
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
We propose a novel approach for modeling capture-recapture (CR) data on open populations that exhibit temporary emigration, while also accounting for individual heterogeneity to allow for differences in visit patterns and capture probabilities between individuals. Our modeling approach combines changepoint processes—fitted using an adaptive approach—for inferring individual visits, with Bayesian mixture modeling—fitted using a nonparametric approach—for identifying clusters of individuals with similar visit patterns or capture probabilities. The proposed method is extremely flexible as it can be applied to any CR dataset and is not reliant upon specialized sampling schemes, such as Pollock’s robust design. We fit the new model to motivating data on salmon anglers collected annually at the Gaula river in Norway. Our results when analyzing data from the 2017, 2018, and 2019 seasons reveal two clusters of anglers—consistent across years—with substantially different visit patterns. Most anglers are allocated to the “occasional visitors” cluster, making infrequent and shorter visits with mean total length of stay at the river of around seven days, whereas there also exists a small cluster of “super visitors,” with regular and longer visits, with mean total length of stay of around 30 days in a season. Our estimate of the probability of catching salmon whilst at the river is more than three times higher than that obtained when using a model that does not account for temporary emigration, giving us a better understanding of the impact of fishing at the river. Finally, we discuss the effect of the COVID-19 pandemic on the angling population by modeling data from the 2020 season. Supplementary materials for this article are available online.
1 Introduction
Capture-recapture (CR) data provide a method for monitoring wildlife populations, or more generally populations for which a census is infeasible because the probability of detecting individuals is lower than one. Appropriate means for capturing individuals are employed in a series of capture occasions. During these capture occasions, newly caught individuals are uniquely marked and all caught individuals are released back into the population. Repeating the process T times gives rise to a capture history, of length T, for each caught individual with entries equal to one (zero) indicating the capture occasions at which the particular individual was caught (not caught). At the end of the study, there remains an unknown number of individuals that were never caught and hence have capture histories with all entries equal to zero.
There exists a rich literature dealing with models for CR data. This covers closed-population models, which assume that the same individuals are present and available for capture at all T occasions (Darroch Citation1958; Otis et al. Citation1978; Pledger Citation2000), open-population models that allow for arrivals and departures during the study (Jolly Citation1965; Seber Citation1965; Schwarz and Arnason Citation1996; Pledger et al. Citation2009; Lyons et al. Citation2016) and a recent body of work exploring Bayesian nonparametric methods for CR data (Manrique-Vallier Citation2016; Matechou and Caron Citation2017, closed and open populations, respectively).
Typically, one of the assumptions of open-population CR models is that emigration is permanent; once individuals depart they are assumed to never arrive again. However, the assumption of permanent emigration is not always satisfied. Existing approaches for modeling temporary emigration in population ecology (see e.g., Zhou et al. Citation2019) so far mostly use Pollock’s robust design (Pollock Citation1982), which assumes that there are two types of sampling periods: primary periods, for example seasons, between which the population is open, and secondary periods, for example sampling days within a season, between which the population is closed. Clearly, there exist cases where methods relying on Pollock’s robust design cannot be employed.
In this article we propose a novel solution for modeling temporary emigration for CR data by developing a flexible, general and mathematically tractable Bayesian mixture model that also accounts for individual heterogeneity in the visit pattern and capture probability. We treat the visit history of each individual as a changepoint process with visits, when an individual transitions from nonpresent to present, signifying a changepoint. We model the corresponding departure times as dependent on these changepoints and we extend recently developed adaptive MCMC methods (Benson and Friel Citation2018) for updating the number and position of changepoints of each individual. These adaptive methods provide us with an elegant and computationally efficient way to infer individual visit histories, without requiring any tuning or complicated proposal distributions.
Additionally, we model individual heterogeneity using a random finite measure as the intensity of a Poisson process that jointly models the number of individuals and their visit histories. Conditionally on the number of individuals, the visit histories are shown to be a sample from a mixture model, which, although technically is finite dimensional, we fit using Bayesian nonparametric techniques. Our approach builds upon recent work by Argiento and De Iorio (Citation2022) that exploits the relationship between finite and infinite mixtures in a Bayesian framework. Argiento and De Iorio (Citation2022) show that a mixture model with a random number of components is indeed a nonparametric model since its complexity is a-priori unbounded and inferred by the data. Moreover, while an infinite mixture model can lead to an a posteriori inconsistency on the estimation of the number of clusters (Miller and Harrison Citation2018), this is not the case for finite mixture models with a random number of components. The use of a finite mixture model allows us to devise a blocked conditional Gibbs sampler, which is faster than the marginal algorithms that are usually adopted, as in Matechou and Caron (Citation2017). Finally, we show that when the number of elements being clustered is itself random, the clustering can be expressed via a function, which we call N-exchangeable random probability function, that can be used to derive the marginal distribution of N, and gives rise to an interpretation of the clustering in terms of the Chinese restaurant process.
Our proposed modeling approach has several distinctive advantages. In contrast to methods relying on Pollock’s robust design, we do not need to assume population closure. From a computational point of view, we design an adaptive scheme for the changepoint process part of the model that is free from complicated tuning strategies and we tackle the mixture model from a Bayesian point of view via a conditional algorithm that is computationally efficient and allows for full Bayesian inference.
We fit our model to CR data on salmon anglers in Norway. The anglers only report a visit to the river on a particular day if they catch at least one salmon. This gives rise to a standard CR dataset indicating the days when each angler reported a catch. However, the number of anglers who visited the river, the number of days on which they were present each season and their probability of catching salmon whilst at the river are unknown. Our results in terms of types of visit patterns and fishing abilities are consistent across the 2017, 2018, and 2019 seasons. Specifically, we identify two clusters, with the largest cluster, consisting of around 95% of the angler population, making two to three visits on average each year, which last for around two days on average. The second cluster of anglers make around eight visits each year, each lasting on average two to three days. This leads to substantial differences in the total number of days spent at the river on average between the two clusters. Additionally, we estimate that the total number of anglers who visited the river each year is considerably higher than the number of anglers who caught at least one salmon, and, for the first time in the Gaula river, we estimate the total number of anglers who are present at the river on each day of the season. Finally, we quantify the effect of the COVID-19 pandemic on the angling population by analyzing the 2020 season data. Our findings suggest that there was a considerable increase in the number of anglers who visited that year, with anglers spending longer on average per visit compared to previous seasons but having an overall lower ability to catch fish. Such information is invaluable for managing the river, and correctly and precisely setting fishing quotas and introducing further regulations, as required.
