
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Event-related potentials (ERPs) extracted from electroencephalography (EEG) data in response to stimuli are widely used in psychological and neuroscience experiments. A major goal is to link ERP characteristic components to subject-level covariates. Existing methods typically follow two-step approaches, first identifying ERP components using peak detection methods and then relating them to the covariates. This approach, however, can lead to loss of efficiency due to inaccurate estimates in the initial step, especially considering the low signal-to-noise ratio of EEG data. To address this challenge, we propose a semiparametric latent ANOVA model (SLAM) that unifies inference on ERP components and their association with covariates. SLAM models ERP waveforms via a structured Gaussian process (GPs) prior that encode ERP latency in its derivative and links the subject-level latencies to covariates using a latent ANOVA. This unified Bayesian framework provides estimation at both population- and subject-levels, improving the efficiency of the inference by leveraging information across subjects. We automate posterior inference and hyperparameter tuning using a Monte Carlo expectation–maximization (MCEM) algorithm. We demonstrate the advantages of SLAM over competing methods via simulations. Our method allows us to examine how factors or covariates affect the magnitude and/or latency of ERP components, which in turn reflect cognitive, psychological, or neural processes. We exemplify this via an application to data from an ERP experiment on speech recognition, where we assess the effect of age on two components of interest. Our results verify the scientific findings that older people take a longer reaction time to respond to external stimuli because of the delay in perception and brain processes.
1. Introduction
Event-related potentials (ERPs) refer to the electrical potentials measured by extracting voltages from electroencephalography (EEG) data in response to internal or external stimuli, typically during visual, auditory, or gustatory experiments. Raw EEG signals summarize all neural activity in the brain, making it difficult to distinguish specific neural processes related to perception, cognition, and emotion. In contrast, ERPs can identify multiple neurocognitive and affective processes contributing to behavior (Gasser and Molinari, Citation1996). With other advantages such as noninvasiveness, continuous high temporal resolution, and relatively low cost compared to other neuroimaging modalities such as functional magnetic resonance imaging, ERPs have become a widely used tool in psychological and neuroscience research (Luck, Citation2022; Vogel and Machizawa, Citation2004).
Clinical studies usually focus on specific characteristic components of the ERP waveforms, defined as voltage deflections produced when specific neural processes occur in specific brain regions (Luck, Citation2012). A main task of any ERP analysis is to estimate the amplitude, i.e. magnitude (in microvolts, μV) and the latency, i.e. position in time (in milliseconds, ms) of specific ERP components. In current ERP studies, most often researchers identify such components by visually inspecting the grand ERP waveform averaged across trials and subjects, often relying on previous scientific research findings. When the statistical analysis is done at the subject level, two-step approaches are typically used, first extracting the ERP components of interest and then performing an analysis of variance (ANOVA) to relate the extracted components to the subject-level covariates. In such analyses, in order to obtain a smooth ERP curve, the whole EEG experiment needs to be averaged across many trials and/or participants. In addition, filtering is necessary to remove the signal trend or drifts, together with noise that comes from biological artifacts or the electrical activity recording environment. Once a smoothed ERP curve has been obtained, a time window needs to be specified as the range of the component of interest. This is a critical choice in many of the analyses. For example, one of the common ways to quantify the amplitude of an ERP component of interest is as the mean amplitude integrated over the chosen window. This may lead to false discoveries when comparing the amplitudes of ERP components across control and experimental groups.
In statistics, there is limited contribution to methods for the identification and estimation of ERP components. Jeste et al. (Citation2014) and Hasenstab et al. (Citation2015) use LOESS-based methods that first smooth the noisy waveforms and then apply a peak detection algorithm on the smoothed curve to identify optima within a specified time window. Hasenstab et al. (Citation2015), in particular, propose MAP-ERP, a meta-preprocessing step based on a moving average of the ERP functions over trials in a sliding window, to preserve the longitudinal information in ERP data, and then employ peak detection. With peak detection algorithms, latency is calculated as the location of the stationary point identified within a pre-set window and the amplitude is calculated as the value of the smoothed curve at the location of the stationary point or by integrating the area under the curve. Other approaches for detecting ERP components, in single subjects, use continuous wavelet transformation techniques (see for example Kallionpää et al. (Citation2019).
Recently, various extensions of Gaussian Processes (GPs) have been applied to neuroscience problems. Kang et al. (Citation2018) propose a soft-thresholded GP prior for feature selection in scalar-on-image regression utilized to represent sparse, continuous, and piecewise-smooth functions. Yu et al. (Citation2023) employ GPs with derivative constraints, defining a peak or dip location as the stationary point such that the first derivative of the underlying smooth ERP waveform at the point is zero. While this method takes the data averaged across trials for analysis, as traditional studies do, it does not need separate smoothing steps of the ERP waveforms. Ma et al. (Citation2022) develop the split-and-merge GP prior for selecting time windows in which the P300 ERP components in response to the target and non-target stimuli may be different. While the model considers multiple channel EEG signals and spatial correlation, it focuses on the amplitude difference and uncertainty about ERP functions.
In this article, we propose a novel semiparametric latent ANOVA model (SLAM) as a data-driven model-based approach that provides a unified framework for the estimation of ERP characteristics components and their association with subject-level covariates. Following Yu et al. (Citation2023), we employ a Bayesian model with derivative-constrained GP priors, to produce smooth estimates of the ERP waveform together with amplitude and latency of ERP components, and incorporate into the model a flexible ANOVA setting, to examine how multiple factors or covariates, such as gender and age, affect the ERP components’ latency and amplitude. Unlike the model of Yu et al. (Citation2023), which considers one single ERP waveform at a time, either as an averaged single-subject ERP or a grand mean across subjects, our hierarchical framework allows estimates of latency and amplitude at the group level as well as at the individual subject level. To produce such inference, SLAM starts with an initial partition of the experimental time interval into sub-intervals, one for any potential ERP component location, and then employs derivative-constrained GPs to identify the latency of the components. The posterior distribution of latency parameters not only provides a more precise identification of the ERP component location, but allows the calculation of credible intervals that can be used as a refined search window where to compute amplitude estimates or, indirectly, as a reference in follow-up studies, to corroborate previous scientific findings or experts’ knowledge. We perform posterior inference and hyperparameter tuning via a Monte Carlo expectation–maximization (MCEM) algorithm. Through simulations, we demonstrate how our proposed method produces smaller root mean square error for both latency and amplitude estimates, compared to the LOESS-based method. Unlike these methods, our approach provides a direct estimate of the latency parameter, without the need to apply curve smoothing. Moreover, SLAM provides automatic group-level estimates, while an additional ANOVA is needed when the LOESS-based methods are used.
