
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Severe accident codes (e.g. MAAP, RELAP, and MELCORE) model various physical phenomena during severe accidents. Many analyses using these codes for safety margin evaluation are impractical due to large computational costs. Surrogate models have an advantage of quickly reproducing multiple results with a low computational cost. In this study, we apply the singular value decomposition to the time-series results of a severe accident code to develop a reduced order modeling (ROM). Using the ROM, the probabilistic safety margin analysis for the station blackout with a total loss of feedwater capabilities at a boiling water reactor is carried out. The dominant parameters to the accident progression are assumed to be the down-time and the recovery-time of the reactor core isolation cooling system, and decay heat. To reduce the number of RELAP5/SCDAPSIM analyses while maintaining the prediction accuracy of ROM, we develop a data sampling method based on adaptive sampling, which selects the new sampling data based on the dissimilarity with the existing training data for ROM. Our ROM can rapidly reproduce the time-series results and can estimate core conditions. By reproducing multiple results by ROM, a time-dependent core damage probability distribution is calculated instead of the direct use of RELAP5/SCDAPSIM.
1. Introduction
After the severe accident (SA) at Fukushima Daiichi nuclear power plant in March 2011, the newly established Nuclear Regulation Authority (NRA) has developed the new regulatory standards for commercial nuclear reactor plants in July 2013 [Citation1]. One of the key points in the new standards is the legal requirements for prevention and mitigation measures of SAs, which were voluntarily implemented by the utilities before the Fukushima Daiichi accident. Recently, some nuclear power plants, whose application has been approved by NRA, have started in Japan. In the future, each electric power company would consider the following in the view of safety and efficiency:
Plant installation modifications.
Additional safety measures for SAs.
Plant life extension to 60 years.
Improving operational efficiency using risk information and so on.
Utilities have strong motivation to quantify not only the frequency of SA (e.g. core damage frequency and CDF), but also actual safety margin distribution. Quantification of safety margin characteristics is called the risk-informed safety margin characterization (RISMC) [Citation2]. For example, RISMC quantitatively evaluates the increased safety margin by accident management in accident scenarios. In reference [Citation3], this evaluation is conducted by a large number of direct SA code analyses. However, such evaluation would be impractical for actual applications because it requires considerable longer calculation time (typically several hours for each analysis). Therefore, surrogate models, which quickly predict the results of SA analysis, have been proposed. The surrogate model methods are divided into two categories. The first one is the use of machine learning for the multiple results of an SA code. The proposed learning methods in the previous work were Gaussian Process Models (GPMs), K-Neighbors Regressor (KNR), Support Vector Regressor (SVR), Sheppard Interpolation Method, and Generalized Polynomial Chaos expansion (gPC) [Citation4]. The previous study could reduce the computational cost of RISMC by using these surrogate models. However, these surrogate models were independently applied to each time-step of the time-series data. In other words, it requires many surrogate models to estimate a result with many time-steps. The second one is the use of an approximate physical model for SA progression. In the reference [Citation5], the accident progression was estimated by a simple adiabatic and heat balance model; however, there are problems in this approach, i.e. the physical phenomena in SA progressions cannot be treated precisely and expertise is required in the choice of appropriate approximate models of the physical phenomena. The surrogate model developed in our study is classified as the former surrogate model using the results of an SA code.
In various accident scenarios, the time-series data have different characteristics. In a specific scenario, however, the time-series data often have similar behaviors; therefore, we consider the possibility that the time-series data can be reconstructed using the representative time-series vectors in a specific scenario. When the time-series data have lower similarity, the many representative vectors are necessary to cover various characteristics of the time-series data. Meanwhile, when the time-series data have higher similarity, the reconstruction accuracy will be high even with a smaller number of representative vectors. In our study, the singular value decomposition (SVD) is applied to extract representative vectors for ROM from the results of an SA code [Citation6,Citation7]. The basic idea of this approach is based on the study in the reference [Citation8], in which a ROM for the time-series data of fission gas release rate in fuel performance modeling code Bison is constructed by the principal component analysis (PCA). PCA is a mathematical technique that decomposes a square matrix into an eigenvalue and an eigenvector, and SVD is regarded as an expansion from PCA into a non-square matrix. Because SVD can extract the dominant (representative) vectors of all time-series data, ROM can be constructed using the dominant vectors. In our study, the dominant vectors represent the trend of the time-series data calculated by an SA code. With the approach of our ROM using SVD, construction of ROM at each time-step is not necessary. Our ROM can reproduce the whole time-series data regardless of the number of time-steps in a scenario. The proposed method also has an advantage for the construction of ROM, as the choice of a learning model for physical phenomena and the optimization of hyperparameters are not necessary. The use of an approximate physical model requires a careful choice of an appropriate calculation model for physical phenomena to maintain the prediction accuracy; however, our ROM can be constructed using the results of an SA code, and can thus model various physical phenomena without a difficult choice of calculation models. The prediction accuracy of the machine-learning generally depends on the hyperparameters, which are tuned by the users. Such tuning by the users is however not desirable from the viewpoint of usability. Our ROM is easily constructed while maintaining accuracy because it does not require the optimization of hyperparameters. By using SVD, our study aims to develop a ROM for an SA code and to perform a probabilistic safety margin analysis by the constructed ROM.
The new contribution of this paper is the following three points. Firstly, we develop a new ROM using SVD for the results of an SA code to reduce computational cost. Our ROM can reproduce whole time-series data because it is constructed by representative time-series vectors extracted from the results of an SA code. Secondly, we introduce the concept of the gravity field into the adaptive sampling method [Citation9]. The gravity field method gives the priority to select new sampling data based on the dissimilarity with the existing training data for ROM. The data sampling method based on adaptive sampling reduces the number of training data for ROM construction while maintaining the prediction accuracy of ROM. We also develop the convergence criterion for the data sampling method to avoid producing extra training data, which does not contribute to the improvement of prediction accuracy of ROM. Thirdly, we apply the ROM, which is constructed by SVD through the data sampling method based on the adaptive sampling, to a probabilistic safety margin analysis. In this study, the time-dependent core damage probability (CDP) distribution for station blackout (SBO) scenario is estimated by our ROM.
