
Abstract
An accurate definition of river geometry is essential to implement one-dimensional (1D) hydraulic models and, in particular, appropriate spacing between cross-sections is key for capturing a river’s hydraulic behaviour. This work explores the potential of an entropy-based approach, as a complementary method to existing guidelines, to determine the optimal number of cross-sections to support 1D hydraulic modelling. To this end, given a redundant collection of existing cross-sections, a location subset is selected minimizing total correlation (as a measure of redundancy) and maximizing joint entropy (as a measure of information content). The problem is posed as a multi-objective optimization problem and solved using a genetic algorithm: the Non-dominated Sorting Genetic Algorithm (NSGA)-II. The proposed method is applied to a river reach of the Po River (Italy) and compared to standard guidelines for 1D hydraulic modelling. Cross-sections selected through the proposed methodology were found to provide an accurate description of the flood water profile, while optimizing computational efficiency.
Editor D. Koutsoyiannis
Citation Ridolfi, E., Alfonso, L., Di Baldassarre, G., Dottori, F., Russo, F., and Napolitano, F., 2013. An entropy approach for the optimization of cross-section spacing for river modelling. Hydrological Sciences Journal, 59 (1), 126–137.
Résumé
Une définition précise de la géométrie de la riviére est essentielle pour mettre en œuvre des modéles hydrauliques unidimensionnels (1D). L’espacement approprié entre les sections en travers de la riviére est un élément clé pour reproduire son comportement hydraulique. Ce travail a pour objectif de fournir une méthode se basant sur l’entropie, complémentaire des guides existants et permettant de fournir des informations supplémentaires pour l’optimisation des modéles hydrauliques 1D et la gestion des jeux de données sur les sections en travers. Plus spécifiquement, sur la base d’une collecte redondante de sites de sections en travers existantes, un sous-ensemble de sites est sélectionné en minimisant la corrélation totale (comme mesure de redondance) et en maximisant l’entropie conjointe (comme mesure du contenu en information). Le probléme est posé sous la forme d’une optimisation multi-objectif, résolue en utilisant un algorithme génétique (NSGA-II). Nous appliquons la méthode proposée aux données de sections en travers sur le Po, en Italie, et nous la comparons aux méthodes existantes en utilisant un modéle hydraulique 1D. Les jeux de sections en travers sélectionnées par la méthodologie proposée fournissent une description précise du profil des eaux en crue, tout en optimisant l'efficacité de calcul.
1 INTRODUCTION
Hydraulic modelling of river flooding has become an important step in most flood risk studies (Cunge Citation2003, Abida et al. Citation2005, Di Baldassarre et al. Citation2009b, Citation2010). In this context, the optimal spacing of river cross-sections is fundamental to thoroughly describe the hydraulic behaviour of a river. The usual approach in hydraulic modelling is to use a large number of cross-sections, which implies not only significant computational modelling time, but also considerable fieldwork effort for data collection and updating. Therefore, it is very important to know the minimum number of cross-sections needed (and their locations) to yield an acceptable accuracy of modelling results, by identifying useful and non-redundant data. In particular, in developing countries and in inaccessible areas, model input optimization has a great impact on the development of models, because data may be of limited availability or poor quality.
Despite the relevance of estimating the optimal number of cross-sections in hydraulic modelling, only a few guidelines have been presented on this issue (e.g. Samuels Citation1990, Castellarin et al. Citation2009). In this work, we present an entropy approach to determine the optimal number of river cross-sections and their locations. The aim is to supply a complementary method to the existing guidelines, in order to provide additional information for optimization and management of cross-section data sets of one-dimensional (1D) models.
The so-called heuristic entropy was defined by Shannon (Citation1948) as the measure of the uncertainty about the knowledge of the state of a given system. In recent years heuristic entropy has had a wide range of applications in hydrology and water resources; an extensive review of these applications is reported by Singh (Citation1997a, Citation2000). In statistical analysis, the principle of maximum entropy (ME; Jaynes Citation1957) provided the least biased estimation of probability distributions on the basis of partial knowledge, opening the way to applications in several fields. Koutsoyiannis (Citation2005a, Citation2005b, Citation2006) demonstrated that the principle of ME can be applied to derive the appropriate distribution of a studied variable and to evaluate the dependence properties of the rainfall occurrence process as clustering behaviour and persistence. Papalexiou and Koutsoyiannis (Citation2012) used this principle to construct an appropriate probability distribution for rainfall processes.
In the context of flood mapping analysis, Horritt (Citation2006) applied an entropy-based methodology for evaluating the uncertainty and assessing the accuracy of probabilistic flood maps. In the field of rainfall–runoff analysis, Pechlivanidis et al. (Citation2010) proposed an entropy-based measure for the rainfall–runoff model diagnostic, and Pechlivanidis et al. (Citation2012) extended the work evaluating the non-dynamical information contained in streamflow analysis; Montesarchio et al. (Citation2011) and Ridolfi et al. (Citation2013) defined rainfall threshold values minimizing a risk function based on the entropy concept.
Weijs et al. (Citation2010) proposed a theoretical framework based on relative entropy involving the analysis of a divergence score measure to evaluate the quality of hydrological forecasts. Weijs and van de Giesen (Citation2011) generalized the decomposition of the Kullback–Leibler divergence to the case where the observation is uncertain.
Informative entropy has been used effectively as a tool for optimizing, designing and managing networks. Husain (Citation1989) used the entropy to choose the optimum raingauge stations from a dense network and to expand the network in an optimum way. Krstanowicz and Singh (Citation1992) optimized rainfall networks describing the rainfall with continuous distribution functions, and Yoo et al. (Citation2008) compared this to a mixed continuous-discrete method. By using the approach presented by Krstanowicz and Singh (Citation1992), Ridolfi et al. (Citation2011) found that the non-redundant information of a raingauge network has a scale-invariant behaviour. Using Information Theory quantities as objective functions, Alfonso et al. (Citation2010a, Citation2010b) optimized the location of water-level monitors. In the field of the assessment and design of water-quality monitoring networks, Ozkul et al. (Citation2000), Mogheir and Singh (Citation2002) and Mogheir et al. (Citation2003, Citation2004) used entropy as the main tool for leading optimal decisions.
