
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Information technology (IT) providers should use cloud-based services due to their flexibility, reliability, and scalability to handle the rising requirement for processing capacity. The maintenance of dependable services between cloud providers and their customers in a cloud environment, on the other hand, depends on Quality of Service (QoS) assurance. Virtual machine (VM) consolidation is nondeterministic polynomial time (NP) hard issue, and numerous heuristic techniques have been suggested to solve it. In this work, the suggested VM consolidation technique takes into account both current and future uniform distribution elephant herding optimization (UDEHO) based VM consolidation approaches for resource utilization via host overload detection (utilization prediction based potential overload detection (UP-POD)) and host underload detection (UP-PUD). A UDEHO method efficiently predicts resource use in the future. Depending on the power utilization and the number of migrations, a power-saving value is advised for identifying under-loaded hosts. Furthermore, the CloudSim toolkit is used to construct and test these techniques using the same experimental parameters. Lastly, the findings demonstrate that the suggested methodologies considerably decrease the number of VM migrations by about 0.073%, the energy usage of about 11%, and SLA violations by 6.15% while retaining QoS guarantees when compared to conventional techniques.
1. Introduction
Due to the major advantages of the cloud for users and providers in the areas of economics, the environment, and technology, adoption and migration of the cloud are on the rise worldwide. Cloud computing has quickly evolved into one of the contemporary economy’s backbones since its inception. Government agencies, academic institutions, and commercial enterprises are all cloud users who have adopted it and reaped its benefits to a significant extent. Cloud computing also allows for the rapid establishment of new companies, the worldwide expansion of enterprises, speeding up scientific investigation, and creating of new applications and models. For customers that desire pay-as-you-go on-demand access to services, cloud providers can provide a variety of cloud services [Citation1,Citation2]. Numerous companies that offer public cloud services, like Amazon, Yahoo, and Microsoft, construct enormous cloud data centres worldwide the globe to provide cloud computing services to their clients [Citation3].
Cloud data centres should preferably assign resources to users in a manner that matches the requisite Quality of Service (QoS) as defined by cloud customers via service level agreement (SLA). An SLA in cloud computing is described as a two-sided contract between a cloud provider and its customers that specifies the content of services offered, the degree of performance, fees, and penalties for failure to supply the services. Any breach of the QoS results in an SLA violation, and as a result, service providers must pay a penalty [Citation4]. As a result, using less energy is the main objective of this investigation in cloud data centres while maintaining QoS standards. Cloud infrastructures have grown increasingly difficult and complex as a result of the fast rise of cloud services and their accompanying technologies. As a result, amongst the highly significant difficulties in current cloud systems is resource management, which has a direct impact on the successful deployment of cloud services. Hence, guaranteeing that the fewest amount of physical machines (PMs) reduce energy expenses in cloud data centres effectively by being operational.
Consolidation of VMs is one amongst the most effective techniques in cloud computing’s energy-efficient resource management; this strategy improves resource usage while decreasing energy usage. Consolidation is the live movement of VMs across hosts with minimal performance disruption. Consolidation aims to reduce the number of hosts hosting virtual machines (VMs) while setting idle hosts to power-saving modes [Citation5].
Static and dynamic VM consolidation is the two main kinds. When a job comes, the dimensions and location of VMs on PMs are predetermined, and the positioning does not alter over time. Therefore, since PMs resources for various types of VMs are established, this type of VM consolidation is typically acceptable for short-running tasks lasting a few hours [Citation6]. The majority of energy savings are based on basic heuristics on past VMs demand trends. Despite the possibility of an increase in the application provider’s costs in times of both high and low demand, the resources available may be inadequate [Citation7]. By moving VMs across PMs or live migrating them, dynamic VM consolidation can result in the utilization of fewer PMs without significantly disrupting services. It considers performance since it is dependent on QoS, which is set by SLA among the tenant and the service provider. It improves data centre power effectiveness by shutting off underutilized servers to conserve energy [Citation8]. Dynamic provisioning-based energy usage may be a highly effective way for improving resource use and lowering energy usage.
By moving VMs across PMs or live migrating them without significantly disrupting services, dynamic VM consolidation can result in the utilization of fewer PMs. It considers performance since it is dependent on QoS that is established by an SLA among the tenant and the service provider. This will improve data centre power effectiveness by shutting off underutilized servers to conserve energy. Energy utilization based on dynamic provisioning may be the most efficient method for improving resource use and lowering energy usage. A great way to reduce resource and energy consumption is through dynamic VM consolidation [Citation9]. Many VMs are hosted on the same physical server using hardware virtualization technology, and each VM can run single or several applications. Furthermore, individual tasks may be divided among fewer servers, thanks to hardware virtualization, increasing resource efficiency. VMs may be condensed and packed on fewer PMs employing live VM migration methods, lowering energy usage. VM consolidation is often divided into four parts [Citation10]: selecting VMs, locating under-loaded hosts, finding overloaded hosts, and placing VMs. The difficulty of VM consolidation is mostly addressed in the first and second stages of the work. More specifically, anytime a host is found to be overloaded, a few of the VMs on that server must be carefully picked for migration to other acceptable hosts. Switching a host’s power state from idle to low-power and vice-versa wastes extra energy. As a result, switching hosts’ states is crucial to save power, but limiting their frequency is more critical.
