
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Simultaneous allocation of service times and buffer capacities in manufacturing systems in a random environment is a NP-hard combinatorial optimisation problem. This paper presents a sophisticated simulation-based optimisation approach for the design of unreliable production lines to maximise the production rate. The proposed method allows for a global search using a Genetic Algorithm (GA), which is coupled with Finite Perturbation Analysis (FPA) as a local search technique. Traditional techniques based on perturbation analysis optimise decision variables of the same nature (e.g. service time only, buffer capacity only), whereas the proposed technique simultaneously provides an allocation of service times and buffer capacities. One of the main focuses of this paper is the investigation of the persistence or absence of the buffer and service rate allocation patterns which are among the most essential insights that come from designing production lines. The results show the superiority of the combined GA-FPA approach regarding GA and FPA in terms of solution quality and convergence behaviour. Moreover, considering instances ranging from 3 to 100 machines, our numerical experiments are in line with the literature for small instances (as similar allocation patterns are identified in our work), but important differences are highlighted for medium/large instances.
1. Introduction
Serial production lines are widely employed for mass and batch production systems. These lines are composed of machines connected in series with buffers between each pair of adjacent machines. Items/units (products, components, or parts) move through these machines according to predefined sequences. In such production lines, material flow disruptions can be caused by different factors such as service time variations, machine repair cycles, machine failures, or specific events linked to buffer levels such as starvation or blocking. When these types of disruptions occur, the performance of the production lines is impaired, and their efficiency is reduced since even a small change in the design parameters may lead to significant performance losses. Therefore, allocating optimal buffer capacities and the assignment of appropriate service time to each machine is fundamental to enhance the production rate (PR) and to reduce investment costs (either in the form of work-in-process inventory costs, floor space use or capital investment). In addition, considering a joint Buffer and Service Time allocation Problem (BSTAP) is a challenging problem. The computational complexity of this problem is NP-Hard, as considering the Buffer Allocation Problem (BAP) is in itself NP-Hard (Smith and Cruz Citation2005; Dolgui et al. Citation2013).
Several studies have been conducted on production-lines design and optimisation. Much of the research has focused on the BAP. It has been a central theme that has attracted attention over the last 30 years (Papadopoulos, Li, and O’Kelly Citation2019). Demir, Tunali, and Eliiyi (Citation2014) and Weiss, Schwarz, and Stolletz (Citation2019) have reviewed in detail the literature on BAPs. Despite the substantial studies dedicated to the design of such systems, only a few publications deal with the BSTAP.
Furthermore, various methods that are related to the design of manufacturing systems are based on coupling simulation to optimisation techniques. These methods require a high number of iterations or replications and a huge amount of time, which makes their implementation in industry difficult (Shi and Men Citation2003). To reduce the time required to reach convergence, this paper uses Perturbation-Analysis (PA) methods that can reach good solutions on the basis of a single simulation run of the model, which reduces the convergence time (Ho and Cao Citation2012).
Considering the simultaneous allocation of buffer capacities and service times, a contribution of this paper is to combine the Finite Perturbation Analysis (FPA) and the Genetic Algorithm (GA). Indeed, such methods have been proved to be efficient in the case of BAP (Kassoul, Cheikhrouhou, and Zufferey Citation2022). In line with other techniques having a learning mechanism (Schindl and Zufferey Citation2015; Thevenin and Zufferey Citation2019), GA has a good exploration ability as it can quickly generate a variety of solutions that are spread over a large portion of the solution space. In contrast, FPA has a good exploitation ability as it can intensify the search around some promising solutions by determining an exploration direction in the search space provided by the gradient of the PR with respect to the system's parameters. Another goal of this paper is to develop (near-)optimal solutions for the BSTAP in unreliable production lines for various configurations and different system sizes. The impact of the topology of the (near-)optimal buffer-capacities and service-time allocations is one of the main goals of this study. Indeed, it helps the involved decision maker in designing the production line. To the best of our knowledge, the considered problem differs from all problems in previous works since the very scarce literature on the BSTAP deals only with reliable machines.
The remainder of the paper is organised as follows. Section 2 gives a literature review on the BSTAP. Section 3 formulates the problem in terms of a mathematical programming model and presents the detailed approach for solving the simultaneous allocation problem of both buffer capacities and service times. The development of the optimisation technique and related assumptions are presented in Section 4. In Section 5, various experiments are presented. Finally, Section 6 provides conclusions and future research directions.
2. Literature review
There are three main allocation problems: (1) the buffer allocation problem (i.e. the identification of the buffer capacities and their location in a production or manufacturing line), (2) the service time (workload) allocation problem (i.e. determine the appropriate workload allocated to each machine), and (3) the server allocation problem (i.e. the number of machines allocated to each workstation). The literature shows that the combinatorial complexity of each of the three allocation problems is NP-hard (Xi et al. Citation2022). Furthermore, as the size of the problem increases, the computational complexity of the problem increases considerably. The design of production lines may involve one, two or all three of the decision variables (i.e. buffer, workload, and server). When two decision variables are concerned (i.e. the simultaneous allocation of buffers/service times, buffers/servers, or service times/servers), the context is known as a double optimisation problem. If the problem includes the simultaneous allocation of buffers, service times and severs, it is known as a triple optimisation problem. For more details on the concept of double and triple optimisation in discrete part production lines, the reader can refer to Papadopoulos et al. (Citation2009). This section considers only the simultaneous buffer and service time allocation problem, giving the fact that the literature addressing BAP and service time allocation solely is rich and will not be discussed in this paper. Buzacott and Shanthikumar (Citation1993) propose the first study on the simultaneous allocation of buffers and service rates. They develop an analytical method for the joint optimisation problem and note that the maximum PR is generally obtained for a balanced buffer and service time allocations (i.e. a uniform-as-possible buffer and service time allocations). Hillier and So (Citation1995) consider small tandem queueing systems with a fixed total number of buffer spaces to maximise the throughput. They formulate the problem as a continuous-time Markov chain and show that uniform-as-possible allocations are interesting solutions, as those reported by Buzacott and Shanthikumar (Citation1993), when the total storage space to be allocated is a multiple of the number of buffers, with less buffer spaces allocated to the end buffers rather to the centre buffers of the system. Spinellis, Papadopoulos, and Smith (Citation2000) present an evaluative procedure for optimising small and large production line configurations using simulated annealing. They propose an approach for simultaneously balancing servers, buffers, and service times allocation on large reliable production lines. For the allocation of buffers, they obtain similar results as Hillier and So (Citation1995), i.e. there is an accumulation of buffers to the ends of the line. However, the allocation of service times does not show the uniform-as-possible allocation and follows a decreasing rate across the line. Zhang et al. (Citation2017) propose a simulation cutting method based on the decomposition technique to solve the discrete-event optimisation model of the joint buffer, service time, and server allocation problem. However, the computational time to solve the problem increases significantly when many iterations are needed to reach optimal allocations. Hillier and Hillier (Citation2006) use a cost model that considers both cost per buffer space and revenue per unit of throughput to optimise simultaneously buffer spaces and service times for small lines (up to four machines). The problem is formulated as a Markov chain using both Erlang and exponential processing times. They conclude that the service times of the solutions consistently satisfy a bowl allocation (i.e. the value of service times of the first and last machine is considerably larger than the other machines) when a small number of buffer spaces is used, and that the allocation is symmetric at the interior of the line. All these works conclude that, for both storage and service times, the bowl phenomenon occurs when the number of buffer spaces is large. Cruz et al. (Citation2012) combine a generalised expansion method with a multi-objective GA for the allocation of service times and buffers by generating solution-curves for several single-objective functions. The interest of their study is not essentially in the designs of allocation. These obtained solution curves show a compromise between total service time allocation, overall buffer allocation and throughput. Ng, Shaaban, and Bernedixen (Citation2017) propose a multi-objective optimisation approach for unpaced production lines. They analyse four performance measures of production systems, a set of optimal patterns of workload, and buffer allocation (average buffer level, average idle times, work in process, and throughput). Their main objective is to propose a methodology for the BSTAP to real complex production lines. They find that some interesting relationships among the performance measures studied are observed when a multi-objective design framework is considered. Instead of using simulation for the evaluation of the performance of production lines, decomposition methods have been used; Diamantidis et al. (Citation2020) use an efficient decomposition algorithm for evaluating the PR in a production line with parallel machines. The decomposition equations are derived and applied for each parallel machine at each workstation instead of substituting an equivalent machine for the non-identical parallel machines.
