
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
As a metaheuristic method for the continuous optimization problem, the grey wolf optimizer (GWO) has attracted much attention from researchers because the method is reported to be superior to other methods. However, some works show that the GWO is too specialized only to problems having the zero-optimal solution, which can lead to a significant deterioration of the efficiency for other problems. In this paper, we, first, theoretically prove the shift-dependence of the GWO, which is the underlying cause of the over-specialization of the GWO, and we experimentally analyze the property by using a larger number of problems. Secondly, we propose am shift-invariant GWO, GWO-SR, and, modify the GWO-SR by adding two methods: an adjustment technique the size of the search area and a mutation process to enhance the diversity of the search (GWO-AS) Finally, we show advantages of two proposed GWOs by comparing them with other metaheuristic methods.
1. Introduction
The grey wolf optimizer (GWO) is one of the nature-inspired metaheuristic methods which exploits hunting techniques and social hierarchy of the grey wolves in order to solve global optimization problems [Citation1, Citation2]. The GWO has attracted significant attention from researchers because the method has been reported to have high performance in seeking high-quality solutions regardless its simple algorithm according to many studies [Citation3–8], and thus, it has been applied to a wide range of fields [Citation9–12].
However, a previous work [Citation13] shows that the GWO is not invariant to shift-transformations in the orthogonal coordinate representation of the optimization problem. In addition, the some works [Citation14, Citation15] show that the performance of the GWO is often considerably low when the optimal solution is far from the origin. In addition, a work [Citation16] showed that the search behavior of the GWO is too specialized for problems having the optimal solution at the origin through numerical experiments, and that the updating systems of the GWO widely depend on the distance of the origin to the best solution found so far. The property can lead to a significant deterioration of the efficiency of the search process for other problems whose optimal solution is not the origin. Thus, many improved GWOs, which have been investigated [Citation3–8], can have the same drawbacks if its updating systems are not shift-invariant similar to the original GWO. Furthermore, in the work, authors proposed a shift-invariant method GWO with reference points (GWO-R) to overcome the drawback, in which grey wolves are updated by shift-invariant systems exploiting the reference points instead of the origin.
In this paper, we first analyze the underlying causes of too specialized properties of the GWO in more detail. We theoretically show that the GWO is not invariant to shift-transformations, and experimentally clarify ineffective search of the GWO due to the property by using more shifted problems than in work [Citation16]. These results show that the performance evaluations of the GWO in many studies are not fair for a general-purpose metaheuristic method for global optimization problems.
Secondly, we propose a modified GWO-R, GWO-SR, to improve the insufficient intensive search of GWO-R in the final stages, in which the size of search areas are adjusted more reasonably with respect to the distance between the reference point and the best solutions. Then, we experimentally show that the search is effective if the reference point is chosen appropriately. Moreover, we improve the GWO-SR by adding an adjusting method of search areas and a mutation process in order to strengthen the diversity of the search, which is called the GWO with adjustment of the search area (GWO-AS). Finally, we show the good performance of the proposed GWOs, GWO-SR and GWO-AS, by comparing them with other metaheuristic methods such as particle swarm optimization (PSO) [Citation17, Citation18] and firefly algorithm (FA) [Citation19, Citation20].
This paper is organized as follows. In Section 2, we introduce the GWO, and in Section 3, we analyze the property of its search process, and point out the shift-dependence and the over-specialization of its search process. In Sections 4 and 5, we propose new modified GWOs exploiting a reference point or an adjustment of search area and a mutation process, which overcome the above drawbacks. In Section 6, through numerical experiments, we verify the effectiveness of the proposed methods. Finally, we conclude this paper in Section 7.
2. Grey wolf optimizer
The GWO is one of metaheuristic methods for continuous global optimization, in which the hunting technique and the social hierarchy of grey wolves are mathematically exploited in order to solve global optimization problems [Citation1, Citation2]. Regardless of its simple algorithm, the GWO is reported to have a high performance of finding desirable solutions of the optimization. In this section, we introduce the standard GWO.
Throughout this paper, we mainly consider the following continuous optimization problems having many local minima and the rectangular constraint.
Here,
denotes the objective function to be minimized, and X
does the feasible region. In order to solve the problem, the GWO uses a number of search agents called grey wolves. The position of each grey wolf i,
denotes a candidate solution of the problem, which are represented as
at iteration t, where W denotes an index set of all grey wolves. These positions are updated in a way that models the social hierarchy and tracking, encircling, and attacking a prey of the grey wolves as follows:
(1)
(1)
(2)
(2)
(3)
(3) where
,
and
denote the first, second and third best solutions obtained by grey wolves until iteration t, respectively, which are called the alpha, beta and delta wolves. In addition,
denotes the vector whose components are all one, and
for a vector
denotes a vector whose components are
,
, and ⊗ denotes the element-wise product of two vectors. The vector
is a coefficient vector whose components are linearly decreased from 2 to 0 over the course of iterations, and components of
,
are random numbers which are independently and uniformly chosen from
for each p and i. In Matlab code [Citation21], the vector
is given by
, where
denotes the maximal number of iterations. We also used the above linear function
in numerical experiments at 3.3.
