
Abstract
Spearman’s rho, a distribution-free statistic, has been suggested in the literature for testing the significance of trend in time series data. Although the use of the test based on Spearman’s rho (also known as the Daniels test) is less widespread than that based on Kendall’s tau (the Mann-Kendall test), the two tests have been shown in the literature to be equivalent for time series with independent observations. The distribution of the Mann-Kendall trend statistic for persistent data has been previously addressed in the literature. In this paper, the distribution of Spearman’s rho as a trend test statistic for persistent data is studied. Following the same procedures used for Kendall’s tau in earlier work, an exact expression for the variance of Spearman’s rho for persistent data with multivariate Gaussian dependence is derived, and a method for calculating the exact full distribution of rho for small sample sizes is also outlined. Approximations for moderate and large sample sizes are also discussed. A case study of testing the significance of trends in a group of world river flow station data using both Kendall’s tau and Spearman’s rho is presented. Both the theoretical results and those of the case study confirm the equivalence of trend testing based on Spearman’s rho and Kendall’s tau for persistent hydrologic data.
Editor Z. W. Kundzewicz; Associate editor S. Grimaldi
1 Introduction
The distribution-free trend test based on Kendall’s tau, commonly known as the Mann-Kendall trend test, has been widely used as a test for trends in hydrologic and climatic data. Another distribution-free test, the Spearman’s rho (Daniels) test, has also been used for the same purpose, but its use is not as widespread as that of the Mann-Kendall trend test. Spearman’s rho is relatively easier to calculate, but approaches normality much more slowly than Kendall’s tau does (Kendall and Gibbons Citation1990, Sec. 4.13). However, using Monte Carlo simulation of independent data, it has been shown by Yue et al. (Citation2002) that these two tests have similar power in detecting trends to the point of being indistinguishable in practice, and that the associated p values are almost identical.
The purpose of this paper is to derive the distribution of Spearman’s rho for persistent data with multivariate Gaussian dependence. While the assumption of multivariate Gaussian dependence greatly simplifies derivations (Hamed Citation2009), many natural time series have been shown to follow non-Gaussian dependence, and alternative dependence models have been suggested in the literature using other models including copula functions (e.g. Grimaldi and Serinaldi Citation2006). Nevertheless, Hamed (Citation2011) has shown that the effect of deviation from the assumption of multivariate Gaussian dependence has a negligible effect on the final trend test results when compared with the effect of persistence itself. Therefore, the derivation in this work will be based on the assumption of multivariate Gaussian dependence, and the results should be approximate for other forms of dependence. The full distribution of Spearman’s rho is derived for small samples (up to n = 7) and approximations for moderate sample sizes (say, n < 50) are suggested. The relationship between Spearman’s rho and Kendall’s tau in the presence of persistence in the data is also discussed.
2 Mean and variance of Spearman’s rho
For two sets of data X = x1, x2, …, xn and Y = y1, y2, …, yn, the sample estimate rs of Spearman’s rho rank correlation coefficient can be calculated as (Kendall and Gibbons Citation1990, Sec. 1.14):
where
i.e. is the sum of the squares of the differences between the corresponding ranks of X and Y. The sum
ranges from 0 in the case of identical rankings to (n3 − n)/3 in the case of reverse order rankings, with increments of two. The value of rs thus varies between −1 and +1, where rs = −1 indicates perfect disagreement (reverse order) and rs = +1 indicates perfect agreement, suggesting the use of rho as a measure of correlation between X and Y.
Spearman’s rho can be used to test the significance of trends by comparing the ranks of the values of series X with their time order, i.e. replacing the variable Y with the natural numbers 1 to n, in which case the test is known as the Daniels test (Kendall and Gibbons Citation1990, Sec. 4.24). In this case the sum of squares of the differences simplifies to:
Kendall and Gibbons (Citation1990, Sec. 4.13 and 4.24) show that, in the case of independent data and when no trend exists in the data, rs is symmetrical about zero with a variance equal to 1/(n – 1).
