
Abstract
More than half of the world population lives in Asia and hypertension (HTN) is the most prevalent risk factor found in Asia. There are numerous articles published about HTN in Eastern Mediterranean Region (EMRO) and artificial intelligence (AI) methods can analyze articles and extract top trends in each country. Present analysis uses Latent Dirichlet allocation (LDA) as an algorithm of topic modeling (TM) in text mining, to obtain subjective topic-word distribution from the 2790 studies over the EMRO. The period of checked studied is last 12 years and results of LDA analyses show that HTN researches published in EMRO discuss on changes in BP and the factors affecting it. Among the countries in the region, most of these articles are related to I.R Iran and Egypt, which have an increasing trend from 2017 to 2018 and reached the highest level in 2021. Meanwhile, Iraq and Lebanon have been conducting research since 2010. The EMRO word cloud illustrates ‘BMI’, ‘mortality’, ‘age’, and ‘meal’, which represent important indicators, dangerous outcomes of high BP, and gender of HTN patients in EMRO, respectively.
1. Introduction
Middle-income countries (MICs) face a disproportionately high burden of hypertension (HTN), as well as considerable population aging. It is therefore critical to understand how individuals move through HTN care stages. In a recent study, Mauer and colleagues longitudinally assessed how individuals with HTN move through care by using waves of cohort data from China, Indonesia, Mexico, and South Africa [Citation1]. Their findings highlight the challenges faced by MICs in trying to improve HTN control and suggest that different approaches, beyond improving diagnosis, and initiating treatment, are needed.
The applying of computational artificial intelligence (AI) technologies for diagnosing disease outbreak trends and related studies have gained traction, given the potential to reduce cost and time necessary for extract hot topics and analyze them. Specifically, text mining is emerging as a viable method, leveraging available Latent Dirichlet allocation (LDA) and combining those with in visualizing methodologies of machine learning, topic modeling (TM), and clinical text mining to detect novel trends researches.
More than half of the world population lives in Asia [Citation2,Citation3] and HTN is the most prevalent risk factor found in Asia; Moreover, the most important reason of non-communicable diseases, such as increased stroke as the primary cause of disability and vascular death worldwide is HTN [Citation4]. Indeed, high blood pressure (BP) levels increases linearly risk of recurrent ischemic and hemorrhagic strokes [Citation5–7]. A recent meta-analysis showed that globally, stroke is the second-leading Level 3 cause of death (11·6% [10·8–12·2] of total deaths) in the world after ischemic heart disease (16·2% [15·0–16·9]) [Citation8].
Stroke impacts of decreasing quality of life (QoL) and its higher average mortality rate compared to Europe, America, and Australia make it a serious problem in Asia. [Citation2,Citation3]. In 2019, age-standardized HTN prevalence was lowest in Canada and Peru for both men and women; in Taiwan, South Korea, Japan, and some countries in western Europe including Switzerland, Spain, and the UK for women; and in several low-income and MICs such as Eritrea, Bangladesh, Ethiopia, and Solomon Islands for men. HTN prevalence surpassed 50% for women in two countries and men in nine countries, in central and Eastern Europe, central Asia, Oceania, and Latin America. Globally, 59% (55–62) of women and 49% (46–52) of men with HTN reported a previous diagnosis of HTN in 2019, and 47% (43–51) of women and 38% (35–41) of men were treated. Control rates among people with HTN in 2019 were 23% (20–27) for women and 18% (16–21) for men. In 2019, treatment and control rates were highest in South Korea, Canada, and Iceland (treatment >70%; control >50%), followed by the USA, Costa Rica, Germany, Portugal, and Taiwan. Treatment rates were less than 25% for women and less than 20% for men in Nepal, Indonesia, and some countries in sub-Saharan Africa and Oceania. Control rates were below 10% for women and men in these countries and for men in some countries in North Africa, central and south Asia, and eastern Europe. Treatment and control rates have improved in most countries since 1990, but we found little change in most countries in sub-Saharan Africa and Oceania. Improvements were largest in high-income countries, central Europe, and some upper-middle-income and recently high-income countries including Costa Rica, Taiwan, Kazakhstan, South Africa, Brazil, Chile, Turkey, and Iran [Citation9].
There are numerous articles published on the effects of HTN in Eastern Mediterranean Region (EMRO). To comprehensively analyze and extract the data of published documents using methods, such as review articles is difficult as well as time-consuming. Therefore, AI methods to analyze and extract the data effectively and comprehensively are needed.
To put it more clearly, while reading this large number of articles by traditional and non-robotic methods and by one person is very time-consuming, AI methods can speed up and reveal the knowledge published by the researchers of each country to the analysts. As an intelligent method in the process of health and disease risk factors, data mining has become very pervasive [Citation10–21] and even with data mining, possible adverse effects can be achieved, including the positive effect found in one of the studies on vascular surgery in patients with HTN and published by Nature [Citation22].
