
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Residual plots are often used to interrogate regression model assumptions, but interpreting them requires an understanding of how much sampling variation to expect when assumptions are satisfied. In this article, we propose constructing global envelopes around data (or around trends fitted to data) on residual plots, exploiting recent advances that enable construction of global envelopes around functions by simulation. While the proposed tools are primarily intended as a graphical aid, they can be interpreted as formal tests of model assumptions, which enables the study of their properties via simulation experiments. We considered three model scenarios—fitting a linear model, generalized linear model or generalized linear mixed model—and explored the power of global simulation envelope tests constructed around data on quantile-quantile plots, or around trend lines on residual versus fits plots or scale-location plots. Global envelope tests compared favorably to commonly used tests of assumptions at detecting violations of distributional and linearity assumptions. Freely available R software (ecostats::plotenvelope) enables application of these tools to any fitted model that has methods for the simulate, residuals and predict functions.
1 Introduction
When fitting a regression model, residual plots are typically relied upon as a diagnostic tool to check assumptions are reasonable. However, a challenge for interpretation is that residuals will always stray from expected trends to some extent—we would like to know if deviations from expected patterns are large relative to sampling variation.
One way to compare observed patterns to expected sampling variation is to construct a global envelope—a region of the diagnostic plot within which we expect the observed data to always lie if assumptions are satisfied (at a chosen level of confidence ). Rosenkrantz (Citation2000) developed an approach to construct global confidence bands around a quantile-quantile (or “QQ”-) plot, under the assumption that observations are independent and normally distributed, by exploiting Mood joint confidence sets for the mean and variance. Aldor-Noiman et al. (Citation2013) devised a closely related method, but used simulation to estimate the desired multiple testing correction needed for global envelopes.
Many regression models do not assume errors are independent and normally distributed, as for example when analyzing discrete data (). In such cases simulation could be used to construct envelopes, repeatedly simulating new responses from the fitted model, refitting the model and constructing residuals. Moral, Hinde, and Demétrio (Citation2017) used this approach to generate pointwise simulation envelopes around half normal plots. Note however that pointwise envelopes can be quite misleading, as they do not correct for multiple testing. The chance that not all observations fall inside a pointwise envelope can be much higher than the nominal rate, so naïve interpretation of pointwise envelopes could too often lead to the conclusion that assumptions have been violated, in situations where they have not been violated. What is needed here is to construct global simulation envelopes—controlling the chance that all observations are contained inside the simulation envelope, across datasets that satisfy model assumptions.
Fig. 1 Example diagnostic plots with global simulation envelopes, constructed using ecostats::plotenvelope, for the Salamanders data (Price et al. Citation2016) available in the glmmTMB package on R (Brooks et al. Citation2017). Three types of residual plot are presented: (a) a residual versus fitted values plot, (b) a QQ-plot, (c) a scale-location plot. A Poisson loglinear model with a random intercept was fitted using glmmTMB, and Pearson residuals computed from the fit. Global envelopes are the shaded areas, not that in (a) the envelope is so narrow that it is hardly visible. Note from (b) that many residuals on the QQ-plot fall outside their simulation envelope (taking unusually large values), and there is an increasing trend on the scale-location plot, which strays outside its envelope. Both of these trends are suggestive of overdispersion.
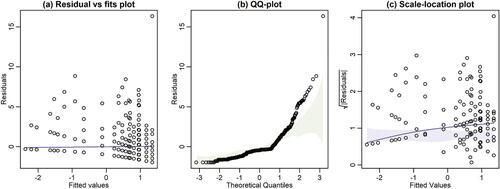
This article describes a method of constructing global simulation envelopes for residual plots from any fitted model, using the method of Myllymäki et al. (Citation2017). Their method was designed as a diagnostic tool for point patterns, but in principle, it can be used to construct global simulation envelopes around any function. Their method is used in this article to construct global simulation envelopes around three commonly used types of residual plot (), as a visual tool to aid interpretation of residual plots. Such envelopes may also be useful as a teaching tool, to assist students in learning when departures from expected trends are large relative to sampling variation. A global envelope could also be used in a formal test of assumptions, and while this is not the primary intention of the proposed tool, it does enable study of its properties via power simulation. Simulations presented here suggest that global envelopes on residual plots have power that is competitive with formal tests designed to interrogate model assumptions. The proposed global envelope approach has been implemented on R as the plotenvelope function in the ecostats package (Warton Citation2022), and can in principle be applied to any model object that has methods for the simulate, residuals and predict functions.