The technique is employed in this research to forecast short-term future resource use formed on past data from sample hosts. This article suggests a VM consolidation method that considers present and future uniform distribution elephant herding optimization (UDEHO) based VM consolidation method for resource usage via host UP-PUD. As a result, cloud providers can improve energy effectiveness and the SLA performance assurance. The suggested technique decreases energy usage while limiting the number of migrations through various simulations based on real-world workloads. As a result, it improves cloud data centre performance with an increased SLA performance guarantee.
2. Literature review
Takouna et al. [Citation11] presented a robust consolidation strategy to attain energy-performance equilibrium. The suggested method is made up of three techniques: overutilized host identification, VM location, and choice. Additionally, wasteful VM migration is minimized by using an adaptive historical window selection technique. The CloudSim simulator was used to create the concept, and simulations of a genuine Planet Lab workload trace were conducted for several days to assess it. Moreover, it can reduce network energy usage as a consequence of VM relocation.
Farahnakian et al. [Citation12] provided a framework for predicting computer processing unit (CPU) consumption relying on the linear regression (LR) approach. Depending on the history of usage in every host, the suggested technique approximates the short-term future CPU consumption. During the live migration procedure, it is employed to foresee overloaded and underloaded hosts. The host then enters sleep mode to decrease power utilization. The suggested approach can dramatically reduce energy utilization and SLA violation rates, based on test results from over a thousand Planet Lab VMs with actual workload traces. CPU consumption forecast may simply lead to unnecessary migrations, increasing the overhead like VM migration energy costs, performance deterioration due to migration, and additional traffic.
Mastroianni et al. [Citation13] eco Cloud, a self-organizing and flexible solution for VM consolidation on two resources: CPU and Random Access Memory, was created. The method is very simple to implement since decisions about VM allocation and migration are made using probabilistic algorithms using just local data. A fluid-like mathematical model and tests on a real data centre show that the method quickly combines workloads and balances VMs that are CPU- and RAM-bound, enabling efficient use of both resources. For cloud data centres with fluctuating workloads, resource usages are ineffective measurement methodologies.
Hieu et al. [Citation14] presented VMCUP-M to increase cloud data centre energy efficiency. Multiple usages in this respect apply to both resource kinds and the time range used to forecast future consumption. The suggested technique is run during the VM consolidation procedure to base on particular server history, forecast the long-term usage of various resource kinds. Findings indicate that a union with numerous use predictions lowers migrations number and server power usage while meeting SLA. Even though the criteria under consideration are not static, these techniques make VM migration choices based only on current resource use.
Ismaeel et al. [Citation15] conducted a thorough review with a focus on energy conservation, the most modern proactive dynamic provisioning architecture in a data centre. Cloud data centres (CDCs) with diverse settings are the focus of proactive dynamic VM consolidations. A general structure is described, along with numerous steps that result in a comprehensive consolidation process. It is critical to ensure that the level of QoS is preserved in accordance with the SLA while attempting to fully use data centre resources.
Sayadnavard et al. [Citation16] proposed a methodology for predicting future resource use using discrete-time Markov chain (DTMC). Through the DTMC framework in conjunction with the PM reliability model results in more accurate PM categorization depending on their state. Then, using the multi-objective VM placement methodology, which is based on the dominance-based multi-objective artificial bee colony technique, the ideal VMs to PMs mapping is obtained. This mapping can efficiently balance resource waste, energy consumption, and system reliability to meet SLA and QoS requirements. A performance evaluation study using the Clouds tool shows the recommended strategy’s effectiveness.
Liu et al. [Citation17] suggested by maintaining VMs that are prone to migration thrashing on the same physical servers rather than relocating them, the dynamic consolidation with minimization of migration thrashing (DCMMT) framework prioritizes VMs with high capacity while drastically reducing the number of migrations necessary to provide SLA. The suggested technique spreads present VM consolidation techniques by requiring that high-capacity VMs not be transferred.
The recommended technique reduces the number of servers used and, to the maximum degree possible, gets rid of migration thrashing. The findings of these studies were encouraging, as data centres may readily benefit from the DCMMT process because it requires little adjustments to be added to an existing resource management system.
Hsieh et al. [Citation18] suggested a VM consolidation method which considers present UP-POD and UP-PUD. A Gray–Markov (GM)-based model correctly predicts resource consumption in the future. The new methodologies were applied to real-world workload traces in clouds and contrasted against current benchmark techniques in the test. Jheng et al. [Citation19] offered the first string in the study field, a workload prediction approach employing the GM forecasting model to distribute VMs.