In this work, the problem of finding the optimal number of cross-sections and their positions is posed as a multi-objective optimization problem (MOOP). Given a redundant set of cross-sections, their total correlation (C) and their joint entropy (JH) can be used as measures of redundancy and joint information content, respectively. The MOOP consists of minimizing the total correlation and maximizing the joint entropy of a given set of cross-sectional locations. Similarly to Alfonso et al. (Citation2010b), the MOOP is solved by means of the Non-dominated Sorting Genetic Algorithm (NSGA)-II, which produces collections of solutions that evolve towards a Pareto-optimal front solution set (Deb et al. Citation2002).
First, an overview on the entropy method and existing guidelines in the literature is presented; second, the MOOP is posed and the two objective functions are formally introduced. Then, the Pareto front of the best set of solutions is presented. Finally, the methodology is applied to a river reach of the Po River (Italy) and the results are compared with guidelines presented by Samuels (Citation1990) and with results proposed by Castellarin et al. (Citation2009).
2 AN OVERVIEW OF ENTROPY AND TOTAL CORRELATION CONCEPTS
Heuristic entropy can be defined as the measure of uncertainty about the occurrence of a certain event (Papoulis Citation1991). Amorocho and Espildora (Citation1973) provided one of the first applications of entropy concept to hydrology to evaluate the hydrologic information transfer among river points.
Formally, for any discrete random vector (RV) X, entropy is defined as:
where p(xi) is the probability that X assumes the value xi and n is the length of X (Shannon Citation1948). The units of entropy depend on the base of the logarithm used; if base 2 is adopted, entropy is measured in bits. For any probability distribution it is possible to define a quantity, called entropy, which measures the amount of information contained in a RV. This quantity can be used as an answer to questions in many fields such as communication, statistics and hydrology. A fully comprehensive introduction to entropy can be found in Cover and Thomas (Citation1991).
If all the vector’s components are different, uncertainty about the outcome of randomly selecting a component will be maximum: this uncertainty is the RV’s entropy. However, if all the RV components are the same, there is no uncertainty about the outcome of randomly selecting a component, and RV’s entropy is equal to zero (Koutsoyiannis Citation2005a). For this reason, entropy can be considered as a measure of the information that is potentially contained in the RV.
Let us now take M discrete RVs. Their joint entropy is (Papoulis Citation1991):
where is the joint probability of the M variables.
In this paper, total correlation is used to evaluate the amount of redundant information among two or more RVs by providing an estimation of the non-linear, multi-order dependence among the variables. It is defined as the difference between the sum of the marginal entropies of the RVs and their joint entropy (Watanabe Citation1960):
where H(Xi) is the marginal entropy of the ith RV and H(X1, X2,..., XM) is the joint entropy of the M RVs.
In order to estimate the marginal and joint entropy of M RVs, it is necessary to evaluate their marginal and joint probabilities, which is not trivial. In this paper, the joint entropy of the considered set of RVs is determined using the grouping property of mutual information (Kraskov et al. Citation2005). In particular, to evaluate marginal and joint probabilities, a non-parametric estimation is adopted through a data-binning procedure. This method is also used in the univariate analysis to build histograms. Therefore, considering two discrete RVs, X and Y, let us subdivide their values in bins. Several authors have explored the issue of bin size definition: Chapman (Citation1986) studied the differences in using different class sizes; Singh (Citation1997b) studied the effect of class interval width; Mogheir et al. (Citation2003) defined the class intervals as a function of the RV length; Knuth (Citation2006) proposed a Bayesian based method for determining the optimal bins size. Increasing the number of bin partitions of a RV, its entropy increases as well. For this reason the number of bins needs to be accurately defined.
In this paper, RV values are water depths; in order to avoid a subjective selection, each RV value is divided in bins that have a width of 0.20 m, corresponding to hydraulic model sensitivity (i.e. HEC-RAS, see Section 4). The marginal probability of each bin is determined by evaluating the number of components that fall in each bin and dividing it by the total length of the vector. In order to evaluate the joint probability of the two RVs, it is necessary to agglomerate their values, thereby obtaining a new RV. For instance, if two RVs are X = [a, c, b] and Y = [b, c, a], the resulting vector A obtained by agglomerating X and Y is A = [ab, cc, ba]. This procedure guarantees that the marginal entropy of the new variable A is equivalent to the joint entropy of the two RVs X and Y, i.e. H(A) = H(X,Y).
For evaluating the joint entropy of three RVs (X, Y and Z) it is necessary to agglomerate A with Z, obtaining a new variable (e.g. B), with marginal entropy H(B) = H(A,Z) = H(X,Y,Z). Thanks to the grouping property of mutual information (Kraskov et al. Citation2005), the joint entropy of M RVs can be easily evaluated by agglomerating them in pairs, without the need to estimate their joint probability p(x1,...xM).
3 OPTIMIZATION OF THE SPATIAL DISTANCE AMONG CROSS-SECTIONS
3.1 Hydraulic approaches
In the literature there are only a few guidelines on the selection of convenient spacing between river cross-sections in 1D hydraulic modelling; they were proposed by Samuels (Citation1990) and Castellarin et al. (Citation2009), hereinafter referred to as S90 and C09, respectively. These guidelines were derived by S90 by applying hydraulic theory and were verified by C09 by means of numerical experiments with real-world case studies. S90 presented some suggestions for the locations of cross-sections:
– at the beginning and at the end of the considered reach;
– at either side of structures (e.g. bridges);
– at each point of interest;
– at a location corresponding to each gauge located on the river profile.
In addition to these simple recommendations, S90 provided an equation for determining the distance between cross-sections:
where B (m) is the bankfull surface width of the main channel and k is a dimensionless constant, chosen in the range 10–20. In case of backwater at the end of the river reach:
where F is the dimensionless Froude number, D (m) is the bankfull depth of flow and s is the surface (or main channel) slope.