2 Global Envelopes
Assume we have a diagnostic plot which defines a function T(r) over some set of values , which could be an interval, or a discrete set of values. In constructing a
level global envelope over
, we want to find functions
and
such that when the assumed regression model is satisfied
2.1 Constructing Global Envelopes via Simulation
Myllymäki et al. (Citation2017) proposed a method of constructing a global envelope for T(r) via simulation—making inferences from a set of simulated realizations of the function for
, where we additionally include
, the observed function, in this functional sample. While Myllymäki et al. (Citation2017) were motivated by the problem of diagnosing goodness of fit in point process models, for example, using Ripley’s (Citation1976) K-function, the approach could equally well be applied to any type of function. Here we will define functions using common residual diagnostic plots, and simulate new residuals by simulating data from the fitted regression model, refitting the regression model, and recomputing the residuals (a “parametric bootstrap,” Davison and Hinkley Citation1997).
The core idea (Myllymäki et al. Citation2017) is to construct a global statistic that measures the maximal distance u of each function from the center of the B functions
, and construct envelopes such that the
-quantile of u is only exceeded with probability α. For example, we could compute the maximum absolute difference (MAD) measure, as compared to the mean function, and construct global envelopes based on absolute distance from
. Specifically, if we let the mean function be
, then for each function
we compute
. We can then construct a
% global envelope as
where
is the
-quantile of the ub, computed as the
-smallest value of ub. Since
is only exceeded by a proportion α of the ub, only a proportion α of the simulated functions
will stray outside this envelope.
An issue with using MAD is that T(r) may have non-constant variance—in fact for most diagnostic plots we consider below, we would expect T(r) to have a smaller variance for intermediate values of r. We will compute the pointwise sample variance function and measure maximal standardized distance between
and
, computed as
. Hence, we construct a Studentized MAD global envelope (Myllymäki et al. Citation2017):
where as before
is the
-quantile of the vb. Up to Monte Carlo error, this envelope provides an exact global test of a simple hypothesis, where the distribution of simulated data has been exactly specified (Myllymäki et al. Citation2017). It has been noticed empirically that the method is often conservative for composite hypotheses, where the distribution we wish to sample from is a function of unknown parameters (Myllymäki et al. Citation2017). When using global simulation envelopes to diagnose regression models, we find ourselves in this latter situation. Software to compute Studentized MAD global envelopes is available on R in GET::global_envelope_test using the option type=“st”.
2.2 Diagnostic Plots in Regression Models
Now consider the situation where we have univariate responses stored in a vector y of length n, with the ith observation denoted yi for . We can define vectors of linear predictors
and residuals e, whose ith elements are
and ei. The residual ei is some pre-defined function of yi and
, an ideal choice being a function such that the distribution of residuals does not vary as a function of linear predictors when assumptions are satisfied. There are many different types of diagnostic plot that could be constructed. Below we describe three commonly used plots, and how we define the interval
and the function T(r) for each plot:
QQ-plot:
This is a plot of sorted residuals against theoretical normal quantiles. Let be the ith residual when placed in rank order. In a normal quantile or “QQ”-plot we plot
against
for
, where
is the cumulative distribution function of the standard normal distribution
. Inverting this formula for zi, we get
.
We define as our function the sorted residual, as a function of its corresponding normal quantile. Specifically, we let be the set of normal quantiles
, and
.
Residuals versus fits plot:
We plot residuals ei against linear predictors , for
. If there is no violation of the mean model, residuals ei should have no trend, as a function of linear predictors. We can diagnose this by fitting a smoother to the residuals, as a function of linear predictors:
where ϵi are errors centered on zero, and
is estimated using some nonparametric or semi-parametric regression method. We will estimate
using thin plate regression splines (Wood Citation2003), assuming the ϵi are Gaussian with constant variance, using mgcv::gam on R with maximum likelihood estimation (Wood Citation2011, method=“ml”).
The function we will use as a diagnostic tool for residual versus fits plots is the smoother defined above, , acting on the interval containing the observed range of linear predictors,
.
