
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
A popular way to estimate the parameters of a hidden Markov model (HMM) is direct numerical maximization (DNM) of the (log-)likelihood function. The advantages of employing the TMB [Kristensen K, Nielsen A, Berg C, et al. TMB: automatic differentiation and Laplace approximation. J Stat Softw Articles. 2016;70(5):1–21] framework in R for this purpose were illustrated recently [Bacri T, Berentsen GD, Bulla J, et al. A gentle tutorial on accelerated parameter and confidence interval estimation for hidden Markov models using template model builder. Biom J. 2022 Oct;64(7):1260–1288]. In this paper, we present extensions of these results in two directions. First, we present a practical way to obtain uncertainty estimates in form of confidence intervals (CIs) for the so-called smoothing probabilities at moderate computational and programming effort via TMB. Our approach thus permits to avoid computer-intensive bootstrap methods. By means of several examples, we illustrate patterns present for the derived CIs. Secondly, we investigate the performance of popular optimizers available in R when estimating HMMs via DNM. Hereby, our focus lies on the potential benefits of employing TMB. Investigated criteria via a number of simulation studies are convergence speed, accuracy, and the impact of (poor) initial values. Our findings suggest that all optimizers considered benefit in terms of speed from using the gradient supplied by TMB. When supplying both gradient and Hessian from TMB, the number of iterations reduces, suggesting a more efficient convergence to the maximum of the log-likelihood. Last, we briefly point out potential advantages of a hybrid approach.
1. Introduction
Hidden Markov models (HMMs) are a well-studied and popular class of models in many areas. While they have been used for speech recognition historically [see, e.g. Citation1–5], these models also became important in many other fields due to their flexibility. These are, to name only a few, biology and bioinformatics [Citation6–8], finance [Citation9], ecology [Citation10], stochastic weather modelling [Citation11,Citation12], and engineering [Citation13]. In short, HMMs are a class of models where the given data is assumed to follow varying distributions according to an underlying unknown Markov chain. Parameter estimation for HMMs is typically achieved either by the Baum-Welch (BW) algorithm [Citation3,Citation14–17] – an Expectation–Maximization(EM)-type algorithm – or in a quite straightforward fashion by direct numerical maximization (DNM) of the (log-)likelihood function [see, e.g. Citation18,Citation19]. A discussion of both approaches can be found in [Citation20, p. 358]. Furthermore, [Citation21] points out that it is challenging to fit complex models with the BW algorithm, [Citation22, pp. 77–78] advises using DNM with HMMs due to the ease of fitting complex models, and [Citation18,Citation23] report a greater speed of DNM compared to the BW algorithm. The arguments of [Citation24] point in a similar direction, underlining the often increased amount of mathematical and programming labor required by the EM algorithm, in particular for non-standard models. Nevertheless, the BW is highly accepted and finds widespread application. However, we will only use DNM in the following due to the possibility of accelerating the estimation via the R-package TMB [Citation25,Citation26].
In this paper, we present a straightforward procedure to calculate uncertainty estimates of the smoothing probabilities through appropriate use of TMB. Hence, we quantify the uncertainty of the state classifications of the observations at a low computational cost. To the best of our knowledge, such results on confidence intervals for the aforementioned probabilities are not available in the literature. Furthermore, the chosen optimization routine for DNM plays an important role in parameter estimation. While e.g. [Citation22] focuses on the unconstrained optimizer nlm, alternatives include the popular nlminb [Citation27] and many others, such as those provided by the optim function [Citation28]. In this context, [Citation29] compare different estimation routines for two-state HMMs: a Newton-Type algorithm [Citation30,Citation31], the Nelder–Mead algorithm [Citation32], BW, and a hybrid algorithm successively executing BW and DNM. To complement these studies, we investigate the speed of several optimization algorithms, many of which allow the gradient and Hessian of the objective function as input. Particular focus lies on the ability of the TMB framework, which allows for easy retrieval of the exact gradient and Hessian (up to machine precision). This enriches the existing literature on parameter estimation for HMMs. Among others, Zucchini et al. [Citation22] report that ‘Depending on the starting values, it can easily happen that the algorithm (i.e. DNM) identifies a local, but not the global, maximum’. The literature on how to tackle this problem is rich, and includes among others: the use of artificial neural networks to guess the initial values [Citation33], model induction [Citation34], genetic algorithms in combination with HMMs [Citation35], hybridizing both the BW and the DNM algorithms [Citation21,Citation29,Citation36], specific assumptions on the parameters [Citation37], educated guesses [Citation22, p. 53], and short EM-runs with 10 iterations or (model-based) clustering [Citation38]. We investigate how stable the various considered optimization routines are towards poor initial values. Again, this part takes under consideration the special features of TMB, which have not been investigated yet. In this context, it is noteworthy that the recently developed R-package hmmTMB [see Citation39] provides a framework for working with HMMs and TMB. This package offers the choice between various optimization routines with the Nelder-Mead algorithm as default. Hence, our results may also provide guidance for users of hmmTMB.
The paper is organized as follows. In Section 2, we provide a brief overview of parameter estimation for HMMs, including inference for CIs. In Section 3 we show how uncertainty estimates of the smoothing probabilities can be computed via TMB. Then, we apply our results to a couple of data sets with different characteristics. We perform simulation studies in Section 4 to compare measures of performance and accuracy of various optimizers. In Section 5, we check how well these optimizers perform in the presence of poor initial values. Section 6 provides some concluding remarks. All code necessary to reproduce our results is available in the supporting information.
2. Basics on hidden Markov models
The HMMs considered here are fit on observed time series where t denotes the (time) index ranging from one to T. In this setting, a mixture of conditional distributions is assumed to be driven by an unobserved (hidden) homogeneous Markov chain, whose states will be denoted as
. We will use different conditional distributions in the paper. First, we specify an m-state Poisson HMM, i.e. with the conditional distribution
with parameters
. Secondly, we consider Gaussian HMMs with conditional distribution specified by
with parameters
. In addition,
denotes the transition probability matrix (TPM) of the HMM's underlying Markov chain, and
is a vector of length m collecting the corresponding stationary distribution. We assume that the Markov chains underlying our HMMs are irreducible and aperiodic. This ensures the existence and uniqueness of a stationary distribution as the limiting distribution [Citation40]. However, these results are of limited relevance for most estimation algorithms, because the elements of
are generally strictly positive. Nevertheless, one should be careful when manually fixing selected elements of
to zero.
The basis for our estimation procedure is the (log-)likelihood function. We denote the ‘history’ of observations and the observed process
up to time t by
and
, respectively. In addition, let
be the vector of model parameters. As explained, e.g. by Zucchini et al. [Citation22, p. 37], the likelihood function can then be represented as a product of matrices:
(1)
(1) where the m conditional probability density functions evaluated at x (we use this term for discrete support as well) are collected in the diagonal matrix
and
and
denote a transposed vector of ones and the stationary distribution, respectively. That is, we assume that the initial distribution corresponds to
. The likelihood function given in Equation (Equation1
(1)
(1) ) can be efficiently evaluated by a so-called forward pass through the observations, as illustrated in Appendix 1. Consequently, it is possible to obtain
, the ML estimates of
, by -- in our case - unconstrained DNM. Since several of our parameters are constrained, we rely on known re-parametrization procedures (see Appendix 2 for details).
Confidence intervals (CIs) for the estimated parameters of HMMs can be derived via various approaches. The most common ones are Wald-type, profile likelihood, and bootstrap-based CIs. Bacri et al. [Citation26] shows that TMB can yield valid Wald-type CIs in a fraction of the time required by classical bootstrap-based methods as investigated e.g. by Bulla and Berzel [Citation29] and Zucchini et al. [Citation22]. Furthermore, the likelihood profile method may fail to provide CIs [Citation26]. Therefore, we rely on Wald-type confidence intervals derived via TMB. For details, see Appendix 3.
3. Uncertainty of smoothing probabilities
When interpreting the estimation results of an HMM, the so-called smoothing probabilities often play an important role. These quantities, denoted by in the following, correspond to the probability of being in state i at time t given the observations, i.e.
and can be calculated for
and
[see, e.g. Citation22, p. 87]. The involved quantities
and
, which also depend on
, result directly from the forward- and backward algorithm, respectively, as illustrated in Appendix 1. Estimates of
are obtained by
where
is the ML estimate of
.
An important feature of TMB is that it not only permits obtaining standard errors for (and CIs for
), but in principle also for any other quantity depending on the parameters. This is achieved by combining the delta method with automatic differentiation (see Section A.1 in Appendix 3 for details). A minor requirement for deriving standard deviations for
via the ADREPORT function provided by TMB consists in implementing the function
in C++. Then, this part has to be integrated into the scripts necessary for the parameter estimation procedure. It is noteworthy that, once implemented, the procedures related to inference of the smoothing probabilities do not need to change when the HMM considered changes, because the input vector for
remains the same. The C++ code in the supporting information illustrates how to complete these tasks. Note that population value we are interested in constructing a CI for is
, which should not be confused with
. That is, we treat
as the probability of the event
conditional on
being equal to the particular sequence of observations
. After all, it is this sequence and the corresponding smoothing probabilities which are of interest to the researcher.
