
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Objective
The aim was to create and validate an audiovisual version of the German matrix sentence test (MST), which uses the existing audio-only speech material.
Design
Video recordings were recorded and dubbed with the audio of the existing German MST. The current study evaluates the MST in conditions including audio and visual modalities, speech in quiet and noise, and open and closed-set response formats.
Sample
One female talker recorded repetitions of the German MST sentences. Twenty-eight young normal-hearing participants completed the evaluation study.
Results
The audiovisual benefit in quiet was 7.0 dB in sound pressure level (SPL). In noise, the audiovisual benefit was 4.9 dB in signal-to-noise ratio (SNR). Speechreading scores ranged from 0% to 84% speech reception in visual-only sentences (mean = 50%). Audiovisual speech reception thresholds (SRTs) had a larger standard deviation than audio-only SRTs. Audiovisual SRTs improved successively with increasing number of lists performed. The final video recordings are openly available.
Conclusions
The video material achieved similar results as the literature in terms of gross speech intelligibility, despite the inherent asynchronies of dubbing. Due to ceiling effects, adaptive procedures targeting 80% intelligibility should be used. At least one or two training lists should be performed.
1. Introduction
Speech audiometry is an essential element in audiology (Talbott and Larson Citation1983; Sanchez Lopez et al. Citation2018). It assesses the ability to understand speech acoustically, which is crucial for human communication. The matrix sentence test (MST) (Wagener and Brand Citation2005) is a well-established method in speech audiometry, and it exists in several languages (Kollmeier et al. Citation2015). MSTs use sentences of five words with a "noun–verb–number–adjective–object" structure. There are 10 possible words for each word category (e.g. 10 nouns, 10 verbs, etc.); these are combined to create semantically unpredictable, syntactically correct sentences. Lists of 20 sentences are commonly used to test speech intelligibility.
Although speech can be understood through sounds only, it is a multimodal process. Being able to see the speaker provides additional cues such as lip movements, which make speech much easier to understand (Sumby and Pollack Citation1954). Audiovisual speech perception has been mentioned as a predictor of real-world hearing disability (Corthals et al. Citation1997) but it is usually not considered in audiometry (Woodhouse et al. Citation2009). Visual information supports speech intelligibility, particularly severely impaired listeners are relying on visual information in adverse listening conditions (Schreitmüller et al. Citation2018). The MST is also intended as a speech test for severely impaired listeners, therefore an audiovisual version is an important extension for its applicability. Nevertheless, audiovisual (or auditory–visual) MSTs with video recordings have only been developed in Malay, New Zealander English, and Dutch (Trounson Citation2012; Jamaluddin Citation2016; Van de Rijt et al. Citation2019).
The ability to speechread (most commonly known as lipreading) plays a key role in audiovisual speech tests. In particular, audiovisual MSTs are highly affected by speechreading ability. In the Malay MST (Jamaluddin Citation2016) young, normal-hearing participants scored from 25% to 85% speech reception just by speechreading, i.e. in the visual-only condition. Such visual-only scores indicate that participants are able to understand speech without any acoustic cues. This means that there is a ceiling effect in the audiovisual MSTs: even if speech is completely masked by noise and not heard, participants achieve their visual-only score.
Recording and validating an MST is quite an extensive undertaking: selection of the phonetically balanced speech material, recording of the speech, cutting and processing of the sound files, making each word equally intelligible to the others, evaluation, and validation (Kollmeier et al. Citation2015).
To reduce cost and effort in the creation of an audiovisual MST from scratch, existing audio-only MST can be reused. Because audio-only MSTs already exist and have been used extensively, it is reasonable to reuse the audio material in audiovisual tests. New audio recordings cannot be compared directly to other recordings of the same language, as the speaker influences the intelligibility of the MST (up to 6 dB differences between talkers) (Hochmuth et al. Citation2015). Reusing the audio material ensures validity across studies, and saves time and effort. If the audio recordings are newly created, they need to be optimised to allow for a steep intelligibility function (a prerequisite for an accurate test), which includes measuring the intelligibility functions for each word of the test in a large number of participants. This would multiply the effort in comparison to producing dubbed videos.
One approach that has been proposed uses virtual characters with lip-synchronisation together with existing audio-only speech tests (Devesse et al. Citation2018; Schreitmüller et al. Citation2018; Grimm et al. Citation2019). The advantage of virtual characters is that they can be set in different configurations with relatively little effort (Llorach et al. Citation2018). The proposed approach in this paper is to create video recordings dubbed with existing audio for speech tests. A video recording usually provides better quality and realism than a virtual character. Nevertheless, asynchronies between the audio and the video have to be kept below 45 ms (audio ahead) and 200 ms (audio delayed) to pass unnoticed (Baskent and Bazo Citation2011) and not affect speech intelligibility (Grant, Wassenhove, and Poeppel Citation2003). Additionally, further considerations must be taken into account, such as the head movements and facial expressions of the speaker (Jamaluddin Citation2016).
One of the advantages of MSTs is that the sentences are unpredictable and there are too many word combinations to be memorised, so consecutive tests in different conditions can be carried out. Nevertheless, the simple sentence structure and the limited number of words enable participants to learn and improve their results. This training effect has already been shown in audio-only MSTs (Wagener, Brand, and Kollmeier Citation1999; Ahrlich Citation2013) and is particularly noticeable in the first list of 20 sentences, where differences in SRTs of about 1 dB are expected. After 2–4 lists, there is usually an absolute improvement of 2 dB, and the training effects in the following lists are quite small. In audiovisual MSTs, it is expected that participants further improve their SRTs by becoming familiar with the speaker and the visual material (Lander and Davies Citation2008) and because training effects have been found to be stronger in audiovisual speech (Lidestam et al. Citation2014).
Another factor to take into account is the response format of the MST. After hearing a sentence, participants either repeat what they heard (open-set response format) or select the answers from all possible words (closed-set response format). In the open-set format, a researcher must be present to assess whether the answer is correct, while in the closed-set format, participants can do the test by themselves. The closed-set format may give participants an advantage, since they are provided with a list of all possible words; in fact, SRTs have been found to be lower with closed-set type in some MSTs (Hochmuth et al. Citation2012; Puglisi et al. Citation2014), although not for German and other languages (Kollmeier et al. Citation2015). Whether such effects appear in audiovisual MSTs has not yet been investigated.
In this work, we created an audiovisual version of the female German MST (AV-OLSAf). We recorded videos with a female speaker, dubbed them with the original sentences of the female speaker (Ahrlich Citation2013; Wagener et al. Citation2014) and evaluated the material. Our first contribution is the methodology for producing the dubbed videos and getting the best synchronised video recordings. The final video recordings for the AV-OLSAf can be found in Llorach et al. (Citation2020). Our second contribution is the evaluation of the AV-OLSAf with normal-hearing listeners in different conditions: we show the audiovisual training effects in the open-set and closed-set responses; we discuss the speechreading scores and the effects of speechreading in the audiovisual SRTs; and we compare the audio-only and audiovisual SRTs in noise and in quiet conditions. To conclude, we discuss the implications and recommendations for using the AV-OLSAf.