Scale versus location plot:
To look for violation of variance assumptions it is common to plot the absolute value of residuals against linear predictors
, for
. If there is no violation of the mean model, there should be no trend. We can diagnose this by fitting a smoother to
, as a function of linear predictors:
where as previously ϵi are errors centered on zero, and we will estimate
using mgcv::gam(…, method=“ml”).
The function we will use as a diagnostic tool for scale-location plots is the smoother defined above, , acting on the interval containing the observed range of linear predictors,
.
2.3 Global Envelopes for Residual Plots
We have described how to construct a global envelope via simulation, using the methods of Myllymäki et al. (Citation2017), given a set of simulated functions , and we have defined three different types of function T(r) based on different residual diagnostic plots that could be used to query goodness of fit of a regression model
that has been fitted to sample data y. We will construct simulated realizations of these functions by simulating data
from the fitted regression model and recomputing the relevant residual function
, for each
, as follows:
Simulate data
from fitted regression model,
Refit the regression model to simulated data, to obtain
Compute residuals
Hence, compute
This procedure is sometimes referred to as a parametric bootstrap (Davison and Hinkley Citation1997). Note that this procedure requires us to fit the model to data B times, which can potentially be quite computationally intensive, if the model cannot be fitted quickly.
In residual versus fits and scale-location plots, note that linear predictors were not resampled, but were kept fixed at their observed value as computed using the regression model fitted to the observed data
. Initial simulations considered resampling the linear predictor—computing
from
to use in residual plots—but in noisy data settings, the variability in
often suppressed the signal in subsequent residual plots.
2.4 Software Implementation in the ecostats Package
Software to implement this approach is available from the Comprehensive R Archive Network (R Core Team Citation2022) in the ecostats package, which was written to accompany an introductory text on regression modeling (Warton Citation2022). The key function is plotenvelope, which by default will produce a residual versus fits plot and a QQ-plot as discussed in this article, with accompanying 95% global envelopes constructed via calls to GET::global_envelope_test. The user can control the method of envelope construction and the number of sets of simulated residuals used. Default settings construct Studentized MAD global envelopes (type=“st”) from B = 199 sets of residuals. A scale-location plot can be constructed using the argument which = 3 (analogous to behavior of plot.lm in base R).
As an example of how to use plotenvelope, Brooks et al. (Citation2017) used generalized linear mixed models to study counts of salamander abundance across 23 sites, with four replicates at each site, in order to look for an impact of mining. Below we fit a Poisson log-linear model to the data with a random intercept for site (using the glmmTMB package), then check assumptions using all three of the proposed plots:
library(glmmTMB) data(Salamanders) m1 <- glmmTMB(count ∼ mined + (1|site), family = poisson, data = Salamanders) library(ecostats) plotenvelope(m1,which = 1:3)
We see for this dataset () signs of overdispersion relative to the Poisson distribution, with points lying above their simulation envelope in the quantile plot (), and an increasing trend that exceeds its bounds in the scale-location plot (), for large fitted values.
The ecostats::plotenvelope function can in principle be applied to any model object that has methods for the simulate, residuals and predict functions. To date it has been tested on common tools for fitting linear or generalized linear models, mixed models (Bates et al. 2015; Brooks et al. Citation2017), generalized additive models (Wood Citation2011), and software for multivariate responses (Wang et al. Citation2012).
The method used to construct residuals and linear predictors in plotenvelope can be controlled by the user via the resFunction and predFunction arguments, which must be functions that take a fitted model as input and are expected to return residuals and linear predictors, respectively. These arguments default to the generic residuals and predict functions, respectively, but if unavailable for a particular model object then resFunction and predFunction could be used to define suitable alternatives. If desired, these functions could also be used to construct other types of plots beyond residual versus fitted value plots, by setting these functions such that they return values beyond residuals and/or fitted values. For example, we could use this function to obtain global envelopes around the expected trend on an added variable plot by setting predFunction to return the predictor of interest.
