
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
As one of the effective access control mechanism, CAPTCHA can provide privacy protection and multimedia security for big data. In this paper, an attack on hollow CAPTCHA using accurate filling and nonredundant merging is proposed. Firstly, a thinning operation is introduced to repair character contour precisely. Secondly, an inner-outer contour filling algorithm is presented to acquire solid characters, which only fills the hollow character components rather than noise blocks. Thirdly, the segmentation to the solid characters produces mostly individual characters and only a small number of character components. Fourthly, a minimum-nearest neighbor merging algorithm is proposed to obtain individual characters without redundancy. Lastly, the convolutional neural network (CNN) is applied to acquire the final recognition results. The experimental results based on the real CAPTCHA data sets show that comparing with the existing attack methods on hollow CAPTCHA, the proposed method has higher success rate and superior efficiency.
1. INTRODUCTION
With the proliferation of network, huge amounts of data are being explosively generated every day. How to protect the security and privacy for big data becomes a key issue in this field. As one of the effective access control mechanisms, CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart [Citation1]) is widely applied to many large websites, including Google, Yandex, and so on. Nowadays, CAPTCHA has played an increasingly important role in privacy protection and multimedia security for big data.
At present, the frequently used CAPTCHAs are text-based CAPTCHA, image-based CAPTCHA, short-message-service -based CAPTCHA, audio-based CAPTCHA, etc. Among them, the most widely-used CAPTCHA is the text-based schemes [Citation2], an image containing several distorted characters. The typical types of text-based CAPTCHA are solid CAPTCHA, hollow CAPTCHA, 3D CAPTCHA, etc.
In order to verify the security and reliability of CAPTCHA, some corresponding attack technologies came into being. The research on CAPTCHA attack is always a win-win result [Citation2]. Some CAPTCHAs are hard to break, and their features can be used as an important theoretical reference for designing high-security CAPTCHA systems. Some CAPTCHAs can be successfully broken, relevant techniques can be extended to other related fields, such as document recognition [Citation3], speech recognition [Citation4] and network localization [Citation5]. It is of great significant to research the CAPTCHA attack technique.
In this paper, we propose an attack on hollow CAPTCHA using accurate filling and nonredundant merging (AF&NM). The main contributions of this paper are as follows.
A new framework of hollow CAPTCHAs attack is presented. Within this framework, five steps are effectively integrated, including preprocessing, filling, segmentation, merging, recognition. It can improve efficiency due to a classification of segmented images. If the segmented image is an individual character, it will be recognized directly; otherwise, it will be merged firstly and then recognized.
A thinning operation based on removing pixels iteratively is introduced in the preprocessing stage. It can repair the character contour precisely while retaining the original structure.
An inner-outer contour filling algorithm based on 8-neighborhood pixel detection is proposed in the filling stage. It can accurately distinguish character blocks from noise blocks, and quickly convert hollow characters into solid characters.
A minimum-nearest neighbor merging algorithm of character components is presented in merging stage. According to structural features and connection order, the algorithm can combine character components into individual characters without redundancy. It can improve the attack efficiency by reducing candidate characters’ number.
2. RELATED WORK
There are two known ways of text-based CAPTCHA attack: whole-based strategy and segmentation-based strategy.
In whole-based strategy, the character image of CAPTCHA can be recognized without segmentation. Some CAPTCHA attack methods have been proposed. For example, Mori and Malik [Citation6] used the shape context matching technique to break the Gimpy scheme with a success rate of 33%. Bursztein et al. [Citation7] showed that 13 kinds of CAPTCHAs on popular websites were vulnerable to automated attacks with Spatial Displacement of the Neutral Network, and they proposed a universal method for global recognition of the overlapping and adherent CAPTCHAs.
In a segmentation-based strategy, the boundary of the characters should be determined first, and then the CAPTCHA image can be segmented into individual character images to be recognized finally. The key to the strategy is whether CAPTCHA images can be segmented correctly. Starostenko et al. [Citation8] defined three-color bar code by skillfully using the number of vertical pixels to break reCAPTCHA scheme with a success rate of 54.6%. Ahmad et al. [Citation9] segmented characters by thoroughly analyzing distinctive shape patterns, and achieved 46.75% success on Google scheme and 33% success on reCAPTCHA scheme. Moy et al. [Citation10] developed distortion estimation techniques to attack EZ-Gimpy of CMU with a success rate of 99% and four-letter Gimpy-r with a success rate of 78%. Nachar et al. [Citation11] used edge corners and fuzzy logic segmentation/ recognition technique to break the CAPTCHAs of eBay, Wikipedia, reCAPTCHA, Yahoo!, and the success rates were 68.2%, 76.7%, 62.5% and 57.3% respectively.