2. Method
2.1. Recording the video material
Although in theory there are 100,000 possible sentences (5 word categories with 10 words per category, ), the female OLSA uses only 150 predetermined sentences. This relatively small number of sentences permitted us to record videos of the spoken sentences in a single afternoon. We were able to recruit the same speaker that recorded the audio-only version of the German female MST (OLSA) (Ahrlich Citation2013; Wagener et al. Citation2014). She was a speech therapist and a singer. During the recording session, the speaker had to speak the sentences simultaneously while hearing them through an earphone on the right ear. Each sentence was played five times consecutively. Three short "beep" signals were given before each repetition started. The first repetition was used as a reference: the speaker was to listen only to know what sentence was coming. In the remaining four repetitions, she was to speak simultaneously while hearing the sentence.
Table 1. Set of words used in the German matrix sentence test.
The videos of the female speaker were recorded in the studio of the Media Technology and Production of the CvO University of Oldenburg. The available lights of the studio were set up to achieve a homogeneous illumination of the face and of the background green chroma key. The videos were recorded with a Sony α7S II camera at 50 pfs/full HD, and a condenser microphone in front of the speaker at the height of the knees. The speech was recorded in one channel with a 48 kHz sampling rate and a 16 bit linear pulse-code modulation (LPCM) sample format. An image sample of the final video recordings is shown in .
Figure 1. Example of a frame of the video material.
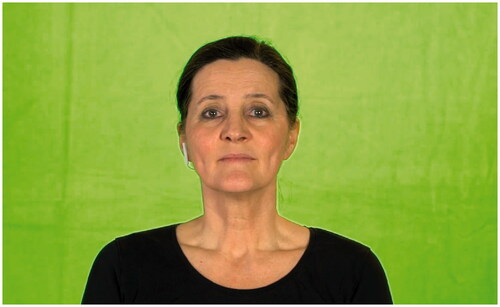
A computer was used to reproduce the original OLSA sentences, which at the same time was sending a linear time code (LTC) signal to the second audio channel of the camera. This way, the recorded speech of the session and the original sentences could be synchronised. The recording session lasted around 2 h in total.
2.2. Selection of the videos
We manually discarded videos in which the speaker smiled or showed other non-neutral facial expressions. The recorded speech signals were synchronised to the reproduced original sentences using the LTC signal. When dubbing speech, there are inevitable asynchronies: time offsets (words spoken too early or too late) and/or words spoken slower or faster than the original words. As all these asynchronies could happen in one single sentence, we used dynamic time warping (DTW) (Sakoe and Chiba Citation1978) to find the best match between the recordings and the original sentences. The DTW quantified the temporal misalignment between the original and recorded sentences. The algorithm compares two temporal signals and provides a warping path. We computed the mel spectrograms of the signals and used them for the DTW function. The mel spectrograms were done using frame windows of 46 ms with a frame shift of 23 ms. An example of the mel spectrograms and the corresponding warping path can be seen in . Once the warping path was calculated, we used EquationEquations (1)(1)
(1) and Equation(2)
(2)
(2) to compute the asynchrony score:
(1)
(1)
(2)
(2)
Figure 2. Mel spectrogram of original sentence and one of the four recordings of that sentence.
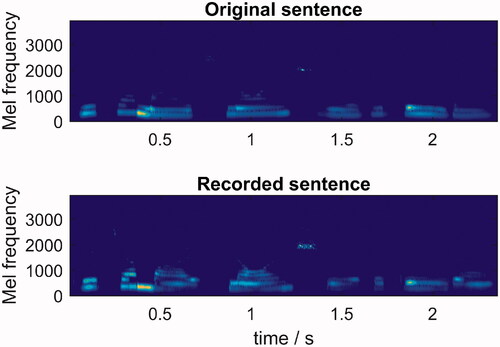
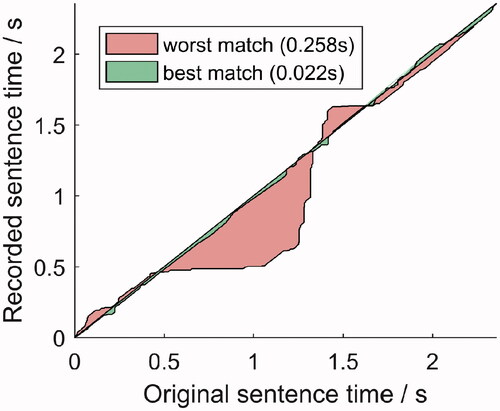
Figure 3. Warping path between the original and two recorded sentences. The best match and the worst match are shown. The size of the shaded surface corresponds to the asynchrony score.
for (original sentence number) and
(recording nº per original sentence) where the
is the mel spectrogram of the original sentence
is the mel spectrogram of its corresponding recording (4 recordings
per sentence
),
is the frame number of the
is the frame number of the
is the warping path between the mel spectrograms in frames,
is the difference in frames,
is the root mean square, and
is the asynchrony score between the ith original sentence and the jth recording of that sentence. The RMS was used because it represents the asynchrony score over a whole sentence. As our main interest is the speech intelligibility of the whole sentence, we did not consider momentary asynchronies, such as maximum asynchrony, as a measure to choose the best video recording. The asynchrony score can be further expressed in seconds instead of frames, as it represents a temporal difference.
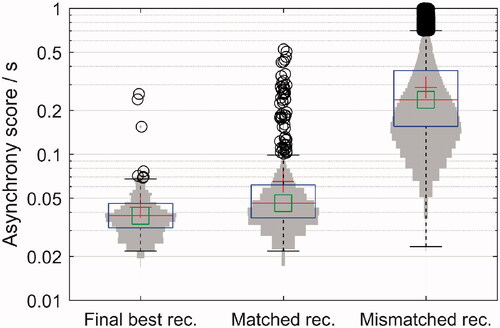
We checked the sensitivity of this measure by comparing each recording to its corresponding original sentence and to the remaining unmatching original sentences (). For each original sentence, we chose the video recording with the smallest asynchrony score. Of the final best selections, we found three outliers, with asynchrony scores greater than 80 ms, that had to be manually corrected with time offsets. Once corrected, these outliers were shown to 5 normal-hearing participants along with the best-matched sentences; the outliers could not be distinguished from the best-matched sentences and no asynchronies were noticed. We decided that the mean asynchrony score was small enough (∼40 ms) to minimise the perceptual asynchrony/dubbing effects when measuring speech intelligibility with lists of 20 sentences: in Grant, Wassenhove, and Poeppel (Citation2003), the authors evaluated the speech intelligibility of different timing misalignments with video and audio. According to them, visual asynchronies from −45 ms to +200 ms are not perceivable and speech recognition does not decline. Therefore, we proceeded with the evaluation of the material. The asynchrony score, maximum asynchronies and asynchrony over time of each sentence can be found in Table S1 in the Supplementary material. The final video recordings can be found in Llorach et al. (Citation2020).
Figure 4. Asynchrony scores comparing the original sentences and their best-matched recordings before manual correction of the three outliers (left; 150 scores), the original sentences and all 4 of their recordings (middle; 600 scores) and the original sentences and the mismatched recordings (right; 150 × 149 × 4 scores). The vertical axis is on a logarithmic scale. The mean is represented as a red cross and the median as a green square. The outliers are depicted with black circles.
