
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The fraction model has been widely used to represent a range of engineering systems. To accurately identify the fraction model is however challenging, and this paper presents a regularised fast recursive algorithm (RFRA) to identify both the true fraction model structure and the associated unknown model parameters. This is achieved first by transforming the fraction form to a linear combination of nonlinear model terms. Then the terms in the denominator are used to form a regularisation term in the cost function to offset the bias induced by the linear transformation. According to the structural risk minimisation principle based on the new cost function, the model terms are selected based on their contributions to the cost function and the coefficients are then identified recursively without explicitly solving the inverse matrix. The proposed method is proved to have low computational complexity. Simulation results confirm the efficacy of the method in fast identification of the true fraction models for the targeted nonlinear systems.
1. Introduction
Machine learning is a powerful tool for technological progress and has been widely adopted for approximating nonlinear dynamic systems (Yildiz et al., Citation2017). The nonlinear system modelling has been a subject of intensive research in the past decades, and various machine learning regression (Singh & Dhiman, Citation2021) models have been proposed, such as polynomial nonlinear models (Paduart et al., Citation2010; Wang et al., Citation2021; C. Yang et al., Citation2020), rational models (Austin et al., Citation2021; Zhu et al., Citation2015, Citation2019), support vector machine (SVM) based regression models (Liang & Zhang, Citation2021; Suykens et al., Citation2002) and neural network models (Du et al., Citation2022; Qiao et al., Citation2018; Z. Yang et al., Citation2020), to just name a few.
Among them, polynomial nonlinear regression models are the most popular machine learning regression methods due to their simplicity to develop and capture complex relationships between system inputs and system outputs (Gambella et al., Citation2021). In particular, the rational model which is a ratio of two polynomials has attracted more attentions in the community as many engineering systems can be modelled as the ratio of two linear-in-the-parameter equations (Andreev & Borulko, Citation2017; Curtain & Morris, Citation2009; Hussein & Batarseh, Citation2011; Kambhampati et al., Citation2000; Swarnakar et al., Citation2017, Dec; Zhu et al., Citation2019), each consisting of some base functions. They are often referred to fraction models, and the rational models which all consist of polynomial terms in both numerator and denominator is a special case (Li, Citation2005). The fraction model has the capability of concisely approximating a wide range of nonlinear systems, while traditional models such as nonlinear polynomial ARX models, neural networks, support vector machines (SVM) (J. Zhang et al., Citation2012) may become overly complex in order to achieve the same level of modelling accuracy.
To fit a fraction model using the training data is a machine learning regression modelling problem. To establish an accurate fraction model, an efficient automatic learning method is the key to both determine the model structure and identify unknown parameters. This is however technically challenging, and for rational models as a special case, the solutions fall into two major categories. The first one is to transform the rational form to a linear-in-the-parameter expression (Billings & Zhu, Citation1991, Citation1994). Based on the transformed system, various algorithms have been developed to identify a suitable model structure and in the meantime to identify the unknown linear coefficients (Billings & Mao, Citation1998; Billings & Zhu, Citation1991; Zhu, Citation2003, Citation2005; Zhu & Billings, Citation1996; Zhu et al., Citation2017). These algorithms all have the same aim to iteratively offset the bias by updating the coefficients and the regressors based on the variance of estimation errors. The resultant models identified by these well-established methods are often less complex, though they still suffer from high computation complexity. The other approach is directly selecting the base function using the orthogonal methods, such as an orthogonal rational model estimation (Billings & Zhu, Citation1994) and Stieltjes process (Austin et al., Citation2021).
In particular, the popular orthogonal least square (OLS) method has been widely used for identifying a range of nonlinear models including the rational models (Zhu & Billings, Citation1996) although the conventional OLS scheme is still computationally expensive, particularly for backward model reduction. To reduce the computational complexity, Li et al proposed a fast recursive algorithm (FRA) (Li et al., Citation2005). The FRA framework has further led to the development of a series of effective algorithms for nonlinear system modelling, such as the two-stage stepwise algorithm (Li et al., Citation2006), two-stage OLS method (L. Zhang et al., Citation2015), least squares support vector machine (LSSVM) (Zhao et al., Citation2015) as well as methods to construct compact RBF networks (Deng et al., Citation2012, Citation2013, Citation2010). This paper will use the similar algorithmic framework to build fraction models for nonlinear systems, aiming to both develop a compact model and reduce the computational complexity.
A challenge for identifying the fraction model is to eliminate the bias caused by the errors introduced by the transformation. To tackle this challenge, various methods have been proposed to estimate the errors (J. Chen et al., Citation2018; Jin & Weng, Citation2019; Manela & Biess, Citation2021; Piga & Tóth, Citation2014). In order to penalise the bias induced by the linear transformation, this paper adopts a negative regularisation term to penalise the errors introduced into the transformed linear model. In essence, the regularisation term is used to balance the linear model estimation error and the bias of the estimated parameters due to the linear transformation (Ohlsson et al., Citation2010). The regularisation method proposed by Tikhonov (Tikhonov & Glasko, Citation1965) and its variants (Luo et al., Citation2016; Münker & Nelles, Citation2016; L. Zhang et al., Citation2019) have been widely used in machine learning to reduce the bias introduced into the parameter estimation. Popular regularisation methods include the regularisation,
regularisation and
regularisation (Castella et al., Citation2018; Luo et al., Citation2016; Senhaji et al., Citation2020; Tao et al., Citation2015; Torres-Barrán et al., Citation2018) where the weight of the regularisation term is often set positive to avoid over-fitting, while in this paper a negative weight is applied to the penalty term to reduce the bias introduced by the linear transformation. However, the weight has to be sufficiently small to ensure that the contributions to the cost function are positive.
Within the regularisation framework, to choose a suitable regularisation term is critical, and a number of kernel functions have been used to define the regularisation term (Birpoutsoukis et al., Citation2017; T. Chen et al., Citation2014; Pillonetto, Citation2018). The kernel method which performs a nonlinear data transformation has been widely applied in system identification, machine learning and function estimation (Bai et al., Citation2014; T. Chen et al., Citation2014; Hofmann et al., Citation2008; Pillonetto & De Nicolao, Citation2010; Pillonetto et al., Citation2014). Reproducing kernel Hilbert spaces (RKHSs) (Pillonetto et al., Citation2014; Valencia & lvarez, Citation2017) is a popular one. Similarly, in this paper, the inner product of nonlinear mapping terms in the denominator is added to the cost function with the aim to reduce the bias caused by the linear transformation. The effectiveness of this treatment will be assessed in the simulation section.
Given the quadratic cost function as a trade-off between the linear model error and model parameters bias caused by linear transformation, a regularised fast recursive algorithm is proposed in this paper to solve the optimisation problem. The main contributions in this paper are summarised as follows:
A duality formulation is introduced to translate the fraction model identification problem to a quadratic linear regression problem. Based on the structural risk minimisation principle, the dual linear regression problem is minimised by a variant of the least squares solution. In essence, identification of a fraction model is thus translated to solving a linear regression problem, thus significantly reduced the computational complexity.
To eliminate the bias induced by the linear-in-the-parameters transformation and to recover the true fraction model rather than identify a parsimonious model, a regularisation term is added to the cost function. The optimisation problem can be easily solved by a regularised least-squares method.
