
Abstract
The semantic web and linked data technologies show great promise for organising and integrating information on the Web. As custodians of bibliographic information, libraries are ideally placed to play a leading role by providing authoritative information in this domain. The semantic web and linked data have been hyped as the solution for everything from integrating legacy data-sets and improving search through to working with big data problems. However, the vision of the semantic web is a long way from being realised. This paper explores how linked data is being used in libraries and related institutions in Australia and globally. Examples are given of linked data in practice and what makes some projects more successful than others.
Keywords::
Implications for best practice
Exposing linked data for collections can enhance search results and make resources easier to find.
Linked data can be incorporated into online content relatively easily using well-known vocabularies.
Linked data projects work best within a defined community of users.
Many linked data tools are difficult to use and are not ready for widespread adoption, but this is changing.
Linked data show great promise and will be an integral part of the information landscape in the years to come.
Introduction
Semantic web technologies have been discussed and promoted for 15 years or more (Berners-Lee and Fischetti Citation1999; Berners-Lee Citation2009a; Gartner Citation2013). However, there has, as yet, been relatively little uptake, particularly in the commercial sector. This article examines how linked data is being used in libraries, government and the commercial sector and discusses the future of linked data and the part that libraries can play.
The concepts of linked data and the semantic web have emerged as a logical extension of the World Wide Web, and comprise a set of best practices for publishing and connecting structured data on the Web (Berners-Lee Citation2009b). Most content on the Web today is linked only in the most basic way, through the use of hyperlinks between pages. Even though this simple linking has been exploited to great effect by search engines to rank content based on relevance, there are significant shortcomings when it comes to identifying what a string of characters on the Web actually means. Techniques such as statistical analysis and natural language processing have been used in attempts to identify entities in web content. However, these techniques are complex, time-consuming and prone to false positives and negatives (Van Hooland et al. Citation2013).
Ideally, content on the Web would be marked up with tags or statements that identify unambiguously what a particular string of characters means and what the content is about. This idea has become known as moving from ‘strings to things’. Linked data essentially involves creating identifiers for things or resources on the Web and then linking these resources together, using statements in a standard format called RDF (Resource Description Framework). RDF itself consists of simple ‘triple statements’ to describe the relationship (predicate) between a subject and an object (Figure ).
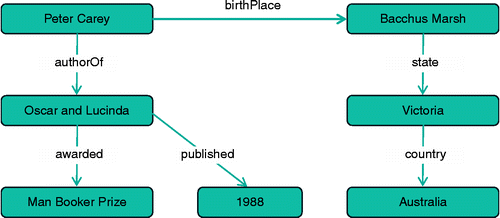
For the example in Figure , the subject Peter Carey is linked to the object Bacchus Marsh by the predicate birthPlace. Simplifying information into triple statements means that computers can parse and build a graph of how the information is linked. This can lead to some powerful techniques, where computers are able to navigate the graph of information and validate or make inferences about the data by analysing and comparing the data to predefined terms or ontologies. New linkages and information can be discovered in ways that were not possible before the data were linked. In our simplified example, a computer can follow the links between resources to work out that the 1988 Man Booker Prize was awarded to an Australian author. Adding more triple statements would allow us to link more information together. For example, if we added in birthDate, we could start to look at the age profile of authors in particular regions. Importantly, there is no requirement on the data being structured in a particular way. Using linked data allows users and agents to query and navigate their way through the data in any way that makes sense to them.
Linked data: current usage
Despite linked data and the semantic web having garnered much publicity and discussion, there are still relatively few concrete examples that demonstrate how implementing linked data can benefit an institution. In some respects, there is a chicken-and-egg problem with linked data. One of the main promises of linked data is the increased value that the links between entities can provide; however, if there are few other data-sets with which the data can link, then this benefit is not realised. Other barriers to adopting linked data include technological complexity, risk aversion, economic constraints, politics or system constraints (Martin Citation2012). Even so, the projects that have implemented linked data give a glimpse into what might be possible when a critical mass of data is reached.
Search
One significant driver of semantic technology is search. Three of the major search engines (Bing, Google and Yahoo!) joined forces to create schema.org to provide a standard that web content creators could use to mark up their pages with semantic data. Marking up data at the time of creation means that the creator has control over how the data are described. The benefit for the search engine is that it reduces or eliminates the need to analyse and extract entities from web content. This increases the relevance of the search results and can allow faceting on meaningful attributes.
