
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose Narrowest Significance Pursuit (NSP), a general and flexible methodology for automatically detecting localized regions in data sequences which each must contain a change-point (understood as an abrupt change in the parameters of an underlying linear model), at a prescribed global significance level. NSP works with a wide range of distributional assumptions on the errors, and guarantees important stochastic bounds which directly yield exact desired coverage probabilities, regardless of the form or number of the regressors. In contrast to the widely studied “post-selection inference” approach, NSP paves the way for the concept of “post-inference selection.” An implementation is available in the R package nsp. Supplementary materials for this article are available online.
1 Introduction
We propose a new generic methodology for determining, for a given data sequence and at a given global significance level, localized regions of the data that each must contain a change-point. We define a change-point in on an interval [s, e] as an abrupt departure, on that interval, from a linear model for
with respect to pre-specified regressors. We now give examples of scenarios covered by the proposed methodology.
Scenario 1.
Piecewise-constant signal plus noise model.
(1)
(1) where
is a piecewise-constant vector with an unknown number N and locations
of change-points, and
is zero-centered noise. The location
is a change-point if
but
.
Scenario 2.
Piecewise-polynomial (e.g., piecewise-constant or piecewise-linear) signal plus noise model. In (1), is a piecewise-polynomial vector, in which the polynomial pieces have a fixed degree
, assumed known to the analyst. The location
is a change-point if
can be described as a polynomial vector of degree q on
, but not on
.
Scenario 3.
Linear regression with piecewise-constant parameters. For a given design matrix ,
,
, the response
follows the model
(2)
(2) where the parameter vectors
are such that
.
Each of these scenarios is a generalization of the preceding one. We permit a broad range of distributional assumptions for , from iid Gaussianity to autocorrelation, heavy tails and heterogeneity. We now review the existing literature on uncertainty in multiple change-point problems which seeks to make confidence statements about the existence or locations of change-points in particular regions of the data, or significance statements about their importance.
In the iid Gaussian piecewise-constant model, SMUCE (Frick, Munk, and Sieling Citation2014) estimates the number N of change-points as the minimum among those candidate fits for which the empirical residuals pass a certain test at level
. An issue for SMUCE, discussed for example in Chen, Shah, and Samworth (Citation2014), is that the smaller the significance level
, the more lenient the test on the empirical residuals, and therefore the higher the risk of underestimating N. This leads to the counter-intuitive behavior of the coverage properties of SMUCE illustrated in Chen, Shah, and Samworth (Citation2014). SMUCE2 (Chen, Shah, and Samworth Citation2014) remedies this issue, but still requires that the number of estimated change-points agrees with the truth for successful coverage, which puts it at risk of being unable to cover the truth with a high nominal probability requested by the user. In the approach taken in this article, this issue does not arise as we shift the inferential focus away from N. SMUCE is extended to heterogeneous Gaussian noise in Pein, Sieling, and Munk (Citation2017) and to dependent data in Dette, Eckle, and Vetter (Citation2020).
Some authors approach uncertainty quantification for multiple change-point problems from the point of view of post-selection inference (PSI, a.k.a. selective inference); these include Hyun, G’Sell, and Tibshirani (Citation2018), Hyun et al. (Citation2021), Jewell, Fearnhead, and Witten (Citation2022), and Duy et al. (Citation2020). To ensure valid inference, PSI conditions on many aspects of the estimation process, which tends to produce p-values with somewhat complex definitions. PSI also does not permit the selection of the tuning parameters of the inference procedure from the same data. Useful as they are in assessing the significance of previously estimated change-points, these PSI approaches share the following features: (a) they do not consider uncertainties in estimating change-point locations, (b) they do not provide regions of globally significant change in the data, (c) they define significance for each change-point separately, as opposed to globally, (d) they rely on a particular base change-point detection method with its potential strengths or weaknesses. Our approach contrasts with these features; in particular, in contrast to PSI, it can be described as enabling “post-inference selection,” as we argue later on.
Some authors provide simultaneous asymptotic distributional results for the distance between the estimated change-point locations and the truth. In the linear regression context, this is done in Bai and Perron (Citation1998), Bai and Perron (2003), and in the piecewise-constant signal plus noise model—in Eichinger and Kirch (Citation2018). These approaches are asymptotic, conditional on the estimated change-point locations, and involve unknown quantities. In contrast, our methodology has a finite-sample nature, makes no assumptions on the signal, is unconditional and automatic. A further discussion of the differences between our approach and that of Bai and Perron (Citation1998), Bai and Perron (2003) can be found in Section 1 of the supplement.
Inference for multiple change-points is also sometimes posed as control of the False Discovery Rate (FDR), see for example, Li and Munk (Citation2016), Hao, Niu, and Zhang (Citation2013), and Cheng, He, and Schwartzman (Citation2020), but that approach is focused on the number of change-points rather than on their locations.
The objective of our methodology, called “Narrowest Significance Pursuit” (NSP), is to automatically detect localized regions of the data , each of which must contain at least one change-point (in a suitable sense determined by the given scenario), at a prescribed global significance level. NSP performs unconditional inference without change-point location estimation, and proceeds as follows. A number M of intervals are drawn from the index domain
, with start- and end-points chosen over an equispaced deterministic grid. On each interval drawn,
is then checked to see whether or not it locally conforms to the prescribed linear model, with any set of parameters. This check is performed through estimating the parameters of the given linear model locally by minimizing a particular multiresolution sup-norm loss, and testing the residuals from this fit via the same norm; self-normalization is involved if necessary. In the first greedy stage, the shortest interval (if one exists) is chosen on which the test is violated at a certain global significance level
. In the second greedy stage, the selected interval is searched for its shortest sub-interval on which a similar test is violated. This sub-interval is then chosen as the first region of global significance, in the sense that it must (at a global level
) contain a change-point, or otherwise the local test would not have rejected the linear model. The procedure then recursively draws M intervals to the left and to the right of the chosen region (with or without overlap), and stops when there are no further local regions of global significance.
Fang, Li, and Siegmund (Citation2020), in the piecewise-constant signal plus iid Gaussian noise model, approximate the tail probability of the maximum CUSUM statistic over all sub-intervals of the data. They then propose an algorithm, in a few variants, for identifying short, nonoverlapping segments of the data on which the local CUSUM exceeds the derived tail bound, and hence, the segments identified must contain at least a change-point each, at a given significance level. Fang and Siegmund (Citation2020) present results of similar nature for a Gaussian model with lag-one autocorrelation, linear trend, and features that are linear combinations of continuous, piecewise differentiable shapes. The most important high-level differences between NSP and these two approaches are that (a) NSP is ready for use with any user-provided design matrix X, and this requires no new calculations or coding, and yields correct coverage probabilities in finite samples of any length; (b) NSP searches for any deviations from local model linearity with respect to the regressors provided; (c) NSP is able to handle regression with autoregression practically in the same way as without, in a stable manner and on arbitrarily short intervals, and does not need accurate estimation of the unknown (nuisance) AR coefficients. We expand on these points in Section 1 of the supplement.