To automatically identify both the fraction model coefficients and the fraction model structure, a regularised fast approach (RFRA) is proposed based on the original fast recursive algorithm (Li et al., Citation2005). Unlike the locally regularised automatic construction (LRAC) method (Du et al., Citation2012), the regularisation matrix does not have to be a diagonal matrix when using the novel regularised fast recursive method. In order to efficiently evaluate the candidate base function, a recursive net contribution is developed. The proposed RFRA method simplifies the calculation of the net contribution of model terms and computation of the least squares equations for the coefficients by defining a set of recursive matrices, and the fraction model structure is determined according to the net contribution easily.
Finally, the complexity of the proposed method is analysed and compared with the well-known orthogonal method proposed in Zhu and Billings (Citation1996) to confirm its efficiency.
The remainder of the paper is organised as follows. The fraction model identification problem is formulated in Section 2. Section 3 gives some necessary preliminaries for the proposed algorithm. Then a regularised fast method is detailed in Section 4, covering the principle of the new method, fast computation of the net contribution of model terms, fast computation of model coefficients, and computational complexity analysis. Simulation case studies are presented in Section 5. Finally, Section 6 concludes this paper.
2. Problem formulation
2.1. Fraction model
Considering a multiple-input single-output system, the fraction model can be expressed as the ratio of two linear-in-the-parameter models.
(1)
(1) where
,
and
are the model output, the model input vector with q dimension and the model error at time instant t, respectively.
represents the ith nonlinear base mapping term of the numerator and
represents the jth nonlinear base mapping term of the denominator. r and h denote the numbers of the nonlinear terms in the numerator and in the denominator of the fraction model respectively. Also
and
represent the coefficients of the ith regressor in the numerator and the jth regressor in the denominator respectively.
To identify the fraction model from the training data, the system (Equation1(1)
(1) ) can be expressed in the matrix representation first. Then the cost function of the corresponding dual quadratic linear regression problem can be calculated and further simplified. Suppose N data samples
are used for model identification, Equation (Equation1
(1)
(1) ) can be formulated as
(2)
(2) where
is the model output vector.
is the numerator sample vector.
is the denominator sample vector. The components of
are
.
is the model error vector.
is the selected nonlinear mapping matrix for the numerator with
.
is the coefficients vector for the numerator.
is the selected nonlinear mapping matrix for the denominator with
.
is the coefficients vector for the denominator.
2.2. Transformation to linear-in-the-parameter formulation
Fraction models are not naturally linear in the parameters and its identification presents a challenge. To identify fraction models, an elementwise product of the two vectors is first defined, namely Hadamard product using ⊙ to denote the product (Nielsen, Citation2019). Suppose and
are two vectors of the same dimension, then the lth component of
is
.
To obtain the matrix representation of the corresponding linear system in the sense of least squares, both sides of Equation (Equation2(2)
(2) ) are Hadamard multiplied by '
', thus:
(3)
(3) Expanding
and
in (Equation3
(3)
(3) ) gives
(4)
(4) Thereby,
(5)
(5) Then all the terms except '
' are moved to the right side, resulting in a linear-in-the-parameter model
(6)
(6) By defining
,
and
, the system can be reformulated as follows:
(7)
(7) where
generally takes the value of 1,
,
is the output vector of new system,
is the new system linear parameter vector,
is the coloured noise of the new system,
with M regressors for inclusion in the model, where M = r + h−1.
2.3. Model identification challenges
By transforming the fraction model in the linear-in-the-parameter form, the model identification is simplified to a linear regression problem. Both the least squares method and the likelihood estimation are two well-established methods. Here the least squares method (LS) is applied to model equation (Equation7(7)
(7) ) given that the distribution of the training samples is unknown prior.
For the new system formulated in Equation (Equation7(7)
(7) ), the input matrix and output vector of the model are
and
, respectively. Then m candidate nonlinear features
are generated if the true system is unknown a priori. Generally speaking, if the true model is unknown, then various parsimonious nonlinear models such as polynomial models and other linear-in-the-parameter models can be built to achieve equivalent modelling performance under certain conditions (Li & Peng, Citation2007). Thus, a polynomial is often used to approximate a range of nonlinear systems. To this end,
can be defined as a polynomial term. If the system model is partially known a priori, then fundamental knowledge can be obtained for an engineering system (Li, Citation2005) based on which fundamental functions (
) can be identified, such as exponential, fraction order polynomial terms, trigonometric, or rational functions, etc. The resultant model structure is illustrated in Figure .
Figure 1. The structure of the new linear-in-parameters system.

In statistics, there exists biased parameter estimators to dominate any unbiased parameter estimator in terms of the mean squared error (MSE) (Hong et al., Citation2008), therefore there is always a requirement to balance the variance and bias using the least square method. In LS method, the linear coefficients can be estimated by
(8)
(8) In theory, for the linear-in-the-parameter system subject to white noise, the least square solution of the coefficients (
) is equal to the true value
if the sample number is sufficiently large. However, for the system in Equation (Equation7
(7)
(7) ), the linear coefficients in Equation (Equation8
(8)
(8) ) can be described as
(9)
(9) It is clear that the noise
in Equation (Equation9
(9)
(9) ) comes from
defined in Equation (Equation7
(7)
(7) ), therefore it is a coloured noise. From Figure ,
is correlated with
as it is included in the information of the output
. Therefore, the expectation of estimation coefficients (
) is
rather than
. Thus, the least square method applied to system (Equation7
(7)
(7) ) has a bias term in the solution, and it is necessary to eliminate the bias to improve the generalisation performance of a parsimonious model or to identify the true system model from a model candidate term pool consisting of the true model terms.
From Equation (Equation9(9)
(9) ), it is clear that the bias is related to the selected terms of the denominator and
. Accordingly, an improved method is proposed in the following to eliminate the bias.
3. Preliminaries
Through the linear transformation, noises have been introduced into both input and outputs of the new system (Equation2(2)
(2) ). Furthermore, the output-error is a coloured noise which is the response excited by the white noise of the original system. Given the coloured noise, the conventional recursive least square method leads to a biased solution. To achieve unbiased coefficients estimation, a similar process to the reproducing kernel Hilbert space (RKHS) method (Pillonetto, Citation2018) which uses the inner products of the denominator is employed to mitigate the contribution of the bias to the cost function. By adding a regularisation term with a negative weight, it is possible to eliminate the bias introduced into the estimation of the original system.
3.1. The original cost function
Lemma 3.1
Suppose obeys a Gaussian distribution with zero mean, for given sufficient enough data samples, then Hadamard product (
) satisfies:
(10)
(10) The proof is given as follows.
According to the multiplication of matrices, the right side of Equation (Equation10(10)
(10) ) can be expanded as
(11)
(11) If the system error ‘
’ is a white noise with the variance ‘
’, Equation (Equation11
(11)
(11) ) can be reformulated as follows given that there are sufficient data samples.
(12)
(12) Accordingly, Equation (Equation10
(10)
(10) ) is true.
