
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
As the use of digital systems in nuclear power plants increases, the reliability of the software becomes one of the important issues in probabilistic safety assessment. In this paper, two viewpoints for a software failure during the operation of a digital system or a statistical software test are identified, and the relation between them is provided. In conventional software reliability analysis, a failure is mainly viewed with respect to the system operation. A new viewpoint with respect to the system input is suggested. The failure probability density functions for the two viewpoints are defined, and the relation between the two failure probability density functions is derived. Each failure probability density function can be derived from the other failure probability density function by applying the derived relation between the two failure probability density functions. The usefulness of the derived relation is demonstrated by applying it to the failure data obtained from the software testing of a real system. The two viewpoints and their relation, as identified in this paper, are expected to help us extend our understanding of the reliability of safety-critical software.
1. Introduction
Probabilistic safety assessment (PSA) provides a macroscopic view of the safety of nuclear power plants (NPPs) by systematically combining the likelihood of initiating events, potential scenarios, and their consequences. As more and more digital systems are used in the safety-critical instrumentation and control (I&C) systems in NPPs, the PSA of digital I&C systems becomes more important because concerns about the reliability and safety of digital I&C systems increase. Lu and Jiang [Citation1] provided an overview of PSA applications in three areas of digital I&C systems in NPPs. Kang et al. [Citation2] described the risk quantification issues related to digitalized safety systems in NPPs. The state-of-the-art of the PSA of digital I&C systems in NPPs was reviewed by Authen and Holmberg in [Citation3].
One of the important issues in the PSA of digital I&C systems in NPPs is the reliability of the software inside digital I&C systems [Citation4]. Software reliability is defined as the probability of a failure-free operation for a specified period of time in a specified environment [Citation5], and is one of the attributes of software quality. Failure data from the operational history or software testing have been used for software reliability analysis. In order to use failure data from software tests for software reliability analysis, the operational profile should be designed so that the information domain (or input domain) can be reflected properly in the operational profile [Citation6].
Many approaches have been reviewed and applied to find a consensus method for software reliability analysis of digital I&C systems in NPPs. Chu et al. [Citation7] reviewed various approaches for software reliability analysis of safety-critical software. They identified test-based software reliability analysis as one of the two most technically sound approaches for the reliability analysis of safety-critical software in NPPs. Keeping in mind the increasing focus on test-based software reliability analysis, the establishment of a firm theoretical basis is very important.
According to Myers [Citation8], software testing is defined as the process of executing a program or system with the intention of finding errors. In IEEE Std 829-1998 [Citation9], software testing is defined as the process of analyzing a software item to detect the differences between existing and required conditions (i.e., bugs) and to evaluate the features of the software item. Software testing can also be used to estimate or demonstrate the reliability of software. This form of software testing is called statistical software testing.
The idea of using statistical software testing to demonstrate the reliability of software was first suggested by Currit et al. [Citation10] and Musa et al. [Citation11]. As explained by Chillarege [Citation12], the central goal of statistical software testing is to assess the reliability of software, as opposed to the popular application of software testing as a debugging method. Therefore, instead of preparing the test cases based on specifications, requirements, and testers’ expectations of what an implementation is most likely to do wrong [Citation13], test cases should be prepared based on the operational profile of the software.
The analysis of failure data from the operational history or software testing is an important issue in estimating the quality of software. According to Musa et al. [Citation11], binomial-type models and Poisson-type models occupy an important position in software reliability work. The Jelinski–Moranda model [Citation14] and the Goel–Okumoto model [Citation15] are generally considered to be the two most representative models for binomial-type models and Poisson-type models, respectively. In most of the conventional software reliability growth models such as the Jelinski–Moranda model or the Goel–Okumoto model, time-to-system-failure data or the number of system failures during a predefined time period is used. This means that a failure in these conventional models is viewed only with respect to the system operation.
