
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Nonlinear dynamic modeling of spatio-temporal data is often a challenge, especially due to irregularly observed locations and location-wide nonstationarity. In this article we propose a semiparametric family of Dynamic Functional-coefficient Autoregressive Spatio-Temporal (DyFAST) models to address the difficulties. We specify the autoregressive smoothing coefficients depending dynamically on both a concerned regime and location so that the models can characterize not only the dynamic regime-switching nature but also the location-wide nonstationarity in real data. Different smoothing schemes are then proposed to model the dynamic neighboring-time interaction effects with irregular locations incorporated by (spatial) weight matrices. The first scheme popular in econometrics supposes that the weight matrix is pre-specified. We show that locally optimal bandwidths by a greedy idea popular in machine learning should be cautiously applied. Moreover, many weight matrices can be generated differently by data location features. Model selection is popular, but may suffer from loss of different candidate features. Our second scheme is thus to suggest a weight matrix fusion to let data combine or select the candidates with estimation done simultaneously. Both theoretical properties and Monte Carlo simulations are investigated. The empirical application to an EU energy market dataset further demonstrates the usefulness of our DyFAST models. Supplementary materials for this article are available online.
1 Introduction
Nonlinear modeling of complex spatio-temporal processes has been widely recognized an important but challenging issue in analysis of geospatial big data (see Comber and Wulder Citation2019). In this article we propose a semiparametric family of Dynamic Functional-coefficient Autoregressive Spatio-Temporal (DyFAST) models to address the difficulty in modeling and analysis of our spatio-temporal data, ,
, observed at locations
,
, that are irregularly positioned on the earth surface, with the data nonstationary over the irregular locations in space, where
and
stand for the latitude and longitude of the location
. It is well known that time is unidirectional from the past to the future and the popular differencing operation along time hence, makes it easy to change a nonstationary time series into a stationary series (see, Box et al. Citation2015). However, locations are multidirectional, which makes it harder to turn nonstationary data into stationary ones across locations, in particular with irregularly positioned locations (see, Lu et al. Citation2009; Al-Sulami et al. Citation2017). We therefore consider our DyFAST models with such spatio-temporal data that are with irregularly observed locations and location-wide non-stationarity but the data are stationary in the time direction.
The proposed DyFAST models at least own two significant features that make the model family useful. The first feature lies in the autoregressive smoothing coefficients depending both on concerned regime variable and spatial location. They extend linear or semiparametric spatial autoregressive models (see Ord Citation1975; Gelfand et al. Citation2003; Hallin, Lu, and Tran Citation2004; Gao, Lu, and Tjøstheim Citation2006; Sun et al. Citation2014, among others) to nonlinear spatio-temporal modeling with irregular locations. Here the dynamic features of spatio-temporal data are characterized by the autoregressive structure together with the advantage of functional (or varying) coefficients (see, e.g., Chen and Tsay Citation1993; Fan and Zhang Citation1999). In fact, through the autoregressive smoothing coefficients depending on both regime and location, the DyFAST models not only well characterize the nonlinear dynamic regime-switching nature but also overcome the irregular-location-wide nonstationarity existent in spatio-temporal data.
The second feature of our DyFAST models lies in two schemes proposed to model the dynamic spatial neighboring temporal-lagged effects with the irregular locations by spatial weight matrix. Our first scheme is popular in spatial econometrics with the idea of using spatial weight matrix pre-specified either by experts or by information of spatial locations (see, Anselin Citation1988). In practice, such spatial weight matrix can be pre-specified in many different ways. Although the idea of model selection can be applied to select an optimal weight matrix among the candidates, it may lead to loss of the important features of different spatial weight matrices (see Zhang and Yu Citation2018). Our second scheme is therefore to suggest using the idea of weight matrix fusion to combine the candidate spatial weight matrices, letting data decide the significance of each candidate weight matrix. This idea is different from the average of spatial linear AR models with different weight matrices in Zhang and Yu (Citation2018).
Accordingly, different semiparametric estimation procedures for our DyFAST models are suggested. Differently from the two-step estimation procedure (see Lu et al. Citation2009; Al-Sulami et al. Citation2017) that separates utilization of spatial and temporal information into two steps, we will first explore a one-step estimation procedure in our Scheme one, where all the data across space and time are used together to estimate the unknown coefficients in one step. Compared with the two-step procedure, we will investigate the differences between both procedures both in theory and in simulation. From the comparisons we will clearly see some advantages of the one-step procedure for data analysis, which will be more identified through simulations. In particular, when the sample sizes are not sufficiently large, we recommend one-step procedure for estimation, while with large sample sizes, we can apply the two-step procedure but should carefully select the bandwidths as done for the one-step one. In fact, we will show that the optimal greedy bandwidths in each step of the two-step procedure would generate poor estimation. Further smoothing estimation procedure by fuzing the spatial weight matrices with Scheme two will be developed on the basis of Scheme one. The large sample theoretical properties and the finite sample Monte Carlo simulations for all the procedures are examined. Our empirical applications to an EU energy market dataset will further illustrate the usefulness of the suggested models and smoothing procedures.
Before ending this section, we should mention that the literatures on spatio-temporal modeling based on linear and/or covariance assumptions are abundant; see Cressie and Wikle (Citation2015) for a comprehensive review and the related references therein. Such linearity assumptions, for many real temporal and spatial data, may actually not be true but an initial or coarse approximation. The nonlinear analyses of time series data have been widely explored in the literature (see, e.g., Tong Citation1990; Fan and Yao Citation2003; Gao Citation2007; Teräsvirta, Tjøstheim, and Granger Citation2010). However, studies of nonlinear spatio-temporal modeling, in particular with irregular locations, are still rare when compared with the abundant literature of nonlinear time series analysis.