Given the similarity with data mining and clustering, it is no surprise that the use of topic models comes with a number of challenges typical for the application of unsupervised learning methods [Citation23]. So in the analytical encounter with textual data – such as articles – text mining as a branch of data mining can be helpful; And more specifically, TM is a useful method of text mining technique that has been recently used widely in research fields [Citation24]. TM is a kind of method that discovers hidden semantic structure from text corpus. It assumes that a document is a mixture distribution of topics, where the topic is a multinomial distribution about vocabulary [Citation25]. It is based on text mining to retrieve information and identify latent topics in a collection of publications. The goal of TM is to reveal and better understand the construct of a phenomenon through the written text. Therefore, using TM, the aim of this study was to identify the multiple topics over the relevant documents on the HTN researches in EMRO.
2. Materials and methods
In this study, the overall proposed scheme can be divided into three sub-processes: (i) content crawling, (ii) pre-processing data, and (iii) TM deployment. Each step and their methods are explained in detail in the following sections. illustrates a flowchart of the dataset acquisition and analysis methodology and shows a big picture of the processes from the beginning to the achievement of the TM outputs:
Figure 1. Detail of stages in this study from dataset acquisition to TM.
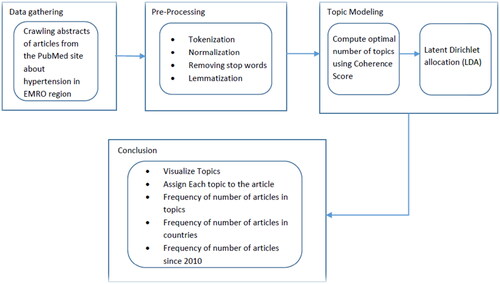
Figure 2. The infographic of input/output of the present analysis.
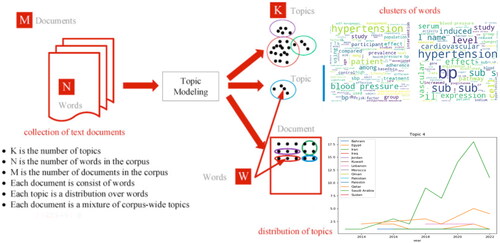
2.1. Crawling contents
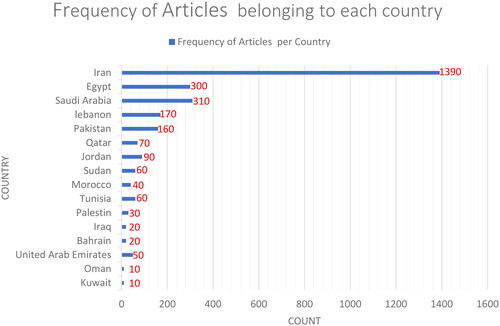
In this phrase, web scrapping techniques and the Bio package in Python were used to gather data. In this study, 2790 articles on HTN, belonging to the countries listed in , were gathered from the PubMed database. The selection and collection of articles were based on the relevance of their content to the concepts related to ‘hypertension’; The introduction of these concepts to the software robot was done based on terms suggested by half of the authors of this article, who are either doctors or have a specialized doctorate in the field of health. In order to detect and collect articles from those countries, the affiliation of the corresponding author institutions was considered. indicates the frequency of articles belonging to each country of the EMRO.
Figure 3. The frequency of articles belonging to each country of the EMRO.
2.2. Data pre-processing
Regular expression was used in order to detect text patterns. After recognizing all URLs and numbers, they were replaced with URLs and #. In the second step, all words were converted to lower-case letters, and then punctuation marks were removed. In the next step, the stop words were removed, which included 179 common English stop words. Moreover, 590 words that did not have a special meaning in this analysis, such as ‘account’, ‘world’, ‘clinical’, and ‘first’ were removed as advised by the medical staff. Deciding which of the words have the least connection with the subject under study was also determined by the doctors and researchers in the field of health who are among the authors of this article.
In this study, the n-gram language model was implemented by using the Gensim library. n-gram language models are now widely used in text mining and natural language processing tasks. An n-gram model is a type of probabilistic language model for predicting the next item in a sequence of text or speech in the form of a (n − 1)-order. Having a good n-gram language model leads to predicting p (w | h) – the likelihood of seeing the word w given a history of previous words h – where the history contains n − 1 words. An n-gram of size 1 is referred to as a ‘unigram’; size 2 is a ‘bigram’; and size 3 is a ‘trigram’. When N is more than 3, this is commonly referred to as ‘four grams’ or ‘five grams’ and so on. Lemmatization was also developed by the Gensim library. By using a vocabulary and analyzing words morphologically, lemmatization groups together the inflected forms of a word and returns the base or dictionary forms of a word based on its intended meaning, identified as the lemma, or dictionary form. Lemmatization only keeps nouns, adjectives, verbs, and adverbs.
2.3. Topic modeling
The widespread use of TM for text mining provides a computational technique for realizing topics that obtain meaningful structures among documentary sources [Citation26]. In machine learning and natural language processing, a topic model is a type of statistical model used to discover abstract ‘topics’ that occur in a set of documentary sources. TM is commonly used as a text-mining tool to discover hidden semantic structures in a textual context. TM procedures create ‘topics’, which are groups of analogous words [Citation27]. This comprehension is captured by a topic model in a mathematical context, making it possible to examine a series of documentary sources and to discover the probable nature of the topics and the concept of the balance of topics in every document based on the statistics of the words in individual documents [Citation27].