Considering the coloured noise '' in Equation (Equation7
(7)
(7) ), the sum of squared coloured noises can be calculated as follows:
(13)
(13) where
and
are the linear-in-the-parameter system error vector and the original system error vector respectively. To estimate coefficients (
), the denominator (
) of the original system in Equation (Equation2
(2)
(2) ) can be written as follows:
(14)
(14) where
with M = r + h−1 and
together represent the nonlinear mapping matrix
in Equation (Equation2
(2)
(2) ). M represents the number of the regressors for inclusion in the model.
with size
represent the constant bias (
) of the denominator on the left.
is augmented from the terms (
) of the denominator being moved to the right side, hence they are referred to augmented terms in the following context. And
Notice from Equation (Equation13
(13)
(13) ) that the cost function using the sum of the squared fraction system errors can be computed by:
(15)
(15)
3.2. The dual solution
To minimise the modelling error, Equation (Equation15(15)
(15) ) is often used as the criterion. However, the cost function is nonlinear with respect to the model coefficients. To this end, a linear optimisation algorithm is a well-known approach for many nonlinear problems, for example, the least squares SVM is identified by solving linear equations in the dual instead of solving a quadratic programming problem with inequality constraints in the primal (Mall & Suykens, Citation2015). Thus, instead of using a complex nonlinear derivative-based methods, similar to Pillonetto et al. (Citation2014), a linear dual problem combining the original linear cost function and the inner product of the denominator sample vector, is proposed as the cost function which is expressed in Proposition 3.1.
Proposition 3.1
Subject to the existence of 'λ' which satisfies '', minimising the cost function (Equation16
(16)
(16) ) for the transformed model (Equation7
(7)
(7) ) is equivalent to minimising (Equation15
(15)
(15) ) for the original model (Equation2
(2)
(2) ).
(16)
(16) where
is used to evaluate the estimation error of the transformed linear-in-the-parameter system in Equation (Equation7
(7)
(7) ). From the expansion of Equation (Equation16
(16)
(16) ),
includes the regularisation parameter λ and the
and
norms of the estimated coefficients (
). Thus,
with the regularisation parameter λ is used as the regularisation penalty term. Meanwhile, '
' is the minimum value of the cost function (Equation16
(16)
(16) ), i.e. the optimal cost function.
The proof of the Proposition 3.1 is given below.
Considering the new cost function, the minimum estimation is given when the partial derivative of the cost function with respect to the coefficients is equal to zero. Thus, the coefficients can be estimated using:
(17)
(17) Setting Equation (Equation17
(17)
(17) ) equal to zero, the optimal coefficients are given as
(18)
(18) Similarly, for the nonlinear original cost function in Equation (Equation15
(15)
(15) ), its partial derivative with respect to the coefficients is calculated as
(19)
(19) To calculate the partial derivative in Equation (Equation19
(19)
(19) ) using the optimal coefficients,
is added in the first part, thus
(20)
(20) Obviously, the first part of the numerator in Equation (Equation20
(20)
(20) ) is the partial derivative in Equation (Equation17
(17)
(17) ). Substituting Equation (Equation18
(18)
(18) ) into Equation (Equation20
(20)
(20) ), the first part of Equation (Equation20
(20)
(20) ) is zero and it can be rewritten as follows after N is left out:
(21)
(21) Since both
and
are scalars, extracting
after changing its position, then (Equation21
(21)
(21) ) can be expressed as
(22)
(22) Now setting Equation (Equation22
(22)
(22) ) equal to zero, yielding
(23)
(23) The above derivations show that if there exists a negative number λ which makes the dual problem in Equation (Equation16
(16)
(16) ) of system (Equation7
(7)
(7) ) equal to zero for the optimal coefficients, then the minimum of
is zero, and Equations (Equation22
(22)
(22) ) and (Equation23
(23)
(23) ) are satisfied. Thus, λ should be optimised to ensure that its absolute value is sufficiently small such that
, and our study shows that the order of its magnitude is generally no greater than
. This shows that the identification of the fraction system is equivalent to optimising the proposed dual problem, and the proposed dual problem (Equation16
(16)
(16) ) can be solved based on the regularised least squares. It should be noted that the regularisation penalty term (
) has only three parts and they are only related to part of the model coefficients. This is different from conventional regularisation problem where penalty is applied to all model coefficients. To reduce the computation complexity of the regularised least squares, this paper proposes to simplify the general regularised least squares according to the FRA framework.
4. Regularised fast recursive algorithm
According to Section 3, the fraction system is identifiable using the proposed primal–dual solution. To solve the transformed quadratic cost function, the least squares methods are most popular. In particular, the orthogonal least squares (OLS) (Zhu & Billings, Citation1996) and the fast recursive algorithm (FRA) (Li et al., Citation2006, Citation2005) can not only be used for parameters estimation, but also for model structure selection. Among them, the FRA method solves the least squares problem recursively without requiring matrix decomposition, and it further allows both fast forward and backward model identification. In the following, an regularised fast recursive method is presented.
4.1. The principle of regularised fast recursive method
4.1.1. Model term selection based on the regularised cost function
Referring to Li et al. (Citation2005), a fast calculation of the net contribution of each term chosen into the model is a key. As discussed earlier, the cost function can be defined as
(24)
(24) Substituting the optimal coefficients Equation (Equation18
(18)
(18) ) into Equation (Equation24
(24)
(24) ), the corresponding minimal cost function is given as follows and the simplification procedure is given in Appendix 1:
(25)
(25) The elegance of the FRA approach lies in the efficient and stable calculation of the net decrease in the cost function when a candidate term is added to the model and the model coefficients can be efficiently obtained using backward substitution (Li et al., Citation2005). This framework also allows for both forward and backward model identification (Li et al., Citation2006). In this paper, to select the regressors and estimate the coefficients efficiently using RFRA, a proper selection criteria with the associated coefficient estimation method needs to be derived and implemented using a simplified and efficient computational framework.
Therefore, in the following, the net contribution of each model term will be derived first based on the cost function (Equation25(25)
(25) ) for the RFRA. Then, the four stages of the RFRA method are introduced in detail. Firstly, a cost function is designed for the fraction system identification based on the dual transformation. Secondly, according to the conventional regularised least squares method, the selection criteria and the coefficients are calculated based on Equations (Equation25
(25)
(25) ) and (Equation18
(18)
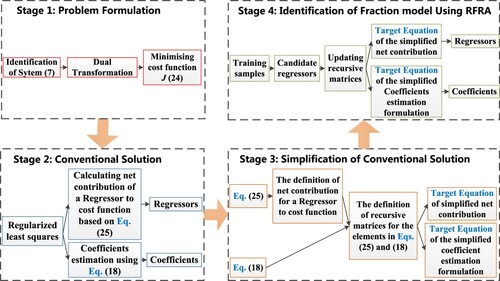
(18) ). Thirdly, recursive matrices are defined to derive a simplified and efficient computational framework for calculating the net contributions of model terms and the model coefficients. Finally, to identify the fraction model using RFRA, the elements of recursive matrices can be updated recursively without incurring much calculations. Substituting these recursive matrices into the target equations, the regressors are selected and the coefficients are estimated respectively. The schematic of the proposed RFRA is illustrated in Figure .
Figure 2. The schematic of the proposed RFRA method.
Suppose the model (Equation2(2)
(2) ) has a maximum of
regression terms both in the numerator and the denominator, the matrix of candidate regression terms for (Equation2
(2)
(2) ) can be initially set as
. Then the transformed linear model (Equation7
(7)
(7) ) has a maximum of m regression terms because the constant term in the denominator should have been moved as a part of the output. The matrix of candidate regression terms in (Equation7
(7)
(7) ) can be initially set as
and the corresponding auxiliary matrix for regularisation can be initially set as
respectively, where the indices of the elements in
and
at the kth iteration start from k, and thus
and
are the
th candidate terms in the candidate regression matrix
and the augmented matrix
, respectively.