In neuroscience and psychological sciences, ERP components are typically used to examine perception or cognitive differences between control and experimental groups or under different levels of an influential factor. In fact, the components are usually named by whether it is a positive wave (peak) or a negative wave (dip), and when it occurs. For example, the peaks occurring around 100 ms, N100, or around 200 ms, P200, after the start of the stimulus, have been implicated in speech recognition (Noe and Fischer-Baum Citation2020), the N170 component in object recognition (Tanaka and Curran Citation2001), and the N400 in language processing (Kutas and Hillyard Citation1980). Here we consider ERP data collected during an experiment designed to determine whether early stages of speech perception are independent of top-down influences. Our hierarchical framework allows us to estimate latency at both subject- and group-level. Our results show that the older group people tend to have longer latency of both the N100 and P200 ERP components. We also find that the older group people tend to have larger N100 amplitude. These results verify the scientific findings that older people take a longer reaction time to respond to external stimuli because of the delay in perception and brain processes (Noe and Fischer-Baum Citation2020; Tremblay et al. Citation2003; Yi and Friedman Citation2014).
The rest of the article is organized as follows: Section 2 describes our proposed Bayesian hierarchical model and its associated algorithm for learning ERP waveforms and components. Section 3 provides a simulation study, showing the estimation performance of the proposed method against LOESS-based approaches, and Section 4 illustrates the application of our methodology to an ERP data set. Section 5 presents our conclusions.
2. Methods
In this section, we describe the proposed general SLAM framework, for the analysis of multi-subject-multi-group ERP data. To ease exposition, we consider a one-way ANOVA setting, and will use age (“old” and “young”) as a demonstrative example to illustrate our approach. We note, however, that the model construction can be easily generalized to incorporate any given number of factors and continuous covariates.
2.1. Derivative-Constrained Gaussian Process
Let yigs be the observation at time for
with
indicating the levels of a factor, and with
indexing the subject within the gth group. We assume the following model:
(1)
(1)
In ERP applications, represents the underlying true ERP waveform at level g of the factor, e.g. the ERP waveform for the older adult group. This waveform is usually believed to be a smooth curve.
We adopt the Bayesian modeling approach of Yu et al. (Citation2023) and impose a derivative-constrained GP prior on the function Ghosal and van der Vaart (Citation2017); Rasmussen and Williams Citation2006). We assume that the function has M stationary points,
each corresponding to the latency of an ERP component. The parameters
and their association with subject-level covariates are of interest here. We encode the stationary points
in the modeling of the ERP waveforms via a derivative GP (DGP) as
(2)
(2)
where
is a GP with mean 0 and covariance kernel
conditioned upon
for
which is also a GP with
-dependent mean and covariance functions. Here
indicates the hyperparameters in the kernel. GP priors are widely used for modeling unknown functions, and the covariance kernel is instrumental in determining sample path properties. Yu et al. (Citation2023) and Li et al. (Citation2023) show that a general
forms a n-dimensional Gaussian distribution
with mean vector
and covariance matrix
where k00 is the n × n covariance matrix of x,
is the M × n covariance matrix of x and
and k11 is the M × M covariance matrix of
Following these authors, we use the squared exponential kernel, that is
(3)
(3)
as the waveform in ERP studies is typically believed to be smooth.
In the absence of prior information on M, the number of stationary points, the method developed in Yu et al. (Citation2023) and Li et al. (Citation2023) can be used to estimate M and provide interval estimates for each latency. Specifically, M is estimated by the number of disjoint segments in the highest posterior density region of the posterior distribution of stationary points. In many ERP applications, however, the number M can be easily pre-specified at a small fixed value, say one to three, based on prior knowledge of the process under study, and a time interval can be specified as the search window of interest for the mth ERP component before building the model. When only vague information is available, the search windows could form a partition of the entire EEG experiment epoch, that is,
for
and
Note that am and bm can be specified in a factor-dependent manner.
2.2. Latent ANOVA Model
Unlike Yu et al. (Citation2023), which focused on employing DGP to infer the unknown M components on a single ERP waveform, our goal is to model ERP components across multiple subjects and examine how multiple factors or covariates, such as gender and age, affect the ERP components’ latency and amplitude. For this, we incorporate a flexible ANOVA construction into our model, that allows estimation of the ERP components at both the population and subject-specific levels.
For each level g, the subject-level parameter is governed by the general beta prior supported on
(4)
(4)
The general beta distribution supported on is distributed as
for the standard beta variable X supported on [0, 1]. The first two parameters in the general beta distribution are parametrized such that
is the location parameter and
is the scale parameter. The prior mean of
is
Note that all subjects in the same level g have the mth stationary point from the common level general beta distribution centered at
in its time window. Such hierarchy is a starting point of the ANOVA structure as the mean
is then further decomposed into the overall mean and the main effect from the factor.
The group-level parameter indicates the relative location of the mean in the interval
or the weight between the two end points of the search window. The larger
is, the closer the prior mean is to bm. The weight
can be easily transformed to have the same scale as
and serves as the group-level latency that is common across subjects at the same factor levels. Given
the value of
controls the prior variance of
which is
One can specify
using fixed values based on domain knowledge or preliminary estimates, or apply a common prior for within-group variability.