In numerical experiments in this paper, in order to keep the feasibility of ,
,
obtained in (Equation3
(3)
(3) ) are projected onto the feasible region X of (P1) for the original GWO and the proposed GWOs. In the GWO, the size of search area of each wolf i depends on
and
by updating systems (Equation1
(1)
(1) )–(Equation3
(3)
(3) ). In (Equation2
(2)
(2) ),
is uniformly reduced by using
for all i
,
, which works to enhance the diversification of the search at the early stages and the intensification at the last stages according to only iteration t.
On the other hand, is determined by (Equation1
(1)
(1) ) to adjust the search area for each grey wolf i according to its position or alpha, beta and delta wolves: When random variables
,
are all close to 0.5, then
and thus, the wolf i can search for solutions around
,
. Conversely, when
,
are all close to 1 or 0, then
or
, which means that wolf i can explore a wider area. In many studies, the GWO is reported to have excellent intensification ability, while it is relatively weak in the extensive search, and thus, various improvement methods have been proposed such as improving updating mechanisms, introducing new operators, encoding scheme of the solutions and social hierarchy of grey wolves [Citation3–8].
However, the GWO is not invariant to the shift-transformations and is too specialized only for problems having the zero-optimal solution, which can cause the ineffectiveness of the search for other problems. Therefore, in the next section, we point out its drawbacks and analyze the properties.
3. Analysis of the search behavior of GWO
3.1. Shift-dependence of original GWO
In this subsection, we show that the GWO is not invariant to shift-transformations in the orthogonal coordinate representation of the optimization problem, and compare it with other metaheuristic methods. Although the previous work [Citation13] shows that the GWO is not invariant to affine transformations, in this subsection, we show more precisely that the GWO is not invariant to shift-transformations as well as affine transformations.
First, let's consider the orthogonal coordinate system which is shifted by a constant vector from the original orthogonal coordinate system of (P1). In the shifted coordinate system, the position
in the original coordinate system is represented as
. Then, the problem (P1) can be expressed in the shifted-coordinate system as follows:
where note that problems (P1) and (P2) are essentially the same except the coordinate system.
Now, we define the invariance of a metaheuristic method for shift-transformations in the coordinate representation of optimization problems. If the updating system is invariant to any shift-transformation, the metaheuristic method is called to be invariant, where for the sake of simplicity, we assume that all random variables used in the updating system are same in the original and shifted systems.
Definition 3.1
Suppose that for a constant vector and all search agents i ∈I of a metaheuristic method, the positions
and
of search agent i are feasible solutions for (P1) and (P2), respectively, such that
(4)
(4) where I denotes the index set of all search agents. In addition,
and
are the next points which are obtained by updating
and
, respectively. If
and
satisfy the relation
(5)
(5) then the metaheuristic method is said to be shift-invariant.
The shift-invariance guarantees that the method can search for solutions in exactly the same way and independently to the shift-transformations. Conversely, if a metaheuristic method is not invariant to shift transformations, the search performance can vary depending on the choice of the coordinate representation of even the same problem, which can cause difficulties in executing an efficient search for each problem. Therefore, the property is significant with respect to the general purpose metaheuristic method. Moreover, many metaheuristic methods such as variations of PSO, FA, DE and others have the property because, in those methods, is determined by only difference vectors between two points, which are independent of the vector
. On the other hand, the GWO is not shift-invariant as follows:
Theorem 3.2
The GWO is not shift-invariant in the coordinate representation of the optimization problem.
Proof.
Now, we focus on a grey wolf i and assume that ,
,
and
,
satisfy (Equation4
(4)
(4) ). In addition, we have that
and
are the same constant vectors in the different coordinate systems. Then, from (Equation1
(1)
(1) ), we can derive that
We can easily show that
unless random variables
are all 0.5 or
,
. In addition, from (Equation2
(2)
(2) ) and (Equation3
(3)
(3) ), we have that
(6)
(6) The second term of (Equation6
(6)
(6) ) is not zero unless random variables
are all 0.5 or
,
. As a result, we can see that (Equation5
(5)
(5) ) does not necessarily hold. Thus, the GWO is not invariant.
3.2. Search area control of GWO
Next, let us consider that the updating system of GWO is also too specialized only for optimization problems having the zero-optimal solution. In the previous work [Citation16] inefficient searches of the GWO were analyzed by the relations between the size of search area and the degree of degradation of search.
Figure 1. Relations of ,
and
.
