
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This article establishes a comprehensive theory of the optimality, robustness, and cross-validation selection consistency for the ridge regression under factor-augmented models with possibly dense idiosyncratic information. Using spectral analysis for random matrices, we show that the ridge regression is asymptotically efficient in capturing both factor and idiosyncratic information by minimizing the limiting predictive loss among the entire class of spectral regularized estimators under large-dimensional factor models and mixed-effects hypothesis. We derive an asymptotically optimal ridge penalty in closed form and prove that a bias-corrected k-fold cross-validation procedure can adaptively select the best ridge penalty in large samples. We extend the theory to the autoregressive models with many exogenous variables and establish a consistent cross-validation procedure using the what-we-called double ridge regression method. Our results allow for nonparametric distributions for, possibly heavy-tailed, martingale difference errors and idiosyncratic random coefficients and adapt to the cross-sectional and temporal dependence structures of the large-dimensional predictors. We demonstrate the performance of our ridge estimators in simulated examples as well as an economic dataset. All the proofs are available in the supplementary materials, which also includes more technical discussions and remarks, extra simulation results, and useful lemmas that may be of independent interest.
1 Introduction
Improving the bias-variance tradeoff is crucial in many high-dimensional forecasting applications. The classical least-squares regression can suffer from substantial predictive variance when the number of predictors is large compared with the sample size. One useful variance reduction strategy is summarizing massive raw features into a few leading principal components and then predicting the response with these low-dimensional predictors. When the large-dimensional covariates obey a factor structure, the principal component estimator can provide consistent forecasts of the regression function if the factors suffice to predict the target variable. The principal component regression (PCR) often shows better performance than the LASSO regression and ensemble algorithms such as bagging for macroeconomic forecasting; see, for example, Stock and Watson (Citation2002), De Mol, Giannone, and Reichlin (Citation2008), Stock and Watson (Citation2012), Castle, Clements, and Hendry (Citation2013), and Carrasco and Rossi (Citation2016). The PCR is also widely used when studying DNA microarrays (Alter, Brown, and Botstein Citation2000), medical shapes (Cootes et al. Citation1995), climate (Preisendorfer Citation1998), robust synthetic control (Agarwal et al. Citation2021) and many other fields (see Chapter 6 of James et al. Citation2021). While the PCR model is dense at the variable level (see, e.g., the discussions in Ng Citation2013), it relies on only low-dimensional principal components in forecasting. However, when many idiosyncratic components are useful, even though each is negligible, the PCR is not optimal and leaves room for improvement in many empirical applications.
Consider a toy example with covariates
, where we denote the transpose of any matrix or vector A by
, and
observations from a factor model given by
(1.1)
(1.1)
The latent factors and
, the entries of idiosyncratic variables
, and the entries of loading coefficients
and
are all generated independently from the standard normal distribution. One may think of the data vector
as a set of economic variables at a given time. We then generate the target variables
from a factor-augmented predictive regression model given by
(1.2)
(1.2) where the regression errors
are generated from the standard normal distribution independently of the regression means
. We generate the direction of the coefficient vector
uniformly over the
unit sphere, and thus each entry
is stochastically negligible for large p. Then we scale the total idiosyncratic signal
through the grid
. The PCR model is the special case with
. The idiosyncratic information, at aggregate level, becomes more important as
increases.
We plot the median, over 5000 replications, of the training predictive loss as a function of idiosyncratic signal length
on the left-hand-side of , where
and
denote the population and estimated means of the target variable
, respectively. We consider both the oracle PCR estimator using the true number of factors
, and the feasible PCR estimator using a number of PCs selected by 5-fold cross-validation. We compare these PCR estimators with the ridge regression estimator, hereinafter abbreviated as RR estimator, that uses all the raw variables
and does not require selecting the number of factors. We select the ridge penalty using 5-fold cross-validation. The median predictive loss of the PCR estimators grows (almost) linearly in the idiosyncratic signal length
, but that of the RR estimator grows significantly slower. The cross-validated RR estimator is only slightly worse than the oracle PCR estimator but comparable to the cross-validated PCR estimator for small
, whereas the advantage of RR estimator emerges quickly as
grows.
Figure 1: Median predictive loss (left) and change in median sample variance of estimated means (right) as functions of idiosyncratic signal .
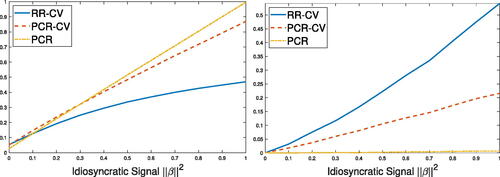
To illustrate the sensitivity of RR to the idiosyncratic information, we plot the median of the sample variance of the estimated means (which equals to the sum of squared estimated coefficients on all standardized components) over the replications on the right-hand-side of . To emphasize the changes, we only plot the differences to the values for . The variance of RR estimates grow quickly with
, while that of the oracle PCR coefficients hardly change. The cross-validation selection improves the sensitivity of PCR to
only slightly because a few extra components are actually asymptotically negligible in our dense models.
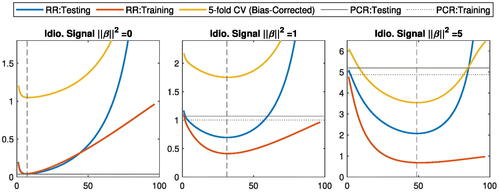
compares the training and testing predictive losses for ridge regression, averaged over 1000 replications, as functions of the effective degrees of freedom (see Hastie, Tibshirani, and Friedman Citation2009, p. 64) implied by the ridge penalty. We define testing predictive loss as the expected squared forecast error of the out-of-sample regression mean with new variables
and
using the estimated regression function and the new covariates
, where
and
are the population coefficients in (1.2). Again, the optimal ridge estimator (dashed line) for testing predictive loss matches the performance of PCR when
but outperforms PCR when
. More importantly, these plots illustrate an important relation between training and testing predictive losses for performance evaluation: they share (almost) the same optimal ridge penalty. We formally establish this universal property in Section 2 using a general notation of predictive loss, and generalize the results to time series data in Section 3.
Figure 2: Average training and testing predictive losses for RR and Oracle PCR.
Our toy example illustrates that omitting idiosyncratic information can lead to nontrivial loss in predictive efficiency, and the ridge regression is more robust against PCR capturing both factor and idiosyncratic information. The contribution of this article is a comprehensive theory of the optimality, robustness, and cross-validation consistency of the ridge regression under a general factor-augmented regression model given by
(1.3)
(1.3)
(1.4)
(1.4) where the left-hand side of the equations represent a large sample of observations in high dimensions:
is the demeaned design matrix of predictors
with large n and p, and
is the demeaned vector of univariate targets
. Throughout,
denotes the sample mean of any variable a. The low-rank matrix
collects low-dimensional latent factors
, r finite, and
is a large-dimensional random matrix of idiosyncratic components
. The matrix
is a rotation matrix, possibly unknown. The fixed-effects
on the factors and the random-effects
on the idiosyncratic components are both unknown. The noise component
is a demeaned vector of uncorrelated (but possibly dependent) regression errors
. One may also interpret (1.3) and (1.4) as an error-in-variables regression model (6.1) but we postpone the discussions to Section 6.
