
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Covariance function estimation is a fundamental task in multivariate functional data analysis and arises in many applications. In this article, we consider estimating sparse covariance functions for high-dimensional functional data, where the number of random functions p is comparable to, or even larger than the sample size n. Aided by the Hilbert–Schmidt norm of functions, we introduce a new class of functional thresholding operators that combine functional versions of thresholding and shrinkage, and propose the adaptive functional thresholding estimator by incorporating the variance effects of individual entries of the sample covariance function into functional thresholding. To handle the practical scenario where curves are partially observed with errors, we also develop a nonparametric smoothing approach to obtain the smoothed adaptive functional thresholding estimator and its binned implementation to accelerate the computation. We investigate the theoretical properties of our proposals when p grows exponentially with n under both fully and partially observed functional scenarios. Finally, we demonstrate that the proposed adaptive functional thresholding estimators significantly outperform the competitors through extensive simulations and the functional connectivity analysis of two neuroimaging datasets. Supplementary materials for this article are available online.
1 Introduction
The covariance function estimation plays an important role in functional data analysis, while existing methods are restricted to data with a single or small number of random functions. Recent advances in technology have made multivariate or even high-dimensional functional datasets increasingly common in various applications: for example, time-course gene expression data in genomics (Storey et al. Citation2005), air pollution data in environmental studies (Kong et al. Citation2016) and different types of brain imaging data in neuroscience (Li and Solea Citation2018; Qiao, Guo, and James Citation2019). Under such scenarios, suppose we observe n independent samples for
defined on a compact interval
with covariance function
From a heuristic interpretation, we can simply treat each curve as an infinitely long vector and replace the (j, k)th entry of
by
the cross-covariance matrix of two infinitely long vectors. Then
can be understood as a block matrix with infinite sizes and its (j, k)th block being
Besides being of interest in itself, an estimator of
is useful for many applications including, for example, multivariate functional principal components analysis (FPCA) (Happ and Greven Citation2018), multivariate functional linear regression (Chiou, Yang, and Chen Citation2016), functional factor model (Guo, Qiao, and Wang Citation2022) and functional classification (Park, Ahn, and Jeon Citation2021). See Section 2.3 for details.
Our article focuses on estimating under high-dimensional scaling, where p can be comparable to, or even larger than n. In this setting, the sample covariance function
where
performs poorly, and some lower-dimensional structural assumptions need to be imposed to estimate
consistently. In contrast to extensive work on estimating high-dimensional sparse covariance matrices (Bickel and Levina Citation2008; Rothman, Levina, and Zhu Citation2009; Cai and Liu Citation2011; Chen and Leng Citation2016; Avella-Medina et al. Citation2018; Wang et al. Citation2021), research on sparse covariance function estimation in high dimensions remains largely unaddressed in the literature.
In this article, we consider estimating sparse covariance functions via adaptive functional thresholding in the sense of shrinking some blocks ’s in an adaptive way. To achieve this, we introduce a new class of functional thresholding operators that combine functional versions of thresholding and shrinkage based on the Hilbert-Schmidt norm of functions, and develop an adaptive functional thresholding procedure on
using entry-dependent functional thresholds that automatically adapt to the variability of blocks
’s. To provide theoretical guarantees of our method under high-dimensional scaling, it is essential to develop standardized concentration results taking into account the variability adjustment. Compared with adaptive thresholding for nonfunctional data (Cai and Liu Citation2011), the intrinsic infinite-dimensionality of each
leads to a substantial rise in the complexity of sparsity modeling and theoretical analysis, as one needs to rely on some functional norm of standardized
’s, for example, the Hilbert–Schmidt norm, to enforce the functional sparsity in
and tackle more technical challenges for standardized processes within an abstract Hilbert space. To handle the practical scenario where functions are partially observed with errors, it is desirable to apply nonparametric smoothers in conjunction with adaptive functional thresholding. This poses a computationally intensive task especially when p is large, thus calling for the development of fast implementation strategy.
There are many applications of the proposed sparse covariance function estimation method in neuroimaging analysis, where brain signals are measured over time at a large number of regions of interest (ROIs) for individuals. Examples include the brain-computer interface classification (Lotte et al. Citation2018) and the brain functional connectivity identification (Rogers et al. Citation2007). Traditional neuroimaging analysis models brain signals for each subject as multivariate random variables, where each ROI is represented by a random variable, and hence the covariance/correlation matrices of interest are estimated by treating the time-course data of each ROI as repeated observations. However, due to the nonstationary and dynamic features of signals (Chang and Glover Citation2010), the strategy of averaging over time fails to characterize the time-varying structure leading to the loss of information in the original space. To overcome these drawbacks, we follow recent proposals to model signals directly as multivariate random functions with each ROI represented by a random function (Li and Solea Citation2018; Qiao, Guo, and James Citation2019; Zapata, Oh, and Petersen Citation2022; Lee et al. in press). The identified functional sparsity pattern in our estimate of can be used to recover the functional connectivity network among different ROIs, which is illustrated using examples of functional magnetic resonance imaging (fMRI) datasets in Section 6 and Section E.3 of the supplementary material.
Our article makes useful contributions at multiple fronts. On the method side, it generalizes the thresholding/sparsity concept in multivariate statistics to the functional setting and offers a novel adaptive functional thresholding proposal to handle the heteroscedastic problem of the sparse covariance function estimation motivated from neuroimaging analysis and many statistical applications, for example, those in Section 2.3 and Section C.2 of the supplementary material. It also provides an alternative way of identifying correlation-based functional connectivity with no need to specify the correlation function, the estimation of which poses challenges as the inverses of ’s are unbounded. In practice when functions are observed with errors at either a dense grid of points or a small subset of points, we also develop a unified local linear smoothing approach to obtain the smoothed adaptive functional thresholding estimator and its fast implementation via binning (Fan and Marron Citation1994) to speed up the computation without sacrificing the estimation accuracy. On the theory side, we show that the proposed estimators enjoy the convergence and support recovery properties under both fully and partially observed functional scenarios when p grows exponentially fast relative to n. The proof relies on tools from empirical process theory due to the infinite-dimensional nature of functional data and some novel standardized concentration bounds in the Hilbert–Schmidt norm to deal with issues of high-dimensionality and variance adjustment. Our theoretical results and adopted techniques are general, and can be applied to other settings in high-dimensional functional data analysis.