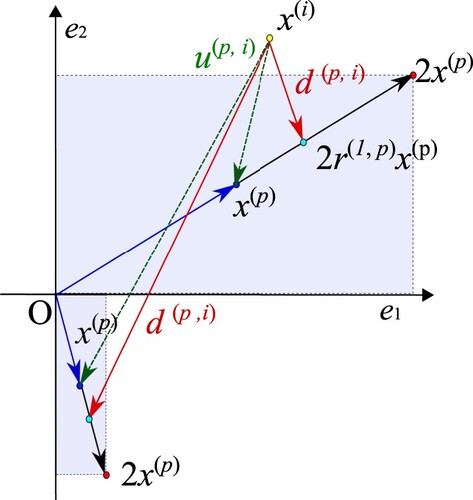
Now, we focus on the size of the search area of grey wolf i, at iteration t. Since the size is mainly determined by
,
, let us consider the upper bound
of jth component of
at iteration t, which is shown in Figure . Here, we define
. We can see that the jth component of
is varied in
or
,
, which are represented as light blue areas in Figure . Therefore, the upper bound
is given by
(7)
(7)
(8)
(8) From the results we can see that
increases as
or
increases. It is reasonable to choose a large
for a large
because the solution
which is far from the three best solutions
,
should be changed drastically. However, it is not well-founded to choose a large
for a large
because
just represents the distance from the origin, which is simply a reference point in the coordinate representation, and thus,
does not contain any useful information for a search. This property can cause an inefficient search, which is discussed in Ref. [Citation16].
From these results, we can see that when the problem has the global optimal solution at the origin, an intensive search around the origin, and an extensive search far from the origin can effectively work in the GWO. On the other hand, when the optimal solutions are far from the origin, the intensive and extensive searches cannot be expected to work so effectively. In the next subsection, we experimentally clarify the ineffective search of the GWO due to the property by using a large number of shifted problems in more detail than in work [Citation16].
3.3. Numerical experiments
In this subsection, we investigate how search efficiency of GWO for (P2) changes as the shift vector is varied through numerical experiments, which analyzes the quantitative relevance such as the relationship between the size of the shift vector and the mean size of the search areas, the means of
and
,
(9)
(9) on 50 trials at iteration t, where
and
denote vectors obtained at iteration t on trial l, respectively. In addition, we observed the mean of the best function values obtained on 50 trials at iteration t,
(10)
(10) where
denotes the best solution obtained at iteration t on trial l. The maximal number of iteration
is 5000, the number of wolves
was 80, and we used
as mentioned at Section 2.
We used 18 basic functions of CEC'17 benchmark problems [Citation22] (C1: BentCigar, C2: Sum of Different Power, C3: Zakharov, C4: Rosenbrock, C5: Rastrigin, C6: Expanded Schaffer F6, C7: Levy, C8: Modified Schwefel, C9: High Conditioned Elliptic, C10: Discus, C11: Ackley, C12: Weierstrass, C13: Griewank, C14: Katsuura, C15: HappyCat, C16: HGBat, C17: Expanded Griewank plus Rosenbrock, C18: Schaffer F7 ). In the experiments, relatively simple functions were used to compare the behavior of the original GWO for shift transformations. All functions have a hypercube constraint whose sides are 100, and functions C4, C15–C17 have the optimal solution at or
, while others have the zero-optimal solution. In addition, we used other two problems: O1:2n-minima Func. and O2:Schwefel Func., which have the optimal solution far from the origin as shown in Table . All problems have a hypercube constraint whose side is the same constant
, namely,
,
. As a shift vector
, four vectors
, ρ ∈
were used, where
is a randomly selected unit vector, and thus, ρ determines the relative size of
toward
. Note that (P2) with
is equivalent to (P1).
Table 1. Benchmark problems.
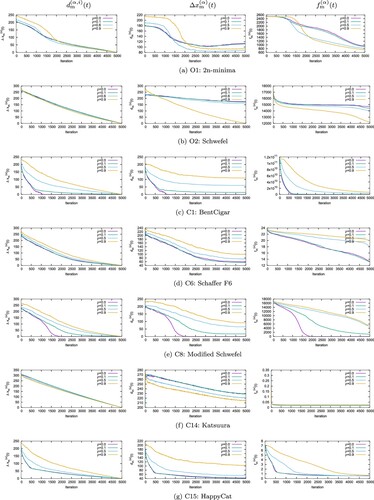
Figure depicts the results of seven problems for which typical transitions of each of (Equation9(9)
(9) ) and (Equation10
(10)
(10) ) were observed. They are selected from all results obtained by the GWO to 20 benchmark problems with four shift vectors, respectively.
Figure 2. Means of ,
, and
for four shift vectors.
Furthermore, Table indicates the mean function values and their standard deviations (SD) obtained by GWO for 20 benchmark problems with four shift vectors on 50 trials, where the first and second best values of the means or SDs obtained for the same problem with four shift vectors are indicated by bold and italic numbers, respectively.
Table 2. Comparison of results obtained by GWO for 20 benchmark problems (P1) and (P2) with three kinds of shift vectors ().
First, we focus on the results of problems C1–C18 which have the optimal solution at the origin or close to the origin. From the figure and table, we can see in most of problems with a small ρ, the GWO can find exactly the global optimal solutions or considerably high-quality solutions, and that and
are large at early stages of the search, gradually decrease and finally approach zero, which shows that the adjustment of the size of search area is appropriate. On the other hand, GWO finds considerably low-quality solutions for the problems with a large ρ. In this case, although
and
are decreasing, the rate of decrease becomes slower as ρ becomes larger. In particular,
is relatively large until the final stage, which means that the search is not sufficiently intensified. Moreover, the function value does not decrease as smoothly as the problem with smaller ρ, and the function values obtained finally are considerably worse for the problem with a larger ρ. These results show that adjustment of the search area is not appropriate, which are consistent with the previous discussion.
