
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Speech emotion recognition (SER) has become an increasingly attractive machine learning task for domain applications. It aims to improve the discriminative capacity of speech emotion utilising a certain type of features (e.g. MFCC, Spectrograms, Wav2vec2) or multi-type combination features. However, the potential of acoustic-related deep features is frequently overlooked in existing approaches that rely solely on a single type of feature or employ a basic combination of multiple feature types. To address this challenge, a multi-level acoustic feature cross-fusion approach is proposed, aiming to compensate for missing information between various features. It helps to enhance the SER performance by integrating different types of knowledge through the cross-fusion mechanism. Moreover, multi-task learning is utilised to share useful information through gender recognition, which can also obtain multiple common representations in a fine-grained space. Experimental results show that the fusion approach can capture the inner connections between multilevel acoustic features to refine the knowledge. The SOTA results were obtained under the same experimental conditions.
1. Introduction
Speech emotion recognition (SER) involves analysing emotional features in speech to simulate and understand human emotion perception and recognition. SER holds significant potential for various practical applications, including but not limited to automatic telephone services, smart vehicles, and voice assistants. In automatic telephone services, it is essential to not only analyse the linguistic content of a customer's speech but also accurately ascertain their emotional state. This is because the emotional state of a customer can greatly influence their satisfaction with the service provided and may inform decisions regarding the necessity of transferring the customer to human assistance. However, accurately recognising emotions contained within speech is a challenging task that requires sophisticated techniques and models.
Effective feature extraction is crucial for accurately recognising the emotion conveyed by speech. Therefore, most of the research in the field of SER concentrates on developing more effective features for this task. In the past decade, researchers have used manual features such as energy, over-zero pitch, Mel-scale Frequency Cepstral Coefficients (MFCC), and tiger energy operator for SER. Most contemporary researchers use speech spectrograms as input features for SER. They leverage deep learning techniques to improve performance in this domain. Speech spectrograms are representations of speech signals in two-dimensional form. Convolutional Neural Networks (CNNs) have shown exceptional performance in image processing. Therefore, an increasing number of approaches have been developed for SER using CNNs (Cummins et al., Citation2017). Due to the high degree of sequentiality and temporal dependency of sound signals, CNNs are not well suited for processing such signals. To address this challenge, Long Short-Term Memory (LSTM) networks were introduced to improve model performance by learning hidden temporal features and recognising emotions within speech sequences. CNN and LSTM are examples of neural networks that can perform both feature extraction from speech signals and end-to-end model construction. The end-to-end model can directly generate sentiment labels from either raw or processed speech features as input. In Bakhshi et al. (Citation2020), an end-to-end approach was adopted where the original speech signal is used as input, and the emotion recognition results were directly outputted from the model. Both traditional manual feature extraction and deep learning feature extraction through neural networks such as CNN and LSTM rely on a single speech feature. While they may simplify the complexity of SER systems to a certain extent, they also have limitations in capturing multidimensional emotional information in speech signals. In order to enhance the accuracy of Speech Emotion Recognition, it is crucial to investigate supplementary techniques for feature extraction and refinement.
To overcome this limitation, researchers have explored the fusion of information from multiple modalities for emotion recognition. In the case of SER, information from three modalities (speech, text, and video) were utilised, and their features were fused using a multimodal Transformer (Tsai et al., Citation2019), leading to superior recognition accuracy. Additionally, Cai et al. (Citation2021)employed a multi-task learning approach, utilising the Wav2vec2.0 pre-training model, and designed a speech transcription auxiliary task to facilitate training of the emotion recognition task. The approach yielded promising recognition results. However, both approaches shared a commonality: the use of two or even three modalities of information. For example, Tsai et al. (Citation2019) employed information from three modalities: speech, text, and video, while Cai et al. (Citation2021) used data from both speech and text modalities. Incorporating multiple modalities into the SER task can enhance its accuracy, but this enhancement comes at the cost of increased model complexity. Moreover, obtaining and labelling multimodal data is more challenging than single-modality data.
For the speech unimodal SER task, Zhang et al. (Citation2022) has utilised a multi-scale deep LSTM to capture the temporal dependence of all speech spectrogram segments to enhance sentiment recognition. Zou et al. (Citation2022) conducted a study to investigate the effect of various levels of speech features on SER performance, such as MFCC and other features. The study employed a simple fusion of two out of three features to validate their complementarity, following with noticeable shortcomings. On the one hand, Prematurely compressing the dimensions of the three features results in the loss of information in the time dimension, preventing the joint attention mechanism from capturing the temporal association of the three features. On the other hand, implementing the co-attention mechanism solely through matrix multiplication fails to reflect the nonlinear correlation between the three features (Li et al., Citation2020). In contrast to the initial three features, the above simple fusion of input features loses some critical information, which affects the classification accuracy. Inspired by this work, an enhanced method for cross-fusion of multi-level acoustic features is proposed. The contributions of this method are as follows:
At various time points, various levels of feature representation are examined. The capture of their inherent links contributes to the filling in of missing information in the speech emotion recognition challenge.
