
Abstract
Background
The objective of this study was to develop and validate a machine learning (ML) model for predict in-hospital mortality among critically ill patients with congestive heart failure (CHF) combined with chronic kidney disease (CKD).
Methods
After employing least absolute shrinkage and selection operator regression for feature selection, six distinct methodologies were employed in the construction of the model. The selection of the optimal model was based on the area under the curve (AUC). Furthermore, the interpretation of the chosen model was facilitated through the utilization of SHapley Additive exPlanation (SHAP) values and the Local Interpretable Model-Agnostic Explanations (LIME) algorithm.
Results
This study collected data and enrolled 5041 patients on CHF combined with CKD from 2008 to 2019, utilizing the Medical Information Mart for Intensive Care Unit. After selection, 22 of the 47 variables collected post-intensive care unit admission were identified as mortality-associated and subsequently utilized in the development of ML models. Among the six models generated, the eXtreme Gradient Boosting (XGBoost) model demonstrated the highest AUC at 0.837. Notably, the SHAP values highlighted the sequential organ failure assessment score, age, simplified acute physiology score II, and urine output as the four most influential variables in the XGBoost model. In addition, the LIME algorithm explains the individualized predictions.
Conclusions
In conclusion, our study accomplished the successful development and validation of ML models for predicting in-hospital mortality in critically ill patients with CHF combined with CKD. Notably, the XGBoost model emerged as the most efficacious among all the ML models employed.
Background
Congestive heart failure (CHF) persists as a prominent contributor to morbidity and mortality worldwide, affecting over 23 million individuals [Citation1]. Concurrently, chronic kidney disease (CKD) is prevalent in CHF patients and is associated with an unfavorable prognosis in terms of global and cardiovascular mortality prognosis [Citation2]. According to pivotal CHF trials, the prevalence of CKD ranges from 32 to 50% [Citation3]. The prognosis for patients with CHF combined with CKD is notably grim, exacerbating as renal function deteriorates, ultimately leading to elevated mortality rates [Citation4]. Recent research underscores the importance of early identification of critically ill individuals at risk of rapid deterioration, with potential implications for improved clinical outcomes [Citation5]. Predictive models tailored to identify high-risk patients with CHF combined with CKD for in-hospital mortality offer a promising avenue for healthcare professionals to allocate resources more efficiently. This facilitates personalized interventions and intensified monitoring for those individuals most likely to benefit. Therefore, the development of accurate prediction models capable of reliably estimating an individual’s survival prognosis holds significant potential for advancing therapeutic practice.
In leveraging substantial datasets, encompassing demographics, diagnoses, regularly measured values, and treatments from electronic health records, machine learning (ML) algorithms presents a promising avenue to mitigate mortality rates in critically ill patients with CHF combined with CKD. These sophisticated, data-driven strategies excel in handling high-dimensional data, model intricate relationships, and identifying vital predictors linked to outcomes. A growing body of evidence demonstrates that ML techniques outperform traditional models [Citation6, Citation7]. ML approaches have gained prominence in disease prognostication, allowing clinicians, with well-constructed prediction models, to identify patients at high risk for poor outcomes, facilitating more timely interventions and yielding improved results [Citation8–10]. Notably, analyses of outcome prediction in patients with CHF combined with CKD are relatively scarce. Therefore, the objective of this research is to forecast in-hospital mortality rates among critically ill patients with CHF combined with CKD using the ML method.
Methods
Database introduction
The Medical Information Mart for Intensive Care IV (MIMIC IV) database stands as a thorough, de-identified clinical dataset, sanctioned by both the Beth Israel Deaconess Medical Center and the Massachusetts Institute of Technology [Citation11]. The necessity for individual patient consent and ethically informed consent declarations was waived, given that the study had no impact on clinical decision-making, and the anonymity of all patients in the database was maintained [Citation12]. The author XL successfully completed the protection of human research participants exam and secured a certificate authorizing access to the database (No. 35970146).
Study population
All patients within the MIMIC IV database diagnosed with CKD combined with CHF were included in this study. The diagnosis of CKD and CHF was relied on the International Classification of Diseases, Ninth Revision (ICD-9) and International Classification of Diseases, Tenth Revision (ICD-10) codes documented by hospital personnel during patient discharge (Supplementary Table S1). Only the first admission will be considered for patients with a history of multiple ICU admissions. Exclusions comprised patients below 18 years old and those with an ICU stay of less than 24 h.