In this paper, a new viewpoint for a software failure with respect to system input is introduced. The relation between the viewpoint for a failure with respect to the system operation and that with respect to system input is also derived and explained. The author's understanding is that the viewpoint for a failure with respect to the system input is not widely recognized. This is partly because clear distinction has not been significantly required when an exponential distribution is assumed as a failure probability density function, since the failure probability density functions from the two viewpoints are identical (as will be explained in Section 2). Because the failure probability density functions from the two viewpoints are different in general, care should be taken when distributions other than an exponential distribution is assumed in the analysis of software reliability.
2. Theoretical considerations
For software reliability analysis, the failure data from the operating history or software testing should be analyzed. The failure data are considered to be the most representative example of a safety-critical digital I&C system in an NPP.
2.1. Characteristics of safety-critical software in NPPs
To identify the characteristics of the safety-critical software in NPPs, the operation of one of the most important safety-critical digital I&C systems is reviewed, as an example. The plant protection system (PPS) in an NPP is responsible for generating safety actuation signals such as reactor trip signals and engineered safety features (ESF) actuation signals, while monitoring the plant parameters. Even though the integrity of the PPS is examined every month or every three months, the PPS is required to operate without experiencing any failures during one refueling cycle. The software in the PPS is also subject to the same requirement. A refueling cycle is normally 12 or 18 months. Hence, this relatively long time period is of interest from the viewpoint of the system operation.
If we examine the operation of the PPS, it repeatedly receives plant parameters as inputs, processes them, determines whether safety actuation signals need to be generated, and provides outputs corresponding to the input in a predefined maximum allowed time. In other words, the time is divided with short time interval, and it is supposed that a single input is provided to PPS at the start of each time interval. A single input consists of all plant parameters the PPS needs to decide whether reactor trip signals have to be generated or not. Hence, this relatively short time period is of interest from the viewpoint of an input to the system (and therefore to the software).
The failure data are normally collected from the operating history or software testing with a relatively long time frame. However, the PSA of digital I&C systems is concerned with the failure probability for an input provided to the system with a relatively short time frame. Therefore, there exist two different viewpoints for software failures in digital I&C systems corresponding to the two time frames. Moreover, it is important to identify the theoretical relation between the two viewpoints so that the failure data from the operating history or software testing can be converted to the failure probability for an input, which is necessary for the PSA of digital I&C systems.
2.2. Two viewpoints for software failures
illustrates the two different viewpoints for a software failure described in Section 2.1. From the viewpoint of an input to the system, the failure occurs at some time point during the processing of the (i + 1)th input after successfully providing outputs for i consecutive inputs. From the viewpoint of the system operation, the failure occurs at some point of time after the system starts its operation.
Figure 1. Time relation for a failure from the input viewpoint and from the system operation viewpoint.
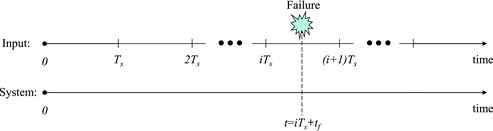
To distinguish between the two different viewpoints, two random variables are defined as follows:
TI: random variable indicating the time a failure occurs after an input is provided (0 ⩽ t < Tmax )
TS: random variable indicating the time a failure occurs after the system starts its operation (t ⩾ 0)
From the two random variables, the following two probability density functions can be defined:
(1)
(1)
(2)
(2) wherefI(t) is the failure probability density function for an input (0 ⩽ t < Tmax ) andfS(t) is the failure probability density function for the system operation (t ⩾ 0).
Basically, whether a failure occurs or not for a given input is deterministic in the case of software. An input to the system can be understood as a result of sampling in a distribution of possible inputs, which is related to the plant condition at the time of sampling. The failure probability density functions, fI(T) and fs(T), depend on inputs and the sequence of inputs to the system, respectively. In summary, the failure probability density functions depend on the plant condition under consideration.
In a probabilistic analysis, the distribution of inputs that is weight-averaged over possible plant conditions with the consideration of the frequencies of the plant conditions needs to be used instead of a distribution of inputs for a specific plant condition. Therefore, the operational profile (various plant conditions with their frequencies considered) should be designed so that the input domain (the distribution of inputs) can be properly reflected to the operational profile.
