
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
For autonomous vehicles, free-space detection is an essential part of visual perception. With the development of multi-modal convolutional neural networks (CNNs) in recent years, the performance of driving scene semantic segmentation algorithms has been dramatically improved. Therefore most free-space detection algorithms are developed based on multiple sensors. However, multi-modal CNNs have high data throughput and contain a large number of computationally intensive convolution calculations, limiting their feasibility for real-time applications. Field Programmable Gate Arrays (FPGAs) provide a unique combination of flexibility, performance, and low power for these problems to accommodate multi-modal data and the computational acceleration of different compression algorithms. Network lightweight methods offer great assurance for facilitating the deployment of CNNs on such resource-constrained devices. In this paper, we propose a network lightweight method for a multi-modal free-space detection algorithm. We first propose an FPGA-friendly multi-modal free-space detection lightweight network. It comprises operators that FPGA prefers and achieves a MaxF score on the test set of KITTI-Road free-space detection tasks and 81 ms runtime when running on 700 W GPU devices. Then we present a pruning approach for this network to reduce the number of parameters in case the complete model exceeds the FPGA chip memory. The pruning is in two parts. For the feature extractors, we propose a data-dependent filter pruner according to the principle that the low-rank feature map contains less information. To not compromise the integrity of the multi-modal information, the pruner is independent for each modality. For the segmentation decoder, we apply a channel pruning approach to remove redundant parameters. Finally, we implement our designs on an FPGA board using 8-bit quantisation, and the accelerator achieves outstanding performance. A real-time application of scene segmentation on KITTI-Road is used to evaluate our algorithm, and the model achieves a
MaxF score and minimum 14 ms runtime on 20W FPGA devices.
1. Introduction
Free-space detection is a part of driving scene understanding, which classifies each pixel in an image as drivable or non-drivable areas, usually realised by image segmentation algorithms. Other modules in the autonomous system benefit from these pixel-level segmentation results, such as trajectory prediction and path planning, to ensure autonomous vehicles safely navigate in complex environments. In recent years, multi-modal data fusion convolutional neural networks (CNN) architectures have greatly improved the performance of free-space detection algorithms (X. Zhang et al., Citation2021). For robust and accurate scene understanding, autonomous vehicles are usually equipped with different sensors, and multiple sensing modalities can be fused through their complementarity (X. Bai et al., Citation2021). In multi-modal learning, modalities can be combined from bottom to top according to fusion level. Pixel level fusion is to fuse the original data with the smallest granularity (C. Wang et al., Citation2020). Feature level fusion sends images of different modalities into different segmentation sub-networks, fuses the feature maps obtained by different sub-networks, and then inputs them into the decision layer (C. Wang et al., Citation2022). Decision level fusion sends images of different modalities in various networks and fuses the results after segmentation (Zhou et al., Citation2020). Feature-level fusion is the most commonly used method among them. This fusion strategy's models usually consist of multiple encoders and one decoder. However, the number of parameters in the network doubles with each additional input modality, which makes the model computationally expensive (Yan et al., Citation2021).
The calculation of such a large model relies heavily on computational acceleration devices. Graphics Processing Units (GPUs) provide the infrastructure of multi-core parallel computing and has many cores, which can support parallel computing of large amounts of data. Its high floating-point computing capabilities are often used to accelerate CNN algorithms. For autonomous vehicles, both real-time processing speed and low power consumption are desirable. As GPU consumes much electricity, few GPU devices can be installed in an autonomous vehicle due to a limited power supply. But dozens of perception and planning tasks need to be processed simultaneously on the vehicle. Field Programmable Gate Arrays (FPGAs) are low-power devices with highly-parallel bit-oriented architecture, support both pipeline parallelism and data parallelism. The training of CNN models uses Single Instruction Multiple Data (SIMD) calculation, in which large batches of data can be processed in parallel by executing only one instruction. However, the calculation of model inference after the training is an application of Multiple Instruction Single Data (MISD), which is precisely the advantage of FPGA over GPU. We evaluate FPGAs as a platform to meet computational power requirements and constraints.
Since multi-modal data fusion CNNs usually have larger weight matrix and activation values than single-modal models, the FPGA chip memory cannot afford the entire model (L. Bai et al., Citation2020). Model compression reduces the computation and data storage by simplifying the network structure and has become an essential step in deploying CNN algorithms on the FPGA platforms (Xiong et al., Citation2021; J. Zhang et al., Citation2021). There are several model compression methods, such as pruning, quantisation, low-rank factorisation, and knowledge distillation. Among them, pruning and quantisation are techniques that compress both activation and weight representations, allowing the FPGA platform to store all intermediate results.
Pruning is a technique for eliminating unnecessary weights from neural networks based on the over-parameterisation of CNNs (Ye et al., Citation2018). As a machine learning method, CNNs can be divided into two stages: training and inference. In the training phase, the parameters are learned according to the data; in the inference phase, new data are fed into the model, and the result is obtained after calculation (Guo et al., Citation2016). Over-parameterisation means that there are a large number of parameters in the training phase to capture the information in the dataset. Once the training is completed to the inference phase, most of these parameters are redundant, which means the network can be pruned before deployment. There are many benefits of network pruning. The most immediate one is reducing the high amount of calculation, resulting in less computation time and less power consumption. The smaller memory footprint also allows algorithms to run on lower-end devices, such as replacing DRAMs with faster and more power-efficient SRAMs. Finally, smaller package size is conducive to model updates, making product upgrades more convenient.
According to the granularity of pruned feature, pruning techniques can be grouped into weight pruning and filter pruning. Early methods are based on weight pruning, whose pruning granularity is the weight kernels. The kernels after pruning are sparse matrices filled with element zero. Under the support of today's hardware, sparse matrices cannot be optimised by using the existing Basic Linear Algebra Subprograms (BLAS) libraries, so it is difficult for the pruned model to achieve substantial performance improvement. Therefore, researches in recent years have focussed on filter pruning. Different granularities of filter pruning exist, such as filter-based, channel-based, block-based, and layer-based. Since filter pruning does not change the sparsity of the weight matrices, it can be well supported by existing computing platforms and frameworks. In this paper, we focus on filter pruning to achieve model compression and acceleration, aiming to provide a versatile solution for FPGA devices.