The rest of the study is organized as follows. The theoretical description, procedure, data sampling, and limitations of ROM construction are given in Section 2. Calculation conditions in this study and verification results of ROM for SBO with a total loss of feedwater capabilities are provided in Section 3. Finally, concluding remarks are summarized in Section 4.
2. Theory
2.1. Overview of ROM construction method
In this section, the overview of ROM construction is described. There are three key points in our developed ROM, i.e. SVD, the low-rank-approximation (LRA), and a data sampling method based on adaptive sampling.
In our study, the theory of our ROM is based on SVD, which extracts the dominant vectors that well express the trend of the matrix of many time-series data (Section 2.2.1). Considering the contribution ratio of vectors, LRA is applied to remove the minor vectors that have a small effect on the ROM results (Section 2.2.2). Finally, our ROM is constructed using the representative vectors and its expansion coefficients generated by SVD and LRA (Section 2.2.3). In the ROM that we have studied, the linear interpolation method is used for expansion coefficients corresponding to representative vectors extracted by SVD. The linear interpolation has three advantages: (1) avoidance of over-learning or over-fitting, (2) affinity with the present data sampling method, and (3) simplicity (Section 2.2.4).
To improve the prediction accuracy of ROM, the number of training data, i.e. the results by an SA code is generally increased. Because the computational cost of an SA code is usually high, a smaller number of training data is desirable to construct ROM. A data sampling method based on adaptive sampling is therefore applied to generate the training data that is expected to most improve the prediction accuracy of ROM while reducing extra computational cost. In the data sampling method based on adaptive sampling, our study newly introduces the concept of gravity field and convergence criterion (Section 2.3).
Finally, the proposed ROM assumes limitations to realize higher prediction accuracy. These limitations are described in Section 2.4.1. The time-series data are preprocessed to make the interval and the number of time-steps among different time-series data consistent for ROM construction with SVD. The approaches to align the interval and the number of time-steps are described in Section 2.4.2.
2.2. Theory of ROM construction
2.2.1. SVD
The SVD is a matrix operation to decompose any matrix to a diagonal matrix and orthogonal matrices [Citation10]. The feature of SVD is to extract representative vectors, which express the trend of the original matrix. This section briefly describes the mathematical interpretation of SVD.
Using square matrices and
, an
Hermitian matrix
is transformed into an
diagonal matrix
:
where the diagonal matrix is expressed as
The diagonal components are singular values that take positive and monotonically decreasing values, i.e. (
). The number
corresponds to the rank of matrix
. This diagonalization operation can be regarded as an extension of the diagonalization of a square matrix into a non-square matrix.
Because the matrices and
are unitary, EquationEquation (1)
(1)
(1) becomes
where ,
, and
contain the left singular vectors, the singular values, and the right singular vectors, respectively. Note that
for unitary matrix is used in the above derivation.
In general, singular values take positive and monotonically decreasing values. The right and left singular vectors are arranged in descending order of associate singular values. In other words, they are arranged in descending order from the viewpoint of the contribution ratio to the variance of matrices and
. The cumulative contribution ratio of singular vectors can be calculated by
For example, if the cumulative contribution ratio up to the -th vector is 0.99, the 1st to
-th right singular vectors can cover 99% variance of the matrix
, which means these vectors almost capture the behavior of the row direction of the matrix A. In other words, the rest
right singular vectors only cover 1% variance of the matrix
. This property also holds true in the case of
.
Let us consider a matrix A which is arranged by (
) in the row direction.
where is a row vector with
elements and there is no identical
. The matrix A can be expanded as EquationEquation (7)
(7)
(7) in correspondence with EquationEquation (3)
(3)
(3) :
Therefore, is expressed by using the right singular vector as
In other words, the common orthogonal vectors, which can express with linear combinations, are extracted from the matrix A by SVD. This property becomes key in the construction of ROM.
2.2.2. LRA
The orthogonal vectors of the right and the left singular vectors are arranged in the descending order of the contribution ratio of the variance of matrices and
. Even if small singular values are neglected, the matrix A can be accurately reconstructed by the rest of singular vectors and singular values. This dimensional reduction is known as LRA. Assuming that the behavior of
can be almost reproduced by the first
singular values (
),
can be approximated as EquationEquation (9)
(9)
(9) . A similar approximation can be applied in the case of
.
where the reproduction ratio is calculated by EquationEquation (5). The contribution ratio of each right singular vector decreases as the singular value
decreases. The right singular vectors, which have a high contribution ratio (e.g.
,
, and
), are therefore chosen as vectors for ROM. In other words, LRA reduces computational cost with minimum loss of reproduction accuracy by ROM. Meanwhile, the right singular vectors, which have a low contribution ratio, do not express the overall trend of the matrix A, but express the unique trend of each
(i.e. noises). In other words, LRA can eliminate noises in each data of the matrix A.
2.2.3. Application of SVD and LRA to SA analysis
In this section, the procedure of ROM construction from the results of an SA code using SVD and LRA is described. The ROM is constructed by the following procedures:
Sample input parameters and perform a calculation by an SA code. This procedure is repeated m times.
Construct the matrix A of EquationEquation (10)
(10)
Apply LRA to the matrix A through SVD. The m simulation results are expanded by the orthogonal basis obtained by SVD (EquationEquation (13)
Each expansion coefficient
Estimate the expansion coefficients
Reconstruct time-series data of an SA code for any input parameters by the expansion coefficients obtained in Step 5 and the orthogonal basis in EquationEquation (13)
Some details of the ROM construction using SVD are explained. An SA code considers many input parameters because it models various physical phenomena that occur in SA processes. At first, the perturbed input parameters (e.g. decay heat) for ROM are selected in an accident scenario. The accident progressions are repeatedly analyzed m times within the range of perturbed input parameters (Step 1 in the above procedures). In other words, the number of samples is m. The identical number of time-steps (it is defined as t) is used for all simulations. For example, the number of time-steps is 150 when the time-step size of 100 [s] is applied for a 15,000 [s] simulation. To align the number of time-steps in different simulations, the final state of time-series data is assumed to be maintained up to 15,000 [s] when the analysis of an SA code is terminated before 15,000 [s]. The calculated time-series results, which are the row vectors, are gathered and formed into an matrix as shown in EquationEquation (10)
(10)
(10) . In the following equation, the operation in the case of
is described, but the case of
can be considered in a similar way.
where is the output data at the
-th time-step in the
-th sample (Step 2 in the above procedures). The matrix A can be decomposed into three matrices with the SVD:
where the left singular vector is an column orthogonal matrix
, the singular value is an
matrix, and the right singular vector is a
transpose row orthogonal matrix
. When the identical accident progressions do not exist in the
simulations, the rank of the matrix A is
.