From the two failure probability density functions, the following two cumulative failure probability density functions can be defined:
(3)
(3)
(4)
(4) where FI(t) is the cumulative failure probability density function for an input (0 ⩽ t < Tmax ) and FS(t) is the cumulative failure probability density function for the system operation (t ⩾ 0).
It should be noted that fS(t) satisfies the condition
(5)
(5)
On the other hand, fI(t) does not satisfy such a condition, because it is defined for a finite time duration as
(6)
(6)
The value of the left-hand side of Equation (6) is the failure probability required for the PSA of digital I&C systems, i.e., the failure probability for an input provided to the system with a relatively short time frame.
2.3. Relation between the two failure probability density functions
The failure probability of a system due to a software failure that occurs between time t and t + dt after successfully providing outputs corresponding to i consecutive inputs is given as
(7)
(7) where i is the number of consecutive inputs whose outputs are provided successfully (i = 0, 1, 2, …).
After successfully providing outputs for i consecutive inputs, the (i + 1)th input will be provided at time iTmax . After time iTmax , if it is assumed that the inputs prior to (i + 1)th input do not have effect on the (i + 1)th time interval, the conditional probability of a failure from the system operation viewpoint is determined by the probability of a failure from the viewpoint of an input with time parameter t − iTmax . Since the failure to generate the correct output for the (i + 1)th input also indicates the failure of the system, the failure probability from the system operation viewpoint after successful operation for the time iTmax is given as
(8)
(8) for iTmax ⩽ t < (i + 1)Tmax and i = 0, 1, 2, ….
The probability of successful operation for i consecutive inputs can be calculated as
(9)
(9)
The conditional probability of successful operation for i consecutive inputs after successful operation for (i − 1) consecutive inputs is the probability of successfully operating for a single input. In other words, it is the probability that no failure is experienced for the duration of Tmax . Therefore,
(10)
(10)
From Equation (10), the probability of successful operation for i consecutive inputs is given as
(11)
(11) for i = 0, 1, 2, ….
Taking Equations (8) and (11) into consideration, Equation (7) becomes
(12)
(12) for iTmax ⩽ t < (i + 1)Tmax and i = 0, 1, 2, ….
fS(t) in Equation (12) satisfies Equation (5). The proof is provided in the Appendix 1. In a system that repeatedly receives inputs and provides outputs corresponding to these inputs, such as the safety-critical digital I&C systems (and therefore the software inside the systems), fS(t) may be assumed to satisfy Equation (12).
Equation (12) can be applied to any fI(t) as long as it satisfies Equation (6).
In deriving Equation (12), it is assumed that Tmax is constant for each input for simplicity. If Tmax varies depending on the input to the system, it is possible to derive equations in similar ways.
3. Applications
3.1. Exponential distribution – a special case
Exponential distributions are widely used for modeling the failure density function of a system or a software program. Examples of the application of exponential distribution to a software failure can be found in many research studies such as Musa et al. [Citation11] and Malaiya et al. [Citation16]. If fI(t) is represented as an exponential distribution as
(13)
(13) for 0 ⩽ t < Tmax , where λ is the constant failure rate, and fS(t) is written using Equation (10) as
(14)
(14) for iTmax ⩽ t < (i + 1)Tmax , then Equation (14) can be rewritten as
(15)
(15) for t ⩾ 0.
A unique characteristic of the exponential distribution is that fI(t) and fS(t) have the same form. The advantage of this property is that if an exponential distribution is assumed for fI(t), fI(t) can be derived directly by determining fS(t) based on the failure data from the operating history or software testing. It should also be noted that fS(t) is independent of Tmax .
fS(t) in Equation (15) can be determined based on the failure data from the operating history or software testing, especially time-to-failure data. One of the most widely used methods for this purpose is the minimum mean square error (MMSE) estimation [Citation17–19]. The time-to-failure data for a system or a software program is given as
(16)
(16) where j is the serial number for the time-to-failure data for a system or a software program (j = 1, 2, …, n), tj is the jth time-to-failure data item, and n is the total number of time-to-failure data items.