NSP has other distinctive features in comparison with the existing literature. It is specifically constructed to target the shortest possible significant intervals at every stage of the procedure, and to explore as many intervals as possible while remaining computationally efficient. NSP furnishes exact coverage statements, at a prescribed global significance level, for any finite sample sizes, and works in the same way regardless of the scenario and for any given regressors X. Also, thanks to the fact that the multiresolution sup-norm used in NSP can be interpreted as Hölder-like norms on certain function spaces, NSP naturally extends to the cases of unknown or heterogeneous distributions of via self-normalization. Finally, if simulation needs to be used to determine critical values for NSP, then this can be done in a computationally efficient manner.
Section 2 introduces the NSP methodology and provides the relevant finite-sample coverage theory. Section 3 extends this to NSP under self-normalization and in the additional presence of autoregression. Section 4 provides finite-sample and traditional large-sample detection consistency and rate optimality results for NSP in Scenarios 1 and 2. Section 5 provides comparative simulations and extensive numerical examples under a variety of settings. Section 6 describes two real-data case studies. Complete R code implementing NSP is available in the R package nsp. There is a supplement, whose contents are mentioned at appropriate places in the article. Proofs of our theoretical results are in the supplement.
2 The NSP Inference framework
Throughout the section, we use the language of Scenario 3, which includes Scenarios 1 and 2 as special cases. In Scenario 1, the matrix X in (2) is of dimensions and has all entries equal to 1. In Scenario 2, the matrix X is of dimensions
and its ith column is given by
,
. Scenario 4 (for NSP in the additional presence of autoregression), which generalizes Scenario 3, is handled with in Section 3.2.
2.1 Generic NSP Algorithm
We start with a pseudocode definition of the NSP algorithm, in the form of a recursively defined function NSP. In its arguments, [s, e] is the current interval under consideration and at the start of the procedure, we have ; Y (of length T) and X (of dimensions
) are as in the model formula (2); M is the number of sub-intervals of [s, e] drawn;
is the threshold corresponding to the global significance level
(typical values for
would be 0.05 or 0.1) and
(respectively
) is a functional parameter used to specify the degree of overlap of the left (respectively right) child interval of [s, e] with respect to the region of significance identified within [s, e], if any. The no-overlap case would correspond to
. In each recursive call on a generic interval [s, e], NSP adds to the set
any globally significant local regions (intervals) of the data identified within [s, e] on which Y is deemed to depart significantly (at global level
) from linearity with respect to X. We provide more details underneath the pseudocode below.
1: function NSP(s, e, Y, X, M, ,
,
)
2: if then
3: RETURN
4: end if
5: if then
6:
7: draw all intervals ,
, s.t.
8: else
9: draw a representative (see description below) sample of intervals ,
, s.t.
10: end if
11: for do
12: DeviationFromLinearity
13: end for
14:
15: if then
16: RETURN
17: end if
18: AnyOf
19: ShortestSignificantSubinterval
20: add to the set
of significant intervals
21: NSP
22: NSP
23: end function
The NSP algorithm is launched by the pair of calls: ; NSP
. On completion, the output of NSP is in the variable
. We now comment on the NSP function line by line. In lines 2–4, execution is terminated for intervals that are too short. In lines 5–10, a check is performed to see if M is at least as large as the number of all sub-intervals of [s, e]. If so, then M is adjusted accordingly, and all sub-intervals are stored in
. Otherwise, a sample of M sub-intervals
is drawn in which
and
are all possible pairs from an (approximately) equispaced grid on [s, e] which permits at least M such sub-intervals (a random alternative, in which
and
are obtained uniformly with replacement from [s, e], is possible).
In lines 11–13, each sub-interval is checked to see to what extent the response on this sub-interval (denoted by
) conforms to the linear model (2) with respect to the set of covariates on the same sub-interval (denoted by
). This core step of the NSP algorithm is described in more detail in Section 2.2.
In line 14, the measures of deviation obtained in line 12 are tested against threshold , chosen to guarantee global significance level
. How to choose
depends (only) on the distribution of
; this question is addressed in Section 2.3 and in Sections 4 and 8 of the supplement. The shortest sub-interval(s)
for which the test rejects the local hypothesis of linearity of Y versus X at global level
are collected in set
. In lines 15–17, if
is empty, then the procedure decides that it has not found regions of significant deviations from linearity on [s, e], and stops on this interval as a consequence. Otherwise, in line 18, the procedure continues by choosing the sub-interval, from among the shortest significant ones, on which the deviation from linearity has been the largest. The chosen interval is denoted by
.
In line 19, is searched for its shortest significant sub-interval, that is, the shortest sub-interval on which the hypothesis of linearity is rejected locally at a global level
. Such a sub-interval certainly exists, as
itself has this property. The structure of this search again follows the workflow of the NSP procedure; more specifically, it proceeds by executing lines 2–18 of NSP, but with
in place of s, e. The chosen interval is denoted by
. This two-stage search (identification of
in the first stage and of
in the second stage) is crucial in NSP’s pursuit to force the identified intervals of significance to be as short as possible, without unacceptably increasing the computational cost. The importance of this two-stage solution is illustrated in Section 5 of the supplement. In line 20, the selected interval
is added to the output set
.
In lines 21–22, NSP is executed recursively to the left and to the right of the detected interval . However, we optionally allow for some overlap with
. The overlap, if present, is a function of
and, if it involves detection of the location of a change-point within
, then it is also a function of Y, X. Executing NSP without an overlap, that is, with
, means that the procedure runs, in each recursive step, wholly on data sections between (and only including the end-points of) the previously detected intervals of significance. This ensures that the intervals of significance returned by NSP are nonoverlapping; however, this also reduces the amount of data that the procedure is able to use at each recursive stage, which shows the importance of optionally allowing nonzero overlaps
and
in NSP. One possibility is for example the following.
(3)
(3)
This setting means that upon detecting a generic interval of significance within [s, e], the NSP algorithm continues on the left interval
and the right interval
(recall that the no-overlap case results uses the left interval
and the right interval
). See Section 5.1 for more on the overlap parameters.
In NSP, having growing with T is possible, but we must have
or otherwise no regions of significance will be found. Section 2 of the supplement comments on a few other generic aspects of the NSP algorithm.
2.2 Measuring Deviation from Linearity in NSP
This section completes the definition of NSP (in the version without self-normalization) by describing the DeviationFromLinearity function (NSP algorithm, line 12). Its basic building block is a scaled partial sum statistic, defined for an arbitrary input sequence by
. We define the scan statistic of an input vector y (of length T) with respect to the interval set
as
(4)
(4)
The set used in NSP contains intervals at a range of scales and locations. For computational efficacy, instead of the set
of all subintervals of [1, T], we use the set
of all intervals of dyadic lengths and arbitrary locations, that is
. A simple pyramid algorithm of complexity
is available for the computation of all
for
. We also define restrictions of
and
to arbitrary intervals [s, e] as
, and analogously for
. We refer to
,
and their restrictions as multiresolution sup-norms (see Nemirovski Citation1986; Li Citation2016) or, alternatively, multiscale scan statistics if they are used as operations on data. If the context requires this, the qualifier “dyadic” will be added to these terms when referring to the
versions. The facts that, for any interval [s, e] and any input vector y (of length T), we have
(5)
(5) are trivial consequences of the facts that
and
. With this notation in place, DeviationFromLinearity
is defined as follows.