For unsteady conditions, the wave profile should be represented. S90 highlights that the wave is reasonably represented by a number of grid points Ngp from 30 to 50, and recommends:
where c (m s-1) is the wave propagation speed and T (s) is the period of the flood wave (their product represents the wavelength). After some preliminary tests, in this case study the average value of 40 was found to provide an acceptable representation of the wave profile. Finally, a minimum distance:
takes into account the effect of rounding error. In equation (7), p is the number of numerical digits of precision, d is the digits lost due to cancellation of the leading digits of the stage values, s is the average surface slope, εs is the relative error on the surface that can be tolerated in the computation.
In the spacing between cross-sections, found applying equations (5) and (6), are presented for the Po River case study (Section 4.1). The two equations are solved using parameters values reported in the table itself.
Table 1 Average and maximum values of the parameters of the Po River, Italy: D is the bankfull width, s is the slope, F is Froude’s number computed by the HEC-RAS model, c is the wave celerity and T is the period of the flood wave. Using equations (5) and (6), the spacing between cross-sections Δx2 and Δx3 are evaluated. Each optimum number of cross-sections ni is evaluated dividing the length of the reach by the spacing Δxi.
3.2 The proposed entropy-based approach
In order to explain the concept of locating optimal river cross-sections through the entropy concept, let us consider the Venn diagrams in . Assuming that high water level time series produced at a particular cross-section can be treated as a RV, the entropy of the series (or its information content) can be represented by a circle’s area. If a large number (M) of cross-sections is available and all of them are considered for modelling, they would provide redundant information, so that their corresponding circles will overlap, .
Fig. 1 (a) Venn diagram illustrating the multi-objective optimization problem of selecting three circles out of eight with the maximum covered area (JH) and the minimum multi-order overlapping area (C); (b) two possible solutions; (c) JH of each solution, representing the amount of information content of the set; and (d) C of each solution, representing the multi-order redundant information of the set. Adapted from Alfonso et al. (Citation2013).
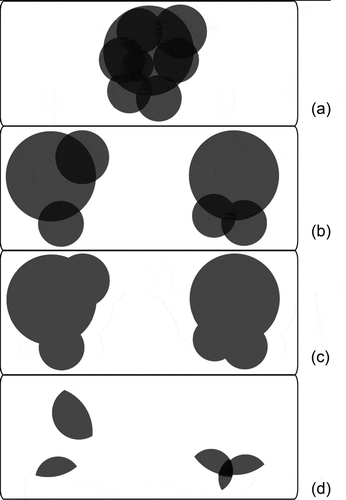
Let us now consider the task of selecting the three best cross-section sites out of the M sites. Referring back to the Venn diagrams, this translates into selecting a set of three circles from , such that the area contained by the three is maximized and, simultaneously, that their overlapped area is minimized. Two possible solutions are represented in . For each of these solutions, the marginal entropy (area of each circle), joint entropy (the total inscribed area) and total correlation (the total overlapping area) for the three RVs are shown in , (c) and (d), respectively. It should be noted that C sums up all multi-order dependencies, which implies that for a large number of variables (i.e. circles), the resulting C can be larger than JH. For example, the option on the left of shows two second-order dependencies, while on the right there are three second-order dependencies and one three-order dependence. From the Venn diagram, the set of optimal locations for cross-sections must have minimum total correlation and maximum joint entropy, thus a multi-objective optimization approach is considered:
where C is the total correlation and JH is the joint entropy of M RVs.
In this way, the optimum set of cross-sections has the minimum redundant information and the maximum joint information. Both objectives are needed because simply minimizing the total correlation would result in a set of non-redundant RVs that would not necessarily provide enough information content. Likewise, only maximizing joint entropy would result in a set of very informative but highly redundant RVs. Here, each RV Xi is the series of maximum water stages at the ith cross-section, obtained using different combination of Manning’s coefficients in model calibration (see Section 4).
3.3 MOOP solution through NSGA-II genetic algorithm
In order to solve the MOOP, the NSGA-II, proposed by Deb et al. (Citation2002), is used. The NSGA-II creates a mating pool by combining the parent and offspring population, selecting the best solution. The next generation is populated with the best non-dominated front until the population size is reached (Farmani et al. Citation2006). It searches for the best Pareto front solution among all the mutually non-dominated solutions determined, identifying the best trade-off between sets of competitive objectives (Olsson et al. Citation2009). In this case study, the two competitive objectives are represented by the minimization of total correlation and maximization of joint entropy of the M considered variables (equation (8)). The best solutions are found by the algorithm and then plotted on a Pareto front. Each point represents the best trade-off in fulfilling the two conditions. An enhanced performance in one of the two objectives is achieved to the detriment of the other objective.
4 CASE STUDY: PO RIVER, ITALY
The methods described in Section 3 were applied to the 98 km reach of the Po River between Cremona and Borgoforte (Italy), . The floodplain is confined by two continuous levee systems and the width of the channel is approximately constant (300 m) (Schumann et al. Citation2010, Brandimarte and Di Baldassarre Citation2012). The Po River Basin Authority has developed a high-quality 2-m digital terrain model (DTM) of the middle-lower part of the Po River, integrating airborne laser scanning with boat and ground surveys of channel bathimetry (Castellarin et al. Citation2009, Citation2011, Brandimarte and Di Baldassarre Citation2012).
Fig. 2 Po River, Italy, between Cremona and Borgoforte. LiDAR topography (grey scale) is shown.

4.1 Hydraulic model
The hydraulic behaviour of this site of study was analysed through the 1D code HEC-RAS (HEC Citation2001) in unsteady flow conditions. HEC-RAS has been largely applied for hydraulic modelling (e.g. Pappenberger et al. Citation2005, Citation2006, Cesur Citation2007, Schumann et al. Citation2007, Brandimarte et al. Citation2009, Di Baldassarre et al. Citation2009a, Brandimarte and Di Baldassarre Citation2012). Moreover, its reliability has been proven in a wide number of studies (e.g. Horritt and Bates Citation2002, Castellarin et al. Citation2009).
