
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
What causes turnover on the Billboard charts? The neutral model of cultural evolution, which assumes that taste is transmitted via an unbiased copying process, provides precise predictions regarding expected popularity distributions and turnover within a popularity-ranked list. Recent advances in this line make it possible to characterize the likelihood of music taste transmission mechanisms by investigating departures of observed turnover rates from neutral model predictions. Here, I bias the neutral model to investigate four alternative conceptions of individual music taste transmission (song quality, individual status, social network, and anticonformist) and use agent-based simulations to examine the impact on turnover. I then compare modeled with empirical turnover data from the Billboard Hot 100 over the period from 1958 to 2021 and find that observed turnover patterns are reproduced only in an anticonformist model simulating the systematic rejection of the most popular songs. This finding was unexpected and challenges the notion of a generalized “preference for the popular.” Overall, this study contributes to ongoing debates regarding the mechanisms involved in the transmission of taste and the mechanics of fashion change.
1. Introduction and background
Since August 4, 1958, Billboard’s Hot 100 Chart has tracked the 100 most popular songs in the United States. Each week, the latest list is released; and, each week, it is a little bit different from the week before. The number of differences from week to week is referred to as turnover. Turnover is a key feature in ranked popularity lists. Ranked popularity lists, ubiquitous in popular culture domains, often appear in the form of “Top Charts” (e.g., Top-10, Top-40, etc.). Popularity is by definition a social process, and “Top Charts” reflect the aggregate, macro-level effects of many individual people making the same music choices. To date however, there is remarkably little research focused on isolating the impact of demand-side mechanisms on the amount of turnover we observe.
Sociologists have long been interested in the antecedents and consequences of individual consumption practices, or “tastes.” Even while it is generally understood that individual music taste is a social process, it is less clear where taste comes from. In general, there are two major schools of thought. On the one hand, some researchers argue that individual music taste is a function of an individual’s position within existing macro-level social hierarchies (e.g., class, education, socio-economic status, etc.); on the other hand, other researchers argue that taste is a function of peer influence and local network effects. In reality, of course, both kinds of influence exist simultaneously, and theoretical work in these areas is considerably more nuanced than this dichotomy would imply. In Bourdieu’s (Citation1984) argument, for example, we find the first of these given as the main causal element, but the second as the more proximate cause of tastes.
The two lines forward distinct mechanisms for the social diffusion of taste. Yet, despite a long tradition of research directed at these issues, a variety of difficulties have thwarted attempts at making progress toward empirically distinguishing between the two transmission types. In the first place, datasets relevant to understanding the demand side of cultural markets are rare. With the possible exception of the 1993 GSS Cultural Module and handful of SPPA surveys, representative public datasets with information relevant to understanding how people make consumption choices simply do not exist. Second, even when such data is available, it is not suitable for distinguishing between hypotheses related to social transmission mechanisms because social transmission is a fundamentally endogenous social effect. As a result, it is impossible to distinguish between transmission mechanisms in post-hoc analyses of population-level data without experimental methods (Manski, Citation1993). As a consequence, despite some limited success with laboratory investigations (e.g., Salganik, Citation2006), we still miss a full understanding of the impact of theorized transmission mechanisms in real life cultural dynamics (Henrich & Broesch, Citation2011).
For all of these reasons, it would be very desirable to develop methodologies that enable us to characterize the likelihood of theorized transmission mechanisms operating at an individual level using only data from observed, population scale frequency distributions and turnover rates (Kandler & Shennan, Citation2013; Mesoudi & Lycett, Citation2009; Shennan, Citation2011). The use of observed frequency distributions and turnover rates as a means for characterizing the likelihood of various cultural transmission mechanisms has a variety of precedent among sociologists (e.g., Harrison & Carroll, Citation1991; Lieberson, Citation2000; Obukhova et al., Citation2014). To date, however, empirical work has proceeded slowly and has been hampered, in part, by little methodological agreement and, in particular, a lack of an agreed-upon null model to test and evaluate alternative hypotheses.
Over the last few decades, researchers have begun to employ the tools and methodologies from evolutionary biology to explain aspects of human cultural change (Boyd & Richerson, Citation2005; L. L. Cavalli-Sforza & Feldman, Citation1981). As Mesoudi and Lycett (Citation2009) note, a significant advance in this line occurred with the realization that biological change can occur through the nonselective process of genetic drift (Crow & Kimura, Citation1997; Kimura, Citation2020), whereby changes in gene frequencies can come about through random chance alone.
Something akin to “drift” has been similarly recognized as an important factor in explaining differences in frequency distributions in some of the very earliest models of cultural evolution (L. Cavalli-Sforza & Feldman, Citation1973). In other words, significant changes to the popularity of cultural objects can come about by random events, such as sampling error (Merton, Citation1948). The random-copying model, sometimes referred to as the “neutral model,” simulates the behavior of people copying the behavior of other people at random. It has been described as the cultural analogue of genetic drift (Mesoudi & Lycett, Citation2009, p. 42).
Bentley et al. (Citation2004) demonstrated through agent-based simulation that the random-copying model reliably generates the distinct “power-law” popularity distributions observed in many cultural domains.Footnote1 For example, early work in this line noted that observed differences in the frequency distributions of cultural traits such as pottery decorations (Bentley et al., Citation2004; Neiman, Citation1995), scientific paper citations (Simkin & Roychowdhury, Citation2003), baby names (Hahn & Bentley, Citation2003), dog breeds (Herzog et al., Citation2004), and patent citations (Bentley et al., Citation2004) can be explained using a relatively simple model of random-copying. The results of this work has led some researchers to begin speculating that perhaps the observed popularity of cultural traits in these domains is more the result of random chance than the result of any particular selection mechanism. Unlike other mechanisms proposed for generating power-law distributions, the neutral model has the ability to show change (Bentley, Citation2008). For example, in the preferential attachment mechanism proposed in Barabási and Albert (Citation1999) or the popularity-based selection mechanism explored in Salganik (Citation2006), the most popular items only become more popular over time; there is no way for popular items to become less popular, and as a result other models do not account for the observed turnover that occurs in reality.
Because the neutral model provides precise predictions regarding expected frequency distributions and turnover rates within popularity-ranked lists, it can function as a powerful null hypothesis, as it also functions in population genetics (Kreitman, Citation1996). In particular, although the neutral model does not purport to accurately describe human behavior or decision-making processes, its ability to reproduce observed popularity distributions and turnover rates across a variety of cultural domains enables it to function as a powerful null hypothesis for investigating alternative social transmission mechanisms (Bentley et al., Citation2004; Mesoudi & Lycett, Citation2009). However, so far as the present author is aware, no attempt has yet been made to employ these methods to make inferences about social diffusion mechanisms related to individual status or social network structure.
Following a variety of prior sociological work (e.g., Bryson, Citation1996; Goldberg, Citation2011; Peterson & Kern, Citation1996), I situate this study in the context of music consumption and focus on uncovering mechanisms related to the transmission of music taste from population level data. I consider five theories regarding the formation of individual music taste and song selection behavior (1) song selection is a function of random-copying – i.e., the neutral model, (2) song selection is a function of song quality, (3) song selection is a function of individual status, (4) song selection is a function of an individual’s position in a social network, (5) song selection is a function of anticonformist copying behavior. To help make progress toward disentangling these hypotheses, I adopt the analytical procedures detailed in a variety of recent work involving the neutral model (e.g., Acerbi & Bentley, Citation2014; Bentley et al., Citation2004, Citation2007; Evans & Giometto, Citation2011; Hahn & Bentley, Citation2003; Obukhova et al., Citation2014). First, using the neutral model as a null hypothesis, I compare observed turnover with turnover we would have observed if individual music selection consisted of an unbiased, entirely random copying process. Next, using the neutral model as a baseline, I use agent-based simulations to examine the extent to which alternative conceptions of song selection behavior are able to reproduce the diagnostic features of observed turnover data. Examining the extent to which modeled turnover patterns match real data will help us to infer, from population scale observations, when deviations from the expectations of the neutral model have occurred, and, to some extent, what sort of song-selection behavior may or may not be operating at an individual level (Mesoudi & Lycett, Citation2009). Overall, this study contributes to ongoing debates regarding the mechanisms involved in the transmission of taste and the mechanics of fashion change.