Many datasets support the low-rank perturbation form (1.3); see the survey by Johnstone and Paul (Citation2018) for many examples in electrocardiogram tracing, microarrays, satellite images, medical shapes, climate, signal detection, and finance. We assume that the low-rank coefficient matrix
has a divergent strength
at an arbitrary rate to separate the spectrum of the factor component
from the stochastically bounded spectrum of the idiosyncratic component
in (1.3). Therefore, we can analyze the spectral regularization using the standard eigenbasis without suffering from PCA inconsistency issues (Paul Citation2007; Johnstone and Lu Citation2009; Onatski Citation2012). Following Cai, Han, and Pan (Citation2020), we allow the unobservable idiosyncratic components to enter the factor model (1.3) subject to a possibly unknown rotation
for generality. We discuss the possibility of extending our results for
, especially when PCA becomes inconsistent, as future works in Appendix A.9 in the supplementary materials.
Our regression model (1.4) is the factor-augmented model proposed by Kneip and Sarda (Citation2011). Substituting under model (1.3) and using the identity
, we can reparameterize the regression model (1.4) as follows:
(1.5)
(1.5) where the entries of
and
are called common and specific effects, respectively. One might also interpret the last equation as a misspecified model where we only observe the design matrix X but not the latent factor matrix F. Throughout the article, we refer factor-augmented regression models to these two equivalent representations (1.4) and (1.5) exchangeably. Note that our model augments the purely variable-based model (with
) in, for example, Castle, Clements, and Hendry (Citation2013), Fan, Ke, and Wang (Citation2020) by adding extra factor information.
Unlike the aforementioned papers, we study the cases where the coefficient vector is possibly dense. Even if the true regression vector
on the idiosyncratic components is sparse, the regression vector
on the variables may contain little (or even no) zero entries due to a nontrivial rotation
. In general, we are interested in the models that are possibly dense at both variable and principal component levels. We consider every idiosyncratic component to be asymptotically negligible but allow them to have nontrivial aggregate explanatory power; see Jolliffe (Citation1982), Dobriban and Wager (Citation2018), Giannone, Lenza, and Primiceri (Citation2021), Hastie et al. (Citation2022), and many references therein for examples of applications.
Based on spectral analysis of large-dimensional random matrices, this article shows that the ridge regression is optimal in capturing factor and idiosyncratic information simultaneously among the entire class of spectral regularized estimators under the mixed-effects hypothesis. Ridge regression has a long tradition in statistics tracing back at least to Tikhonov (Citation1963a, Citation1963b) and Hoerl and Kennard (Citation1970); see Liu and Dobriban (Citation2020) for an excellent survey. To our knowledge, we are the first to study the ridge regression model with factor augmentation. Our analysis of large-dimensional covariance matrices under factor models requires a different approach from that in Dicker (Citation2016) and Dobriban and Wager (Citation2018). In particular, our results extend to more general data generating processes of covariates by analyzing limiting predictive loss instead of predictive risk (i.e., the expected predictive loss); see Appendix A.1 in the supplementary materials for comparisons with Dobriban and Wager (Citation2018).
We prove that the k-fold cross-validation selects the asymptotically optimal ridge penalty, as illustrated in , subject to a straightforward bias correction. The bias-corrected selection is uniformly consistent for all positive ridge penalties bounded away from zero, including those diverging to infinity. We extend the scope of the k-fold cross-validation to non-iid data and provide theoretical guarantee for dealing with martingale difference regression errors. Furthermore, we propose a new method called “double” ridge regression and an asymptotically correct k-fold cross-validation method in the presence of nuisance variables, in particular autoregressors, under mild conditions.
The rest of the article is organized as follows. We develop the asymptotic theories for independent errors in Section 2 and then generalize the results to martingale difference errors and autoregressive models in Section 3. More simulated and real-life examples are discussed in Sections 4 and 5, respectively. We conclude the article in Section 6. All the proofs of the theorems are postponed to the supplementary materials. The supplementary materials also provides more technical discussions and remarks about the conditions and auxiliary results, together with additional simulation results and some important lemmas that may be of independent interest.
2 Main Results
First, consider the factor model (1.3) in introduction. We are interested in the asymptotic regime where the number of predictors is comparable to the sample size:
Assumption 1
(Large-dimensional Asymptotics).
The number of covariates and the sample size n are comparable in such a way that
as
.
The concentration ratio , possibly larger than 1, plays a central role in our asymptotic theory. Unless specified otherwise, all asymptotic results hold as
simultaneously in the probability space, enlarged if necessary, with the largest sigma-algebra.
Without loss of generality, we treat both the in-sample factor scores matrix F and the loading matrix in (1.3) as fixed parameters. When factors are random, our approach is equivalent to conditioning on a particular realization of F. The number of factors r is finite but not necessarily known.
Assumption 2
(Factor Model).
The following conditions hold:
The total factor loading
, and
(b)
(c)
Conditions (a)–(c) are the weaker factor models in Bai and Ng (Citation2021) allowing an arbitrarily slow rate of total factor strength . When all entries, say, of the loading matrix
are bounded away from infinity, we readily have
in condition (a). We allow the loading matrix
to have many vanishing entries and one may use
for any
; see, for example, Bai (Citation2003), Hallin and Liska (Citation2007), and Agarwal et al. (Citation2021) for the linear case
and Onatski (Citation2009) for the case
. Via the factor decomposition (1.3) of
, these conditions ensure that singular values of the factor part
to be much larger than (hence, separated from) those of the idiosyncratic part
; see, for example, Cai, Han, and Pan (Citation2020) for discussions and comparisons with the generalized spiked model in Johnstone (Citation2001).
Remarkably, our condition (b) relaxes some identification conditions in the previous papers. We allow ties in the proportion of total loading and require only the subspace consistency of PCA in the spirit of Jung and Marron (Citation2009). When there are ties, all bases of the span of corresponding latent factors satisfy our conditions and therefore we are not able to identify the true ones in the data generating process. Nevertheless, we could estimate the subspace as a whole consistently and unify the further factor analysis for cross-validation and autoregressive models, as train-test splits and residual-based estimation can make latent factors indistinguishable in subsamples or after projections. One limitation of condition (b) is that all eigenvalues of
must diverge at the same rate of
, but we can easily relax this requirement and allow different rates if necessary.
Condition (c) holds for a separable random matrix in (1.3) where
and
are positive-definite matrices with bounded spectral norms and
is a random matrix of iid standardized entries with a bounded fourth moment; see, for example, Paul and Silverstein (Citation2009) and Chapter 5 of Bai and Silverstein (Citation2010). Condition (c) also holds for high-dimensional linear time series satisfying the conditions in Remark 8 of Onatski and Wang (Citation2021). See Appendix A.2 of the supplementary materials for more detailed discussions.