Step 1. Find
. This fits the postulated linear model between X and Y restricted to the interval
Step 2. Compute the same multiresolution sup-norm of the empirical residuals from the above fit,
Step 3. Return
Steps 1 and 2 can be carried out in a single step as , however, for comparison with other approaches, it will be convenient for us to use the two-stage process in steps 1 and 2 for the computation of
. Computationally, the linear model fit in step 1 can be carried out via simple linear programming; we use the R package lpSolve. The following important property lies at the heart of NSP.
Proposition 2.1 .
Let the interval [s, e] be such that . We have
.
This is a simple but valuable result, which can be read as follows: “under the local null hypothesis of no signal on [s, e], the test statistic , defined as the multiresolution sup-norm of the empirical residuals from the same multiresolution sup-norm fit of the postulated linear model on [s, e], is bounded by the multiresolution sup-norm of the true residual process
.” This bound is achieved because the same norm is used in the linear model fit and in the residual check, and it is important to note that the corresponding bound would not be available if the postulated linear model were fitted with a different loss function, for example, via OLS. Having such a bound allows us to transfer our statistical significance calculations to the domain of the unobserved true residuals
, which is much easier than working with the corresponding empirical residuals. It is also critical to obtaining global coverage guarantees for NSP, as we now show.
Theorem 2.1 .
Let be a set of intervals returned by the NSP algorithm. We have
.
Theorem 2.1 should be read as follows. Let . For a set of intervals returned by NSP, we are guaranteed, with probability of at least
, that there is at least one change-point in each of these intervals. Therefore,
can be interpreted as an automatically chosen set of regions (intervals) of significance in the data. In the no-change-point case (
), the correct reading of Theorem 2.1 is that the probability of obtaining one of more intervals of significance (
) is bounded from above by
.
NSP uses a multiresolution sup-norm fit to be checked via the same multiresolution sup-norm. This leads to exact coverage guarantees for NSP with very simple mathematics. In contrast to the confidence intervals in for example, Bai and Perron (Citation1998), the NSP regions of significance are not conditional on any particular estimator of N or of the change-point locations, and are in addition of a finite-sample nature. Still, they have a “confidence interval” interpretation in the sense that each must contain at least one change, with a certain prescribed global probability.
For , we define
. A simple corollary of Theorem 2.1 is that for
, if the corresponding sets
are mutually disjoint (as is the case for example, if
), then we must have
with probability at least
. It would be impossible to obtain a similar upper bound on N without order-of-magnitude assumptions on spacings between change-points and magnitudes of parameter changes; we defer this to Section 4. The result in Theorem 2.1 does not rely on asymptotics and has a finite-sample character.
in Step 1 above does not have to be an accurate estimator of the true local
for the bound in Proposition 2.1 to hold; it holds unconditionally and for arbitrary short intervals [s, e].
NSP is not automatically equipped with pointwise estimators of change-point locations. This is an important feature, because thanks to this, it can be so general and work in the same way for any X. If it were to come with meaningful pointwisechange-point location estimators, they would have to be designed for each X separately, for example, using the maximum likelihood principle. (However, NSP can be paired up with such pointwise estimators; see immediately below for details.) We now introduce a few new concepts, to contrast this feature of NSP with the existing concept of post-selection inference.
“Post-inference selection” and “inference without selection.” If it can be assumed that an interval only contains a single change-point, its location can be estimated for example, via MLE performed locally on the data subsample living on
. Naturally, the MLE should be constructed with the specific design matrix X in mind, see Baranowski, Chen, and Fryzlewicz (Citation2019) for examples in Scenarios 1 and 2. In this construction, “inference,” that is, the execution of NSP, occurs before “selection,” that is, the estimation of the change-point locations, hence, the label of “post-inference selection.” This avoids the complicated machinery of post-selection inference, as we automatically know that the p-value associated with the estimated change-point must be less than
. Similarly, “inference without selection” refers to the use of NSP unaccompanied by a change-point location estimator.
“Simultaneous inference and selection” or “in-inference selection.” In this construction, change-point location estimation on an interval occurs directly after adding it to
. The difference with “post-inference selection” is that this then naturally enables appropriate nonzero overlaps
and
in the execution of NSP. More specifically, denoting the estimated location within
by
, we can set, for example,
and
, so that lines 21–22 of the NSP algorithm become, respectively, NSP
and NSP
.
By Theorem 2.1, the only piece of knowledge required to obtain coverage guarantees in NSP is the distribution of (or
), regardless of the form of X. Much is known about this distribution for various underlying distributions of Z; see Section 2.3 and Section 4 of the supplement for Z Gaussian and following other light-tailed distributions, respectively. Any future further distributional results of this type would only further enhance the applicability of NSP. However, if the distribution of
(
) is unknown, then an approximation can also be obtained by simulation, which is particularly computationally efficient for
. See Section 8 of the supplement for more details on simulation-based threshold selection.
2.3 Gaussian
We now recall distributional results for , in the case
with
assumed known, which will permit us to choose
so that
as
. The resulting
can then be used in Theorem 2.1. As the result of Theorem 2.1 is otherwise of a finite-sample nature, some users may be uncomfortable resorting to large-sample asymptotics to approximate the distribution of
. However, (a) the asymptotic results outlined below approximate the behavior of
well even for small samples, and (b) users not wishing to resort to asymptotics have the option of approximating the distribution of
by simulation (see Section 8 of the supplement), which is computationally fast. The assumption of a known
is common in the change-point inference literature, see for example Hyun, G’Sell, and Tibshirani (Citation2018), Fang and Siegmund (Citation2020), and Jewell, Fearnhead, and Witten (Citation2022). Section 4 of the supplement covers the unknown
case. Results on the distribution of
are given in Siegmund and Venkatraman (Citation1995) and Kabluchko (Citation2007). We recall the formulation from Kabluchko (Citation2007) as it is slightly more explicit.
Theorem 2.2
(Theorem 1.3 in Kabluchko (Citation2007)).
Let be iid
. For every
, we have
, where
and
is the standard normal cdf.
We use the approximate value in our numerical work. Using the asymptotic independence of the maximum and the minimum (Kabluchko and Wang Citation2014), and the symmetry of Z, we get the following simple corollary.
(6)
(6) as
. In light of (6), we obtain
for use in Theorem 2.1 as follows: (a) equate
and obtain
, (b) form
.