We present the model in Section 3 and discuss its clustering behavior in Section 4. Our algorithm used for inference, including the adaptive MCMC changepoint sampler and the Bayesian nonparametric algorithm used for clustering, is presented in Section 5. The results from fitting the model to simulated data and to the angler data are presented in Section 6 while the article concludes in Section 7. Additional technical details about our model and algorithm, as well as results of an extensive simulation study, are provided in the supplementary materials.
2 Salmon Angler Data
The Gaula is an unregulated river in Norway that is a very popular destination for salmon anglers. Any catches of salmon have to be reported by the anglers to the river management board. However, individual anglers only report that they were fishing on a particular day of the season, which lasts for T = 92 (1st of June to 31st of August) days, if they catch at least one salmon that day. This creates a capture history, which is a vector of length T, for each angler, with entry t equal to one if the angler caught salmon on day t, and zero otherwise, with . There also exists an unknown number of anglers who visited the river but did not catch salmon, and hence share the capture history with all T entries equal to 0. The population is open, with anglers entering and exiting the river throughout the season. Anglers need to purchase fishing licenses from land owners along the river in advance, but the information on the number of licenses that have been sold each year is considered sensitive and not shared. Licenses are often sold-out months in advance, and the only restriction placed on anglers is that they can only remove a maximum of four salmon a year for the period we are considering in this article. However, they can catch as many salmon as they want and release them back in the river.
Individual anglers can return to the river to fish an arbitrary number of times in the season, meaning that their emigration from the site needs to be treated as temporary. Clearly, we cannot employ methods relying on Pollock’s robust design in this case as the population cannot be assumed closed for any period in the season. Additionally, our inference needs to account for individual heterogeneity in the visit behavior and fishing ability, the latter expressed through the probability of an angler catching salmon whilst at the river, and hence being themselves “caught,” henceforth referred to as observed, while present at the river. For example, some anglers may visit often for shorter periods of time while others may visit less regularly for longer periods of time, with capture probability also linked to the visit behavior, with, for example, frequent visitors being more skilled in fishing and vice versa.
We are interested in inferring the size of the population of anglers, N, and the visit history of each angler, which consists of the number, timing and duration of their visits, as well as the probability of an angler catching salmon on any given day. We note here that if an open population model that does not allow for temporary emigration is fitted to the data, such as the “POPAN” model in the R package RMark (Laake Citation2013), then the resulting estimates of capture probability, which are between 0.06 and 0.07 for all years, are certainly under-estimates; since the model assumes that individuals are present between their first and last observation, it inevitably underestimates the probability of capture.
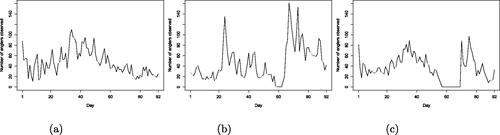
The total number of anglers observed in the 2017, 2018, and 2019 seasons is equal to 2057, 1901, and 1687, respectively, but we cannot infer the total number of visitors to the river each season using the raw data alone. The median number of times that each angler has been observed is equal to one in 2017 and 2019 and to two in 2018 but it is not possible to decipher from the data alone the total number of days each angler has spent at the river. Similarly, the number of visits made by individual anglers each year is unknown. Clearly, we can safely assume that consecutive days on which an individual angler was observed belong to a single visit. However, observations of individual anglers are also separated by days on which the particular angler was not observed. If we assume that visits are separated by at least one day of non-observation, then we find that the proportion of anglers making a single visit would be set to around 60% with an average visit length of around 1.2 days for all seasons, while if we assume that visits are separated by at least two days of non-observation, then these figures change to around 70% and 1.4–1.5 days on average. Finally, shows that the pattern in the number of anglers observed each day of the season varies greatly between years, but it is of interest to compare the arrival and departure patterns between years, which cannot be achieved using the raw capture histories. These questions motivate the development of the model presented in Section 3.
Fig. 1 Number of anglers observed each day of the season in 2017, (a), 2018, (b), and 2019, (c). The river may be closed occasionally for fishing, which results in days when no fish are caught, such as the days around day 60 in 2018 and in 2019.
Inferring the number of anglers present at any one time within the season enables the river management to assess the fishing pressure and consequently decide on fishing quotas or additional regulations. Information on the probability of catching salmon is valuable to the river management board for the purposes of fisheries management, for ensuring the conservation of salmon in the river and the availability of resources, such as accommodation and food, for anglers. Knowledge about the number of anglers who visit the river each season and the number of visits they each make can help demonstrate to local politicians and stakeholders the importance and attractiveness of the river Gaula as a tourist destination and increase the appreciation of the value of salmon fishing to the local community, resulting in policies that ensure protection and conservation of the river and the salmon stock. Finally, by modeling the 2020 season and quantifying the differences compared to previous seasons in terms of numbers of visitors, visit patterns and capture probabilities can shed light on the effect of the COVID-19 pandemic and the corresponding global travel restrictions on the angling and hence salmon population at the Gaula river.
3 Model
We denote the number of individuals caught at least once by n and the number of sampling occasions by T. The population size is denoted by N. Let index individuals and
, which we refer to as time, index equally spaced sampling occasions.
The data consist of n capture histories, each of length T. We denote the capture history of individual i by with entry
if individual i was caught at time t and 0 otherwise. Individuals with index
have capture histories with all entries equal to 0.
Individual i, , makes an unknown number of visits, ki, and has an unknown visit history summarized by the arrival times
and the corresponding departure times
. The arrival times are an increasing sequence of length ki with
, in
and the corresponding departure times are an increasing sequence in
, such that
for each
, with
by definition. The visit history uniquely defines a corresponding presence history, with the presence history of individual i denoted by
and
if individual i was present at time t and 0 otherwise. For example in , the presence history
is coded as a sequence of 0s (absent) and 1s (present) and represented by a piecewise constant function. In this case we have ki = 2 visits,
and
, corresponding to the points where the piecewise constant function jumps from 0 to 1, represented by the two filled circles on the x-axis, and ki = 2 departure times,
and
, corresponding to the points where the function jumps from 1 to 0, represented by the two filled triangles on the x-axis. We observe that, as mentioned above,
and
uniquely define
, but not vice versa. Nevertheless, to simplify notation, in the following we use
, since it is the latter that we infer.
Fig. 2 Example presence history for individual i. Gray ticks indicate external points, , black ticks indicate internal points,
, solid circles indicate changepoints, that is, arrivals times,
, and solid triangles indicate their corresponding departure times,
. The arrival and departure times are indicated on the x-axis.