Next, let us consider the two problems, O1 and O2, in which the optimal solution is far from the origin. In these cases, the mean of obtained function values is smallest for (P2) with , and the obtained solutions are not overwhelmingly high quality, which are considerably different from the case for problems having the zero-optimal solution. In these cases, we find that the search of GWO is not so efficient regardless of the shift transformations.
From the above observations, the following conclusions can be derived. Since, in general, many global optimization problems can be expected to have many local solutions other than the origin, the technique of adjusting the search area in GWO as mentioned above can be regarded as a fatal drawback as a metaheuristic method, and it is difficult to find high-quality solutions by the GWO to many real-world problems. Therefore, in the subsequent sections, we propose modified GWOs to overcome the drawbacks which were pointed out in this section.
4. Shift-invariant GWO
4.1. Modification of GWO-R
In this subsection, we first introduce the GWO-R, which was proposed in Ref. [Citation16], and show that it is shift-invariant to overcome the drawback of the original GWO. Secondly, we theoretically and experimentally point out that the intensification of the GWO-R is insufficient in the final stages and propose its modified method such that its search areas are more reasonably controlled than GWO-R. Then, we show theoretically the shift-invariance of the GWO-R and the modified GWO-R.
In GWO-R, the point called a reference point is used to adjust adaptively the search area of each grey wolf i
on the basis of the distance of
to
,
or
:
(11)
(11)
(12)
(12)
(13)
(13) where (Equation11
(11)
(11) ) was derived by replacing
with
in (Equation1
(1)
(1) ),
is given by
, and
is a positive value for adjusting the search area. The GWO using (Equation11
(11)
(11) )–(Equation13
(13)
(13) ) is called GWO with reference points (GWO-R).
The reference point was selected by using information obtained until iteration t through the search process. As the reference point, three candidates were proposed as follows:
Centroid of all pbests:
,
Centroid of all grey wolves:
Centroid of three best solutions:
where ,
denotes the personal bests (pbests), which is the best solution found by grey wolf i until iteration t as follows:
The pbests have been used in PSO, which exploits information obtained by each search agent. In addition, as reference points, authors introduced internally dividing point of two reference points,
and
, selected from the three kinds of candidates, in which its weights vary linearly as follows:
By using these kinds of reference points, updating systems (Equation11
(11)
(11) )–(Equation13
(13)
(13) ) of the GWO-R are shift-invariant, as shown at the end of this subsection,
Moreover, in Ref. [Citation16], the relations between the upper bound of and the difference vector between the best solution and the reference point, namely
, were derived in the similar way in 3.2 as follows:
(14)
(14) The relations indicate that the search process can be classified into three stages: in the first stage the upper bound
increases with a large proportional constant to
, which can be considered to be an extensive search, and in the second and third stages, it increases with a small proportional constant, which means an intensive search. These results show that independently of the distance between the optimal solution and the origin, GWO-R gradually shifts from diverse to intensive search as the search progresses. At the same time, the effective search by GWO-R was reported through numerical experiments in Ref. [Citation16].
Furthermore, we can observe that in the first and second stages, under the assumption that is fixed,
is minimal when
. The observation means that the search area is minimal when the best solution is equal to the reference point. Such behavior is reasonable because if additionally
holds, namely,
, the size of the search area is zero.
On the other hand, under the same assumption, only in the third stage, is not minimal even if
, which is not reasonable. In such cases, the detailed search may be insufficient.
Therefore, in this paper, we modify the updating system (Equation11(11)
(11) ) such that
is minimal when
as follows:
(15)
(15) The GWO with updating systems (Equation12
(12)
(12) ), (Equation13
(13)
(13) ) and (Equation15
(15)
(15) ) is called simplified GWO-R (GWO-SR), in which the search process can be classified into two stages, and under the same assumptions as above, the upper bound
is minimal in all stages when
,
and
are equal. The properties can be shown as follows.
Now, we analyze the search area of each grey wolf. First, let us consider the upper bound of
in (Equation15
(15)
(15) ). In the same way to derivate (Equation14
(14)
(14) ), we have that
(16)
(16) Thus,
can be evaluated by dividing into the following cases:
(17)
(17)
(18)
(18)
(19)
(19) where we define
.
Note that and
mean the first and second halves of the search such that
and
, respectively, and
is the iteration at which the two kinds of searches are switched, as mentioned below:
From (Equation17(17)
(17) ), (Equation18
(18)
(18) ) and (Equation19
(19)
(19) ), we can see that in the first half,
increases with proportional constant
for large
, and does with 1 for small
, respectively, which widens the search area at a relatively high rate according to
, and that in the second half of the search,
increases with the proportional constant 1 for large
, and does with
for small
, respectively, which means that the effect of
on the search area is relatively small. These relations are depicted in Figure , in which
was chosen to be 3.0, and the switching occurs at
. The same
was used in the numerical experiment at the next subsection. The results coincide with the above results. Furthermore, note that the results show that the upper bound
is always minimal at
under the assumption that
is fixed, which means that the intensive search of GWO-SR is more reasonable than that of GWO-R.