Furthermore, topic models are referred to as probabilistic topic models, which refer to statistical algorithms used to discover the hidden semantic structures of a large textual context [Citation28]. The use of topic models makes it possible to organize and offer visions for users to understand large clusters of unstructured text-based contexts. Topic models were originally developed as a text-mining tool, but they are now used to detect instructional structures in data, such as genetic information, images, and networks. Moreover, their applications are expanded to other areas, such as bioinformatics and computer vision.
2.3.1. Latent Dirichlet allocation (LDA)
LDA is a famous TM procedure for extracting topics from a specified corpus. LDA models describe the arrangement of words that are repeated together, occur frequently, and resemble one another. The Bayesian method is used in this probabilistic procedure. The model uses the examined documents and words to deduce the hidden topic structure, generating per-document topic distributions, P (topic | document), and per-topic word distributions, P (word | topic) [Citation27].
Despite the fact that it was introduced by the perplexity-based technique, it is unlikely to result in distinct interpretations. LDA performs two functions: it finds topics in the corpus and assigns these topics to documents in the same corpus at the same time. Following preprocessing on the article abstracts, TM can be processed using the LDA algorithm, which is implemented in the Python Genism library. To answer the question ‘How does LDA work and how does it derive the specific distributions?’ we will go over its steps in general. All corpora, in the form of gathered documentary sources, can be considered as a document-word (or document term matrix) (DTM). The initial stage with textual data is cleaning, preprocessing, and tokenizing the text into words. The document-word matrix is broken into two matrices by LDA: DTM and Topic Word Matrix (TWM).
There are probable topics (denoted by K above) in the DTM in advance, which may be present in the documentary sources;
There are words (or terms) in the TWM that may be present in those topics.
To achieve sparse topic and word distributions for more understandable topics, small values on the Dirichlet hyper-parameters, α (parameter of Dirichlet prior to the per-document topic distributions) and β (parameter of Dirichlet prior to the per-topic word distributions) were chosen equal to 0.1 and 0.01, respectively. Choosing an optimal number of topics is complicated [Citation29].
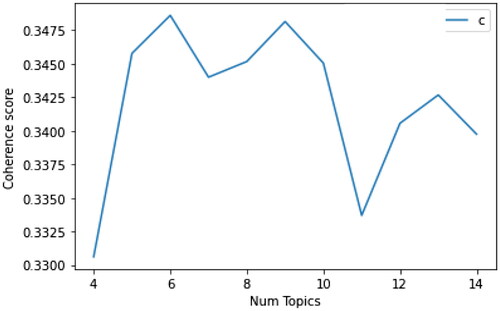
We need to build many LDA models with a different number of topics (k) and select the one that gives the highest coherence to find the best number of topics. Choosing a ‘k’ that represents the end of a dramatic growth in topic coherence usually yields meaningful and interpretable topics. Choosing an even higher value can sometimes result in more granular sub-topics. When the same keywords are repeated in multiple topics, it is likely that the ‘k’ is too large. Six topics were selected according to the calculation of the value coherence of 0.3486, and after running the LDA model with six candidate topics, each topic word and the frequency of each word were obtained. displays Coherence score of different topic numbers on LDA.
Figure 4. Coherence score of different topic numbers on LDA.
2.3.2. Comparison of LDA with LSA, NMF, and BERTopic methods
In a nutshell, a topic model is a form of statistical modeling used in machine learning and NLP, as discussed earlier, that identifies hidden topical patterns within a collection of texts [Citation30]. Those viewed as the most established, go-to techniques include LDA, latent semantic analysis (LSA), and probabilistic LSA [Citation31]. More recently, however, newly developed algorithms such as non-negative matrix factorization (NMF), Corex, Top2Vec, and BERTopic have also received, and are continuing to attract, increasing attention from researchers [Citation32,Citation33].
Although such and LDA model, NMF also requires the data to be preprocessed, necessary steps to be performed beforehand include a classical NLP pipeline containing, amongst others, lowercasing, stopword removal, lemmatizing or stemming as well as punctuation, and number removal [Citation34]. Additionally, for instance, while both models disclose users’ opinions on healthcare programs, but the LDA results appear to be more geographically oriented [Citation35].
Lastly, when comparing BERTopic to NMF, a major shortcoming of NMF revolves around its low capability to identify embedded meanings within a corpus [Citation36]. Considering that the algorithm depends primarily on the Frobenius norm [Citation37], which is typically useful for numerical linear algebra, this issue ultimately leads to difficulties in interpreting findings [Citation38]. Though NMF can effectively analyze noisy data [Citation36], others argue that accuracy cannot be guaranteed [Citation31].
3. Results
This section may be divided by subheadings. It should provide a concise and precise description of the experimental results, their interpretation, as well as the experimental conclusions that can be drawn.
