
Abstract
Objective
Hearing loss commonly causes difficulties in understanding speech in the presence of background noise. The benefits of hearing-aids in terms of speech intelligibility in challenging listening scenarios remain limited. The present study investigated if phoneme-in-noise discrimination training improves phoneme identification and sentence intelligibility in noise in hearing-aid users.
Design
Two groups of participants received either a two-week training program or a control intervention. Three phoneme categories were trained: onset consonants (C1), vowels (V) and post-vowel consonants (C2) in C1-V-C2-/i/ logatomes from the Danish nonsense word corpus (DANOK). Phoneme identification test and hearing in noise test (HINT) were administered before and after the respective interventions and, for the training group only, after three months.
Study sample
Twenty 63-to-79 years old individuals with a mild-to-moderate sensorineural hearing loss and at least one year of experience using hearing-aids.
Results
The training provided an improvement in phoneme identification scores for vowels and post-vowel consonants, which was retained over three months. No significant performance improvement in HINT was found.
Conclusion
The study demonstrates that the training induced a robust refinement of auditory perception at a phoneme level but provides no evidence for the generalisation to an untrained sentence intelligibility task.
Introduction
Hearing loss causes substantial difficulties in understanding speech, especially in noisy environments. Hearing-aids compensate for the loss of audibility by amplifying the acoustic signal based on individual hearing thresholds. However, several studies reported a limited benefit of amplification on speech intelligibility (e.g. Scheidiger, Allen and Dau Citation2017; Woods et al. Citation2015). One of the reasons for these findings is that the frequency- and level-dependent gain generally does not compensate for other deficits associated with a hearing loss, such as, e.g. a loss of auditory spectral and temporal resolution. Furthermore, years of listening with reduced sensitivity to sound before receiving the first hearing-aids lead to changes in how individuals utilise the information contained in the acoustic signal. People with hearing loss, even after substantial experience with hearing-aids, tend to apply different cue- and spectral weighting strategies than people without hearing deficits (e.g. Varnet et al. Citation2019). Wearing hearing-aids in daily life was not found to be effective enough to relearn the usage of certain cues that are crucial for speech perception.
Formal auditory training targeting skills relevant for understanding speech in background noise has been suggested as a way to complement the provision of hearing-aids (Boothroyd Citation2010). Several training strategies have been considered, ranging from auditory-cognitive training (Sweetow and Sabes Citation2006) to an “analytic” training, which targets low-level representations of speech in isolation (such as individual phonemes). The need for the latter approach can be explained in light of the theoretical framework provided by the Reverse Hierarchy Theory (RHT; Ahissar et al. Citation2009). The RHT proposes that rapid perception (such as in real-life speech communication) is based on high-level, global, abstract representations, and does not leave enough time for the perception of detailed, early representations of the sensory signal (such as phonemes). Thus, relearning at these early processing stages does not occur spontaneously but can only be achieved by a task- or cue-specific practice regime.
The effects of perceptual training on phoneme perception have previously been investigated in several listener populations differing in their hearing abilities. A training-induced improvement of phoneme perception measures has been demonstrated in normal-hearing listeners (Schumann, Garea Garcia and Hoppe Citation2017), cochlear implant (CI) patients (Schumann et al. Citation2015) as well as non-aided individuals with a mild-to-moderate hearing loss (Ferguson et al. Citation2014). Studies with listeners who used amplification in daily life yielded similar outcomes. Improvements of syllable identification scores (Stecker et al. Citation2006), consonant identification thresholds (Woods et al. Citation2015) and phoneme discrimination thresholds (Henshaw and Ferguson Citation2014) after the training have also been reported in experienced hearing-aid users. Successful on-task learning is a promising finding; however, it does not guarantee that the training will have implications for speech comprehension in everyday situations. This would require that the learning effects generalise to untrained tasks and conditions. Demonstrating the generalisation effect is crucial to consider the training intervention for potential use in clinical settings.
While assessing the generalisation of the training, it is important to control for other factors than the training itself that can cause the improvement of the participants’ performance. These factors include the effect of test–retest (procedural learning), the effect of social interaction and the effect of the expectation of improvement. Only a study design involving a group that receives a “placebo” intervention (an active control group) allows controlling for all these factors. In earlier studies on auditory training, this criterion was not always fulfilled as designs with a passive control group or a delayed training group were more common (Henshaw and Ferguson Citation2013). The more recent studies (Humes et al. Citation2019; Saunders et al. Citation2016; Whitton et al. Citation2017) included active controls while assessing the efficacy of training programs for hearing-aid users. However, none of these studies focussed specifically on phoneme training.
This study evaluated the efficacy of phoneme-in-noise training in experienced hearing-aid users. First, it was hypothesised that the proposed training would improve the phoneme identification skills in noise in a group of experienced hearing-aid users. Second, it was investigated whether the training resulted in an improved performance on untrained speech material. To provide solid evidence for the presence or absence of such generalisation, an active control group was involved. The third objective of this study was to investigate if the potential effects of training persist over time. Such information would be particularly useful from a clinical perspective so as to know, for example, if the training should be repeated in regular time intervals to maximise its benefits (Stropahl, Besser and Launer Citation2020).
Materials and methods
Participants
Participants were recruited from three databases: DTU Hearing Systems in Lyngby, Audiological Clinic of Bispebjerg Hospital in Copenhagen and WSAudiology in Lynge, Denmark. The inclusion criteria were: (1) age 60–80 years – similar to the range in a study by Woods et al. (Citation2015), (2) Danish as a first language, (3) mild to moderate hearing loss – defined as better-ear pure-tone average (PTA) of thresholds for 0.5, 1, 2 and 4 kHz within the range 26–55 hearing level (dB HL), (4) symmetric hearing loss, i.e. an interaural difference between the PTAs no greater than 10 dB (Noble and Gatehouse Citation2004), (5) at least one year of experience using hearing-aids (to eliminate the potential effect of acclimatisation), (6) minimum 23 points in Montreal Cognitive Assessment (MoCA; Nasreddine et al. Citation2005) – a screening tool for mild cognitive impairments. The cut-off value of 23 was recommended by Carson, Leach, and Murphy (Citation2018) – instead of usually used 26 points – as it lowers the false positive rate in older adults. Individuals identified as suitable candidates based on the information available in the databases were contacted according to the routine procedures of the respective institutions. The initial sample size was aimed at 15 participants per group (to reach a similar number as in Schumann et al. Citation2015) but the study was downscaled after the start of COVID-19 pandemic. In the end, out of 24 individuals who expressed interest in the study and were assessed for eligibility, two did not meet the inclusion criteria and two discontinued the intervention due to COVID19-related restrictions. The ongoing recruitment was run in parallel with the measurements from August 2019 to September 2020 and the trial was terminated when 20 participants completed the study. The detailed information about the participants can be found in .