Taking advantage of multi-task learning, a gender recognition task is introduced to boost the performance of the main SER task with additional auxiliary information.
Experiments have demonstrated that improved recognition accuracy and state-of-the-art (SOTA) results can be achieved in comparison to single features when multi-level feature cross-fusion and assisted multi-tasking are employed.
The remainder of this paper is structured as follows: Section 2 provides an overview of existing research on speech-emotion recognition systems. In Section 3, the proposed model is presented. Section 4 describes the experiments conducted to evaluate the model's performance. The results and analysis are presented in Section 5. Finally, Section 6 concludes the paper.
2. Related work
The main steps of SER include speech signal preprocessing, feature extraction, and emotion classification. Extracting effective features has a huge impact on the results of SER. In the subsequent section, we will delve into the developmental trajectory of SER and showcase some key literature that has served as inspiration for the present work.
In the feature extraction stage, features that can reflect the speaker's emotional state need to be extracted from the speech signal, and these features are divided into manual features and deep learning features. Prosodic features do not affect the recognition of speech semantic information, but determine the fluency, naturalness and clarity of speech. Rao et al. (Citation2013) extracted the global features and local features corresponding to prosodic feature duration, fundamental frequency, and energy. They used SVM to classify seven emotions on the EMO-DB corpus and achieved an average recognition performance of 64.38%. Sheikhan et al. (Citation2015) employed a hybrid approach that incorporates traditional speech features for constructing feature sets, alongside the utilisation of recurrent neural networks as classifiers. This methodology has been showcased to exhibit a streamlined structure and superior performance on Berlin emotional database. The voice quality feature is a subjective evaluation index of speech. Through the evaluation of voice quality, the physiological and psychological information of the speaker can be obtained and the emotional state can be distinguished. In Kumbhar and Bhandari (Citation2019), MFCC was utilised to extract 39 coefficients for the purpose of emotion recognition. An LSTM model was implemented to carry out the recognition task. The accuracy of the recognition task was evaluated using Receiver Operating Characteristic (ROC) curve analysis. During the training phase, the accuracy achieved was lower compared to that of the test phase. The average accuracy of the test data was found to be 84.81%.
With the development of deep learning techniques, SER methods based on deep learning have gradually become mainstream. Different variants of neural networks have been used for SER tasks. Many researchers worked on extracting high-level features from the speech spectrogram. CNNs were used to extract high-level features from spectrograms (Badshah et al., Citation2017). Ren et al. (Citation2018) used 2D-CNNs to extract spatial information from extracted spectral maps for sentiment recognition. The model presented in (Latif et al., Citation2019) utilised parallel convolutional layers of CNNs to manage distinct temporal resolutions in feature extraction blocks. This model was then trained using LSTM-based classification networks to identify emotions. The proposed model captured both short-term and long-term interactions, thereby improving the performance of SER systems. A different CNN framework called DSCNN was implemented in Wani et al. (Citation2020), which utilised strides instead of pooling layers for emotion recognition. In Zhao et al. (Citation2020), an RSSGAN method was proposed, which improved the robustness of the model through distribution smoothing techniques and could be used for speech emotion recognition.
As transformer models have demonstrated significant achievements in NLP, researchers have attempted to apply them to SER. Tarantino et al. (Citation2019) improved Speech Emotion Recognition (SER) using a transformer encoder with self-attention. Their experiments on various datasets showed that the self-attention mechanism boosted the model, particularly for longer speech segments. The study concluded that this SER model outperformed traditional ones, highlighting the significant impact of attention heads. However, it lacked a detailed explanation of self-attention and comprehensive dataset analysis. As Transformer has achieved greater results in SER, some researchers have focused on multimodal SER. Tsai et al. (Citation2019) used information from three modalities: speech, text, and video. The features from the three different modalities have been fused by a multimodal Transformer module for sentiment classification. The final results were presented in CMU-MOSI (Zadeh et al., Citation2016), CMU-MOSEI (Zadeh et al., Citation2018), and IEMOCAP (Busso et al., Citation2008), all three datasets, have achieved significant breakthroughs. Han et al. (Citation2021)proposed an emotion recognition method based on cross-modal emotion embedding, which can handle both text and speech inputs simultaneously and utilise a shared emotion embedding for SER. The method achieved excellent results on multiple datasets. While multimodal SER was identified with high accuracy, SER for single modal was equally relevant for research. Zhang et al. (Citation2022) took the approach of convolving a multi-scale deep LSTM. This approach was utilised to capture the temporal dependence of all speech spectrogram segments. It was experimentally shown to increase the feature richness and improve sentiment recognition. Most of the unimodal SER studies used the speech spectrogram as the signal input and worked on extracting more effective features from the speech spectrogram. Alternatively, an end-to-end SER system was directly used, where the speech signal was input and the recognition results were directly output.