The above attack methods are used on solid CAPTCHAs and not aimed at hollow CAPTCHAs directly. In 2013, Gao et al. [Citation12] first analyzed hollow CAPTCHAs’ robustness and proposed a general method to break a variety of hollow CAPTCHAs, with the success rates ranging from 36% to 89% and the average time per challenge ranging from 1.23s to 5.30s. In addition, Gao et al. [Citation13] effectively broke both hollow and solid CAPTCHAs based on 2D Log-Gabor filters and achieved a success rate ranging from 5% to 77% and the average time per challenge ranging from 2.81s to 28.56s.
Despite having advantages, there is some room for Gao’s two methods to improve.
Recognition accuracy can be improved. Both methods are “jigsaw puzzle” [Citation12] thinking, all character blocks that are likely to be grouped together are taken as candidate characters. Since the number of candidate characters is large, the relative proportion of correct characters is small. Naturally, the recognition accuracy would be reduced.
The attack time cost can be decreased. In [Citation12], the breakpoint location algorithm used in repairing contour needed traverse all characters. It leads to high time cost and much redundancy. In [Citation13], hollow characters are segmented into a large number of segments. It can further produce a huge set of possible combinations during the recognition stage. It would increase the time and difficulty on attack.
3. PROPOSED AF&NM METHOD
In order to solve the above problems, this paper proposes an attack on hollow CAPTCHA using accurate filling and nonredundant merging. By observing and analyzing the features of hollow CAPTCHAs, we propose a principal framework () and some algorithms to improve the accuracy and reduce the complexity, mainly including 8-neighborhood detection outer contour algorithm, inner-outer contour filling algorithm and minimum-nearest neighbor merging algorithm.
Figure 1: Principal framework of proposed method
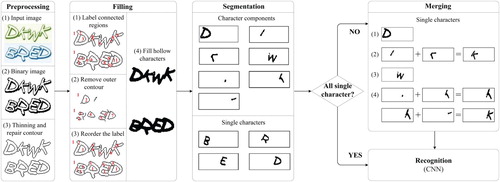
3.1 Principal Framework and Main Steps
The principal framework of AF&NM method mainly includes five steps: preprocessing, filling, segmentation, merging and recognition.
Preprocessing: Convert images into binary ones, then thin and repair the character contour.
Filling: First, mark all connected components with different labels. Second, acquire noncharacter components by eliminating outer contour. Third, change noncharacter components’ labels to the same as background’s label. Lastly, fill character components.
Segmentation: According to the different connected component labels, segment solid character image obtained in step b) into most of individual characters and a small number of character components.
Merging: Merge character components obtained in step c) into individual characters.
Recognition: Recognize individual characters by CNN.
The principles and the algorithms involved in our method will be described in detail in the following subsections.
3.2 Preprocessing
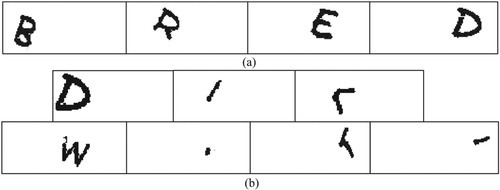
The purpose of preprocessing is to highlight the information related to characters in the given image and to weaken or eliminate interfering information. In our method, the preprocessing includes image binarization, image thinning and repairing contour. We take two CAPTCHA images in as examples to illustrate the whole process.
Figure 2: Two examples of Tencent CAPTCHAs. (a) “BRED” (b) “DKWK”

Firstly, image binarization is to highlight interesting targets’ contour and remove noises in the background. Using Otsu’s algorithm [Citation14], we can get binary images, i.e. white-and-black images (see ).
Figure 3: Binarized images. (a) “BRED” (b) “DKWK”
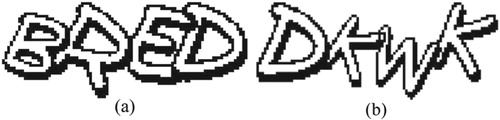
Image thinning is to process character contours as the skeleton, yet which won’t change the adhesion of characters (). The main effect of this step lies in two aspects. First, in a CAPTCHA image, the contours with irregular and uneven thickness are converted into single-pixel-width ones by thinning. It can reduce redundant points. Second, compared to unprocessed characters, the thinned characters have clearer contours without shadows. Thus, the subsequent processing will be simpler, too.
Figure 4: Thinned images. (a) “BRED” (b) “DKWK”
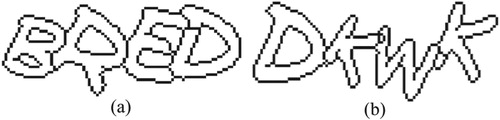
The method in [Citation15] is fast and effectively, thereby we adapt it to thin CAPTCHA images. By image thinning, we obtain hollow characters with one-pixel-thick contours. Furthermore, we find some broken contours.
To get the closed hollow characters, we use the endpoint detection algorithm in [Citation16] to mark the endpoints of each line. Then examine and draw a one-pixel-thick line to connect those neighboring pairs.
After the above steps, we get preprocessed CAPTCHAs, which are binary images containing several closed hollow characters with single-pixel-width contour (see ).