After the kth regressors has been selected into the model (Equation7(7)
(7) ), the selected regression term matrix is recorded as
and the selected augmented term matrix is recorded as
. Then the remaining candidate regressor matrix and the candidate augmented matrix are
and
respectively. Thus the optimal model coefficients and the corresponding cost function are given as
(26)
(26)
(27)
(27) Before introducing the regularised fast recursive algorithm, a recursive matrix at the kth iteration is defined as
(28)
(28) And the inversion of
can be computed as follows
(29)
(29) where
and
.
Given that , then
,
and
can be calculated as follows
(30)
(30) According to the matrix inversion lemma
,
can be computed as follows
(31)
(31) Thus, after kth selection, the cost function of Equation (Equation27
(27)
(27) ) becomes
(32)
(32) Assuming the regression term
is selected from the candidate matrix
at
th selection, the selected regression term matrix becomes
and the selected augmented regression term matrix is
, while the remaining candidate regressor matrix and the candidate augmented matrix are
and
respectively.
Thus, the cost function is updated as follows
(33)
(33) where
.
Then, the net contribution of the selected term () is given as
(34)
(34) In order to simplify the calculations, three recursive matrices (indexed with (1), (2) and (3)) at
th iteration, recorded as
,
and
, are defined as
(35)
(35)
(36)
(36)
(37)
(37) where the matrix sizes of
,
and
are all N by N, and
,
,
.
Having defined these three recursive matrices, the explicit formulation to efficiently calculate the net contribution can be derived first. According to the calculation of using Equations (Equation30
(30)
(30) ) and (Equation31
(31)
(31) ), the recursive matrices defined in Equations (Equation35
(35)
(35) ), (Equation36
(36)
(36) ) and (Equation37
(37)
(37) ) can be recursively updated as follows
(38)
(38)
(39)
(39)
(40)
(40) The proof of these properties in Equations (Equation38
(38)
(38) )–(Equation40
(40)
(40) ) is given in Appendix 2.
In addition, based on the definitions in Equation (Equation35(35)
(35) )–(Equation37
(37)
(37) ), several properties can be inferred as given in Equations (Equation41
(41)
(41) )–(Equation44
(44)
(44) ).
(41)
(41)
(42)
(42)
(43)
(43)
(44)
(44) Then, the cost function
at the kth iteration can be reformulated as
(45)
(45) And, the net contribution of the selected term (
) in Equation (Equation34
(34)
(34) ) can be rewritten as
(46)
(46) According to the properties given in Equations (Equation38
(38)
(38) )–(Equation39
(39)
(39) ), Equation (Equation46
(46)
(46) ) can be calculated as follows
(47)
(47)
4.1.2. Fast computation of net contributions of model terms to the cost function
Note that there are m−k candidate terms (i.e. ) to be evaluated at the
th iteration, and in order to select a new term
in
to be included into the model, one needs to calculate
(
) using (Equation47
(47)
(47) ) and the candidate term which is selected as
for inclusion into the model must have the maximal net contribution to the cost function, i.e.
(48)
(48) However, calculating the net contribution of m−k candidate terms using (Equation47
(47)
(47) ) will consume a large amount of computing resources including memory and time, to further simplify the calculations, a few intermediate matrices
,
(l = 1, 2, 3, 4) are further introduced to calculate the net contribution to the cost function of the remaining m−k candidates. For
, the elements
are given by:
(49)
(49)
(50)
(50)
(51)
(51)
(52)
(52) where the first three terms in each equation are used for recursive update of the elements, while the last term in each equation is used to calculate the net contribution of a candidate term and only the diagonal elements are used.
For , the elements
for the remaining candidates at
th iteration are given by:
(53)
(53)
(54)
(54)
(55)
(55)
(56)
(56) where the first term in each equation is used for recursive update of the elements, while the last term in each equation is used to calculate the net contribution.
Because of the symmetrical property and the properties in Equations (Equation41(41)
(41) )–(Equation44
(44)
(44) ), it is evident that
,
,
and
.
Using Equation (Equation38(38)
(38) ) and the definition of
in Equation (Equation49
(49)
(49) ),
can be recursively computed. Taking the second term of (Equation49
(49)
(49) ) as an example, it can be recursively updated as follows
(57)
(57) This updating procedure based on (Equation38
(38)
(38) ) will continue until the recursive matrix reaches the values
, then
(58)
(58) By adopting the similar recursive procedure to the other terms in (Equation38
(38)
(38) ),
can be calculated as follows
(59)
(59)
Similarly, ,
,
,
,
,
and
can be quickly calculated as follows using the properties Equations (Equation38
(38)
(38) )–(Equation40
(40)
(40) ).
(60)
(60)
(61)
(61)
(62)
(62)
(63)
(63)
(64)
(64)
(65)
(65)
(66)
(66)
Noticing from Equations (Equation47(47)
(47) ) and (Equation49
(49)
(49) )–(Equation56
(56)
(56) ), the net contribution of any candidate term
at
th iteration can be quickly calculated as follows
(67)
(67) Equation (Equation67
(67)
(67) ) gives a simplified formulation for calculating the net contribution with low demand on computation and memory resources. Accordingly, the regressor with the maximum net contribution will be selected from the candidates based on their net contributions
. The selected term will then be moved to the
th position of the matrix
and denoted as
.
4.1.3. Fast computation of model coefficients
The next step is then to develop effective formula for estimating coefficients. According to the definition (Equation28(28)
(28) ), the optimal model coefficients (Equation26
(26)
(26) ) can be rewritten as
(68)
(68) To use (Equation35
(35)
(35) ) and (Equation37
(37)
(37) ) to simplify the calculations, both sides of (Equation68
(68)
(68) ) are multiplied by
, yielding
(69)
(69) Expanding
in Equation (Equation69
(69)
(69) ) gives:
(70)
(70) Referring to Li et al. (Citation2005), a recursive matrix at
th iteration is defined as
(where
) for parameter estimation using the backward substitution.
Then, both sides of Equation (Equation70(70)
(70) ) are multiplied by
and consider the property
(
) (Li et al., Citation2005), yielding
(71)
(71) For the final model consisting of M = h + r−1 regressors, Equation (Equation70
(70)
(70) ) can be rewritten as
(72)
(72) Obviously, the model coefficients of the last selected term can be first calculated using (Equation72
(72)
(72) ) and then the others can be backward recursively computed. However, the computation is still high due to the presence of
,
and
. To simplify the calculations, a recursive matrix
and three recursive vectors
,
and
are defined as
(73)
(73)
(74)
(74)
(75)
(75)
(76)
(76) where
representing the number of selected model terms and
is the index of the term whose coefficient has been estimated.
For the selected model terms at th time, Equation (Equation72
(72)
(72) ) can be rewritten as
(77)
(77) To further simplify
and
, two recursive regressors
are defined as follows:
(78)
(78)
(79)
(79) where
and
.