2. Data and methods
2.1. Turnover on the billboard hot 100 chart
Billboard’s Hot 100 Chart was used as a basis for characterizing our expectations concerning the turnover of popular music in the United States. Data was obtained by compiling information from all Billboard Hot 100 Charts published over the period from August 4, 1958 to April 24, 2021. A total of 3,274 unique Billboard Hot 100 Charts and 29,314 unique songs were considered in this analysis.
Billboard’s Hot 100 Chart, published once weekly since August 4, 1958, contains a ranked list of the 100 most popular songs in the United States. It is widely accepted as the most accurate index of its kind. Indeed, record labels have historically relied more on Billboard Charts than their own sales data (Anand & Peterson, Citation2000). The methodology of constructing the list has always been something of a black box, as neither the field data nor formulas used to translate data into chart rankings have ever been published (Haampland, Citation2017). However, Billboard does occasionally publish notes concerning major changes to its chart compilation methodology. In general, there are three major “epochs” in the methodology of constructing this list. Prior to 1991, Billboard’s chart rankings were determined by a combination of radio play and record sales. In this earliest period, data collection was often survey-based, with each weekly sample being obtained by calling a selection of sales outlets and radio stations (Hesbacher et al., Citation1975), a process that was subjective, error prone, and vulnerable to manipulation (Anand & Peterson, Citation2000). This process was changed in 1991, when Billboard began relying exclusively on SoundScan data collected at the point-of-sale (e.g., from each cash register transaction in most record stores in the United States). The third epoch began in 2005, when SoundScan data began including digital music consumption (Klein & Slonaker, Citation2010). Since then, a variety of additional measurement parameters have been added to reflect changes in the technology and formats of digital music consumption; music downloads were included in 2005, streaming services like Spotify were included in 2007, and YouTube views have been included since 2013 (Haampland, Citation2017).
Here, I define a “ Chart” as a list of songs ranked in order of popularity, truncated to include only the top y most-popular songs. Top Charts can be of varying sizes (Top 5, Top 10, Top 40, etc.), so the variable y refers to the size of the list. Turnover
is defined as the number new songs that entered (or, equivalently, exited) the
Chart, relative to the previous week. For example, in the Billboard Hot 100, turnover of songs on the
Chart is on average around 1, meaning that, each week, on average, 1 new song entered the list of the Top 5 most popular songs (or, equivalently, 1 song exited). Likewise, turnover is around 4.32 for the
, meaning that, each week, on average, 4.32 new songs entered the
. describes the turnover observed across all
Charts up to
=40 in the Billboard Hot 100 over the period from 1958 to 2021. This information is used to generate , which plots observed turnover (z) over Top Chart size (y).
Table 1. Turnover on the Billboard Hot 100 (1958–2021).
Figure 1. Figure 1 depicts average turnover, (black dots), observed in the Top Chart of size
on the Billboard Hot 100 Chart from 1958–2021. Black solid lines depict ± one standard deviation. Variation increases with the size of the Top Chart.
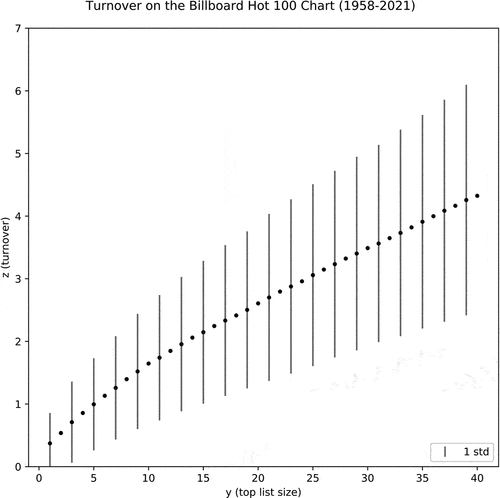
Adapting the terminology introduced in Bentley et al. (Citation2007), I refer to the function that maps Charts to turnover (z) for
} as a “Turnover Profile.” To give an example of one such turnover profile, as a thought experiment, we might imagine a plot of the curve z =
. This would be a diagonal line running from the lower left to the upper right of the graph and would indicate that, each week, the
Chart contained none of the songs from the week before; this is the maximum amount of turnover that can occur and thus constitutes the upper-bound for a turnover profile.
Describing social processes in terms of a turnover profile is useful in that turnover is detached from social context and can be used to characterize any social domain in which there is significant oscillation in popularity distributions over time (Lieberson, Citation2000). Here, a key advantage of focusing on a turnover profile function lies in the fact that the turnover profiles produced by the neutral model are fairly well understood (Bentley et al., Citation2007; Evans & Giometto, Citation2011). For instance, after running many simulations of the neutral model (see section 2.3.1 for a formal definition) across a wide array of parameter values, Bentley et al. (Citation2007) proposed the following turnover profile function for the neutral model:
where is average turnover,
is the size of the Top Chart, and
is the rate of innovation (i.e., the chance of a new song being introduced. See section 2.3.1 for a formal definition). This linking function is remarkable for its simplicity and the number of parameters that are not included. In particular, N, population size, is not included, although this was a parameter in the models evaluated. This simple function proved sufficient to not only reliably characterize turnover observed in the neutral model but was also capable of making predictions regarding expected popularity distributions across a variety of real world datasets (Bentley et al., Citation2007).
A more exact analytical solution was provided in later work by Evans and Giometto (Citation2011), who demonstrated that the turnover profile for the neutral model is indeed approximately linear but is more precisely described by the function
where is average turnover,
is the size of the Top Chart,
is the rate of innovation,
is population size, and
,
, and
are constants which vary for different parameter combinations. However, as Acerbi and Bentley (Citation2014) note, it is nevertheless possible to describe the turnover profile for a large area of the parameter space with a much simpler generic function
with ,
, and
defined as previously and
encompassing all remaining variables in EquationEquation 2
(2)
(2) . This is possible because, for the purposes of hypothesis testing, we are only interested in the shape of the turnover profile (i.e.,
for
). As can be seen directly, when
, the turnover profile is simply a linear function of the chart size (
). In other words, the value of
determines the shape of the turnover profile curve.
EquationEquation 3(3)
(3) is very useful for two key reasons. In the first place, it is possible to solve for b without necessarily also having to know the size of the underlying population. Second, and more importantly, in the case of the neutral model, the value of
is known (Evans & Giometto, Citation2011). Specifically, the equation for the neutral model is:
This gives us a null hypothesis to test against (Acerbi & Bentley, Citation2014). Specifically, we can use this information to compare the turnover that we do observe on the Billboard Hot 100 with the turnover we would have observed if individuals selected music according to behavior defined in the neutral model (section 2.3.1). This enables us to formally evaluate the extent to which observed turnover departs from neutral model expectations.
depicts the average turnover profile on the Billboard Hot 100 Chart from 1958 to 2021. In order to determine whether observed turnover deviates significantly from neutral model expectations, I used Akaike’s Information Criterion (AIC) to compare the relative likelihood of the two competing model fits (generic [EquationEquation 3](3)
(3) vs. neutral model [EquationEquation 4]
(4)
(4) ). Results of AIC analysis (Burnham & Anderson, Citation1998; Wagenmakers & Farrell, Citation2004) indicate that the neutral model can be rejected with high confidence, since the fit obtained with the generic model yields a lower AIC and an Akaike’s weight that exceeds ω > 0.999. Akaike weight can here be interpreted as the relative probability that the generic model is to be preferred over the model that assumes the underlying process of music selection is unbiased copying.
Figure 2. Figure 2 depicts average turnover, z, observed in the Top Chart of size on the Billboard Hot 100 Chart from 1958–2021 (dots) along with predicted values according to the best-fit of EquationEquation 3
(3)
(3) (b = 0.68, solid line) and the neutral model (b = 0.86, dashed line). Best-fit parameter values were obtained via OLS regression on log-transformed data (inset) .