To begin, the time-dependent workload is employed at the same time every day to anticipate the VM workload inclination to increase or decrease. Then, contrast the expected value to the prior time period on workload consumption, and then decide which VM should be migrated to PM for a balanced workload and reduced power usage. The findings of the simulation indicate that the suggested strategy not only employs fewer data points to effectively forecast workload but also distributes VM resources in a power-efficient manner.
Table shows the comparison of the existing approaches with merits and demerits. Hence by analysing the existing approaches of cloud computing solutions that may not solely minimize operational prices but conjointly cut back the environmental impact. By setting up many virtual machine (VM) instances on a real server using virtualization, cloud providers may address the energy inefficiency, maximizing resource usage and ROI (ROI). Switching off idle nodes will result in a reduction in energy usage since they no longer use any power when idle. Additionally, live migration enables the VMs to be dynamically condensed on the fewest possible physical nodes in accordance with their current resource needs. However, modern service applications frequently encounter very unpredictable workloads that result in dynamic resource use patterns, making efficient resource management in clouds challenging. Therefore, if VMs are aggressively consolidated, applications will perform worse as demand rises, resulting in higher resource utilization. The energy-performance trade-off is another issue that cloud service companies must handle. This research focuses on resource management techniques that may be used by a provider in a virtualization CDC and that are both energy and performance efficient.
Table 1: Comparison of the existing approaches.
3. Proposed methodology
Here, an effective usage prediction technique based on the UDEHO model is used to anticipate short-term future CPU consumption based on data collected from the considered hosts. An efficient VM consolidation strategy is shown that maximizes VM placement for the greatest projected benefit reducing the number of state hosts in an active state. The advantage is derived from two major factors: The quantity and frequency of SLA breaches during VM migrations. Furthermore, integrating data on current and near-future CPU consumption provides a reliable system for classifying hosts that are overloaded and underloaded. This problem may be handled by detecting host overload UP-POD and host underload UP-PUD. When overloaded hosts are found and when underloaded hosts are found, whole VMs with a potential increase in CPU consumption are relocated from these hosts to maintain QoS, and entire VMs from these hosts are relocated to save energy usage. As a result, cloud providers may enhance the energy effectiveness and performance guarantee of SLA. The recommended utilization-prediction-aware VM consolidation method for cloud data centres is divided into several pieces in this section. Sections 3.1 and 3.2 go into the specifics of the cloud data centre’s system architecture and give a UDEHO prediction model. Furthermore, and most importantly, Section 3.3 presents the resource usage prediction methods (UP-POD and UP-PUD) and power saving value depending on expected CPU use. Figure depicts the suggested system design.
Figure 1. Suggested system architecture.
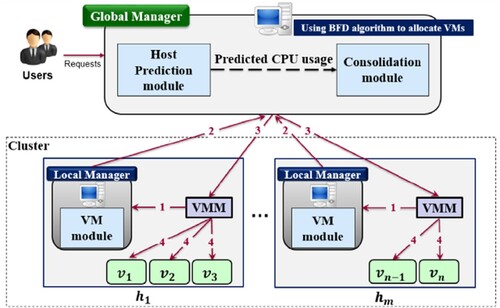
3.1. System architecture
In a cloud data centre, the suggested technique comprises m heterogeneous hosts (that is, ). Various resource types, like CPU, size of memory, network bandwidth, and storage capacity, distinguish every host. Furthermore, CPU performance is typically evaluated in MIPS. A cloud data centre’s services are used by numerous users at the same time. Users request the provisioning of n VMs (that is,
). The best fit decreasing (BFD) approach is used to first allocate VMs to hosts, that is, among most extensively used heuristic techniques for bin-packing problems.
The BFD method eliminates all unutilized space in destination hosts. The system chooses a host whose existing resources are nearby to the quantity of resources sought by VM. This describes why the BFD method executes the first allocation of VMs so well. Nevertheless, because of dynamic workloads with frequent fluctuation, operating hosts’ and virtual machines’ requested usages evolve over time: thus, the initial allocation method is improved with a VM consolidation method which is implemented on a regular basis to enhance cloud data centres’ performance. To reduce energy costs and the number of active state hosts, the recommended solution is implemented every 5 min in a cloud data centre. System architecture is made up of two sorts of agents: (1) a global manager installed on a master node and (2) completely dispersed local managers (LMs) scattered across entire hosts. At every cycle, two agents do the subsequent actions:
Every LM monitors present resource use of entire VMs on a host on a regular basis. Every LM correctly forecasts a host’s future CPU use based on past data in a log file by using the UDEHO prediction algorithm.
For the purpose of understanding the overall position of hosts, the GM solicits status information from LMs.
To implement the UP-POD and UP-PUD techniques of the recommended methodology, GM sends migration commands to the VM monitor. Based on the consolidation methods, the instructions specify that VMs have to be transferred to which destination hosts.
The VMMs migrate VMs after getting instructions from GM.