3 Simulations
Although global simulation envelopes are proposed here primarily as a graphical aid, they can also be used to construct formal tests of assumptions. Simulations have been undertaken to study the performance of such tests, as compared to some other commonly available tests of model fit, for situations where we have n univariate responses yi, , assumed to be related to a single predictor xi via a linear function
, and we fit one of three different types of model for the response yi:
A linear model,
A Poisson log-linear model,
A Poisson log-linear model with random intercept term,
The glmmTMB package (Brooks et al. Citation2017), used to fit Model (c), is an alternative to the widely used lme4 package (Bates et al. 2015). It is used here because it tends to provide faster, more stable fits (while also having a broader range of possible variance structures and family arguments). This extra functionality is made available via Template Model Builder (Kristensen et al. Citation2016), an environment for statistical model-building that makes use of automatic differentiation and C++ for computational expediency.
Standardized residuals were used to evaluate fits of Model (a) via the rstandard function, which are normally distributed when assumptions are satisfied. For other models, we used deviance residuals (García et al. Citation2012), the default residual output for glm. In the mixed model setting (c), fitted values were estimated marginally with respect to the random effect. Note that in both (b) and (c), residuals are not normally distributed when assumptions are satisfied, motivating the use of simulation to construct global envelopes for residual plots.
Models (a)–(c) were each fitted to data simulated under settings similar to what was assumed by the corresponding model, but under three different configurations, corresponding to three different types of assumption violations. Specifically, in each case the linear predictor used in simulations had the form
but data were simulated under the following three different configurations:
Assumptions satisfied
Data were simulated from Models (a)–(c) as described previously, with and
(and for Model (c), ω = 1).
Mixture distribution
A 9:1 mixture of responses was simulated as follows:
Quadratic response
Data were simulated from Models (a)–(c) with and
(and, as previously,
and ω = 1). This produced (on the linear predictor scale) a parabolic response whose axis of symmetry was at the center of the xi, and whose values for the ηi were centered on similar values to those produced by other simulation scenarios.
This gives a total of nine simulation scenarios, consisting of three models (a)–(c) fitted under each of three assumption violation configurations—when assumptions are satisfied, when distributional assumptions are violated, and when the mean model is not correctly specified. Under each scenario, 1000 datasets were simulated at each of four different sample sizes—. The following tests were compared, in terms of their rejection rate at the
level:
Global simulation envelopes around smoothers on a residual versus fits plot or scale-location plot as described in the previous section (using Studentized MAD envelopes). We expected the residual versus fits plot to be useful for detecting assumption violations in Quadratic response simulations, and the scale-location plot to be more useful for Mixture distribution simulations.
Global simulation envelopes around a normal quantile (QQ-) plot or a probability (PP-) plot (using Studentized MAD envelopes). We expected these to be most useful in Mixture distribution simulations.
For Model (a), a Shapiro-Wilks test was computed using the shapiro.test function on R.
For Models (b)–(c), the maximized log-likelihood was used as a goodness-of-fit test statistic, and compared to its null distribution as estimated from simulated datasets
In all cases, simulation envelopes were constructed using 999 simulated datasets (in addition to the observed data), and interpreted as a hypothesis test by asking whether the observed data (or smoother) fell outside its 95% global envelope at any stage. Because this whole process was repeated 1000 times, for each sample size and simulation setting, simulations were quite computationally intensive and were undertaken on a computational cluster (UNSW Sydney Citation2022), requiring several thousand hours in total computation time on processors with 20-60GB RAM.
Results for these nine simulation scenarios are summarized in . Note first that the global envelopes all adequately control Type I error (, left), although some methods were conservative. Myllymäki et al. (Citation2017) also saw conservativeness in their simulations, and noted that it is often observed empirically in Monte Carlo testing of composite hypotheses.
Fig. 2 Simulation results when fitting Models (a-c) to data simulated under the assumed model (left column), from a mixture distribution (center) or with a quadratic response to the predictor (right). In (a), the gray area is a 95% global envelope around the observed Type I error of an exact test, at significance level of 0.05, in this simulation design. Note in particular that all global simulation envelopes adequately control Type I error (left), that envelopes around QQ-plots (green solid line) were most effective at finding violations of distributional assumptions (center), and envelopes around a smoother on a residual versus fits plot (green dotted line) was most effective at finding violations of linearity (right).
