximately. If the true distribution is on the boundary of the parameter space, as in the case of the log-normal, the best fit may involve very large (or small) parameters, but there is nothing wrong in using the computer solution as it is even if it could have been interpreted as some simpler sub-model. This is the convenient way of programming a completely automatized procedure with the computer converting loss data to actuarial evaluations on its own.
In unimodal families fitted distributions are much more stable than parameter estimates, and over-parameterization did not raise errors in actuarial projections substantially unless the parent distribution was very heavy-tailed. This was demonstrated by Monte Carlo and also by asymptotics as the number of historical losses . Much of the latter argument used the log-normal as a vehicle, and its special properties allowed us to derive simple mathematical expressions for asymptotic errors, in particular prove that they are the same under PowerGamma and PowerBurr.
Supplemental Material
Download PDF (154.7 KB)Acknowledgments
The authors wish to thank the two Reviewers and the Associate Editor for their helpful and constructive comments and suggestions.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Bakar S., Hamzah N., Maghsoudi M. & Nadarajah S. (2015). Modeling loss data using composite models. Insurance: Mathematics and Economics 61, 146–154.
- Beirlant J., Teugels J. & Vynckier P. (1996). Practical analysis of extreme values. Leuven University Press.
- Bølviken E. (2014). Computation and modelling in insurance and finance. Cambridge University Press.
- Box G. & Cox D. (1964). An analysis of transformations (with discussion). Journal of the Royal Statistical Society Series B 26, 231–252.
- Burr I. J. (1942). Cumulative frequency functions. Annals of Mathematical Statistics 13, 215–232.
- Chan J. S. K., Choy S. T. B., Makov U. R. & Landsman Z. (2018). Modelling insurance losses using contaminated, generalized beta type II distributions. ASTIN Bulletin 48(02), 871–904.
- Cooray K. & Ananda M. M. A. (2005). Modeling actuarial data with composite lognormal-Pareto model. Scandinavian Actuarial Journal 2005, 642–660.
- Cummins J. D., Dionne G., MacDonald J. B. & Pritchett B. M. (1990). Applications of the GB2 family of distributions in modeling insurance loss processes. Insurance: Mathematics and Economics 9(4), 257–272.
- Embrechts P., Klüppelberg C. & Mikosch T. (Modelling extremal events. Stochastic Modelling and Applied Probability.1997). Springer Verlag.
- Gui W., Huang R. & Lin X. S. (2021). Fitting multivariate Erlang mixtures to data: a roughness penality approach. Journal of Computational and Applied Mathematics 386, 113216.
- Hoeting J. A., Madigan D., Raftery A. E. & Volinsky C. T. (1999). Bayesian model averaging: a tutorial. Statistical Science 14(4), 382–401.
- Huber P. (1967). The behavior of maximum likelihood estimates under nonstandard conditions. In Proceedings of the Fifth Berkely Symposium in Mathematical Statistics and Probability. University of California Press.
- Kleiber C. & Kotz S. (2003). Statistical size distributions in economics and actuarial sciences. Wiley.
- Lee S. & Lin X. (2010). Modeling and evaluating insurance losses via mixtures of Erlang distributions. North American Actuarial Journal 14(1), 107–130.
- Marlin P. (1984). Fitting the log-normal distribution to loss data subject to multiple deductibles. The Journal of Risk and Insurance 51( 4), 687–701.
- Miljkovic T. & Grün B. (2016). Modeling loss data using mixtures of distributions. Insurance: Mathematics and Economics 70, 387–396.
- Omari C. O., Nyambura S. G. & Mwangi J. M. W. (2018). Modeling the frequency and severity of auto insurance claims using statistical distributions. Journal of Mathematical Finance 8(1), 137–160.
- Reynkens T., Verbelen R., Beirlant J. & Antonio K. (2017). Modelling censored losses using splicing: a global fit strategy with mixed Erlang and extreme value distributions. Insurance Mathematics & Economics 77, 65–77.
- Scollnik D. P. M. (2007). On composite lognormal-Pareto distributions. Scandinavian Actuarial Journal2007(1), 20–33.