The structure of the remaining of this article is as follows. Section 2 introduces the proposed DyFAST models. Estimation by Scheme one with pre-specified spatial weight matrix is presented in Section 3. Section 4 further develops Scheme two for model estimation with the idea of fusion of spatial weight matrices. Asymptotic properties for the suggested smoothing procedures are developed in those sections. Numerical examples are demonstrated in Section 5 with simulation and Section 6 with real data of retail gasoline prices in European Union countries, both of which illustrate the usefulness of our proposed models and estimation schemes. All technical details together with the related supplementary materials including regularity conditions and proofs for the theorems are provided in an Appendix.
2 Dynamical Functional-Coefficient Autoregressive Spatio-Temporal (DyFAST) Models
We consider a spatio-temporal process that is observed at discrete time points,
and at irregularly positioned locations,
,
, on a spatial domain
, with
and
being the latitude and longitude of the location
, respectively. In practice, the data collected are usually nonstationary across space. For example, as indicated in the real data section, Section 6, we will consider the weekly changes of retail gasoline prices over different countries in the EU, which can be seen as stationary along time but nonstationary across different countries of the EU. Here note that different countries are irregularly positioned on the earth surface. We are therefore concerned with how to model the dynamic spatio-temporal lag interactions for this kind of data that are with irregularly observed locations and of location-wide non-stationarity.
To deal with the irregularly observed locations, a popular idea in spatial econometrics (see Anselin Citation1988) is to model the spatial neighboring effects of by using a spatial weight matrix
, the idea of which can be traced back to Cliff and Ord (Citation1972) and Ord (Citation1975), to define a so-called spatial lag (SL) variable
(2.1)
(2.1) where W is a row-wise standardized
matrix, with its elements
satisfying
,
and
. This pre-specified spatial weight matrix W can be presented either by experts’ knowledge or by using location-related information (see Anselin Citation1988, chap. 3). Often, the elements
’s are specified as a continuous function of
, say, the inverse of the distance between
and
, except at
, for which
. Here
is allowed to be of the so-called nugget effect involved in
(see, (3.2) in Section 3 and Assumption (A3)(iv) in Appendix A.1).
The idea of our proposed family of DyFAST models comes from taking into account the dynamic autoregressive impacts on from both the spatial neighboring lags and the temporal lags of
, the coefficients of which not only depend on the location s but also vary with a regime-switching covariate variable
, either a temporal or spatio-temporal process that is observable. In applications, this
may either be exogenous or some temporal lag of
that is of some real meaning. Then our semiparametric class of DyFAST models can be defined in the form
(2.2)
(2.2) where p and q are the neighboring and the location itself autoregressive lag orders, respectively, with
, and the autoregressive coefficients,
,
, are unknown functional of the regime variable
and location
, to characterize the nonlinear dynamic behavior and location-wise nonstationarity of
, with
for intercept,
,
, for spatial neighboring time-lag interactions, and
,
, for time-lag effects of
itself, and
is the error process of the model.
This semiparametric family takes account of some salient features of dynamic spatio-temporal data. It covers a wide range of existent models in the literature. For example, it extends, to the spatio-temporal network setting, the nonlinear functional-coefficient autoregressive time series model at each fixed location , which is very popular in the literature of time series data analysis (see Chen and Tsay Citation1993; Cai, Fan, and Yao Citation2000). Our DyFAST family also extends the semiparametric spatio-temporal models of Subba Rao (Citation2008), Lu et al. (Citation2009), and Al-Sulami et al. (Citation2017), among others. For example, when
,
, are independent of the regime variable
, the DyFAST models reduce to a linear or partially linear spatio-temporal autoregressive model from the forecasting perspective (see Al-Sulami et al. Citation2017). This kind of autoregressive spatio-temporal model can hence well characterize the location-wise nonstationarity existent in the data. However, at each location
, it is still a constant coefficient linear time series model. In fact, Subba Rao (Citation2008) only considered the temporal lag effect without taking the spatial neighboring effects into account, while Lu et al. (Citation2009) only applies to the case when the data are observed regularly on a lattice with a small same number of neighboring variables able to be well specified for each site, which is impossible to be implemented for irregularly positioned data considered in this article. Furthermore, the considered model of Al-Sulami et al. (Citation2017) is only a special case of model (2.2) as mentioned, which is unable to capture the dynamic regime-switching effects in reality. Clearly, our DyFAST model (2.2) can overcome these shortcomings.
We will propose two schemes to estimate the dynamic spatial neighboring temporal-lagged effects in model (2.2) adapting to the irregular locations. Our first scheme uses the idea of spatial weight matrix pre-specified either by experts or by the prior information of spatial locations. Because such a spatial weight matrix may be pre-specified in many different ways (see, Anselin Citation1988), our second scheme is to propose an idea of combining the candidate spatial weight matrices, letting data decide the significance of each candidate. Accordingly, we will suggest different semiparametric estimation procedures detailed below.
3 Scheme 1: Pre-specified Spatial Weight Matrix
With a pre-specified spatial weight matrix W given, the DyFAST models given in (2.2) can be rewritten as(3.1)
(3.1) for
, with
, and
, where the notation
denotes the transpose of a vector or matrix A,
(3.2)
(3.2)
the vector of spatio-temporally lagged variables, and
(3.3)
(3.3)
the corresponding vector of functional autoregressive coefficients.
3.1 A One-Step Estimation Method
We first consider to estimate the coefficients in (3.1). Differently from the two-step estimation procedure (see, Lu et al. Citation2009; Al-Sulami et al. Citation2017) separating utilization of spatial and temporal information into two steps, this study suggests a one-step estimation procedure by considering
as a function of
and
. In this procedure, all the data across space and time are used together to estimate the coefficients
in one step.