The remainder of this article is organized as follows. Section 2 introduces a class of functional thresholding operators, based on which we propose the adaptive functional thresholding of the sample covariance function. We then discuss a couple of applications of the sparse covariance function estimation. Section 3 presents convergence and support recovery analysis of our proposed estimator. In Section 4, we develop a nonparametric smoothing approach and its binned implementation to deal with partially observed functional data, and then investigate its theoretical properties. In Sections 5 and 6, we demonstrate the uniform superiority of the adaptive functional thresholding estimators over the universal counterparts through an extensive set of simulation studies and the functional connectivity analysis of a neuroimaging dataset, respectively. All technical proofs are relegated to the supplementary material. We also provide the codes to reproduce the results for simulations and real data analysis in supplementary materials.
2 Methodology
2.1 Functional Thresholding
We begin by introducing some notation. Let denotes a Hilbert space of square integrable functions defined on
and
where ⊗ is the Kronecker product. For any
we denote its Hilbert–Schmidt norm by
With the aid of Hilbert–Schmidt norm, for any regularization parameter
we first define a class of functional thresholding operators
that satisfy the following conditions:
for all Z and
Our proposed functional thresholding operators can be viewed as the functional generalization of thresholding operators (Cai and Liu Citation2011). Instead of a simple pointwise extension of such thresholding operators under functional domain, we advocate a global thresholding rule based on the Hilbert–Schmidt norm of functions that encourages the functional sparsity, in the sense that , for all
if
under condition (ii). Condition (iii) limits the amount of (global) functional shrinkage in the Hilbert–Schmidt norm to be no more than
Conditions (i)–(iii) are satisfied by functional versions of some commonly adopted thresholding rules, which are introduced as solutions to the following penalized quadratic loss problem with various penalties:
(1)
(1) with
being a penalty function of
to enforce the functional sparsity.
The soft functional thresholding rule results from solving (1) with an type of penalty,
and takes the form of
where
for
This rule can be viewed as a functional generalization of the group lasso solution under the multivariate setting (Yuan and Lin Citation2006). To solve (1) with an
type of penalty,
we obtain hard functional threhsolding rule as
where
is an indicator function. As a comparison, soft functional thresholding corresponds to the maximum amount of functional shrinkage allowed by condition (iii), whereas no shrinkage results from hard functional thresholding. Taking the compromise between soft and hard functional thresholding, we next propose functional versions of SCAD (Fan and Li Citation2001) and adaptive lasso (Zou Citation2006) thresholding rules. With a SCAD penalty (Fan and Li Citation2001) operating on
instead of
for the univariate scalar case, SCAD functional thresholding
is the same as soft functional thresholding if
and equals
for
and Z if
where
Analogously, adaptive lasso functional thresholding rule is
with
Our proposed functional generalizations of soft, SCAD and adaptive lasso thresholding rules can be checked to satisfy conditions (i)–(iii), see Section B.1 of the supplementary material for details. To present a unified theoretical analysis, we focus on functional thresholding operators satisfying conditions (i)–(iii). Note that, although the hard functional thresholding does not satisfy condition (i), theoretical results in Section 3 still hold for hard functional thresholding estimators under similar conditions with corresponding proofs differing slightly. For examples of functional data with some local spikes, one may possibly suggest supremum-norm-based class of functional thresholding operators. See the detailed discussion in Section C.1 of the supplementary material.
2.2 Estimation
We now discuss our estimation procedure based on Note the variance of
depends on the distribution of
through higher-order moments, which is intrinsically a heteroscedastic problem. Hence, it is more desirable to use entry-dependent functional thresholds that automatically takes into account the variability of blocks
’s to shrink some blocks to zero adaptively. To achieve this, define the variance factors
with corresponding estimators
Then the adaptive functional thresholding estimator is defined by
(2)
(2) which uses a single threshold level to functionally threshold standardized entries,
for all j, k, resulting in entry-dependent functional thresholds for
’s. The selection of the optimal regularization parameter
is discussed in Section 5.
An alternative approach to estimate is the universal functional thresholding estimator
where a universal threshold level is used for all entries. In a similar spirit to Rothman, Levina, and Zhu (Citation2009), the consistency of
requires the assumption that marginal-covariance functions are uniformly bounded in nuclear norm, that is,
where
However, intuitively, such universal method does not perform well when nuclear norms vary over a wide range, or even fails when the uniform boundedness assumption is violated. Section 5 provides some empirical evidence to support this intuition.
2.3 Applications
Many statistical problems involving multivariate functional data require estimating the covariance function
Under a high-dimensional regime, the functional sparsity assumption can be imposed on
to facilitate its consistent sparse estimates. Here we outline three applications of our proposals for the sparse covariance function estimation.
Our first application is multivariate FPCA serving as a natural dimension reduction approach for With the aid of Karhunen-Loève expansion for multivariate functional data (Happ and Greven Citation2018),
admits the following expansion
(3)
(3) where the principal component scores
and eigenfunctions
,
are attainable by the eigenanalysis of
Under a large p scenario, we can adopt the proposed functional thresholding technique to obtain the sparse estimation of
which guarantees the consistencies of estimated eigenvalues/eigenfunctions pairs. In Section E.1 of the supplementary material, we follow the proposal of a normalized version of multivariate FPCA in Happ and Greven (Citation2018) and use a simulated example to illustrate the superior sample performance of our functional thresholding approaches.
