
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The main purpose of this paper is to provide an effective nonparametric method of kernel estimation of the density function for various specific data. A convex linear combination of the most locally effective known kernel estimators constructed using different approaches allows one to build an estimator that combines the best features of all analysed estimators. The paper presents an original concept for studying the local effectiveness of the kernel estimator of the density function based on the Marczewski–Steinhaus metric. It is shown that none of the applied kernel estimators can be considered globally optimal if local effectiveness is taken into account. The presented numerical calculations were done for experimental data recording groundwater levels on a melioration facility and supported by simulation studies.
Introduction
In the statistics literature, many forms of kernel estimators of density functions for a given random sample X1, X2, ..,Xn are known (e.g. [Citation1–5]). The construction of these estimators was based on various analytical and numerical approaches. In the papers [Citation6,Citation7] Karczewski and Michalski considered eight kernel estimators of the density function f in the form
where h is the window width, also called the smoothing parameter or bandwidth, and K is a real positive function integrable to 1 as a kernel of estimator
. The authors considered two kernels:
a Gaussian kernel and the kernel given by Epanechnikov, using several methods: Silverman’s rule of thumb, the Sheather–Jones method, cross-validation methods and other more known plug-in methods. From a theoretical point of view, the most important features of kernel estimators are strong consistency, asymptotic unbiasedness and uniform convergence [Citation2] and optimal choice of the smoothing bandwidth.
For assessing the effectiveness of the considered estimates and their similarity, we applied a distance measure for measurable and integrable functions proposed by Marczewski and Steinhaus in 1958 [Citation8]. The reference point for testing the effectiveness of selected estimators was the frequency histogram at the intervals indicated, e.g. by the experimenter. In the numerical analysis, the structure of the frequency histogram was flexible as needed. The analysed estimators showed a different effectiveness depending on the selected interval and it was impossible to select the most effective estimator for all given intervals.
In this paper, we propose a new data-driven kernel estimator (DDKE) in the form of a convex linear combination of the locally most effective kernel estimators, i.e. the construction of this estimator involves the analysed estimators that showed the best efficiency for each of the examined intervals.
Methods – construction of a data-driven kernel estimator
The starting point for the construction of the data-driven kernel estimator (DDKE) is the selection of a set of kernel estimators of the density function f from a certain wider class of kernel estimators of a density function. The results of testing the effectiveness of the considered kernel estimators led to the selection of eight different estimators:
– Silverman’s [Citation9],
– Sheather & Jones [Citation5],
– unbiased cross-validation,
– biased cross-validation [Citation4,Citation5],
– Altman & Leger [Citation1],
– Bowman with Gaussian kernel,
– Bowman with Epanechnikov kernel [Citation3,Citation10],
– Polansky & Baker [Citation11]. It should be noted, however, that at the beginning of this procedure, one can start with any reasonable set of estimators which are not necessarily kernel density function, i.e.:
(in our case k = 8).
Now, let’s define a set of intervals for i = 0, … , m, (x0 = min and xm+1 = max, in our example m = 14) covering each of the lines that make up the frequency polygon
, and the set
of estimators
which in the i-th interval turned out to be the most effective, i.e.
For the most efficient estimator of consideration we accept the one that reaches the shortest distance in relation to the empirical frequency polygon when using the Marczewski–Steinhaus metric, defined as below
for non-negative and integrable functions f and g [Citation8].
Finally, we create a convex linear combination of the estimators of the form:
(1)
(1) for weights
defined as follows
The downside of this approach was the potential to choose a version of the kernel density estimator that has the lowest M-S distance in a single interval but a potentially bad fit outside of it. This could lead to suboptimal overall performance. To combat that, an additional rule was introduced. The estimator can only be a part of a linear combination if its average M-S distance over all intervals is not higher than 150% of smallest mean distance among all chosen estimators.
Note
In the past, attempts were made to create a linear combination of kernel estimators [Citation12]. The approach presented in this paper takes into account the local fit of the estimator to the data, which in turn allows the creation of an estimator as a convex linear combination of the analysed estimators with the i-th weights inversely proportional to the distance of point from the edges of interval
The method proposed in this article shows some similarity to the methods that use the smoothing parameter h (x), which depends on the argument x with the constant kernel K instead of the constant parameter h and methods for determining the asymptotic mean integrated squared error (AMISE (h))[Citation13,Citation14].