A single feature only expresses the speech emotion information from a certain aspect, and cannot represent the speech emotion well. Therefore, multiple single features can be fused. This can further improve the SER performance without using multimodal features and system complexity. Multi-task learning has been widely adopted as a promising approach in the field of emotional speech conversion, with researchers such as Kim et al. (Citation2020) and others utilising this methodology. It enables models to effectively address both emotion con-version and text-to-speech synthesis (TTS) tasks simultaneously, leading to enhanced overall performance. Chen et al. (Citation2023) introduced a unified framework named IIM, leveraging the Information Interaction Mechanism (IIM) framework to amalgamate subtasks. This approach effectively mitigated the learning error rate. Ye et al. (Citation2023) presented the Attention-Based Depthwise Parameterized Convolutional Gated Recurrent Unit (ABDPCGRU) model, validated through a comprehensive experiment conducted on the SEED and SEED-IV datasets. Mao et al. (Citation2023) proposed SCAR-NET, an enhanced convolutional neural network designed for extracting emotional features from speech signals and enabling accurate classification. Experimental results demonstrate a noteworthy accuracy of 96.45%, 83.13%, and 89.93% on the EMODB, SAVEE, and RAVDESS datasets, respectively. Furthermore, Zhao et al. (Citation2023) have introduced an innovative pri-vacy-enhanced method for sentiment/emotion recognition (SER), specifically de-signed to withstand attribute inference attacks. This approach aims to safeguard data privacy when describing emotions. Experimental findings from their study demon-strate a significant reduction in the gender prediction model's attack capability, bring-ing it down to chance levels, all while maintaining satisfactory SER performance.
In this study, a SER method is proposed, drawing inspiration from the works of Tsai et al. (Citation2019) and Zou et al. (Citation2022). The method is based on the cross-fusion of multi-level acoustic features. A middle fusion strategy is employed to combine the three features, and the cross-fusion module is designed to effectively capture their temporal associations. A cross-fusion module of multi-level acoustic features is introduced, providing potential cross-level adaptation. By directly attending to the features from other levels to fuse multi-level information, the final features are more comprehensive.
3. Proposed method
In this section, a detailed description of the SER system is provided, focusing on the cross-fusion of multi-level acoustic features. The general structure of our proposed method is illustrated in Figure , and the algorithm flow is shown in Algorithm 1. Our method consists of four main parts: pre-processing, extraction of different levels of features, cross-fusion, and emotion classification. Each of these parts is discussed in detail in the following subsections.
Figure 1. The framework of multi-level feature cross-fusion for SER.
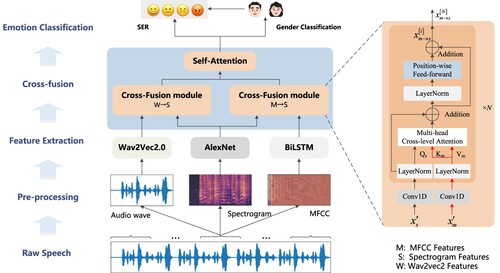
3.1. Pre-processing
Before further processing, it is common practice to subject speech signals to several preprocessing operations aimed at improving their quality and the accuracy of classification. In this study, the librosa library (McFee et al., Citation2015) is utilised to frame the speech signal, which results in the extraction of the speech segments for obtaining the wav2vec2 features. Subsequently, a corresponding library function is invoked to extract the MFCC of the framed speech segments, thereby obtaining
. In a similar vein, the spectrogram
is obtained through the STFT and the spectrogram plotting function. It is noteworthy that the dimensions of the above three preprocessed signals are denoted by
,
, and
, respectively.

3.2. Extraction of different levels of features
Three distinct levels of acoustic features are employed in our research, namely, MFCC based on prior human knowledge, advanced spectrogram based on deep learning techniques, and Wav2vec2 features which encompass features of speech in both frequency and time domains. The MFCC is processed by a bidirectional LSTM with a dropout rate of 0.5, and the formula is shown below:
(1)
(1) where
.