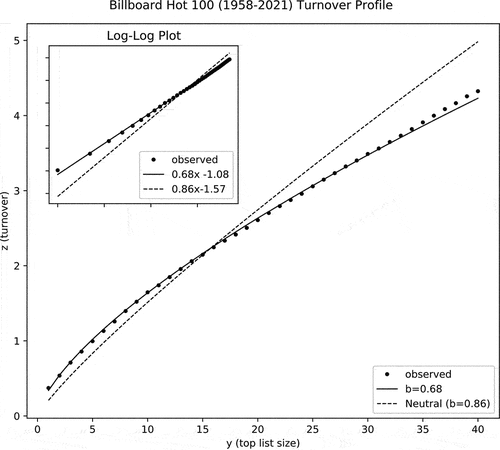
Of course, many things have changed in both society and the music industry between 1958 and 2021. Indeed, as mentioned above, the methodology used by Billboard to determine song popularity has itself changed in three major ways over this long period, moving from a survey-based methodology (1958–1991) to a point-of-sale-based methodology that did not include digital consumption (1991–2005), to a point-of-sale-based methodology that does include internet consumption (2005–2021). Here, the goal is to focus on demand side mechanisms. Therefore, to better understand how the shape of these curves have changed over time, I split the Billboard data into 1-year bins and run the same comparative analysis. This might be thought of as the equivalent of including a series of one-year dummy variables, with the intended effect of holding constant the many changes to technology, society, population size, etc. which occurred over the long period between 1958 and 2021.
Results of AIC analysis () indicate that the neutral model (EquationEquation 4(4)
(4) ) can be rejected in favor of the generic model (EquationEquation 3
(3)
(3) ) in all cases, since, for each year between 1958 and 2021, fits obtained with the generic model yielded lower AIC values than those obtained with the neutral model (Akaike weights ranged from ω = 0.974 to 0.999). depicts the average turnover profile on the Billboard Hot 100 Chart over the 1958–2021 period, split by year.
Table 2. Results of AIC Analysis for two competing model fits (generic vs. neutral model) of the Billboard Hot 100 Turnover Profile, by year.
Figure 3. Figure 3 depicts a graph of graphs containing 1958–2021 Billboard Hot 100 Chart turnover profiles, split by year. Each figure reports turnover (z) over the size of the Top Chart (y), averaged across all available weeks in the given year (upper left). Black dots are data. Blue solid line indicates the best-fit predictions according to EquationEquation 3(3)
(3) (b value located in bottom right). Red-dashed line depicts the best-fit predictions according to neutral model (i.e., EquationEquation 4
(4)
(4) ; b = 0.86) .

We gain from this analysis a few key pieces of information. First, we obtain a high degree confidence in the feasibility of using EquationEquation 3(3)
(3) to accurately describe observed turnover profiles. In all cases, observed turnover rates are more accurately described by the generic model (EquationEquation 3
(3)
(3) ) than the neutral model (EquationEquation 4
(4)
(4) ). In addition, predicted turnover values obtained via EquationEquation 3
(3)
(3) very closely match observed data patterns. This is reflected in the high
values () and can be seen directly in (blue line). This in turn gives us confidence in the use of the b value derived from EquationEquation 3
(3)
(3) . This is important, because, as was partially mentioned above, the overall shape of the turnover profile generated via EquationEquation 3
(3)
(3) is dictated entirely by the b value. In summary, we have now determined the generic model (EquationEquation 3
(3)
(3) ) can be used to accurately characterize empirical turnover data, with the b value determining the shape of the turnover profile curve.
2.2. Dependent variable: Billboard Hot 100 turnover profiles (1958-2021)
plots the results of the above procedures as a time series (). Since the goal of the present investigation is to characterize the likelihood of demand side mechanisms given the turnover observed on the Billboard Hot 100 Charts over time, this time series functions as the dependent in the models and analyses that follow.
Figure 4. Figure 4 plots b values obtained for turnover profiles observed on the Billboard Hot 100 Chart from 1958–2021. Note that all b values are lower than neutral model expectations (dashed line) .
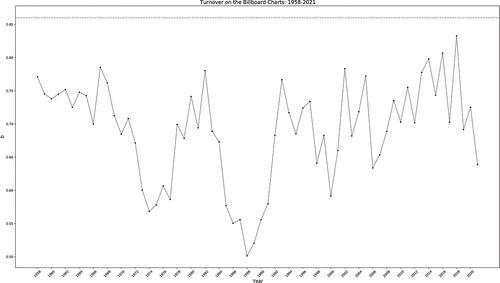
Notice that, in all cases, the values of the exponent b (Mean = .69; SD = 0.08; N = 64) obtained from Billboard Hot 100 turnover profiles are lower than the expected value of 0.86 (). It was determined via AIC analysis () that observed turnover deviates from the amount of turnover we would have observed if the underlying population selected music via a completely random (i.e., which is to say, completely unbiased) copying process. Since the shape of turnover profiles with low b values are concave (), this indicates that the most popular songs are consistently changing faster than less popular songs for the whole period from 1958 to 2021. Combined, these results suggest the existence of some type of selection pressure acting to increase the turnover rate of the most popular songs relative to other chart positions.
This effect can be seen more directly by examining changes in the turnover rate (i.e., z/y) over time (Lieberson, Citation2000). This is accomplished in , which plots the turnover rate observed on Billboard Hot 100 Charts from 1958 to 2021 for y = {10, 40, 100}.
Figure 5. Figure 5 plots the turnover rate observed on Billboard Hot 100 Charts from 1958–2021 for y = {10, 40, 100}, along with 95% confidence intervals.
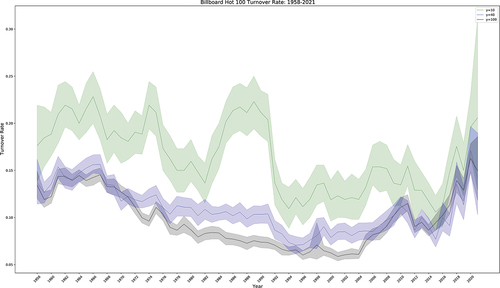
Songs in the Top10 turnover faster than do songs in the Top40 or Top100 chart, and this overall trend remains consistently the case over the full 1958–2021 period. However, the turnover rate observed in the Top10 fluctuates dramatically over time and follows a different trend than turnover in the Top40 or Top100 charts. additionally enables us to more readily discern the fact that most of the change occurring over time is happening at the top of the charts. Notice for instance, that the turnover rate observed in the Top10 () mirrors the pattern of b results (); as b decreases, the Top10 turnover rate increases and overall turnover profiles become more concave (). The two periods between 1973 and 1977 and 1985–1991 are particularly interesting. During this period of time, b values are the lowest obtained over the full 1958–2021 period, and a distinct “bend” can be discerned in the shape of turnover profiles at approximately y = 10. This existence of this downward bend suggests that the turnover of songs in the Top10 may have been influenced by process separate from songs located elsewhere on the chart. This possibility is reinforced by the fact that the turnover rate of songs in the Top10 appears to follow a completely separate pattern than the rest of chart during the period of time in question (). The turnover rate of songs in the Top10 diverges most sharply from the rest of the chart in 1974 and 1988.
Conversely, years with highest b values (e.g., 1982 and 2018) have more linear turnover profile shapes and begin to approach neutral model expectations (). This indicates that the turnover rate of the Top10 is approximately similar to the turnover occurring across the rest of the chart and can be seen in with overlapping 95% confidence intervals.
2.3. Models
The neutral model assumes that individual music selection is entirely a function of random imitation. This is clearly not an accurate description of actual music selection behavior, but it does provide a very useful null hypothesis. In particular, now that we know the extent to which observed data deviates from the predictions of this null model, we can also begin exploring alternative models of music selection by adding theoretically aligned biases to the neutral model and then exploring how these biases impact the shape of the turnover profiles produced. I focus in particular on biases such as status- and network-position, given the evidence that such biases appear to often be prevalent in actual instances of music selection (Bourdieu, Citation1984; Goldberg, Citation2011; Mark, Citation1998; Peterson & Kern, Citation1996).
I begin by constructing an agent-based model which implements the neutral model of cultural evolution presented in Bentley et al. (Citation2004) and related turnover profile extensions described in (Bentley et al., Citation2007). Then, I follow prior authors (Acerbi & Bentley, Citation2014; Mesoudi & Lycett, Citation2009) and introduce additional models with small modifications designed to capture important aspects of the alternative social transmission mechanisms outlined above. I describe the modeling assumptions used to characterize the transmission mechanisms in the sections below.