3.2. UDEHO algorithm
The EHO method [Citation20,Citation21] is a heuristic intelligence approach that relies on elephant migratory tendencies that are utilized for CPU prediction in the VM. The elephant herd possesses the following two features based on observation and research of the elephants. The first distinguishing feature is the presence of several clans in an elephant herd, for the future prediction of CPU in the VM, each group has its own patriarch, and its members adhere to his or her instructions. Another distinguishing feature of the herd is the absence of one adult male elephant. Whenever the elephants grow up, the young elephants will live apart from the elephants in order to anticipate the CPU in the VM in the future. UDEHO’s goal is divided into two parts: clan update and separating. It is defined by Equation (1)
(1)
(1) wherein
and
are according to Elephant J’s previous and current status in clan i;
is a scaling factor; and
is location with the greatest fitness data in clan i. r is a normal-distributed arbitrary value in the range [0, 1]. The updating procedure of most individuals is represented by Equation (1), however, the matriarch in every clan has not been changed for future prediction of CPU in the VM. As a result, the matriarch’s updating process is depicted in Equations (2)–(3)
(2)
(2)
(3)
(3) The uniform distribution function is used to obtain wherein β is the scale factor between [0, 1]. Equation (4) gives a general formula for uniform distribution’s probability density function (PDF)
(4)
(4) Here A is the VM’s forecast range for CPUs and (B− A) the standard uniform distribution is the scaling parameter is the situation wherein A = 0 and B = 1. Centre location in clan iis
, which may be computed using Equation (3). For future CPU prediction in the VM, the elephant number in clan i is
. A connection exists between the knowledge about every member of the clan and the updating of the matriarch position (VM position) in Equation (2). From the second characteristic of the elephant herd, the separation operator may be taken out for use in the VM’s following CPU prediction. Equation (5) describes the separation process
(5)
(5) wherein
is the location in clan i with the lowest fitness value;
and
are upper and lower bounds of elephant’s location, correspondingly; r is an arbitrary integer with a normal distribution between [0, 1]. Individuals in EHO refresh themselves with data from other members of the clan in order to find an improved forecast value of CPU in the VM. As illustrated in Algorithm 1, the separation of people is substituted by the arbitrary production of new individuals, which excludes testing of new individuals for future CPU prediction in the VM. The notion of updating people from the original EHO was kept in the UDEHO method.
Table
Firstly, establish a key point. SepPoint is responsible for determining the probability of executing the separation strategy. Equations (6)–(7) explain how to calculate SepPointand
, correspondingly.
(6)
(6)
(7)
(7) wherein
denotes the number of clans,
the size of
, the index k for CPU prediction in the VM is determined by the current number of generations, and
how many clans there are today. Equation demonstrates (7), the more clans there are, the less likely it is that the separation process will be performed. And, after the number of clans influences SepPoint, the separation procedure is carried out. Next, I added an individual assessment link and set a low probability Pr. When a new person (VM) outperforms the present one in terms of evaluation, the departure is carried out. When a new person is not as excellent as the existing one, but rand < Pr, the separation process is carried out. The separation procedure is not carried out if this condition is not met. R and is a arbitrary value between [0, 1] with a normal distribution.
3.3. Resource utilization prediction algorithm
Resource usage is via host overload detection UP-POD and host underload detection UP-PUD.
3.3.1. Utilization prediction-based on overload detection
Every host, whether overcrowded or not, should be detected in every dynamic VM consolidation operation. Algorithm 2 presents the suggested usage prediction based potential overload detection (UP-POD), which is prompted by the latest work. Algorithm 2 takes as input a collection of active hosts . It is identified which hosts in
are overloaded. Following that, the overloaded hosts are uploaded to Hover as output to carry out the migration choice. The following is a step-by-step explanation of Algorithm 2. Line 1 gives the GM
, that is described as
(host h load at time t) divided by
. In line 2, a time-series-based prediction model may be used to compute the short-term CPU utilisation (i.e.
) by compiling earlier information about a host’s CPU usage that has been recorded in a log file. The UDEHO model is used to forecast
, which is shown in Section 3.1. Moreover, the past data on CPU use recorded at 5-min intervals in every host is used as time series data input. After preprocessing, the choice is determined on line 3 using the dynamic upper threshold approach. Here, a host is deemed overloaded if its usage exceeds the upper threshold. The dynamic upper threshold is determined using the median absolute deviation (MAD) method, and the parameter s is set at 2.5 in accordance with previous work. A measure of statistical dispersion is the MAD. It performs better with distributions devoid of a mean or variance, such as the Cauchy distribution, making it a more reliable estimator of scale than the sample variance or standard deviation. Compared to the standard deviation, the MAD is a robust statistic that can withstand outliers in a data collection. Outliers can have a significant impact on the standard deviation since it is based on squared deviations from the mean, which generally gives greater weight to big deviations. A limited number of outliers’ distances are irrelevant to the MAD’s calculations in terms of their size. In lines 5–9, the time-series model requires enough previous data to anticipate the
correctly. If there is insufficient historical CPU use data on every host, a choice is made using
. Tests using historical data with durations of 12, 16, 20, 24, and 28 were run during the simulation. Depending on the outcomes, the suggested methods outperform historical data with 24 lengths. Therefore, when historical data length
(host h historical data at time t) is smaller than 24, the decision is made by
. If the hosts’
values are more than
, they will be regarded overloaded and added to Hover (upper threshold value of CPU utilization). In contrast, if
is more than 24, the host is deemed overloaded and is added to Hover when current and expected short-term CPU utilization values
>. The scenario indicates that the host is a prospective candidate for carrying out when it is overloaded now and in the near future, the migration option. Algorithm 2 as a result looks at not only current situation and also scenario in the near future. Algorithm 2 can avoid redundant migrations, reducing overall number of migrations and executing an acceptable migration choice; furthermore, the SLA violation rate may be predicted in advance.