Analysis was performed for real hydrological data recording groundwater levels on a melioration facility [Citation7,Citation15] as well as on simulated datasets created from mixtures of density functions. Calculations were performed in R for Windows software [Citation16]. Kernel estimation was performed using the kedd [Citation17] and kerdiest [Citation18] packages.
Results and conclusions
In this section, the behaviour of DDKE is presented for both real and simulated data. An important goal of these analyses was to investigate the sensitivity of the DDKE estimator to the multimodality of the estimated density function. Once the concept of a mode is defined, the question arises whether an observed mode in a density estimate really arises from a corresponding feature in the assumed underlying density [Citation9]. The study of the effectiveness of kernel estimators strongly related to empirical data has serious consequences with effects on possible forecasts, which is of paramount importance for a researcher of a given phenomenon. In this section, we present the numerical calculations performed for the data from the real experiment and additionally for the simulation data, for a mixture of probability distributions of the type beta and further for a mixture of two-parameter gamma distributions with appropriate shape and scale parameters.
Experimental data
In this example, we use groundwater level data from melioration studies on the foothill object Długopole. Daily registered groundwater levels were averaged based on measurements from a dozen or so piezometers suitably located at the research station. The experimental data are derived from the Institute of Agricultural and Forest Improvement of Wroclaw University of Environmental and Life Sciences (currently). The data set includes the groundwater level measurements for specified ranges of levels from 10 to 150 cm, taken every 10 cm. The experimental data aggregated in a frequency table were reproduced by repeated use of a random number generator with a given frequency structure.
Table shows the matrix of distances d() calculated according to the Marczewski–Steinhaus metric between the kernel estimator
and the frequency polygon
built on the empirical data. Additionally, the first row shows the bandwidth calculated for each base kernel estimator and the last row shows the average distance (D) from all intervals, respectively. On the basis of the calculated distances d(
), for each of the determined intervals
, the most effective estimator
was selected. Then, based on the set of the most effective local estimators, a linear combination was created according to the formula (1). In this example, the following estimators have been selected: Bowman with Gaussian kernel, Sheather & Jones and Bowman estimator with Epanechnikov kernel. The DDKE achieved the shortest distance for 4 out of 15 intervals (including two without a clear advantage). In other cases, the differences between the approach we proposed and the most effective estimator were relatively small and satisfy the assumption of an acceptable sufficiently small distance Δ from the minimum distance [Citation12]. Additionally, the determined combination of estimators showed the greatest efficiency globally, that is over the entire range of the studied variability, and has the lowest mean error in the individual intervals. Figure .
Figure 1. Comparison of the DDKE and locally most effective kernel density estimators for the Długopole dataset.
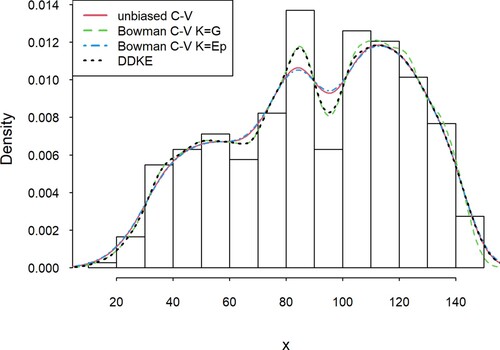
Table 1. Matrix of distances d() calculated according to the Marczewski–Steinhaus metric for each interval, averaged over all intervals and bandwidth of each estimator – Długopole dataset. Estimators used for DDKE marked in bold.
The proposed hybrid model can also be modified by generalizing
This change increases the impact of the most effective local estimator in relation to the estimators from other intervals. In our examples, however, this change had little effect on the fit.
Illustrative example – beta mixture
In this example, a sample size of 200 was generated from a mixture of two beta density functions f(x, p, q) with parameters (p, q) = (10, 30) and (p, q) = (3, 3) and equal weights for both. To make the intervals clear, the values were multiplied by 140. Table , similarly to Table , shows the matrix of Marczewski–Steinhaus distances for intervals of 10 lengths, an average of all intervals for every kernel density estimation and bandwidth calculated for each base kernel estimator (Figure ).
Figure 2. Comparison of the DDKE and locally most effective kernel density estimators for the simulated data (beta mixture).