The spectrograms provide a visual representation of the frequency components of a speech signal, which facilitates the analysis of its pitch, intonation, and other acoustic characteristics. Being essentially a 2D image, a pre-trained AlexNet can be utilised for processing and reshaping spectrograms, yielding results as shown below,
(2)
(2) where
.
The Wav2vec2 is an advanced speech model that employs self-supervised learning. The model undergoes pre-training on a vast corpus of examples to acquire robust speech signal representations. These representations can be fine-tuned for different downstream SER tasks. The raw audio segments are directly fed into the pre-trained Wav2vec2 model, resulting in the following target outputs,
(3)
(3) where
.
3.3. Cross-fusion
The three types of acoustic features are derived from distinct levels and emphasise different aspects. The spectrogram comprises both time-domain and frequency-domain features, while MFCC emphasises the frequency-domain features and Wav2vec2 features are centred on time-domain features (Chen & Rudnicky, Citation2021). A cross-fusion mechanism is employed to adaptively merge two features into the third feature, yielding a more comprehensive feature for the classification task. In the baseline (Zou et al., Citation2022), the obtained features were flattened after processing the MFCC and spectrogram, which resulted in some loss of effective information in the time domain.
In this work, a cross-fusion module is introduced, as illustrated in Figure , to adaptively fuse three different levels of features. First, one-dimensional temporal convolutions are applied to the three features extracted from the previous stage, resulting in the following.
(4)
(4) where
,
,
. This part aim to ensure that each element of the input sequence has sufficient perception of its neighbouring elements.
After that, the convolved features are fed into the cross-fusion module. Before the introduction of the cross-fusion module, the discussion will focus on how features from different levels can be fused. Inspired by Tsai et al. (Citation2019), the crossmodal transformer allows for potential adaptation between two modalities through its cross-fusion module, which forms its core. Let and
be the spectrogram and MFCC feature sequences, respectively, with sizes
and
.
Here, and
denote the sequence length and feature dimension, respectively. As can be seen from Figure ,
and
have the same length
, but are represented in the feature space of
. Specifically, for the kth head,
is multiplied by the transpose of
, and the item
in it represents the degree of attention given by the ith time step of
to the time step of
. As shown in Equation (Equation5
(5)
(5) ) below,
(5)
(5) The purpose of dividing by the root sign
is to ensure that the output value will not be too large, thereby avoiding the disappearance of the gradient; the purpose of the softmax operation is to map the previous output to between 0-1. So,
is the weighted summation of
at the ith time step, with weights determined by the ith line in softmax
.
is obtained by concatenating
along the feature dimension. The structure depicted in Figure is referred to as multi-head cross-level attention with h heads.
Figure 2. The structure of multi-head cross-level attention for the cross-fusion module.
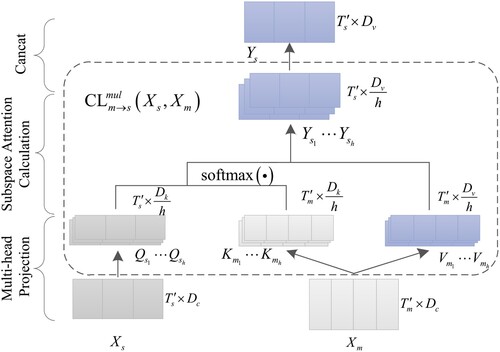
As shown on the right side of Figure , each cross-fusion module consists of N layers of cross-level attention blocks. Each layer of the cross-fusion block consists of three normalisation layers, one multi-head cross-level attention layer, and one position-wise feed-forward layer. Formally, for layers,
(6)
(6) Let's denote s as spectrogram features, m denotes MFCC features, and w denotes wav2vec2 features. where
is a position-wise feed-forward sublayer parametrised by θ, and
means a multi-head version of
at layer i. In particular, the
should be divisible by the number of heads. LN means normalisation layer.
The cross-fusion part consists of two cross-fusion modules that implement an adaptive fusion of MFCC features and wav2vec2 features to spectrogram features.
Finally, the two sets of fused features are stitched together along the feature size, and then input into the self-attention layer to obtain the final fused features.
(7)
(7) In this step, the fusion features acquired in the preceding section are concatenated to generate a comprehensive feature with a dimensionality of
. Our model includes an important self-attention layer. It helps the model better understand the relationship between different positions in the input feature sequence. The comprehensive features are fed into the self-attention layer for integration processing, and the last element is utilised for emotion classification.