2.3.1. Neutral model
I begin by replicating the neutral model of cultural evolution described in Bentley et al. (Citation2004). The model begins with agents and
songs. Time passes in discrete time steps
. At each time step, all agents simultaneously select a song. With a small probability,
, an agent introduces a new song to the population. Each of the remaining
N individuals select an agent at random from the previous generation and copy their song choice. At the end of each time step, I record all of the songs present in the population and their frequency, and then rank songs according to observed frequency at time
(i.e., popularity). I then cut this list into 40
Charts, where the size of the top chart is specified by the variable
. Turnover (z) is defined as the set difference between the
Chart at time t relative to
In other words,
records the number of new songs to enter the
at each time step. The model was run for (
) total time steps. As Evans and Giometto (Citation2011) note, this gives the model enough time for it to overcome the transient phase of the initial time steps and achieve relative stability (
time steps). After that, turnover will begin fluctuating around a nominal average. Following their recommendations, I allow the model an additional (
time steps) and then calculate turnover, averaging it on the last (
time steps). Turnover profiles produced by the neutral model were consistent with those obtained by prior researchers (Acerbi & Bentley, Citation2014; Bentley et al., Citation2007; Evans & Giometto, Citation2011).
In each of the four models outlined below, I add slight modifications to the underlying architecture of the neutral model and “bias” some proportion of agents away from the neutral model and toward one of four alternative models of human decision-making behavior. The specific alterations are outlined in detail for each of the models below.
2.3.2. Song quality
The first alternative model I consider is the song quality model. It is designed to simulate the notion that some songs are intrinsically higher or lower quality than some other songs. The song quality model is implemented as follows. Prior to the model beginning, each song is randomly assigned a level of quality. Song quality is drawn at random from a standard normal distribution (). In this way, the majority of songs are assigned an intermediate level of quality (i.e., approximately 0), while a few songs will be extremely high/low quality. As was the case in the neutral model,
individuals select an agent at random from the previous generation. Here, instead of simply automatically copying their song selection, agents that follow the quality-based selection rule first consider the song’s quality level: if it is higher quality than their current song, they switch; if it is the same or lower, they do not switch songs. A masking parameter, C, determines the proportion of agents that follow the quality-based selection rule. Specifically, at each time step, a total of
agents, on average, are selected at random from the population and marked to follow the quality-based selection rule, while the remaining
agents follow the neutral model, and copy the agent’s song without considering its quality. (upper left) depicts turnover profiles produced by the song quality model for various C values, all other parameter values as described previously.
Figure 6. Figure 6 depicts turnover () over
Charts produced by the song quality (upper left), elite tastemaker (
=0.01, upper right), neighbor (
=1.6, bottom left), and anticonformist (bottom right) models for N = 5000,
for various C values (solid colored lines). Data is averaged across 100 simulation runs for the song quality and anticonformist models, 10 simulation runs for the elite tastemaker model and 20 simulation runs for the neighbor model.
values (each figure, upper left) derive from the best-fit of EquationEquation 3
(3)
(3) for the depicted data at the given parameter values. Maximum turnover (each figure, black dotted line) is equivalent to the curve
.
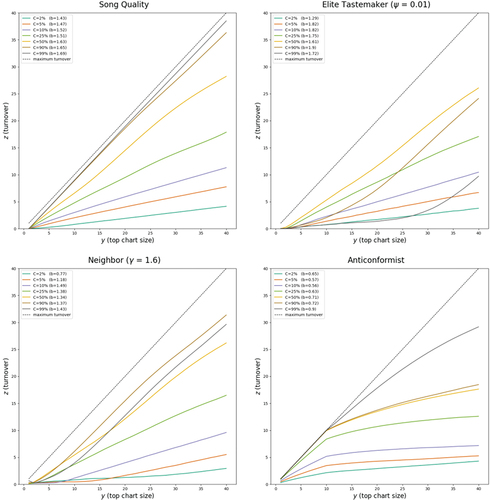
2.3.3. Elite tastemaker
The elite tastemaker model incorporates status or class and simulates the idea of a minority social elite leading the tastes expressed by the masses. The model is implemented as follows. First, as was the case in the song quality model, before the model begins each song is randomly assigned a level of quality, with song quality drawn at random from a standard normal distribution (). Next, a small proportion of agents are randomly assigned “elite” status according to the parameter
: approximately
N agents are coded as elite, and the remaining (
)N agents are coded as non-elites. Like the two previous models, at each time step,
agents consider a new song. Here however, elite and non-elite agents behave differently. The
elite agents consider a song selected at random from among the full universe of possible songs and consider the song’s quality level: if it is higher quality than the song they currently have selected, they switch; if it is the same or lower quality, they do not switch songs. The
non-elite agents begin as in the neutral model: that is, they select an agent at random from the previous generation and consider their song. Here, instead of simply copying their song selection, non-elite agents first consider whether or not it is also selected by one of the elites: if it is, they switch; if it is not, they do not switch songs. As before, a masking parameter C determines the proportion of agents that follow the elite tastemaker behavior rules. (upper right) depicts turnover profiles produced by the elite tastemaker model for
(i.e., approximately 1% of agents coded as “elite”) for various C values, all other parameters as defined previously.
2.3.4. Neighbor
The neighbor model simulates a preference for songs selected by socially proximate others. In this model, the neutral model is modified to incorporate an underlying social network structure. Beginning with agents as before, I generate a Barabási and Albert (Citation1999) scale-free random graph
where
and
if agent
and agent
are linked. All
links are referred to as “neighbors.” Each agent
is connected to
total neighbors with probability
, with probabilities decreasing with increased
such that
.Footnote2 As before, a masking parameter C determines the proportion of agents that follow the neighbor-biased selection rule. At each time step,
N agents, on average, follow the neighbor model; these agents select a neighbor at random and copy their song choice. The remaining
N agents follow the neutral model; these agents select an agent at random from the population and copy their song choice. (bottom left) depicts turnover profiles produced by the neighbor model for
(i.e., a graph with degree distribution
) for various C values, all other parameter as defined previously.
2.3.5. Anticonformist
The anticonformist model simulates a negative reaction to the most popular songs. In keeping with prior implementations of frequency-dependent selection biases (e.g., Acerbi & Bentley, Citation2014; Mesoudi & Lycett, Citation2009), the anticonformist model presented here is implemented by providing agents access to information on the prior to making song selections. Specifically, the model works as follows. Agents designated to follow the anticonformist model first check the
to see if the song they have selected is one of the Top-10 most-popular songs in the population. If it is not, they keep their current song. If it is, they behave according to the neutral model (i.e., select an agent at random from the population, and copy their song choice). In other words, anticonformist agents get rid of their songs if they are “too popular.” As before, the parameter C determines the proportion of agents designated to follow the anticonformist model. Specifically, a total of
agents, on average, follow the anticonformist model, while the remaining
agents follow the neutral model. (bottom right) depicts turnover profiles produced by the anticonformist model for various C values, all other parameter values as defined previously.
3. Model results
Information on model behavior is provided in the supplemental online appendix. Key characteristics are presented below.
3.1. Song quality
The song quality model produces convex turnover profiles in which the top songs change more slowly than all other chart positions. Fitting EquationEquation 3(3)
(3) to the song quality model yielded b values above those expected from an unbiased random copying process (Mean = 1.60, SD = .09, N = 100), and this is true for all C values considered. In fact, even a tiny minority of individuals in the underlying population behaving as specified in the song quality model is enough for the predictions of this model to deviate substantially deviate from the amount of turnover observed in reality, with the shape of the turnover profile becoming approximately linear (b = 0.99) at 1% and noticeably convex at 2% (b = 1.43) or 3% (b = 1.50), a result that indicates that only 1–2% of agents following the song quality model is enough to substantially impact the overall the shape of its overall turnover profile. Turnover profiles rapidly approach maximum turnover as the proportion of agents participating in quality-based selection increases ().
3.2. Elite tastemaker
The elite tastemaker model produces convex turnover profiles fitted with b values greater than those expected from the neutral model (Mean = 1.38, SD = 0.49, N = 4900). Turnover profile shapes are strongly impacted by both the C and the parameter. visualizes expected turnover profiles with 1% of agents assigned elite status and provides a typical example of the C parameter on overall model behavior. Turnover profiles become noticeably convex when approximately 2–5% of agents follow elite tastemaker rules and exhibit a very distinctive upward bend, indicating that the most popular songs are changing much more slowly than songs at lower chart regions. Increasing the C parameter pushes the location of this bend outward toward greater y values.
