
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The mid-p-value is a proposed improvement on the ordinary p-value for the case where the test statistic is partially or completely discrete. In this case, the ordinary p-value is conservative, meaning that its null distribution is larger than a uniform distribution on the unit interval, in the usual stochastic order. The mid-p-value is not conservative. However, its null distribution is dominated by the uniform distribution in a different stochastic order, called the convex order. The property leads us to discover some new finite-sample and asymptotic bounds on functions of mid-p-values, which can be used to combine results from different hypothesis tests conservatively, yet more powerfully, using mid-p-values rather than p-values. Our methodology is demonstrated on real data from a cyber-security application.
1. Introduction
Let T be a real-valued test statistic, with probability measure P0 under the null hypothesis, denoted H0. Let X be a uniform random variable on the unit interval that is independent of T under P0. X is a randomization device which is in practice usually generated by a computer.
We consider the (one-sided) p-value,
(1)
(1) the mid-p-value (Lancaster Citation1952),
(2)
(2) and the randomized p-value,
(3)
(3) where T* is a hypothetical independent replicate of T under P0. If T is absolutely continuous under H0, then the three quantities are equal and distributed uniformly on the unit interval. More generally, that is, if discrete components are possible, the three are different. Two main factors, one obvious and one more subtle, make this a very common occurrence. First, T is discrete if it is a function of discrete data, for example, a contingency table, categorical data, or a presence/absence event. Second, discrete test statistics often occur as a result of conditioning, as in the permutation test or Kendall’s tau test (Sheskin Citation2003). Partially discrete tests occur, for example, as a result of censoring.
When P, Q, and R are not equal, it is a question which to choose. The ordinary p-value is often preferred in relatively strict hypothesis testing conditions, for example, in clinical trials, where the probability of rejecting the null hypothesis must not exceed the nominal level (often 5%). The randomized p-value has some theoretical advantages, for example, the nominal level of the test is met exactly. However, to quote one of its earliest proponents, “most people will find repugnant the idea of adding yet another random element to a result which is already subject to the errors of random sampling” (Stevens Citation1950). Randomized p-values also fail Birnbaum’s admissibility criterion (Birnbaum Citation1954). Note that we can also work with an unrealized version of the randomized p-value, known as the fuzzy or abstract p-value (Geyer and Meeden Citation2005), and either stop there—leaving interpretation to the decision-maker—or propagate uncertainty through to any subsequent analysis, for example, multiple-testing (Kulinskaya and Lewin Citation2009; Habiger Citation2015).
Although it can allow breaches of the nominal level, the mid-p-value is often deemed to better represent evidence against the null hypothesis than the ordinary or randomized p-values. Justifications are not just heuristic as, for example, the mid-p-value can arise as a Rao–Blackwellization of the randomized p-value corresponding to the uniformly most powerful test (Wells Citation2010), as an optimal estimate of the H0 versus H1 truth indicator under squared loss (Hwang and Yang Citation2001), or from asymptotic Bayesian arguments (Routledge Citation1994). Performance has also been demonstrated in applications, for example, in the context of healthcare monitoring (Spiegelhalter et al. Citation2012) (an article read before the Royal Statistical Society), genetics (Graffelman and Moreno Citation2013), a wealth of examples involving contingency tables (Lydersen, Fagerland, and Laake Citation2009), and more. Our own interest stems from cyber-security applications, and a motivating example is given in Section 3. Most arguments for using the mid-p-value in hypothesis testing scenarios also work for confidence intervals. Here, using the mid-p-value over the p-value can result in a smaller interval, with a closer-to-nominal coverage probability (Berry and Armitage Citation1995; Fagerland, Lydersen, and Laake Citation2015).
In this article, we are able to make further mathematical progress on the mid-p-value by using a stochastic order known as the convex order. The problem we focus on is meta-analysis, that is, combining evidence from different hypothesis tests into one, global measure of significance. In several scenarios analyzed, the use of the ordinary p-value leads to suboptimal, and even spurious results. New bounds for some commonly used methods for combining ordinary p-values are derived for mid-p-values. These allow large gains in power over using ordinary p-values, while, unlike any previous study based on mid-p-values, the false positive rate is still controlled exactly (albeit conservatively).
