
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Both the Menzerath-Altmann law and the Zipf-Mandelbrot law note that language is a fractal structure and, like any other fractals, follows power laws. Studies on fractal linguistics demonstrated that the relation between the scaling measures and the number of constituents in language indeed follow the power law probability distribution. However, most of these studies looked at languages from the structural perspective only, often ignoring the grammatical aspects of language structures. In this study, we ventured into English grammar and used a multifractal analysis to explore the nature of multifractality in three grammatical structures in English texts – i.e. the Finite Verb Phrases, Noun Phrases, and Head Nouns. In this paper, we present the evidence of multifractality in the distribution of these constructs and discuss how the parameters of multifractality align with the current understanding of register variation in different text types.
Introduction
What do cauliflowers, snowflakes, and the coast of Britain have in common? Not much, except that they are all fractal structures. Fractal is a mathematical concept that originally referred to geometric figures that can be split, infinitely, into self-similar yet reduced-size copies of the original, such as the Sierpinski triangle and the Koch snowflakes.Footnote1 This definition, however, has been extended to include non-geometric figures and abstract constructs that are self-affine statistically, such as the coastlines of Britain and language constructs. The complexity of a fractal is described by a measure called the Fractal Dimension (FD, or in some cases, just D), which is operationalized as the negative ratio between log N and log ε (where N is the number of copies in each split, and ε is the scaling ratio). Such a log–log relationship is also referred to as the power law relationship and is generally considered as evidence of fractality, including fractality in language constructs.
Recent studies in fractal linguistics, such as Ausloos (Citation2012) and Chatzigeorgiou et al. (Citation2017), highlighted the multifractal property of language. The current paper builds on the concept of multifractality and explores the multifractal characteristics of the distribution of three grammatical constructs in English (i.e. Finite Verb Phrase, Noun Phrase, and Head Noun). To do this, we will employ the multifractal analysis to test our hypothesis that the distribution of these constructs manifests on the characteristics of multifractality. The outcomes of this study will advance our understanding of the nature of multifractality in language and open a channel for future discussions on the possibilities for universality or comparability among fractal structures across languages. It is hoped that this study will constitute an important step in bringing the field of linguistics and its sub-disciplines closer to the frontier of fractal studies as have been reached in other disciplines. Furthermore, this study will contribute to demonstrating the use of multifractal analysis, which is a relatively new and uncommon approach to exploring the distribution of grammatical constructs in texts, in understanding the fractal nature of language.
Literature Review
Fractals in Languages
In the study of fractal linguistics, the Zipf-Mandelbrot Law and the Menzerath-Altmann Law are perhaps the two most important laws observed in fractal structures in languages. Both the Zipf-Mandelbrot Law and the Menzerath-Altmann Law highlight the self-similarity property of language structures and note the power law relationship that exists in many levels of language. This power law relationship is considered the evidence of fractality.
The Zipf-Mandelbrot Law was proposed as a generalization of Zipf’s law and combined the work of these two great scholars – Benoit Mandelbrot’s concept of fractal (Mandelbrot, Citation1967, Citation1983) and George Kingsley Zipf’s power law. It is operationalized as a mathematical model that describes the inverse proportional relationship between the frequency rank of words and their number of occurrences. Such a relationship is observed in many natural languages. For example, Jayaram and Vidya (Citation2008) demonstrated how this law applied to four Indian languages while Abney et al. (Citation2014) noted power law clustering in their dyadic conversational data. A more recent study by Cong (Citation2021) confirmed that the log-log rank-frequency distribution of words in an English corpora and words in a Mandarin Chinese corpus followed this law. Najafi et al. (Citation2015) went further to suggest that this characteristic can be effectively utilized for automatic extraction of keywords in a text as the word distribution follows this law.
Such an inverse proportional relationship is also noted in the Menzerath-Altmann Law, which was based on Paul Menzerath’s work on the negative correlation between the size of a linguistic unit and its complexity (Menzerath, Citation1954) and was later operationalized by Gabriel Altmann into a mathematical formula (Altmann, Citation1980). According to the Menzerath-Altmann Law, the longer a language construct is, the smaller its constituents are. For example, the longer a sentence is (as measured in the number of clauses), the shorter the clauses are (as measured in the number of words). When plotted onto the logarithmic axes, the resulting graph is a linear line, confirming this relationship to be that of the power law – hence, fractality. This relationship has been observed, through empirical investigations, in natural languages, e.g. Japanese (Sanada, Citation2016), Chinese (Chen, Citation2018), as well as in translated texts (Jiang & Ma, Citation2022), interpreted texts (Jiang & Jiang, Citation2022), and in sign language (Andres et al., Citation2021), showing that the Menzerath-Altmann Law applies rather universally to human languages and across different levels of linguistic constructs. This also aligns with Hřebíček’s conjecture that such relationship is not dependent on ‘the unit of measurement used’ (Citation1998, p. 236).
More recently, with the introduction and integration of Complex Dynamic Systems Theory (CDST) into the fields of linguistics and language studies, the notion of fractality in language is again emphasized and revisited through the lens of CDST. Within the framework of CDST, there are a small handful of studies that investigated fractality in language and put forward evidence to show how this property manifests in language. Lowie et al.’s (Citation2014) study, for example, demonstrated that the pattern of lexical processing in second language use showed characteristics of pink noise, which is a self-similar (fractal) pattern of variability. Their findings corroborated Kello’s et al. (Citation2008) study which reported evidence of pink noise in the intrinsic fluctuation of a spoken word – showing a fractal pattern in the acoustic measurements of word repetition. Similarly, Evans (Citation2020) found that the frequency/density plot of clausal use by his participant across 30 weeks followed the power-law distribution and that the amount of variance in the data set was about the same across the three different temporal scales chosen for analysis (i.e. from 30 weeks, to 30 conversational turns in 1 week, to 28 AS-units in one conversational turn), hence evidence of self-similarity in the developmental trajectory of complex syntax. The findings of this study lent strong support to the CDST’s notion of fractality in language.