Spieckermann et al. (Citation2000) propose an approach based on a GA and simulated annealing integrated with a simulation model for solving a practical buffer planning problem for a car body assembly shop. Their objective function includes buffer sizes, deviations of service times from their respective upper bounds, and the variance of service times. Optimisation aims to minimise the objective function by calibrating weights for the overall buffer space used and service times of each station. The proposed approach is evaluated using a real-life case study of a car manufacturer. They conclude, in agreement with the planning engineers of the car, that the simulation-based optimisation is a helpful tool to enhance the design process. Tempelmeier (Citation2003) uses a decomposition method to determine the performance evaluation and optimal buffer allocation for a real-life car body assembly shop where both variable and deterministic processing time are considered. The author sets a desired throughput (obtained before the optimisation by an initial buffer allocation) and minimises the total buffer space. Then, he fixes the value of the total buffer found to maximise the throughput (target). Finally, he reduces the service time of each station until reaching the target throughput found earlier.
Cruz, Duarte, and Souza (Citation2018) optimise the performance of general finite single-server queueing networks as well as studying simultaneously the minimisation of service times and buffer spaces with the objective of maximising the PR. They employ a GA for generating solutions of total buffer space and service times. To improve the throughput of the system, they redistribute the total buffer while keeping the optimal service-time allocations found by reorganising the buffers to be allocated along the line using simulated annealing. To evaluate their methodology, they consider the automotive assembly system proposed by Spieckermann et al. (Citation2000). The authors show that improvements in throughput are achieved using the evolutionary algorithm under various scenarios. Recently, to solve the joint BSTAP for different open queueing network topologies in reliable lines, Smith (Citation2018) uses a sequential quadratic-programming approach and examines the allocation patterns for small merge and split topologies (two or three stages with up seven machines). The main objective is to investigate the absence or persistence of allocation schemes of the buffers and service rates. The obtained allocation patterns corroborate, in one sense, those found in Hillier and Hillier (Citation2006).
The literature shows a clear gap in the case of unreliable production systems. The very few studies available for the BSTAP have only focused on reliable machines. This article offers a powerful optimisation approach that significantly improves upon the state of the art. Therefore, the interest of our work is twofold. On the one hand, the development of a design technique for stochastic production systems with unreliable machines based on the simultaneous design of buffer capacities and service times will enhance the research in production-line design. On the other hand, the development of a comprehensive optimisation technique using a single-simulation run will reduce the time needed for convergence, which contributes to the development of new generation of global-local optimisation techniques.
3. Problem formulation and solution approach
3.1. Problem formulation
We consider open serial production lines (also denoted as flow lines, tandem lines, transfer lines) as presented in Figure , composed of n machines connected in series and separated by (n-1) buffers
, where
denotes the buffer size located between two consecutive machines
and
. Parts enter the system from the machine
, then move to the first buffer
, then to machine
and so on until they reach the last machine
and leave the system.
Figure 1. Open serial production line.
The assumptions of the system are the following.
The first machine is never starved, and the last machine is never blocked.
Any machine is subject to breakdown but can only fail when it is up, neither starved nor blocked. The repair and failure rates of the machines are geometrically distributed.
The transfer times of parts from machines to stocks (and inversely) are negligible.
Probability (machine i is DN for next part | i is UP for current part)
Consider the vector of decision variables that has a dimension of (2n-1), where
represent the buffer capacities of available physical locations, and
represent the service times of machines. Moreover,
is a fixed nonnegative integer representing the total buffer space,
is the total time for the manufacturing of the product, and
is the mathematical function representing the Production Rate (PR) of the line.
The design problem addressed in this paper is to allocate over (n-1) buffers and
over n machines. The objective is to maximise the average PR of the production line. As in Donohue and Spearman (Citation1993) and in Suri and Leung (Citation1989), we consider the assumption that the total time
can be distributed in some way throughout all the machines. The problem can be stated, in mathematical terms, as follows:
(1)
(1)
(2)
(2)
(3)
(3)
3.2. Solution approach
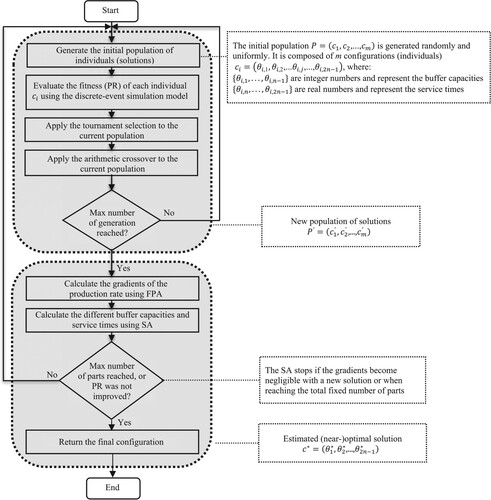
The proposed approach is a global-search procedure using a genetic algorithm (GA), which is coupled with a Finite Perturbation Analysis (FPA) local search. The goal of combining GA and FPA is to benefit from the advantages of both methods. GA allows for approaching optimal solutions in a small computing time whereas FPA can improve the solutions with the Stochastic Algorithm (SA) using the same simulation for estimating the gradients (i.e. the simulation and optimisation are conducted simultaneously). First, the GA operators are applied until a stopping condition is satisfied. Next, FPA iteratively replaces a current solution (found by GA) by a new one, until some stopping criterion is achieved. The detailed optimisation approach is presented in Figure , where the initial population, , is composed of m different configurations (solutions), where each solution
is generated uniformly and randomly (see Kassoul, Cheikhrouhou, and Zufferey (Citation2022) for more details on the way to generate such a population of random solutions).
represents the jth design parameter of the ith configuration, where
are integer (resp. real) numbers and represent the buffer capacities (resp. the service times) for
(resp.