In other words, when n failures have been observed after the operation of the system or software program for a long time, j is the identifier to indicate one of the n failures, especially jth failure.
For an exponential distribution, the mean square error function is given as
(17)
(17) where M(λ) is the mean square error function for an exponential distribution.
The best estimator for λ can be determined by finding the point where the derivative of the mean square error function equals 0. This is given as
(18)
(18) where
is the best estimator for λ.
From Equation (18), it can be found that satisfies the following relation:
(19)
(19)
Therefore, can be determined by finding the numerical solutions to Equation (19).
3.2. Weibull distribution
Weibull distributions are also widely used in modeling failures in which the failure rate varies as time changes. If fI(t) is represented as a Weibull distribution by the equation
(20)
(20) for 0 ⩽ t < Tmax , where α and β are constant coefficients, then fS(t) is given by using Equation (12) as
(21)
(21) for iTmax ⩽ t < (i + 1)Tmax and i = 0, 1, 2, ….
For a Weibull distribution, the mean square error function is given as
(22)
(22) where M(α, β) is the mean square error function for a Weibull distribution.
The best estimators for α and β can be determined by finding the point where the partial derivatives of the mean square error function equals 0. They are given as the solutions for the following simultaneous equations:
(23)
(23)
(24)
(24) where
is the best estimator for α and
is the best estimator for β.
The best estimators, and
, can be determined by finding the numerical solutions of Equations (23) and (24).
4. An example
Table 4 in NUREG/CR-6848 [Citation20] provides 42 failure data items out of 500 inputs from the software testing of the Personnel entry/exit ACcess System (PACS). According to NUREG/CR-6848 [Citation20], PACS is a simplified version of an automated personnel entry access system used to provide privileged physical access to rooms or buildings. shows the failure data and related calculations. Software testing was performed for 500 inputs. It took 53,888 s and 42 failures were observed. From the viewpoint of system operation, the time to failure ranged from 105 to 4911 s, mostly in the range of 0–1000. From the viewpoint of system input, failures did not occur during the processing of 458 inputs, while failures occurred at sometime during the processing of each of the 42 inputs.
Table 1. Failure data in NUREG/CR-6848 [Citation20] and related calculations.
The 42 failure data items were obtained by testing the system against its operational profile. The probability of successfully providing outputs for an input is calculated to be 0.916 and, therefore, the failure probability for an input is calculated to be 0.084.
The failure data can be used to derive fS(t). In this example, the derivation of fI(t) from the software failure data by using Equation (12) is demonstrated. fS(t) can also be determined by using Equation (12) if the failure data for inputs are provided.
For simplicity, it is assumed that an exponential distribution can be applied to describefI(t). As shown in Equations (13) and (15), if fI(t) follows an exponential distribution, fS(t) also follows the same exponential distribution.
To obtain , the time-to-failure data are calculated from the 42 failure data items and rearranged so that Equation (16) is satisfied. also shows the rearranged time-to-failure data. shows M(λ) as a function λ as given in Equation (17), and shows the derivative of M(λ) with respect to λ as given in Equation (18). The numerical solution for Equation (18) is given as the point in where the derivative of M(λ) with respect to λ becomes zero. Then, the best estimator for λ is given as
(25)
(25)
Figure 2. Mean square error as a function of failure rate for the example failure data.
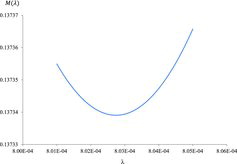
Figure 3. Derivative of mean square error function with respect to the failure rate for the example failure data.

Therefore, fS(t) is given as
(26)
(26) for t ⩾ 0.