Quantifying the uncertainty in the estimated smoothing probabilities can be of interest in multiple fields because the underlying states are often linked to certain events of interest (e.g. the state of an economy or the behaviour of a customer). In the following, we illustrate the results of our approach through a couple of examples.
3.1. Track Your Tinnitus
The ‘Track Your Tinnitus’ (TYT) mobile application gathered a large data set, a description of which is detailed in [Citation41] and [Citation42]. The data plotted in Figure shows the so-called ‘arousal’ variable reported for an individual over 87 consecutive days. This variable takes high values when a high level of excitement is achieved and low values when the individual is in a calm emotional state. The values are measured on a discrete scale; we refer to [Citation43,Citation44] for details.
Figure 1. Plot of a two-state Poisson HMM fitted to the TYT data (of size 87), with a fitted two-state Poisson HMM. The coloured dots correspond to the conditional mean of the inferred state at each time. Table displays the corresponding parameter estimates.
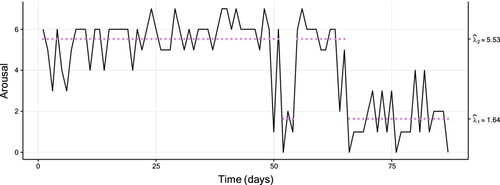
We estimated Poisson HMMs with varying number of states by nlminb with TMB's gradient and Hessian functions passed as arguments (this approach was chosen for all estimated models in our examples). The preferred HMM in terms of AIC and BIC is a two-state model, see Table in Appendix 4.
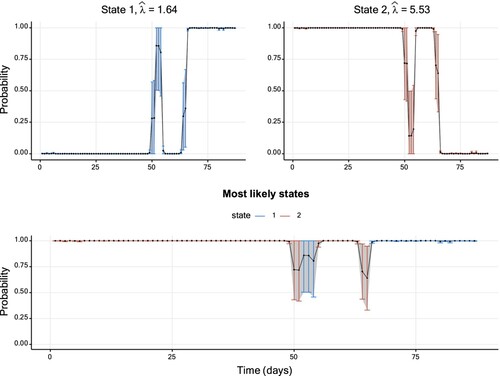
Figure displays the corresponding smoothing probabilities with 95% Wald-type CIs, constructed using the standard error provided by TMB. Intuitively, one might expect the uncertainty to be low when a smoothing probability takes values close to zero or one, whereas higher uncertainty should be inherent to smoothing probabilities further away from these bounds. The CIs illustrated in Figure follow this pattern. However, as pointed out by Bacri et al. [Citation26], this data set is atypically short for fitting HMMs. As we will see in the following, different patterns will emerge for longer sequences of observations.
Figure 2. Smoothing probabilities and confidence intervals of a two-state Poisson HMM fitted to the TYT data set. The solid line shows the smoothing probability estimates and the 95% CIs are represented by vertical lines. The lower graph displays smoothing probabilities for the most likely state estimated for each data point. The vertical confidence interval lines are coloured differently per hidden state. Further details on parameter estimates are available in Table .
3.2. Soap
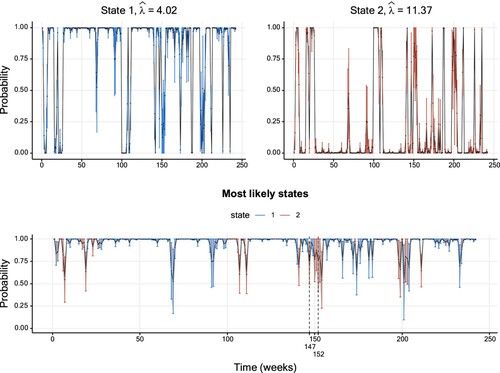
In the following, we consider a data set of weekly sales of a soap in a supermarket. The data were provided by the Kilts Center for Marketing, Graduate School of Business of the University of Chicago and are available in the database at https://research.chicagobooth.edu/kilts/marketing-databases/dominicks. The data are displayed in Figure . Similarly to the previous section, we fitted multiple Poisson HMMs, and the preferred HMM in terms of AIC and BIC is a two-state model as well (see Table in Appendix 4). Figure displays the smoothing probabilities resulting from this model. The patterns of the CIs described in the previous section are, in principle, also present here. Nevertheless, an exception is highlighted in the bottom panel of Figure : at t = 152, the smoothing probability of State 2 is closer to the upper boundary of one than the corresponding probability at t = 147. Yet, the uncertainty is higher at t = 152.
Figure 3. Plot of the soap data (of size 242), with a fitted two-state Poisson HMM. The coloured dots correspond to the conditional mean of the inferred state at each time. Table displays the corresponding parameter estimates.
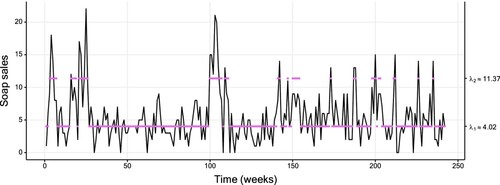
Figure 4. Smoothing probabilities and confidence intervals of a two-state Poisson HMM fitted to the soap data set. The solid line shows the smoothing probability estimates and the 95% CIs are represented by vertical lines. The lower graph displays smoothing probabilities for the most likely state estimated for each data point. The vertical confidence interval lines are coloured differently per hidden state. Further details on the parameter estimates are available in Table .
3.3. Weekly returns
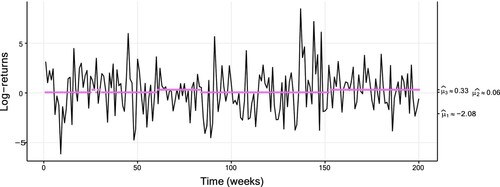
The data set considered in this section are 2230 weekly log-returns based on the adjusted closing share price of the S&P 500 stock market index retrieved from Yahoo Finance, between January 1st 1980 and September 30th 2022. The returns are expressed in per cent to facilitate reading and interpreting the estimates. As shown, e.g. by Rydén et al. [Citation45], Gaussian HMMs reproduce well certain stylized facts of financial returns. We thus estimated such models with varying number of states. A three-state model is preferred by the BIC, whereas the AIC is almost identical for three and four states (see Table in Appendix 4). The estimates show a decrease in conditional standard deviation with increasing conditional mean. This is a well-known property of many financial returns (see, e.g.[Citation46–48]) related to the behaviour of market participants in crisis and calm periods. Figure shows the first 200 data points plotted along with conditional means from the preferred model.
Figure 5. Plot of the weekly returns data (of size 2230), with a fitted three-state Gaussian HMM. The coloured dots correspond to the conditional mean of the inferred state at each time, with a fitted three-state Gaussian HMM. Table displays the corresponding parameter estimates. For readability, only the first 200 data are plotted.
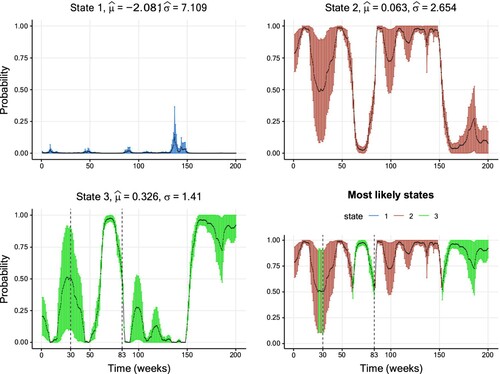
The subsequent Figure shows inferred smoothing probabilities together with their CIs. In addition to the previous applications, where smoothing probabilities close to the boundary seemed to be linked to lower uncertainty, this data set shows also some clear exceptions from this pattern. For example, the smoothing probabilities of State 3 inferred at t = 30 and t = 83 take the relatively close values 0.51 and 0.53, respectively. However, the associated uncertainty at is visibly higher than the corresponding uncertainty at t = 83 (the estimated standard errors are 0.205 and 0.045). This may be explained by the fact that the inferred states closely around t = 30 oscillated between State 2 and 3, thus indicating a high uncertainty of the state classification during this period. On the contrary, around t = 83 a quick and persistent change from State 2 to 3 takes place.
Figure 6. Smoothing probabilities and confidence intervals of a three-state Gaussian HMM fitted to the weekly returns data set. The solid line shows the smoothing probability estimates and the 95% CIs are represented by vertical lines. The lower-right graph displays smoothing probabilities for the most likely state estimated for each data point. The vertical confidence interval lines are coloured differently per hidden state. For readability, only the first 200 out of the 2230 values are shown for readability purposes. Further details on the parameter estimates are available in Table .