Table 1. Characteristics of the participants.
Study design and procedure
The study design is illustrated in . Participants were allocated either to the training group (n = 10), which received the phoneme training program or to the control group (n = 10), which completed another activity program (described below). For practical reasons, the training program was ready to use earlier than the control procedure so the data collection in the training group was launched earlier. Therefore, the allocation to the groups depended on the order of the enrolment in the study: the first 10 recruited participants were assigned to the training group, and the remaining ones to the control group. The first author (A.K.) enrolled the participants, assigned them to groups and conducted all the measurements (apart from the control intervention). Thus, only the participants were blind to the allocation (single-blinded design). After completing the study, individuals who had been assigned to the control group were informed about this fact and offered the phoneme training program.
Figure 1. Study design. Participants completed eight (control group) to nine (training group) visits. The eligibility assessment and tests of word recognition in quiet (WRS) and auditory working memory (digit span) were performed during the first visit. Outcome measures of phoneme identification and sentence intelligibility were obtained upon the first (pre-intervention), the eighth (post-intervention) and the ninth (follow-up) visit. During two weeks between the first and the eighth visit, the participants received the allocated intervention.
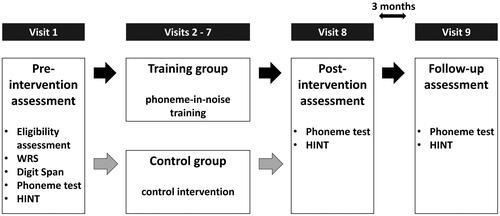
The six visits comprising one of the allocated interventions were distributed equally over two weeks with two- to three-day intervals. Each session lasted for approximately 1.5 h. The pre-training assessment took place no more than one week before the beginning of the intervention and the post-training assessment took place no more than one week after the intervention was completed. This schedule was adhered to with minor exceptions enforced by the limited lab capacity, the participants’ availability and safety measures related to COVID-19 pandemic. Seven out of 10 participants in the training group completed an additional follow-up visit three months after the post-intervention assessment.
The primary outcome measures were: phoneme identification scores obtained using the Danish nonsense word corpus (DANOK; Nielsen and Dau Citation2019) and speech recognition thresholds (SRTs) measured using the Danish hearing in noise test (HINT; Nielsen and Dau Citation2011). Both were administered prior to and after receiving the allocated intervention.
In addition, the participants completed a monosyllabic word recognition test (WRS – word recognition score measured using words from DANTALE I corpus; Elberling, Ludvigsen and Lyregaard Citation1989) and a working memory test (auditory digit span test; Wechsler Citation2008) before the intervention. The respective purposes of these tests were to assess the participants’ eligibility for the study in terms of a functional benefit of the hearing-aids and to characterise their memory span, which could be used as a predictor of training benefits. The digit span test comprised both forward and backward recall. The revised administration and scoring method proposed in Blackburn and Benton (Citation1957) was used and the final score was computed as a sum of scores for both tasks. Due to technical problems, the auditory digit span scores were not measured for three participants in the training group and two participants in the control group.
Pre-, post- and follow-up assessment as well as the measurements on the control group and half of the training sessions were conducted in a room designed according to IEC 268-13 standard (suitable for listening tests on loudspeakers) at the Technical University of Denmark, Lyngby, Denmark. The other half of the training took place in a measurement booth in the Audiology Clinic of Bispebjerg Hospital, Copenhagen, Denmark. The experiment was approved by the Science-Ethics Committee for the Capital Region of Denmark (reference H-16036391). All participants signed an informed consent and received a nominal reimbursement. The reporting adheres to the CONSORT statement (Schulz et al. Citation2010), whenever the guidelines are applicable in the context of the current study (Supplementary Files 1 and 2).
Training
Training program
The training intervention was based on the SchooLo (School + Logatome) phoneme training program (Serman Citation2012). SchooLo is a PC-based tool intended both for clinical studies and for usage at home by hearing-impaired individuals. In its original version, it was targeted towards the German-speaking population. SchooLo allows for using a variety of talkers with or without background noise, multiple repetitions of the stimulus, providing both visual and auditory feedback as well as adjusting the level of difficulty to avoid tiredness and maintain the user’s focus and motivation. The program has been successfully used with normal-hearing listeners (Schumann, Garea Garcia and Hoppe Citation2017) and CI patients (Schulz, Altman and Moher et al. Citation2015). The modifications introduced in SchooLo for the sake of the present study concerned a replacement of the speech material and a change in the rules for adjustments of the difficulty level, as explained below.
Training material
The speech material used in the present study was the Danish nonsense word corpus (DANOK). DANOK consists of logatomes that are built according to the template C1-V-C2-/i/, where C1 indicates an onset consonant, V indicates a vowel, C2 corresponds to a post-vowel consonant. The final /i/ sound is added to achieve the nonsense character. Each of the three phoneme categories (C1, V and C2) was trained in separate training blocks. There were 14 consonants (/p t k b d g m n l f v s r j/) trained in the C1 position, nine vowels (/i e a arFootnote1 y ø u o å/) trained in the V position and 12 consonants (/p t k b d g m n l f v s/) trained in the C2 position.
All possible coarticulation effects that exist in the DANOK were present in the logatomes selected for the training, such that each consonant appearing in the C1 position could be followed by one of three vowels (/ar e u/), each vowel in the V position could be embedded in a combination of three consonants (/b n v/) and each consonant in the C2 position could be proceeded by /ar/, /e/ or /u/ and was always followed by /i/. The number of possible consonant-vowel (CV) and/or vowel-consonant (VC) configurations for each target phoneme appeared equal number of times throughout the whole training.
Six training lists, corresponding to six planned training sessions, were combined for each possible target position (C1, C2 and V), resulting in 18 training lists in total. The lists were compiled such that each phoneme alternative was trained twice within each session. As a result, each training session included three lists of 28, 18 and 24 items, respectively, in total 70 items per session.
The recordings of two talkers (male and female) were used in the training. Within each training list, half of the logatomes were spoken by a male and half by a female talker. The logatomes were presented in stationary speech-shaped noise spectrally matched to the talker, using noise files provided in DANOK corpus.
Training procedure, interface and feedback
Each training visit consisted of three mandatory blocks dedicated to three different target positions. The order of these blocks was balanced across the sessions. Before each block, information about which target position is trained (C1, C2 or V) was provided. The items of the training list were presented in randomised order.