Our second application, multivariate functional linear regression (Chiou, Yang, and Chen Citation2016), takes the form of
(4)
(4) where
is p-vector of functional coefficients to be estimated. The standard three-step procedure involves performing (normalized) multivariate FPCA on
’s based on
then estimating the basis coefficients vector of
and finally recovering the estimated functional coefficients, where details are presented in Section E.1 of the supplementary material and Chiou, Yang, and Chen (Citation2016). When p is large, we can implement our functional thresholding proposals to obtain consistent estimators of
and hence
In Section E.1 of the supplementary material, we demonstrate via a simulated example the superiority of our adaptive-functional-thresholding-based estimator over its competitors.
Our third application considers another dimension reduction framework via functional factor model (Guo, Qiao, and Wang Citation2022) in the form of where the common components are driven by r functional factors
the idiosyncratic components are
and
is the factor loading matrix. Denote the covariance functions of
and
by
and
respectively. Under the orthogonality of
can be decomposed as the sum of
and the remaining smaller order terms. Intuitively, with certain identifiable conditions,
can be recovered by carrying out an eigenanalysis of
To provide a parsimonious model and enhance interpretability for near-zero loadings, we can impose subspace sparsity conditions (Vu and Lei Citation2013) on
that results in a functional sparse
and hence our functional thresholding estimators become applicable. See an application of our functional thresholding technique to improve the estimation quality when fitting sparse functional factor model in Guo, Qiao, and Wang (Citation2022). See also Section C.2 of the supplementary material for other applications including functional graphical model estimation (Qiao, Guo, and James Citation2019) and multivariate functional classification.
3 Theoretical Properties
We begin with some notation. For a random variable W, define where
is a nondecreasing, nonzero convex function with
and the norm takes the value
if no finite c exists for which
Denote
for
. Let the packing number
be the maximal number of points that can fit in the compact interval
while maintaining a distance greater than ϵ between all points with respect to the semimetric d. We refer to Chapter 8 of Kosorok (Citation2008) for further explanations. For
define the standardized processes by
where
.
To present the main theorems, we need the following regularity conditions.
Condition 1
. (i) For each i and is a separable stochastic process with the semimetric
for
(ii) For some
is bounded.
Condition 2
. The packing numbers ’s satisfy
for some constants
and
Condition 3
. There exists some constant such that
Condition 4
. The pair (n, p) satisfies as n and
Conditions 1 and 2 are standard to characterize the modulus of continuity of sub-Gaussian processes ’s, see Chapter 8 of Kosorok (Citation2008). These conditions also imply that there exist some positive constants C0 and η such that
for all
and j with
which plays a crucial role in our proof when applying concentration inequalities within Hilbert space. Condition 3 restricts the variances of
’s to be uniformly bounded away from zero so that they can be well estimated. It also facilitates the development of some standardized concentration results. This condition precludes the case of a Brownian motion
starting at 0 for some j. However, replacing
with a contaminated process
where ξij’s are independent from a normal distribution with zero mean and a small variance and are independent of
’s, Condition 3 is fulfilled while the cross-covariance structure in
remains the same in the sense of
for
and
Condition 4 allows the high-dimensional case, where p can diverge at some exponential rate as n increases.
We next establish the convergence rate of the adaptive functional thresholding estimator over a large class of “approximately sparse” covariance functions defined by
for some
where
and
means that
is positive semidefinite, that is,
for any
and
See Cai and Liu (Citation2011) for a similar class of covariance matrices for nonfunctional data. Compared with the class
over which the universal functional thresholding estimator
can be shown to be consistent, the columns of a covariance function in
are required to be within a weighted
ball instead of a standard
ball, where the weights are determined by
’s. Unlike
no longer requires the uniform boundedness assumption on
’s and allows
In the special case q = 0,
corresponds to a class of truly sparse covariance functions. Notably,
can depend on p and be regarded implicitly as the restriction on functional sparsity.
Theorem 1
. Suppose that Conditions 1–4 hold. Then there exists some constant such that, uniformly on
if
(5)
(5)
Theorem 1 presents the convergence result in the functional version of matrix norm. The rate in (5) is consistent to those of sparse covariance matrix estimates in Rothman, Levina, and Zhu (Citation2009) and Cai and Liu (Citation2011).
We finally turn to investigate the support recovery consistency of over the parameter space of truly sparse covariance functions defined by
which assumes that
has at most
nonzero functional entries on each row. The following theorem shows that, with the choice of
for some constant
exactly recovers the support of
with probability approaching one.
Theorem 2
. Suppose that Conditions 1–4 hold and for all
and some
where δ is stated in Theorem 1. Then we have that
Theorem 2 ensures that achieves the exact recovery of functional sparsity structure in
that is, the graph support in functional connectivity analysis, with probability tending to 1. This theorem holds under the condition that the Hilbert-Schmidt norms of nonzero standardized functional entries exceed a certain threshold, which ensures that nonzero components are correctly retained. See an analogous minimum signal strength condition for sparse covariance matrices in Cai and Liu (Citation2011).
4 Partially Observed Functional Data
In this section we consider a practical scenario where each is partially observed, with errors, at random measurement locations
Let Zijl be the observed value of
Then
(6)
(6) where
’s are iid errors with
and
independent of
For dense measurement designs all Lij’s are larger than some order of n, while for sparse designs all Lij’s are bounded (Zhang and Wang Citation2016; Qiao et al. Citation2020).
4.1 Estimation Procedure
Based on the observed data, we next present a unified estimation procedure that handles both densely and sparsely sampled functional data.