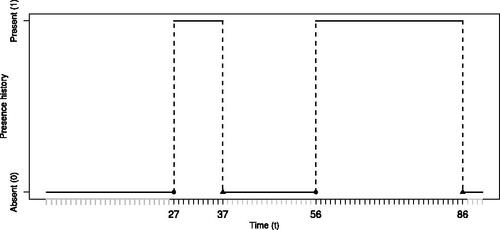
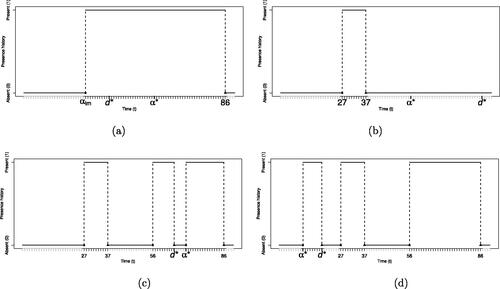
Fig. 3 Four examples of presence histories that can lead to the presence history shown in : (a) Split move; we propose an internal point as a new changepoint ( ), which forms a visit with the next available departure point (dim = 86), while the existing previous arrival time aim = 27 forms a visit with the newly proposed departure time (
), (b) Add move; we propose an external point as a new changepoint (
), which forms a visit with the newly proposed departure time (
), (c) Merge move; we propose to delete an existing changepoint (
) and the departure time of the previous visit (
), so the two visits are merged, and (d): Delete move: we propose to delete an existing changepoint (
) and its corresponding departure time (
).
We refer to the set as the augmented data because it includes both the
caught individuals and the
uncaught individuals. We note that each observation
is a pair of sequences such that its tth entry is (CHit,PH
. We denote by
the space of all these possible sequences, that is, the sample space, and we model the augmented data as a marked Poisson process over (
), that is,
where ν is a random intensity function. The approach originally developed by Kottas and Sansó (Citation2007), extended by Taddy and Kottas (Citation2012) and adapted for CR models by Matechou and Caron (Citation2017) employs an infinite mixture model for ν. Here, we employ a mixture model with
components, where
, that is, the number of components, M, is distributed according to a shifted Poisson. Conditionally on M,
where
are (unnormalized) weights of the mixture and
is the joint probability mass function of the presence history
and capture history
, conditional on individual i belonging to component c, and is a function of the component-specific parameter τc for
.
The overall intensity of the Poisson process is
The model can be represented in the following hierarchical form(1)
(1) where P0 is the prior distribution of the component specific parameters, described in Section 5.2.
We let , where
is the probability that an individual from component c arrives at a particular time,
pc is the probability that an individual from component c is caught at a particular time given presence at that time.
Given , the time between consecutive arrivals is modeled as a
random variable with support
}, probability mass function g1 and cumulative distribution function G1. In other words, the process of arrival times
is a realization of a homogeneous Bernoulli process with parameter
observed at times
; consequently, the joint probability mass function of the vector
and its length ki, with
, is given by
Conditionally on , ki, and
, the probability mass function of departure times
is given by
with g0 and G0, respectively, the probability mass function and cumulative distribution function of a geometric distribution with support on
and component-specific parameter
.
The different support for g1 and g0 ensures that a departure can occur at the same time as an arrival, while no more than one arrival can occur at any one time.
Following the CR stopover literature (Pledger et al. Citation2009; Matechou et al. Citation2016) individuals are assumed to be available for capture on both their arrival and departure times. Hence, the probability mass function of conditionally on
and pc is
(2)
(2)
Finally, the joint sampling model in component c of augmented data is
(3)
(3)
4 Clustering Behavior of the Model
In this section we examine the clustering structure that our mixture model induces on the data.
In particular, we observe that the mixing measure P in model (1) belongs to the wide class of species sampling models, investigated in detail in Pitman (Citation1996) and largely adopted in Bayesian nonparametric clustering (Ishwaran and James 2003; Miller and Harrison Citation2018; Argiento and De Iorio Citation2022). Building upon the latter literature, we derive quantities of interest for our model.
Given the population size N, each of the N individuals belongs to one of the M components of the mixture in (1). We denote the component to which individual i belongs by ci. To study the clustering behavior of the model, it is useful to represent the first two lines of model (1), conditionally on the parameters Λ, η and ζ, in terms of the cluster allocations(4)
(4)
With probability greater than zero we will obtain ties among the component allocations, and we denote by
the unique values among these allocations. The vector of
’s induces a random partition (i.e., clustering) among the augmented data that we denote by
, where the clusters are given by
. Each cluster Jj,
corresponds to a component of the mixture, namely the component c such that
. Note that there is a random number C of occupied components, namely the clusters, and
empty components. For ease of notation we refer to
as the parameters of the clusters.
When P0 is continuous, we can explicitly write (see Section 1 of the supplementary materials for details) the prior distribution that model (4) induces on and
:
where Nj is the number of individuals in cluster j and
. We call
the N-exchangeable partition probability function given by
(5)
(5)
with
. We observe that N ranges in
and if N = 0 then ρ is not defined, otherwise ρ is a partition of the indices
. Moreover, Nj = 0 for each j if N = 0, while
and
if N > 0. EquationEquation (5)
(5)
(5) is the prior probability of having N individuals (augmented observations) clustered in C exchangeable groups with frequencies
. We would like to highlight that our model induces a joint distribution on the number of individuals N and the number of clusters C. This can be obtained by marginalizing out the cluster frequencies
from (5), as described in Section 1 of the supplementary materials. The joint probability mass function of (N, C) at points
and
is
where, for any nonnegative integers
and real numbers η,
denotes the central generalized factorial coefficient (see Charalambides (Citation2005) formula 2.67 for details). Here we mention that these indices can be easily computed using the recursive formula
with
. Furthermore, the marginal distribution of N can be computed by the hierarchical representation
so that for
the probability mass function of N at x is
Hence, we can easily calculate and
.
The N-eppf in EquationEquation (5)(5)
(5) jointly regulates the size of the augmented data and the clustering behavior of the process. We use a slightly modified version of the Chinese restaurant metaphor (Aldous Citation1985) to describe this behavior. This modification is required because the number of customers, N, arriving in this case is random.
The probability that the first customer arrives is equal to . The first customer sits with probability one at the first table and the second customer arrives with conditional probability
and selects a table according to EquationEquations (6)
(6)
(6) and Equation(7)
(7)
(7) where in this case C = 1 and
. In general, given that x customers have arrived and are sitting on C tables with frequencies
, the probability that customer x + 1 arrives is
and selects a table again according to EquationEquations (6)
(6)
(6) and Equation(7)
(7)
(7) . After x customers have arrived, the process stops with probability
and no more customers arrive.