For inference on we introduce an ANOVA structure to model how the two factors affect the location of the ERP component. Since
is bounded between zero and one, we use a link function
followed by an ANOVA:
(5)
(5)
Here, we write the one-way ANOVA as a linear model using dummy variables where
is a binary variable denoting the level of the factor. Coefficient
denotes the grand mean at the baseline level, and
quantifies the effect of level a compared to the baseline.
This latent structure is flexible and inclusive in the following sense. First, it can accommodate any linear model with categorical and numerical variables. For example, subject-level numerical covariates (e.g. blood pressure) can be included in the latent regression. Second, the latent structure is able to accommodate interactions between factors. Moreover, any link function for parameter values restricted in (0, 1) can be used in the modeling setup, such as logit, probit, and complementary log-log links.
2.3. Complete Model
We complete the model by placing standard normal priors on the beta coefficients in (5), a gamma prior on the positive variable and standard inverse gamma priors on
In summary, the full Bayesian SLAM is summarized as follows. For time point
subject
factor level
and stationary point index
With no prior knowledge, we suggest setting hyperparameters at zero, and
at one, i.e. standard Gaussian distribution. In our experience, the parameter learning is insensitive to the variance size. Furthermore, to circumvent overfitting, we choose hyperparameters in the inverse gamma prior on
so that its mean is around the empirical mean of the data. As for the hyperparameters
and h in the covariance function, we follow Yu et al. (Citation2023) and estimate then based on the marginal maximum likelihood (MML) by embedding an EM algorithm into the posterior sampling, as explained in the section below, therefore avoiding a separate tuning of these hyperparameters.
2.4. Posterior Inference
We adopt the MCEM algorithm for joint parameter tuning and posterior sampling of Yu et al. (Citation2023) to our SLAM framework. More specifically, in the E-step, we sample the subject-level latency parameters, the factor main effect for group-level latencies,
the general beta scale parameters,
and the noise variance,
and optimize the hyperparameters
and h in the M-step.
Let with
and
Similarly, let
with
and
with
Let us also define
with
with
and
At iteration j, the posterior density for the E-step is
and, for each g and s, the marginal likelihood with fgs being integrated out is
which is a n-dimensional Gaussian distribution
where
and
are as defined in Section 2.1. The full conditional distributions for all parameters can be found in the Supplementary Material.
Given the posterior samples of and
drawn from the E-step, the hyperparameters
and h are updated in the M-step by maximizing the log marginal conditional likelihood:
(6)
(6)
where
and
are the lth posterior sample of
and
at the jth iteration in the algorithm respectively. Therefore,
is the maximum marginal likelihood (MML) estimates at
th iteration in the MCEM algorithm. The optimization step can be solved numerically using standard numerical optimization approaches. The detailed sampling scheme in the MC E-step is discussed in the Appendix, and the entire algorithm is summarized in Algorithm 1.
The MCEM reaches convergence when at the
th iteration Bai and Ghosh (Citation2021). The threshold ϵ is set to be
in the simulation and data analysis. With the sample size of 100, our R code takes about 70 s for J = 500 to finish one M-step, and 30–35 s for drawing 1000 samples in the MC E-step or final simulation.
Algorithm 1:
Monte Carlo EM Algorithm for SLAM
Initialize:
Set model values of ϵ, D, G, L, M, am, bm,
αh, βh
Set initial values for the algorithm:
For iteration
Monte Carlo E-step: for do
For each g and s, draw in blocks using Metropolis–Hastings steps on its conditional density
For each m, draw using Metropolis–Hastings steps on its conditional density
For each a and m, draw using Metropolis–Hastings steps on its conditional density
Obtain and use the inverse link to transform
to
For each g and m, draw using Metropolis–Hastings steps on its conditional density
Draw from its inverse gamma conditional distribution
end
Draw sample from
Draw sample from
M-step:
Given samples of and
at the jth iteration,
and
update
to
by optimizing
according to EquationEquation (6)
(6)
(6) .
Result: MML estimate of and posterior samples of
and
For multi-way ANOVA, for example with two factors, A with levels and B with levels
the latent ANOVA structure can be directly extended into
where
is a binary variable for factor A, and
for factor B. The posterior inference and learning algorithm are similar to the one-way ANOVA demonstration.
3. Simulation Study
In this section, we examine the performance of our proposed method through a simulation study, where we also compare results with the LOESS-based method of Jeste et al. (Citation2014). For latency inference, we also discuss the difference between SLAM and the DGP-MCEM method of Yu et al. (Citation2023).
3.1. Data Generation
For a fair comparison of the proposed method with other competing methods, in this section, we consider a simulation setting where the data are not generated directly from the proposed model. We show that our model estimates the latency location better than the other methods. Later in Section 3.5, we examine how well the model learns the parameters in a scenario where the data are generated from our model. We consider the case of one factor with two levels or groups, each having ten subjects and ERP waveforms. Depending on how smooth or noisy the data set is, the ten ERP signals could be treated as either waveforms of ten trials of a single subject or waveforms averaged across trials for ten subjects. The two groups have significantly different ERP patterns, while individuals within each group behave similarly with little latency and/or amplitude shifts.
For subject group g = 1, 2, the simulated regression functions of the two groups are
and
respectively, where
The regression functions are shown in . The simulated data are generated from
g = 1, 2, where
and
and n = 100.
Both groups have two components in their waveforms. Note that in group 1 where data are generated from the sine functions, all the curves have the same amplitude size and only latency changes, accounting for individual differences. If zero is the baseline, the amplitude is two and negative two for the peak and dip for all the subjects. The latency for the dip or the first ERP component ranges from 0.19 to 0.29, and the latency for the peak or the second ERP component ranges from 0.69 to 0.79. The curves in the second group, on the other hand, have their own latency and amplitude. For the dip, its latency ranges from 0.23 to 0.37, and its amplitude changes from −1.57 to −2. For the peak, its latency ranges from 0.57 to 0.71, and its amplitude changes from −0.83 to −1.26. For each curve, 100 observed data points are generated by adding mean zero Gaussian errors with a standard deviation 0.25. The simulation is set to mimic real ERP data.