Google's Knowledge Graph was added to the Google search engine in 2012. This system uses a graph of linked data to understand the links between objects in order to present the information alongside search results. It contains information from the CIA World Factbook, Freebase and Wikipedia (Singhal Citation2012).
Social media
Facebook makes use of semantic technologies to track relationships between people and web content using the Open Graph protocol (“The Open Graph Protocol” Citation2012). Adding Open Graph tags to the metadata of a web page allows Facebook to display an image and a description for that web page within the Facebook site. This single feature has led to wide adoption of these tags. In addition to Facebook, Google makes use of Open Graph data in their search technologies.
Media
The BBC implemented another successful linked data project to deliver information around sport and news (Bartlett Citation2013). It has since been expanded to cover education and music and includes ontologies for creative works, curricula, food, politics, programmes, sport and wildlife (“BBC – Ontologies – Home’ Citation2014). Inspired by the work of the BBC, Yahoo7 have begun to adopt semantic technology to display local program information (Wolf Citation2014).
Life sciences
Some of the best examples of successful linked data implementations are in the life sciences and medical fields. Genomics, proteomics and related fields benefit hugely by being able to link data between genes, proteins, medical trials and other data to discover new information from existing bodies of work (see the Open Biological and Biomedical Ontologies website for examples and best practice documents: http://obofoundry.org).
In the last few years, a portal to Australia's biodiversity, the Atlas of Living Australia (http://ala.org.au) has been built. At the heart of this site is a service that combines data about the names and descriptions, images and literature of all life forms in Australia. By creating permanent identifiers for species names and concepts, data about the same species held in different institutions can be combined without having to resort to error-prone string matching. Also, name changes of organisms (common in disciplines such as botany and zoology) can be tracked unambiguously to allow users to find relevant matches. For example, a search on an older plant name Eucalyptus citriodora can still find results, because behind the scenes there will be triple statements pointing from the older name Eucalyptus citriodora to the accepted name Corymbia citriodora.
Governments and parliaments
In the last few years, there has been a strong push for governments to publicly release data-sets under their control. Under the banner of Open Government many country, state and local government bodies have embraced this initiative. The site datacatalogs.org (http://datacatalogs.org) currently lists 385 data catalogues mainly from government organisations. Although there are more data-sets than ever being published, the quality, timeliness and format vary greatly. Linked data provides an opportunity to harmonise these data and to create linkages between the disparate data-sets. The US data.gov site is experimenting with converting data on its site to RDF, and now has over 6.4 billion triples of open government data available (“Semantic Developer | Data.gov Citation2013). In parallel, there have been a growing number of grass-roots organisations working towards making governments more accountable and open. My Society in the United Kingdom (http://www.mysociety.org), the Sunlight Foundation in the US (http://sunlightfoundation.com) and the Open Australia Foundation in Australia (http://www.openaustraliafoundation.org.au) have been building systems and tools to make releasing and working with government data easier. The Australian Parliament has opened its archive of Hansard (the proceedings of parliamentary debates) and provides these data in a standard format through their ParlInfo service (http://parlinfo.aph.gov.au). Importantly, they allow their data to be reused by others, including the Open Australia Foundation who have incorporated it into their OpenAustralia site.
Libraries
National libraries have been early adopters of linked data. The Swedish Union Catalogue began providing linked data in 2008 (Malmsten Citation2008) and the German National Library started publishing data in 2010 (“The European Library” Citation2014). A project is now underway to link German linked data with the British National Bibliography, which has been published as linked data since 2011.
One of the motivations for libraries to explore linked data has been the development of the Resource Description and Access (RDA) cataloguing rules and the underlying conceptual model, the Functional Requirements for Bibliographic Records (FRBR). Testing of RDA in the last few years has shown that the flat file MARC21 standard does not accommodate the use of relationships between bibliographic entities that both FRBR and RDA internalise (Coyle Citation2012). The Bibliographic Framework Initiative (BIBFRAME, http://www.loc.gov/bibframe) is working to provide tools and standards to help the library community transition to linked data. An immediate goal is to facilitate a transition from the MARC21 exchange format to a more Web-based linked data standard. One of the most challenging aspects of this is dealing with the huge amount of legacy data held in library catalogues, and the transition to future data formats.
In parallel with the BIBFRAME initiative, OCLC and the W3C Schema Bib Extend Community Group have been working towards extending schema.org to better describe library resources for the purpose of search and discovery. This is a work in progress and is complementary to BIBFRAME. OCLC ‘envision[s] a model for describing library resources in which key concepts required for discovery are expressed in schema.org, while the details required for curation and management are expressed in BIBFRAME and associated standards defined in the library community’ (Godby and OCLC Research Citation2013).