The procedure is visualised in . For each item of the training list, three attempts were allowed. If the listener provided a correct response at the first attempt, the program proceeded to the next list item. In case of an incorrect response, the program proceeded to a second attempt with increased salience of speech cues. In our adaptation of SchooLo, this was achieved by reducing the noise level by 2 dB compared with the first attempt. In the case of another incorrect response, the program proceeded to a third attempt and the salience of speech cues was further increased, i.e. the logatome was presented in quiet. If the user’s third response was again incorrect, the correct response was displayed, and the program proceeded to the first attempt of the following list item.
Figure 2. Training procedure. After the stimulus was presented, the participants were asked to select a response from five alternatives displayed on a screen. The response was followed by feedback, which was both visual and auditory. The participants were provided with a Repeat button (available both before and after the response) to replay the audio examples as many times as they wanted.
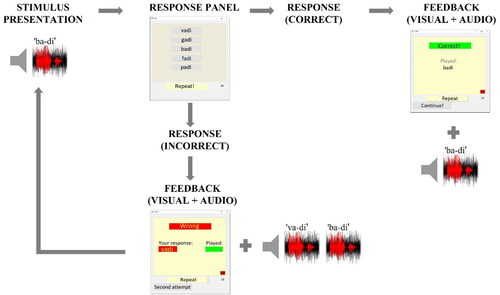
The procedure was repeated until all logatomes from the training list were played. Then, a congratulation message was displayed on the screen and the training block ended.
Performance- and consonant-based difficulty adjustment
At the beginning of the first session, the SNR for all participants was +4 dB for the consonant blocks (C1 and C2) and 0 dB for the V block. Two types of adjustments of the SNR values during the training were introduced in this study, which were not present in the original SchooLo. First, the SNR was adjusted according to the listener’s performance. The result was evaluated every fifth trial. If a person responded correctly five times out of five trials, the SNR was lowered by 2 dB. If a person responded correctly four times, the SNR was decreased by 1 dB. If three responses were correct, the SNR remained unchanged. Likewise, when the number of correct responses within five trials was two, the SNR was increased by 1 dB. If there were fewer than two correct responses, the SNR was increased by 2 dB. The SNR upon the end of the block was set as an initial value for the next session (for the block dedicated to the same target position).
The second type of adjustment was applied only in the consonant blocks. The intention was to compensate for differences in identification thresholds between different consonants in speech-weighted noise. It has been shown that some of the consonants, especially those with high-frequency components, are much less affected by masking in speech-shaped noise due to their spectral content (Woods et al. Citation2010). A set of consonants with lower identification thresholds was selected based on data from the DANOK evaluation study (Nielsen and Dau Citation2019) and included:/f j k r s t/. If any of those consonants appeared on the target position, a correction of −4 dB SNR was added on top of the manipulations described in the previous paragraph. Both types of adjustment were used to define the SNR value corresponding to the first presentation of the training item (i.e. during the first attempt).
Stimuli presentation and setup
The training stimuli were presented via a loudspeaker at a distance of 1 m in front of the aided listener. The noise started 3 s before the onset and finished 1 s after the offset of the logatome. The speech level was roved between the sound pressure level (SPL) of 65 and 71 dB. In principle, the level of the noise was adjusted to achieve the desired SNR. However, if the computed level of the noise exceeded 70 dB SPL, the noise was set to 65 dB SPL and the speech was adjusted to achieve the desired SNR. The participants performed the training while wearing their own hearing-aids. The experimenter was present in the room, available to provide help or to answer questions.
Control intervention
The control intervention was based on a procedure previously developed to record electrophysiological responses to running speech as part of another research project (Bachmann, MacDonald and Hjortkjaer Citation2021). During each of the six visits, the participants listened to 36 50-s-long excerpts of audiobooks in Danish (Lord of the Flies by William Golding and classical fairy tales read by a male and a female talker, respectively) and answered three multiple-choice comprehension questions. The stimuli were delivered via ER-3A insert earphones (Etymotic Research) and an audiogram-based linear amplification using the “Cambridge formula” (Moore, Glasberg and Stone Citation1999) was provided, except for the fifth session where the speech was not amplified.
The participants were seated in a soundproof booth and their neural responses were measured using an Active Two system (BioSemi). Apart from responses to running speech, auditory-evoked potentials (AEPs) to short sinusoids, frequency-following responses (FFRs) to modulated tones, auditory brainstem responses to clicks (click-ABRs) and resting state measurements were also obtained, lasting approximately 20 min. The EEG data were not of interest from the perspective of the research goals presented in this paper but were collected for a study that investigated the test-retest reliability of subcortical responses to running speech in older hearing-impaired adults (for details, see: Bachmann Citation2021).
Outcome measures
The outcome metrics of speech intelligibility included phoneme identification scores – measured with DANOK – and speech recognition thresholds (SRTs) obtained in HINT. All stimuli were presented via a loudspeaker placed at a 1-m distance in front of the listener. The participants were wearing their hearing-aids during the test.
Phoneme identification test
Logatomes from the DANOK were used to assess the phoneme identification in the presence of background noise. An 84-item consonant list and a 54-item vowel list were compiled from the corpus. The number of repetitions of each phoneme and combination of phonemes was kept as close as possible to those used in Nielsen and Dau (Citation2019), such that all of them were equally represented to the greatest possible degree. The logatomes in the test lists were spoken by a female talker, which was not used during the training. Logatomes were presented in stationary noise matching the frequency magnitude spectrum of the talker’s voice. The noise started 3 s before and ended 1 s after the presentation of the logatome. The speech level was fixed at 65 dB SPL. The test lists were administered at fixed SNRs, following the approach taken in the DANOK validation study. The consonant list was presented at +4 dB SNR and the vowel list was presented at 0 dB SNR. These values were selected to achieve a good sensitivity of the test and to avoid floor or ceiling performance.
The participants were provided with a touchscreen and were asked to begin the procedure by pressing the Start button, whenever they felt ready. After the first stimulus presentation, the target logatome appeared spelled out on the screen with empty spaces instead of the target phonemes. All response alternatives were displayed underneath. In the consonant list, the participant was required to identify both C1 and C2 within the same trial. The participants were informed that they would not have a possibility to repeat the sound and that they must provide a response even if they need to guess. After selecting the response, the participants decided when to proceed to the next trial by pressing the Next button. No feedback was provided during the test.
