Abstract
This study evaluated prototype multichannel nonlinear frequency compression (NFC) signal processing on listeners with high-frequency hearing loss. This signal processor applies NFC above a cut-off frequency. The participants were hearing-impaired adults (13) and children (11) with sloping, high-frequency hearing loss. Multiple outcome measures were repeated using a modified withdrawal design. These included speech sound detection, speech recognition, and self-reported preference measures. Group level results provide evidence of significant improvement of consonant and plural recognition when NFC was enabled. Vowel recognition did not change significantly. Analysis of individual results allowed for exploration of individual factors contributing to benefit received from NFC processing. Findings suggest that NFC processing can improve high frequency speech detection and speech recognition ability for adult and child listeners. Variability in individual outcomes related to factors such as degree and configuration of hearing loss, age of participant, and type of outcome measure.
| Abbreviations | ||
| ANOVA | = | Analysis of variance |
| BTE | = | Behind-the-ear |
| CP | = | Conventional processing |
| DR | = | Dead regions |
| DSL v5.0 | = | Desired sensation level multistage input/output algorithm |
| HFPTA | = | High-frequency pure-tone average |
| HI | = | Hearing impaired |
| MPO | = | Maximum power output |
| NFC | = | Nonlinear frequency compression |
| RAU | = | Rationalized arcsine units |
| RECDs | = | Real ear to coupler differences |
| SNR | = | Signal-to-noise ratio |
| TEN | = | Threshold equalizing noise |
| UWO-DFD | = | University of Western Ontario distinctive features differences test |
Hearing aid technology provides hearing-impaired (HI) individuals with level- and frequency-dependent amplification. For most hearing aid users, hearing aids provide the most gain at higher frequencies, because hearing loss tends to increase with frequency. Current hearing aids have a limited ability to provide sufficient gain for less intense high-frequency sounds (Stelmachowicz et al, Citation2004). This limits the audibility of high-frequency sounds, particularly for individuals with sloping and/or severe to profound hearing losses. High-frequency speech energy provides listeners with important linguistic information. For example, speech sounds such as /s/ and /z/ are important grammatical markers that denote plurality and possession in the English language (Stelmachowicz et al, Citation2004). A reliable cue used to perceive the phoneme /s/ is the frequency of the frication (Newman, Citation2003). Specifically, the spectral peak frequency for the phoneme /s/ is at approximately 5 kHz for male speech, 6 to 9 kHz for female speech, and 9 kHz for child speech (Boothroyd & Medwetsky, Citation1992; Stelmachowicz et al, Citation2001). Therefore, consideration should be given to the hearing aid pass-band when attempting to provide audibility of high-frequency speech cues.
Large variability in aided listening performance is often observed for individuals with severe to profound, high-frequency hearing loss. Individual performance with hearing aids can be influenced by both the audibility of high-frequency signals, as well as the listener's proficiency in extracting useful information from the audible signals. Providing audibility through amplification in the high-frequencies for severe or profound HI listeners still remains a controversial topic. Some studies on the relationship between audibility and speech recognition suggest that providing audibility at frequencies where a hearing impairment is severe provides little or no speech recognition benefit; this is thought to be due to limitations in the perceptual abilities of the listener in extracting information from high-frequency energy (Ching et al, Citation1998, Citation2001; Hogan & Turner, Citation1998). Other studies have demonstrated that providing high-frequency information to listeners with sloping sensorineural hearing loss can significantly improve speech understanding, especially when in noisy listening environments (Plyler & Fleck, Citation2006; Turner & Henry, Citation2002). Individual performance in such studies indicates that listeners receive varying degrees of speech recognition benefit from amplified high-frequencies. Therefore, it may be necessary to determine efficacy of high-frequency audibility on an individual basis.
Several studies have found significant adult/child differences in the bandwidth required for accurate fricative recognition for listeners with moderate to moderately-severe hearing loss (Pittman & Stelmachowicz, Citation2000; Stelmachowicz et al, Citation2001, Citation2004). In these studies, children required greater high-frequency bandwidth than adults (i.e. above 5 kHz) to achieve similar speech recognition scores for the phoneme /s/ (Stelmachowicz et al, Citation2001). This suggests that children require audibility of a broad bandwidth of speech for optimal access to fricatives. High-frequency audibility is related to speech perception and production abilities, as well as overall language learning ability. Children provided with extended bandwidth perform better on short-term word learning tasks than children who are provided with a limited bandwidth, regardless of hearing status (Pittman, Citation2008). Furthermore, infants with hearing loss show a significant delay in fricative and affricate production (Moeller et al, Citation2007; Stelmachowicz et al, Citation2004). Children with hearing loss who communicate with female caregivers may therefore experience inconsistent exposure to the spectral cues for /s/, important when forming language-based rules and when learning to monitor their own speech (Stelmachowicz et al, Citation2002; Pittman et al, Citation2003).
Frequency-lowering has been suggested as one possible alternative to overcoming bandwidth limitations (Stelmachowicz et al, Citation2004). The terminology associated with frequency-lowering in hearing aids varies and is not standardized. For the purposes of this paper, we will categorize frequency-lowering technologies into two groups: frequency transposing devices and frequency compressing devices.
Frequency transposition shifts high-frequency sounds to lower frequency regions by a fixed amount. Early attempts at frequency transposition technology included the use of a modulated carrier frequency (Johansson, Citation1961, Citation1966) and slow playback speeds to present high-frequency signals at a lower frequency (Beasley et al, Citation1976; Bennett & Byers, Citation1967; Ling & Druz, Citation1967). These early attempts at frequency transposition were somewhat successful in improving speech recognition, but produced unwanted sound quality degradations. Further research by Turner and Hurtig (Citation1999) examined speech recognition scores using a frequency–lowering processor labelled as frequency compression. However, it maintained proportional relations between the formant peaks for a given speech sound, and will therefore be classified as a transposer in this paper. Results suggested significant speech recognition improvement in the transposed condition for approximately half of the adult subjects, with greater benefit for the listeners with more steeply sloping audiograms (i.e. better hearing below 1–2 kHz). Transposition technology has also been evaluated on listeners with suspected dead regions along the basilar membrane; results suggest fricative identification improvement for the phoneme /s/ for listeners with dead regions who were individually fitted with a laboratory transposer (Robinson et al, Citation2007).
The AVR TranSonic FT-40 was the first commercially available transposition device. This device used a processing unit to analyse incoming signals and apply frequency-lowering to sounds with predominantly high-frequency energy (i.e. above 2.5 kHz). Early studies indicated mixed outcomes with the body-worn FT-40 on adults and children, concluding that the FT-40 system was suitable for a select group of listeners (MacArdle et al, Citation2001; Parent et al, Citation1997). AVR Sonovations later introduced the ImpaCt behind-the-ear (BTE) hearing aid. McDermott and Knight (Citation2001) found limited benefit attributable to the ImpaCt transposition signal processing when evaluated on adult listeners; age, training, and audiometric configuration may have contributed to the results. The ImpaCt has also been evaluated on children in a study by Miller-Hansen et al (Citation2003), suggesting significant word recognition benefit could be achieved for children with severe hearing loss when using transposing hearing aids, in comparison to conventional hearing aids.