2.3. Evaluation of the audiovisual material
2.3.1. Participants
Twenty-eight normal-hearing participants (14 female, 14 male) took part in the evaluation measurements. Their ages ranged from 20 to 29 years (mean age 24.9 years). They had normal or corrected-to-normal vision and their pure tone averages (PTAs) in the better ear were between −5 and 7.5 dB HL (mean −0.31 dB HL). The PTAs were computed using the frequencies 0.5, 1, 2 and 4 kHz. Participants were recruited through the database of the Hörzentrum Oldenburg GmbH and were paid an expense allowance. Permission was granted by the ethics committee of the CvO University of Oldenburg.
2.3.2. Setup
Participants were seated in a chair inside a soundproof booth. The evaluation measurements were done using binaural headphones (Sennheiser HDA 200). A 22 in. touchscreen display with full HD (ViewSonic TD2220, ViewSonic Corp., Walnut, CA) was placed in front of the participant within arm's reach at a height of 0.8 m. The experiment was programmed in Matlab2016b. The videos and original sentences were reproduced with VLC 3.03. The acoustic signal was routed with RME Total Mix with an RME Fireface 400 sound card.
The acoustic levels were calibrated using a sound level metre placed at the approximate head position where participants would be seated. The sound and video reproduction was calibrated for synchronisation using an external camera. For this purpose, we reproduced a video with frame numbering together with a LTC signal using the experiment setup. The external camera recorded the display screen of the experiment. The LTC signal was connected directly to the external camera instead of the headphones. Using the recording of the external camera we found a consistent asynchrony of 80 ms, which we corrected by delaying the audio signal in the experiment setup.
2.3.3. Stimuli
The acoustic stimulus was the female version of the German MST (OLSA) (Ahrlich Citation2013; Wagener et al. Citation2014) and the visual stimuli was the best-matched video recording (see Section Selection of the videos). For the conditions with noise, we used continuous test-specific noise (TSN) based on the female speech material. The presentation level of the noise was kept constant at 65 dB SPL. The speech level of the first sentence was 60 dB SPL for conditions with and without noise. The adaptive procedure used varied the speech presentation level depending on the responses of the participant.
2.3.4. Conditions
There were nine conditions in the experiment (see ). Each condition used a list of 20 sentences. The sentences in each list were predefined by the MST. In total, we used 45 different predefined lists. The speech presentation levels were adapted after each sentence to reach an individual SRT of 80%, i.e. 4 out of 5 words correctly recognised per sentence. During the open-set response format, participants were asked to repeat orally what they understood after each sentence. In the closed-set response format, participants chose the words they understood from an interface displayed on the touch screen after stimulus presentation. The closed-set interface showed all 50 possible words plus one no-answer option per word category. In the visual-only condition (VONoiseClosed), there was no acoustic speech but only test-specific noise at 65 dB SPL. In this condition, the speech could only be understood through speechreading. For this condition, the percentage of correct words per sentence was averaged over 20 sentences (a list). In all conditions, no feedback was given about correctness of responses.
Table 2. Conditions tested for the evaluation and validation of the AV-OLSA.
2.3.5. Adaptive procedure
We chose a SRT of 80% to avoid ceiling effects in audiovisual conditions due to the visual-only contribution, i.e. some participants might be able to understand more than 50% of the content just by speechreading (Trounson Citation2012; Jamaluddin Citation2016; Van de Rijt et al. Citation2019). The adaptive procedure used in this experiment is described in Brand and Kollmeier (Citation2002) and in Brand et al. (Citation2011). It is an extended staircase method that changes its step size depending on the responses. The change in the presentation level is done in two stages. The first stage follows the equation presented in Brand and Kollmeier (Citation2002):
(1)
(1)
where
is the increment level, prev is the current result, tar is the target value, and slope is set to 0.1 dB−1 in this study. The function f(i) defines the convergence rate, where i is the number of reversals in the presentation level, i.e. i increases every time the participant goes from being above/below threshold. In our study the current result is the discrimination value of the previous sentence and the target value is 0.8 (80% SRT). The value of f(i) is defined by 1.5/1.41i and its set to 0.25 for
The step size gets smaller when the participant crosses the target value. The second stage is described and examined in Brand et al. (Citation2011). In this second stage, the step size is multiplied by 2 when two conditions are met: the step is a decrement (it lowers the presentation level) and f(i) is bigger than 0.5. This last condition is usually met in the first sentences of a list.
(2)
(2)
The final level estimate of a list is computed using a maximum-likelihood method and discrimination function described in Brand and Kollmeier (Citation2002).
2.3.6. Training
We added training lists prior to evaluating the nine conditions to assess the training effects of the AV-OLSA. We also tested the participants in two different sessions (test, retest). In the first session, 4 audiovisual lists were presented in noise (80 sentences in total). Participants were randomly assigned to do the 4 training lists in open-set or closed-set formats (AVNoiseClosed or AVNoiseOpen); 13 participants completed the training in the closed-set format and 15 participants in the open-set format. In the second session, the training was a single list with the same format as the first session (20 sentences in AVNoiseClosed or AVNoiseOpen).
2.3.7. Procedure
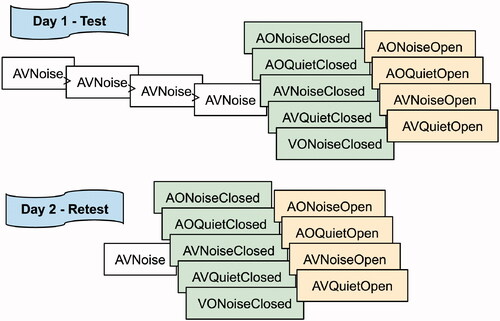
For the test lists, participants started with the same response format (open-set or closed-set) as in the training. Next, they did the conditions with the opposite response format. The conditions of one response format were presented in pseudo-randomized order (). On the retest session, participants performed a training list with the same response format as on training lists of the first session; then they continued with the conditions with that same format before doing the ones with the other format, as on the test session. The test and retest sessions were temporally spaced from 1 day to 2 weeks.
Figure 5. Ordering of the lists in the test and retest sessions. Conditions stacked in columns were pseudo-randomized within the column. If the participants were trained in AVNoise with the open-set format, they performed the open-set format lists before the closed-set lists; if they were trained with the closed-set format, they proceeded with the closed-set format lists before doing the open-set lists.
3. Results
For each list, a final level estimate was computed as described in Section Adaptive procedure. This value, i.e. the SRT at 80%, was expressed in dB SNR for the conditions in noise and in dB SPL for the conditions in quiet. For the VONoiseClosed lists, it was different: the percentage of words understood over all 20 sentences was computed (i.e. the speechreading score). For each participant there were 5 audiovisual training lists, 4 in the first session and 1 in the second session, and 18 test lists, 9 in each session (see ). For the analysis of the results, we removed an outlier of +9 dB SNR belonging to an AONoiseClosed list of the first session (test).
3.1. Training effects
In general, audiovisual SRTs tended to improve across lists. shows the mean SRTs during the training lists, and the test and retest for the audiovisual in noise condition. In the aforementioned figure, the participants and its SRTs are separated in two groups depending on the training response format (open versus closed). On an average, participants improved their SRTs by −1.6 dB SNR on their third training list. The total improvement between the first training list and the test list was −2.9 dB SNR. On the second session, participants retained the same SRT scores in the training as in their last list of the first session. SRTs improved further on the list of the retest session, by −3.8 dB SNR relative to the first training list of the first session. shows that there was a consistent difference of ∼1.8 dB SNR between the mean SRTs of the open-set and closed-set lists.