The remainder of this article is structured as follows. In Section 2, we summarize our main results. Section 3 gives a cyber-security application where, using mid-p-values, we are able to detect a cyber-attack that would likely fall under the radar if only ordinary p-values were used. Section 4 elaborates on the results of Section 3, with improved (although more complicated) bounds, simulations, and discussion. Section 5 concludes. All proofs are relegated to the Appendix.
2. Main Results
This section summarizes the main ideas and findings of the article. Let U denote a uniform random variable on the unit interval, with expectation operator E, and let E0 denote expectation with respect to P0. Under the null hypothesis, it is well known, see, for example, Casella and Berger (Citation2002), that P dominates U in the usual stochastic order, denoted P ⩾ stU. One way to write this is
(4)
(4) for any nondecreasing function f, whenever the expectations exist (Shaked and Shanthikumar Citation2007). It is also well known, and in fact true by design, that R is uniformly distributed under the null hypothesis, denoted R = stU. On the other hand, it is not widely known that, under the null hypothesis, Q is dominated by U in the convex order, denoted Q ⩽ cxU. One way to write this is (Shaked and Shanthikumar Citation2007, chap. 3)
(5)
(5) for any convex function h, whenever the expectations exist. We have used the qualifier “widely,” because an effective equivalent of Equation (Equation5
(5)
(5) ) can be found in Hwang and Yang (Citation2001). However, even there, Equation (Equation5
(5)
(5) ) is not recognized as a major stochastic order, meaning that some of its importance is missed.
In particular, we now present three concrete, new results, made possible by the literature on the convex order. Each provides a method for combining mid-p-values conservatively, the first two in finite samples and the last asymptotically. Details and improved (but more complicated) bounds are given in Section 4. In what follows, Q1, …, Qn denote independent (but not necessarily identically distributed) mid-p-values, with joint probability measure denoted under the null hypothesis.
Let denote the average mid-p-value. For t ⩾ 0,
(6)
(6) Note that, first, no knowledge of the specific individual mid-p-value distributions is required. Second, Hoeffding’s inequality (Hoeffding Citation1963), which would be available more generally, gives the larger bound exp ( − 2nt2) (the cubic root).
Let Fn = −2∑ni = 1log (Qi), known as Fisher’s statistic (Fisher Citation1934) and the most popular method for combining p-values. In the continuous case, it is well-known that Fn has a chi-square distribution with 2n degrees of freedom under H0. For t ⩾ 2n,
(7)
(7) Finally, assume additionally that Q1, …, Qn are identically distributed. Then applying Fisher’s method as usual, that is, treating the mid-p-values as if they were ordinary p-values and using the chi-square tail, is asymptotically conservative as n → ∞.
3. Example: Network Intrusion Detection
The perceived importance of cyber-security research has risen dramatically in recent years, particularly after several well-publicized events in 2016 and 2017. In this area, anomaly detection over very high volumes and rates of network data is a key statistical problem (Adams and Heard Citation2016). In our experience of the field, discrete data, whether they be presence/absence events, counts or categorical data, are the norm rather than the exception. We will demonstrate the value of our article’s contributions in a network intrusion detection problem.
shows publically available authentication data covering 58 days on the Los Alamos National Laboratory computer network (Kent Citation2016). Nodes in the graph are computers, and an edge indicates that there was at least one connection from one computer to the other, resulting in a graph with m ≈ 18,000 nodes and directed edges. An exciting opportunity offered by this data resource is that it contains an actual cyber-attack: or, to be precise, records of penetration testing activity conducted by a “red-team.” One of the four computers used for the attack (the highest degree of the four, ID “C17693,” with 296 out of 534 edges labeled as nefarious) is highlighted in red on the left, with its connections highlighted in pink on the right.
Figure 1. Authentication data: Full network of connections comprising nodes and
directed edges. Edges are colored by authentication type. On the left, nodes are shown as black points, with node ID “C17693” highlighted in red (and larger). On the right, the points are hidden to better see the connections made by node ID “C17693,” which are now highlighted in pink.