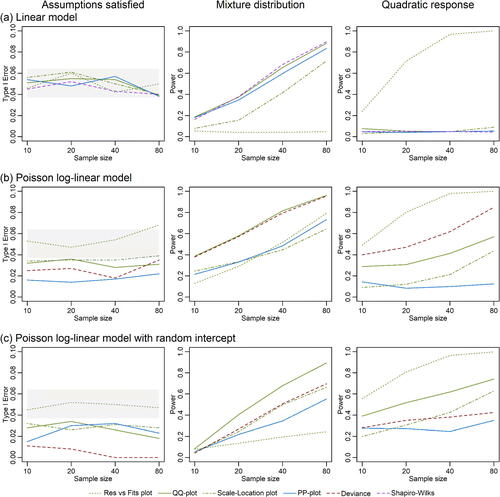
When looking at power of different methods to detect assumption violations, the most striking result was that the most effective tools were simulation envelopes around a QQ-plot or a residual versus fits plot, for mixture distributions (, center) and quadratic response (, right), respectively. Note that global envelopes on a QQ-plot performed comparably to a Shapiro-Wilks test at finding violations of normality (, center) and better than a deviance test at detecting violations of a Poisson assumption (, center). When there was a quadratic response to predictors, a global envelope around a smoother on a residual versus fits plot was by far the most effective method (, right) for all three models.
Note that for non-Gaussian models () there was some interaction between nonnormality and nonlinearity, with residual versus fits plots having some ability to detect mixture distributions and a QQ-plot having some power under nonlinearity. Mean and variance parameters are orthogonal in the linear model, hence, it is not surprising that diagnostics designed to target the mean trend performed poorly when distributional assumptions were violated, and diagnostics designed to target distributional assumptions performed poorly when the mean model was incorrect. In the Poisson model, in contrast, a missing quadratic term introduces overdispersion, which can be detected on a QQ-plot (, right).
As a secondary result, note that the scale on which diagnostic tools are plotted was important—QQ-plots consistently outperformed PP-plots at detecting assumption violations. This was expected since assumption violations occurred in the tails of the distribution, and plotting residuals on the quantile scale puts the emphasis on the tails, whereas a PP-plot transforms residuals to fit in the unit interval.
A global envelope around the smoother on a scale-location plot was the least effective of the proposed methods. As expected, it was useful for identifying distributional assumption violations (, center), but was noticeably less effective than a QQ-plot, or a Shapiro-Wilks test of normality (, center), or a deviance-based test for Poisson data (, center).
4 Discussion
In this article we showed how recent advances in tools for global simulation envelopes can be used to aid in the interpretation of common residual plots. Previously, global simulation envelopes had been proposed for QQ-plots (Rosenkrantz Citation2000; Aldor-Noiman et al. Citation2013), assuming residuals were Gaussian and independently and identically distributed (“iid”). However, one or both of the Gaussian and iid assumptions will not be satisfied for residuals from many types of regression model, an issue which we resolve here by using simulation to explore the expected distribution of residuals and residual functions, by simulating data from the true model and recomputing residuals. Software is provided (the plotenvelope function in the ecostats package) to compute global simulation envelopes for various types of residual plot for a broad class of regression models, and illustrated its effectiveness by simulation for a few common types of regression model.
The intention is that global envelopes be used as a visual tool to help the analyst determine whether any departures from expected trends are large relative to what would be expected if assumptions were true. This could be especially useful as a teaching tool, for students not experienced with interpreting residual plots—in fact, the motivation for this work arose for the author while writing a text for ecologists on data analysis (Warton Citation2022). While not the primary intention, the global envelope approach can also be interpreted as a formal test of assumptions, which was helpful as a way to study the effectiveness of the tool. It was interesting to see in simulations that the proposed methods tended to compare favorably to common goodness-of-fit tests, suggesting that using global envelopes on residual plots is relatively effective as a way to detect violations of assumptions.
Simulations reinforce the idea that different diagnostic plots detect different types of assumption violations, by design, and as such it is a good idea to use multiple diagnostic plots when interrogating multiple assumptions. Beyond the plots discussed here, one could also look at response to predictors, as advocated for by Cook and Weisberg (Citation1997). The plotenvelope function could be used to produce plots against a predictor of particular interest by setting predFunction to be a function that returned the predictor in question.