By the idea of local linear fitting (see Fan and Gijbels Citation1996), we can approximate the unknown function by a local linear function if
is close to
. For a given
, we denote
by
and
by
, where
and is defined similarly. Then for any
and
in the neighborhood of x and s, respectively, we have
(3.4)
(3.4)
Locally, estimating is equivalent to estimating
, where
for
. This motivates an estimator by setting
,
, and
, minimizing
(3.5)
(3.5) with respect to
,
, where
, with K a kernel function on
and
a bandwidth, and
with L a kernel function on
and
another bandwidth.
We let denote a
-dimensional vector, with
. Also, denote by
the Kronecker product and
the
-dimensional vector with all components being 1. Then, with
, the local linear estimator of
derived from (3.5) is given by
(3.6)
(3.6) where
and
with
denoting an
matrix with its
th row equal to
for and
, and
3.2 Asymptotic Property
We establish the asymptotic property for the estimator in this section. All the regularity assumptions needed are collected in Appendix A.1. Let
. Then it follows from (3.6) that
(3.7)
(3.7)
(3.8)
(3.8)
Then by (3.6) together with (3.7) and (3.8), we have(3.9)
(3.9)
(3.10)
(3.10) where
.
We give some preliminary lemmas before stating the asymptotic normality for . We need to introduce some additional notations. Denote by
the marginal probability density function of
at a given location s,
the intensity function of the observing locations
,
, and
,
.
Lemma 3.1
.
Under the assumptions given in Appendix A.1,as
, where
stands for convergence in probability.
Next, we consider the asymptotic behavior of , with its components
, for
, corresponding to those of
in (3.10), respectively.
Lemma 3.2
.
Under the assumptions given in Appendix A.1,(3.11)
(3.11)
as
, where
, with
The following lemma provides the asymptotic variance of .
Lemma 3.3
.
Under the assumptions in Appendix A.1,(3.12)
(3.12) where
Here ,
and
are the limits of
and
, respectively, and
is the limit of the joint probability density
of
, defined in Assumption (A1), as
and
tend to s (i.e.,
and
with
for the Euclidean norm in
).
We remark that the notations ,
and
given in
in Lemma 3.3 are denoted simply for the limits of
,
and
as
and
tend to s. They do not mean that
,
and
are continuous at
, which may not hold true in the presence of the so-called nugget effect (Cressie Citation1993, sec. 2.3.1). See also the discussions in Lu, Tjøstheim, and Yao (Citation2008) and Lu et al. (Citation2009).
We now present the asymptotic normality result.
Theorem 3.1
.
Let the Assumptions in Appendix A.1 hold. Then(3.13)
(3.13) as
, where
is defined in Lemma 3.2,
is a
-dimensional normal random vector with zero mean and identity variance matrix, and
and
are two
matrices, satisfying
The proof of the lemmas and Theorem 3.1 will be given in Appendix A.3.
Remark 1.
From Theorem 3.1, the optimal bandwidths for estimating in the one-step method can be obtained by minimizing the asymptotic mean squared error of the estimator in the form
(3.14)
(3.14) minimizing of which with respect to
leads to the optimal bandwidths
(3.15)
(3.15)
where
,
, and
Remark 2.
Based on the optimal bandwidths as given in Remark 1, we have . Therefore, if
, then the rate of the convergence for
is of the usual semiparametric order
on the left hand side of (3.13). Alternatively, if
, then the rate of the convergence for
is of order
on the left hand side of (3.13). This implies that if the observing (spatial) locations are sufficiently dense with the number N sufficiently large relatively to the time series sample size T, our semiparametric estimator can even achieve the time series parametric rate of root T (up to the bias), which is an interesting finding with modeling of spatio-temporal data by the one-step procedure.
3.3 Discussion on Comparison with a Two-Step Procedure
Alternative to the above estimation, we can develop a two-step procedure for estimating the unknown function as in Lu et al. (Citation2009) and Al-Sulami et al. (Citation2017), which is sketched for comparison as follows.
Step 1: (Time-series based estimation) This step just follows the estimation procedure in Cai, Fan, and Yao (Citation2000). For each location , the functions
are estimated by a local linear fitting. For
in the neighborhood of x,
(3.16)
(3.16)
Then, we define an estimator by and
, minimizing
(3.17)
(3.17) w.r.t.
, where
, with K the kernel function on
and
denoting the temporal bandwidth.
Then the local linear estimators can be expressed as(3.18)
(3.18)
where ,
denotes an
matrix with
as its
th row for
, and
Step 2: (Spatial smoothing) The estimators based on Step-1 procedure can be improved by pooling the information from neighboring locations by spatial smoothing (Lu et al. Citation2009). At the observing locations , there is a spatial sampling intensity function
over S (see Assumptions in Appendix A.1). Then a spatial smoothing estimator of
is obtained by
(3.19)
(3.19) where
is the ith component of
, a local linear fitting equivalent kernel function on
. Here
,
denotes an
matrix with the ith-row
, and
with
and
a kernel on
.
Theorem 3.2
.
Under Assumptions in Appendix A.1, as , the Step 1 estimator satisfies that for
,
(3.20)
(3.20) and the Step 2 estimator satisfies that for
,
(3.21)
(3.21)
where
is a
random vector with zero mean and identity variance matrix, with
,
and
and
as defined in Theorem 3.1.
Remark 3
.
The optimal greedy bandwidth for time series based estimation at each location
is derived similarly to that of Cai, Fan, and Yao (Citation2000), which is
following from (3.20). Here “greedy” means that the bandwidths are chosen to be optimal locally stepwise at all the locations, respectively, a popular idea applied in machine learning modeling. Then, with this order of
, by minimizing the squared bias plus variance of
given in (3.21), we can find
for the two-step procedure (note that this differs from the standard optimal bandwidth for spatial smoothing that is of order
in view of the two-dimensional smoothing). Clearly these
and
are different from those optimal bandwidths in (3.15) for the one-step estimation procedure given in Theorem 3.1.