We now extend NSP to positively dependent Gaussian innovations. Let be a stationary, zero-mean, nonnegatively autocorrelated process with long-run standard deviation
. Let
, and note
. In the notation of Theorem 2.2,
This demonstrates that valid coverage guarantees are obtained for a system with innovations by applying the NSP threshold equal to the threshold suitable for iid
innovations times the long-run standard deviation of
. Long-run standard deviation estimation, especially in the presence of change-points, is a difficult problem, but several solutions have been proposed, including one in Dette, Eckle, and Vetter (Citation2020) (in our Scenario 1). See also Section 10 of the supplement for a related discussion of NSP with autocorrelated innovations.
2.4 Tightening the Bounds: X-dependent Thresholds
We now show how to obtain thresholds lower than those in Theorem 2.1 if the analyst is willing to allow their dependence on the design matrix X. This calls for the reexamination of Proposition 2.1. Consider the following alternative version.
Proposition 2.2 .
Let the interval [s, e] be such that . We have
.
This leads to a tighter version of Theorem 2.1.
Theorem 2.3 .
Let be a set of intervals returned by the NSP algorithm. We have
.
In Theorem 2.3, the probability is bounded from above by
. As
, the threshold
obtained by solving
(7)
(7) will be lower than that obtained by solving
(which was done in Theorem 2.1). In addition, unlike the solution to
, the solution to (7) accounts for the number and form of the covariates X. To solve (7), the distribution of
can be obtained by simulation, separately for each set of covariates X and sample size T; see Section 8 of the supplement for details. The better localization properties of the thus-obtained tighter bounds are illustrated, for Scenario 1, in Section 5.1.
3 NSP with Self-Normalization and with Autoregression
3.1 Self-Normalized NSP for Possibly Heavy-Tailed, Heteroscedastic
Kabluchko and Wang (Citation2014) point out that the square-root normalization used in is not natural for distributions with tails heavier than Gaussian. We are interested in obtaining a universal normalization in
which would work across a wide range of possibly heavy-tailed distributions without requiring their explicit knowledge, including under heterogeneity. One such solution is offered by the self-normalization framework developed in Rac˘kauskas and Suquet (Citation2003) and related papers. We now recall the basics and discuss the necessary adaptations to our context; the less mathematically inclined reader is welcome to skip this description and proceed directly to formula (9), which gives the oracle self-normalized statistic computed on the true residuals
.
We first discuss the relevant distributional results for the true residuals . We only cover the case of symmetric distributions of
. For the nonsymmetric case, which requires a slightly different normalization, see Rac˘kauskas and Suquet (Citation2003). In the latter work, the following result is proved. Let
,
,
, where
if
and
if
. Further, suppose
. This last condition, in particular, is satisfied if
and
. The function
will play the role of a modulus of continuity. Let
be independent and symmetrically distributed with
; note they do not need to be identically distributed. Define
and
. Assume further
in probability as
. Egorov (Citation1997) shows that this last condition is equivalent to
being within the domain of attraction of the normal law. Therefore, the material of this section applies to a much wider class of distributions than the heterogeneous extension of SMUCE in Pein, Sieling, and Munk (Citation2017), which only applies to normally distributed
.
Let the random polygonal partial sums process be defined on [0, 1] as linear interpolation between the knots
,
, where
, and let
. Denote by
the set of continuous functions
such that
, where
.
is a Banach space in its natural norm
. Define
, a closed subspace of
, by
.
is a separable Banach space. Under the assumptions above, we have the following convergence in distribution as
:
(8)
(8) in
, where
is a standard Wiener process. Define
and, with
and
, consider the statistic
(9)
(9)
In the notation and under the conditions listed above, it is a direct consequence of the distributional convergence (8) in the space that for any level
, we have
(10)
(10) as
, and the quantiles of the distribution of
, which does not depend on the sample size T, can be computed (once) by simulation.
Following the narrative of Sections 2.2 and 2.3, to make these results operational in a new function DeviationFromLinearity.SN (where “SN” stands for self-normalization) for use in line 12 of the NSP algorithm, we need the following development. Assume initially that the global residual sum of squares is known. For a generic interval [s, e] containing no change-points, we need to be able to obtain empirical residuals
for
and
for
for which we can guarantee that
(11)
(11)
This provides a self-normalized equivalent of Proposition 2.1 and requires that the deviation from linearity computed on an interval containing no change-points (left-hand side of (11)) does not exceed the analogous oracle quantity computed on the true residuals (right-hand side of 11). Section 6 of the supplement describes the construction of for
so that (11) is guaranteed, and introduces a suitable estimator of
for use in (11).
3.2 NSP with Autoregression
To accommodate autoregression while retaining the serial independence of , we introduce the following additional scenario.
Scenario 4.
Linear regression with autoregression, with piecewise-constant parameters.
For a given design matrix ,
,
, the response
follows the model
(12)
(12) for
, where the regression parameter vectors
and the autoregression parameters
are such that either
or
for some k (or both types of changes occur).
In this work, we treat the autoregressive order r as fixed and known to the analyst. Fang and Siegmund (Citation2020) consider and treat the autoregressive parameter as known, but acknowledge that in practice it is estimated from the data; however, they add that “[it] would also be possible to estimate [the autoregressive parameter] from the currently studied subset of the data, but this estimator appears to be unstable.” NSP circumvents this instability issue, as explained below. NSP for Scenario 4 proceeds as follows.
Supplement the design matrix X with the lagged versions of the variable Y, or in other words substitute
Run the NSP algorithm of Section 2.1 with the new X and Y (with a suitable modification to line 12 if using the self-normalized version), with the following single difference. In lines 21 and 22, recursively call the NSP routine on the intervals
The result of Theorem 2.1 applies to the output of NSP for Scenario 4 too. The NSP algorithm offers a new point of view on change-point analysis in the presence of autocorrelation. Unlike Fang and Siegmund (Citation2020), who require accurate estimation of the autoregressive parameters for successful change-point detection, NSP circumvents the issue by using the same multiresolution norm in the local regression fits on each [s, e], and in the subsequent tests of the local residuals. In this way, the autoregression parameters do not have to be estimated accurately for the relevant stochastic bound in Proposition 2.1 to hold; it holds unconditionally and for arbitrary short intervals [s, e]. Therefore, NSP is able to deal with autoregression, stably, on arbitrarily short intervals. We illustrate the performance of this version of NSP in Section 7 of the supplement.
4 Detection Consistency and Lengths of NSP Intervals
We now study the consistency of NSP in detecting change-points, and the rates at which the lengths of the NSP intervals contract, as the sample size increases. We consider a version of the NSP algorithm that considers all sub-intervals of [1, T], and we provide results in Scenario 1 as well as in Scenario 2 with continuous piecewise-linearity (this parallels the scenarios for which consistency is shown in Baranowski, Chen, and Fryzlewicz Citation2019).