We first develop a nonparametric smoothing approach to estimate ’s. Without loss of generality, we assume that
has been centered to have mean zero. Denote
for a univariate kernel function K with a bandwidth
A Local Linear Surface smoother (LLS) is employed to estimate cross-covariance functions
(
) by minimizing
(7)
(7) with respect to
Let the minimizer of (7) be
and the resulting estimator is
To estimate marginal-covariance functions
’s, we observe that
and hence apply a LLS to the off-diagonals of the raw covariances
We consider minimizing
with respect to
thus obtaining the estimate
Note that we drop subscripts j, k of
and j of
to simplify our notation in this section. However, we select different bandwidths
and
across
in our empirical studies.
To construct the corresponding adaptive functional thresholding estimator, a standard approach is to incorporate the variance effect of each into functional thresholding. However, the estimation of
’s involves estimating multiple complicated fourth moment terms (Zhang and Wang Citation2016), which results in high computational burden especially for large p. Since our focus is on characterizing the main variability of
rather than estimating its variance precisely, we next develop a computationally simple yet effective approach to estimate the main terms in the asymptotic variance of
For
let
(8)
(8) where
According to Section D.1 of the supplementary material, minimizing (7) yields the resulting estimator
(9)
(9)
where
can be represented via (S.12) in terms of
(10)
(10)
It is notable that the estimator in (9) is expressed as the sum of n independent terms. Ignoring the cross-covariances among observations within the subject that are dominated by the corresponding variances, we propose a surrogate estimator for the asymptotic variance of
by
(11)
(11) where
(12)
(12)
(13)
(13)
The rationale of multiplying the rate Ijk in (11) is to ensure that converges to some finite function when
and
as justified in Section D.4 of the supplementary material. In particular, the rate Ijk can be simplified to
for the sparse or moderately dense case and to
for the very dense case. Note that Ijk is imposed in (11) mainly for the theoretical purpose and hence will not place a practical constraint on our method.
In a similar procedure as above, the estimated variance factor of
for each j can be obtained by operating on
instead of
for
Substituting
in (2) by
we obtain the smoothed adaptive functional thresholding estimator
(14)
(14)
For comparison, we also define the smoothed universal functional thresholding estimator as with
A natural alternative to the proposed LLS-based smoothing procedure considers pre-smoothing each individual data. For densely sampled functional data, the observations for each i and j can be pre-smoothed through the local linear smoother to eliminate the contaminated noise, thus, producing reconstructed random curves
’s before subsequent analysis (Zhang and Chen Citation2007). See detailed implementation of pre-smoothing in Section D.2 of the supplementary material. For sparsely sampled functional data, such pre-smoothing step is not viable, while our smoothing proposal builds strength across functions by incorporating information from all the observations, and hence is still applicable. See also Section 5.3 for the numerical comparison between pre-smoothing and our smoothing approach under different measurement designs.
4.2 Theoretical Properties
In this section, we investigate the theoretical properties of for partially observed functional data. We begin by introducing some notation. For two positive sequences
and
we write
if there exits a positive constant c0 such that
We write
if and only if
and
hold simultaneously. Before presenting the theory, we impose the following regularity conditions.
Condition 5
. (i) Let be iid copies of a random variable U with density
defined on the compact set
with the Lij’s fixed. There exist some constants mf and Mf such that
(ii)
and Uijl are independent for each
Condition 6
. (i) Under the sparse measurement design, for all i, j and, under the dense design,
as
with Uijl’s independent of
(ii) The bandwidth parameters
as
Condition 5 is standard in functional data analysis literature (Zhang and Wang Citation2016). Condition 6 (i) treats the number of measurement locations Lij as bounded and diverging under sparse and dense measurement designs, respectively. To simplify notation, we assume that for the dense case and hC is of the same order as hM in Condition 6 (ii).
Condition 7
. There exists some constant such that
(15)
(15)
Condition 8
. There exist some positive constants and some deterministic functions
’s with
such that
(16)
(16)
Condition 9
. The pair (n, p) satisfies and
for some positive constant c2 as n and
We follow Qiao et al. (Citation2020) to impose Condition 7, in which the parameter γ1 depends on h and possibly L under the dense design. This condition is satisfied if there exist some positive constants such that for each
and
(17)
(17)
The presence of h2 comes from the standard results for bias terms under the boundedness condition for the second-order partial derivatives of over
(Yao, Müller, and Wang Citation2005; Zhang and Wang Citation2016). This concentration result is fulfilled under different measurement schedules ranging from sparse to dense designs as γ1 increases. For sparsely sampled functional data, Lemma 4 of Qiao et al. (Citation2020) established L2 concentration inequality for
for
which not only results in the same L2 rate as that in the sparse case (Zhang and Wang Citation2016) but also ensures (17) with the choice of
and
for some positive constant
Following the same proof procedure, the same concentration inequality also applies for
and hence Condition 7 is satisfied. This condition is also satisfied by densely sampled functional data, since it follows from Lemma 5 of Qiao et al. (Citation2020) that (17) holds for j = k and, with more efforts, also for
by choosing
for some small constant
when
and
for some constants
As L grows sufficiently large,
thus leading to the same rate as that in the ultra-dense case (Zhang and Wang Citation2016). Condition 8 gives the uniform convergence rate for
in the same form as (15) but with different parameter
A denser measurement design corresponds to a larger value of γ2 and a faster rate in (16). See the heuristic verification of Condition 8 in Section D.4 of the supplementary material. Condition 9 indicates that p can grow exponentially fast relative to n.
We next present the convergence rate of the smoothed adaptive functional thresholding estimator over a class of “approximate sparse” covariance functions defined by
for some
Theorem 3.
