
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We introduce a unified framework for rapid, large-scale portfolio optimization that incorporates both shrinkage and regularization techniques. This framework addresses multiple objectives, including minimum variance, mean-variance, and the maximum Sharpe ratio, and also adapts to various portfolio weight constraints. For each optimization scenario, we detail the translation into the corresponding quadratic programming (QP) problem and then integrate these solutions into a new open-source Python library. Using 50 years of return data from US mid to large-sized companies, and 33 distinct firm-specific characteristics, we utilize our framework to assess the out-of-sample monthly rebalanced portfolio performance of widely-adopted covariance matrix estimators and factor models, examining both daily and monthly returns. These estimators include the sample covariance matrix, linear and nonlinear shrinkage estimators, and factor portfolios based on Asset Pricing (AP) Trees, Principal Component Analysis (PCA), Risk Premium PCA (RP-PCA), and Instrumented PCA (IPCA). Our findings emphasize that AP-Trees and PCA-based factor models consistently outperform all other approaches in out-of-sample portfolio performance. Finally, we develop new and
regularizations of factor portfolio norms which not only elevate the portfolio performance of AP-Trees and PCA-based factor models but they have a potential to reduce an excessive turnover and transaction costs often associated with these models.
1. Introduction
Institutional investors often manage portfolios comprising hundreds of assets, and the performance of such portfolios is evaluated through frequent backtesting exercises. These backtests rely different models and numerous optimizations, performed repetitively using a rolling-window scheme and a long history of return data. In this paper, we introduce a unified framework for portfolio optimization. This framework employs Quadratic Programming (QP) methods to calculate portfolios with and
regularization, long-short constraints, and various portfolio objective functions such as minimum-variance, mean-variance, and maximum-Sharpe ratio. Owing to the efficiency of the QP optimization algorithms, our proposed models are suitable for the realistic settings of large-dimensional portfolios. These can be applied repeatedly in a rolling window scheme, facilitating backtesting evaluations and refining investment strategies.
Our portfolio optimization framework requires the estimation of a mean vector and a covariance matrix. The two main approaches for the latter are shrinkage covariance matrix estimation and financial factors modeling. The former uses information contained in the assets returns only. It has been studied extensively starting from linear shrinkage covariance matrix estimator by Ledoit and Wolf (Citation2004), nonlinear shrinkage estimators such as Ledoit and Wolf (Citation2012), and Ledoit and Wolf (Citation2020b), up to the most recent nonlinear quadratic shrinkage estimator proposed by Ledoit and Wolf (Citation2022) (see Section 3 for more details). The latter approach uses common risk factors with financial or economic interpretations, which are well-known to capture large amounts of variation in the returns. Among the most famous models are CAPM-model of Treynor (Citation1961), Sharpe (Citation1964), Lintner (Citation1965), and Mossin (Citation1966), the three-factor, four-factor, and the five-factor model by Fama and French (Citation1993), Carhart (Citation1997) and Fama and French (Citation2015), respectively. The extensions of these models under the non-Gaussianity assumption for the asset returns and factors are given in Hediger et al. (Citation2023). There is also the relative momentum factor, which extends the three-factor model. It was first introduced and analyzed by Jegadeesh and Titman (Citation1993), see also Chitsiripanich et al. (Citation2022) and the references therein for momentum-based portfolio strategy without crashes.
While the aforementioned classical common risk factors remain among the most important, a large literature now exists on determining the inclusion of particular factors from the dozens, if not hundreds, available: see, e.g. Bai and Ng (Citation2002), Stock and Watson (Citation2002), Tsai and Tsay (Citation2010), Bai and Ng (Citation2013), Bai and Liao (Citation2016), and the references therein. The amount of available alternative data, coupled with advancements in computational power and statistical techniques, such as the estimation of sparse models as in Tibshirani (Citation1996) and Hastie et al. (Citation2015), has led to the proliferation of different factor models, giving rise to what Feng et al. (Citation2020) describes as a “zoo of factors.”
In this paper, we consider a large universe of liquid US stocks and 33 asset-specific characteristics, as listed in Table A1 in the Appendix. To extract relevant information from this large number of factors while capturing the dynamics in the dependency between factors and returns in a large portfolio of assets, we use different models, such as: Asset Pricing (AP) Trees introduced in Bryzgalova et al. (Citation2020), and three different Principal Component Analysis (PCA) based factor models that invest in leading factor portfolios including the PCA on the factor portfolios, the Risk Premium PCA (RP-PCA) introduced in Lettau and Pelger (Citation2020), and the Instrumented PCA (IPCA) from Kelly et al. (Citation2019). All of these papers show that their asset-specific factor based models outperform the common risk factors models mentioned earlier in terms of higher in-sample and predicted R2 values, leading to higher out-of-sample portfolio performance. In their paper, Goyal and Saretto (Citation2022) applied IPCA to explain the returns of option contracts and achieved a significantly better out-of-sample R2. Similarly, Bali et al. (Citation2023) used IPCA to jointly analyze the returns of bonds, stocks, and options contracts, also resulting in a notably improved out-of-sample Sharpe ratio. Motivated by these successes of these recent factor-based models and their flexibility in capturing information from a large number of stock-specific characteristics, we forgo the aforementioned common risk factors models and focus on the AP-Trees and PCA-based models in our unified portfolio optimization framework. We compare these emerging models and the aforementioned shrinkage approaches in portfolio optimization with liquid stocks under realistic portfolio constraints.
Table 1. Summary of the total running time (in seconds) for 100 rolling windows of three different portfolio optimization problems from our general framework described in Section 2 for different dimensions of the problem (), and two different levels of tolerance and precision in the optimizer: (i) default precision used in the OSQP package https://osqp.org…; (ii) high precision with 104 maximum iterations, and the absolute and relative tolerance set to
In Lettau and Pelger (Citation2020) and Kelly et al. (Citation2019), the portfolio performance of PCA-based models is evaluated using the tangent portfolio. This is a closed-form portfolio that permits unbounded long and short positions in individual assets, as well as highly leveraged long-short portfolio strategies. In this paper, we contrast the portfolio performance of the PCA-based models with commonly used benchmarks, such as the shrinkage covariance matrix estimator. We employ a rolling window exercise on an extensive history of a large set of liquid US equity returns, excluding small and micro-caps. We also apply realistic constraints on individual positions and long-short strategies to prevent highly concentrated positions and excessively leveraged portfolios. Our portfolio performance largely agrees with the original results in Lettau and Pelger (Citation2020) and Kelly et al. (Citation2019). But this more grounded setup further illustrates the versatility of the proposed unified portfolio optimization framework, making it relevant to the practical portfolio challenges faced by large institutional investors.
Our paper presents four primary contributions. First, we introduce a unified framework for large-scale, rapid portfolio optimization that incorporates realistic constraints and innovative regularizations to enhance investment performance. This framework is particularly relevant for institutional investors managing portfolios with hundreds or even thousands of assets, facilitating cost-efficient investment decisions. As a practical tool, we’ve made our Python implementation of this framework available as open-source code online.Footnote1 Second, we offer fresh insights into the performance of the recently discussed AP-Trees and PCA-based models. Third, our framework supports a multitude of portfolio problem combinations, varying in portfolio objective functions, regularizations, and constraints. This includes the and
regularized portfolio problems, as introduced by DeMiguel et al. (Citation2009a) for the minimum-variance portfolio. We expand upon this by introducing the
+
regularized maximum-Sharpe ratio portfolios and the comprehensive
+
regularized mean-variance portfolio frontier. Lastly, within the scope of AP-Trees and PCA-based models, we demonstrate how to apply our novel regularizations to both managed portfolios and individual stocks. We further illustrate how these new regularizations result in superior performance, leading to more stable and streamlined portfolio positions. Importantly, we show how to solve all of these optimization problems using QP methods.
The rest of the paper is structured as follows. Section 2 presents our comprehensive framework for portfolio optimization. Section 3 elaborates on the various covariance matrix estimators discussed in this study. Section 4 introduces a novel regularization for factor-based portfolio optimization challenges with an emphasizes on maximum Sharpe ratio portfolio. Empirical comparisons of the estimators and models across distinct portfolio optimization problems are detailed in Section 5. Concluding observations are given in Section 6. The Appendix provides details on the asset-specific factors.
