
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Traditional clustering methods fail to accurately cluster the feature vectors of backers and macth the potential backers to compatible crowdfunding projects, mainly due to their sensitivity to the setting of the initial value. In this paper, we use the Apriori algorithm in conjunction with other machine learning tools to cluster the potential backers and provide more accurate recommendations for crowdfunding projects. Focusing on potential projects listed in a major reward-based crowdfunding platform, we first train the data obtained from the available list of backers. Using the Apriori algorithm, the degree of association between different project backers is then obtained, and weight calculation of the backers is carried out according to the association degree of the backers. The degree of association is used as a key index to cluster similar backers. Finally, we test the model and determine whether clustering can correctly classify the data in the test set based on the Apriori algorithm. Our experimental results show that there is 90% accuracy, precision and recall of the model. The proposed solution outperforms the other five benchmark methods and offers an imporved matchmaking by connecting the listed crowdfunding projects to the right backers.
1. Introduction
The rapid development of analytics and digitisation has enriched the hierarchy of the capital market. In the field of start-up financing, the emergence of new financial technology (FinTech) solutions that can directly secure public funding support through the Internet has led to the rise of multi-sided crowdfunding platforms (Mollick and Nanda Citation2016; Reza-Gharehbagh et al. Citation2021). Nowadays, crowdfunding has become one of the most important components of the platform economy in the financial field (Xu et al. Citation2022). In the digital supply chain context, a crowdfunding platform acts as an intermediary between manufacturers, investors, service providers, and customers (Chiu, Chu, and Kuo Citation2019; Reza-Gharehbagh et al. Citation2022). It is an innovative approach for nurturing capital from a crowd rather than traditional sources (Drover et al. Citation2017; Fatehi and Wagner Citation2019; Kumar, Langberg, and Zvilichovsky Citation2020; Reza-Gharehbagh et al. Citation2021). Compared with traditional financing, crowdfunding is more accessible and flexible, and it provides more opportunities for individuals and enterprises to raise funds from crowds. The main benefit of crowdfunding is that it creates crowdfunding products through the backers’ support and reduces creators’ start-up cost and risk (Bouncken, Komorek, and Kraus Citation2015; Mollick and Nanda Citation2015).
Amongst the different types of crowdfunding, reward-based crowdfunding has become a dominant source of start-up financing in China and other countries (Fleming and Sorenson Citation2016; Cornelius and Gokpinar Citation2020). Under reward-based crowdfunding, creators initiate crowdfunding projects on a platform website and publish the project information, such as the detailed content, target amount, and deadline. Potential backers purchase the proposed products in advance and provide financial support. The project is considered successful when the fund raised meets the funding target and the entrepreneur delivers the product or service to the backers; otherwise, the project is regarded as a failure (Kumar, Langberg, and Zvilichovsky Citation2020). Despite its advantages, reward-based crowdfunding is known to have a low success rate. The performance of Kickstarter,Footnote1 the largest crowdfunding platform, has been declining since its launch in 2009. This decline occurs even though most entrepreneurs consider crowdfunding as a main alternative to raise their required funds (Mollick and Nanda Citation2015). One of the possible causes of the underperformance of crowdfunding platforms is the inefficiency of their matchmaking feature (Wu et al. Citation2018).
Over the past decade, many researchers have studied the factors that influence the success of crowdfunding projects, such as financing target, return level, project characteristics, fundraising time, and number of backers (Mollick Citation2014; Wessel, Thies, and Benlian Citation2016; Zhou, Lu, and Fan Citation2018; Tang, Baker, and An Citation2020). In this stream of study, an increasing number of researchers have begun to examine how to reduce the failure rate of crowdfunding projects. In general, most backers have their own preferences for crowdfunding projects. Meanwhile, despite the relatively mature research on the success of crowdfunding, only a few studies (Rakesh, Choo, and Reddy Citation2015; Rakesh, Lee, and Reddy Citation2016; Shafqat and Byun Citation2019; Xiao et al. Citation2021) have examined how suitable crowdfunding products/projects can be effectively matched with the right backers to enhance the success rate of crowdfunding. These existing studies suggest solutions on how platforms can provide recommendation mechanisms to deliberately push suitable crowdfunding projects to the right backers. However, these solutions require knowledge of backers’ attributes in advance. In practice, such insights are not easy to obtain, and relevant information can only be provided after analysing the historical records of the backers who possibly supported other projects on similar crowdfunding platforms.
The identification and incorporation of the factors that may affect the success of crowdfunding projects in the future are indeed critical for enhancing the matchmaking attribute of crowdfunding platforms. Given its significance and associated complexity, this topic has become a research hotspot in recent years and attracted considerable attention, particularly from data science and FinTech scholars (Chan et al. Citation2021). The information characteristics of data mining are also important to machine learning practitioners (Ismagilova et al. Citation2020). Selecting the right set of characteristics can help identify the influential factors and enrich the understanding of the underlying structure of data, which plays an important role in further improving the performance of developed models and algorithms (Courtney, Dutta, and Li Citation2017). Information characteristics have two main functions: Firstly, they reduce the number of features and dimensions to enhance the generalisation ability of models and reduce overfitting. Secondly, they can enhance our understanding of existing relationships between features and eigenvalues (Wang et al. Citation2022). Characteristic selection can be performed using a variety of algorithms, such as low variance feature elimination, univariate feature selection, Apriori clustering algorithm, linear models and regularisation, random forest, stability selection, and recursive feature elimination (Chan et al. Citation2021). The Apriori algorithm is commonly used to mine data association rules and find frequent datasets in data values (Yuan Citation2017). Learning the patterns of these datasets helps us to make better informed decisions (Jo and Lee Citation2021).
In the current study, we use machine learning methods to recommend crowdfunding products to backers. Our objective is to propose an effective association mining algorithm to mine the relationship between backers and sponsored products on a crowdfunding platform. We also further use a clustering algorithm to cluster the products sponsored by backers and analyse which products are the most popular. This information reflecting the preferences of backers will help the crowdfunding platform to recommend crowdfunding products. In particular, we investigate how the Apriori algorithm can be used in conjunction with other tools to optimise the traditional clustering and provide more accurate recommendations for crowdfunding projects. For the support record of backers, we adopt the methods developed by Agrawal, Imielinski, and Swami (Citation1993) and Agrawal and Srikant (Citation1994). Agrawal and Srikant (Citation1994) proposed the Apriori algorithm, the most influential frequent itemset algorithm for mining Boolean association rules. Using the Apriori algorithm, we analyse the association rules between backers and optimise the traditional clustering method. Using the outputs of the Apriori model, we perform a clustering analysis. The basic model involves the clustering of backers of crowdfunding projects on the basis of the Apriori algorithm. This model optimises the traditional clustering algorithm by clustering the same backers according to their behavioural records. A backer can first identify the most relevant backers and then choose the types of projects he or she may support later on according to the successful projects that others have supported.