3.4. Hospital
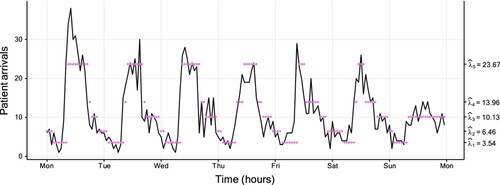
Basis for our last example is a data set issued by the hospital ‘Hôpital Lariboisière’ from Assistance Publique – Hôpitaux de Paris (a french hospital trust). This data set consists of the hourly number of patient arrivals to the emergency ward during a period of roughly 10 years. A subset of the data (over one week) is displayed in Figure . We examine this due to several reasons. First, with 87648 observations, this data set is much larger than the ones examined previously. Secondly, the medical staff noticed differences between the rates of patient arrivals at day and night, respectively, which motivates the use of, e.g. an HMM. Last, a Poisson HMM is a natural candidate for the observed count-type data. The preferred model by both AIC and BIC has five states (see Table in Appendix 4) and confirms the impression of the hospital employees: State 5 is mainly visited during core operating hours during day time. The fourth and third states mainly occur late afternoon, early evening, and early morning. Last, State 1 and 2 correspond to night time observations.
Figure 7. Plot of the hospital data (of size 87,648), with a fitted five-state Poisson HMM. The coloured dots correspond to the conditional mean of the inferred state at each time. Table displays the corresponding parameter estimates. For readability, only the first week starting on Monday (from Monday January 4th 2010 at 00:00 to Sunday January 10th 2010 at 23:59) is plotted instead of the entire 10 years.
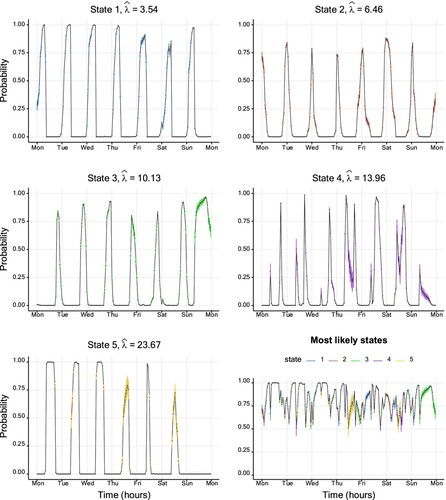
Even for a data set of this size, the smoothing probabilities and corresponding CIs can be derived with moderate computational effort and time: Figure displays the results. Overall, the inferred CIs are relatively small, in particular in comparison with those obtained for the stock return data discussed in the previous example. The low uncertainty in the state classification may most likely result from the clear, close to periodic transition patterns.
Figure 8. Smoothing probabilities and confidence intervals of a five-state Poisson HMM fitted to the hospital data set. The solid line shows the smoothing probability estimates and the 95% CIs are represented by vertical lines. The lower-right graph displays smoothing probabilities for the most likely state estimated for each data point. The vertical confidence interval lines are coloured differently per hidden state. For readability, only the first week starting on Monday (from Monday January 4th 2010 at 00:00 to Sunday January 10th 2010 at 23:59) is plotted instead of the entire 10 years. Further details on the parameter estimates are available in Table .
3.5. Simulated data
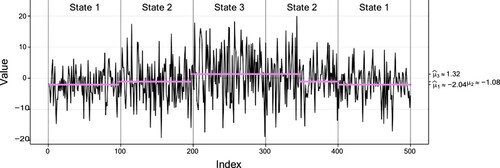
In contrast to the previous examples, we consider two simulated settings with data sets consisting of 500 observations each in this section. For both data sets, the underlying Gaussian HMM possesses three states with conditional mean vector . The difference lies in the conditional standard deviations. These equal
and
for the first and second data set, respectively. Thus, the two settings differ substantially w.r.t. the overlap of their conditional distributions. To facilitate comparability, we did not simulate state sequences from a pre-defined TPM, but generated identical state sequences in each setting: the states are visited in the order 1-2-3-2-1 with sojourns of length 100 in each state. Figures and show the observations along with the true sequence of states and their inferred conditional means for the setting with low and high overlap, respectively. Noteworthy is that
deviates quite a bit from the true value in the setting with high overlap. This may most likely result from the high conditional variance in the third state.
Figure 9. Plot of the first simulated data set (of size 500) with low overlap, with a fitted three-state Gaussian HMM. The vertical dotted lines separate the true states of the data indicated by text, and the coloured dots correspond to the conditional mean of the inferred state at each time. Table displays the corresponding parameter estimates.
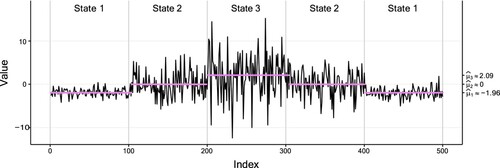
Figure 10. Plot of the second simulated data set (of size 500) with high overlap, with a fitted three-state Gaussian HMM. The vertical dotted lines separate the true states of the data indicated by text, and the coloured dots correspond to the conditional mean of the inferred state at each time. Table displays the corresponding parameter estimates.
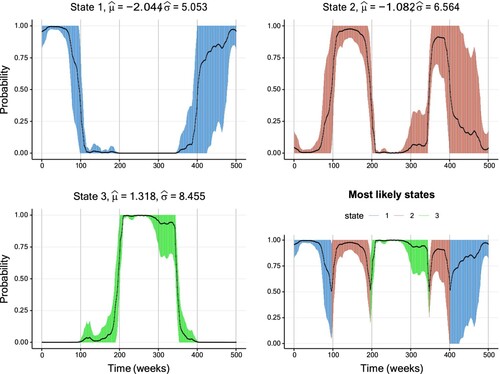
Furthermore, Figure displays the inferred smoothing probabilities together with their CIs for the first setting. For these well-separated conditional distributions, the inferred state sequence is in high accordance with the true states. Furthermore, the width of the CIs is generally low with a slight increase around periods of state changes. In contrast, Figure corresponding to the second setting with high overlap paints a different picture. First, the width of the CIs is substantially higher than in the first setting. Secondly, the inferred state sequence partly deviates substantially from the true state sequence, in particular from t = 300 until approximately t = 350. During this period, the inferred state sequence remains in State 3, although state change to the second state has already happened. Along with this misclassification come comparably wide CIs, considering that the smoothing probabilities take values mostly above 90%.
Figure 11. Smoothing probabilities and confidence intervals of a three-state Gaussian HMM fitted to the first simulated data set with low overlap. The solid line shows the smoothing probability estimates and the 95% CIs are represented by vertical lines. The lower-right graph displays smoothing probabilities for the most likely state estimated for each data point. The vertical confidence interval lines are coloured differently per hidden state. Further details on the parameter estimates are available in Table .
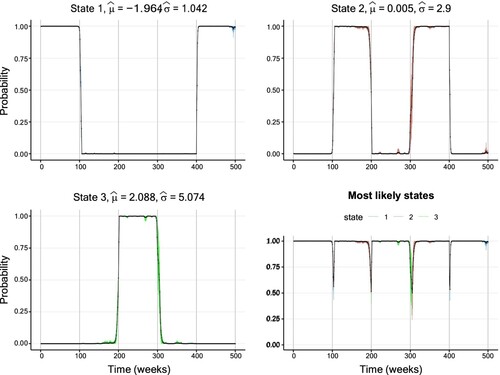
Figure 12. Smoothing probabilities and confidence intervals of a three-state Gaussian HMM fitted to the second simulated data set with high overlap. The solid line shows the smoothing probability estimates and the 95% CIs are represented by vertical lines. The lower-right graph displays smoothing probabilities for the most likely state estimated for each data point. The vertical confidence interval lines are coloured differently per hidden state. Further details on the parameter estimates are available in Table .
4. Performance and accuracy of different optimizers
This section compares the speed and accuracy of different optimizers in R using TMB in an HMM estimation setting with DNM by several simulation studies with different settings.
In the first setting, we simulate time series consisting of 87 observations from a two-state Poisson HMM fitted to the TYT data, as we want to examine the different optimizers performance on data sets with relatively few observations. In the second setting, we simulate time series of length 200 from a two-state Poisson HMM, and in the third setting, time series of length 200 from a two-state Gaussian HMM are simulated. The specific choice of parameters is described in more detail in the forthcoming sections.
The comparisons that focus on computational speed and iterations of the different optimizers, are based on 200 replications from the different models, while the studies focusing on the accuracy of the optimizers are based on 1000 replications from the different models. Hence, the Monte-Carlo simulation setup in this paper closely resembles the setup of [Citation26].