Data collection
We used Navicat Premium software for data extraction from the MIMIC IV database. Taking into account all available parameters and utilizing clinical expertise, we selected 47 candidate variables based on association with outcomes. We collected age, sex, weight, and ethnicity as demographic information for this study. Comorbidities included cerebrovascular disease, rheumatic disease, chronic obstructive pulmonary disease (COPD), diabetes, peripheral vascular disease, myocardial infarction, peptic ulcer disease, liver disease, paraplegia, cancer, and acute kidney injury. The patient’s CKD stage was also collected. We gathered initial values of vital sign data, including temperature, respiration rate, mean arterial pressure, heart rate, systolic blood pressure, and oxygen saturation, within 24 h of admission. For biochemical indices, we collected initial values within the first 24 h after admission for serum sodium, serum potassium, bicarbonate, serum chloride, serum calcium, serum glucose, serum creatinine, international normalized ratio, anion gap, blood urea nitrogen, white blood cell, platelets, hemoglobin, hematocrit, prothrombin time, and partial thromboplastin time. Blood urea nitrogen is a blood test that measures the level of urea nitrogen in the bloodstream. It is commonly used to assess kidney function. Elevated BUN levels can indicate kidney dysfunction or other medical conditions. Prothrombin time is a laboratory test that measures how long it takes for blood to clot. It is often used to assess the function of the coagulation (blood clotting) system and to monitor the effects of anticoagulant medications. We recorded the total amount of urine voided within the initial 24 h following admission to the ICU. Within the same time frame, we recorded medical treatments such as mechanical ventilation, vasopressors, and renal replacement therapy. In the initial 24 h post-admission, we assessed the first values of the sequential organ failure assessment (SOFA) score and the simplified acute physiology score II (SAPS II) as severity scores of illness. The SOFA score is a clinical tool used to assess the severity of organ dysfunction/failure in critically ill patients. It evaluates the function of six organ systems: neurological, renal, coagulation, hepatic, cardiovascular, and respiratory. SAPS II is a severity-of-illness scoring system used to predict the risk of mortality in critically ill patients. It takes into account several physiological parameters, age, and underlying comorbidities to estimate the probability of survival. The decision to use SOFA and SAPS II scores was based on their wide recognition and established utility in assessing disease severity in critically ill patients across various studies and clinical settings. These scoring systems offer a comprehensive evaluation of organ dysfunction and physiological derangements, allowing for a reliable quantification of disease severity.
Preprocessing of data
Missing values are common in the MIMIC IV database, and all variables in this study had missing values of less than 20% (Supplementary Table S2). We used multiple interpolation methods to fill in the missing data. The least absolute shrinkage and selection operator (LASSO) regression can construct a penalty function to obtain a finer model, which is a data downscaling algorithm that helps to filter out key factors affecting the results, improve model performance, and reduce overfitting. Therefore, we used LASSO regression to identify variables that may be associated with mortality. For the LASSO analysis, we utilized the entire dataset for model development and implemented cross-validation to optimize the tuning parameter (λ). To enhance the robustness of our model, we adopted a 10-fold cross-validation strategy, wherein the dataset was partitioned into 10 subsets. The LASSO analysis was then iteratively applied on each fold, with the λ parameter selected based on the minimization of cross-validated error. This approach ensures a comprehensive exploration of the regularization parameter space, ultimately leading to the identification of the optimal λ that maximizes the model’s predictive performance.
Statistical analysis
Continuous variables in this study were presented as the median and interquartile range (IQR), and the Mann-Whitney test was employed to discern differences between groups owing to their non-normal distribution. Categorical variables were conveyed as numbers and percentages, with group comparisons conducted using either the chi-square test or Fisher’s exact test, as appropriate.
In our analysis, we conducted the statistical analysis using a combination of Python (Version 3.9.12) and R software (Release 4.2.1, Foundation R for Statistical Computing). We utilized several Python and R software packages for data processing; Python software packages include pandas, NumPy, scikit-learn, XGBoost, SHapley Additive exPlanation (SHAP), and, Local Interpretable Model-Agnostic Explanations (LIME) and R software packages include glmnet and ROCR. Statistical significance was defined as a P value below 0.05.