When the cumulative contribution ratio up to the -th vector is sufficiently large to accurately reproduce the matrix A, the matrix
is approximated as
with LRA described in Section 2.2.2:
where the left singular vector is an column orthogonal matrix
, the singular value is a
matrix, and the right singular vector is a
transpose row orthogonal matrix
. The rank of the matrix A is regarded as
.
The right singular vector is regarded as the set of orthogonal vectors for time-series data. The
-th simulation result
in the matrix A (
) can thus be approximately expanded by the orthogonal vectors as
where is the expansion coefficient corresponding to the right singular vector of the
-th row (
). The expansion coefficient is calculated by the left singular vector and the singular value:
where is the expansion coefficient of the
-th right singular vector for the
-th sample. We can thus represent a simulation result by the orthogonal vectors (i.e. the right singular vectors) and the associate expansion coefficients (Step 3 in the above procedures). Because a simulation result depends on input parameters, we can expect a correlation among the input parameters and the expansion coefficient
. For example,
can be expressed as a polynomial of perturbed input parameters used in an SA code (Step 4 in the above procedures). When
is expressed as a linear function, the expansion coefficient
corresponding to unknown ‘
’ input data is estimated as
where and
are constants (Step 5 in the above procedures). Using the correlation among input parameters and
, we can estimate
for any input parameter. Once we know
, a simulation result can be easily reconstructed by EquationEquation (13)
(13)
(13) (Step 6 in the above procedures).
2.2.4. Functionalization of expansion coefficients
In this section, the functionalization method of the expansion coefficient corresponding to input parameters is described.
As discussed in Section 2.2.3, can be expressed as a function of perturbed input parameters used in an SA code. There are many interpolation methods, e.g. polynomial interpolation, Kriging, and so on, for functionalization. The linear interpolation method is however used for the ROM construction in this study as the linear interpolation method can avoid over-fitting and can also avoid the choice of models or hyperparameters in other interpolation models. The method of linear interpolation on N-dimensional scattered data [Citation11] is used in this study to interpolate the expansion coefficient
. Before performing the interpolation, the normalization of each input parameter is carried out in our study. The value
of each input parameter is normalized so that the maximum (
) and minimum (
) values correspond to 1 and 0, respectively:
where is the
after normalization.
2.3. Data sampling method based on adaptive sampling for ROM construction
2.3.1. Outline of ROM construction with adaptive sampling
In this section, the concept of a data sampling method based on the adaptive sampling is described to reduce the number of SA analyses for ROM construction while maintaining the prediction accuracy of ROM. We develop the concept of gravity field and convergence criterion introduced into adaptive sampling. The overview of the data sampling method used in our study is illustrated in . The parts enclosed by the bold solid line in indicate the contributions of our study.
Figure 1. Overview of the data sampling method based on adaptive sampling.
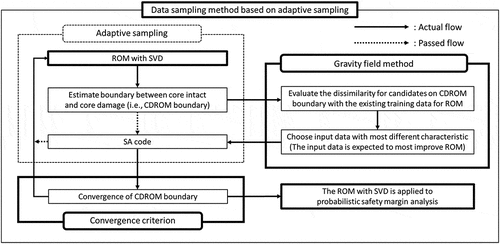
The purpose of ROM is a quick reproduction of the results of an SA code. In the construction of ROM, the minimization of the number of training data obtained by an SA code while maintaining the prediction accuracy of ROM is desirable, as an SA code requires longer computational time. To apply the ROM for the CDP distribution calculation, the boundary between core intact and core damage in the input parameter space (it is named as the CD boundary in this study) should be accurately captured by ROM. A data sampling method to sample training data at the vicinity of CD boundary is therefore desirable for ROM construction; however, the actual CD boundary is unknown at the beginning of ROM construction. ROM has the advantage of quickly reproducing the multiple simulation results. The approximate CD boundary is estimated using multiple reproductions by ROM (it is named as the CDROM boundary in this study). The CDROM boundary is used to sample training data instead of the actual CD boundary. By sampling training data on the CDROM boundary, the prediction accuracy of ROM will improve because the selected data is densely sampled around the CDROM boundary. This sampling method is classified as an adaptive sampling method.
There are many input data on the CDROM boundary, as many combinations of input data on the CDROM boundary exist in input parameter space. A selection method of input data on the CDROM boundary is therefore necessary. In the selection of input data, we would like to choose input data that effectively improves the prediction accuracy of ROM. In our study, the concept of gravity field is developed to select data based on the dissimilarity with the existing training data for ROM. In other words, the data having less similarity with the existing training data is selected in the gravity field method. The dissimilarity is measured by the ‘distance’ in input data space as described later.
The convergence criterion is necessary for the adaptive sampling method because it utilizes an iteration method to obtain the training data for ROM. In our study, the convergence criterion is developed by focusing on the improvement of CDR boundary during iterations based on the gravity field method.
2.3.2. Details of ROM construction with adaptive sampling
In this section, more detail explanations of the ROM construction in our study are provided.