So far in the article, we avoided introducing any assumptions on the signal: our coverage guarantees in Theorem 2.1 held under no conditions on the number of change-points, their spacing, or the sizes of the breaks. This was unsurprising as they amounted to statistical size control. By contrast, the results of this section relate to detection consistency (and therefore “power” rather than size) and as such, require minimum signal strength assumptions.
4.1 Scenario 1 – Piecewise Constancy
In this section, falls under Scenario 1. We start with assumptions on the strength of the change-points. For each change-point
,
, define
(13)
(13)
Recalling that and
, we require the following assumption.
Assumption 4.1.
We have the following theorem.
Theorem 4.1 .
Let Assumption 4.1 hold, with defined in (13). On the set
, a version of the NSP algorithm that considers all sub-intervals, executed with no overlaps and with threshold
, returns exactly N intervals of significance
such that
and
, for
.
Theorem 4.1 leads to the following corollary.
Corollary 4.1 .
Let the assumptions of Theorem 4.1 hold, and in addition let . Let
for any
. Let
denote the set of intervals of significance
returned by a version of the NSP algorithm that considers all sub-intervals, executed with no overlaps and with threshold
. Let
. We have
as
.
Corollary 4.1 is a traditional, large-sample consistency result for NSP. Consider first Assumption 4.1, under which it operates. With as in Corollary 4.1, Assumption 4.1 permits
, a quantity that characterizes the difficulty of the multiple change-point detection problem, to be of order
, which is the same as in Baranowski, Chen, and Fryzlewicz (Citation2019) and minimax-optimal as argued in Chan and Walther (Citation2013). Further, the statement of Corollary 4.1 implies statistical consistency of NSP in the sense that with probability tending to one with T, NSP estimates the correct number of change-points and each NSP interval contains exactly one true change-point. Moreover, the length of the NSP interval around each
is of order
, which is near-optimal and the same as in Baranowski, Chen, and Fryzlewicz (Citation2019). Finally, this also implies that this consistency rate is inherited by any pointwise estimator of
that takes its value in the jth NSP interval of significance; this applies even to naive estimators constructed for example, as the middle points of their corresponding NSP intervals
, that is,
. More refined estimators, for example, one based on CUSUM maximization within each NSP interval, can also be used and will also automatically inherit the consistency and rate.
4.2 Scenario 2—Continuous Piecewise Linearity
In this section, falls under Scenario 2 and is piecewise linear and continuous. Naturally, the definition of change-point strength has to be different from that in Section 4.1. For each change-point
,
, let
(14)
(14) where
and
are, respectively, the slopes of
immediately to the left and to the right of
, and
is a certain universal constant (i.e., valid for all
), suitably large. The following theorem holds.
Theorem 4.2 .
Let Assumption 4.1 hold, with defined in (14). On the set
, a version of the NSP algorithm that considers all sub-intervals, executed with no overlaps and with threshold
, returns exactly N intervals of significance
such that
and
, for
.
We note that Assumption 4.1 is model-independent: we require it as much in the piecewise-constant Scenario 1 as in the piecewise-linear Scenario 2 (and in any other scenario), but with defined separately for each scenario. Theorem 4.2 leads to the following corollary.
Corollary 4.2 .
Let the assumptions of Theorem 4.2 hold, and in addition let . Let
for any
. Let
denote the set of intervals of significance
returned by a version of the NSP algorithm that considers all sub-intervals, executed with no overlaps and with threshold
. Let
. We have
as
.
Corollary 4.2 implies that with as defined therein, and if
(a case in which
is bounded; see Baranowski, Chen, and Fryzlewicz Citation2019), we have that the accuracy of change-point localization via NSP (measured by
) is
, the same as in Baranowski, Chen, and Fryzlewicz (Citation2019) and within a logarithmic factor of Raimondo (Citation1998). Our comment (made in Section 4.1) regarding this rate being inherited by any pointwise estimator of
, as long as it falls within
, applies equally in this case.
5 Numerical Illustrations
5.1 Scenario 1—Piecewise Constancy
In this section, we demonstrate numerically that the guarantee offered by Theorem 2.1 holds for NSP in practice over a variety of Gaussian models with and without change-points in Scenario 1. We start by describing the competing methods. “NSP” is the NSP method executed with a deterministic grid using intervals, with the threshold chosen as in Section 2.3 and no interval overlaps, that is,
;
is estimated via MAD. “NSP-SIM” is like “NSP” but uses the simulation-based thresholds of Section 2.4. “NSP-O” is like “NSP” but uses the overlap functions defined in (3). “NSP-SIM-O” is like “NSP-SIM” but uses the overlap functions as in “NSP-O.” “BP” is the method of Bai and Perron (Citation2003) as implemented in the routine breakpoints of R package strucchange (version 1.5-3) with the minimum segment size set to 2; the number of change-points is chosen by BIC, and confidence intervals are then formed conditionally on the estimated model by using the confint.breakpointsfull routine, with the significance level Bonferroni-corrected for the estimated number of change-points. “BP-LIM” is like “BP” but with the number of change-points limited from above by the number of intervals returned by NSP (or one if NSP returns no intervals). “SMUCE” is the method of Frick, Munk, and Sieling (Citation2014), for which the execution is stepR::stepFit(data, alpha, confband = TRUE); we use version 2.1-3 of stepR.
We begin with null models, by which we mean models (1) for which is constant throughout, that is,
. For null models, Theorem 2.1 promises that NSP at level
returns no intervals of significance with probability at least
. In this section, we use
. There are similar parameters in BP, BP-LIM and SMUCE, and they are also set to 0.1. All models used are listed in .
Table 1: Models for the comparative simulation study in Section 5.1; “no. of cpts” means “number of change-points.”
shows the null model results. All methods tested keep the nominal size well for both null signals; note that the empirical binomial proportion of 0.86, observed in NSP-SIM and NSP-SIM-O, is only insignificantly (in the sense of the binomial Z-test) different from the nominal value of 0.9, with the sample size used (100 simulated sample paths).
Table 2: Numbers of times, out of 100 simulated sample paths of each null model, that the respective method indicated no intervals of significance.
We now discuss performance for signals with change-points (). For each model and method tested, we evaluate the following aspects: the empirical coverage (i.e., whether at least
of the simulated sample paths are such that any intervals of significance returned contain at least one true change-point each); if any intervals are returned, the proportion of those that are genuine (i.e., the proportion of those intervals returned that contain at least one true change-point); the number of genuine intervals; the number of all intervals; and the average length of genuine intervals. shows the results; note that the Wide Teeth model is challenging from the point of view of detection for all methods tested, but this should not surprise on visual inspection of its sample paths.
Table 3: Results for each model + method combination: “coverage” is the number of times, out of 100 simulated sample paths, that the respective model + method combination did not return a spurious interval of significance; “prop. gen. int.” is the average (over 100 simulated sample paths) proportion of genuine intervals out of all intervals returned, if any (if none are returned, the corresponding 0/0 ratio is ignored in the average); “no. gen. int.” is the average (over 100 sample paths) number of genuine intervals returned; “no. all int.” is the average (over 100 sample paths) number of all intervals returned; “av. gen. int. len.” is the average (over 100 sample paths) length of a genuine interval returned in the respective model + method combination.