The key contributions of this study can be summarised as follows:
Current product recommendation models cannot accurately gauge backers’ behavioural characteristics merely on the basis of information provided on websites. Our proposed hybrid machine learning approach can make reliable predictions about backers’ behaviours by analysing their previous crowdfunding products.
Traditional clustering methods are ineffective in product recommendations. Powered by the Apriori algorithm, our proposed clustering method can cluster backers on the basis of their association rules and group similar backers together. This can enable crowdfunding platforms to predict more accurately which type of crowdfunding projects each group of backers will support next time. This feature will ultimately improve the effectiveness of crowdfunding platforms’ matchmaking attribute.
The remainder of the paper is organised as follows. Section 2 provides our literature survey. Section 3 introduces an improved clustering algorithm based on the Apriori algorithm. Section 4 presents our experimental study and discusses the key findings. Finally, Section 5 provides the conclusion and scope for future work.
2. Literature review
2.1. Analysis of factors affecting the success of crowdfunding projects
With the expeditious development of the sharing economy, more and more people are participating in crowdfunding activities. To promote the success of crowdfunding projects and create more profit for the creator, many researchers have studied the factors that affect the success of crowdfunding projects (Mollick Citation2014; Wessel, Thies, and Benlian Citation2016; Zhou, Lu, and Fan Citation2018). Mollick (Citation2014) described the underlying dynamics of the success and failure of crowdfunding enterprises, but the study was qualitative and lacked models and data support. Zhou, Lu, and Fan (Citation2018) regarded crowdfunding as a process of persuasion through project description and developed a model to verify the influential factors of successful financing. Wessel, Thies, and Benlian (Citation2016) evaluated the impact of untrue social information on consumer decision making in the context of reward-based crowdfunding.
Li et al. (Citation2018a) studied the financing targets of crowdfunding projects. Ma et al. (Citation2020) analysed the success factors and main effects of crowdfunding projects. Liu, Liu, and Balachander (Citation2021) developed an optimal product menu for crowdfunding project design. Fatehi and Wagner (Citation2019) analysed revenue-sharing contracts in crowdfunding mainly through cash buffers to deal with cash flow uncertainties. Roma, Gal-Or, and Chen (Citation2018) found that the informationisation level of crowdfunding activities and the related factors in obtaining venture capital financing impact the way entrepreneurs choose their activities and decide whether to carry out such activities. Drawing lessons from traditional research on risk financing, we know that the market, execution, and agency risks in equity crowdfunding can affect crowdfunding’s success rate. In a study of the issues affecting crowdfunding success, Li et al. (Citation2018b) introduced a new variable to find an effective model for successful crowdfunding projects. This variable can be used as a factor to predict the results of future crowdfunding projects.
Many researchers (Mollick Citation2014; Wessel, Thies, and Benlian Citation2016; Zhou, Lu, and Fan Citation2018) have analysed crowdfunding success factors, but few (Wei and Lin Citation2016) have analysed the related factors amongst crowdfunding platforms, crowdfunding backers, and crowdfunding project creators. The research on crowdfunding is generally conducted from the perspective of platforms, which consist of creators, backers, and digital tools. Ammara et al. addressed the issue of whether different types of creators affect the setting and development of crowdfunding activities and provided some suggestions for platforms to attract different creators. Research has also shown that the complexity of logos on crowdfunding platforms can be interpreted by backers as a signal of risk. With the development of crowdfunding activities, the roles of backers in crowdfunding projects need to be assessed when studying influential factors. Wang et al. (Citation2018) studied the impact of the characteristics of reviews and responses, including the number of reviews, the length of text, the emotions contained in the reviews, and the length and speed of the responses. The results emphasised the significance of the interaction between the creators and backers of crowdfunding projects for the success of crowdfunding projects. Xiao and Yue (Citation2018) examined whether the inertia behaviour of investors existed in their repeated investment decision making and concluded that the related attributes of crowdfunding projects influence backers’ decision making. The framework proposed by Ahsan, Cornelis, and Baker (Citation2018) describes the concepts of human-related behaviour and how to organise backers’ decision making effectively so as to help creators raise funds. Creators can also promulgate and formulate crowdfunding activities to attract more backers. Bitterl and Schreier (Citation2018) identified the need to know how to acquire financing in crowdfunding activities to entice backers effectively; in this way, consumers can engage in crowdfunding activities as backers, consequently affecting the development of enterprises. Many researchers (Mollick Citation2014) have studied the behavioural factors affecting backers’ crowdfunding decisions, but no study has analysed the mechanism of this influence. Some scholars (Belleflamme, Lambert, and Schwienbacher Citation2014) have studied the types of projects and the limits of crowdfunding financing. These two factors regulate the relationship between the factors affecting crowdfunding success and backers (Liang, Ping-Ju Wu, and Huang Citation2019).
2.2. Recommended algorithms used in crowdfunding platforms
With the development of big data, machine learning has become applicable in all fields. In this study, we aim to improve crowdfunding product recommendation on the premise of analysing backers’ behaviour, that is, how to relate the behavioural relationship between backers. In particular, we intend to use the Apriori algorithm of machine learning to examine the existing association between backers. Agrawal, Imielinski, and Swami (Citation1993) were amongst the first who proposed mining association rules among transaction data items. With the application of association rules, Agrawal and Srikant (Citation1994) proposed the Apriori algorithm, the most influential frequent itemset algorithm for mining Boolean association rules. On the basis of this algorithm proposed by Agrawal and Srikant (Citation1994), we combine the results of the analysis of association rules with a clustering algorithm, aiming to improve the recommendation of crowdfunding products to different backers. Clustering algorithms include k-nearest neighbour (K-NN), k-means, k-centre, and CLARANS (Alsabti, Ranka, and Singh Citation1997; Bradley and Fayyad Citation1998; Hammerly and Elkan Citation2002; Wu and Yang Citation2002; Likas, Vlassis, and Verbeek Citation2003; Zhang and Chen Citation2004; Hansen et al. Citation2005). We use the K-NN clustering algorithm to provide product recommendations to backers mainly because this algorithm is intuitive and relatively straightforward. We construct backer clustering based on the Apriori algorithm, which optimises the traditional clustering algorithm, to recommend crowdfunding products. This method improves the success rate of crowdfunding products.
3. Proposed work
3.1. Modelling
Researchers and practitioners have long faced the challenge of finding the best ways to recommend crowdfunding projects effectively. Our literature survey confirmed that traditional clustering methods could not accurately cluster the feature vectors of investors and are thus unable to recommend compatible crowdfunding projects. To address this issue, we use the Apriori algorithm and other machine learning tools in optimising the traditional clustering methods so as to provide more accurate recommendations and improve the success rate of crowdfunding projects. Table shows the parameters used herein.