The data sampling method based on the adaptive sampling in our study is explained as follows. As the simplest case, one input parameter for an SBO scenario is considered. There is the time-series data [°C] of peak cladding temperature (PCT) as a function of the time
[s], which is the duration of a total loss of water injection during the accident progression. The maximum temperature
exists in
. The
becomes higher as
becomes longer and vice versa. Let us consider
[°C], which is the criterion for core damage. An input parameter
satisfying
exists when the duration of the total loss of water injection is sufficiently long. The
corresponds to the input data on the CD boundary. When
is known, we can accurately predict core conditions: however, the rigorous
cannot be identified before performing multiple calculations of an SA code. Instead of
,
on the CDROM boundary can be obtained, as we can quickly reproduce a large number of simulation results
by ROM. When
in
equals
, the input data is regarded as
. In other words,
satisfies
. After performing the calculation of an SA code on
by an SA code, the new
is added to the training data of ROM. The prediction accuracy of the CDROM boundary can be improved because
approaches the vicinity of CD boundary as the number of iterations increases. When ROM perfectly predicts the results of an SA code,
converges to the rigorous CD boundary. It is noted that the training data for our ROM are required to include core intact and damage results to estimate
by interpolation, as the accuracy of extrapolation is generally worse than interpolation. The above explanation is the basis of a data sampling method based on the adaptive sampling in our study.
The gravity field method, which gives the priority to select data from the CDROM boundary, is explained as follows. In the case of multiple input parameters, cannot be uniquely defined because many
are on the CDROM boundary. A selection method is, therefore, necessary to choose the next sampling data (
) from the CDROM boundary. In the selection of the next sampling data, we would like to choose training data that efficiently improves the prediction accuracy of ROM with the view of reducing the computational cost. Let us assume that there are two candidate data for the next sampling. The first data is very close (similar) to the existing training data for ROM while the second one is far (dissimilar) from the existing training data. Because the ROM is based on interpolation of the training data, the second one will be more suitable than the first one, as the small improvement is expected by the first data. The gravity field method directly reflects this concept. In the gravity field method, each data is assumed as a planet with the same mass. Each planet has its own gravity field. Similarly, the existing training data form a gravity field. If we put new data into the existing system, the new data will receive gravity force from the existing data. The gravity force is larger when the location of the data is closer to the existing data and vice versa. The gravity force represents the similarity or dissimilarity between the new data and existing data. If we have several candidates for the next sampling data, we can, therefore, choose sampling data whose gravity force is the smallest. It should be noted that the similarity or dissimilarity is represented by the ‘distance’ in the gravity field method; thus, the definition of distance is important. Its definition will be described later.
This selection based on the concept of gravity field is carried out as follows. Two-dimensional input parameters, , are considered for simplicity.
The range of
In the grid point for
The one
where
EquationEquation (17)(17)
(17) indicates that the
for
is evaluated using the distance from each training data of ROM. When the evaluated value of
is small, the
is dissimilar from the existing training data for ROM construction in the view of the location, and vice versa. When the value of
is large, the
will have little new information. On the contrary, when the value of
is small,
have different characteristic from the existing training data for ROM; thus, the
has sufficient new information and is expected to effectively improve the prediction accuracy of ROM. Therefore, the
with the minimum
is selected for the next sampling data. It is noted that the elements of input parameters in
and
are normalized (EquationEquation (16)
(16)
(16) ) when EquationEquation (17)
(17)
(17) is applied. The above explanation is our development of the adaptive data selecting method based on the gravity field method.
Finally, the convergence of the CDROM boundary in the data sampling method based on the adaptive sampling is explained as follows. To observe the convergence of the CDROM boundary, matrix , which consists of the n candidates for
in the gravity field method, is used. The numbers of rows and columns of the matrix
correspond to ‘the dimension of input parameters’ and ‘the number of candidates (
);
,’ respectively. EquationEquation (18)
(18)
(18) is used to evaluate the
in each iteration, which is used for the determination of convergence:
where the subscript l indicates the number of iterations. EquationEquation (18)(18)
(18) shows the change of CDROM boundary when the new
is added to the training data of ROM. The value of
converges to zero because
in
is expected to approach the vicinity of
as the number of iterations increases. The convergence of the algorithm can be judged by the value of
. The degree of convergence is controlled by the user, which is compared with
.
To sum up, our ROM is constructed with the data sampling method based on the adaptive sampling by the following procedures when the number of input parameters is :
Specify the range of input parameters by the user and choose the minimum and maximum values for each parameter. Minimum and maximum values correspond to core intact and damage (damage and intact) conditions, respectively.
Perform calculations of an SA code for
Construct ROM using SVD for the
Calculate the
Using EquationEquation (17)
Calculate the
Repeat the iteration from Step 4 to 6. Iterations are finished when the convergence criterion is satisfied (EquationEquation (18)
2.4. Limitations of ROM with SVD
2.4.1. Assumptions of ROM with SVD
In this section, two assumptions of ROM with SVD to achieve high prediction accuracy are described. Firstly, a ROM with SVD can be used for a specific accident scenario. Many accident scenarios for a nuclear power plant contain various time-scales and show completely different behaviors. Because SVD extracts dominant vectors that represent a majority of the time-series data, simultaneous treatment of accident scenarios having a completely different time-scale and the behavior will be difficult. Secondly, the perturbation range for input data should not be very large, as the treatment of completely different time-series data by SVD is difficult. The above two assumptions are considered to achieve higher accuracy of ROM with SVD.
2.4.2. Application of SVD to simulations of SA code
In this section, the treatment of the time-series data with different intervals and the number of time-steps is described to apply SVD. For the application of SVD, the time-series data are required to have an identical interval and the number of time-steps. However, the interval of time-steps is not uniform nor fixed in an SA code due to automated time-step control to minimize the calculation cost. Furthermore, a simulation may be terminated before the expected calculation time due to numerical instability of a calculation. The intervals and the number of time-steps can thus be different even in the same accident scenario. To align the intervals and the number of time-steps, the following approaches are considered. For the interval of time-step, the specific time-step to edit output parameter is provided through input data. For the number of time-steps, the data in the last step of time-series data is assumed to be maintained up to the expected simulation time as described in Section 2.2.3. By applying the above treatment, the intervals and the number of time-steps are identical among simulation results and can thus be directly used for SVD. When the above treatments are not appropriate to the time-series data, different treatments should be considered, but these are future tasks.
3. Calculations
3.1. Calculation conditions
3.1.1. Accident scenario
The accident scenario used in this study is the SBO with a total loss of feedwater capabilities at a boiling water reactor (BWR). The accident scenario is illustrated in .
Figure 2. Accident progression in SBO with a total loss of feedwater capabilities.