For out-of-sample analysis, we assume that the data obeying (1.3) and (1.4) are from the following data generating process (DGP):
(2.1)
(2.1)
(2.2)
(2.2) where
is an unspecified intercept possibly indexed by n and the regression errors
satisfy the following condition:
Assumption 3
(Independent Errors).
The regression errors are mutually independent with zero mean
and a common variance
bounded away from zero and infinity, and they are independent of
. They are uniformly integrable in second moment such that
is bounded away from infinity for some
.
This assumption is common in statistical learning literature. We will relax it to handle uncorrelated but dependent errors in Section 3. See also Remark 2 for the relaxation of the homoscedasticity condition. We consider strongly exogenous predictors to allow for a standard factor estimation using the entire sample of raw predictors as in, for example, Stock and Watson (Citation2012).
Throughout the article, we consider a mixed-effects model where the factor coefficients are arbitrary fixed-effects and the entries of idiosyncratic coefficient vector
are stochastic. In particular, we make the following assumption throughout the article for
:
Assumption 4
(Random Effects).
The idiosyncratic coefficient vector , where
is independent of the predictors
and the regression errors
, and has uncorrelated entries such that
and
is bounded away from infinity for some
. The total idiosyncratic signal length
is unknown, possibly dependent on
, and
. When
, the augmented model (2.2) reduces to the principal component regression model.
This condition is based on the hypothesis of the random effect in, for example, Dobriban and Wager (Citation2018), but here we relax the dependence structure between the entries and allow them to be non-identically distributed. See Appendix A.3 in the supplementary materials for more examples and comparisons. We emphasize that this assumption is only needed for modeling the idiosyncratic coefficients
, and we allow for arbitrary fixed-effects
on the latent factors in our factor-augmented model (2.2).
We split our main results into two sections: the first one shows the efficiency of the ridge regression among the general class of spectral regularized estimators; the second one establishes the uniform consistency of the bias-corrected k-fold cross-validation for selecting the best ridge penalty.
2.1 On the Optimality of Ridge Regression
In this section, we show that the ridge regression is asymptotically optimal among the spectral regularized estimators in capturing idiosyncratic information and it is more robust than principal component regression against factor augmentation.
Consider the singular value decomposition , where
denotes the ith largest eigenvalue (counting multiplicities) and
denotes the rank of X. Note that
are all orthogonal to the n-dimensional unit vector proportional to the all-ones vector, denoted by
, due to data centering. To reduce the estimation variance of regression means
in (1.4), we shrink the projections of the (uncentered) target vector
onto the eigenbasis
via a shrinkage function
:
(2.3)
(2.3) where
is the estimated regression function given by
(2.4)
(2.4)
and
is a penalized least-squares estimator (Tikhonov Citation1963a, Citation1963b) given by
(2.5)
(2.5)
with denoting the Moore-Penrose inverse of any matrix A and the weight matrix
(2.6)
(2.6)
In particular, choosing and
for some constant
in (2.5) yields the ridge (Hoerl and Kennard Citation1970) estimator
. We allow for infinite penalties for dimension reduction purpose: one should interpret
if and only if
, and then we must set
orthogonal to
in estimation. For more discussions we refer to Hastie, Tibshirani, and Friedman (Citation2009, chap. 3). Henceforth we call (2.3) a spectral regularized estimator of the regression means.
We define the predictive loss as the reducible mean squared forecast error (see James et al. Citation2021 for decomposition into reducible and irreducible errors), conditional on a realization of the training set, given by
where
and
are out-of-sample (OOS) random covariates and the regression mean from the DGPs (2.1) and (2.2) with the same factor model parameters and regression coefficients. The sigma-algebra
is generated by the in-sample variables
and the random coefficients
.
We use the following paradigm to evaluate the spectral regularized estimators.
Assumption 5
(Evaluation Paradigm).
The new variables and
are independent of both in-sample regression errors
and random coefficients
, given the in-sample random variables
. The conditional covariance matrices of
centered around the sample mean given by
have spectral norms bounded in n for both
.
This paradigm is flexible enough to include both the training and testing predictive losses used in :
If one draws the pair of new variables
A more typical implementation is to generate
Our estimated regression function (2.4) uses oracle estimators and
of
and
, respectively via the decomposition:
The following theorem relates to the estimation error of linear coefficients and gives further stochastic approximations based on spectral analysis.
Theorem 1.
Under Assumptions 1–5, for any sequence of candidate shrinkage function may or may not depend on the covariates in the training set,
(2.8)
(2.8)
where denotes the weighted norm of any vector v. Furthermore,
(2.9)
(2.9)
(2.10)
(2.10)
where
and
, if there is no tie values in
and the penalty function
is bounded away from 0. The probability mass
when the data matrix X is column-rank deficient with
. More generally, the result remains true if
for every tie values
with
.
The estimation errors of fixed and random effects are asymptotically orthogonal in (2.8) because their interaction vanishes through aggregation of the uncorrelated mean-zero random coefficients and regression errors. Via the approximation (2.8) one can interpret different predictive loss functions using different weight matrices: (a) the training errors weight the coefficient estimation errors by the sample covariance matrices; (b) the testing errors weight the coefficient estimation errors by the population covariance matrices (centered around sample means); (c) the norm of coefficient estimation error
uses identity weight matrices
for
. The asymptotic limit in (2.9) shows the bias of shrinkage estimator of fixed-effects
, and that in (1) shows the bias-variance tradeoff for random-effects estimation.
Remark 1
(PCR).
Plugging in the shrinkage function for the oracle PCR estimator yields a limit increasing linearly in
as depicted in :
where the last equation is due to the facts that
and the random slope
. In fact, this linear pattern generalizes for any PCR estimator using a finite number of
principal components as adding a few idiosyncratic components does not change its asymptotic behavior in dense models.
Note that the candidate shrinkage function is arbitrary on the positive line as long as it is “honest” in the sense that it only depends on the covariates but not the target variable before selection. Our limit theorem shows that shrinking the projections of the target vector onto the first r principal components can only increase the predictive loss asymptotically via the squared bias (2.9). We should keep the leading principal components unshrunk asymptotically by choosing a shrinkage function such that
for all
and thus the fixed-effects estimator is consistent in the sense that
.
We will discuss how to choose the optimal (ridge) estimator satisfying this condition later on. Therefore, now we focus on this subset of shrinkage functions and study the limiting predictive loss in the following corollary:
Corollary 1.
Suppose that for all
. Theorem 1 implies that
(2.11)
(2.11) where we integrate the limiting error over the entire domain of
for notational convenience although it is asymptotically equivalent to integrate over only the sub-interval
.
If further provided that, with probability one, is bounded by some absolute constant and
converges vaguely to a nonrandom limit
, then Corollary 1 remain true with
replaced by the nonrandom limit
for every continuous shrinkage function
. In particular, we have the following special cases.
Corollary 2.
