
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Valid inference after model selection is currently a very active area of research. The polyhedral method, introduced in an article by Lee et al., allows for valid inference after model selection if the model selection event can be described by polyhedral constraints. In that reference, the method is exemplified by constructing two valid confidence intervals when the Lasso estimator is used to select a model. We here study the length of these intervals. For one of these confidence intervals, which is easier to compute, we find that its expected length is always infinite. For the other of these confidence intervals, whose computation is more demanding, we give a necessary and sufficient condition for its expected length to be infinite. In simulations, we find that this sufficient condition is typically satisfied, unless the selected model includes almost all or almost none of the available regressors. For the distribution of confidence interval length, we find that the κ-quantiles behave like for κ close to 1. Our results can also be used to analyze other confidence intervals that are based on the polyhedral method.
1 Introduction
Lee et al. (2016) recently introduced a new technique for valid inference after model selection, the so-called polyhedral method. Using this method, and using the Lasso for model selection in linear regression, Lee et al. (2016) derived two new confidence sets that are valid conditional on the outcome of the model selection step. More precisely, let denote the model containing those regressors that correspond to nonzero coefficients of the Lasso estimator, and let
denote the sign-vector of those nonzero Lasso coefficients. Then Lee et al. (2016) constructed confidence intervals
and
whose coverage probability is
, conditional on the events
and
, respectively (provided that the probability of the conditioning event is positive). The computational effort in constructing these intervals is considerably lighter for
. In simulations, Lee et al. (2016) noted that this latter interval can be quite long in some cases; cf. Figure 10 in that reference. We here analyze the lengths of these intervals through their (conditional) means and through their quantiles.
We focus here on the original proposal of Lee et al. (2016) for the sake of simplicity and ease of exposition. Nevertheless, our findings also carry over to several recent developments that rely on the polyhedral method and that are mentioned in Section 1.2; see Remark 1(i) and Remark 3.
1.1 Overview of Findings
Throughout, we use the same setting and assumptions as Lee et al. (2016). In particular, we assume that the response vector is distributed as with unknown mean
and known variance
(our results carry over to the unknown-variance case; see Section 3.3), and that the nonstochastic regressor matrix has columns in general position. Write
and
for the probability measure and the expectation operator, respectively, corresponding to
.
For the interval , we find the following: Fix a nonempty model m, a sign-vector s, as well as
and
. If
, then
(1)
(1) see Proposition 2 and the attending discussion. Obviously, this statement continues to hold if the event
is replaced by the larger event
throughout. And this statement continues to hold if the condition
is dropped and the conditional expectation in (1) is replaced by the unconditional one.
For the interval , we derive a necessary and sufficient condition for its expected length to be infinite, conditional on the event
; cf. Proposition 3. That condition is never satisfied if the model m is empty or includes only one regressor; it is also typically never satisfied if m includes all available regressors (see Corollary 1). The necessary and sufficient condition depends on the regressor matrix, on the model m and also on a linear contrast that defines the quantity of interest, and is daunting to verify in all but the most basic examples. We also provide a sufficient condition for infinite expected length that is easy to verify. In simulations, we find that this sufficient condition for infinite expected length is typically satisfied except for two somewhat extreme cases: (a) If the Lasso penalty is very large (so that almost all regressors are excluded). (b) If the number of available regressors is not larger than sample size and the Lasso parameter is very small (so that almost no regressor is excluded). See for more detail.
Of course, a confidence interval with infinite expected length can still be quite short with high probability. In our theoretical analysis and in our simulations, we find that the κ-quantiles of and
behave like the κ-quantiles of
with
, that is, like
, for κ close to 1 if the conditional expected length of these intervals is infinite; cf. Proposition 4, and the attending discussions.
The methods developed in this article can also be used if the Lasso, as the model selector, is replaced by any other procedure that relies on the polyhedral method; see Remark 1(i) and Remark 3. In particular, we see that confidence intervals based on the polyhedral method in Gaussian regression can have infinite expected length. Our findings suggest that the expected length of confidence intervals based on the polyhedral method should be closely scrutinized, in Gaussian regression but also in non-Gaussian settings and other variations of the polyhedral method.
“Length” is arguably only one of several possible criteria for judging the “quality” of valid confidence intervals, albeit one of practical interest. Our focus on confidence interval length is justified by our findings.
The rest of the article is organized as follows: We conclude this section by discussing a number of related results that put our findings in context. Section 2 describes the confidence intervals of Lee et al. (2016) in detail and introduces some notation. Section 3 contains our core results, Propositions 1–4 which entail our main findings, as well as a discussion of the unknown variance case. The simulation studies mentioned earlier are given in Section 4. Finally, in Section 5, we discuss some implications of our findings. In particular, we argue that the computational simplicity of the polyhedral method comes at a price in terms of interval length, and that computationally more involved methods can provide a remedy. The appendix contains the proofs and some auxiliary lemmas.
1.2 Context and Related Results
There are currently several exciting ongoing developments based on the polyhedral method, not least because it proved to be applicable to more complicated settings, and there are several generalizations of this framework (see, among others, Fithian et al. 2015; Gross, Taylor, and Tibshirani 2015; Reid, Taylor, and Tibshirani 2015; Tian and Taylor 2016, 2017; Tian et al. 2016; Tibshirani et al. 2016; Tian, Loftus, and Taylor 2017; Markovic, Xia, and Taylor 2018; Panigrahi, Zhu, and Sabatti 2018; Taylor and Tibshirani 2018; Panigrahi and Taylor 2019). Certain optimality results of the method of Lee et al. (2016) are given in Fithian, Sun, and Taylor (2017). Using a different approach, Berk et al. (2013) proposed the so-called PoSI-intervals which are unconditionally valid. A benefit of the PoSI-intervals is that they are valid after selection with any possible model selector, instead of a particular one like the Lasso; however, as a consequence, the PoSI-intervals are typically very conservative (i.e., the actual coverage probability is above the nominal level). Nonetheless, Bachoc, Leeb, and Pötscher (2019) showed in a Monte Carlo simulation that, in certain scenarios, the PoSI-intervals can be shorter than the intervals of Lee et al. (2016). The results of the present article are based on the first author’s master’s thesis.