Machine learning
All patients participating in this study were randomly divided into a training set (70%) and a validation set (30%). Six ML techniques: extreme gradient boosting (XGBoost), k-nearest neighbor (KNN), support vector machine (SVM), random forest (RF), decision tree and logistic regression were used to build and validate the model for in-hospital mortality risk. We calculated the accuracy, sensitivity, specificity, area under the curve (AUC), recall, precision, F1 Score, and Matthews correlation coefficient (MCC) of the models for evaluating the predictive performance of different ML models. The testing AUC values corresponding to the different models were compared using paired Delong’s test. The calibration curve is plotted and used to compare the actual with the predicted mortality risk. Based on the AUC, our final candidate model was selected. Since SOFA and SAPS II scores are used as common tools to predict severity and prognosis in critically ill patients, we compared the predictive power of the final model with that of traditional scoring systems. The American Heart Association Get With The Guidelines-Heart Failure (GWTG-HF) risk score is a widely accepted in-hospital mortality risk stratification scoring system. This scoring system is calculated based on patient-related data, including age, systolic blood pressure, blood urea nitrogen, heart rate, serum sodium, COPD, and non-African American ethnicity. We also compared our final model to the GWTG-HF risk score. The SHAP value is a concept rooted in cooperative game theory. It is used to attribute a value to each feature in a prediction, indicating its contribution to the prediction outcome. In the context of ML, SHAP values provide a way to explain the output of a model by quantifying the impact of each feature on that output. We utilized the SHAP values to examine the significance of individual features affecting the model’s output and to depict the relevant features influencing the mortality risks. LIME is a method designed to provide local explanations for the predictions of complex ML models. It aims to explain the predictions of any black-box model by training a simpler, interpretable model on a local subset of the data around the instance being explained. By generating and analyzing a dataset of perturbed instances, LIME facilitates the creation of local models that mimic the intricate model’s behavior around specific cases. This study applies the LIME algorithm to fit the predictive behavior of the model to individuals. Finally, subgroup analyses were performed according to the presence of sepsis, diabetes, paraplegia, cancer, AKI and different CKD stages.
Results
Participants
A total of 9377 participants with CHF combined with CKD were determined to be eligible; of these 9377 patients, 3637 were disqualified for non-first ICU admissions, and 1672 patients were excluded due to a length of stay in the ICU of less than 24 h. Finally, 5041 patients met this study’s inclusion and exclusion criteria (). The in-hospital death rate among ICU-admitted CHF combined with CKD patients was 18.5% (933/5041). Of these patients, 60.5% (3049/5041) were male, with a median age of 76.9 (IQR: 67.9-84.8) years. Diabetes (2742/5041, 54.4%), sepsis (2095/5041, 41.6%), and COPD (1874/5041, 37.2%) were the top three comorbidities. The demographics, comorbidities, vital signs, biochemical indices, urine output, medical treatments, and severity scores of illness of the patients are listed in .
Figure 1. The flowchart of patient selection.
Abbreviations: CHF: congestive heart failure, CKD: chronic kidney disease, MIMIC IV: Medical Information Mart for Intensive Care IV, ICU: intensive care unit.
Table 1. Demographic and clinical characteristics at baseline.
Predictor selection
A total of 47 clinical variables were included in the LASSO regression, and Supplementary Figure S1A shows a plot of the regression coefficients for the model. Each curve represents one variable. At each different input, factors with nonzero coefficients and corresponding nonzero coefficients formed a LASSO model. The LASSO feature selection process is shown in Supplementary Figure S1B. We chose 10-fold cross-validation to further determine the optimal model. The cross-validation error of the model is minimized when λ = 0.0077. Ultimately, 22 variables were still significant predictors of death (Supplementary Table S3). Correlation coefficients between these variables are shown in Supplementary Table S4.
Model development and validation
The included patients were randomized into the training set (3528, 70%) and the validation set (1513, 30%), and no significant differences were observed in the variables between the two sets (Supplementary Table S5). We built six ML models (XGBoost, KNN, SVM, RF, decision tree and logistic regression) with 22 variables chosen by LASSO regression as input components. The XGBoost model has the highest AUC (0.837) in the validation set (logistic regression: 0.828; SVM: 0.737; KNN: 0.670; decision tree: 0.616; RF: 0.820) ( and Supplementary Table S6). Supplementary Table S7 shows the AUC of the six models in the training set. Similarly, the XGBoost model outperformed the SAPS II (AUC: 0.752), SOFA (AUC: 0.766) score and GWTG-HF (AUC: 0.688) (). displays the results of an evaluation of the AUC, accuracy, sensitivity, specificity, recall, precision, F1 Score, and MCC of these six ML models. Calibration plots for the six ML models are shown in Supplementary Figure S2.
Figure 2. ROC Curves for predicting the incidence of in-hospital mortality with ML models and the traditional severity of illness scores.
A ROC curves of six ML models for predicting in-hospital mortality; B ROC curves for the traditional severity of illness scores predicting in-hospital mortality. Abbreviations: ROC: receiver operating characteristic, SVM: support vector machine, KNN, k-nearest neighbors, AUC: area under the curve, SOFA: sequential organ failure assessment, SAPS II: simplified acute physiology score II.