Remark 4
.
It is interesting to discuss the comparison between the one-step and the two-step procedures. We note from (3.13) in Theorem 3.1 and (3.21) in Theorem 3.2 that the one-step and two-step methods have the same form of asymptotic biases and variances so they have the same form of Asymptotic Mean Squared Estimation Error (AMSE) as given in (3.14) in Remark 1. However, for the two-step estimation with the optimal bandwidths in Step 1 and
in Step 2 (or even worse if
), it leads to, from (3.14), that
(3.22)
(3.22) while for the one-step procedure with the optimal bandwidths
and
given in (3.15), it leads to, from (3.14), that
(3.23)
(3.23)
Remark 5
.
Clearly in (3.22) is much larger than
in (3.23). In fact it follows from (3.22) and (3.23) that
(3.24)
(3.24)
For example, consider the summation of the first and fourth terms on the RHS of (3.24), the minimum of which is achieved and equal to when
, that is,
. Therefore, (3.24) actually tends to infinity as
. This implies that the usual two-step estimation procedure with optimal greedy bandwidths in each of the two steps is not an optimal estimation. See more comparison of both methods in Section 5.
From Theorems 3.1 and 3.2 and the discussions above, we may conclude that when the sample sizes tend to infinity, both procedures of one-step and two-step share the same asymptotic mean squared errors. However, when applying the two-step procedure, the optimal greedy (i.e., locally optimal) bandwidths would generate poor estimation. In particular, when the sample sizes are not sufficiently large, we recommend one-step procedure for estimation, while with large sample sizes, we can apply the two-step procedure but should carefully select the bandwidths as done for the one-step one (see Section A.2).
4 Scheme 2: Fusion of Spatial Weight Matrices
In Section 3, we assume the spatial weight matrix W is well pre-specified. In real applications, it may not be always the case, and one can often specify different spatial weight matrices based on different features of the real data, such as distance based spatial weight matrix or contiguity based spatial weight matrix
, and so on (see, Anselin Citation1988). A significant problem is how those spatial weight matrices should be used for modeling in applications. We suggest a weight matrix fusion idea to solve the issue.
For simplicity, let us look at two spatial weight matrices and
(the case for more than two spatial weight matrices is easily extended), which we suppose are well pre-specified and linearly independent so that both weight matrices are essentially different, for model identifiability. We consider a convenient fusion idea of combining different individual spatial weight matrices in a form
(4.1)
(4.1) where
and
are unknown constants satisfying
so that W is row-wise standardized if
and
are row-wise standardized. Here we do not suppose
’s are necessarily nonnegative. So the elements of our new W may be negative and W is a kind of generalized spatial weight matrix. We let the data decide the combining weights
. Therefore, we have here extended model (2.2) with our Scheme 2 by combining spatial weight matrices as follows:
(4.2)
(4.2)
where ,
, are as specified in model (2.2), and
with
is the
th component of
, satisfying
and
.
This idea of combining weight matrices, in our setting of nonlinear modeling, is essentially different from, and more convenient than, the usual idea of spatial weights matrix selection and model averaging (see Zhang and Yu Citation2018, in the linear model setting). Note that in the usual model averaging, one first needs to establish different models with individual spatial weight matrices ’s taken, respectively, for W in the DyFAST modeling of Section 3 and then consider to average/combine those different models. Clearly, this model averaging idea is more involved from the modeling perspective. Actually, in our Scheme 2, for example, if
, then the model with
is automatically selected, while if
, so is the model with
. In the general case with
, it indicates that fusing different features in
and
is important for our DyFAST modeling.
We need to extend the procedure in Section 3 to include estimation of in Scheme 2 as follows. Let
for
. Then we can express (4.2) in the vector form of model (3.1) with newly defined
(4.3)
(4.3) denoting the vector of spatio-temporally lagged variables, and
(4.4)
(4.4)
the corresponding vector of functional autoregressive coefficients. Therefore, we can follow the one-step estimation procedure in Section 3 to get an estimator
(4.5)
(4.5)
As , we have
for
in model (4.2), can hence construct an estimator of
by
(4.6)
(4.6)
Further, note that for
and
. So we have
and can hence construct an estimator of
by
(4.7)
(4.7)
if the denominator of the RHS of (4.7) is not equal to zero. Otherwise, note that
so there must exist one
such that
Then we can estimate
by
Thus, with no loss of generality, we may assume
for simplicity below as the proofs for the
’s are similar.
Similar to Theorem 3.1, for the given in (4.5), we have
Theorem 4.1
.
Let Assumptions A1–A6 in Appendix A.1 hold and . Then
(4.8)
(4.8) as
, where
is a
random vector with zero mean and identity variance matrix, and
,
, and
are defined similarly to those in Lemma 3.2 and Theorem 3.1 with new
and
defined in (4.3) and (4.4), respectively.
The proof of Theorem 4.1 is similar to that for Theorem 3.1, so we omit the details here. For the estimators given in (4.6), by the continuous mapping theorem, it follows from Theorem 4.1 that
Corollary 4.1.
Under the assumptions of Theorem 4.1, we have(4.9)
(4.9) where
is a standard normal random variable,
with
is an
unit vector with 1 at the ith position.
Next, we give an asymptotic result for defined in (4.7).
Theorem 4.2
.
If Assumption A1(ii) holds for some and
holds for all s, then under the assumptions of Theorem 4.1
(4.10)
(4.10) where
and
with
,
, and
given in Lemma A.6 in Appendix A.4.