A typical neural network pruning framework is training, pruning, and fine-tuning. The first step is to train the complete network. The second step is to delete parameters according to the filter evaluation function. The third step is to train the network with additional epochs using a low learning rate so that the network has an opportunity to recover from the performance penalty. Generally, the last two steps are iterative, and each iteration increases the pruning rate. The core of a pruner lies in selecting pruning filter evaluation functions, whose goal is to achieve a minor accuracy loss under the highest compression ratio. Based on whether the training data is utilised to determine the pruned filters, the filter pruning can be categorised into data-dependent and data-independent. The methods of data-independent pruning are based on the inherent weights of the network and do not rely on the input data. After the pruning, fine-tuning is required to restore the accuracy. Typical methods include L1 or L2 norm, first-order gradient metric, the rank of feature maps, and geometric median in network layers. These filters bring advantages in low time complexity but have limitations in accuracy and compression ratio. The methods of data-dependent pruning are adding additional regular terms to the input data, making it sparse, and embedding the pruning into the training process so that the data flow raises a better pruning strategy during the network training. This category belongs to methods such as scaling factors in BN layers and masking structural sparsity parameters. These methods of directly adding sparse constraints to the network generally achieve better results than the first one. In multi-modal learning, the model usually supports multiple data inputs, which makes the data have a significant influence on the network. Therefore we prefer a data-dependent filter pruning as the evaluation function.
Quantize is to convert the trained model into a low-precision representation for calculation. Today's maturing quantisation method is to convert 32-bit floating-point tensors into 8-bit fixed-point tensors for calculation. The memory space of each parameter reduces from 32-bit to 8-bit. Thus, the model size decreases to a quarter. Another advantage of quantisation in model acceleration is improving throughput and reducing latency. After quantification, the theoretical computing peak of the chips can be quadrupled, further accelerating the inference of the model. The hardware digital signal processor (DSP) core integrated into the FPGA chip is a high-performance hardware multiplier and accumulator, which is highly appropriate for convolution operation. However, DSP units can only operate multiplications below the specified bit width, i.e. fixed-point calculations. Therefore, quantisation is also essential for running CNNs on FPGA platforms. We choose the 8-bit quantisation method in the TensorFlow platform proposed by Google (Krishnamoorthi, Citation2018). As one of the most basic quantisation methods, it is supported by mature software tools on TensorFlow and Pytorch to facilitate subsequent model deployment on the FPGA platform.
In this research, we propose a lightweight multi-modal free-space detection network appropriate for FPGA platforms. The foundation is a lightweight multi-input U-shaped architecture that supports multi-modal data input and returns reliable free-space detection results adequate for self-driving. Then we prune this lightweight model with two strategies. First, according to the rank of each modal feature map, layer pruning is performed separately for each modality to ensure their independence. Second, for the segmentation decoder, channel pruning further removes unnecessary parameters. With the pruned model, we quantise the model to 8-bit and deploy the inference on FPGA.
Our contributions in this paper are four-fold:
We propose a multi-modal learning CNN performing free-space detection tasks with RGB and depth images. The network achieves excellent performance on drivable area segmentation and has a suitable structure for transplanting to FPGA devices.
We propose a two-stage filter pruning strategy, including a data-dependent pruning based on the rank of feature maps and a data-independent pruning for the segmentation decoder.
We apply an 8-bit quantisation to maximise the computation capability of FPGA, which improves the operations per second(OPS) by
with little accuracy penalty.
We introduce a hardware architecture design for executing the lightweight model, which helps compute neural networks with high performance.
2. Related work
We review some related work on free-space detection and pruning below.
2.1. Free-space detection
Free-space detection presents an informative perception of the environment toautonomous vehicles. For several decades, research based on image processing has been expanding to address road segmentation problems. RBNet (Z. Chen & Chen, Citation2017) investigates the contextual relationship between the road structure and its boundary arrangement. RBA (Sun et al., Citation2019) uses a residual refinement module composed of the reverse attention and boundary attention units. Along with algorithms based on low-level features, many studies attempting to solve segmentation problems with deep CNNs have been carried out (Cordts et al., Citation2017), and studies that considered free space problems to be semantic segmentation tasks have been conducted (X. Han et al., Citation2018). Earlier approaches, including FCN (Long et al., Citation2015) and SegNet (Badrinarayanan et al., Citation2017), proposed the encoder-decoder architecture, where the encoder generates feature maps in multiple scales and the decoder provides high prediction accuracy pixel-wise classification. Strong backbone networks, e.g. GoogLeNet (Szegedy et al., Citation2015), ResNet (K. He et al., Citation2016), DenseNet (G. Huang et al., Citation2017), performance better segmentation features. U-Net (Ronneberger et al., Citation2015) based models concatenate the lower-level features to the feature maps as skip connections in order to predict more detailed output. Recent researches focus on non-local operations (X. Wang et al., Citation2018) in semantic segmentation models for the purpose of eliminating the noises in feature maps (Fu et al., Citation2019; Vaswani et al., Citation2017). These methods use transformers with extremely large parameters to ensure that the network learns the correlation between semantics, featuring high-accuracy results.
Methods combining geometric information from multi-modal data were gradually introduced to tackle this segmentation problem. Early works (Couprie et al., Citation2013; Eigen & Fergus, Citation2015; Hazirbas et al., Citation2016) convert depth into a single-channel image and used the early fusion to concatenate depth and RGB as a four-channel image input simply. HHA (Gupta et al., Citation2014) is another depth encoding of three channels, including horizontal disparity, height above ground, and norm angle. In other studies (Z. Li et al., Citation2016; D. Lin et al., Citation2013; Park et al., Citation2017), RGB and HHA images were fed into two DCNNs to extract features separately and finally use the middle fusion to concatenate or sum up the features. Other researches using LiDAR output with RGB data for free space detection have been published (Caltagirone et al., Citation2019; Teichmann et al., Citation2018). SNE-RoadSeg (Fan et al., Citation2020) generates surface normal information from dense depth images and aggregates it with RGB images by a densely-connected fusion. PLARD (Z. Chen et al., Citation2019) introduced an altitude difference image as a second input of the network. The cross-fusion approach (Caltagirone et al., Citation2019) and the cascaded fusion approach (Gu et al., Citation2021) were proposed to get better RGB and projected point cloud fused features.