We refer to the C groups as the occupied tables with
customers each, and to
as the new empty table:
(6)
(6)
(7)
(7)
We observe that, if for some
and let Λ go to
, so that the mixing measure P in (4) approaches in law the Dirichlet process with mass parameter α, then (6) reduces to Nl and (7) reduces to α, so that we obtain, a-priori, the clustering behavior of the Chinese restaurant process (i.e., the clustering induced by the Dirichlet process with mass parameter α).
As a final note, we mention that the Chinese restaurant metaphor is quite popular in the machine learning and Bayesian nonparametric literature. It is widely adopted and it is customary to describe any related extensions, such as Favaro and Teh (Citation2013) for normalized completely random measures and Teh et al. (Citation2006) for Hierarchical Dirichlet processes, using this metaphor, and this is the approach we employ here.
5 Inference
Our MCMC algorithm iterates between the following steps: (a) conditionally on N, and
, we update the individual visit histories using an adaptive changepoint sampler, as described in Section 5.1, (b) conditionally on N and the individual visit histories, we update
and
, using a conditional algorithm for mixture models, as described in Section 5.2. We note that as a result of this update, we also achieve an update for Ω, and, (c), conditionally on Ω and
, we update N using a rejection algorithm, as described in Section 5.3.
5.1 Adaptive MCMC Changepoint Sampler
The adaptive MCMC algorithm proposed by Benson and Friel (Citation2018) gives rise to the posterior distribution of the latent vector indicating the presence (or not) of a changepoint, which in our case indicates an arrival time for an individual at each time point. We denote the iteration number, say j, for objects that are iteration specific using a superscript (j). The design of the algorithm ensures that time points that are unlikely to be changepoints are not proposed as frequently as time points that have been accepted as changepoints in earlier iterations of the algorithm. This is ensured by introducing individual- and time-specific weights where for individual i, each time point t has a specific weight, , of being proposed as a changepoint that is, an arrival time and a specific weight,
, of being proposed to be deleted from a changepoint if it already is one. These weights are unnormalized selection weights and are updated if time t is accepted as or deleted from a changepoint, respectively as explained below.
For the current visit history described by and corresponding presence history
, we define the set of all changepoints (arrivals) of individual i by
, the set of all departures by
, the set of points exterior to the visits, that is all t at which individual i is absent, by
, and the remaining t, which are interior to the visits, by
; see for an illustration. Additionally, we define
and
. At iteration j of the algorithm we can propose to increase ki by one, as long as
, or to decrease ki by one, as long as
. That is, we can propose to add a changepoint, with probability
, at any
and a departure time while we can propose to delete any changepoint
(and a departure time), with probability
. This leads to a proposed visit history described by
.
We describe the two cases in detail below.
Increasing
We note that there is a nonzero probability of selecting any interior point
Split move If
We accept this update with probability
Note that the 1/2 in the numerator of the last fraction is only needed if the visit to be deleted is not the first one as if that were the case then we cannot delete it by merging it with the previous visit.
The first fraction in χ1 is the ratio of the joint posterior probabilities of the parameters and visit histories while the product of the three following fractions gives the ratio of the proposal probabilities when considering a delete move (numerator and also described below) and when considering an add move (denominator).
Add move If
We accept this update with probability
We note here that the 1/2 in the numerator of the last fraction in χ1 is needed only if the visit to be added is not going to be the first one as if that were the case then we could not delete it in the reverse move by merging it with the previous visit.
Decreasing
At this stage, we propose, with probability 1/2, to delete the visit by merging it with the previous visit, which we refer to as a merge move, or not, which we refer to as a delete move. We describe the two cases below.
Merge move We note here that this is the inverse of the split move defined above (see for an illustration). We accept this update with probability
Delete move Alternatively, if we do not propose the merge move, then we propose to delete this visit and we accept this update with probability
We note here that if
Finally, at each iteration we propose to shift all arrival and departure times of all individuals using a Metropolis-Hastings move. We propose to shift each by adding to it a discrete Unif
, while we propose to shift
by adding to it a discrete Unif
. We accept this update with probability
If the proposal to increase ki, either via an add or a split move, is accepted, and hence a new visit at time t is introduced, then we update the corresponding weight according to the adaptation scheme proposed by Benson and Friel (Citation2018), where h > 0 is the initial adaptation parameter, j is the iteration number and
is the target acceptance rate of the move.
Consequently, if the proposal to decrease ki, either via a delete or a merge move, is accepted, and hence the visit that started at time t no longer exists, then we update the corresponding weight using
5.2 Sampling the Posterior Distribution of ν and the Partition
Borrowing notation from the Bayesian nonparametric literature (Ishwaran and James 2003), we develop a blocked Gibbs sampler for finite mixture models with a random number of components, as suggested by Argiento and De Iorio (Citation2022), based on the posterior characterization given in Section 4. As opposed to the marginal samplers considered in Taddy and Kottas (Citation2012) and Matechou and Caron (Citation2017), our approach does not require updating of the cluster-specific parameters every time an individual is removed from or added to a cluster. As a result, it is computationally more efficient.
Let be the unnormalized weights and
be the random locations of the model in (4). Drawing inference on
is equivalent to drawing inference on ν. Consequently, conditionally on ρ and
, our algorithm to update ν is based on the following characterization of
given the augmented data.
We refer to as the occupied components of the mixture and to the remaining M – C components as the unoccupied. An important observation in order to implement our algorithm is that we can always assume that the vector of unique values
corresponds to the first C components of the mixture, that is,
. This statement as well as everything that follows in this Section are proven in Sections 1 and 2 of the supplementary materials.
Under model (4), the intensity ν given the augmented data and a sample
of cluster allocation indices, such that
, satisfies the following distributional equation
In particular:
The number of unoccupied components,
Conditionally on
The locations of the unoccupied components τj, for
The weights of occupied components, Sj for
Conditionally on everything else,
The locations of occupied components
The latter is the posterior density of a parametric Bayesian model where the sampling model is
Conditionally on ν and N, we update ρ and by, first, reparameterising ρ and
in terms of the individual cluster allocation indices
and, then, by sampling the new allocation ci for individual i from
.
5.3 Sampling N
We update N using a rejection algorithm, as introduced by Matechou and Caron (Citation2017) and also employed by Diana et al. (Citation2020). We outline the algorithm below and provide more details in Section 2.3 of the supplementary materials.