Table
3.3.2. Utilization prediction-based underload detection
Following the identification of overloaded hosts, the underload detection method is initiated. To lower the number of active state host and hence decrease energy utilization, finding underused hosts and switching them over to low-power methods are crucial. Algorithm 3 presents the suggested UP-PUD. Algorithm 3 takes as input a collection of active hosts Hactive. Which hosts in Hactive are candidates of under-loaded hosts are identified for each host, and these hosts are then added to Hunder (set of candidates of under-loaded hosts) as output. The following is a step-by-step explanation of Algorithm 3. Algorithm 3’s process and idea are identical to those of Algorithm 2. The difference in lines 5–9, the host is added to Hunder if ≤
(lower threshold value of CPU usage). Furthermore, in 10–13 lines, dah(t) when the host is regarded to be underloaded and added to the list if it is at least 24Hunder if the short-term CPU use that is now and anticipated ≤
.
Table
Once Algorithm 3 selects and adds candidates of under-loaded hosts to Hunder, the suggested Shvalue is used to choose the ultimate under-loaded host from Hunder. According to Fu et al. [Citation22], the host’s power usage is nearly proportionate to its CPU use. As a result, utilizing Equation (8), the power usage of every host may be estimated
(8)
(8) where in the notation
signifies the host’s maximum power consumption value when fully loaded. The notation μrepresents the host’s CPU use, which varies. As a result, under the VM consolidation strategy, the host’s CPU usage is primarily evaluated for employment. The latest research [Citation23] computes a power-efficient value for active state hosts. The value is used to choose an under-utilized host. By enhancing the power-efficient value, a power-saving value (Sh) is given in Equation (9) based on the prediction model. This metric is used to identify under-loaded hosts more accurately. Equation (9) describes it
(9)
(9) In Equation (9), Ph denotes the hth host’s power usage in the cloud data centre,
indicates the hth host’s power usage calculated using
, and Mh denotes VMs number operating on the hth host. Lastly, as the under-loaded host, the host with the highest Sh value can be selected. Clearly, because Sh only considers the host’s current power usage, power utilization at time t + 1, and VM migrations’ number, it will discover an under-loaded host more effectively.
4. Experimental setup
Workload categories, the simulation environment, and performance measures are used in this part to compare the efficiency of the suggested methodology versus current methods.
4.1. Workload data
Simulation employs workloads from the same 10-day period for efficient comparison with current work. The VMs’ CPU usage correlates to their workloads and statistical analyses. Planet Lab data provided as part of the common project is used to conduct the research, which are based on real-world workloads that are publicly accessible: monitoring apparatus from Planet Lab. Workload information was gathered on 10 different days in March and April 2011 and comprises CPU use of a VM recorded at 5-min intervals. Every VM has 288 data on CPU consumption, which are fed into dynamic VM consolidation. Furthermore, information is compiled from over 1000 VMs hosted on servers at over 500 different locations throughout the world. Workload really represents an IaaS cloud environment, such as Amazon EC2, where individual users create and operate virtual machines.
4.2. Details of simulation environment
The study applies the Clouds 3.0.3 toolbox to objectively analyse the performance of the proposed short-term-based VM consolidation technique time series prediction [Citation24,Citation25]. A data centre with 800 disparate PMs was used in the simulation.
The HP ProLiant ML110 G4 servers have 1860 MIPS per core, whereas the HP ProLiant ML110 G5 servers have 2660 MIPS per core, making up half of the PMs in each workload. Every PM is designed to have two cores, four gigabytes of memory, and one gigabit per second of network connectivity. Table shows the CPU (in MIPS) rating and RAM quantity of 4 VM instances utilized in CloudSim that correspond to Amazon EC2.
Table 2: VM Information.
4.3. Performance metrics
The suggested solution has four goals: (1) decrease power consumption, (2) lower SLA violation rates, (3) decrease the number of active state hosts, and (4) decrease migrations number. Consequently, the measures listed below are used to evaluate the effectiveness of the suggested technique and current methodologies.