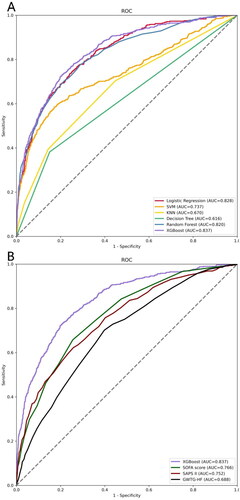
Table 2. Performance comparison of the six models in the testing set.
Model explainability
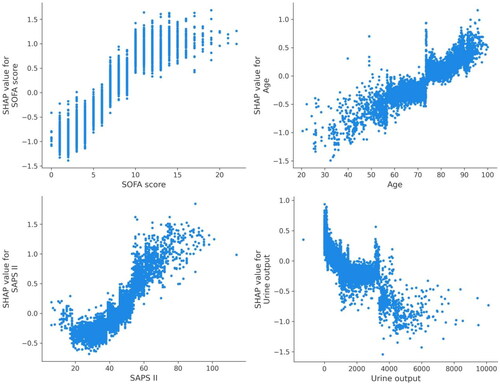
Utilizing SHAP values, our goal was to elucidate the mortality prediction mechanism employed by the XGBoost model. illustrates the feature importance ranking of the XGBoost model through SHAP summary plots, highlighting SOFA score, age, SAPS II, and urine output as the four primary contributors to the model. To provide more detailed information about , we provide dependence plots of the top four most weighted clinical features output by the XGBoost prediction model to show the relationship between the feature values and the SHAP values of the features ( and ).
Figure 3. The important features derived from the XGBoost model.
Ranking of feature importance indicated by SHAP. The matrix plot depicts the importance of each covariate in the development of the final predictive model.
Abbreviations: SHAP: SHapley Additive explanation, SOFA: sequential organ failure assessment, SAPS II: simplified acute physiology score II, PTT: partial thromboplastin time, BUN: blood urea nitrogen, PT: prothrombin time, SpO2: oxygen saturation, MAP: mean arterial pressure.
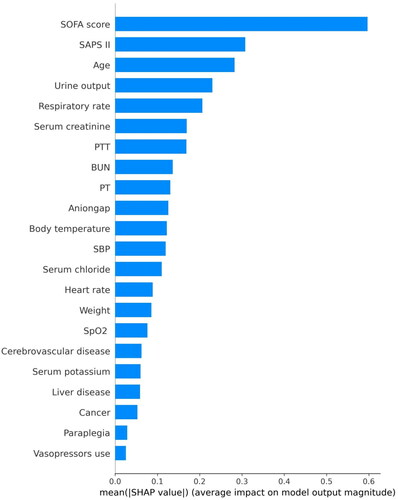
Figure 4. SHAP summary plot of the features of the XGBoost model.
The higher the SHAP value of a feature, the higher the probability of death development. Each line represents a feature, and the abscissa is the SHAP value. Red dots represent higher feature values, and blue dots represent lower feature values.
Abbreviations: SHAP: SHapley Additive explanation, SOFA: sequential organ failure assessment, SAPS II: simplified acute physiology score II, PTT: partial thromboplastin time, BUN: blood urea nitrogen, PT: prothrombin time, SpO2: oxygen saturation, MAP: mean arterial pressure.
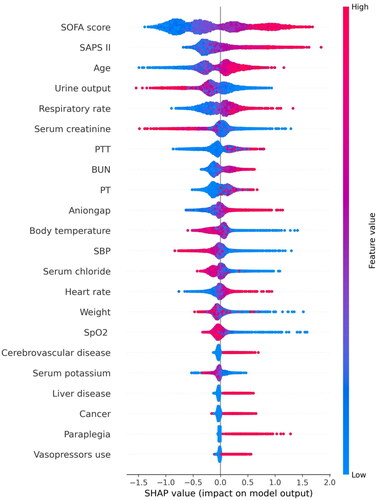
Figure 5. SHAP dependence plot of the XGBoost model.
SHAP values for specific features exceed zero, representing an increased risk of death development.
Abbreviations: SHAP: Shapley Additive explanation, SOFA: sequential organ failure assessment, SAPS II: simplified acute physiology score II.