Table 1. The notations.
The Apriori algorithm is a commonly used to mine data association rules in business, network security, and other fields. Its core idea is to mine frequent item sets through two stages of candidate set generation and downward closed detection of plots, learning the frequent data sets in data values. Identifying the patterns of these sets facilitates informed decision making. A classic example of association rules is the analysis of items purchased by customers in a supermarket. By summing up the relationship between the goods purchased by customers, we can analyse the habitual psychology of customers in the purchase process. Understanding the kinds of products that are frequently purchased at the same time helps merchants to reformulate and improve their marketing strategies.
In this study, we use the Apriori algorithm to provide more accurate recommendations for potential projects listed on a major commercial crowdfunding website. The Apriori algorithm involves different elements, such as the concepts of projects and financial transactions. Before running the algorithm, we need to preprocess the data and assign numbers to different backers of crowdfunding projects. We define a backer as a project, represented by . All backers make up the complete set of projects
:
. An item set (
) is a collection of one or more items. If
are item sets, then
is included in
, and
is included in
. The backer record of a crowdfunding project constitutes a transaction
. Each transaction has a uniquely identified
, and
is included in
.
When analysing the strength of the association of backers, the rule is to find the frequent item sets of the backers, that is, all the item sets whose support is greater than the minimum support, and then generate rules on the basis of the frequent item sets. Two evaluation indicators are obtained from the Apriori algorithm: support and confidence (Agrawal and Srikant Citation1994). Support refers to the percentage of all crowdfunding projects that contain
and
and is formulated as follows:
(1)
(1)
Confidence is the proportion of that also supports the project based on the support of
. It reflects the degree of understanding of the rules and is written as
(2)
(2) where
represents the total number of transactions,
represents the number of transactions in which both conditions and results occur, and
represents the number of transactions in which the condition occurs (Hegland Citation2007). We set the minimum support and minimum confidence according to the actual situation: if there are few existing rules, we lower the threshold according to the situation; if there are too many rules, we raise the threshold.
The confidence obtained by the Apriori algorithm is used to express the correlation strength between backers. According to the correlation strength, the same backers are clustered. We adopt the notion of the K-NN algorithm. The input of the K-NN algorithm is the feature vector of the related instance whilst the output is the category to which the instance belongs. We cluster the backers whose distance is relatively close, that is, the backers who have strong correlations are clustered into one category.
After obtaining similar backers, we test the model. The most commonly used performance matrices in machine learning are confusion matrices, through which the metrics of accuracy, precision, and recall can be calculated and whose outcomes include true positive , true negative
, false positive
, and false negative
. The specific definitions are as follows (Agrawal and Srikant Citation1994):
:
Accuracy is the correct percentage of the total sample in the predicted results, that is, . Precision is the probability of a sample being class ‘1’ amongst all samples predicted to be class ‘1’. It relates to the prediction result, that is,
. Precision represents the accuracy of the prediction in positive sample results whilst accuracy represents the overall accuracy of the prediction, including the positive and negative samples. Recall shows how many positive examples in the sample are predicted correctly; here,
.
3.2. Apriori clustering algorithm
In Figure , we introduce the basic process of the model construction in this study. In recommending crowdfunding products to backers, the key is to find similar backers. We employ the Apriori algorithm to analyse the backer records of crowdfunding projects and analyse backers’ associations. Thereafter, we cluster similar backers. Finally, backers are recommended according to the results of the clustering. In summary, we divide the model process into three phases.
Figure 1. The basic flow of the model.
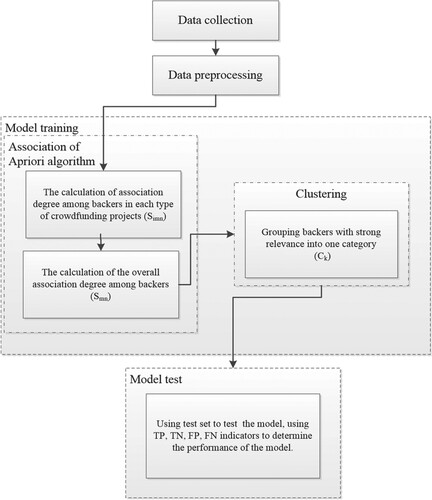
In the first stage, the Apriori algorithm is used to analyse the correlation strength between different backers. We evaluate the association rules between the backers of each type of crowdfunding products and then determine the total correlation strength between the backers under all projects.
In the second stage, we generate recommendations of crowdfunding products. According to the backers’ correlation strength obtained in the first stage, we cluster the backers with stronger correlation strength.
In the third stage, we test the model. On the basis of the clusters obtained from the previous two stages, we test the clustering results using a test set.
3.2.1. Stage 1
In stage 1, we define the type of crowdfunding projects as and retain j crowdfunding projects for each type. The crowdfunding projects are recorded as
, and the correlation strength
between the
backer and the
backer is analysed separately for
crowdfunding products. The final correlation strength
between the
backer and the
backer is then obtained. Each type of crowdfunding product involves
pieces of information and m backers. We record the backers of each project as a transaction
, and one transaction containing one or more backers, such as
, indicates that the first crowdfunding project under the first category is supported by
.
We follow the association rules when analysing the strength of the associations amongst backers. Stage 1 in our study is different from that in the Apriori algorithm when finding frequent item sets in all item sets. However, we analyse several backers who support crowdfunding projects many times at the stage of preprocessing the data before the first phase. After calculating confidence using the Apriori algorithm, it is then used as the correlation strength between backers. In this stage, the pseudocode is as follows (Agrawal and Srikant Citation1994):
Table
3.2.2. Stage 2
In stage 2, the backers are clustered on the basis of the correlation strength obtained in stage 1, that is, the backers with similar behaviours are grouped together. The clustering algorithm uses the idea of k-NN to classify the closest backers into one category. The pseudocode for this stage is as follows (Agrawal and Srikant Citation1994):
Table
3.2.3. Stage 3
In stage 3, the results of the model are obtained on the basis of the operations in the first two stages. The next stage is to predict the model’s performance, for which we use the test set. Considering the actual situation, we use the model test indicators of accuracy and precision, which are the most commonly used performance evaluation indicators in machine learning.
4. Experimental design
4.1. Data collection
We use Python crawler technology to obtain the needed information on the backer records online (Table ). As shown in Figure , the zhongchou.cn site has seven types of crowdfunding projects: ‘public welfare’, ‘agriculture’, ‘publishing’, ‘entertainment’, ‘art’, ‘blockchain’, and ‘others’. As the blockchain type only comprises one project, we focus our analysis on the remaining six types of crowdfunding projects. We capture the relevant information of the crowdfunding projects, including the tag information: ‘project_name’, ‘hangye’, ‘have_monkey’, ‘support_num’, and ‘progress’. At the same time, we capture the backer information for each crowdfunding project (Table ), including the following tag information: ‘user_id’, ‘user_name’, ‘deal_price’, ‘deal_num’, and ‘pay_time’. The information is captured from the crowdfunding projects under the six categories and their corresponding backer records.