Regardless of the underpinning theoretical perspective, be it the Menzerath-Altmann Law or the Zipf-Mandelbrot Law or CDST, all these studies demonstrated one main characteristic of fractal structures that is observed in language, i.e. the power law relationship, and hence supported the notion of language as a fractal structure. However, more in-depth exploration into the fractal structure in languages revealed the possibility of multifractality in human languages.
Multifractal Structures and Multifractality in Languages
Multifractals are stochastic fractals, in which each of the smaller copies may not be in the exact geometrical shape as the original, and may, therefore, have a different fractal dimension from the other copies. Each level of iteration is formed with the same mechanism but with different random probability. The resulting structures are not geometrically self-similar in each level but are instead statistically similar while manifesting a random looking appearance, such as the human’s vein structure. Real life fractals, like urban morphology (Ariza-Villaverde et al., Citation2013b; Chen & Huang, Citation2018), heartbeat and brain activity (Lin & Sharif, Citation2010), temperature anomaly (de Souza et al., Citation2013), air flow and pollutant dispersion (Mouzourides et al., Citation2021), river network (Ariza-Villaverde et al., Citation2013a), drainage system (Ariza-Villaverde et al., Citation2015), structure of blood vessels (Li et al., Citation2021) are shown to be of multifractal nature. These real-life multifractals do not manifest perfect self-similarity as do the mathematical fractals. In other words, they are not geometrically neat and are rather random-looking shapes. Common to all multifractals is that they are not possible to be explained by a simple rule or function nor described by a single fractal dimension – they are to be described by the combination of rules and chances.
Turning to the multifractals in the linguistic world, when we think about how language is produced, it is not difficult to notice that each language output is subject to the grammatical rules of the language and the stylistic choice, among other things, of the language users. In other words, there are so many possible options that we can use to express our thoughts. Each of these options has a probability to be selected as the output (i.e. what we eventually choose to produce). This probability is subject (largely) to the grammar of the language we are using and our own style of using that language. What we eventually produce is therefore the combined outcome of grammatical rules and probability (which is then finalized through our selection), which makes up the output itself. Following this line of thought, it is highly probable that fractals in language are multifractal. Moreover, according to CDST, language is a nonlinear dynamic system, in which chaos and order, attractors and repellors, probability and self-organization, among others, guide its manifestation (Larsen-Freeman, Citation2012; Lowie, Citation2013). Given these many factors in play, and particularly since all of them are stochastically contingent, it is likely that the fractal structures in language are multifractal.
Indeed, evidence of multifractality in human languages has been put forward by several studies. Carrizales-Velazquez et al. (Citation2022), for example, reported the presence of multifractality in their study of word length sequences in 22 English texts regardless of the methods used for detection, be it the Multi-Fractal Higuchi Dimension Analysis or the Multi-Fractal Detrended Fluctuation Analysis. Multifractality is also detected in 10 European languages, including English, in Chatzigeorgiou et al. (Citation2017) who studied part of the Europarl parallel corpus. By converting texts into word-length series, they measured the multifractal spectrum of the resulting series and found evidence of multifractality in all of the 10 languages they focussed on. Similarly, Ausloos (Citation2012) also found evidence of multifractality in both natural and human-made languages (such as Esperanto). By converting three texts (two English fantasy novels and one translation in Esperanto) into frequency time series as well as length time series and subsequently applying multifractal analysis to the resulting series, Ausloo found the existence of multifractal spectrum in all three texts examined. All these studies lend support to the hypothesis that fractals in language are of multifractal nature.
Therefore, in this paper, we will test this hypothesis by investigating the nature of fractality in the distribution of three grammatical constructs – i.e. Finite Verb Phrases (FVP), Noun Phrases (NP), and Head Noun (HN), respectively – in three types of written English texts: literary texts, children’s literary texts, and academic texts (See the This Study section for the rationale of this selection). In this study, we will use multifractal analysis to detect and measure the multifractal spectrum of these constructs.
Multifractal Analysis
Multifractals cannot be described by a single fractal dimension. Each of the smaller copies of a multifractal may have a different fractal dimension from the other copies. This is because multifractals are stochastic fractals, where there is an element of randomness in their formation. Therefore, when measuring multifractals, probability needs to be taken into consideration. Analysis of mono-fractals, however, does not take into consideration the role of probability, understandably, because each level of iterations in mono-fractals is guided by the same rule with exact (non-randomized) probability. When exploring real-life fractals, which are mostly multifractals, it is therefore important to use a more appropriate analysis method that considers the role of stochastic probability. A multifractal analysis is one appropriate method to do this.
Multifractal Analysis is a method of analysing and characterizing multifractal structures through measurements and descriptions of global parameters and local parameters. The global parameters include the generalized correlation dimensions and the mass exponent, while the local parameters include the Lipschitz – Hölder (singularity) exponent and the fractal dimensions of the fractal subsets. These parameters are obtained through the following formulae:
where
EquationEquation (1)(1)
(1) returns a series of values for the generalized correlation dimensions and Equationequation (2)
(2)
(2) a series of values for the mass exponent. EquationEquation (3)
(3)
(3) returns a series of values for the Lipschitz – Hölder (singularity) exponent and Equationequation (4)
(4)
(4) a series of fractal dimensions of the fractal subsets (Interested readers are referred to Long et al. (Citation2021) and Chen and Wang (Citation2013) for more detailed explanation of multifractal analysis).