Suppose that Conditions 5–9 hold. Then there exists some constants such that, uniformly on
if
(18)
(18)
The convergence rate of in (18) is governed by internal parameters
and other dimensionality parameters. Larger values of γ1 correspond to a more frequent measurement schedule with larger L and result in a faster rate. The convergence result implicitly reveals interesting phase transition phenomena depending on the relative order of L to n. As L grows fast enough,
and the rate is consistent to that for fully observed functional data in (5), presenting that the theory for very densely sampled functional data falls in the parametric paradigm. As L grows moderately fast,
and the rate is faster than that for sparsely sampled functional data but slower than the parametric rate.
We finally present Theorem 4 that guarantees the support recovery consistency of
Theorem 4
. Suppose that Conditions 5–9 hold and for all
and some
where
is stated in Theorem 3, then
4.3 Fast Computation
Consider a common situation in practice, where, for each we observe the noisy versions of
at the same set of points,
across
Then the original model in (6) is simplified to
(19)
(19) under which the proposed estimation procedure in Section 4.1 can still be applied. Suppose that the estimated covariance function is evaluated at a grid of R × R locations,
To serve the estimation of
marginal- and cross-covariance functions and the corresponding variance factors, LLSs under the simplified model in (19) reduce the number of kernel evaluations from
to
which substantially accelerate the computation under a high-dimensional regime.
Apparently, such nonparametric smoothing approach is conceptually simple but suffers from high computational cost in kernel evaluations. To further reduce the computational burden, we consider fast implementations of LLSs by adopting a simple approximation technique, known as linear binning (Fan and Marron Citation1994), to the covariance function estimation. The key idea of the binning method is to greatly reduce the number of kernel evaluations through the fact that many of these evaluations are nearly the same. We start by dividing into an equally spaced grid of R points,
with binwidth
Denote by
the linear weight that Uil assigns to the grid point ur for
For the ith subject, we define its “binned weighted counts” and “binned weighted averages” as
respectively. The binned implementation of smoothed adaptive functional thresholding can then be done using this modified dataset
and related kernel functions
for
It is notable that, with the help of such binned implementation, the number of kernel evaluations required in the covariance function estimation is further reduced from
to
while only
additional operations are involved for each j in the binning step (Fan and Marron Citation1994).
We next illustrate the binned implementation of LLS, denoted as BinLLS, using the example of smoothed estimates for
in (9). Under Model (19), we drop subscripts j, k in
, and
due to the same set of points
across
Denote the binned approximations of
and Sab by
and
respectively. It follows from (8) and (10) that
both of which together with (9) yield the binned approximation of
as
where
, and
are the binned approximations of W1, W2, and
computed by replacing the related Sab’s in (S.12) of the supplementary material with the
’s. It is worth noting that, for each pair
the above binned implementation reduces the number of operations (i.e., additions and multiplications) from
to
since the kernel evaluations in
no longer depend on individual observations. presents the computational complexity analysis of LLS and BinLLS under Models (6) and (19). It reveals that the binned implementation dramatically improves the computational speed for both densely and sparsely sampled functional data, which is also supported by the empirical evidence in Section 5.3.
Table 1 The computational complexity analysis of LLS, BinLLS under Models (6), (19) when evaluating the corresponding smoothed covariance function estimates at a grid of R × R points.
To aid the binned implementation of the smoothed adaptive functional thresholding estimator, we then derive the binned approximation of the variance factor denoted by
It follows from (13) that
can be approximated by
Substituting each term in (11) with its binned approximation, we obtain that
It is worth mentioning that, when the binned approximations of
and
can be computed in a similar fashion except that the terms corresponding to r1 = r2 should be excluded from all double summations over
Finally, we obtain the binned adaptive functional thresholding estimator
with
and the corresponding universal thresholding estimator
with
5 Simulations
5.1 Setup
We conduct a number of simulations to compare adaptive functional thresholding estimators to universal functional thresholding estimators. Sections 5.2 and 5.3 consider scenarios where random functions are fully and partially observed, respectively.
In each scenario, to mimic the infinite-dimensionality of random curves, we generate functional variables by for
and
where
is a 50-dimensional Fourier basis function and
is generated from a mean zero multivariate Gaussian distribution with block covariance matrix
whose (j, k)th block is
for
The functional sparsity pattern in
with its (j, k)th entry
can be characterized by the block sparsity structure in
Define
with
and hence
for
Then we generate
with different block sparsity patterns as follows.
Model 1 (block banded). For
Model 2 (block sparse without any special structure). For
We implement a cross-validation approach (Bickel and Levina Citation2008) for choosing the optimal thresholding parameter in
. Specifically, we randomly divide the sample
into two subsamples of size n1 and
where
and
and repeat this N times. Let
and
be the adaptive functional thresholding estimator as a function of λ and the sample covariance function based on n1 and n2 observations, respectively, from the νth split. We select the optimal
by minimizing
where
denotes the functional version of Frobenius norm, that is, for any
with each
The optimal thresholding parameters in
can be selected in a similar fashion.
5.2 Fully Observed Functional Data
We compare the adaptive functional thresholding estimator to the universal functional thresholding estimator
under hard, soft, SCAD (with a = 3.7) and adaptive lasso (with η = 3) functional thresholding rules, where the corresponding
’s are selected by the cross-validation with
We generate n = 100 observations for
and replicate each simulation 100 times. We examine the performance of all competing approaches by estimation and support recovery accuracies. In terms of the estimation accuracy, reports numerical summaries of losses measured by functional versions of Frobenius and matrix
norms. To assess the support recovery consistency, we present in the average of true positive rates (TPRs) and false positive rates (FPRs), defined as
and
Since the results under Models 1 and 2 have similar trends, we only present the numerical results under Model 2 here to save space. See Tables 9 and 10 of the supplementary material for results under Model 1.
Table 2 The average (standard error) functional matrix losses over 100 simulation runs.
Table 3 The average TPRs/FPRs over 100 simulation runs.