Earlier work on network intrusion has suggested that the occurrence of new edges on the network can be (weakly) indicative of nefarious behavior (Neil et al. Citation2013; Neil Citation2015). Looking at the outward connections from a given computer, in particular, those which at the other end involve a computer otherwise receiving relatively few new connections present special interest. Because the first day of data has no red-team activity, we use this day to learn a rate λj, j = 1, …, m at which each computer receives new connections, assuming, admittedly unrealistically, that the times are right-censored independent and identically distributed exponential random variables. For every computer on the network, the set of outward new connections made over the remainder of the observation period [1, 58] is scored according to this model. The test-statistic
is considered for every directed pair (i, j) not occurring as an edge on the first day, so that each node i has associated with it a collection of test statistics Ti ·, which are partially discrete, with a point mass at 57.
For regularization purposes, the rates λj, j = 1, …, m are assumed a priori to follow a Gamma distribution matching the mean and variance of the empirical rates computed for each j = 1, …, m over the full period of 58 days. The use of this prior implies that before censoring Tij has a Gamma-Exponential (also called Lomax) predictive distribution, which is used to compute the collection of ordinary, mid, and randomized p-values Pi ·, Qi ·, Ri · corresponding to the outward connections of each node i = 1, …, m. Mathematical details about the calculations above are in the Appendix.
Since we are interested in the ranking of computer ID “C17693” among the other computers, as well as its p-value, it makes sense to extend the ranges of the bounds (Equation6
(6)
(6) ) and (Equation7
(7)
(7) ) as follows:
(8)
(8)
(9)
(9) which preserves monotonicity, and remains valid because larger values than unity are returned outside the old ranges. Our options are:
| 1. | to compute the average ordinary, mid, and randomized p-values, and obtain a significance level using bound (Equation8 | ||||
| 2. | to compute Fisher’s statistic for the ordinary, mid, and randomized p-values, and obtain a global significance level using bound (Equation9 | ||||
| 3. | to assume an asymptotic regime and use the chi-square tail for the Fisher-with-mid-p-values statistic instead. Computer ID “C17693” then ranks 8th (p-value ≈ 1). | ||||
As rankings go, therefore, the mid-p-value is never beaten, with computer ID “C17693” coming in the top 10 every time and coming second once. The most obvious approach of using Fisher’s method with ordinary p-values fails completely. As for the other three red-team computers: using the best performing method, that is, Fisher’s statistic with mid-p-values and bound (Equation9(9)
(9) ), where Computer ID “C17693” comes second, their ranks are 384th (ID “C18025”), 550th (ID “C19932”), and 1079th (ID “C22409”).
4. Meta-Analysis of Mid-p-Values: Further Details
This section elaborates on the results of Section 2. We say that a random variable (and its measure and distribution function) is subuniform if it is less variable than a uniform random variable, U, in the convex order.
To see why the mid-p-value is sub-uniform, notice that Q = E0(R∣T). By Jensen’s inequality, for any convex function h,
(10)
(10) whenever the expectations exist, since R = stU. Remember that we do not claim this result is new, see, for example, Hwang and Yang (Citation2001), but rather the idea to exploit the literature on the convex order.
To formalize the meta-analysis framework, let T1, …, Tn be a sequence of independent test statistics. We consider a joint null hypothesis, , under which T1, …, Tn have probability measure
, respectively. The p-values, Pi, mid-p-values, Qi, and randomized p-values, Ri, are obtained by replacing P0 with P(i)0 in (Equation1
(1)
(1) ), (Equation2
(2)
(2) ), and (Equation3
(3)
(3) ), respectively. In the case of the randomized p-value, an independent uniform variable, Xi, is generated each time.
denotes the implied joint probability measure of the statistics under
. The focus of this section is on testing the joint null hypothesis
. Probability bounds that follow often have the form
. If the observed mid-p-values are q1, …, qn and level of the test is α (e.g., 5%), then a procedure that rejects when bn{f(q1, …, qn)} ⩽ α is conservative: the probability of rejecting the null hypothesis
, if it holds, does not exceed α.