The calculation of the mean and variance of rs can be greatly simplified in the case of dependent data if rs can be expressed in terms of an indicator function, similar to the case of Kendall’s tau. Such an expression is given by Moran (Citation1948) corresponding to equation (1) above as:
where
in which the indicator function H(t) is defined as:
In the case of testing trends, y is replaced with the natural numbers 1 to n as mentioned earlier, such that H(yi − yk) equals unity whenever k < i, and equals zero otherwise. The summation on k thus reduces to (i − 1) and the expression for s in equation (5) in the case of trend testing reduces to:
The basic idea in deriving the distribution of rs is that, since the statistic depends only on the ranks of the observations, the mean and variance, as well as the full distribution, can be derived by substituting the ranks with an equivalent set of standard normal variates (Hamed Citation2008). In the case of independent observations, the equivalent normal variates are also independent. However, when the observations are serially correlated, an estimate of the serial correlation between the equivalent normal variates is needed, which can be obtained from the serial correlation between the ranks
(Kendall and Gibbons Citation1990, Sec. 9.15) as
That is, the distribution of rs will depend on the correlation structure between the ranks of the observations through equation (8). Alternatively, the serial correlation between the equivalent normal variates can be obtained after transforming the ranks of the observations to standard normal variates using the inverse normal distribution function and a suitable estimate of the empirical distribution function (plotting position) of the data, but this step is not necessary in the presence of the relationship in equation (8).
Considering series X now to be the equivalent standard normal variates with Gaussian dependence, we note that (xi − xj) is normally distributed with mean zero and variance (2 − 2), where
is the correlation between xi and xj from equation (8). Also, it can be seen that when
we have
where P(.) indicates the probability of the event within the parentheses. The value of 0.5 is a result of the symmetry of the normal distribution of (xi − xj), while the expectation is equal to zero when i = j. The expected value of s in equation (7) can thus be calculated as
where the subtracted summation accounts for the n cases when i = j that result in zero terms. Substituting back in equation (4), we see that the mean of rs remains to be zero as in the independent case, and is not affected by the dependence between the observations.
Similarly, the expected value of s2 can be calculated as
We note again that (xi − xj) is normally distributed with mean zero and variance (2 − 2), and that (xk − xl) is also normally distributed with mean zero and variance (2 − 2
). Under the assumption of Gaussian dependence, (xi − xj) and (xk − xl) are jointly bivariate normal with correlation given by
where, for any two subscripts p and q, is the correlation between the corresponding equivalent normal variates. Since H(t) = 1 only when t > 0, this requires dropping the terms for which i = j or k = l. For the remaining terms, the expectation in equation (11) is equal to the probability that (xi − xj) and (xk − xl) are both positive, which can be calculated using Sheppard’s formula (Kendall and Stuart Citation1976, Sec. 15.6) as:
Substituting equation (13) into equation (11), the expected value of s2 can be calculated. The variance of s can now be calculated as:
It can be shown that the constant term 1/4 in equation (13) when substituted in equation (11) cancels with the second term on the right hand side of equation (14), resulting in the simplified expression
The variance of rs can finally be obtained, considering its relationship with s in equation (4), as
In the case of independent data, many terms in equation (15) vanish, since = 0 in this case for distinct suffixes i, j, k and l. For a few terms, the value of
becomes ±0.5 when only one suffix is common, or ±1 when two suffixes are common. It can be verified that in this case the expression in equation (16) reduces to 1/(n − 1). However, when the data are positively correlated, as is the case with persistent data, many terms in equation (15) become non-zero, thus increasing the value of the variance, which is commonly known as variance inflation. The variance inflation factor is defined as the ratio of the variance of rs as calculated by equation (16) to the original variance for independent data, which is 1/(n − 1) as mentioned earlier. As the variance inflation factor increases, the test based on the original variance becomes more liberal, falsely indicating a larger proportion of significant trends than is expected by chance at a given significance level, when none really exists in the data.