The Widex Inteo device utilizes spectral analysis to identify the frequency region with peak intensity above a cut-off frequency (i.e. peak frequency). Field studies indicated that 33% of subjects (N = 16), with sloping high-frequency hearing loss preferred listening to conversational speech with the transposer enabled than without (Kuk et al, Citation2006). Case studies indicated speech recognition improvement for individuals with high-frequency hearing loss wearing the Inteo, in comparison to participants’ previously used hearing aids (Auriemmo et al, Citation2008).
Frequency compression is an alternative frequency-lowering technology. This technology compresses the output bandwidth of the signal by a specified ratio. If applied across the entire frequency range of the device, frequency compression can alter the positions of vowel formants in the frequency domain. Therefore, recent attempts at frequency compression have used a multichannel approach rather than a single-channel approach (Simpson et al, Citation2005). This strategy applies nonlinear frequency compression (NFC) only to the high-frequency band, preserving the natural formant ratios in the low band. Simpson et al (Citation2005, Citation2006) used an adjustable cut-off frequency between the high and low bands, and an adjustable frequency compression ratio in the high band. These two parameters were individually fitted per participant.
Simpson et al (Citation2005) reported significant improvements in speech recognition for eight of the seventeen participants with the experimental NFC device. Information on place and voicing cues were made more available to listeners when NFC was used (Simpson et al, Citation2005). Further research examined the effects of NFC on adult listeners with steeply sloping audiograms (Simpson et al, Citation2006). No significant benefit in performance was demonstrated in group mean scores when comparing results with NFC to conventional technology; however, subjective preference for the sound quality was noted for conventional technology.
In summary, current conventional hearing aid technology is limited in bandwidth, thereby limiting consistent audibility of high-frequency sound. This has specific detrimental effects on speech sound recognition, particularly in children, but also in adults. This may explain, at least in part, the delay in high-frequency speech sound production observed in children with hearing impairment (Stelmachowicz et al, Citation2004). Two classes of frequency-lowering technology (i.e. frequency transposition and frequency compression) have been proposed to lower the frequency content of sound in an attempt to overcome this limitation. Such technologies are in the early stages of development and have not been extensively evaluated, particularly in the paediatric population. The purpose of this study was to evaluate one such technology, multichannel NFC, in both children and adults. This investigation provided wearable hearing aids employing NFC processing to HI listeners, and tested both laboratory outcomes (speech recognition) and real world outcomes (functional performance and preference) with and without the NFC processor activated. Results will be presented for group-level and individual-level outcomes.
Method
Participants
A total of 24 hearing-impaired participants were included; 13 adults (ages 50–81 years, M = 69) and 11 children (ages 6–17 years, M = 11). Participants were recruited from The University of Western Ontario (UWO) H.A. Leeper Speech and Hearing Clinic, as well as from local audiology clinics and schools. Pure-tone air and bone conduction thresholds were measured bilaterally at all octave and inter-octave frequencies between 250 and 6000 Hz for each participant using a Grason-Stadler 61 audiometer. Air conduction thresholds were obtained using Etymotic Research ER-3A insert earphones coupled to each participant's personal earmolds. Bone conduction thresholds were obtained using a Radioear B-71 bone oscillator. Audiometric testing was completed in a double-walled sound booth. Participants presented with sloping high-frequency hearing losses that ranged from moderately severe to profound in the better ear, and were sensorineural in nature for all but one participant with a mixed loss.
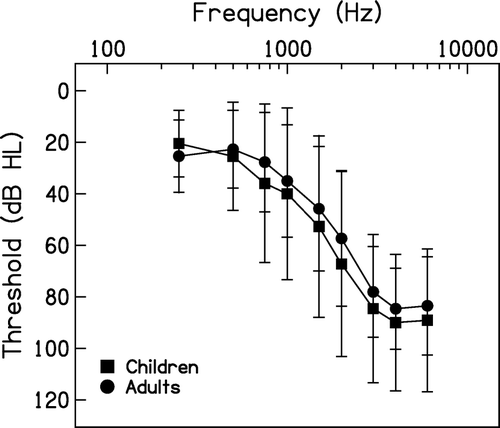
presents air conduction thresholds for the children and adults. A repeated measures analysis of variance (ANOVA) was completed using audiometric threshold as the dependent variable, repeated across nine frequencies from 250 to 6000 Hz, and age group (adults versus children) as the between-subjects variable. Results did not provide evidence of a significant interaction between audiometric frequency and age group (F(8,15)=.75, p=.65). All hearing losses were symmetrical, with the exception of one subject (2062) who had differences in the range of 10–30 dB between ears in the 2–4 kHz region. Previous hearing aid use included mostly digital hearing aid technology, with three participants having no previous experience with hearing aids and three having previous use of analog hearing aid technology (see ). Participants were evaluated for suspected dead regions using a CD version of the threshold equalizing noise (TEN) test calibrated in dB HL (Moore et al, Citation2004).
Figure 1. Mean better ear pure-tone thresholds±1 standard deviation for adults and children.
Trial design
This study used a modified withdrawal design, with both single- and double-blind outcome measures, as follows (). Participants completed the initial trial, allowing for familiarization to the study worn hearing aid programmed with conventional processing (CP). Following this trial, the outcome test battery was to familiarize participants to the tasks. NFC processing was then enabled and a real world trial allowed participants to familiarize to the NFC processor, and the outcome test battery was administered again. In the final phase of the study, NFC was made optional (via a multi-memory fitting) for real world usage, allowing measurement of subjective preference. Allocation of frequency compression to memories was counterbalanced across participants. Prior to re-administering the outcome test battery, NFC was disabled during laboratory measurement, allowing for evaluation of the withdrawal-of-treatment condition; therefore, the objective outcome measures adhered to a true ‘withdrawal’ design while the real world measures of preference did not. provides a description of the durations of each phase for each participant. These varied due to scheduling limitations of the participants (e.g. illness, travel).
Table 1. Description of the time course of each phase included in the study, corresponding objectives, and phase duration. CP refers to ‘conventional processing’ (i.e. fitting assessment without NFC enabled). Treatment assessment was completed with NFC enabled in the same hearing aid device used for CP evaluation.
Table 2. Individual participant hearing aid fitting schedule and corresponding adaption times, expressed in weeks.
A withdrawal study includes three measurement intervals: baseline, treatment, and withdrawal of treatment. In this study, the comparison of interest is benefit with NFC versus benefit without NFC. This was scored using the withdrawal versus treatment intervals (see Results section for details). The withdrawal versus treatment comparison loads any advantage due to practice and acclimatization effects on the withdrawal condition. Therefore, this study employed a more stringent evaluation of NFC benefit, compared to a baseline versus treatment comparison.