Archives, universities and research data
Like libraries, the archive, university and research communities have a long history of curating data about people, places, organisations, observations, and archival and published resources. They also have a long history of providing tools and systems for its description and discovery. The Australian Science Archives Project developed a tool called the Online Heritage Resource Manager (OHRM) that is an early example of linking data on the Web (McCarthy and Evans Citation2008). Within the tool, links can be created from one entity to another, building up a graph of relationships. This graph is then transformed into HTML for display on the Web. Significantly, every entity has a unique identifier and these are used to build permanent URLs. Early examples such as Bright Sparcs (now part of the Encyclopaedia of Australian Science; The University of Melbourne eScholarship Research Centre Citation2014) have been continuously available for 20 years.
The OHRM system has been used successfully as the underlying technology for other systems including the Australian Dictionary of Biography Online, which is now harvested into Trove at the National Library of Australia using standard exchange protocols and truly persistent URLs. As an aggregator of collections and authorities, Trove itself provides unique identifiers for people and organisations, which will no doubt be the cornerstone of future national linked data initiatives.
Another system that makes use of disparate data-sets is HuNI (the Humanities Networked Infrastructure). HuNI is a Virtual Laboratory that aims to link 28 Australian humanities data-sets using semantic technologies (Verhoeven, Burrows, and Hawker Citation2013). These data-sets have been combined into a single store of semantic information that allows researchers to discover, analyse and share data across disciplines.
In Australia, the Australian National Data Service (ANDS) has been supporting universities and other research institutions by creating resources for managing research data (Visser and Love Citation2014). ANDS has published guides, policies and standards on research data and built software, registries and services to support the research community. Crucially, ANDS provides services for minting unique identifiers which, as we have seen, underpin the entire concept of linked data.
Victorian Parliamentary Library & Information Service
At the Victorian Parliamentary Library & Information Service, linked data is being piloted as a way of combining data about people, organisations, media and documents (Neish Citation2014). The library wanted to create a system where users could query across databases to discover information that would not be possible in a traditional relational database or federated search. For example, one database records biographical details for each Member of Parliament (MP), while another keeps track of newspaper articles. Although it is easy to retrieve a list of newspaper articles mentioning a particular MP, it is quite difficult to return all articles mentioning members of a particular party. The only way to do this at present is to query the members database to discover all the MPs for a particular party and then query the Newspaper database for this set of members. By storing this information as linked data, there is the potential to assign properties and classes to MPs that can be used for querying. It would then be straightforward to search for all newspaper articles mentioning a particular party. More sophisticated queries would also be possible, for example, ‘find me all newspaper articles about MP entitlements that mention MPs who have served in the parliament for more than 10 years.’
The Victorian Parliamentary Library has also used semantic technologies to automatically tag media releases that are harvested from political websites (Neish Citation2012). An online service, OpenCalais (http://opencalais.com), discovers the names of people, places, organisations and topics embedded in the text of media releases. These metadata are stored in a database as an aid to search and discovery. The library has now brought the entity extraction in house using a commercial product called Semaphore by Smartlogic (http://smartlogic.com). The system classifies, filters and assigns a relevance ranking to thousands of newspaper articles each day.
Publishing linked data
Linked data can be published in many ways. One of the simplest is to include it as metadata tags in web content using an ontology such as schema.org or the Open Graph protocol. Another relatively simple way to implement linked data is to provide a data dump in RDF on a regular basis. This allows others to reuse the data, but the data are static and end users would need to update their local copy if the data change. At the more complex end of the spectrum is providing linked data through an API or standard query interface such as SPARQL. This can be achieved by using middleware to map concepts in a relational database to linked data output or by storing data in a dedicated database known as a triple store.
The vocabulary or ontology used to mark up data will have an impact on how well the data can be reused. Standard ontologies that have wide adoption, such as schema.org and the Open Graph protocol, are a good place to start. However, depending on the specialised nature of your data, other ontologies might be more appropriate. The Victorian Parliamentary Library chose to use the Popolo Ontology, which has been developed to model parliamentary information (“The Popolo Project” Citation2014). The Popolo ontology is a standard naming scheme for the basic pieces of the legislative branch of government: people, memberships, organisations and posts. The ontology is undergoing rapid change and, more recently, the project has started to model motions, votes and counts. Being open and community driven, the Parliamentary Library was able to provide feedback to the Popolo community on how well the ontology represented parliamentary information in the Victorian context and suggest a number of improvements.