3.2. Parameter Settings
We fit our novel SLAM with one-factor ANOVA to the entire data containing 20 ERP trajectories by setting M = 2 components in both groups, and assuming that one stationary point is in and the other in
The initial values of the MCEM algorithm are specified as follows. The subject or individual level latency is randomly drawn from the uniform distribution, all the beta coefficients are set to zero and the parameters
and σ are set to one. In each E-step, the first 100 draws are considered burnin, and then further 2000 MCMC iterations, with no thinning, are saved for estimation, with 500 subsampled draws used for the subsequent M-step, to optimize the hyperparameters of the GP kernel. The iterative algorithm stops when the current updated parameters and those from the previous iteration have a difference less than
The final 20,000 MCMC samples are saved, and the posterior distribution of the stationary points is summarized based on the MCMC samples. To do the inference for group-level latency, the logit link function is used for transformation. When comparing with the LOESS-based method we applied the loess.wrapper() function in the R package bisoreg and the function PeakDetection() provided in the online supporting information of Hasenstab et al. (Citation2015) at https://onlinelibrary.wiley.com/doi/10.1111/biom.12347 to each individual curve to estimate the underlying ERP waveform, latency and amplitude. The LOESS smoothing parameter was determined by 5-fold cross-validation from a sequence of values from 0.25 to 1 with increments 0.05. The dip searching window is set to be
and the peak time window is
The method provides point estimates with no uncertainty quantification.
3.3. Results on Latency Estimation
The latency estimates from SLAM, for all subjects, calculated as posterior means, are shown in , together with the 95% credible intervals. For comparison, the LOESS-based estimates are also shown. Results show that, even though some of the LOESS-based estimates are closer to their corresponding true stationary points than the posterior mean estimates derived from our algorithm, there is more variability in the LOESS-based estimates, with more of the estimates away from the true values. This unstable phenomenon is more significant for group 2, with the cosine functions. This is confirmed by the root mean square error (RMSE), calculated as as shown in , which reports RMSEs averaged over 100 replicates, with standard deviations in parentheses. Indeed, the proposed method outperforms the LOESS-based method in terms of estimation for individual data sets, as well as consistency from sample to sample. We note that the LOESS-based fit relies completely on the sample data and requires a large sample to produce reliable estimates of the latency. In our experiment, when the simulation sample size is doubled to n = 200 the RMSE measures, averaged over 100 replicates, are 0.009 (0.0028) for the sine group and 0.021 (0.0027), with the value in parentheses indicating standard deviation. The metrics are improved compared to the values with n = 100. However, LOESS with n = 200 is still outperformed by SLAM with n = 100.
Using the posterior median for point estimation does not change the values of the RMSEs much, due to the fact that the posterior distribution of stationary point is basically symmetric and unimodal with small variation, as shown, for one subject, in the top panel of .
The middle panel of shows the posterior distribution of the group-level parameters r1 and r2 for the sine and cosine regression function settings. The 95% credible interval for r1 and r2 are specified by the red segments. The original LOESS-based methods do not account for group effects and, consequently, cannot provide inference on group-level parameters. To address this limitation, we employ a two-step adaptation as in Hasenstab et al. (Citation2015), involving LOESS fitting followed by one-way ANOVA. The resulting 95% confidence intervals are represented by black segments in . The confidence intervals appear to be narrower than the credible intervals. We also note that, while the sampling distribution of r1 and r2 is assumed to be Gaussian, the posterior distributions from SLAM are not necessarily Gaussian.
As for the comparison with the DGP-MCEM method of Yu et al. (Citation2023), we found that the latency posterior means were almost identical to the SLAM estimates (results not shown). Also, on average, the SLAM and DGP-MCEM methods produced 95% uncertainty bands of similar length. However, the SLAM intervals exhibited less variation than the DGP-MCEM intervals, with standard deviations 0.002 and 0.007, for the sine group, and 0.005 and 0.006 for the cosine group, respectively. More importantly, the DGP-MCEM method does not provide group-level latency estimation and has no information about the group-level latency distribution. Indeed, in Yu et al. (Citation2023), the DGP-MCEM model is fitted separately to each group of data. With this method, however, population-level estimates can be obtained, by fitting a Gaussian mixture and calculating the normal interval where
is the mean of the Gaussian mixture and
is the standard deviation of those means. We found that SLAM has a more precise estimation with a shorter interval than DGP-MCEM. Specifically, for the sine group, SLAM produces interval
for r1 and
for r2, compared to the normal intervals
and
For the cosine group, SLAM produces
for r1 and
for r2. The corresponding normal intervals are
and
for r1 and r2, respectively.
3.4. Results on Amplitude
As for amplitude, we can derive estimates from the SLAM output as follows. First, for each sampled latency, given the data, a posterior path is drawn from the posterior derivative GP. Then, the fitted regression curve is obtained as the mean of those realizations. Examples, for one of the subjects, are shown in . With traditional approaches for ERP data analysis, different heuristic methods are used to estimate amplitudes, for example as the amplitude value of the peak of the component or as the mean/area amplitude over a selected time window or search window, such as in the LOESS-based methods Luck (Citation2005). Since our method is able to quantify possible locations of the ERP components, or latencies, we can essentially use this information to narrow down the search window by measuring amplitudes over the range of the posterior distribution of latency. Alternatively, an even shorter search interval could be used, by considering for example any credible interval of the distribution of latency. Since the search window is usually set wider so as to include all individual peaks of the same component, our latency intervals provide a more precise location of those peaks. Here, to compare with the LOESS-based method, we define a peak as the largest local extremum within the search window, that is, in our case, the range of the posterior samples of latency. The method is summarized in Algorithm 2. This method cares only about the largest extremum, and the shape of components does not matter.