Let the signal length and error variance
be constants, and generate the new variables
independent of the training data. Suppose that all the entries of
and
are from an iid array with mean zero and variance
. Then, Corollary 1 implies that for every continuous shrinkage functions
such that
,
(2.12)
(2.12)
where F is the Marčenko and Pastur (Citation1967) law with a point mass at the origin, and the positive density function
on [a, b] (and zero density elsewhere) with
and
. More examples satisfying (2.12) with various limits F are available in Appendix A.4 in the supplementary materials.
For generality, we use the stochastic approximation (2.11) according to the random nature of the predictive loss. We shall show that the optimal (ridge) estimator is asymptotically invariant to the random measure (or its limit F if any), and therefore the optimality of ridge regression does not rely on the spectral convergence of large-dimensional covariance matrices.
First, consider the degenerate scenario in that the PCR model is correct with , or more generally
. One may still use a ridge estimator to minimize the limiting error (2.11) with the shrinkage function
such that the ridge penalty
is diverging at a slower rate of the smallest spiked value
. To our knowledge, this finding first appeared formally in De Mol, Giannone, and Reichlin (Citation2008) who studied the PCR model with
diverging at a linear rate of p. Such ridge estimator is a smoothed approximation of the PCR estimator performing an asymptotic selection of principal components in the sense that
as
for
, while
for all the non-spiked eigenvalues
that are stochastically bounded as
. In practice, one may select such a ridge penalty coefficient by using cross-validation and we postpone the details to next section. The optimal predictive loss vanishes to zero in probability as we can estimate the fixed-effects consistently and the random-effects are negligible.
A more interesting case is the augmented model with an idiosyncratic signal length bounded away from zero (stochastically), minimizing the asymptotic limit in (2.11) is equivalent to minimizing the integrand
That is, for each , we choose
as the minimum point of the convex quadratic function
By solving the first-order condition , it is elementary to show that the optimal shrinkage function is given by
(2.13)
(2.13) which corresponds to a ridge estimator with the penalty coefficient
, that is, with
in (2.5). One can interpret
as the noise-to-signal ratio
scaled by the aspect ratio
. Note that the optimal predictive loss is not vanishing in this case as the high-dimensional random-effects
cannot be estimated consistently. Since the ridge coefficient
is now (stochastically) bounded, the optimal shrinkage function (2.13) naturally satisfies the conditions that
as the spiked eigenvalues
for
, leading to a consistent estimation of the fixed-effects
.
Remarkably, the optimal shrinkage function (2.13) is the same for all our predictive loss functions sharing the approximate form (2.11). We summarize the optimality of ridge regression into the following corollary:
Corollary 3
(Optimality of ridge regression).
Consider any predictive loss admitting the asymptotic approximation in Theorem 1. For an arbitrarily small
and any candidate shrinkage function
from Theorem 1,
where
denotes the shrinkage function for the optimal ridge estimator with the penalty coefficient
when
is bounded away from 0 with probability approaching 1, or otherwise an arbitrary diverging penalty
but
if
. In the latter case,
and we may take
where
are arbitrary fixed weights such that
for any pre-specified bound
. However, in general, only the fixed-effects are consistently estimated in the sense that
and the optimal ridge estimator trades off the estimation bias and variance of random-effects.
Remark 2.
Corollary 3 generalizes for heteroscedastic errors with different variance under more strengthened conditions on the covariates
, where one can relax expression (2.13) by replacing
with the average variance
. Due to the space limit, we postpone the details to Appendix A.8 in the supplementary materials.
2.2 Uniform Consistency of Bias-Corrected k-Fold Cross-Validation
This section establishes the uniform consistency of the k-fold cross-validation (CV) algorithm for selecting the best ridge estimators, subject to a straightforward bias correction. Our asymptotic limits of the cross-validated mean squared error is uniform for all positive ridge penalties bounded away from zero, including those diverging to infinity. Throughout we use a fixed number of folds . Generally speaking, there are both computational and statistical advantages to use k-fold CV rather than the leave-one-out CV; see, for example, Section 5.1.3 of James et al. (Citation2021). On the other hand, using a small number of folds may introduce a bias in the selection if the optimal parameter depends on the sample size of the training set.
To fix ideas, the procedure starts from partitioning the entire index sets into k mutually exclusive subsets
. For generality, we treat the partition
as fixed for any given n. When the folds are randomly created, our setup is equivalent to conditioning on a particular realization. One simple choice is to divide
into blocks, using consecutive indexes in each fold. In general, it is unnecessary to use blocks, and we may assign indexes randomly to the folds. Following the common practice, we generate folds of approximately equal size such that
where
denotes the cardinality of the index subset
.
Let and
be the demeaned observations,
and
are the sample means using all data. For any fold
treated as a validation set, we fit a ridge estimator
on the remaining
folds by minimizing the
penalized error given by
(2.14)
(2.14) where
denotes the number of training observations, and
is a candidate ridge penalty coefficient. Recall the demeaned design matrix
and demeaned target vector
. Let
be the
diagonal matrices that selects the observations on the training set
. Solving the quadratic optimization problem (2.14) yields a close-form solution given by
(2.15)
(2.15)
The mean squared error on the observations in the held-out fold is given by
We repeat the procedure for , and average these errors to compute the k-fold cross-validation MSE given by
Then we choose the value of over a sufficiently fine grid that minimizes
. Note that we do not need to estimate the factor scores nor to determine the number of factors with ridge regression.
To apply factor analysis to the training subsamples rather than the full sample, we assume one additional regularity condition:
Assumption 6.
Let denote the training covariance matrix latent factor scores. For every
, the eigenvalues of the
matrix
converge to some limits
.
The condition allows us to reparameterize the factor scores and loadings on the training set to maintain similar orthogonal structures in Assumption 2. More specifically, consider the spectral decomposition where
is a diagonal matrix and
is an orthogonal matrix. Define the demeaned matrix of the idiosyncratic information
. The training design matrix obeys the approximate factor model
where
and
satisfy the orthogonal conditions:
Assumption 6 holds under a stronger condition that for all
, in which case the limiting eigenvalue
. If
are iid random vectors with an identity covariance matrix, the conditions holds almost surely by strong law of large numbers. When
is a (multivariate) time series and the folds are blocks, that is, each time index subset
corresponds to a continuous time period, the condition follows from ergodicity:
for any stationary ergodic process
with zero mean and identity covariance matrix, where
denotes the set of integers; see Blum and Eisenberg (Citation1975) for more discussions. Assumption 6 then holds with probability approaching 1.
Furthermore, when the folds are randomly generated, the results remain true if the projection process is stationary and strong mixing for every unit vectors
by combining the theorem in Blum and Hanson (Citation1960) and Cramér–Wold device. See Bradley (Citation1986) and Bradley (Citation2005) for the various types of sufficient conditions for strong mixing.
Theorem 2.
Suppose that Assumptions 1–4 and 6 hold. Uniformly for all positive ridge penalties bounded away from 0,
where is some (improper) empirical distribution depending only on the covariates
, the effective training sample size is given by
provided that
converges to the same limit for all j, and
is a random weight matrix being stochastically bounded and positive-definite with probability tending to 1 when
. The closed-form expressions of
and
are available in Section E.3 of the supplementary materials.