For illustrating the effect of persistence, gives the variance inflation factor when the data come from a first-order autoregressive AR(1) model, for different sample sizes and different values of the first-order autocorrelation coefficient . The autocorrelation function of the AR(1) model is given by
Table 1. Spearman’s rho variance inflation factors for AR(1) data.
Table 2. Spearman’s rho variance inflation factors for FGN data.
As expected, the variance inflation factor increases as the sample size increases and as the value of the autocorrelation coefficient increases. According to the values in , the effect of AR(1) dependence on the test results is substantial even for moderate sample sizes and moderate values of . It is straightforward to verify, for example, that a moderate inflation factor of 2 leads to a Type I error (false rejection rate) of 18% at the 10% level (i.e. an increase of error by a factor of 1.8), 12% at the 5% level (a factor of 2.4), and 5% at the 1% level (a factor of 5.0).
For comparison, gives the variance inflation factor when the data come from a Fractional Gaussian Noise (FGN) scaling model with different scaling parameters (Hurst coefficients), for different sample sizes and the same values of the first-order autocorrelation coefficient as in . The autocorrelation function of the FGN model is given by:
where H is the Hurst coefficient. The first-order autocorrelation coefficient (k = 1) is given by:
It is evident, by comparing and , that the value of the inflation factor also depends on the particular structure of autocorrelation between the data. It can be seen that the FGN model in tends to give larger inflation factors than those resulting from the AR(1) model in , as the sample size increases when the value of is not too large (shaded area in ), but the situation is reversed when
becomes large (shaded area in ).
Since Spearman’s rho and Kendall’s tau have been shown to be equivalent in the case of independent data, as mentioned earlier (Yue et al. Citation2002), we note that the ratio between rho and tau approaches 3/2 for large sample sizes of independent data (Kendall and Gibbons Citation1990, Sec. 9.19 and 9.20, Fredricks and Nelsen Citation2007). At the same time, the ratio of their variances approaches 9/4, which is the main reason for their equivalence. It is straightforward to verify that this equivalence is not affected by persistence through comparison with the results of Hamed (Citation2009).
3 Full distribution of Spearman’s rho
Kendall and Gibbons (Citation1990) give detailed tables for the distribution of rs for sample sizes less than 17, as well as the values of rs for selected quantiles for n up to 35, while for n > 35 they recommend the normal distribution, which gives an accurate approximation for large sample sizes. Following the same procedure used by Hamed (Citation2009) for Kendall’s tau, the full distribution of rs can be obtained by counting the relative number of times each unique value of rs is repeated in a total of n! rankings of the data, where rs will assume (n3 − n)/6 + 1 different values distributed between −1 and +1 in increments of 12/(n3 − n). However, noting that calculating the distribution of rs for a sample of size n involves the evaluation of n! multivariate normal integrals each with (n − 1) variates, it becomes obvious that the exact distribution can be practically calculated only for small values of n, say n < 10.
and give the exact tail probabilities of rs for sample sizes n = 4 to 7 for AR(1) and FGN data, respectively, for different values of the first-order autocorrelation coefficient as an example. The distribution is given in terms of positive values of
, which is the same notation used by Kendall and Gibbons (Citation1990). The values in and correspond to negative values of rs and are therefore lower tail probabilities. Upper tail probabilities for the corresponding positive values of rs are identical due to symmetry.
Table 3. Lower tail probabilities of Spearman’s rho for AR(1) data with different values of n and first-order autocorrelation coefficient .
Table 4. Lower tail probabilities of Spearman’s rho for FGN data with different values of n and first-order autocorrelation coefficient .
shows the exact distribution of Spearman’s rho for n = 7 for different values of the first-order autocorrelation coefficient for the case of AR(1) as an example. The effect of persistence on the distribution is clear, where the distribution becomes flatter and the tails become heavier as persistence increases, to the extent of producing a bimodal distribution in the case of AR(1) data for this small sample size. The non-smooth nature of the distribution of rho compared to that of Kendall’s tau (cf. Hamed Citation2008) may help explain the slow convergence of the distribution to the normal, which becomes even slower with the added effect of persistence on the tails of the distribution.