Algorithm 2:
Max Peak
For stationary point samples and the curve realizations
Decide the range of latency (a, b) of, i.e.,
For
Compute
Define
Collection
Result: Posterior samples of amplitude.
Finally, to examine the two methods’ performance, we use the same measure, the RMSE, calculated as where
is the true amplitude value and
is its estimate, obtained as the posterior mean of our method. compares SLAM and LOESS-based methods on the amplitude estimation. The SLAM method on average has smaller RMSEs as well as smaller standard deviations. One distinct advantage of our method is that it provides uncertainty quantification. The bottom panel of shows the amplitude distribution of the sine and cosine function, for one subject, in one simulated data using the Max Peak method in Algorithm 2. The distribution is Gaussian-like.
Additional investigations of this simulated setting with non-Gaussian noises and under mis-specification of M can be found in the supplementary material. We find that the proposed method works well for noise terms that are not extremely far away from Gaussian. Also, while, as expected, the estimation of latency, both at group- and subject-level, is distorted, the curve fitting is somehow robust to mis-specifying M.
3.5. Simulation from the Model
In this section, we generate simulated data from the proposed model, and examine the ability of SLAM to capture the true parameters.
The data are simulated from the generating process described by the proposed model. Suppose there are two ERP components and a factor with two levels being considered. The βs are set to be and
Through the logit link, the true group level latencies are
Each group has 10 subjects and for each subject s the subject-level latencies are generated from
where
and
The regression function for
is set to be
and the one for
is
The true regression function defined in (0, 1) is the one with
and
combined. Data of size n = 100 are generated by adding Gaussian random noise
with
set to a level similar to the noise variation in the real ERP data used in the next section. The regression functions are shown in .
For prior specification, we assign standard normal priors to all βs and impose an on all ηs and an
on
To implement the algorithm, the initial values of
are randomly drawn from the uniform distribution
and those for
from
The initial values of all βs are set to 0, and those for the ηs and
to 1. The variance of the proposal distribution is updated every 40 iterations, so that the acceptance rate of the M-H steps is around 35%. The posterior samples are such that Gelman and Rubin’s potential scale reduction factors or
is less than 1.1 for all parameters. It takes about 800 s to obtain a posterior sample of size 10,000.
Examples of curve fitting, for one subject, are shown in , while summarizes the results for the group-level latencies, βs and σ. Mean and standard deviations of posterior mean and RMSE are computed based on 50 replicated data sets. The parameters are well estimated by SLAM, and the inference improves when more subjects are under study. Plots of the posterior distributions of βs and rs, as well as median and MAP estimates are reported in the supplementary material.
4. ERP Data Analysis
We now perform an analysis of real ERP data on speech recognition, where we assess the effect of age on two ERP components of interest. We provide subject- and group-level estimates of latencies and amplitudes of these characteristic components, with uncertainty quantification, and discuss comparisons with the inference provided by the method of Yu et al. (Citation2023).
4.1 Data
ERP data were collected from an experiment on speech recognition conducted at Rice University (Noe and Fischer-Baum Citation2020) and analyzed in Yu et al. (Citation2023). The experiment involved 18 college-age students and 11 older controls, as aging is known to cause difficulties in perceiving speech, especially in noisy environments (Peelle and Wingfield Citation2016). The older subjects have ages ranging from 47 to 91 years old with a mean age of 67.78 years (Noe Citation2022). EEG signals recorded continuously during the speech task and standard preprocessing (Luck Citation2005) was done using the ERPLAB toolbox (Lopez-Calderon and Luck Citation2014) in EEGlab (Delorme and Makeig Citation2004) before the data analysis. The experiment resulted in a total of 2304 trials. The top panel of displays the ERP waveforms for all subjects, averaged across all trials and six electrodes.
Common methods of analyzing ERP data involve averaging ERP waveforms over a particular condition and window of interest, to obtain the magnitudes and latencies of specific components. Specific ERP components are expected to be associated with speech perception (Tremblay et al. Citation2003). In particular, the N100 component, which captures phonological (syllable) representation, is of interest. This component is identified by the latency of the negative deflection in the time window [60, 140] ms after the stimulus onset. The specific starting point of the N100 window is typically chosen by visually inspecting the grand average data, to obtain a window where the ERP curve has a negative value. In addition to the N100, we also considered the P200 component, in the window [140, 220] ms, an auditory feature representing higher-order perceptual processing, modulated by attention. Recent studies have identified the P200 time window as potentially critical for processing higher order speech perception.
For posterior inference, we generated 21000 MCMC draws with 1000 burn-ins and thinned the chain by keeping every 10th draw, obtaining 2000 posterior samples. The final MCMC simulation in the MCEM algorithm was monitored and stopped when the potential scale reduction factor of every parameter was below 1.1, reaching approximate convergence. The full MCMC diagnostics are reported in the supplementary materials.
4.2. Inference on Latency
The bottom panel of illustrates the posterior density of the subject-level latency parameters in both young and older groups, based on 2000 posterior samples produced by the MC procedure in the E-step. We observe higher variability in the latency distribution for the older group, especially in the period after N100. Plots show substantial subject-level variability, as also noticed by Yu et al. (Citation2023). Overall, most of the subjects show latencies nicely concentrated around the two components of interest, with a few showing larger uncertainty, and one (subject 11 in the older group) having a third smaller latency, suggesting a possible outlier.
Furthermore, we can obtain a probabilistic statement on whether the ERP peaks of the older group occur later than the peaks of the young group by calculating the posterior distribution of the difference in latency between groups. This is shown in . In general, the peaks of N100 and P200 occur on average with a delay of 11.02 and 21.72 ms, respectively, in the older group. Also, the probability that the latency difference of N100 is greater than zero is 95.9% and that of P200 is 98.5%, suggesting significant latency differences between the two groups. These insights align with established results in aging theory, as these components rely on inhibitory connections to resolve perceptual objects and older adults are thought to have generally less inhibition and slower resolution of objects (Tremblay et al. Citation2003; Yi and Friedman Citation2014).