2. Portfolio Optimization Framework
We consider a universe of N assets, with prices observed over a given period of time with T observations. Let be the price of asset
at time index
where the time index t corresponds to a fixed unit of time such as days, weeks, or months. The corresponding simple returnsFootnote2 (also known as linear or net returns) are given by
and the log-returns (also known as continuously compounded returns) are
We denote the vector of -returns of N assets at time t with
It is a multivariate stochastic process with conditional mean and covariance matrix denoted by
and
where
denotes the previous historical data. In this work, except for the IPCA model, we will drop the subscript t on the mean and covariance matrix since all models assume iid returns. For more general multivariate time-series models of returns with the dynamics in the conditional mean and covariance matrix together with their applications in portfolio optimization, we refer to Paolella and Polak (Citation2015), Paolella et al. (Citation2019), and Paolella et al. (Citation2021).
The investment portfolio is usually summarized by an N-vector of weights indicating the fraction of the total wealth of the investor held in each asset. If the investor is assumed to hold her total wealth in the portfolio, then
where
denotes an N-vector of ones. The corresponding portfolio return
is a random variable with the mean and variance given by
and
respectively.
The general theory of portfolio optimization, as introduced in a seminal work by Markowitz (Citation1952), summarizes the trade-off between risk and investment return using the portfolio’s mean and variance. In particular, for a given choice of target mean return in Markowitz portfolio optimization, one chooses the optimal portfolio as
(1)
(1)
where
is a set of constraints on the portfolio weights which correspond to a fully invested portfolio with the expected return above the α0 threshold. Under these constraints, (1) has a closed-form solution given by
(2)
(2)
where
The minimum-variance portfolio (Min-Var in ) is a solution to (1) with The solution to this problem also has a closed-form expression given by
(3)
(3)
where C is defined above. However, when short-selling is not allowed, i.e.
or when it is constrained, e.g. as in Section 2.5, then the optimization problem Equation(1)
(1)
(1) does not have a closed-form solution and needs to be solved numerically.
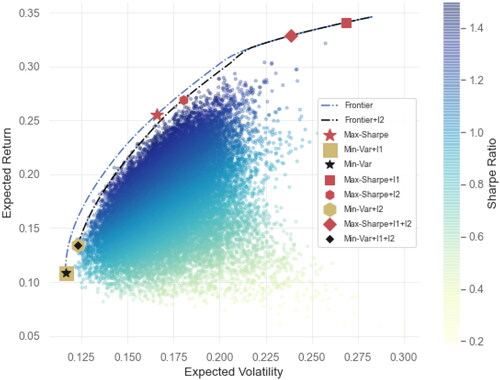
Figure 1. Portfolio frontier (with and without regularization) and all of the optimal portfolios considered in our portfolio framework with the long-only constraints and
and
+
regularization for eight stocks (AMZN, MSFT, GOOGL, F, TM, AAPL, KO, and PEP), with the mean and covariance matrix estimated using daily returns over eight years (2015/01/01-2022/01/01). Among them are two optimal portfolios: the minimum-variance portfolio and the maximum Sharpe ratio portfolio, and a collection of random portfolios.
Nevertheless, Equation(1)(1)
(1) is a QP problem with convex constraints (hence also a convex problem). It has closed-form expressions for the gradient and hessian of the objective function, and a unique global optimal portfolio satisfying the constraints in
In particular, by changing α0, one can derive a whole portfolio frontier of optimal investments
summarizing the risk-return trade-off.
Following Li (Citation2015), we can reinterpret the mean-variance portfolio optimization problem as a linear regression with independent variables and
observations. This relationship can be expressed as:
(4)
(4)
where
represents a vector of random errors, and
is the risk aversion coefficient (Lagrange multiplier) associated with the
threshold in
described above. The least squares estimator of
given by
corresponds to the closed-form optimal portfolio weight when the constraint
is omitted. In other words,
In practice,
and
are unknown and they are replaced by their (random) estimators. Thus, the principles of linear regression can be naturally extended to portfolio optimization. In a similar vein, the theories of
and
regularized regression can be directly related to the regularized portfolio optimization problem. When the portfolio constraint
is incorporated, this mirrors the analogous constraint in the least squares problem.
presents two long-only mean-variance portfolio efficient frontiers, both with and without the regularization discussed in Section 2.2. For varying levels of portfolio variances, the expected return of the top-performing portfolio is plotted. Alongside these frontiers, we illustrate various optimal portfolios discussed in this paper. Additionally, a cloud of points represents the means and variances of 25,000 randomly drawn iid Dirichlet distributed portfolios. Specifically, each portfolio weight vector
is independently and identically distributed as
for
In this example, the portfolios are comprised of eight stocks from the US market with tickers: AMZN, MSFT, GOOGL, F, TM, AAPL, KO, and PEP. The mean and covariance matrix are estimated using daily returns spanning the period from 2015-01-01 to 2022-01-01. Such a low dimensional portfolio problem is common in the aforementioned PCA-based models which invest into K factor portfolios that are mapped into the individual assets.
In practice, it is often the case that the investment portfolio consist of a much larger number of assets than in the example above.
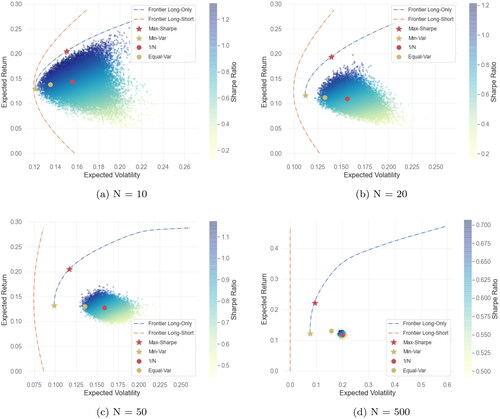
Figure 2. Four plots of two different portfolio frontiers (long-only and the closed-form long-short from (2)), together with different optimal long-only portfolios (maximum-Sharpe ratio (14) and minimum-variance), the equally weighted portfolio (), equal volatility contribution portfolio (Equal-Var), and 25000 iid Dirichlet distributed portfolios
for different number of assets
selected from the largest market-capitalization stocks in the US market. Mean and covariance matrix estimated from 10 years of daily returns (2520 observations).
depicts portfolio frontiers alongside 25,000 iid Dirichlet distributedFootnote4 portfolios for
The assets number varies as
chosen from the largest market-capitalization stocks in the US market. The mean and covariance matrix are derived from ten years of daily returns, a period significantly longer than our monthly data in Section 5.
From the varying panels in , we discern two significant implications of portfolio dimensionality. First, as the assets universe expands, random portfolios veer further from and concentrate more around the mark. This suggests that without appropriate portfolio optimization in high-dimensional setups, achieving any optimal risk-reward profile is challenging. Even the frequently endorsed
portfolio, often hailed for naive-diversification and robust performance (see DeMiguel et al. Citation2009b and the cited references), performs equivalently to a random guess. The figure also presents the equal volatility contribution portfolio, a variant of the risk parity portfolio (Roncalli Citation2013; Paolella et al. Citation2022). While it slightly outperforms random portfolios and the
the gap between this portfolio and the mean-variance portfolio frontier indicates a lot of room for improved portfolio allocation.
Secondly, the closed-form long-short frontier, represented by (2) and illustrated with dotted black lines in all the panels in , appears almost vertical in relation to the long-only portfolio as assets increase. Consequently, marginal shifts in optimal portfolio volatility can lead to theoretically substantial hikes in the expected returns of the optimal portfolio. This highlights the sensitivity of optimal portfolio weight estimates to new data points, with weights potentially exhibiting significant variations across consecutive rolling windows. Such behavior stems from high dimensionality and proximate non-singular covariance matrix estimates. Effective covariance matrix estimation in expansive dimensions, combined with long-short constraints, counters these over-leveraged yet theoretically optimal portfolios.
In practice the true mean vector and covariance matrix are unknown, and one needs to rely on their estimates. Financial markets, especially at low frequencies, are highly efficient—or, as suggested by Pedersen (Citation2015), they are “efficiently-inefficient”. We do not attempt to construct individual stocks prediction signals—for that we refer to recent results in Chitsiripanich et al. (Citation2022). Instead, we focus on various mean and covariance matrix shrinkage estimators as well as different factor portfolios. The former address the bias-variance trade-off, aiming to construct biased estimators that minimize the mean-square error and perform better out-of-sample. The latter offers conditional predictions of expected returns based on asset characteristics. As we will demonstrate, the factor portfolios significantly enhance the signal-to-noise ratio, leading to more accurate mean predictions and higher out-of-sample performance. However, before we turn to stock returns models, we introduce the rest of our general portfolio optimization framework.