The performance of the global envelope tests depend heavily on the type of residual used to construct plots, the scale on which residuals are plotted, and if envelopes are constructed around smoothers, the method of smoother construction, as discussed in more detail below.
The way residuals are constructed is clearly an important consideration when constructing any residual plot. In preliminary investigations, we found for example that when fitting a generalized linear mixed model, residual plots had difficulty detecting violations of distributional assumptions (, center) when using unscaled residuals () rather than deviance residuals. A potentially useful alternative way to construct residuals for non-Gaussian models is randomized quantile residuals (Dunn and Smyth Citation1996), which introduce jittering to discrete data to ensure that residuals computed from the true model will be marginally standard normal, for any parametric model. Such residuals can be computed on R for generalized linear mixed models using the statmod::qres function, and can be computed by simulation from broader classes of distribution using the DHARMa package (Hartig Citation2022).
The scale on which residuals are plotted can also be important to performance of global envelopes, as evidenced by the differences in performance between QQ-plots and PP-plots (, center and right). While PP-plots are often used as a diagnostic tool (e.g., Hartig Citation2022), they were consistently outperformed by QQ-plots. These plots differ only in their scale, with PP-plots mapping residuals to the unit interval (via ), then comparing to standard uniform rather than to standard normal quantiles. But violations of assumptions typically are expressed in the tails of a distribution, with the occasional very large (in magnitude) residual. When converted to the unit interval, such outliers become values that are unusually close to zero or one, which does not provide a strong visual cue. For example, in , a striking feature is the outlying Pearson residual, with a value of about 15, which had an expected normal quantile closer to 3. On a PP-plot, this would be expressed as a probability that was equal to one up to machine error, as compared to an expected probability of 0.998. Mapping residuals to the unit interval compresses the regions of primary interest to narrow ranges of values, making it difficult to diagnose violations of assumptions. For this reason Dunn and Smyth (Citation1996) advocated mapping quantile residuals to the normal distribution.
Preliminary investigations also suggested that when constructing a global envelope around a smoother, performance of envelope tests was sensitive to the method of smoother construction. When using the default mgcv::gam method, which minimizes a generalized cross-validation (GCV) measure, our smoothers had quite poor performance at detecting assumption violations. The relatively good performance seen in was achieved through use of maximum likelihood estimation to fit smoothers (method=“ml”), which is noticeably more computationally intensive, but known to perform better at estimating smooth functions, largely eliminating the chance of “severe undersmoothing failures” seen in GCV techniques (Wood Citation2011).
Finally, it is worth reminding the practitioner that significant violations of assumptions are not necessarily of practical importance. Linear models for example are known to be quite robust to violations of normality due to the Central Limit Theorem, especially at large sample sizes (see, e.g., Lumley et al. Citation2002). Large sample sizes however lead to narrower simulation envelopes and a greater chance of detecting assumption violations, in the very situation where they are less important. It should always be kept in mind by the practitioner that global envelopes are graphical tools that show how large deviations are relative to those that might be expected due to sampling error, but they do not indicate if deviations are large enough to be of practical importance. Effect size is best measured by looking at the magnitude of deviations from expected behavior (Kim and Cribbie Citation2018, for example), rather than just looking at whether these deviations stray outside a global envelope.
Acknowledgments
Thanks to anonymous reviewers for suggestions that improved this article.
Disclosure Statement
The author reports there are no competing interests to declare.
Additional information
Funding
References
- Aldor-Noiman, S., Brown, L. D., Buja, A., Rolke, W., and Stine, R. A. (2013), “The Power to See: A New Graphical Test of Normality,” The American Statistician, 67, 249–260. DOI: 10.1080/00031305.2013.847865.
- Bates, D., Mächler, M., Bolker, B. M., and Walker, S. C. (2015a), “Fitting Linear Mixed-Effects Models Using lme4,” Journal of Statistical Software, 67, 1–48. DOI: 10.18637/jss.v067.i01.
- Brooks, M. E., Kristensen, K., van Benthem, K. J., Magnusson, A., Berg, C. W., Nielsen, A., Skaug, H. J., Mächler, M., and Bolker, B. M. (2017), “glmmTMB Balances Speed and Flexibility among Packages for Zero-Inflated Generalized Linear Mixed Modeling,” R Journal, 9, 378–400. DOI: 10.32614/RJ-2017-066.