Blinding in hearing aid efficacy research is necessary to avoid spurious labelling effects that are akin to placebo effects (Bentler et al, Citation2003). In the present study, two blinding techniques were used. For computer-administered tests of speech detection and/or recognition, study participants were unaware of the status of the hearing aid signal processing (i.e. single blinding). During experimenter-administered tests of real-world preference, both the participants and experimenters were unaware which condition denoted treatment versus the control (i.e. double blinding). The nature of the NFC processor was not disclosed to the participants at study onset. Participants remained naive to the treatment condition, with the exception of two subjects (1104, and the parent of 2066). These two participants had advanced educational/professional backgrounds in related areas and specifically expressed an understanding of the nature of the treatment based on listening to the hearing aids. No other participants expressed this type of awareness. All participants were debriefed as to the nature of the signal processing upon exiting the study.
Device fitting without NFC
For the CP hearing aid fittings, the prescriptive targets and clinical protocols from the desired sensation level (DSL) method version 5.0 were used (DSL v5: Bagatto et al, Citation2005; Scollie et al, Citation2005). Prototype BTE hearing aids (similar to Phonak Savia 311 or 411, allocated per hearing level, see ) were provided to each participant along with FM compatible audio-shoes. Digital noise reduction features and automatic program selectors were disabled.
Table 3. Case history information including previous hearing aid use and conventional make/model of hearing aid fitted for the purpose of the study. Hearing instruments used were prototype versions of the algorithm implemented in current Savia 311/411 hearing aids.
For fitting, age-dependent prescriptive targets were matched using simulated real ear measures incorporating individual real ear to coupler differences (RECDs). Note that the DSL v5 algorithm prescribes more gain for children than for adults (Scollie et al, Citation2005). The Audioscan® Verifit VF-1 was used to measure aided responses for speech at 55, 65, and 75 dB SPL, and for a 90 dB SPL tone burst test signal. Fit to targets in the acclimatization phase within 5 dB up to 4000 Hz were obtained for participants with better-ear, high-frequency pure-tone averages (HFPTA) of up to 77 dB HL for the adults and 87 dB HL for the children. Above this, the target gain values could not be achieved, and the upper bandwidth of fit to targets became lower as hearing levels and/or audiometric slopes increased. Target MPO values achieved target at 2000 Hz even for the participants with the greatest hearing loss. Taken together, these fitting results indicate that the hearing aids, although powerful enough for the participants’ losses, were affected by bandwidth limitations typical of hearing aid technology, particularly for the participants with greater hearing losses.
Device fitting with NFC
Custom software was used to enable the NFC processor while holding gain and amplitude compression parameters constant. Two NFC parameters were programmable: (1) the cut-off frequency, which determined the start of the upper band; and (2) the compression ratio, which determined the amount of frequency compression applied to the upper band. The cut-off frequency and compression ratios were determined on an individual basis as follows. The goal was to provide more audibility of high-frequency speech cues, compared to the CP fitting, while limiting negative effects such as poor sound quality or confusion of /s/ with /∫/. The fitter was instructed to evaluate the audibility of the peaks of average-level conversational speech, and of live voice productions of both /s/ and /∫/, on the same display used to fit the hearing aids without NFC. The fitter then enabled NFC and re-evaluated using the same signals to determine if NFC produced an increase in audibility for high-frequency speech energy. Listening checks and aided spectra were used to judge whether the current NFC setting caused confusion and/or spectral overlap of /s/ and /∫/, as judged by the fitter. Fitter judgments were used so that fitting could proceed even if the wearer was too young to participate in the fitting process via subjective comments. Wearer feedback was elicited if the participant could provide it, sometimes resulting in fine tuning. Tuning was most often aimed at reducing the amount of NFC, in response to reports of perceived slurring or excessive audibility of high frequency sounds. In these cases, fitters aimed to provide enough NFC to provide audibility of new sounds without slurring, at an acceptable level. In this process, the better ear was used to select initial NFC settings for both ears, in order to provide symmetrical frequency lowering to the binaural system. Final fittings were symmetrical in all participants (based on better-ear HFPTA values), with the exception of one participant with a significant asymmetry in audiometric thresholds (see and for NFC settings per individual). The fitting for this participant used asymmetrical NFC parameters in order to provide high-frequency audibility per ear.
Objective outcome measures
Four objective tests were administered (aided speech sound detection, consonant recognition, plural recognition, and vowel recognition, details below). For these tests, stimuli were digitized at a sampling frequency of 48828 Hz and routed through a computer-controlled psychoacoustic workstation (TDT) to the external inputs of a clinical audiometer. The outputs of the audiometer were routed to power amplifiers (R300 for the front speaker, and two Amcron D-75 amplifiers for speakers 2 through 5). The majority of the outcome measures utilized the front speaker only, with the exception of the plural recognition task (described below). The power amplifiers were routed to loudspeakers arranged at 72 degree spacing, one metre from the participants’ test location. Participants were seated in an adjustable chair, facing a loudspeaker and computer display, adjusted in height to the level of the loudspeaker.
Aided detection thresholds for speech sounds were measured in the sound field using an adaptive, computer-controlled version of the Ling six-sound test (Ling, Citation1989; Tenhaaf & Scollie, Citation2005). The /∫/ and /s/ sounds were selected from this test. These items were spoken by a female talker and recorded and digitized using a studio grade microphone (AKG) coupled to a pre-amplifier and analog to digital converter (USB Pre) and sound recording software (SpectraPlus). The participants selected ‘heard it’ or ‘didn't hear it’ options on the computer monitor. A phoneme-specific detection threshold was bracketed via computer control of programmable attenuators (TDT PA5). Thresholds were estimated as the average level of the last four reversals to a 50% detection criterion, using a 5-dB step size.
The consonant recognition task was a modified version of The University of Western Ontario Distinctive Features Differences test (UWO-DFD) (Cheesman & Jamieson, Citation1996). The UWO-DFD test was originally developed with four talkers and 21 nonsense disyllables. For the purpose of this study, the task was modified to include a subset of 10 high-frequency consonants: /t∫, d, f, j, k, s, ∫, t, ð, z/. All items were presented in a fixed, word-medial context (i.e. λCIl). Each of the 10 stimuli were spoken by two different female talkers and repeated three times for a total of 60 stimulus presentations.
A plural recognition task was included to assess participant ability to use the fricatives /s/ and /z/ as bound morphemes. Stimuli for this task were chosen to be similar to those used in previous research to test sensitivity to high-frequency audibility in children who use hearing aids (Stelmachowicz et al, Citation2002). The task included the singular and plural forms of 15 words: ant, balloon, book, butterfly, crab, crayon, cup, dog, fly, flower, frog, pig, skunk, sock, and shoe. These items were recorded using the same talker and procedures used for the Ling 6 stimuli. The female speaker was instructed to speak in a monotonic fashion to avoid inclusion of unnecessary intonation across test items. Four recordings of each item were made, and the token with the least intonation as perceived by the experimenter was selected. The final tokens were equalized in level and had 250 ms of silence added to the beginning and end using sound editing software (Goldwave). The resulting stimuli were presented in the sound field at zero degrees azimuth. Speech-shaped noise was presented simultaneously to the test items at a + 20 dB signal-to-noise ratio (SNR) from a clinical audiometer to four other loudspeakers encircling the subject at 72-degrees spacing. The noise was included to mask a low-level stimulus offset cue that could have served as a surrogate cue for plural identification. Pilot data indicated that the +20 dB SNR was adequate for this purpose. Participants selected either the singular or plural form of the target word from a picture and orthographic display on the computer monitor. Two repetitions of all items were presented in random order, for a total of 60 items per score.