2.1. Portfolio Constraints
The set of feasible portfolio weights usually includes additional constraints. Among the most commonly used are:
Long only:
Asset specific holding constraints:
where
Turnover constraints:
○ for individual assets limits
where
○ for the total portfolio limit
Benchmark exposure constraints:
Tracking error constraints: for a given benchmark portfolio B with weights
Risk factor constraints: estimate the risk factors exposure for all the assets in the portfolio, e.g. via the following regression (see (19) for details)
Given these estimates, one can
constrain the exposure to a given factor k by
neutralize the exposure to all the risk factors by
All the constraints listed above (including those that involve the absolute value function—see the remarks in Section 2.3) can be written as linear or quadratic constraints, i.e.
linear constraints: we can specify N-columns matrices Aw and AB and vectors uw, uB to introduce linear inequality constraints for the relative positions between the assets or the benchmark
quadratic constraints: we can specify N × N matrices Qw, QB and scalars qw, qB to build constraints
Once the constraints are converted into these standard forms, they can be easily combined and incorporated into our portfolio optimization framework. We consider next, a different type of constraint that is often incorporated into portfolio optimization using the method of Lagrange multipliers. These constraints are not imposed by the portfolio manager because of her trading goals or position requirements. They are added because they are a form of regularization of the problem in high dimensions, and they help to improve the out-of-sample portfolio performance in large dimensions.
2.2. Portfolio Optimization with Penalized Portfolio Norms
Consider now an -constrained (also called the ridge penalty) portfolio optimization problem for the minimum-variance portfolio (1). Using the method of Lagrange multipliers, we can write the corresponding optimization problem as
(5)
(5)
where
is the penalty strength parameter and
Using the spectral decomposition of
where
and
and since
we can rewrite the
penalized objective function as
(6)
(6)
where
has all the eigenvalues shifted up by
This is, again, a QP optimization problem that falls into our unified framework.
2.3. Portfolio Optimization with Penalized Portfolio Norms
Similarly to the -constraint, we can write the Lagrangian of
-constrained minimum-variance portfolio optimization problem as
(7)
(7)
where
is the penalty strength parameter and
The main difference compared to Equation(5)
(5)
(5) is that the objective function in Equation(7)
(7)
(7) is non-differentiable because of the kinks in the absolute value function, and the spectral decomposition will not help in converting Equation(7)
(7)
(7) into a standard QP problem. Instead, we define
and
Then
We can rewrite the
-regularized objective function as
(8)
(8)
where
This way, we rewrote the original non-differentiable problem in N variables as a QP problem in 3 N variables with additional N equality constraints.Footnote5
The following remarks can be made about this new optimization problem:
Note that we do not have to include the constraint
If the portfolio is long-only, the
Note that any of the constraints listed in Section 2.1 such that it involves an absolute value function, can be rewritten using the
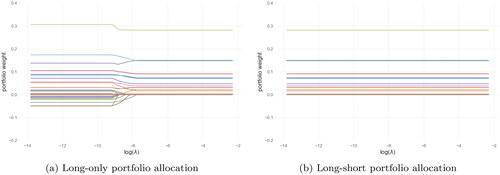
Figure 3. Portfolio weights of N = 50 assets as a function of the regularization strength parameter λ of penalty in minimum-variance
regularized portfolio (long-only vs. long-short with
), the x-axis are in
scale.
2.4. Portfolio Optimization with + Penalized Portfolio Norms
Naturally, we can consider both the -constrained and
-constrained, which we call
+
-constrained portfolio. For that purpose, we modify our objective function (1) to
(9)
(9)
By combining Equation(6)
(6)
(6) and Equation(8)
(8)
(8) , we can use again the eigenvalues decomposition of
where
and
(10)
(10)
where
and
has shifted by
all the eigenvalues.
2.5. Long-Short Constrained Portfolio
The long-short constrained minimum-variance portfolio optimization from Equation(1)(1)
(1) is defined as
(11)
(11)
where
This is a different type of portfolio weights constraint that aggregates them based on their sign. Long-only portfolio constraint is a special case given by
for
We can take again
and
So,
and
Hence, we can replace the with a new constraint set given by
and solve the corresponding QP problem.
2.6. Mean-Variance Optimization with Risk-Free Asset
In mean-variance portfolio in Equation(1)(1)
(1) , the goal is to optimize the trade-off between portfolio returns and risk. In other words, the mean-variance method looks for a portfolio with the lowest variance while the expected portfolio returns
is constraint from below by α0. Because of the convexity of the problem, the optimal value corresponds to the minimum volatility portfolio under the target return level.
In addition to the risky assets () we can assume there is a risk-free asset for which
Suppose the investor can invest in the N risky investments as well as in the risk-free asset. The portfolio with investment in risk-free assets consists of two parts:
(invested in risky assets) and
(risk-free asset).
If borrowing is allowed, can be negative. Long-short portfolio with return
where
has expected return
and variance
For a given choice of target mean return α0, choose the portfolio to
(12)
(12)
where
Then we can derive the Lagrangian as
(13)
(13)
Solving the Lagrangian, we get and
So the expected return and the variance of the optimal portfolio are given by
respectively.
Note that because of the risk-free asset, the resulting portfolio frontier will be a line (it is the so-called one fund theorem) connecting two points in the mean-variance plane: the where all the money is invested only in the risk-free asset; and the mean and variance of so called market portfolio
which is the tangent point to the portfolio frontier without the risk-free asset. So in order to find solutions for different α0, it suffices to solve for the portfolio without risk-free asset, and take linear combinations of that portfolio with the risk-free investment. Hence, again this can be considered as part of our general portfolio framework.
2.7. Maximum Sharpe Ratio Portfolio
Markowitz’s mean-variance framework in (1) provides portfolios along the optimal frontier, and the choice of the specific portfolio depends on the risk-aversion of the investor. Typically one measures the investment performance using the Sharpe ratio, and there is only one portfolio on the optimal frontier that achieves the maximum Sharpe ratio
(14)
(14)
where
and rf is the return for a risk-free asset.
This problem – although nonconvex – belongs to the family of so called Fractional Programming (FP) optimization problems that involve ratios. It is a concave-convex single-ratio and can be solved by different approaches. This specific FP issue can be efficiently solved using a reparametrization technique, originally introduced by Schaible (Citation1974); see also Cornuejols and Tütüncü (Citation2006) for its application in portfolio optimization contexts. One can note that the objective function in (14) is homogeneous of degree zero, and reformulate this problem as a QP problem. If there exists at least one portfolio vector w such that then for
and
we can change the maximization problem into an equivalent minimization
(15)
(15)
where
Now by the homogeneity of degree zero of the objective function, we can choose the proper scaling factor for our convenience. We define
with scaling factor
So that the objective becomes
the sum constraint
and the above problem is equivalent to
(16)
(16)
where
The optimal portfolio weights are recovered after doing the optimization through the transformation
Importantly note that all the aforementioned constraints and regularizations can also be incorporated into this optimization problem (16), and it will remain equivalent to the original maximum Sharpe ratio portfolio with the same regularizations and constraints properly rescaled as in (25). In Section 4, we will provide a more detailed and precise presentation. The advantage of (16) is that even with these constraints and regularizations, it will be easy to solve numerically using QP methods.
In our portfolio optimization framework, once the portfolio problems are turned into standard QP problems, we use the OSQP solver from Stellato et al. (Citation2020) to solve them. The solver uses ADMM algorithm for the optimization (see Boyd et al. Citation2011 and references therein for the detail introduction of the algorithm). It is an open-source solver available at https://osqp.org/docs/solver/index.html. As summarized in , portfolios with 50 assets or less can be optimized with very high precision especially compared to any numerical gradient based method. All the evaluations in are done on a single core of the AMD Ryzen Threadripper 2990WX Processor. This concludes our summary of portfolio optimization problems that we can solve using the QP framework. The corresponding code with the implementation in Python is available online at https://github.com/PawPol/PyPortOpt. We describe next all the covariance matrix estimators considered in this paper.
3. Modeling Stock Returns
In Markowitz’s portfolio theory, the mean vector and the covariance matrix
are assumed to be known. However, in practice, these parameters must be estimated from data. A prevalent method involves using the historical sample mean and sample covariance matrix under the assumption of iid observations. This approach frequently results in suboptimal out-of-sample performance. As highlighted in the introduction, there exist alternative estimators that offer improved out-of-sample outcomes. In the subsequent empirical section, we utilize our portfolio optimization framework to compare the portfolio performance yielded by various mean and covariance matrix shrinkage methodologies against that from different factor-based models. The former, the shrinkage methods, derive their estimates from daily data, while the latter, the factor-based models, utilize monthly returns and stock specific characteristics for their evaluations.