3.4. Emotion classification
The target categories for emotion and gender are denoted by variables y and g, respectively, with and
representing the predicted outcomes. The interrelationship between these variables can be formally articulated using the subsequent mathematical expression,
(8)
(8) Among these, f and
denote frequently employed linear classifiers. Cross-entropy loss functions are employed for both emotion classification and gender recognition, and the two sets of cross-entropy loss values are subsequently aggregated through a linear combination to formulate the ultimate objective function of the model. In this function, α serves as an adaptively tuned coefficient, initially set to 0.1.
(9)
(9)
4. Experiment
In this section, our proposed method is validated on the IEMOCAP (Busso et al., Citation2008) dataset. The dataset processing and the audio sources used will first be described. Subsequently, the experimental setup and employed validation strategy are explicated. The configuration parameters for the input and output of each module in our algorithmic model are outlined in Table .
Table 1. The shape settings of the input and output of each module of cross-fusion.
4.1. Datasets
The IEMOCAP database is chosen for our experiments, recorded by ten different actors and providing audio, video, transcription and motion capture information. In addition, it contains high-frequency recorded audio data (16 kHz sampling rate) including gender, nine emotions, and improvised and scripted speech. Following the work of others (Guo et al., Citation2021; Wu et al., Citation2021), the merging of “happy” and “excited” into the “happy” category is carried out, and consideration is given to 5531 sounds from voices expressing four emotions: anger, sadness, happiness, and neutrality.
To more accurately evaluate the performance of our models, 5-fold cross-validation and 10-fold cross-validation strategies are employed to test our models. Additionally, we use two common metrics: Weighted Accuracy (WA) and Unweighted Accuracy (UA). The model performs better when these two metrics have higher values.
4.2. Experimental setup
Our objective is to segment each speech clip in the IEMOCAP dataset into 3-second segments and pad them with zeros as needed to ensure equal length. The resulting segmented data will be collectively analysed to determine the final prediction for that utterance.
To leverage different levels of speech information, three distinct acoustic features are employed: MFCC, speech spectrogram, and Wav2Vec2 features. The MFCC is a 40-dimensional HTK-style Mel frequency feature extracted from the raw speech clips using the librosa library, which accounts for human auditory perception. The speech spectrogram is generated using a series of Hamming windows with a step size of 10ms and a window length of 40ms. Each window is treated as a frame and transformed into the frequency domain via a DFT of length 800. The first 200 DFT points are used as spectral features input to the subsequent network, resulting in a spectrogram image of size 300*200 for each audio clip. Wav2Vec2 features are obtained from a pre-trained transformer-based Wav2vec2.0 network, capturing the deep temporal features of speech, similar to multi-task-based SER methods (Cai et al., Citation2021).
To ensure a fair comparison, our SER system is implemented in the same experimental environment as the baseline model, and some hyperparameters are adjusted as needed. We employ the AdamW optimiser with a learning rate of 1e-5, set the training batch size to 32, and implement early stopping after 15 epochs. Due to GPU limitations, we are unable to utilise the same batch size as the baseline (Zou et al., Citation2022), but all other parameters are maintained. Each run utilises two NVIDIA GeForce RTX 2080 Ti GPUs with 12GB of memory.
5. Results and analysis
In this section, we detail the performance of the model and design ablation experiments to verify the effectiveness of the cross-fusion module. We also design the final normalised confusion matrix to visualise the effect of our method.
5.1. Performance
In this section, we present the results obtained using our proposed method. As presented in Table , our method achieved a weighted accuracy (WA) and unweighted accuracy (UA) of 70.98% and 71.76%, respectively, in 5-fold cross-validation. Similarly, in 10-fold cross-validation, our method achieved a WA and UA of 72.04% and 73.26%, respectively. These results illustrate an enhancement of approximately 2% to 3% across all four metrics when compared to the baseline results obtained using our experimental setup. It is noteworthy that the comparative experimental results of the researched methods were exclusively derived from assessments conducted on the IEMOCAP dataset.
Table 2. Performance of different methods for emotion recognition on the dataset IEMOCAP using 5-fold and 10-fold cross-validation. The scores of WA and UA are reported.
It is important to note that our method was evaluated using rigorous cross-validation techniques, which helps to ensure the robustness and reliability of our results. These findings suggest that our proposed method is effective in accurately classifying the target dataset, and has the potential to improve the performance of existing classification models.