2.2. Pruning
Many works (Carreira-Perpinán & Idelbayev, Citation2018; S. Han, Mao et al., Citation2015; H. Li et al., Citation2022; Tung & Mori, Citation2018; T. Zhang et al., Citation2018) focus on pruning the fine-grained weight of filters. S. Han, Pool et al. (Citation2015) proposes an iterative method to discard the small weights whose values are below the predefined threshold. Carreira-Perpinán and Idelbayev (Citation2018) formulates pruning as an optimisation problem of finding the weights that minimise the loss while satisfying a pruning cost condition. However, the sparse matrix obtained by weight pruning does not support the corresponding accelerated operation.
Opposed to weight pruning, filter pruning removes the entire filter according to certain metrics. It is one of the most popular methods to accelerate over-parameterised CNNs since the pruned deep networks can be directly applied on any off-the-shelf platforms and hardware to obtain the online speed-up. Some data-independent filter pruning strategies (Y. He et al., Citation2018, Citation2019; H. Li et al., Citation2016) have been explored. H. Li et al. (Citation2016) utilises an l1-norm criterion to prune unimportant filters. Y. He et al. (Citation2018) proposes to select filters with an l2-norm criterion and prune those selected filters in a soft manner. Ye et al. (Citation2018) proposes to prune models by enforcing sparsity on the scaling parameter of batch normalisation layers. Zhuo et al. (Citation2018) uses spectral clustering on filters to select unimportant ones. Y. He et al. (Citation2019) proposed a filter pruning via geometric median to compress the model. Some filter pruning approaches (Dubey et al., Citation2018; Q. Huang et al., Citation2018; M. Lin et al., Citation2020; S. Lin et al., Citation2019; Suau et al., Citation2018; D. Wang et al., Citation2018; Yu et al., Citation2018; Zhuang et al., Citation2018) need to utilise training data to determine the pruned filters. Luo et al. (Citation2017) adopts the statistics information from the next layer to guide the filter selections. Dubey et al. (Citation2018) aims to obtain a decomposition by minimising the reconstruction error of training set sample activation. Suau et al. (Citation2018) proposes an inherently data-driven method which use Principal Component Analysis (PCA) to specify the proportion of the energy that should be preserved. D. Wang et al. (Citation2018) applies subspace clustering to feature maps to eliminate the redundancy in convolutional filters. M. Lin et al. (Citation2020) develops a method that is mathematically formulated to prune filters with low-rank feature maps.
Efficient free-space detection algorithms are of great importance for deployment on mobile devices. However, there are few works discussing the pruning of semantic segmentation neural networks for free-space detection tasks. Pruning methods designed over the classification task have been straightforwardly applied to segmentation neural networks (W. He et al., Citation2021; Q. Huang et al., Citation2018; Yamamoto & Maeno, Citation2018). Luo et al. (Citation2017) pruned filters in the backbone network on ImageNet and transferred it to the segmentation network. X. Chen et al. (Citation2020) proposed a multi-task channel pruning to obtain a lightweight semantic segmentation network.
3. Method
The purpose of this article is to implement a free-space detection algorithm on an autonomous driving platform using low-power devices. FPGA is a feasible solution due to its high performance and energy efficiency. We first introduce a lightweight multi-modal free-space detection network, with less convolutional operators and smaller feature maps. Then reduce the parameters of the model through filter pruning and 8-bit quantisation. Finally, the model is transplanted to a FPGA so that it can predict independently in the low-power devices.
3.1. Multi-modal free-space detection network
The free-space detection network is built with a classic encoder-decoder architecture as shown in Figure . Unlike software platforms, convolutional computing resources built by hardware cannot be released during the program. It means that the fewer operators that are implemented, the FPGA resources are better used. Common image encoders include VGG (Simonyan & Zisserman, Citation2014), Deeplab (L. C. Chen et al., Citation2017), mobilenet (Howard et al., Citation2017), ResNet (K. He et al., Citation2016), etc. VGG uses stacked convolution, but due to the problem of gradient disappearance, the network is shallow and it is difficult to achieve high accuracy. Deeplab achieves good results, but the spatial pyramid structure contains a variety of atrous convolution operators, and it generates large feature tensors during multi-scale fusion, which is difficult to implement in FPGA. Mobilenet is a lightweight network using depthwise separable convolution to reduce the parameters of
convolution, but the cost is the increased calculation steps and the detail loss in low-dimensional features. ResNet greatly increases the depth of the network through shortcut connection, has strong feature extraction ability, and basically only consists of
convolution and
convolution, which is the first choice for our encoder (Figure ).
Figure 1. Our proposed lightweight multi-modal free-space detection network. An encoder-decoder architecture is employed. The input of the network is a pair of RGB and depth images. They are processed by the ResNets (K. He et al., Citation2016) encoders. The multi-modal fusion strategy is the concatenation of the feature maps. A U-shape segmentation decoder (Ronneberger et al., Citation2015) is propagated for the final prediction.
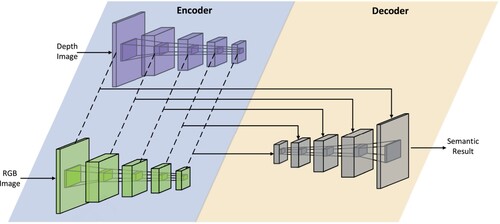
Figure 2. Replacing the convolution with
convolutions.
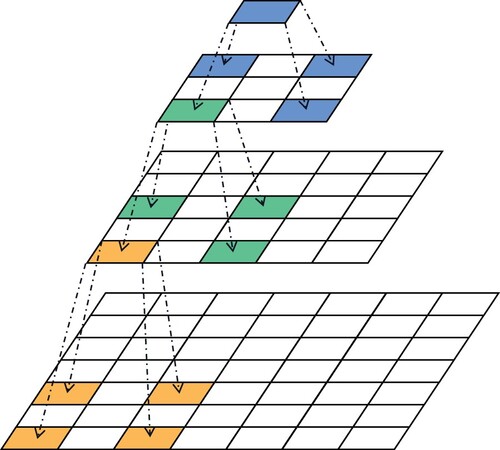
Convolution decomposition: The calculations in a ResNet are convolution,
convolution,
convolution, and shortcut concatenation. It should be noted that in FPGAs, concatenation can be achieved only by scheduling the memories without the involvement of computing units. Therefore, the computation of
convolution is the largest one. Meanwhile, this convolution appears only once in the first layer, and is not reused subsequently, which led us to the idea of optimising it. Convolutions with
spatial filters means the receptive field of this operation is
. Without changing the size of the receptive field, we try to find a multi-layer network with a smaller convolution kernel to replace this operation. The theoretical receptive field of a convolutional layer can be calculated by the recursive formula:
(1)
(1)
where r is the receptive field, k is the kernel size, and s is the stride. Assume that the length and width of a feature map are both
. We use a
convolution kernel to slide with a stride of 1, which requires
slides. The same in the vertical direction, sliding
times, so there are
convolutions, where the size of the receptive field is
. In the same way, the output size after the
convolution is
. Use two more
convolutions on the output map to get the receptive field
, which is equal to the
convolution result. Therefore, it can be concluded that three
convolutions and one
convolution have the same feature extraction ability.