Figure 6. Audiovisual training effects. The average and the standard deviation of SRTs over groups are shown. The black dashed line with circles shows the SRTs of the 13 participants that did the training in closed response format. The continuous grey line with whiskers shows the SRTs of the 15 participants that did the training in open response format. It should be noted that, due to the other measurement conditions, there could be up to 4 lists in between the Training 4 and Test lists and between Training Retest and Retest lists.
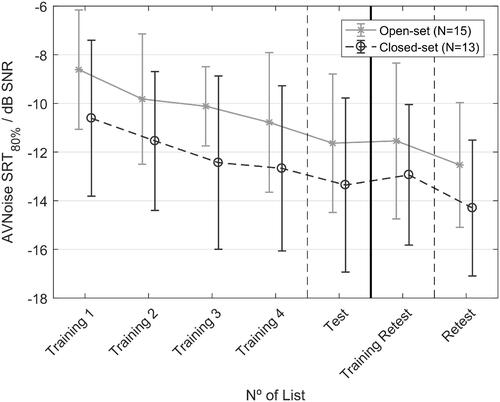
A repeated-measures ANOVA was performed with response format as the between-subjects factor (open versus closed) and position within the initial training lists (1st, 2nd, 3rd, and 4th training list) as the within-subjects factor. The dependent variable was the SRT. The sphericity assumption had not been violated according to Mauchly’s test (χ 2(5) = 2.33; p = 0.80). A significant main effect was found for the within-subjects factor (training list order) (F(3, 78) = 10.96; p < 0.001). No significant effect was found for the between-subjects factor (response format in the training lists) (F(1, 26) = 4.17; p = 0.052), although it was close to being significant. No significant interaction was found between the training list’s position and the response format (F(3, 78) = 0.21; p = 0.82). Multiple comparisons with Bonferroni corrections showed that the SRT of the first list was significantly different from the SRTs of the other three. The SRTs of the second, third and fourth list did not differ significantly.
3.2. Audio-only and audiovisual SRTs
Mean SRTs and standard deviations of the lists for the different conditions are shown in . In the table, test and retest SRTs are grouped together per condition. The average SRT differences between audio-only and audiovisual lists were 5.0 dB SNR for speech in noise and 7.0 dB SPL in quiet. The listeners' PTAs were not significantly correlated with the audio-only in quiet scores (Pearson’s r = 0.15, p = 0.11).
Table 3. Mean audio-only and audiovisual SRTs and between-subjects standard deviations in the test and retest sessions (56 scores per cell).
3.3. Ceiling effects
Participants reached SNRs below −20 dB and speech presentation levels below 0 dB SPL (no sound pressure) in the audiovisual conditions. At these levels, there is no contribution of acoustic information to speech reception: the speech detection threshold for the female OLSA is around −16.9 dB SNR in audio-only tests with TSN (Schubotz et al. Citation2016), a threshold that can be theoretically lowered by around −3 dB when adding visual speech (Bernstein, Auer, and Takayanagi Citation2004). Therefore, below these thresholds (−20 dB SNR and 0 dB SPL), participants used only visual speech in this experiment, i.e., they were speechreading. In consequence, the scores below these thresholds do not represent audiovisual speech perception, but rather visual-only. shows that during the adaptive procedure, participants could reach levels where there was no acoustic contribution.
Figure 7. Adaptive SNRs and speech presentation levels for AVQuiet (top) and AVNoise (bottom) conditions. The adaptive procedure changed the speech levels to reach 80% intelligibility. Below the horizontal line at 0 dB SPL (top) and at -20 dB SNR (bottom), participants understood speech using only visual cues. Each line shows a single list, adding up to 4 lines per participant in each subfigure.
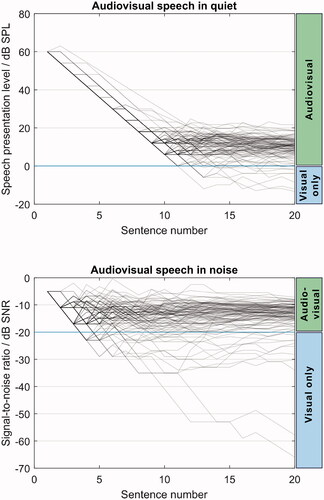
For the analysis of the data, we decided to limit the values that were below the acoustic speech detection thresholds, as they were not representative of audiovisual speech reception. In total, 18 out of 364 SRTs of audiovisual lists (5%) were modified by limiting them to −20 dB SNR for speech in noise and 0 dB SPL for speech in quiet. We decided to include these scores as they were representing the best speechreading scores. The lists affected had varied conditions: of the 18 lists, 3 were training lists, 5 AudiovisualNoiseOpen, 5 AudiovisualNoiseClosed, 3 AudovisualQuietOpen, and 2 AudiovisualQuietClosed. Of the 28 participants, 6 were able to go below the speech detection thresholds.
3.4. Speechreading and audiovisual benefit
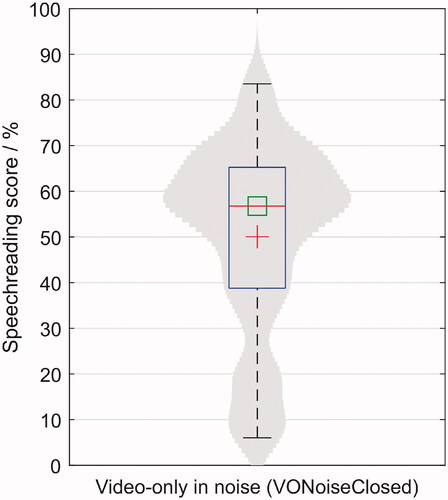
Participants had a wide range of speechreading abilities. The individual VONoiseClosed scores ranged from 0% to 84% intelligibility, had an average of 50% and a standard deviation of 21.4%. shows the distribution of the visual-only scores. There was an average intelligibility improvement of 6.1% in the retest over the test session, although not all participants improved their scores.
Figure 8. Boxplot and distribution of the speechreading scores. In this figure, each participant has a data point: the average word scoring percentage over 40 sentences. The mean and the median are represented as a red cross and a green square, respectively.
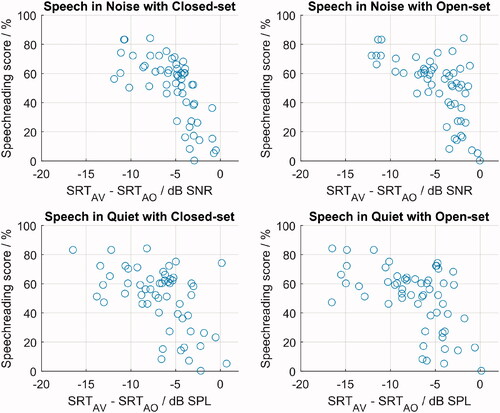
Speechreading scores were correlated with the audiovisual benefit (i.e. the SRT difference between audiovisual and audio-only condition). This correlation can be seen in , where the visual-only scores are plotted against the individual SRT benefits in different conditions. The Pearson’s r correlation scores between the speechreading scores (VONoiseClosed) and the audiovisual benefits were −0.76 (p < 0.001) for AVNoiseClosed minus AONoiseClosed, −0.69 (p < 0.001) for AVNoiseOpen minus AONoiseOpen, −0.65 (p < 0.001) for AVQuietClosed minus AOQuietClosed, and −0.65 (p < 0.001) for AVQuietOpen minus AOQuietOpen. Participants that were good speechreaders gained more from having visual information in the audiovisual lists. Whether participants were trained in open-set or closed-set formats did not make any difference for the audiovisual benefit.