4.1. Sums of Mid-p-Values
An early advocate of mid-p-values, Barnard (Citation1989, Citation1990) proposed to combine test results from different contingency tables by taking the sum of standardized mid-p-values. His exposition relies on some approximations. Our results make exact inference possible.
We begin with a bound on the sum of independent mid-p-values. This bound bears an interesting resemblance to Hoeff-ding’s inequality (Hoeffding Citation1963). It will later be extended to be relevant to Barnard’s analysis.
Theorem 1.
Let X1, …, Xn denote n independent sub-uniform random variables with mean . Then, for 0 ⩽ t ⩽ 1/2,
(11)
(11)
(12)
(12)
(13)
(13)
A subuniform random variable has expectation 1/2 and is bounded between 0 and 1. Hoeffding’s inequality would therefore give us for 0 ⩽ t ⩽ 1/2, the cubic root. Our improvement is substantial, for example, suppose we observe an average of 0.4 from n = 100 mid-p-values. This is very significant:
using (Equation13
(13)
(13) ). However, we would only find
using Hoeffding’s inequality.
Instead of summing the mid-p-values directly, Barnard (Citation1990) actually considered sums of the standardized statistics
where σi is the standard deviation of Qi under
. The upper tail probability of the sum is then estimated by Gaussian approximation. In the purely discrete case, Barnard shows that σi = {(1 − si)/12}1/2 where
and Si is the (countable) support of Qi. Instead of appealing to the Gaussian approximation, the convex order allows us to find an exact bound.
Lemma 1.
Let X1, …, Xn denote n independent subuniform random variables with standard deviations σ1, …, σn, respectively, and let
Then, for t ⩾ 0,
(14)
(14)
(15)
(15) where
is the geometric mean of the standard deviations.
In practice, the bound (Equation14(14)
(14) ), which is an important improvement over (Equation15
(15)
(15) ), can be found numerically by minimizing over h. Of course, even if the optimum cannot be determined exactly the obtained bound still holds, because the tail area is simply over-estimated.
To illustrate how the bound (Equation14(14)
(14) ) performs in practice, we now revisit Barnard’s example (Barnard Citation1990, p. 606). The first experiment he considers yields Q1 = 1/7, s1 = 9002/423, D1 = 1.32. The second yields Q2 = 1/9, s2 = 141/729, D2 = 1.5. Since the sum divided by
is almost two, that is, two standard deviations away, he finds “serious evidence” against the null hypothesis. Lemma 1 gives
, providing some evidence in favor of the alternative, but not significant at, say, the 5% level. On the other hand, evidence would start to become compelling if we were to observe the second result again, Q3 = 1/9, s3 = 141/729, D3 = 1.5; Lemma 1 then finds
.
4.2. Products of Mid-p-Values (Fisher’s Method)
Fisher’s method (Fisher Citation1934) is the most popular way of combining p-values. As is well-known, under , the statistic − 2∑ni = 1log (Pi) has a chi-square distribution with 2n degrees of freedom if Pi are absolutely continuous. Therefore, the p-value of the combined test is P† = S2n{ − 2∑ni = 1log (Pi)}, where Sk is the survival function of a chi-square distribution with k degrees of freedom. This results in an exact procedure when Pi are absolutely continuous, and a conservative one otherwise, that is, P† ⩾ stU under
.
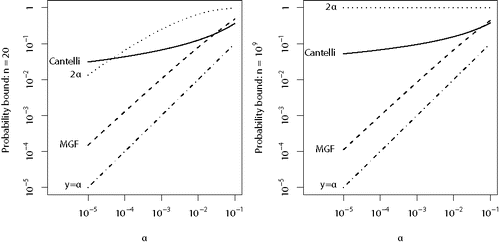
Our next result allows us to use the mid-p-values Q1, …, Qn in place of P1, …, Pn while retaining a conservative procedure. We were able to derive three probability bounds. None beats the other two uniformly for all n and all significance levels (see ), but the last is often the winner, hence the simpler statement of Section 2.
Figure 2. Comparison of the probability bounds given by Theorem 2 for Fisher’s method using mid-p-values. Theorem 2 gives explicit formulas for 2α, Cantelli and MGF, in that order. Both axes are on the logarithmic scale.