Further probabilistic evidence on the latency shifting effect is provided by the distribution of see . For example, for the young group, the probability that
is between 70 and 80 ms is about 56.4%, and that of the older group is about 41.9%. Notice that the time lag between N100 and P200 in the young group is shorter than the lag in the older group which has a higher chance of a time lag longer than 90 ms.
4.3. Inference on Magnitude
As with latency estimation, magnitude estimation can be performed at both group level and subject level. In particular, the posterior samples of the ERP curves can be used to quantify the uncertainty about amplitudes of N100 and P200 by integrating the estimated curve over the range of latency, say (a, b), and finding the time point or latency t such that the integral is at half of its full value. The 50% area latency method or the half-integral method shown in Algorithm 3 is more robust to noise, compared with the basic point estimate peak amplitude (Luck Citation2012). In addition to Max Peak and Half-integral Peak, other methods such as measuring mean voltage over a given time window can be used to compute the amplitude using the posterior samples within our modeling framework. We note that it is common to use zero micro voltage as the reference, or baseline, to compute the amplitude. However, the positive peak at P200 of the older group is all below zero micro voltage. Therefore, to make the amplitude comparable, we use the peak of N100 as the baseline for the calculation of the amplitude of P200. Therefore, the amplitude shows the increase in units of micro voltage after N100, in response to the stimulus of the experiment.
Algorithm 3:
Half-Integral Peak
Decide the range of latency (a, b) of samples
For
(1) Find
(2) Compute and define
Collection
Result: Posterior samples of amplitude of N100 and P200.
shows that the amplitude size of N100 for the older group is significantly larger than the amplitude for the young group. We preserve the negative sign to indicate that the peak is below zero. For P200, the peak measurements are greater than zero since the baseline is at the peak of N100. The 95% credible interval for P200_Old - P200_Young includes zero, showing a weak significance of the P200 amplitude difference. Nevertheless, with about 80% probability, the P200 amplitude for the young group is larger than that of the older group.
We conclude by noting that, with respect to the method proposed in Yu et al. (Citation2023), the hierarchical structure of SLAM allows learning the latency parameters at the subject and group level in a single model. Yu et al. (Citation2023) estimate subject-level latencies only, and the group-level latencies are estimated separately by fitting a Gaussian mixture on the posterior samples of t, of all participants. With their approach, the 95% confidence intervals of the N100 group-level latencies are and
for the young and older group, respectively. With SLAM, the 95% credible intervals for r1 are
and
for the young and older group, respectively. The SLAM intervals are generally shorter and provide more precise interval estimation.
As for the other parameters, posterior means and 95% credible intervals are 0.49 (0.48, 0.51) for σ, −0.13 (−0.57, 0.23) for −0.59 (−0.92, −0.26) for
0.50 (−0.11, 1.10) for
and 1.17 (0.41, 2.04) for
5. Discussion
In this article, we have proposed SLAM, a novel Bayesian approach for the estimation of the amplitude and latency of ERP components. The novel SLAM is a unified framework and integrative approach that enhances the DGP model proposed in Yu et al. (Citation2023) and offers comprehensive statistical inference about the parameters of interest in ERP studies. As for the method of Yu et al. (Citation2023), SLAM estimates the uncertainty about latency and hence provides a data-driven model-based time window for measuring the magnitude of ERP components. While traditional methods provide a point estimate of magnitude, we further exploit our approach to obtain posterior samples of magnitude. Moreover, SLAM uses the fitted smooth ERP curve and therefore washes out noise that tends to affect the point estimate of a peak, especially when the Max Peak method is used.
In addition, SLAM incorporates a latent ANOVA structure that allows us to examine how factors or covariates affect the magnitude and/or latency of ERP components, which is the main interest in ERP research as magnitude and latency reflect cognitive, psychological, or neural processes. While traditional methods require a two-step approach or several methods to complete the statistical analysis, SLAM wraps up everything in one single model, producing inference by posterior samples of the group latency/magnitude difference. It examines not only the subjects’ individual differences but also group-level differences that facilitate comparing different characteristics or factors, such as age in our illustration. Our results have shown that ERP components N100 and P200 are delayed in older adults, and that the N100 amplitude is generally larger for adults than for the younger group (with a negative sign).
Our model lays the foundation for more sophisticated statistical modeling for ERP analysis. As with generalized linear models and neural networks, SLAM can accommodate various valid link functions or activation functions with input domain (0, 1). Besides the logit function, which we have used in our analyses, other popular link functions for a variable between zero and one include the probit and complementary log-log (cloglog) functions. Both logit and probit are symmetric functions, and cloglog is asymmetrical. In our explorations on simulated data, we find that SLAM is robust to the choice of link functions, as different link functions produced nearly the same posterior distribution of the parameters, leading to similar RMSE of latency and amplitude, as well as to similar credible intervals. This robustness adds to the flexibility of our model. When the interest is in how latency changes with factor levels, that is the β coefficients, we recommend using the logit function for ease of interpretation, as the coefficients are related to the change in log odds. Furthermore, although ERP studies focus on how categorical factors affect amplitude and latency, numerical covariates such as blood pressure and weight can be included in our latent regression hierarchy. Other extensions of the proposed method could include treatments of other noise distributions accounting, for example, for autoregressive correlation or trial variability. Spatial modeling and mapping on multiple electrodes could be other possible extensions.
Supplemental Material
Download PDF (1.8 MB)Disclosure Statement
The authors have no relevant financial or non-financial interests to disclose. The authors have no competing interests to declare that are relevant to the content of this article. All authors certify that they have no affiliations with or involvement in any organization or entity with any financial interest or non-financial interest in the subject matter or materials discussed in this manuscript. The authors have no financial or proprietary interests in any material discussed in this article.