Sentence intelligibility in noise
Sentence intelligibility was measured using the Danish version of the hearing in noise test (Nielsen and Dau Citation2011). A 20-item list spoken by a male talker was presented in stationary background noise with a frequency magnitude spectrum matched to that of the speaker’s voice. The noise started 3 s before and ended 1 s after the presentation of the sentence. The level of the noise was fixed at 65 dB SPL. The level of the speech was initially set to be equal to the level of the noise and then changed adaptively according to a staircase procedure to define the speech recognition threshold (SRT), i.e. the SNR, at which the participant correctly repeated 50% of the test items (Brand and Kollmeier Citation2002). A correct word scoring procedure (see e.g. Wendt, Hietkamp and Lunner Citation2017) was used, i.e. the magnitude of the change of the speech level depended on the number of correctly repeated words and varied between +2 dB (zero correctly repeated words out of five) to −2 dB (five correctly repeated words out of five) in 0.8 dB steps. These numbers were doubled for the first four sentences.
The participants were instructed to repeat each sentence as precisely as possible and encouraged to guess if uncertain. The responses were scored by a native Danish-speaking audiologist.
Analysis
The first step of the analysis investigated if the training had an effect on the outcome measures of phoneme identification and sentence intelligibility in noise. Separate linear mixed-effects models were implemented in R (R Core Team Citation2020) in lmer package (Kuznetsova, Brockhoff and Christensen Citation2017) for each outcome measure: C1, C2 and V identification scores as well as the SRTs. Each model included fixed factors of Visit (pre, post) and Group (training, control) as well as a Visit × Group interaction, and a random Participant factor. A backward elimination of non-significant terms was performed on each model. In case of a significant Visit × Group interaction, planned comparisons between the pre and post levels of Visit within each Group were performed using the least-squares means approach (Lenth Citation2016). This analysis included all the participants (10 per group) and was done by the original group assignment.
Second, a correlational analysis was performed to investigate if participants’ characteristics could be used to predict training outcomes. Differences between post- and pre-training scores were calculated for those of outcome measures, for which a mixed-effect model revealed a significant Visit × Group interaction and for which subsequent post hoc analysis showed a significant difference between pre-training and post-training levels. Correlations between these differences and three predictor variables (age, PTA and auditory digit span score) were computed. Only 10 participants from the training group were included (except for the correlation with digit span scores, where only seven scores were available due to missing data).
Finally, the analysis of a retention effect included only those outcome measures that revealed significant training effect and only seven participants that completed the follow-up session. A non-parametric paired one-tailed Wilcoxon signed-rank test was chosen to compare the post-training and follow-up scores. A rejection of the alternative hypothesis that the median difference between the samples is not equal to zero was considered an indication that the training effect did not diminish over time.
Results
None of the participants expressed the desire to withdraw from the study. All participants in the control group completed the assigned activity. Eight participants in the training group completed all six planned sessions. Two other participants (no. 2 and 10) completed only five out of six planned sessions due to technical problems with their hearing-aids. The hearing-aids of participant 2 stopped functioning once on the way to study location (probably due to receiver being blocked with cerumen), whereas participant 10 forgot to bring his hearing-aids to one of the training sessions.
The comparison between the training group and the control group in terms of their characteristics and baseline performance is summarised in . The age and hearing loss as well as the baseline performance in the outcome measures were similar in the two groups. The training group had lower working memory capacity than the control group. In addition, there were differences in terms of the gender ratio (female to male 3:7 in the training group, 1:1 in the control group) and hearing-aid brands ().
Table 2. Group means, standard deviations (SD) and results of a between-group t-test (t-statistics and p-values) for age, PTA, auditory digit span (DS) score, baseline phoneme identification scores (C1, V and C2) and SRTs in HINT.
The effect of the intervention on phoneme identification scores
shows the pre-intervention (empty bars) and post-intervention (filled bars) identification scores for the three phoneme targets: C1 (upper row), V (middle row) and C2 (bottom row). The left column shows the results for the training group and the right column shows the results obtained with the control group. Numbers 1–20 represent individual participants and the group means (M) are shown on the right of the respective columns.
Figure 3. Pre-intervention (empty bars) and post-intervention (filled bars) phoneme identification scores in % correct. The targets C1, V and C2 are represented in the upper, middle and bottom row, respectively. Results for the training group are shown in the left column and results for the control group are represented in the right column. Numbers 1–20 correspond to the individual participants. M indicates mean scores for each group. Error bars represent one standard error of the mean.
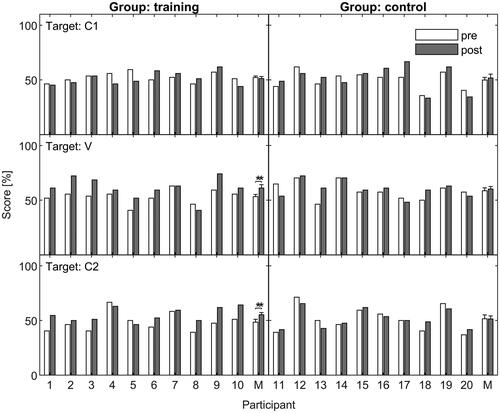
The visual inspection of the individual data reveals that the majority (8/10) of the participants improved their individual scores for V and C2 targets, which was not seen in the control group. This trend was not visible for the C1 target, where nearly half (4/10) of the participants achieved lower scores after the training. There was no common characteristic among these individuals that could potentially explain it (such as e.g. lower cognitive function). Two of these participants (no. 2 and 10) completed one session less than the rest of the group; however, the worsening of performance in their case was seen only for the C1 target and did not extrapolate to V and C2 outcomes.
For the onset consonants (C1), the analysis revealed no significant Visit × Group interaction (F(1,18) = 0.9, p = .35), indicating that there was no difference between the pre- and post-intervention scores across the groups. The main effects of Visit (F(1,18) = 0.1, p = .75) and Group (F(1,18) = 0.09, p = .76) were not significant either.
For the vowels (V), the analysis showed a significant main effect of Visit (F(1,18) = 8.48, p < .01) and a non-significant main effect of Group (F(1,18) = 0.48, p = .49). The Visit × Group interaction term only approached but did not reach statistical significance (F(1,18) = 3.92, p = .06). Considering that the p-value was just above the threshold 0.05, a post hoc analysis was still conducted. The outcome was a significant (t = −3.46, p < .01) difference between the pre- and post-intervention scores: M = 7.78 percentage points (pts.), only for the group that received the training.