3.1. Visualizing topic modeling with pyLDAvis
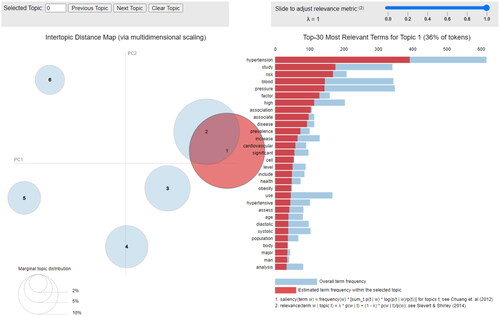
pyLDAvis helps the elucidation of the topics in a topic model. Each circle represents a topic, and when the percentage of the total number of words in the corpus is greater, it results in the greater circle. The distance between the centers of the circles indicates the similarity between topics. The blue bars represent the total frequency of each word in the corpus. When no topics are selected, the blue bars of the words with the highest frequency will be displayed. Red bars represent the calculated number of times during which a given term was produced by a specified topic. The word ‘hypertension’ was the most frequently used in Topic 1, as shown in .
Figure 5. The six extracted ‘topics’, such as ‘clusters of words’.
3.1.1. Naming the topics
A subject was chosen for each topic number for studying, analyzing, and presenting results more conceptually. The subject was selected based on the ten most likely words, the weight value of these words in the analysis, and studying the abstracts and keywords of the articles in each topic. shows the frequency of words associated with each topic.
Table 1. Top frequented words associated with each topic.
3.2. Identifying the semantic relationships between topics
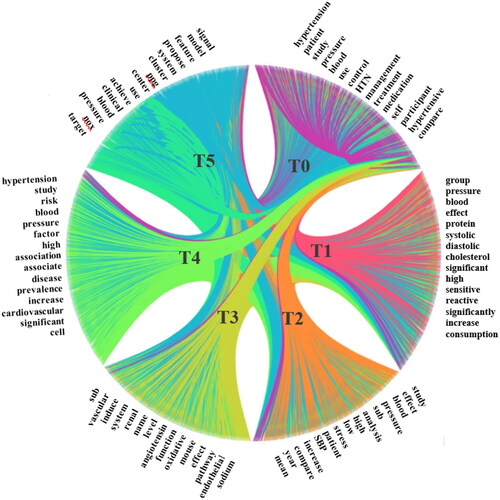
The semantic relationship between topics is identified, which are defined as co-occurrence statistics between topics, i.e., two topics are discussed in the same article; the way to identify such relationships is described as follows: 1) assigning each article to two topics with the highest probabilistic proportion in a topic proportion matrix; 2) measuring the relationships between two topics by using their co-occurrence statistics; and 3) generating a topic co-occurrence matrix and visualizing it [Citation39]. As shown in , each segment represents a topic, with the short label given in . The ribbons between segments stand for their semantic relationships, i.e., a stronger relationship between the two linked segments – such as T0 and T2, T0, and T3, T0, and T4 – is represented by a wider ribbon:
Figure 6. Identifying semantic relationship between 6 topics in by co-occurrence map.
3.3. Content analysis of topics
The topics retrieved from LDA with k topics are named T0 − T (k − 1). In this survey, six topics were chosen by LDA, namely T0 − T5. illustrates the selected subject as well as the 15 most likely words for each topic.
Table 2. The selected subjects in topics.
3.3.1. Distributions of articles in each topic
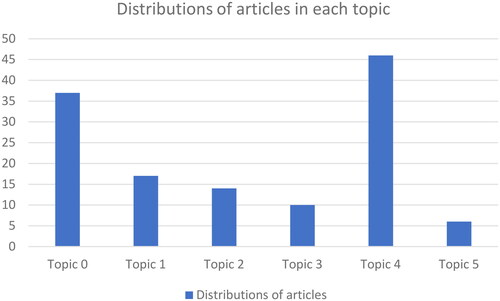
Distributions of articles in each topic are shown in .
Figure 7. Distribution of articles in each topic.
Distributions of articles in each country based on topics since 2010 are shown in .
Figure 8. Distributions of articles ‘in each country on topics’ since 2010.
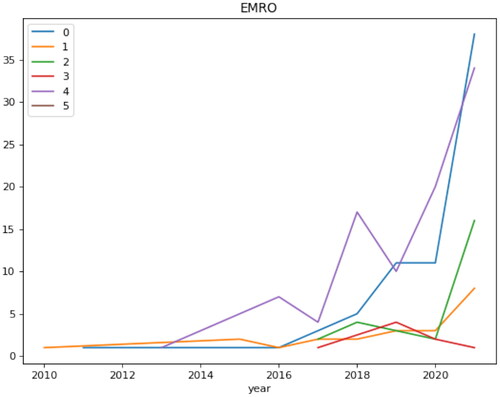
Distributions of articles based on topics since 2010 are shown in .
Figure 9. Distributions of articles based ‘on topics’ since 2010.
3.3.2. Word cloud of topics
The word cloud is a data visualization technique, and the more a specific word appears in a source of text-based data, the bigger, and bolder it appears in the word cloud. It is possible to highlight important text-based data points by a word cloud, which has wide applications in data analysis. illustrates the word cloud of every topic.
Figure 10. Word clouds of selected six topics and total words.