Figure 2. Seven types of crowdfunding projects.
Table 2. The data of crowdfunding projects.
Table 3. The record of backers of crowdfunding projects.
4.2. Data processing
For data processing, we screen the six types of projects and select the crowdfunding projects whose progress exceeded 100%, that is, the crowdfunding project was successfully financed. We keep 100 crowdfunding projects for each type.
Given the sparse data (Wang et al. Citation2020; Xiao et al. Citation2021), we only keep the top 10 backers with the largest number of pledges under the six project types. In this way, our model can more accurately classify the same backers. We divide the data into a training set and test set and assess the model’s reliability and efficiency.
We define the type of crowdfunding projects as . The six types of ‘public welfare’, ‘agriculture’, ‘art’, ‘publishing’, ‘entertainment’, and ‘others’ are respectively recorded as
,
,
,
,
, and
. In the training set, 100 crowdfunding projects are reserved for each type, and these crowdfunding projects are recorded as
. In the test set, 20 crowdfunding projects are reserved for each type. The backers’ record of projects is recorded as a transaction, denoted as
. Each transaction contains the backer
, and the range of the number of items m is
. In the experimental analysis, we only consider the top 10 backers with the most pledges and use the Apriori algorithm to analyse the confidence level as the correlation strength of the 10 backers. The k-NN algorithm is then used for clustering.
In the training process, we analyse four types of crowdfunding projects and find the correlation strength amongst the 10 backers of the four types. Then, the final correlation strength
amongst the 10 backers is calculated.
We take the A1 crowdfunding project as an example.
We collect 100 projects that have been successfully crowdfunded for A1, with each project containing one or more . As shown in Table , we organise the data into the form of transactions.
Table 4. The transaction of crowdfunding projects of A1.
Then, the transaction set is written into stage 1. We can then obtain the correlation strength between the
backer and the
backer of
. Some of the results are shown in Figure .
Figure 3. Some results of correlation strength of .
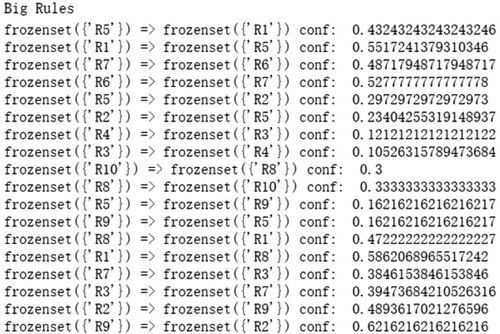
We organise the results of the analysis in Table .
Table 5. The results of correlation strength of .
In the study, and
are strongly associated if
. According to Table , we can obtain the following:
The same operation is performed to obtain ,
,
,
, and
, as shown in Tables , respectively. For the A2 type of crowdfunding project, we obtain the results shown in Figure .
Figure 4. Some results of correlation strength of .

We organise the results of the analysis in Table .
Table 6. The results of correlation strength of .
According to Table , we find the following:
For the type of crowdfunding project, the results are shown in Figure .
Figure 5. Some results of correlation strength of .
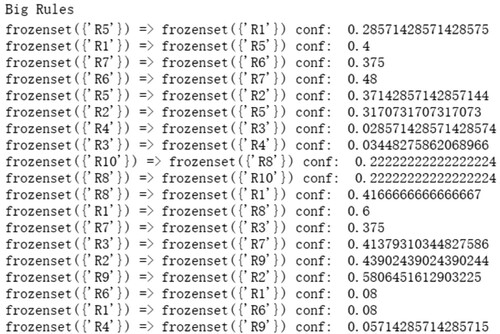
We organise the results of the analysis in Table .
Table 7. The results of correlation strength of .
According to Table , we obtain the following:
For the type of crowdfunding project, we obtain the results shown in Figure .
Figure 6. Some results of correlation strength of .
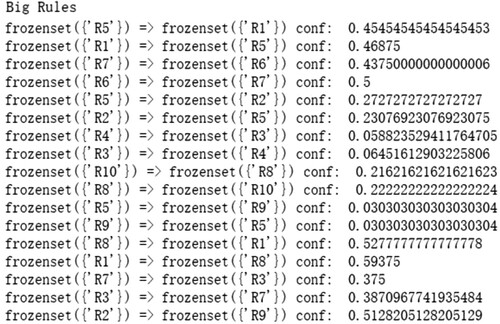
We organise the results of the analysis in Table .
Table 8. The results of correlation strength of .
According to Table , we obtain the following:
For the type of crowdfunding project, we obtain the results shown in Figure .
Figure 7. Some results of correlation strength of .
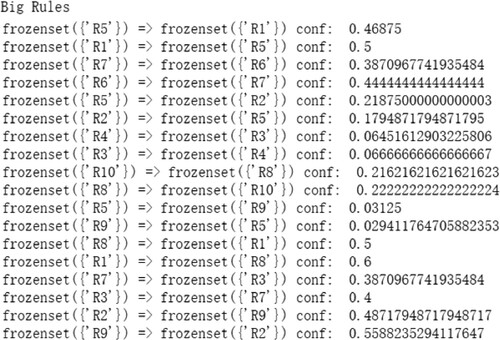
We organise the results of the analysis in Table .
Table 9. The results of correlation strength of .
According to Table , we find the following:
For the type of crowdfunding project, we obtain the results shown in Figure .
Figure 8. Some results of correlation strength of .
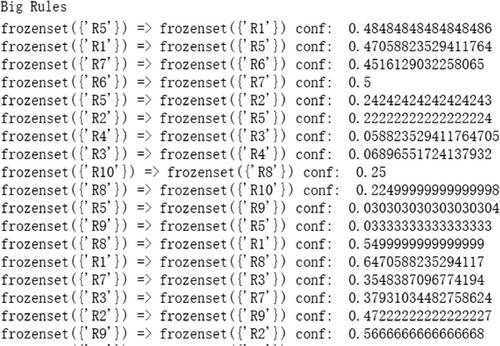
We organise the results of the analysis in Table .
Table 10. The results of correlation strength of .
According to Table , we obtain the following:
According to the formula , we can obtain the final correlation strength of backers
in all projects. The final results are shown in Table .
Table 11. The results of correlation strength of all projects.