The first term is irreducible but irrelevant to the choice of
. The second term
represents the cross-validated estimation error of the fixed-effects at the same (stochastic) order of
. The rest represents the cross-validated error for the random-effects where we use
due to the train-test split.
Let denote the optimal ridge penalty selected by the regular k-fold CV. When
, the k-fold CV chooses some divergent penalty
to shrink the random-effects estimator toward zero as much as possible but
(unless
) such that the fixed-effect estimation errors vanish as well. Note that any divergent penalty sequence proportional to
is also asymptotically optimal. When
is bounded away from 0, by the same arguments above Corollary 3, one should again minimize the integrand
by using the optimal penalty
for all
where
denotes the optimal ridge penalty in Corollary 3. To conclude, the bias-corrected estimator of the optimal ridge penalty given by
satisfies the asymptotic optimality criterion in Corollary 3.
3 Extension of Main Results
This section discusses two extensions of the main results for handling dependent data. Since our applications are often (although not necessarily) based on time series data, we shall index the observation by instead of i to emphasize the concept of time.
Our first extension is to relax the independence Assumption 3 on regression errors and only require them to be martingale differences.
Assumption 7
(MD Errors).
The regression errors , where
is a martingale difference sequence for each n such that
and
, and
denotes the conditional expectation given the sigma-algebra
generated by
,
and
. The variance
is bounded away from zero almost surely, and may or may not depend on the covariates
. For some
,
.
This MD assumption is required for the theory of k-fold cross-validation with uncorrelated (but dependent) errors using the usual random train-test splits. Note that the conditional variance can be stochastic, meaning that we allow for conditionally heteroscedastic errors with stochastic volatilities such as the GARCH-type error processes (see, e.g., Davis and Mikosch Citation2009 for an excellent survey). The last part of the assumption, allowing for heavy-tailed distributions, is needed for the uniform integrability of
. In general
are even not necessarily to be identically distributed, but if they are then the last part simplifies to be
.
Theorem 3.
All theorems and corollaries in Section 2 remain true by replacing the IID Assumption 3 with the MD Assumption 7, provided the temporal dependence conditions on in Appendix A.5 in the supplementary materials.
The most shocking finding is that, at least for ridge regression, we can in fact split the time series arbitrarily without worrying about the so-called “time leakage” issues in machine learning. In other words, the time order between the training and validation data is unimportant and the usual random train-test splits are allowed.
Our second extension is the factor-augmented autoregressive model given by
(3.1)
(3.1)
(3.2)
(3.2) where
are martingale differences as in Assumption 7. The first equation is the same as (2.1), while the second equation adds the lagged target variables into (2.2). In forecasting applications,
are often lagged variables that are observable before time t. Let
collect the lagged target values, and their coefficient vector be
. We can rewrite the model into a general form given by
(3.3)
(3.3)
For simplicity, we assume that the order of autoregression q is finite and known. Unless specified otherwise, we assume that the autoregressive model satisfies the standard stability condition (see, e.g., Chapter 6 of Hayashi Citation2000, p. 373):
Assumption 8.
All the roots of the qth degree polynomial equation are greater than 1 in absolute value, when
. The target variables has finite second moment, that is,
is bounded uniformly over t.
We extend the ridge regression to allow for the nuisance variables and minimize the penalized mean squared errors of the parameters
given by
where
is some candidate ridge penalty that may depend on
. When
, this reduces to the standard ridge problem. Let
be the demeaned design matrix of autoregressors with
, and define the projection matrix onto its column space by
. Solving the quadratic optimization problem yields a three-steps estimator
(3.4)
(3.4)
We are interested in minimizing the predictive loss given by
(3.5)
(3.5)
The sigma-algebra is generated by the past variables
and the random coefficients
. An inevitable challenge here is that the target variables in training and test samples must be dependent due to autoregression (3.2). Nevertheless, we can generate new covariates in the future according to a similar paradigm in Section 2:
Assumption 9
(Testing Paradigm for AR Models).
The testing paradigm in Assumption 5 holds with and
for all horizons
. For all
,
.
Theorem 4.
Under the conditions of Theorem 3, Assumptions 8–9, and the conditions in Appendix A.6 in the supplementary materials, the optimal ridge penalty remains the same as in Corollary 3 for the testing predictive loss (3.5) at all forecast horizons .
Nevertheless, the classic results for the standard k-fold cross-validation do not extend to the autoregressive models with large-dimensional covariates. We notice that there are some recent findings in Bergmeir, Hyndman, and Koo (Citation2018) for simple autoregressive models with no exogenous variable, but their results neither do not apply in the presence of large-dimensional covariates. Hence, we suggest to remove the autoregressive components before the cross-validation using the following algorithm:
Step 1 Let
Step 2 Calculate the bias-corrected ridge penalty
Step 3 Calculate the estimators
Theorem 5.
Under the conditions of Theorem 4, Theorem 2 remains true provided that the preliminary estimator is consistent toward
.
In the rest of this section, we discuss how to obtain a consistent estimator under our mixed-effects models. We show in Appendix A.7 of the supplementary materials that the naive least-squares estimator using the autoregressors alone (i.e., neglecting the covariates) is consistent if the latent factors are asymptotically uncorrelated over time. To avoid this restrictive condition, we suggest to use the estimator
from a preliminary ridge regression (3.4) instead according to the following theorem. We call this approach “double” ridge regression because we need to apply ridge regression twice, once in Step 1 and one more time in Step 3 using different penalties.
Theorem 6
(Double ridge regression).
Suppose that the conditions of Theorem 4 hold. The ridge estimator defined in (3.4) is consistent toward
if
and
is bounded away from 0 with probability approaching 1, where
may depend on the covariates
. When
, the result remains true if
diverges at the same or even higher rate of
. In particular, the following choices all satisfy the consistency condition:
Any constant ridge penalty
Any diverging ridge penalty of the form
An interesting implication of this proposition is that, even with a possibly inconsistent estimator of in Step 1 (e.g., the least-squares estimator omitting covariates), the final estimator
in Step 3 can recover consistency as long as the ridge penalty from Step 2 is not too large in the sense of Theorem 6. Unless specified otherwise, we use the ridge penalty
for our preliminary ridge regression in numerical analysis.
4 Monte Carlo Simulations
In this section, we compare the predictive performance of the ridge estimators and that of their competitors under factor augmented models using Monte Carlo experiments. We fix the number of predictors but vary the sample size
, yielding concentration ratios
. These dimensions are calibrated from our empirical analysis where
. The results for a fixed sample size
but a much larger number of predictors
are available in Appendix C.3 in the supplementary materials.