Figure 9. Speechreading scores (VONoiseClosed) shown against the audiovisual benefit of each participant; each participant has two circles per plot for test and retest lists. Top left: audiovisual benefit in noise with closed-set response. This condition was the most similar to the visual-only condition, as both had noise and a closed-set format. Top right: audiovisual benefit in noise with open-set format. Bottom: audiovisual benefit in quiet with closed-set (left) and open-set formats (right).
3.5. Test–retest differences
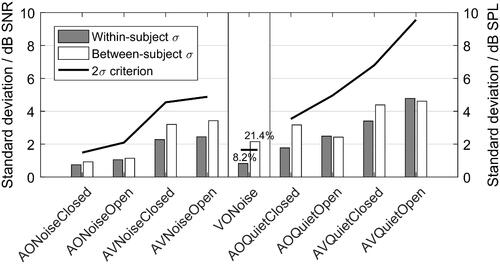
The within-subject and the between-subject standard deviations of the SRTs are shown in . The standard deviations of the within-subject differences (test minus retest) are shown as grey bars. The between-subjects standard deviations are shown as white bars. The 2σ criterion is shown as a thick black line. The 2σ criterion represents the threshold where it is possible to differentiate significantly between individuals: if the between-subject standard deviation is higher than the double of the within-subject standard deviation, i.e. the 2σ criterion, it means that it is possible to differentiate significantly between subjects (Wagener and Brand Citation2005). None of the conditions but the VONoise exceeded the 2σ criterion. The audiovisual conditions had a higher within-subject and between-subject variability in comparison to their respective audio-only conditions.
Figure 10. Within-subject (grey bars) and between-subject (white bars) standard deviations for all conditions. The 2σ criterion is indicated as a thick black line. On the left, STDs of speech in noise conditions expressed in dB SNR; on the middle, STDs of the speechreading scores expressed in percentage; and on the right, STDs of speech in quiet expressed in dB SPL.
4. Discussion
4.1. Validity of the video material
The audio-only and audiovisual scores found were similar to those expected based on the literature. A difference of 3 dB between audio-only and audiovisual scores was reported previously (Van de Rijt et al. Citation2019), whereas we found a difference of more than 5 dB in the equivalent conditions. This difference could arise from the specific speaker, as some speakers are easier to speechread than others (Bench et al. Citation1995), or from language differences (Kollmeier et al. Citation2015).
The results of the audiovisual MST were in concordance with the literature, thus validating the video material for measuring speech reception thresholds using lists of 20 sentences. Nevertheless, due to the inherent dubbing asynchronies, the material presented here might not be suitable for investigating fine-grained effects of audiovisual interactions. Audiovisual asynchronies can detriment speech perception (Grant, Wassenhove, and Poeppel Citation2003), but we believe that these asynchronies did not affect severely the results. In another publication (Llorach and Hohmann Citation2019), the data of this study were analysed on a word level. Speech intelligibility detriments due to dubbing asynchronies were not looked at, but it was shown that if a word was harder to understand in the audiovisual version it was because this word was hard to speechread. In other words, audiovisual benefits and detriments were explained in Llorach and Hohmann (Citation2019) by how easy to speechread a word was.
In our study, participants were not specifically asked about audiovisual asynchronies in the audiovisual material during the evaluation, and none reported any temporal artefacts.
4.2. Advantages of optimized and validated audio material
As mentioned in the Introduction, one of the advantages of using existing audio material is that it maintains the validity of acoustic speech. For example, Van de Rijt et al. (Citation2019) reported a large variability in intelligibility across words, which probably arose because the word acoustic levels were not balanced and optimised, as is usually done in MSTs. Nevertheless, this does not mean that a non-optimised MST is not usable: MSTs without level adjustments (Nuesse et al. Citation2019) are used in research and can be used to evaluate speech recognition thresholds with almost the same precision.
Another advantage of using existing audio material is that it makes the recording procedure simpler. Limiting the final number of sentences (150) simplifies and speeds up the recording process. Jamaluddin (Citation2016) did not have a final selection of sentences, and so they created all 100,000 possible sentences by re-mixing 100 recorded sentences. During the recording session, they had to ensure that the speaker's head was in the same physical position so that the videos could be cut and blended without artefacts. For this purpose, they had to fabricate a head-resting apparatus to keep the head in the same position. The material required an additional evaluation step to validate the re-mixed recordings, resulting in 600 final sentences.
Another possible solution for creating visual speech, and one that offers more flexibility and control, is animated virtual characters. Ideally, the virtual character's lip-syncing should achieve the same intelligibility scores as the videos of real speakers. Some of the current virtual characters used in audiological research improve speech intelligibility. Schreitmüller et al. (Citation2018) used the German MST with virtual characters: CI and NH participants achieved 37.7% and 12.4% average word scoring in the visual-only condition, respectively. These values are below the scores we found in this study (50%), but they cannot be compared directly because we only considered young normal-hearing listeners. Similarly, Grimm et al. (Citation2019) used the German MST with virtual characters and compared it to the material presented here (AV-OLSAf), but no SRT improvements were found. Devesse et al. (Citation2018) reported an SRT improvement of 1.5–2 dB SNR with virtual characters, while we found a 5 dB SNR improvement; the speech material in that study was different from ours and thus cannot be compared directly.
For each research application, one has to find the best compromise when creating audiovisual MSTs. For some, it might be enough to use synthetic speech and virtual characters with lip-sync, whereas others might need audiovisual synchronous recordings with balanced word acoustic levels. We found that dubbed videos were the most cost-effective solution for the research applications in our laboratory and that it might be a useful technique for others to measure gross audiovisual speech intelligibility.
On a side note, we would like to encourage audiovisual MSTs as a tool for evaluating the lip-syncing animations of virtual characters. Most current research in lip animation and visual speech does not consider human–computer communication and speech understanding in their evaluation procedures (Taylor et al. Citation2017; Jamaludin, Chung, and Zisserman Citation2019).
4.3. Speechreading
The ceiling effects found in the audiovisual MST resulted from the visual speech contribution. These ceiling effects change how the audiovisual MST can be tested. Some participants achieved scores up to 84% just by speechreading. If the audiovisual MST is tested with an adaptive procedure targeting 50% SRT, there will be quite some participants that will be able to speechread half the material without using acoustic information.
Even at 80% SRT, we found few participants that could achieve SNRs were the sentences are not audible anymore. Excluding these data points would have been equivalent to removing the best audiovisual scores. But keeping them as they were would have led to unrealistic audiovisual SNR benefits (some participants reached scores below −60 dB SNR in audiovisual lists). We decided that limiting these values to the level were acoustic information disappears was the best trade-off. Another sensible approach would be to use the median SNR instead of the mean.