Data Availability Statement
Behavioral and Event-Related Potentials data that support the findings in this paper are available on PsyArxiv Noe and Fischer-Baum (Citation2020) at https://osf.io/c7k4s/ (DOI 10.17605/OSF.IO/C7K4S).
References
- Bai R, Ghosh M. 2021. On the beta prime prior for scale parameters in high-dimensional Bayesian regression models. Stat Sin. 31:843–865.
- Delorme A, Makeig S. 2004. Eeglab: an open source toolbox for analysis of single trial eeg dynamics including independent component analysis. J Neurosci Methods. 134(1):9–21.
- Gasser T, Molinari L. 1996. The analysis of EEG. Stat Methods Med Res. 5(1):67–99.
- Ghosal S, van der Vaart A. 2017. Fundamentals of nonparametric bayesian inference. Cambridge (MA): Cambridge University Press.
- Hasenstab K, Sugar CA, Telesca D, McEvoy K, Jeste S, Şentürk D. 2015. Identifying longitudinal trends within EEG experiments. Biometrics. 71(4):1090–1100.
- Jeste SS, Kirkham N, Senturk D, Hasenstab K, Sugar C, Kupelian C, Baker E, Sanders A, Shimizu C, Norona A, et al. 2014. Electrophysiological evidence of heterogeneity in visual statistical learning in young children with ASD. Dev Sci. 18(1):90–105.
- Kallionpää RE, Pesonen H, Scheinin A, Sandman N, Laitio R, Scheinin H, Revonsuo A, Valli K. 2019. Single-subject analysis of N400 event-related potential component with five different methods. Int J Psychophysiol. 144:14–24.
- Kang J, Reich BJ, Staicu A. 2018. Scalar-on-image regression via the soft-thresholded Gaussian process. Biometrika. 105(1):165–184.
- Kutas M, Hillyard SA. 1980. Reading senseless sentences: brain potentials reflect semantic incongruity: brain potentials reflect semantic incongruity. Science. 207(4427):203–205.
- Li M, Liu Z, Yu C, Vannucci M. 2023. Semiparametric Bayesian inference for local extrema detection. J Am Stat Assoc. arXiv. :210310606.
- Lopez-Calderon J, Luck SJ. 2014. ERPLAB: an open-source toolbox for the analysis of event-related potentials. Front Hum Neurosci. 8:213.
- Luck SJ. 2005. An introduction to the event-related potential technique. Cambridge (MA): The MIT Press.
- Luck SJ. 2012. Event related potentials. In: Cooper H, Camic PM, Long DL, Panter AT, Rindskopf D, Sher KJ, editors. Apa handbook of research methods in psychology, vol 1: foundations, planning, measures, and psychometrics. Washington (DC): American Psychological Association. p. 266–290.
- Luck SJ. 2022. Applied event-related potential data analysis. LibreTexts: LibreTexts.
- Ma T, Li Y, Huggins JE, Zhu J, Kang J. 2022. Bayesian inferences on neural activity in EEG-based brain-computer interface. J Am Stat Assoc. 117(539):1122–1133.
- Noe C. 2022. Cognitive correlate of the N1 ERP response to speech sounds [dissertation]. Houston (TX): Rice University.
- Noe C, Fischer-Baum S. 2020. Early lexical influences on sublexical processing in speech perception: evidence from electrophysiology. Cognition. 197:104162.
- Peelle J, Wingfield A. 2016. The neural consequences of age-related hearing loss. Trends Neurosci. 39(7):486–497.
- Quinonero Candela J. 2004. Learning with uncertainty - gaussian processes and relevance vector machines [dissertation]. Kongens Lyngby, Denmark: Technical University of Denmark.
- Rasmussen CE, Williams CK. 2006. Gaussian process for machine learning. Cambridge (MA): The MIT Press.
- Siivola E, Piironen J, Vehtari A. 2016. Automatic monotonicity detection for Gaussian Processes. arXiv e-Prints:arXiv:1610.05440.
- Tanaka JW, Curran T. 2001. A neural basis for expert object recognition. Psychol Sci. 12(1):43–47.
- Tremblay K, Piskosz M, Souza P. 2003. Effects of age and age-related hearing loss on the neural representation of speech cues. Clin Neurophysiol. 114(7):1332–1343.
- Vogel EK, Machizawa MG. 2004. Neural activity predicts individual differences in visual working memory capacity. Nature. 428(6984):748–751.
- Yi Y, Friedman D. 2014. Age-related differences in working memory: ERPs reveal age-related delays in selection- and inhibition-related processes. Neuropsychol Dev Cogn B Aging Neuropsychol Cogn. 21(4):483–513.
- Yu C, Li M, Noe C, Fischer-Baum S, Vannucci M. 2023. Bayesian inference for stationary points in Gaussian process regression models for event-related potentials analysis. Biometrics. 79(2):629–641.
Appendix:
Monte Carlo Sampling in the E-Step of the MCEM Algorithm
In the Monte Carlo E-step of the proposed MCEM Algorithm 1 for SLAM, we simulate and
using the following conditional distributions and Metropolis–Hastings steps.
With the property that
The conditional distribution of
A Metropolis step is done with Gaussian proposal where
is the
th draw of
in the E-step, and
is the tuning variance that keeps the acceptance rate at around 30%.
The conditional distribution of
A Metropolis step is done with the Gaussian proposal where
is the
th draw of
in the E-step, and
is the tuning variance that keeps the acceptance rate at around 30%.
The conditional distribution of
A Gibbs step is done on
which is an inverse gamma distribution with shape parameter and scale parameter
where
and
Figure 1. Simulation study. (Top) The ten simulated regression functions and corresponding curve fitting, for the first subject only, for group 1 with sine functions, and (Bottom) for group 2 with cosine functions. In the curve fitting plots, the light blue shaded area indicates the 95% credible interval for f(x), estimated from the sample paths drawn from the posterior derivative Gaussian process, and corresponding to the sampled latencies
The mean of those realizations is shown as the red dashed line, the green dashed fitted curve is obtained from the LOESS method, and the true f(x) is shown in blue color.