Figure 3. Relation between and
when
and
.
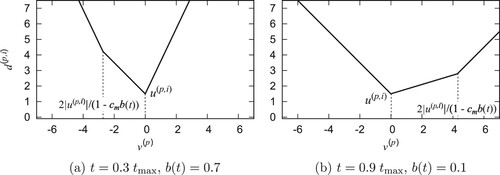
As discussed above, the search of the GWO-SR aims to suitably adjust the search area in a feasible way for more general cases. Note that determines not only the proportional constant
of the search but also the switching iteration
. Thus, an appropriate selection of
can tune the balance between diversification and intensification of the search.
Finally, we theoretically show the invariance of GWO-R and GWO-SR. Since in the updating systems (Equation11(11)
(11) ), (Equation12
(12)
(12) ), (Equation13
(13)
(13) ) of GWO-R, or in (Equation12
(12)
(12) ), (Equation13
(13)
(13) ), (Equation15
(15)
(15) ) of GWO-SR, the position of grey wolf i is updated by using only difference vectors between
and
or
, we can show shift-invariance of them as follows:
Theorem 4.1
GWO-R and GWO-SR are shift-invariant in the coordinate representation of the optimization problem.
Proof.
In the same way to Theorem 3.2, we assume that ,
,
and
,
satisfy (Equation4
(4)
(4) ). In addition,
and
denote the reference points in the original and shifted coordinate systems, namely for (P1) and (P2), respectively. Then, since from the definition of the reference point,
is a weighted sum of points satisfying the relation (Equation4
(4)
(4) ), we have that
, which means that
, p
, and
,
. Therefore, the relation
always holds at t + 1 if all random variables are the same in both systems. As a results, the position of any grey wolf satisfies the relation (Equation5
(5)
(5) ).
4.2. Numerical experiments
In this subsection, we applied GWO-R and GWO-SR to the same problems (P) with no shift-transformation as 3.3, namely, twenty 50-dimensional problems. Note that even if they are applied to (P2) with different shift vectors, the same results are obtained because of shift-invariance of them. We compared GWO-SRs with different reference points and GWO-R with . In Ref. [Citation16], GWO-R with
was shown to have better performance than others. We compared the mean function values of the best solutions obtained by GWO-R and GWO-SR on 50 trials. The maximal number of iteration
was 5000, the number of wolves
was 80, the constant
of GWO-R was 1.5, and
of GWO-SR was 3, which was selected in the preliminary experiments.
Table 3. Comparison of results obtained by GWO-SRs with seven different reference points and GWO-R with for 20 benchmark problems (P1).
Table shows the result obtained by GWO-R using and GWO-SRs using
, i = 1, 2, 3 and four internally dividing points,
,
,
and
, which are the first to fourth best results in ones obtained by GWO-SRs using internally dividing points of all combinations of two points,
,
∈
. We can see that GWO-SRs with
,
and
obtained better solutions than others, which demonstrates that it is advantageous to use the centroid of pbests for the diversification in the first half of the search, and the centroid of
,
or
,
for the intensification in its second half. At the same time, the results indicate that the selection of the reference point is considerably important because the reference point is a significant criterion to adjust the size of the search area.
Next, comparing GWO-R with GWO-SR using the same , we can observe that GWO-SR is superior to GWO-R, which indicates that the method of adjusting reasonably the search area works effectively in GWO-SR due to (Equation15
(15)
(15) ). In addition, since most of the results of the GWO-SR are better than those of the original GWO for (P2) with different shift vectors (
) shown in Table , we can conclude that the proposed GWO-SR is more useful than the original GWO. These results and the reasonable control of the search areas in GWO-SR show that if the reference point is a temporal prey, GWO-SR can be considered to search for solutions reasonably around the prey, which means that GWO-SR more naturally and effectively simulates the hunting mechanism of grey wolves than the original GWO or GWO-R.
On the other hand, GWO-SR has a search ability that is almost comparable to other metaheuristic methods, as shown in Section 6, while it does not have significant advantages over others. The limitation of its search ability can be mainly caused by the fact that the search areas are controlled only on the basis of the distance from the reference points, and in addition, there is room for improvement in the method. Therefore, in the next section, we add two techniques to the proposed GWO, which can control the search areas adaptively as the search progresses.
5. GWO with adjustment of search area
In this section, first, we propose a method which adaptively selects the size of the search area for each grey wolf by evaluating objective function values at candidates of its next point additionally. Its updating system is given as follows: (20)
(20)
(21)
(21)
(22)
(22) In this method, at the beginning,
,
are calculated by using the best solution
with different
,
, such that
by (Equation20
(20)
(20) ) for grey wolf i. Then, three candidate points
,
for i are selected from the search areas determined by
,
, respectively, by (Equation21
(21)
(21) ). Next, among three candidate points, the point with the smallest objective function value is selected as the next point of
by (Equation22
(22)
(22) ). Namely, the next point of each grey wolf is the best point of three candidates selected from search areas with different sizes.