These effects could be because the limited set of words in the MST is easy to learn, to differentiate visually, and to speechread. Additionally, because there are only 150 possible sentences, some participants might memorise some of them after several repetitions. However, it is rather difficult to memorise the sentences because of their syntactical structure with low context (Bronkhorst, Brand, and Wagener Citation2002). In sentences for which participants have no previous knowledge of content, one would expect lower speechreading scores, of around 30% (Duchnowski et al. Citation2000; Fernandez-Lopez and Sukno Citation2017). Nevertheless, it can be argued that having some expectations about sentence content is probably closer to a real-life conversation.
Another possible factor is that the female speaker was easy to speechread. Additionally, Bench et al. (Citation1995) reported that young female speakers were judged to be easier to speechread than males and older females. We did not make a selection of speakers, as we wanted to have the same person that recorded the audio-only MST. Furthermore, female speakers have been recommended as a compromise between the voice of an adult male and a child (Akeroyd et al. Citation2015), so this was a reasonable starting point. Selecting speakers that are more difficult to speechread would probably reduce the ceiling effects.
An interesting alternative to audiovisual MSTs would be to develop a viseme-balanced MST. The audio-only MST is designed to be phonetically balanced, but this does not mean that the visual speech is balanced, as each phoneme does not necessarily correspond to a viseme (Taylor et al. Citation2012, July). Visual cues were previously reported to affect word intelligibility and word error for the AV-OLSAf (Llorach and Hohmann Citation2019), demonstrating that acoustic speech and visual speech provide different information. Therefore it is possible that the visual speech found in the current MST sentences is not representative of the language tested. Language-specific viseme vocabularies (Fernandez-Lopez and Sukno Citation2017) should be developed for this purpose.
That the audiovisual lists were correlated with the speechreading scores was expected (MacLeod and Summerfield Citation1987; Summerfield Citation1992; Van de Rijt et al. Citation2019). The better a participant was at speechreading, the less acoustic information he or she needed to understand speech. This correlation was present in noise and in quiet conditions; the audiovisual benefit was therefore resilient to the acoustic condition.
4.4. Training effects
An improvement of 2.2 dB SNR between the 1st and the 8th list at 50% speech reception is expected in audio-only MSTs (Ahrlich Citation2013). We found a ∼3 dB SNR improvement at 80% speech reception between the first training list and the test list; this additional dB probably arose from the participants learning to speechread the material and becoming familiarised with the speaker (Lander and Davies Citation2008). According to the statistical report, the training effect disappeared after one training list. Nevertheless, an average constant improvement was observed. This training effect was not reported in the audiovisual Dutch MST (Van de Rijt et al. Citation2019) after a familiarisation phase with the complete set of words and a training list of 10 audiovisual sentences.
4.5. Within- and between-subject variability
In the audio-only speech in noise SRTs, we found little within- and between-subject variability, which was expected, as all participants were young and did not have any hearing disability (Souza et al. Citation2007). Both within- and between-subject variability increased in the audio-only speech in quiet lists, which is expected in quiet conditions (Smoorenburg Citation1992). Hearing thresholds and noise-induced hearing loss are usually correlated with speech in quiet scores: the worse the hearing levels, the worse the speech intelligibility in quiet (Smoorenburg Citation1992). Nevertheless, we did not find this correlation in our study, probably because the PTAs were all very similar and we did not include hearing-impaired participants.
The speechreading scores were highly individual and diverse in a homogeneous group of participants, which was expected from the literature (Jamaluddin Citation2016; Van de Rijt et al. Citation2019). The test–retest analysis showed that the visual-only lists could differentiate significantly between individuals, meaning that the visual-only MST can assess the speechreading ability of an individual.
The larger between-subject variability found in audiovisual lists can be explained by individual speechreading abilities. If a participant had a high speechreading score, it would be reflected in its audiovisual score. Nevertheless, when looking at the test–retest differences, the within-subject variability in the audiovisual scores did not permit to differentiate between participants significantly. Why could the audiovisual MST not differentiate between participants in the audiovisual modality, given that they all had the same hearing abilities but very different speechreading scores? One possible explanation for the within-subject variability in the audiovisual condition is that the asynchronies of the audiovisual material reduced the test–retest reliability. Another plausible explanation is that the integration between two types of modalities (acoustic and visual) led to a variance that could not be accounted for, assuming that audiovisual integration is an independent modality (Grant Citation2002). Further research should look into the within-subject variability in audiovisual speech perception, as it cannot be derived from this study.
Audiovisual MSTs are particularly relevant for testing severe-to-profound hearing-impaired listeners in the clinic. These listeners cannot perform audio-only intelligibility tests and, therefore, the audiovisual MST would be useful for investigating whether hearing aid or cochlear implant provision improves their audiovisual speech comprehension. Additionally, the test provides information about the speechreading abilities of an individual. If the individual can speechread well, further recommendations could be provided to the patient for everyday-live situations, such as placing yourself in a position where you can see the mouth of the speakers.
We believe that our material can be used for clinical purposes, when taking into account aforementioned effects: to minimise ceiling effects, an 80% SRT is recommended; and at least one or two training list should be used to minimise training effects. Further research should evaluate the AV-OLSAf with hearing-impaired and elderly participants, as some effects are expected: hearing-impaired listeners tend to be better speechreaders (Auer and Bernstein Citation2007), and the ability to speechread decreases with age (Tye-Murray, Sommers, and Spehar Citation2007). Furthermore, the influence of the type of noise could change in the audiovisual version and should be investigated (Wagener and Brand Citation2005). Audiovisual integration needs to be further investigated with specific tests of audiovisual integration and different subject groups, as it has been suggested as an indicator of audiovisual speech intelligibility in noise, especially for those individuals with a hearing loss (Gieseler et al. Citation2020).
5. Conclusions
The method presented here keeps the validity of the original audio material while introducing concordant visual speech. Dubbed video recordings gave similar benefit in terms of gross speech intelligibility measures as naturally synchronous audiovisual recordings, according to literature data, and, thus, are applicable for our purposes of assessing audiovisual speech intelligibility scores. Other fine-grain effects of audiovisual interaction may not be accessible through the dubbed recordings.
The audiovisual MST suffers from ceiling effects, which are closely related to the speechreading abilities of the participant. These effects should be considered when designing experiments for audiovisual perception. High target SRTs such as 80% SRT are recommended instead of 50% SRT in adaptive procedures.
Audiovisual stimuli gave an SRT benefit of 5 dB SNR in test-specific noise and 7 dB SPL in quiet in comparison to audio-only stimuli for young, normal-hearing participants. Reference values for 80% SRT found in this study were −13.2 dB SNR for audiovisual speech in noise and 10.7 dB SPL for audiovisual speech in quiet.
At least one training list should be completed to avoid statistically significant training effects. These effects may continue after a certain number of training lists. It is, therefore, recommended that two training lists are used to evaluate an audiovisual condition.
Audiovisual SRTs correlated with speechreading abilities. The better participants could speechread, the more they benefitted in the audiovisual conditions.
The visual-only MST can be used to differentiate between the speechreading abilities of young normal-hearing individuals. Due to the variability in the audiovisual SRTs, we recommend including a visual-only condition when assessing audiovisual speech perception with the AV-OLSAf.