For the post-vowel consonants (C2), there was a significant Visit × Group interaction (F(1,18) = 6.72, p = .018) as well as significant main effect of Visit (F(1,18) = 6.27, p = .02). The Group effect (F(1,18) = 0.01, p = .91) was not significant. A post hoc analysis revealed that the difference between the pre- and the post-intervention C2-scores was significant for the training group (M = 6.9 pts., t = −3.6, p < .01).
Differences between the post-training and pre-training scores were calculated for the targets C2 and V. Pearson correlations between these differences and the three predictor variables (age, PTA and auditory working memory) were computed. There were no significant correlations between the predictors and the individual improvements in C2 and V identification scores.
The effect of the intervention on sentence intelligibility in noise
shows pre- (empty boxes) and post- (filled boxes) intervention SRTs for the training group (left) and the control group (right). The average change in SRT (the mean of differences between the post- and pre-intervention scores) was −0.7 dB for the training group and −0.3 dB for the control group. For seven out of 10 participants in the training group, a negative difference in SRT between the post- and the pre-intervention results was observed, i.e. speech intelligibility improved following training. In the control group, half of the participants showed lower SRTs after the intervention than before.
Figure 4. Pre-intervention (empty boxes) and post-intervention (filled boxes) SRTs for the training group (left) and the control group (right). The medians are indicated by the horizontal lines. The 25th and 75th percentiles are represented by the bottom and the top edge of the box respectively. The whiskers indicate the most extreme observations not considered outliers. Individual data points are represented by the black dots. Results for the pre-intervention and the post-intervention condition obtained from the same listener are indicated by the connecting dashed lines.
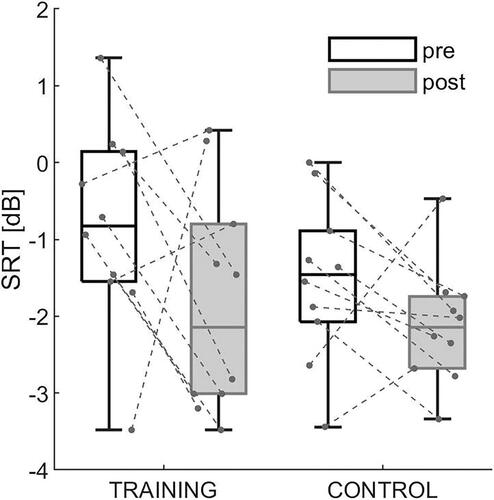
The analysis showed a significant main effect of Visit (F(1,18) = 4.49, p < .05). Neither the main effect of Group (F(1,18) = 2.81, p = .11) nor Visit × Group interaction (F(1,18) = 0.76, p = .39) were significant.
The retention of the training effects
shows individual and mean phoneme identification scores obtained at the pre-training (empty bars), post-training (grey bars) and follow-up (black bars) visit for the C1 (top), V (middle) and C2 (bottom) targets. The individual results for those seven participants who completed all three visits, and the mean results (the rightmost bars) are shown. All scores are expressed as % correct.
Figure 5. Phoneme identification scores obtained at pre-training (white), post-training (grey) and follow-up (black) visit. Results are shown for target C1 (upper panel), V (middle panel) and C2 (bottom panel). Numbers 1–6 and 9 represent the individual participants. The mean scores are shown on the right. Error bars represent one standard error of the mean.
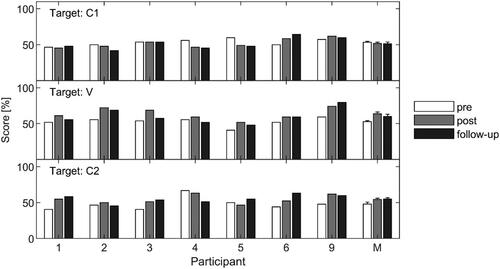
For target C1 (top panel), there was no indication of an improvement (pre-training: M = 53.23%, standard deviation (SD) = 4.65; post-training: M = 51.70%, SD = 6.41; follow-up: M = 51.36%, SD = 8.14). Regarding the V target (middle panel), the participants scored higher at the follow-up visit (M = 60.05%, SD = 10.74) than at the pre-training visit (M = 52.65%, SD = 5.84). Even though the scores at the follow-up visit were slightly below those at the post-training visit (M = 63.76%, SD = 8.06), they still deviated from the values obtained before the training. For target C2 (bottom panel), on average, higher scores were obtained at the follow-up visit (M = 55.10%, SD = 5.90) than at the pre-training visit (M = 47.96%, SD = 8.98). Notably, the score from the follow-up visit did not deviate much from the post-training result (M = 54.25%, SD = 6.18). The Wilcoxon signed-rank test showed that the difference between follow-up and post-training performance was non-significant, both for C2 (p = .63) and V target (p = .09).
Discussion
The present study investigated whether phoneme-in-noise auditory training can provide improvement in speech intelligibility in individuals who already benefit from hearing-aids. The hypotheses were that the training would improve phoneme identification in noise and would also provide a benefit with untrained, higher context speech. Furthermore, it was hypothesised that any improvement would still be present three months after the training. A correlational analysis between significant training outcomes and the participants’ age, degree of hearing loss and auditory working memory score was provided.
The effect of training on the outcome measures of speech perception
Phoneme identification
The results of the phoneme identification test showed that the training was accompanied by significantly higher recognition scores for two out of the three tested phoneme targets: vowels (V) and post-vowel consonants (C2). There were major differences between the testing and the training procedures, including the presence or absence of feedback, the talker, the number of response alternatives, the SNR as well as the task (i.e. identifying one consonant vs. identifying both consonants within one trial). Therefore, the improvement in performance due to procedural learning, i.e. related to increased familiarity with the task (Woods et al. Citation2015), should not have been larger for the training than for the control group. The finding that the improvement was observed in a setting with untrained parameters for two out of three tested targets supports the first hypothesis that training can improve phoneme identification in noise.
The finding that the effects of training were observed only for one position of the consonant (C2 but not C1) was unexpected. Woods et al. (Citation2015) found no effect of consonant position on training benefits in a study considering CVC (consonant-vowel-consonant) units. The effect of position might therefore be specific to the DANOK material and linked to the presence of the second vowel /i/. In DANOK, the initial consonant C1 is involved in coarticulatory effects with the following vowel only. C2, on the other hand, is part of a VCV (vowel-consonant-vowel) sequence. Thus, in the case of C2, more coarticulation cues are available for the listener. Assuming that the training improved the ability to utilise those cues, the benefit might be higher for the second consonant. The listeners might have adapted their strategy to optimise their score and therefore might have focussed their attention on the target, which was easier to identify, neglecting the first consonant. This explanation is also consistent with the minor drop in the C1 score in the training group, which was not observed in the control group.