Theorem 2.
Let X1, …, Xn be a sequence of independent sub-uniform random variables. Then for x ⩾ 2n,
The first uses P(Xi ⩽ α) ⩽ 2α for α ⩾ 0, obvious in the case of a mid-p-value, but actually true of any subuniform random variable (Meng Citation1994). The second uses bounds on the mean and variance of − log (Xi) (given in Lemma 2, in the Appendix) and then applies the Chebyshev-Cantelli inequality. The third is based on a bound on the moment generating function of − log (Xi). Derivation details are in the Appendix.
For a given n and α ∈ (0, 1], let tα, n denote the critical value of Fisher’s statistic, that is, tα, n satisfies S2n(tα, n) = α. presents the behavior of the different bounds for different n (20 on the left and 1 billion on the right) and α. The curves show the bound given by each formula at different α (which can be interpreted as “canonical levels”), that is, inputting x = tα, n in Theorem 2, as α ranges from 10− 5 to 0.1. For low α, the bound based on the moment generating function, marked MGF, is by far superior.
Let Q† = un{ − 2∑ni = 1log (Qi)}. Then Q† is again conservative, that is, Q† ⩾ stU under . Both P† and Q† are valid p-values. Clearly, if the underlying p-values are continuous, then the standard P† is superior (in fact, deterministically smaller). However, Q† seems to be substantially more powerful in a wide range of discrete cases. This is demonstrated by simulation in Section 4.3.
Finally, we find this interesting asymptotic result.
Theorem 3 (Fisher’s method is asymptotically conservative).
Let X1, X2, … denote independent and identically distributed sub-uniform random variables. For any α ∈ (0, 1], there exists such that
for any n ⩾ N.
Hence, we can dispense with any correction entirely if n is large enough and the Qi are identically distributed. A formal proof is given in the Appendix. Since , from the definition of the convex order, a direct application of the law of large numbers gets us most of way, except for the possibility
. In fact, this exception is no problem because, perhaps surprisingly, it implies that the Xi are uniform, using Shaked and Shanthikumar (Citation2007, Theorem 3.A.43).
4.3. Simulations
To illustrate the potential improvement of employing Fisher’s method with mid-p-values, using the bound (Equation7(7)
(7) ), over the traditional approach of using ordinary p-values and the chi-square tail, we considered p-values from three types of support. In the first column of , each p-value Pi can only take one of two values, 1/2 and 1. We therefore have Qi = 0.25 if Pi = 1/2 and Qi = 0.75 if Pi = 1. Under the null hypothesis,
. In the second column, each p-value Pi is supported on the pair {pi, 1}, where pi were drawn uniformly on the unit interval but are subsequently treated as fixed known values. We have Qi = pi/2 if Pi = pi and Qi = (1 + pi)/2 otherwise. Under the null hypothesis, we have
, for each i. Finally, in the third column each p-value Pi takes one of 10 values, 1/10, 2/10, …, 1, and therefore Qi = Pi − 1/20. Under the null hypothesis, P(i)0(Pi = j/10) = 1/10, for j = 1, …, 10. The rows represent two different alternatives and sample sizes. In both cases, the Pi are generated by left-censoring a sequence of independent and identically distributed Beta variables, B1, …, Bn, that is, Pi is the smallest supported value larger than Bi. In the first scenario, the dataset is small (n = 10), but the signal is strong (a Beta distribution with parameters 1 and 20). In the second, the dataset is larger (n = 100) but the signal is made weaker accordingly (a Beta distribution with parameters 1 and 5). Comparing just the solid and dashed lines first, we see that Q† always outperforms P† substantially, and sometimes overwhelmingly. In the bottom-left corner, for example, we have a situation where, at a false positive rate set to 5% say, the test Q† would detect the effect with probability close to one whereas with P† the probability would be close to zero.