It is important to note that all confidence sets discussed so far are nonstandard, in the sense that the parameter to be covered is not the true parameter in an underlying correct model (or components thereof), but instead is a model-dependent quantity of interest. (See Section 2 for details and the references in the preceding paragraph for more extensive discussions.) An advantage of this nonstandard approach is that it does not rely on the assumption that any of the candidate models is correct. Valid inference for an underlying true parameter is a more challenging task, as demonstrated by the impossibility results in Leeb and Pötscher (2006a, 2006b, 2008). There are several proposals of valid confidence intervals after model selection (in the sense that the actual coverage probability of the true parameter is at or above the nominal level) but these are rather large compared to the standard confidence intervals from the full model (supposing that one can fit the full model); see Pötscher (2009), Pötscher and Schneider (2010), and Schneider (2016). In fact, Leeb and Kabaila (2017) showed that the usual confidence interval obtained by fitting the full model is admissible also in the unknown variance case; therefore, one cannot obtain uniformly smaller valid confidence sets for a component of the true parameter by any other method.
2 Assumptions and Confidence Intervals
Let Y denote the -distributed response vector,
, where
is unknown and
is known. Let
, with
for each
, be the nonstochastic n × p regressor matrix. We assume that the columns of X are in general position (this mild assumption is further discussed in the following paragraph). The full model
is denoted by mF. All subsets of the full model are collected in
, that is,
. The cardinality of a model m is denoted by
. For any
with
, we set
. Analogously, for any vector
, we set
. If m is the empty model, then Xm is to be interpreted as the zero vector in
and vm as 0.
The Lasso estimator, denoted by , is a minimizer of the least squares problem with an additional penalty on the absolute size of the regression coefficients (Frank and Friedman 1993; Tibshirani 1996):
The Lasso has the property that some coefficients of are zero with positive probability. A minimizer of the Lasso objective function always exists, but it is not necessarily unique. Uniqueness of
is guaranteed here by our assumption that the columns of X are in general position (Tibshirani 2013). This assumption is relatively mild; for example, if the entries of X are drawn from a (joint) distribution that has a Lebesgue density, then the columns of X are in general position with probability 1 (Tibshirani 2013). The model
selected by the Lasso and the sign-vector
of nonzero Lasso coefficients can now formally be defined through
(where is left undefined if
). Recall that
denotes the set of all possible submodels and set
for each
. For later use we also denote by
and
the collection of models and the collection of corresponding sign-vectors, that occur with positive probability, that is,
These sets do not depend on μ and as the measure
is equivalent to Lebesgue measure with respect to null sets. Also, our assumption that the columns of X are in general position guarantees that
only contains models m for which Xm has column-rank m (Tibshirani 2013).
Inference is focused on a nonstandard, model dependent, quantity of interest. Consider first the nontrivial case where . In that case, we set
For , the goal is to construct a confidence interval for
with conditional coverage probability
on the event
. Clearly, the quantity of interest can also be written as
for
. For later use, write
for the orthogonal projection on the space spanned by ηm. Finally, for the trivial case where
, we set
.
At the core of the polyhedral method lies the observation that the event where and where
describes a convex polytope in sample space
(up to a Lebesgue null set): Fix
and
. Then
(2)
(2) see Theorem 3.3 in Lee et al. (2016) (explicit formulas for the matrix
and the vector
are also repeated in Appendix C in our notation). Fix
orthogonal to ηm. Then the set of y satisfying
and
is either empty or a line segment. In either case, that set can be written as
. The endpoints satisfy
[see Lemma 4.1 of Lee et al. (2016); formulas for these quantities are also given in Appendix C in our notation]. Now decompose Y into the sum of two independent Gaussians
and
, where the first one is a linear function of
. With this, the conditional distribution of
, conditional on the event
, is the conditional
-distribution, conditional on the set
(in the sense that the latter conditional distribution is a regular conditional distribution if one starts with the conditional distribution of
given
and
—which is always well-defined—and if one then conditions on the random variable
).
Fig. D1 For n = 2, the sample space is partitioned corresponding to the model and the sign-vector selected by the Lasso when λ = 2 and
, with
and
. We set
and
, so that
. The point y lies on the black line segment
for
, which is bounded on the left. In particular,
is bounded. For the point
, the corresponding black line segments together are unbounded on both sides, and hence
is unbounded.
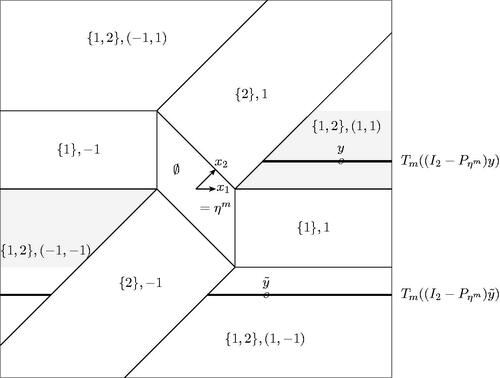
To use these observations for the construction of confidence sets, consider first the conditional distribution of a random variable conditional on the event
, where
, where
and where
is the union of finitely many open intervals. The intervals may be unbounded. Write
for the cumulative distribution function (cdf) of V given
. The corresponding law can be viewed as a “truncated normal” distribution and will be denoted by
in the following. We will construct a confidence interval based on W, where
. Such an interval, which covers θ with probability
, is obtained by the usual method of collecting all values θ0 for which a hypothesis test of
against
does not reject, based on the observation
. In particular, for
, define L(w) and U(w) through
which are well-defined in view of Lemma A.2. With this, we have
irrespective of
.