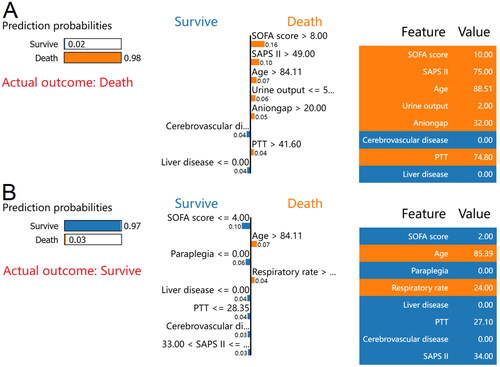
The LIME method was then used for two random samples from the validation set to provide insight into the individual mortality forecast. The case of death, as reported by the LIME algorithm, is depicted in . According to the XGBoost model, 98% was the estimated probability of death. A SOFA score of 10, SAPS II of 75, age of 88.51 years, urine volume of 2 mL, anion gap of 32 mEq/L, and PTT of 74.8 s were all associated with an increased risk of death in the XGBoost model. The lack of a history of cerebrovascular disease or liver disease was discovered to lessen the probability of mortality. For this case, both the XGBoost model and the actual outcome were death. Similarly, depicts a survival case with the LIME method. According to the XGBoost model, the probability of mortality was 3%. An age of 85.39 years, and a respiratory rate of 24 breaths/min in the XGBoost model was associated with an increased risk of death. In contrast, a SOFA score of 2, SAPS II of 34, PTT of 27.1 s, and the absence of paraplegia, liver disease, or cerebrovascular disease reduced the risk of death. The XGBoost model for this patient predicted survival, and survival was also the actual outcome.
Figure 6. LIME algorithm for explaining individual’s prediction results.
Screenshot of the death prognosis for critically ill patients with CHF combined with CKD. (A) Utilizing the LIME method, show a death case. (B) Present a case of survival using the LIME method. The left portion of the picture depicts expected LIME findings. The center section lists, from highest to lowest, the eight variables that had the greatest impact on survival or death. The length of the bar for each feature reflects the weight of that feature in the prediction. A longer bar represents a characteristic that contributes more to survival or mortality. The right panel displays the crucial values of these eight factors at which they had the greatest influence on survival or death.
Abbreviations: LIME: Local Interpretable Model-Agnostic Explanations, CHF: congestive heart failure, CKD: chronic kidney disease, SOFA: sequential organ failure assessment, SAPS II: simplified acute physiology score II, PTT: partial thromboplastin time.
Subgroup analyses
Subgroup analyses for the presence or absence of sepsis, diabetes, paraplegia, cancer, AKI and different CKD stages showed that the sustained robustness of the XGBoost model in predicting mortality among these patients. Comprehensive results can be found in Supplementary Figure S3.
Discussion
This study involved the development and validation of six models, incorporating 22 clinical factors, to predict in-hospital mortality among critically ill patients with CHF combined with CKD. Notably, the XGBoost model surpassed other models (KNN, SVM, RF, decision tree and logistic regression) as well as traditional risk scores (SAPS II, SOFA score and GWTG-HF) in predicting death in critically ill patients with CHF combined with CKD. Analysis of feature importance revealed that the SOFA score, age, SAPS II, and urine volume constituted the top four features with the most significant impact on the XGBoost model’s prediction of in-hospital mortality. In addition, we describe how these factors influence the XGBoost model. These insights contribute to a comprehensive understanding of ML models for predicting in-hospital mortality in critically ill patients with CHF combined with CKD.
More than one million primary and roughly three million secondary hospital admissions occur annually in the United States due to heart failure (HF), a condition linked with a high mortality risk and significant morbidity [Citation13–15]. Thus, it significantly burdens impacted people and global healthcare systems. HF frequently coexists with various prognosis-relevant comorbidities and directly affects other organs, such as the kidneys. The progression of HF or kidney illness might negatively impact patient outcomes by activating vicious cycles that frequently accelerate cardiac and renal deterioration [Citation16,Citation17]. A study conducted in the United States discovered that hospitalization rates for HF were high among patients with CKD and that individuals with CKD combined with HF had an increased risk of CKD progression and death [Citation18]. To mitigate mortality, it is necessary to establish and advocate for predictive models that can precisely and promptly identify patients at a heightened risk of clinical deterioration.
In our comparative analysis, the p-value for the difference in AUC between the XGBoost and Logistic regression models was not statistically significant. However, it is crucial to note that the selection of an optimal model goes beyond statistical significance. The practical effectiveness of XGBoost in predicting in-hospital mortality for critically ill patients with congestive heart failure combined with chronic kidney disease is evident in several aspects. XGBoost excels in capturing complex, nonlinear relationships within the dataset, a vital consideration given the intricate nature of critically ill patients. Additionally, the model’s interpretability is enhanced through the use of SHAP values and the LIME algorithm, providing insights into influential factors. The robustness of XGBoost across diverse datasets and its potential for better generalization further contribute to its practical superiority. Moreover, a comprehensive evaluation considering metrics beyond AUC, such as sensitivity, specificity, and positive predictive value, consistently demonstrates the favorable performance of XGBoost. Despite the lack of statistical significance in the AUC comparison, the nuanced strengths of XGBoost collectively support its effectiveness in predicting in-hospital mortality, underscoring the significance of our findings in a clinical context.