Here, note that since function values of three candidate points are evaluated for each grey wolf per iteration, with regard to the number of evaluations of function values the method requires three times greater than GWO-SR. In addition, although selection from more candidates based on all of ,
might improve current solutions more significantly, it requires a larger amount of computational resources. Thus, this method uses only three candidates based on
.
Next, let us remind that in (Equation11
(11)
(11) ), which corresponds to
in (Equation20
(20)
(20) ), determines the switching iteration
between the extensive and intensive searches, as discussed in 4.1. Since
is different for different
, the balance between extensive and intensive searches is also different for each
. Hence, we can expect the various searches by selecting different
. In the numerical experiments in the next section, we selected
,
,
, in which we have
,
and
.
Secondly, we introduce a mutation procedure for a more extensive search because the diversity of the search may be relatively weakened due to selecting the next point from three candidates based on the same . In the procedure, at each iteration t, a mutation procedure is executed with a probability of
at t as follows: A grey wolf i
and an index
are selected uniformly at random, respectively, and the jth component of
is also selected uniformly at random among
. Then, after updating
by (Equation21
(21)
(21) ), a mutational modification of
is added as follows:
(23)
(23) where
is a uniform random variable from
, and
is the upper bound of modification amount.
This modified GWO-SR is called the GWO with adjustment of the search area (GWO-AS). Here, note that we can easily show that the modified GWO-AS is also invariant to shift-transformations in the same way as Theorem 4.1 because the updating systems (Equation20(20)
(20) )–(Equation22
(22)
(22) ) and (Equation23
(23)
(23) ) include only difference vectors between
and
or
similarly to GWO-SR.
6. Numerical experiments
6.1. Experimental conditions
In this section, we apply the proposed GWOs, GWO-SR and GWO-AS, and other metaheuristic methods, FA and PSO, to 18 basic functions of CEC'17 benchmark problems and the other two problems, which were used in 3.3 and 4.2. Note that in order to evaluate the characteristics of the proposed methods, the search behavior was investigated by comparing them with the original metaheuristic methods rather than the various modifications of them. Since the four methods differ in the number of function evaluation per iteration, we selected the maximum number of iteration for each method such that the total number of function evaluations were equal in four methods. We set
and 4800000 for 50 and 200-dimensional problems, respectively, in which 50 trials were performed for 50-dimensional and 30 trials were 200-dimensional problems. All methods used 80 search agents such as particles, fireflies and grey wolves. In addition, the parameter values of PSO were selected as the recommended ones [Citation23]. Those of FA and the proposed methods were done by preparatory experiments. For GWO-SR,
and the reference point was
, while for GWO-AS,
and
the reference point was
.
First, we compared the mean and standard deviations of function values obtained on 50 trials of four methods for twenty 50-dimensional benchmark problems, and compared those on 30 trials for nineteen 200-dimensional benchmark problems, where all four methods did not obtain any computable objective function value for 200-dimensional problem , which are shown in Tables and , respectively.
Table 4. Comparison of PSO, FA, GWO-SR and GWO-AS for 50-dimensional problems ().
Table 5. Comparison of PSO, FA, GWO-SR and GWO-AS for 200-dimensional problems ( ).
Next, we evaluated the transitions of the best function values obtained by four methods with for all 50-dimensional problems, and selected six typical results in them, which are shown in Figure . In the figures, its horizontal axis denotes the function evaluation count per agent, and its vertical axis does the mean of the best function values in the search process of each method on 50 trials. Finally, we focus on the number of times
,
is selected in (Equation22
(22)
(22) ) of GWO-AS at iteration t + 1 as follows:
, and compare the mean of
on 50 trials at each iteration in GWO-AS for four typical results, which are shown in Figure .
Figure 4. Means of the best function values obtained by four methods, PSO, FA, GWO-SR and GWO-AS, until function evaluation count per agent for 50-dimensional six benchmark problems.
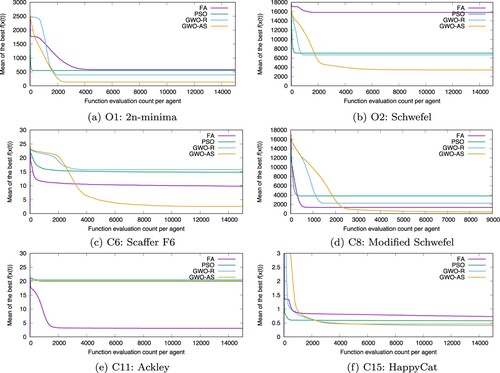
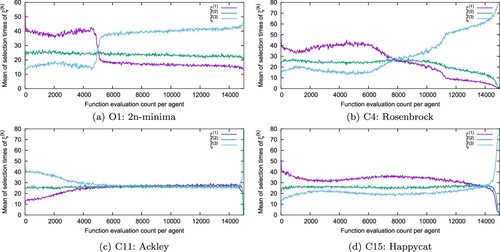
Figure 5. Means of ,
for three candidates on 50 trials at each count when GWO-AS is applied to 50-dimensional four benchmark problems.