The parameter impacts the magnitude of these overall patterns. However, somewhat interestingly, the impact of the
parameter is not linear; across all C values, the most convex turnover profiles are obtained in populations consisting of between 3% and 7% elites. Turnover profiles become less convex as the proportion of elites in the underlying population increases beyond 7% and become indistinguishable from the neutral model when the proportion of elites exceed 20% of the total population. More substantively, the most popular songs change least often when the underlying population contains between 3% and 7% of elites, regardless of the number of agents paying attention to them. Conversely, when the proportion of elites exceeds 20% of the total population, turnover profiles become indistinguishable from a model of simple random copying. This latter effect might well be expected, since a population composed only of elites (and no elite followers) is similar in many respects to the default behavior of the neutral model.
3.3. Neighbor
Turnover profiles produced by the neighbor model were either indistinguishable from the neutral model or convex. b values followed a bimodal distribution determined by the parameter. Turnover profiles for
<1.24 were indistinguishable from the neutral model (Mean = 0.83, SD = 0.03, N = 6200); turnover profiles for
>1.24 (b = 1.27, SD = 0.14, N = 8800) are convex and exhibit a clear upward bend, indicating that the most popular songs change very slowly relative to less popular songs. visualizes the impact of the C parameter on the shape of this curve at
=1.6 and provides a typical example of overall model behavior. The neighbor model requires approximately 3% of agents to participate before the turnover shape is impacted; thereafter, a distinct upward bend appears. The location of this bend moves closer to the top of chart with increasing C and the uptick occurs more sharply with increasing
. Maximum b values are obtained with approximately 10% agent participation. Some exceptions to these general trends can be observed in models with very high C (e.g., C = 97–100%).
3.4. Anticonformist
The anticonformist model produces turnover profiles fitted with values lower than those produced by the neutral model. Turnover profile shapes are extremely sensitive to the existence of agents exhibiting anticonformist behavior; merely 1% of agents behaving as specified in the anticonformist model is enough to produce a concave turnover profile fitted with a b value of .71. Turnover profiles exhibit a distinct downward bend at y = 10, the location of which is readily explained as a function of how anticonformist behavior was implemented in the model (anticonformist agents reject songs in the
Chart). The overall concave shape indicates that the most popular songs are changing faster than less popular songs; the downward bend at y = 10 indicates a higher turnover rate in the
than all other chart positions. visualizes the impact of the C parameter. The turnover rate of songs in the
increases very rapidly as C increases; turnover in
for y > 10 changes more slowly.
4. Turnover analysis: Billboard Hot 100 charts (1958-2021)
In this section, I focus on using the predictions of the different models to interpret the time series presented above (). To help focus this effort, I concentrate analytical attention on chart years in which certain diagnostic features of modeled turnover profiles appear in observed turnover data.
4.1. The SoundScan revolution
A variety of technological innovations and entrepreneurial actions forced Billboard to accept a change in the methodology for compiling the weekly charts in 1991. The entire music industry reorganized itself around this methodology change, and for this reason it is sometimes referred to as the SoundScan Revolution (Anand & Peterson, Citation2000). Charts with the new methodology appeared for the first time on May 25, 1991. Following the switch to SoundScan methodology, turnover dynamics changed significantly. Armed with the new information contributed by the above models, we can now supplement prior analyses of this interesting period with some additional insights.
The impact of the SoundScan revolution is clearly visible in Hot 100 turnover profiles. For example, the 10 lowest b values are observed prior to the 1991 arrival of SoundScan, and the lowest b values observed over the entire course of the Billboard chart’s 63-year history are found between 1985 and 1990, the five years immediately preceding SoundScan’s arrival. A more substantive interpretation of the low b values observed over this period is readily gleaned by evaluating the turnover rate of the Top10 relative to all other chart positions (). In this regard, notice that there are two periods prior to SoundScan that follow similar trends, the first occurring between 1973 and 1977 and the second between 1985 and 1991. The b values obtained over these two periods are the lowest observed over the full 1958–2021 period, and a distinct bend can be discerned in the shape of turnover profiles at approximately y = 10. Within these two periods, b values reach local minimums in 1974 (b = .57) and 1988 (b = .50) (). The existence of this downward bend suggests that the turnover of songs in the Top10 may have been influenced by process separate from songs located elsewhere on the chart. This possibility is reinforced by the fact that the turnover rate of songs in the Top10 appears to follow a completely separate pattern than the rest of chart during the period of time in question ().
Figure 7. Figure 7 depicts average turnover, z, observed in the Top Chart of size on the Billboard Hot 100 Chart in 1974 and 1988 (dots) along with predicted values according to the best-fit of EquationEquation 3
(3)
(3) (solid line) and the neutral model (b = 0.86, dashed line) .
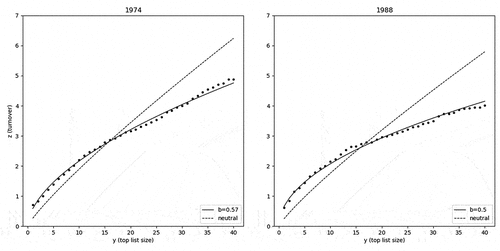
Of the four models considered above, only the anticonformist model reproduces the characteristics of turnover profiles observed during these two periods. In fact, the shape of the 1974 turnover profile can be reproduced almost exactly in an anticonformist model in which 5% of the underlying population rejects songs in the Top10, and all others copy the music selections of other people at random. Anticonformist models with 11% bias reproduce turnover profiles observed in 1987 and 1990 (b = .56) and come the closest to approximating the turnover profiles of 1988 (b = .50) and 1989 (b = .52), though these extremely low b values were below those produced in any turnover simulations. Since the success of musicians is known to have involved at least some amount of industry-side manipulation, particularly during the period immediately preceding the 1991 SoundScan revolution, the notion that consumption dynamics over this same period of time are best characterized by a model in which sizable minorities of the underlying population are systematically rejecting the industry’s proffered music fare is not altogether far-fetched. This possibility is reinforced by the fact that the distinctive turnover dynamics found only at the very top of the chart disappear completely in 1992, immediately after the methodology change has occurred ().
4.2. Digital era: quality searches and long tail effects
The vast majority of all music, book, and movie sales occur within a very small range of total product offerings (Brynjolfsson et al., Citation2011). Although popularity distributions in the music industry have traditionally been dominated by the superstar effect (Rosen, Citation1981), this became somewhat less true in digital environments as a result of diminishing search-costs and so-called “long-tail” effects (Anderson, Citation2008). In short, the long tail theory states that demand and production is increasingly shifting away from the selection and marketing of a small number of best-selling products toward a greater number of niche products in the tail. Just as the superstar effect can explain the phenomenon of long-lasting hit songs as a result of artificially concentrated consumption patterns, the long-tail effect can explain the phenomenon of an increasing number of hit songs as a result of individuals performing more effective or more wide-ranging song quality searches over a less restricted market. There are a variety of indicators of long-tail effects in the digital music era, stemming from a variety of interrelated effects related to reduced search costs, access to online music files, and improved consumer information (Brynjolfsson et al., Citation2011; Gopal et al., Citation2006; Hendricks & Sorensen, Citation2009). A growing body of evidence suggests similar long-tail effects following the arrival of music streaming platforms (Datta et al., Citation2018; Im et al., Citation2019). Most relevantly, reducing search cost increases expected turnover (Bhattacharjee et al., Citation2007; Brynjolfsson et al., Citation2011; Gopal et al., Citation2006). The song quality model captures important aspects of the search-related long-tail effect, and the model implemented here similarly predicts rapidly increasing turnover across all chart positions as the proportion of successful song quality searchers in the underlying population is increased. The song quality model is broadly consistent with overall turnover trends and is suggestive of its influence. For example, the overall turnover rate has increased very substantially since 2004 (). Spotify became widely available to United States subscribers in 2011, and, shortly thereafter, overall turnover rates increased very dramatically. In 2018, the overall turnover rate reached a level not previously seen since the 1960s, and in 2020 the overall turnover rate on the Hot 100 chart exceeded any point in its entire 63-year history.