The BP method suffers from under-coverage in all models tested with the exception of Single 300; this is the most pronounced for Teeth 10, for which the empirical coverage is only 50 (to the nominal 90). BP-LIM (a method designed not to over-detect the true number of change-points) does not suffer from the same problem (with the exception of Single 100, for which it under-covers slightly); however, the price to pay for the mostly satisfactory coverage performance of BP-LIM is the fact that it only detects a small proportion of the true change-points: for example, on average 1.75 out of 3 for Wave, and 1.92 out of 13 for Teeth 10. The message is that in the presence of under-detection (as in BP-LIM), conditional confidence intervals can be capable of offering correct unconditional coverage; but this advantage disappears if more realistic change-point models are chosen and post-equipped with conditional confidence intervals (as in BP). SMUCE suffers from under-coverage in most of the models tested, most notably in Teeth 10 (coverage 24) and Blocks (52).
All of the NSP-* methods offer correct coverage for all the signals tested (empirical coverage of to the nominal 90). As expected, the coverage of the -SIM versions does not exceed that of their theoretical threshold counterparts. Being based on lower thresholds, the -SIM versions also return more genuine intervals on average, which are in addition on average shorter. Also as expected, the -O versions return more intervals on average than the corresponding non-O versions.
We further test the NSP-* in the presence of noise autocorrelation as follows. We modify the Noise 300 and Single 300 signals of so that the innovations used are simulated from an AR(1) process with the marginal variance set to 1 and the autocorrelation coefficient spanning the set 0.1, 0.3, 0.5, and 0.7. Instead of estimating via MAD (which would lead to incorrect behavior for autocorrelated noise), we set it to the true long-run standard deviation of the relevant noise process, as per the discussion of Section 2.3. and confirm the correct coverage behavior of all NSP-* methods in these settings. Note, in , the increasing detection challenge in the Single 300 (a) model as a increases to 0.7. Satisfactory estimation of the long-run standard deviation, especially in the presence of change-points, is a difficult problem but several solutions exist; we refer the reader in particular to Dette, Eckle, and Vetter (Citation2020).
Table 4: Numbers of times, out of 100 simulated sample paths of each null model, that the respective method indicated no intervals of significance.
Table 5: Results for each model + method combination under auto-correlation: the process is autocorrelated and the
is set to its true long-run standard deviation, rather than being estimated via MAD.
We now illustrate NSP and NSP-SIM-O on the Blocks model (simulated with random seed set to 1). This represents a difficult setting for change-point detection, with practically all state of the art multiple change-point detection methods failing to estimate all 11 change-points with high probability (Anastasiou and Fryzlewicz Citation2022). A high degree of uncertainty with regards to the existence and locations of change-points can be expected.
NSP returns 7 intervals of significance, shown in the left-hand plot of . We recall that at a fixed significance level, it is not the aim of the NSP procedure to detect all change-points. The correct interpretation of the result is that we can be at least certain that each of the intervals returned by NSP covers at least one true change-point. This coverage holds for this particular sample path, with exactly one true change-point being located within each interval of significance.
Figure 1: Left: realization of noisy blocks with
(light grey), true change-point locations (blue), NSP intervals of significance (
, shaded red). Middle: the same for NSP-SIM-O. Right: “prominence plot” – bar plot of
,
, plotted in increasing order, where
are the NSP significance intervals; the labels are “
–
”. See Section 5.1 for more details.
![Figure 1: Left: realization Yt of noisy blocks with σ=10 (light grey), true change-point locations (blue), NSP intervals of significance (α=0.1, shaded red). Middle: the same for NSP-SIM-O. Right: “prominence plot” – bar plot of e˜i−s˜i, i=1,…,7, plotted in increasing order, where [s˜i,e˜i] are the NSP significance intervals; the labels are “s˜i–e˜i”. See Section 5.1 for more details.](/cms/asset/3c898a7a-9d75-49a4-a12f-c138820e5954/uasa_a_2211733_f0001_c.jpg)
NSP enables the following definition of a change-point hierarchy. A hypothesized change-point contained in the detected interval of significance is considered more prominent than one contained in
if
is shorter than
. The right-hand plot of shows a “prominence plot” for this output of the NSP procedure.
The output of NSP-SIM-O is in the middle plot of . This version of the procedure returns 10 intervals of significance, such that (a) each interval covers at least one true change-point, and (b) they collectively cover 9 of the signal’s change-points, the only exceptions being
and
.
Finally, we mention computation times for this particular example, on a standard 2015 iMac: 14 sec (NSP, ), 24 sec (NSP-O,
), 1.6 sec (NSP,
), and 2.6 sec (NSP-O,
).
5.2 Scenario 2—Piecewise Linearity
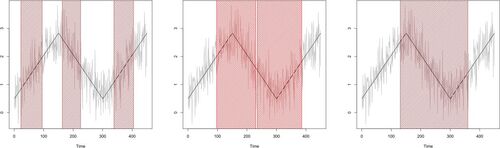
We consider the continuous, piecewise-linear wave2sect signal, defined as the first 450 elements of the wave2 signal from Baranowski, Chen, and Fryzlewicz (Citation2019), contaminated with iid Gaussian noise with . The signal and a sample path are shown in . In this model, we run the NSP procedure, with no overlaps and with the other parameters set as in Section 5.1, (wrongly or correctly) assuming the following, where q denotes the postulated degree of the underlying piecewise polynomial: (a)
, which wrongly assumes that the true signal is piecewise constant; (b)
, which assumes the correct degree of the polynomial pieces making up the signal; (c)
, which over-specifies the degree. We denote the resulting versions of the NSP procedure by NSP
for
. The intervals of significance returned by all three NSP
methods are shown in . Theorem 2.1 guarantees that the NSP1 intervals each cover a true change-point with probability of at least
and this behavior occurs in this particular realization. The same guarantee holds for the over-specified situation in NSP2, but there is no performance guarantee for NSP0.
Figure 2: Noisy (light grey) and true (black) wave2sect signal, with NSP significance intervals for
(left, misspecified model),
(middle, well-specified model),
(right, over-specified model). See Section 5.2 for more details.
5.3 Self-Normalized NSP
We briefly illustrate the performance of the self-normalized NSP. We define the piecewise-constant squarewave signal as taking the values of 0, 10, 0, 10, each over a stretch of 200 time points. With the random seed set to 1, we contaminate it with a sequence of independent t-distributed random variables with 4 degrees of freedom, with the standard deviation changing linearly from to
. The simulated dataset, showing the “spiky” nature of the noise, is in the left plot of .
Figure 3: Left: squarewave signal with heterogeneous noise (black), self-normalized NSP intervals of significance (shaded red), true change-points (blue); see Section 5.3 for details. Right: time series
for
. Red: the center of the (single) NSP interval of significance. See Section 6.2 for details.