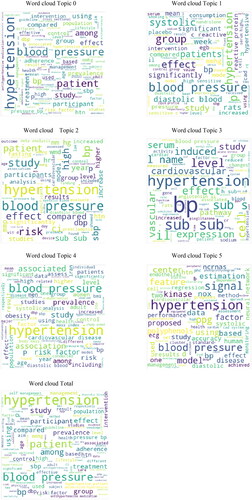
It is noteworthy that big words in word clouds only mean frequent appearance, not importance or meaning; but the simultaneous appearance of some words in a super word is important and should be interpreted by the relevant expert. For example, in , in ‘Word cloud Topic 3’ when we see the words ‘Vascular’ and ‘Shear Stress’ [Citation40–44] together with BP (blood pressure [BP]), these need to be interpreted by vascular access surgeon; Or when ‘Cardiac disease’ and ‘kinase’ [Citation45–47] are mentioned in ‘Word cloud Topic 5’ next to ‘Hypertension’, it is appropriate to bring the matter to the attention of a cardiologist.
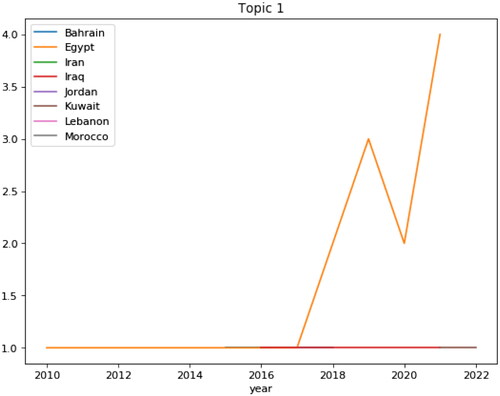
3.3.3. Distribution of topics per country
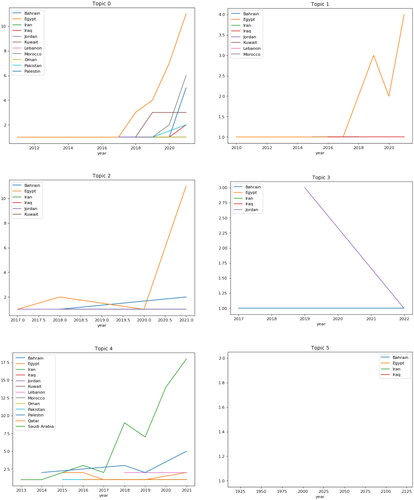
shows the published articles in the EMRO countries on changes in BP and the factors affecting it. Most articles in this field are related to Egypt, which has an increasing trend from 2017 to 2018 and its plummeted to the lowest point in 2020 and reached the highest level in 2021. Among the countries in the region, Iraq and Lebanon have been conducting research since 2010. This chart illustrated that Egypt is ahead of other countries in the region in terms of factors affecting changes in BP.
Figure 11. Distributions of articles based ‘on topic 1’ since 2010.
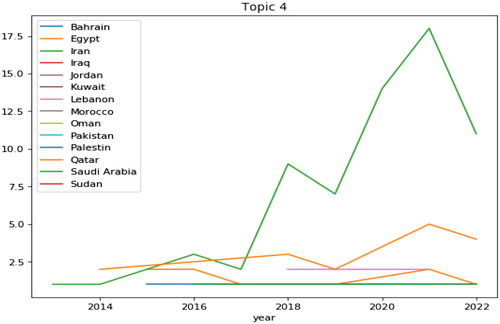
Studies on BP do not have the same level among EMRO countries, but differ significantly. As can be seen in . In the period studied – i.e., the last 12 years – the Iranian studies started in 2013 and reached the highest level in 2021. After Iran, Egypt has the most research in this field. Lebanon and Pakistan, meanwhile, have published articles on the subject.
Figure 12. Distributions of articles based ‘on topic 4’ on the EMRO.
4. Discussion
HTN is a major risk factor for cardiovascular diseases and has a high prevalence in the EMRO [Citation48]. The World Health Organization (WHO) reported that 30.7% of men and 29.1% of women in the EMRO were estimated to have HTN in 2008. HTN is a major risk factor for cardiovascular diseases, including coronary heart disease, heart failure, arrhythmia, and cardiomyopathy. There is also an increased risk of chronic kidney disease and stroke among hypertensive patients. According to The Global Burden of Disease Study, hypertensive heart disease accounted for 17.5 million disability-adjusted life years in 2015 [Citation48].
Recently, an analysis of HTN in nationwide population is studied by cross sectional analysis method on the Korean adults aged 20 years or older [Citation49].
Scholarly journals and data sources are increasingly available in electronic format making them more accessible to researchers and innovators. However, accessibility and availability do not mean that users can easily analyze the content and data that underpins scholarly output to find sought-after information or to develop new insights. Text mining comes with solutions for this problem offering automated methods to extract condensed information hidden within huge volumes of publications [Citation50].
Text mining techniques, including LDA, LSA, and NMF, can be valuable tools for analyzing large volumes of textual data to identify patterns, topics, and trends within the literature. In the context of HTN research at EMRO, these methods can help researchers uncover hidden relationships, common themes, and emerging topics in published articles.