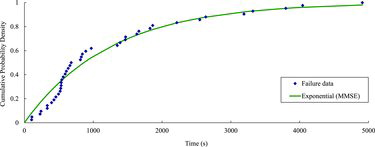
shows the failure data for the example system. FS(t) is determined by the MMSE method.
Figure 4. Failure data and the cumulative failure probability density function for the system determined by the MMSE method.
As mentioned above, it is already shown in Equations (13) and (15) that in the case of exponential distributions, fI(t) has the same form as fS(t). In other words, the best estimator for λ in fS(t) can also be used for fI(t) as follows:
(27)
(27) for 0 ⩽ t ⩽ Tmax .
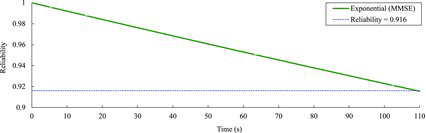
and show fI(t) and RI(t) = 1 − FI(t), respectively. In this example, fI(t) and RI(t) decrease monotonically for the defined duration as can be seen in and , respectively. Even though Tmax for the example system is not specified in NUREG/CR-6848 [Citation20], also provides the probability of successful operation for an input depending on Tmax . For example, if Tmax is given as 100 s, the success probability for an input is calculated to be 0.923, and the failure probability for the input is 0.077. As mentioned above, this failure probability is of interest in PSA of digital I&C systems. It should also be noted that the failure probabilities used in PSA of digital I&C systems will be much less than the one calculated for this example system. The time at which the reliability curve in meets the observed probability of successful operation (calculated from the software testing, i.e., 0.916) is calculated to be 109.3 s.
Figure 5. Failure probability density function for an input determined by the MMSE method.
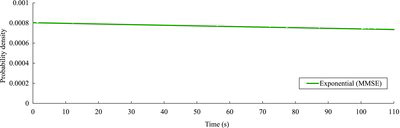
Figure 6. Reliability curve corresponding to the failure probability density function for an input determined by the MMSE method.
The method by which the failure data can be used to determine fS(t), and eventually fI(t), by using Equation (12) is demonstrated. As mentioned above, Equation (12) can also be used to derive fI(t) from fS(t).
It should be noted that even though a non-exponential distribution is assumed for fI(t), the procedure to determine fI(t) from the failure data will be similar to the one described above for the exponential distribution assumption. For example, when a Weibull distribution is assumed, fS(t) can be defined as shown in Equation (21), and the best estimates for the two coefficients, α and β, can be determined by applying the MMSE method as shown in Equations (23) and (24).
The best estimates for the two coefficients can be used to determine fI(t), as shown in Equation (20).
5. Conclusions
When the software reliability of a digital system is estimated based on the failure data from the operating history or software testing (especially statistical software testing), the failure data are generally collected from the viewpoint of the system operation. However, for conducting PSA of the digital I&C system, the failure probability with respect to an input to the system is required. Thus, there exist two viewpoints for a system failure: one with respect to the system operation and the other with respect to an input to the system. Therefore, it is important to clearly distinguish between the two different viewpoints and obtain the correct relation between them.
In this paper, two failure probability density functions for the two viewpoints were defined, and the relation between the two failure probability density functions was derived and presented. Based on the two failure probability density functions, it was also shown how the failure probability density function from the system operation viewpoint can be derived from the failure probability density function from the viewpoint with respect to an input to the system. This was illustrated using two example distributions, the exponential distribution and the Weibull distribution.
The derivation of the failure probability density function for an input from the software testing results was also demonstrated. This derivation was based on the assumption that the failure probability density function for an input follows an exponential distribution. In addition, the failure probability density function for an input was derived in a similar way when a non-exponential distribution was assumed.
The relation between the failure probability density function from the system operation viewpoint and that from the viewpoint of an input to the system, presented in this paper, not only helps us derive one from the other but also extend our understanding of how statistical software testing can be used to estimate or demonstrate the reliability of the software.
Additional information
Funding
References
- Lu L, Jiang J. Probabilistic safety assessment for instrumentation and control systems in nuclear power plants: an overview. J Nucl Sci Technol. 2004;41(3):323–330.