In summary, we find the following correlations amongst backers:
According to these results, we cluster the backers with high similarity (strong correlation), in which is strongly associated with
and
. Progressively,
is strongly associated with
and
; and
is strongly associated with
,
, and
. Then,
,
,
, and
are strongly associated; and
is strongly associated with
and
. Finally,
,
,
, and
are strongly associated, that is,
,
,
, and
are grouped together. Similarly,
,
,
,
,
, and
are classified into one class. The specific hierarchical clustering diagram is shown in Figures and .
Figure 9. Cluster 1 (,
,
,
).
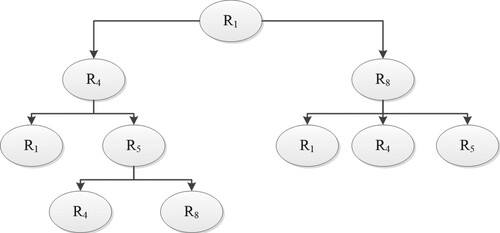
Figure 10. Cluster 2 (,
,
,
,
,
).
Through the analysis of the correlation and clustering, we assume that similar backers can choose a project on the basis of the types of projects that other backers support the most.
4.3. Model performance evaluation
We capture 10 item information and 60 test data for the six types of crowdfunding projects. Each project contains one or more backers. Accuracy and precision are used to test the performance of the model classification through each project’s backer records. Before analysing the model, we define the above classification: Cluster 1 (,
,
,
) is defined as ‘class 0’, which represents negative cases. Cluster 2 (
,
,
,
,
,
) is defined as ‘class 1’, which represents positive cases.
In the test set data, each project has a backer record; for example, P11 (,
,
,
) can be considered to support the ‘0’ backers of the P11 project because in the backer record,
,
,
are ‘0’ whilst in
, ‘1’ and ‘0’ backers account for a large proportion. Thus, the P11 project is supported by ‘0’ backers. Therefore,
,
,
are all correctly classified as negative cases whilst
is incorrectly classified as a negative case. There will be
,
. The results of the analysis of the other projects using the same method are shown in Table .
Table 12. The classification situation.
On the basis of the analysis of Table , we can conclude that
(3)
(3)
(4)
(4)
(5)
(5)
The results show that the accuracy and precision of clustering in this model reach about 90%. The evaluation value of this index is high relative to the evaluation index of machine learning. It indirectly proves that the performance of the model is better than that of others. It can cluster the same backers correctly and then make recommendations to them. Meanwhile, we find that the accuracy and recall rates of some methods summarised by Wang et al. (Citation2017) are lower than ours. The specific comparisons of the sparse data are shown in Table .
Table 13. Comprehensive comparison results.
In sum, the proposed method outperforms the other five recommendation methods and can better recommend suitable crowdfunding projects for backers. Take for example the following two categories: Cluster 1 (,
,
,
) and Cluster 2 (
,
,
,
,
,
). Let us assume that
supports projects 2, 3, 8, 9. On the basis of clustering, if
supports project 3, then he/she can choose to support projects 2, 8, and 9. By clustering similar backers and offering recommendations to them, we can improve the probability of success of crowdfunding projects and thus promote the development of the shared economy. In addition, the Apriori algorithm is an interpretable algorithm that is easy to implement. It adopts the association rule mining of transaction databases and is suitable for the characteristics of sample data, that is, data sets with short frequent item sets. The experimental results indicate that the Apriori clustering algorithm is effective in crowdfunding project recommendations.
5. Discussion and implications
This study improves the traditional clustering algorithm by combining the Apriori algorithm with other machine learning tools. Our improved method can boost the performance of the proposed clustering method for crowdfunding projects.
5.1. Theoretical insights
The theoretical contributions of the current study are summarised as follows:
A novel clustering method is developed and demonstrated for clustering complex crowdfunding projects. The quality of clustering methods (Abbasimehr and Sheikh Baghery Citation2022) affects the clustering effect of complex crowdfunding projects. Our research applies the Apriori algorithm to improve the quality of clustering and product recommendations in complex crowdfunding ecosystems.
The previous literature on clustering (Du, Li, and Wang Citation2019; Geiger and Moore Citation2022; McSweeney et al. Citation2022) undermines the importance of the simultaneous consideration of the behaviour characteristics of backers and future crowdfunding projects. This research proposes the association rule-based clustering method for backers by considering backers’ behavioural characteristics and future crowdfunding projects simultaneously.
This study combines different machine learning methods to optimise clustering algorithms. The results show that the Apriori algorithm and other machine learning tools are able to improve the performance of the proposed clustering method for crowdfunding projects.
The comparative analysis reveals the advantages of the proposed model. Our findings showed that the degree of association rule-based model for crowdfunding backers outperforms the other five existing benchmark methods.
5.2. Managerial insights
This study clusters the backers of crowdfunding so as to effectively recommend crowdfunding products. Validating the proposed model through an actual crowdfunding case study, we achieve a 90% product recommendation accuracy.
The managerial contributions of the current study are summarised as follows:
It is very important to investigate behaviour characteristics (Vanpoucke and Vereecke Citation2010) and uncertainty (Qu, Li, and Ji Citation2021) in decision science. The behavioural dimensions of backers and the sensitivity of crowdfunding projects cannot be overlooked during clustering. Therefore, the proposed model enables decision makers to cluster backers by considering their behavioural characteristics and the uncertainties of crowdfunding projects concurrently.
In the field of product recommendation, Wang (Citation2015) studied the recommendations of smart phones and wearable devices. Wu et al. (Citation2021) developed a knowledge recommendation system for industrial products and illustrated the performance of the model in a crane case. However, few studies have applied product recommendation to the field of crowdfunding. Decision makers can use the proposed method for effective recommendations of crowdfunding products.
Clustering is particularly important in simulation analysis. However, it is often difficult to obtain accurate clustering results. The most effective methods include association rules (Buddhakulsomsiri et al. Citation2006) and machine learning (Yeou-Ren, Ruey-Shiang, and Ken-Chun Citation2012). Decision makers can cluster backers more accurately and effectively using the proposed model that combines association rules and machine learning.
The accuracy of the proposed model is relatively high, and the model can achieve good results in crowdfunding. Using the developed model based on the Apriori algorithm, managers can achieve 90% accuracy in relating suitable crowdfunding projects to the right backers.
6. Conclusions
This study utilised clustering based on the Apriori clustering algorithm, which further enhances the crowdfunding products’ success rate. We collected data from crowdfunding websites, analysed the association rules of relevant backers, and then clustered similar backers. Unlike in cases that use traditional clustering algorithms, we could not take advantage of the behaviour information of backers to describe the specific value of the clustering algorithm. This problem was reflected in the data of the backers’ behaviour records on the platform. We overcame this problem by utilising the Apriori algorithm of machine learning to analyse the association rules between backers. We also calculated the correlation strength coefficients amongst different backers and performed cluster analysis.