In case of daily data and the mean and covariance matrix shrinkage, for the mean estimation we use the sample mean and three shrinkage estimators from Wang et al. (Citation2014) and Bodnar et al. (Citation2019). For the covariance matrix, first, we use the classical linear shrinkage covariance matrix estimator Ledoit and Wolf (Citation2004) defined as
(17)
(17)
where
and
is the estimated structured covariance matrix. In particular,
and
denotes the estimator of optimal shrinkage constant δ. In practice, the authors propose to use
where
and
and
be estimated as
with
with
and
In situations when the number of assets (variables) is commensurate with the sample size, the sample covariance matrix is usually not well-conditioned and not invertible. Getting the linear combination of the sample covariance matrix and identity matrix is a way to shrink the eigenvalues of the sample covariance matrix away from zero and towards their average in with
denoting the shrinkage intensity. As a result, we get a well-conditioned covariance matrix estimator that has a lower mean-square error than the sample covariance matrix, and, in large dimensions, when N grows asymptotically with T, it is a consistent estimator of the covariance matrix.
Second, we consider a more recent nonlinear shrinkage covariance matrix estimator—the quadratic inverse shrinkage estimator from Ledoit and Wolf (Citation2020a). The estimator can be written as
(18)
(18)
where
and
is a real univariate function of
for
denotes the eigenvalues and
are the corresponding eigenvectors. By introducing the nonlinear transformation (Hilbert transform) of the sample eigenvalues, this method helps with the curse of dimensionality.he shrinkage techniques previously described are typically employed for large-dimensional portfolio problems. A different strategy to address the challenges of dimensionality in portfolio optimization involves the use of factor models. Classical factor modeling, as presented by Fama and French (Citation1993), Carhart (Citation1997), and Fama and French (Citation2015), assumes that returns adhere to the linear model:
(19)
(19)
where
represents a vector of observed factors,
is the zero-mean noise that captures the idiosyncratic component uncorrelated with the observed factors, and
denotes a vector of unknown factor loadings. In many of these models, αi is set to 0 for all assets i. Given that this is essentially a linear regression problem and the factors are presumed to be uncorrelated with
the return’s covariance matrix divides into a section explained by the factors and an idiosyncratic section. Additionally, if the
components are assumed to be uncorrelated across assets, the covariance matrix of the idiosyncratic component can be directly estimated from the regression residuals. Consequently, this model remains applicable even when N significantly exceeds T.
However, the factor model given in (19) has its limitations. First, it assumes that the factors are both known and common across all assets. This means they can only elucidate risk to a certain extent and may not always correlate strongly with the actual risk in specific market conditions. Second, the factor loadings, represented by are considered constant over time.
An alternative method that addresses the first limitation is to employ Principal Component Analysis (PCA) to derive latent factors directly from the covariance matrix of asset returns, without needing additional information. However, the covariance matrix for individual stock returns does not possess a lower-dimensional latent subspace that can precisely capture the variations in these returns. As a consequence, executing PCA on the covariance matrix of individual stock returns tends to introduce significant noise. This can lead to unstable portfolios and underperformance in out-of-sample scenarios. Thus, rather than applying PCA directly to the matrix of stock returns, it’s more effective to work with the matrix of returns from portfolios that are single or double-sorted based on a cross-section of firm characteristics, as discussed in Bryzgalova et al. (Citation2020) and the references therein.
PCA, when applied to managed portfolios, can extract factors that encapsulate the co-movement among returns and identify systematic time-series factors that predominantly influence cross-sectional risk. Typically, the top eigenvectors are selected as assets in the portfolios, and one then optimizes the best capital allocation among them. Lettau and Pelger (Citation2020) introduce the Risk Premium (RP)-PCA that identifies pivotal factors in explaining asset returns. While traditional PCA focuses solely on data comovement, it does not incorporate data means. Consequently, it may miss out on capturing vital differences in the mean risk premia of assets. In contrast, RP-PCA takes into account both the first and second moments of data, thereby enhancing estimation efficiency. Our empirical results confirm that RP-PCA outperforms PCA in portfolio performance.
Bryzgalova et al. (Citation2020) introduced the so-called Asset Pricing (AP) Trees, which serve as a generalization of sorting portfolios using tree-based methods. AP-Trees offer concise and interpretable portfolios that span the stochastic discount factor (SDF) on stock returns; and they address challenges related to complexity, high dimensionality, and duplication. Their trees are of depth four and use median of the characteristic for the split location at each step. This allows for any cutoff points that are multiples of where d is the depth of the tree. In our empirical analysis, in order to save some computational time and reduce the dimensionality of the portfolio problem, we construct trees with depth at most three using also the median at each step. Hence, we assemble the forest from different permutations of three (not four) selected factors. Similarly to Bryzgalova et al. (Citation2020) we exclude trees with uniform characteristics. However, our tree pruning strategy diverges notably. Bryzgalova et al. (Citation2020) employs Lasso regression for selecting a sparse set of portfolios and incorporates robust estimates for means and variances to prevent overfitting. The pruning process involves dividing data into training, validation, and testing sets, to maximize the Sharpe ratio estimated with robust estimates of the mean and covariance matrix. In our study, we prune trees by implementing our maximum Sharpe ratio portfolio as in (16) and incorporate both
and
regularization. AP-Trees approach results in 36 different sortings—out of 10 stock specific characteristics we always use Size, and remaining two (9 choose 2) give 36 different trees of depth three. Each of these cross sections comprises 360 managed AP-Trees portfolios.
In addition to AP-Trees portfolios, we construct a broad cross-section of single-sorted decile portfolios. These portfolios are derived from ten distinct deciles of 33 anomaly characteristics, resulting in a total of 330 managed portfolios for the single sorting. We do not work with double sorted portfolios because in our universe of mid- and large-cap stocks considered in the empirical analysis many of the double sorted portfolios were empty.
The AP-Trees and the aforementioned PCA-based models (PCA and RP-PCA) still assume static loadings, and they lack accuracy and flexibility because after constructing the managed portfolios, they use only the information from their returns to estimate optimal portfolio positions. In a similar way Kelly et al. (Citation2019) motivated their IPCA model, where asset returns are assumed to admit the following factor structure
(20)
(20)
The major distinctions from the classical factor models discussed previously are:
The IPCA model, analogous to BARRA’s factor model, posits that the alphas
Due to the dimension reduction introduced by the matrix
The factors
This model is predictive, with observable factors lagged by one period relative to the returns they explain.
The rationale behind the IPCA model lies in the challenge of high-dimensional factor models: an excess of characteristics can lead to significant noise and collinearity among factors. This makes the results challenging to interpret and can diminish the model’s out-of-sample performance. Hence, is introduced to aggregate large-dimensional characteristics into a linear combination of exposure risks. Any errors orthogonal to the dynamic loadings are accounted for in the
In the empirical analysis, we assume that while focusing on the estimation of
Hence, for the restricted model (
), we have
(21)
(21)
where
We can derive this based on the vector form
where
is an
vector of assets returns,
is an N × L vector of observable characteristics and
is an L × K mapping matrix,
is an
vector of the combination latent factor. Then we can write the objective function of IPCA model as
(22)
(22)
with constrain
and
To minimize the objective function (22), one iterates
(23a)
(23a)
and
(23b)
(23b)
where ⊗ denotes the Kronecker product of matrices. Formula (23a) shows that latent factors represent the coefficients of returns regressed on the latent loading matrix
Meanwhile,
denotes the regression coefficients of
on the combination of latent factors and firm characteristics. This first-order condition system does not have a close form solution, but it can be solved numerically by the alternating least squares method.
4. Regularizing Factor-Based Portfolios: An Application to the Maximum Sharpe Ratio Objective
In portfolio optimization, among all the objective functions in our framework, we focus on two fully-invested optimal portfolios: the minimum variance (min Var) portfolio, as detailed in Section 2.1, and the maximum Sharpe ratio (max SR) portfolio, discussed in Section 2.7. We consider both with and without the regularization, which is covered in Section 2.4. The minimum variance portfolio is commonly employed to evaluate models that emphasize covariance matrix estimation without mean prediction. In our study, we use it for daily data, specifically for all covariance matrix shrinkage models and for the
regularized portfolio problems. On the other hand, the maximum Sharpe ratio portfolio aims to maximize the risk-adjusted return of the portfolio strategy, meaning it offers the highest return for each unit of risk, measured in terms of portfolio volatility. Positioned centrally on the portfolio efficient frontier, it is one of the most computationally intensive problems in our framework, as it necessitates reparametrization into a higher dimensional space. Therefore, we consider it a good representative for our mean (and covariance matrix) shrinkage models using daily returns, as well as for the factor-based models employing monthly returns, given the persistence of the mean signal in the constructed factor portfolios. The corresponding optimization problem can be expressed as:
(24)
(24)
where
represents the short-selling threshold parameter (set to
in our study). The matrix
encapsulates the linear mapping between managed portfolios and individual assets in our investment universe. We set the other parameters as follows:
and
for all
If the optimal portfolio weights w pertain to individual stocks, then V is the identity matrix, and
and
signify the mean and covariance matrix (after shrinkage) estimators of those individual stock returns. For AP-Trees, we employ the high-dimensional sample mean and covariance matrix of factor portfolios. With PCA-based models, we consider
dimensional
and
derived from PCA, RP-PCA, and IPCA estimated means, along with the estimated covariance matrix of the corresponding K factor portfolios. For PCA and RP-PCA, V comprises the first K eigenvectors of the PCA and RP-PCA covariance matrices, respectively. In the case of the IPCA model,
describes the transformation from the IPCA factors of the last observation to individual stocks.