TIJA-2020-02-0060-File014.docx
Download MS Word (58.3 MB)Acknowledgements
The authors thank the Media Technology and Production of the CvO University of Oldenburg for helping out with the recordings. Special thanks to Anja Gieseler for giving feedback on the evaluation procedures and the manuscript and to Bernd T. Meyer for counselling on the video selection metric.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Ahrlich, M. 2013. Optimierung und Evaluation des Oldenburger Satztests mit weiblicher Sprecherin und Untersuchung des Effekts des Sprechers auf die Sprachverständlichkeit. Optimization and evaluation of the female OLSA and investigation of the speaker‘s effects on speech intelligibility. Bachelor thesis.
- Akeroyd, M. A., S. Arlinger, R. A. Bentler, A. Boothroyd, N. Dillier, W. A. Dreschler, J. P. Gagne, et al. 2015. “International Collegium of Rehabilitative Audiology (ICRA) Recommendations for the Construction of Multilingual Speech Tests: ICRA Working Group on Multilingual Speech Tests.” International Journal of Audiology 54 (Suppl 2): 17–22. doi:https://doi.org/10.3109/14992027.2015.1030513.
- Auer, Edward T., and Lynne E. Bernstein. 2007. “Enhanced Visual Speech Perception in Individuals with Early-Onset Hearing Impairment.” Journal of Speech, Language, and Hearing Research 50 (5): 1157–1165. doi:https://doi.org/10.1044/1092-4388(2007/080).
- Baskent, D., and D. Bazo. 2011. “Audiovisual Asynchrony Detection and Speech Intelligibility in Noise with Moderate to Severe Sensorineural Hearing Impairment.” Ear and Hearing 32 (5): 582–592. doi:https://doi.org/10.1097/AUD.0b013e31820fca23.
- Bench, J., N. Daly, J. Doyle, and C. Lind. 1995. “Choosing Talkers for the BKB/a Speechreading Test: A Procedure with Observations on Talker Age and Gender.” British Journal of Audiology 29 (3): 172–187. doi:https://doi.org/10.3109/03005369509086594.
- Bernstein, L. E., E. T. Auer, Jr, and S. Takayanagi. 2004. “Auditory Speech Detection in Noise Enhanced by Lipreading.” Speech Communication 44 (1–4): 5–18. doi:https://doi.org/10.1016/j.specom.2004.10.011.
- Brand, T., and B. Kollmeier. 2002. “Efficient Adaptive Procedures for Threshold and Concurrent Slope Estimates for Psychophysics and Speech Intelligibility Tests.” The Journal of the Acoustical Society of America 111 (6): 2801–2810. doi:https://doi.org/10.1121/1.1479152.
- Brand, T., S. Kissner, T. Jürgens, D. Berg, and B. Kollmeier. 2011. “Adaptive Algorithmen Zur Bestimmung Der 80%-Sprachverständlichkeitsschwelle. Adaptive Algorithms for Determining the 80% Speech Intelligibility Threshold.” Jahrestagung Der Deutschen Gesellschaft Für Audiologie, Jena 14: 4.
- Bronkhorst , A. T. Brand, and K. Wagener. 2002. “Evaluation of Context Effects in Sentence Recognition.” The Journal of the Acoustical Society of America 111 (6): 2874–2886. doi:https://doi.org/10.1121/1.1458025.
- Corthals, P., B. Vinck, E. D. Vel, and P. V. Cauwenberge. 1997. “Audiovisual Speech Reception in Noise and Self-Perceived Hearing Disability in Sensorineural Hearing Loss.” Audiology 36 (1): 46–56. doi:https://doi.org/10.3109/00206099709071960.
- Devesse, A., A. Dudek, A. van Wieringen, and J. Wouters. 2018. “Speech Intelligibility of Virtual Humans.” International Journal of Audiology 57 (12): 914–922. doi:https://doi.org/10.1080/14992027.2018.1511922.
- Duchnowski, P., D. S. Lum, J. C. Krause, M. G. Sexton, M. S. Bratakos, and L. D. Braida. 2000. “Development of Speechreading Supplements Based on Automatic Speech Recognition.” IEEE Transactions on Biomedical Engineering 47 (4): 487–496. doi:https://doi.org/10.1109/10.828148.
- Fernandez-Lopez, A., and F. M. Sukno. 2017. Automatic viseme vocabulary construction to enhance continuous lip-reading. In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2017), Vol. 5, pp. 52–63.
- Gieseler, A., S. Rosemann, M. Tahden, and K. Wagener. 2020. “Linking Audiovisual Integration to Audiovisual Speech Recognition in Noise.” Preprint. 1: 1–48. doi:https://doi.org/10.31219/osf.io/46caf.
- Grant, K. W. 2002. “Measures of Auditory-Visual Integration for Speech Understanding: A Theoretical Perspective (L).” The Journal of the Acoustical Society of America 112 (1): 30–33. doi:https://doi.org/10.1121/1.1482076.
- Grant, K. W., V. V. Wassenhove, and D. Poeppel. 2003. Discrimination of Auditory-Visual Synchrony. In AVSP 2003-International Conference on Audio-Visual Speech Processing.
- Grimm, G., G. Llorach, M. M. Hendrikse, and V. Hohmann. 2019. Audio-visual stimuli for the evaluation of speech-enhancing algorithms. In Proceedings of the 23rd International Congress on Acoustics, Aachen.
- Hochmuth, S., T. Brand, M. A. Zokoll, F. Z. Castro, N. Wardenga, and B. Kollmeier. 2012. “A Spanish Matrix Sentence Test for Assessing Speech Reception Thresholds in Noise.” International Journal of Audiology 51 (7): 536–544. doi:https://doi.org/10.3109/14992027.2012.670731.
- Hochmuth, S., T. Jürgens, T. Brand, and B. Kollmeier. 2015. “Talker-and Language-Specific Effects on Speech Intelligibility in Noise Assessed with Bilingual Talkers: Which Language is More Robust against Noise and Reverberation?” International Journal of Audiology 54 (Suppl. 2): 23–34. doi:https://doi.org/10.3109/14992027.2015.1088174.
- Jamaluddin, S. A. 2016. “Development and Evaluation of the Digit Triplet and Auditory-Visual Matrix Sentence Tests in Malay.” Doctoral thesis.
- Jamaludin, A., J. S. Chung, and A. Zisserman. 2019. “You Said That?: Synthesising Talking Faces from Audio.” International Journal of Computer Vision 127 (11–12): 1713–1767. doi:https://doi.org/10.1007/s11263-019-01150-y.
- Kollmeier, B., A. Warzybok, S. Hochmuth, M. A. Zokoll, V. Uslar, T. Brand, and K. C. Wagener. 2015. “The Multilingual Matrix Test: Principles, Applications, and Comparison across Languages: A Review.” International Journal of Audiology 54 (Suppl. 2): 3–16. doi:https://doi.org/10.3109/14992027.2015.1020971.
- Lander, K., and R. Davies. 2008. “Does Face Familiarity Influence Speechreadability?” Quarterly Journal of Experimental Psychology 61 (7): 961–967. doi:https://doi.org/10.1080/17470210801908476.