The results of the model classification were obtained through model training. The test results showed that the accuracy, precision, and recall of the model clustering were approximately 90%. The performance of the proposed method was also better than that of five other methods. Hence, the proposed method was proved to perform well and able to cluster the same backers correctly. This method enables us to recommend crowdfunding projects for different backers. It also optimises the traditional clustering algorithms and clusters the same backers according to their behaviours. Using this model, we can predict backers with the most decisive relevance and identify the kinds of projects that they could support next time on the basis of their successful projects. From the perspective of the backers, they can achieve their own value to a large extent and invest where they can get the best return. For creators, their crowdfunding projects’ success rate can be improved, and they can thus generate higher profits.
Similar to any other research, this study has several shortcomings. The presented Apriori-based model can be enhanced in different ways, from pruning frequent set strategy optimisation to connect strategy library optimisation strategy. Moreover, our analysis was centred on a single method, the amount of collected data was rather small, and a robustness analysis was not conducted. Hence, developing new methods and comparing them with the presented model, testing the models with larger datasets, and conducting an empirical analysis to investigate the improved success rate of crowdfunding projects (as a result of the new product recommendation system) are suggested as possible directions for future research.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Additional information
Funding
Notes on contributors

Shaojian Qu
Prof. Shaojian Qu received the Ph.D. degree in operations research from Xi’an Jiao tong University, Xi’an, China, in 2008. He was a Postdoctoral Fellow with the National University of Singapore, Singapore, and the Harbin Institute of Technology, Harbin, China, in 2011. He is currently a Professor with the School of Management Science and Engineering, Nanjing University of Information Science and Technology, Nanjing, China. He has published more than 50 papers by the first author, including 40 SCI articles in internationally renowned journals. His research interests include robust optimisation, decision theory and method, supply chain management, portfolio management, and game theory. Dr. Qu also serves as a Reviewer for several publications, such as European Journal of Operational Research, Omega, and Information Science. He is also the Executive Director of the Economic Mathematics and Management Mathematics Society, the Director of the Game Theory Committee of the Operations Research Society of China, and the Executive Director of the Sustainable Operation and Management System Branch of the Systems Engineering Society of China.

Lei Xu
Prof. Lei Xu received the Ph.D. degree in logistics and supply chain management from Nankai University, Tianjin, China, in 2012. He is currently a Full Professor with the Civil Aviation University of China, Tianjin. From January 2012 to August 2012, he visited as a Visiting Scholar with the Hong Kong Polytechnic University, Hong Kong. From 2020, he has been named as the High-cited Scholar by Elsevier. He has published over 50 articles in Web of Science indexed journals, such as the International Journal of Production Research, European Journal of Operational Research, International Journal of Production Economics, Transportation Research – Part E: Logistics and Transportation Review, Annals of Operations Research, and Computer and Operations Research, IEEE Transactions on Systems, Man, and Cybernetics: Systems. His research interests include logistics and supply chain management, behavioural operations management, and revenue management.

Sachin Kumar Mangla
Dr. Sachin Kumar Mangla is working in the field of Green and Sustainable Supply Chain and Operations; Industry 4.0; Circular Economy; Decision Making and Simulation. He has a teaching experience of more than five years in Supply Chain and Operations Management and Decision Making, and currently associated in teaching with various universities in U.K., Turkey, India, China, France, etc. He is committed to do and promote high quality research. He has published/presented several papers in repute international/national journals (International Journal of Production Economics; Journal of Business Research; International Journal of Production Research; Computers and Operations Research; Production Planning and Control; Business Strategy and the Environment; Annals of Operations Research; Transportation Research Part-D; Transportation Research Part-E; Renewable and Sustainable Energy Reviews; Resource Conservation and Recycling; Information System Frontier; Journal of Cleaner Production; Management Decision; Industrial Data and Management System) and conferences (POMS, SOMS, IIIE, CILT – LRN, MCDM, GLOGIFT). He has an h-index 60, i10-index 110, Google Scholar Citations of more than 10000. He is involved in several editorial positions and editing couple of Special issues as a Guest Editor in top tier journals. Currently, he is also involved in several research projects on various issues and applications of Circular economy and Sustainability. Among them, he also contributed to for knowledge-based decision model in ‘Enhancing and implementing knowledge based ICT solutions within high risk and uncertain conditions for agriculture production systems (RUC-APS)’, European Commission RISE scheme, €1.3M. Recently, he has also received a grant as a PI from British Council – Newton Fund Research Environment Links Turkey/U.K. – Circular and Industry 4.0 driven solutions for reducing food waste in supply chains. He has also won the first prize for the prestigious Basant Kumar Birla Distinguished Scholar Award 2022.

Felix T. S. Chan
Prof. Felix Chan received his B.Sc. Degree in Mechanical Engineering from Brighton University, U.K., and obtained his M.Sc. and Ph.D. in Manufacturing Engineering from the Imperial College of Science and Technology, University of London, U.K. Prior joining Macau University of Science and Technology, Prof. Chan has many years of working experience in other universities including The Hong Kong Polytechnic University; University of Hong Kong; University of South Australia; University of Strathclyde. His current research interests are Logistics and Supply Chain Management, Operations Research, Production and Operations Management, Distribution Coordination, Smart Manufacturing, AI Optimisation. To date, Prof. Chan has published over 16 book chapters, over 370 SCI refereed international journal papers and 310 peer-reviewed international conference papers. His total number of citations >10,700, h Index = 53. Prof. Chan is a chartered member of the Chartered Institute of Logistics and Transport in Hong Kong. Based on the recent compilation (2020) from a research group of Stanford about the impact of scientists (top 2% listed). The work is published in the following website: https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.3000918. Prof. Felix Chan is categorised in the field of Operations Research, ranked 10 out of 23,455 scientists worldwide, i.e. Top 0.04% worldwide.

Jianli Zhu
Jianli Zhu, born in 1996, M. S. candidate with University of Shanghai for Science and Technology. His research interests include supply chain management, Internet finance.

Sobhan Arisian
Dr. Sobhan Sean Arisian is an applied operations researcher with special interests in modelling and solving complex Logistics and Supply Chain Management problems. Sean’s multidisciplinary research addresses problems related to supply chain security and resiliency at the international trade-global supply chains interface. Another stream of Sean’s research is the development of transformative and sustainable supply chain strategies that foster indigenous innovation at regional and national levels. Sean is the Editorial Advisory Board (EAB) member of ‘Transportation Research Part E’ and ‘Logistics’ journal, and Associate Editor of ‘Modern Supply Chain Research and Application’ journal.
Notes
1 In the last nine years, the growth rate of the total crowdfunding amount on the platform has declined. Statistics show that out of 424,980 projects launched with campaigns as of November 2018 on the Kickstarter platform, the success rate was low at 36.52% (e.g. http://Kickstarter.com).