In order to solve it efficiently, we reformulate (24) into an equivalent QP problem from Section 2.7 with constraints rewritten as in Section 2.5. In Section 5, we introduce factor portfolios based on Principal Component Analysis (PCA), Risk Premium PCA (RP-PCA), and Instrumented PCA (IPCA). All these PCA-based models correspond to low-dimensional portfolio problems with If we were to continue applying the
and
penalties to each factor, it would not yield a sparse solution for either the managed portfolios or the individual stock weights. Therefore, for the PCA-based models, we define an
regularized maximum Sharpe ratio portfolio as:
(25)
(25)
where
is the same as in Equation(24)
(24)
(24) . Depending on the choice of V, the regularization terms in Equation(25)
(25)
(25) are with respect to the managed portfolios (in PCA and RP-PCA) or the individual stocks (in IPCA). Next, we reparametrize the optimization problem in Equation(25)
(25)
(25) as
(26)
(26)
subject to an additional constraint
Now, by defining
we obtain the corresponding quadratic programming problem
(27)
(27)
Similarly to Equation(6)(6)
(6) and Equation(8)
(8)
(8) , we can employ the eigenvalues decomposition of
where
and
to reduce (27) to
(28)
(28)
where
F denotes the factors from PCA, RP-PCA, IPCA models,
and V is an N × K mapping matrix, the eigenvector corresponding to the first K largest eigenvalues of the PCA, RP-PCA, or IPCA covariance matrix;
are
vectors, which denote the positive and negative part of
Importantly, the final objective function in the optimization is quadratic, and the constraints are linear. Hence, the corresponding problem falls into the general class of QP problems that we solve using our framework. In the following empirical analysis we also use
and
for all
as in all the previous methods.
5. Empirical Results
We gather both daily and monthly data for all stocks traded on the NYSE, Amex, and Nasdaq from January 1965 to December 2022. The daily and monthly stock returns, adjusted for splits and dividends, are sourced from the Center for Research in Security Prices (CRSP). Additionally, we obtain quarterly accounting-related information for public firms from the Compustat dataset, which includes metrics such as BE (book equity), AT (total assets), and CTO (capital turnover). Following the methodologies of Fama and French (Citation1993) and Freyberger et al. (Citation2020), we merge the returns data with the firm-specific information, introducing a 6-month lag for all firms to ensure our results are genuinely out-of-sample.
After obtaining the merged datasets, we construct 33 characteristics, with a full list provided in the Appendix, using data from firms in the Compustat dataset as described by Freyberger et al. (Citation2020) and references therein. For imputation purposes, we adopt the backward cross-sectional model proposed by Bryzgalova et al. (Citation2022). In our research, we utilize the stock universe defined by Asness et al. (Citation2013), to which we refer as the AMP universe. To assemble this universe, we implement a rolling window approach and select stocks in each window based on specific criteria. Initially, in our market capitalization-based stock selection, we exclude the smallest market capitalization stocks, focusing mainly on large- and mid-cap stocks, which together account for 90% of the overall market capitalization. Subsequently, we filter out stocks priced below a designated threshold, ensuring the exclusion of penny stocks. Finally, to maintain the consistency of the dataset, we remove stocks with significant missing data in the last selection phase.
Depending on the specific model under consideration, we use either daily or monthly simple returns from the constructed AMP universe. For daily returns, the AMP universe typically consists of 500 to 1,000 stocks at any given time within a one-year rolling window. For monthly returns, we employ a rolling window of 20 years, resulting in an AMP universe of approximately 900 tickers for each window. Crucially, our methodology in constructing the rolling window-specific assets universe ensures that the portfolio and its performance are not affected by survivorship bias.
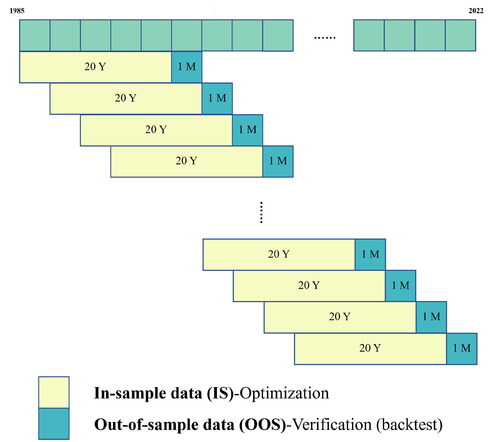
In portfolio optimization, the evaluation of out-of-sample performance of a specific model is often of interest. For this purpose, a rolling window backtest analysis is typically employed. illustrates our rolling window scheme for the monthly data utilized in factor-based models (AP-Trees and all PCA-based models). We partition the 38 years of data into a 20-year training sample (1985–2004) and allocate the subsequent 18 years (2005–2022) for out-of-sample rolling window analysis. This involves monthly reestimation of all model parameters and optimization of portfolio weights. For models investing in individual stocks without leveraging information from stock-specific factors, we adopt a rolling window of daily returns with a one-year look-back period. The rebalancing occurs monthly, commencing on the same start date as in the case of the 20-year window of monthly returns. Thus, all out-of-sample results presented in the following sections span the identical time frame and maintain consistent rebalancing frequency. In terms of portfolio weight constraints, for all the scenarios discussed, we restrict asset concentration to no more than for a single asset and cap short positions at 20% of the total capital. We selected these thresholds to mirror a realistic industry environment, as described in Lunde et al. (Citation2016).
Figure 4. Summary of the rolling window analysis. We use data going back to 1985 and slide 20 years of monthly returns to estimate the parameters, with monthly rebalancing and performance updates.
For our benchmark methods, we utilize daily data and incorporate three distinct mean shrinkage estimators as proposed by Wang et al. (Citation2014) and Bodnar et al. (Citation2019). Additionally, we employ four covariance matrix estimators: the Sample Covariance Matrix, POET (as detailed by Fan et al. (Citation2013)), and both the Ledoit & Wolf Linear and Non-Linear Shrinkage methods from Ledoit and Wolf (Citation2004) and Ledoit and Wolf (Citation2020a), respectively, as discussed in Section 3.
In contrast, we evaluate these benchmarks against the +
regularized minimum variance portfolio. The out-of-sample annualized Sharpe ratio results of these methods are illustrated in . This figure showcases heatmaps that detail the out-of-sample Sharpe ratios for portfolios, rebalanced monthly using one year of daily data for parameters. Meanwhile, highlights the minimum variance portfolio that implements a long-short constraint, complemented by
and
shrinkage. Further insights into Sharpe ratios, derived from various mean and covariance matrix estimator combinations, are provided in .
Figure 5. Heatmaps of annualized Sharpe ratios for different minimum-variance portfolios on individual assets from the AMP universe using one year of daily returns data and monthly rebalancing. Left: The annualized Sharpe ratios of regularized minimum-variance portfolio strategy for different regularization strength parameters. Right: Row-wise: different mean estimators and portfolio without the dependency on the mean. Namely, maximum Sharpe ratio portfolio with four types of mean estimators: Sample Mean, Mean Shrinkage I from Wang et al. (Citation2014), Mean Shrinkage II from Bodnar et al. (Citation2019), Mean Shrinkage III from Bodnar et al. (Citation2019), and minimum variance that does not depend on the mean estimation. Column wise: different covariance matrix estimators: Sample Covariance Matrix (SCM), POET from Fan et al. (Citation2013), Linear Shrinkage covariance matrix estimator from Ledoit and Wolf (Citation2004) (L&W-LS), Nonlinear Shrinkage covariance matrix estimator from Ledoit and Wolf (Citation2020a) (L&W-NLS). (a) min Var + ℓ1 + ℓ22; (b) max SR and min Var with mean and covariance matrix shrinkage.