To select M model terms, the output and the regressors
,
will be recursively updated for M times. Their updated notations are defined as
,
,
and
respectively. Based on Equations (Equation38
(38)
(38) ), (Equation40
(40)
(40) ) (Equation73
(73)
(73) ), (Equation74
(74)
(74) ), (Equation78
(78)
(78) ) and (Equation79
(79)
(79) ), the four vectors are recursively updated by
or
. Similar to the derivation of
, the four vectors can be calculated as
(80)
(80)
(81)
(81) Thus
(82)
(82) And then
(83)
(83)
(84)
(84) For the definitions of
, Equations (Equation75
(75)
(75) ) and (Equation76
(76)
(76) ) are similar as those defined in Li et al. (Citation2005), and
and
can be calculated in a similar way as for the calculation of
using
(85)
(85)
(86)
(86) Accordingly, after updating these above matrices and vectors in M iterations, Equation (Equation77
(77)
(77) ) can be reformulated as follows:
(87)
(87)
Remark 1
To identify a fraction model using the proposed RFRA, Equation (Equation67(67)
(67) ) is first used for model term selection, which computes the net contribution of a candidate regression term to the cost function, then Equation (Equation87
(87)
(87) ) is used for model coefficient estimation once the model terms have been selected.
4.2. Regularisation analysis and the proposed algorithm
In this paper, a regularisation term is used to compensate the estimation bias which is induced by the linear transformation. The value of the regularisation parameter has to be carefully chosen, as inappropriate value will either lead to the overfitting or underfitting problem. According to Proposition 3.1, the regularisation parameter needs to satisfy Equation (Equation23(23)
(23) ). Furthermore, Equation (Equation23
(23)
(23) ) is based on known model structure. However, the structure is unknown a prior, therefore, the regularisation parameter has to be identified in two steps, including the selection of the magnitude order of the regularisation parameter and value refinement during the process.
The proposed method is detailed in Algorithm 1:

4.3. Computation complexity
The proposed algorithm, the orthogonal least sqare method (OLS) (Billings & Zhu, Citation1994) and the fast orthogonal identification method (Zhu & Billings, Citation1996) are all capable of simultaneously selecting the model terms and estimating the linear parameters. In Zhu and Billings (Citation1996), it is shown that the fast orthogonal identification method is computationally more efficient than the conventional OLS method. In the following, the computational complexity of the proposed method will be compared with that of the fast orthogonal identification algorithm when both are applied to the identification problem including the structure detection and the parameters estimation.
Suppose there are initially m candidate nonlinear terms to build a fraction nonlinear dynamic model expressed in Equation (Equation2(2)
(2) ), M terms (M<m) will be selected to construct the model from the candidate terms and the coefficients of the resultant model should be estimated. The basic arithmetic operations used in the two identification algorithms are addition/subtraction, and multiplication/division. According to the procedures of RFRA in Algorithm 1, the model term selection process should repeat M−1 times and there are m−k times for updating any of
,
,
,
,
,
,
,
and the net contribution at each selection. Thus the operations in Equations (Equation59
(59)
(59) )–(Equation67
(67)
(67) ) should be counted m−k times at
th selection. In addition, Equations (Equation82
(82)
(82) )–(Equation87
(87)
(87) ) only need to repeat M times because there are M coefficients for the selected terms. Thereby, for the proposed method, the total number of addition/subtraction and multiplication/division operations is:
(88)
(88) Referring to Zhu and Billings (Citation1996), though there are also M−1 selections, additional calculations are however needed for the coefficients estimation and for computing the errors at each selection iteration. According to the implementation using Equation 5.4 in Zhu and Billings (Citation1996), the total number of addition/subtraction and multiplication/division operations for the fast orthogonal method applied to the same model identification problem is:
(89)
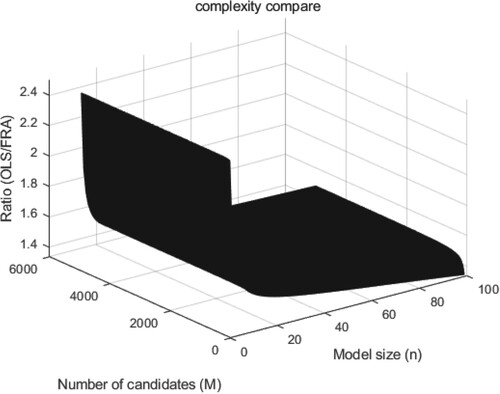
(89) The ratio of the computational complexity of the fast OLS algorithm in Zhu and Billings (Citation1996) and the computational complexity of the proposed algorithm is illustrated in Figure as a function of the number of candidate terms m and actual model size M. It is graphically shown that the proposed method is computationally more efficient than the fast OLS algorithm in all cases, and the efficiency is much higher as the model size decreases.
Figure 3. The ratio of computational complexities between the fast OLS method and the proposed method.
5. Simulation and analysis
To verify the effectiveness of the proposed method, two simulation examples are used. The first example is a rational model. The second one is the case where the regressors are not all polynomials. For each case, 1000 samples are generated with the same distribution of input and error signals.
The input signals for generating the training and testing samples are independent and uniformly distributed signals with amplitude range and variance of
and an independent zero mean Gaussian error with variance
is generated as used in Zhu and Billings (Citation1996), S. Chen et al. (Citation1989).
The proposed method is then applied to identify the system defined in Equation (Equation90(90)
(90) ).
(90)
(90) The rational fraction system in Equation (Equation90
(90)
(90) ) is a typical rational nonlinear autoregressive moving average with eXogenous inputs (NARMAX) model (Waheeb et al., Citation2019). Models of this kind include past inputs, past outputs and past model errors which are the differences between the estimated values and the true values. Though incorporating the past error signal into the model may lead to a more accurate model, they are often difficult to measure or make the modelling process rather complicated. It should be noted that errors always exist in modelling nonlinear systems (Nelles, Citation2020). The model error is often decomposed into the bias and the variance. The bias can be decreased to zero by increasing the model nonlinearity, while the variance is significantly influenced by the data size and data quality. Thus the error in Equation (Equation90
(90)
(90) ) is often treated as known a priori (Neji & Beji, Citation2000). In general, the errors are assumed as independent Gaussian random variables with zero mean and a finite variance, and the variance is often given a priori. To this end, in this case study, the variance is set to
. Accordingly, 27 polynomial terms are generated first based on the principle that the highest order is 2 and the maximal delays of input, error and output signals are 2. According to Equation (Equation7
(7)
(7) ), the candidate terms consist of 54 polynomial regressors.
First, the regularisation parameter is symmetrically adjusted around 0 and a number of trials are tested. Table shows four cases with different values for the regularisation parameter. It is found that is the optimal magnitude order for the regularisation parameter in Example 1. Then, the regularisation parameter is fine tuned around the optimal magnitude order, and the final value for the regularisation parameter is chosen to be 1.8276e−9.
Table 1. Different regularisation parameters for Example 1.
Then the rational fraction system in Equation (Equation90(90)
(90) ) is identified by the RFRA algorithm and the fast OLS method in reference Zhu and Billings (Citation1996), respectively. The selected nonlinear terms from the above 54 nonlinear terms and their estimated linear parameters are listed in Table . By comparing the parameters obtained by the two algorithms, it is clear that the parameters identified by RFRA algorithm are closer to the actual parameters of the model, and the model obtained is more accurate than that produced by the fast OLS method in reference Zhu and Billings (Citation1996).