Fix and
, and let
and
for z orthogonal to ηm. With this, we have
(3)
(3) for each
. Now define
and
through
for each y so that . By the considerations in the preceding paragraph, it follows that
(4)
(4)
Clearly, the random interval covers
with probability
also conditional on the event that
and
or on the event that
.
In a similar fashion, fix . In the nontrivial case where
, we set
for z orthogonal to ηm, and define
and
through
Arguing as in the preceding paragraph, we see that the random interval covers
with probability
conditional on any of the events
and
. In the trivial case where
, we set
with probability
and
with probability α, so that similar coverage properties also hold in that case. The unconditional coverage probability of the interval
then also equals
.
Remark 1.
If
is any other model selection procedure, so that the event
We focus here on equal-tailed confidence intervals for the sake of brevity. It is easy to adapt all our results to the unequal-tailed case, that is, the case where
In Theorem 3.3 of Lee et al. (2016), relation (2) is stated as an equality, not as an equality up to null sets, and with the right-hand side replaced by
3 Analytical Results
3.1 Mean Confidence Interval Length
We first analyze the simple confidence set introduced in the preceding section, which covers θ with probability
, where
. By assumption, T is of the form
where
and
. exemplifies the length of
when T is bounded (left panel) and when T is unbounded (right panel). The dashed line corresponds to the length of the standard (unconditional) confidence interval for θ based on
. In the left panel, we see that the length of
diverges as w approaches the far left or the far right boundary point of the truncation set (i.e., –3 and 3). On the other hand, in the right panel we see that the length of
is bounded and converges to the length of the standard interval as
.
Fig. 1 Length of the interval for the case where
(left panel) and the case where
(right panel). In both cases, we took
and
.
![Fig. 1 Length of the interval [L(w),U(w)] for the case where T=(−3,−2)∪(−1,1)∪(2,3) (left panel) and the case where T=(−∞,−2)∪(−1,1)∪(2,∞) (right panel). In both cases, we took ς2=1 and α=0.05.](/cms/asset/b64a9f6c-672a-405b-92ba-3eaa81358c23/uasa_a_1732989_f0001_c.jpg)
Write and
for the cdf and pdf of the standard normal distribution, respectively, where we adopt the usual convention that
and
.
Proposition 1
(The interval for truncated normal W). Let
. If T is bounded either from above or from below, then
If T is unbounded from above and from below, thenwhere
and where
is to be interpreted as 0 in case K = 1. [The first inequality trivially continues to hold if T is bounded, as then
.]
Intuitively, one expects confidence intervals to be wide if one conditions on a bounded set because extreme values cannot be observed on a bounded set and the confidence intervals have to take this into account. We find that the conditional expected length is infinite in this case. If, for example, T is bounded from below, that is, if , then the first statement in the proposition follows from two facts: First, the length of
behaves like
as w approaches a1 from above; and, second, the pdf of the truncated normal distribution at w is bounded away from 0 as w approaches a1 from above. See the proof in Section B for a more detailed version of this argument. On the other hand, if the truncation set is unbounded, extreme values are observable and confidence intervals, therefore, do not have to be extremely wide. The second upper bound provided by the proposition for that case will be useful later.
We see that the boundedness of the truncation set T is critical for the interval length. When the Lasso is used as a model selector, this prompts the question whether the truncation sets and
are bounded or not, because the intervals
and
are obtained from conditional normal distributions with truncation sets
and
, respectively. For
, and z orthogonal to ηm, recall that
, and that
is the union of these intervals over
. Write
for the orthogonal complement of the span of ηm.
Proposition 2
(The interval for the Lasso). For each
and each
, we have
or both.
For the confidence interval , the statement in (1) now follows immediately: If m is a nonempty model and s is a sign-vector so that the event
has positive probability, then
and
. Now Proposition 2 entails that
is almost surely bounded on the event
, and Proposition 1 entails that (1) holds.
For the confidence interval , we obtain that its conditional expected length is finite, conditional on
with
, if and only if its corresponding truncation set
is almost surely unbounded from above and from below on that event. More precisely, we have the following result.
Proposition 3
(The interval for the Lasso). For
, we have
(5)
(5)
if and only if there exists a and a vector y satisfying
, so that
(6)
(6)
To infer (5) from (6), that latter condition needs to be checked for every point y in a union of polyhedra. While this is easy in some simple examples like, say, the situation depicted in of Lee et al. (2016), searching over polyhedra in is hard in general. In practice, one can use a simpler sufficient condition that implies (5): After observing the data, that is, after observing a particular value
of Y, and hence also observing
and
, we check whether
is bounded from above or from below (and also whether
and whether
, which, if satisfied, entails that
and that
). If this is the case, then it follows, ex post, that (5) holds. Note that these computations occur naturally during the computation of
and can hence be performed as a safety precaution with little extra effort.
The next result shows that the expected length of is typically finite conditional on
if the selected model m is either extremely large or extremely small.
Corollary 1
(The interval for the Lasso). If
or
, we always have
; the same is true if
for Lebesgue-almost all γm (recall that
is meant to cover
conditional on
).