It is interesting to note from (4.10) that has a root-T convergence rate, which is independent of N. This is due to the infill asymptotic over space as specified in Assumption (A4) in Appendix A.1.
In the estimation procedures for Schemes 1 and 2 above, there are two lag orders in models (2.2) and (4.2) and two bandwidths
as indicated in (3.5), which need to be selected in application. See Appendix A.2 for their selections by a corrected AIC and cross-validation with details.
5 Simulation Study
We will consider the following data-generating simulating model, with a spatially varying exogenous variable specified below,
(5.1)
(5.1) where
, with
from a pre-specified spatial weight matrix W, satisfying
and
, and
follows iid Gaussian distribution
. For example, as in the real data Section 6, we can take
the centroid, a representing location, consisting of the latitude and longitude (scaled down by 100) of the ith country,
, in the EU. The covariate process
follows an autoregressive model of order 1,
, where
for
, and
follows iid
over t and
, which is independent of the model innovation
in (5.1). We take the functional coefficients
where
for
.
We generate data from model (5.1) as follows. At each location for
, the initial values of
are set to zero. Then we generate
for
, with the data at the first 50 time points discarded to warm up for stationary series in time, denoted as
,
,
. In practice, it is often more common that the number of the observations along time increases while the number of locations does not change that much. We therefore focus on the simulations in this scenario, with
, the number of the centroids of the EU countries considered in Section 6, and consider three time series lengths:
,
, and
, respectively. The temporal bandwidth
and the spatial bandwidth
are selected to be 0.4 and 7, respectively, in the estimation for simplicity. To assess the estimate of an unknown function
as a function of x over
(approximately between the 10th and the 90th percentiles of the data for the covariate
), we examine 50 points of x partitioning
. The performance of estimation will then be assessed by defining a squared estimation error (SEE) as a measure of the accuracy of curve estimation
(as a function of x) at a location s (see, Lu et al. Citation2009). Let
,
, be the 50 points that equally partition the interval
. To measure the accuracy of estimation for
as a function of x over
at
locations, we define, for
,
(5.2)
(5.2)
In the simulations, we will consider two spatial weight matrices, namely binary contiguity matrix () and distance function matrices (
), which are two most commonly used specifications for spatial weight matrix (LeSage and Pace Citation2009). For
, its elements are taken as
if two countries
and
are boundary to each other and 0 otherwise, and
. For
, its elements
, where
is the Euclidean distance between the centroids of two countries,
and
, and
. Both are then row-wise standardized so that all the new elements (say
) in each row sum up to 1, that is,
, for
, which are denoted as
and
, respectively.
We will study the finite sample performances of our two schemes from different aspects. In particular, we are concerned with how the one-step procedure performs when compared with the two-step one and with varying sample sizes in Scheme 1, and how the estimated fused spatial weight matrix impacts the performances of the proposed estimation procedure in Scheme 2.
First, we compare the performances of the estimation of by the one-step and the two-step procedures, respectively. We suppose the spatial weight matrix
in model (5.1). We repeat the simulation 100 times with time series length
, and thus have 100 values of SEE defined in (5.2) for each of
,
, with the one-step and the two-step methods, respectively, summarized in boxplots in with the four panels for
,
,
, and
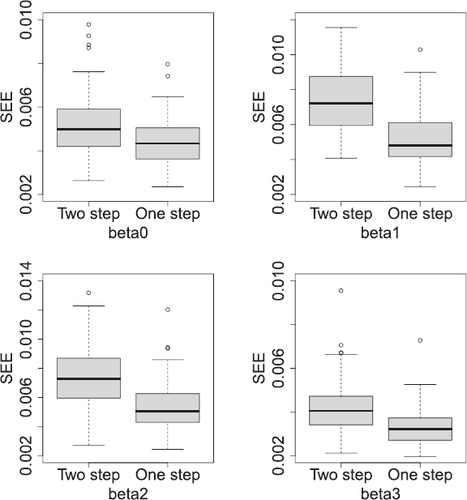
, respectively. The results clearly show that the one-step method has consistently smaller SEE values than the two-step method, and hence gets more accurate estimation than the two-step method for the considered T and N.
Figure 1: Boxplots of 100 Monte Carlo SEE values defined in (5.2) for the estimation of ,
, in the four panels, where the two-step (left) and the one-step (right) with
and
are presented in each panel.
Second, we compare the performances of the one-step method under three different time series sample sizes of ,
, and
, respectively. We repeat the Monte Carlo simulation 100 times, and thus obtain 100 SEE values defined in (5.2) for each of
,
, with the DyFAST (5.1) by the one-step estimation method, summarized in boxplots in in Appendix A.5. As expected, from , with the time series sample size increasing, the accuracy of the estimation of the
’s apparently improves. As shown, our Scheme 1 given in Section 3 can work well even for the sample size
.
Third, we examine Scheme 2 with the fusing/combining procedure of spatial weight matrices in Section 4 by estimating the combining weight a. Here we suppose the true spatial weight matrix with
and
as given in (4.1), in model (5.1). We consider the estimation with Scheme 2 under three time series sample sizes of
,
, and
, respectively. in Appendix A.5 shows the boxplots of 100 Monte Carlo values for the estimation of a, under
,
and
, respectively, which appears rather acceptable with the median of the 100 estimates of a very close to 0.6 even for the sample size
.
Figure 2: Boxplots of 100 Monte Carlo SEE values for the estimation of ,
, with
and
, for the DyFAST under the real (oracle) spatial weight matrix (
) and the estimated combined spatial weight matrix (
), respectively, in each panel.