From the available DTM, it was possible to extract 88 cross-sections, which were used in the 1D model for describing the geometry of the river reach. The model built using the entire cross-section data set (henceforth referred to as Po-88) was calibrated considering the major flood that occurred in October 2000 (about 11 850 m3 s-1). The inflow hydrograph at Cremona was taken as the upstream condition, whereas the friction slope at Borgoforte was used as the downstream boundary condition (Brandimarte and Di Baldassarre Citation2012).
The values of the Manning’s coefficient, n, were calibrated against the high water marks surveyed after the October 2000 flood event (Coratza Citation2005, Brandimarte and Di Baldassarre Citation2012). The set of n values considered for the floodplain varies between 0.050 m-1/3 s and 0.140 m-1/3 s with a step of 0.010 m-1/3 s, while the channel n value varies between 0.020 m-1/3 s and 0.060 m-1/3 s with a step of 0.005 m-1/3 s. Manning’s values are chosen according to values reported in commonly used tables in the literature (Chow Citation1959).
For each simulation with different values of roughness, the mean absolute error (MAE) evaluation metric is computed through:
where Xobs and Xsim are the vectors of observed and simulated maximum water stage for each Manning’s value combination, respectively. This metric evaluates the level of overall agreement between observations and simulations, determining the deviation of simulated from observed values (Dawson et al. Citation2007).
For the Po-88 configuration, the combination of n values that provided the lowest MAE was 0.045 m-1/3 s for the channel and 0.050 m-1/3 s for the floodplain.
5 NUMERICAL ANALYSIS AND RESULTS
The optimal spacing of river cross-sections was evaluated using both the proposed entropy approach and the guidelines provided by S90 and C09. The results were then compared with those given using the geometry of the Po-88 model. It is important to note that the application of the two approaches (i.e. guidelines and entropy) differs significantly. Guidelines provided in Samuels (Citation1990) can be applied even when no cross-sections are available, being based on minimal topographic information of the river reach. In contrast, the entropy-based approach requires an existing cross-section data set to be applied.
5.1 Spacing optimization by the entropy method
The entropy method was applied to find the set of cross-sections that fulfilled the conditions presented in equation (8). As it is necessary to establish a priori the number of cross-sections for this equation, a preliminary analysis was performed to explore the value of adding cross-sections by looking at the increment of joint entropy in relation to the decrease in total correlation.
To compare the behaviour of different values of M (the number of cross-sections), the MOOP was solved considering M = 2, 3, 4, 5, 6, 10, 15 and 20 (excluding the upstream and downstream cross-sections). From HEC-RAS simulations, for each cross-section a vector (i.e. Xi) is created, the values of which are the maximum water stages associated with a particular combination of Manning’s coefficients. Once JH and C were calculated for a given set M, the Pareto front was obtained after solving the MOOP for each M ().
Fig. 3 Pareto-optimal set of solutions for joint entropy and total correlation, discriminated by the MOOP, considering an increasing number of cross-sections, M (see Sections 3.2 and 3.3 for details).
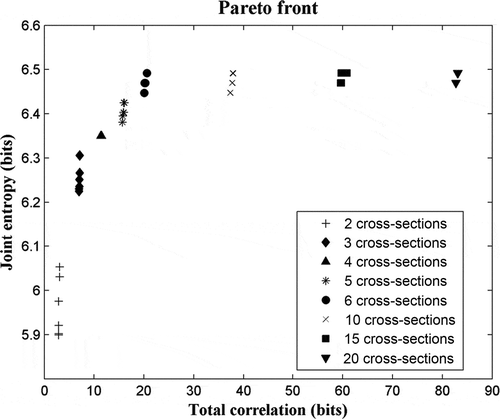
The total correlation and joint entropy () indicate that the most informative sets of cross-sections are found when the value of M is between 3 and 5. When less than three sections are used, the value of joint entropy is low; using more than five sections results in a high total correlation. In addition, shows that joint entropy does not increase when 6 or more sections are used, as JH tends to its maximum value log2n, where n is the length of RV. Thus, using fewer cross-sections does not affect the description of the river profile in terms of information content.
Results in for four and five cross-sections show that the difference between the two solutions in terms of total correlation is 4.55 bits, while the gain in joint entropy is only 0.07 bits. This means that the gain in information content is not as high as the redundancy increment.
The value of joint information corresponding to four cross-sections is 0.04 bits higher than the joint information related to three sections, and the loss in redundancy is 4.36 bits, as shown in . also shows that four sections provide as much information as five, but more than three. Because of this large difference in redundancy, the model was calibrated using three and four cross-sections and the results were compared in order to determine which was the optimal number.
The solution of the MOOP provided several sets of three and four cross-sections models. The model was calibrated considering these different sets and the MAE value was used as a discriminating factor for choosing the best combination of Manning’s coefficients. The Manning’s coefficients and MAE for each set of calibrated cross-sections are presented in and . All sets are characterized by a MAE value lower than 0.5 m, which is comparable with the expected accuracy of high water marks (Neal et al. Citation2009, Horritt et al. Citation2010, Brandimarte and Di Baldassarre Citation2012).
Table 2 River reach models built with all cross-sections (Po-88), three cross-sections given by S90 (Po-3) and by the MOOP solutions (Po3-Entropy1, ~2) and their corresponding MAE values, Manning’s coefficients for the channel (nch) and of the floodplain (nf). The values for Po-88 are included for the sake of comparison.