The corollary raises the suspicion that the conditional expected length of could also be finite if the selected model m either includes almost no regressor (
close to zero) or excludes almost no regressor (
close to p). Our simulations seem to support this; see . The statement concerning Lebesgue-almost all γm does not necessarily hold for all γm; see Remark D.1. Also note that the case where
can only occur if
, because the Lasso only selects models with no more than n variables here.
Remark 2.
We stress that property (5) or, equivalently, (6), only depends on the selected model m and on the regressor matrix X but not on the parameters μ and (which govern the distribution of Y). These parameters will, of course, impact the probability that the model m is selected in the first place. But conditional on
, they have no influence on whether or not the interval
has infinite expected length.
3.2 Quantiles of Confidence Interval Length
Both the intervals and
are based on a confidence interval derived from the truncated normal distribution. We therefore first study the length of the latter through its quantiles and then discuss the implications of our findings for the intervals
and
.
Consider with
being the union of finitely many open intervals, and recall that
covers θ with probability
. Define
through
for
; that is,
is the κ-quantile of the length of
. If T is unbounded from above and from below, then
is bounded (almost surely) by Proposition 1; in this case,
is trivially bounded in κ. For the remaining case, that is, if T is bounded from above or from below, we have
by Proposition 1, and the following result provides an approximate lower bound for the κ-quantile
for κ close to 1.
Proposition 4.
If , then
is an asymptotic lower bound for
in the sense that
. If
, then this statement continues to hold if, in the definition of
, the last fraction is replaced by
.
We see that goes to infinity at least as fast as
as κ approaches 1 if T is bounded. Moreover, if
, then
goes to infinity as
as
(cf. the end of the proof of Lemma A.4 in Appendix A), and a similar phenomenon occurs if
and as
. (In a model-selection context, the case where
often corresponds to the situation where the selected model is incorrect.) The approximation provided by Proposition 4 is visualized in for some specific scenarios.
Fig. 2 Approximate lower bound for from Proposition 4 for
and
. Starting from the bottom, the curves correspond to
.
![Fig. 2 Approximate lower bound for qθ,ς2(κ) from Proposition 4 for α=0.05,T=(−∞,0] and ς2=1. Starting from the bottom, the curves correspond to θ=−2,−1,0.](/cms/asset/3637d933-0c47-42b4-b214-dda6a5cc39ef/uasa_a_1732989_f0002_b.jpg)
Proposition 4 a
lso provides an approximation to the quantiles of , conditional on the event
whenever
and
. Indeed, the corresponding κ-quantile is equal to
in view of (3) and by construction, and Proposition 4 provides an asymptotic lower bound. In a similar fashion, the κ-quantile of
conditional on the event
is given by
whenever
and (5) holds. Approximations to the quantiles of
conditional on smaller events like
or
are possible but would involve integration over the range of z in the conditioning events; in other words, such approximations would depend on the particular geometry of the polyhedron
; cf. (2). Similar considerations apply to the quantiles of
. However, comparing Figure 2 with the simulation results in Figure 4 of Section 4.2, we see that the behavior of
also is qualitatively similar to the behavior of unconditional κ-quantiles obtained through simulation, at least for κ close to 1.
Remark 3.
If is any other model selection procedure, so that the event
is the union of a finite number of polyhedra (up to null sets), then the polyhedral method can be applied to obtain a confidence set for
with conditional coverage probability
, conditional on the event
if that event has positive probability. In that case, Propositions 3 and 4 can be used to analyze the length of corresponding confidence intervals that are based on the polyhedral method: Clearly, for such a model selection procedure, an equivalence similar to (5)–(6) in Proposition 3 holds, with the Lasso-specific set
replaced by a similar set that depends on the event
. And conditional quantiles of confidence interval length are again of the form
for appropriate choice of θ,
, and T, for which Proposition 4 provides an approximate lower bound; cf. the discussion following the proposition. Examples include Fithian et al. (2015, sec. 5), Fithian, Sun, and Taylor (2017, sec. 4), or Reid, Taylor, and Tibshirani (2015, sec. 6). See also Tian, Loftus, and Taylor (2017, sec. 3.1) and Gross, Taylor, and Tibshirani (2015, sec. 5.1), where the truncated normal distribution is replaced by truncated t- and F-distributions, respectively.
3.3 The Unknown Variance Case
Suppose here that is unknown and that
is an estimator for
. Fix
and
. Note that the set
does not depend on
and hence also
and
do not depend on
. For each
and for each y so that
define
,
, and
like
, and
in Section 2 with
replacing
in the formulas. (Note that, say,
depends on
through
.) The asymptotic coverage probability of the intervals
and
, conditional on the events
and
, respectively, was discussed in Lee et al. (2016).
If is independent of
and positive with positive probability, then it is easy to see that (1) continues to hold with
replacing
for each
and each
. And if, in addition,
has finite mean conditional on the event
for
, then it is elementary to verify that the equivalence (5)–(6) continues to hold with
replacing
(upon repeating the arguments following (5)–(6) and upon using the finite conditional mean of
in the last step).
In the case where p < n, the usual variance estimator is independent of
, is positive with probability 1 and has finite unconditional (and hence also conditional) mean. For variance estimators in the case where
, we refer to Lee et al. (2016) and the references therein.