). To approach a (near–)optimal solution
, the new population
is generated from the population P by applying the usual GA operators (i.e. selection, crossover, and mutation) for a fixed-number of generations. In this region, the employed stochastic algorithm (SA) relies on the gradient descent technique (Robbins and Monro Citation1951). SA takes the configurations of P’ and calculates the PR gradients
according to the design decisions (buffer capacities and service times)
.
Figure 2. Global approach of the adopted design.
Consider the original discrete-event simulation of L parts. represents the decision variable
at the iteration
. The iteration
allows the progression of the variables
by simulating
parts (
to determine a new evaluation of the gradients using FPA. The new search direction for the design solution is determined by this gradients’ evaluation. For each iteration k, the projections of the gradients’ vector on the following hyperplanes
and
is estimated. In fact, for a fixed parameter
, the projected gradients allow for determining the best direction for enhancing the current solution. As the search for solutions takes place in two spaces, two iterative variants of SA are constructed.
Hence:
(4)
(4) and
(5)
(5) where
•
• the term
4. Development of the optimisation technique
4.1. Genetic algorithm (GA)
4.1.1. Background
GA is one of the commonly used population-based stochastic metaheuristics (Chaudhry and Luo Citation2005). GA needs an initial population P of solutions to start with (such solutions are usually generated randomly to have a sufficient diversity of characteristics). Then, for a fixed number of generations, GA repeats the following steps. (1) Selection: some solutions of P are selected according to their fitness (i.e. objective-function values). (2) Crossover: the selected solutions are used to generate a new population . (3) Mutation: the solutions of
are randomly modified (individually).
4.1.2. Selection operator
In this study, we use a robust and effective selection mechanism commonly used by GAs, which is tournament selection (Lei, Zheng, and Guo Citation2017). First, two individuals of the population are selected randomly. Next, their PR (obtained by the execution of the simulation model) are compared, and finally, the winner is selected for the next generation.
4.1.3. Crossover operator
The arithmetic crossover operator with a constraint criterion is used (Duman Citation2018). First, two parents from the actual population, say and
, are selected. Then, the two parents are linearly combined to generate two new children
and
using Equations (7) and (8), where α is a coefficient selected randomly and uniformly in the interval [0, 1]. Note that an adjustment procedure is performed to fulfil constraints (2) (see our comments below).
(7)
(7)
(8)
(8)
4.1.4. Mutation operator
Since the buffer size is an integer variable, some values of the children are decreased or increased (modified) to ensure that the value of each buffer size is an integer. The adjustment procedure and the rounding mechanism for the arithmetic crossover used in this work correspond to the mutation operator (Türkyılmaz and Bulkan Citation2015).
Algorithm 1 summarises the steps of the proposed GA for the considered problem.
Table
4.2. Finite perturbation analysis (FPA)
We give here an overview of the generation and propagation of perturbation through FPA. A more comprehensive work on the generation and propagation rules is presented in (Cheikhrouhou Citation2001). The basic idea of the Perturbation Analysis (PA) technique is to analyse a nominal sample path (from the observation of real system or single-model simulation) and to use it to construct perturbed sample-paths. The perturbed path is the result of injecting variations of decision variables into the system. Suppose that during the experiment time T, a total of parts are served by machine i. Then the production rate of machine i in the nominal path is:
(9)
(9) Production lines are considered as Discrete-EventDynamic Systems in which perturbations do not only affect the events times and durations, but also the number of parts served by the different machines, resulting in the increase or the decrease of blocking and/or starvation periods. Let
be the total event time perturbation on machine i at the end of a simulation replication. The production rate of machine i in the perturbed path is:
(10)
(10)
is derived from the nominal path observation, and
is calculated through the application of perturbation generation and propagation rules on the nominal path. Since perturbation generation rules are parameter specific, it is related here to the variation of buffer capacities and service times. As buffer capacities are discrete variables, a simple increase of the size could lead to a highly perturbed path with important changes in the order of the events, which does not reflect the system under consideration. Therefore, Infinitesimal Perturbation Analysis (IPA) cannot be considered (Glasserman Citation1991; Suri Citation1987). We consider thus the development of FPA as an extension of PA when perturbations are finite (large amplitude) and where the system's performance is not affected by the order changes in events (Ho Citation1987; Suri and Leung Citation1989). Indeed, we assume that the type of future interactions that a perturbation, once introduced, can encounter and/or lead through the system in the perturbed path in and the nominal path is statistically similar (Ho Citation1987). Therefore, the nominal path can be used to determine the response of the system to a perturbation. This shows the advantage provided by this technique compared to the usual techniques of gradients estimates. Let
be the end time of the service duration on machine i, and
be the nominal service start times of the event under consideration. Figure shows a case where the machine
is NI (starved) in the nominal path, ended by a part transfer from
to
(the arrow indicates the direction of passage of the release part from one machine to another). To determine how the system may evolve in the perturbed environment, we assume that both
and
encounter the perturbation
and
(generated or propagated), respectively. The total perturbation value propagated on
is calculated through the formula:
(11)
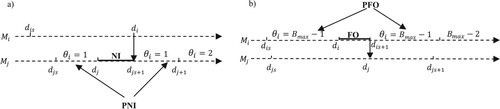
(11) We also define a potential starvation (resp. blocking) PNI (resp. PFO) on a server
as a state in which its upstream (resp. downstream) buffer contains only one (resp.
) unit(s). When a server is starved (resp. blocked), it is no longer able to receive or to deliver, and no routing of parts can be possible (see Figure a,b, respectively).
Figure 3. Sample path with NI case.
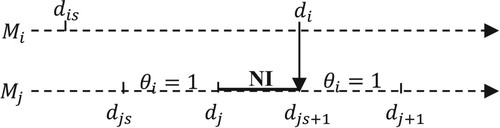
Figure 4. PNI and PFO periods.
4.2.1. Case of starvation (NI)
Consider the nominal event path in Figure a. After interaction between the two sequences of perturbed events of and
, two cases can occur.
Case 1: . The NI period still exists in the perturbed path. The perturbation on
is fully propagated to
. The new value of the perturbation resulting on
is:
(12)
(12) Case 2:
. The NI period is eliminated and replaced by a PNI period. The perturbation is partially propagated, and the new perturbation generated is then:
(13)
(13) Note that the term (
) is negative, attenuating the effect of the perturbation
on
, but it does not make it possible to obtain a value of the new negative perturbation
.