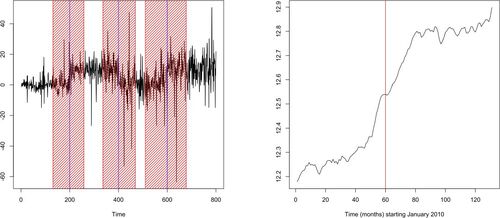
We run the self-normalized version of NSP with the following parameters: a deterministic equispaced interval sampling grid, ,
,
, no overlap; the outcome is in the left plot of . Each true change-point is correctly contained within a (separate) NSP interval of significance, and we note that no spurious intervals get detected despite the heavy-tailed and heterogeneous character of the noise.
In addition, we run the self-normalized NSP, with the parameters as above, on heavy-tailed versions of the Noise 300 and Single 300 models from , in which the Gaussian innovations have been replaced with -distributed innovations scaled to have marginal variance 1. For the thus-modified Noise 300 model, self-normalized NSP correctly identifies no intervals of significance in 100 out of 100 simulated sample paths. For the modified Single 300 model, self-normalized NSP correctly identifies one interval of significance in 100/100 simulated sample paths, with the average interval length of 124.54.
6 Data Examples
6.1 The US Ex-post Real Interest Rate
We re-analyze the time series of U.S. ex-post real interest rate (the 3-month treasury bill rate deflated by the CPI inflation rate) considered in Garcia and Perron (Citation1996) and Bai and Perron (Citation2003). The dataset is available at http://qed.econ.queensu.ca/jae/datasets/bai001/. The dataset , shown in the left plot of , is quarterly and the range is 1961:1–1986:3, so
. The arguments outlined in Section 11 of the supplement justify the applicability of NSP in thiscontext.
Figure 4: Left plot: time series ; right plot: time series
; both with piecewise-constant fits (red) and intervals of significance returned by NSP (shaded grey). See Section 6.1 for a detailed description.
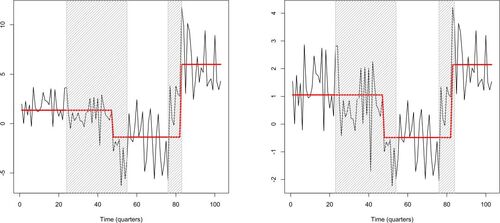
We first perform a naive analysis in which we assume our Scenario 1 (piecewise-constant mean) plus iid innovations. This is only so we can obtain a rough segmentation which we can then use to adjust for possible heteroscedasticity of the innovations in the next stage. We estimate
via
and run the NSP algorithm with the following parameters:
,
,
. This returns the set
of two significant intervals:
. We estimate the locations of the change-points within these two intervals via CUSUM fits on
and
; this returns
and
. The corresponding fit is in the left plot of . We then produce an adjusted dataset, in which we divide
by the respective estimated standard deviations of these sections of the data. The adjusted dataset
is shown in the right plot of and has a visually homoscedastic appearance. NSP run on the adjusted dataset with the same parameters produces the significant interval set
. CUSUM fits on the corresponding data sections
produce identical estimated change-point locations
,
. The fit is in the right plot of .
We could stop here and agree with Garcia and Perron (Citation1996), who also conclude that there are two change-points in this dataset, with locations within our detected intervals of significance. However, we note that the first interval, [23, 54], is relatively long, so one question is whether it could be covering another change-point to the left of . To investigate this, we rerun NSP with the same parameters on
but find no intervals of significance (not even with the lower thresholds induced by the shorter sample size
rather than the original
). Our lack of evidence for a third change-point contrasts with Bai and Perron’s (Citation2003) preference for a model with three change-points.
However, the fact that the first interval of significance [23, 54] is relatively long could also be pointing to model misspecification. If the change of level over the first portion of the data were gradual rather than abrupt, we could naturally expect longer intervals of significance under the misspecified piecewise-constant model. To investigate this further, we now run NSP on but in Scenario 2, initially in the piecewise-linear model (
), which leads to one interval of significance:
.
This raises the prospect of modeling the mean of as linear. We produce such a fit, in which in addition the mean of
is modeled as piecewise-constant, with the change-point location
found via a CUSUM fit on
. We also produce an alternative fit in which the mean of
(up to the change-point) is modeled as linear, and the mean of
(post-change-point) as constant. This is in the right plot of and has a lower BIC value (9.52) than the piecewise-constant fit from the right plot of (10.57). This is because the linear + constant fit uses four parameters, whereas the piecewise-constant fit uses five.
Figure 5: Left plot: with the quadratic + constant fit; right plot:
with the linear + constant fit. See Section 6.1 for a detailed description.
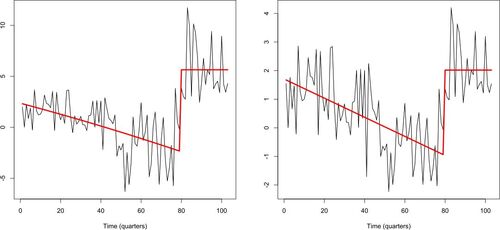
The viability of the linear + constant model for the scaled data is encouraging because it raises the possibility of a model for the original data
in which the mean of
evolves smoothly in the initial part of the data. We construct a simple example of such a model by fitting the best quadratic on
(resulting in a strictly decreasing, slightly concave fit), followed by a constant on
. The change-point location, 79, is the same as in the linear + constant fit for
. The fit is in the left plot of . It is interesting to see that the quadratic + constant model for
leads to a slightly lower residual variance than the piecewise-constant model (4.9–4.94). Both models use five parameters. We conclude that more general piecewise-polynomial modeling of this dataset can be a viable alternative to the piecewise-constant modeling used in Garcia and Perron (Citation1996) and Bai and Perron (Citation2003). This example shows how NSP, beyond its usual role as an automatic detector of regions of significance, can also serve as a useful tool in achieving improved modelselection.
6.2 House Prices in London Borough of Newham
We consider the average monthly property price in the London Borough of Newham, for all property types, recorded from January 2010 to November 2020 (
) and accessed on 1st February 2021. The data is available on https://landregistry.data.gov.uk/. We use the logarithmic scale
and are interested in the stability of the autoregressive model
. Again, the arguments of Section 11 of the supplement justify the applicability of NSP here.
NSP, run on a deterministic equispaced interval sampling grid, with and
, with the
estimator of the residual variance (see Section 4 of the supplement) and both with no overlap and with an overlap as defined in formula (3), returns a single interval of significance [24, 96], which corresponds to a likely change-point location between December 2011 and December 2017. Assuming a possible change-point in the middle of this interval, that is, in December 2014, we run two autoregressions (up to December 2014 and from January 2015 onwards) and compare the coefficients. shows the estimated regression coefficients (with their standard errors) over the two sections.
Table 6: Parameter estimates (standard error in brackets) in the autoregressive model of Section 6.2.