A vowel recognition task was included to evaluate whether frequency compression negatively affected vowel perception. Stimuli were selected from a publicly available database of vowels presented in an hVd context, created by Hillenbrand (2003) at Western Michigan University (http://homepages.wmich.edu/~hillenbr/voweldata.html). For the purpose of this study, vowel stimuli included five items (heed, hid, head, had, and hayed), spoken by both adult female and child female talkers. These stimuli had energy at the second formant that spanned the range from roughly 1800 to 3400 Hz, and third formant energy from 2800 to 3700 Hz (Hillenbrand et al, Citation1995). We expected these frequency regions to be important for vowel perception and likely included in the high band affected by NFC. Each item was presented twice for a total of 20 items per score. Participants selected from one of five orthographic representations on a computer screen.
Presentation level was varied to accommodate the various hearing levels and speech recognition abilities of participants. The minimum testing level was 50 dB SPL, representing speech at a low vocal effort level (Olsen, Citation1998). The test level was increased if the participant's score for a given test level was at or below chance performance. Increases up to a test level of 65 dB SPL were required for some participants, particularly for the plural identification and consonant recognition tasks. For this reason, comparison of performance across participants in this study was not completed, because test conditions were not held constant. Rather, the relative performance with and without NFC was evaluated, because the test levels were held constant across the final two stages of the trial.
Real world preference measure
A diary of hearing aid performance was completed in the treatment withdrawal phase of the study. Participants were asked to make direct comparisons between two memories in the hearing aid (with and without NFC). All other aspects of hearing aid processing (i.e. omnidirectional microphone, gain, amplitude compression) were matched between these two programs. The hearing aids automatically started up in program one; therefore listeners were required to use the program switch to select each program for comparison purposes. Participants indicated which program they preferred overall. Participants were given the option of choosing ‘same’ if they felt there was no difference between the programs being compared.
Results
Analysis strategies
Two analysis strategies were used. First, an analysis of group-level results was completed. Second, results for individual participants were analysed using single subject design methods, specifically using a modified two standard deviation band technique (Portney & Watkins, Citation2000). Contributing factors to individual results were explored using multiple regression analysis.
Group level analyses
Speech sound detection
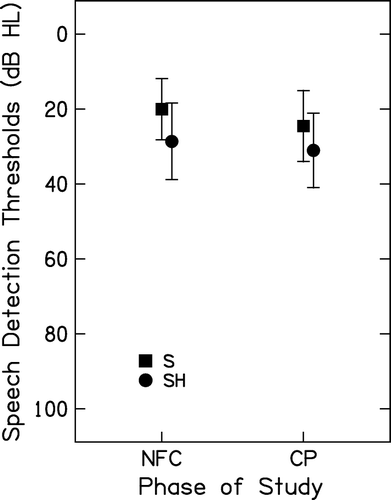
A repeated measures ANOVA was completed with processor type (CP versus NFC) and phoneme (/s/ or /∫/) as within-subject variables, and age group (adults versus children) as a between-subjects variable. Significant simple main effects were found for the processor type as well the phoneme type (F(1,22) = 42.97, p<.001; F(1,22) = 6.84, p=.02). displays mean changes in aided speech sound detection thresholds for each phoneme. These results indicate that the /s/ phoneme had a lower threshold level than did the /∫/ phoneme. Also, aided thresholds were somewhat lower (i.e. better) when the NFC processor was activated.
Figure 2. Mean speech sound detection thresholds for adults and children combined, plotted in dB HL for CP (conventional processing) and NFC (nonlinear frequency compression) study phases.
Speech recognition
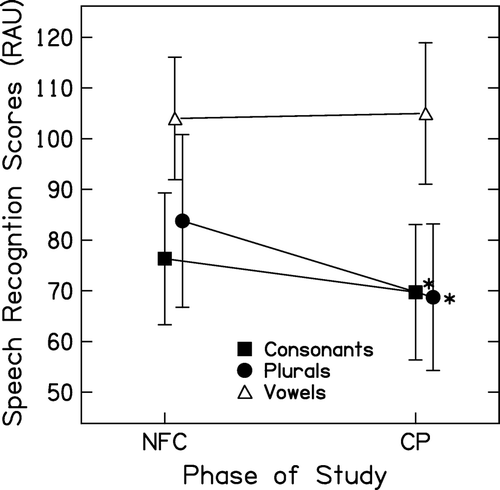
A repeated measures ANOVA was completed with processor type (CP versus NFC) and test type (consonant, plural, or vowel recognition) as within-subject variables, and age group (adults versus children) as a between-subjects variable. Mean values were substituted for one participant with missing data on the consonant recognition task. Raw scores for the three speech recognition tasks were converted to rationalized arcsine units (RAU) prior to analysis (Studebaker et al, Citation1995). Results suggest a significant interaction between test type and processor type (F(2,21) = 8.99, p<.001). Post hoc paired comparisons were conducted with a Bonferroni correction to control familywise error rate to a level of. 05. These comparisons indicated that scores were significantly higher with NFC activated, for the consonant and plural recognition tests (t(23) = 3.40, p=.002; t(23) = 5.15, p<.001). Mean speech recognition scores are shown in . An asterisk is displayed for pairs of means that differed significantly. These results indicate that, on average, high frequency speech recognition was improved with the use of frequency compression, while vowel perception did not change significantly.
Figure 3. Mean speech recognition scores for adults and children combined, plotted in RAU for CP (conventional processing) and NFC (nonlinear frequency compression) study phases. Statistical significance based on post-hoc analysis at the level of p<.05 is displayed using an asterisk.
Single-subject results
Individual scores obtained in the treatment versus withdrawal phases were analysed using confidence limits for performance change. Significant change was deemed to occur when performance in the treatment condition exceeded statistically determined confidence limits. These limits were calculated for levels of significance equivalent to the 90th, 95th, and 99th percentiles.