4.3. Promotion and network effects
New information made available by the revised chart ranking methodology introduced in 1991 triggered additional industry changes soon thereafter. Of particular note in this regard was the realization that albums exhibited strongest sales immediately following their initial release, which led industry executives to concentrate marketing efforts before rather than after an album’s release (Anand & Peterson, Citation2000). Since music industry marketing executives have the explicit goal of encouraging others to adopt their music choices, it is possible to examine the effectiveness of various music marketing regimes by searching for diagnostic signatures of the elite tastemaker model in observed turnover profiles. Turnover profiles produced by the elite tastemaker model have a characteristic upward bend, whereby turnover is depressed well below neutral model expectations over multiple top chart positions and then increases dramatically at lower chart positions. As might be expected, a similar effect also occurs in turnover profiles produced by the network model, though the upward bend is generally more subdued for most values. Although the underlying behavior of the population is different in the two models, it is not surprising that the two models express themselves in similar ways, since the neighbor model is essentially providing a more generalized form of the elite tastemaker model. Indeed, the neighbor model can be made to produce almost identical effects to the elite tastemaker model by moving the
parameter toward higher values, since this has the effect of concentrating the distribution of all network ties into a very small set of extremely well-connected agents.
The exact location of the upward bend depends on various parameter combinations, but in both models it is most directly impacted by C. In the case of the elite tastemaker model, the C parameter directly refers to the proportion of the underlying population adopting the song selections of tastemaking “elites.” Increasing the C parameter results causes the songs selected by tastemakers to remain at the top of the charts for longer periods of time and pushes the location of this bend outward, toward lower chart positions. Conversely, decreasing the C parameter reduces the proportion of agents following the decisions of tastemakers and pushes the location of this bend closer to the top of the chart. As a result, observed turnover profiles exhibiting a clearly discernible upward bend potentially suggest a reduction in the effectiveness of professional song promoters.
Using this information as a diagnostic criterion, I search for Hot 100 turnover profiles with a sudden uptick in turnover at lower chart positions. The single clearest example of this effect occurs in 2020, though faint traces of possibly similar effects can also be discerned in certain earlier chart years (1983, 2004, 2016).
Further considering the very unusual 2020 turnover dynamics, if indeed this uptick effect is telling us something about disrupted promotion, we might also use the results of the neighbor model to further examine the potential mechanisms involved. In the case of the neighbor model, something akin to the 2020 effect can be made to occur by increasing the C parameter, or, in other words, by reducing the likelihood of random information exchange and increasing the role of more localized, strong-tie network effects.
5. Discussion
It was demonstrated above that the simple generic function provided by Acerbi and Bentley (Citation2014) (EquationEquation 3(3)
(3) ) can be used to characterize the turnover of popular songs on the Billboard Hot 100 charts over the period from 1958 to 2021. Building on prior work involving the neutral model, I began by comparing observed turnover profiles with the turnover profiles we would have observed if music selection in the underlying population consisted of an unbiased random-copying process. Data analysis focused on turnover profile shapes and centered on the value of the exponent b. Observed turnover profiles have overall concave shapes (), capturing the higher turnover rate observed in the Top 10 relative to other chart positions and are best fit with an exponent b lower than would be expected under conditions of an unbiased random-copying process (). Thus, one of the key takeaways of this analysis is that the most popular songs have consistently been changing faster than would be expected from an unbiased selection process over the full 1958–2021 period. This result suggests the existence of selection pressures in the underlying population acting to increase the turnover rate of the most popular songs relative to other chart positions.
Next, using the unbiased neutral model as a baseline, I then investigated departures from this model in order to characterize the likelihood of alternative individual music taste transmission mechanisms in the underlying population. In each of four separate models (song-quality, elite tastemaker, neighbor, anticonformist), I introduced small biases to the neutral model of cultural transmission and then examined the impact of these biases on the shape of turnover profiles produced across a wide variety of parameter combinations. Then, I characterized the likelihood of these four transmission mechanisms by examining the extent to which the models were able to reproduce the diagnostic features of the empirical turnover profiles collected from the Billboard Hot 100 charts over time.
At the broadest level, the models can be usefully contrasted with one another in terms of their predictions concerning turnover at the top of the charts. The song quality, elite-tastemaker, and neighbor models (for >1.24) yield turnover profiles with an overall convex shape, b values greater than those expected from an unbiased random copying process, and predict rapidly increasing turnover as we move down the chart. As a result, the existence of any of these three selection mechanisms in the underlying population acts to depress the turnover rate in the most popular songs relative to other chart positions. Only the anticonformist model proved capable of reproducing the concave turnover profiles and low b values observed in empirical turnover data.
Although key aspects of each of the four models can be discerned in the turnover data over time, the fact that empirical turnover profiles remained most consistent with anticonformist model expectations over the full 63 year history of the Billboard Hot 100 chart may suggest the presence of similar individual-level biases in the underlying population, with some minority of United States music consumers similarly biased against the consumption of the most popular songs. This result is somewhat surprising. Prior work has demonstrated a fairly consistent bias toward the selection of the most popular items in empirical turnover rates over time, with, e.g., Lieberson (Citation2000) arguing in favor of the existence of something akin to a generalized popularity preference driving individual consumption choices. Additionally, experimental work has demonstrated the existence of a significant “preference for the popular” in individual music selection (Salganik et al., Citation2006). The results of this prior work led us to believe that we ought to find evidence of a fairly consistent bias toward the selection of the most popular songs in empirical turnover rates over time. However, I find no such evidence of a generalized “preference for the popular” here. In fact, the shape of observed turnover profiles appear to suggest precisely the opposite conclusion: i.e., individuals engaged in the active avoidance of the most popular songs, rather than seeking them out. If indeed there is such a wide-ranging popularity preference, there is no evidence to this effect in the observed data. It could be, however, that a “preference for the popular” does exist but is somewhat more complicated in its effect. For instance, individuals may prefer songs at some level of popularity, but reject songs that have become “too” popular. Something akin to this effect has been pursued elsewhere (e.g., Mesoudi & Lycett, Citation2009), but has not been specifically connected to turnover profile shapes. The anticonformist model may also provide a plausible explanation for the puzzling data patterns reported by Salganik and Watts (Citation2008), in which the previously reported popularity-based selection mechanisms (Salganik, Citation2006), were not able to account for the substantial amount of turnover observed in the most-popular songs over time; indeed, to that end, the two authors also note that significant minorities of individuals appeared to demonstrate anticonformist music-selection behavior. Population level turnover patterns reported here are consistent with this hypothesis. Taken together, the two results seem to suggest that individual music consumption is perhaps better modeled not as a preference for popularity, but instead as a simple model of random “drift,” with some small proportion of individuals rejecting popular songs.
With regard to the “bend” sometimes observed in the shape of turnover profiles, I find that this bend is a clearly identifiable data pattern, appearing in both modeled (anticonformist, elite tastemaker, neighbor) and empirical turnover data (; ). This finding suggests that the bend effect is neither a coding artifact (since it appears in empirical data), nor is it always indicative of frequency-dependent individual selection (since it appears in both the neighbor and elite tastemaker models, which do not involve frequency-dependent selection), as had previously been supposed (Acerbi & Bentley, Citation2014). The bend effect is therefore interesting and can be used to meaningfully distinguish between various selection processes in the underlying population.
Figure 8. Figure 8 depicts average turnover, z, observed in the Top Chart of size on the Billboard Hot 100 Chart in 1983, 2004, 2016, and 2020 (dots) along with predicted values according to the best-fit of EquationEquation 3
(3)
(3) (solid line) and the neutral model (b = 0.86, dashed line) .
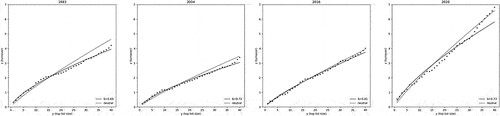
The existence of distinct bends in observed turnover data suggests the existence of two distinct selection mechanisms, the first applying to the selection of the most popular songs and a second process applying to all other songs. It is worth noting, for instance, that the turnover we observe in the Top 40 positions of the Hot 100 chart only very rarely exceeds neutral model expectations for nearly the entirety of its 63-year history. In the few instances where this does occur (2020 being the most obvious example), this occurs only at later chart positions. While the song quality, elite-tastemaker, and neighbor models each depress the turnover rate below neutral model expectations at the top of the chart, only in the elite-tastemaker and neighbor model is the turnover rate depressed across multiple chart positions before suddenly spiking upwards. That this behavior is sometimes observed is rather suggestive. Specifically, in years where a bend upwards occurs is consistent with a lessening role of marketing or promotion activities (elite tastemaker) or, more generally, a disruption in underlying communication networks (neighbor).