Table 2. Comparison of estimation coefficients for Example 1.
Finally, a more general fraction system given in Equation (Equation91(91)
(91) ), which contains both polynomials and other nonlinear terms in the rational function, is used as the second case study.
(91)
(91) Similarly, nonlinear candidate items are generated. Considering the small number of samples which is only 1000, different basis functions are used as the numerator and denominator candidate terms, leading to the generation of 52 candidate terms.
It is shown that the bias becomes greater in the positive direction in Example 1, hence, similarly the regularisation parameter is fine tuned along the negative values for Example 2. Following the same procedure in example 1, the regularisation parameter is firstly coarsely adjusted and Table shows some cases with different values for the regularisation parameter. After numerous trials, it is evident again that is the optimum magnitude order for the regularisation parameter. Then, the regularisation parameter is further fine tuned. It is noted that the magnitude order of the MSE validation errors in all the two examples could achieve to
even without fine-tuning. The nonlinear regressors are selected and the coefficients are estimated which are shown in Table . It is again evident that the fraction system can be well identified using the proposed method.
Table 3. Different regularisation parameters for Example 2.
Table 4. Structure selection and parameters estimation for Example 2.
6. Conclusion
This paper has proposed a novel fast method to identify the fraction models where the model structure and the coefficients are simultaneously estimated. The identification of the fraction system is first transformed to an equivalent quadratic optimisation problem by adding a regularisation term which is formulated as the inner product of the denominator terms. To solve the quadratic optimisation problem, a regularised fast recursive algorithm is developed. The proposed method is further validated by two simulation examples to confirm its efficacy. The method can be further applied to build the output layer of the traditional neural networks or the full connected layer of the deep neural networks which can reduce the size of the neural networks. However, a potential limitation of the proposed method is the computational effort to fine tune the regularisation parameter though we have shown that it value has to be negative and can not exceed . It will inevitably cost more computations to optimise the regularisation parameter if the system is too complex. Fast optimisation of the penalty parameter will be a future research topic.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The authors confirm that the data supporting the findings of this study are available within the article.
Additional information
Funding
Notes on contributors
Li Zhang
Li Zhang received the B.Sc. and M.Sc. degrees from Anhui University of Technology, Anhui, China, in 2009 and 2013, respectively. She is currently pursuing the Ph.D. degree in control theory and control engineering at Shanghai University. Between 2018 and 2019, she was a visiting Ph.D. student with the University of Leeds, U.K. Her current research interests include nonlinear system modeling and identification, machine learning algorithm and power system.
Kang Li
Kang Li (M'05-SM'11) received the B.Sc. degree in Industrial Automation from Xiangtan University, Hunan, China, in 1989, the M.Sc. degree in Control Theory and Applications from Harbin Institute of Technology, Harbin, China, in 1992, and the Ph.D. degree in Control Theory and Applications from Shanghai Jiaotong University, Shanghai, China, in 1995. He also received D.Sc. degree in system identification from Queen's University Belfast, UK, in 2015. Between 1995 and 2002, he worked at Shanghai Jiaotong University, Delft University of Technology and Queen's University Belfast as a research fellow. Between 2002 and 2018, he was a Lecturer (2002), a Senior Lecturer (2007), a Reader (2009) and a Chair Professor (2011) with the School of Electronics, Electrical Engineering and Computer Science, Queen's University Belfast, Belfast, U.K. He currently holds the Chair of Smart Energy Systems at the University of Leeds, UK. His research interests cover nonlinear system modelling, identification, and control, and machine learning, with substantial applications to energy and power systems, smart grid, electric vehicles, railway systems, and energy management in energy intensive manufacturing processes. He has authored/co-authored over 200 journal publications and edited/co-edited 19 conference proceedings.
Dr Li chaired the IEEE UKRI Control and Communication Ireland chapter, and was the Secretary of the IEEE UK & Ireland Section.
Dajun Du
Dajun Du received the B.Sc. degree in electrical technology, and M.Sc. degrees in control theory and control engineering all from the Zhengzhou University, China in 2002 and 2005, respectively, and his Ph. D. degree in control theory and control engineering from Shanghai University in 2010. From September 2008 to September 2009, he was a visiting PhD student at Queen's University Belfast, UK. From April 2011 to August 2012, he was a Research Fellow at Queen's University Belfast, UK. He is currently a professor in Shanghai University. His main research interests include system modelling and identification and networked control systems.
Yihuan Li
Yihuan Li received the B.Sc. and M.Sc. degrees from North China Electric Power University, Beijing, China, in 2014 and 2017, respectively, and the PhD degree from University of Leeds in 2021. She is currently a lecture in North China Electric Power University. Her main research interests include system identification and state estimation, and the application of machine learning techniques in the field of battery management.
Minrui Fei
Minrui Fei received his B.S. and M.S. degrees in Industrial Automation from the Shanghai University of Technology in 1984 and 1992, respectively, and his PhD degree in Control Theory and Control Engineering from Shanghai University in 1997. Since 1998, he has been a full professor at Shanghai University. He is Chairman of Embedded Instrument and System Sub-society, and Standing Director of China Instrument & Control Society; Chairman of Life System Modeling and Simulation Sub-society, Vice-chairman of Intelligent Control and Intelligent Management Sub-society, and Director of Chinese Artificial Intelligence Association. His research interests are in the areas of networked control systems, intelligent control, complex system modeling, hybrid network systems, and field control systems.
References
- Andreev, M., & Borulko, V. (2017). Polynomial and rational approximate models of microwave elements. In 2017 XXIIND International Seminar/Workshop on Direct and Inverse Problems of Electromagnetic and Acoustic Wave Theory (DIPED) (pp. 256–259). IEEE.
- Austin, A. P., Krishnamoorthy, M., Leyffer, S., Mrenna, S., Mller, J., & Schulz, H. (2021). Practical algorithms for multivariate rational approximation. Computer Physics Communications, 261, 107663. https://doi.org/10.1016/j.cpc.2020.107663.