The results obtained at the follow-up session for the V and C2 targets did not differ significantly from the post-training performance, indicating that the training-related improvement was still present after three months. This result supports the third hypothesis about the retention of the training effects.
Sentence intelligibility in noise
The analysis of HINT suggested that the improvement in sentence intelligibility after the phoneme-in-noise training did not differ significantly from the improvement attributed to the effects of test-retest and the “placebo” intervention. Hence, the second hypothesis concerning the generalisation of the training effects towards higher-context speech could not be supported in the present studyFootnote2. Nonetheless, the magnitude of the change of the SRT was larger for the training (0.7 dB) than for the control group (0.3 dB) and comparable to the result previously obtained using HINT (0.8 dB in sentence recognition thresholds; Woods et al. Citation2015).
The reports on the generalisation of phoneme training to untrained intelligibility measures remain mixed. Ferguson et al. (Citation2014) did not find any significant improvement of speech-in-noise measures in the group of unaided individuals with mild-to-moderate hearing loss (even though an improvement in terms of cognitive measures and self-reported outcomes was reported). Similarly, in Woods et al. (Citation2015), the training did not result in any improvement of sentence recognition thresholds. In contrast, for CI patients, an improvement of sentence intelligibility scores was revealed only in a moderately difficult (+5 dB SNR) noise condition (Schumann et al. Citation2015).
The discrepancies between these findings may stem from the differences between the target populations. The mechanisms and the degree of training-related improvements can differ greatly between hearing-aid and CI users as the underlying hearing deficits are largely different. Although hearing-aid wearers can perceive and to some extent understand speech without the amplification, CI listeners are fully dependent on the electric input provided by their devices. The first group trained only with hearing-aids but in real life was confronted with both aided and unaided listening conditions. On the other hand, the second group had no option but to rely on the same stimulation both during the training and in everyday life. That is why the CI users might have to a greater extent utilised and consolidated the trained material. Contradictory findings potentially could also be linked to the difference in the outcome measure, i.e. the adaptive measurement of the SRT versus the percentage of correctly repeated test items at fixed SNR.
The duration of the training is another factor the generalisation to untrained measures may rely on. In the present study, the participants trained only for two weeks, which is shorter than in the other studies (e.g. three weeks in Schumann et al. Citation2015). Such a two-week regimen may be sufficient to observe an on-task improvement, but more training would be required to utilise the trained skill in other tasks and conditions. This explanation is in line with the Reverse Hierarchy Theory, which states that prolonged learning of lower-level representations may eventually lead to increased generalisation to global contexts (Ahissar et al. Citation2009). The observed improvement in phoneme identification may reflect the modification of low-level representations, but not enough time was given to modify the high-level representations and hence, the lack of the effect on sentence intelligibility.
Limitations
Sample size
The drawback of the current study is the relatively small number of participants (n = 10) that does not allow for detecting a small SRT improvement such as the one observed in this study. Nevertheless, it is worth considering whether an improvement of this magnitude (0.7 dB), even when statistically significant, is meaningful for a listener. Currently, there seems to be no consensus on a clinically significant improvement in HINT but based on the normative data for the Danish HINT (within-subject standard deviation and a slope of psychometric function), a value of 2.1 dB seems a reasonable choice (Nielsen and Dau Citation2009). Given the pooled standard deviation of 1.79 dB, this would correspond to a large effect size (Cohen’s d = 1.2), which can be detected with 80% power even with a small number of participants per group (n = 7; paired t-test for the one-tailed hypothesis with 0.05 critical region). From this perspective, the present study should have had the potential to detect meaningful treatment effects, despite the small number of participants.
Similarities and differences between the groups
Another limitation is that no state-of-art randomisation procedure was involved. A lack of such a procedure leads to the risk of group statistics (e.g. age, gender, baseline performance) not being evenly distributed between groups, which may introduce a bias in the data. In the current study, the two groups were similar in terms of age, PTA, hearing-aid experience and speech score. The observed significant difference in working memory capacity could have had implications for the outcomes of the study. However, the correlation analysis showed no indications that this was the case since working memory scores did not predict the magnitude of the improvement in any of the outcome measures.
Control group
Another potentially suboptimal aspect of this study is the character of the control intervention given that the task, stimuli and the total duration of sound exposure were very different from the training. Although control groups that listened to audiobooks have previously been employed in training studies (Humes et al. Citation2019; Saunders et al. Citation2016), such an approach can fail to result in a similar degree of engagement in the study and the expectation of improvement.
The selection of outcome measures
Finally, the battery of outcome measures could have been extended to a cognitive assessment. It has previously been shown that phoneme training can benefit the executive processes (Ferguson et al. Citation2014) and the allocation of cognitive resources (Henshaw and Ferguson Citation2014). As such, the assessment of the generalisation of training effects in the cognitive domain could have led to interesting findings in the current study. In addition, complementing the behavioural outcomes with subjective measures would have allowed for assessing the effect of training on self-perceived hearing abilities.
Perspectives
Not “if” but “how?” – investigating mechanisms behind the improvement
The current study investigated whether auditory training could improve phoneme perception in hearing-aid users but did not explore mechanisms that might underlie such improvement. It remains unknown whether the training indeed stimulated changes in terms of utilising certain acoustic cues in speech. This question could be addressed in an experiment that would directly investigate if the weighting of acoustic cues can be altered through perceptual training (using e.g. method developed by Varnet et al. Citation2013). It would be particularly valuable to know if the listening strategies of hearing-impaired individuals can be retrained to become more like those of normal-hearing listeners.
Measuring the generalisation of training – the impact of a test’s sensitivity
The importance of selecting an appropriate and sensitive training outcome measure has previously been emphasised in the literature on auditory training (Henshaw and Ferguson Citation2014). Several training studies that used more than one speech outcome reported that the effects of training were revealed only for a subset of those measures (Stropahl, Besser and Launer Citation2020). It has been shown, for example, that the improvement was present only in an adequately challenging noise condition but not when the task was either too easy or too difficult (Henshaw and Ferguson Citation2014). The sensitivity of sentence test can be affected by i.e. the amount of contextual cues and the masker characteristics. Woods et al. (Citation2015) argued that the dominant role of top-down processing in the comprehension of predictable HINT sentences limits the benefits of training on sentence recognition thresholds. In addition, using a stationary background noise with primarily energetic masking might have limited access to perceptual cues for understanding speech. All in all, the HINT setup in the present study might have had relatively low sensitivity, which have most likely contributed to the negative outcome.