Speech sound detection
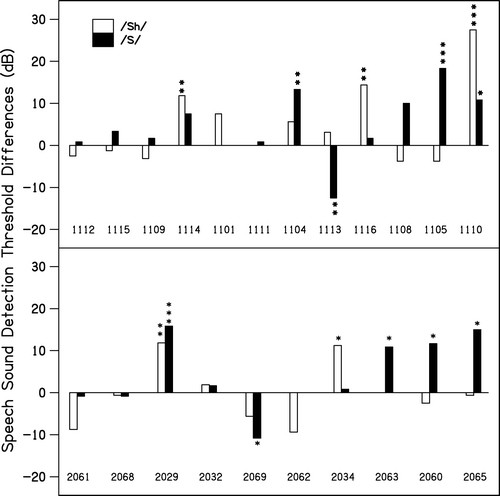
displays individual speech sound detection results plotted as difference scores. Negative scores indicate improvement with CP and positive scores indicate improvement with NFC. For the speech sound detection task, 99%, 95% and 90% confidence limits were computed as ±2.58, ±1.96, and ±1.65 times the standard deviation of test-retest differences across all test stimuli, all participants, in all phases of this trial (SD = 6.04 dB). The 99%, 95% and 90% confidence interval for individual change in speech recognition scores were therefore ±16 dB, ±12 dB and ±10 dB respectively. Two participants (1100, 2066) could not complete the speech sound detection task reliably due to cognitive and/or developmental status; therefore, results for these participants do not appear in .
Figure 4. Individual speech sound detection thresholds plotted as difference scores, with a negative score indicating improvement with CP (conventional processing) and a positive score indicating improvement with NFC (nonlinear frequency compression). Results displayed in the top and bottom panes represent the adult and child participants respectively, with participants arranged in order of increasing hearing loss. Statistical significance is shown by asterisk symbols: * p<.10, ** p<.05, *** p<.01.
Speech recognition
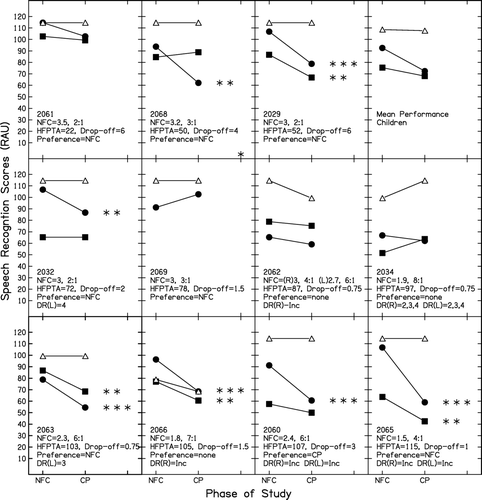
and display individual speech recognition results plotted for the treatment evaluation (NFC) and treatment withdrawal (CP) phases of the study. In each figure, individual participants have been sorted according to their hearing levels. Scores for the consonant recognition task (60 items), the plural recognition task (60 items), and the vowel recognition task (20 items) are shown for each participant. One child participant (2069) was unable to complete the consonant recognition task due to developmental status. The confidence limits for significant change on each task were calculated based on the binomial theorem, at a score of 50% correct (Raffin & Thornton, Citation1980). Prior to application of the confidence limits, speech recognition scores were converted to RAU. Conversion to RAU ensured that confidence limits derived at the 50% performance level would be applicable across other performance levels (Studebaker et al, Citation1995). The 99% confidence limit for individual change in speech recognition scores on the consonant and plural recognition tasks was ±24 RAU, the 95% confidence limit was ±18 RAU, and the 90% confidence limit was ±15 RAU. For the vowel recognition task the 99% confidence limit for individual change was ±41 RAU, the 95% confidence limit was ±31 RAU, and the 90% confidence limit was ±26 RAU. Using these limits, individual changes were judged per task, and significant changes are indicated by the asterisks in the figures.
Figure 5. Individual speech recognition results for the adult participants, plotted for treatment (NFC) and treatment withdrawal (CP) study phases. Results are displayed from left to right in order of increasing hearing loss determined by better-ear, high-frequency pure-tone average (HFPTA). Speech recognition scores have been displayed in RAU. Statistical significance is shown by asterisk symbols: * p<.10, ** p<.05, *** p<.01. Individual participant figure panes include: subject number, NFC setting (cut-off in kHz, compression ratio), HFPTA (dB HL), hearing loss drop-off (point at which thresholds drop to 70 dB HL, in kHz), self-reported processing preference, and presence of cochlear dead regions (DR) in kHz right (R) and/or (L) side, with ‘Inc’ denoting inconclusive TEN test results.
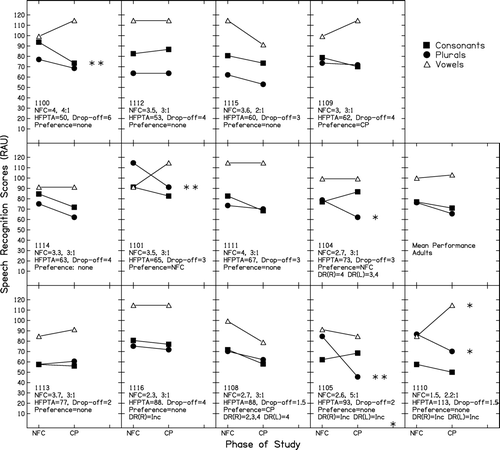
Figure 6. Individual speech recognition results for the child participants, plotted for treatment (NFC) and treatment withdrawal (CP) study phases. Refer to legend on . Results are displayed from left to right in order of increasing hearing loss determined by better-ear, high-frequency pure-tone average (HFPTA). Speech recognition scores have been displayed in RAU. Statistical significance is shown by asterisk symbols: * p<.10, ** p<.05, *** p<.01. Individual participant figure panes include: subject number, NFC setting (cut-off in kHz, compression ratio), HFPTA (dB HL), hearing loss drop-off (point at which thresholds drop to 70 dB HL, in kHz), self-reported processing preference, and presence of cochlear dead regions (DR) in kHz right (R) and/or (L) side, with ‘Inc’ denoting inconclusive TEN test results.
Self-reported preference
Measures of real world preference collected via multi-memory comparison prior to the withdrawal phase are noted per participant in and .
Individual results and contributing factors
through 6 demonstrate variability in benefit received from NFC processing across both adult and child participants included in the study. Trends observed in the data warranted further exploration into the relationships between degree of hearing loss and speech recognition/detection benefit, and age group and speech recognition/detection benefit. Multiple linear regression analyses were completed to investigate the relationships between possible candidacy variables and scores reported across all measures. Three candidacy variables were included: age group, magnitude of high-frequency hearing loss, and audiometric drop-off frequency. Age group was determined by classifying participants as a child (i.e. less than or equal to 18 years) or an adult (i.e. greater than or equal to 19 years). Magnitude of loss was computed using HFPTA. Audiometric drop-off frequency, in kHz, was defined as the frequency at which thresholds met or exceeded 70 dB HL in the better ear. Predictor variables were entered into a stepwise multiple linear regression analysis with backward elimination. The regression was repeated for five measures: consonant recognition, plural recognition, /∫/ detection, /s/ detection, and self-reported preference. Predictors with significant (alpha less than. 05) partial correlations were included, and those with nonsignificant partial correlations (alpha greater than. 10) were excluded at each step of the analysis. Results for the final step are included in .
Table 4. Final results for multiple linear regression using backward elimination, repeated across measures. Predictor variables are included for plural recognition, /∫/ detection, and /s/ detection tasks, as well as for the self-reported preference measure. Predictor variables include age group, denoted by ‘group’, magnitude of high-frequency hearing loss, denoted by ‘HFPTA’, and audiometric drop-off frequency, denoted by ‘drop-off’. Excluded variables have been removed from the Table. Multiple R squared values are listed for the final equations corresponding to measures with significant findings.