- Scollnik D. P. M. & Sun C. (2012). Modelling with Weibull-Pareto models. North American Actuarial Journal 16(2), 260–272.
- Scott P. W. (1992). Multivariate density estimation: theory, practice and visualization. John Wiley & Sons.
- Venter C. (1985). Transformed Beta and Gamma distributions and aggregate losses. Casually Actuarial Society 70, 156–193.
- Verbelen R., Gong L., Antonio K., Badescu A. & Lin S. (2015). Fitting extremes of Erlangs to censored and truncated data using the EM algorithm. ASTIN Bulletin 45, 729–758.
- White H. (1982). Maximum likelihood estimation of misspecified models. Econometrica 50(1), 1–25.
- White H. (1994). Estimation, inference and specification analysis. Cambridge: Cambridge University Press.
- Zuanetti D. & Diniz C. (2006). A lognormal model for insurance claims data. REVSTAT – Statistical Journal 4, 131–142.
Appendices
Appendix 1.
Burr uncertainty for Pareto data
Section 3.2 required the information matrix for the Burr family and the gradient vectors for its moments and percentiles. If is the information matrix with elements
,
and so on, then
where
The derivation of
from the density function (Equation9
(9)
(9) ) is straightforward (albeit lengthy) and is omitted.
The gradient vectors for moments and percentiles are most conveniently calculated by differentiating their expressions numerically. The k'th order moment was given in (Equation3(3)
(3) ) whereas for the percentiles there is a simple relationship between Burr and Beta variables that can be utilized. Let
be the ϵ-percentile of the Beta distribution with shape parameters α and θ, available in standard software. Then
is the same Burr percentile.
Appendix 2.
Asymptotics in tilting models
A.1. General
Several of the uncertainty evaluations in Section 3 apply to models with density functions of the form
(A1)
(A1) with ν a tilting parameter adding to the parameter vector
and with
a known function. Note that ν is a transformation of those in Section 3, but when using likelihoods this does not affect uncertainty. The idea is to study how much the asymptotic standard deviation of moments and percentile estimates go up when we fit
for data generated by its limit
as
. This requires the information matrix
under
and the gradient vector
of the quantity
of interest, again in the limit as
. Notation with superscript ν, for example
and
for expectation and ϵ-percentile, applies to
whereas E and
without ν refer to
.
The information matrix and gradient vector
under
are of the form
(A2)
(A2) with
and
row vectors. A recepy for calculating the limits of these quantities is
(A3)
(A3)
(A4)
(A4)
(A5)
(A5)
(A6)
(A6) To verify this start by recalling that
and
in (EquationA3
(A3)
(A3) ) are information matrix and gradient vector under
, and become the limits as stated since
when
. Next note that
and inserting (EquationA1
(A1)
(A1) ) implies (EquationA4
(A4)
(A4) ). The limits for the gradients remain. The k'th order moment is
and replacing the density function by (EquationA1
(A1)
(A1) ) and then differentiating leads to (EquationA5
(A5)
(A5) ). Finally, the ϵ-percentile
is from (EquationA1
(A1)
(A1) ) the solution of
which when differentiated with respect to ν yields
and (EquationA6
(A6)
(A6) ) follows since
.
A.2. Burr uncertainty for Gamma data
The asymptotics when the Burr model is fitted Gamma data is covered by Section A.1. Start with the expression for the Burr density function in (Equation2(2)
(2) ). It applies when
, but when it is rewritten for general β and with
replacing α, it becomes
Its limit when
or equivalently
is the Gamma density function
and it is shown below that
and
are connected by the tilting relationship (EquationA1
(A1)
(A1) ) with
(A7)
(A7) Table was computed by inserting this function into (EquationA3
(A3)
(A3) )–(EquationA6
(A6)
(A6) ). Calculations were numerical since simple mathematical expressions are not available.
To verify (EquationA7(A7)
(A7) ) note that the logarithm of the ratio between
and
is
The two log-Gamma functions can be simplified though the tail approximation
(A8)
(A8) whereas the Taylor series for
yields
and after some simple calculations
with
as in (EquationA7
(A7)
(A7) ).
Appendix 3.