4.3.1. SLA violations
In order to maintain the QoS promise in an IaaS between cloud service providers and consumers, Equation (10) is used to determine cloud service quality, resulting in a good SLA. Two metrics, SLAVO (SLA violations due to over-utilization) and SLA violations due to migration (SLAVM) are used to quantify SLA violations.
(10)
(10) where SLAVO denotes the average ratio during the time that the host uses 100% of its CPU, as shown in Equation (11)
(11)
(11) Wherein M is the host number and
is the total time host i that suffered 100% CPU use, resulting in an SLA violation. The symbol
indicates period that host i is active. As illustrated in Equation (12), SLAVM indicates the total performance decrease caused by VM migrations
(12)
(12) wherein N indicates the number of VMs,
indicates performance degradation due to migrating VM, and
represents total CPU usage demanded by VM j throughout its lifespan.
4.3.2. Energy consumption
According to several research, CPU resources consume increased power than memory, network interfaces, or disc storage. The energy use is calculated using real-world data from the SPEC power benchmark results. Significantly, whenever underutilized servers adopt low-power mode, their energy usage drops dramatically. As a result, limiting the number of active hosts is essential.
4.3.3. Number of VM migrations
As a result of higher CPU use on the source host, increased network bandwidth, application unavailability during VM migrations, and total migration time, live VM migration entails significant expenses and performance deterioration. Limiting VM migrations is essential since doing otherwise would almost surely lead to SLA violations.
4.3.4. Energy and SLA violations (ESV)
The suggested VM consolidation approach’s major purpose is to decrease both energy costs and SLA breaches at the same time. Since there is still a trade-off between energy consumption and performance, Equation (13) illustrates a combined indicator called energy and SLA violations that may be used to properly analyse the trade-off
(13)
(13)
4.4. Comparison benchmarks
The suggested technique is contrasted with the techniques given for detecting overloaded hosts as follows for effective verification. The CloudSim simulator displays these methods.
Static threshold (THR): the hot threshold is set to 90%. Hosts are deemed overloaded if their current CPU usage exceeds 90%.
The MAD and interquartile range (IQR) are two adaptive criteria. The algorithm works in the same way as the THR. The latest research presents a thorough estimate of MAD and IQR.
Dynamic threshold termed as the local regression (LR) technique: hosts that are overloaded are determined by calculating local regression changes over time.
Figure depicts the performance of the SLAVO measure in contrast to THR, IQR, MAD, GM, and the suggested UDEHO method under 10 workloads. Conventional techniques do not outperform the suggested system in terms of performance. The suggested approach has a lower SLAVO value of 6.15%, while other systems like THR, IQR, MAD, and GM have higher SLAVO values for the 10th workload of 7.5%, 7.2%, 7.23%, and 6.75%, respectively (see Table ).
Figure 2. SLAVO measure comparison for 10 workloads.
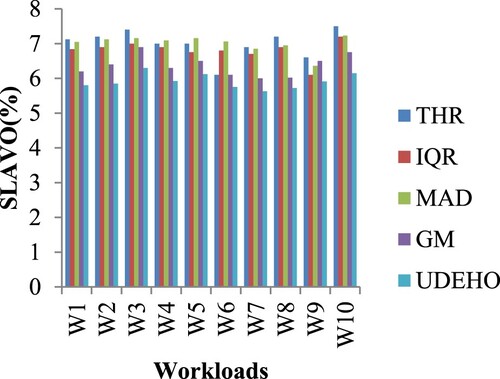
Figure depicts a performance comparison using the SLAVM measure. When compared to THR, IQR, MAD, and GM, the performance improves more since the technique caused a significant decrease in VM migration number. The suggested approach has a lower SLAVM value of 0.073%, while other systems like THR, IQR, MAD, and GM have higher SLAVM values for the 10th workload of 0.101%, 0.099%, 0.098%, and 0.085% (see Table ).
Figure 3. SLAVM measure comparison for 10 workloads.
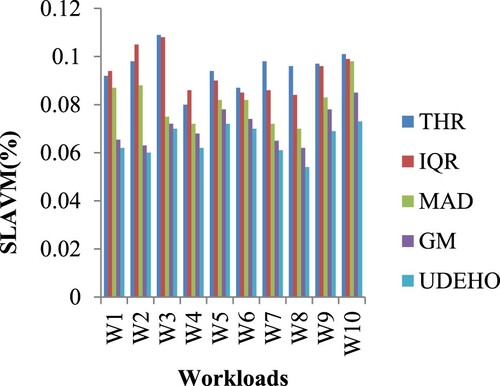
Table 3: Performance Metrics Comparison of 10 Workloads under Methods.
Figure depicts a performance comparison using the SLAV measure (SLAV, x0.00001). Because the suggested technique performs on the SLAV measure, it decreases the SLA violation rate by an average of 40.73%, 37.01%, 36.63%, and 21.75% when compared to THR, IQR, MAD, and GM, correspondingly (SEE Table ). Nevertheless, multiplying the SLAVO and SLAVM metrics yields the SLAV measure, and while the suggested performance in the SLAVM measure is rather excellent, the performance in the SLAVO measure has a slight increase that is insignificant in the suggested methodology. This is easily noticeable when assessing performance using the SLAV measure.