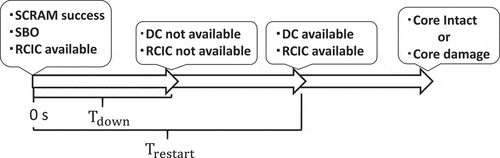
At 0 [s], loss of off-site power occurs and the reactor is successfully shut down by scram. The feedwater and the recirculation pumps are tripped, the turbine throttle valve and main steam isolation valve are rapidly closed. The startup of the diesel generators is in fail (i.e. SBO). The reactor core isolation cooling system (RCIC) continuously injects water to the core because the direct current (DC) is available. Total feedwater is however lost owing to the RCIC or the battery fault at the time of . Therefore, the decay heat cannot be removed. The accident then becomes more serious because the core temperature increases owing to the effect of decay heat. At
, RCIC restarts owing to repairing. The occurrence of core damage depends on
. If
is too large, the accident scenario progresses and the PCT reaches the critical temperature (i.e. the run-away temperature, approximately 1200°C). If
is small, the PCT is kept low and the core is intact. In the above accident scenario, quantitative evaluation of
is very important to terminate the accident sequence.
In this scenario, ,
, and
, which is decay heat (relative value), are considered as the input parameters having higher importance for accident progression in our study. In general, the dominant input parameters should be identified through sensitivity analysis; however, because the purpose of this study is the verification of our ROM construction method, exhaustive sensitivity analyses for input parameters have not been carried out. summarizes the range of
,
, and
considered in our study. It is noted that Trestart in is the subtracted value of Tdown. In this study, the probability distributions of
and
are assumed to be uniform because our study aims to verify the construction of ROM with SVD. The other distributions based on probabilistic risk analysis or human reliability analysis would be considered as realistic safety analysis. The uncertainty of decay heat is considered as obeying a normal distribution (relative standard deviation:
10%) [Citation12]. The range of
is thus set as 2
to include the true value of decay heat with approximately 95% probability.
Table 1. Uncertainties of the input parameter.
3.1.2. SA code and plant model
The RELAP5/SCDAPSIM code [Citation13] is used in the SA analysis. The plant model for Lagna Verde Unit 1 and Unit 2 (rated power: 1931 MW), which is BWR-5 designed by General Electric company, is used.
3.1.3. Criterion of core damage
The output training data obtained by RELAP5/SCDAPSIM code is PCT. To judge core intact or damage, maximum PCT (MPCT), which is the maximum value reached during the entire course of the simulation, is focused. The MPCT of 1200°C has been used as the criterion for core damage, which is adopted in the Japanese ECCS safety assessment guideline for LWRs [Citation14].
The ROM to predict PCT during the accident is constructed using the calculation results by RELAP5/SCDAPSIM. When MPCT exceeds 1200°C, the core is judged as damaged.
3.1.4. Setting of time-steps
In this study, the accident progression of 15,000 [s] is analyzed. The calculation results are then discretized into 150 time-steps while assuming that the time-step size to edit output is 100 [s]. Identical discretization is used for all RELAP5/SCDAPSIM calculation results.
In some cases, RELAP5/SCDAPSIM calculations terminated during execution due to the instability of the calculation. Such termination usually occurs at the water injection by RCIC to the heated core. In this case, the value of PCT at the terminated time-step is used for the successive time-steps as described in section 2.2.3 and section 2.4.2. This treatment would be appropriate because PCT usually decreases when RCIC starts water injection. Because MPCT during the accident is important in this study, this treatment would be justified.
3.2. Calculation procedures
3.2.1. ROM construction
In accordance with the ROM construction described in Section 2.2, the procedures of ROM construction, which estimate fuel cladding temperature with the perturbed input parameters ,
, and
are summarized as follows.
Make eight (
Perform RELAP5/SCDAPSIM calculations. In our study,
Generate the matrix A of EquationEquation (10)
Construct ROM through SVD and LRA for the matrix A. Unless otherwise noted, the vectors for ROM were reduced to cover 99.99% variance of the matrix
Estimate the input parameters
Select 12 points from 961 candidates for
Perform RELAP5/SCDAPSIM calculations on the 12
The 12 results by RELAP5/SCDAPSIM are added to the training data for ROM. The total number of training data for ROM becomes 21 (9 + 12).
Repeat Steps from 4 to 8. The total number of training data in the l-th iteration becomes 9 + 12(l-1). In our study, 13 iterations are carried out.
3.2.2. Core damage probability distribution
The final purpose of our study using ROM is to reduce the computational cost in the probabilistic safety margin analysis. The calculation procedure of CDP distribution using ROM is described in this section.
In this study, the core condition depends on the three parameters, i.e. the down, restart time of RCIC, and decay heat: . In general, CDP becomes higher when
is shorter and/or
is longer. In this study, the CDP distribution considering the uncertainty of decay heat is calculated for various
and
as follows:
Divide the range of
Perform 10,000 random samplings of
ROM reproduces the 6.5 million (13
In each combination of
where the uncertainty of CDP is estimated as
It is noted that in EquationEquation (20)
(20)
(20) only includes the statistical uncertainty and excludes the uncertainty propagated from the ROM construction.
3.3. Results and discussions
3.3.1. Construction result of ROM
and show the initial input data for ROM and the time-series data of PCT obtained by RELAP5/SCDAPSIM calculations using initial data.
Figure 3. Input parameters to construct initial ROM.
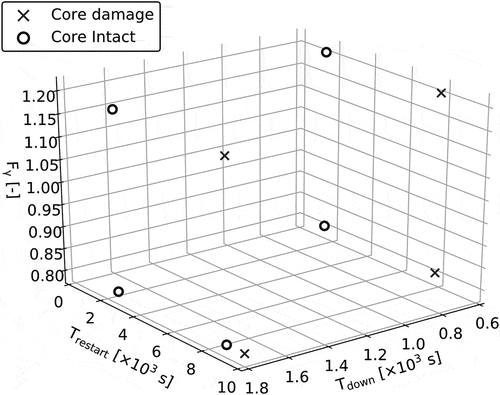
Figure 4. Time-series data of peak cladding temperature calculated by RELAP5/SCDAPSIM used to construct initial ROM.