Figure 1. The exact distribution of Spearman’s rho for AR(1) data with different values of ρ1 and sample size n = 7.
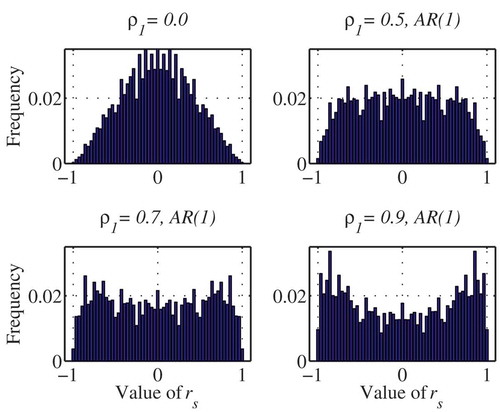
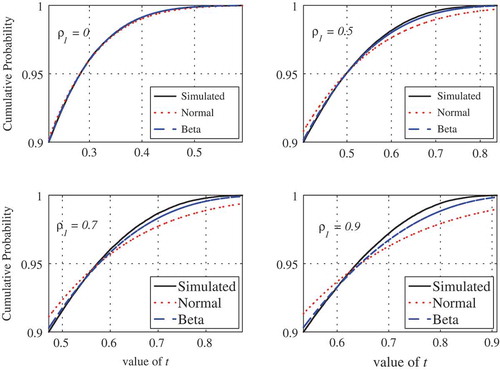
The exact distribution for small samples (n < 10) is mainly intended for theoretical purposes and comparison with earlier work, since relatively longer time series are needed in practice in order to reliably assess trends, especially in the presence of persistence. For practical problems it would be more efficient to approximate the full distribution using a suitable probability distribution. After investigating several candidate probability distributions, the beta distribution was found to be suitable as an approximation to the distribution of rho for moderate values of the sample size n (say n < 50), similar to the case of Kendall’s tau (Hamed Citation2009). The single parameter of the symmetric beta distribution can be obtained using the variance calculated from equation (15). The reader is referred to Hamed (Citation2009) for details. shows a comparison between the simulated distribution for a sample of size n = 10, along with the beta and normal approximations for different values of the first-order autocorrelation coefficient. The superiority of the beta approximation for persistent data is evident from . As the sample size increases, however, the differences between the two approximations become smaller, but not as fast as in the case of non-persistent data. shows the case for a sample size n = 35, where the beta distribution performs much better at higher values of the first-order autocorrelation coefficient. In fact, the beta distribution remains superior to the normal distribution for large sample sizes (n > 50), but the differences become too small to justify using the beta approximation. An interesting feature, however, which can be clearly observed in both and , is that both the beta and normal approximations coincide with the actual distribution near the probability of 0.95. In fact, this was also found to be true for the case of Kendall’s tau. This suggests that the normal distribution would be a reasonable approximation, even for small sample sizes, for the particular significance level of 5% (one-sided).
Figure 2. Comparison of simulated and approximate distributions of Spearman’s rho for a sample of size n = 10.
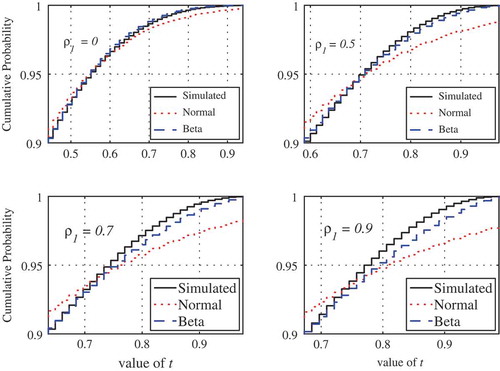
Figure 3. Comparison of simulated and approximate distributions of Spearman’s rho for a sample of size n = 35.