4.2.2. Case of potential starvation (PNI)
Consider Figure , where the machine is in a PNI state in the nominal path due to the unique part existing in the buffer
.
Figure 5. Sample path with PNI case.
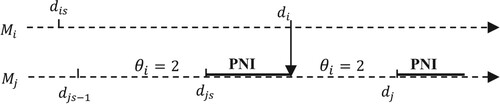
Interaction between servers may be transformed into real NI in the perturbed path and two cases can be distinguished.
Case 1: . The PNI remains PNI, and all service event sequences retain their perturbations:
(14)
(14)
(15)
(15) Case 2:
. In the perturbed path, the part transferred from
arrives later than the end of the service of the last part contained in the stock and thus in use by
. This situation creates a starvation period during which
remains idle. The PNI is transformed into a starvation period on
. The perturbation is then partially propagated, creating a NI period on
. Note that (
) is negative, which asserts the phenomenon of partial propagation.
(16)
(16) All cases of NI or PNI periods can be summarised in the following equation, where
denotes the algebraic value of the duration of a starvation interval for the machine
, i.e.
.
(17)
(17)
4.2.3. Case of blocking (FO)
The development of the perturbation propagation rules in the case of blocking (Figure b) is treated similarly to the case of starvation.
4.2.4. Case of potential blocking (PFO).
Consider Figure where the machine is in a PFO period in the nominal path.
Figure 6. Sample path with PFO case.
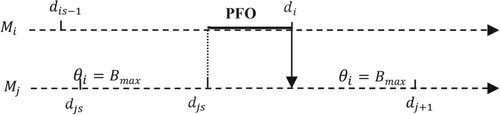
Two cases can be presented in the perturbed path.
Case 1: . The PFO still exists in the perturbed path of
. There is no upstream propagation, and each machine keeps its already acquired perturbations.
(18)
(18)
(19)
(19)
Case 2: . The potential FO is transformed into a blocking period on
. The perturbation is partially propagated from
, creating thus a FO period on
:
(20)
(20) All cases of FO or PFO periods can be summarised in the next equation, where
is the algebraic value of the duration of a blocking interval for the machine
, i.e.
.
(21)
(21)
4.3. FPA algorithm
4.3.1. FPA algorithm for buffer capacities
Consider an observation (or a simulation) of a production line, on which a total of parts are treated within a time duration T. We assume that all possible events during the simulation run can occur (i.e. the simulation is sufficiently long). The PR calculated over the duration T is approximated by the Equation (22):
(22)
(22) Hence,
(23)
(23) Assuming that the stopping criterion of the simulation is the total number of parts served by the output machine of the system (i.e. L), we have
(24)
(24) where
denotes the total perturbation time that affects the system when a perturbation
is introduced. In this study, the perturbation is one unit stock capacity related to each relevant event. The prediction of the impact of the perturbation concerns the event's persistence in the perturbed path and its duration. Thanks to the propagation rules of FPA, this incrementation of one unit is virtual and used only to evaluate the PR gradient and the value of
as follows:
(25)
(25) where
represents the total temporal perturbation acquired by the output machine
after the treatment of
parts, which is also the total time gain (or loss) that is cumulated at the output machine
. In other ways,
is an estimator of
. Algorithm 2 is a simplified FPA algorithm for buffer capacities.
Table
4.3.2. FPA algorithm for service times
To estimate (for
), we use the perturbation analysis gradient estimator. Algorithm 3 is a slightly modified version of the method presented by Suri and Leung (Citation1987). The first step is the initialisation of accumulators
(
), where
are separate accumulators needed for the gradient calculations. So, at each event (end of operation on a machine), the value of the gradient is calculated and
is added to
.
denotes the sample gradient of the variable
, where
since in this work
(Step 2). At the end of the simulation, an estimation of
is given by the following equation, where
denotes the value of accumulator at the end of the simulation.
(26)
(26)
Table
4.4. Stochastic algorithm (SA)
The gradient estimates resulting from FPA are injected into a SA to compute the (near-)optimal allocation of buffer capacities and service times for the production line. The SA presented in Algorithm 4 is based on Robbins and Monro (Citation1951), where the gradients are considered from the PR function's projection on the constraint hyperplane = constant. The SA updates intermediate variables
(buffer capacities and service times) at each iteration corresponding to a perturbed path generation, following the direction of the gradient. Here, a single run optimisation algorithm is used, in the sense that the update procedure is activated at each end service of p units
. The value of p is fixed empirically. The update procedure of the configuration uses the gradients calculation's technique based on FPA (Step 3). Also, we chose
(respectively
) as numerical suites of type
(respectively
), where
(resp.
) is a random constant with a chosen initial value such that the value of the
after each iteration are kept in the same order. Their values determine the step size of the production rate. A precaution is proposed in Step 4 if some updated values of
are negative. Step 5 returns the final variable values where a discretisation of buffer capacities values is necessary. The algorithm stops when a (near-)optimal solution is obtained. A trade-off between the accuracy of the estimated parameter and the simulation length is acquired by the parameter ϵ, set here to
. The benefit of the stopping criterion used is that it considers simultaneously the variations of all variables
. In other words, the algorithm stops when the variation of the variables becomes negligible within the same iteration.
Table
5. Experiments
Since one of the goals of the paper is to identify design principles, guidelines, and patterns that could help production managers in determining the optimal values for buffer sizes and service times, the experiments are designed to reach this goal. We consider unreliable production lines with a number of machines ranging from 3 to 100 (for the case of reliable machines, see for instance Spinellis, Papadopoulos, and Smith Citation2000). Not only the PR values reached by the method proposed are compared with the ones obtained by other techniques from the literature, but also the obtained solution patterns are compared with the ones from other studies. Several experiments are conducted: (i) small instances have
= 3, 5 and 7 machines; (ii) medium/large instances have
= 10, 20 and 40 machines; and (iii) very large instances have
= 50, 75 and 100 machines. The algorithms are implemented in Java and the models are developed by using the simulation language Arena V14.0 (Altiok and Melamed Citation2010). The experiments are run on intel Core (TM) i5 CPU @ 1.9-GHz with 8 GB of RAM. In all cases, the PR average is calculated by simulating 10,000 parts with 20 runs/replications. The total service time
is 3N time-units for each machine. All machines are identical and are subject to breakdown. Except if other information is provided, for all the instances, the repair and failure times are geometrically distributed with MTTR = 10 and MTBF = 70, respectively. GA uses tournament selection, arithmetic crossover operators, and a population size of 30. The algorithm stops when it reaches the maximum fixed number of 20 generations or when achieving (at a given generation) a PR better than the best PR ever reached. The computation times (presented in the last column of Tables , and ) are not discussed in detail, but the order of magnitude is 84 (resp. 160) minutes on average for large (resp. very large) production lines, which is reasonable from a practical standpoint with respect to various studies in production (e.g. Respen, Zufferey, and Amaldi (Citation2016), Zufferey (Citation2016)).