5.2 Cross-section spacing following S90 and C09
The optimum spacing among river cross-sections was evaluated using equations (5) and (6) from the S90 guidelines. The two equations were solved using parameter values reported in . As far as the bankfull depth of flow (D) is concerned, its variation range is 11.56–21.82 m with an average value of 14.00 m; the range of the Froude number (F) is 0.04–0.18 with an average value of 0.12; finally, the range of the flood wave celerity (c) is 0.65–4.41 m s-1 with an average of 2.46 m s-1. The resulting number of cross-sections n2 and n3 are computed by dividing the total length of the reach by the spacing Δx2 and Δx3 found applying equations (5) and (6), respectively. shows that when one uses equation (6) (i.e. the relation to be used in the case of unsteady flow analysis) the mutual spacing among cross-sections (i.e. Δx3) assumes high values. The consequent number of cross-sections is very low: 2 and 1 considering average and maximum parameters values, respectively. These results are not reliable for this test site. Therefore, the optimal spacing has been evaluated through equation (5), valid for steady flow conditions. This is consistent with the findings of the works by Brandimarte and Di Baldassarre (Citation2012) and Di Baldassarre et al. (Citation2009c), in which the performances of the steady and unsteady models were comparable in the same reach of the Po River. Considering the values of the parameters in , the application of equation (5) determines a maximum spacing (i.e. Δx2) of 30 km and an average of 20 km. Dividing the spacing for the total length of the river reach, the number of optimal cross-sections is 3 and 4, respectively. Therefore, two different models, named Po-3 and Po-4, were built, adding the first and the last cross-sections, according to S90. These models were calibrated by varying Manning’s coefficients and the MAE was evaluated. In and simulations with the lowest MAE and the corresponding combination of Manning’s coefficients are presented, reporting the cases of the model built with three and four cross-sections, respectively.
Considering three cross-sections, the simulation with the lowest MAE value corresponds to Manning’s n equal to 0.045 m-1/3 s for the channel and 0.050 m-1/3 s for the floodplain.
Considering four cross-sections, two simulations had the same minimum MAE: for both of these, nch was 0.040 m-1/3 s while nf is 0.09 m-1/3 s for Po-4a and 0.10 m-1/3 s for Po-4b, where nf and nch represent the floodplain and the channel roughness, respectively.
It is interesting to note that using equation (7) with d = 2 (stage in cm), p = 6, s ≈ 10-3 and εs ≈ 10-3, as reported in Castellarin et al. (Citation2009), Δx4 > 100 m. This represents a lower limit to the choice of the optimal spacing, which is in agreement with results of equations (5) and (6).
6 DISCUSSION
Besides the evaluation of MAE for model configurations based on reduced cross-section data sets, further information can be obtained by the analysis of the roughness coefficients that provide the best results for each configuration.
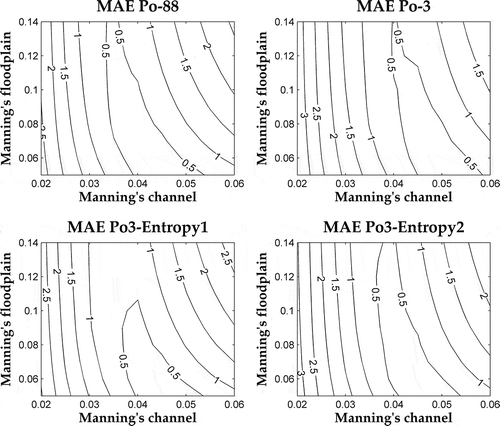
In and the MAE contours are plotted for the Po-88 model configuration and for each chosen model with three and four cross-sections, respectively. The MAE contours of models built with three cross-sections are slightly shifted with respect to the contours of Po-88, as shown in . This shift is reflected in the Manning’s coefficients with the lowest MAE: the best Manning’s nch lies in the interval between 0.045 and 0.060 m-1/3 s for Po-3, whereas it lies between 0.040 and 0.055 m-1/3 s for Po-88, Po3-Entropy1 and ~2. However, this shift falls within the standard range of roughness values used for 1D modelling. Interestingly, the Po3-Entropy1 and ~2 models show the same contours as the Po-88 model: the minimum MAE value corresponds to the same combination of Manning’s coefficient values.
Fig. 4 MAE contours of the three models of the Po River built with three cross-sections and the values for the reference model with 88 cross-sections.
Similar considerations can be drawn comparing MAE contours of Po-88 and models built with four cross-sections (). The Po-4 results are shifted a bit, while for Po4-Entropy1 and ~2 the MAE value of 0.5 is limited to nf equals 0.10 m-1/3 s. The latter two contour plots confirm the similar performance of the two models, as shown in .
Fig. 5 MAE contours of the three models of the Po River built with four cross-sections and the values for the reference model with 88 cross-sections.
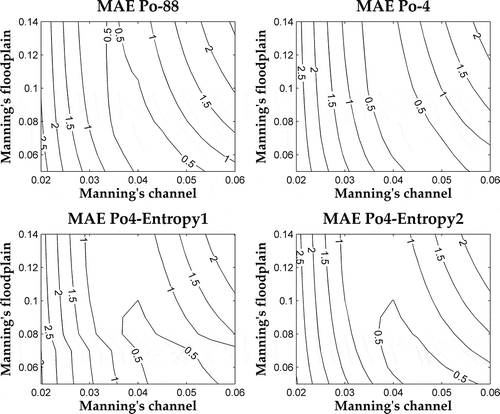
The model configurations obtained using the entropy approach show a better performance in terms of similarity with the Manning’s values of the original model, compared with Po-4a and ~4b, which are based on the S90 guidelines (). The Manning’s coefficient combinations yielded by Po-4a and ~4b () are different to those of Po-88, although the MAE values of the former are low. As explained by Hunter et al. (Citation2006), this is a typical example of parameters compensation: as the Manning’s value of the floodplain increases, the channel value decreases. This behaviour was also noticed by Brandimarte and Di Baldassarre (Citation2012) for the same case study. A lower MAE value is presented only if the nch is lowered and balanced by an increased nf. In spite of the fact that these two models show a lower MAE, their Manning’s values do not correspond to those of the redundant model.