4.1. Computational setup
The results presented in this paper required installing and using the R-package TMB and the software Rtools, where the latter is needed to compile C++ code. Scripts were coded in the interpreted programming language R [Citation49] using its eponymous software environment RStudio. For the purpose of making our results reproducible, the generation of random numbers is handled with the function set.seed under R version number 3.6.0. A seed is set multiple times in our scripts, ensuring that smaller parts can be easily duplicated without executing lengthy prior code. A workstation with 4 Intel(R) Xeon(R) Gold 6134 processors (3.7 GHz) running under the Linux distribution Ubuntu 18.04.6 LTS (Bionic Beaver) with 384 GB RAM was used to execute our scripts.
4.2. Selected optimizers and additional study design
There exist a large number of optimizers for use within the R ecosystem, see e.g. [Citation50]. In a preliminary phase, multiple optimization routines were attempted, and the ones failing to converge on a few selected test data sets from the designs mentioned above were excluded (details available from the author upon request). Hence, the following optimizers were selected for the simulation studies:
optim from the stats package to test the BFGS [Citation51–54], L-BFGS-B [Citation55], CG [Citation56], and Nelder–Mead [Citation32] algorithms.
nlm [Citation57] and nlminb [Citation27] from the same package to test popular nonlinear unconstrained optimization algorithms.
hjn from the optimr package [Citation28] to test the so-called Hooke and Jeeves Pattern Search Optimization [Citation58].
marqLevAlg from the marqLevAlg package [Citation59] to test a general-purpose optimization based on the Marquardt-Levenberg algorithm [Citation60,Citation61].
BBoptim from the BB package [Citation62] to test a spectral projected gradient method for large scale optimization with simple constraints [Citation63].
newuoa from the minqa package [Citation64] to test a large-scale nonlinear optimization algorithm [Citation65].
By also providing the Hessian and/or gradient to the optimizers that support such inputs, 22 optimization procedures are examined for each study design. For the study of the computational speed and number of iterations, we applied the microbenchmark package [Citation66] that allows us to obtain precise durations for each of the simulated data sets. Furthermore, HMM ML estimates were reordered by increasing Poisson rates or Gaussian means to avoid a random order of the states.
It is important to note that we discarded all those samples for which the simulated state sequence did not sojourn at least once in each state. This was to avoid identifiability and convergence issues when trying to estimate a m-state HMM on a data set where only m−1 states are visited. Further, samples where at least one optimizer failed to converge were also discarded to ensure comparability. For the same reason, we set the maximum number of iterations to whenever possible. Note that some optimizers (BFGS, CG, hjn, L-BFGS-B, Nelder-Mead, newuoa) do not report a number of iterations and are therefore missing from our comparisons of iterations. Finally, we use the true values as initial parameters. For the TYT data, initial values are calculated as medians from the fitted models resulting from all optimizers listed above.
4.3. Results
In this section, we report the results from the simulation studies focusing on the performance of different optimizers in terms of the computational speed and the lack or presence of unreasonable estimates. This section uses R scripts that may be of interest to users investigating their own HMM settings, and are available in the supporting information. We begin by reporting the speed of all optimization routines and thereafter the accuracy. The routine names contain the optimizer names and may be followed by either ‘_gr’ to indicate that the routine uses TMB's provided gradient function, ‘_he’ to indicate the use of TMB's provided Hessian function, or ‘_grhe’ to indicate the use of both gradient and Hessian functions provided by TMB. Note that some optimizers cannot make use of these functions and hence bear no extension at the end of their names.
4.3.1. Simulation study: TYT setting
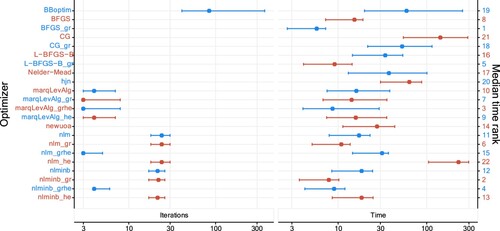
Figure shows the time required by each optimization routine, measured over the 200 replication. The number of iterations required by each optimization routine is also reported where available. Times range from 1 to 1340 milliseconds. As shown by the large medians and wide CIs, CG and CG_gr require substantially more time to estimate an HMM, compared to the other optimizers. Furthermore, optimizers that take a long time to estimate HMMs require a high amount of iterations as well, as expected. Notably, optimization routines almost always take longer when the Hessian is passed. This likely results from a higher computational burden due to handling and evaluating Hessian matrices via TMB.
Figure 13. Median number of iterations and median duration (in milliseconds and ranked) together with 2.5%- and 97.5%-quantile when fitting two-state Poisson HMMs to 200 replications in the first setting. The horizontal axes are on a logarithmic scale (base 10). More detailed values are available at Table .
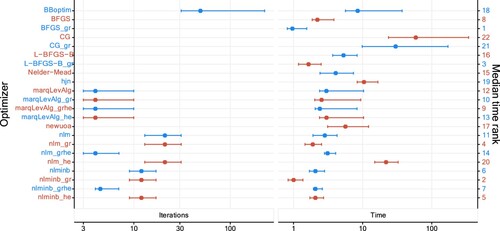
Figure 14. Median number of iterations and median duration (in milliseconds and ranked) together with 2.5%- and 97.5%-quantile when fitting two-state Poisson HMMs to 200 replications in the second setting. The horizontal axes are on a logarithmic scale (base 10). More detailed values are available at Table .
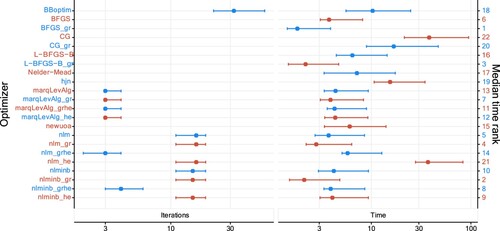
Figure 15. Median number of iterations and median duration (in milliseconds and ranked) together with 2.5%- and 97.5%-quantile when fitting two-state Gaussian HMMs to 200 replications in the third setting. The horizontal axes are on a logarithmic scale (base 10). More detailed values are available at Table .
Looking at the details, the optimizer BFGS_gr is among the fastest optimizers, and this is partly explained by a relatively low number of iterations, and by the fact that it does not make use of the Hessian. However, we note that nlm and nlmimb families of optimizers are slower when the gradient and Hessian are not passed as argument. The optimizer BBoptim is comparatively slow, and nlminb_grhe fails to converge comparably often.
In addition to time durations, we investigate the accuracy of the optimizers, based on another 1000 replications from the two-state Poisson HMM in the first setting. The main conclusion from this simulation is that the medians and empirical quantiles calculated are in fact almost identical across all optimizers, and very close to the true parameter values used in the simulations. Results are reported in Figure in Appendix 5. These result imply that the different optimizers are equally accurate. Note, however, that the variation is quite high for some of the estimated parameters and for the nll, which results most likely from the limited number of observations.
4.3.2. Simulation study: two-state Poisson HMM
In this second simulation setting, the parameters of our two-state Poisson HMM are given by
and the sample size is fixed at 200. Figure illustrates our results, which are in line with those obtained in the first setting. More precisely, BBoptim still dominates the number of iterations, and CG and CG_gr require more computational time than the others. Overall, most optimizers need more time compared to the previous setting as there is more data to process, but the time increase for nlm_he and hjn is much more substantial than for other optimizers. Moreover, although the data set is larger, some optimizers (e.g. BBoptim and BFGS_gr) perform as fast as or faster than in the previous setting. Furthermore, passing TMB's Hessian to optimizers does not always slow down the optimization. This can be seen, e.g. from nlminb_he which exhibits a lower median time than nlminb. A last notable pattern concerns the popular nlm optimizer. When only the Hessian but not the gradient is supplied from TMB, the computational time increases substantially compared to nlm_gr and nlm_grhe. Interestingly, the equally popular optimizer nlminb is not affected in the same way. Thus, one should be careful when only supplying the Hessian from TMB while an optimizer carries out the gradient approximation. In any case, the low number of iterations required by both nlminb_grhe and nlm_grhe indicate a preferable convergence behaviour when supplying both quantities.
In terms of accuracy of the parameter estimates and obtained nlls, our results are highly similar to those described in the first setting (for details, see Figure in Appendix 5).
4.3.3. Simulation study: two-state Gaussian HMM
In our third and last simulation setting, the parameters of a two-state Gaussian HMM are given by
and the sample size is fixed at 200. In terms of computational time and the number of iterations, the results observed for this setup are similar to the previously studied Poisson HMMs (see Figure ). A minor aspect is an increase in both iterations and computational time, which is not surprising given the higher number of parameters.
Regarding estimation accuracy of the parameter estimates and obtained nlls, our results are again highly similar to those obtained in the previous two settings (illustrated graphically by Figure in Appendix 5).