For the consonant recognition task, all three predictors were entered into a backward regression analysis and age group as a predictor variable was removed on step one [partial=.11, t(23)=.51, p=.62]; HFPTA as a predictor variable was removed on step two [partial=.35, t(23) = 1.70, p=.10]; audiometric drop-off as a predictor variable was removed on step three [partial=.13, t(23)=.60, p=.55]. None of the candidacy variables predicted benefit on the consonant recognition task. For the plural recognition task, all three predictor variables were entered and all were included in the final regression equation; benefit was significantly predicted by age group, magnitude of high-frequency hearing loss, and audiometric drop-off frequency. For the /∫/ detection task, all three predictors were entered and age group was removed on step one [partial=.30, t(23) = 1.41, p=.18]. Benefit on the /∫/ detection was significantly predicted by magnitude of high-frequency hearing loss and audiometric drop-off frequency. For the /s/ detection task, all three predictor variables were entered and age group was removed on step one [partial=.01, t(23) =.05, p>.96]. Benefit for the /s/ detection task was significantly predicted by magnitude of high-frequency hearing loss and audiometric drop-off frequency. For the self-reported preference measure, all three predictor variables were entered in the backward regression analysis; HFPTA as a predictor variable was removed in step one [partial = −.01, t(23) = −.06, p=.95]; audiometric drop-off was removed in step two [partial=.10, t(23)=.48, p=.64]. Processing preference, as reported on the self-reported preference measure, was significantly predicted by age group in the multiple regression analysis.
In summary, participants with certain hearing losses derived greater NFC benefit on plural recognition and detection tasks. Specifically, participants with a greater amount of high-frequency hearing loss (based on HFPTA) that occurs at higher frequencies (based on the drop-off frequency) derived greater NFC benefit. In addition, there is evidence of a significant age effect for the plural recognition task and the self-reported preference measure. This implies that children deriving greater plural recognition benefit from NFC also had stronger preference for NFC, when compared to the adults.
Discussion
The main purpose of this study was to examine if prototype multichannel nonlinear frequency compression (NFC) hearing-aid processing provided benefit relative to the same hearing aid fitting without NFC. The NFC processor used in this study was a multichannel (i.e. two-band) strategy that provided frequency lowering (via frequency compression) to the high-frequencies while leaving the low band unaltered in the frequency domain. This was evaluated across a range of participants with varying audiometric characteristics and ages. Results suggest that the NFC processor was, on average, effective at improving high-frequency audibility, resulting in improvements in high-frequency speech sound detection and recognition. No significant changes were observed for low frequency speech sounds (i.e. vowels), on average. Benefit observed from NFC can be attributed to the increased audibility of additional high-frequency energy, albeit presented in a lower frequency range, compared to the conventional hearing aid fittings used in this study. These results generally agree with those reported by Simpson et al (Citation2005) who measured an overall improvement in recognition of high-frequency consonants when a similar NFC processor was used. The results also generally agree with those reported by Miller-Hansen et al (Citation2003), who reported benefits for speech sound detection and recognition with a transposing device.
Analyses performed at the individual level provide evidence that NFC benefit varies across individuals. The results also indicate that the degree of high-frequency hearing loss may predict NFC benefit. This observation agrees with the group findings reported by Miller-Hansen et al (Citation2003), who found greater benefit with a transposition aid for children who had greater hearing losses. In some cases, the individual results presented in this study disagree with the results reported by Simpson et al (Citation2006). Specifically, individuals in this study with high-frequency, steeply sloping losses were more likely to benefit with NFC while those in the Simpson study did not. Participants with steeply sloping losses tested by Simpson et al did not show significant benefit overall, despite having similar losses to the participants included in this study. This may be unexpected, given that the NFC processor in this study was based on the processor proposed by Simpson et al (Citation2005, Citation2006). However, different fitting methods and hearing instruments were used in the two studies. The present study used a later-generation digital signal processor that offered greater processing power. This change allowed such improvements as more channels of amplitude compression, better control of oscillatory feedback, and provision of a separate device and signal processor per ear, overcoming several technology limitations specifically discussed by Simpson et al (Citation2006).
The individual results also provide evidence that the age of the participants included in this study influenced the degree of NFC benefit. Although mean high-frequency thresholds for adults and children were not significantly different, the mean thresholds were 7 to 10 dB higher for the children in the mid/high frequency range. This difference may have been a factor in outcomes reported in this study. Furthermore, adult and child participants were fitted using different levels of audibility; adults received the DSL v5 adult prescription, which provides 5 to 10 dB less gain than the corresponding paediatric prescription (Scollie et al, Citation2005). This difference in levels of audibility may have factored into the adult-child differences observed in benefit; children may have received a greater level of audibility for the speech cues that were examined, compared to the adult group. However, Stelmachowicz et al (Citation2004) argue that children require greater audibility than do adults in order to attain equivalent performance on speech recognition tasks. If this is true, the children in this study may have required the audibility of high-frequency cues of speech more so than did the adults and therefore benefitted more from the NFC. For example, the child participant with the mildest level of hearing loss observed in the study performed at ceiling on all speech recognition tasks, but indicated a significant, blinded preference for NFC technology on the grounds that it reduced listening effort in the classroom. This speaks to the heavy listening demands placed on children in educational environments (Crandell & Smaldino, Citation2000; Hicks & Tharpe, Citation2002), which may also relate to children's candidacy for NFC. Interpretation of the individual findings may be restricted to the small sample employed in this study: further work to investigate whether age and/or hearing status are predictors of outcome with NFC is needed.
The variability in individual phase durations of this study precludes any speculation as to the time course of acclimatization to NFC processing. However, we would speculate that some time may be required to acclimate to the new audibility provided from NFC, just as occurs for other forms of new audibility (e.g. Gatehouse, Citation1992; Horwitz & Turner, Citation1997; Kuk et al, Citation2003; Munro & Lutman, Citation2003). It is also possible that our adult and child participants may have varied in their ability to acclimate to the NFC processor. The aging auditory system demonstrates decreases in speech recognition scores and performance on measures of auditory processing and/or cognition, suggesting a decrease in the plasticity of the auditory system with increasing age (Humes & Christopherson, Citation1991; Humes et al, Citation1994; Gatehouse et al, Citation2006a, Citationb). Furthermore, a larger acclimatization effect may be associated with more severe hearing loss (Horwitz & Turner, Citation1997). The individual results with NFC shown here agree with these suggestions: despite the mean variability in trial durations, the younger participants with more hearing loss seemed to have derived better outcomes. Further research is needed to establish the role of age-related auditory plasticity when measuring benefit change scores, as well as other factors that may be contributing to different rates of auditory acclimatization.