Table 3 River reach models built with all cross-sections (Po-88), with four cross-sections given by S90 (Po-4a and ~b) and by the MOOP solutions (Po4-Entropy1, ~2) and their corresponding MAE values, Manning’s coefficients of the channel (nch) and of the floodplain (nf). The values for Po-88 are included for the sake of comparison.
Despite the different number of cross-sections, flood profiles provided by sets of three and four cross-sections show a good fit to the profile of the original model (i.e. Po-88) ( and ). Concerning the accuracy of the flood profile at boundary conditions, the difference between the water stage values of Po3-Entropy1, ~2 and Po-88 is less than 0.20 m (). A difference lower than this threshold value is still acceptable: it represents the sensitivity of HEC-RAS, as explained at the end of Section 2.
Fig. 6 Po River flood profiles from different models, calibrated by minimizing the MAE: the models were built using S90 or the entropy approach (three cross-section sets), and are compared with the model using the entire data set of sections (Po-88).
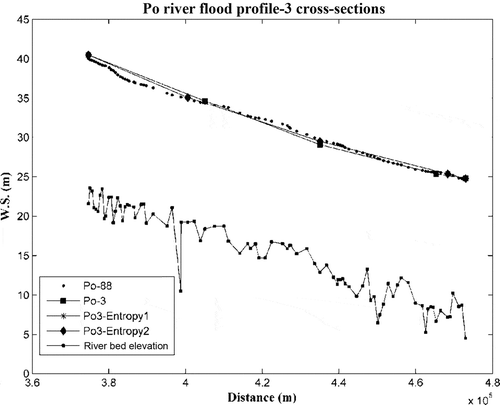
The accuracy of Po-3 at the upstream reach is lower: the difference is greater than 0.20 m, because of the difference in the Manning’s coefficient combination between this model and Po-88, as shown in
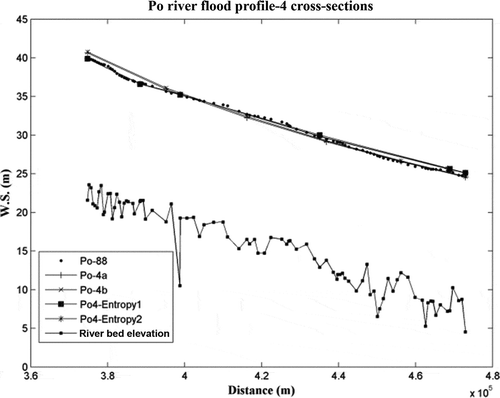
As far as the models built with four cross-sections are concerned, the inaccuracy is located at the upstream reach for Po-4a and ~4b, while the error is less than 0.20 m and at the downstream reach for Po4-Entropy1 and ~2 (). For Po-4a and ~4b the difference is greater, because of the large difference between their best Manning’s coefficient combination and the Po-88 one (). The accuracy of the flood profile is due to the accuracy of HEC-RAS, to the different choice of roughness coefficient, but also to the fact that the downstream boundary generates an error that propagates upstream. For this reason, to increase model performance, the boundary condition should be placed far enough downstream. Thus, particular attention needs to be paid to the reach length and to the definition of the boundary conditions.
Fig. 7 Po River flood profiles from different models, calibrated by minimizing the MAE: the models were built using S90 or the entropy approach (four cross-section sets), and are compared with the model using the entire data set of sections (Po-88).
7 CONCLUSIONS
The entropy-based approach proposed in this work is founded on the evaluation of the information content of data sets of cross-sections applied within a 1D hydraulic model. The methodology aims at determining the optimum number and location of cross-sections needed to preserve an accurate description of the flow profile. The problem is posed as a MOOP, where the total correlation index and the joint entropy have been used as descriptors of redundancy and information content. Solving this problem, several optimal sets of cross-section locations are provided.
The proposed method has been applied to an existing data set of cross-sections for the Po River in Italy and compared to existing approaches based on hydraulic analyses (Samuels Citation1990, Castellarin et al. Citation2009). Results show that the four cross-section data sets selected through the proposed methodology can provide a description of the flow profile comparable to the one given by the original data set composed of 88 sections. These results were also consistent with those coming from literature approaches based on hydraulic analyses.
Therefore, the proposed methodology can be seen as complementing the guidelines proposed by Samuels (Citation1990) and Castellarin et al. (Citation2009). These can be used to design the first topographic survey of riverbed geometry, based on minimal topographic information of the river reach. Once a cross-section data set is available, the proposed methodology can be used to provide indications of the optimal spacing and location of cross-sections for each modelling application, by optimizing computational efficiency. As highlighted by Castellarin et al. (Citation2009), it is important to point out that the results of the proposed method may be inappropriate for some specific applications, e.g. design of a new levee system or prediction of inundation extent. Nevertheless, for hydraulic issues, such as real-time flood forecasting, the proposed method can be extremely useful to determine the minimally redundant geometric description of the river and thus, improve computational efficiency.
A second important application of the entropy-based approach is the updating of existing data sets, by identifying the most valuable sections that should be updated more frequently to survey river bed changes. Optimizing the number of cross-sections is useful when it is necessary to update or extend river geometry surveys. Surveying only non-redundant cross-sections is more economically affordable than checking the whole data set; moreover, it would be possible to conduct field work more often, monitoring river changes over the time.
However, should significant river bed changes occur, the methodology would need the updated cross-sections to work correctly. In addition, the proposed approach can be applied, taking into account several constraints that determine the choice of cross-sections: the area, the river geometry, the presence of infrastructure and gauging stations, and the location of each cross-section itself.
If one or more sections cannot be deleted from the model, it is possible to insert a constraint into the code. A penalty will affect solutions that do not include these key sections into the optimal sets. This is the case of gauged sections providing data for model calibration, or bridge sections. On the other hand, it could be necessary to avoid that the chosen set of solutions comprehends some sections, for instance cross-sections difficult to be reached. As their monitoring is difficult and expensive, a penalty situation leads the genetic algorithm to prefer solutions that do not take into account these particular cross-sections.