- Kang HG, Kim MC, Lee SJ, Lee HJ, Eom HS, Choi JG, Jang S-C. An overview of risk quantification issues for digitalized nuclear power plants using a static fault tree. Nucl Eng Technol. 2009;41(6):849–858.
- Authen S, Holmberg J-E. Reliability analysis of digital systems in a probabilistic risk analysis for nuclear power plants. Nucl Eng Technol. 2012;44(5):471–482.
- Kang HG, Sung T. An analysis of safety-critical digital systems for risk-informed design. Reliab Eng Syst Saf. 2002;78:307–314.
- STD-729-1991. Standard glossary of software engineering terminology. New York (NY): The Institute of Electrical and Electronics Engineers; 1991.
- Lyu MR. Handbook of software reliability engineering. Hightstown (NJ): McGraw-Hill, Inc.; 1996.
- Chu T-L, Yue M, Martinez-Guridi G, Lehner J. Review of quantitative software reliability methods. BNL-94047-2010. Upton (NY): Brookhaven National Laboratory; 2010.
- Myers GJ. The art of software testing. New York (NY): Wiley; 1979.
- IEEE Std 829-1998. IEEE standard for software test documentation. New York (NY): The Institute of Electrical and Electronics Engineers; 1998.
- Currit PA, Dyer M, Mills HD. Certifying the reliability of software. IEEE Trans Softw Eng. 1986;SE-12(1):3–11.
- Musa JD, Iannino A, Okumoto K. Software reliability: measurement prediction application. New York (NY): McGraw-Hill; 1987.
- Chillarege R. Software testing best practices, IBM Research Technical Report RC 21457. Yorktown Heights (NY): ( IBM Thomas J. Watson Research Center; 1999.
- Banks D, Dashiell W, Gallagher L, Hagwood C, Kacker R, Rosenthal L. Software testing by statistical methods – preliminary success estimates for approaches based on binomial models, coverage designs, mutation testing, and usage models. Gaithersburg (MD): National Institute of Standards and Technology; 1998.
- Jelinski Z, Moranda PB. Software reliability research, In: Freiberger W, editor. Statistical computer performance evaluation. New York (NY): Academic Press; 1972. p. 465–484.
- Goel AL, Okumoto K. Time-dependent error-detection rate model for software reliability and other performance measures. IEEE Trans Reliab. 1979;R-28(3):206–211.
- Malaiya YK, von Mayrhauser A, Srimani PK. An examination of fault exposure ratio. IEEE Trans Softw Eng. 1993;19(11):1087–1094.
- Bibby J, Toutenburg H. Prediction and improved estimation in linear models. New York (NY): Wiley; 1977.
- Kay SM. Fundamentals of statistical signal processing: estimation theory. Englewood Cliffs (NJ): Prentice-Hall PTR; 1993.
- Moon TK, Stirling WC. Mathematical methods and algorithms for signal processing. Upper Saddle River (NJ): Prentice Hall; 2000.
- Smidts C, Li M. Validation of a methodology for assessing software quality (NUREG/CR-6848). Washington (DC): United States Nuclear Regulatory Commission; 2004.
Appendix 1
The proof that the failure probability density function for the system provided in Equation (12) satisfies Equation (5) is provided in this appendix.
The left-hand side of Equation (5) is given as
(A1)
(A1)
By substituting k = 1 − FI(Ts), where 0 ⩽ k < 1, Equation (A1) becomes
(A2)
(A2)
Substituting the infinite series part in Equation (A2) with S yields
(A3)
(A3)
Multiplying both sides of Equation (A3) by k, we have
(A4)
(A4)
Subtracting Equation (A4) from Equation (A3), we have
(A5)
(A5)
From Equations (A3)–(A5), the infinite series part in Equation (A2) is given as
(A6)
(A6) Therefore, Equation (A2) becomes
(A7)
(A7)
Equation (A7) proves that the failure probability density function provided in Equation (12) satisfies Equation (5).