In this investigation, the XGBoost model demonstrated superior predictive accuracy for in-hospital mortality in critically ill patients with CHF combined with CKD compared to other models. These findings align with numerous other studies in the field. Li et al. demonstrated that the XGBoost model surpassed other models, including SVM, RF, and logistic regression in predicting in-hospital mortality among ICU patients with HF [Citation19]. Hu et al. found that XGBoost outperformed RF, naive bayes, decision trees, logistic regression, KNN, and SVM in predicting in-hospital mortality among critically ill patients with acute kidney injury [Citation20]. As per a meta-analysis, XGBoost demonstrated superior performance in predicting acute kidney injury compared to other ML techniques, including bayesian networks and SVM [Citation21]. Moreover, conventional severity scoring methods, including the SAPS II, SOFA score and GWTG-HF, exhibited subpar performance compared to ML models. This suggests that traditional scoring tools may not be reliable for predicting mortality in critically ill patients with CHF combined with CKD.While the SAPS II, SOFA score and GWTG-HF are capable of estimating the likelihood of adverse outcomes in critically ill patients, their exclusion of a significant number of pertinent parameters in their studies may lead to less accurate predictions compared to multivariable models [Citation22]. Prior research has indicated that the SAPS II, SOFA score and GWTG-HF have inferior prediction ability compared to ML models [Citation6].
In this study, the ML algorithm was used for the first time to predict in-hospital mortality in critically ill patients with CHF combined with CKD. In critically ill patients with CHF combined with CKD, a complicated XGBoost model revealed that SOFA score, age, SAPS II, and urine output were most strongly linked with mortality. The SOFA score is a tool that describes the presence of organ dysfunction [Citation23]. It assigns a daily score between 1 and 4 to each of the six organ systems based on the severity of dysfunction: respiratory, circulatory, renal, hematologic, hepatic, and central nervous systems [Citation24]. The association between SOFA scores and clinical outcomes was high [Citation25]. Similarly, in the present investigation, the SOFA score had the maximum weight in the XGBoost model. It was determined to be the most significant predictor of mortality in critically ill patients with CHF combined with CKD. Age is a significant risk factor for mortality in critically ill patients with CHF combined with CKD. Numerous studies have demonstrated that aging is associated with an increased risk of death in critically ill patients with CHF combined with CKD. In our investigation, the median age of non-survivors was older than the median age of survivors. SAPS II is also a significant predictor of mortality. The SAPS II includes seventeen variables, and higher total scores are indicative of greater illness severity [Citation26]. Prior studies have established an association between SAPS II and an elevated mortality rate among ICU patients [Citation27]. In addition, we discovered a correlation between urine output and mortality in critically ill patients with CHF combined with CKD. Oliguria is a prevalent condition among ICU patients and represents the primary cause of renal parenchymal damage [Citation28]. Numerous studies have illustrated a correlation between reduced urine output and unfavorable outcomes in critically ill individuals [Citation28,Citation29].
However, this study also has some limitations. First, due to its retrospective design, this can lead to unavoidable selection bias. Second, different comorbidities may somewhat mask outcomes in patients with CKD and CHF. Third, the current study is a single-center study, and the results may not be extrapolated to other centers. In addition, prospective and multicenter studies are needed to validate this study’s findings further.
Conclusions
In conclusion, ML models emerge as dependable tool for mortality prediction in critically ill patients with CHF combined with CKD. Among all the prediction models, the XGBoost model stands out as the most effective, offering clinicians a valuable tool for accurately management and timely interventions to mitigate mortality risks in critically ill patients with CHF combined with CKD who are at high risk of death.
Notably, among all the predictive models, the XGBoost model stands out as the most effective, offering clinicians a valuable tool for accurate management and timely interventions to mitigate mortality risks in critically ill patients with CHF combined with CKD who are at elevated risk of death."
Author contributions
Conceptualization: Xunliang Li, Zhijuan Wang, Haifeng Pan, Deguang Wang; Methodology: Xunliang Li, Zhijuan Wang; Formal analysis and investigation: Xunliang Li, Wenman Zhao, Rui Shi, Yuyu Zhu, Zhijuan Wang. Funding acquisition: Haifeng Pan, Deguang Wang; Supervision: Haifeng Pan, Deguang Wang. All authors read and approved the final manuscript.