Figure 5: Closed hollow characters. (a) “BRED” (b) “DKWK”
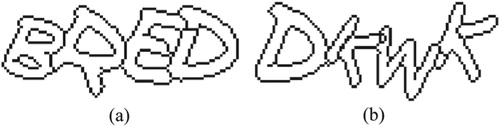
3.3 Filling
For the thinned images, we fill the closed hollow characters acquired in Section 3.2 to solid ones. The main purpose of filling is to enrich the character information and prepare for segmentation. During this phase, the key is to fill the character components accurately rather than noncharacter components. The filling method mainly consists of labeling connect regions, removing noise blocks and filling hollow character.
3.3.1 Labeling Connect Regions
For closed hollow characters, we use Haralick’s run algorithm [Citation17] to label different numbers of connected components (as ). Now a label matrix of the same size as the original image matrix is generated. In this matrix, all black pixels are labeled as 0, white pixels are labeled as the ordinal of connected components, such as 1, 2, 3, etc.
Figure 6: Labeled connect regions. (a) “BRED” (b) “DKWK”
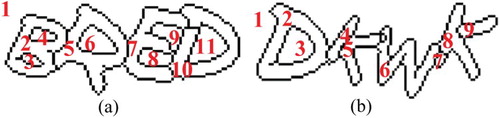
3.3.2 Removing Noise Blocks and Filling Hollow Character
In this paper, noise block refers to the noncharacter connected component. The noise blocks have two types such as (a): One is the connected component inside a character, such as No. 3, 4, 6, 11. The other is the connected component between adherent characters, such as No. 8, 9. They have the common feature: both are circled by character components. As can be seen from , the contour of character components is adjacent to the background area; and because noise blocks are surrounded by character components, their contour will not be adjacent to the background area. Therefore, we can distinguish character components from noise blocks according to this feature.
Let the contour is a set of pixels that are labeled as 0.
(1)
(1)
According to whether their contours are adjacent to the background area, the contour
can be divided into two parts: the outer contour and the inner contour. The set of those pixels which are adjacent to the background area is called the outer contour
. Namely, among the neighborhoods of outer contour, there are pixels whose labels of connected components are 1.
(2)
(2)
The part of contour apart from the outer contour called the inner contour . The pixels of the inner contour are not adjacent to the background area. Among the neighborhoods of inner contour, there are pixels whose labels of connected components are not 1.
(3)
(3)
Table
In order to obtain connected components circled by inner contour and find out noise blocks accurately, we proposed an 8-neighborhood detection outer contour algorithm (Algorithm 1) to remove the outer contour, and then fill character connected components. Its main steps are as follows.
Copy the label matrix to a new matrix.
Examine each pixel of the contour in the copy of label matrix, and if there is a background pixel in its eight neighborhoods, it is the pixel of outer contour, and then its label value is changed to the background label value. When all outer contour pixels are changed to the background, we get inner contour.
Label the connected area circled by the inner contour, namely noise blocks (see ).
Figure 7: Labeled noise blocks. (a) “BRED” (b) “DKWK”
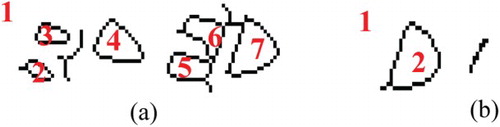
In the original label matrix, the labels of noise blocks are changed to 1, and reorder character connected components, as shown in .
Figure 8: Reorder connect regions. (a) “BRED” (b) “DKWK”
Fill character connected components, and hollow characters become solid ones (see ).
Figure 9: Filled image. (a) “BRED” (b) “DKWK”

In summary, our inner-outer contour filling algorithm is summarized in Algorithm 2.
Table
3.4 Segmentation
For the solid character images obtained in the above subsections, we will segment them to individual characters or character components.
Because each connected component corresponds to a character component, our attack uses different labels of connected components to segment the characters.
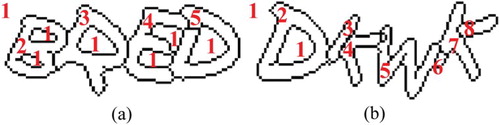
For each character connected component, first, create an all-1 matrix, which has the same size as the original CAPTCHA image matrix. Then, obtain position coordinates of each pixel from the current character component, and then set pixel value to 0 for those pixels that have same position coordinates in all-1 matrix.
After execution, each character component is stored in a separate image, and the original image is segmented to several character component images (such as ). If the number of character components obtained by segmenting a CAPTCHA image is equal to the number of individual characters contained in the CAPTCHA, there is no need to perform a merging operation because the image is segmented into individual characters (as (a)). Otherwise, it needs to perform a merging operation because the image may be segmented into individual characters and character components (as (b)).
Figure 10: Image of segmented character. (a) Individual character images. (b) Character component images
3.5 Merging
For the character components obtained in Section 3.4, we need to merge them into individual characters before recognition. As we know, the character components have two features:
The number is small and random. A CAPTCHA image can be segmented to 5∼7 character component images.