- Bai, E.-w., Li, K., Zhao, W., & Xu, W. (2014). Kernel based approaches to local nonlinear non-parametric variable selection. Automatica, 50(1), 100–113. https://doi.org/10.1016/j.automatica.2013.10.010
- Billings, S., & Mao, K. (1998). Structure detection for nonlinear rational models using genetic algorithms. International Journal of Systems Science, 29(3), 223–231. https://doi.org/10.1080/00207729808929516
- Billings, S., & Zhu, Q. (1991). Rational model identification using an extended least-squares algorithm. International Journal of Control, 54(3), 529–546. https://doi.org/10.1080/00207179108934174
- Billings, S., & Zhu, Q. (1994). A structure detection algorithm for nonlinear dynamic rational models. International Journal of Control, 59(6), 1439–1463. https://doi.org/10.1080/00207179408923140
- Birpoutsoukis, G., Marconato, A., Lataire, J., & Schoukens, J. (2017). Regularized nonparametric volterra kernel estimation. Automatica, 82, 324–327. https://doi.org/10.1016/j.automatica.2017.04.014
- Castella, M., Pesquet, J.-C., & Marmin, A. (2018). Rational optimization for nonlinear reconstruction with approximate ℓ0 penalization. IEEE Transactions on Signal Processing, 67(6), 1407–1417. https://doi.org/10.1109/TSP.2018.2890065
- Chen, J., Liu, Y., & Zhu, Q. (2018). Bias compensation recursive algorithm for dual-rate rational models. IET Control Theory & Applications, 12(16), 2184–2193. https://doi.org/10.1049/cth2.v12.16
- Chen, S., Billings, S. A., & Luo, W. (1989). Orthogonal least squares methods and their application to non-linear system identification. International Journal of Control, 50(5), 1873–1896. https://doi.org/10.1080/00207178908953472
- Chen, T., Andersen, M. S., Ljung, L., Chiuso, A., & Pillonetto, G. (2014). System identification via sparse multiple kernel-based regularization using sequential convex optimization techniques. IEEE Transactions on Automatic Control, 59(11), 2933–2945. https://doi.org/10.1109/TAC.2014.2351851
- Curtain, R., & Morris, K. (2009). Transfer functions of distributed parameter systems: A tutorial. Automatica, 45(5), 1101–1116. https://doi.org/10.1016/j.automatica.2009.01.008
- Deng, J., Li, K., Harkin-Jones, E., Fei, M., & Li, S. (2013). A novel two stage algorithm for construction of RBF neural models based on a-optimality criterion. In 2013 Ninth International Conference On Natural Computation (ICNC) (pp. 1–7). IEEE.
- Deng, J., Li, K., & Irwin, G. W. (2010). A two-stage algorithm for automatic construction of RBF neural models. In Melecon 2010 15th IEEE Mediterranean Electrotechnical Conference (pp. 166–171). IEEE.
- Deng, J., Li, K., & Irwin, G. W. (2012). Locally regularised two-stage learning algorithm for rbf network centre selection. International Journal of Systems Science, 43(6), 1157–1170. https://doi.org/10.1080/00207721.2010.545490
- Du, D., Li, X., Fei, M., & Irwin, G. W. (2012). A novel locally regularized automatic construction method for rbf neural models. Neurocomputing, 98, 4–11. https://doi.org/10.1016/j.neucom.2011.05.045.
- Du, D., Zhu, M., Li, X., Fei, M., Bu, S., Wu, L., & Li, K. (2022). A review on cybersecurity analysis, attack detection, and attack defense methods in cyber-physical power systems. Journal of Modern Power Systems and Clean Energy, to be published. https://doi.org/10.35833/MPCE.2021.000604.
- Gambella, C., Ghaddar, B., & Naoum-Sawaya, J. (2021). Optimization problems for machine learning: A survey. European Journal of Operational Research, 290(3), 807–828. https://doi.org/10.1016/j.ejor.2020.08.045
- Hofmann, T., Schölkopf, B., & Smola, A. J. (2008). Kernel methods in machine learning. The Annals of Statistics, 36(3), 1171–1220. https://doi.org/10.1214/009053607000000677
- Hong, X., Mitchell, R., Chen, S., Harris, C., Li, K., & Irwin, G. (2008). Model selection approaches for non-linear system identification: A review. International Journal of Systems Science, 39(10), 925–946. https://doi.org/10.1080/00207720802083018
- Hussein, A. A.-h., & Batarseh, I. (2011). An overview of generic battery models. In 2011 IEEE Power And Energy Society General Meeting (pp. 1–6). IEEE.
- Jin, R., & Weng, G. (2019). A robust active contour model driven by pre-fitting bias correction and optimized fuzzy c-means algorithm for fast image segmentation. Neurocomputing, 359, 408–419. https://doi.org/10.1016/j.neucom.2019.06.019
- Kambhampati, C., Mason, J., & Warwick, K. (2000). A stable one-step-ahead predictive control of non-linear systems. Automatica, 36(4), 485–495. https://doi.org/10.1016/S0005-1098(99)00173-9
- Li, K. (2005). Eng-genes: A new genetic modelling approach for nonlinear dynamic systems. IFAC Proceedings Volumes, 38(1), 162–167. https://doi.org/10.3182/20050703-6-CZ-1902.01105
- Li, K., & Peng, J.-X. (2007). Neural input selectiona fast model-based approach. Neurocomputing, 70(4), 762–769. https://doi.org/10.1016/j.neucom.2006.10.011
- Li, K., Peng, J.-X., & Bai, E.-W. (2006). A two-stage algorithm for identification of nonlinear dynamic systems. Automatica, 42(7), 1189–1197. https://doi.org/10.1016/j.automatica.2006.03.004
- Li, K., Peng, J.-X., & Irwin, G. W. (2005). A fast nonlinear model identification method. IEEE Transactions on Automatic Control, 50(8), 1211–1216. https://doi.org/10.1109/TAC.2005.852557
- Liang, Z., & Zhang, L. (2021). Support vector machines with the epsilon-insensitive pinball loss function for uncertain data classification. Neurocomputing, 457, 117–127. https://doi.org/10.1016/j.neucom.2021.06.044
- Luo, X., Chang, X., & Ban, X. (2016). Regression and classification using extreme learning machine based on l1-norm and l2-norm. Neurocomputing, 174, 179–186. https://doi.org/10.1016/j.neucom.2015.03.112
- Mall, R., & Suykens, J. A. K. (May 2015). Very sparse LSSVM reductions for large-scale data. IEEE Transactions on Neural Networks and Learning Systems, 26(5), 1086–1097. https://doi.org/10.1109/TNNLS.2014.2333879
- Manela, B., & Biess, A. (2021). Bias-reduced hindsight experience replay with virtual goal prioritization. Neurocomputing, 451, 305–315. https://doi.org/10.1016/j.neucom.2021.02.090
- Münker, T., & Nelles, O. (2016). Nonlinear system identification with regularized local fir model networks. IFAC-PapersOnLine, 49(5), 61–66. https://doi.org/10.1016/j.ifacol.2016.07.090
- Neji, Z., & Beji, F.-M. (2000). Neural network and time series identification and prediction. In Proceedings Of The IEEE-INNS-ENNS International Joint Conference on Neural Networks. IJCNN 2000. Neural Computing: New Challenges and Perspectives For The New Millennium (Vol. 4, p. 461–466). IEEE.
- Nelles, O. (2020). Nonlinear system identification, from classical approaches to neural networks, fuzzy models, and gaussian processes. Springer.
- Nielsen, M. (2019). Neural networks and deep learning. Retrieved from http://neuralnetworksanddeeplearning.com/chap2.html (Online Book).