Relation to clinical practice
These data were collected using prototype hearing instruments, with pre-clinical software that allowed independent manipulation of cut-off frequency and frequency compression ratio per ear and over a wide range of values. A manual fitting approach was used to individualize settings. Since this study was conducted, several similar although not identical clinical hearing instruments have been issued by the manufacturer of these prototype hearing devices (Phonak). These devices use a very similar processing strategy for NFC, with a range of NFC settings that (1) tie the crossover frequency together with the frequency compression ratio; and (2) use a more restricted range of settings than was available in the pre-clinical software. However, the range of settings available clinically is similar to the range actually used in this project (i.e. the pre-clinical software offered a wider range of settings than were actually used). If the clinical hearing devices are fitted to children, the default NFC settings are based on a regression analysis of the pediatric fittings described in this paper; better-ear HFPTA hearing loss values were used as the basis for calculation of NFC settings, which are the same for both ears in the case of bilateral fittings. Clinicians using this technology may choose to employ the more detailed fitting method and/or findings in the present study to better understand one possible method for fitting NFC. Knowledge outcomes presented in this paper may further support fine tuning and troubleshooting of NFC devices.
Summary
Prototype nonlinear frequency compression (NFC) technology was evaluated for 24 hearing-impaired listeners using various objective and subjective outcome measures. Results can be summarized as follows:
On average, the NFC processor improved speech sound detection thresholds, as well as consonant and plural recognition scores; vowel perception was not significantly changed. These findings are consistent with the fitting rationale and processor used in the study, which aimed at lowering high-frequency speech energy without affecting low and mid frequency speech energy.
Individual results indicated that age group and degree and configuration of hearing loss were related to NFC benefit. The following trends were observed: (1) magnitude of high-frequency hearing loss and individual benefit on plural recognition/speech sound detection tasks were related, and (2) audiometric drop-off frequency and individual benefit on plural recognition/speech sound detection tasks were related. Age group was also related to individual benefit on the plural recognition task; children were more likely to benefit compared to adults.
Individual preference for NFC processing was related to age group and to benefit; children were more likely to have preference for NFC processing than were adults. Also, individual participants were more likely to prefer NFC if they benefited from it.
Variance in outcome results at the individual level was considerable. Some individuals experienced greater or lesser benefit than the candidacy predictors would lead one to expect. Further research is needed to generalize predictions of candidacy for this technology.
Acknowledgements
This work has been supported by The Natural Sciences and Engineering Research Council of Canada (Collaborative Health Research Project #313114-2005), The Hearing Foundation of Canada, The Canada Foundation for Innovation, the Masons Help-2-Hear Foundation, and Phonak AG. Special thanks to Melissa Polonenko, Andreas Seelisch, and Julianne Tenhaaf for their assistance on this project, and to Andrea Simpson and Andrea Pittman for their comments on the project in various stages of development and writing. Declaration of interest: One author (DG) completed a student summer internship with the manufacturer of the hearing instruments used in this study. Two other authors (SS, RS) sit on the Pediatric Advisory Board of the manufacturer. None of these activities are/were related to the outcomes of this study, nor do the authors have a financial interest in the commercialization of any product or knowledge arising from this work. The manufacturer provided equipment, technical support, and a portion of the operating costs of the study, but did not design the protocols or analyse/interpret the findings. The authors alone are responsible for the content and writing of the paper.
Sumario
El estudio evaluó el procesamiento de la señal de un prototipo multicanal de compresión no lineal de la frecuencia (NFC) en sujetos con pérdida auditiva en las frecuencias agudas. Este procesador de señal aplica la NFC por encima de la frecuencia de corte. Los participantes fueron adultos hipoacúsicos (13) y niños (11) con pérdidas auditivas con pendiente hacia las frecuencias agudas. Se repitieron múltiples mediciones de resultados utilizando un modelo modificado de retirada. Éstas incluyeron detección de sonidos del lenguaje, reconocimiento del lenguaje y medidas auto-reportadas de preferencia. Los resultados de grupo aportaron evidencia de una mejoría significativa en el reconocimiento de consonante y plurales cuando se activó la NFC. El reconocimiento de vocales no cambió significativamente. El análisis de resultados individuales permitió la exploración de factores individuales que contribuyeron al beneficio recibido del procesamiento con NFC. Los hallazgos sugieren que el procesamiento con NFC puede mejorar la detección del lenguaje de alta frecuencia y la capacidad de reconocimiento del lenguaje para adultos y niños. La variabilidad en los resultados individuales se relacionó con factores tales como el grado y la configuración de la pérdida auditiva, la edad del participante y el tipo de medición de resultados.
References
- Auriemmo J., Kuk F., Stenger P. Criteria for evaluating the performance of linear frequency transposition in children. Hear J 2008; 61: 50–54
- Bagatto M., Moodie S., Scollie S., Seewald R., Moodie S.K., et al. Clinical protocols for hearing instrument fitting in the desired sensation level method. Trends in Amplif 2005; 9(4)199–226
- Beasley D., Mosher N., Orchik D. Use of frequency-shifted/time-compressed speech with hearing-impaired children. Audiology 1976; 15: 395–406
- Bennett D., Byers V. Increased intelligibility in the hypacusis by slow-play frequency transposition. J Aud Res 1967; 7: 107–118
- Bentler R.A., Niebuhr D.P., Johnson T.A., Flamme G.A. Impact of digital labeling on outcome measures. Ear Hear 2003; 24(3)215–224
- Boothroyd A., Medwetsky L. Spectral distribution of /s/ and the frequency response of hearing aids. Ear Hear 1992; 13(3)150–157
- Cheesman M.F., Jamieson D. G. Development, evaluation, and scoring of a nonsense word test suitable for use with speakers of Canadian English. Canadian Acoustics 1996; 24(1)3–11
- Ching T.Y., Dillon H., Byrne D. Speech recognition of hearing-impaired listeners: Predictions from audibility and the limited role of high-frequency amplification. J Acoust Soc Am 1998; 103(2)1128–1140
- Ching T.Y., Dillon H., Katsch R., Byrne D. Maximizing effective audibility in hearing aid fitting. Ear Hear 2001; 22(3)212–224
- Crandell C.C., Smaldino J.J. Classroom acoustics for children with normal hearing and with hearing impairment. Lang Speech Hear Serv Sch 2000; 31: 362–370
- Gatehouse S., Naylor G., Elderling C. Linear and nonlinear hearing aid fittings: 1. Patterns of benefit. Int J Audiol 2006; 45: 130–152
- Gatehouse S., Naylor G., Elderling C. Linear and nonlinear hearing aid fittings: 2. Patterns of candidature. Int J Audiol 2006; 45: 153–171
- Gatehouse S. The time course and magnitude of perceptual acclimatization to frequency responses: Evidence from monaural fitting of hearing aids. J Acoust Soc Am 1992; 92(3)1258–1269
- Hicks C.B., Tharpe A.M. Listening effort and fatigue in school-age children with and without hearing loss. J Speech Hear Res 2002; 45: 573–584
- Hillenbrand J., Getty L.A., Clark M.J., Wheeler K. Acoustic characteristics of American English vowels. J Acoust Soc Am 1995; 97(5)1–13
- Hogan C.A., Turner C.W. High-frequency audibility: Benefits for hearing-impaired listeners. J Acoust Soc Am 1998; 104(1)432–441
- Horwitz A.R., Turner C.W. The time course of hearing aid benefit. Ear Hear 1997; 18(1)1–11
- Humes L.E., Christopherson L. Speech identification difficulties of hearing-impaired elderly persons: The contributions of auditory processing deficits. J Speech Hear Res 1991; 34: 686–693
- Humes L.E., Watson B.U., Christersen L.A., Cokely C.G., Halling D.C., et al. Factors associated with individual differences in clinical measures of speech recognition among the elderly. J Speech Hear Res 1994; 37: 465–474
- Johansson, B. 1961. A new coding amplifier system for the severely hard of hearing. In:. L. Cremer. Proceedings of the 3rd International Congress on Acoustics, 2, 655–657.