Finally, the entropy methodology reported in this paper can also be applied in a 2D framework, for instance, for the optimization of a sensor network deployed in a river-floodplain system (Ridolfi et al., 2012). In particular, the method can assess the optimum amount of data necessary to build reliable flood maps while saving computational time and money in collecting data over the floodplain and the river channel.
Acknowledgements
The authors are grateful to the Interregional Agency for the Po River (Agenzia Interregionale per il Fiume Po, AIPO, Italy) and Po River Basin Authority (Autorità di Bacino del Fiume Po, Italy) for allowing access to their high-resolution DTM of the River Po and to data concerning the river. The authors would like to acknowledge Micah Mukolwe for his technical support. Ilias G. Pechlivanidis and Attilio Castellarin are also acknowledged for their valuable comments and suggestions in reviewing an earlier version of this paper.
REFERENCES
- Abida, H., Ellouze, M., and Mahjoub, M.R., 2005. Flood routing of regulated flows in Medjerda River, Tunisia. Journal of Hydroinformatics, 7 (3), 209–216.
- Alfonso, L., et al., 2013. Information theory applied to evaluate the discharge monitoring network of the Magdalena River. Journal of Hydroinformatics, 15 (1), 211–228. doi:10.2166/hydro.2012.066.
- Alfonso, L., Lobbrecht, A., and Price, R., 2010a. Information theory-based approach for location of monitoring water level gauges in polders. Water Resources Research, 46, W03528. doi:10.1029/2009WR008101.
- Alfonso, L., Lobbrecht, A., and Price, R., 2010b. Optimization of water level monitoring network in polder systems using information theory. Water Resources Research, 46, W12553. doi:10.1029/2009WR008953.
- Amorocho, J. and Espildora, B., 1973. Entropy in the assessment of uncertainty in hydrologic systems and models. Water Resources Research, 9 (6), 1511–1522. doi:10.1029/WR009i006p01511.
- Brandimarte, L., et al., 2009. Isla Hispaniola: a trans-boundary flood risk mitigation plan. Physics and Chemistry of the Earth, 34 (4–5), 209–218.
- Brandimarte, L. and Di Baldassarre, G., 2012. Uncertainty in design flood profiles derived by hydraulic modelling. Hydrology Research, 43 (6), 753–761.
- Castellarin, A., et al., 2009. Optimal cross-section spacing in Preissman Scheme 1D hydrodynamic models. Journal of Hydraulic Engineering, 135 (2), 96–105.
- Castellarin, A., Di Baldassarre, G., and Brath, A., 2011. Floodplain management strategies for flood attenuation in the river Po. River Research Applications, 27, 1037–1047. doi:10.1002/rra.1405.
- Cesur, D., 2007. GIS as an information technology framework for water modelling. Journal of Hydroinformatics, 9 (2), 123–134.
- Chapman, T.G., 1986. Entropy as a measure of hydrologic data uncertainty and model performance. Journal of Hydrology, 85 (1–2), 111–126.
- Chow, V.T., 1959. Open channel hydraulics. New York: McGraw-Hill.
- Coratza, L., 2005. Aggiornamento del catasto delle arginature maestre del Po. Parma: Po River Basin Authority.
- Cover, T.M. and Thomas, J.A., 1991. Information theory. New York: John Wiley.
- Cunge, J.A., 2003. Of data and models. Journal of Hydroinformatics, 5 (2), 75–98.
- Dawson, C.W., Abrahart, R.J., and See, L.M., 2007. Hydrotest: a web-based toolbox of evaluation metrics for the standardised assessment of hydrological forecasts. Environmental Modelling & Software, 22 (7), 1034–1052.
- Deb, K., et al., 2002. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Transactions on Evolutionary Computation, 6 (2), 182–197. doi:10.1109/4235.996017.
- Di Baldassarre, G., et al., 2009a. Probability weighted hazard maps for comparing different flood risk management strategies: a case study. Natural Hazards, 50 (3), 479–496.
- Di Baldassarre, G., et al., 2010. Floodplain mapping: a critical discussion on deterministic and probabilistic approaches. Hydrological Sciences Journal, 55 (3), 364–376.
- Di Baldassarre, G., Castellarin, A., and Brath, A., 2009b. Analysis on the effects of levee heightening on flood propagation: some thoughts on the River Po. Hydrological Sciences Journal, 54 (6), 1007–1017.
- Di Baldassarre, G., Laio, F., and Montanari, A., 2009c. Design flood estimation using model selection criteria. Physics and Chemistry of the Earth, 34 (10–12), 606–611.
- Farmani, R., Walters, G.A., and Savic, D., 2006. Evolutionary multi-objective optimization of the design and operation of water distribution network: total cost vs. reliability vs. water quality. Journal of Hydroinformatics, 8 (3), 165–179.
- HEC (Hydrologic Engineering Center), 2001. Hydraulic reference manual. Davis, CA: US Army Corps of Engineers, HEC.
- Horritt, M.S., 2006. A methodology for the validation of uncertain flood inundation models. Journal of Hydrology, 326 (1–4), 153–165.
- Horritt, M.S., et al., 2010. Modelling the hydraulics of the Carlisle 2005 flood event. Proceedings of the Institution of Civil Engineers: Water Management, 163 (6), 273–281.
- Horritt, M.S. and Bates, P.D., 2002. Evaluation of 1D and 2D numerical models for predicting river flood inundation. Journal of Hydrology, 268 (1–4), 87–89.
- Hunter, N.M., et al., 2006. Improved simulation of flood flows using storage cell models. Proceedings of the ICE – Water Management, 159 (1), 9–18.
- Husain, T., 1989. Hydrologic uncertainty measure and network design. Water Resources Bulletin, 25 (3), 527–534.
- Jaynes, E.T., 1957. Information theory and statistical mechanics. The Physical Review, 106 (4), 620–630.
- Knuth, K.H., 2006. Optimal data-based binning for histograms. arXiv preprint physics/0605197.