4 Simulation Results
4.1 Mean of
We seek to investigate whether or not the expected length of is typically infinite, that is, to which extent the property of the interval
, as described in Proposition 2, carries over to
, which is characterized in Proposition 3. To this end, we perform an exploratory simulation exercise consisting of 500 repeated samples of size n = 100 for various configurations of p and λ, that is, for models with varying number of parameters p and for varying choices of the tuning parameter λ. The quantity of interest here is the first component of the parameter corresponding to the selected model. For each sample
, we compute the Lasso estimator
, the selected model
, and the confidence interval
for
. Finally, we check whether
and whether the sufficient condition for infinite expected length outlined after Proposition 3 is satisfied. If so, the interval
is guaranteed to have infinite expected length conditional on the event
, irrespective of the true parameters in the model. The results, averaged over 500 repetitions for each configuration of p and λ, are reported in .
Fig. 3 Heat-map showing the fraction of cases (out of 500 runs) in which we found a model m for which the confidence interval for
is guaranteed to have infinite expected length conditional on
, for various values of p and λ. For those cases where infinite expected length is not guaranteed, the number in the corresponding cell shows the percentage of variables (out of p) in the smallest and in the largest selected model.
![Fig. 3 Heat-map showing the fraction of cases (out of 500 runs) in which we found a model m for which the confidence interval [Lm̂(Y),Um̂(Y)] for β1m̂(Y) is guaranteed to have infinite expected length conditional on m̂=m, for various values of p and λ. For those cases where infinite expected length is not guaranteed, the number in the corresponding cell shows the percentage of variables (out of p) in the smallest and in the largest selected model.](/cms/asset/2504f184-9a5e-48c9-bd5b-f0319bd1f22e/uasa_a_1732989_f0003_c.jpg)
We see that the conditional expected length of is guaranteed to be infinite in a substantial number of cases (corresponding to the dark cells in the figure). The white cells correspond to cases where the sufficient condition for infinite expected length is not met. These correspond to simulation scenarios where either (a)
and λ is quite small or (b) λ is quite large. In the first (resp. second) case, most regressors are included (resp. excluded) in the selected model with high probability.
A more detailed description of the simulation underlying is as follows: For each simulation scenario, that is, for each cell in the figure, we generate an n × p regressor matrix X whose rows are independent realizations of a p-variate Gaussian distribution with mean zero, so that the diagonal elements of the covariance matrix all equal 1 and the off-diagonal elements all equal 0.2. Then we choose a vector so that the first
components are equal to
and the last
components are equal to zero. Finally, we generate 500 n-vectors
, where the ui are independent draws from the
-distribution, compute the Lasso estimators
and the resulting selected models
. We then check if
and if the interval
satisfies the sufficient condition outlined after Proposition 3 with
, where e1 is the first canonical basis vector in
. This corresponds to the quantity of interest being
, that is, the first component of the parameter corresponding to the selected model. If said condition is satisfied, the confidence set
is guaranteed to have infinite expected length conditional on the event that
(and hence also unconditional). The fraction of indices i,
, for which this is the case, are displayed in the cells of . If this fraction is below 100%, we report, in the corresponding cell,
and
, where the minimum and the maximum are taken over those cases i for which the sufficient condition is not met.
We stress here that the choice of β does not have an impact on whether or not a model m is such that the mean of is finite conditional on
. Indeed, the characterization in Proposition 3 as well as the sufficient condition that we check do not depend on β. The choice of β does have an impact, however, on the probability that a given model m is selected in our simulations.
4.2 Quantiles of
We approximate the quantiles of through simulation as follows: For n = 100, p = 14, and λ = 10, we choose
proportional to
so that
. For each choice of β, we generate an n-vector y as described in the preceding section, compute
and the interval
for
, and record its length. This is repeated 10,000 times. The resulting empirical quantiles are shown in .
Fig. 4 Simulated κ-quantiles. The black curves are functions of the form , with a and b fitted by least squares. Starting from the bottom, the curves and the corresponding empirical quantiles correspond to
equal to 0,
and
.
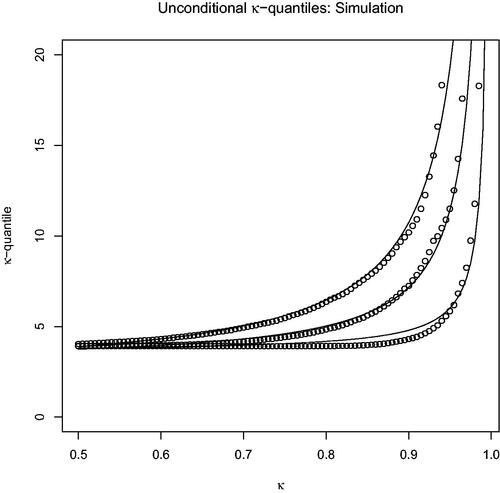
suggests that the unconditional κ-quantiles also grow like for κ approaching 1. This growth-rate was already observed in Proposition 4 for conditional quantiles. Also, the unconditional κ-quantiles increase as
increases, which is again consistent with that proposition. Repeating this simulation for a range of other choices for p, β, and λ gave qualitatively similar results, which are not shown here for the sake of brevity. For these other choices, the corresponding κ-quantiles decrease as the probability of selecting either a very small model or an almost full model increases, and vice versa. This is consistent with our findings from Corollary 1 and .
5 Discussion
The polyhedral method can be used whenever the conditioning event of interest can be represented as a polyhedron. And our results can be applied whenever the polyhedral method is used for constructing confidence intervals. Besides the Lasso, this also includes other model selection methods as well as some recent proposals related to the polyhedral method that are mentioned in Remark 3.
By construction, the polyhedral method gives intervals like and
that are derived from a confidence set based on a truncated univariate distribution (in our case, a truncated normal). Through this, the former intervals are rather easy to compute. And through this, the former intervals are valid conditional on quite small events, namely
and
, respectively, which is a strong property; see EquationEquation (4)
(4)
(4) . But through this, the former intervals also inherit the property that their length can be quite large. This undesirable property is inherited through the conditioning on
. Example 3 in Fithian, Sun, and Taylor (2017) demonstrates that requiring validity only on larger events, like
or
, can result in much shorter intervals. But when conditioning on these larger events, the underlying reference distribution is no longer a univariate truncated distribution but an n-variate truncated distribution. Computations involving the corresponding n-variate cdf are much harder than those in the univariate case.