Figure 3. Fisher’s method with discrete p-values. Empirical distribution functions of Fisher’s combined p-value under different conditions. 50/50: Each p-value is equal to 1/2 or 1 (with probability 1/2 each under ). Random binary: Each p-value is equal to p or 1 (with probability p and 1 − p, respectively, under
). p is drawn uniformly on [0, 1] (independently of whether
or
holds). Grid of 10: Each p-value is drawn from 1/10, 2/10…, 1 (with probability 1/10 each under
). n = 10, β = 20: 10 p-values from a left-censored Beta(1, 20) distribution. n = 100, β = 5: 100 p-values from a left-censored Beta(1, 5) distribution. Dotted line: Randomized p-values. Solid line: Mid-p-value. Dashed line: Standard p-values. Further details in the main text.
![Figure 3. Fisher’s method with discrete p-values. Empirical distribution functions of Fisher’s combined p-value under different conditions. 50/50: Each p-value is equal to 1/2 or 1 (with probability 1/2 each under H˜0). Random binary: Each p-value is equal to p or 1 (with probability p and 1 − p, respectively, under H˜0). p is drawn uniformly on [0, 1] (independently of whether H˜0 or H˜1 holds). Grid of 10: Each p-value is drawn from 1/10, 2/10…, 1 (with probability 1/10 each under H˜0). n = 10, β = 20: 10 p-values from a left-censored Beta(1, 20) distribution. n = 100, β = 5: 100 p-values from a left-censored Beta(1, 5) distribution. Dotted line: Randomized p-values. Solid line: Mid-p-value. Dashed line: Standard p-values. Further details in the main text.](/cms/asset/82d8b458-5b50-4fbc-9d1f-1be9bf8a1034/uasa_a_1469994_f0003_b.gif)
As a final possibility, consider R† = S2n{ − 2∑ni = 1log (Ri)}. A disappointment is that this randomized version, the dotted line in , tends to outperform even the mid-p-values, and by a substantial margin. On the other hand, as pointed out in the introduction, the randomized p-value has some important philosophical disadvantages, and did not perform better in our real data example.
5. Conclusion
The convex order provides a formal platform for the treatment and interpretation of mid-p-values. This article used mathematical results from this literature to combine mid-p-values, which are not conservative individually, into an overall significance level that is conservative. As shown in real data and simulations, the gains in power can be substantial.
Whereas the focus of this article was on meta-analysis, another canonical problem is multiple testing, where the task is to subselect from or adjust a set of p-values, for example, subject to a maximum false discovery rate (Benjamini and Hochberg Citation1995). The case of discrete data has been analyzed in a number of articles, including Kulinskaya and Lewin (Citation2009); Habiger and Pena (Citation2011); Liang (Citation2016); Habiger (Citation2015). A promising (but ostensibly harder) avenue of research would be to investigate the use of the convex order in this problem.
Additional information
Funding
References
- Adams, N., and Heard, N. (2016), Dynamic Networks and Cyber-Security (Vol. 1), London, UK: World Scientific.
- Barnard, G. (1989), “On Alleged Gains in Power from Lower p-Values,” Statistics in Medicine, 8, 1469–1477.
- ——— (1990), “Must Clinical Trials be Large? The Interpretation of p-values and The Combination of Test Results,” Statistics in Medicine, 9, 601–614.
- Benjamini, Y., and Hochberg, Y. (1995), “Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing,” Journal of the Royal Statistical Society, Series B, 57, 289–300.
- Berry, G., and Armitage, P. (1995), “Mid-P Confidence Intervals: A Brief Review,” The Statistician, 44, 417–423.
- Birnbaum, A. (1954), “Combining Independent Tests of Significance,” Journal of the American Statistical Association, 49, 559–574.
- Casella, G., and Berger, R. L. (2002), Statistical Inference (Vol. 2), Pacific Grove, CA: Duxbury.
- Fagerland, M. W., Lydersen, S., and Laake, P. (2015), “Recommended Confidence Intervals for Two Independent Binomial Proportions,” Statistical Methods in Medical Research, 24, 224–254.
- Fisher, R. A. (1934), Statistical Methods for Research Workers (4th ed.), Edinburgh: Oliver & Boyd.
- Geyer, C. J., and Meeden, G. D. (2005), “Fuzzy and Randomized Confidence Intervals and p-Values,” Statistical Science, 20, 358–366.