There are mutual relations. Character components are created from an individual character, and there are inevitable links in structure and order.
According to the above features, we propose a minimum-nearest neighbor merging algorithm:
(a) Due to the small number of components and to avoid merging errors and confusion, only two components are merged each time. Therefore, the number of mergers can be calculated by:
(4)
(4)
where
represents the number of mergers,
represents the number of character components produced by segmenting a single image, and
represents the actual number of characters in a single image.
(b) In general, the one character component with the minimum number of pixels is most likely to be merged.
(5)
(5)
where
are elements in the array
, which used to store the number of pixels corresponding to the ordinal of characters,
returns the ordinal of the minimum number of pixels to
.
(c) During selecting the other character component to be merged, the inevitable connection among character components in structure and order should be fully considered in order to reduce the blindness of merging.
In terms of structure, the width of two character components together must be less than the maximum width of an individual character.
In terms of order, the character components are segmented from an individual character, so the left and right neighbors of the th character component to be merged are prioritized as the other component to be merged. So, the ordinal of the other character component to be merged can be calculated by:
(6)
(6)
where
respects the ordinal of another character component to be merged,
is the width of new character component consisted of the character component
and its left neighbor
.
is the width of new character component consisted of the character component
and its right neighbor
,
is the maximum width of a character component among the CAPTCHA image.
Finally, the proposed minimum-nearest neighbor merging algorithm is summarized in Algorithm 3.
Table
In order to help the readers to understand Algorithm 3, we describe the merging process in detail using an example. Take for example the character components in (b) and the specific parameter values are shown in . In addition, let is the loop times,
is the corresponding ordinal of
which is the minimum element of array
, and
.
Table 1: Parameters in character part merging process
When , the character components are segmented and sorted. The number of pixels, left boundary, right boundary of each character component are obtained respectively. For example, the number of character components segmented from CAPTCHA image is 7, the number of individual characters in a CAPTCHA image is 4. So it needs 3 times of merging.
When , the 5th component is the smallest character component, then
,
. First, the minimum character component is in the middle,
,
, and they are less than the maximum width of character 30. Next, compare the number of pixels of left and right neighbor components, we found
. Therefore, the 5th and 6th character components are merged into a new 5th character component. Accordingly, it needs to update the pixel number, left and right boundary and other related information (see ). Lastly, the 6th character component information is deleted, and all character components are reordered.
Figure 11: Result of first merging.

When , the 6th component is the smallest character component,
,
. The minimum character component is in the end, it and its left neighbor can be merged into the new 5th character component. (see ).
Figure 12: Result of second merging

When , the 2nd component is the smallest character component, that is,
,
. First, the minimum character component is in the middle,
,
. Therefore, the 2nd and 3rd character components are merged into a new 2nd character component. (see ).
Figure 13: Result of third merging

After 3 loops, the merging operation has been completed. Character components are merged into individual characters (show as ).
Figure 14: The merged characters

3.6 Recognition
After segmentation and merging, all CAPTCHA images are segmented to individual characters, and we can recognize them by some machine learning methods. As well as the method of [Citation12], we also use CNN to recognize these individual characters for high accuracy.
CNN allows to directly inputting the individual character images to be recognized without feature extraction, and it has a certain degree of robustness in displacement, scale, and deformation. As a deep learning network, CNN has been widely used in the fields of CAPTCHA recognition [Citation7, Citation12, Citation13], information hiding [Citation18, Citation19, Citation20, Citation21], and so forth.
4. ANALYSIS OF AF&NM METHOD
Compared with the methods of [Citation12] and [Citation13], proposed AF&NM method has some difference. In the preprocessing stage, the thinning operation has been used to reduce redundant breakpoints. In the filling stage, our attack removes noise blocks with inner-outer contour quickly. Next, we acquire candidate characters without redundancy by merging rather than combination. So, our attack has no search stage.
High accuracy in repairing contours
In the method of [Citation12], there are redundant breakpoints, which might produce noise blocks.
In the AF&NM method, the character contour is thinned into single-pixel-width lines. Thus, redundant breakpoints can be correspondingly reduced, and the right breakpoints will be located more accurately.
As shown in , in the original binary image, redundant breakpoints account for 46.67% of the total number of marked breakpoints, and the redundant breakpoints are only 17.24% in the thinned images. The processing times of nonthinning image and thinned image are 14.08 and 8.64 ms, respectively. So with the reduction of the pixels in thinned contour, the redundant breakpoints are reduced by nearly 30% and the processing time is shortened by approximately 40%. The results show that this method is more effective in improving accuracy and shortening time.
Fast denoising
Table 2: The result of comparing nonthinning and thinned
In [Citation12], all nonblack pixels components are filled; and black contour is removed by dilation operation. If structure element processes
image, the time complexity is
.