We calibrate the data generating process of the latent factors from a vector autoregressive model (VAR) with four lags and the factor loading matrices
from a multivariate Gaussian distribution using the estimated scores and loadings of
factors using the FRED-MD database in Section 5. The details of the calibration procedure is available in Appendix B.1 of the supplementary materials. We then generate exogenous predictors from the factor model give by
where the entries
are independently generated from the standard normal distribution,
is a diagonal covariance matrix from Bai and Silverstein (Citation1998) (with 20% of its eigenvalues equal to
, 40% equal to
, and 40% equal to
) such that
, the idiosyncratic matrix
is generated uniformly from the class of orthogonal matrices. The factor scores
are unobservable to the statistician, who always approximate the factor scores as
times the leading eigenvectors of
when needed. We then generate the target variable from the factor augmented autoregressive model of order
given by
where we set a zero intercept
without loss of generality, and the autoregressive coefficients
are calibrated from the monthly growth in U.S. industrial production index. In the supplementary materials we repeat the analysis for the case with no autoregressor (i.e.,
), and the conclusions remain qualitatively the same. The entries of factor coefficients
are generated from the uniform distribution on
. All these coefficients are unknown to the statistician who always demeans the predictors in each sample and estimate all the coefficients. We consider two different data generating processes of the regression errors:
independent errors
GARCH(1,1) errors
Without loss of generality, we maintain a long run variance in both cases. The errors are independent of the covariates. The results are similar for these two types of errors. To save space, we only report the results for GARCH errors in the main document and postpone the results for independent
errors to Appendix C in the supplementary materials.
To compare sparse and dense models in terms of idiosyncratic information, we generate the entries of the idiosyncratic regression coefficients independently from a “spike-and-slab” distribution (Mitchell and Beauchamp Citation1988) such that
and the signal strength
controls the dense level; the larger
, the less zero entries in
in probability.
reports the median, over 5000 replications, of the testing errors at the horizon
outside brackets and training errors
inside brackets for the following seven estimators:
Table 1: The testing errors (and training errors) over 5000 replications for GARCH errors.
PCR: Principal component regression using true number of factors
KS2011: Factor-adjusted LASSO estimator proposed by Kneip and Sarda (Citation2011) with
PCR-CV: PCR using the number of factors selected by k-fold cross-validation.
SRR: Single ridge regression with the ridge penalty parameter selected by the bias-corrected k-fold cross-validation procedure proposed in the last section, using the least-squares estimator of the autoregressive coefficients in Step 1.
FaSRR: Factor-adjusted ridge regression that shrinks the eigenvalues as SRR except for the largest r eigenvalues.
DRR: Double ridge regression with the ridge penalty parameter selected by the bias-corrected k-fold cross-validation procedure, using the preliminary ridge regression of the autoregressive coefficients in Step 1 given in Theorem 6.
FaDRR: Factor-adjusted ridge regression that shrinks the eigenvalues as DRR except for the largest r eigenvalues.
The estimators SRR and DRR are what we propose in the last section, except they use different estimators of the autoregressive coefficients. The SRR estimator is slightly worse than DRR overall due to a larger estimation error of the autoregressive residuals in the cross-validation algorithm. The other estimators PCR, KS2011, FaSRR, and FaDRR are oracle in the sense that they use the true number of factors . They can be feasible in practice when the number of factors can be consistently selected; see, for example, Bai and Ng (Citation2002). In contrast, the SRR and DRR estimators do not require estimating the number of factors but use all raw covariates. More implementation details of these algorithms are available in Appendix B.2 of the supplementary materials.
When the idiosyncratic signal , the PCR and factor-adjusted Ridge estimators usually perform the best. Although the SRR and DRR estimator suffers from more estimation bias of fixed-effects due to the shrinkage, they still show good performance and remain robust against the absence of idiosyncratic signals. The LASSO estimator KS2011 is the worst and suffers from variable selection errors in dense models especially when
.
On the other hand, when , our ridge estimators SRR and DRR consistently outperform all sparse learning methods PCR, KS2011 and PCR-CV in terms of both testing and training errors according to our asymptotic theory. The advantages of the ridge estimator becomes more significant as the signal length
grows.
It is noteworthy that direct factor adjustments cannot improve the ridge regression when . FaSRR and FaDRR violate the full-rank condition (Appendix A.6) on the residual factor matrix by removing all the in-sample factor information asymptotically. As a result, the residual ridge regression fails to shrink the divergent loading matrix
(via Lemma A7 in the supplementary materials), leading to an inflation of fixed-effects estimation errors.
To conclude, the simulation results confirm that our double ridge regression with bias-corrected cross-validation is a robust forecasting method for factor-augmented models with potential idiosyncratic information and nuisance variables. It delivers the best performance and nontrivial improvements in dense models with large consistently, while remaining robust against sparse idiosyncratic information with small
.
5 A Real-life Example
One empirical application of dense learning is to forecast the monthly growth rate of the U.S. industrial production index using a large set of macroeconomic variables from the FRED-MD database publicly available at: https://research.stlouisfed.org/econ/mccracken/fred-databases/.
This monthly database has similar predictive content as that in Stock and Watson (Citation2002), and it is regularly updated through the Federal Reserve Economic Data. The industrial production index is an important indicator of macroeconomic activity. We calculate its monthly grow rate in percentage by
where
denotes the U.S. industrial production index for month t. Our sample size span from January, 1959 to August, 2021 and all the data are available on a monthly basis. We transform the nonstationary economic variables into stationary forms and remove the data outliers using the MATLAB codes provided on the website mentioned above; see also McCracken and Ng (Citation2016) for details.
In every month, we forecast the next-month growth ahead using autoregressor(s) and (the principal components of) all the other covariates in the database. We estimate the factors and regression coefficients in rolling windows of a sample size
, which equals to a time span of ten years. In each window we use the lagged variables with no missing values for training and forecasting. The covariates are normalized within each window, and we transform the latest observation accordingly.
compares the out-of-sample mean squared forecast errors of the rolling-window predictions using the following six methods: purely autoregressive (AR), principal component regression (PCR), factor-adjusted LASSO regression (KS2011), principal component regression with the number of components selected by cross-validation (PCR-CV), the “single” ridge regression (SRR), and the “double” ridge regression (DRR) in Theorem 6. We report only the results using the 5-fold cross-validation after bias correction, which are slightly better than that before correction. The implementation details are available in Appendix B.3 of the supplementary materials. The mean squared errors are normalized by that of the moving average forecasts (i.e., autoregressive estimator with ) for comparison.
Table 2: Out-of-sample relative mean squared forecast errors for the growth rate of U.S. industrial production index.
Our double ridge estimator, namely DRR, systematically improves the PCR estimators over different choices of the autoregressive orders , while the factor-adjusted LASSO estimator KS2011 consistently underperform the PCR. The cross-validation procedure hardly improves PCR predictions. These findings suggest that the underlying model tend to be dense rather than sparse in terms of idiosyncratic information. The DRR estimator consistently improves the prediction errors against SRR, which is consistent with our theory that DRR is more robust against complex covariates structures; see Theorem 6 and the discussions above it.