PowerGamma asymptotics
A.3. Tilting against the log-normal
The PowerGamma variable has the density function
(A9)
(A9) It was claimed in Section 3.3 that it can under a suitable reparameterization be tilted against a log-normal density function as
. Introduce new parameters
so that limits are in terms of
. With the new parameters the density function in (EquationA9
(A9)
(A9) ) is on log-form
(A10)
(A10) where
By invoking the tail series (EquationA8
(A8)
(A8) ) for the log Gamma function
reduces to
(A11)
(A11) To simplify the other terms in (EquationA10
(A10)
(A10) ) start by noting that (EquationA9
(A9)
(A9) ) right yields
where the second term on the right through β tends to 0 at exponential rate as
. Hence after inserting for η and β
(A12)
(A12) This will be the vehicle for much of the calculations to follow. Utilize that
which from the Taylor series of the exponential function becomes
(A13)
(A13) Take logarithms on both sides and use the Taylor series of the logarithmic function. Some straightforward calculations and rearrangements then lead to
(A14)
(A14) Finally, when inserting (EquationA11
(A11)
(A11) )–(EquationA14
(A14)
(A14) ) into (EquationA10
(A10)
(A10) ), a lot of terms cancel, and it follows after some straightforward manipulations that
or
after inserting
. This is the tilting relation (Equation15
(15)
(15) ).
A.4. The information matrix
The information matrix when the PowerGamma family is fitted log-normal data is
(A15)
(A15) To verify this start by noting that when Z is log-normal, then
is
with second, fourth and sixth order moments 1, 3 and 15. Hence (EquationA4
(A4)
(A4) ) left and (Equation15
(15)
(15) ) right yield
Next from (Equation14
(14)
(14) )
so that by (EquationA4
(A4)
(A4) ) right
where the right hand side vanishes in expectation since all powers of Y are odd when multiplied out. This establishes the first row and column in (EquationA15
(A15)
(A15) ), and the rest are elementary results for the log-normal.
A.5. Moment estimation
The moment of order k under the log-normal is
(A16)
(A16) and we seek the asymptotic standard deviation of its estimate when the PowerGamma model has been fitted. We need the inverse of the matrix (EquationA15
(A15)
(A15) ) which is
(A17)
(A17) and also the limit of the gradient
. The latter is
(A18)
(A18) The limits for
and
follows by differentiating (EquationA16
(A16)
(A16) ) whereas the one for
is determined from (EquationA5
(A5)
(A5) ) and (Equation15
(15)
(15) ) right which yield
and an elementary calculation utilizing that
closes the argument.
Let be the asymptotic standard deviation for the moment estimate when fitting the PowerGamma model to log-normal data. Then
is the limit of the square root of
and becomes
which is to be compared with its counterpart
under log-normal fitting. Now the information matrix is the
block in the lower, left corner of (EquationA15
(A15)
(A15) ) and the gradient the last two elements in (EquationA18
(A18)
(A18) ) so that
Hence
leading to (Equation17
(17)
(17) ) left.
A.6. Percentile estimation
The quantity we are now trying to estimate is
(A19)
(A19) with
the ϵ-percentile of the standard normal. The study of asymptotic uncertainty is the same as above except for the gradient which has become
(A20)
(A20) Only the expression for
requires a calculation since the rest are obvious consequences of differentiating (EquationA19
(A19)
(A19) ). By (EquationA6
(A6)
(A6) )
where
is the log-normal density function above and
is the function (Equation15
(15)
(15) ) right. The integral is evaluated by substituting
. With
this yields
(A21)
(A21) whereas
and (EquationA20
(A20)
(A20) ) left follows.
The quadratic form when combining the vector (EquationA20(A20)
(A20) ) with the matrix (EquationA17
(A17)
(A17) ) yields the coefficient
as
whereas for the log-normal the similar quantity is
after using the last two elements in (EquationA20
(A20)
(A20) ) as the gradient vector and the lower
block in (EquationA15
(A15)
(A15) ) as information matrix. It follows that
so that
as claimed in (Equation17
(17)
(17) ) right.
Appendix 4.
PowerBurr density
The PowerBurr model defined in (Equation5(5)
(5) ) right has density function
(A22)
(A22)