- Cook, R. D., and Weisberg, S. (1997), “Graphics for Assessing the Adequacy of Regression Models,” Journal of the American Statistical Association, 92, 490–499. DOI: 10.1080/01621459.1997.10474002.
- Davison, A. C., and Hinkley, D. V. (1997), Bootstrap Methods and their Application (Vol. 1), Cambridge: Cambridge University Press.
- Dunn, P. K., and Smyth, G. K. (1996), “Randomized Quantile Residuals,” Journal of Computational and Graphical Statistics, 5, 236–244.
- García, M., Víctor, B., Yohai, J., Ben, M. G., and Yohai, V. J. (2012), “Quantile–Quantile Plot for Deviance Residuals in the Generalized Linear Model,” Journal of Computational and Graphical Statistics, 13, 36–47.
- Hartig, F. (2022), DHARMa: Residual Diagnostics for Hierarchical (Multi-Level/Mixed) Regression Models . R package version 0.4.5. Available at https://CRAN.R-project.org/package=DHARMa
- Kim, Y. J., and Cribbie, R. A. (2018), “ANOVA and the Variance Homogeneity Assumption: Exploring a Better Gatekeeper,” British Journal of Mathematical and Statistical Psychology, 71, 1–12. DOI: 10.1111/bmsp.12103.
- Kristensen, K., Nielsen, A., Berg, C. W., Skaug, H., and Bell, B. M. (2016), “TMB: Automatic Differentiation and Laplace Approximation,” Journal of Statistical Software, 70, 1–21. DOI: 10.18637/jss.v070.i05.
- Lumley, T., Diehr, P., Emerson, S., and Chen, L. (2002), “The Importance of the Normality Assumption in Large Public Health Data Sets,” Annual Review of Public Health, 23, 151–169. DOI: 10.1146/annurev.publhealth.23.100901.140546.
- Moral, R. A., Hinde, J., and Demétrio, C. G. (2017), “Half-normal Plots and Overdispersed Models in R: The hnp Package,” Journal of Statistical Software, 81, 1–23. DOI: 10.18637/jss.v081.i10.
- Myllymäki, M., Mrkvička, T., Grabarnik, P., Seijo, H., and Hahn, U. (2017), “Global Envelope Tests for Spatial Processes,” Journal of the Royal Statistical Society, Series B, 79, 381–404. DOI: 10.1111/rssb.12172.
- Price, S. J., Muncy, B. L., Bonner, S. J., Drayer, A. N., and Barton, C. D. (2016), “Effects of Mountaintop Removal Mining and Valley Filling on the Occupancy and Abundance of Stream Salamanders,” Journal of Applied Ecology, 53, 459–468. DOI: 10.1111/1365-2664.12585.
- R Core Team. (2022), R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. Available at https://www.R-project.org/
- Ripley, B. D. (1976), “The Second-Order Analysis of Stationary Point Processes,” Journal of Applied Probability, 13, 255–266. DOI: 10.2307/3212829.
- Rosenkrantz, W. A. (2000), “Confidence Bands for Quantile Functions: A Parametric and Graphic Alternative for Testing Goodness of Fit,” The American Statistician, 54, 185–190.
- UNSW Sydney (2022), Katana . PVC (Research Infrastructure), UNSW Sydney. DOI: 10.26190/669x-a286.
- Wang, Y., Naumann, U., Wright, S. T., and Warton, D. I. (2012), “mvabund – an R Package for Model-based Analysis of Multivariate Abundance Data,” Methods in Ecology and Evolution, 3, 471–474. DOI: 10.1111/j.2041-210X.2012.00190.x.
- Warton, D. I. (2022), Eco-Stats: Data Analysis in Ecology, from t-tests to Multivariate Abundances, Cham: Springer.
- Wood, S. N. (2003), “Thin Plate Regression Splines,” Journal of the Royal Statistical Society, Series B, 65, 95–114. DOI: 10.1111/1467-9868.00374.
- Wood, S. N. (2011), “Fast Stable Restricted Maximum Likelihood and Marginal Likelihood Estimation of Semiparametric Generalized Linear Models,” Journal of the Royal Statistical Society, Series B, 73, 3–36.