5. Robustness to initial value selection
In this section, we examine the impact of initial values of the parameters – including poorly selected ones – on the convergence behaviour and accuracy of different optimizers. We investigate one real and several simulated data sets. In order to ‘challenge’ the optimizers, all data sets are of comparable small size.
5.1. Study design
We again consider three settings in the following. In the first, we investigate the TYT data set. In the second and third setting, we focus on simulated data from Poisson and Gaussian HMMs, respectively. More specifically, for the Poisson HMMs we generate one data set of sample size 200 for each of the HMMs considered. These HMMs are defined by all possible combinations of the following Poisson rates and TPMs:
This setup leads to the generation of
data sets. For the Gaussian HMMs, we follow the same approach, where the Gaussian means and standard deviations are selected from the sets
This setting thus generates
data sets.
For each data set, we pass a large range of initial values to the same optimizers considered in the previous section. In this way, we investigate the resistance of each optimizer to potentially poor initial values when fitting HMMs. To generate sets of initial values, we consider the following potential candidates for Poisson rates , Gaussian means
, Gaussian standard deviations
, and TPMs
:
where
,
,
and
. The motivation for this selection is as follows. First, Poisson means have to be greater than zero, so we set their lower boundary to M. Secondly, the
's have to belong to the interval
, cfr. [Citation67]. This applies to the Gaussian means as well. Thirdly, the upper and lower limit of
is motivated by the Bhatia-Davis [Citation68] and the von Szokefalvi Nagy inequalities [Citation69].
For the Poisson HMMs fitted, we consider all possible combination of the parameters described above. For the Gaussian HMMs, however, we sample 12,500 initial parameters for each of the 16 data sets to reduce computation time (the total amount reduces from 39,066,300 to 200,000). These sets of initial values are identical for all optimizers. As in the previous Section 4, we limit the maximal number of iterations to whenever possible. Other settings were left as default.
To evaluate the performance of the optimizers considered, we rely on two criteria. First, we register whether the optimizer converges (all errors are registered regardless of their type). Secondly, when an optimizer converges, we also register if the nll is equal to the ‘true’ nll (with a gentle margin of ± 5%). We calculate this ‘true’ nll as the median of all nlls derived with all optimizers initiated with the true parameter values.
5.2. Results
Table shows the results for the two-state Poisson HMMs fitted to the TYT data. The four marqLevAlg follow closely. We note that hjn has the best performance: it basically does not fail and converges almost always. Moreover, nlminb_grhe fails to converge much more often than other optimizers, but is the most likely to find the global maximum when it converges. For the other optimizers, the failure rate is generally low (less than 5%) and the global maximum is found in more than 65% of the cases.
Table 1. Performance of multiple optimizers estimating Poisson HMMs from the TYT data (first setting) over 7371 different sets of initial parameters.
Table reports the results from the second setting, also with two-state Poisson HMMs. The results show that all optimizers find the global maximum in the majority of cases() when converging. Moreover, the failure rates are relatively low for all optimizers with the exception of CG, which stands out with comparably high failure rates.
Table 2. Performance of multiple optimizers estimating Poisson HMMs from the second setting over 194,481 different sets of initial parameters.
Finally, Table presents the results from the third setting with Gaussian HMMs. The results regarding the failure rates point in the same direction as those from the Poisson HMM setting: CG attains the highes failure rate, followed by newuoa and L-BFGS-B. The remaining optimizers perform satisfactorily. Note, however, that nlminb does not benefit from being supplied with the gradient and Hessian from TMB. Regarding the global maximum found, many algorithms reach success rates of about 95% or more. Notable exceptions are Nelder-Mead and nlm when not both gradient and Hessian are provided by TMB. As observed previously for the TYT data, nlm benefits strongly from the full use of TMB.
Table 3. Performance of multiple optimizers estimating Gaussian HMMs from the third setting over 200,000 different sets of initial parameters randomly drawn from 39,066,300 different candidate sets of initial values.
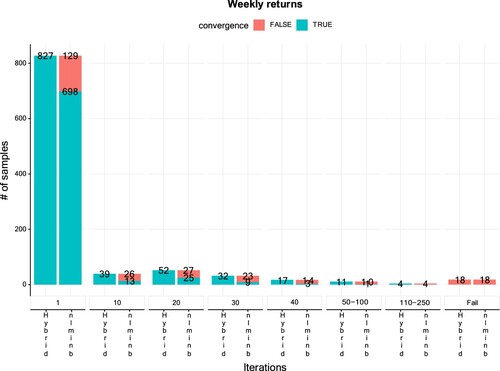
Figure 16. Convergence counts of nlminb and a hybrid algorithm (first Nelder-Mead, then nlminb). The hybrid algorithm uses iterations for the Nelder-Mead, then passes the estimates to nlminb as initial values. We randomly picked 1000 sets of initial values out of 1,458,000 potential candidates.
5.3. Hybrid algorithm
Last, we ran a small simulation study investigating a hybrid algorithm within the TMB framework in the spirit of [Citation29]. The hybrid algorithm starts with the Nelder-Mead optimizer and switches to nlminb after a certain number of iterations. The idea is to benefit from both Nelder-Mead's rapid departure from poor initial values and from the high convergence speed of nlminb. Our study is performed on 1000 random sets of initial values in a similar fashion to Section 5, using the weekly returns data set. For every set of initial values, we sequentially increase the number of iterations carried out by Nelder-Mead by ten (starting at one) until convergence or until 10,000 iterations has been reached, in which case we classify the attempt as a failure. For comparison, we also run an optimization only with nlminb starting directly with the same sets of inital values. In both cases, nlminb benefits from the gradient and Hessian provided by TMB.
Figure reports the results of our study. The left most columns show that only one iteration was required to converge in 827 of the 1000 sets of initial values with the hybrid algorithm, while nlminb converges in only 698 out of these 827 sets. Furthermore, for 39 additional sets of initial values, the hybrid algorithm converges with 10 iterations carried out by the Nelder-Mead optimizer, whereas nlminb fails 26 times on these sets. Increasing the number of initial iterations carried out by Nelder-Mead for the hybrid algorithm leads to similar patterns. Finally, both optimization routines fail to converge for 18 sets of initial values. Thus, in total, the hybrid algorithm with one or more Nelder-Mead iterations failed in only of the cases. In comparison, direct use of nlminb failed in around
of the cases. This indicates that the hybrid algorithm requires rather few iterations of Nelder-Mead to improve the convergence rate substantially.
6. Concluding remarks
This paper addresses a couple of aspects concerning parameter estimation for HMMs via TMB and R using direct numerical maximization (DNM) of the likelihood. The advantage of TMB is that it permits to quantify the uncertainty of any quantity depending on the estimated parameters. This is achieved by combining the delta method with automatic differentiation. Moreover, TMB provides exact calculations of first- and second-order derivatives of the (log-)likelihood of a model by automatic differentiation. This allows for efficient gradient- and/or Hessian-based optimization of the likelihood. In the first part of the paper, we propose a straightforward technique to quantify the uncertainty of smoothing probabilities via the calculation of Wald-type CIs. The advantage of this approach is that one avoids computationally intensive bootstrap methods. By means of several examples, we illustrate how such CIs provide additional insight into the commonly used state classification via smoothing probabilities. For a practitioner working with HMMs, the presented uncertainty quantification constitutes a new tool for obtaining a better understanding of the dynamics of the hidden process.
Subsequently, we examine speed and accuracy of the different optimizers in three simulation settings. Our results show a slight variation in both number of iterations and computational speed. In particular, the optimizers nlminb, nlm, marqLevAlg, and BFGS usually possess the highest computational speed. The computing time required by all optimizers reduces when using the gradient provided by TMB. The number of iterations reduces in particular for nlminb and nlm when employing both gradient and Hessian from TMB. This suggests a more direct path towards the (global) likelihood maximum compared to optimizer-internal approximation routines. Regarding the accuracy, measured in terms of attained negative log-likelihood and parameter estimates (and their variability) the results show little variations across the different optimizers. This is indeed a positive finding, indicating that the performance of the optimizers is relatively equal in terms of accuracy – however, this statement only holds true when using the optimal initial value. Then, we examine robustness towards initial values across different optimizers. In three settings, we measure (a) how often optimizers fail to converge and (b) how often they successfully reach the global maximum of the log-likelihood function when starting from a wide range of sets of initial values. In particular, nlm, nlminb, and hjn show an overall good performance. Notably, nlm benefits strongly from employing both gradient and Hessian provided by TMB, which is not the case for nlminb. Altogether, we observe a trade-off between failure rates and convergence to the global maximum. Nevertheless, none of the optimizers shows an exceptionally bad performance.
Finally, we illustrate that a hybrid algorithm starting with the Nelder-Mead optimizer and switching to nlminb after a certain number of iterations converges more often than nlminb. Notably an effect is visible even with a single initial iteration carried out by Nelder-Mead.