In contrast, we mark the noise blocks firstly, and then only fill the character strokes to avoid useless work. It can be seen from that the filling area and the processing time of the method of [Citation12] are 6481 pixels and 63.85ms, while the filling area and the processing time of our method are 777 pixels and 4.02ms. We calculate that the filling area is 1/8 of the method of [Citation12] and the processing time is its 1/16.
No redundancy in merging stage
Table 3: Statistical indicator per image of different filling methods
A large number of characters to be recognized are produced by the combination method of [Citation12], and the analysis of algorithm is as follows.
It’s assumed that represents the number of character components produced by segmenting a single image,
represents the number of components in character components,
represents the number of the starting component in a character component,
represents the number of character components whose starting component is
,
represents the number of character components that are merged by components. In addition, the actual number of characters in a single image is
, and for the width limit of the character component, the maximum number of components per character component is
. Then the following analysis of the combination methods of [Citation12] and [Citation13] can be known.
When , that is, the first component is the start of the combination. Due to the limit of
, the number of character components produced by combining
character components is
, thus
(7)
(7)
So, the total number of character components which start from the 1st character component is the sum of the above numbers.
(8)
(8)
Likewise, when
, when the combination starts from the 2nd character component, the total number of character components is
.
When , when the combination starts from the
th character component, the total number of character components is
.
When , since the remaining character components have been less than
, so when the combination starts from the
th character component, the total number of character components is
.
To sum up the above two cases, we can get the formula for calculating the number of combined characters components in a single image:
(9)
(9)
(10)
(10)
Therefore,
is the number of candidate characters for a single image. It is more than the actual number of characters
.
In AF&NM method, no redundant characters to be recognized are generated. Let is the number of images,
is the number of images to be merged,
is the number of components in the current image, thus the total merging times:
(11)
(11)
where if
, all images are divided into individual characters directly without merging, and the minimum of merging times is 0. If
, all images are divided into the maximum
character components, and the maximum of merging times is
. Moreover, no matter how many times of merging, the number of characters to be recognized is always the same as
, hence the number of the actual individual characters without redundancy.
5. EXPERIMENTAL RESULTS
In order to verify the performance of proposed AF&NM method, we performed experiments on real CAPTCHA data sets. We respectively test the success rate of AF&NM method and its attack speed, and complete contrast experiments with methods of [Citation12] and [Citation13].
5.1 Experimental Environment and Settings
We implemented experiment in MATLAB 2015a, and tested it on a desktop computer with a 3.10 GHz Intel Core i5-2400 CPU, 4 GB RAM, and Windows 10 professional x64.
We have implemented our attack and tested it on two hollow CAPTCHA schemes: TencentFootnote1 and BotDetectFootnote2. Tencent is the largest Internet platforms in China. BotDetect was the world’s first commercially available CAPTCHA component in 2004. Therefore, the two representative CAPTCHA schemes with applicability and professional are used to test the performance of our attack method.
For each scheme, we collected from the corresponding website 800 random CAPTCHA images as a training set, and another 200 as a test set. The CAPTCHA samples possess the following features (see ).
Every CAPTCHA image consists of 4 capital hollow letters with rotation;
CAPTCHA images have light background without interference lines and noise blocks.
For Tencent scheme, the CAPTCHA image consists of characters with adhesion; For BotDetect scheme, the CAPTCHA image consists of characters with adhesion and overlap.
Figure 15: The CAPTCHA samples used in experiments. (a) Tencent CAPTCHA examples. (b) BotDetect CAPTCHA examples

We ran AF&NM method and the methods of [Citation12] and [Citation13] on Tencent scheme and BotDetect scheme. In [Citation22], Gao et al. pointed out that “We have converted hollow characters into solid characters in advance.” In this way, the method of [Citation13] can be more specific for attack hollow CAPTCHAs.
We implement a CNN as our recognition engine. The CNN’s classical structure adapted from LeNet-5 [Citation23], which has 6 layers in total (see ).
Figure 16: Network structure of CNN [Citation23]
![Figure 16: Network structure of CNN [Citation23]](/cms/asset/43187a6b-c8b7-4942-ad1d-a91146619302/titr_a_1520152_f0016_oc.jpg)
5.2 Experiments of Attack Success Rate
The success rate is an important indicator to evaluate the effectiveness of the attack method. In experiments, we count the success rate of individual characters and the success rate of single images. The total of images and characters were respectively 200, 800.
For Tencent scheme, the success rate of each phase in AF&NM method shows on . Considering the mistakes accumulated in all stages, the success rates for individual characters of each phase of AF&NM are 99.25%, 84.00%, 98.50% and 97.25%. Accordingly, the success rates for single images of each phase are 97.00%, 56.00%, 97.00% and 91.00%.