- Johansson B. The use of the transposer for the management of the deaf child. International Audiology 1966; V(3)362–372
- Kuk F., Korhonen P., Peeters H., Keenen D., Jessen A., et al. Linear frequency transposition: Extending the audibility of high-frequency energy. Hear Rev 2006; 13: 10
- Kuk, F., Potts, L., Valente, M., Lee, L. & Picirrillo, J. 2003. Evidence of acclimatization in persons with severe-to-profound hearing loss. J Am Acad Audiol, 14(2)
- D Ling, 1989. Foundations of Spoken Language for Hearing-impaired Children. Washington, DC: Alexander Graham Bell Association for the Deaf, Inc.
- Ling D., Druz W.S. Transposition of high frequency sounds by partial vocoding of the speech spectrum: Its use by deaf children. J Aud Res 1967; 7: 133–144
- MacArdle B.M., West C., Bradley J., Worth S., Mackenzie J., et al. A study of the application of a frequency transposition hearing system in children. Br J Audiol 2001; 35: 17–29
- Mackersie C.L., Crocker T.L., Davis R. Limiting high-frequency hearing aid gain in listeners with and without suspected cochlear dead regions. J Am Acad Audiol 2004; 15: 498–507
- McDermott H.J., Knight M.R. Preliminary results with the AVR ImpaCt frequency-transposing hearing aid. J Am Acad Audiol 2001; 12(3)121–127
- Miller-Hansen D.R., Nelson P.G., Widen J.E., Simon S.D. Evaluating the benefit of speech recoding hearing aids in children. Am J Audiol 2003; 12: 106–113
- Moeller M.P., Hoover B., Putman C., Arbataitis K., Bohnenkamp G., et al. Vocalizations of infants with hearing loss compared with infants with normal hearing: Part I. Phonetic development. Ear Hear 2007; 28(5)605–627
- Moore B.C., Glasberg B.R., Stone M.A. New version of the TEN test with calibration in dB HL. Ear Hear 2004; 25(5)478–487
- Munro K.J., Lutman M.E. The effect of speech presentation level on measurement of auditory acclimatization to amplified speech. J Acoust Soc Am 2003; 114(1)484–495
- Newman R.S. Using links between speech perception and speech production to evaluate different acoustic metrics: A preliminary report. J Acoust Soc Am 2003; 113(5)2850–2860
- Olsen W.O. Average speech levels and spectra in various speaking/listening conditions: A summary of the Pearson, Bennett, & Fidell (1977) report. Am J Audiol 1998; 7: 1–5
- Parent T.C., Chmiel R., Jerger J. Comparison of performance with frequency transposition hearing aids and conventional hearing aids. Am J Audiol 1997; 8(5)355–365
- Pittman A.L. Short-term word-learning rate in children with normal hearing and children with hearing loss in limited and extended high-frequency bandwidths. J Speech Hear Res 2008; 51(3)785–797
- Pittman A.L., Stelmachowicz P.G. Perception of voiceless fricatives by normal-hearing and hearing-impaired children and adults. J Speech Hear Res 2000; 43: 1389–1401
- Pittman A.L., Stelmachowicz P.G., Lewis D.E., Hoover B.M. Spectral characteristics of speech at the ear: Implications for amplification in children. J Speech Hear Res 2003; 46(3)649–657
- Plyler P.N., Fleck E.L. The effects of high-frequency amplification on the objective and subjective performance of hearing instrument users with varying degrees of high-frequency hearing loss. J Speech Hear Res 2006; 49(3)616–627
- L.G Portney. & Watkins, M.P. 2000. Foundations of Clinical Research: Applications to Practice. New Jersey: Prentice Hall Health.
- Raffin M.J., Thornton A.R. Confidence levels for differences between speech-discrimination scores: A research note. J Speech Hear Res 1980; 23(1)5–18
- Robinson J., Baer T., Moore B.C.J. Using transposition to improve consonant discrimination and detection for listeners with severe high-frequency hearing loss. Int J Audiol 2007; 46: 293–308
- Scollie S., Seewald R., Cornelisse L., Moodie S., Bagatto M.P., et al. The desired sensation level multistage input/output algorithm. Trends in Amplif 2005; 9(4)159–197
- Simpson A., Hersbach A.A., McDermott H.J. Improvements in speech perception with an experimental nonlinear frequency compression hearing device. Int J Audiol 2005; 44: 281–292
- Simpson A., Hersbach A.A., McDermott H.J. Frequency-compression outcomes in listeners with steeply sloping audiograms. Int J Audiol 2006; 45: 619–629
- Stelmachowicz P.G., Pittman A.L., Hoover B.M., Lewis D.E. Effect of stimulus bandwidth on the perception of /s/ in normal and hearing-impaired children and adults. J Acoust Soc Am 2001; 110(4)2183–2190
- Stelmachowicz P.G., Pittman A.L., Hoover B.M., Lewis D.E. Aided perception of /s/ and /z/ by hearing-impaired children. Ear Hear 2002; 23(4)316–324
- Stelmachowicz P.G., Pittman A.L., Hoover B.M., Lewis D.E., Moeller M.P. The importance of high-frequency audibility in the speech and language development of children with hearing loss. Arch Otolaryngol Head Neck Surg 2004; 130(5)556–562
- Studebaker G.A., McDaniel D.M., Sherbecoe R.L. Evaluating relative speech recognition performance using proficiency factor and rationalized arcsine differences. J Am Acad Audiol 1995; 6(2)173–182
- Tenhaaf, J.J. & Scollie, S.D. 2005. Normative threshold levels for a calibrated, computer-assisted version of the Ling six-sound test. Canadian Acoustics.
- Turner C.W., Henry B. Benefits of amplification for speech recognition in background noise. J Acoust Soc Am 2002; 112: 1675–1680
- Turner C.W., Hurtig R.R. Proportional frequency compression of speech for listeners with sensorineural hearing loss. J Acoust Soc Am 1999; 106(2)877–886
- Vickers D.A., Moore B.C., Baer T. Effects of low-pass filtering on the intelligibility of speech in quiet for people with and without dead regions at high frequencies. J Acoust Soc Am 2001; 110(2)1164–1175