Several conclusions can be drawn from and 9–10 of the supplementary material. First, in all scenarios, provides substantially improved accuracy over
regardless of the thresholding rule or the loss used. We also obtain the sample covariance function
the results of which deteriorate severely compared with
and
Second, for support recovery, again
uniformly outperforms
, which fails to recover the functional sparsity pattern especially when p is large. Third, the adaptive functional thresholding approach using the hard and the adaptive lasso functional thresholding rules tends to have lower losses and lower TPRs/FPRs than that using the soft and the SCAD functional thresholding rules.
5.3 Partially Observed Functional Data
In this section, we assess the finite-sample performance of LLS and BinLLS methods to handle partially observed functional data. We first generate random functions for
by the same procedure as in Section 5.1 with either nonsparse or sparse
depending on p. We then generate the observed values Zijl from (19), where the measurement locations Uil and errors
are sampled independently from
and
respectively. We consider settings of n = 100 and
changing from sparse to moderately dense to very dense measurement schedules. We use the Gaussian kernel with the optimal bandwidths proportional to
and
respectively, as suggested in Zhang and Wang (Citation2016), so for the empirical work in this article we choose the proportionality constants in the range
which gives good results in all settings we consider.
To compare BinLLS with LLS in terms of the computational speed and estimation accuracy, we first consider a low-dimensional example p = 6 with nonsparse generated by modifying Model 1 with
for
In addition to our proposed smoothing methods, we also implement local-linear-smoother-based pre-smoothing and its binned implementation, denoted as LLS-P and BinLLS-P, respectively. reports numerical summaries of estimation errors evaluated at R = 21 equally spaced points in
and the corresponding CPU time on the processor Intel(R) Xeon(R) CPU E5-2690 v3 @ 2.60GHz. The results for the sample covariance function
based on fully observed
are also provided as the baseline for comparison. Note that, LLS is too slow to implement for the case
so we do not report its result here.
Table 4 The average (standard error) functional matrix losses and average CPU time for p = 6 over 100 simulation runs.
A few trends are observable from . First, the binned implementations (BinLLS and BinLLS-P) attain similar or even lower estimation errors compared with their direct implementations (LLS and LLS-P) under all scenarios, while resulting in considerably faster computational speeds especially under dense designs. For example, BinLLS runs over 400 times faster than LLS when Second, all methods provide higher estimation accuracies as Li increases, and enjoy similar performance when functions are very densely observed, for example, Li = 51 and 101, compared with the fully observed functional case. However, the performance of LLS-P and BinLLS-P deteriorates severely under sparse designs, for example, Li = 11 and 21, since limited information is available from a small number of observations per subject. Among all competitors, we conclude that BinLLS is overall a unified approach that can handle both sparsely and densely sampled functional data well with increased computational efficiency and guaranteed estimation accuracy.
We next examine the performance of BinLLS-based adaptive and universal functional thresholding estimators in terms of estimation accuracy and support recovery consistency using the same performance measures as in . and Tables 11–14 of the supplementary material report numerical results for settings of p = 50 and 100 satisfying Models 1 and 2 under different measurement schedules. We observe a few apparent patterns from and 11–14. First, substantially outperforms
with significantly lower estimation errors in all settings. Second,
works consistently well in recovering the functional sparsity structures especially under the soft and SCAD functional thresholding rules, while
fails to identify such patterns. Third, the estimation and support recovery consistencies of
and
are improved as Li increases. When curves are very densely observed, for example,
we observe that both estimators enjoy similar performance with
and
in and 9–10 of the supplementary material. Such observation provides empirical evidence to support our remark for Theorem 3 about the same convergence rate between very densely observed and fully observed functional scenarios.
Table 5 The average (standard error) functional matrix losses for partially observed functional scenarios and p = 50 over 100 simulation runs.
Table 6 The average TPRs/FPRs for partially observed functional scenarios and p = 50 over 100 simulation runs.
6 Real Data
In this section, we aim to investigate the association between the brain functional connectivity and fluid intelligence (gF), the capacity to solve problems independently of acquired knowledge (Cattell Citation1987). The dataset contains subjects of resting-state fMRI scans and the corresponding gF scores, measured by the 24-item Raven’s Progressive Matrices, from the Human Connectome Project (HCP). We follow many recent proposals based on HCP by modeling signals as multivariate random functions with each region of interest (ROI) representing one random function (Lee et al. in press; Miao, Zhang, and Wong in press; Zapata, Oh, and Petersen Citation2022). We focus our analysis on subjects with intelligence scores
and
subjects with
, and consider p = 83 ROIs of three generally acknowledged modules in neuroscience study (Finn et al. Citation2015): the medial frontal (29 ROIs), frontoparietal (34 ROIs) and default mode modules (20 ROIs). For each subject, the BOLD signals at each ROI are collected every 0.72 sec for a total of L = 1200 measurement locations (14.4 min). We first implement the ICA-FIX preprocessed pipeline (Glasser et al. Citation2013) and a standard band-pass filter at
Hz to exclude frequency bands not implicated in resting state functional connectivity (Biswal et al. Citation1995). Figure 12 of the supplementary material displays examplified trajectories of pre-smoothed data. The adaptive functional thresholding method is then adopted to estimate the sparse covariance function and therefore the brain networks.