6 Concluding Remarks
This article studies the high-dimensional ridge regression methods under factor models. Our theory of the efficiency and robustness of ridge regression in capturing both factor and idiosyncratic information simultaneously helps explain its excellent performance in many complicated applications. Our results are applicable to large-dimensional datasets showing spiked eigenstructure, serial dependence, conditional heteroscedasticity, and heavy tails simultaneously. In particular, we extend the theory of k-fold cross-validation beyond iid setting and provide theoretical support for its applications to more complex data.
One can compare the factor-augmented models (1.3)–(1.4) with the following synthetic control models studied by Agarwal et al. (Citation2021) (see also Abadie, Diamond, and Hainmueller Citation2010; Amjad, Shah, and Shen Citation2018; Arkhangelsky et al. Citation2021):
(6.1)
(6.1) where X is the corrupted covariate matrix, the latent factor matrix
is the true covariate matrix of low rank r with a strong signal
,
contains response noises, and
are model misspecification errors. Rather than treating the misspecification error
as deterministic and “inevitable” (see the interpretation below their Theorem 3.1 on p. 1735), here we model
as a projection of noise matrix H through the random-effects
and an arbitrary rotation
. Therefore, the RR can outperform PCR by optimizing the bias-variance tradeoff on the misspecification errors
. It is an exciting future research topic is to allow for weak factors in (6.1) such that
.
One may wonder whether our findings generalize beyond the random matrix regime. In higher dimensions with , our results remain true by generalizing Assumption 2 as follows:
(which is trivial if
is linear in p) and
. To see this, first apply our results to the rescaled covariates
with corresponding coefficients
, and then transform back to the original scales. For lower dimensions with
(but
sufficiently fast) and
, the optimal penalty
in (2.13), meaning that the optimal ridge estimator should approximate the least-squares estimator and outperform PCR. Otherwise, the optimal RR asymptotically reduces to the PCR when
; see in Appendix A.9 for illustration. Non-asymptotic comparison between PCR and RR is possible using the concentration inequalities in martingale limit theory, but we leave it as future works.
Finally, our analysis assumes that the factor strength so the standard PCA is (subspace) consistent. Is the RR still favorable otherwise? This is an interesting future research topic. Using the simulation example in the Introduction, we can illustrate that the ridge regression still consistently outperforms the PCR when the standard PCA becomes inconsistent. Due to the space limit, we leave the detailed illustrations to Appendix A.9 in the supplementary materials, where we also compare the regular and bias-corrected cross-validation and discuss a possible extension for “sparse + dense” idiosyncratic information.
Supplementary Materials
All the proofs of the theorems are available in the supplementary document, which also includes more technical discussions and remarks, extra simulation results, and useful lemmas that may be of independent interest.
Supplemental Material
Download Zip (152.7 MB)Acknowledgments
The author thanks the Editor, Professor Marina Vannucci, an Associate Editor, and two reviewers for their valuable comments that led to this improved version of the article.
Disclosure Statement
The author reports there are no competing interests to declare.
References
- Abadie, A., Diamond, A., and Hainmueller, J. (2010). “Synthetic Control Methods for Comparative Case Studies: Estimating the Effect of California’s Tobacco Control Program,” Journal of the American Statistical Association, 105, 493–505. DOI: 10.1198/jasa.2009.ap08746.
- Agarwal, A., Shah, D., Shen, D., and Song, D. (2021) “On Robustness of Principal Component Regression,” Journal of the American Statistical Association, 116, 1731–1745. DOI: 10.1080/01621459.2021.1928513.
- Alter, O., Brown, P. O., and Botstein, D. (2000). “Singular Value Decomposition for Genome-wide Expression Data Processing and Modeling,” Proceedings of the National Academy of Sciences, 97, 10101–10106. DOI: 10.1073/pnas.97.18.10101.
- Amjad, M., Shah, D., and Shen, D. (2018). “Robust Synthetic Control,” Journal of Machine Learning Research, 19, 802–852.
- Arkhangelsky, D., Athey, S., Hirshberg, D. A., Imbens, G. W., and Wager, S. (2021). “Synthetic Difference-In-Differences,” American Economic Review, 111, 4088–4118. DOI: 10.1257/aer.20190159.
- Bai, J. (2003), “Inferential Theory for Factor Models of Large Dimensions,” Econometrica, 71, 135–171. DOI: 10.1111/1468-0262.00392.
- Bai, J., and Ng, S. (2002), “Determining the Number of Factors in Approximate Factor Models,” Econometrica, 70, 191–221. DOI: 10.1111/1468-0262.00273.
- Bai, J., and Ng, S. (2021), “Approximate Factor Models with Weaker Loadings,” ArXiv Working Paper arXiv:2109.03773.
- Bai, Z. D., and Silverstein, J. W. (1998). “No Eigenvalues Outside the Support of the Limiting Spectral Distribution of Large-Dimensional Sample Covariance Matrices,” The Annals of Probability, 26, 316–345. DOI: 10.1214/aop/1022855421.
- Bai, Z. D., and Silverstein, J. W. (2010), Spectral Analysis of Large Dimensional Random Matrices, New York: Springer.
- Bergmeir, C., Hyndman, R. J., and Koo, B. (2018), “A Note on the Validity of Cross-Validation for Evaluating Autoregressive Time Series Prediction,” Computational Statistics & Data Analysis, 120, 70–83. DOI: 10.1016/j.csda.2017.11.003.
- Blum, J., and Eisenberg, B. (1975), “The Law of Large Numbers for Subsequences of a Stationary Process,” The Annals of Probability, 3, 281–288. DOI: 10.1214/aop/1176996398.
- Blum, J., and Hanson, D.(1960), “On the Mean Ergodic Theorem for Subsequences,” Bulletin of the American Mathematical Society, 66, 308–311. DOI: 10.1090/S0002-9904-1960-10481-8.
- Bradley, R. C. (1986), “Basic Properties of Strong Mixing Conditions,” in Dependence in Probability and Statistics: A Survey of Recent Results, eds. E. Eberlein and M. S. Taqqu, pp. 165–192, Boston: Birkhäuser.
- Bradley, R. C. (2005), “Basic Properties of Strong Mixing Conditions. A Survey and Some Open Questions,” Probability Surveys, 2, 107–144. DOI: 10.1214/154957805100000104.
- Cai, T. T., Han, X., and Pan, G. (2020), “Limiting Laws for Divergent Spiked Eigenvalues and Largest Nonspiked Eigenvalue of Sample Covariance Matrices,” The Annals of Statistics, 48, 1255–1280. DOI: 10.1214/18-AOS1798.
- Carrasco, M., and Rossi, B. (2016), “In-Sample Inference and Forecasting in Misspecified Factor Models,” Journal of Business & Economic Statistics, 34, 313–338. DOI: 10.1080/07350015.2016.1186029.
- Castle, J. L., Clements, M. P., and Hendry, D. F. (2013), “Forecasting by Factors, by Variables, by Both or Neither?,” Journal of Econometrics, 177, 305–319. DOI: 10.1016/j.jeconom.2013.04.015.