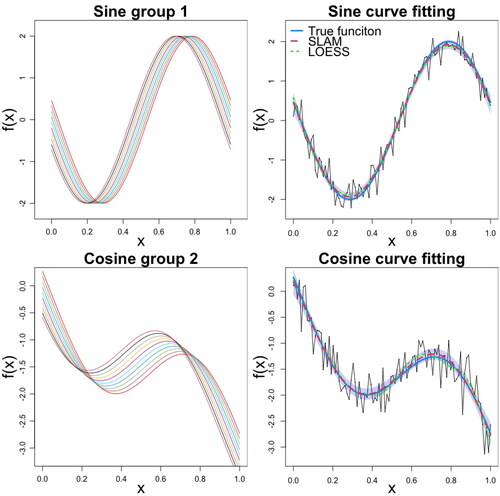
Figure 2. Simulation study: (Top) Latency estimates for group 1 with sine functions and (Bottom) for group 2 with cosine functions.
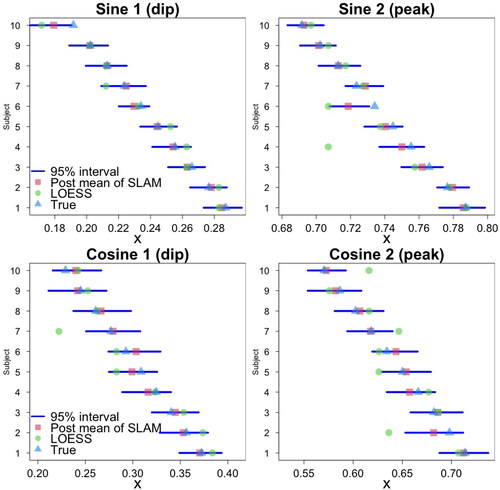
Figure 3. Simulation study: (Top) Posterior histograms of t of the sine regression function for the 8th subject. (Middle) Posterior distribution of group-level parameters r1 and r2 for the sine and cosine regression function settings. The blue vertical dashed lines indicate true subject-level latencies. The red segments are the 95% credible intervals from the posterior distributions by SLAM, and the black segments are the 95% confidence intervals using the two-step approach by fitting LOESS followed by one-way ANOVA. (Bottom) Amplitude distributions using the Max Peak method in Algorithm 2. Vertical red lines indicate the true amplitudes, and the green lines indicate the LOESS estimates.
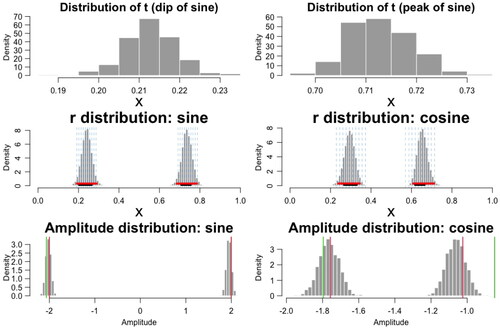
Figure 4. Simulation study: (Top) Examples of simulated regression functions and corresponding curve fitting, for the first subject only, for group 1 with sine functions, and (Bottom) for group 2 with cosine functions. There is a group-level stationary point in the region and in
The black dashed line separates the two regions, and the red vertical lines indicate the true group-level latencies. The true f(x) is shown in blue color.
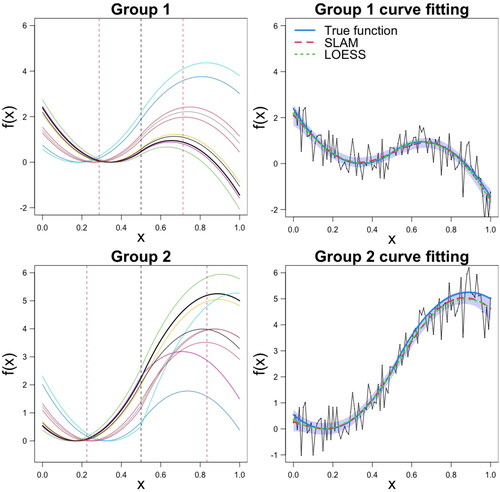
Figure 5. Case study: (Top) Subject-level ERP curves and grand average ERP curves. Solid: Young group. Dashed: Older group. The 0 ms time, which corresponds to time point 100, is the start of the onset of sound. The N100 component of interest is the dip characterizing the signal in the time window [60–140] ms colored in green. The P200 component characterizes the time window [140–220] ms, colored in yellow. (Bottom) Posterior distribution of subject-level latencies.
![Figure 5. Case study: (Top) Subject-level ERP curves and grand average ERP curves. Solid: Young group. Dashed: Older group. The 0 ms time, which corresponds to time point 100, is the start of the onset of sound. The N100 component of interest is the dip characterizing the signal in the time window [60–140] ms colored in green. The P200 component characterizes the time window [140–220] ms, colored in yellow. (Bottom) Posterior distribution of subject-level latencies.](/cms/asset/61cd82aa-32be-4e5d-9a0c-34a6b2388d31/udss_a_2294204_f0005_c.jpg)
Figure 6. Case study: (Top) Latency difference between groups and latency shift effect on the right. (Bottom) Amplitude difference between groups.
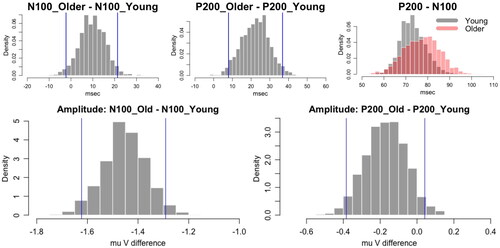
Table 1. Simulation study: Latency and amplitude comparison. Average and the standard deviations (in parentheses) of the RMSEs from the 100 replicated data sets.
Table 2. Simulation study: Parameter estimation. The mean and standard deviation of posterior mean and RMSE are computed from 50 replicates of data with size 100.