Concerning future research, initialization strategies and the hybrid algorithm may merit further investigation. While our hybrid strategy is implemented easily and seems effective, initial values considered are based on a simple random sampling process. More complex approaches could be considered in case of unsatisfactory performance, which may be expected, e.g. for models with a high number of parameters or high-dimensional data. Then one may consider EM short-runs, (model-based) clustering, or other alternatives [see Citation29, Citation38, and the references therein] – potentially at the expense of increased mathematical and programming efforts. In our results concerning different optimization algorithms in the context of TMB provide useful guidance when pre-selecting suitable candidates for further analyses. Furthermore, smoothing probabilities play a key role for the model selection criterion ICL [Citation70] through their contribution to the entropy term (roughly speaking,ICL = BIC – Entropy). Hence, it may be possible to develop a model selection criterion which additionally takes the uncertainty of the smoothing probabilities into account. The increasing width of the CIs during periods of wrongful state classification could serve as additional input for model selection on the one hand. On the other hand, it could constitute itself an interesting measure for identifying misclassification.
Acknowledgments
We thank the University of Regensburg and European School for Interdisciplinary Tinnitus Research (ESIT) for providing access to the TYT data. Special thanks go to J. Simões for data preparation, and W. Schlee and B. Langguth for helpful comments and suggestions. We also thank Anthony Chauvin and Bertrand Galichon for providing access to the hospital data set along with the necessary authorizations. Furthermore, our thanks go to an anonymous reviewer, who provided very valuable feedback and criticism. Many thanks go to Hans Karlsen for his valuable help. Last, J. Bulla's profound thanks for the continued moral support go to the highly skilled, very helpful, and always friendly employees of Vestbrygg AS (Org. ID 912105954).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Juang BH, Rabiner LR. Hidden Markov models for speech recognition. Technometrics. 1991 Aug;33(3):251–272. doi: 10.1080/00401706.1991.10484833
- Baum LE, Petrie T. Statistical inference for probabilistic functions of finite state Markov chains. Ann Math Stat. 1966 Dec;37(6):1554–1563. doi: 10.1214/aoms/1177699147
- Rabiner L, Juang B. An introduction to hidden Markov models. IEEE ASSP Mag. 1986 Jan;3(1):4–16. doi: 10.1109/MASSP.1986.1165342
- Rabiner L. A tutorial on hidden Markov models and selected applications in speech recognition. Proc IEEE. 1989 Feb;77(2):257–286. doi: 10.1109/5.18626
- Fredkin DR, Rice JA. Bayesian restoration of single-channel patch clamp recordings. Biometrics. 1992;48(2):427–448. doi: 10.2307/2532301
- Schadt EE, Sinsheimer JS, Lange K. Computational advances in maximum likelihood methods for molecular phylogeny. Genome Res. 1998 Jan;8(3):222–233. doi: 10.1101/gr.8.3.222
- Durbin R. Biological sequence analysis: probabilistic models of proteins and nucleic acids. Cambridge: Cambridge University Press; 1998.
- Eddy SR. Profile hidden Markov models. Bioinformatics. 1998 Jan;14(9):755–763. doi: 10.1093/bioinformatics/14.9.755
- Hamilton JD. A new approach to the economic analysis of nonstationary time series and the business cycle. Econometrica. 1989;57(2):357–384. doi: 10.2307/1912559
- McClintock BT, Langrock R, Gimenez O, et al. Uncovering ecological state dynamics with hidden Markov models. Ecol Lett. 2020;23(12):1878–1903. doi: 10.1111/ele.v23.12
- Lystig TC, Hughes JP. Exact computation of the observed information matrix for hidden Markov models. J Comput Graph Stat. 2002 Sep;11(3):678–689. doi: 10.1198/106186002402
- Ailliot P, Allard D, Monbet V, et al. Stochastic weather generators: an overview of weather type models. J Soc Fr Stat. 2015;156(1):101–113.
- Mor B, Garhwal S, Kumar A. A systematic review of hidden Markov models and their applications. Arch Comput Methods Eng. 2021 May;28(3):1429–1448. doi: 10.1007/s11831-020-09422-4
- Baum LE, Petrie T, Soules G, et al. A maximization technique occurring in the statistical analysis of probabilistic functions of Markov chains. Ann Math Stat. 1970;41(1):164–171. doi: 10.1214/aoms/1177697196
- Dempster AP, Laird NM, Rubin DB. Maximum likelihood from incomplete data via the EM algorithm. J R Stat Soc Ser B (Methodol). 1977;39(1):1–22. doi: 10.1111/j.2517-6161.1977.tb01600.x
- Liporace L. Maximum likelihood estimation for multivariate observations of Markov sources. IEEE Trans Inform Theory. 1982 Sep;28(5):729–734. doi: 10.1109/TIT.1982.1056544
- Wu CFJ. On the convergence properties of the EM algorithm. The Ann Stat. 1983;11(1):95–103. doi: 10.1214/aos/1176346060
- Turner R. Direct maximization of the likelihood of a hidden Markov model. Comput Stat Data Anal. 2008 May;52(9):4147–4160. doi: 10.1016/j.csda.2008.01.029
- MacDonald IL, Zucchini W. Hidden Markov and other models for discrete-valued time series. London: Chapman & Hall; 1997. (Monographs on statistics and applied probability; vol. 70).
- Cappé O, Moulines E, Ryden T. Inference in hidden Markov models. Berlin: Springer Science & Business Media; 2005.
- Lange K, Weeks DE. Efficient computation of lod scores: genotype elimination, genotype redefinition, and hybrid maximum likelihood algorithms. Ann Hum Genet. 1989;53(1):67–83. doi: 10.1111/ahg.1989.53.issue-1
- Zucchini W, MacDonald I, Langrock R. Hidden markov models for time series: an introduction using R. 2nd ed. CRC Press; 2016. (Chapman & Hall/CRC Monographs on Statistics & Applied Probability).
- Altman RM, Petkau AJ. Application of hidden Markov models to multiple sclerosis lesion count data. Stat Med. 2005;24(15):2335–2344. doi: 10.1002/(ISSN)1097-0258
- MacDonald IL. Numerical maximisation of likelihood: a neglected alternative to EM? Int Stat Rev. 2014 Aug;82(2):296–308. doi: 10.1111/insr.v82.2
- Kristensen K, Nielsen A, Berg C, et al. TMB: automatic differentiation and Laplace approximation. J Stat Softw Articles. 2016;70(5):1–21. doi: 10.18637/jss.v070.i05
- Bacri T, Berentsen GD, Bulla J, et al. A gentle tutorial on accelerated parameter and confidence interval estimation for hidden Markov models using template model builder. Biom J. 2022 Oct;64(7):1260–1288. doi: 10.1002/bimj.v64.7
- Gay DM. Usage summary for selected optimization routines. Computing Science Technical Report. 1990;153:1–21.
- Nash JC, Varadhan R. Optimr: a replacement and extension of the optim function; 2019. R package version 2019-12.16; Available from: https://CRAN.R-project.org/package=optimr.
- Bulla J, Berzel A. Computational issues in parameter estimation for stationary hidden Markov models. Comput Stat. 2008 Jan;23(1):1–18. doi: 10.1007/s00180-007-0063-y
- Dennis Jr JE, Moré JJ. Quasi-Newton methods, motivation and theory. SIAM Rev. 1977 Jan;19(1):46–89. doi: 10.1137/1019005
- Schnabel RB, Koonatz JE, Weiss BE. A modular system of algorithms for unconstrained minimization. ACM Trans Math Softw. 1985 Dec;11(4):419–440. doi: 10.1145/6187.6192
- Nelder JA, Mead R. A simplex method for function minimization. Comput J. 1965 Jan;7(4):308–313. doi: 10.1093/comjnl/7.4.308
- Hassan MR, Nath B, Kirley M. A fusion model of HMM, ANN and GA for stock market forecasting. Expert Syst Appl. 2007 Jul;33(1):171–180. doi: 10.1016/j.eswa.2006.04.007
- Stolcke A, Omohundro S. Hidden Markov model induction by Bayesian model merging. Adv Neural Inf Process Syst. 1993;11–11.
- Oudelha M, Ainon RN. HMM parameters estimation using hybrid Baum-Welch genetic algorithm. In: 2010 International Symposium on Information Technology; Vol. 2; Jun.; 2010. p. 542–545. Kuala Lumpur, Malaysia
- Redner RA, Walker HF. Mixture densities, maximum likelihood and the EM algorithm. SIAM Rev. 1984 Apr;26(2):195–239. doi: 10.1137/1026034
- Kato J, Watanabe T, Joga S, et al. An HMM-based segmentation method for traffic monitoring movies. IEEE Trans Pattern Anal Mach Intell. 2002 Sep;24(9):1291–1296. doi: 10.1109/TPAMI.2002.1033221
- Maruotti A, Punzo A. Initialization of hidden Markov and semi-Markov models: A critical evaluation of several strategies. Int Stat Rev. 2021 Dec;89(3):447–480. doi: 10.1111/insr.v89.3
- Michelot T. hmmTMB: Hidden Markov models with flexible covariate effects in R; 2023.