A recently proposed construction, selective inference with a randomized response, provides higher power of hypothesis tests conditional on the outcome of the model selection step, and hence also improved confidence sets based on these tests; cf. Tian and Taylor (2016) and, in particular, in that reference. This increase in power is obtained by decreasing the “power” of the model selection step itself, in the sense that the model selector is replaced by
, where ω represents additional randomization that is added to the data. Again, finite-sample computations are demanding in that setting compared to the simple polyhedral method (see Tian and Taylor 2016, sec. 4.2.2).
Another alternative construction, uniformly most accurate unbiased (UMAU) confidence intervals should be mentioned here. When the data-generating distribution belongs to an exponential family, UMAU intervals can be constructed conditional on events of interest like or on smaller events like
; cf. Fithian, Sun, and Taylor (2017). In either case, UMAU intervals require more involved computations than the equal-tailed intervals considered here.
Acknowledgments
We thank the associate editor and two referees, whose feedback has led to significant improvements of the article. Also, helpful input from Nicolai Amann is greatly appreciated.
References
- Bachoc, F., Leeb, H., and Pötscher, B. M. (2019), “Valid Confidence Intervals for Post-Model-Selection Predictors,” The Annals of Statistics, 47, 1475–1504. DOI: https://doi.org/10.1214/18-AOS1721.
- Berk, R., Brown, L., Buja, A., Zhang, K., and Zhao, L. (2013), “Valid Post-Selection Inference,” The Annals of Statistics, 41, 802–837. DOI: https://doi.org/10.1214/12-AOS1077.
- Feller, W. (1957), An Introduction to Probability Theory and Its Applications (Vol. 1, 2nd ed.), New York: Wiley.
- Fithian, W., Sun, D., and Taylor, J. (2017), “Optimal Inference After Model Selection,” arXiv no. 1410.2597.
- Fithian, W., Taylor, J., Tibshirani, R., and Tibshirani, R. J. (2015), “Selective Sequential Model Selection,” arXiv no. 1512.02565.
- Frank, I. E., and Friedman, J. H. (1993), “A Statistical View of Some Chemometrics Regression Tools,” Technometrics, 35, 109–135. DOI: https://doi.org/10.1080/00401706.1993.10485033.
- Gross, S. M., Taylor, J., and Tibshirani, R. (2015), “A Selective Approach to Internal Inference,” arXiv no. 1510.00486.
- Lee, J. D., Sun, D. L., Sun, Y., and Taylor, J. (2016), “Exact Post-Selection Inference, With Application to the Lasso,” The Annals of Statistics, 44, 907–927. DOI: https://doi.org/10.1214/15-AOS1371.
- Leeb, H., and Kabaila, P. (2017), “Admissibility of the Usual Confidence Set for the Mean of a Univariate or Bivariate Normal Population: The Unknown Variance Case,” Journal of the Royal Statistical Society, Series B, 79, 801–813. DOI: https://doi.org/10.1111/rssb.12186.
- Leeb, H., and Pötscher, B. M. (2006a), “Can One Estimate the Conditional Distribution of Post-Model-Selection Estimators?,” The Annals of Statistics, 34, 2554–2591. DOI: https://doi.org/10.1214/009053606000000821.
- Leeb, H., and Pötscher, B. M. (2006b), “Performance Limits for Estimators of the Risk or Distribution of Shrinkage-Type Estimators, and Some General Lower Risk-Bound Results,” Econometric Theory, 22, 69–97.
- Leeb, H., and Pötscher, B. M. (2008), “Can One Estimate the Unconditional Distribution of Post-Model-Selection Estimators?,” Econometric Theory, 24, 338–376.
- Markovic, J., Xia, L., and Taylor, J. (2018), “Unifying Approach to Selective Inference With Applications to Cross-Validation,” arXiv no. 1703.06559.
- Panigrahi, S., and Taylor, J. (2019), “Approximate Selective Inference via Maximum-Likelihood,” arXiv no. 1902.07884.
- Panigrahi, S., Zhu, J., and Sabatti, C. (2018), “Selection-Adjusted Inference: An Application to Confidence Intervals for cis-eQTL Effect Sizes,” arXiv no. 1801.08686.
- Pötscher, B. M. (2009), “Confidence Sets Based on Sparse Estimators Are Necessarily Large,” Sankhyā, Series A, 71, 1–18.
- Pötscher, B. M., and Schneider, U. (2010), “Confidence Sets Based on Penalized Maximum Likelihood Estimators in Gaussian Regression,” Electronic Journal of Statistics, 4, 334–360. DOI: https://doi.org/10.1214/09-EJS523.
- Reid, S., Taylor, J., and Tibshirani, R. (2015), “Post-Selection Point and Interval Estimation of Signal Sizes in Gaussian Samples,” arXiv no. 1405.3340.
- Schneider, U. (2016), “Confidence Sets Based on Thresholding Estimators in High-Dimensional Gaussian Regression Models,” Econometric Reviews, 35, 1412–1455. DOI: https://doi.org/10.1080/07474938.2015.1092798.
- Taylor, J., and Tibshirani, R. (2018), “Post-Selection Inference for l1-Penalized Likelihood Models,” Canadian Journal of Statistics, 46, 41–61. DOI: https://doi.org/10.1002/cjs.11313.