- Lidestam, B., S. Moradi, R. Pettersson, and T. Ricklefs. 2014. “Audiovisual Training is Better than Auditory-Only Training for Auditory-Only Speech-in-Noise Identification.” The Journal of the Acoustical Society of America 136 (2): EL142–EL147. doi:https://doi.org/10.1121/1.4890200.
- Llorach, G., and V. Hohmann. 2019. “Word Error and Confusion Patterns in an Audiovisual German Matrix Sentence Test (OLSA.” In Proceedings of the 23rd International Congress on Acoustics, Aachen.
- Llorach, G., F. Kirschner, G. Grimm, and V. Hohmann. 2020. “Video Recordings for the Female German Matrix Sentence Test (OLSA)”. Zenodo. doi:https://doi.org/10.5281/zenodo.3673062.
- Llorach, G., G. Grimm, M. M. Hendrikse, and V. Hohmann. 2018. October. Towards realistic immersive audiovisual simulations for hearing research: Capture, virtual scenes and reproduction. In Proceedings of the 2018 Workshop on Audio-Visual Scene Understanding for Immersive Multimedia. London: ACM, pp. 33–40.
- MacLeod, A., and Q. Summerfield. 1987. “Quantifying the Contribution of Vision to Speech Perception in Noise.” British Journal of Audiology 21 (2): 131–141. doi:https://doi.org/10.3109/03005368709077786.
- Nuesse, T., B. Wiercinski, T. Brand, and I. Holube. 2019. “Measuring Speech Recognition with a Matrix Test Using Synthetic Speech.” Trends in Hearing 23: 2331216519862982. doi:https://doi.org/10.1177/2331216519862982.
- Puglisi, G. E., A. Astolfi, N. Prodi, C. Visentin, A. Warzybok, S. Hochmuth, and B. Kollmeier. 2014. “Construction and First Evaluation of the Italian Matrix Sentence Test for the Assessment of Speech Intelligibility in Noise.” In Forum Acusticum 2014. Lyon, France: European Acoustics Association, EAA, pp. 1–5.
- Sakoe, H., and S. Chiba. 1978. “Dynamic Programming Algorithm Optimization for Spoken Word Recognition.” IEEE Transactions on Acoustics, Speech, and Signal Processing 26 (1): 43–49. doi:https://doi.org/10.1109/TASSP.1978.1163055.
- Sanchez Lopez, R., F. Bianchi, M. Fereczkowski, S. Santurette, and T. Dau. 2018. “Data-Driven Approach for Auditory Profiling and Characterization of Individual Hearing Loss.” Trends in Hearing 22:2331216518807400. doi:https://doi.org/10.1177/2331216518807400.
- Schreitmüller, S., M. Frenken, L. Bentz, M. Ortmann, M. Walger, and H. Meister. 2018. “Validating a Method to Assess Lipreading, Audiovisual Gain, and Integration during Speech Reception with Cochlear-Implanted and Normal-Hearing Subjects Using a Talking Head.” Ear & Hearing 39 (3): 503–516. doi:https://doi.org/10.1097/AUD.0000000000000502.
- Schubotz, W., T. Brand, B. Kollmeier, and S. D. Ewert. 2016. “Monaural Speech Intelligibility and Detection in Maskers with Varying Amounts of Spectro-Temporal Speech Features.” The Journal of the Acoustical Society of America 140 (1): 524–540. doi:https://doi.org/10.1121/1.4955079.
- Smoorenburg, G. F. 1992. “Speech Reception in Quiet and in Noisy Conditions by Individuals with Noise‐Induced Hearing Loss in Relation to Their Tone Audiogram.” The Journal of the Acoustical Society of America 91 (1): 421–437. doi:https://doi.org/10.1121/1.402729.
- Souza, P. E., K. T. Boike, K. Witherell, and K. Tremblay. 2007. “Prediction of Speech Recognition from Audibility in Older Listeners with Hearing Loss: Effects of Age, Amplification, and Background Noise.” Journal of the American Academy of Audiology 18 (1): 54–65. doi:https://doi.org/10.3766/jaaa.18.1.5.
- Sumby, W. H., and I. Pollack. 1954. “Visual Contribution to Speech Intelligibility in Noise.” The Journal of the Acoustical Society of America 26 (2): 212–215. doi:https://doi.org/10.1121/1.1907309.
- Summerfield, Q. 1992. “Lipreading and Audio-Visual Speech Perception.” Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences 335 (1273): 71–78.
- Talbott, R. E., and V. D. Larson. 1983. “Research Needs in Speech Audiometry.” Seminars in Hearing 4 (03): 299–308. doi:https://doi.org/10.1055/s-0028-1091432.
- Taylor, S. L., M. Mahler, B. J. Theobald, and I. Matthews. 2012, July. “Dynamic Units of Visual Speech.” In Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation. New York; NY: Eurographics Association, pp. 275–284.
- Taylor, S., T. Kim, Y. Yue, M. Mahler, J. Krahe, A. G. Rodriguez, J. Hodgins, and I. Matthews. 2017. “A Deep Learning Approach for Generalized Speech Animation.” ACM Transactions on Graphics 36 (4): 1–11. doi:https://doi.org/10.1145/3072959.3073699.
- Trounson, R. H. 2012. “Development of the UC Auditory-Visual Matrix Sentence Test.” Master thesis.
- Tye-Murray, N., M. S. Sommers, and B. Spehar. 2007. “The Effects of Age and Gender on Lipreading Abilities.” Journal of the American Academy of Audiology 18 (10): 883–892. doi:https://doi.org/10.3766/jaaa.18.10.7.
- Van de Rijt, L. P. H., A. Roye, E. A. M. Mylanus, A. J. van Opstal, and M. M. van Wanrooij. 2019. “The Principle of Inverse Effectiveness in Audiovisual Speech Perception.” Frontiers in Human Neuroscience 13: 335. doi:https://doi.org/10.3389/fnhum.2019.00335.
- Wagener, K. C., and T. Brand. 2005. “Sentence Intelligibility in Noise for Listeners with Normal Hearing and Hearing Impairment: Influence of Measurement Procedure and Masking Parameters. La inteligibilidad de frases en silencio para sujetos con audición normal y con hipoacusia: la influencia del procedimiento de medición y de los parámetros de enmascaramiento.” International Journal of Audiology 44 (3): 144–156. doi:https://doi.org/10.1080/14992020500057517.
- Wagener, K., S. Hochmuth, M. Ahrlich, M. Zokoll, and B. Kollmeier. 2014. Der weibliche Oldenburger Satztest. The female version of the Oldenburg sentence test. In Proceedings of the 17th Jahrestagung der Deutschen Gesellschaft für Audiologie, Oldenburg, Germany.
- Wagener, K., T. Brand, and B. Kollmeier. 1999. “Entwicklung Und Evaluation Eines Satztests Für Die Deutsche Sprache I-III: Design, Optimierung Und Evaluation Des Oldenburger Satztests.” ZfA 38 (1–3): 4–15.
- Woodhouse, L., L. Hickson, and B. Dodd. 2009. “Review of Visual Speech Perception by Hearing and Hearing‐Impaired People: clinical Implications.” International Journal of Language & Communication Disorders 44 (3): 253–270. doi:https://doi.org/10.1080/13682820802090281.