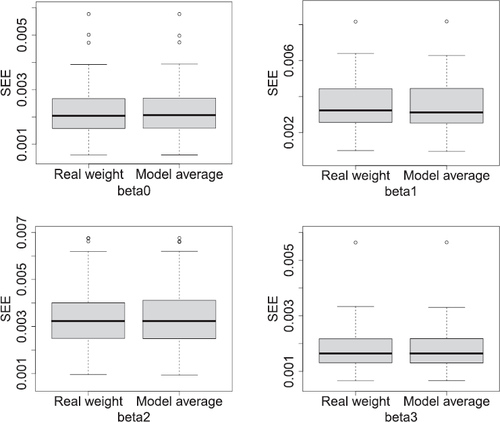
We further examine the impacts of the estimated combined weight matrix on the estimation of the coefficient functions of the DyFAST model. displays boxplots of the 100 Monte Carlo SEE values defined in (5.2) for the estimation of ,
, under the real spatial weight matrix W and the estimated combined spatial weight matrix
, respectively, under the sample size
. Moreover, Figure A.3 in Appendix A.5 presents the mean of the 100 Monte Carlo estimates of
,
with the DyFAST under the true spatial weight matrix W (in dotted lines) and the estimated combined spatial weight matrix
(in dashed lines), respectively, when compared with the true curves plotted in solid lines. We observe from both .3 that our estimates
,
mimic the corresponding true curves quite well even for the relatively small size
. The estimation results indicate that with our estimated combined spatial weight matrix, our DyFAST method can still accurately estimate the coefficient functions.
Moreover, we examine the efficiency of the estimation in the case that the true combined spatial weight matrix contains negative combining weight in the form with
and
. Figure A.4 in Appendix A.5 shows the boxplots of the 100 Monte Carlo values for estimation of
and
under
. It clearly follows from Figure A.4 that the proposed procedure can also accurately identify the negative combining weight for the candidate spatial weight matrices. The impacts of the estimated weight matrix on the estimation of the coefficient functions are omitted with similar outcomes as reported above. To sum up, these findings further demonstrate that our DyFAST method works very well with Scheme 2 even for the combined spatial weight matrix with negative combining weights.
6 Real Data Example
6.1 Background and Data
Retail gasoline prices are considerably fluctuating over time and across countries within the Europe. Numerous studies have examined the impact of crude oil price on retail gasoline prices, particularly focusing on the asymmetries in price transmission (see Wlazlowski et al. Citation2009; Clerides Citation2010). Any price dis-equilibria of retail gasoline in neighbor countries can cause “fuel travels” and create significantly cross-national spatial price spillovers in EU countries (Banfi, Filippini, and Hunt Citation2005; Wlazlowski et al. Citation2009). Negligence of the spatial dependency may hence cause a biased result. To better measure the price transmission of the retail gasoline in the EU, we will apply our DyFAST analysis in this study.
Our data consist of panel data of weekly spot prices for Brent crude oil price and diesel prices in European countries from January 26, 2015 to December 19, 2016. The data are obtained from European Commission (Source from: https://ec.europa.eu/energy/en/data-analysis/weekly-oil-bulletin), with all commodity prices expressed in EUR and the diesel prices inclusive of duties and taxes (Wlazlowski et al. Citation2009). The descriptive statistics for the raw data are reported in in Appendix A.5. As all the series at the price level are nonstationary (see, ), we will consider the data at the return level by computing the Brent crude oil price return (
) and the diesel prices return (
), through the difference in the logarithm of two consecutive weekly prices, multiplied by 100. For such country-level data, as usual, we take
to be the centroid (latitude and longitude, scaled down by 100) for country i,
, in the EU, where we have got the latitude and longitude scaled down by 100 for easy operations of nonparametric smoothing; see Figure A.5 in Appendix A.5 for the locations plotted. In the analysis as a demonstration, we took a simple and easy way to see, by a view of infill asymptotic, the centroid locations
’s simply as the observing locations in a continuous domain
of the EU, and the data as a realization of a space-continuous process indexed by location
in space, not of a “constant-by-area” process or a spatially discrete process, in population. See more discussions on this in Appendix A.6.
Table 1: Country groups.
6.2 The DyFAST Analysis
We are modeling the diesel prices return for country
by our DyFAST model (2.2) associated with the Brent crude oil price return (
), that is
for different countries. In estimating the spatial neighboring effect for diesel prices, there are different candidate weight matrices. In this study, for example, we can consider two pre-specified spatial weight matrices
and
, which are distance based. Let the centroid distances from each spatial unit (country) i to all other units
be ranked as follows:
, where
, and
is the Euclidean distance between the centroids of two countries
and
, and
stands for the country that is the kth closest to country i. Then for each
, the set
contains the k closest units to unit i. Then for
we consider
, and
containing the 2 closest units to unit i. The elements of
are set as
for
, and
otherwise. For
, we consider all neighboring countries with
, for
with
. All spatial weight matrices are then row-wise standardized, which we still denote as
and
below.
First, we apply the DyFAST to estimate the spatial neighboring effect for diesel price returns by Scheme 1, with and
considered as follows:
(6.1)
(6.1) where
and
are defined as in (2.1) with
and
, respectively, and the functional autoregressive coefficients are as given in (4.4). Because the
’s are irregularly positioned in space, we simply see them as the observing locations in space that is continuous as in geostatistics (see, Cressie Citation1993), in particular, in view of that fact that citizens of EU member countries can move freely around the countries of the EU. We therefore put the functional coefficients
’s in (6.1) as smooth functions of
as done in Lu et al. (Citation2009) and Al-Sulami et al. (Citation2017). The orders
of spatial neighboring and temporal lagged autoregressive effects are determined by Akaike Information Criterion with correction (AICc), which are listed in in Appendix A.5, with the model of optimal orders
and
as follows
(6.2)
(6.2)
Table 2: Comparison of forecasting results.