An alternative way of measuring the effects of training would be to characterise its impact on processing effort. This approach might be especially relevant in the case of an analytic phoneme-based training approach as the one considered in the present study. Improved discriminability of individual phonemes, even if not reflected in the change of intelligibility thresholds, might reduce the proportion of misperceived speech segments. Thereby, a potential benefit of phoneme training is that listeners need to resolve fewer ambiguities present in the perceived signal. This, in turn, could alleviate the cognitive load that would otherwise be required to achieve comprehension. This potential benefit is likely to be captured by means of a dual-task paradigm (as suggested by Henshaw and Ferguson Citation2014) or by combining a speech intelligibility test with a physiological correlate of listening effort, e.g. pupillometry, functional magnetic resonance imaging or electroencephalography (McGarrigle et al. Citation2014). The effect of training on listening effort could be an interesting topic for future investigations.
Summary and conclusion
This study investigated the efficacy of auditory phoneme-in-noise training in experienced hearing-aid users. After only two weeks of training, a significant increase in phoneme identification scores was found in the training group as opposed to the active control group for vowels and post-vowel consonants but not for onset consonants. The improved performance was retained until three months after completing the training. Despite a promising trend, no significant benefit on SRTs in sentences in noise was found, suggesting that there was no generalisation of the trained skill to an untrained condition after two weeks. The lack of the effect on sentence intelligibility can potentially be linked to the relatively short duration of the training, to the insufficient sensitivity of the outcome measure or to the lack of statistical power. Nonetheless, based on the findings of this study, the claim that this type of training will improve speech comprehension in real life cannot be supported.
Supplemental Material
Download MS Word (219.5 KB)Supplemental Material
Download MS Word (54 KB)Acknowledgements
The authors thank Rikke Skovhøj Sørensen for her contribution to the data collection and Florine Bachmann for collaboration in planning and conducting the joint part of the experiment as well as Jens Bo Nielsen for fruitful discussions about the properties of DANOK and Danish HINT. WSAudiology is acknowledged for the support with recruiting participants.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 The symbol “ar” corresponds to phonemes pronounced like the first phoneme in the Danish word “arbejde”.
2 However, we did find a training-related improvement after the same training in the same group of participants in a specific setup, where the percentage of correctly repeated words was measured at the individualized SNR corresponding to 50% intelligibility. This condition was part of a setup aimed at measuring listening effort and the result will be reported in a separate article.
References
- Ahissar, M., M. Nahum, I. Nelken, and S. Hochstein. 2009. “Reverse hierarchies and sensory learning.” Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences 364 (1515):285–299. doi:10.1098/rstb.2008.0253.
- Bachmann, F. L. 2021. “Subcortical electrophysiological measures of running speech.”. PhD thesis, Technical University of Denmark, Kgs. Lyngby.
- Bachmann, F. L., E. N. MacDonald, and J. Hjortkjaer. 2021. “Neural Measures of Pitch Processing in EEG Responses to Running Speech.” Frontiers in Neuroscience 15:738408. doi:10.3389/fnins.2021.738408.
- Blackburn, H. L, and A. L. Benton. 1957. “Revised Administration and Scoring of the Digit Span Test.” Journal of Consulting Psychology 21 (2):139–143. doi:10.1037/h0047235.
- Boothroyd, A. 2010. “Adapting to Changed Hearing: The Potential Role of Formal Training.” Journal of the American Academy of Audiology 21 (9):601–611. doi:10.3766/jaaa.21.9.6.
- Brand, T, and B. Kollmeier. 2002. “Efficient Adaptive Procedures for Threshold and Concurrent Slope Estimates for Psychophysics and Speech Intelligibility Tests.” The Journal of the Acoustical Society of America 111 (6):2801–2810. doi:10.1121/1.1479152.
- Carson, N., L. Leach, and K. J. Murphy. 2018. “A Re-Examination of Montreal Cognitive Assessment (MoCA) cutoff scores.” International Journal of Geriatric Psychiatry 33 (2):379–388. doi:10.1002/gps.4756.
- Elberling, C., C. Ludvigsen, and P. E. Lyregaard. 1989. “DANTALE: A New Danish Speech Material.” Scandinavian Audiology 18 (3):169–175. doi:10.3109/01050398909070742.
- Ferguson, M. A., H. Henshaw, D. P. A. Clark, and D. R. Moore. 2014. “Benefits of Phoneme Discrimination Training in a Randomized Controlled Trial of 50- to 74-Year-Olds with Mild Hearing Loss.” Ear and Hearing 35 (4):e110–e121. doi:10.1097/AUD.0000000000000020.
- Henshaw, H, and M. Ferguson. 2014. Assessing the Benefits of Auditory Training to Real-World Listening: Identifying Appropriate and Sensitive Outcomes. In Proceedings of ISAAR 2013: Auditory Plasticity - Listening with the Brain. 4th Symposium on Auditory and Audiological Research, edited by T. Dau, S. Santurette, J. C. Dalsgaard, L. Tranebjaerg, T. Andersen, and T. Poulsen, 45–52. Nyborg, Denmark: The Danavox Jubilee Foundation.
- Henshaw, H, and M. A. Ferguson. 2013. “Efficacy of Individual Computer-Based Auditory Training for People with Hearing Loss: A Systematic Review of the Evidence.” PLOS One 8 (5):e62836. doi:10.1371/journal.pone.0062836.
- Humes, L. E., K. G. Skinner, D. L. Kinney, S. E. Rogers, A. K. Main, and T. M. Quigley. 2019. “Clinical Effectiveness of an At-Home Auditory Training Program: A Randomized Controlled Trial.” Ear and Hearing 40 (5):1043–1060. doi:10.1097/AUD.0000000000000688.
- Kuznetsova, A., P. B. Brockhoff, and R. H. B. Christensen. 2017. “lmerTest Package: Tests in Linear Mixed Effects Models.” Journal of Statistical Software 82 (13):1–26. doi:10.18637/jss.v082.i13.
- Lenth, R. V. 2016. “Least-Squares Means: The R Package Lsmeans.” Journal of Statistical Software 69 (1):1–33. doi:10.18637/jss.v069.i01.
- McGarrigle, R., K. J. Munro, P. Dawes, A. J. Stewart, D. R. Moore, J. G. Barry, and S. Amitay. 2014. “Listening Effort and Fatigue: What Exactly are we Measuring? A British Society of Audiology Cognition in Hearing Special Interest Group “White Paper.” International Journal of Audiology 53 (7):433–445. doi:10.3109/14992027.2014.890296.