Ethics approval and consent to participate
MIMIC IV was set up with the approval of the Institutional Review Board at the Massachusetts Institute of Technology. All participant data were anonymized to safeguard their privacy. Due to the use of anonymized health records, ethical approval and informed consent were not required. This study adheres to the ethical criteria outlined in the Declaration of Helsinki of 1964.
Supplemental Material
Download PDF (464.5 KB)Acknowledgments
The authors would like to acknowledge our previous work titled ‘Machine learning algorithm to predict the in-hospital mortality in critically ill patients with chronic kidney disease’ by Li et al. (Renal Failure, 45(1), 2212790), which shares some similarities in study design and sections with the current manuscript. It is essential to note that this manuscript is not derived from the previously published work and presents unique contributions focused on critically ill patients with congestive heart failure combined with chronic kidney disease.
Disclosure statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data availability statement
The datasets presented in the current study are available in the MIMIC IV database (https://physionet.org/content/mimiciv/1.0/).
Additional information
Funding
References
- Cleland JG, Khand A, Clark A. The heart failure epidemic: exactly how big is it? Eur Heart J. 2001;22(8):1–13. Epub 2001/04/05. doi: 10.1053/euhj.2000.2493.
- McAlister FA, Ezekowitz J, Tonelli M, et al. Renal insufficiency and heart failure: prognostic and therapeutic implications from a prospective cohort study. Circulation. 2004;109(8):1004–1009. Epub 2004/02/11. doi: 10.1161/01.cir.0000116764.53225.a9.
- Damman K, Valente MA, Voors AA, et al. Renal impairment, worsening renal function, and outcome in patients with heart failure: an updated meta-analysis. Eur Heart J. 2014;35(7):455–469. Epub 2013/10/30. doi: 10.1093/eurheartj/eht386.
- Damman K, Testani JM. The kidney in heart failure: an update. Eur Heart J. 2015;36(23):1437–1444. Epub 2015/04/04. doi: 10.1093/eurheartj/ehv010.
- Alam N, Hobbelink EL, van Tienhoven AJ, et al. The impact of the use of the early warning score (ews) on patient outcomes: a systematic review. Resuscitation. 2014;85(5):587–594. Epub 2014/01/29. doi: 10.1016/j.resuscitation.2014.01.013.
- Hou N, Li M, He L, et al. Predicting 30-Days mortality for mimic-Iii patients with sepsis-3: a machine learning approach using xgboost. J Transl Med. 2020;18(1):462. doi: 10.1186/s12967-020-02620-5.
- Du M, Haag DG, Lynch JW, et al. Comparison of the tree-based machine learning algorithms to cox regression in predicting the survival of oral and pharyngeal cancers: analyses based on seer database. Cancers (Basel). 2020;12(10):2802. Epub 2020/10/03. doi: 10.3390/cancers12102802.
- Weis C, Cuénod A, Rieck B, et al. Direct antimicrobial resistance prediction from clinical Maldi-Tof mass spectra using machine learning. Nat Med. 2022;28(1):164–174. doi: 10.1038/s41591-021-01619-9.
- Hu C, Li L, Huang W, et al. Interpretable machine learning for early prediction of prognosis in sepsis: a discovery and validation study. Infect Dis Ther. 2022;11(3):1117–1132. Epub 2022/04/12. doi: 10.1007/s40121-022-00628-6.
- Zhang Z, Chen L, Xu P, et al. Effectiveness of automated alerting system compared to usual care for the management of sepsis. NPJ Digit Med. 2022;5(1):101. doi: 10.1038/s41746-022-00650-5.
- Zhou S, Zeng Z, Wei H, et al. Early combination of albumin with crystalloids administration might be beneficial for the survival of septic patients: a retrospective analysis from mimic-Iv database. Ann Intensive Care. 2021;11(1):42. Epub 2021/03/11. doi: 10.1186/s13613-021-00830-8.
- Johnson AE, Pollard TJ, Shen L, et al. Mimic-Iii, a freely accessible critical care database. Sci Data. 2016;3:160035. doi: 10.1038/sdata.2016.35.
- Schocken DD, Benjamin EJ, Fonarow GC, et al. Prevention of heart failure: a scientific statement from the American heart association councils on epidemiology and prevention, clinical cardiology, cardiovascular nursing, and high blood pressure research; quality of care and outcomes research interdisciplinary working group; and functional genomics and translational biology interdisciplinary working group. Circulation. 2008;117(19):2544–2565. Epub 2008/04/09. doi: 10.1161/circulationaha.107.188965.