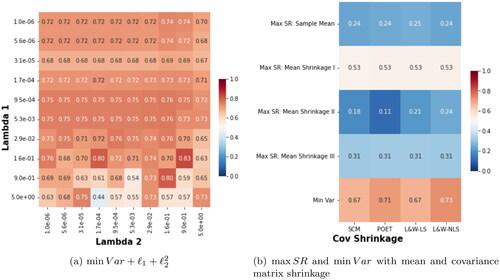
From a vertical perspective, the heatmap sorts portfolios based on five mean estimators: the Sample Mean, Mean Shrinkage I (from Wang et al. (Citation2014)), Mean Shrinkage II and III (both from Bodnar et al. (Citation2019)), and a minimum variance portfolio that does not factor in mean estimation. Horizontally, the heatmap is structured according to covariance matrix estimators, namely: the Sample Covariance Matrix (SCM), POET (by Fan et al. (Citation2013)), Linear Shrinkage (L&W-LS) from Ledoit and Wolf (Citation2004), and Nonlinear Shrinkage (L&W-NLS) from Ledoit and Wolf (Citation2020a).
Intriguingly, the minimum variance portfolios showcased in Panel (a) and the base of Panel (b) in outperform maximum Sharpe ratio portfolios that apply shrinkage either to the mean, the covariance matrix, or both. Moreover, the norms of the minimum-variance regularized portfolio in Panel (a) of in most of the cases mirror or surpass the performance of the covariance matrix shrinkage methods when applied to a minimum-variance portfolio. These findings indicate that the and
regularized portfolio methods perform similarly to best performing covariance shrinkage estimators.
The findings presented in show that the minimum-variance portfolio consistently outperforms the maximum Sharpe ratio portfolio, regardless of the shrinkage applied. This observation aligns with our earlier comments regarding the inherent noisiness of individual stock means. Optimization strategies based on individual stocks frequently yield suboptimal out-of-sample results. Subsequent analyses will highlight that managed portfolios can mitigate the idiosyncratic noise present in individual stock returns, thereby delivering optimal portfolios with superior out-of-sample performance.
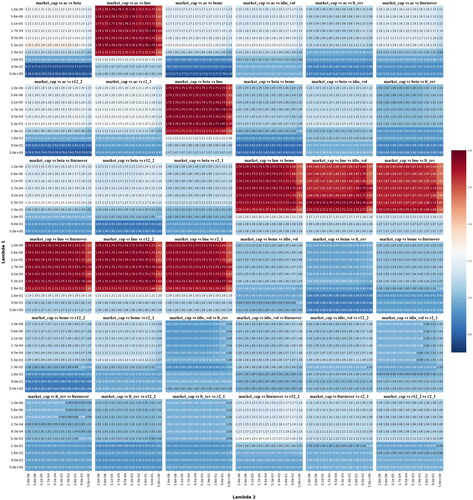
displays the out-of-sample annualized Sharpe ratios for AP-Trees portfolios, which are rebalanced monthly. These portfolios are derived from the regularized maximum Sharpe ratio portfolio strategy, as outlined in (28). Each heatmap represents a unique managed portfolio, distinguished by market capitalization and paired with two other characteristics from in the Appendix. The differences across heatmaps also reflect variations in the regularization strength parameters, λ1 and λ2. In all cases, a 20-year rolling window of monthly data is used. The short-selling constraint is set at
and the maximum concentration in an individual managed portfolio is capped at 8%. We observe a notable improvement in Sharpe ratios compared to the top-performing portfolios invested in individual assets. This suggests that grouping stocks with analogous characteristics into managed portfolios effectively diminishes noise and enhances mean prediction.
Figure 6. Thirty-six heatmaps of out-of-sample annualized Sharpe ratios from monthly rebalanced AP-Trees portfolios obtained from regularized maximum Sharpe ratio portfolio strategy computed using (27). Different heatmaps correspond to different managed portfolios of market capitalization with the combination of another two characteristics from in the Appendix, and different regularization strength parameters, λ1 and λ2. In all the cases, we use a rolling window of 20 years of monthly data with short-selling constraint
and no additional constraints.
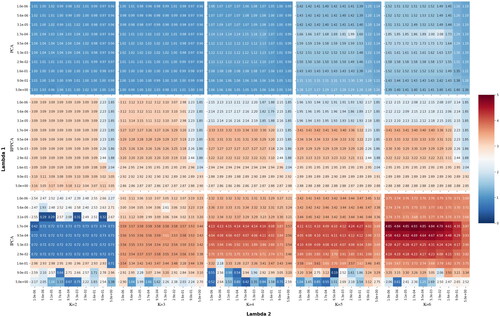
Next, we examine the three PCA-based models outlined in Section 3. presents heatmaps depicting the out-of-sample Sharpe ratios for a monthly rebalanced portfolio that invests in factors from the PCA, RP-PCA, and IPCA models, respectively. The figure comprises 15 heatmaps, all on a consistent scale. Each heatmap demonstrates performance across different levels of
and
regularization parameters, taken from an exponential grid spanning
and
Empirically, within these parameter ranges, the regularization has the most pronounced impact on the portfolio weights across all models. For every model and every factor count K, the proposed regularization consistently enhances performance. The peak performance is observed with K = 6 factors. Specifically, the Sharpe ratios rise for (i) the PCA from 1.52 to 2.00; (ii) the RP-PCA from 2.12 to 3.40; and (iii) the IPCA from 3.75 to 4.93. Furthermore, as illustrated in , there is a marked improvement as the number of components from PCA and IPCA increases. Exploring a broad range of regularization parameters enables us to pinpoint their most effective values. For
the optimal value is approximately
while for
it lies between
and
Across all values of K and various regularization strengths, the RP-PCA model consistently surpasses the corresponding PCA models. The most outstanding performer among all considered models is the IPCA model with 6 factors and combined
and
shrinkage.
Figure 7. Fifteen heatmaps of out-of-sample performance gains from monthly rebalanced portfolio in the annualized Sharpe ratios of regularized maximum Sharpe ratio portfolio strategy. The strategy varies based on the number of components from PCA, RP-PCA, and IPCA estimated covariance matrix, and different regularization strength parameters, λ1 and λ2. In all the cases, we use the maximum Sharpe ratio portfolio estimated based on the last 20 years of data with short-selling constraint
and no additional constraints. Columns: Different size components from PCA, RP-PCA, IPCA models. First Row: Annualized Sharpe ratios for the covariance matrix derived from PCA factors, regularized with
Second Row: Annualized Sharpe ratios for the covariance matrix derived from RP-PCA factors, regularized with
Third Row: Annualized Sharpe ratios for the covariance matrix derived from IPCA factors, regularized with
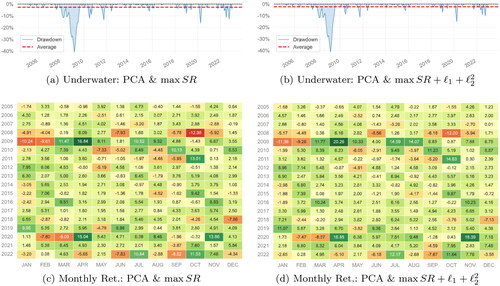
contrasts the performance of the PCA factor model for the maximum Sharpe ratio portfolio (K = 6) with and without regularization on the portfolio norms, as delineated in Equation(24)(24)
(24) and Equation(28)
(28)
(28) , respectively. Panels 8(a) and 8(c) present the results for the PCA max Sharpe ratio portfolio without regularization. In contrast, panels 8(b) and 8(d) showcase the results with the inclusion of
regularization, utilizing the optimal λ1 and λ2 parameters. Both panels 8(a) and 8(b) suffer from a large drawdown during the financial crisis. Nevertheless, in other periods, the regularized PCA factor model demonstrates enhanced performance. This distinction becomes even more evident in Panels 8(c) and 8(d), where the regularized portfolio model outperforms in the majority of the months considered.
Figure 8. Out-of-sample underwater plots (Panels (a) and (b)) and Monthly Returns performance (Panels (c) and (d)) for our long-short maximum-Sharpe ratio with PCA factors without regularization (Panels (a) and (c)), and with +
regularization from (28) (Panels (b) and (d)).
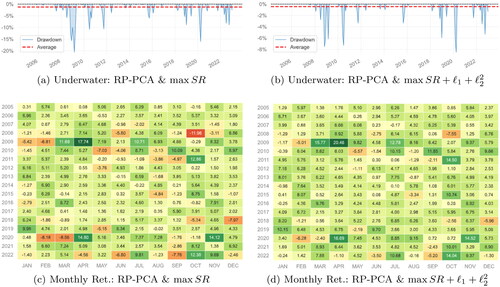
parallels but focuses on the RP-PCA model (K = 6). We examine both the inclusion and exclusion of the regularization, specifically selecting the optimal λ1 and λ2 parameters. Panels 9(a) and 9(c) depict the underwater and monthly return plots for the RP-PCA factor model without the
constraints. Conversely, panels 9(b) and 9(d) showcase these plots with the
regularization applied. The regularized RP-PCA displays a trend akin to the benchmark model (RP-PCA factor model without
regularization). Notably, the application of regularization in the RP-PCA model considerably mitigates drawdowns; for instance, the maximum monthly drawdown shrinks from –20% to –8.2%. This enhancement is further confirmed by panels 9(c) and 9(d), which consistently indicate elevated returns for the regularized RP-PCA model.
