
ABSTRACT
This paper assesses the possibility of using multi-model averaging techniques for continuous streamflow prediction in ungauged basins. Three hydrological models were calibrated on the Nash-Sutcliffe Efficiency metric and were used as members of four multi-model averaging schemes. Model weights were estimated through optimization on the donor catchments. The averaging methods were tested on 267 catchments in the province of Québec, Canada, in a leave-one-out cross-validation approach. It was found that the best hydrological model was practically always better than the others used individually or in a multi-model framework, thus no averaging scheme performed statistically better than the best single member. It was also found that the robustness and adaptability of the models were highly influential on the models’ performance in cross-verification. The results show that multi-model averaging techniques are not necessarily suited for regionalization applications, and that models selected in such studies must be chosen carefully to be as robust as possible on the study site.
Editor M.C. Acreman; Associate editor S. Grimaldi
1 Introduction
The science of predicting continuous streamflow time series in ungauged basins has progressed in the past few years, especially since the IAHS issued the 2003–2012 decade on prediction in ungauged basins (Sivapalan et al. Citation2003). Parajka et al. (Citation2013) and Razavi and Coulibaly (Citation2013) have published comprehensive reviews of the many attempts and breakthroughs made thus far, and Hrachowitz et al. (Citation2013) show which difficulties persist in this ever-evolving aspect of hydrology. As the term “regionalization” has taken different meanings during these years (He et al. Citation2011), it should be noted that in this paper, regionalization refers to the art predicting streamflow values on ungauged basins using models calibrated on other, gauged basins. The body of literature is well established in single model regionalization and a few methods have been used extensively such as the spatial proximity or physical similarity methods (Merz and Blöschl Citation2004, McIntyre et al. Citation2005, Parajka et al. Citation2005, Bárdossy Citation2007, Oudin et al. Citation2008, Zhang and Chiew Citation2009). The reader is invited to consult any of these works for details on the inner workings of the aforementioned strategies.
1.1 Multi-model averaging
In other subsets of hydrology, such as in model parameter calibration, precipitation forecasting and flood forecasting, multi-model averaging has been used extensively in the past years (Shamseldin et al. Citation1997, Ajami et al. Citation2006, Diks and Vrugt Citation2010). The body of literature suggests that the model averaging techniques make the best use of the information provided by each model in the group, thus reducing uncertainty and model error while improving on performance. The first noteworthy case of multi-model averaging for rainfall–runoff modelling was proposed by Shamseldin et al. (Citation1997). They showed that the Weighted Average Method (WAM) and Neural Network Method (NMM) produced better results than the Simple Average Method (SAM), which is a simple arithmetic mean of the multiple model outputs.
Other multi-model approaches have been proposed by Ajami et al. (Citation2006). They compared the SAM and WAM methods to the Multi-Model Super Ensemble (MMSE) and Modified MMSE (M3SE) methods using the Distributed Model Intercomparison Project Results (Smith et al. Citation2004). These methods include bias correction and variance reduction to further improve simulation quality. However these methods cannot be used in regionalization as they require knowing the measured streamflow time series.
Arsenault et al. (Citation2015) compared 9 multi-model averaging schemes using 421 catchments from the MOPEX database (Duan et al. Citation2006). The authors used the same hydrological models as in the present study and they concluded that multi-model averaging increases prediction skill better than any single model. They also found that the popular Bayesian Model Averaging method (BMA) (Neuman Citation2003, Raftery and Zheng Citation2003, Raftery et al. Citation2005, Vrugt and Robinson Citation2007) performs well but is not as robust as others, and is costly in terms of required computing power. They conclude that the Unconstrained Granger-Ramanathan variant C is as good as BMA but is much quicker to implement and is more robust, which seconds Diks and Vrugt (Citation2010) original findings.
The averaging aspect is quite well understood and promising for use on a single basin. For example, estimating streamflow during calibration using multi-model averaging and then applying to validation is common and has been shown to be efficient. However, in regionalization projects, the streamflow must be predicted on a different basin. In this case, the weights are not guaranteed to be good or even acceptable. In the case of ungauged catchments, this is a problem which cannot be avoided.