References
- Abbasimehr, H., and F. Sheikh Baghery. 2022. “A Novel Time Series Clustering Method with Fine-Tuned Support Vector Regression for Customer Behavior Analysis.” Expert Systems with Applications 204: 117584.
- Agrawal, R., T. Imielinski, and A. Swami. 1993. “Mining Association Rules Between Sets of Items in Large Databases.” ACM SIGMOD Record 22 (2): 207–216.
- Agrawal, R., and R. Srikant. 1994. “Fast Algorithms for Mining Association Rules in Large Databases.” In Proceedings of the 20th International Conference on Very Large Databases. Vol. 1215, 487–499. Santiago de Chile: Morgan Kaufmann.
- Ahsan, M., E. Cornelis, and A. Baker. 2018. “Understanding Backers’ Interactions with Crowdfunding Campaigns.” Journal of Research in Marketing and Entrepreneurship 20 (2): 252–272.
- Alsabti, K., S. Ranka, and K. Singh. 1997. “An Efficient K-Means Clustering Algorithm.” In Proceedings of PPS/SPDP Workshop on High Performance Data Mining, 34–39, Orlando, FL.
- Belleflamme, P., T. Lambert, and A. Schwienbacher. 2014. “Crowdfunding: Tapping the Right Crowd.” Journal of Business Venturing 29 (5): 585–609.
- Bitterl, S., and M. Schreier. 2018. “When Consumers Become Project Backers: The Psychological Consequences of Participation in Crowdfunding.” International Journal of Research in Marketing 35: 673–685.
- Bouncken, R., M. Komorek, and S. Kraus. 2015. “Crowdfunding: The Current State of Research.” The International Business & Economics Research Journal 14 (3): 407–416.
- Bradley, P., and U. Fayyad. 1998. “Refining Initial Points for K-Means Clustering.” Proceedings of the 15th International Conference on Machine Learning, 91–99, San Francisco, CA.
- Buddhakulsomsiri, J., Y. Siradeghyan, A. Zakarian, and X. Li. 2006. “Association Rule-Generation Algorithm for Mining Automotive Warranty Data.” International Journal of Production Research 44 (14): 2749–2770.
- Chan, H. F., N. Moy, M. Schaffner, and B. Torgler. 2021. “The Effects of Money Saliency and Sustainability Orientation on Reward Based Crowdfunding Success.” Review of Journal of Business Research 125: 443–455.
- Chiu, M., C. Chu, and T. Kuo. 2019. “Product Service System Transition Method: Building Firm’s Core Competence of Enterprise.” International Journal of Production Research 57 (20): 6452–6472.
- Cornelius, P., and B. Gokpinar. 2020. “The Role of Customer Investor Involvement in Crowdfunding Success.” Management Science 66 (1): 452–472.
- Courtney, C., S. Dutta, and Y. Li. 2017. “Resolving Information Asymmetry: Signaling, Endorsement, and Crowdfunding Success.” Review of Entrepreneurship Theory and Practice 41 (2): 265–290.
- Drover, W., L. Busenitz, S. Matusik, D. Townsend, A. Anglin, and G. Dushnitsky. 2017. “A Review and Road map of Entrepreneurial Equity Financing Research: Venture Capital, Corporate Venture Capital, Angel Investment, Crowdfunding, and Accelerators.” Journal of Management 43 (6): 1820–1853.
- Du, Z., M. Li, and K. Wang. 2019. “‘The More Options, the Better?’ Investigating the Impact of the Number of Options on Backers’ Decisions in Reward-Based Crowdfunding Projects.” Information Management 56 (3): 429–444.
- Fatehi, S., and M. Wagner. 2019. “Crowdfunding via Revenue-Sharing Contracts.” Manufacturing & Service Operations Management 21 (4): 875–893.
- Fleming, L., and O. Sorenson. 2016. “Financing by and for the Masses.” California Management Review 58 (2): 5–19.
- Geiger, M., and K. Moore. 2022. “Attracting the Crowd in Online Fundraising: A Meta-Analysis Connecting Campaign Characteristics to Funding Outcomes.” Computers in Human Behavior 128: 107061.
- Hammerly, G., and C. Elkan. 2002. “Alternatives to the K-Means Algorithm that Find Better Clusterings.” In Proceedings of the 11th International Conference on Information and Knowledge Management, 600–607. New York, USA.
- Hansen, P., E. Ngai, B. Cheung, and N. Mladenovic. 2005. “Analysis of Global K-Means, an Incremental Heuristic for Minimum Sum-of-Squares Clustering.” Journal of Classification 22 (2): 287–310.
- Hegland, M. 2007. “The Apriori Algorithm – a Tutorial.” In Mathematics and Computation in Imaging Science and Information Processing, edited by Say Song Goh, Amos Ron, and Zuowei Shen, 209–262. Singapore.
- Ismagilova, E., E. Slade, N. P. Rana, and Y. K. Dwivedi. 2020. “The Effect of Characteristics of Source Credibility on Consumer Behaviour: A Meta-Analysis.” Review of Journal of Retailing and Consumer Services 53: 101736.
- Jo, H. G., and D. Lee. 2021. “Oral Administration of East Asian Herbal Medicine for Peripheral Neuropathy: A Systematic Review and Meta-Analysis with Association Rule Analysis to Identify Core Herb Combinations.” Review of Pharmaceuticals 14 (11): 50.
- Kumar, P., N. Langberg, and D. Zvilichovsky. 2020. “Crowdfunding, Financing Constraints, and Real Effects.” Management Science 66 (8): 3561–3580.
- Li, H., X. Chen, Y. Zhang, and M. Hai. 2018a. “Empirical Analysis of Factors on Crowdfunding with Trust Theory.” Procedia Computer Science 139: 120–126.
- Li, H., X. Chen, Y. Zhang, and M. Hai. 2018b. “Prediction of Financing Goal of Crowdfunding Projects.” Procedia Computer Science 139: 108–113.
- Liang, T., S. Ping-Ju Wu, and C. Huang. 2019. “Why Funders Invest in Crowdfunding Projects: Role of Trust from the Dual-Process Perspective.” Information & Management 56: 70–84.
- Likas, A., N. Vlassis, and J. Verbeek. 2003. “The Global K-Means Clustering Algorithm.” Pattern Recognition 36: 451–461.
- Liu, Q., X. Liu, and S. Balachander. 2021. “Crowdfunding Project Design: Optimal Product Menu and Funding Target.” Production and Operations Management 30 (10): 3800–3811.
- Ma, S., Y. Hua, D. Li, and Y. Wang. 2020. “Proposing Customers Economic Value or Relational Value? A Study of Two Stages of the Crowdfunding Project.” Decision Sciences 53 (4): 712–749.