Not only does this analysis integrate the role of probability (through the term in the equations), but it also considers the possibilities that different subsets might have different weighing effects (through the power term q) on the overall pattern. Moreover, this analysis has a main benefit on the practical level, i.e. it will return different results for mono-fractals and for multifractals, making this analysis a good tool to use as a preliminary check on whether a structure is mono-fractal or multifractal.
As can be seen from the formulae, multifractal analysis does not produce a single measure of fractal dimension, but instead a set of 4 parameters, which form the spectrum of dimensions of the fractal structures in the overall pattern, including the global multifractal spectrum, i.e. Dq-q spectrum, and local parameter spectrum, i.e. f(α)-α spectrum. These four parameters and their associated spectra form a set of criteria for testing whether a structure is multifractal or not. These criteria include: (1) The inequality D0> D1> D2, (2) An inverse S-shape for the Dq-q spectrum, (3) A non-linear plot of τq with respect to q, and (4) A unimodal curve for the f(α)-α spectrum. These criteria will be used in the present study to look for evidence of multifractality in language. In this study, only when all 4 criteria are satisfied will we contend that multifractality is evidenced.
Register Variation
Large-scale corpus linguistic studies and register studies, such as Biber and Gray (Citation2016), Goulart et al. (Citation2020), have pointed out that language manifests differently in different genres and modalities. For example, the oral and narrative discourse in English is more clausal, while the written non-narrative literate discourse (such as English academic prose) is more phrasal (Biber, Citation2014). Looking at registration variation through these textual-differences linguistically, Biber (Citation2019) noted that modern academic prose in English, particularly the non-narrative content-focussed literate discourse, is heavily characterized by phrasal features, such as abstract nominalization and complex noun phrases. Literary texts, on the hand, are shown to have a preference for reporting verbs, adverbials of time, participle adjectives, action-describing features, clausal structures, verbal structures, past-tense verbs, etc (Biber & Conrad, Citation2009; Egbert & Mahlberg, Citation2020; Mazdayasna & Firouzi, Citation2013). As such, the widely held understanding regarding the register variation between academic and literary texts is that academic texts are generally less verbal, more nominal, and employ more phrasal elaboration, and that literary texts are more narrative in nature and employ more clausal elaboration, with many grammatical features that are more common in the conversational contexts than in the written discourse (Biber & Conrad, Citation2019).
Similarly, children’s literature (such as fairy tales and picture books) is shown to have the features that are similar or relatively close to those of literary texts. Relative clauses, for example, were found to be common in this register and their usage seemed to increase with the intended age of their readership (Montag & MacDonald, Citation2015). This grammatical feature was found to co-occur frequently with noun animacy and pronouns in children’s literary texts (Hsiao et al., Citation2022). This aligns with the characteristics of child-directed language being generally characterized with rather frequent word repetition and lower word density (Hindman et al., Citation2021), which is usually reflected in children fiction through high use of lexical verbs and direct speech (Thompson & Sealey, Citation2007). Perhaps also due to its educational purposes, children’s literary texts were frequently found to contain prevalent uses of canonical utterances (i.e. the Subject-Verb-Object/Complement constructions) (Cameron-Faulkner & Noble, Citation2013), as well as compound sentences (e.g. sentences joined with ‘and’) (Rahman, Citation2012). These, however, are not as ubiquitous in the non-children-directed literary texts.
We were therefore interested to see, for example, how the dimensions of multifractality of the distribution of FVP in academic texts compare to those of the same construct in literary texts, given the less verbal and more nominal characteristics of academic prose. We were also interested to see if these parameters are also affected by the level of complexity of the texts themselves – for example, how the dimensions of multifractality of the distribution of NP in novels compare to those of the same construct in fairy tales. We hypothesized that while multifractality is a universal trait, its dimensions, however, vary across different types of texts.
This Study
In this study, we tested this hypothesis by examining three grammatical structures in English: Finite Verb Phrases (FVP), Noun Phrases (NP), and Head Nouns (HN). Our research questions were as follows:
a. Do the distributions of Finite Verb Phrases (FVP), Noun Phrases (NP), and Head Nouns (HN) in English manifest fractal structures?
b. If yes, are they mono-fractal or multifractal?
How does the generalized correlation dimension of these multifractal distributions align with or differ from the field’s current understanding about the register characteristics of English texts?
In this study, we chose to include three types of texts for investigation: literary texts (novels written in English), children’s literary texts (fairy tales), and academic texts (journal articles) – see Text Selection and Coding subsection for more information on these texts. The rationale for choosing to include these three types of texts was twofold: (1) to see if the characteristics of multifractality could be universally found across different types of texts, and more importantly (2) to leverage on the different characteristics of texts across these three different types to see whether the information unveiled by the property of multifractality in language aligns with (or differs from) the current understanding of text characteristics in different registers.
In this paper, a total of 12 sets of analysis were conducted. Of these, nine sets were conducted on texts, while the other three were done on a rectangle, a triangle, and a Cantor ternary set, respectively. The results of the analysis on texts are the main focus of the study, while the analyses on a rectangle, a triangle, and a Cantor ternary set were conducted as our internal proof of the validity of this Multifractal Analysis method in differentiating non-fractal, mono-fractal, and multifractal structures.Footnote2
Text Selection and Coding
We selected three texts per category for inclusion into the analysis in this paper. The details about these texts are summarized in .
Table 1. Descriptions of texts selected for MFA in this study.