- Cootes, T. F., Taylor, C. J., Cooper, D. H., and Graham, J. (1995). “Active Shape Models-Their Training and Application,” Computer Vision and Image Understanding, 61, 38–59. DOI: 10.1006/cviu.1995.1004.
- Davis, R. A., and Mikosch, T. (2009). “Probabilistic Properties of Stochastic Volatility Models,” in Handbook of Financial Time Series, eds. T. G. Andersen, R. A. Davis, J. P. Kreiß, and T. V. Mikosch, pp. 255–267, Berlin: Springer.
- De Mol, C., Giannone, D., and Reichlin, L. (2008), “Forecasting Using a Large Number of Predictors: Is Bayesian Shrinkage a Valid Alternative to Principal Components?,” Journal of Econometrics, 146, 318–328. DOI: 10.1016/j.jeconom.2008.08.011.
- Dicker, L. H. (2016). “Ridge Regression and Asymptotic Minimax Estimation Over Spheres of Growing Dimension,” Bernoulli, 22, 1–37. DOI: 10.3150/14-BEJ609.
- Dobriban, E., and Wager, S. (2018), “High-Dimensional Asymptotics of Prediction: Ridge Regression and Classification,” The Annals of Statistics, 46, 247–279. DOI: 10.1214/17-AOS1549.
- Fan, J., Ke, Y., and Wang, K. (2020), “Factor-Adjusted Regularized Model Selection,” Journal of Econometrics, 216, 71–85. DOI: 10.1016/j.jeconom.2020.01.006.
- Giannone, D., Lenza, M., and Primiceri, G. E. (2021), “Economic Predictions with Big Data: The Illusion of Sparsity,” Econometrica, 89, 2409–2437. DOI: 10.3982/ECTA17842.
- Hastie, T., Tibshirani, R., and Friedman, J. H. (2009), The Elements of Statistical Learning: Data Mining, Inference, and Prediction, New York: Springer.
- Hastie, T., Montanari, A., Rosset, S., and Tibshirani, R. J. (2022), “Surprises in High-Dimensional Ridgeless Least Squares Interpolation,” The Annals of Statistics, 50, 949–986. DOI: 10.1214/21-aos2133.
- Hayashi, F. (2000), Econometrics Princeton: Princeton University Press.
- Hallin, M., and Liska, R. (2007). “The Generalized Dynamic Factor Model: Determining the Number of Factors,” Journal of the American Statistical Association, 102, 603–617. DOI: 10.1198/016214506000001275.
- Hoerl, A. E., and Kennard, R. W. (1970), “Ridge Regression: Biased Estimation for Nonorthogonal Problems,” Technometrics, 12, 55–67. DOI: 10.1080/00401706.1970.10488634.
- James, G., Witten, D., Hastie, T., and Tibshirani, R. (2021), An Introduction to Statistical Learning: with Applications in R (2nd ed), New York: Springer.
- Johnstone, I. M. (2001). “On the Distribution of the Largest Eigenvalue in Principal Components Analysis,” The Annals of Statistics, 29, 295–327. DOI: 10.1214/aos/1009210544.
- Johnstone, I. M., and Lu, A. Y. (2009). “On Consistency and Sparsity for Principal Components Analysis in High Dimensions,” Journal of the American Statistical Association, 104, 682–693. DOI: 10.1198/jasa.2009.0121.
- Johnstone, I. M., and Paul, D. (2018). “PCA in High Dimensions: An Orientation,” Proceedings of the IEEE, 106, 1277–1292. DOI: 10.1109/JPROC.2018.2846730.
- Jolliffe, I. T. (1982). “A Note on the Use of Principal Components in Regression,” Journal of the Royal Statistical Society, Series C, 31, 300–303. DOI: 10.2307/2348005.
- Jung, S., and Marron, J. S. (2009). “PCA Consistency in High Dimension, Low Sample Size Context,” The Annals of Statistics, 37, 4104–4130. DOI: 10.1214/09-AOS709.
- Kneip, A., and Sarda, P. (2011), “Factor Models and Variable Selection in High-Dimensional Regression Analysis,” The Annals of Statistics, 39, 2410–2447. DOI: 10.1214/11-AOS905.
- Liu, S., and Dobriban, E. (2020), “Ridge Regression: Structure, Cross-Validation, and Sketching,” in International Conference on Learning Representations.
- Marčenko, V. A., and Pastur, L. A. (1967). “Distribution of Eigenvalues for Some Sets of Random Matrices,” Mathematics of the USSR-Sbornik, 1, 457–483. DOI: 10.1070/SM1967v001n04ABEH001994.
- McCracken, M. W., and Ng, S. (2016), “FRED-MD: A Monthly Database for Macroeconomic Research,” Journal of Business & Economic Statistics, 34, 574–589. DOI: 10.1080/07350015.2015.1086655.
- Mitchell, T. J., and Beauchamp, J. J. (1988), “Bayesian Variable Selection in Linear Regression,” Journal of the American Statistical Association, 83, 1023–1032. DOI: 10.1080/01621459.1988.10478694.
- Ng, S. (2013), “Variable Selection in Predictive Regressions,” In Handbook of Economic Forecasting (Vol. 2), eds. G. Elliott and A. Timmermann, pp. 752–789, Amsterdam: Elsevier.
- Onatski, A. (2009). “Testing Hypotheses About the Number of Factors in Large Factor Models,” Econometrica, 77, 1447–1479.
- Onatski, A. (2012). “Asymptotics of the Principal Components Estimator of Large Factor Models With Weakly Influential Factors,” Journal of Econometrics, 168, 244–258.
- Onatski, A., and Wang, C. (2021), “Spurious Factor Analysis,” Econometrica, 89, 591–614. DOI: 10.3982/ECTA16703.
- Paul, D. (2007). “Asymptotics of Sample Eigenstructure for a Large Dimensional Spiked Covariance Model,” Statistica Sinica, 17, 1617–1642.
- Paul, D., and Silverstein, J. W. (2009). “No Eigenvalues Outside the Support of the Limiting Empirical Spectral Distribution of a Separable Covariance Matrix,” Journal of Multivariate Analysis, 100, 37–57. DOI: 10.1016/j.jmva.2008.03.010.
- Preisendorfer, R. W. (1988). Principal Component Analysis in Meteorology and Oceanography, Amsterdam: Elsevier.
- Stock, J. H., and Watson, M. W. (2002), “Forecasting Using Principal Components from a Large Number of Predictors,” Journal of the American Statistical Association, 97, 1167–1179. DOI: 10.1198/016214502388618960.
- Stock, J. H., and Watson, M. W. (2012), “Generalized Shrinkage Methods for Forecasting Using Many Predictors,” Journal of Business & Economic Statistics, 30, 481–493.
- Tikhonov, A. N. (1963a), “Regularization of Incorrectly Posed Problems,” Soviet Mathematics Doklady, 4, 1624–1627 (English translation).
- Tikhonov, A. N. (1963b), “Solution of Incorrectly Formulated Problems and the Regularization Method,” Soviet Mathematics Doklady, 4, 1035–1038 (English translation).