Moreover, the bandwidths used for estimation are decided by cross-validation, which are and
, respectively. Figure A.6 in Appendix A.5 shows the estimated coefficient functions of model (6.2). We can see that the functions
depicted in the top-middle panel and
in the top-right panel in Figure A.6, both of which are as functions of x with
, associated with
, appear to fluctuate around zero mostly. Intuitively, with more neighboring countries considered in
, it would be more important as indicated in bottom left and middle panels of Figure A.6. Therefore, we are considering the DyFAST by combining spatial weight matrices
and
to see whether the combining weight
is statistically significant by Scheme 2:
(6.3)
(6.3) where
and
are two constants, satisfying
. Moreover, the used bandwidths are decided by cross-validation, which are
and
, respectively. Then we can obtain the estimated combining weight vector (
,
), and the estimated functional coefficients
,
, are plotted in Figure A.7 in Appendix A.5. To test whether the
is statistically significant, we consider a bootstrap approach as the asymptotic variance of the estimator appears complex (see, Theorem 4.2). Given the observed sample
,
,
, the method proceeds as detailed in the Algorithm (Bootstrap for DyFAST) given in Appendix A.7.
By repeating the bootstrap 1000 times, we can obtain the t-values for and
based on the replications, which are equal to
and 2.7506, with the corresponding p-values equal to 0.6203 and 0.0061, respectively. These show that
is not, while
is, statistically significant at 1% significance level, which indicates that our method selects
as the optimal weight matrix (
and
). The top middle and right sub-figures in Figure A.7 further confirm that
and
as functions of x fluctuate nearly close to zero.
We now consider only to investigate the impacts of Brent crude oil price return on diesel price returns in the
EU countries, which is of a form
(6.4)
(6.4)
Figure A.8 in Appendix A.5 shows the estimated ’s as a function of x for the ith country, with the bandwidths
and
. Here we can see that for temporal lag equal to 1, the spatial neighboring effects (i.e.,
) are positive. Further, from Figure A.7,
(especially at the right side) and
(especially at the left side), as functions of x, can be categorized as three groups, as given in , with higher, medial or lower valued coefficients, respectively, for different
’s (i.e., the centroids, as representing locations, of different countries) . Such a division is useful for parameterization of the thresholds used for forecasting in Appendix A.8. Note that, for simplicity, we put
’s as usual the centroids, representing locations, of different countries, which are actually separated though both countries among them may be neighbored. Here the Group 1 countries are basically located in North-Western Europe (except Portugal), and the Group 3 countries are located in Balkans, while the other countries belonging to Group 2 are in the middle belt between them. Finally, from Figure A.8, the self temporal lag effects (i.e.,
) are positive and relatively larger for Group 3 than those for Group 1 (near zero) and Group 2 (negative). These empirical findings seem to be interesting, which may help governments and energy users to mitigate the negative impacts from the expected or unexpected fluctuations in the oil and the neighboring retail gasoline markets and to better manage energy risk. Moreover, the local country governments may formulate relevant energy policies on the basis of their geographical locations.
To further evaluate our methods and findings in application, we have compared the one-step ahead prediction performances of our DyFAST specifications (6.2)–(6.4) together with threshold parameterization of the smoothing coefficients in (6.4) (denoted by ‘Threshold’; see, Appendix A.8) as well as the (location-wise) linear model with spatial lags (i.e., (6.4) with the coefficients independent of x; denoted by “LinearSpat”) and the (location-wise) time series linear AR model (i.e., the mentioned LinearSpat model without considering spatial lag terms; denoted by LinearAR). The corresponding Mean Squared Prediction Errors (MSPEs) for one-step ahead forecasting are reported in with the details presented in Appendix A.9, where we set aside the last
data for forecasting evaluation and used the first
data as training set. Clearly, our DyFAST model and schemes can well uncover the nonlinear effects of the crude oil price fluctuations on the retail gasoline prices with prediction significantly improved by our models, especially the “Threshold” model with the smallest MSPE of 1.507, as indicated in ; see Appendix A.8 for more discussions.
In summary, our proposed methodologies can help to meet the challenges well in our setting, especially: (a) the irregularly positioned locations that make it hard to characterize the neighboring effects for selection of an optimal spatial weight matrix for forecasting; (b) the spatio-temporal dependencies with location-wide non-stationarity making it difficult to characterize the mutual interactions for a dynamic system across time and space; (c) the complex spatio-temporal interactions that make it hard to build an efficient procedure for computation of the estimation. We have hence proposed two DyFAST models characterizing nonlinear dynamic behavior of regime-switching nature, with two different estimation schemes defining spatial weight matrices together with one- and two-step procedures for estimation developed. The asymptotic theories for these estimation schemes are then established. Both simulation and real data examples have demonstrated the usefulness of the proposed methods in nonlinear analysis of spatio-temporal data.
Supplemental Material
Download PDF (508.9 KB)Acknowledgments
The authors are grateful to the Editor, Associate Editor, and two referees for their helpful comments for improvement of this article. All the authors contributed equally with names listed in an alphabetical order.
Key Projects of National Natural Science Foundation of Zhejiang Province;National Natural Science Foundation of China;Natural Science Foundation of Hunan Province;
Supplementary Materials
In the “Appendix: supplementary materials” file, we have collected the related supplementary materials with regularity conditions in Appendix A.1, practical bandwidth and model order selection in Appendix A.2, proofs for Sections 3 and 4 in Appendix A.3 and Appendix A.4, respectively, additional figures and tables for Sections 5 and 6 in Appendix A.5, more discussions on viewing data, locations and space continuous process in population for Section 6 in Appendix A.6, the bootstrap procedure for Section 6 in Appendix A.7, and evaluation of prediction for Section 6 in Appendix A.8.