- Feller W. An introduction to probability theory and its applications. New York: Wiley; 1968.
- Pryss R, Reichert M, Langguth B, et al. Mobile crowd sensing services for tinnitus assessment, therapy, and research. In: 2015 IEEE International Conference on Mobile Services; Jun. IEEE; 2015. p. 352–359.
- Pryss R, Reichert M, Herrmann J, et al. Mobile crowd sensing in clinical and psychological trials–a case study. In: 2015 IEEE 28th International Symposium on Computer-Based Medical Systems; Jun. IEEE; 2015. p. 23–24.
- Probst T, Pryss R, Langguth B, et al. Emotion dynamics and tinnitus: Daily life data from the ‘TrackYourTinnitus’ application. Sci Rep. 2016 Aug;6(1):31166. doi: 10.1038/srep31166
- Probst T, Pryss RC, Langguth B, et al. Does tinnitus depend on time-of-day? An ecological momentary assessment study with the ‘TrackYourTinnitus’ application. Front Aging Neurosci. 2017 Aug;9:253. doi: 10.3389/fnagi.2017.00253
- Rydén T, Teräsvirta T, Åsbrink S. Stylized facts of daily return series and the hidden Markov model. J Appl Econom. 1998;13(3):217–244. doi: 10.1002/(ISSN)1099-1255
- Schwert GW. Why does stock market volatility change over time. J Finance. 1989;44(5):1115–1153. doi: 10.1111/j.1540-6261.1989.tb02647.x
- Maheu John M, McCurdy Thomas H. Identifying bull and bear markets in stock returns. J Bus Econ Stat. 2000 Jan;18(1):100–112. doi: 10.1080/07350015.2000.10524851.
- Guidolin M, Timmermann A. Economic implications of bull and bear regimes in UK stock and bond returns. Econom J. 2005 Jan;115(500):111–143. doi: 10.1111/j.1468-0297.2004.00962.x
- R Core Team. R: a language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing; 2021.
- Schwendinger F, Borchers HW. CRAN task view: optimization and mathematical programming. 2022. [Available from: https://cran.r-project.org/view=optimization].
- Broyden CG. The convergence of a class of double-rank minimization algorithms 1. General considerations. IMA J Appl Math. 1970 Mar;6(1):76–90. doi: 10.1093/imamat/6.1.76
- Fletcher R. A new approach to variable metric algorithms. Comput J. 1970 Jan;13(3):317–322. doi: 10.1093/comjnl/13.3.317
- Goldfarb D. A family of variable-metric methods derived by variational means. Math Comput. 1970;24(109):23–26. doi: 10.1090/mcom/1970-24-109
- Shanno DF. Conditioning of quasi-Newton methods for function minimization. Math Comput. 1970;24(111):647–656. doi: 10.1090/mcom/1970-24-111
- Byrd RH, Lu P, Nocedal J, et al. A limited memory algorithm for bound constrained optimization. SIAM J Sci Comput. 1995 Sep;16(5):1190–1208. doi: 10.1137/0916069
- Fletcher R. Practical methods of optimization. Hoboken, New Jersey, U.S.A: John Wiley & Sons; 2013.
- Dennis JE, Schnabel RB. Numerical methods for unconstrained optimization and nonlinear equations. Society for Industrial and Applied Mathematics; 1996. (Classics in Applied Mathematics).
- Hooke R, Jeeves TA. ‘Direct search’ solution of numerical and statistical problems. J ACM. 1961 Apr;8(2):212–229. doi: 10.1145/321062.321069
- Philipps V, Proust-Lima C, Prague M, et al. Marqlevalg: a parallelized general-purpose optimization based on marquardt-levenberg algorithm; 2023. R package version 2.0.8; Available from: https://CRAN.R-project.org/package=marqLevAlg.
- Levenberg K. A method for the solution of certain non-linear problems in least squares. Quart Appl Math. 1944;2(2):164–168. doi: 10.1090/qam/1944-02-02
- Marquardt DW. An algorithm for least-squares estimation of nonlinear parameters. J Soc Indust Appl Math. 1963 Jun;11(2):431–441. doi: 10.1137/0111030
- Varadhan R, Gilbert P. Bb: solving and optimizing large-scale nonlinear systems; 2019. R package version 2019.10-1; Available from: http://www.jhsph.edu/agingandhealth/People/Faculty_personal_pages/Varadhan.html.
- Varadhan R, Gilbert P. BB: an R package for solving a large system of nonlinear equations and for optimizing a high-dimensional nonlinear objective function. J Stat Softw. 2010;32:1–26. doi: 10.18637/jss.v032.i04
- Bates D, Mullen KM, Nash JC, et al. minqa: derivative-free optimization algorithms by quadratic approximation; 2022. R package version 1.2.5; Available from: http://optimizer.r-forge.r-project.org.
- Powell MJD. The NEWUOA software for unconstrained optimization without derivatives. In: Di Pillo G, Roma M, editors. Large-scale nonlinear optimization. Boston (MA): Springer US; 2006. p. 255–297. (Nonconvex Optimization and Its Applications).
- Mersmann O. microbenchmark: accurate timing functions; 2023. R package version 1.4.10; Available from: https://github.com/joshuaulrich/microbenchmark/.
- Böhning D. Computer-assisted analysis of mixtures and applications: meta-analysis, disease mapping and others. Vol. 81. Boca Raton, Florida: CRC press; 1999.
- Bhatia R, Davis C. A better bound on the variance. Am Math Mon. 2000 Apr;107(4):353–357. doi: 10.1080/00029890.2000.12005203
- Nagy J. Über algebraische Gleichungen mit lauter reellen Wurzeln. Jahresbericht Der Deutschen Mathematiker-Vereinigung. 1918;27:37–43.
- Biernacki C, Celeux G, Govaert G. Assessing a mixture model for clustering with the integrated completed likelihood. IEEE Trans Pattern Anal Mach Intell. 2000 Jul;22(7):719–725. doi: 10.1109/34.865189
- Visser I, Raijmakers MEJ, Molenaar PCM. Confidence intervals for hidden Markov model parameters. British J Math Stat Psychol. 2000;53(2):317–327. doi: 10.1348/000711000159240
- Pawitan Y. In all likelihood: statistical modelling and inference using likelihood. Oxford: Oxford University Press; 2001.
- Zheng N, Cadigan N. Frequentist delta-variance approximations with mixed-effects models and TMB. Comput Stat Data Anal. 2021 Aug;160:107227. doi: 10.1016/j.csda.2021.107227
- Efron B, Tibshirani RJ. An introduction to the bootstrap. New York (NY); London: Chapman & Hall; 1993.
- Härdle W, Horowitz J, Kreiss JP. Bootstrap methods for time series. Int Stat Revi. 2003;71(2):435–459. doi: 10.1111/insr.2003.71.issue-2
Appendices
Appendix 1.
Forward algorithm and backward algorithm
The pass through observations can be efficiently computed piece by piece, from left (i.e. time s = 1) to right (i.e. time s = t) or right to left by the so-called ‘forward algorithm’ and ‘backward algorithm’ respectively. With these two algorithms, the likelihood can be computed recursively. To formulate the forward algorithm, let us define the vector for
so that
for
. The name of the algorithm comes from computing it via the recursion
After passing through all observations until time T, the likelihood is derived from
The backward algorithm is very similar to the forward algorithm. The sole difference lies in starting from the last instead of the first observation. To specify the backward algorithm, let us define the vector
for
so that
The name backward algorithm results from the way of recursively calculating
by
As before, the likelihood can be obtained after a pass through all observations by
Usually, only the forward algorithm is used for parameter estimation. Nonetheless, either or both algorithms may be necessary to derive certain quantities of interest, e.g. smoothing probabilities (as we explore in Section 3) or forecast probabilities. For practical implementation, attention needs to be paid to underflow errors which can quickly occur in both algorithms (due to the elements of the TPM and / or conditional probabilties taking values in
). Therefore, we implemented a scaled version of the forward algorithm as suggested by Zucchini et al. [Citation22, p. 48]. This version directly provides the negative log-likelihood (nll) as result.
Appendix 2.
Reparameterization of the likelihood function
Along with the data, serves as input for calculating the likelihood by the previously illustrated forward algorithms. Some constraints need to be imposed on
:
In the case of the Poisson HMM, the parameter vector
necessary for computing the conditional distribution has to consist of strictly positive elements.