Figure 9. Analogous to but for the RP-PCA model.
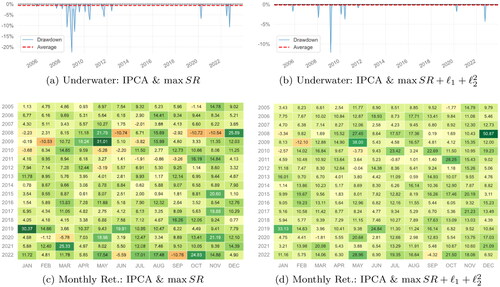
Finally, offers a similar comparison but focuses on the IPCA model. Analogous to previous observations, the IPCA model augmented with the regularization for the maximum Sharpe ratio portfolio exhibits consistently fewer and smaller drawdowns compared to the unregularized IPCA model. Moreover, the monthly returns for the regularized maximum Sharpe ratio portfolio are consistently higher throughout the entire out-of-sample analysis period.
Figure 10. Analogous to but for the IPCA model.
In summary, both the AP-Trees and the three PCA-based models gain significantly from the proposed regularization of the linear transformation of the portfolio norms, Among all the models considered, the IPCA model stands out as the top performer. The out-of-sample performance of both the original and regularized IPCA models is truly exceptional. Even when accounting for market frictions, such as transaction costs, implementation lags, liquidity concerns, and potential complications arising from the construction of certain asset-specific characteristics, a significant portion of this remarkable performance is expected to remain intact. While various methods exist to further refine the investment process and mitigate the effects of these market frictions, delving into them remains a topic for future research. It is worth noting that our IPCA model results without regularization are in agreement with findings from the original IPCA paper (refer to Kelly et al. Citation2019). Our regularization of the linear combinations of the portfolio norms further enhances the model’s efficacy. Moreover, the portfolio results presented in this study deviate from the original Kelly et al. (Citation2019) portfolio due to the incorporation of a 20% long-short constraint, a cap of 8% on individual positions, and trading restrictions to only the AMP universe of mid- and large-capitalization stocks. That the portfolio, despite these constraints, can achieve such impressive monthly returns, high annualized Sharpe ratios, and minimal drawdowns over nearly 18 years of out-of-sample rolling windows is intriguing and noteworthy.
presents key performance metrics across various benchmarks: the S&P 500 index; two minimum variance portfolios utilizing Ledoit & Wolf’s linear and non-linear shrinkage covariance matrices; the best performing AP-Trees and factor portfolios based on PCA, RP-PCA, and IPCA with K = 6 models and regularization. The latter is also presented without regularization, as per the original model by Kelly et al. (Citation2019). The initial three benchmarks are based on individual daily stock returns. For the AP-Trees, we employ 360 managed portfolios conditionally sorted based on size, beta, and lagged market capitalization using a depth-three tree (refer to for the highest Sharpe). The PCA and RP-PCA models utilize 330 single-sort monthly managed portfolios. Contrarily, the IPCA model strictly operates on individual stock returns, incorporating stock-specific firm data. The first IPCA portfolio is the constrained tangency portfolio without regularization, with its covariance matrix determined via the IPCA factors model. The subsequent IPCA portfolio is the same but with optimal regularization employed. In summation, the regularized IPCA portfolio, results in an annualized Sharpe ratio of 4.91, and it surpasses all other methods across nearly every metric considered. The regularized RP-PCA is performs best in terms of the lowest maximum drawdown, highest information ratio, and the lowest loss in the worst month. It also has lower volatility than the IPCA models.
Table 2. Key performance metrics from a rolling window exercise with monthly rebalancing from 2005-01-31 until 2022-12-31.
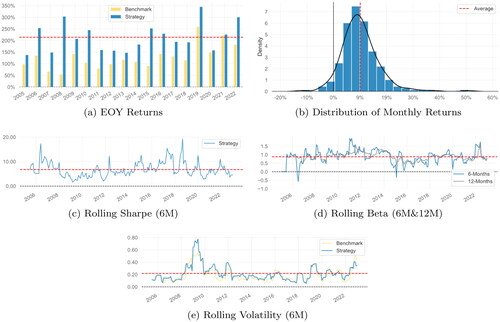
Other key performance, such as rolling beta, rolling Sharpe, and rolling volatility, of our top-performing IPCA factor model employing the maximum-Sharpe ratio portfolio with regularization, are illustrated in . compares the annual returns of the IPCA model in maximum Sharpe ratio portfolio without (Benchmark) and with our
regularization (Strategy). The regularization systematically improves the performance. Hence, it should be also simple to calibrate the λ1 and λ2 parameters based on past performance. The distribution of the monthly returns is centered around 9% per month, rolling 6 M Sharpe ratio is very high, rolling beta (against the non-regularized benchmark) is oscillating around 1, and the rolling volatility is around 20% only with a large burst during the Great Financial Crises and recent COVID period—variance levels deemed acceptable by quantitative portfolio managers without necessitating additional (de-)leveraging.
Figure 11. Five plots of different out-of-sample performance measures for our long-short maximum-Sharpe ratio with +
regularization and IPCA covariance matrix estimator portfolio strategy from (27) versus maximum-Sharpe ratio with IPCA factors covariance matrix without shrinkage as a benchmark. (a) EOY Returns. (b) Distribution of Monthly Returns. (c) Rolling Sharpe (6M). (d) Rolling Beta (6M&12M). (e) Rolling Volatility (6M).
6. Concluding Remarks
This study presents a unified framework for portfolio optimization using quadratic programming. This framework integrates various conventional objectives for portfolio optimization, constraints, and regularizations frequently adopted in practice. As a result, it is exceptionally suited for rapid backtesting of extensive portfolio scenarios, ensuring both accuracy and computational speed.
Employing this framework, we introduce a novel maximum Sharpe ratio portfolio problem, incorporating new types of regularizations on the norms of portfolio weights or their linear transformations. We demonstrate that, within the framework of recent tree-based and PCA-based factor models, our proposed regularization and optimization framework yield systematically enhanced returns, diminished drawdowns, reduced volatilities, and elevated Sharpe ratios for the optimal portfolios. Among the models assessed, the IPCA factor model detailed in Kelly et al. (Citation2019) emerges as the superior performer, especially when utilizing the proposed regularization.
In future studies, it would be interesting to delve deeper into the ramifications of transaction costs on our optimal portfolios. Factor based models because of its conditional mean prediction that depends on stock specific factors lead to inherently higher turnover numbers in portfolio optimization. Nevertheless, we believe that because of the monthly rebalancing considered in this paper, the majority of the qualitative results will remain, also the additional smoothing constraints on the level of changes in the individual assets (similar to our
regularizations) should help to reduce turnover without large impact on the performance. Additionally, integrating alternative portfolio problems within our expansive framework could help mitigate these transaction costs. As optimal portfolio weights are deduced from the inverse covariance matrix, it’s vital to consider applying shrinkage methods to this matrix, which could further bolster the robustness and efficiency of the portfolio optimization. Such strategies have been explored in Kourtis et al. (Citation2012), Wang et al. (Citation2015), and Bodnar et al. (Citation2016). Further, a comprehensive examination of the asset-specific factors in the IPCA model that significantly influence return predictions and boost portfolio performance is essential. Ideally, emphasizing factor sparsity would enhance the model’s signal-to-noise ratio. This can also be achieved by incorporating sparse PCA extensions into the IPCA model.
Acknowledgements
We thank two anonymous referees and the Associate Editor for their insightful suggestions, which significantly enhanced the quality of our paper. We are also thankful for valuable comments by Andrew Mullhaupt, Milind Sharma, and Stan Uryasev, as well as the participants of the 2023 Winter School in Quantitative Finance at the University of Zurich, and QWAFAXNEW webinar series in New York.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Notes
1 The latest version of the code can be found at https://github.com/PawPol/PyPortOpt
2 In the empirical analysis we work with dividend and split adjusted simple returns.
3 Here, we use Dirichlet distributed random vectors to guarantee uniform sampling on the N dimensional simplex (). The results for the weights sampled from uniform distribution normalized on the simplex, i.e.
where
and
and for the weights sampled from the absolute value of standard normal distribution normalized on the simplex, i.e.
where
and
are similar.