The operations for a convolution is 9, for a
convolution is 49. For images whose length and width are both x, the computations of three
convolution and one
convolution are
and
respectively. Calculating
, we can get x>12, which means for image larger than
, the three-layers
convolution have advatage in both number of parameters and calculation. For the first layer of Resnet, the input is the original image, which is much larger than
, so using three layers of
convolution instead of
convolution always performances better. The optimised accelerating
convolution layer designed in this paper is shown in Figure (a).
Figure 3. (a) Detail of the optimised accelerating convolution layer. (b) Detail of the dimensionality reduction for large features.
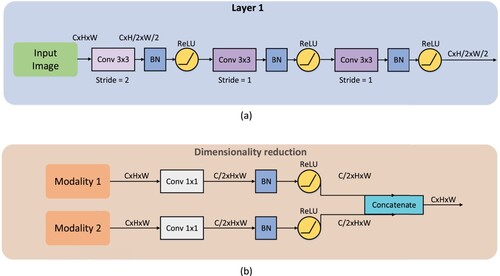
Dimensionality reduction: In the semantic segmentation model, the deeper the network, the larger the receptive field, but the more information is missing in the decoder. Thus, the retrieval of edge features is extremely important. U-Net uses the method of skip connection to fuse the same-level feature map in the encoder with the recovery result of deconvolutional layer to achieve a retrieval of edge features. Referring to this U-shaped structure, we concatenate the multi-modal same-level features to the skip connection, and used them for the calculation of the deconvolution layer at the same time. The disadvantage is that the concatenated feature tensor will be very thick. Taking the KITTI dataset as an example. The size of the original image is , the size of the feature map after four times downsampling is
, the dimension of the feature map of the 4th layer of ResNet-50 is 1024. So the size of the feature tensor of the two-modality network after concatenation is
, occupying about 8.13 Mb of FPGA block RAM. Although this size is within the acceptable range, it just takes up more than half of the memory space, which makes the device unable to run double batch parallelism. This is wasteful, so we reduced the dimensionality of the fused features, using two
convolutional layers as shown in Figure (b).
The entire lightweight free space detection network uses ResNet-50 as the backbone, U-net as the segmentation head, and uses concatenation as the feature fusion method, which effectively maintains the complexity and feature extraction capability of the network. The lightweight network only contains two convolution operators, convolution and
convolution, which greatly saves computing resources on the FPGA. At the same time, the size of the intermediate result of the algorithm is precisely controlled, so that the algorithm can prosess inside the FPGA in multi-batch parallelism, avoiding the delay caused by external data exchange.
3.2. Filter pruning
Filter pruning is a method of acceleration by removing the convolution kernels with weak feature extraction ability and making the network sparse. This method can greatly reduce the parameters in the network. The accuracy of can be recovered quickly after retraining the pruned model. The procedure can be divided into five steps. Step 1 is to train the entire network with the dataset to generate the initial network model file. Step 2 is to record the weight distribution of the convolution kernel of the first layer, and set the pruning rate according to the importance of convolution kernel. Step 3 is to delete the corresponding relationship between the convolution kernel and feature map with little impact on the network performance according to the pruning rate. Step 4 is to retrain the network to recover the performance penalty. Step 5 is to repeat the above process layer-by-layer, pruning and fine-tuning until output the pruned network model file.
Assume is the ith convolutional layer of a pre-trained CNN model. The weights in
can be represented as
, where
represents the number of filters in
and
denotes the kernel size. The input feature maps are denoted as
, where b is the batch size,
and
are the height and width of the feature map. Filter pruning aims to identify and remove the less important weights set from
, which can be fomulated as an optimisation problem:
(2)
(2)
where
measures the importance of a weight in the CNN. δ is a filter which is 1 if
is important or 0 if
is unimportant. Minimizing p is to removing the least important weights in
.
Encoder pruning: Our key problem falls in designing a function which can well reflect the information richness of multi-modal features. Since the feature maps of different modalities are relatively independent, most pruning methods that directly design
based on network weights will concentrate on a certain modality, which causes the algorithm to ignore important cross-modal information. Therefore, for the encoder, we propose to define
according to the feature map for each independent modality, because feature maps are intermediate steps that can reflect both the filter properties and the input images. The optimisation function p is thus reformulated as:
(3)
(3)
where
estimates the information of feature maps generated by
and
. The more information the feature map contains, the more important the corresponding filter is.
The rank of a matrix is the number of irrelevant row or column vectors. For the matrix of an image, the rank can represent the degree of information redundancy and the amount of information in the image. We perform the singular value decomposition (SVD) onimage :
(4)
(4)
where R is the rank of an input feature map,
,
and
are the singular values. A feature map with rank R can be decomposed into a lower-rank feature map with rank
and additional information, which demonstrates that higher-rank feature maps contain more information than lower-rank feature maps. It can be not only an effective measure of information, but also a stable representation. We thus define our information measurement as:
(5)
(5)
Decoder pruning: Since the scaling factors in encoder and decoder network are optimised alternately, setting the same global threshold for both the backbone and decoder is inappropriate. No need to consider the influence of intermediate results, applying traditional pruning methods on the decoder is enough to remove redundant parameters. We sort the convolution kernels according to their L1-norm:
(6)
(6)
We introduce a scaling factor for each channel, which is multiplied by the output of that layer. We then jointly train the network weights and these scaling factors, and sparse regularise them. Finally, we prune those channels with small factors and fine-tune the pruned network. Since the pruning corresponds to removing all inputs and outputs of the layer, we can directly obtain a narrow network. The scaling factor acts as a weight selection and are jointly optimised with the weights. The network can automatically identify insignificant channels and safely remove them without greatly affecting the generalisation performance.