Discussion
With the exception of the life sciences and biomedical communities, the main successful examples of linked data have been single-institution initiatives (e.g. BBC and Google Knowledge Graph) rather than Web-wide data integration projects. Bergman (Citation2014) suggests that this is because data integration is the hardest part of implementing linked data and is easier to solve within a single organisation. He also suggests that software tools needed for this integration are either non-existent or have not yet developed to the standard and ease of use required for widespread adoption.
The degree of data integration varies between projects, with data often linked only to other data elements within the same data-set using a bespoke embedded ontology. While this is often the best choice for a closed system that needs to stay flexible and support new requirements, it limits integration with other systems (Rogers Citation2013).
Libraries are turning to linked data to solve many different problems. Making catalogue records more discoverable is a primary goal of using linked data. This can be readily achieved through the established technique of adding mark-up to library catalogue records exposed on the Web using schema.org and the proposed extensions to this ontology. Other use cases for linked data have been compiled by the W3C Library Linked Data Incubator Group (Library Linked Data Incubator Group: Use CasesCitation2011) that cover bibliographic, authority, vocabulary, collection, archive, citation and social examples. It is important to remember how varied the use cases are – linked data can provide much more than simply replacing the MARC21 standard.
Connecting and semantically linking content on the Web are where libraries are particularly well placed to contribute to the linked data ecosystem. However, like other content on the web, there is nothing to stop anyone from publishing linked data and making assertions on how things are linked. This means that the reputation of the person or institution making the statement becomes paramount. As more and more resources become linked on the web, there will be a greater need to establish who is asserting the link and on what basis.
Another area of linked data where libraries can provide value is in providing unique identifiers for resources (both real-world and digital). Linked data uses Uniform Resource Identifiers (URIs) to identify resources on the web. Anyone can ‘mint’ a new linked data identifier for a resource, but it makes sense for institutions to issue identifiers for things under their control. Already there are multiple linked data identifiers for the same thing and while there are mechanisms for dealing with this, it is preferable that everyone use the same identifier. By being early adopters of the technology, libraries can establish a degree of ownership by managing the identifiers of their own resources.
Conclusion
The semantic web and linked data initiatives we see today are not the same as the vision originally proposed by Tim Berners-Lee. Rather than an interconnected web of data, we are seeing linked data being used in specific applications and domains where the benefits are realised by a single organisation or community. Although this could be seen as a failure of linked data to live up to the promise of the semantic web, it could also be a necessary transition phase for the technology. The discrete, stepwise adoption of linked data allows the technology to be proved, it avoids the chicken-and-egg problem by building up data incrementally and it allows tools to mature to a level that they can support linked data and the larger semantic web. According to Gartner (Citation2013), after languishing for almost 20 years, the semantic web is seeing a rebirth based on its applicability to big-data problems. Libraries and related institutions can play a part in this rebirth by expanding the use of linked data to the wider semantic web, bringing Tim Berners-Lee's vision a step closer to reality.
Acknowledgements
This work is based on a paper presented at VALA 2014. I thank Julie Gardner for her encouragement and comments on a previous draft of this paper.
Additional information
Notes on contributors
Peter Neish
Peter Neish has worked at the Parliament of Victoria since 2008 in both the library and the IT department. He works to make databases and parliamentary information more available, standards-based and useful. Before Parliament, he worked at the Royal Botanic Gardens Melbourne integrating botanical information and biodiversity data systems, and he has contributed to national and international data transfer standards
Notes
1. This paper has been double-blind peer reviewed to meet the Department of Education's Higher Education Research Data Collection (HERDC) requirements.
References
- BartlettOliver. 2013. “BBC – Blogs – Internet Blog – Linked Data: Connecting Together the BBC's Online Content.” http://www.bbc.co.uk/blogs/internet/posts/Linked-Data-Connecting-together-the-BBCs-Online-Content.
- “BBC – Ontologies – Home”. 2014. BBC – Ontologies. http://www.bbc.co.uk/ontologies.
- BergmanMike. 2014. “A Decade in the Trenches of the Semantic Web.” http://www.mkbergman.com/1771/a-decade-in-the-trenches-of-the-semantic-web/.
- Berners-LeeTim. 2009a. “Linked Data – Design Issues.” http://www.w3.org/DesignIssues/LinkedData.html.