As can be seen from , all the texts excerpted from the sources (except those in the children’s literary text category) were of around 1100–1200 words long. The reason for this length is operational (see below for more details) in order to ensure that there were at least 3–4 words in each of the subsets in the last level of analysis. However, for children’s literary texts, the length of the texts did not reach this range because of practical reasons– children’s literary texts are generally not long. As such, the levels of analysis were adjusted accordingly, to ensure that at least 3–4 words in each of the subsets in the last level of analysis as well.
In excerpting the literary texts, we took the first 1100–1200 words from the sections as indicated in . In determining the end of the excerpt, we included as many complete paragraphs as possible. When this was not possible, we would end the excerpt at the last sentence where the word count drew closest to the upper margin of our target word count. In excerpting the academic texts, we intentionally chose the sections with the least amount of in-text citation, paraphrasing, referencing. We then cleaned the texts to remove any of citation brackets, footnotes/endnotes, etc., and the remaining first 1100–1200 words were included in our analysis. Again, we included as many complete paragraphs as possible. Where not possible, we would end the excerpt at the last sentence where the word count was the closest to our upper margin.
Once the texts were excerpted, they were then coded for three types of grammatical constructions, namely finite verb phrases (FVP), noun phrases (NP), and head nouns (HN). We followed Verspoor and Sauter’s (Citation2000) definition in operationalizing these three constructs in this study and did not distinguish between a single-word FVP and a multi-word FVP, as well as between a single-word NP and a multi-word NP, as the focus of this study was not on the structural distinction between them.
Once the coding phase was completed, the coded texts were then submitted to the following steps:
Step 1: each text was considered as a whole at this first level of analysis (k = 1; ε = 1), and the occurrences of the target constructions were tallied. When analysing the FVP constructions, then occurrences of all FVPs were counted in words. Similarly, when analysing the NP constructions and the HN constructions, their occurrences were also counted in words. For example, in the following text of Little Red Riding Hood (text no. 4 in this study), the FVP constructions were identified (underlined here for the purpose of illustration):
Figure 1. FVP constructs in the Little Red Riding Hood.

The number of words that were underlined (i.e. identified as FVP constructs) was tallied (amounting to 40 words) and recorded in the first line in .
Table 2. An example of tally sheet for FVP constructions in the Little Red Riding Hood.
Step 2: each text was split into two halves in the next level of iteration (k = 2; ε = ½). In each half, the occurrences of the target constructions were tallied (see ). For example,
The total number of words in the FVP constructions in box 1 and box 2 was 20 and 20, respectively, and recorded in the next two lines in .
Step 3: This process was repeated until the subsets became too small to be meaningful. In this study, this was reached at k = 9 (ε = 1/256), in which the text of approximately 1200 words were split into 256 subsets of about 4–5 words each.
Step 4: Once all the occurrences of the target constructions in each subset in each iteration were noted, they were then converted to probability. To make sure that the results were comparable, this study opted for normalized probability, which was calculated by dividing the number of occurrences at each level by total number of occurrences in the text. Hence, in the conversion for probability, the denominator was always the number of occurrences of the target construction at level 1.
Step 5: The probability was then converted to Renyi’s information entropy through the following formula:
Step 6: The results were then fitted to the four formulae (see formulae 1–4) to obtain the global parameters (Dq, τq) and the local parameters (α, f). The partition function was defined as:
In this paper, we reported on the results of this multifractal analysis to answer our first research question and explored more deeply on the generalized fractal dimension parameter to answer our second research question.
Results
The results of the analyses showed that the distributions of all the three grammatical constructions (i.e. FVP, NP, and HN), across the three categories of texts explored in this study, were multifractal. They satisfied all four criteria of multifractality, i.e. (1) The inequality D0 > D1 > D2, (2) An inverse S-shape for the Dq-q spectrum, (3) A non-linear plot of τq with respect to q, and (4) A unimodal curve for the f(α)-α spectrum.
shows an example of the results of MFA on the FVP constructs in an academic text (text no. 7 in ).
Table 3. Satisfying the criteria of multifractality.
Therefore, the answer to Research Question no.1 in this study is positive. The distributions of Finite Verb Phrases (FVP), Noun Phrases (NP), and Head Nouns (HN) in English manifest multifractal structures.
In regard to research question no. 2, the generalized correlation dimension (Dq) offers interesting findings. As can be seen in , all the Dq values reported here had a very good goodness-of-fit value of about 90% or above. There are 3 important findings highlighted by the Dq values reported in :
For FVPs, the Dq values for all the three academic texts were the lowest. This aligns with the characteristics of academic texts being not verbal.
For NPs, the Dq values for academic texts and literary texts were comparable, while the Dq values for children’s literary texts were slightly lower. This is expected of both text types: academic texts are generally compact and heavily nominalized, while for literary texts, nouns are generally accompanied by other constituents (premodifiers, postmodifiers, etc) to give a rich description of the story, the characters, the place, etc. In children’s literary texts, noun phrases are generally, and relatively, shorter to align with children’s cognitive capacity in processing them.
For HNs, there was no significant difference among the 3 types of texts.
Table 4. The generalised correlation Dimensions of FVP, NP, and HN in all 9 texts.
Discussion
While the distributions of the three grammatical constructs (i.e. FVP, NP, and HN) showed the characteristics of multifractality across each of the 9 texts analysed in this study, the parameters of their distributions differed across types of grammatical constructs and across categories of texts. In this section, we will discuss in detail how these parameters differed and what the differences might mean.