LDA is a probabilistic TM technique that can be used to identify clusters of words that frequently co-occur in documents. By applying LDA to a corpus of articles on HTN from EMRO, researchers can identify key topics and themes prevalent in the literature, such as treatment strategies, risk factors, comorbidities, or epidemiological trends.
LSA is another text-mining method that analyzes the relationships between terms and documents based on the underlying semantic structure of the text. By using LSA, researchers can uncover similarities and differences between articles, detect patterns in the use of terminology, and identify common concepts across the literature on HTN at EMRO.
NMF is a dimensionality reduction technique that can be applied to text data to extract latent features and patterns. In the context of EMRO’s HTN literature, NMF can help researchers identify clusters of related articles, extract important keywords or phrases, and reveal trends in research focus or methodologies over time.
4.1. Recommendations for future researches
By applying text mining methods to the corpus of published articles on HTN at EMRO, researchers can gain valuable insights into the evolving landscape of research in the region, identify emerging trends, and inform future research directions in the field.
Also, if geographical differentiation is included to compare research output based on the level of income (GDP per capita) in a country or to compare rural and urban areas, this can also help reveal research inequalities.
Moreover, temporal analysis can track if research on each topic or by specific countries is growing, declining, or plateauing over the 12-year span. This could inform future research investments and policy priorities.
Lastly, citation analysis of the articles could identify the most impactful or influential studies that may reveal pivotal developments like new HTN genes or breakthrough clinical trials. Highly cited works likely represent key research milestones.
5. Conclusions
TM as a branch of text mining used in this analysis and TM outputs describes the current situation of HTN researches published by EMRO authors and helps knowing notified patterns in recent articles, without necessity of reading all documents. In fact, the unsupervised TM method extracts topics and then show us the orientation of the edge of knowledge in this field and even inform non-specialists about different aspects of the field, without needing to have Prior Awareness or thought about different areas of that science or incorporated an idea into their research.
Note that this result may be obvious to BP specialists or cardiologists or neurologists, but we have obtained it with AI learning analyses. In addition, we did not work on a limited number of patients in a single country; instead, this study is an analysis of nearly 300 other studies over the entire EMRO. For example, by looking closely at the whole EMRO word clouds – located in the last word clouds of – even an engineer can learn that if researchers publish articles about HTN or BP subjects, they must be measured ‘sbp’ (systolic BP) as well as ‘dbp’ (diastolic BP). The mentioned word cloud (last of ) also contains words with special meanings on EMRO researches: for example, ‘BMI’, ‘mortality’, ‘age’, and ‘meal’, which represent important indicators, dangerous outcomes of high BP, and gender of HTN patients in EMRO, respectively.
Institutional Review Board statement
Not applicable.
Informed consent statement
Not applicable.
Author contributions
Conceptualizations, M.R. and M.Y.; methodology and software, M.R., M.Y., and F.R.K.; formal analysis, M.R., H.R., M.H.B., Z.K., E.P., and M.K.Z.; investigation, M.H.B., Z.K., and M.K.Z.; resources, M.R., H.R., and M.H.B.; data curation, M.Y. and F.R.K.; writing – original draft preparation, M.R., M.Y., and M.H.B.; writing – review and editing, M.R.; visualization, M.R., M.Y., and F.R.K.; supervision, M.R. and H.R; project administration. All authors have read and agreed to the published version of the manuscript.
Disclosure statement
The authors report no conflicts of interest. None of the authors have any financial relation with the online archive or software systems, used in this article.
Data availability statement
All cleaned and pre-processed data and/or analyzed during this research are available from the corresponding author on reasonable request, but the original articles are available online in PubMed.
References
- Mauer N, Geldsetzer P, Manne-Goehler J, et al. Longitudinal evidence on treatment discontinuation, adherence, and loss of hypertension control in four middle-income countries. Sci Transl Med. 2022;14(652):1. doi: 10.1126/scitranslmed.abi9522.
- Abduboriyevna RK, Yusufjonovich NS. Stroke burden in Asia: to the epidemiology in Uzbekistan. Eur Sci Rev. 2018;7:156–15.
- Johnson W, Onuma O, Owolabi M, et al. Stroke: a global response is needed [internet]. Bull World Health Organ. 2016;94(9):634–634A. doi: 10.2471/BLT.16.181636.
- Turana Y, Tengkawan J, Chia YC, et al. Hypertension and stroke in Asia: a comprehensive review from HOPE Asia. J Clin Hypertens (Greenwich). 2021;23(3):513–521. doi: 10.1111/jch.14099.
- Toyoda K. Intensive blood pressure lowering for ischemic stroke patients: does it prevent ischemia or bleeding? Hypertens Res. 2022;45(5):769–771. doi: 10.1038/s41440-022-00892-6.
- Kitagawa K. Blood pressure management for secondary stroke prevention. Hypertens Res. 2022;45(6):936–943. doi: 10.1038/s41440-022-00908-1.
- Hägg-Holmberg S, Dahlström EH, Forsblom CM, et al. The role of blood pressure in risk of ischemic and hemorrhagic stroke in type 1 diabetes. Cardiovasc Diabetol. 2019;18(1):88. doi: 10.1186/s12933-019-0891-4.