Figure 4. SLAV measure comparison for 10 workloads.
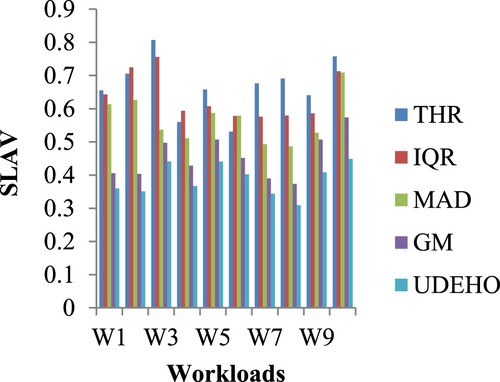
Figure depicts a performance comparison based on the energy usage parameter. When contrasted to THR, IQR, MAD, and GM, the suggested method minimizes energy usage by an average of 26.4285%, 23.7037%, 21.3740%, and 12.7118% (see Table ). Those hosts can be chosen more accurately by under loaded hosts that can be found using UP-PUD and power-saving values. Complete VMs on these hosts may be relocated to other suitable hosts after the discovery of the underutilized hosts, and the host may then be put to sleep. As a result, by converting idle hosts to low-power states throughout the consolidation procedure, energy may be conserved.
Figure 5. Energy consumption comparison for 10 workloads.
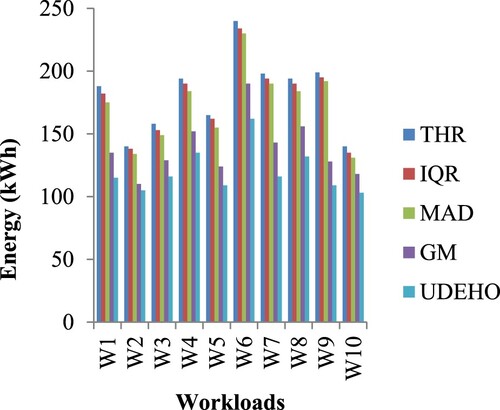
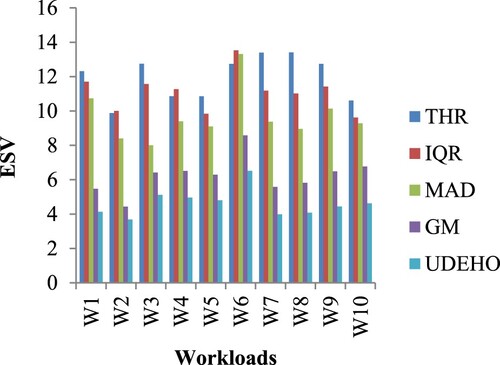
Figure depicts a performance comparison based on the ESV measure (ESV, x0.001). When contrasted to THR, IQR, MAD, and GM, the suggested technique decreases energy usage by an average of 56.3961%, 51.9455%, 50.1804%, and 31.6984%, correspondingly (see Table ). As energy usage reduction and violation rate of SLAV, the suggested technique results in such significant improvements. In reality, these significant findings suggest that the technique incorporates an effective trade-off between power cost and QoS assurance.
Figure 6. ESV measure comparison for 10 workloads.
5. Conclusion and future WORK
The dynamic VM consolidation issue is handled in this research by anticipating CPU consumption using the UDEHO model. To optimize the effectiveness of cloud data centres, starting allocation strategy has to be supplemented by a VM consolidation process which may be applied on a regular basis. The primary contribution of the work is the inclusion of a distribution function for random number generation in the EHO method, it enhances how well the VM consolidation method performs. The UP-POD and UP-PUD protocols for host underload and overload detection. When overloaded hosts are found, to maintain QoS, full VMs that may see an increase in CPU use are removed from these hosts; when underloaded hosts are recognized, entire VMs from these hosts are relocated to save energy usage. The proposed technique decreases energy usage while limiting depending on real-world workloads and varying number of migrations at different simulations setup. For instance, when contrasted to THR, IQR, MAD, and GM, the suggested method minimizes energy usage by an average of 26.4285%, 23.7037%, 21.3740%, and 12.7118%. As a result, it enhances cloud data centre performance by improving SLA performance indicators like SLAVO, SLAVM, SLAV, energy usage, and ESV guarantee. The present system has been enhanced to include a Web application that may consolidate and deconsolidate VMs in order to balance CPU load use across PMs in accordance to the number of PMs in use.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statements
Since no datasets were created or analysed for this topic, data sharing is not relevant.
References
- Buyya R, Srirama SN, Casale G, et al. A manifesto for future generation cloud computing: research directions for the next decade. ACM Comput Surv (CSUR). 2018;51(5):1–38.