Finite Verb Phrases
The generalized correlation dimensions of the distributions of the FVP constructs showed a clear descending pattern of D0 > D1 > D2 in all texts. While such a descending order met the first criterion of multifractality, the values in each of these dimensions offered information about the said distributions. The value of D0, for example, indicates the space filling capacity, which offers information on the extent on which this construct fills the space of the text. From , it is clear that the D0 values were the lowest in the academic texts, and highest in the children’s literary texts. This is in line with our common understanding of these three registers: academic texts are less verbal than the other two registers, and children’s literary texts are mainly verbal (Biber & Conrad, Citation2019).
Equally interesting is the value of D1 which bears the information on the uniformity of the distribution of the multifractals. In other words, the D1 value offers information on how uniformly distributed a certain multifractal construct is. In our study, this value can be interpreted as how many fractal elements (i.e. FVP constructs) appear at a place (i.e. the text). Our results showed that, this value was again lowest in the academic texts. Interestingly, this value was higher in the literary texts than in the children’s literary texts, suggesting that the FVP constructs were more uniformly distributed in the literary texts than in the children’s literary texts, most likely due to the lower word density in child-directed language (Hindman et al., Citation2021).
The global multifractal spectrum, which was obtained by plotting the values of the generalized correlation dimensions against the q values, offered a visual comparison of the multifractality of the distribution of FVP constructs in the 9 texts (see ).
As can be seen in , the highest tails are of the literary texts and the children’s literary texts.Footnote3 This is not unexpected as literary texts are generally verbally rich (Thompson & Sealey, Citation2007). The lowest tails are of the academic texts, as this register is possibly the least verbal type of text. Also, as a higher right tail suggests a more compact structure, this observation therefore converges with the above discussion on the space filling capacity and the uniformity of distribution of the FVP constructs in these texts.
Noun Phrases
Looking at the generalized correlation dimensions of the multifractal distributions of the NP constructs (see ), it is clear that the D0 values were quite comparable between the literary texts and the academic texts, and relatively lower in the children’s literary texts. While one would expect that these values for the academic texts would be higher than those of the other 2 registers as academic texts are known to be highly nominalized (and hence will be more saturated with NPs), the results showed that there was not much difference in the values of D0 between the academic texts and the literary texts.
However, considering the syntactic constructions in literary works, one would notice that nouns are more than often modified with adjectives (and sometimes, a string of adjectives) for description of places, characters, events, etc. in literary works, as noted in findings from the corpus linguistics field, that many literary texts are of narrative nature with high occurrences of adjectives (Biber & Conrad, Citation2019; Thompson & Sealey, Citation2007). Therefore, it is perhaps not surprising to see that the distributions of NP constructs in literary texts were quite comparable to those in the academic texts.
During the coding process in this study, the authors noticed that there were many NPs (Adj + N constructions) in the literary texts, and they were distributed rather uniformly across the body of the texts, as can be seen in the values of D1. Interestingly, the D1 and D2 values were also comparable between the literary texts and the academic texts, and slightly lower in the children’s literary texts. This suggests that in the literary texts and the academic texts (more than in the children’s literary texts), there was a more uniform distribution of NP constructs, as well as a higher chance of finding other NP constructs in neighbouring segments of the texts. In other words, if a text was cut into many segments of (roughly) similar length, the chance of finding an NP in a segment and then yet another NP in the next segment appeared to be higher in the literary texts and the academic texts than in the children’s literary texts as this construct seemed to be more uniformly distributed in literary texts and academic texts than in children’s literary texts – as seen in the D1 and D2 values obtained in this study.
The global multifractal spectra of the multifractal distributions of NP constructs in the 9 texts in this study are presented in . There are two main points of observation that can be made from these spectrums:
Figure 2. The text split into two.

The academic texts had higher right tails than the literary texts and the children’s literary texts. This suggests that the academic texts were more nominal than the literary texts which were in turn also more nominal than the children’s literary texts.
The curly left tails show the abnormal range of Dq values that exceeded the upper limit of this parameter (i.e. its topological dimension Dt = 1). This suggests that the range of q values chosen in these rounds of analysis was wider than necessary.
Head Nouns
The last construct analysed in this study is the HN constructs. Like the other two constructs in this study, the distributions of HN constructs also manifested the characteristics of multifractality.
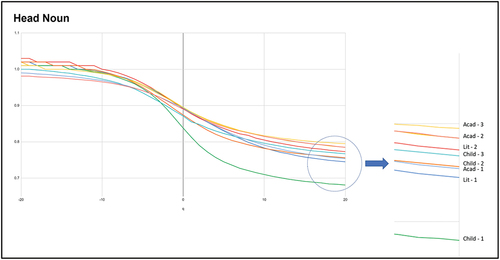
shows the values of D0, D1, D2 in the HN constructs across the 9 texts analysed in this study. Very similar to those of the NP constructs, the values of D0, D1, D2 of the HN constructs were comparable between the literary texts and the academic texts, followed by lower values in the children’s literary texts. This is, again, not unexpected, as the HN constructs are part of the NP constructs and therefore likely to share similar characteristics.
As can be seen in , the Dq spectrums are all in an inverse S-shape, again confirming the multifractal characteristics of the constructs under investigation. However, unlike in the NP constructs, there is less obvious clustering in the right tails here and that they converge quite well together, except for children text no. 1 (which has a significantly low word count). This means that the distribution of this construct in all the texts was relatively comparable. Sucha finding aligns with Thompson and Sealey’s (Citation2007) study that reported comparable frequency of nouns in the children and the adult fiction corpora.
Figure 3. Global spectrums of FVP distribution in all 9 texts.