- Koutsoyiannis, D., 2005a. Uncertainty, entropy, scaling and hydrological statistics. 1. Marginal distributional properties of hydrological processes and state scaling. Hydrological Sciences Journal, 50 (3), 381–404.
- Koutsoyiannis, D., 2005b. Uncertainty, entropy, scaling and hydrological statistics. 2. Time dependence of hydrological processes and time scaling. Hydrological Sciences Journal, 50 (3), 405–426.
- Koutsoyiannis, D., 2006. An entropic-stochastic representation of rainfall intermittency: The origin of clustering and persistence. Water Resources Research, 42, W01401. doi:10.1029/2005WR004175.
- Kraskov, A., et al., 2005. Hierarichical clustering based on mutual information. Europhysics Letters, 70 (2), 278–284.
- Krstanovic, P.F. and Singh, V.P., 1992. Evaluation of rainfall net-works using entropy, I: theoretical development. Water Resources Management, 6, 279–293.
- Mogheir, Y. and Singh, V.P., 2002. Application of information theory to groundwater quality monitoring networks. Water Resources Management, 16, 37–49.
- Mogheir, Y., de Lima, J.L.M.P., and Singh, V.P., 2003. Assessment of spatial structure of groundwater quality variables based on the entropy theory. Hydrology and Earth System Science, 7 (5), 707–721. doi:10.5194/hess-7-707-2003.
- Mogheir, Y., de Lima, J.L.M.P., and Singh, V.P., 2004. Characterizing the spatial variability of groundwater quality using the entropy theory, I. Synthetic data. Hydrological Processes, 18, 2165–2179.
- Montesarchio, V., et al., 2011. Rainfall threshold definition using an entropy decision approach and radar data. Natural Hazards and Earth System Science, 11, 2061–2074.
- Neal, J.C., et al., 2009. Distributed whole city water level measurements from the Carlisle 2005 urban flood event and comparison with hydraulic model simulations. Journal of Hydrology, 368 (1–4), 42–55.
- Olsson, R.J., Kapelan, Z., and Savic, D.A., 2009. Probabilistic building block identification for the optimal design and rehabilitation of water distribution systems. Journal of Hydroinformatics, 11 (2), 89–105.
- Ozkul, S., Harmancioglu, N., and Singh, V.P., 2000. Entropy-based assessment of water quality monitoring networks. Journal of Hydrologic Engineering, 5 (1), 90–100.
- Papalexiou, S.M. and Koutsoyiannis, D., 2012. Entropy based derivation of probability distributions: a case study to daily rainfall. Advances in Water Resources, 45, 51–57.
- Papoulis, A., 1991. Probability, random variables and stochastic processes. 3rd ed. New York: McGraw-Hill.
- Pappenberger, F., et al., 2005. Uncertainty in the calibration of effective roughness parameters in HEC-RAS using inundation and downstream level observations. Journal of Hydrology, 302 (1–4), 46–69.
- Pappenberger, F., et al., 2006. Influence of uncertain boundary conditions and model structure on flood inundation predictions. Advances in Water Resources, 29 (10), 1430–1449.
- Pechlivanidis, I.G., et al., 2012. Using an informational entropy-based metric as a diagnostic of flow duration to drive model parameter identification. Global NEST Journal, 14 (3), 325–334.
- Pechlivanidis, I.G., Jackson, B., and McMillan, H., 2010. The use of entropy as a model diagnostic in rainfall–runoff modelling. iEMSs 2010. International Congress on Environmental Modelling and Software. 5–8 July, Ottawa, Canada: 2, 1780–1787.
- Ridolfi, E., et al., 2011. An entropy approach for evaluating the maximum information content achievable by an urban rainfall network. Natural Hazards and Earth System Science, 11, 2075–2083. doi:10.5194/nhess-11-2075-2011.
- Ridolfi, E., et al., 2012. An entropy method for floodplain monitoring network design. AIP Conference Proceedings, 1479, 1780. doi: 10.1063/1.4756522.
- Ridolfi, E., et al., 2013. Evaluation of rainfall thresholds through entropy: influence of bivariate distribution selection. Irrigation and Drainage. doi:10.1002/ird.1807.
- Samuels, P.G., 1990. Cross section location in one-dimensional models. In: White, W.R. ed. Proceedings of the International Conference on River Flood Hydraulics. Chichester, UK: Wiley, 339–350.
- Schumann, G., et al., 2007. Deriving distributed roughness values from satellite radar data for flood inundation modelling. Journal of Hydrology, 344, 96–111.
- Schumann, G., et al., 2010. Near real time flood wave approximation on large rivers from space: application to the River Po, Italy. Water Resources Research, 46, W05601. doi:10.1029/2008WR007672.
- Shannon, C.E., 1948. A mathematical theory of communication. Bell System Technical Journal, 27, 379–423, 623–656.
- Singh, V.P., 1997a. The use of entropy in hydrology and water resources. Hydrological Processes, 11, 587–626.
- Singh, V.P., 1997b. Effect of class-interval size on entropy. Stochastic Hydrology and Hydraulics, 11 (5), 423–431.
- Singh, V.P., 2000. The entropy theory as a tool for modelling and decision-making in environmental and water resources. Water SA, 26 (1), 1–10.
- Watanabe, S., 1960. Information theoretical analysis of multivariate correlation. IBM Journal of Research Development, 4, 66–82.
- Weijs, S.V., Schoups, G., and van de Giesen, N., 2010. Why hydrological predictions should be evaluated using information theory. Hydrology and Earth System Science, 14, 2545–2558.
- Weijs, S.V. and van de Giesen, N., 2011. Accounting for observational uncertainty in forecast verification: An information-theoretical view on forecasts, observations, and truth. Monthly Weather Review, 139 (7), 2156–2162.
- Yoo, C., Jung, K., and Lee, J., 2008. Evaluation of rain gauge network using entropy theory: comparison of mixed and continuous distribution function applications. Journal of Hydrologic Engineering, 13 (4), 226–235.