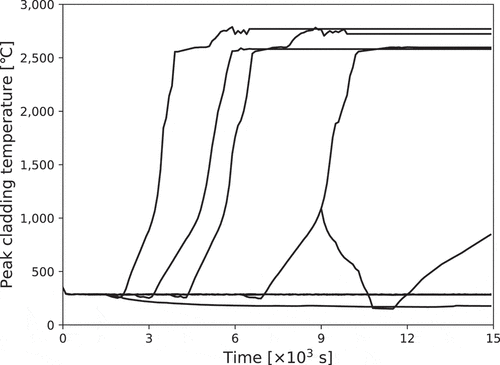
Using the data in and , the initial ROM was constructed. The three main vectors with a high contribution ratio in the right singular vector are shown in .
Figure 5. Right singular vectors which represent over 99.34% variance of time-series data in initial ROM in . The contribution ratio of each vector is shown in the legend.
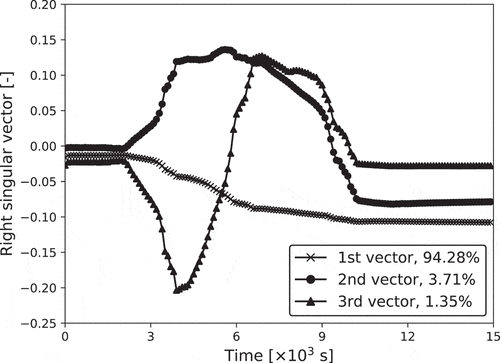
These three vectors cover more than 99.34% variance of the training data in .
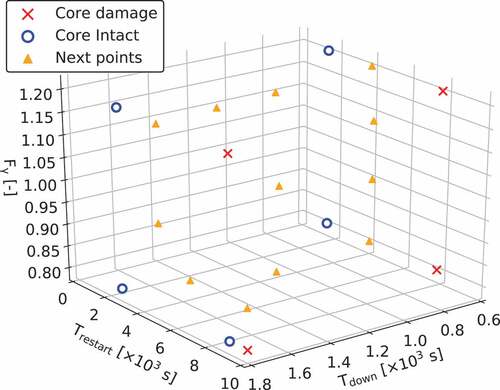
The (961 points) estimated by the initial ROM (the CDROM boundary), which are marked as triangles, are shown in . The 12 points in
for the next sampling are shown in . These 12 points are chosen based on the procedure described in Section 2.3.2 and equally scattered in input space.
Figure 6. The candidates for on CDROM boundary at the initial iteration (triangular).
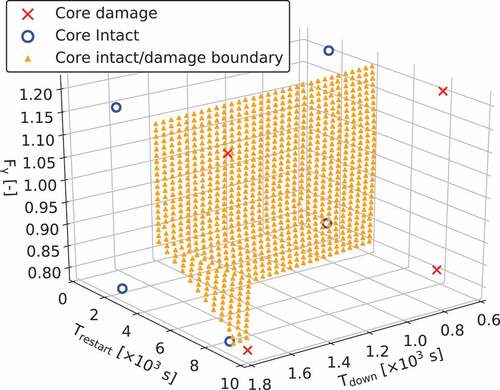
Figure 7. The next sampling points selected from at the initial iteration.
shows the input training data for ROM construction and the improvement of the CDROM boundary predicted by ROM up to the 13th iteration.
Figure 8. The candidates for on CDROM boundary in the 2nd, 5th, 9th, and 13th iterations.
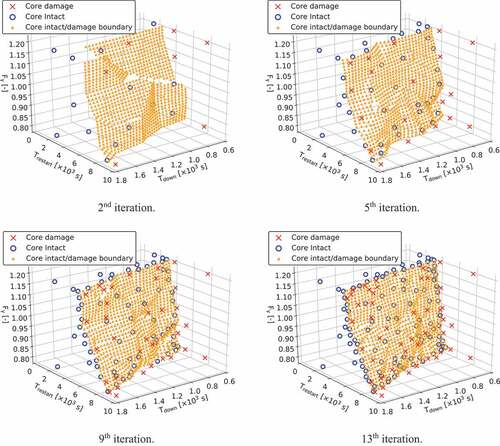
indicates that the input training data gathered in the vicinity of as the number of iteration increases. In other words, the output training data is sampled around MPCT = 1200°C.
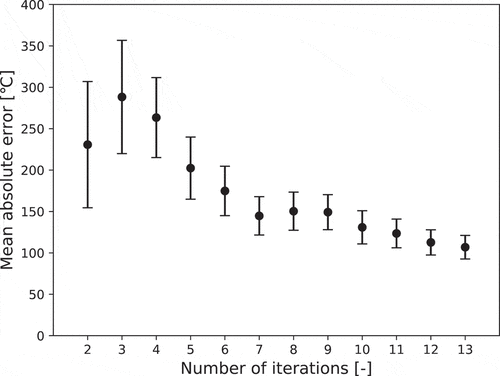
Both the convergence and accuracy of the sampling method used in this study are shown in and , respectively.
Figure 9. The variation of in each iteration (the number of iterations;
).
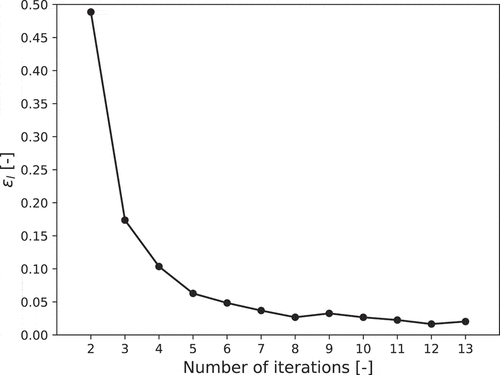
Figure 10. The variation of mean absolute error calculated by leave-one-out cross-validation in each iteration.