First, we propose a value for the number of individuals in N that were never caught from a Poisson(Ω) distribution. Consecutively, we thin this number as follows: we first allocate each of the proposed individuals to a cluster according to our process outlined in Section 4, then we simulate a presence history for each individual using the cluster-specific q1 and q0 parameters and finally, given the presence history, we simulate a capture history for individuals using the cluster-specific capture probability, pc. Individuals with simulated capture histories with at least one nonzero entry are discarded, as any caught individuals are already part of the sample. Finally, the obtained sample from the posterior distribution of N at the particular iteration consists of the remainder of simulated individuals with capture histories with all entries equal to zero, together with the n individuals caught at least once in the original sample.
5.4 Summarizing the Clustering
Inference on clustering and cluster-specific parameters is made marginally with respect to the (latent) uncaught individuals, so that all of the summary statistics presented in this section are obtained using the n caught individuals.
Our iterative algorithm results in G draws from the posterior distribution of the random partition, ρ. In Bayesian model-based clustering, the choice of a single partition based on this posterior sample is a critical point. Here we employ the approach of Wade and Ghahramani (Citation2018) because it also explores partitions that are not visited by the MCMC chain. This approach is essentially a greedy search algorithm informed by the posterior similarity matrix, which is obtained by calculating the average number of times each pair of individuals has been allocated to the same cluster.
Estimation of cluster-specific parameters is a well-known and open problem in Bayesian nonparametric model-based clustering, mainly due to the label-switching problem. Here we employ the simple and intuitive approach proposed by Molitor et al. (Citation2010). Once we obtain an estimation of the data clustering, that is, that define the partition of
called
, as explained above, we average each of the cluster specific parameters across all G iterations to obtain
6 Results
6.1 Simulation
We simulated data on populations exhibiting temporary emigration and heterogeneity to assess the performance of our model and algorithm in identifying the number of clusters and in estimating the associated parameters as well as the size of the population.
We set T = 100, N = 500, C = 2, ,
and
. We fit the model of EquationEquation (1)
(1)
(1) using different scenarios for parameters Λ, η and ζ and to five different simulated data for each scenario. In all cases, we let P0 be the product of three independent uniform distributions for p, q0, and q1 to represent absence of information for these parameters. Then, we investigate three different scenarios regarding parameters Λ, η and ζ. In the first two scenarios, the three parameters are fixed: in the first case
, and in the second
. Finally, in the third scenario, the three parameters are assumed random with independent Gamma prior distributions (see Model 1). Details on the hyperparameter choices are given in Tables 1, 2, and 19 of the supplementary materials.
For each simulation, we run our algorithm using initial adaptive weights equal to 1, h = 0.001 and . The choice of h was made after running several chains for the same dataset using the same starting values for the parameters but different values for h (
and comparing effective sample sizes and mean squared errors for all model parameters. Our choice for the target acceptance rates was based on the general recommendation of a 0.234 acceptance rate in MCMC algorithms (Roberts, Gelman, and Gilks Citation1997) and the comment by Benson and Friel (Citation2018) that values in the
range work well in practice. We note here that Benson and Friel (Citation2018) suggest that the algorithm is insensitive to the choice of h and of the acceptance rates, provided that the first is set to a small value, such as the reciprocal of the length of the time-series.
Our results in all scenarios suggest that clustering estimation is quite robust with respect to choices on parameters Λ, η, and ζ, thanks to the method of Wade and Ghahramani (Citation2018). In fact, in most cases we obtain an a posteriori estimate of two clusters with high rand index (i.e., >0.76) between the true partition and the estimated partition (see Tables 5, 6, and 21 of the supplementary materials). Estimation of N and of cluster specific parameters is also good in terms of coverage of the posterior credible intervals (PCIs).
We note that some issues in posterior inference can arise in the extreme case where the prior induced on N, C by the parameter choice is such that these two quantities are very strongly correlated (see for instance case a of Table 2 of the supplementary materials). We also mention that if a cluster consists of individuals with very low capture probabilities, the model can slightly overestimate this parameter. Finally, we highlight that the best performance in terms of estimation is obtained when all three parameters are assumed random with vague priors, such as independent Gamma(0.1,0.1) priors (this is denoted as case g in Table 19 of the supplementary materials), and this is indeed the approach we take for the angler dataset.
Under this third hyperparameter scenario, clustering estimation is satisfying, since for all five replications we obtain a posterior mean of two clusters, with average width of the 95% PCI equal to 1.80, and Rand index of 0.76.
We present the average, over the five datasets, of the posterior mean and the average width
of the 95% PCI as well as the coverage for N and all cluster-specific parameters in . Posterior summaries for the visit, arrival and departure patterns obtained for one of the simulated datasets are presented in . In all cases,
is close to the true value used to simulate the data, while the coverage is satisfactory, and always higher than 0.8.
Fig. 4 Posterior medians, indicated by the empty circles, and 95% PCI, indicated by the vertical bars, of the visit, (a), arrival, (b), and departure, (c), patterns. The true values are indicated by the gray dots. The plots refer to one (among five) of the simulated data, results for other datasets are quite similar.
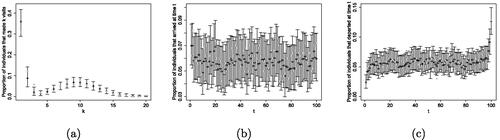
Table 1 Simulation results.
Hence, our results demonstrate that we can estimate parameters of interest, such as N, and retrieve the latent clustering of the population as well as estimate the corresponding cluster-specific parameters. More details about the simulation study are presented in Section 2.2 of the supplementary materials.
6.2 Angler Data
We fit model of EquationEquation (1)(1)
(1) to three datasets collected in 2017, 2018, and 2019. We set p = 0 on days when the river was closed for fishing in each season. We adopt an informative approach in the choice of the hyperparmameters of P0, that is the choice of
,
, and αp, βp. Our information can be summarized as follows:
an a priori 95% credible interval for the number of visits equal to
an a-priori mean length of stay for an angler equal to 6 days, with a 50% credible interval of roughly [3,7] days. This gives a, roughly, (0.12, 0.26) corresponding interval for q0, which translates into a Beta(3, 12) prior distribution.
a 95% prior credible interval for p equal to (0.1,0.5);
Finally, we assigned vague prior distributions on the parameters Λ, η, and ζ, as described in Section 6.1.
Similarly to the simulation study, we run our algorithm for each dataset using initial adaptive weights equal to 1, h = 0.001 and target acceptance rates equal to 0.2. Convergence was assessed by visual inspection of trace plots and using the Geweke diagnostic in package coda (Plummer et al. Citation2006), shown in Section 3 of the supplementary materials.