- Moore, B. C. J., B. R. Glasberg, and M. A. Stone. 1999. “Use of a Loudness Model for Hearing Aid Fitting: III. A General Method for Deriving Initial Fittings for Hearing Aids with Multi-channel Compression.” British Journal of Audiology 33 (4):241–258. doi:10.3109/03005369909090105.
- Nasreddine, Z. S., N. A. Phillips, V. Bédirian, S. Charbonneau, V. Whitehead, I. Collin, J. L. Cummings, and H. Chertkow. 2005. “The Montreal Cognitive Assessment, MoCA: A Brief Screening Tool for Mild Cognitive Impairment.” Journal of the American Geriatrics Society 53 (4):695–699. doi:10.1111/j.1532-5415.2005.53221.x.
- Nielsen, J. B., and T. Dau. 2009. “Development of a Danish speech intelligibility test.” International Journal of Audiology 48 (10):729–741. doi:10.1080/14992020903019312.
- Nielsen, J. B., and T. Dau. 2011. “The Danish hearing in noise test.” International Journal of Audiology 50 (3):202–208. doi:10.3109/14992027.2010.524254.
- Nielsen, J. B., and T. Dau. 2019. “A Danish Nonsense Word Corpus for Phoneme Recognition Measurements.” Acta Acustica United with Acustica 105 (1):183–194. doi:10.3813/aaa.919299.
- Noble, W., and S. Gatehouse. 2004. “Interaural Asymmetry of Hearing Loss, Speech, Spatial and Qualities of Hearing Scale (SSQ) Disabilities, and Handicap.” International Journal of Audiology 43 (2):100–114. doi:10.1080/14992020400050015.
- R Core Team. 2020. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing.
- Saunders, G. H., S. L. Smith, T. H. Chisolm, M. T. Frederick, R. A. McArdle, and R. H. Wilson. 2016. “A Randomized Control Trial: Supplementing Hearing Aid Use with Listening and Communication Enhancement (LACE) Auditory Training.” Ear and Hearing 37 (4):381–396. doi:10.1097/AUD.0000000000000283.
- Scheidiger, C., J. B. Allen, and T. Dau. 2017. “Assessing the Efficacy of Hearing-Aid Amplification Using a Phoneme Test.” The Journal of the Acoustical Society of America 141 (3):1739–1748. Doi : doi:10.1121/1.4976066.
- Schulz, K. F., D. G. Altman, and D. Moher. 2010. “CONSORT 2010 Statement: Updated Guidelines for Reporting Parallel Group Randomised Trials.” Journal of Pharmacology & Pharmacotherapeutics 1 (2):100–107. doi:10.4103/0976-500X.72352.
- Schumann, A., L. Garea Garcia, and U. Hoppe. 2017. “Trainierbarkeit der Diskrimination von Phonemen im Störgeräusch bei normalhörenden Erwachsenen.” Laryngo- Rhino- Otologie 96 (2):98–103. doi:10.1055/s-0042-113134.
- Schumann, A., M. Serman, O. Gefeller, and U. Hoppe. 2015. “Computer-Based Auditory Phoneme Discrimination Training Improves Speech Recognition in Noise in Experienced Adult Cochlear Implant Listeners.” International Journal of Audiology 54 (3):190–198. doi:10.3109/14992027.2014.969409.
- Serman, M. 2012. “SchooLo: New Speech Training Method Based on Changes in Speech Cues.” 15th Annual Meeting of the German Society of Audiology, Erlangen, Germany.
- Stecker, G. C., G. A. Bowman, E. W. Yund, T. J. Herron, C. M. Roup, and D. L. Woods. 2006. “Perceptual Training Improves Syllable Identification in New and Experienced Hearing Aid Users.” Journal of Rehabilitation Research and Development 43 (4):537–552. doi:10.1682/JRRD.2005.11.0171.
- Stropahl, M., J. Besser, and S. Launer. 2020. “Auditory Training Supports Auditory Rehabilitation.” Ear and Hearing 41 (4):697–704. doi:10.1097/aud.0000000000000806.
- Sweetow, R, and J. H. Sabes. 2006. “The Need for and Development of an Adaptive Listening and Communication Enhancement (LACE TM) Program.” Journal of the American Academy of Audiology 17 (8):538–558. doi:10.3766/jaaa.17.8.2.
- Varnet, L., K. Knoblauch, F. Meunier, and M. Hoen. 2013. “Using Auditory Classification Images for the Identification of Fine Acoustic Cues Used in Speech Perception.” Frontiers in Human Neuroscience 7:865. doi:10.3389/fnhum.2013.00865.
- Varnet, L., C. Langlet, C. Lorenzi, D. S. Lazard, and C. Micheyl. 2019. “High-Frequency Sensorineural Hearing Loss Alters Cue-Weighting Strategies for Discriminating Stop Consonants in Noise.” Trends in Hearing 23:2331216519886707–2331216519886718. doi:10.1177/2331216519886707.
- Wechsler, D. 2008. Wechsler Adult Intelligence Scale. San Antonio, TX: The Psychological Corporation.
- Wendt, D., R. K. Hietkamp, and T. Lunner. 2017. “Impact of Noise and Noise Reduction on Processing Effort: A Pupillometry Study.” Ear and Hearing 38 (6):690–700. doi:10.1097/AUD.0000000000000454.
- Whitton, J. P., K. E. Hancock, J. M. Shannon, and D. B. Polley. 2017. “Audiomotor Perceptual Training Enhances Speech Intelligibility in Background Noise.” Current Biology 27 (21):3237–3247.e6. doi:10.1016/j.cub.2017.09.014.
- Woods, D. L., T. Arbogast, Z. Doss, M. Younus, T. J. Herron, and E. W. Yund. 2015. “Aided and Unaided Speech Perception by Older Hearing Impaired Listeners.” PLOS One 10 (3):e0114922. doi:10.1371/journal.pone.0114922.
- Woods, D. L., Z. Doss, T. J. Herron, T. Arbogast, M. Younus, M. Ettlinger, and E. W. Yund. 2015. “Speech Perception in Older Hearing Impaired Listeners: Benefits of Perceptual Training.” PLOS One 10 (3):e0113965. doi:10.1371/journal.pone.0113965.
- Woods, D. L., E. W. Yund, T. J. Herron, and M. A. Cruadhlaoich. 2010. “Consonant Identification in Consonant-Vowel-Consonant Syllables in Speech-Spectrum Noise.” The Journal of the Acoustical Society of America 127 (3):1609–1623. doi:10.1121/1.3293005.