From , the indicates the convergence of the CDROM boundary estimated by ROM. At the beginning of the iteration, the CDROM boundary significantly changes when the new training data are added. The
tends to decrease as the number of iterations increases, which means that the CDROM boundary converges to a certain surface. From , the mean absolute error of MPCT, which is evaluated by leave-one-out cross-validation, tends to decrease as the number of iterations increases. In the 13th iteration, ROM can estimate MPCT obtained by RELAP5/SCDAPSIM calculations with an average error of approximately
°C. It is noted that the eight combinations of upper and lower
,
,
are excluded in leave-one-out cross-validation because the interpolation is used. From the above, the validity of ROM construction by the sampling method used in this study is shown in the view of the convergence and accuracy of the algorithm.
3.3.2. Core damage probability distribution by ROM using SVD
The CDP distribution considering the uncertainty of decay heat is shown in .
Figure 11. Core damage probability distribution for various and
estimated by multiple reproductions of ROM.
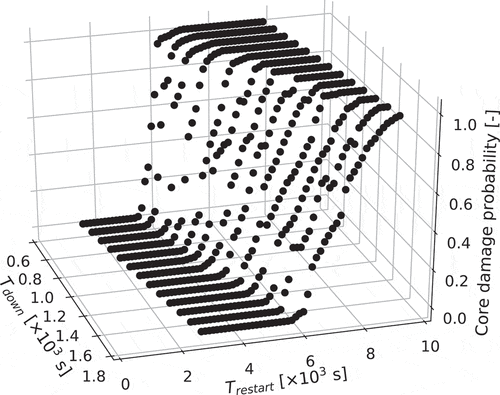
Increase of CDP as a function of gradually becomes slower as
becomes longer because heat decay decreases as a function of elapsed time after scram. This is the reason why CDP becomes lower as
becomes longer. The CDP distribution shown in is consistent with physical insight.
The CDP calculated by ROM is compared with the CDP calculated by RELAP5/SCDAPSIM. Owing to the limitation of computational resources, four representative points are selected for verification and the accurate CDP was estimated by 1,000 calculations of RELAP5/SCDAPSIM in each point. The representative points are selected in the surrounding center and the edge of CDP distribution in . The CDPs are shown in .
Table 2. Comparison of estimated core damage probability between ROM and RELAP5/SCDAPSIM. The number of samples is 10,000 for ROM and 1,000 for RELAP5/SCDAPSIM.
From , the CDPs by ROM roughly reproduce the CDPs calculated by RELAP5/SCDAPSIM within the error of approximately 16%. These results are caused by the difference in the CDROM boundary between ROM and RELAP5/SCDAPSIM. The limits of on the CDROM boundary predicted by ROM and RELAP5/SCDAPSIM are compared in as a function of the number of iterations.
Figure 12. Comparison of the limit on the CDROM boundary between ROM and RELAP5/SCDAPSIM in each iteration. If the limit
estimated by ROM is out of [0.8, 1.2], it is evaluated by using the value of
boundary.
![Figure 12. Comparison of the limit Fγ on the CDROM boundary between ROM and RELAP5/SCDAPSIM in each iteration. If the limit Fγ estimated by ROM is out of [0.8, 1.2], it is evaluated by using the value of Fγ boundary.](/cms/asset/63de464b-4967-444f-8080-8437aedddf59/tnst_a_1699190_f0012_b.gif)
From , the limit estimated by ROM approaches the limit
calculated by RELAP5/SCDAPSIM as the number of iterations increases. In the case of
and
, ROM can accurately estimate the limit
calculated by RELAP5/SCDAPSIM at least once. The limit
however becomes worse occasionally because the developed data sampling method based on the adaptive sampling aims to improve the overall reproduction by ROM rather than locally. As the number of iterations increases, the improvement of the limit
also becomes smaller. This is the reason why the result of linear interpolation does not improve unless new training data are generated around the interpolated point. From the above considerations, the difference in CDP between ROM and RELAP5/SCDAPSIM occurs.
3.3.3. Comparison of computation burden
The reduction of computational cost is discussed in three perspectives in this section. The first is the reduction of the orthogonal vectors for ROM by LRA. The second is the reduction of the training data for ROM construction by the data sampling method based on the adaptive sampling. The third is the reduction of computational time to estimate CDP distribution.
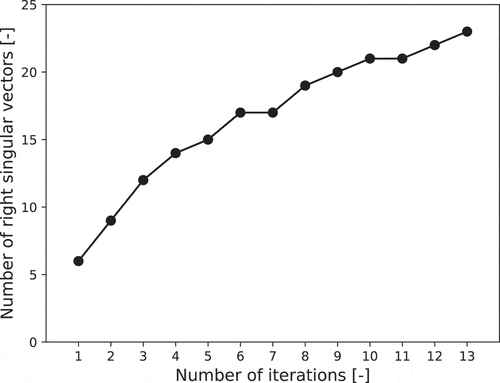
As described in the introduction, the surrogate models in the previous study were independently applied to each time-step of time-series data. Therefore, 150 surrogate models are required in this study with the conventional approach, as the total number of time-step is 150. The proposed ROM can, however, estimate the time-series data by the orthogonal vectors on time-series. As described in Sections 2.2.1 and 2.2.2, LRA with SVD can reduce the orthogonal vectors with minimum loss of reproduction accuracy by our ROM. The number of vectors in this study, which cover over 99.99% variance of training data, is shown in . Although the number of vectors increases as the number of iterations increases, the number of vectors is less than 150. Our ROM is, therefore, simpler than that in the conventional approach.
Figure 13. The variation of the number of right singular vectors to cover over 99.99% variance of the training data.
The proposed data sampling method based on the adaptive sampling contributes to the reduction of computational cost by focusing on data near the vicinity of the CD boundary. Without the data sampling method based on the adaptive sampling, the random sampling method would be considered as the alternative sampling method; however, random sampling usually performs uniform sampling in the input space. The fraction of the data near the vicinity of the CD boundary will, therefore, be very small. Consequently, ROM cannot accurately learn the vicinity of the CD boundary; hence, the random sampling will be inefficient for ROM construction. Meanwhile, the sampling method used in this study takes many samples around the CDROM boundary as shown in . Note that is consistent with the figure with the 13th iteration in , although a different viewing angle is adopted.
Figure 14. The CDROM boundary and input training data for ROM construction in the 13th iteration (View the last figure in from another angle).