4 We utilize Dirichlet distributed random vectors to ensure uniform sampling on the N dimensional simplex (). The results from weights sampled from the uniform distribution normalized on the simplex (i.e.
where
and
); and from the weights derived from the absolute value of the standard normal distribution normalized on the simplex (i.e.
where
and
) align closely.
5 It is possible to further simplify the optimization problem from 3 N to 2 N variables by incorporating these constraints explicitly. But we tested this empirically, and it slows down the algorithms because one needs to use then the matrix instead of
in (8). The same argument applies to the similar optimization problems below.
References
- Asness CS, Moskowitz TJ, Pedersen LH. 2013. Value and momentum everywhere. J Finance. 68(3):929–985.
- Bai J, Liao Y. 2016. Efficient estimation of approximate factor models via penalized maximum likelihood. J Econometric. 191(1):1–18.
- Bai J, Ng S. 2002. Determining the number of factors in approximate factor models. Econometrica. 70(1):191–221.
- Bai J, Ng S. 2013. Principal components estimation and identification of static factors. J Econometric. 176(1):18–29.
- Bali TG, Beckmeyer H, Goyal A. 2023. A joint factor model for bonds, stocks, and options. Swiss Finance Ins Res Paper. 23(106):1–52. https://ssrn.com/abstract=4589282.
- Bodnar T, Gupta AK, Parolya N. 2016. Direct shrinkage estimation of large dimensional precision matrix. J Multivariate Anal. 146:223–236.
- Bodnar T, Okhrin O, Parolya N. 2019. Optimal shrinkage estimator for high-dimensional mean vector. J Multivariate Anal. 170:63–79.
- Boyd S, Parikh N, Chu E, Peleato B, Eckstein J, et al. 2011. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundation and Trend in Machine Learning. 3(1):1–122.
- Bryzgalova S, Lerner S, Lettau M, Pelger M. 2022. Missing financial data. Available at SSRN 4106794.
- Bryzgalova S, Pelger M, Zhu J. 2020. Forest through the trees: building cross-sections of stock returns. Available at SSRN 3493458.
- Carhart MM. 1997. On persistence in mutual fund performance. J Finance. 52(1):57–82.
- Chitsiripanich S, Paolella MS, Polak P, Walker PS. 2022. Momentum without crashes. Swiss Finance Institute Research Paper No. 22–87. p. 1–51.
- Cornuejols G, Tütüncü R. 2006. Optimization methods in finance. Cambridge, U.K.: Cambridge University Press. (Mathematics, Finance and Risk; 5).
- DeMiguel V, Garlappi L, Nogales FJ, Uppal R. 2009a. A generalized approach to portfolio optimization: improving performance by constraining portfolio norms. Manage Sci. 55(5):798–812.
- DeMiguel V, Garlappi L, Uppal R. 2009b. Optimal versus naive diversification: how inefficient is the 1/n portfolio strategy? Rev Financ Stud. 22(5):1915–1953.
- Fama EF, French KR. 1993. Common risk factors in the returns on stocks and bonds. J Financ Econ. 33(1):3–56.
- Fama EF, French KR. 2015. A five-factor asset pricing model. J Financ Econ. 116(1):1–22.
- Fan J, Liao Y, Mincheva M. 2013. Large covariance estimation by thresholding principal orthogonal complements. J Royal Stat Soc Series B: Stat Method. 75(4):603–680.
- Feng G, Giglio S, Xiu D. 2020. Taming the factor zoo: a test of new factors. J Finance. 75(3):1327–1370.
- Freyberger J, Neuhierl A, Weber M. 2020. Dissecting characteristics nonparametrically. Rev Financ Stud. 33(5):2326–2377.
- Goyal A, Saretto A. 2022. Are equity option returns abnormal? IPCA Says No (August 19, 2022).
- Hastie T, Tibshirani R, Wainwright M. 2015. Statistical learning with sparsity: the lasso and generalizations. Boca Raton, FL: CRC press.
- Hediger S, Näf J, Paolella MS, Polak P. 2023. Heterogeneous tail generalized common factor modeling. Digit Finance. 5:389–420.
- Jegadeesh N, Titman S. 1993. Returns to buying winners and selling losers: implications for stock market efficiency. J Finan. 48(1):65–91.
- Kelly BT, Pruitt S, Su Y. 2019. Characteristics are covariances: a unified model of risk and return. J Finan Econ. 134(3):501–524.
- Kourtis A, Dotsis G, Markellos RN. 2012. Parameter uncertainty in portfolio selection: shrinking the inverse covariance matrix. J Bank Finan. 36(9):2522–2531.
- Ledoit O, Wolf M. 2004. Honey, i shrunk the sample covariance matrix. JPM. 30(4):110–119.
- Ledoit O, Wolf M. 2012. Nonlinear shrinkage estimation of large-dimensional covariance matrices. Ann Statist. 40(2):1024– 1060.
- Ledoit O, Wolf M. 2020a. Analytical nonlinear shrinkage of large-dimensional covariance matrices. Ann Statist. 48(5):3043–3065.
- Ledoit O, Wolf M. 2020b. The Power of (Non-)Linear Shrinking: a Review and Guide to Covariance Matrix Estimation. Journal of Financial Econometrics. 20(1):187–218.
- Ledoit O, Wolf M. 2022. Quadratic shrinkage for large covariance matrices. Bernoulli. 28(3):1519–1547.
- Lettau M, Pelger M. 2020. Factors that fit the time series and cross-section of stock returns. Rev Finan Stud. 33(5):2274–2325.
- Li J. 2015. Sparse and stable portfolio selection with parameter uncertainty. J Busin Econ Stat. 33(3):381–392.
- Lintner J. 1965. Security prices, risk, and maximal gains from diversification. J Finance. 20(4):587–615.
- Lunde A, Shephard N, Sheppard K. 2016. Econometric analysis of vast covariance matrices using composite realized kernels and their application to portfolio choice. J Busin Econ Statist. 34(4):504–518.
- Markowitz H. 1952. Modern portfolio theory. J Finan. 7(11):77–91.
- Mossin J. 1966. Equilibrium in a capital asset market. Econometrica: J Econometric. 34(4):768–783.
- Paolella MS, Polak P. 2015. Portfolio selection with active risk monitoring. Swiss Finance Institute Research Paper. No 15–17. p. 1–37.
- Paolella MS, Polak P, Polino A, Walker PS. 2022. Risk parity versus risk minimization portfolio allocation under heavy-tailed returns. Working Paper.
- Paolella MS, Polak P, Walker PS. 2019. Regime switching dynamic correlations for asymmetric and fat-tailed conditional returns. J Econometric. 213(2):493–515.
- Paolella MS, Polak P, Walker PS. 2021. A non-elliptical orthogonal garch model for portfolio selection under transaction costs. J Bank Finan. 125:106046.
- Pedersen LH. 2015. Efficiently inefficient: how smart money invests and market prices are determined. Princeton, NJ: Prienceton University Press.
- Roncalli T. 2013. Introduction to risk parity and budgeting. Boca Raton, FL: CRC Press.
- Schaible S. 1974. Parameter-free convex equivalent and dual programs of fractional programming problems. Zeitschrift für Operations Research. 18:187–196.
- Sharpe WF. 1964. Capital asset prices: a theory of market equilibrium under conditions of risk. J Finance. 19(3):425–442.
- Stellato B, Banjac G, Goulart P, Bemporad A, Boyd S. 2020. OSQP: an operator splitting solver for quadratic programs. Math Prog Comp. 12(4):637–672.
- Stock JH, Watson MW. 2002. Forecasting using principal components from a large number of predictors. J Am Stat Assoc. 97(460):1167–1179.
- Tibshirani R. 1996. Regression shrinkage and selection via the lasso. J Royal Stat Soc: Series B (Methodol). 58(1):267–288.
- Treynor JL. 1961. Market value, time, and risk. Time and Risk (August 8, 1961).
- Tsai H, Tsay RS. 2010. Constrained factor models. J Am Stat Assoc. 105(492):1593–1605.
- Wang C, Pan G, Tong T, Zhu L. 2015. Shrinkage estimation of large dimensional precision matrix using random matrix theory. Stat Sinica. 25:993–1008.
- Wang C, Tong T, Cao L, Miao B. 2014. Non-parametric shrinkage mean estimation for quadratic loss functions with unknown covariance matrices. J Multivariate Anal. 125:222–232.
Appendix.
Description of asset specific factors
In , we list the details of the firm specific characteristics used in the factors models.
Table A1. Acronyms and factor names.