- van Riet EE, Hoes AW, Wagenaar KP, et al. Epidemiology of heart failure: the prevalence of heart failure and ventricular dysfunction in older adults over time. A systematic review. Eur J Heart Fail. 2016;18(3):242–252. Epub 2016/01/05. doi: 10.1002/ejhf.483.
- Redfield MM, Jacobsen SJ, Burnett JC, Jr., et al. Burden of systolic and diastolic ventricular dysfunction in the community: appreciating the scope of the heart failure epidemic. Jama. 2003;289(2):194–202. Epub 2003/01/09. doi: 10.1001/jama.289.2.194.
- Bagshaw SM, Cruz DN, Aspromonte N, et al. Epidemiology of Cardio-Renal syndromes: workgroup statements from the 7th adqi consensus conference. Nephrol Dial Transplant. 2010;25(5):1406–1416. Epub 2010/02/27. doi: 10.1093/ndt/gfq066.
- House AA, Anand I, Bellomo R, et al. Definition and classification of Cardio-Renal syndromes: workgroup statements from the 7th adqi consensus conference. Nephrol Dial Transplant. 2010;25(5):1416–1420. Epub 2010/03/17. doi: 10.1093/ndt/gfq136.
- Bansal N, Zelnick L, Bhat Z, et al. Burden and outcomes of heart failure hospitalizations in adults with chronic kidney disease. J Am Coll Cardiol. 2019;73(21):2691–2700. Epub 2019/05/31. doi: 10.1016/j.jacc.2019.02.071.
- Li J, Liu S, Hu Y, et al. Predicting mortality in intensive care unit patients with heart failure using an interpretable machine learning model: retrospective cohort study. J Med Internet Res. 2022;24(8):e38082. doi: 10.2196/38082.
- Hu C, Tan Q, Zhang Q, et al. Application of interpretable machine learning for early prediction of prognosis in acute kidney injury. Comput Struct Biotechnol J. 2022;20:2861–2870. Epub 2022/06/30. doi: 10.1016/j.csbj.2022.06.003.
- Song X, Liu X, Liu F, et al. Comparison of machine learning and logistic regression models in predicting acute kidney injury: a systematic review and Meta-Analysis. Int J Med Inform. 2021;151:104484. Epub 2021/05/16. doi: 10.1016/j.ijmedinf.2021.104484.
- Wu J, Huang L, He H, et al. Red cell distribution width to platelet ratio is associated with increasing in-hospital mortality in critically ill patients with acute kidney injury. Dis Markers. 2022;2022:4802702. doi: 10.1155/2022/4802702.
- He Y, Xu J, Shang X, et al. Clinical characteristics and risk factors associated with icu-Acquired infections in sepsis: a retrospective cohort study. Front Cell Infect Microbiol. 2022;12:962470. Epub 2022/08/16. doi: 10.3389/fcimb.2022.962470.
- Minne L, Abu-Hanna A, de Jonge E. Evaluation of sofa-based models for predicting mortality in the icu: a systematic review. Crit Care. 2008;12(6):R161–Epub 2008/12/19. doi: 10.1186/cc7160.
- Zhu Y, Zhang R, Ye X, et al. Saps iii is superior to sofa for predicting 28-Day mortality in sepsis patients based on sepsis 3.0 criteria. Int J Infect Dis. 2022;114:135–141. Epub 2021/11/15. doi: 10.1016/j.ijid.2021.11.015.
- Le Gall JR, Lemeshow S, Saulnier F. A new simplified acute physiology score (saps Ii) based on a european/North American multicenter study. Jama. 1993;270(24):2957–2963. Epub 1993/12/22. doi: 10.1001/jama.270.24.2957.
- Mirzakhani F, Sadoughi F, Hatami M, et al. Which model is superior in predicting icu survival: artificial intelligence versus conventional approaches. BMC Med Inform Decis Mak. 2022;22(1):167. Epub 2022/06/28. doi: 10.1186/s12911-022-01903-9.
- Macedo E, Malhotra R, Bouchard J, et al. Oliguria is an early predictor of higher mortality in critically ill patients. Kidney Int. 2011;80(7):760–767. Epub 2011/07/01. doi: 10.1038/ki.2011.150.
- Kellum JA, Sileanu FE, Murugan R, et al. Classifying aki by urine output versus serum creatinine level. J Am Soc Nephrol. 2015;26(9):2231–2238. Epub 2015/01/09. doi: 10.1681/asn.2014070724.