With regard to the neighbor model, one of the more interesting results is that the neighbor model produced turnover profiles indistinguishable from neutral model predictions for all social networks with < 1.28, and produced convex turnover profiles for
>1.28. At a general level these effects are in line with intuition. In less hierarchical social networks (
<1.28, i.e., social networks in which all agents have approximately the same number of friends, all agents have an equal chance of picking the hits. As might be expected, song popularity and turnover in such networks is essentially random, and cannot be distinguished from a completely unbiased cultural drift process. As we increase the
parameter, the social network becomes more hierarchical (i.e., degree distributions become more unequal, with a decreasing proportion of total agents receiving an increasing proportion of all edges). This effectively concentrates decision making power in the hands of fewer people and results in the production of convex turnover profiles in which the most popular songs change more slowly than less popular songs. This effect occurs because in more hierarchical social networks (
>1.28), the ability to pick the hits becomes a function of agent-popularity: songs selected by popular agents always become hits while songs selected by unpopular agents rarely do. Since unpopular agents have less ability to voice their opinions, the most popular songs are “challenged” less often. As a result, songs selected by best-connected agents move to the top of the chart quickly and remain there until they select a new song. Overall, this has the effect of compressing turnover at the top of the charts and produces a convex turnover profile, in which the most popular songs change more slowly than less popular songs.
The network model provides an interesting sociological complement to the neutral model. In particular, another way to think about the neutral model is to imagine it as modeling the transmission of information across a social network consisting exclusively of weak ties, with information being passed only through acquaintances rather than directly connected friends or peers. In such a network, social transmission might be thought of as occurring essentially at random, exactly as the neutral model stipulates. Conversely, if the transmission of information occurs exclusively though directly connected agents, we might think of that type of model as one in which information is transmitted only through strong ties. As a result, the C parameter serves a somewhat unique role in the case of the neighbor model, as it may usefully be thought of as the proportion of strong ties.
Some of the results of the neighbor model are more interesting when considered from this perspective. For instance, in less hierarchical social networks ( <1.28), turnover is apparently completely unaffected by tie strength. Indeed, whether information is received through strong or weak ties, there is no discernible impact on overall song turnover until the degree distribution of the overall social network exceeds a
value of 1.28. However, in more hierarchical networks (
>1.28), the strength of ties begins to matter a great deal. At a broad level, the general pattern of results is as might be expected: as we increase the proportion of agents relying on information received through strong ties (i.e., C), we are increasing the role of friendship networks and thus concentrating decision making power into the people with the most friends. Unsurprisingly, this reduces the amount of turnover we observe in the most popular songs. Zooming in a bit, I find interesting deviations from this general pattern. For instance, the most convex turnover profiles are consistently produced in social networks in which 10% of agents receive information from strong ties and 90% receive information from weak ties (see supplemental online appendix, Figure A11). There are also interesting effects as we remove weak ties entirely. Perhaps as we might expect given prior theory (Granovetter, Citation1973; Onnela et al., Citation2007),, turnover profile shapes change very dramatically as we begin to approach a network in which information is passed only through strong ties (i.e., as C parameter approaches 1.0). To put this another way, I find that allowing even a small amount of random information exchange is enough to substantially alter the shape of the population level turnover profile, reminiscent of a small world effect (Watts & Strogatz, Citation1998). This is interesting in relation to the positioning of the bend observed in turnover profiles produced by the neighbor model. In particular, increasing the proportion of information passed through strong ties even slightly (i.e., increasing C) rapidly pushes the bend closer to the top of the chart; conversely, increasing the role of weak ties (i.e., decreasing C) pushes the bend farther out and depresses overall turnover across more total chart positions.
The fact that none of these effects are observable until the parameter crosses the
=1.28 threshold was unexpected. While it is perhaps somewhat more possible in the case of the network model that this effect is somehow related to network size (N, see supplemental online appendix B for related discussion), approximately similar
thresholds occur for different N, and it therefore seems more likely that this effect is related to the difficulty of passing messages across networks without clear hubs or other information transmitters (Albert et al., Citation2000). Future work might make progress in this area by exploring the relationship between turnover and measures of network characteristics related to the difficulty of message passing (e.g., span, average path distance, closeness, etc.). Pursuing this direction would be useful in that it would enable us to characterize turnover in terms of network centrality measures rather than in terms of
values, making the results more intuitive and directly applicable to any number of social network structures.
In this paper, an attempt was made to infer, from aggregated, macro-level turnover data, the likelihood of various conceptions of individual consumption behavior. While the present analysis is set in the context of music consumption, these techniques might easily be applied elsewhere. Indeed, a variety of work has investigated departures from the neutral model (see Shennan, Citation2011 for a review). However, this analysis is, so far as the present author is aware, the first to link this work to social transmission mechanisms related to network structure or status, known to be relevant in actual instances of music selection (Bourdieu, Citation1984; Goldberg, Citation2011; Mark, Citation1998; Peterson & Kern, Citation1996). The results presented here document the results of an initial investigation and were necessarily somewhat descriptive. Even so, we learn a variety of things by this method of analysis that were less easily detectable in prior methods, and which may open the way for future research. While we are not able to definitively identify biases operating at an individual level, this analysis has shown that it is possible to make informed inferences about individual level consumption behavior using information from aggregated population level turnover data. Overall, this study contributes to ongoing debates regarding the transmission of taste and the mechanics of fashion change.
Supplemental Online Appendices A and B
Download MS Word (1.5 MB)Supplemental data
Supplemental data for this article can be accessed on the publisher’s website.
Notes
1 A power-law popularity distribution means that the vast majority of items are unpopular, and a small minority of items are many, many times more popular than the majority.
2 While any number of stochastic graph generators might be employed for this purpose (e.g., Erdos-Renyi, small-world [Watts & Strogatz, Citation1998]; hierarchical [Clauset et al., Citation2008], etc.), the Barabási and Albert (Citation1999) scale-free random graph has a variety of characteristics that make its use desirable here. In particular, power-law degree distributions are a common feature in many real-world networks (Albert & Barabási, Citation2002), the resulting degree distribution is intuitive and can be manipulated directly via the parameter, it minimizes the number of isolates, and it is computationally efficient.
References
- Acerbi, A., & Bentley, R. A. (2014). Biases in cultural transmission shape the turnover of popular traits. Evolution and Human Behavior, 35(3), 228–236. https://doi.org/10.1016/j.evolhumbehav.2014.02.003
- Albert, R., & Barabási, A.-L. (2002). Statistical mechanics of complex networks. Reviews of Modern Physics, 74(1), 47. https://doi.org/10.1103/RevModPhys.74.47
- Albert, R., Jeong, H., & Barabási, A.-L. (2000). Error and attack tolerance of complex networks. Nature, 406(6794), 378–382. https://doi.org/10.1038/35019019
- Anand, N., & Peterson, R. A. (2000). When market information constitutes fields: Sensemaking of markets in the commercial music industry. Organization Science, 11(3), 270–284. https://doi.org/10.1287/orsc.11.3.270.12502
- Anderson, C. (2008). The long tail: Why the future of business is selling less of more. Hachette Books.
- Barabási, A.-L., & Albert, R. (1999). Emergence of scaling in random networks. Science, 286(5439), 509–512. https://doi.org/10.1126/science.286.5439.509
- Bentley, R. A. (2008). Random drift versus selection in academic vocabulary: An evolutionary analysis of published keywords. PloS One, 3(8), e3057. https://doi.org/10.1371/journal.pone.0003057
- Bentley, R. A., Hahn, M. W., & Shennan, S. J. (2004). Random drift and culture change. Proceedings of the Royal Society of London B: Biological Sciences, 271(1547), 1443–1450. https://doi.org/10.1098/rspb.2004.2746
- Bentley, R. A., Lipo, C. P., Herzog, H. A., & Hahn, M. W. (2007). Regular rates of popular culture change reflect random copying. Evolution and Human Behavior, 28(3), 151–158. https://doi.org/10.1016/j.evolhumbehav.2006.10.002
- Bhattacharjee, S., Gopal, R. D., Lertwachara, K., Marsden, J. R., & Telang, R. (2007). The effect of digital sharing technologies on music markets: A survival analysis of albums on ranking charts. Management Science, 53(9), 1359–1374. https://doi.org/10.1287/mnsc.1070.0699
- Bourdieu, P. (1984). Distinction: A social critique of the judgment of taste. Harvard University Press.
- Boyd, R., & Richerson, P. J. (2005). The origin and evolution of cultures. Oxford University Press.