- McSweeney, J. J., K. T. McSweeney, J. W. Webb, and C. E. Devers. 2022. “The Right Touch of Pitch Assertiveness: Examining Entrepreneurs’ Gender and Project Category fit in Crowdfunding.” Journal of Business Venturing 37 (4): 106223–106239.
- Mollick, E. 2014. “The Dynamics of Crowdfunding: An Exploratory Study.” Journal of Business Venturing 29 (1): 1–16.
- Mollick, E., and R. Nanda. 2015. “Wisdom or Madness? Comparing Crowds with Expert Evaluation in Funding the Arts.” Management Science 62 (6): 1533–1553.
- Mollick, E., and R. Nanda. 2016. “Wisdom or Madness? Comparing Crowds with Expert Evaluation in Funding the Arts.” Review of Management Science 62 (6): 1533–1553.
- Qu, S., Y. Li, and Y. Ji. 2021. “The Mixed Integer Robust Maximum Expert Consensus Models for Large-Scale GDM Under Uncertainty Circumstances.” Applied Soft Computing 107: 107369.
- Rakesh, V., J. Choo, and C. K. Reddy. 2015. “Project Recommendation Using Heterogeneous Traits in Crowdfunding.” In Proceedings of the International AAAI Conference on Web and Social Media, Vol. 9, no. 1, 337–346. Atlanta, GA, USA.
- Rakesh, V., W. C. Lee, and C. K. Reddy. 2016. “Probabilistic Group Recommendation Model for Crowdfunding Domains.” In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, 257–266. Shanghai, China.
- Reza-Gharehbagh, R., S. Arisian, A. Hafezalkotob, and A. Makui. 2022. “Sustainable Supply Chain Finance Through Digital Platforms: A Pathway to Green Entrepreneurship.” Annals of Operations Research 149: 1–35.
- Reza-Gharehbagh, R., S. Asian, A. Hafezalkotob, and C. Wei. 2021. “Reframing Supply Chain Finance in an Era of Reglobalization: On the Value of Multi-Sided Crowdfunding Platforms.” Transportation Research Part E: Logistics and Transportation Review 149: 102298.
- Roma, P., E. Gal-Or, and R. Chen. 2018. “Reward-Based Crowdfunding Campaigns: Informational Value and Access to Venture Capital.” Information Systems Research 29 (3): 679–697.
- Shafqat, W., and Y. C. Byun. 2019. “Topic Predictions and Optimized Recommendation Mechanism Based on Integrated Topic Modeling and Deep Neural Networks in Crowdfunding Platforms.” Applied Sciences 9 (24): 5496.
- Tang, L., R. Baker, and L. An. 2020. “The Success of Crowdfunding Projects: Technology, Globalization, and Geographic Distance.” Economics of Innovation and New Technology, 1–22. doi:10.1080/10438599.2020.1838412.
- Vanpoucke, E., and A. Vereecke. 2010. “The Predictive Value of Behavioural Characteristics on the Success of Strategic Alliances.” International Journal of Production Research 48 (22): 6715–6738.
- Wang, C. 2015. “A Market-Oriented Approach to Accomplish Product Positioning and Product Recommendation for Smart Phones and Wearable Devices.” International Journal of Production Research 53 (8): 2542–2553.
- Wang, W., W. Chen, X. Zhu, and H. Wang. 2017. “Personalized Recommendation of Crowdfunding Campaigns: A Bipartite Graph Approach for Sparse Data.” Systems Engineering – Theory & Practice 37 (4): 1011–1023.
- Wang, N., Q. Li, H. Liang, T. Ye, and S. Ge. 2018. “Understanding the Importance of Interaction Between Creators and Backers in Crowdfunding Success.” Electronic Commerce Research and Applications 27: 106–117.
- Wang, Z., L. Wang, Y. Ji, L. L. Zuo, and S. Qu. 2022. “A Novel Data-Driven Weighted Sentiment Analysis Based on Information Entropy for Perceived Satisfaction.” Review of Journal of Retailing and Consumer Services 68: 103038.
- Wang, B., W. Wu, W. Zheng, Y. Liu, and L. Yin. 2020. “Recommendation Algorithm of Crowdfunding Platform Based on Collaborative Filtering.” Journal of Physics: Conference Series 1673 (1): 012030.
- Wei, Z., and M. Lin. 2016. “Market Mechanisms in Online Peer-to-Peer Lending.” Management Science 63 (12): 4236–4257.
- Wessel, M., F. Thies, and A. Benlian. 2016. “The Emergence and Effects of Fake Social Information: Evidence from Crowdfunding.” Decision Support Systems 90: 75–85.
- Wu, Z., L. He, X. Ming, and M. Goh. 2021. “Service-Oriented Knowledge Recommender System and Performance Evaluation in Industrial Product Development.” International Journal of Production Research. doi:10.1080/00207543.2021.1988748.
- Wu, W., X. Huang, Y. Li, and C. C. Chu. 2018. “Optimal Quality Strategy and Matching Service on Crowdfunding Platforms.” Sustainability 10 (4): 1053.
- Wu, K., and M. Yang. 2002. “Alternative Fuzzy c-Means Clustering Algorithm.” Pattern Recognition 35: 2267–2278.
- Xiao, Y., C. Liu, W. Zheng, H. Wang, and C. H. Hsu. 2021. “A Feature Interaction Learning Approach for Crowdfunding Project Recommendation.” Applied Soft Computing 112: 107777.
- Xiao, S., and Q. Yue. 2018. “Investors’ Inertia Behavior and Their Repeated Decision-Making in Online Reward-Based Crowdfunding Market.” Decision Support Systems 111: 101–112.
- Xu, L., D. Li, C. H. Chiu, Q. Zhang, and R. Gao. 2022. “Implications of Warm-Glow Effect and Risk Aversion in Reward-Based Crowdfunding.” Transportation Research Part E: Logistics and Transportation Review 160: 102681.
- Yeou-Ren, S., G. Ruey-Shiang, and L. Ken-Chun. 2012. “Development of Machine Learning-Based Real Time Scheduling Systems: Using Ensemble Based on Wrapper Feature Selection Approach.” International Journal of Production Research 50 (20): 5887–5905.
- Yuan, X. 2017. “An Improved Apriori Algorithm for Mining Association Rules.” AIP Conference Proceedings 1820 (1): 080005.
- Zhang, D., and S. Chen. 2004. “A Comment on ‘Alternative c-Means Clustering Algorithms’.” Pattern Recognition 37 (2): 173–174.
- Zhou, M., B. Lu, and W. Fan. 2018. “Project Description and Crowdfunding Success: An Exploratory Study.” Information Systems Frontiers 20 (2): 259–274.