- Berners-LeeTim. 2009b. “Linked Data – The Story So Far.” International Journal on Semantic Web and Information Systems5 (3): 1–22. doi:10.4018/jswis.2009081901.
- Berners-LeeTim, and MarkFischetti. 1999. Weaving the Web: The Original Design and Ultimate Destiny of the World Wide Web by Its Inventor. San Francisco: Harper.
- CoyleKaren. 2012. “Chapter 1: Introduction.” Library Technology Reports48 (4): 6–9.
- “The European Library”. 2014. http://www.theeuropeanlibrary.org/tel4/newsitem/5802.
- Gartner. 2013. “Hype Cycle for Web Computing.” https://www.gartner.com/doc/2568621/hype-cycle-web-computing-.
- GodbyCarolJean, and OCLC Research. 2013. The Relationship Between BIBFRAME and the Schema.org “Bib Extensions” Model a Working Paper. Dublin, Ohio: OCLC Research. http://www.oclc.org/content/dam/research/publications/library/2013/2013-05.pdf.
- Library Linked Data Incubator Group: Use Cases. 2011. http://www.w3.org/2005/Incubator/lld/XGR-lld-usecase-20111025/.
- MalmstenMartin. 2008. Making a Library Catalogue Part of the Semantic Web. International Conference on Dublin Core and Metadata Applications, 146–152. DC 2008, Berlin, Germany. Göttingen: Universitätsverlag Göttingen.
- MartinChris. 2012. “A Socio-Technical Systems Analysis of the Potential Barriers to Adoption of Open Data Approaches by UK Public Bodies.” In Web Science 2012. Evanston, IL. https://www.academia.edu/4640006/A_Socio-Technical_Systems_Analysis_of_the_Potential_Barriers_to_Adoption_of_Open_Data_Approaches_by_UK_Public_Bodies.
- McCarthyGavan, and JoanneEvans. 2008. “Mapping the Socio-Technical Complexity of Australian Science: From Archival Authorities to Networks of Contextual Information.” Journal of Archival Organization5 (1–2): 149–175. doi:10.1300/J201v05n01_08.
- NeishPeter. 2012. “Harvesting and Semantically Tagging Media Releases from Political Websites Using Web Services.” http://www.vala.org.au/vala2012-proceedings/vala2012-session-12-neish.
- NeishPeter. 2014. “Linked Data: Thinking Big, Starting Small.” http://www.vala.org.au/vala2014-proceedings/813-vala2014-session-10-neish.
- “The Open Graph Protocol.” http://ogp.me/2012.
- “The Popolo Project.” 2014. The Popolo Project. http://popoloproject.com/.
- RogersDavid. 2013. “Ontologies in Software: A Conflict of Interest? Dave's Blog.” http://daverog.wordpress.com/2013/05/30/ontologies-in-software-a-conflict-of-interest/.
- “Semantic Developer | Data.gov.” 2013. http://www.data.gov/developers/page/semantic-web.
- SinghalAmit. 2012. “Introducing the Knowledge Graph: Things, Not Strings.” Official Google Blog. http://googleblog.blogspot.com/2012/05/introducing-knowledge-graph-things-not.html.
- The University of Melbourne eScholarship Research Centre. 2014. “Home – Encyclopedia of Australian Science.” Document. http://www.eoas.info/home.html.
- Van HoolandSeth, MaxDeWilde, RubenVerborgh, ThomasSteiner, and RikVande Walle. Named-Entity Recognition: A Gateway Drug for Cultural Heritage Collections to the Linked Data Cloud? 2013. http://freeyourmetadata.org/publications/named-entity-recognition.pdf.
- VerhoevenDeb, TobyBurrows, and AlexHawker. 2013. “Humanities E-Research at a National Scale: The HuNI Virtual Laboratory.” In 7th eResearch Australasia Conference, Brisbane. http://eresearchau.files.wordpress.com/2013/08/eresau2013_submission_95.pdf.
- VisserKaren, and CynthiaLove. 2014. “Research Data: Transforming the next Generation of Academic Libraries and Librarians.” ALIA National 2014 Conference, September 1. http://nationalconference2014.alia.org.au/content/research-data-transforming-next-generation-academic-libraries-and-librarians.
- WolfPenny. 2014. “Yahoo7 Swaps SQL for Graph Database.” iTnews June 18http://www.itnews.com.au/News/388296,yahoo7-swaps-sql-for-graph-database.aspx.