4 Case study
The aim of this case study is to illustrate the effect of persistence on trend test results using Spearman’s rho, and to show the equivalence of the results to those obtained by using Kendall’s tau. The trend tests based on Spearman’s rho and Kendall’s tau are applied to a group of world river flow time series that have been studied earlier by Hamed (Citation2008) using the Mann-Kendall trend test. The data were kindly supplied by the Global Runoff Data Centre in Koblenz, Germany (http://grdc.bafg.de). Hamed (Citation2008) has shown that a large number of stations exhibited a significant scaling behaviour. For the purposes of this study, and in order to show the equivalence of the two studied test statistics for persistent data, only stations with scaling coefficients that are significant at the 5% level (20 stations) are considered. Details of these 20 stations are given in .
Table 5. Details of river flow stations used in the case study.
An important problem in testing the significance of trends in persistent data is the estimation of persistence parameter(s). Since one cannot tell a priori if an observed trend is a real trend or not (this is why a trend test is being performed in the first place), one has to account for the interaction between trend and persistence. On one hand, if one ignores a real trend, the estimated persistence parameter(s) will be inflated, resulting in the inflation of the variance of the trend test statistic, thus reducing the significance of the real trend. On the other hand, if one removes an apparent stochastic trend, the persistence parameter(s) will be underestimated, resulting in deflation of the variance of the trend test statistic, thus increasing the significance of the apparent (false) trend. This is in addition to the fact that persistence parameters are usually downward biased even in the trend-free case (cf. Hamed Citation2007). Hamed (Citation2008) suggests a two-step approach to overcome this difficulty. First, apparent trends are removed from the data using a suitable non-parametric trend estimate, such as Sen’s estimator (Sen Citation1968), which can be calculated as
The second step involves compensating for the underestimation of the persistence parameters by applying a bias correction factor obtained by simulation using purely persistent data (i.e. without trends). Hamed (Citation2008) uses a bias correction factor for the variance of Kendall’s tau. Following the same procedure, a bias correction factor B for the variance of Spearman’s rho has been estimated using 10 000 samples of FGN data with different values of the scaling coefficient and different sample sizes as
where HDet is the sample scaling coefficient estimated from the data after removing an apparent trend, n is the sample size, and
To correct for the bias due to the underestimation of the scaling parameter H and due to the removal of apparent trends, the variance calculated from equation (16) using the autocorrelation function of the FGN model in equation (18) with a scaling parameter HDet is multiplied by the coefficient B from equation (21).
The results of applying both Spearman’s rho and Kendall’s tau trend tests on the selected flow station data are given in . The first column in gives the station ID number. The second and third columns give the estimated scaling coefficients H for the original data, and HDet for the detrended data, respectively. The fourth column gives the ratio between the sample estimates of Spearman’s rho, rs, and Kendall’s tau, t. The fifth to seventh columns compare the variance inflation factor, the p value of the original test (without taking the effect of persistence into account), and the corrected p value of the test (after accounting for the effect of persistence) for Spearman’s rho and Kendall’s tau (in parentheses), respectively.
Table 6. Comparison between trend test results using Spearman’s rho and Kendall’s tau (in parentheses) for selected world river flow stations. Bold face indicates significant trend at the 5% level.