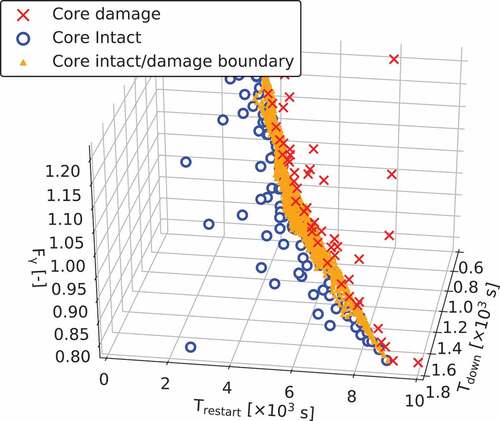
indicates that the training data are sampled near the CDROM boundary surface.
Computation of the CDP distribution requires many predictions of SA progression. In this study, 6.5 million predictions are used to make the CDP distribution in . For ROM construction, the 153 data calculated by RELAP5/SCDAPSIM are necessary. The total computational cost of this approach is approximately the 153 RELAP5/SCDAPSIM calculations and the 6.5 million predictions of ROM for the evaluation of the CDP distribution. However, the 6.5 million calculations are necessary by RELAP5/SCDAPSIM to directly calculate the CDP distribution. While a calculation cost is about 0.4 [s] by the ROM in python, a calculation cost of RELAP5/SCDAPSIM is about 2 h. A ROM calculation is about 18,000 times faster than a RELAP5/SCDAPSIM calculation for the SBO scenario. Eventually, the usage of ROM will reduce the total computational cost of estimating the CDP.
4. Conclusions
In this study, the reduced order modeling (ROM) to reproduce the results of a severe accident (SA) code was developed to reduce the computational cost for probabilistic safety margin analysis. The singular value decomposition (SVD) and the low-rank-approximation (LRA) were newly applied to construct ROM for time-series data of an SA code.
ROM with SVD was constructed for the station blackout (SBO) with a total loss of feedwater capabilities. ROM with SVD for variation of peak cladding temperature was constructed to estimate the core condition. A data sampling method based on the adaptive sampling was used to improve the prediction accuracy of ROM while reducing the number of calculations by an SA code. In the adaptive sampling, the approximate boundary between core intact and core damage was estimated using multiple reproductions by ROM. We newly introduced the concept of gravity field and convergence criterion into the adaptive sampling to improve the prediction accuracy of ROM.
The probabilistic safety margin analysis was conducted by the constructed ROM with SVD. As an example of the probabilistic safety margin analysis, the core damage probability (CDP) distribution for the SBO was estimated by ROM. The estimated CDP distribution by ROM was consistent with that estimated by RELAP5/SCDAPSIM and was within the error of approximately 16%. Consequently, this study had made it possible to estimate the CDP distribution while reducing the number of SA code calculations.
There are several issues to be addressed. Because the number of input variables considered in this study is three (down and recovery time of RCIC, and decay heat), the larger number of input variables would be considered in actual probabilistic safety margin analysis. An extension of input variables will, therefore, be desirable. Because the accident scenario considered in this study is limited to SBO, the application of the method used in this study to other scenarios will be necessary.
Acknowledgments
The RELAP/SCDAPSIM used in this study has been introduced by the funding of Nuclear Regulatory Authority (NRA) for the educational program of nuclear regulation and nuclear safety.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- NRA JAPAN Nuclear Regulation Authority: Regulatory Requirements [Internet]. Japan: Japan nuclear regulation authority; [ cited 2018 July 13]. Available from: http://www.nsr.go.jp/english/regulatory/index.html.
- Smith C, Rabiti C, Martineau R Risk-Informed Safety Margins Characterization (RISMC) Pathway Technical Program Plan. Idaho Falls (Idaho): Idaho National Laboratory; 2014. (INL/EXT-11-22977).
- Mandelli D, Smith C, Riley T, et al. Risk-Informed Safety Margin Characterization (RISMC) BWR station blackout demonstration case study. Idaho Falls (Idaho): Idaho National Laboratory; 2013. (INL/EXT-13-30203)
- Mandelli D, Smith C, Alfonsi A, et al. Reduced order model implementation in the risk-informed safety margin characterization toolkit. Idaho Falls (Idaho): Idaho National Laboratory; 2015. (INL/EXT-15-36649)
- Otsuki S, Endo T, Yamamoto A. Development of dynamic probabilistic risk assessment model for PWR using simplified plant simulation method. Proceedings of ICAPP-2017; Fukui and Kyoto, Japan; 2017 Apr 24–28.
- Matsushita M, Endo T, Yamamoto A, et al. Development of reduced order model of severe accident code for probabilistic safety margin analysis. Proceedings of PHYSOR-2018; Cancun, Mexico; [USB]; 2018 Apr 22–28.
- Matsushita M, Endo T, Yamamoto A Surrogate model of severe accident analysis code for SBO aiming probabilistic safety margin analysis. Transactions of the American Nuclear Society; 2018 Nov. 11–15; Orland, United States. p. 900–903.
- Yankov A. Analysis of reactor simulations using surrogate models. Michigan (USA): University of Michigan; 2015.
- Mandelli D, Smith C Adaptive sampling using support vector machines. California (USA): Transactions of the American Nuclear Society; 2012 Nov. 11–15. p. 736–738.
- Katano R, Endo T, Yamamoto A, et al. Estimation of sensitivity coefficients of core characteristics based on reduced order modeling using sensitivity matrix of assembly characteristics. J Nucl Sci Technol. 2017;54:637–647.
- Russell P. High-dimensional linear data interpolation. Berkeley (CA): University of California. 1993.
- Katakura J. Uncertainty analyses of decay heat summation calculations using JENDL, JEFF, and ENDF files. J Nucl Sci Technol. 2013;50:799–807.
- Allison MC, Hohorst JK. Role of RELAP/SCDAPSIM in nuclear safety. Dubrovnik (Croatia): Topsafe 2008;2008 Oct 1–3. p. 87–108.
- Nuclear Commission Monthly Newsletter [Internet]. Japan: Japan nuclear commission; 1974 May 24 [cited 2018 Jul 13]. [in Japanese]. Available from: http://www.nsr.go.jp/english/regulatory/index.html