

ABSTRACT
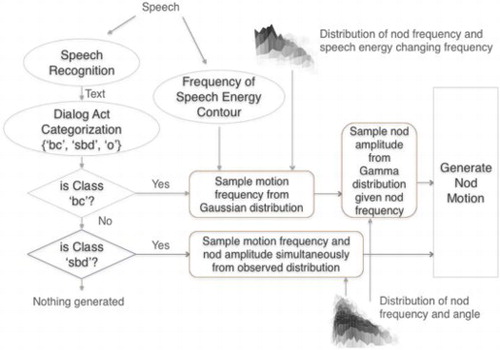
We proposed and evaluated a probabilistic model that generates nod motions based on utterance categories estimated from the speech input. The model comprises two main blocks. In the first block, dialog act-related categories are estimated from the input speech. Considering the correlations between dialog acts and head motions, the utterances are classified into three categories having distinct nod distributions. Linguistic information extracted from the input speech is fed to a cluster of classifiers which are combined to estimate the utterance categories. In the second block, nod motion parameters are generated based on the categories estimated by the classifiers. The nod motion parameters are represented as probability distribution functions (PDFs) inferred from human motion data. By using speech energy features, the parameters are sampled from the PDFs belonging to the estimated categories. The effectiveness of the proposed model was evaluated using an android robot, through subjective experiments. Experiment results indicated that the motions generated by our proposed approach are considered more natural than those of a previous model using fixed nod shapes and hand-labeled utterance categories.
GRAPHICAL ABSTRACT
KEYWORDS:
Disclosure statement
No potential conflict of interest was reported by the authors.
Notes
1. MeCab: Yet Another Part-of-Speech and Morphological Analyzer. http://taku910.github.io/mecab/.
Additional information
Funding
Notes on contributors
Chaoran Liu
Chaoran Liu received his PhD degree from the Graduate School of Engineering Science, Osaka University, Japan in 2015. He is currently working at Advanced Telecommunications Research Institute. His research interests include sound signal processing and machine learning.
Carlos Ishi
Carlos Ishi received the PhD degree in engineering from The University of Tokyo in 2001. He worked at the JST/CREST Expressive Speech Processing Project from 2002 to 2004 at ATR. He joined ATR Intelligent Robotics and Communication Labs, since 2005, and is currently the group leader of the Dept. of Sound Environment Intelligence at ATR Hiroshi Ishiguro Labs, since 2013.
Hiroshi Ishiguro
Hiroshi Ishiguro received a D.Eng. in systems engineering from Osaka University, Japan in 1991. He is currently Professor of the Department of Systems Innovation in the Graduate School of Engineering Science at Osaka University (2009–) and Distinguished Professor of Osaka University (2017–). He is also visiting Director (2014–) (group leader: 2002–2013) of Hiroshi Ishiguro Laboratories at the Advanced Telecommunications Research Institute and an ATR fellow. His research interests include sensor networks, interactive robotics, and android science. He received the Osaka Cultural Award in 2011. In 2015, he received the Prize for Science and Technology (Research Category) by the Minister of Education, Culture, Sports, Science and Technology (MEXT).