- Ohlsson, H., Ljung, L., & Boyd, S. (2010). Segmentation of arx-models using sum-of-norms regularization. Automatica, 46(6), 1107–1111. https://doi.org/10.1016/j.automatica.2010.03.013
- Paduart, J., Lauwers, L., Swevers, J., Smolders, K., Schoukens, J., & Pintelon, R. (2010). Identification of nonlinear systems using polynomial nonlinear state space models. Automatica, 46(4), 647–656. https://doi.org/10.1016/j.automatica.2010.01.001
- Piga, D., & Tóth, R. (2014). A bias-corrected estimator for nonlinear systems with outputerror type model structures. Automatica, 50(9), 2373–2380. https://doi.org/10.1016/j.automatica.2014.07.021
- Pillonetto, G. (2018). System identification using kernel-based regularization: New insights on stability and consistency issues. Automatica, 93, 321–332. https://doi.org/10.1016/j.automatica.2018.03.065
- Pillonetto, G., & De Nicolao, G. (2010). A new kernel-based approach for linear system identification. Automatica, 46(1), 81–93. https://doi.org/10.1016/j.automatica.2009.10.031
- Pillonetto, G., Dinuzzo, F., Chen, T., De Nicolao, G., & Ljung, L. (2014). Kernel methods in system identification, machine learning and function estimation: A survey. Automatica, 50(3), 657–682. https://doi.org/10.1016/j.automatica.2014.01.001
- Qiao, J., Meng, X., & Li, W. (2018). An incremental neuronal-activity-based rbf neural network for nonlinear system modeling. Neurocomputing, 302, 1–11. https://doi.org/10.1016/j.neucom.2018.01.001
- Senhaji, K., Ramchoun, H., & Ettaouil, M. (2020). Training feedforward neural network via multiobjective optimization model using non-smooth l1/2 regularization. Neurocomputing, 410, 1–11. https://doi.org/10.1016/j.neucom.2020.05.066
- Singh, J., & Dhiman, G. (2021). A survey on machine-learning approaches: Theory and their concepts. Materials Today: Proceedings. Advance online publication. Retrieved from https://www.sciencedirect.com/science/article/pii/S2214785321039298.
- Suykens, J. A., De Brabanter, J., Lukas, L., & Vandewalle, J. (2002). Weighted least squares support vector machines: Robustness and sparse approximation. Neurocomputing, 48(1), 85–105. https://doi.org/10.1016/S0925-2312(01)00644-0
- Swarnakar, J., Sarkar, P., Dey, M., & Singh, L. J. (2017, Dec). Rational approximation of fractional order system in delta domain a unified approach. In 2017 IEEE Region 10 Humanitarian Technology Conference (R10-HTC) (pp. 144–150). IEEE.
- Tao, J., Wen, S., & Hu, W. (2015). L1-norm locally linear representation regularization multi-source adaptation learning. Neural Networks, 69, 80–98. https://doi.org/10.1016/j.neunet.2015.01.009
- Tikhonov, A. N., & Glasko, V. B. (1965). Use of the regularization method in non-linear problems. USSR Computational Mathematics and Mathematical Physics, 5(3), 93–107. https://doi.org/10.1016/0041-5553(65)90150-3
- Torres-Barrán, A., Alaíz, C. M., & Dorronsoro, J. R. (2018). ν-svm solutions of constrained lasso and elastic net. Neurocomputing, 275, 1921–1931. https://doi.org/10.1016/j.neucom.2017.10.029
- Valencia, E. A., & lvarez, M. A. (2017). Short-term time series prediction using hilbert space embeddings of autoregressive processes. Neurocomputing, 266, 595–605. https://doi.org/10.1016/j.neucom.2017.05.067
- Waheeb, W., Ghazali, R., & Shah, H. (2019). Nonlinear autoregressive moving-average (NARMA) time series forecasting using neural networks. In 2019 International Conference on Computer and Information Sciences (ICCIS) (pp. 1–5).IEEE.
- Wang, L., Liu, J., & Qian, F. (2021). Wind speed frequency distribution modeling and wind energy resource assessment based on polynomial regression model. International Journal of Electrical Power and Energy Systems, 130, 106964. https://doi.org/10.1016/j.ijepes.2021.106964
- Yang, C., Zhu, X., Qiao, J., & Nie, K. (2020). Forward and backward input variable selection for polynomial echo state networks. Neurocomputing, 398, 83–94. https://doi.org/10.1016/j.neucom.2020.02.034
- Yang, Z., Mourshed, M., Liu, K., Xu, X., & Feng, S. (2020). A novel competitive swarm optimized rbf neural network model for short-term solar power generation forecasting. Neurocomputing, 397, 415–421. https://doi.org/10.1016/j.neucom.2019.09.110
- Yildiz, B., Bilbao, J., & Sproul, A. (2017). A review and analysis of regression and machine learning models on commercial building electricity load forecasting. Renewable and Sustainable Energy Reviews, 73, 1104–1122. https://doi.org/10.1016/j.rser.2017.02.023
- Zhang, J., Li, K., Irwin, G. W., & Zhao, W. (2012). A regression approach to LS-SVM and sparse realization based on fast subset selection. In 2012 10th World Congress on Intelligent Control and Automation (WCICA) (pp. 612–617). IEEE.
- Zhang, L., Li, K., Bai, E.-W., & Irwin, G. W. (2015). Two-stage orthogonal least squares methods for neural network construction. IEEE Transactions on Neural Networks and Learning Systems, 26(8), 1608–1621. https://doi.org/10.1109/TNNLS.2014.2346399
- Zhang, L., Zhang, D., Sun, J., Wei, G., & Bo, H. (2019). Salient object detection by local and global manifold regularized svm model. Neurocomputing, 340, 42–54. https://doi.org/10.1016/j.neucom.2019.02.041
- Zhao, W., Zhang, J., & Li, K. (2015). An efficient ls-svm-based method for fuzzy system construction. IEEE Transactions on Fuzzy Systems, 23(3), 627–643. https://doi.org/10.1109/TFUZZ.2014.2321594
- Zhu, Q. (2003). A back propagation algorithm to estimate the parameters of non-linear dynamic rational models. Applied Mathematical Modelling, 27(3), 169–187. https://doi.org/10.1016/S0307-904X(02)00097-5
- Zhu, Q. (2005). An implicit least squares algorithm for nonlinear rational model parameter estimation. Applied Mathematical Modelling, 29(7), 673–689. https://doi.org/10.1016/j.apm.2004.10.008
- Zhu, Q., & Billings, S. (1996). Fast orthogonal identification of nonlinear stochastic models and radial basis function neural networks. International Journal of Control, 64(5), 871–886. https://doi.org/10.1080/00207179608921662
- Zhu, Q., Wang, Y., Zhao, D., Li, S., & Billings, S. A. (2015). Review of rational (total) nonlinear dynamic system modelling, identification, and control. International Journal of Systems Science, 46(12), 2122–2133. https://doi.org/10.1080/00207721.2013.849774
- Zhu, Q., Yu, D., & Zhao, D. (2017). An enhanced linear Kalman filter (enlkf) algorithm for parameter estimation of nonlinear rational models. International Journal of Systems Science, 48(3), 451–461. https://doi.org/10.1080/00207721.2016.1186243
- Zhu, Q., Zhang, W., Zhang, J., & Sun, B. (2019). U-neural network-enhanced control of nonlinear dynamic systems. Neurocomputing, 352, 12–21. https://doi.org/10.1016/j.neucom.2019.04.008
Appendices
Appendix 1.
Simplifying the regularized cost function
According to the principles of matrix manipulation, the cost function is simplified in Equation (EquationA1(A1)
(A1) ).
(A1)
(A1)
Appendix 2.
Proof of Properties of the recursive matrices
From the definition of in Equation (Equation29
(29)
(29) ), substituting Equations (Equation30
(30)
(30) ) and (Equation31
(31)
(31) ) to the definition of
in Equation (Equation35
(35)
(35) ), the recursive formulation of
is given in Equation (EquationA2
(A2)
(A2) ).
(A2)
(A2) Similarly, it can be proved that Equations (Equation39
(39)
(39) ) and (Equation40
(40)
(40) ) are indeed true.