Table 4: Success rates of AF&NM method on Tencent scheme (%)
For contrast results, the success rates of three methods are listed in . For Tencent scheme, our attack achieved 97.50% success rate for individual characters and 91.00% success rate for single images. The method of [Citation12] achieved 94.38% success rate for individual characters and 83.00% success rate for single images. The method of [Citation13] achieved 94.50% success rate for individual characters and 82.00% success rate for single images. And the methods of [Citation12] and [Citation13] maintain the nearly equal success rate whether for individual characters or images, both of which are lower than those of AF&NM method. By and large, compared to the methods of [Citation12] and [Citation13], AF&NM method is better in terms of the success rate on Tencent scheme.
Table 5: Success rates contrast on Tencent scheme
Similarly, we ran our attack on BotDetect scheme. In , the success rates for individual characters of each phase of AF&NM are 80.88%, 66.13%, 80.75% and 89.00%. Accordingly, the success rates for single images of each phase are 62.00%, 36.50%, 71.50% and 75.50%. As shown in , we achieved 89.00% success rate for individual characters and 75.50% success rate for single images by AF&NM method. The method of [Citation12] achieved 67.88% success rate for individual characters and 64.00% success rate for single images. The method of [Citation13] achieved 57.75% success rate for individual characters and 53.00% success rate for single images. The success rate of our attack is still higher than the ones of the methods of [Citation12] and [Citation13].
Table 6: Success rates of AF&NM method on BotDetect scheme (%)
From Tables and , we also can see that the success rate of Tencent scheme is higher than that of BotDetect scheme. Compared to Tencent CAPTCHA, BotDetect CAPTCHA images have more characters with adhesion and overlap, which will have an impact on success rate. This is because overlapping characters produce a large number of character components, which adds to the difficulties for subsequent combinations.
Table 7: Success rates contrast on BotDetect scheme
Bursztein et al [Citation7] suggested that a CAPTCHA scheme is broken when the attacker achieves an accuracy rate of at least 1%. According to the criterion, two hollow schemes are successfully broken by our attack. Thus, the AF&NM method is applicable to the hollow and adherent CAPTCHA and has some effect on the hollow and overlap CAPTCHA. The experimental data show that our method is superior to the other two methods in success rate.
5.3 Experiments of Attack Speed
The attack speed is an important indicator to measure an attack method. The shorter attack time indicates that the security of a CAPTCHA scheme is worse. In addition, improving the attack speed of CAPTCHAs can reduce the time spent in the massive CAPTCHAs attack test.
For Tencent scheme, our attack speed of each stage and the proportion are as shown in . The average time cost for each image is only 48.25ms. The average time cost of segmentation and merging are 2.55ms and 6.96ms. The sum of two average time cost makes up less than 20% of the total time. And nearly half time is consumed in the preprocessing stage, in which thinning and closing contours respectively take up 17.24% and 17.90%. The filling stage, including 3 steps, is easy to implement and accounts for only 8.32%. Besides, because the CNN can automatically extract features and classify, recognition costs 13.78ms and accounts for 28.58% of the total time.
Table 8: Attack speed per image of each phase of AF&NM method on Tencent scheme Breaking time
To evaluating the attack speed of AF&NM method, contrast experiments have been conducted with methods of [Citation12] and [Citation13]. In the attack process of Tencent and BotDetect CAPTCHAs, the time cost of three methods is as shown in Figures and . For Tencent scheme, the attack speeds with [Citation12] and [Citation13] are respectively 139.29ms and 134.63ms, our attack speed is 48.25ms. For BotDetect scheme, the attack speeds with [Citation12] and [Citation13] are respectively 1032.93ms and 979.94ms, our attack speed is 177.54ms.
Figure 17: Attack speed contrast on Tencent scheme
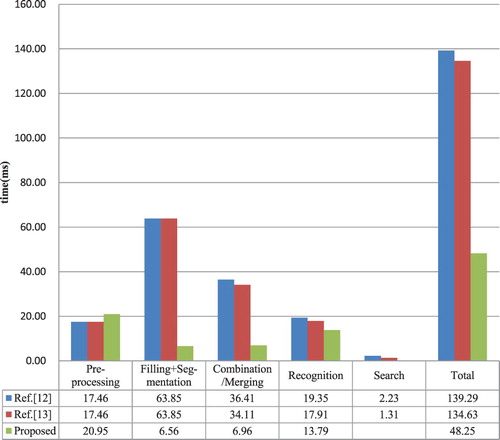
Figure 18: Attack speed contrast on BotDetect scheme
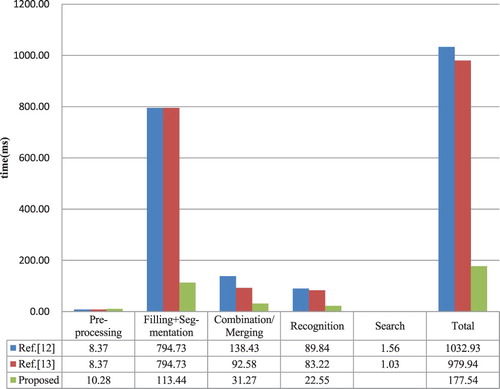
According to contrast results, the average attack speed of [Citation12] and [Citation13] are very close to each other and both far slower than our attack speed. Meanwhile, we can see that the attack speed of Tencent scheme is faster than that of BotDetect scheme because the latter has more character components. Comprehensively, AF&NM method is superior to the methods of [Citation12] and [Citation13] in terms of the attack speed.