3.3. Quantization and layer fusion
8-bit quantisation: Our quantisation strategy is to use floating-point computations in network training and integer computations in inference. Against the characteristics of FPGA, the goal of quantisation is to use only integer calculations to complete all arithmetic operations. It is implemented by an affine transformation between the real value r and the integer value q:
(7)
(7)
where Z is the quantisation zero-point, which is constant. r is the real value to be quantised, usually a 32-bit floating-point number. For B-bit quantisation, q is an integer of B-bit. In this paper, we set B = 8. S is the quantisation scale, calculated by counting the maximum and minimum values of the entire array:
(8)
(8)
Z is the quantisation zero-point, representing the bias of q relative to 0, which is the same data type as q.
Quantized layer fusion: Generally, a layer in CNN consists of convolution, BN and ReLU. Since all parameters during inference are constant, the fusion of these calculations can greatly reduce the number of parameters. Because of the batch normalisation, the convolution computation can be set as unbiased. The convolution can thus be expressed as:
(9)
(9)
where ω is the weight, x is the input feature, and
is the convolutional result. Quantize Equation (Equation9
(9)
(9) ) with
and
, the convolution is equivalent to:
(10)
(10)
Batch Normalization(BN) is widely used to solve the internal covariate shift problem. The computation of BN during inference can be summarised as a combination of normalisation and scaling:
(11)
(11)
where ϵ is the mean, σ is the variance, α is the scale, and β is the shift. Then we have the quantised BN:
(12)
(12)
The convolution operations are followed by nonlinear activation units, to process the linear output of the previous layer through a nonlinear activation function to simulate any function, thereby enhancing the representation ability of the network. ReLU is a piecewise linear function, which is the most commonly used activation layer. A ReLU operator be expressed as:
(13)
(13)
The output y should also be quantised as
. Thus when
:
(14)
(14)
Then we have the quantisation result as:
(15)
(15)
When
:
(16)
(16)
Note that
and
, we have the quantised convolutional layer:
(17)
(17)
where M, b,
,
and
are five constants which can be offline calculated before inference. The fused convolution layer greatly reduces the computational steps in the inference, further accelerating the network.
3.4. Hardware architecture
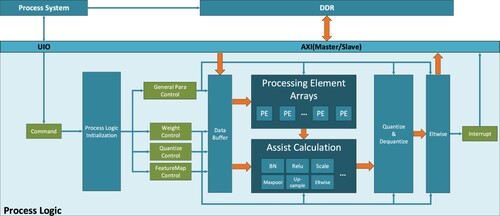
The calculation and data exchange of the entire CNN are independently completed by the FPGA core. The CPU side is only responsible for sending start signals and receiving interrupts. The overview of hardware architecture is demonstrated in Figure . It consists of computation kernels, data buffers for memory optimisation, and several kinds of signal control units. A Process Logic Initialization block generates the internal control signals for each layer. The Data Buffer reads the weights and features of the current layer, then sent them into the computation kernels. We adopted DSP48E2 cores to perform two 8-bit multiplications simultaneously. The convolutional operations are performed in a pipelined Processing Element Arrays, and additional assist calculations such as maxpooling, up-sampling, etc. are performed according to the characteristics of each layer. The quantised features are re-assembled into feature maps after dequantization, and are sent to DDR for the next loop.
Figure 4. Block diagram of hardware architecture.
convolution unit: Each unit in the weight buffer stores a
weight of a fliter, with a length of 9 bits for the carry-save addition. In the feature map buffer, a
window is sent to the DSP for convolution operation input every cycle, and each element is 8bit. A group of 9 DSPs corresponds to one
window accumulation.The channel accumulation is performed in each DSP, and summed up after accumulating three times. A subscriber is introduced to calculate Equation (Equation16
(16)
(16) ). The architecture contains 16 computing units (Figure (a)), which output 16 channels of 1 pixel per frame.
Figure 5. (a) convolution unit. (b)
convolution unit.
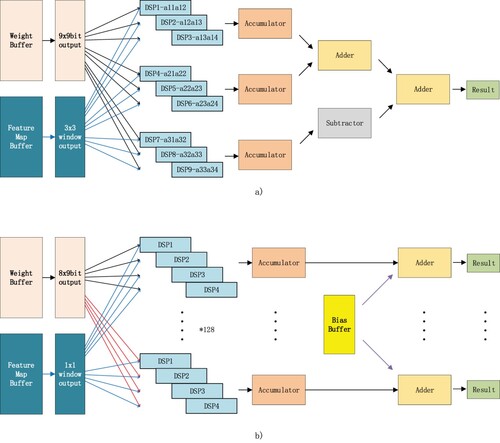
convolution unit: The weight buffer shares the same unit as it of
Conv, and each unit stores the weight of 4 channels corresponding to 1 Kernel. The feature map buffer sends a
window of 4 channels to the DSP for convolution operation input. A group of 4 DSPs is used for channel accumulation. Each DSP is responsible for the 1/4 channel-accumulation of 1 kernel. The DSPs differ by one cycle. After the accumulation, the result is output to the accumulator to complete the convolution operation of the entire kernel. The bias-add is displayed at the end of convolution computing.
4. Experiments
4.1. Dataset
We construct our experiments on KITTI-ROAD (Fritsch et al., Citation2013) dataset to demonstrate our efficiency in reducing model complexity. : This dataset provides RGB-D data in real-world driving scenarios. Specifically, it contains 289 pairs of training data with ground truth for freespace detection and 290 pairs of testing data without ground truth.
4.2. Implementation details
Our network is trained on an NVIDIA Tesla V100 platform using CUDA10.0, which requires 600–700 W power suply. The quantised model is infrenced on a Xilinx Zynq UltraScale+ MPSoC ZCU106 kit with XCZU7EV-2FFVC1156 FPGA core, powered by a 12V5A direct current(DC) electricity supply, draws 20–60 W of power.
We use PyTorch to implement the network training. The training batch size is set to 6, the initial learning rate is set to 1e−4, and the Adam solver is used to optimise the network. We train the network over 100 epochs, and decay the learning rate linearly with a decay rate of 0.99. For pruning the pre-trained model, we reduce the learning rate to one-tenth of the original learning rate, and use fewer epochs to finetune the pruned model. In the filter pruning step, we prune all the weighted layers in a encoder/decoder with the same pruning rate at the same time. The pruning operation is conducted at the end of every training epoch.