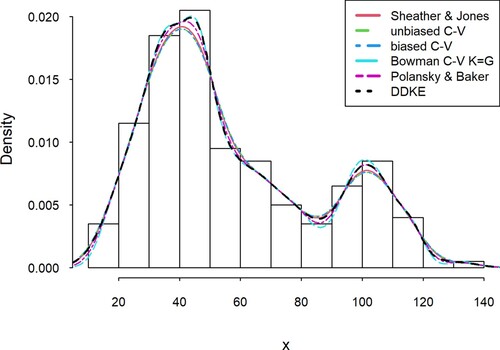
Table 2. Matrix of distances d() calculated according to the Marczewski–Steinhaus metric for each interval, averaged over all intervals and bandwidth of each estimator – simulated dataset (beta mixture). Estimators used for DDKE marked in bold.
Illustrative example – gamma mixture
For this example, a sample size of 200 was generated from a mixture of two gamma density functions f(x, p, λ) with parameters (p, λ) = (5, 4) and (p, λ) = (13, 3) and equal weights for both, and multiplied by 12. Table shows the matrix of Marczewski–Steinhaus distances for intervals of 5 lengths, an average of all intervals for every kernel density estimation and bandwidth calculated for each base kernel estimator (Figure ).
Figure 3. Comparison of the DDKE and locally most effective kernel density estimators for the simulated data (gamma mixture).
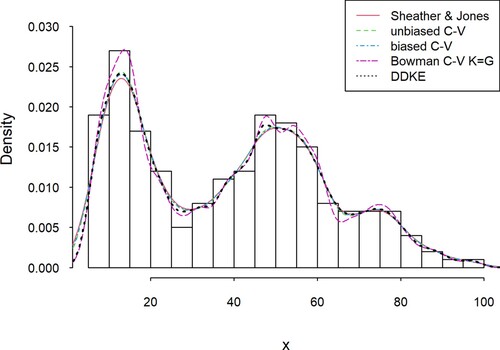
Table 3. Matrix of distances d() calculated according to the Marczewski–Steinhaus metric for each interval, averaged over all intervals and bandwidth of each estimator – simulated dataset (gamma mixture). Estimators used for DDKE marked in bold.
Among the eight considered estimators, four had at least one interval with minimal M-S distance; Unbiased CV twice, Biased CV twice, Bowman’s CV on gaussian kernel nine times and Sheater–Jones nine times. DDKE was optimal in seven of those intervals (0–5, 20–25, 45–50, 65–70, 90–95, 95–100), but it excelled in the average distance among all intervals. This illustrates that while it may not necessarily be best for every small interval, it eliminates the potential problematic local range each kernel density could have.
Simulation study
Additionally, a simulation study based on five hundred replications of a sample size of two hundred was performed. Twenty-eight distribution functions discussed by Berlinet and Devroy [Citation2] implemented in ‘Benchden’ R package [Citation19] were considered. To assess global accuracy, nine kernel density estimators are compared using averaged Marczewski–Steinhaus distance, and average integrates squared error (AISE). DDKE was calculated separately for both measures since in each case we consider different definitions of estimator effectiveness.
Tables and show that DDKE outperformed the remaining considered estimators both in terms of Marczewski–Steinhaus distance and AISE. In some cases, e.g. symmetric Pareto distribution, the effectiveness was very similar to that of kernel estimators that were used to build DDKE. This is linked to situations where most of analysed intervals have the same optimal estimator.
Table 4. Average Marczewski–Steinhaus distances with standard error times 103 for 28 types of density functions. Calculations were performed on 500 replications with n = 200.
Table 5. AISE with standard error times 103 for 28 types of density functions. Calculations were performed on 500 replications with n = 200.
Discussion
The DDKE, a linear combination of selected kernel estimators, although not necessarily always locally optimal, provides us with the best overall efficiency in the average value of local efficiency relative to the frequency polygon. In addition, in the ranges where the estimator DDKE did not reach the minimum distance compared to the single estimators, the differences were usually not notable.
An important structural element of the presented method is its flexibility, related to a variable smoothing window and a different division, range of variability of the examined features into classes (e.g. groundwater level, as in this paper). Thus, to obtain better prognostic effects, the DDKE algorithm allows for a variable number of classes in which the local efficiency of the estimators is determined. Additionally, the width of the histogram bins does not need to be of the same length.
The method of determining the DDKE shows a certain computational complexity, as it includes two stages: the first one – selecting various kernel estimators (analysis of similarity of objects) and the second one – examining the local behaviour of the selected estimators in the specific ranges of variability of a given feature (efficiency analysis according to the indicated pattern).
Kernel estimation as a nonparametric estimation method is free from additional assumptions, in regard to the class of density function or its parameters. Additionally, kernel estimators have been researched for a long time and there is quite extensive literature on them (e.g. [Citation2,Citation5,Citation9,Citation20]), hence the decision to base construction of DDKE primarily on kernel estimators.