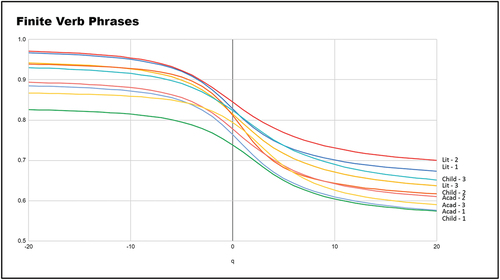
Figure 4. Global spectrums of NP distribution in all 9 texts.
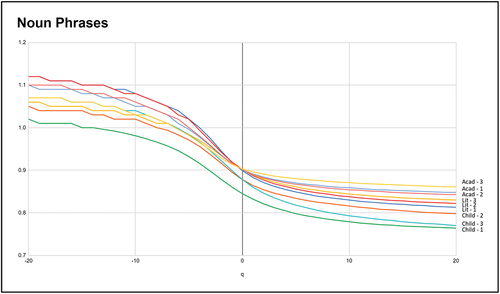
Figure 5. Global spectrums of HN distribution in all 9 texts.
Contribution and Limitations of the Study
This study constitutes an explorative step into understanding and measuring the multifractal nature of language, using an approach relatively new and uncommon to linguists – the multifractal spectrum analysis. It adds to the demonstration of using this analysis to identify the multifractal patterns in texts. Moreover, this study lends support to Hřebíček’s conjecture that fractality is not dependent on the unit of measurement used. Unlike Ausloos (Citation2012) and Chatzigeorgiou et al. (Citation2017) whose measurement unit was word length (operationalized as the number of letter in each word), the unit of measurement in this study was phrase length (operationalized as the number of words in each phrase). Regardless of the measurement units used, evidence of multifractality was found. This could perhaps be an aspect to consider when teaching and assessing language. For example, when teaching the noun phrase constructs, it might benefit learners to show them the (multi-)fractal structure of these phrases and their distribution in English texts. When it comes to language assessment, it might merit consideration to re-evaluate the currently available measurements of syntactic complexity (which are generally based on linear measurements) in light of this (multi-)fractal characteristic of syntactic constructs.
Our results also lend support to the CDST’s hypothesis about fractality in language (Evans, Citation2020; Larsen-Freeman & Cameron, Citation2008). Our analysis of the distribution of FVP, NP and HN constructs in English across three types of texts confirmed this property. Last but not least, this study contributes to expanding our understanding of fractal linguistics on the phrasal level.
However, as an explorative study, we do not have many references to guide us in terms of choosing appropriate benchmarks, or parameter settings, or direction settings. Therefore, many of the choices we made in this first and explorative study were arbitrary. For example, in deciding the number of texts in each category, we were limited by the time and resource constraints, and decided to go with 3 texts per category – an arbitrary number we chose for convenience. In selecting which texts to be included, we resorted to convenient sampling and chose from texts that were readily available in the public domains. Furthermore, the texts we selected for the academic category came from closely related cognate disciplines. Given that texts are written according to the disciplinary conventions, our selection might have limited the extent of the evidential support for our hypothesis.
Also, during the analysis, we made several discretional decisions, due to the lack of extensive referential comparisons in the field. For example, when deciding the range of the epsilon values, we went with k = 9. This value was decided upon checking the application of this analysis in other fields (e.g. urban morphology study such as Long et al. (Citation2021)) and we were aware that there is a possibility that it might not be the most appropriate value for textual analysis, particularly due to the limited number of data points when estimating the limit values through regression analysis. Mathematically speaking, the more data points we have, the better the estimate will be. However, considering our own limited resources, we went with this value (k = 9) as per commonly used in other fields. Similarly, when deciding the width of the moment of order band, we went with q = ± 20, for the same reason – see for example Saeedimoghaddam et al. (Citation2020). The results of this study showed that while this arbitrary q value worked well for the FVP constructs, it was not the case with the NP and the HN constructs. A further customization of q values will be needed for each type of constructs under investigation.
Conclusion
The results of this study show that fractality in the distribution of FVP, NP, and HN constructs in English texts is indeed multifractal. The parameters of their multifractal property offer information to describe their distribution in English texts. Through examining the parameters of these multifractal constructs, this study shows that, (1) academic texts are less verbal compared to the other two categories, (2) while academic texts and literary texts are relatively comparable in terms of the use of NP, and the distribution of NP is more compact in the academic texts, (3) there is not much difference in the distribution of the HN constructs in these 3 categories of texts. All of these align with the general understanding about the characteristics of academic texts, literary texts, and children’s literary texts (Biber & Conrad, Citation2019).
Based on the results of our study and other studies on multifractality in language, we hypothesize that multifractal is likely an inherent property of language and would be found in other registers as well. As the texts analysed in this study were all composed by experienced L1 writers, our findings open a world of possibility for further research, for example, to investigate multifractality in texts written by less experienced and/or L2 writers, or multifractality in language produced in other modalities. We would therefore like to invite passionate colleagues and fellow fractal linguists to try and apply this analysis for other registers/genres/categories of texts and utterances. Together, we are able to test if multifractality is indeed a universal property of language.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
1. See https://www.google.com/search?q=fractal+shapes&sxsrf=APwXEddSkpkCCpeKz_-gV8sbExHNWxw1Rw:1681097634329&source=lnms&tbm=isch&sa=X&ved=2ahUKEwiSuc7asJ7-AhVzyjgGHZyhA-IQ_AUoAXoECAEQAw&biw=1024&bih=481&dpr=1.88 for visual representations of fractal structures.
2. In this study, we fitted this multifractal analysis onto regular Euclidean shapes and a mono-fractal. The results differed greatly from those of multi-fractals. The results can be made available upon request.