- Gill SS, Tuli S, Xu M, et al. Transformative effects of IoT, blockchain and artificial intelligence on cloud computing: evolution, vision, trends and open challenges. Internet Things. 2019;8:1–30.
- Ashraf A, Hartikainen M, Hassan U, et al. Introduction to cloud computing technologies. In: I Porres, T Mikkonen, A Ashraf, editor. Developing cloud software: algorithms, applications, and tools, Turku Centre for Computer Science (TUCS) general publication number 60, bo, Finland. 2013, p. 1–41.
- Khoshkholghi MA, Derahman MN, Abdullah A, et al. Energy-efficient algorithms for dynamic virtual machine consolidation in cloud data centers. IEEE Access. 2017;5:10709–10722.
- Ghosh R, Komma SPR, Simmhan Y. Adaptive energy-aware scheduling of dynamic event analytics across edge and cloud resources. 2018 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID); May 2018. p. 72–82.
- Shim YC. Performance evaluation of static VM consolidation algorithms for cloud-based data centers considering inter-VM performance interference. Int J Appl Eng Res. 2016;11(24):11794–11802.
- Zheng Q, Li R, Li X, et al. Virtual machine consolidated placement based on multi-objective biogeography-based optimization. Future Gener Comput Syst. 2016;54:95–122.
- Abdelsamea A, Hemayed EE, Eldeeb H, et al. Virtual machine consolidation challenges: a review. Int J Innov Appl Stud. 2014;8(4):1504–1516.
- Chang K, Park S, Kong H, et al. ‘Optimizing energy consumption for a performance-aware cloud data center in the public sector. Sustain Comput Informat Syst. 2018;20:34–45.
- Beloglazov A, Buyya R. Optimal online deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in cloud data centers. Concurrency Comput: Pract Exp. 2012;24(13):1397–1420.
- Takouna I, Alzaghoul E, Meinel C. Robust virtual machine consolidation for efficient energy and performance in virtualized data centers. 2014 IEEE International Conference on Internet of Things (iThings), and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom), Taipei, Taiwan; 2014. p. 470–477.
- Farahnakian F, Liljeberg P, Plosila J. LiRCUP: linear regression based CPU usage prediction algorithm for live migration of virtual machines in data centers. 2013 39th Euromicro Conference on Software Engineering and Advanced Applications, Santander, Spain; 2013. p. 357–364.
- Mastroianni C, Meo M, Papuzzo G. Probabilistic consolidation of virtual machines in self-organizing cloud data centers. IEEE Trans Cloud Comput. 2013;1(2):215–228.
- Hieu NT, Di Francesco M, Ylä-Jääski A. Virtual machine consolidation with multiple usage prediction for energy-efficient cloud data centers. IEEE Trans Services Comput. 2017;13(1):186–199.
- Ismaeel S, Karim R, Miri A. Proactive dynamic virtual-machine consolidation for energy conservation in cloud data centres. J Cloud Comput. 2018;7(1):1–28.
- Sayadnavard MH, Haghighat AT, Rahmani AM. A multi-objective approach for energy-efficient and reliable dynamic VM consolidation in cloud data centers. Eng Sci Technol, Int J. 2021;26:1–13.
- Liu X, Wu J, Sha G, et al. Virtual machine consolidation with minimization of migration thrashing for cloud data centers. Math Probl Eng. 2020;2020(7848232):1–13.
- Hsieh SY, Liu CS, Buyya R, et al. Utilization-prediction-aware virtual machine consolidation approach for energy-efficient cloud data centers. J Parallel Distrib Comput. 2020;139:99–109.
- Jheng J, Tseng F, Chao H, et al. A novel VM workload prediction using grey forecasting model in cloud data center. International Conference on Information Networking, Phuket; 2014. p. 40–45.
- Wang GG, Deb S, Gao XZ, et al. A new metaheuristic optimisation algorithm motivated by elephant herding behaviour. Int J Bio-Inspired Comput. 2016;8(6):394–409.
- Li J, Lei H, Alavi AH, et al. Elephant herding optimization: variants, hybrids, and applications. Mathematics. 2020;8(9):1–25.
- Fu X, Zhou C. Virtual machine selection and placement for dynamic consolidation in cloud computing environment. Front Comput Sci. 2015;9(2):322–330.
- Han G, Que W, Jia G, et al. An efficient virtual machine consolidation scheme for multimedia cloud computing. Sensors. 2016;16(2):1–17.
- Rani E, Kaur H. Study on fundamental usage of CloudSim simulator and algorithms of resource allocation in cloud computing. 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India; 2017. p. 1–7.
- Xavier R, Moens H, Volckaert B, et al. Design and evaluation of elastic media resource allocation algorithms using CloudSim extensions. 2015 11th International Conference on Network and Service Management (CNSM), Barcelona, Spain; 2015. p. 318–326.
- Farahnakian F, Ashraf A, Liljeberg P, etal. Energy-aware dynamic VM consolidation in cloud data centers using ant colony system. In IEEE 7th International Conference on Cloud Computing. 2014. p. 104–111