Additional information
Funding
Related Research Data
References
- Al-Sulami, D., Jiang, Z., Lu, Z., and Zhu, J. (2017), “Estimation for Semiparametric Nonlinear Regression of Irregularly Located Spatial Time-Series Data,” Econometrics and Stats, 2, 22–35. DOI: 10.1016/j.ecosta.2017.01.002.
- Anselin, L. (1988), Spatial Econometrics: Methods and Models, Dordrecht: Springer.
- Banfi, S., Filippini, M., and Hunt, L. C. (2005), “Fuel Tourism in Border Regions: The Case of Switzerland,” Energy Economics, 27, 689–707. DOI: 10.1016/j.eneco.2005.04.006.
- Box, G. E., Jenkins, G. M., Reinsel, G. C., and Ljung, G. M. (2015), Time Series Analysis: Forecasting and Control, Hoboken, NJ: Wiley.
- Cai, Z., Fan, J., and Yao, Q. (2000), “Functional-Coefficient Regression Models for Nonlinear Time Series,” Journal of the American Statistical Association, 95, 941–956. DOI: 10.1080/01621459.2000.10474284.
- Chen, R., and Tsay, R. S. (1993), “Functional-Coefficient Autoregressive Models,” Journal of the American Statistical Association, 88, 298–308. DOI: 10.2307/2290725.
- Clerides, S., (2010), “Retail Fuel Price Response to Oil Price Shocks in EU Countries,” Cyprus Economic Policy Review, 4, 25–45.
- Cliff, A., and Ord, K. (1972), “Testing for Spatial Autocorrelation among Regression Residuals,” Geographical Analysis, 4, 267–284. DOI: 10.1111/j.1538-4632.1972.tb00475.x.
- Comber, A., and Wulder, M. (2019), “Considering Spatiotemporal Processes in Big Data Analysis: Insights from Remote Sensing of Land Cover and Land Use,” Transactions in GIS, 23, 879–891. DOI: 10.1111/tgis.12559.
- Cressie, N., (1993), Statistics For Spatial Data, New York: Wiley.
- Cressie, N., and Wikle, C. K. (2015), Statistics for Spatio-Temporal Data, Hoboken, NJ: Wiley.
- Fan, J., and Gijbels, I. (1996), Local Polynomial Modelling and Its Applications. Monographs on Statistics and Applied Probability 66. Boca Ratoon, FL: CRC Press.
- Fan, J., and Yao, Q. (2003), Nonlinear Time Series: Nonparametric and Parametric Methods, New York: Springer.
- Fan, J., and Zhang, W. (1999), “Statistical Estimation in Varying Coefficient Models,” The Annals of Statistics, 27, 1491–1518. DOI: 10.1214/aos/1017939139.
- Gao, J. (2007), Nonlinear Time Series: Semiparametric and Nonparametric Methods, Boca Raton, FL: CRC Press.
- Gao, J., Lu, Z., and Tjøstheim, D. (2006), “Estimation in Semiparametric Spatial Regression,” The Annals of Statistics, 34, 1395–1435. DOI: 10.1214/009053606000000317.
- Gelfand, A. E., Kim, H. J., Sirmans, C., and Banerjee, S. (2003), “Spatial Modeling with Spatially Varying Coefficient Processes,” Journal of the American Statistical Association, 98, 387–396. DOI: 10.1198/016214503000170.
- Hallin, M., Lu, Z., and Tran, L. T. (2004), “Local Linear Spatial Regression,” The Annals of Statistics, 32, 2469–2500. DOI: 10.1214/009053604000000850.
- LeSage, J., and Pace, R. K. (2009), Introduction to Spatial Econometrics, Boca Raton, FL: CRC Press.
- Lu, Z., Steinskog, D. J., Tjøstheim, D., and Yao, Q. (2009), “Adaptively Varying-Coefficient Spatiotemporal Models,” Journal of the Royal Statistical Society, Series B, 71, 859–880. DOI: 10.1111/j.1467-9868.2009.00710.x.
- Lu, Z., Tjøstheim, D., and Yao, Q. (2008), “Smoothing, Nugget Effect and Infill Asymptotics,” Statistics and Probability Letters, 78, 3145–3151. DOI: 10.1016/j.spl.2008.06.002.
- Ord, K., (1975), “Estimation Methods for Models of Spatial Interaction,” Journal of the American Statistical Association, 70, 120–126. DOI: 10.1080/01621459.1975.10480272.
- Subba Rao, S., (2008), “Statistical Analysis of a Spatio-Temporal Model with Location-Dependent Parameters and a Test for Spatial Stationarity,” Journal of Time Series Analysis, 29, 673–694. DOI: 10.1111/j.1467-9892.2008.00577.x.
- Sun, Y., Yan, H., Zhang, W., and Lu, Z. (2014), “A Semiparametric Spatial Dynamic Model,” Annals of Statistics, 42, 700–727.
- Teräsvirta, T., Tjøstheim, D., and Granger, C. (2010), Modelling Nonlinear Economic Time Series, Oxford: Oxford University Press.
- Tong, H., (1990), Non-linear Time Series: A Dynamical System Approach, Oxford: Oxford University Press.
- Wlazlowski, S., Giulietti, M., Binner, J., and Milas, C. (2009), “Price Dynamics in European Petroleum Markets,” Energy Economics, 31, 99–108. DOI: 10.1016/j.eneco.2008.08.009.
- Zhang, X., and Yu, J. (2018), “Spatial Weights Matrix Selection and Model Averaging for Spatial Autoregressive Models,” Journal of Econometrics, 203, 1–18. DOI: 10.1016/j.jeconom.2017.05.021.