Posterior summaries for N for each year are presented in . The posterior medians for N are all greater than 3000 and considerably greater than the number of anglers observed each year. There is substantial overlap between all 95% PCIs, suggesting that the population of anglers that visited the river each year between 2017 and 2019 is fairly stable, which is not surprising, as at least 70% of anglers are expected to be returning year after year.
Table 2 Posterior summaries of the population size, N, of anglers for each season.
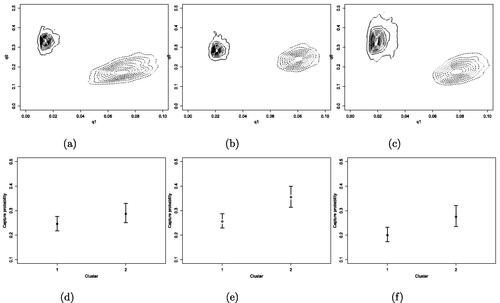
As explained in Section 4, our model induces a clustering amongst anglers, described by our extension of the Chinese restaurant process. We clarify that in this case, the clients are the anglers and the tables are groups of anglers sharing the same characteristics (dishes), with characteristics being the cluster-specific parameters , which describe the visit behavior and fishing ability of anglers. We summarize the clustering as described in Section 5.4 and obtain two clusters. Contour plots of the posterior distributions for q0 and q1 for each cluster and posterior summaries of the cluster-specific probabilities of capture are shown in . The largest cluster each year (labelled cluster 1, consisting of 95% of the individuals) is found to consist of the “occasional visitors,” with the lowest q1 and highest q0. This group of anglers tend to perform between two and three visits per year, with posterior mean visit duration equal to around two days. The smallest cluster corresponds to the “super-visitors” who make on average around eight visits per year, with posterior mean visit duration between two and three days. We highlight that the estimated capture probability for both clusters, which, although higher for the second cluster is not found to differ significantly between clusters within each season, is considerably greater than what is obtained when a model that does not account for temporary emigration is fitted to the data, as mentioned in Section 2.
Fig. 5 Contour plots of cluster-specific q0 and q1 for the 2017, (a), 2018, (b) and 2019, (c), season for cluster 1, solid lines, and cluster 2, dashed lines. Summaries of posterior samples of cluster-specific capture probabilities for the 2017, (d), 2018, (e) and 2019, (f), season.
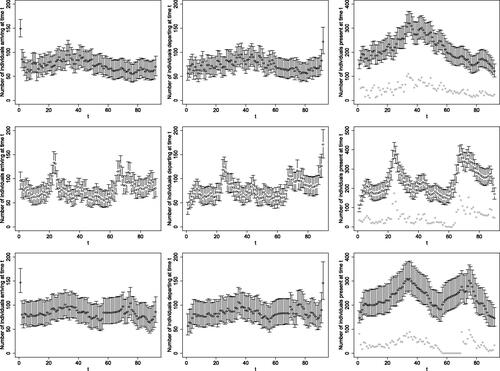
The estimated arrival, departure and presence patterns, presented in , vary substantially between years, although a common feature is a larger proportion of individuals estimated to arrive on the first day of the season and similarly to depart on the last day of the season. A peak in the estimated number of individuals present (third column in ) is observed toward the end of June in all years. This is possibly due to anglers tending to avoid planning a trip to Gaula early in the season as some parts of the river may still be inaccessible due to snow, which is much less likely after the end of June. In 2018 and 2019, there is another peak in the number of anglers present, following river closure at the end of July in both years. We note that, as mentioned above, anglers book their trips typically months in advance, so they tend to remain at the river even when it is closed, waiting for it to reopen once there is sufficient rainfall.
Fig. 6 Posterior medians, indicated by the empty circles, and 95% PCI, indicated by the vertical bars, of the number of individuals arriving (first column), departing (second column), and being present (third column), each day of the season in 2017 (first row), 2018 (second row) and 2019 (third row). The gray dots in the third column indicate the number of anglers who caught at least one salmon that day.
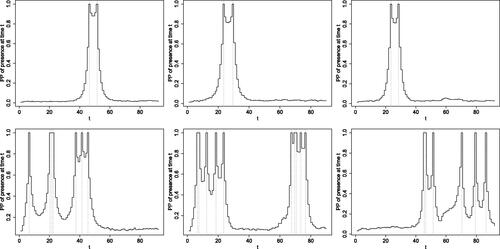
The cluster-specific visit pattern can also be summarized by looking at the posterior probability of presence at any given time point for each individual. In we present these for the most representative individual in each of the two clusters for each year. Individuals representative for each cluster are identified by calculating the distance between each individual and the centroid of each cluster in terms of the number and length of visits and capture probability. The posterior probability of presence is equal to 1 at times when the individual has been observed. This probability decreases as we move away from times of observation. The rate of decrease depends on the cluster and on the number of days between observations. Specifically, the posterior probability of presence reduces slightly more sharply as we move away from the time of observation for individuals in cluster 1 compared to cluster 2. However, even for cluster 1, individuals observed only a few days apart have a high posterior probability of presence between these two observations. As expected, the number of peaks, that is, visits, for each individual corresponds to what we have already identified as typical for each cluster, with individuals in cluster 1 having one or two peaks and individuals in cluster 2 multiple peaks. We focused our interpretation of the clustering results on the individuals observed at least once, since no information, other than the fact that they never caught salmon, is available on the remainder of the individuals. Since our inference on N is performed using a rejection algorithm, the number of individuals that were never observed as well as their corresponding presence histories and hence cluster membership change at every iteration of the algorithm. Therefore, no meaningful posterior summaries exist for particular individuals with index greater than n.
Fig. 7 Posterior probabilities of presence for the most representative individuals in each of the two identified clusters (rows 1 and 2) for 2017 (first column), 2018 (second column) and 2019 (third column).
6.3 The Effect of the COVID-19 Pandemic
In this section, we discuss the results of our model when fitted to the 2020 dataset, presented in Section 3 of the supplementary materials, and compare them to those obtained for the 2017–2019 seasons. In Norway, there were no national travel restrictions in the summer of 2020, so local anglers could still travel to Gaula, but the international travel restrictions meant that the number of anglers traveling from abroad to Norway was dramatically lower. As a result, both the visiting patterns of anglers and their probability of catching salmon whilst at the river were considerably different to pre-pandemic seasons, since the foreign visiting anglers are among the most dedicated and skilled.