In Subsection 5.1, to measure the benefit of combining GA with FPA, we compare the two latter methods (used independently) with GA-FPA. In Subsection 5.2, we measure the benefit of optimising simultaneously buffers and service times. In Subsection 5.3, experiments are conducted to identify the service-time and buffer allocation patterns of the GA-FPA solutions. In Subsection 5.4, a sensitivity analysis is proposed with respect to having a machine with a different repair time or with a different failure time. Finally, in Subsection 5.5, the performance of the proposed hybrid approach is investigated for the very large production lines.
5.1, Comparison of GA, PA, and GA-FPA
GA-FPA is compared with FPA and GA (considered independently). Table gives the results for instances with in 5, 10, 15, 20, 40. Columns 1 and 2 present
and
, respectively. Next, from columns 3–5, the average PR is given for GA, FPA, and GA-FPA, respectively. In terms of solution quality, GA-FPA achieves the best solutions for each instance.
Table 1. Results of GA, FPA and GA-FPA.
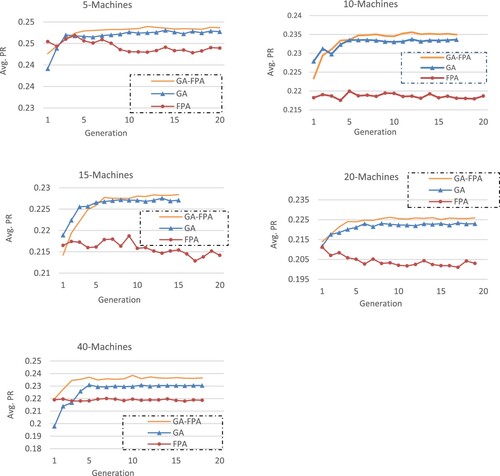
The evolutions of the average PR with respect to the number of generations for the five instances are presented in Figure . Regarding the convergence behaviour, only a few generations are needed for GA-FPA to converge to its best solutions (it is not the case for GA and FPA). We can explain this efficient convergence of GA-FPA by the exploration ability of its GA feature to quickly identify promising regions of the solution space, and by the exploitation ability of its FPA component to intensify the search in such promising regions.
Figure 7. Convergence behaviour of the proposed methods.
5.2. Benefit of optimising simultaneously buffers and service times
To measure the benefit of the simultaneous allocation of buffers and service times, an idea is to compare the results of the simultaneous allocation with those of the buffer allocation and the service time allocation considered alone. In the case of buffer-capacity optimisation, the service times are all equal and satisfy the constraint. Whereas in the case of service-time optimisation, the buffer capacities are as equal as possible, with some balanced adjustments to have integer numbers and to satisfy the
constraint.
Table presents the results for instances with in 5, 10, 15, 20, 40 machines. The first two columns present the instance parameters, followed by the average PR for service time allocation, buffer allocation, and simultaneous allocation. Note that for the instance with
= 40, only five runs (instead of 20) have been carried out.
Table 2. Results of service time, buffer, and simultaneous allocations.
We can easily observe that the joint optimisation of buffers and service rates obtains the best average PR results for all instances. The quantification of this benefit may help practitioners and scientists for designing and planning production lines.
5.3. Solution patterns obtained by GA-FPA
Tables and present experiments with in 3, 5, 7 for the small instances (Table ), and with
in 10, 12, 15, 20, 40 for the medium/large instances (Table ).
is given in the second column. To investigate the buffer allocation scheme with respect to a uniform allocation,
is chosen to be a multiple of the number of buffers. Column 3 (resp. 4) presents the best buffer capacities
(resp. service times
) returned by GA-FPA. Note that for Table , due to the large number of indicated values, both
and
are presented in column 3 (for
> 12). Computing times are given in the last column, in seconds.
Table 3. Results for small production lines (involving 3, 5, and 7 machines).
Table 4. Results for medium/large production lines (involving 12, 15, 20, and 40 machines).
Figure provides the allocation patterns for buffer capacities throughout the available buffer spaces between machines. Eight cases are presented (three cases of small-size production lines with in 3, 5, 7, five cases of medium/large-size production lines with
in 10, 12, 15, 20, 40). For each case, four values of
are tested. Likewise, Figure presents the allocation patterns for the service times of the machines. Note that since we determine the capacity of different buffers (Figure ) and the service time of different machines (Figure ), we could have represented these allocations as clouds of points. However, for sake of clarity, we prefer to connect the different points and consider a representation as if it was a continuous function.
Figure 8. Allocation patterns for buffer capacities.
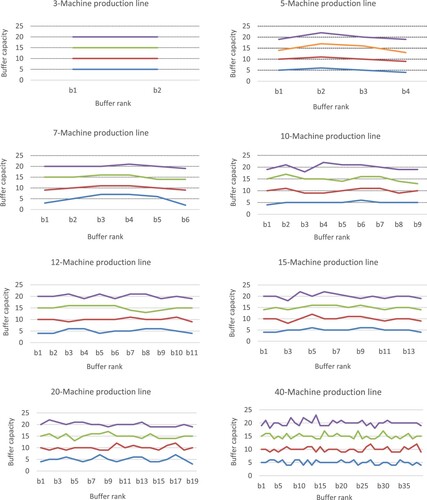
Figure 9. Allocation patterns for service times.
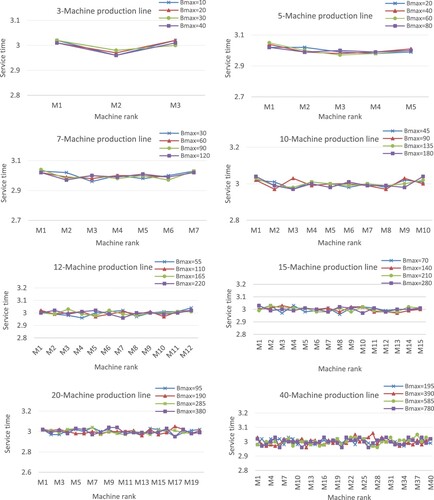
For the small instances, the results for the allocation of buffer capacities (b* values of Tables and , and patterns of Figure ) show that there is more storage space needed in the middle of the production line and less storage space needed at the end. These pattern allocations are likely to facilitate parts flowing downstream and to avoid possible blockages. For the allocation of service times, the results (t* values of Tables and , and patterns of Figure ) show that the machines at the end of the line need more processing time than the machines at the centre. This is certainly to facilitate the passage of parts throughout the production line and thus to avoid congestion at the centre of the line. These results corroborate the findings of Smith (Citation2018) and Hillier and Hillier (Citation2006). In their studies, the authors mentioned this service-time (resp. buffer-capacity) allocation pattern as bowl-shaped (resp. inverted bowl-shaped) allocation. The bowl-shape name arises from the fact that the service-time values of the first and the last machine are larger than the service times of other machines which are relatively close together.