The results in clearly show the extent of the adverse effect of persistence on trend test results using Spearman’s rho as well as Kendall’s tau. While the original tests indicate that 18 out of 20 stations had significant trends at the 5% level (10 increasing and eight decreasing), this number drops to four stations (two increasing and two decreasing) in the case of Spearman’s rho, and five stations (two increasing and three decreasing) in the case of Kendall’s tau, a reduction of more than 70%. The ratios between the sample values of rho and tau in the fourth column vary slightly around their expected value of 3/2 = 1.5, and the variance inflation factors in the fifth column are very close as expected. The p values of the original test in the sixth column are very close, resulting in the same conclusions from either test. The corrected p values in the seventh column are also very close, although slight differences, such as in the case of stations 4119080, 6855500 and 4214210, would suggest different conclusions at the 5% level. However, such slight differences will always occur due to the sampling variation of rho and tau, and the p values for any given station may lie very close to, but on different sides of the critical limit for any given significance level. It can thus be concluded that, similar to the case of independent data covered previously in the literature, trend tests based on Spearman’s rho and Kendall’s tau still give effectively identical results for persistent data, for both the original and the corrected tests.
5 Conclusions
The distribution of Spearman’s rho for persistent data has been considered, and an expression for the variance of the test statistic for persistent data has been developed, together with a method for evaluating the full distribution of rho for small samples. An approximation of the distribution for moderate sample sizes has also been suggested, while the normal distribution approximation can be used for large samples. The effect of persistence on the inflation of the variance of Spearman’s rho has been shown to be comparable to that for Kendall’s tau. A case study of trends in a number of world river flow stations reveals that the p-values resulting from applying the two tests are almost identical. These results confirm the equivalence of the two statistics for testing trends in persistent data. However, the fast convergence of Kendall’s tau to the normal distribution makes it preferable to Spearman’s rho in small samples.
Disclosure statement
No potential conflict of interest was reported by the author.
Acknowledgements
The author would like to thank the Associate Editor, Salvatore Grimaldi, and two anonymous reviewers for their helpful comments. The data used in the case study were kindly provided by the Global Runoff Data Centre (GRDC) in Koblenz, Germany.
References
- Fredricks, G.A. and Nelsen, R.B., 2007. On the relationship between Spearman’s rho and Kendall’s tau for pairs of continuous random variables. Journal of Statistical Planning and Inference, 137, 2143–2150. doi:10.1016/j.jspi.2006.06.045
- Grimaldi, S. and Serinaldi, F., 2006. Design hyetograph analysis with 3-copula function. Hydrological Sciences Journal, 51 (2), 223–238. doi:10.1623/hysj.51.2.223
- Hamed, K.H., 2007. Improved finite-sample Hurst exponent estimates using rescaled range analysis. Water Resources Research, 43, W04413. doi:10.1029/2006WR005111
- Hamed, K.H., 2008. Trend detection in hydrologic data: the Mann–Kendall trend test under the scaling hypothesis. Journal of Hydrology, 349 (3–4), 350–363. doi:10.1016/j.jhydrol.2007.11.009
- Hamed, K.H., 2009. Exact distribution of the Mann-Kendall trend test statistic for persistent data. Journal of Hydrology, 365, 86–94. doi:10.1016/j.jhydrol.2008.11.024
- Hamed, K.H., 2011. The distribution of Kendall’s tau for testing the significance of cross-correlation in persistent data. Hydrological Sciences Journal, 56 (5), 841–853. doi:10.1080/02626667.2011.586948
- Kendall, M.G. and Gibbons, J.D., 1990. Rank correlation methods. 5th edition. London: Griffin.
- Kendall, M.G. and Stuart, A., 1976. The advanced theory of statistics. Vol. I: distribution Theory. London: Griffin.
- Moran, P.A.P., 1948. Rank correlation and product-moment correlation. Biometrika, 35, 203–206. doi:10.1093/biomet/35.1-2.203
- Sen, P.K., 1968. Estimates of the regression coefficient based on Kendall’s tau. Journal American Statistics Association, 63, 1379–1389. doi:10.1080/01621459.1968.10480934
- Yue, S., Pilon, P., and Cavadias, G., 2002. Power of the Mann-Kendall and Spearman’s rho tests for detecting monotonic trends in hydrological series. Journal of Hydrology, 259, 254–271. doi:10.1016/S0022-1694(01)00594-7