We find that we again identify two clusters of anglers, with substantially different visit patterns. The largest cluster, consisting of almost 90% of anglers in the sample, visit one to two times on average in the season. However, the smallest cluster of what we termed “super-visitors” only visit on average around three times in the season, which is considerably lower than in the pre-pandemic seasons. On the other hand, both clusters spent longer at the river per visit on average compared to previous seasons (around six days), which results in average total lengths of stay at the river that are greater than in other seasons (around 15 and 37 days, respectively). Additionally, we estimate that the total number of anglers that visited the river in 2020 was greater than in pre-pandemic seasons (posterior median = 4034, 95% PCI = (3550, 4583)). We note here that once travel restrictions were imposed, the pre-sold fishing licenses where made available to locals in Norway and, given the global travel restrictions, also preventing Norwegians from going on their normal summer vacations, more locals took up the new opportunity to try fishing in Gaula. Finally, our estimated capture probabilities for both clusters are slightly lower than in pre-pandemic seasons (posterior means equal to 0.18 and 0.25, respectively), which is again not surprising as less experienced anglers took the opportunity to visit the river in 2020 compared to the regular and more experienced anglers who usually buy the fishing licenses months in advance.
7 Conclusions
We proposed a novel modeling approach that enables us to estimate parameters of interest, such as the size of a population, from CR data while allowing for temporary emigration and accounting for individual heterogeneity. To our knowledge, this is the only such model for open-populations that does not require the use of methods that rely on Pollock’s robust design, which cannot always be employed, as is the case for the dataset considered in this article.
Our approach brings together CR models, changepoint process and Bayesian nonparametric methodology for the first time and gives rise to a flexible modeling technique for time-series that could be extended to other types of ecological data, such as those collected in occupancy studies (MacKenzie et al. Citation2002) when the assumption of population closure is not satisfied.
The model is fitted by combining and extending recently-developed algorithms in the area of changepoint processes (Benson and Friel Citation2018) and a blocked Gibbs sampler for finite mixture models built upon a Bayesian nonparametric approach (Ishwaran and James 2003; Argiento, Bianchini, and Guglielmi Citation2016; Argiento and De Iorio Citation2022). The first learn from past states of the MCMC and hence yield proposal distributions that quickly discover the position of changepoints while the latter updates the cluster-specific parameters conditioning on the mixing process P, which yields an independent update (for these parameters) that is more efficient than competing approaches.
We presented a simulation study that demonstrated the reliability of the results obtained by our model and the ability of our method to uncover the underlying clusters in the population as well as to estimate the corresponding cluster-specific parameters. Our analysis of CR datasets on anglers in Norway identified two clusters, each with fairly consistent visit patterns each year, except in 2020, when the effect of the COVID-19 pandemic led to a different angling population. Our results can be used to inform the decisions made by the river management board in terms of number and pricing of fishing licenses issued, based on the quality of fishing in terms of probability to catch a fish on a given day. Reliable estimates of the probability of anglers catching salmon whilst at the river are crucial for effective management of the river and can also be used as a marketing tool by the river management board, as success rates are used as indicators for the quality of fishing experience at rivers. On the other hand, estimates that are biased low, obtained from existing models that do not account for temporary emigration, risk underestimating the effect of angling on the salmon population and cannot guide actions for sustainable fishing at the river.
A natural extension of our model is the inclusion of covariates, for example the effect of rainfall on capture probability throughout the season, to inform estimation about clustering and cluster specific parameters. The use of covariates in mixture models is part of a lively stream of research in the Bayesian nonparametric community (see for instance Foti and Williamson Citation2013), under the name of (nonexchangeable) dependent processes for mixtures. One of the main advantages of the framework of finite mixture models introduced in Argiento and De Iorio (Citation2022), which we employ in this article, is exactly the possibility of incorporating covariate dependence in the model, and this is a matter of current research. Another interesting extension could consider following the same individuals over different seasons to study the level of consistency in their visiting pattern and the potential improvement of their fishing ability over the years. In 2018, the river closed for the first time in its history because of low levels of rainfall, and since then river closure toward the middle of the season is a recurring phenomenon. As a result, it is expected that anglers will change their behavior about when to book their fishing trip in the future, and our model, or extensions of it described above, could be used to model this behavioral shift.
Supplemental Material
Download PDF (2.1 MB)Supplemental Material
Download Zip (100.2 MB)Acknowledgments
We are grateful to Reinhard Fellner for bringing this case study to our attention, and for all the discussions on the prior knowledge about the system as well as his insights that highlight the importance of our findings and the potential impact of the work presented in this article. We thank the AE and the anonymous referees for all their comments and advice that helped us improve this article.
Supplementary Materials
Title: Supplementary Material Document with three sections: 1. Bayesian mixture model, 2: Posterior characterization, 3: Angler data. The first two give details on the mathematical results of the Bayesian mixture model presented in the article and the algorithm used for inference, with an additional extensive simulation study on prior sensitivity in section 2.2 and the third includes trace plots and diagnostics for all model parameters for the analysis of the data presented in the article.
R code and data: The angler data analyzed in Section 6.2 and the R code used to perform the simulation study and the angler data analysis and to elicit the prior distributions for a number of model parameters in the simulation study presented in the supplementary material.
Disclosure Statement
The authors report there are no competing interests to declare.
References
- Aldous, D. J. (1985), “Exchangeability and Related Topics,” in École d’Été de Probabilités de Saint-Flour XIII–1983, ed. P. L. Hennequin, pp. 1–198, Berlin: Springer.
- Argiento, R., Bianchini, I., and Guglielmi, A. (2016), “Posterior Sampling from ε-Approximation of Normalized Completely Random Measure Mixtures,” Electronic Journal of Statistics, 10, 3516–3547. DOI: 10.1214/16-EJS1168.
- Argiento, R., and De Iorio, M. (2022), “Is Infinity that Far? A Bayesian Nonparametric Perspective of Finite Mixture Models,” Annals of Statistics (to appear).
- Benson, A., and Friel, N. (2018), “Adaptive MCMC for Multiple Changepoint Analysis with Applications to Large Datasets,” Electronic Journal of Statistics, 12, 3365–3396. DOI: 10.1214/18-EJS1418.
- Charalambides, C. A. (2005), Combinatorial Methods in Discrete Distributions (Vol. 600), Hoboken, NJ: Wiley.
- Darroch, J. N. (1958), “The Multiple-Recapture Census: I. Estimation of a Closed Population,” Biometrika, 45, 343–359. DOI: 10.1093/biomet/45.3-4.343.