- Graffelman, J., and Moreno, V. (2013), “The Mid p-Value in Exact Tests for Hardy-Weinberg Equilibrium,” Statistical Applications in Genetics and Molecular Biology, 12, 433–448.
- Habiger, J. D. (2015), “Multiple Test Functions and Adjusted p-Values for Test Statistics with Discrete Distributions,” Journal of Statistical Planning and Inference, 167, 1–13.
- Habiger, J. D., and Pena, E. A. (2011), “Randomised p-Values and Nonparametric Procedures in Multiple Testing,” Journal of Nonparametric Statistics, 23, 583–604.
- Hoeffding, W. (1963), “Probability Inequalities for Sums of Bounded Random Variables,” Journal of the American Statistical Association, 58, 13–30.
- Hwang, J. G., and Yang, M.-C. (2001), “An Optimality Theory for Mid p-Values in 2 x 2 Contingency Tables,” Statistica Sinica, 11, 807–826.
- Kent, A. D. (2016), “Cybersecurity Data Sources for Dynamic Network Research,” in Dynamic Networks and Cybersecurity, eds. N. Adams and N. Heard, London, UK: World Scientific, pp. 37–66.
- Kulinskaya, E., and Lewin, A. (2009), “On Fuzzy Familywise Error Rate and False Discovery Rate Procedures for Discrete Distributions,” Biometrika, 96, 201–211.
- Lancaster, H. (1952), “Statistical Control of Counting Experiments,” Biometrika, 39, 419–422.
- Liang, K. (2016), “False Discovery Rate Estimation for Large-Scale Homogeneous Discrete p-Values,” Biometrics, 72, 639–648.
- Lydersen, S., Fagerland, M. W., and Laake, P. (2009), “Recommended Tests for Association in 2 × 2 Tables,” Statistics in Medicine, 28, 1159–1175.
- Meng, X.-L. (1994), “Posterior Predictive p-Values,” The Annals of Statistics, 22, 1142–1160.
- Neil, J., Uphoff, B., Hash, C., and Storlie, C. (2013), “Towards Improved Detection of Attackers in Computer Networks: New Edges, Fast Updating, and Host Agents,” in 6th International Symposium on Resilient Control Systems (ISRCS), 2013, IEEE, pp. 218–224.
- Neil, J. C. (2015), “Using New Edges for Anomaly Detection in Computer Networks,” US Patent 9,038,180.
- Niculescu, C. P. (2000), “Convexity According to the Geometric Mean,” Journal of Mathematical Inequalities, 3, 155–167.
- Routledge, R. (1994), “Practicing Safe Statistics with the mid-p,” Canadian Journal of Statistics, 22, 103–110.
- Shaked, M., and Shanthikumar, J. G. (2007), Stochastic Orders, New York: Springer.
- Sheskin, D. J. (2003), Handbook of Parametric and Nonparametric Statistical Procedures, Boca Raton, FL: Chapman and Hall/CRC Press.
- Spiegelhalter, D., Sherlaw-Johnson, C., Bardsley, M., Blunt, I., Wood, C., and Grigg, O. (2012), “Statistical Methods for Healthcare Regulation: Rating, Screening and Surveillance,” Journal of the Royal Statistical Society, Series A, 175, 1–47.
- Stevens, W. (1950), “Fiducial Limits of the Parameter of a Discontinuous Distribution,” Biometrika, 37, 117–129.
- Wells, M. T. (2010), “Optimality Results for mid p–values,” in Borrowing Strength: Theory Powering Applications–A Festschrift for Lawrence D. Brown, eds. J. O. Berger, T. T. Cai, and I. M. Johnstone, Beachwood, OH: Institute of Mathematical Statistics, pp. 184–198.