It appears that both the intercept and the autoregressive parameter change significantly at the change-point. In particular, the change in the autoregressive parameter from 1.03 (standard error 0.02) to 0.95 (0.02) suggest a shift from a unit-root process to a stationary one. This agrees with a visual assessment of the character of the process in the right plot of , where it appears that the process is more “trending” before the change-point than it is after, where it exhibits a conceivably stationary behavior, particularly from the middle of 2016 or so. Indeed, the average monthly change in over the time period January 2010–December 2014 is 0.0061, larger than the corresponding average change of 0.0052 over January 2015–November 2020.
Supplementary Materials
Supplement to the paper in a pdf format; R script to accompany the paper; associated RData file.
Supplemental Material
Download Zip (1.1 MB)Acknowledgments
I wish to thank Yining Chen, Paul Fearnhead, Shakeel Gavioli-Akilagun, Zakhar Kabluchko and David Siegmund for helpful discussions.
Disclosure Statement
There are no competing interests to declare.
Additional information
Funding
References
- Anastasiou, A., and Fryzlewicz, P. (2022), “Detecting Multiple Generalized Change-Points by Isolating Single Ones,” Metrika, 85, 141–174. DOI: 10.1007/s00184-021-00821-6.
- Bai, J., and Perron, P. (1998), “Estimating and Testing Linear Models with Multiple Structural Changes,” Econometrica, 66, 47–78. DOI: 10.2307/2998540.
- Bai, J., and Perron, P. (2003), “Computation and Analysis of Multiple Structural Change Models,” Journal of Applied Econometrics, 18, 1–22. DOI: 10.1002/jae.659.
- Baranowski, R., Chen, Y., and Fryzlewicz, P. (2019), “Narrowest-Over-Threshold Detection of Multiple Change-Points and Change-Point-Like Features,” The Journal of the Royal Statistical Society, Series B, 81, 649–672. DOI: 10.1111/rssb.12322.
- Chan, H. P., and Walther, G. (2013). Detection with the scan and the average likelihood ratio. Statistica Sinica 23, 409–428. DOI: 10.5705/ss.2011.169.
- Chen, Y., Shah, R., and Samworth, R. (2014), “Discussion of ‘Multiscale Change Point Inference’ by Frick, Munk, and Sieling,” Journal of the Royal Statistical Society, Series B, 76, 544–546.
- Cheng, D., He, Z., and Schwartzman, A. (2020), “Multiple Testing of Local Extrema for Detection of Change Points,” Electronic Journal of Statistics, 14, 3705–3729. DOI: 10.1214/20-EJS1751.
- Dette, H., Eckle, T., and Vetter, M. (2020). Multiscale change point detection for dependent data. Scandinavian Journal of Statistics, 47, 1243–1274. DOI: 10.1111/sjos.12465.
- Duy, V. N. L., Toda, H., Sugiyama, R., and Takeuchi, I. (2020), “Computing Valid p-value for Optimal Changepoint by Selective Inference Using Dynaming Programming,” in Advances in Neural Information Processing Systems (Vol. 33), pp. 11356–11367.
- Egorov, V. (1997), “On the Asymptotic Behavior of Self-normalized Sums of Random Variables,” Theory of Probability and Its Applications, 41, 542–548.
- Eichinger, B., and Kirch, C. (2018), “A MOSUM Procedure for the Estimation of Multiple Random Change Points,” Bernoulli, 24, 526–564. DOI: 10.3150/16-BEJ887.
- Fang, X., Li, J., and Siegmund, D. (2020), “Segmentation and Estimation of Change-Point Models: False Positive Control and Confidence Regions,” Annals of Statistics, 48, 1615–1647.
- Fang, X., and Siegmund, D. (2020), “Detection and Estimation of Local Signals,” preprint.
- Frick, K., Munk, A., and Sieling, H. (2014), “Multiscale Change-Point Inference,” (with discussion), Journal of the Royal Statistical Society, Series B, 76, 495–580. DOI: 10.1111/rssb.12047.
- Fryzlewicz, P. (2014), “Wild Binary Segmentation for Multiple Change-Point Detection,” Annals of Statistics, 42, 2243–2281.
- Garcia, R., and Perron, P. (1996), “An Analysis of the Real Interest Rate Under Regime Shifts,” Review of Economics and Statistics, 78, 111–125. DOI: 10.2307/2109851.
- Hao, N., Niu, Y., and Zhang, H. (2013), “Multiple Change-Point Detection via a Screening and Ranking Algorithm,” Statistica Sinica, 23, 1553–1572. DOI: 10.5705/ss.2012.018s.
- Hyun, S., G’Sell, M., and Tibshirani, R. (2018), “Exact Post-Selection Inference for the Generalized Lasso Path,” Electronic Journal of Statistics, 12, 1053–1097. DOI: 10.1214/17-EJS1363.
- Hyun, S., Lin, K., G’Sell, M., and Tibshirani, R. (2021), “Post-Selection Inference for Changepoint Detection Algorithms with Application to Copy Number Variation Data,” Biometrics, 77, 1037–1049. DOI: 10.1111/biom.13422.
- Jewell, S., Fearnhead, P., and Witten, D. (2022), “Testing for a Change in Mean After Changepoint Detection,” Journal of the Royal Statistical Society, Series B, 84, 1082–1104. DOI: 10.1111/rssb.12501.
- Kabluchko, Z. (2007), “Extreme-Value Analysis of Standardized Gaussian Increments,” unpublished.
- Kabluchko, Z., and Wang, Y. (2014), “Limiting Distribution for the Maximal Standardized Increment of a Random Walk,” Stochastic Processes and Their Applications, 124, 2824–2867. DOI: 10.1016/j.spa.2014.03.015.
- Li, H., and Munk, A. (2016), “FDR-control in Multiscale Change-Point Segmentation,” Electronic Journal of Statistics, 10, 918–959. DOI: 10.1214/16-EJS1131.
- Li, H. (2016), “Variational Estimators in Statistical Multiscale Analysis,” PhD thesis, Georg August University of Göttingen.
- Nemirovski, A. (1986), “Nonparametric Estimation of Smooth Regression Functions,” Journal of Computer and System Sciences, 23, 1–11.
- Pein, F., Sieling, H., and Munk, A. (2017), “Heterogeneous Change Point Inference,” Journal of the Royal Statistical Society, Series B, 79, 1207–1227. DOI: 10.1111/rssb.12202.
- Rac˘kauskas, A., and Suquet, C. (2003), “Invariance Principle under Self-normalization for Nonidentically Distributed Random Variables,” Acta Applicandae Mathematicae, 79, 83–103.
- Raimondo, M. (1998), “Minimax Estimation of Sharp Change Points,” Annals of Statistics, 26, 1379–1397.
- Siegmund, D., and Venkatraman, E. S. (1995), “Using the Generalized Likelihood Ratio Statistic for Sequential Detection of a Change-Point,” Annals of Statistics, 23, 255–271.