The sparsity structures in for both groups are displayed in . With
selected by the cross-validation, the network associated with
for subjects with
is more densely connected than that with
, as evident from . We further set the sparsity level to 70% and
and present the corresponding sparsity patterns in . The results clearly indicate the existence of three diagonal blocks under all sparsity levels, complying with the identification of the medial frontal, frontoparietal and default mode modules in Finn et al. (Citation2015). We also implement the universal functional thresholding method. However, compared with
the results of
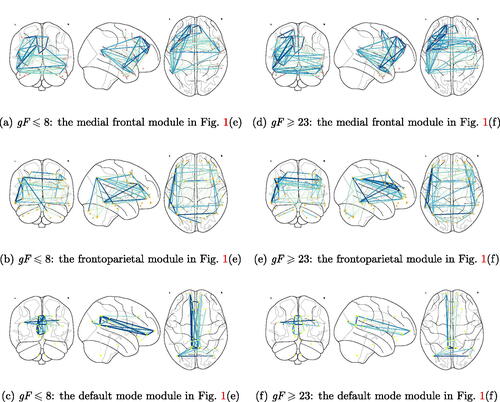
suffer from the heteroscedasticity, as demonstrated in Section 5 and Section E.3 of the supplementary material, and fail to detect any noticeable block structure, hence, we choose not to report them here. To explore the impact of gF on the functional connectivity, we compute the connectivity strength using the standardized form
for
Interestingly, we observe from that subjects with
tend to have enhanced brain connectivity in the medial frontal and frontoparietal modules, while the connectivity strength in the default mode module declines. This agrees with existing neuroscience literature reporting a strong positive association between intelligence score and the medial frontal/frontoparietal functional connectivity in the resting state (Van Den Heuvel et al. Citation2009; Finn et al. Citation2015), and lends support to the conclusion that lower default mode module activity is associated with better cognitive performance (Anticevic et al. Citation2012). See also Section E.3 of the supplementary material, in which we illustrate our adaptive functional thresholding estimation using another ADHD dataset.
Fig. 1 Estimated sparsity structures in using soft functional thresholding rule at fluid intelligence
and
: (a)–(b) with the corresponding
selected by 5-fold cross-validation; (c)–(f) with the estimated functional sparsity levels set at 70% and 85%.
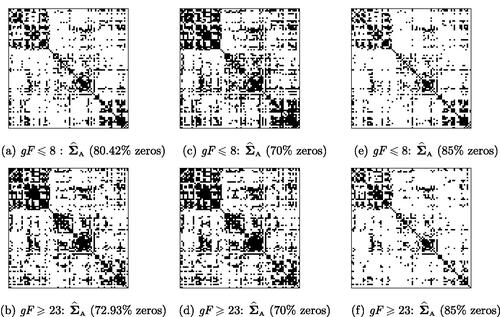
Fig. 2 The connectivity strengths in at fluid intelligence and
. Salmon, orange and yellow nodes represent the ROIs in the medial frontal, frontoparietal and default mode modules, respectively. The edge color from cyan to blue corresponds to the value of
from small to large.
Supplementary Materials
The supplementary materials contain all the technical proofs, further methodological derivations and additional discussion and empirical results. We also provide the codes and datasets in Sections 5 and 6 in the supplementary materials.
Supplemental Material
Download Zip (133.7 MB)Acknowledgments
We are grateful to the editor, the associate editor and two referees for their insightful comments and suggestions, which have led to significant improvement of our article.
Disclosure Statement
The authors report there are no competing interests to declare.
Additional information
Funding
Related Research Data
References
- Anticevic, A., Cole, M. W., Murray, J. D., Corlett, P. R., Wang, X.-J., and Krystal, J. H. (2012), “The Role of Default Network Deactivation in Cognition and Disease,” Trends in Cognitive Sciences, 16, 584–592. DOI: 10.1016/j.tics.2012.10.008.
- Avella-Medina, M., Battey, H. S., Fan, J., and Li, Q. (2018), “Robust estimation of High-Dimensional Covariance and Precision Matrices,” Biometrika, 105, 271–284. DOI: 10.1093/biomet/asy011.
- Bickel, P. J., and Levina, E. (2008), “Covariance Regularization by Thresholding,” The Annals of Statistics, 36, 2577–2604. DOI: 10.1214/08-AOS600.
- Biswal, B., Zerrin Yetkin, F., Haughton, V. M., and Hyde, J. S. (1995), “Functional Connectivity in the Motor Cortex of Resting Human Brain Using Echo-Planar MRI,” Magnetic Resonance in Medicine, 34, 537–541. DOI: 10.1002/mrm.1910340409.
- Cai, T., and Liu, W. (2011), “Adaptive Thresholding for Sparse Covariance Matrix Estimation,” Journal of the American Statistical Association, 106, 672–684. DOI: 10.1198/jasa.2011.tm10560.
- Cattell, R. B. (1987), Intelligence: Its Structure, Growth and Action, Amsterdam: Elsevier.
- Chang, C., and Glover, G. H. (2010), “Time–Frequency Dynamics of Resting-State Brain Connectivity Measured with fMRI,” Neuroimage, 50, 81–98. DOI: 10.1016/j.neuroimage.2009.12.011.
- Chen, Z., and Leng, C. (2016), “Dynamic Covariance Models,” Journal of the American Statistical Association, 111, 1196–1207. DOI: 10.1080/01621459.2015.1077712.
- Chiou, J.-M., Yang, Y.-F., and Chen, Y.-T. (2016), “Multivariate Functional Linear Regression and Prediction,” Journal of Multivariate Analysis, 146, 301–312. DOI: 10.1016/j.jmva.2015.10.003.
- Fan, J., and Li, R. (2001), “Variable Selection via Nonconcave Penalized Likelihood and its Oracle Properties,” Journal of the American Statistical Association, 96, 1348–1360. DOI: 10.1198/016214501753382273.
- Fan, J., and Marron, J. S. (1994), “Fast Implementations of Nonparametric Curve Estimators,” Journal of Computational and Graphical Statistics, 3, 35–56. DOI: 10.2307/1390794.
- Finn, E. S., Shen, X., Scheinost, D., Rosenberg, M. D., Huang, J., Chun, M. M., Papademetris, X., and Constable, R. T. (2015), “Functional Connectome Fingerprinting: Identifying Individuals Using Patterns of Brain Connectivity,” Nature Neuroscience, 18, 1664–1671. DOI: 10.1038/nn.4135.