Table presents the classification report resulting from the cross-fusion evaluation applied to the IEMOCAP dataset. It outlines the precision, recall, and F1_score metrics for the neural network model's recognition of each emotion category. This report offers a comprehensive insight into the efficacy of emotion classification for each category, as well as the overall model performance. Alongside the classification report, a comparison is made between the actual emotion classification labels from the dataset and the labels predicted by the network model, leading to the generation of a confusion matrix. The confusion matrix visually represents the proportion of audio data correctly or incorrectly classified by the model. The horizontal axis denotes the predicted labels, while the vertical axis represents the actual labels. The intersections between each emotion category and others indicate the confusion rates among them. The diagonal values correspond to the recall rates for each emotion classification. From the confusion matrix shown in Figure , it can be observed that our model achieved higher accuracy in recognising the emotions of anger, happiness, and neutrality, as compared to the baseline results. However, the accuracy in recognising sadness was slightly lower than the baseline results. We speculate that the inadequate number of “sadness” samples in the dataset has resulted in the model learning fewer relevant features, leading to suboptimal prediction outcomes.
Figure 3. Final normalised confusion matrix: comparison of baseline's reproduced results and experimental results of the proposed fusion model under 10-fold cross-validation.
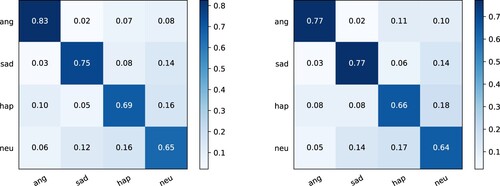
Table 3. The classification report of Cross-Fusion evaluated on IEMOCAP.
5.2. Ablation experiment
Our proposed method combines different levels of acoustic features through cross-fusion. Table presents the results of ablation experiments on the performance of these acoustic features under different combination modes. The first three rows show the emotion recognition results with single-level acoustic information: spectrogram, MFCC, and Wav2vec2 features. The results show that the emotion recognition performance of the Wav2vec2 features is better than that of the other two features. The fourth row represents the emotion recognition results obtained by concatenating the three levels of acoustic information.
Table 4. The table shows the results of the ablation study of cross-fusion on our model. The best results are highlighted in bold font.
In the table, “+” means feature splicing, and “C(A&B-¿C)” means cross-fusion of A-level features and B-level features and C-level features to obtain the final fusion feature C
. “⊕” indicates that two tasks are jointly trained. As can be seen, the performance of emotion recognition with the concatenated three-level acoustic features is better than that of using a single-level acoustic feature. This indicates that using multiple acoustic features simultaneously is effective for emotion recognition. Rows 5–7 present the results of using our proposed cross-fusion method to fuse the three levels of acoustic features. It can be observed that the experiments in which the MFCC and Wav2vec2 features are fused with the spectrogram feature using the cross-fusion method respectively, perform better than the other two methods.
We speculate that the reason for the observed results is due to the different levels and aspects emphasised by the three types of acoustic features. Spectrogram includes both temporal and frequency domain features (Chaurasiya, Citation2020), while MFCC emphasises frequency domain features (Zheng et al., Citation2001), and Wav2vec2 features to focus on temporal domain features (Baevski et al., Citation2020). Therefore, using spectrogram features as the base and fusing the other two types of features can lead to a more comprehensive set of fused features for classification tasks. However, using MFCC or Wav2vec2 features as the base and fusing spectrogram features can result in the loss of either temporal or frequency domain features, leading to poorer classification performance. This aligns with the findings derived from our experimental outcomes.
The ablation experiments demonstrated the effectiveness of the proposed cross-fusion method. As can be seen from the comparison between the data in rows 4 and 5 of the table, the cross-fusion method further optimised the feature data and achieved better results than directly concatenating the three features. The WA and UA were improved by 2.99% and 4.01%, respectively. The ablation experiment also validated the efficacy of utilising the gender recognition task as an auxiliary task to enhance system performance. As evident from the results in the 4th and 5th rows, as well as the 9th and 10th rows of the table, it is apparent that multi-task learning, whether utilising the cross-fusion method proposed in this article or simply concatenating features, has significantly improved performance compared to single-task learning.
5.3. Parameter sensitivity analysis
The Table displays the emotion recognition accuracy attained by our model under varying initial values of the parameter α. The relationship between the initial value of parameter α and the accuracy of gender recognition and emotion recognition exhibits distinct patterns. As the initial value of α increases, gender recognition accuracy shows α linear improvement, while emotion recognition accuracy initially remains relatively stable, then increases before eventually declining. A value of α equal to 0 corresponds to single-task learning, whereas an initial value of 0.1 yields the most favorable outcomes.
Table 5. The table displays the emotion recognition accuracy attained by our model under varying initial values of the parameter α.