- Tian, X., Loftus, J. R., and Taylor, J. (2017), “Selective Inference With Unknown Variance via the Square-Root LASSO,” arXiv no. 1504.08031.
- Tian, X., Panigrahi, S., Markovic, J., Bi, N., and Taylor, J. (2016), “Selective Sampling After Solving a Convex Problem,” arXiv no. 1609. 05609.
- Tian, X., and Taylor, J. (2016), “Selective Inference With a Randomized Response,” arXiv no. 1507.06739.
- Tian, X., and Taylor, J. (2017), “Asymptotics of Selective Inference,” Scandinavian Journal of Statistics, 44, 480–499.
- Tibshirani, R. (1996), “Regression Shrinkage and Selection via the Lasso,” Journal of the Royal Statistical Society, Series B, 58, 267– 288. DOI: https://doi.org/10.1111/j.2517-6161.1996.tb02080.x.
- Tibshirani, R. J. (2013), “The Lasso Problem and Uniqueness,” Electronic Journal of Statistics, 7, 1456–1490. DOI: https://doi.org/10.1214/13-EJS815.
- Tibshirani, R. J., Taylor, J., Lockhart, R., and Tibshirani, R. (2016), “Exact Post-Selection Inference for Sequential Regression Procedures,” Journal of the American Statistical Association, 111, 600–620. DOI: https://doi.org/10.1080/01621459.2015.1108848.
Appendix A:
Auxiliary Results
In this section, we collect some properties of functions like that will be needed in the proofs of Propositions 1 and 2. The following result will be used repeatedly in the following and is easily verified using L’Hospital’s method.
Lemma A.1.
For all a, b with , the following holds
Write and
for the cdf and pdf of the
-distribution, where
with
. For
and for k so that
, we have
if k = 1, the sum in the numerator is to be interpreted as 0. And for w as above, the density
is equal to
divided by the denominator in the preceding display.
Lemma A.2.
For each fixed ,
is continuous and strictly decreasing in θ, and
Proof.
Continuity is obvious and monotonicity has been shown in Lee et al. (2016) for the case where T is a single interval, that is, K = 1; it is easy to adapt that argument to also cover the case K > 1. Next consider the formula for . As
, Lemma A.1 implies that the leading term in the numerator is
while the leading term in the denominator is
. Using Lemma A.1 again gives
. Finally, it is easy to see that
(upon using the relation
and a little algebra). With this, we also obtain that
. □
For and
, define
through
Lemma A.2
ensures that is well-defined. Note that
and
.
Lemma A.3.
For fixed is strictly decreasing in γ on (0, 1). And for fixed
is continuous and strictly increasing in
so that
and
.
Proof.
Fix . Strict monotonicity of
in γ follows from strict monotonicity of
in θ; cf. Lemma A.2.
Fix throughout the following. To show that
is strictly increasing on T, fix
with
. We get
where the inequality holds because the density of
is positive on T. The definition of
and Lemma A.2 entail that
.
To show that is continuous on T, we first note that
is continuous in
(which is easy to see from the formula for
given after Lemma A.1). Now fix
. Because
is monotone, it suffices to show that
for any increasing sequence wn in T converging to w from below, and for any decreasing sequence wn converging to w from above. If the wn increase toward w from below, the sequence
is increasing and bounded by
from above, so that
converges to a finite limit
. With this, and because
is continuous in
, it follows that
In the preceding display, the sequence on the left-hand side is constant equal to γ by definition of , so that
. It follows that
. If the wn decrease toward w from above, a similar argument applies.
To show that , let wn,
, be an increasing sequence in T that converges to bK. It follows that
converges to a (not necessarily finite) limit
as
. If
, we get for each
that
In this display, the inequality holds because is a cdf, and the equality holds because
is continuous in θ. As this holds for each
, we obtain that
. But in this equality, the left-hand side equals γ—a contradiction. By similar arguments, it also follows that
. □
Lemma A.4.
The function satisfies
Proof. A
s both statements follow from similar arguments, we only give the details for the first one. As w approaches bK from below, converges to
by Lemma A.3. This observation, the fact that
holds for each w, and Lemma A.1 together imply that
Because as
(cf. Feller 1957, Lemma VII.1.2.), we get that
The claim now follows by plugging-in the formula for on the left-hand side, simplifying, and then taking the logarithm of both sides. □
Appendix B
Proof of Proposition 1
Proof
of the first statement in Proposition 1. Assume that (the case where
is treated similarly). Lemma A.4 entails that
, where
is positive. Hence, there exists a constant
so that
whenever
. Set
. For
,
is a Gaussian density divided by a constant scaling factor, so that B > 0. Because
in view of Lemma A.3, we obtain that
□
Proof
of the first inequality in Proposition 1. Define through
, that is,
Then, on the one hand, we have
while, on the other,
The inequalities in the preceding two displays imply that
(Indeed, the inequality in the third-to-last display continues to hold with replacing γ; in that case, the upper bound reduces to γ; similarly, the inequality in the second-to-last display continues to hold with
replacing γ, in which case the lower bound reduces to γ. Now use the fact that
is decreasing in θ.) In particular, we get that
and that
. The last two inequalities, and the symmetry of
around zero, imply the first inequality in the proposition. □
Proof
of the second inequality in Proposition 1. Note that , because T is unbounded above and below. Setting
, we note that
and that it is elementary to verify that
. Because
, the inequality will follow if we can show that
or, equivalently, that
. Because
is strictly increasing, this is equivalent to
To this end, we set and show that
for
. Because
, it suffices to show that
is nonnegative for
. The derivative can be written as a fraction with positive denominator and with numerator equal to
The expression in the preceding display is nonnegative if and only if
This will follow if the function is decreasing in
. The derivative
can be written as a fraction with positive denominator and with numerator equal to
Using the well-known inequality for x > 0 (Feller 1957, Lemma VII.1.2.), we see that the expression in the preceding display is nonpositive for x > 0. □
Appendix C
Proof of Proposition 2
From Lee et al. (2016), we recall the formulas for the expressions on the right-hand side of (2), namely and
with
and
given by
respectively, and with
and
(in the preceding display,
denotes the orthogonal projection matrix onto the column space spanned by Xm and ι denotes an appropriate vector of ones). Moreover, it is easy to see that the set
can be written as
, we have
, where
with ; cf. also Lee et al. (2016).