For Tencent scheme, we compare the attack speed of method of [Citation12] and AF&NM method in detail. From , the time cost of filling and segmentation stages of the AF&NM method is 6.56ms per piece, and that of method in [Citation12] is 63.85ms which is 10 times more than AF&NM method. First of all, the time of filling all of the connected components in [Citation12] is 4 times that of only filling characters components regions in AF&NM method. Moreover, the method of [Citation12] performs the dilation algorithm on each stroke to remove the black contour. Its time cost is very large. In addition, the combined time in [Citation12] is nearly 5 times the merging time in AF&NM method. The main reason is that there are a large number of redundant characters in [Citation12] by combining.
As we can see from , it takes a little more time in the preprocessing stage in AF&NM method, for a thinning operation is extra introduced. However, more preparation will only quicken the speed of doing work. In all stages, the proposed method saves approximately 65.35% of the time than in the method of [Citation12]. Especially in the filling & segmentation stages and combination/merging stages, the attack time is approximately reduced by 89.73% and 80.88% respectively. From another perspective, this also fully validates the optimization that thinning has brought to the whole attack.
Table 9: Attack speed difference between methods of [Citation12] and AF&NM
In short, from the experimental results, we can see the proposed AF&NM method can increase the attack accuracy for images by approximately 8%∼22.5% and decrease the attack time by approximately 2/3∼4/5 in average compared with the methods of [Citation12] and [Citation13].
6. CONCLUSIONS
To improve the attack accuracy and reduce the attack time, we gave a simple and novel framework for hollow CAPTCHA attack in this paper. Different from the existing frameworks, our framework supports the classification of character components and individual characters produced by segmentation. In addition, learned from these state-of-the-art attacks, we proposed an attack on hollow CAPTCHA using accurate filling and nonredundant merging. Lastly, the experimental results show that compared with existing typical attack methods on hollow CAPTCHAs, the proposed method has a higher success rate and a superior efficiency in attack. Next, we will further study on seriously distorted CAPTCHA characters.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
Jun Chen http://orcid.org/0000-0002-5526-6952
Xiangyang Luo http://orcid.org/0000-0003-3225-4649
Additional information
Funding
Notes on contributors

Jun Chen
Jun Chen received the MS degree in computer science from Guangxi University, Nanning, Guangxi, China, in 2008. She is a PhD candidate at State Key Laboratory of Mathematical Engineering and Advanced Computing. Her research interests include multimedia security and machine learning. E-mail: [email protected]

Xiangyang Luo
Xiangyang Luo received the MS degree and the PhD degree from Zhengzhou Information Science and Technology Institute, Zhengzhou, China, in 2004 and 2010, respectively. He is currently an associate professor and PhD supervisor at State Key Laboratory of Mathematical Engineering and Advanced Computing. In addition, he also recently served as guest editor of some special issues of International Journal Multimedia Tools and Applications and International Journal of Internet. His research interests include multimedia security.

Jianwei Hu
Jianwei Hu received the MS degree in computer science and technology from Zhengzhou Information Science and Technology Institute, Zhengzhou, China. He is currently a lecturer at State Key Laboratory of Mathematical Engineering and Advanced Computing. His research interests include multimedia security. E-mail: [email protected]

Dengpan Ye
Dengpan Ye received PhD degree at Nanjing University of Science and Technology in 2005 respectively. He worked as a Post-Doctoral Fellow in Information System School of Singapore Management University. And since 2012 he has been a professor in the School of Computer Science at Wuhan University. His research interests include information hiding and multimedia security. E-mail: [email protected]

Daofu Gong
Daofu Gong received the PhD degree in computer application technology from Zhengzhou Information Science and Technology Institute, Zhengzhou, Henan, China, in 2013. Currently, he is a lecturer at State Key Laboratory of Mathematical Engineering and Advanced Computing. His research interests include multimedia security. E-mail: [email protected]
Notes
References
- L. V. Ahn, M. Blum, and J. Langford, “Telling humans and computers apart automatically,” Commun. ACM, Vol. 47, no. 2, pp. 57–60, 2004.
- J. Yan and A. S. E. Ahmad, “ A low-cost attack on a microsoft CAPTCHA,” in Proceedings of ACM Conference on Computer and Communications Security (CCS), Alexandria, USA, Oct. 27–37 2008, pp. 543–54.
- P. Sahare and S. B. Dhok, “Robust character segmentation and recognition schemes for multilingual Indian document images,” IETE Tech. Rev., DOI: 10.1080/02564602.2018.1450649, 2018.