For the medium/large instances (i.e. from = 10), the results show that some buffers in the middle of the line require lesser storage capacities than the buffers at the ends of the production line. This buffer allocation pattern (inverted bowl-shaped) is less accentuated as the number N of machines increases. Indeed, the uniform allocation of buffers becomes more pronounced, as shown in Figure . It can also be seen that most cases favour the allocation of slightly low storage capacities at the end of the production line. This pattern allocation of buffers is likely to facilitate parts flowing downstream and thus to avoid any blockages. Regarding the allocation of service times, the results with
= 10 show that the service times of the first and the last machine are slightly larger than the service times of other machines (which are still relatively close together), and some machines in the middle of the line need service times relatively like those of the end. Figure shows that the bowl-shaped times-allocation patterns tend to disappear as N increases. Instead, a uniform allocation tends to persist. These results are similar to the findings of Spinellis, Papadopoulos, and Smith (Citation2000) considering the buffer allocation. However, as far as the service time is concerned, the service time allocation does not follow a uniform allocation but diminishes towards the end of the line.
In summary, the inverted bowl-shaped pattern for buffer capacities and the bowl-shaped allocation for service times seem to be diminished as the number of machines of the production line increases, and instead, both the service times and buffers allocations tend to follow roughly a uniform allocation.
5.4. Sensitivity analysis
Two series of experiments are presented to determine whether the allocation patterns found when all machines have the same failure and repair times are respected or, otherwise, whether there are specific buffer and service time allocation patterns when the failure and repair rates are modified. Here, the PR of the production line is calculated by treating 10,000 parts for 10 runs/replications. The results are reported in Table and 6 for instances with in 3, 10, 20, where the total buffer size
to be assigned is presented in the second column. The fourth and fifth columns present the returned buffer capacities
and service times
, respectively.
Table 5. Results if one machine has a different repair time.
5.4.1 Impact of having a machine with a different repair time
Table presents the simultaneous buffer and service time allocations for a system where the failure times of all machines are identical and follow a geometric distribution with MTBF = 70, and where the repair times of the machines are different. For each case , only machine k has a different repair time (MTTR = 30) compared to the other machines (MTTR = 10). The values of service time of the machine with a smaller MTTR and the corresponding downstream stock are marked in a grey font.
The results show that the machine which has a larger repair time needs less service time than the other machines and therefore, the downstream buffer size is larger (see the grey cells). These pattern allocations are more pronounced for a production line composed of three machines. For example, in case 1 (resp. case 3), the value of the first stock for the obtained configuration reached is 28 (resp. 15), whereas the value of the second stock is 12 (resp. 25). We notice that when the middle machine has a larger MTTR, the values of the two stocks are roughly similar (19 and 21 when = 3). We can then observe that when N increases, the stock allocation becomes more uniform but the downstream buffer size of the machine with a larger MTTR remains in most cases slightly larger than or equal to the other buffers. In all cases, the service time of the machine with a larger MTTR is significantly smaller compared to the other machines. It can also be noted that the upstream machine and the downstream machine have a reduced service time (forming a bowl-shaped configuration around these three machines). For example, in the highlighted case 6 for
= 10, the best allocation reached for the service times is (3.15, 3.20, 3.10, 3.09, 2.94, 2.44, 2.92, 3.02, 3.06, 3.08) and the best allocation proposed for the buffer capacities is (20, 21, 21, 20, 20, 21, 19, 18, 20). We note also that the upstream machine and the downstream machine have lower service times (2.94 and 292, respectively) compared to the other machines. This certainly helps to improve the fluidity of the system and to reduce the total production time, and consequently to avoid possible blockages.
5.4.2. Impact of having a machine with a different failure time
Table presents the simultaneous buffer and service time allocations for a system where all the machines have the same repair times (MTTR = 10), and for each case , only machine
has a different failure time (MTBF = 100) compared to the other machines (MTBF = 70). The service-time values of the machine with a bigger MTBF and the downstream stock are marked in grey font. The following observations can be made.
In all cases, the service time of the machine with the bigger MTBF is larger than the other machines.
The service times of the downstream machines following the machine with the bigger MTBF tend to decrease towards the end of the line, and as the number of machines increases, a roughly uniform allocation occurs.
In most cases, buffers slightly tend to accumulate towards the downstream buffer of the machine with a high MTBF, and as the number of machines increases, the buffer allocation follows a uniform allocation.
Table 6. Results if one machine has a different failure time.
5.5. Results on very large instances
There are very few studies devoted to the case of very large production lines. They indicate that it takes very long computation times to obtain competitive results (typically tens of hours). In other words, the computing time increases considerably with the number n of machines. We consider production lines with in 50, 75, 100 with five runs. To investigate the buffer allocation scheme with respect to a uniform allocation,
is chosen to be a multiple of the number of buffers.
Table presents the results of GA-FPA. is given in the second column. Column 3 presents both the best allocations of the buffer capacities
and the service times
. Computing times are given in the last column (in seconds).
Table 7. Results for very large production lines (involving 50, 75, and 100 machines).
From Table , we can observe that the buffer allocation (column 3) does not follow the inverted bowl pattern, but the buffer capacities are almost all equal. Thus, it appears that the buffer values for most available physical locations are equal to the average value (i.e. or
, for
, where
is the number of machines) with a variation of
units. This is certainly due to the nature of failure of the machines because if the system is symmetrical (by its structure and its operating parameters), the optimal allocation result should also be symmetrical (Cheikhrouhou, Paris, and Pierreval Citation2002).
Regarding the allocation of service times, the same observation can also be noticed. Indeed, the patterns of service times resulting from the optimisation do not follow the bowl-shaped allocation as in the case of small lines, but the service times of all machines are almost equal. Unlike the balanced case, where the characteristics of all machines are identical and the optimal allocation should be occurring when all service times (
) are the same (
units in our case), the results of
(column 3 of Table ) present some slight deviation from this value (i.e.
units). This can be explained by the fact that the machines are prone to breakdowns. We can also notice that this deviation is much lower (about
) for the very large production lines (i.e.
= 50, 75 and 100 machines) compared to the large production lines (i.e.
= 40 machines), for which it is of the order of
.
In summary, the patterns for buffer capacities and service times for very large production lines seem to follow roughly a uniform allocation. These results are in line with results of Spinellis, Papadopoulos, and Smith (Citation2000) and can be explained by the symmetrical structure of the production line.
6. Conclusion
This study presents a robust hybrid technique coupling Finite Perturbation Analysis (FPA) with Genetic Algorithm (GA) for allocating simultaneously service times and buffer capacities in production lines with unreliable machines. The processing (service) time of each machine and the capacity of each buffer (between machines) must be determined while satisfying the total buffer-space and service-time constraints. The goal consists in maximising the production rate of the production line. FPA (based on the estimation of the production rate's gradients) forms the core of the proposed approach, whereas GA provides its input solutions. Thanks to the exploration and diversification ability of GA, the solution-space regions of the (near-)optimal solutions can be quickly reached. Next, benefiting from the exploitation and intensification ability of FPA, these solution-space regions are deeply investigated to find better solutions. Another benefit of the proposed method relies in being able to use a single simulation for the optimisation. Moreover, our experiments for instances with up to 100 machines show that the buffer and service-time allocation patterns (over the machines) corroborate previous patterns found in the literature but also exhibit some striking differences. These allocation patterns, while context dependent, are one of the most important insights for decision makers in designing production lines.