This analysis suggests that when α is set to 0.01, the weight assigned to auxiliary tasks is too minimal. Consequently, the interference these tasks impose on the primary emotion recognition task outweighs their beneficial impact, resulting in a decrease in emotion recognition accuracy. Conversely, when α equals 0.1, the weight allocated to auxiliary tasks strikes a balance, effectively supplying information to the primary task, which leads to an increase in emotion recognition accuracy. Simultaneously, gender recognition accuracy for auxiliary tasks also reaches higher levels.
However, when α assumes a value of 1, the weights assigned to the auxiliary and primary tasks become equal. Notably, emotion recognition is a more intricate task than gender recognition, leading to a task prioritisation shift. Consequently, the final results reflect this phenomenon: gender recognition accuracy for auxiliary tasks reaches a high level of 95%, while emotion recognition accuracy for the primary task is only approximately 65%, which is lower than when α is set to 0.
6. Conclusion and future work
In this work, a cross-fusion of multi-level acoustic features method for SER is presented. We find that different preprocessing methods for obtaining features provide varying levels of emotional information, enhancing the diversity of SER tasks and facilitating the recognition of emotions. The experimental results show that the W&M-¿S method outperforms other cross-fusion techniques. This is due to the use of spectrogram features as the base feature and the fusion of the other two features through cross-level fusion, resulting in a more comprehensive fusion feature. The gender prediction task helps the SER primary task in learning more about additional information and achieving the SOTA results. It provides a new idea to promote the rapid development of SER.
In our future endeavors, we aim to incorporate features from additional modalities as supplementary tasks to enhance recognition accuracy. Furthermore, we plan to conduct a thorough investigation into the computational efficiency of our proposed model, exploring the viability of model compression and pruning for deployment in real-time applications.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Badshah, A. M., Ahmad, J., Rahim, N., & Baik, S. W. (2017). Speech emotion recognition from spectrograms with deep convolutional neural network. In International conference on platform technology and service (PlatCon) (pp. 1–5).
- Baevski, A., Zhou, Y., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 33, 12449–12460.
- Bakhshi, A., Wong, A. S. W., & Chalup, S. K. (2020). End-to-end speech emotion recognition based on time and frequency information using deep neural networks. In Proceedings of the 24th European conference on artificial intelligence (ECAI) (pp. 969–975).
- Busso, C., Bulut, M., Lee, C. C., Kazemzadeh, A., Mower, E., Kim, S., Chang, J. N., Lee, S., & Narayanan, S. S. (2008). IEMOCAP: Interactive emotional dyadic motion capture database. Language Resources and Evaluation, 42(4), 335–359. https://doi.org/10.1007/s10579-008-9076-6
- Cai, X., Yuan, J., Zheng, R., Huang, L., & Church, K. (2021). Speech emotion recognition with multi-task learning. In Proceedings of the 22nd annual conference of the international speech communication association (Interspeech) (pp. 4508–4512).
- Chaurasiya, H. (2020). Time-frequency representations: Spectrogram, cochleogram and correlogram. Procedia Computer Science, 167, 1901–1910. https://doi.org/10.1016/j.procs.2020.03.209
- Chen, L., Ge, L., & Zhou, W. (2023). IIM: An information interaction mechanism for aspect-based sentiment analysis. Connection Science, 35(1), 2283390. https://doi.org/10.1080/09540091.2023.2283390
- Chen, L., & Rudnicky, A. I. (2021). Exploring Wav2vec 2.0 fine-tuning for improved speech emotion recognition. CoRR abs/2110.06309.
- Cummins, N., Amiriparian, S., Hagerer, G., Batliner, A., Steidl, S., & Schuller, B. W. (2017). An image-based deep spectrum feature representation for the recognition of emotional speech. In Proceedings of the 25th ACM international conference on multimedia (pp. 478–484).
- Guo, L., Wang, L., Xu, C., Dang, J., Chng, E. S., & Li, H. (2021). Representation learning with spectro-temporal-channel attention for speech emotion recognition. In IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 6304–6308).
- Han, J., Zhang, Z., Ren, Z., & Schuller, B. W. (2021). EmoBed: Strengthening monomodal emotion recognition via training with crossmodal emotion embeddings. IEEE Transactions on Affective Computing, 12(3), 553–564. https://doi.org/10.1109/TAFFC.2019.2928297
- Kim, T., Cho, S., Choi, S., Park, S., & Lee, S. (2020). Emotional voice conversion using multitask learning with text-to-speech. In IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 7774–7778).
- Kumbhar, H. S., & Bhandari, S. U. (2019). Speech emotion recognition using MFCC features and LSTM network. In Proceedings of the 5th international conference on computing, communication, control and automation (ICCUBEA) (pp. 1–3).