3. With the exception of Children text 1, which may present itself as an outlier due to its extremely low word count.
References
- Abney, D., Paxton, A., Dale, R., & Kello, C. (2014). Complexity matching in dyadic conversation. Journal of Experimental Psychology: General, 143(6), 2304–2315. https://doi.org/10.1037/xge0000021
- Altmann, G. (1980). Prolegomena to Menzerath’s law. In R. Grotjahn (Ed.). Glottometrika. (vol. 2, pp.1–10). Brockmeyer.
- Andres, J., Benešová, M., & Langer, J. (2021). Towards a fractal analysis of the sign language. Journal of Quantitative Linguistics, 28(1), 77–94. https://doi.org/10.1080/09296174.2019.1656149
- Ariza-Villaverde, A., Jiménez-Hornero, F., & Gutiérrez de Ravé, E. (2013a). Multifractal analysis applied to the study of the accuracy of DEM-based stream derivation. Geomorphology, 197, 85–95. https://doi.org/10.1016/j.geomorph.2013.04.040
- Ariza-Villaverde, A., Jiménez-Hornero, F., & Gutiérrez de Ravé, E. (2013b). Multifractal analysis of axial maps applied to the study of urban morphology. Computers, Environment and Urban Systems, 38, 1–10. https://doi.org/10.1016/j.compenvurbsys.2012.11.001
- Ariza-Villaverde, A., Jiménez-Hornero, F., & Gutiérrez de Ravé, E. (2015). Influence of DEM resolution on drainage network extraction: A multifractal analysis. Geomorphology, 241, 243–254. https://doi.org/10.1016/j.geomorph.2015.03.040
- Ausloos, M. (2012). Measuring complexity with multifractals in texts. Translation effects. Chaos, Solitons & Fractals, 45(11), 1349–1357. https://doi.org/10.1016/j.chaos.2012.06.016
- Biber, D. (2014). Using multi-dimensional analysis to explore cross-linguistic universals of register variation. Languages in Contrast, 14(1), 7–34. https://doi.org/10.1075/lic.14.1.02bib
- Biber, D. (2019). Text-linguistic approaches to register variation. Register Studies, 1(1), 42–75. https://doi.org/10.1075/rs.18007.bib
- Biber, D., & Conrad, S. (2009). Register, genre, and style. Cambridge University Press. https://doi.org/10.1017/CBO9780511814358
- Biber, D., & Conrad, S. (2019). Register, genre, and style (2 ed.). Cambridge University Press. https://doi.org/10.1017/9781108686136
- Biber, D., & Gray, B. (2016). Grammatical complexity in academic English: Linguistic change in writing. Cambridge University Press. https://doi.org/10.1017/CBO9780511920776
- Cameron-Faulkner, T., & Noble, C. (2013). A comparison of book text and child directed speech. First Language, 33(3), 268–279. https://doi.org/10.1177/0142723713487613
- Carrizales-Velazquez, C., Donner, R. V., & Guzmán-Vargas, L. (2022). Generalization of Higuchi’s fractal dimension for multifractal analysis of time series with limited length. Nonlinear Dynamics, 108(1), 417–431. https://doi.org/10.1007/s11071-022-07202-2
- Chatzigeorgiou, M., Constantoudis, V., Diakonos, F., Karamanos, K., Papadimitriou, C., Kalimeri, M., & Papageorgiou, H. (2017). Multifractal correlations in natural language written texts: Effects of language family and long word statistics. Physica A: Statistical Mechanics and Its Applications, 469, 173–182. https://doi.org/10.1016/j.physa.2016.11.028
- Chen, H. (2018). Testing the Menzerath-Altmann Law in the sentence level of written Chinese. Open Access Library Journal, 5, e4747. https://doi.org/10.4236/oalib.1104747
- Chen, Y., & Huang, L. (2018). Spatial measures of urban systems: From entropy to fractal dimension. Entropy, 20(12), 991. https://doi.org/10.3390/e20120991
- Chen, Y., & Wang, J. (2013). Multifractal characterization of urban form and growth: The case of Beijing. Environment and Planning B: Planning and Design, 40(5), 884–904. https://doi.org/10.1068/b36155
- Cong, J. (2021). A Zipfian approach to words in contexts: The cases of Modern English and Chinese. Journal of Quantitative Linguistics, 29(4), 465–484. https://doi.org/10.1080/09296174.2021.1926110
- de Souza, J., Duarte Queirós, S. M., & Grimm, A. M. (2013). Components of multifractality in the central England temperature anomaly series. Chaos: An Interdisciplinary Journal of Nonlinear Science, 23(2), 023130. https://doi.org/10.1063/1.4811546
- Egbert, J., & Mahlberg, M. (2020). Fiction – one register or two?: Speech and narration in novels. Register Studies, 2(1), 72–101. https://doi.org/10.1075/rs.19006.egb
- Evans, D. (2020). On the fractal nature of complex syntax and the timescale problem. Studies in Second Language Learning and Teaching, 10(4), 697–721. https://doi.org/10.14746/ssllt.2020.10.4.3
- Goulart, L., Gray, B., Staples, S., Black, A., Shelton, A., Biber, D., Egbert, J., & Wizner, S. (2020). Linguistic perspectives on register. Annual Review of Linguistics, 6(1), 435–455. https://doi.org/10.1146/annurev-linguistics-011718-012644
- Hindman, A., Farrow, J., Anderson, K., Wasik, B., & Snyder, P. (2021). Understanding child-directed speech around book reading in toddler classrooms: Evidence from early head start programs. Frontiers in Psychology, 12, 719783. https://doi.org/10.3389/fpsyg.2021.719783
- Hřebíček, L. (1998). Language fractals and measurement in texts. Archív Orientální, 66(3), 234–242.