New solutions can be investigated (through the emergence of Industry 4.0 and the progress in manufacturing technologies) to improve the performance and the production rates of these systems. Indeed, the rise of intelligent and interconnected industrial robots in charge of executing system operations is helpful for monitoring inventory levels as well as tracking these different operations (including items/units transfer between operators/robots and the time needed to achieve it). In fact, the proposed approach, which allows for the simultaneous allocation of operator/robot service times and buffer capacities, offers new and interesting perspectives to enhance the performance of such systems. In order to have an in-depth and comprehensive analysis of unreliable production lines, another possible direction for this research is to use different criteria to account for different line combinations. Therefore, the proposed method might require important adjustments to extend it to other production systems such as transportation systems, assembly/disassembly systems or transfer lines.
Acknowledgements
This paper is based on chapter 4 of the PhD Thesis of the first author (Kassoul Citation2022).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The paper includes no data.
Additional information
Funding
Notes on contributors

Khelil Kassoul
Khelil Kassoul obtained his electromechanical engineering degree from the University of Boumerdes in Algeria. Afterward, he continued his studies in Paris for an advanced degree in Electrical Engineering and worked as an associate member in a European project LHC (Large Hadron Collider) which is the largest and most powerful particle accelerator in the world at CERN (European Organization for Nuclear Research). Holder of a postgraduate degree from EPFL (Swiss Federal Institute of Technology in Lausanne) in electrical engineering, he has been a professor of mathematics and physics for Swiss maturity and Baccalaureat classes since 2003. He is currently a PhD candidate at the Geneva School of Economics and Management of the University of Geneva. His research interests include areas related to applied mathematics, optimisation, design, simulation, artificial intelligence, and inventory management.

Naoufel Cheikhrouhou
Naoufel Cheikhrouhou is a Professor of Supply chain, Logistics and Operations Management at Geneva School of Business Administration University of Applied Sciences Western Switzerland. Previously, he was leading the Operations Management research group at the Swiss Federal Institute of Technology at Lausanne (EPFL). He graduated from the School of Engineers of Tunis and received his PhD in Industrial Engineering from Grenoble Institute of Technology in 2001. His main research interests are modelling, simulation and optimisation of enterprise networks, behavioural operations management and Demand planning and forecasting. Dr. Cheikhrouhou received the Burbidge Award in 2003 and the BG Ingénieurs conseils Award in 2013 for his contribution to the research excellence in the fields. Leading different projects with the collaboration of national and international industrial companies, Naoufel Cheikhrouhou published more than 100 papers in scientific journals and conferences and regularly acts as keynote speaker in academic and industrial international conferences.

Nicolas Zufferey
Nicolas Zufferey is a full professor of operations management at the University of Geneva in Switzerland, since 2008. His research activity focuses on designing solution methods for difficult and large optimisation problems, with applications mainly in transportation, scheduling, production, inventory management, network design, and supply chain management. He is member of the CIRRELT transportation and logistics research centre (www.cirrelt.ca) and of the GERAD decision-analysis research centre (www.gerad.ca). He received his BSc and MSc degrees in Mathematics at EPFL (Swiss Federal Institute of Technology at Lausanne), as well as his PhD degree in operations research (2002). He was then successively a post-doctoral trainee at the University of Calgary (2003–2004) and an assistant professor at Laval University (2004–2007). He is the (co)author of more than 120 publications (papers in professional journals, proceedings of conferences, and book chapters). He has had research activities with 26 Universities in Europe and America, as well as with 24 private companies.
References
- Altiok, T., and B. Melamed. 2010. “Simulation Modeling and Analysis with Arena”. 1st ed. London: Academic Press. Elsevier.
- Buzacott, J. A., and J. G. Shanthikumar. 1993. Stochastic Models of Manufacturing Systems. New Jersey: Prentice-Hall.
- Chaudhry, S. S., and W. Luo. 2005. “Application of Genetic Algorithms in Production and Operations Management: A Review.” International Journal of Production Research 43 (19): 4083–4101. doi:10.1080/00207540500143199
- Cheikhrouhou, N. 2001. Apport de l’analyse de perturbation pour le dimensionnement et le pilotage des systèmes de production. PhD thesis. Grenoble INPG.
- Cheikhrouhou, N., J.-L. Paris, and H. Pierreval. 2002. “Une Méthode de Dimensionnement de Lignes de Transfert via L’analyse de Perturbation Finie.” Journal Européen Des Systèmes Automatisés 36 (2): 199–222.
- Cruz, F. R., A. R. Duarte, and G. L. Souza. 2018. “Multi-objective Performance Improvements of General Finite Single-Server Queueing Networks.” Journal of Heuristics 24 (5): 757–781. doi:10.1007/s10732-018-9379-8
- Cruz, F. R. B., G. Kendall, L. While, A. R. Duarte, and N. L. C. Brito. 2012. “Throughput Maximization of Queueing Networks with Simultaneous Minimization of Service Rates and Buffers.” Mathematical Problems in Engineering 2012: 1-19. doi:10.1155/2012/692593
- Demir, L., S. Tunali, and D. T. Eliiyi. 2014. “The State of the art on Buffer Allocation Problem: A Comprehensive Survey.” Journal of Intelligent Manufacturing 25 (3): 371–392. doi:10.1007/s10845-012-0687-9
- Diamantidis, A., J.-H. Lee, C. T. Papadopoulos, J. Li, and C. Heavey. 2020. “Performance Evaluation of Flow Lines with non-Identical and Unreliable Parallel Machines and Finite Buffers.” International Journal of Production Research 58 (13): 3881–3904. doi:10.1080/00207543.2019.1636322
- Dolgui, A., A. Eremeev, M. Y. Kovalyov, and V. Sigaev. 2013. “Complexity of Buffer Capacity Allocation Problems for Production Lines with Unreliable Machines.” Journal of Mathematical Modelling and Algorithms in Operations Research 12 (2): 155–165. doi:10.1007/s10852-012-9199-z
- Donohue, K. L., and M. L. Spearman. 1993. “Improving the Design of Stochastic Production Lines: An Approach Using Perturbation Analysis.” International Journal of Production Research 31 (12): 2789–2806. doi:10.1080/0020754930895-6900
- Duman, S. 2018. “A Modified Moth Swarm Algorithm Based on an Arithmetic Crossover for Constrained Optimization and Optimal Power Flow Problems.” IEEE Access 6: 45394–45416. doi:10.1109/ACCESS.2018.2849599
- Glasserman, P. 1991. “Structural Conditions for Perturbation Analysis of Queueing Systems.” Journal of the Association for Computing Machinery 38 (4): 1005–1025. doi:10.1145/115234.115348
- Hillier, M. S., and F. S. Hillier. 2006. “Simultaneous Optimization of Work and Buffer Space in Unpaced Production Lines with Random Processing Times.” IIE Transactions 38 (1): 39–51. doi:10.1080/07408170500208289
- Hillier, F. S., and K. C. So. 1995. “On the Optimal Design of Tandem Queueing Systems with Finite Buffers.” Queueing Systems 21 (3): 245–266. doi:10.1007/BF01149164
- Ho, Y.-C. 1987. “Performance Evaluation and Perturbation Analysis of Discrete Event Dynamic Systems.” IEEE Transactions on Automatic Control 32 (7): 563–572. doi:10.1109/TAC.1987.1104665
- Ho, Y.-C. L., and X.-R. Cao. 2012. Perturbation Analysis of Discrete Event Dynamic Systems (Vol. 145). New York: Springer. doi:10.1007/978-1-4615-4024-3.