Proof of Proposition 2.
Set and
. In view of the formulas of
and
given earlier, it suffices to show that either
or
is nonempty. Conversely, assume that
. Then
and hence also
. Using the explicit formula for
and the definition of ηm, that is,
, it follows that
, which contradicts our assumption that
. □
Appendix D
Proof of Proposition 3 and Corollary 1
As a preparatory consideration, recall that is the union of the intervals
with
. Inspection of the explicit formulas for the interval endpoints given in Appendix C now immediately reveals the following: The lower endpoint
is either constant equal to
on the set
, or it is the minimum of a finite number of linear functions of y (and hence finite and continuous) on that set. Similarly the upper endpoint
is either constant equal to
on that set, or it is the maximum of a finite number of linear functions of y (and hence finite and continuous) on that set.
Proof of Proposition 3.
Let . We first assume, for some s and y with
and
, that the set in (6) is bounded from above (the case of boundedness from below is similar). Then there is an open neighborhood O of y, so that each point
satisfies
and also so that
is bounded from above. Because O has positive Lebesgue measure, (5) now follows from Proposition 1. To prove the converse, assume for each
and each y satisfying
that
is unbounded from above and from below. Because the sets
for
are disjoint by construction, the same is true for the sets
for
. Using Proposition 1, we then obtain that
is bounded by a linear function of
Lebesgue-almost everywhere on the event . (The maximum and the minimum in the preceding display correspond to aK and b1, respectively, in Proposition 1.) It remains to show that the expression in the preceding display has finite conditional expectation on the event
. But this expression is the maximum of a finite number of Gaussians minus the minimum of a finite number of Gaussians. Its unconditional expectation, and hence also its conditional expectation on the event
, is finite. □
Proof of Corollary 1.
The statement for is trivial. Next, consider the case where
. Take
and y so that
. We need to show that
is unbounded above and below for
. To this end, first recall the formulas presented at the beginning of Appendix C. Together with the fact that, here,
, these formulas entail that
and that
. With this, and in view of the definitions of
,
and
in Appendix C, it follows that
is a set of the form
, which is unbounded.
Finally, assume that . Fix
and y so that
, and set
. Again, we need to show that
is unbounded above and below. For each
, it is easy to see that
and that
is a vector of ones. The condition
hence reduces to
. Note that
, and that the set of its zero-components does not depend on
. We henceforth assume that γm is such that all components of
are nonzero, which is satisfied for Lebesgue-almost all vectors γm. Now choose sign-vectors s+ and s– in
as follows: Set
if
; otherwise, set
. With this, we get that
is a nonzero vector with positive components. Choose s– in a similar fashion, so that
is a nonzero vector with negative components. It follows that
is a set of the form
. We next show that s+ and s– lie in
. Choose y+ so that
and so that
. Because
by construction, it follows that
and hence
and
. Because the same is true for all points in a sufficiently small open ball around y+, the event
has positive probability and hence
. A similar argument entails that
. Taken together, we see that
, so that the last set is indeed unbounded above and below. □
Remark D.1.
The statement in Corollary 1 for the case does not hold for all γm or, equivalently, for all ηm. For example, if γm is such that ηm is parallel to one of the columns of X, then some components of
are zero and
can be bounded for some y. Figure D1 illustrates the situation.
Appendix E
Proof of Proposition 4
We only consider the case where ; the case where
is treated similarly. The proof relies on the observation that
for
in view of Lemma A.4. The quantiles of A(W) are easy to compute: If
denotes the κ-quantile of A(W), then
The denominator in the preceding display, which involves the inverse of , can be approximated as follows.
Lemma
E.1. For , we have
where
.
Proof.
With the convention that and as
, we have
where the second-to-last equality relies on the inverse function theorem and the last equality holds because
. □
Lemma
E.2. The κ-quantiles of A(W) provide an asymptotic lower bound for the κ-quantiles of the length , in the sense that
.
Proof.
Fix and choose
so that
whenever
. In addition, we may assume that δ is sufficiently small so that the cdf of W is strictly increasing on
. Using the formula for A(W), we get that
for x > 0. By Lemma E.1,
converges to infinity as
. Hence, we have
for κ sufficiently close to 1, say,
. For each
and
, we obtain that
which entails thatbecause the cdf of W strictly increases from
to
. It follows that
whenever
and
. Letting ρ go to 1 gives
whenever
. Hence,
. Since
can be chosen arbitrarily close to zero, this completes the proof. □
Proof of Proposition 4.
Use the formula for and Lemma E.1 to obtain that
as (the inequality holds because
). The claim now follows from this and Lemma E.2. □
Remark.
The argument presented here can be extended to obtain an explicit formula for the exact rate of as
or as
(or both). The resulting expression is more involved (the cases where T is bounded from one side and from both sides need separate treatment) but qualitatively similar to
, as far as its behavior for
or
is concerned. In view of this and for the sake of brevity, results for the exact rate are not presented here.