- B. D. Sarma and S. R. M. Prasanna, “Acoutic-phonetic analysis for speech recognition: a review,” IETE Tech. Rev. DOI: 10.1080/02564602.2017.1293570, 2017.
- W. Liu, X. Luo, Y. Liu, J. Liu, M. Liu, and Y. Q. Shi, “Localization algorithm of indoor Wi-Fi access points based on signal strength relative relationship and region division,” Comput. Mater. Continua, Vol. 55, no. 1, pp. 71–93, 2018.
- G. Mori and J. Malik. “Recognizing objects in adversarial clutter: breaking a visual CAPTCHA,” in Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Madison, Wisconsin, June 18–20, 2003, Vol. 1, pp. 134–41.
- E. Bursztein, M. Martin, and J. C. Mitchell. “Text-based CAPTCHA strengths and weaknesses,” in Proceedings of ACM Conference on Computer and Communications Security (CCS), Chicago, USA, Oct. 17–21, 2011, pp. 125–37.
- O. Starostenko, C. Cruz-Perez, F. Uceda-Ponga, and V. Alarcon-Aquino. “Breaking text-based CAPTCHAs with variable word and character orientation,” Pattern Recognit., Vol. 48, no. 4, pp. 1101–12, 2015.
- A. S. E. Ahmad, J. Yan, and M. Tayara. “The robustness of google CAPTCHAs,” Computing Science Technical Report CS-TR-1278, Newcastle University, UK, 2011.
- G. Moy, N. Jones, C. Harkless, R. Potter. “Distortion estimation techniques in solving visual CAPTCHAs,” in Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC USA, 27 June–2 July, 2004, Vol. 2, pp. 23–8.
- R. A. Nachar, E. Inaty, P. J. Bonnin, and Y. Alayli. “Breaking down CAPTCHA using edge corners and fuzzy logic segmentation/recognition technique,” Secur. Commun. Netw., Vol. 8, pp. 3995–4012, 2015.
- H. Gao, W. Wang, J. Qi, X. Wang, X. Liu, and J. Yan. “The robustness of hollow CAPTCHAs,” in Proceedings of ACM Conference on Computer and Communications Security (CCS), Berlin, Germany, Nov. 4–8, 2013, pp. 1075–86.
- H. Gao, J. Yan, F. Cao, Z. Zhang, L. Lei, M. Tang, et al. “A simple generic attack on text CAPTCHAs,” in Proceedings of Network and Distributed System Security Symposium (NDSS), San Diego, California, USA, Feb. 21–24, 2016, DOI:10.14722/Ndss.2016.23154.
- N. Otsu. “A threshold selection method from gray-level histograms,” IEEE Transact. Syst. Man Cybernet., Vol. 9, no. 1, pp. 62–6, 1979. doi: 10.1109/TSMC.1979.4310076
- L. Lam, S. Lee, and C. Y. Suen. “Thinning methodologies – a comprehensive survey,” IEEE Trans. Pattern Anal. Mach. Intell., Vol. 14, no. 9, pp. 869–85, 1992. doi: 10.1109/34.161346
- R. C. Gonzalez and R. E. Woods. Digital Image Processing. Saddle River, NJ, USA: Prentice Hall, August 2007, 3rd ed.
- R. M. Haralick and L. G. Shapiro. Computer and Robot Vision. Middlesex County, MA: Addison-Wesley Longman, 1991, 1st ed.
- Y. Ma, X. Luo, X. Li, Z. Bao, and Y. Zhang. “Selection of rich model steganalysis features based on decision rough set α-positive region reduction,” IEEE Trans. Circuits Syst. Video Technol., 2018. DOI 10.1109/TCSVT.2018.2799243.
- Y. Zhang, C. Qin, W. Zhang, F. Liu, and X. Luo. “On the fault-tolerant performance for a class of robust image steganography,” Signal Process., Vol. 146, pp. 99–111, 2018. doi: 10.1016/j.sigpro.2018.01.011
- X. Luo, X. Song, X. Li, W. Zhang, J. Lu; C. Yang, and F. Liu. “Steganalysis of HUGO steganography based on parameter recognition of syndrome-trellis-codes,” Multimed. Tools Appl., Vol. 75, no. 21, pp. 13557–13583, 2016.
- L. Xiong and Y. Q. Shi, “On the privacy-preserving outsourcing scheme of reversible data hiding over encrypted image data in cloud computing,” Comput. Mater. Continua, Vol. 55, no. 3, pp: 523–39, 2018.
- H. Gao, M. Tang, Y. Liu, P. Zhang, and X. Liu. “Research on the security of Microsoft’s two-layer CAPTCHA,” IEEE Trans. Inf. Forensics Secur., Vol. 12, no. 7, pp. 1671–85, 2017.
- Y. LeCun, et al. “Handwritten digit recognition: applications of neural network chips and automatic learning,” IEEE Commun. Mag., Vol. 27, no. 11, pp. 41–6, 1989. doi: 10.1109/35.41400