- Feigin VL, Stark BA, Johnson CO, et al. Global, regional, and national burden of stroke and its risk factors, 1990–2019: a systematic analysis for the global burden of disease study 2019. Lancet Neurol. 2021;20(10):795–820. doi: 10.1016/S1474-4422(21)00252-0.
- Zhou B, Carrillo-Larco RM, Danaei G, et.al. Worldwide trends in hypertension prevalence and progress in treatment and control from 1990 to 2019: a pooled analysis of 1201 population-representative studies with 104 million participants. Lancet. 2021;398(10304):957–980. doi: 10.1016/S0140-6736(21)01330-1.
- Sepehri MM, Khavaninzadeh M, Rezapour M, et al. A data mining approach to fistula surgery failure analysis in hemodialysis patients. 2011 18th Iranian Conference of Biomedical Engineering (ICBME); 2011 Dec. 14; Iran. Piscataway (NJ): IEEE. p. 15–20. doi: 10.1109/ICBME.2011.6168546.
- Rezapour M, Nakhostin Ansari N, Khavanin Zadeh M, et al. Risk of stroke in hypertensive diabetic chronic kidney disease patients after Central venous catheter placement. Razi J Med Sci. 2020;27(8):10–21.
- Samizadeh R, Zadeh MK, Jadidi M, et al. Discovery of dangerous self-medication methods with patients, by using social network mining. IJBIDM. 2023;23(3):277–287. doi: 10.1504/IJBIDM.2023.133186.
- Rezapour M, Nakhostin Ansari N. Incidence of stroke in hemodialysis patients with Central venous catheter: a systematic review. J Vessels Circulat. 2021;2(1):27.
- Rezapour M, Asadi R, Marghoob B. Machine learning algorithms as new screening framework for recommendation of appropriate vascular access and stroke reduction. Int J Hosp Res. 2021;10(3):4–7. Available from: http://ijhr.iums.ac.ir/article_126609.html
- Rezapour M, Nakhostin Ansari N. Producing a telerehabilitation mobile application and a web-based smart dashboard platform for online monitoring patients with a history of stroke during covid-19 pandemic and Post-Pandemic era. Int J Basic Sci Med. 2021;6(4):127–131. doi: 10.34172/ijbsm.2021.23.
- Rezapour M, Sepehri MM, Zadeh MK, et al. A new method to determine anastomosis angle configuration for arteriovenous fistula maturation. Med J Islam Repub Iran. 2018;32(1):62–370. doi: 10.14196/mjiri.32.62.
- Rezapour M, Payani E, Taran M, et al. Roles of triglyceride and phosphate in atherosclerosis of diabetic hemodialysis patients. Med J Islam Republic Iran. 2017;31(1):465–471. doi: 10.14196/mjiri.31.80.
- Khavanin Zadeh M, Rezapour M, Sepehri MM. Data mining performance in identifying the risk factors of early arteriovenous fistula failure in hemodialysis patients. Int J Hosp Res. 2013;2(1):49–54.
- Rezapour M, Khavanin Zadeh M, Sepehri MM. Implementation of predictive data mining techniques for identifying risk factors of early AVF failure in hemodialysis patients. Comput Math Methods Med. 2013;2013:830745–830748. doi: 10.1155/2013/830745.
- Rezapour M, Taran S, Parast MB, et al. The impact of vascular diameter ratio on hemodialysis maturation time: evidence from data mining approaches and thermodynamics law. Med J Islamic Republic Iran. 2016;30:359.
- Rezapour M, Khavaninzadeh M. Association between non-matured arterio-venus fistula and blood pressure in hemodialysis patients. Med J Islamic Republic Iran. 2014;28:144.
- Rezapour M, Zadeh MK, Sepehri MM, et al. Less primary fistula failure in hypertensive patients. J Hum Hypertens. 2018;32(4):311–318. doi: 10.1038/s41371-018-0052-3.
- Rüdiger M, Antons D, Joshi AM, et al. Topic modeling revisited: new evidence on algorithm performance and quality metrics. PLoS One. 2022;17(4):e0266325. doi: 10.1371/journal.pone.0266325.
- Wang SH, Ding Y, Zhao W, et al. Text mining for identifying topics in the literatures about adolescent substance use and depression. BMC Public Health. 2016;16(1):279. doi: 10.1186/s12889-016-2932-1.
- Liu Y, Du F, Sun J, et al. iLDA: an interactive latent Dirichlet allocation model to improve topic quality. J Inform Sci. 2020;46(1):23–40. doi: 10.1177/0165551518822455.
- Blei DM, Ng AY, Jordan MI. Latent Dirichlet allocation. J Mach Learn Res. 2003;3:993–1022.
- Griffiths TL, Steyvers M. Finding scientific topics. Proc Natl Acad Sci USA. 2004;101(1):5228–5235. doi: 10.1073/pnas.0307752101.
- Blei DM. Probabilistic topic models. Commun ACM. 2012;55(4):77–84. doi: 10.1145/2133806.2133826.