This method achieves the greatest benefits when the unknown probability distribution in the study of a certain phenomenon, e.g. hydrological or meteorological, is a distribution that is difficult to analyse due to multimodality and heavy tails. In such cases, it can be expected that the DDKE will include significantly different single estimators with different analytical properties – this effect is known in the determination of a mixed strategy under various restrictions in game theory. It is worth noting that the DDKE approach is not tied to any base estimator listed in this paper, and could be built on any density function including more complex estimators, focused on dealing with certain distribution characteristics [Citation21,Citation22]. It can also use measures other than the Marczewski–Steinhaus distance e.g. AISE, as shown in simulation study, which only adds to the method robustness.
The authors realize that the method of constructing a hybrid estimator proposed in this paper is only a certain alternative for achieving relatively good practical goals. At the same time, it is a challenge to harness estimation methods that are more robust to various peculiarities of unknown probability distributions governing a given phenomenon, e.g. the double kernel method [Citation23] or the bootstrap method [Citation2].
Disclosure statement
No potential competing interest was reported by the authors.
References
- Altman N, Léger C. Bandwidth selection for kernel distribution function estimation. J Stat Plan Inference. 1995;46:195–214.
- Berlinet A, Devroye L. A comparison of kernel density estimates. Publ L’Institut Stat L’Université Paris. 1994;38:3–59.
- Bowman AW. An alternative method of cross-validation for the smoothing of density estimates. Biometrika. 1984;71:353–360.
- Scott DW, Terrell GR. Biased and unbiased cross-validation in density estimation. J Am Stat Assoc. 1987;82:1131–1146.
- Givens GH, Hoeting JA. Computational statistics. 1st ed. New Jersey: John Wiley & Sons inc; 2005.
- Karczewski M, Michalski A. The study and comparison of one-dimensional kernel estimators – a new approach. Part 1. Theory and methods. ITM Web Conf. 2018;23:00017.
- Karczewski M, Michalski A. The study and comparison of one-dimensional kernel estimators – a new approach. Part 2. A hydrology case study. ITM Web Conf. 2018;23:00018.
- Marczewski E, Steinhaus H. On a certain distance of sets and the corresponding distance of functions. Colloq Math. 1958;6:319–327.
- Silverman BW. Density estimation: For statistics and data analysis. London: Chapman & Hall; 1986.
- Bowman A, Hall P, Prvan T. Bandwidth selection for the smoothing of distribution functions. Biometrika. 1998;85:799–808.
- Polansky AM, Baker ER. Multistage plug-in bandwidth selection for kernel distribution function estimates. J Stat Comput Simul. 2000;65:63–80.
- Rigollet P, Tsybakov AB. Linear and convex aggregation of density estimators. Math Methods Stat. 2007;16:260–280.
- Breiman L, Meisel W, Purcell E. Variable kernel estimates of multivariate densities. Technometrics. 1977;19:135–144.
- Hall P. On global properties of variable bandwidth density estimators. Ann Stat. 1992;20:762–778.
- Michalski A. The use of kernel estimators to determine the distribution of groundwater level. Meteorol Hydrol Water Manag. 2016;4:41–46.
- R Core Team. (2020). R: A Language and Environment for Statistical Computing [Internet]. Vienna, Austria; Available from: https://www.r-project.org/.
- Guidoum AC. Kernel estimator and bandwidth selection for density and its derivatives [Internet]. 2013 [cited 2020 Dec 29]. p. 1–22. Available from: https://cran.r-project.org/package=kedd.
- Quintela-del-Río A, Estévez-Pérez G. Nonparametric kernel distribution function estimation with kerdiest: an R package for bandwidth choice and applications. J Stat Softw. 2012;50(8):1–21.
- Mildenberger T, Weinert H. The Benchden package: benchmark densities for nonparametric density estimation. J Stat Softw. 2012;46:2–14.
- Wand MP, Jones MC. Kernel smoothing. biometrics. London: Chapman & Hall; 1995.
- Buch-Larsen T, Nielsen JP, Guillén M, et al. Kernel density estimation for heavy-tailed distributions using the champernowne transformation. Statistics (Ber. 2005;39:503–516.
- Jiang M, Provost SB. A hybrid bandwidth selection methodology for kernel density estimation. J Stat Comput Simul. 2014;84:614–627.
- Devroye L. The double kernel method in density estimation. Ann. l’I.H.P. Probab. Stat. 1989;25:533–580.