Appendix: Mathematical Details and Proofs
A1. Section 3: Mathematical Details
First, we calculate the empirical rates
for j = 1, …, m, and then set
,
, so that a Gamma distribution with parameters α and β has mean and variance equal to the empirical mean and variance of rj, respectively. This distribution is used as the prior for each rate λj. After a day of observation, the posterior distribution for λj is also Gamma, with parameters
where
For each i, restrict j to the indices of nodes that did not receive a connection from i over [0, 1). Conditional on the observation period [0, 1), each statistic Tij has a probability measure, denoted P(ij)0, with a point mass at 57 and an absolutely continuous distribution over [0, 57) given by
Since low values of Tij are of interest, the p-value and mid-p-value associated with Tij are computed from lower-tailed versions of (Equation1
(1)
(1) ) and (Equation2
(2)
(2) ) by substituting P(ij)0 in for P0, giving
and
respectively.
Proofs
Proof of Theorem 1.
Since 1 − X is subuniform if and only if X is sub-uniform, it is sufficient to prove the bounds in (Equation11(11)
(11) ), (Equation12
(12)
(12) ), and (Equation13
(13)
(13) ) hold for
. Since exp (xh) is a convex function in x for any h, the convex order gives us
. Therefore, for any h ⩾ 0,
where the second line follows from Markov’s inequality. The choice h = 12t (motivated by an analysis of the Taylor expansion in h at 0) leads to
using the fact that e− xsinh (x)/x = (1 − e− 2x)/(2x) is one at x = 0 (using l’Hospital’s rule) and decreasing.
Proof of Lemma 1.
Again, we will prove the bound holds for Wn = n− 1∑(Xi − 1/2)/σi, so that the theorem holds by symmetry. For any h ⩾ 0,
because
for n ⩾ 3, by the convex order, and E{(U/σi)2}/2 = 1/(6σ2i). Therefore,
proving that (Equation14
(14)
(14) ) holds. Next, since σ2i ⩽ 1/12,
using the fact that the function sinh is geometrically convex on [0, ∞) (Niculescu Citation2000). We proceed as in the proof of Theorem 1, choosing
.
The proofs of Theorems 2 and 3 both need the following result.
Lemma 2.
Let X be a sub-uniform random variable. Then either (i) X is uniform on [0, 1] or (ii)
where U is a uniform random variable on [0, 1].
Proof.
Shaked and Shanthikumar (Citation2007, Theorem 3.A.43) provide the following theorem. If X ⩽ cxY and for some strictly convex function h we have then X is distributed as Y. The function − log (x) is strictly convex, therefore either X is uniform or
. If the latter is true, then
In the second line, the fact that the expected squared distance from the mean is smaller than from any other point is used, and in the fourth we used the fact that (log (x) + 1)2 is convex.
Proof of Theorem 2.
Let Gn = −2∑log (Xi). Now, Ui/2 ⩽ stXi, for i = 1, …, n, where U1, …, Un are independent uniform random variables on [0, 1]. This implies − log (Xi) ⩽ st − log (Ui/2). Because the usual stochastic order is closed under convolution (Shaked and Shanthikumar Citation2007, Theorem 1.A.3), we have Gn ⩽ st − 2∑log (Ui) + 2nlog 2. The sum − 2∑log (Ui) has a chi-square distribution with 2n degrees of freedom, proving the first bound.
Lemma 2 implies E(Gn) ⩽ 2n and . Therefore, using Cantelli’s inequality,
for x ⩾ 2n. This proves the second bound. Finally, the moment generating function of Gn is
for t ⩾ 0. For t ∈ [0, 1/2) each
since x− 2t is a convex function in x for x ∈ [0, 1]. Using Markov’s inequality,
for t ∈ [0, 1/2). The minimum of this function is at t = 1/2 − n/x, giving the third bound.
Proof of Theorem 3.
Let Vi = −2log (Xi), μV = E(Vi), Wi = −2log (Ui), where U1, …, Un are independent uniform random variables on [0, 1], and μW = E(Wi). If μV = μW then by Lemma 2 the Xi are uniform on [0, 1] and we are done. The statement is also true if α = 1. Therefore assume μV < μW, α ∈ (0, 1) and let t ∈ (μV, μW). By the weak law of large numbers there exists an such that, for n ⩾ N′,
so that tα, n ⩾ nt. Therefore, for n ⩾ N′,
Again by the law of large numbers, the right-hand side tends to zero. Hence, there exists an N ⩾ N′ such that it is bounded by α for n ⩾ N.