- Brynjolfsson, E., Hu, Y., & Simester, D. (2011). Goodbye pareto principle, hello long tail: The effect of search costs on the concentration of product sales. Management Science, 57(8), 1373–1386. https://doi.org/10.1287/mnsc.1110.1371
- Bryson, B. (1996). “Anything but heavy metal”: Symbolic exclusion and musical dislikes. American Sociological Review, 61(5), 884–899. https://doi.org/10.2307/2096459
- Burnham, K. P., & Anderson, D. R. (1998). Practical use of the information-theoretic approach. In Model selection and inference (pp. 75–117). New York, NY: Springer. https://doi.org/10.1007/978-1-4757-2917-7_3.
- Cavalli-Sforza, L., & Feldman, M. W. (1973). Models for cultural inheritance I. Group mean and within group variation. Theoretical Population Biology, 4(1), 42–55. https://doi.org/10.1016/0040-5809(73)90005-1
- Cavalli-Sforza, L. L., & Feldman, M. W. (1981). Cultural transmission and evolution: A quantitative approach. Princeton University Press.
- Clauset, A., Moore, C., & Newman, M. E. (2008). Hierarchical structure and the prediction of missing links in networks. Nature, 453(7191), 98–101. https://doi.org/10.1038/nature06830
- Crow, J. K., & Kimura, M. (1997). M. (1970) An Introduction To Population Genetics Theory. Harper and Row.
- Datta, H., Knox, G., & Bronnenberg, B. J. (2018). Changing their tune: How consumers’ adoption of online streaming affects music consumption and discovery. Marketing Science, 37(1), 5–21. https://doi.org/10.1287/mksc.2017.1051
- Evans, T. S., & Giometto, A. (2011). Turnover rate of popularity charts in neutral models. ArXiv preprint. ArXiv:1105.4044. https://arxiv.org/abs/1105.4044
- Goldberg, A. (2011). Mapping shared understandings using relational class analysis: The case of the cultural omnivore reexamined. American Journal of Sociology, 116(5), 1397–1436. https://doi.org/10.1086/657976
- Gopal, R. D., Bhattacharjee, S., & Sanders, G. L. (2006). Do artists benefit from online music sharing?. The Journal of Business, 79(3), 1503–1533. https://doi.org/10.1086/500683
- Granovetter, M. (1973). The strength of weak ties. American Journal of Sociology, 78(6), 1360–1380. https://doi.org/10.1086/225469
- Haampland, O. (2017). Power laws and market shares: Cumulative advantage and the Billboard Hot 100. Journal of New Music Research, 46(4), 356–380. https://doi.org/10.1080/09298215.2017.1358285
- Hahn, M. W., & Bentley, R. A. (2003). Drift as a mechanism for cultural change: An example from baby names. Proceedings of the Royal Society of London B: Biological Sciences, 270(Suppl 1), S120–S123. https://doi.org/10.1098/rsbl.2003.0045
- Harrison, J. R., & Carroll, G. R. (1991). Keeping the faith: A model of cultural transmission in formal organizations. Administrative Science Quarterly, 36(4), 552–582. https://doi.org/10.2307/2393274
- Hendricks, K., & Sorensen, A. (2009). Information and the skewness of music sales. Journal of Political Economy, 117(2), 324–369. https://doi.org/10.1086/599283
- Henrich, J., & Broesch, J. (2011). On the nature of cultural transmission networks: Evidence from fijian villages for adaptive learning biases. Philosophical Transactions of the Royal Society B: Biological Sciences, 366(1567), 1139–1148. https://doi.org/10.1098/rstb.2010.0323
- Herzog, H. A., Bentley, R. A., & Hahn, M. W. (2004). Random drift and large shifts in popularity of dog breeds. Proceedings of the Royal Society of London B: Biological Sciences, 271(Suppl 5), S353–S356. https://doi.org/10.1098/rsbl.2004.0185
- Hesbacher, P., Downing, R., & Berger, D. G. (1975). Sound recording popularity charts: A useful tool for music research: I. Why and how they are compiled. Popular Music & Society, 4(1), 3–18. https://doi.org/10.1080/03007767508591066
- Im, H., Song, H., & Jung, J. (2019). The effect of streaming services on the concentration of digital music consumption. Information Technology & People, 33(1), 160–179. https://doi.org/10.1108/ITP-12-2017-0420
- Kandler, A., & Shennan, S. (2013). A non-equilibrium neutral model for analysing cultural change. Journal of Theoretical Biology, 330, 18–25. https://doi.org/10.1016/j.jtbi.2013.03.006
- Kimura, M. (2020). The neutral theory and molecular evolution. In My thoughts on biological evolution (pp. 119–138). Singapore: Springer. https://doi.org/10.1007/978-981-15-6165-8_8
- Klein, C. C., & Slonaker, S. W. (2010). Chart turnover and sales in the recorded music industry: 1990–2005. Review of Industrial Organization, 36(4), 351–372. https://doi.org/10.1007/s11151-010-9250-z
- Kreitman, M. (1996). The neutral theory is dead. long live the neutral theory. Bioessays, 18(8), 678–683. https://doi.org/10.1002/bies.950180812
- Lieberson, S. (2000). A matter of taste: How names, fashions, and culture change. Yale University Press.
- Manski, C. F. (1993). Identification of endogenous social effects: The reflection problem. The Review of Economic Studies, 60(3), 531–542. https://doi.org/10.2307/2298123
- Mark, N. (1998). Birds of a feather sing together. Social Forces, 77(2), 453–485. https://doi.org/10.2307/3005535
- Merton, R. K. (1948). The self-fulfilling prophecy. The Antioch Review, 8(2), 193–210. https://doi.org/10.2307/4609267
- Mesoudi, A., & Lycett, S. J. (2009). Random copying, frequency-dependent copying and culture change. Evolution and Human Behavior, 30(1), 41–48. https://doi.org/10.1016/j.evolhumbehav.2008.07.005
- Neiman, F. D. (1995). Stylistic variation in evolutionary perspective: Inferences from decorative diversity and interassemblage distance in illinois woodland ceramic assemblages. American Antiquity, 60(1), 7–36. https://doi.org/10.2307/282074
- Obukhova, E., Zuckerman, E. W., & Zhang, J. (2014). When politics froze fashion: The effect of the cultural revolution on naming in beijing. American Journal of Sociology, 120(2), 555–583. https://doi.org/10.1086/678318
- Onnela, J.-P., Saramäki, J., Hyvönen, J., Szabó, G., Lazer, D., Kaski, K., Kertész, J., & Barabási, A.-L. (2007). Structure and tie strengths in mobile communication networks. Proceedings of the National Academy of Sciences, 104(18), 7332–7336. https://doi.org/10.1073/pnas.0610245104
- Peterson, R. A., & Kern, R. M. (1996). Changing highbrow taste: From snob to omnivore. American Sociological Review, 61(5), 900–907. https://doi.org/10.2307/2096460
- Rosen, S. (1981). The economics of superstars. The American Economic Review, 71(5), 845–858. https://www.jstor.org/stable/1803469
- Salganik, M. J., Dodds, P.S., & Watts, D.J. (2006). Experimental study of inequality and unpredictability in an artificial cultural market. Science, 311(5762), 854–856. https://doi.org/10.1126/science.1121066
- Salganik, M. J., & Watts, D. J. (2008). Leading the herd astray: An experimental study of self-fulfilling prophecies in an artificial cultural market. Social Psychology Quarterly, 71(4), 338–355. https://doi.org/10.1177/019027250807100404
- Shennan, S. (2011). Descent with modification and the archaeological record. Philosophical Transactions of the Royal Society of London B: Biological Sciences, 366(1567), 1070–1079. https://doi.org/10.1098/rstb.2010.0380
- Simkin, M. V., & Roychowdhury, V. P. (2003). Copied citations create renowned papers? In ArXiv preprint cond-Mat/0305150. https://arxiv.org/abs/cond-mat/0305150
- Wagenmakers, E.-J., & Farrell, S. (2004). AIC model selection using akaike weights. Psychonomic Bulletin & Review, 11(1), 192–196. https://doi.org/10.3758/BF03206482
- Watts, D. J., & Strogatz, S. H. (1998). Collective dynamics of ‘small-world’networks. Nature, 393(6684), 440–442. https://doi.org/10.1038/30918