- Hsiao, Y., Dawson, N. J., Banerji, N., & Nation, K. (2022). The nature and frequency of relative clauses in the language children hear and the language children read: A developmental cross-corpus analysis of English complex grammar. Journal of Child Language, 50(3), 555–580. https://doi.org/10.1017/S0305000921000957
- Jayaram, B., & Vidya, M. (2008). Zipf’s law for Indian languages. Journal of Quantitative Linguistics, 15(4), 293–317. https://doi.org/10.1080/09296170802326640
- Jiang, X., & Jiang, Y. (2022). Menzerath-Altmann Law in consecutive and simultaneous interpreting: Insights into varied cognitive processes and load. Journal of Quantitative Linguistics, 29(4), 541–559. https://doi.org/10.1080/09296174.2022.2027657
- Jiang, Y., & Ma, R. (2022). Does Menzerath–Altmann Law hold true for translational language: Evidence from translated English literary texts. Journal of Quantitative Linguistics, 29(1), 37–61. https://doi.org/10.1080/09296174.2020.1766335
- Kello, C. T., Anderson, G. G., Holden, J. G., & Van Orden, G. C. (2008). The pervasiveness of 1/f scaling in speech reflects the metastable basis of cognition. Cognitive Science, 32(7), 1217–1231. https://doi.org/10.1080/03640210801944898
- Larsen-Freeman, D.(2012). Complex, dynamic systems: A new transdisciplinary theme for applied linguistics. Language Teaching, 45(2), 202–214. https://doi.org/10.1017/S0261444811000061
- Larsen-Freeman, D., & Cameron, L. (2008). Complex systems and applied linguistics. Oxford University Press.
- Lin, D. C., & Sharif, A. (2010). Common multifractality in the heart rate variability and brain activity of healthy humans. Chaos: An Interdisciplinary Journal of Nonlinear Science, 20(2), 023121. https://doi.org/10.1063/1.3427639
- Li, P., Pan, Q., Jiang, S., Yan, M., Yan, J., & Ning, G. (2021). Development of novel fractal method for characterizing the distribution of blood flow in multi-scale vascular tree. Frontiers in Physiology, 12, 12. https://doi.org/10.3389/fphys.2021.711247
- Long, Y., Chen, Y., & Zheng, N. (2021). Multifractal scaling analyses of urban street network structure: The cases of twelve megacities in China. PLoS ONE, 16(2), e0246925. https://doi.org/10.1371/journal.pone.0246925
- Lowie, W.(2013). Dynamic Systems Theory approaches to second language acquisition. In C. Chapelle (Ed.), The Wiley-Blackwell Encyclopedia of Applied Linguistics. Blackwell Publishing Ltd. https://doi.org/10.1002/9781405198431.wbeal0346
- Lowie, W., Plat, R., & de Bot, K. (2014). Pink noise in language production: A nonlinear approach to the multilingual lexicon. Ecological Psychology, 26(3), 216–228. https://doi.org/10.1080/10407413.2014.929479
- Mandelbrot, B. (1967). How long is the coast of Britain? Statistical self-similarity and fractional dimension. Science, 156(3775), 636–638. https://doi.org/10.1126/science.156.3775.636
- Mandelbrot, B. (1983). The fractal geometry of nature. W.H. Freeman.
- Mazdayasna, G., & Firouzi, M. (2013). A corpus based study of adjectives in literary and technical texts. Journal of Foreign Language Teaching and Translation Studies, 2(1), 73–88. https://doi.org/10.22034/efl.2013.79182
- Menzerath, P. (1954). Die architektonik des deutschen wortschatzes. Dümler.
- Montag, J. L., & MacDonald, M. C. (2015). Text exposure predicts spoken production of complex sentences in 8- and 12-year-old children and adults. Journal of Experimental Psychology General, 144(2), 447–468. https://doi.org/10.1037/xge0000054
- Mouzourides, P., Kyprianou, A., & Neophytou, M. K. A. (2021). Exploring the multi-fractal nature of the air flow and pollutant dispersion in a turbulent urban atmosphere and its implications for long range pollutant transport. Chaos: An Interdisciplinary Journal of Nonlinear Science, 31(1), 013110. https://doi.org/10.1063/1.5123918
- Najafi, E., Darooneh, A., & Esteban, F. J. (2015). The fractal patterns of words in a text: A method for automatic keyword extraction. PLoS ONE, 10(6), e0130617. https://doi.org/10.1371/journal.pone.0130617
- Rahman, R. (2012). Semantico-syntactic features of oscar wilde’s fairy tales [Doctoral thesis, University of Peshawar]. Pakistan. http://prr.hec.gov.pk/jspui/handle/123456789//1324
- Saeedimoghaddam, M., Stepinski, T., & Dmowska, A. (2020). Rényi’s spectra of urban form for different modalities of input data. Chaos, Solitons & Fractals, 139, 109995. https://doi.org/10.1016/j.chaos.2020.109995
- Sanada, H. (2016). The Menzerath-Altmann Law and sentence structure. Journal of Quantitative Linguistics, 23(3), 256–277. https://doi.org/10.1080/09296174.2016.1169850
- Thompson, P., & Sealey, A. (2007). Through children’s eyes?: Corpus evidence of the features of children’s literature. International Journal of Corpus Linguistics, 12(1), 1–23. https://doi.org/10.1075/ijcl.12.1.03tho
- Verspoor, M. & Sauter, K.(2000). English sentence analysis: An introductory course. John Benjamins Publishing Company.