6.2. Discussion of results
First of all, we discuss obtained function values by four methods, as shown in Tables and . Now, comparing the results of four methods and the original GWO with , which are shown in Table , we can see that four methods obtained better solutions than the original GWO with
for many problems, especially, GWO-SR and GWO-AS did. These results well demonstrate the disadvantages of the original GWO and the advantages of GWO-SR and GWO-AS. Next, concerning the comparison of three methods, PSO, FA and GWO-SR, the number of the problems for which the least objective functions was obtained by three methods are almost the same, which indicates that GWO-SR is not only invariant to shift-transformations by just introducing the reference point, but also has a similar search ability to other two methods. In addition, let us compare four methods, PSO, FA, GWO-SR and GWO-AS. From the above two tables, we can see that GWO-AS has better search ability than other three methods: GWO-AS obtained the first least function value for ten or eleven problems, and the second least function value for five ones in four methods. From these results, we can conclude that even though the GWO has serious drawbacks, the drawbacks can be overcome by applying the proposed methods, which implies that the basic concept for search in GWO is still promising, comparing other metaheuristic methods.
Secondly, we focus on the two proposed methods, GWO-SR and GWO-AS. From preparatory experiments for the methods with different reference points, which are shown in Tables for GWO-SR, we observed that the appropriate reference points for GWO-SR were and
, while those for GWO-AS were
and
, respectively. It means that the pbests are effective as the reference point for the search in GWO-SR, while the three best solutions are effective in GWO-AS. The difference can be attributed to the different search characteristics of the two methods. Although GWO-AS using the three best solutions may enhance the intensive search too strongly than GWO-SR, the balance between diversification and intensification is considered to be kept due to the proposed adaptive selection and mutation. Moreover, GWO-AS has better performance than GWO-SR in Tables and , which indicates that the two proposed methods,the adaptive selection of search areas and the mutation procedure, are effective.
Thirdly, we discuss the relationship between computational complexity and search ability. In Figure , we can observe that all four methods decrease the objective function values sequentially as the search progresses. On the other hand, in the early stage of the search, the GWO-AS decreases more slowly than others, where the slow decline can be explained by the fact GWO-AS requires three times more function evaluations per iteration than the others, as mentioned previous section, while in the middle to end of the search, the GWO-AS decreases the function value significantly faster for many problems. In addition, as discussed above, the final function value obtained by GWO-AS was the least for many problems. These results suggest that the performance of search ability of GWO in terms of computational complexity is higher than others.
Finally, we analyze the mean of selection times of per each count in GWO-AS, as shown in Figure , in which we can see that three kinds of candidates
,
are variously selected as the search progresses: The candidate
which is most often selected is different in the first and second halves of the search, and its switching count is between 5000 and 8000. In the first half of the search,
with
was most often selected, which is relatively small, while in its second half,
with
was most often selected. From these results, we can see that three kinds of search areas are adaptively selected in GWO-AS for each problem as the search progresses.
7. Conclusion
In this paper, we have theoretically shown that the original GWO relies on a shift transformation of the problem, and have experimentally shown that its search is too specialized for problems with an optimal solution at the origin, which can significantly reduce its effectiveness of the search for other problems.
Next, we have proposed a modified method of GWO-R (GWO-SR) that is not only invariant to shift-transformations, and that can adjust reasonably its search areas. In addition, we have experimentally shown that its search area can be appropriately varied as the search progresses, in which GWO-SR is more efficient than GWO-R, and as efficient as PSO and FA. Moreover, we have proposed the GWO-AS by adding two methods, an adaptive selection method of the size of search area and a mutation procedure, to GWO-SR. Through numerical experiments, we have verified that the GWO-AS outperforms other methods. From these results, we can conclude that the basic concept of the search inspired by the hunting mechanism of grey wolves is promising despite of its serious drawbacks of the orignal GWO because the drawbacks can be easily overcome by the proposed methods.
Furthermore, since various methods have been investigated for the original GWO [Citation3–8], the proposed GWO can be also modified by some of them. As a future issue, the performance evaluation of the proposed GWOs with such modifications should be verified. In addition, note that the whale optimization algorithm (WOA) [Citation24], which is also one of the popular metaheuristic methods, uses basically the same update systems as the GWO. Thus, the method has the same drawbacks, as mentioned in Ref. [Citation15]. It is possible to add the shift-invariance to WOA and modify its search ability as a general-purpose metaheuristic method by applying the methods used in GWO-SR and GWO-AS. Therefore, we would like to verify how useful those methods are when they are applied to the WOA, or what variations are particularly effective.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Keiji Tatsumi
Keiji Tatsumi, received the Ph. D. degree from Kyoto University, Japan, in 2006. In 1998, he joined Osaka University, where he is currently an Associate Professor of the Graduate School of Engineering. His research interests comprise metaheuristics for global optimization and machine learning.