4.3. Evaluation metrics
We take MaxF as segmentation evaluation metric:
(18)
(18)
where TP, FP, FN are the numbers of true positive, false positive, false negative pixels. We adopt the widely-used protocols, i.e. number of parameters and required Float Points Operations (denoted as FLOPs), to evaluate model size and computational requirement. We also compare the inference speed on GPU and FPGA devices.
4.4. Performance evaluation
Performance of lightweight model: We list the performance of some SOTA algorithms from the KITTI leaderboards in Table . Most of them use [email protected] for the evaluation. ChipNet (Lyu et al., Citation2018) only used a single sensor, which preprocessed point cloud data by organising them in a spherical view. RoadNet-RT (L. Bai et al., Citation2020) achieves a very high-speed single-model segmentation network but too much loss in accuracy. PLARD (Z. Chen et al., Citation2019), DFM-RTFNet (H. Wang et al., Citation2021), and SNE-RoadSeg (Fan et al., Citation2020) took advantage of multi-modal data. They transformed the 3D point cloud into the image plane by projecting its LiDAR coordinates and sending it into the network with the RGB image. When comparing our proposed method with other SOTA algorithms using the evaluation measures, it was less accurate than heavy data-fusion networks but two times faster. Furthermore, compared to the FPGA-faced ChipNet, our network showed a
improvement. As a result, the proposed lightweight multi-modal free-space detection network was competitive in inference speed while ensuring high accuracy.
Table 1. Performance on Kitti-road compared to other methods(GPU).
Performance of pruning: As shown in Table , the classic l1-norm pruning suffered from a performance drop of when pruning
of all channels. In contrast, our proposed method boosted the performance of the pruned model and had an insignificant accuracy drop. As the pruning rate increased, the accuracy dropped significantly because of the reduced model complexity. Similarly, the inference speed of the model also increases as the number of parameters decreases. Our method obtained a MaxF of
when keeping
channels, which led to a
decline. Pruning more channels led to a slightly worse score but consistently outperformed the prior method. To prioritise the accuracy of the model, we choose the result of
pruning rate for quantisation.
Table 2. Pruned multi-modal unet-resnet50 on Kitti-road.
Performance of quantisation: As shown in Table , after the 8-bit quantised, the storage of the network was reduced by , and the MaxF dropped by
. The score of no pruning and
pruning are the same, indicating that the drop entirely depends on the quantisation. We also performed a comparison between our model and ChipNet on FPGA. The main advantage of ChipNet in speed is that it only uses one modality, so it has a smaller network structure. However, LiDAR-based free space detection cannot be applied in urban road scenes. In Figure , we demonstrate some detection results of the FPGA model. The performance of this model is hardly affected by lightweight processing and can provide quite good detection results.
Figure 6. Examples of detection results by FPGA.

Table 3. 8-Bit quantised results on FPGA.
FPGA implementation: We used a independent FPGA platform to run our model. All data were stored in Double Data Rate SDRAM (DDR) in advance through the ARM core on the platform, and the FPGA program run through the start signal sent by the arm core. The ARM core will not participate in the whole inference process. It only receives the final output result. System clock frequency is set to 300 MHz. The resource usage of our proposed neural network is listed in . We illustrate the performance of the FPGA implemented model in .
Table 4. Resource usage on the FPGA implementation.
Table 5. Performance evaluation of FPGA inference.
5. Conclusion
In this paper, we propose a lightweight multi-modal free-space detection network suitable for the FPGA platform by simplifying the network structure according to the MISD design of FPGA. The network uses ResNet-50 as the backbone and U-net as the segmentation head and only contains two convolution operators, convolution and
convolution, which fully uses computing resources on the FPGA chip. Meanwhile, the size of the intermediate results is precisely controlled so that the algorithm can perform multiple batches of parallel processing inside the FPGA, avoiding the delay caused by external data exchange. We adopt concatenation as the feature fusion method, which effectively maintains the complexity of the network and the feature extraction ability. Then we prune this lightweight network with two strategies. The first is the encoder pruning according to the rank of each modal feature map. Layers are pruned on each modality separately to remove the convolution kernels with weak feature extraction capabilities and make the network sparse. The second is the decoder pruning, using l1-norm as the pruning function. Since the scale factors in the encoder and decoder networks are alternately optimised, the independence of the multi-modal features is guaranteed. Finally, in order to facilitate the convenient and rapid model deployment on the FPGA platform, we use a mature quantisation method on the pruned lightweight model to convert 32-bit floating-point tensors into 8-bit fixed-point tensors for calculation. The size of the model is reduced to a quarter. The theoretical calculation peak of the chip can be increased by four times because of the improvement of the throughput and the delay. In a common autonomous driving platform, the period of sensors is 100 ms, while the running time of this road perception algorithm is 16 ms. Sufficient time resources are reserved for the following tasks (planning, control, etc.), which is essential in building a real-time autonomous driving system.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Badrinarayanan, V., Kendall, A., & Cipolla, R. (2017). Segnet: A deep convolutional encoder–decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(12), 2481–2495. https://doi.org/10.1109/TPAMI.34
- Bai, L., Lyu, Y., & Huang, X. (2020). Roadnet-rt: High throughput CNN architecture and SOC design for real-time road segmentation. IEEE Transactions on Circuits and Systems I: Regular Papers, 68(2), 704–714. https://doi.org/10.1109/TCSI.8919
- Bai, X., Wang, X., Liu, X., Liu, Q., Song, J., Sebe, N., & Kim, B. (2021). Explainable deep learning for efficient and robust pattern recognition: A survey of recent developments. Pattern Recognition, 120, Article ID 108102. https://doi.org/10.1016/j.patcog.2021.108102
- Caltagirone, L., Bellone, M., Svensson, L., & Wahde, M. (2019). LIDAR–camera fusion for road detection using fully convolutional neural networks. Robotics and Autonomous Systems, 111, 125–131. https://doi.org/10.1016/j.robot.2018.11.002
- Carreira-Perpinán, M. A., & Idelbayev, Y. (2018). ‘Learning-compression’ algorithms for neural net pruning. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 8532–8541). Salt Lake City, USA.
- Chen, L. C., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L. (2017). Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(4), 834–848. https://doi.org/10.1109/TPAMI.2017.2699184
- Chen, X., Wang, Y., Zhang, Y., Du, P., Xu, C., & Xu, C. (2020). Multi-task pruning for semantic segmentation networks. arXiv preprint arXiv:2007.08386.