- Ritter A, Etzioni O. A latent Dirichlet allocation method for selectional preferences. Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics; 2010 Jul. Uppsala (Sweden): SIG. p. 424–434.
- Guo Y, Barnes SJ, Jia Q. Mining meaning from online ratings and reviews: tourist satisfaction analysis using latent Dirichlet allocation. Tour. Manag. 2017;59:467–483 doi: 10.1016/j.tourman.2016.09.009.
- Albalawi R, Yeap TH, Benyoucef M. Using topic modeling methods for short-text data: a comparative analysis. Front Artif Intell. 2020;3:42. doi: 10.3389/frai.2020.00042.
- Obadimu A, Mead E, Agarwal N. Identifying latent toxic features on YouTube using non-negative matrix factorization. The Ninth International Conference on Social Media Technologies, Communication, and Informatics; 2019 November 28; Valencia, Spain. IEEE; p. 1–6.
- Sánchez-Franco MJ, Rey-Moreno M. Do travelers’ reviews depend on the destination? An analysis in coastal and urban peer-to-peer lodgings. Psychol Market. 2022;39(2):441–459. doi: 10.1002/mar.21608.
- Egger R. 2022). Topic modelling. Modelling hidden semantic structures in textual data. In Egger R, editor. Applied data science in tourism. Interdisciplinary approaches, methodologies and applications. Berlin, Germany: Springer; p. 18.
- Egger R, Yu J. A topic modeling comparison between LDA, NMF, top2vec, and bertopic to demystify Twitter posts. Front Sociol. 2022;7:886498. doi: 10.3389/fsoc.2022.886498.
- Blair SJ, Bi Y, Mulvenna MD. Aggregated topic models for increasing social media topic coherence. Appl Intell. 2020;50(1):138–156. doi: 10.1007/s10489-019-01438-z.
- Chen Y, Zhang H, Liu R, et al. Experimental explorations on short text topic mining between LDA and NMF based schemes. Knowl Based Syst. 2019;163:1–13. doi: 10.1016/j.knosys.2018.08.011.
- Wang J, Zhang XL. Deep NMF topic modeling. 2021. [accessed January 18, 2022]. Available from: http://arxiv.org/pdf/2102.12998v1
- Zhang Y, Chen H, Lu J, et al. Detecting and predicting the topic change of knowledge-based systems: a topic-based bibliometric analysis from 1991 to 2016. Knowledge-Based Syst. 2017;133:255–268. doi: 10.1016/j.knosys.2017.07.011.
- Roustaei M, Nikmaneshi MR, Firoozabadi B. Simulation of low density lipoprotein (LDL) permeation into multilayer coronary arterial wall: interactive effects of wall shear stress and fluid-structure interaction in hypertension. J Biomech. 2018;67:114–122. doi: 10.1016/j.jbiomech.2017.11.029.
- Paszkowiak JJ, Dardik A. Arterial wall shear stress: observations from the bench to the bedside. Vasc Endovascular Surg. 2003;37(1):47–57. doi: 10.1177/153857440303700107.
- Samady H, Eshtehardi P, McDaniel MC. Coronary artery wall shear stress is associated with progression and transformation of atherosclerotic plaque and arterial remodeling in patients with coronary artery disease. Circulation. 2011;124(7):779–788. doi: 10.1161/CIRCULATIONAHA.111.021824.
- Zhou M, Yu Y, Chen R. Wall shear stress and its role in atherosclerosis. Front Cardiovasc Med. 2023;10:1083547. doi: 10.3389/fcvm.2023.1083547.
- Rezazadeh M, Ostadi R. Numerical simulation of the wall shear stress distribution in a carotid artery bifurcation. J Mech Sci Technol. 2022;36(10):5035–5046. doi: 10.1007/s12206-022-0917-9.
- Shimokawa H. Rho-kinase as a novel therapeutic target in treatment of cardiovascular diseases. J Cardiovasc Pharmacol. 2002;39(3):319–327. doi: 10.1097/00005344-200203000-00001.
- Ocaranza MP, Jalil JE. Mitogen-activated protein kinases as biomarkers of hypertension or cardiac pressure overload. Hypertension. 2010;55(1):23–25. doi: 10.1161/HYPERTENSIONAHA.109.141960.
- Abedi F, Omidkhoda N, Arasteh O, et al. The therapeutic role of rho kinase inhibitor, fasudil, on pulmonary hypertension; a systematic review and meta-analysis. Drug Res (Stuttg). 2023;73(1):5–16. doi: 10.1055/a-1879-3111.
- Katibeh M, Moghaddam A, Yaseri M, et al. Hypertension and associated factors in the Islamic Republic of Iran: a population-based study. East Mediterr Health J. 2020;26(3):304–314.
- Kim HC, Lee H, Lee HH, et al. Korea hypertension fact sheet 2021: analysis of nationwide population-based data with special focus on hypertension in women. Clin Hypertens. 2022;28(1):1–5. doi: 10.1186/s40885-021-00188-w.
- Lebedev MA, Opris I, Casanova MF. Augmentation of brain function: facts, fiction and controversy. Front Syst Neurosci. 2018;12:45. doi: 10.3389/fnsys.2018.00045.