Nao Kinoshita
Nao Kinoshita, received his M.S. degrees from Osaka University, Japan, in 2022. He is currently working for Nippon Steel Corp. His research interests are in metaheuristics for global optimization.
References
- Mirjalili S, Mirjalili SM, Lewis A. Grey wolf optimizer. Adv Eng Softw. 2014;69:46–61. doi: 10.1016/j.advengsoft.2013.12.007
- Muro C, Escobedo R, Spector L, et al. Wolf-pack (Canis lupus) hunting strategies emerge from simple rules in computational simulations. Behav Processes. 2011;88:192–197. doi: 10.1016/j.beproc.2011.09.006
- Mosav SK, Jalalian E, Gharahchopog FS. A comprehensive survey of grey wolf optimizer algorithm and its application. Int J Adv Robot & Expert Syst (JARES). 2018;1(6):23–45.
- Faris H, Mirjalili S. Grey wolf optimizer: a review of recent variants and applications. Neural Comput Appl. 2018;30:413–435. doi: 10.1007/s00521-017-3272-5
- Panda M, Dan B. Grey wolf optimizer and its applications: a survey. In: Proceedings of the Third International Conference on Microelectronics, Computing and Communication Systems. 2019.p. 179–194.
- Ali S, Sharma A, Jadon S. A survey on grey wolf optimizer. J Emerg Technol Innov Res (JETIR). 2020;7(11):789–790.
- Almufti SM, Ahmad HB, Marqas RB, et al. Grey wolf optimizer: overview, modifications and applications. Int Res J Sci Technol Educ Manage. 2021;1(1):44–56.
- Wu G, Mallipeddi R, Suganthan P. Ensemble strategies for population-based optimization algorithms – A survey. Swarm Evol Comput. 2019;44:695–711. doi: 10.1016/j.swevo.2018.08.015
- Mirjalili S. How effective is the grey wolf optimizer in training multi-layer perceptrons. Appl Intell. 2015;43:150–161. doi: 10.1007/s10489-014-0645-7
- Muangkote N, Sunat K, Chiewchanwattana S. An improved grey wolf optimizer for training q-Gaussian Radial Basis Functional-link nets, 2014 International Computer Science and Engineering Conference (ICSEC); 2014.
- Saremi S, Mirjalili SZ, Mirjalili SM. Evolutionary population dynamics and grey wolf optimizer. Neural Comput Appl. 2015;26:1257–1263. doi: 10.1007/s00521-014-1806-7
- Shankar K, Eswaran P. A secure visual secret share (VSS) creation scheme in visual cryptography using elliptic curve cryptography with optimization technique. Aust J Basic Appl Sci. 2015;9(36):150–163.
- Jian Z, Zhu G. Affine invariance of meta-heuristic algorithms. Inf Sci (Ny). 2021;576:37–53. doi: 10.1016/j.ins.2021.06.062
- Niu P, Niu S, Liu N, et al. The defect of the grey wolf optimization algorithm and its verification method. Knowl Based Syst. 2019;171:37–43. doi: 10.1016/j.knosys.2019.01.018
- Askari Q, Younas I, Saeed M. Emphasizing the importance of shift invariance in metaheuristics by using whale optimization algorithm as a test bed. Soft Comput. 2021;25:14209–14225. doi: 10.1007/s00500-021-06101-9
- Tatsumi K, Kinoshita N. Shift-invariant grey wolf optimizer exploiting reference points and random selection of step-sizes. Proc SICE Ann Conf. 2022;2022:1201–1206.
- Kennedy J, Eberhart RC. Particle swarm optimization. Proc IEEE Int Jt Conf Neural Netw. 1995;4:1942–1948.
- Poli R, Kennedy J, Blackwell T. Particle swarm optimization – an overview. Swarm Intell. 2007;1:33–57. doi: 10.1007/s11721-007-0002-0
- Yang XS. Nature-Inspired metaheuristic algorithms. Frome: Luniver Press; 2008.
- Fister I, Fister J.I, Yang XS, et al. A comprehensive review of firefly algorithms. Swarm Evol Comput. 2013;13:34–46. doi: 10.1016/j.swevo.2013.06.001
- Grey Wolf Optimizer (GWO) version 1.6 (1.85 MB) by Mirjalili S. GWO is a novel meta-heuristic algorithm for global optimization. https://www.mathworks.com/matlabcentral/fileexchange/44974-grey-wolf-optimizer-gwo.
- Awad NH, Ali MZ, Suganthan PN, et al. Problem definitions and evaluation criteria for the CEC 2017 special session and competition on single objective real-parameter numerical optimization, Technical Report of Nanyang Technological Univ., Jordan Univ. and Zhengzhou Univ., 2016.
- Clerc M. Particle swarm optimization. London: ISTE Publishing; 2006.
- Mirjalili S, Lewis A. The whale optimization algorithm. Adv Eng Softw. 2016;95:51–67. doi: 10.1016/j.advengsoft.2016.01.008