- Diana, A., Matechou, E., Griffin, J., and Johnston, A. (2020), “A Hierarchical Dependent Dirichlet Process Prior for Modelling Bird Migration Patterns in the UK,” Annals of Applied Statistics, 14, 473–493.
- Favaro, S., and Teh, Y. W. (2013), “MCMC for Normalized Random Measure Mixture Models,” Statistical Science, 28, 335–359. DOI: 10.1214/13-STS422.
- Foti, N. J., and Williamson, S. A. (2013), “A Survey of Non-exchangeable Priors for Bayesian Nonparametric Models,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 37, 359–371. DOI: 10.1109/TPAMI.2013.224.
- Ishwaran, H., and James, L. F. (2003), “Generalized Weighted Chinese Restaurant Processes for Species Sampling Mixture Models,” Statistica Sinica, 13, 1211–1235.
- Jolly, G. M. (1965), “Explicit Estimates from Capture-Recapture Data with both Death and Immigration-Stochastic Model,” Biometrika, 52, 225–247. DOI: 10.1093/biomet/52.1-2.225.
- Kottas, A., and Sansó, B. (2007), “Bayesian Mixture Modeling for Spatial Poisson process Intensities, with Applications to Extreme Value Analysis,” Journal of Statistical Planning and Inference, 137, 3151–3163. DOI: 10.1016/j.jspi.2006.05.022.
- Laake, J. (2013), “RMark: An R Interface for Analysis of Capture-Recapture Data with MARK,” AFSC Processed Rep. 2013-01, Alaska Fish. Sci. Cent., NOAA, Natl. Mar. Fish. Serv., Seattle, WA.
- Lyons, J. E., Kendall, W. L., Royle, J. A., Converse, S. J., Andres, B. A., and Buchanan, J. B. (2016), “Population Size and Stopover Duration Estimation using Mark–Resight Data and Bayesian Analysis of a Superpopulation Model,” Biometrics, 72, 262–271. DOI: 10.1111/biom.12393.
- MacKenzie, D. I., Nichols, J. D., Lachman, G. B., Droege, S., Andrew Royle, J., and Langtimm, C. A. (2002), “Estimating Site Occupancy Rates when Detection Probabilities are less than one,” Ecology, 83, 2248–2255. DOI: 10.1890/0012-9658(2002)083[2248:ESORWD.2.0.CO;2]
- Manrique-Vallier, D. (2016), “Bayesian Population Size Estimation using Dirichlet Process Mixtures,” Biometrics, 72, 1246–1254.
- Matechou, E., and Caron, F. (2017), “Modelling Individual Migration Patterns using a Bayesian Nonparametric Approach for Capture–Recapture Data,” The Annals of Applied Statistics, 11, 21–40. DOI: 10.1214/16-AOAS989.
- Matechou, E., Nicholls, G. K., Morgan, B. J., Collazo, J. A., and Lyons, J. E. (2016), “Bayesian Analysis of Jolly-Seber Type Models,” Environmental and Ecological Statistics, 23, 531–547. DOI: 10.1007/s10651-016-0352-0.
- Miller, J. W., and Harrison, M. T. (2018), “Mixture Models with a Prior on the Number of Components,” Journal of the American Statistical Association, 113, 340–356. DOI: 10.1080/01621459.2016.1255636.
- Molitor, J., Papathomas, M., Jerrett, M., and Richardson, S. (2010), “Bayesian Profile Regression with an Application to the National Survey of Children’s Health,” Biostatistics, 11, 484–498. DOI: 10.1093/biostatistics/kxq013.
- Otis, D. L., Burnham, K. P., White, G. C., and Anderson, D. R. (1978), “Statistical Inference from Capture Data on Closed Animal Populations,” Wildlife Monographs, 62, 3–135.
- Pitman, J. (1996), “Some Developments of the Blackwell-Macqueen urn Scheme,” in Statistics, Probability and Game Theory: Papers in Honor of David Blackwell, volume 30 of IMS Lecture Notes-Monograph Series, eds. T. S. Ferguson, L. S. Shapley, and J. B. MacQueen, pp. 245–267, Hayward, CA: Institute of Mathematical Statistics.
- Pledger, S. (2000), “Unified Maximum Likelihood Estimates for Closed Capture–Recapture Models Using Mixtures,” Biometrics, 56, 434–442. DOI: 10.1111/j.0006-341x.2000.00434.x.
- Pledger, S., Efford, M., Pollock, K., Collazo, J., and Lyons, J. (2009), “Stopover Duration Analysis with Departure Probability Dependent on Unknown Time Since Arrival,” in Modeling Demographic Processes in Marked Populations, eds. D. L. Thomson, E. G. Cooch, and M. J. Conroy, pp. 349–363, New York: Springer.
- Plummer, M., Best, N., Cowles, K., and Vines, K. (2006), “CODA: Convergence Diagnosis and Output Analysis for MCMC,” R News, 6, 7–11.
- Pollock, K. H. (1982), “A Capture-Recapture Design Robust to Unequal Probability of Capture,” The Journal of Wildlife Management, 46, 752–757. DOI: 10.2307/3808568.
- Roberts, G. O., Gelman, A., and Gilks, W. R. (1997), “Weak Convergence and Optimal Scaling of Random Walk Metropolis Algorithms,” Annals of Applied Probability, 7, 110–120.
- Schwarz, C. J., and Arnason, A. N. (1996), “A General Methodology for the Analysis of Capture-Recapture Experiments in Open Populations,” Biometrics, 52, 860–873. DOI: 10.2307/2533048.
- Seber, G. A. F. (1965), “A Note on the Multiple-Recapture Census,” Biometrika, 52, 249–259. DOI: 10.1093/biomet/52.1-2.249.
- Taddy, M. A., and Kottas, A. (2012), “Mixture Modeling for Marked Poisson Processes,” Bayesian Analysis, 7, 335–362. DOI: 10.1214/12-BA711.
- Teh, Y. W., Jordan, M. I., Beal, M. J., and Blei, D. M. (2006), “Hierarchical Dirichlet Processes,” Journal of the American Statistical Association, 101, 1566–1581. DOI: 10.1198/016214506000000302.
- Wade, S., and Ghahramani, Z. (2018), “Bayesian Cluster Analysis: Point Estimation and Credible Balls” (with discussion), Bayesian Analysis, 13, 559–626. DOI: 10.1214/17-BA1073.
- Zhou, M., McCrea, R. S., Matechou, E., Cole, D. J., and Griffiths, R. A. (2019), “Removal Models Accounting for Temporary Emigration,” Biometrics, 75, 24–35. DOI: 10.1111/biom.12961.