- Latif, S., Rana, R., Khalifa, S., Jurdak, R., & Epps, J. (2019). Direct modelling of speech emotion from raw speech. In Proceedings of the 20th annual conference of the international speech communication association (Interspeech) (pp. 3920–3924).
- Li, Y., Hu, S. L., Wang, J., & Huang, Z. H. (2020). An introduction to the computational complexity of matrix multiplication. Journal of the Operations Research Society of China, 8(1), 29–43. https://doi.org/10.1007/s40305-019-00280-x
- Mao, K., Wang, Y., Ren, L., Zhang, J., Qiu, J., & Dai, G. (2023). Multi-branch feature learning based speech emotion recognition using SCAR-NET. Connection Science, 35(1), 2189217. https://doi.org/10.1080/09540091.2023.2189217
- McFee, B., Raffel, C., Liang, D., Ellis, D. P. W., McVicar, M., Battenberg, E., & Nieto, O. (2015). librosa: Audio and music signal analysis in python. In Proceedings of the 14th python in science conference (SciPy) (pp. 18–24).
- Rao, K. S., Koolagudi, S. G., & Vempada, R. R. (2013). Emotion recognition from speech using global and local prosodic features. International Journal of Speech Technology, 16(2), 143–160. https://doi.org/10.1007/s10772-012-9172-2
- Ren, Z., Kong, Q., Qian, K., Plumbley, M. D., & Schuller, B. W. (2018). Attention-based convolutional neural networks for acoustic scene classification. In Proceedings of the workshop on detection and classification of acoustic scenes and events (DCASE) (pp. 39–43).
- Sheikhan, M., Abbasnezhad Arabi, M., & Gharavian, D. (2015). Structure and weights optimisation of a modified Elman network emotion classifier using hybrid computational intelligence algorithms: A comparative study. Connection Science, 27(4), 340–357. https://doi.org/10.1080/09540091.2015.1080224
- Tarantino, L., Garner, P. N., & Lazaridis, A. (2019). Self-attention for speech emotion recognition. In Proceedings of the 20th annual conference of the international speech communication association (Interspeech) (pp. 2578–2582).
- Tsai, Y. H., Bai, S., Liang, P. P., Kolter, J. Z., Morency, L., & Salakhutdinov, R. (2019). Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the 57th conference of the association for computational linguistics (ACL) (pp. 6558–6569).
- Wani, T. M., Gunawan, T. S., Qadri, S. A. A., Mansor, H., Kartiwi, M., & Ismail, N. (2020). Speech emotion recognition using convolution neural networks and deep stride convolutional neural networks. In Proceedings of the 6th international conference on wireless and telematics (ICWT) (pp. 1–6).
- Wu, W., Zhang, C., & Woodland, P. C. (2021). Emotion recognition by fusing time synchronous and time asynchronous representations. In IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 6269–6273).
- Ye, Z., Jing, Y., Wang, Q., Li, P., Liu, Z., Yan, M., Zhang, Y., & Gao, D. (2023). Emotion recognition based on convolutional gated recurrent units with attention. Connection Science, 35(1), 2289833. https://doi.org/10.1080/09540091.2023.2289833
- Zadeh, A., Liang, P. P., Poria, S., Cambria, E., & Morency, L. (2018). Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph. In Proceedings of the 56th annual meeting of the association for computational linguistics (ACL) (pp. 2236–2246).
- Zadeh, A., Zellers, R., Pincus, E., & Morency, L. (2016). Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages. IEEE Intelligent Systems, 31(6), 82–88. https://doi.org/10.1109/MIS.2016.94
- Zhang, S., Zhao, X., & Tian, Q. (2022). Spontaneous speech emotion recognition using multiscale deep convolutional LSTM. IEEE Transactions on Affective Computing, 13(2), 680–688. https://doi.org/10.1109/TAFFC.2019.2947464
- Zhao, H., Chen, H., Xiao, Y., & Zhang, Z. (2023). Privacy-enhanced federated learning against attribute inference attack for speech emotion recognition. In IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 1–5).
- Zhao, H., Xiao, Y., & Zhang, Z. (2020). Robust semisupervised generative adversarial networks for speech emotion recognition via distribution smoothness. IEEE Access, 8, 106889–106900. https://doi.org/10.1109/Access.6287639
- Zheng, F., Zhang, G., & Song, Z. (2001). Comparison of different implementations of MFCC. Journal of Computer Science and Technology, 16(6), 582–589. https://doi.org/10.1007/BF02943243
- Zou, H., Si, Y., Chen, C., Rajan, D., & Chng, E. S. (2022). Speech emotion recognition with co-attention based multi-level acoustic information. In IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 7367–7371).