- Kassoul, K. 2022. “Hybrid algorithms for designing production lines.” Doctoral dissertation, University of Geneva.
- Kassoul, K., N. Cheikhrouhou, and N. Zufferey. 2022. “Buffer Allocation Design for Unreliable Production Lines Using Genetic Algorithm and Finite Perturbation Analysis.” International Journal of Production Research 60 (10): 3001–3017. doi:10.1080/00207543.2021.1909169
- Lei, D., Y. Zheng, and X. Guo. 2017. “A Shuffled Frog-Leaping Algorithm for Flexible job Shop Scheduling with the Consideration of Energy Consumption.” International Journal of Production Research 55 (11): 3126–3140. doi:10.1080/0020-7543.2016.1262082
- Ng, A. H., S. Shaaban, and J. Bernedixen. 2017. “Studying Unbalanced Workload and Buffer Allocation of Production Systems Using Multi-Objective Optimisation.” International Journal of Production Research 55 (24): 7435–7451. doi:10.1080/00207543.2017.1362121
- Papadopoulos, C. T., J. Li, and M. E. O’Kelly. 2019. “A Classification and Review of Timed Markov Models of Manufacturing Systems.” Computers and Industrial Engineering 128: 219–244. doi:10.1016/j.cie.2018.12.019
- Papadopoulos, C. T., M. E. O’Kelly, M. J. Vidalis, and D. Spinellis. 2009. Analysis and Design of Discrete Part Production Lines. New York: Springer. doi:10.1007/978-0-387-89494-2.
- Respen, J., Zufferey, N, and Amaldi, E. 2016. “Metaheuristics for a Job Scheduling Problem with Smoothing Costs Relevant for the Car Industry.” Networks 67 (3): 246–261. doi:10.1002/net.21656
- Robbins, H., and S. Monro. 1951. “A Stochastic Approximation Method.” The Annals of Mathematical Statistics 22 (3): 400–407. doi:10.1214/aoms/1177729586.
- Schindl, D., and N. Zufferey. 2015. “A Learning Tabu Search for a Truck Allocation Problem with Linear and Nonlinear Cost Components.” Naval Research Logistics 61 (1): 32–45. doi:10.1002/nav.21612
- Shi, L., and S. Men. 2003. “Optimal Buffer Allocation in Production Lines.” IIE Transactions 35 (1): 1–10. doi:10.1080/07408170304431
- Smith, J. M. 2018. “Simultaneous Buffer and Service Rate Allocation in Open Finite Queueing Networks.” IISE Transactions 50 (3): 203–216. doi:10.1080/24725854.2017.1300359
- Smith, MacGregor, J. and Cruz, F. R. 2005. “The Buffer Allocation Problem for General Finite Buffer Queueing Networks.” IIE Transactions 37 (4): 343–365. doi:10.1080/0740817059-0916986
- Spieckermann, S., K. Gutenschwager, H. Heinzel, and S. Voß. 2000. “Simulation-based Optimization in the Automotive Industry-A Case Study on Body Shop Design.” Simulation 75 (5): 276–286.
- Spinellis, D., C. Papadopoulos, and J. M. Smith. 2000. “Large Production Line Optimization Using Simulated Annealing.” International Journal of Production Research 38 (3): 509–541. doi:10.1080/002075400189284
- Suri, R. 1987. “Infinitesimal Perturbation Analysis for General Discrete Event Systems.” Journal of the Association for Computing Machinery 34 (3): 686–717. doi:10.1145/28869.28879
- Suri, R., and Leung, Y. T. 1987. “Single Run Optimization of a SIMAN Model for Closed Loop Flexible Assembly Systems.” Proceedings of the 19th Conference on Winter Simulation: 738–748. Atlanta, GA, USA, December 14-16, 1987.
- Suri, R., and Y. T. Leung. 1989. “Single run Optimization of Discrete Event Simulations—An Empirical Study Using the M/M/l Queue.” IIE Transactions 21 (1): 35–49. doi:10.1080/07408178908966205
- Tempelmeier, H. 2003. “Practical Considerations in the Optimization of Flow Production Systems.” International Journal of Production Research 41 (1): 149–170. doi:10.1080/00207-540210161641
- Thevenin, S., and N. Zufferey. 2019. “Learning Variable Neighborhood Search for a Scheduling Problem with Time Windows and Rejections.” Discrete Applied Mathematics 261: 344–353. doi:10.1016/j.dam.2018.03.019
- Türkyılmaz, A., and S. Bulkan. 2015. “A Hybrid Algorithm for Total Tardiness Minimisation in Flexible job Shop: Genetic Algorithm with Parallel VNS Execution.” International Journal of Production Research 53 (6): 1832–1848. doi:10.1080/00207543.2014.962113
- Weiss, S., J. A. Schwarz, and R. Stolletz. 2019. “The Buffer Allocation Problem in Production Lines: Formulations, Solution Methods, and Instances.” IISE Transactions 51 (5): 456–485. doi:10.1080/24725854.2018.1442031
- Xi, S., J. M. Smith, Q. Chen, N. Mao, H. Zhang, and A. Yu. 2022. “Simultaneous Machine Selection and Buffer Allocation in Large Unbalanced Series-Parallel Production Lines.” International Journal of Production Research 60 (7): 2103–2125. doi:10.1080/00207543.2021.1884306
- Zhang, M., Matta, A., Alfieri, A., and Pedrielli, G. 2017. “A simulation-based Benders’ Cuts Generation for the Joint Workstation, Workload and Buffer Allocation Problem.” 2017 13th IEEE Conference on Automation Science and Engineering (CASE): 1067–1072. Xi'an, China, August 20-23, 2017.
- Zufferey, N. 2016. “Tabu Search Approaches for two car Sequencing Problems with Smoothing Constraints.” Metaheuristics for Production Systems, 167–190. doi:10.1007/978-3-319-23350-5_8