The elements
Tacking these constraints by means of constrained optimization routines when maximizing the likelihood can lead to several difficulties. For example, constrained optimization routines may require a significantly amount of fine-tuning. Moreover, the number of available optimization routines is significantly reduced. A common alternative works by reparametrizing the log-likelihood as a function of unconstrained, so-called ‘working’ parameters , as follows. One possibility to reparametrize
is given by
where
are
unconstrained elements of an
matrix
with missing diagonal elements. The matching reverse transformation is
and the diagonal elements of
follow from
,
(see [Citation22], p. 51).
For a Poisson HMM, a simple method to reparametrize the conditional Poisson means into
is given by
for
. Consequently, the constrained ‘natural’ parameters are obtained via
. Estimation of the natural parameters
can therefore be obtained by maximization of the reparametrized likelihood with respect to
then by a transformation of the estimated working parameters back to natural parameters via the above transformations, i.e.
. In general, the above procedure requires that the function g is one-to-one.
With a Gaussian HMM, the means are already unconstrained and do not require any transformation. However, the standard deviations can be transformed similarly to the Poisson rates via for
, and the ‘natural’ parameters are then obtained via the corresponding reverse transformation
.
Appendix 3.
Confidence intervals
When handling statistical models, confidence intervals (CIs) for the estimated parameters can be derived via various approaches. One common such approach bases on finite-difference approximations of the Hessian. However, as [Citation71] points out, there are better alternatives when dealing with most HMMs. Preferred are profile likelihood-based CIs or bootstrap-based CIs, where the latter are now widely used despite the potentially large computational load [Citation22,Citation29]. With common Poisson HMMs, [Citation26] shows that TMB can yield valid Wald-type CIs in a fraction of the time required by classical bootstrap-based methods.
In this section, we describe the Wald-type and the bootstrap-based approach. The likelihood profile method frequently fails to yield CIs (see [Citation26]) and is therefore not detailed.
A.1. Wald-type confidence intervals
Evaluating the Hessian at the optimum found by numerical optimization procedures is basis for Wald-tye CIs. As illustrated above, the optimized negative log-likelihood function of a HMM typically depends on the working parameters. However, drawing inference on the natural parameters is by far more relevant than inference on the working parameters. To overcome this problem we can take advantage of the delta method [see, e.g. Citation72, Citation73]. For applying the delta method in general, let the d-dimensional vector be an estimate of
based on a sample of size n such that
where
denotes the d-dimensional centred Normal distribution with covariance matrix
, and
denotes convergence in distribution. Then, we have
for any function
with
denoting its Jacobian matrix.
In a general HMM setting, let represent working parameters with a one-to-one correspondence to a set of natural parameters
in an arbitrary conditional distribution. Since the Hessian
relies on the working parameters
, an estimate of the covariance matrix of
can therefore be obtained via the delta method through
with
as defined in Appendix-2. However, note that the described mapping of
to
is specific for the Poisson case in Appendix-2. From this, TMB deduces the standard errors for the working and natural parameters using automatic differentiation and the delta method (see [Citation25] for details), from which 95% CIs can be formed via
where
is the 97.5th percentile from the standard normal distribution, and
denotes the standard error of
.
Similarly, since g is a one-to-one function, the smoothing probabilities can be expressed as a function of the working parameters through
, where
is defined by the equation in Section 3. Thus, the standard deviation of the estimated smoothing probabilities can be obtained by:
A.2. Bootstrap-based confidence intervals
The bootstrap method was described by Efron and Tibshirani [Citation74] in their seminal article, and is widely used by many practitioners. Many bootstrap techniques have been developed since then, and have been extensively applied in the scientific literature. This paper will not review these techniques, but will instead use one of them: the so-called parametric bootstrap. As [Citation75] points out, the parametric bootstrap is suitable for time series, and hence motivates this choice. For details on the parametric bootstrap implementation in R, we refer to [Citation22 Ch. 3.6.2, pp. 58-60].
At its heart, bootstrapping requires some form of re-sampling to be carried out. Then, the chosen model is re-estimated on each new sample, and eventually some form of aggregation of the results takes place. We make use of TMB to accelerate the re-estimation procedure, then look at the resulting median along with the 2.5th and 97.5th empirical percentile to infer a 95% CI.
Appendix 4.
Estimated models for real and simulated data sets
Table E1. Estimates and Wald-type 95% CIs for a two-state Poisson HMM fitted to the TYT data, a two-state Poisson HMM fitted to the soap data, and a three-state Gaussian HMM fitted to the weekly returns data.
Table E2. Estimates and Wald-type 95% CIs for a five-state Poisson HMM fitted to the hospital data.
Table E3. Estimates and Wald-type 95% CIs for a three-state Gaussian HMM fitted to each simulated data discussed in Section 3.5.
Appendix 5.
Performance and accuracy of different optimizers: additional figures and results
Figures – show the median of the parameter estimates and the nll, along with 95% CIs from the three different simulation designs described in Section 4 across all optimizers studied, over 1000 realizations from the different models. All figures show that the different optimizers behave almost identically in terms of accuracy. However, we restate that the initial values used here are equal to the true parameter values.
Figure A1. Plots of estimates and NLL when estimating a two-state Poisson HMM on the TYT data set (87 data), over 1000 realizations. The columns display in order the NLL, Poisson rates, TPM elements, and the stationary distribution. The dots represent the medians, and the lines display the 95% percentile CIs.
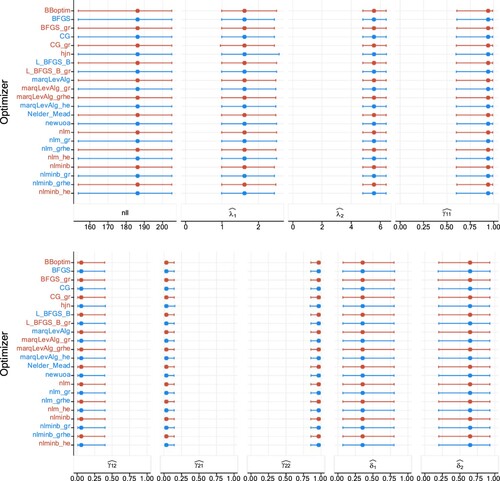
Figure A2. Plots of estimates and NLL when estimating a two-state Poisson HMM in the second study design, with (200 observations), over 1000 realizations. The columns display in order the NLL, Poisson rates, TPM elements, and the stationary distribution. The dots represent the medians, and the lines display the 95% percentile CIs.
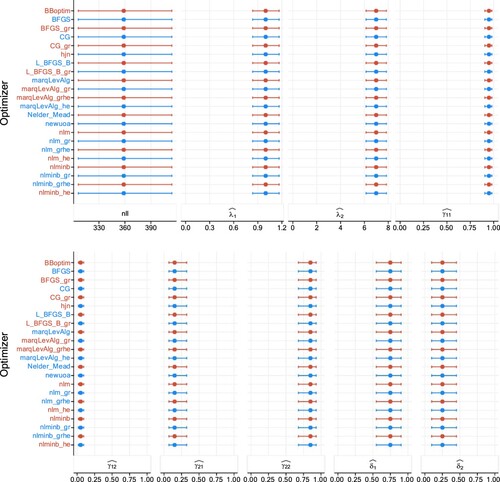
Figure A3. Plots of estimates and NLL when estimating a two-state Poisson HMM in the third study design, with (200 observations), over 1000 realizations. The columns display in order the NLL, Poisson rates, TPM elements, and the stationary distribution. The dots represent the medians, and the lines display the 95% percentile CIs.
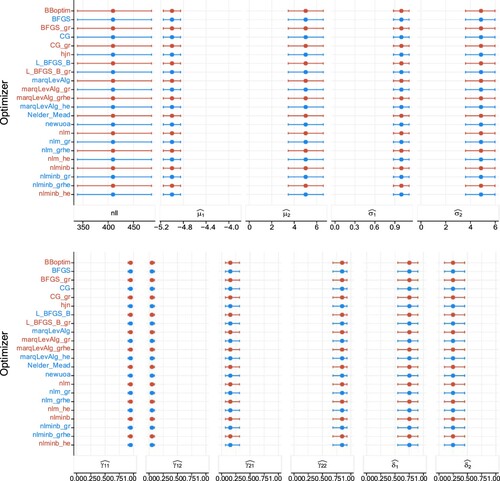
Additionally, Tables – display the descriptive statistics shown graphically by Figure –.
Table F1. Median duration (in milliseconds and ranked) together with 95% CI and number of iterations required for fitting two-state Poisson HMMs to 200 replications in the first setting.
Table F2. Median duration (in milliseconds and ranked) together with 95% CI and number of iterations required for fitting two-state Poisson HMMs to 200 replications in the second setting.
Table F3. Median duration (in milliseconds and ranked) together with 95% CI and number of iterations required for fitting two-state Gaussian HMMs to 200 replications in the third setting.