- Glasser, M. F., Sotiropoulos, S. N., Wilson, J. A., Coalson, T. S., Fischl, B., Andersson, J. L., Xu, J., Jbabdi, S., Webster, M., Polimeni, J. R. et al. (2013), “The Minimal Preprocessing Pipelines for the Human Connectome Project,” Neuroimage, 80, 105–124. DOI: 10.1016/j.neuroimage.2013.04.127.
- Guo, S., Qiao, X., and Wang, Q. (2022), “Factor Modelling for High-Dimensional Functional Time Series,” arXiv:2112.13651v2 .
- Happ, C., and Greven, S. (2018), “Multivariate Functional Principal Component Analysis for Data Observed on Different (dimensional) Domains,” Journal of the American Statistical Association, 113, 649–659. DOI: 10.1080/01621459.2016.1273115.
- Kong, D., Xue, K., Yao, F., and Zhang, H. H. (2016), “Partially Functional Linear Regression in High Dimensions,” Biometrika, 103, 147–159. DOI: 10.1093/biomet/asv062.
- Kosorok, M. R. (2008), Introduction to Empirical Processes and Semiparametric Inference, Springer Series in Statistics, New York: Springer.
- Lee, K.-Y., Ji, D., Li, L., Constable, T., and Zhao, H. (in press), “Conditional Functional Graphical Models,” Journal of the American Statistical Association, DOI: 10.1080/01621459.2021.1924178.
- Li, B., and Solea, E. (2018), “A Nonparametric Graphical Model for Functional Data with Application to Brain Networks based on fMRI,” Journal of the American Statistical Association, 113, 1637–1655. DOI: 10.1080/01621459.2017.1356726.
- Lotte, F., Bougrain, L., Cichocki, A., Clerc, M., Congedo, M., Rakotomamonjy, A., and Yger, F. (2018), “A Review of Classification Algorithms for EEG-based Brain–Computer Interfaces: A 10 Year Update,” Journal of Neural Engineering, 15, 031005. DOI: 10.1088/1741-2552/aab2f2.
- Miao, R., Zhang, X., and Wong, R. K. (in press), “A Wavelet-based Independence Test for Functional Data with an Application to MEG Functional Connectivity,” Journal of the American Statistical Association, DOI: 10.1080/01621459.2021.2020126.
- Park, J., Ahn, J., and Jeon, Y. (2021), “Sparse Functional Linear Discriminant Analysis, Biometrika, 109, 209–226. DOI: 10.1093/biomet/asaa107.
- Qiao, X., Guo, S., and James, G. (2019), “Functional Graphical Models,” Journal of the American Statistical Association, 114, 211–222. DOI: 10.1080/01621459.2017.1390466.
- Qiao, X., Qian, C., James, G. M., and Guo, S. (2020), “Doubly Functional Graphical Models in High Dimensions,” Biometrika, 107, 415–431. DOI: 10.1093/biomet/asz072.
- Rogers, B. P., Morgan, V. L., Newton, A. T., and Gore, J. C. (2007), “Assessing Functional Connectivity in the Human Brain by fMRI,” Magnetic Resonance Imaging, 25, 1347–1357. DOI: 10.1016/j.mri.2007.03.007.
- Rothman, A. J., Levina, E., and Zhu, J. (2009), “Generalized Thresholding of Large Covariance Matrices,” Journal of the American Statistical Association, 104, 177–186. DOI: 10.1198/jasa.2009.0101.
- Storey, J. D., Xiao, W., Leek, J. T., Tompkins, R. G., and Davis, R. W. (2005), “Significance Analysis of Time Course Microarray Experiments,” Proceedings of the National Academy of Sciences, 102, 12837–12842. DOI: 10.1073/pnas.0504609102.
- Van Den Heuvel, M. P., Stam, C. J., Kahn, R. S., and Pol, H. E. H. (2009), “Efficiency of Functional Brain Networks and Intellectual Performance,” Journal of Neuroscience, 29, 7619–7624. DOI: 10.1523/JNEUROSCI.1443-09.2009.
- Vu, V. Q., and Lei, J. (2013), “Minimax Sparse Principal Subspace Estimation in High Dimensions,” The Annals of Statistics, 41, 2905–2947. DOI: 10.1214/13-AOS1151.
- Wang, H., Peng, B., Li, D., and Leng, C. (2021), “Nonparametric Estimation of Large Covariance Matrices with Conditional Sparsity,” Journal of Econometrics, 223, 53–72. DOI: 10.1016/j.jeconom.2020.09.002.
- Yao, F., Müller, H.-G., and Wang, J.-L. (2005), “Functional Data Analysis for Sparse Longitudinal Data,” Journal of the American Statistical Association, 100, 577–590. DOI: 10.1198/016214504000001745.
- Yuan, M., and Lin, Y. (2006), “Model Selection and Estimation in Regression with Grouped Variables,” Journal of the Royal Statistical Society, Series B, 68, 49–67. DOI: 10.1111/j.1467-9868.2005.00532.x.
- Zapata, J., Oh, S. Y., and Petersen, A. (2022), “Partial Separability and Functional Graphical Models for Multivariate Gaussian Processes, Biometrika, 109, 665–681. DOI: 10.1093/biomet/asab046.
- Zhang, J.-T., and Chen, J. (2007), “Statistical Inferences for Functional Data,” The Annals of Statistics, 35, 1052–1079. DOI: 10.1214/009053606000001505.
- Zhang, X., and Wang, J.-L. (2016), “From Sparse to Dense Functional Data and Beyond,” The Annals of Statistics, 44, 2281–2321. DOI: 10.1214/16-AOS1446.
- Zou, H. (2006), “The Adaptive Lasso and Its Oracle Properties,” Journal of the American Statistical Association, 101, 1418–1429. DOI: 10.1198/016214506000000735.