- Chen, Z., & Chen, Z. (2017). RBNet: A deep neural network for unified road and road boundary detection. In International conference on neural information processing (pp. 677–687). Guangzhou, China.
- Chen, Z., Zhang, J., & Tao, D. (2019). Progressive lidar adaptation for road detection. IEEE/CAA Journal of Automatica Sinica, 6(3), 693–702. https://doi.org/10.1109/JAS.6570654
- Cordts, M., Rehfeld, T., Schneider, L., Pfeiffer, D., Enzweiler, M., Roth, S., Pollefeys, M., & Franke, U. (2017). The stixel world: A medium-level representation of traffic scenes. Image and Vision Computing, 68, 40–52. https://doi.org/10.1016/j.imavis.2017.01.009
- Couprie, C., Farabet, C., Najman, L., & LeCun, Y. (2013). Indoor semantic segmentation using depth information. arXiv preprint arXiv:1301.3572.
- Dubey, A., Chatterjee, M., & Ahuja, N. (2018). Coreset-based neural network compression. In Proceedings of the European conference on computer vision (ECCV) (pp. 454–470). Munich, Germany.
- Eigen, D., & Fergus, R. (2015). Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE international conference on computer vision (pp. 2650–2658). Santiago, Chile.
- Fan, R., Wang, H., Cai, P., & Liu, M. (2020). SNE-RoadSeg: Incorporating surface normal information into semantic segmentation for accurate freespace detection. In European conference on computer vision (pp. 340–356).
- Fritsch, J., Kuehnl, T., & Geiger, A. (2013). A new performance measure and evaluation benchmark for road detection algorithms. In 16th international IEEE conference on intelligent transportation systems (ITSC 2013) (pp. 1693–1700). Hague, Netherland.
- Fu, J., Liu, J., Tian, H., Li, Y., Bao, Y., Fang, Z., & Lu, H. (2019). Dual attention network for scene segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3146–3154). Long Beach, USA.
- Gu, S., Yang, J., & Kong, H. (2021). A cascaded LiDAR-camera fusion network for road detection. In 2021 IEEE international conference on robotics and automation (ICRA) (pp. 13308–13314). Xian, China.
- Guo, Y., Yao, A., & Chen, Y. (2016). Dynamic network surgery for efficient DNNs. Advances in Neural Information Processing Systems, 29, 1379–1387.
- Gupta, S., Girshick, R., Arbeláez, P., & Malik, J. (2014). Learning rich features from RGB-D images for object detection and segmentation. In European conference on computer vision (pp. 345–360). Zurich, Switzerlan.
- Han, S., Mao, H., & Dally, W. J. (2015). Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149.
- Han, S., Pool, J., Tran, J., & Dally, W. (2015). Learning both weights and connections for efficient neural network. Advances in Neural Information Processing Systems, 28, 1135–1143.
- Han, X., Lu, J., Zhao, C., You, S., & Li, H. (2018). Semisupervised and weakly supervised road detection based on generative adversarial networks. IEEE Signal Processing Letters, 25(4), 551–555. https://doi.org/10.1109/LSP.2018.2809685
- Hazirbas, C., Ma, L., Domokos, C., & Cremers, D. (2016). FuseNet: Incorporating depth into semantic segmentation via fusion-based cnn architecture. In Asian conference on computer vision (pp. 213–228). Taipei, China.
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778). Las Vegas, USA.
- He, W., Wu, M., Liang, M., & Lam, S. K. (2021). CAP: Context-aware pruning for semantic segmentation. In Proceedings of the IEEE/CVF winter conference on applications of computer vision (pp. 960–969).
- He, Y., Kang, G., Dong, X., Fu, Y., & Yang, Y. (2018). Soft filter pruning for accelerating deep convolutional neural networks. arXiv preprint arXiv:1808.06866.
- He, Y., Liu, P., Wang, Z., Hu, Z., & Yang, Y. (2019). Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 4340–4349). Long Beach, USA.
- He, Y., Zhang, X., & Sun, J. (2017). Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE international conference on computer vision (pp. 1389–1397). Venice, Italy.
- Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., & Adam, H. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861.
- Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700–4708). Hawaii, USA.
- Huang, Q., Zhou, K., You, S., & Neumann, U. (2018). Learning to prune filters in convolutional neural networks. In 2018 IEEE winter conference on applications of computer vision (WACV) (pp. 709–718). Nevada, USA.
- Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Krishnamoorthi, R. (2018). Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv:1806.08342.
- Li, H., Kadav, A., Durdanovic, I., Samet, H., & Graf, H. P. (2016). Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710.
- Li, H., Yue, X., Wang, Z., Chai, Z., Wang, W., Tomiyama, H., & Meng, L. (2022). Optimizing the deep neural networks by layer-wise refined pruning and the acceleration on FPGA. Computational Intelligence and Neuroscience, 2022. https://doi.org/10.1155/2022/8039281
- Li, X., Zhong, Z., Wu, J., Yang, Y., Lin, Z., & Liu, H. (2019). Expectation–maximization attention networks for semantic segmentation. In Proceedings of the IEEE international conference on computer vision (pp. 9167–9176). Seoul, Korea.
- Li, Z., Gan, Y., Liang, X., Yu, Y., Cheng, H., & Lin, L. (2016). LSTM-CF: Unifying context modeling and fusion with LSTMs for RGB-D scene labeling. In European conference on computer vision (pp. 541–557). Amsterdam, Netherlands.
- Lin, D., Fidler, S., & Urtasun, R. (2013). Holistic scene understanding for 3D object detection with RGBD cameras. In Proceedings of the IEEE international conference on computer vision (pp. 1417–1424). Sydney, Australia.
- Lin, M., Ji, R., Wang, Y., Zhang, Y., Zhang, B., Tian, Y., & Shao, L. (2020). HRank: Filter pruning using high-rank feature map. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 1529–1538). Seattle, USA.
- Lin, S., Ji, R., Yan, C., Zhang, B., Cao, L., Ye, Q., Huang, F., & Doermann, D. (2019). Towards optimal structured cnn pruning via generative adversarial learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 2790–2799). Long Beach, USA.
- Liu, Z., Li, J., Shen, Z., Huang, G., Yan, S., & Zhang, C. (2017). Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE international conference on computer vision (pp. 2736–2744). Venice, Italy.
- Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3431–3440). Boston, USA.
- Luo, J. H., Wu, J., & Lin, W. (2017). ThiNet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE international conference on computer vision (pp. 5058–5066). Venice, Italy.
- Lyu, Y., Bai, L., & Huang, X. (2018). Chipnet: Real-time lidar processing for drivable region segmentation on an FPGA. IEEE Transactions on Circuits and Systems I: Regular Papers, 66(5), 1769–1779. https://doi.org/10.1109/TCSI.8919
- Molchanov, P., Tyree, S., Karras, T., Aila, T., & Kautz, J. (2016). Pruning convolutional neural networks for resource efficient inference. arXiv preprint arXiv:1611.06440.
- Mukherjee, S., & Guddeti, R. M. R. (2014). A hybrid algorithm for disparity calculation from sparse disparity estimates based on stereo vision. In 2014 international conference on signal processing and communications (SPCOM) (pp. 1–6). Bangalore, India.
- Park, S. J., Hong, K. S., & Lee, S. (2017). RDFNeT: RGB-D multi-level residual feature fusion for indoor semantic segmentation. In Proceedings of the IEEE international conference on computer vision (pp. 4980–4989). Venice, Italy.
- Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional networks for biomedical image segmentation. In International conference on medical image computing and computer-assisted intervention (pp. 234–241). Munich, Germany.
- Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- Suau, X., Zappella, L., Palakkode, V., & Apostoloff, N. (2018). Principal filter analysis for guided network compression. arXiv preprint arXiv:1807.10585 2.
- Sun, J. Y., Kim, S. W., Lee, S. W., Kim, Y. W., & Ko, S. J. (2019). Reverse and boundary attention network for road segmentation. In Proceedings of the IEEE international conference on computer vision workshops (pp. 0–0). Seoul, Korea.
- Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1–9). Boston, USA.
- Teichmann, M., Weber, M., Zoellner, M., Cipolla, R., & Urtasun, R. (2018). MultiNet: Real-time joint semantic reasoning for autonomous driving. In 2018 IEEE intelligent vehicles symposium (IV) (pp. 1013–1020). Suzhou, China.
- Tung, F., & Mori, G. (2018). CLIP-Q: Deep network compression learning by in-parallel pruning-quantization. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7873–7882). Salt Lake, USA.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998–6008). Long Beach, USA.
- Wang, C., Bai, X., Wang, X., Liu, X., Zhou, J., Wu, X., Li, H., & Tao, D. (2020). Self-supervised multiscale adversarial regression network for stereo disparity estimation. IEEE Transactions on Cybernetics, 51(10), 4770–4783. https://doi.org/10.1109/TCYB.2020.2999492
- Wang, C., Wang, X., Zhang, J., Zhang, L., Bai, X., Ning, X., Zhou, J., & Hancock, E. (2022). Uncertainty estimation for stereo matching based on evidential deep learning. Pattern Recognition, 124, Article ID 108498. https://doi.org/10.1016/j.patcog.2021.108498
- Wang, D., Zhou, L., Zhang, X., Bai, X., & Zhou, J. (2018). Exploring linear relationship in feature map subspace for convnets compression. arXiv preprint arXiv:1803.05729.
- Wang, H., Fan, R., Sun, Y., & Liu, M. (2021). Dynamic fusion module evolves drivable area and road anomaly detection: A benchmark and algorithms. IEEE Transactions on Cybernetics, 10750–10760. https://doi.org/10.1109/TCYB.2021.3064089
- Wang, X., Girshick, R., Gupta, A., & He, K. (2018). Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7794–7803). Boston, USA.
- Xiong, S., Wu, G., Fan, X., Feng, X., Huang, Z., Cao, W., Zhou, X., Ding, S., Yu, J., Wang, L., & Shi, Z. (2021). MRI-based brain tumor segmentation using FPGA-accelerated neural network. BMC Bioinformatics, 22(1), 1–15. https://doi.org/10.1186/s12859-021-04347-6
- Yamamoto, K., & Maeno, K. (2018). PCAS: Pruning channels with attention statistics for deep network compression. arXiv preprint arXiv:1806.05382.
- Yan, C., Pang, G., Bai, X., Liu, C., Ning, X., Gu, L., & Zhou, J. (2021). Beyond triplet loss: Person re-identification with fine-grained difference-aware pairwise loss. IEEE Transactions on Multimedia, 24, 1665–1677. https://doi.org/10.1109/TMM.2021.3069562
- Ye, J., Lu, X., Lin, Z., & Wang, J. Z. (2018). Rethinking the smaller-norm-less-informative assumption in channel pruning of convolution layers. arXiv preprint arXiv:1802.00124.
- Yu, R., Li, A., Chen, C. F., Lai, J. H., Morariu, V. I., Han, X., Gao, M., Lin, C. Y., & Davis, L. S. (2018). NISP: Pruning networks using neuron importance score propagation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 9194–9203). Salt Lake, USA.
- Zhang, J., Yang, T., Li, Q., Zhou, B., Yang, Y., Luo, G., & Shi, J. (2021). An FPGA-based neural network overlay for ADAS supporting multi-model and multi-mode. In 2021 IEEE international symposium on circuits and systems (ISCAS) (pp. 1–5). Daegu, Korea.
- Zhang, T., Ye, S., Zhang, K., Tang, J., Wen, W., Fardad, M., & Wang, Y. (2018). A systematic DNN weight pruning framework using alternating direction method of multipliers. In Proceedings of the European conference on computer vision (ECCV) (pp. 184–199). Munich, Germany.
- Zhang, X., Yang, Y., Li, T., Zhang, Y., Wang, H., & Fujita, H. (2021). CMC: A consensus multi-view clustering model for predicting Alzheimer's disease progression. Computer Methods and Programs in Biomedicine, 199, Article ID 105895. https://doi.org/10.1016/j.cmpb.2020.105895
- Zhou, L., Bai, X., Liu, X., Zhou, J., & Hancock, E. R. (2020). Learning binary code for fast nearest subspace search. Pattern Recognition, 98, Article ID 107040. https://doi.org/10.1016/j.patcog.2019.107040
- Zhuang, Z., Tan, M., Zhuang, B., Liu, J., Guo, Y., Wu, Q., Huang, J., & Zhu, J. (2018). Discrimination-aware channel pruning for deep neural networks. Advances in Neural Information Processing Systems, 31, 875–886.
- Zhuo, H., Qian, X., Fu, Y., Yang, H., & Xue, X. (2018). SCSP: Spectral clustering filter pruning with soft self-adaption manners. arXiv preprint arXiv:1806.05320.