1.2 Multi-model averaging in regionalization
In this paper, the model averaging methods will be used as tools to help predict streamflow in ungauged basins. While multi-model approaches have been popular with hydrologists in general, regionalization studies have not used them quite as often. One major problem is the need to calibrate the weights of the ensemble members. By definition, it is impossible to do so in ungauged basins. However the weights can be determined based on similar donor catchments and then transferred to the ungauged site. McIntyre et al. (Citation2005) were the first to use multi-model averaging in a regionalization context. They showed that ensemble and similarity weighed averaging (SWA) was significantly better than individual model regionalization on 127 catchments in the UK. Goswami et al. (Citation2007) also tested multi-model averaging over 12 catchments in France, and concluded that the method performs better than any single model in calibration, but loses its advantage in validation. Viney et al. (Citation2009) used five lumped rainfall–runoff models on 240 Australian catchments in a multi-model, multi-donor regionalization framework. They showed that a weighted average of the five models is better than unweighted averaging during calibration, but not in validation. They also find that multi-donor ensembles using the five-model averaging approach is better than the single-donor approach. They conclude that the best results are obtained using weighted multi-model and weighted multi-donor methods combined.
Another interesting contribution was made by Reichl et al. (Citation2009), in which the combined flows are calculated as in equation (1):
where Q(t) is the combined streamflow series, h(θk,i, X(t)) is the output of candidate model k of K from donor catchment i of M, given the set of model parameters θk,i and forcing data for the target catchment, X(t). In their work, they forego the use of multiple models and concentrate on optimizing the weights Wi for multiple donors, as in equation (2):
In this study, we attempt to combine the strengths of different models using model averaging schemes conditioned on prior information obtained on the gauged catchments, as in equation (3):
This paper focuses on the set of weights Wk to use during regionalization studies under multi-model averaging frameworks. Please notice that the weighting of multiple models (Wk) is performed before the weighting of multiple donors (Wi) to preserve the weights independence between donors. The weights Wi are computed according to the inverse of the dissimilarity between donor basins. The method we propose is similar to that of McIntyre et al. (Citation2005), except that the weights are deterministically estimated on the local catchments instead of using a prior distribution based on model parameter sampling. Furthermore, we use three hydrological models (each locally calibrated on the gauged donor catchments) whereas McIntyre et al. (Citation2005) use a single model with varying parameters.
Previous studies do not all agree on the methods to be used or expected results, and some have used relatively limited datasets to validate their approach. This study will use three models and four model averaging methods to widen the range of possible outcomes. The scope of the trials will help in understanding and estimating the usefulness of model averaging techniques in continuous streamflow prediction. It will also shed new light on the way model weights influence regionalization performance. For instance, it should be possible to determine whether the weights only correct for local catchment characteristics or, alternatively, compensate for general errors across certain catchment types.
2 Models, study area and data
This section first introduces the hydrological models used in this paper, and then describes the study area and the data for each of the 267 basins.
2.1 Hydrological models
Three models of varying complexity were used during this study, with free parameters ranging from 10 for MOHYSE to 23 for HSAMI. All three are lumped rainfall–runoff models.
2.1.1 HSAMI
The HSAMI model (Fortin Citation2000, Minville et al. Citation2008, Citation2009, Citation2010, Poulin et al. Citation2011, Arsenault et al. Citation2013) has been used by Hydro-Quebec, Quebec’s hydropower company and world leader in hydroelectricity generation, for over two decades to forecast daily flows on more than 100 basins over the province of Quebec. Runoff is generated by surface, unsaturated and saturated zone reservoirs through two unit hydrographs: one for surface and another for intermediate (soil water) reservoir unit hydrographs. The required inputs are spatially averaged maximum and minimum temperatures, as well as liquid and solid precipitation. The model has 23 calibration parameters, all of which were used for this study.
2.1.2 MOHYSE
MOHYSE is a simple model that was first developed for academic purposes (Fortin and Turcotte Citation2007). Since then, the model has been used in research applications (e.g. Velázquez et al. Citation2010). MOHYSE is specifically built to handle Nordic watersheds and has a custom snow accumulation and melt as well as potential evapotranspiration (PET) modules. The required input data are mean daily temperatures, total daily rainfall depth and total daily snow depth (expressed as water equivalent). Ten (10) parameters need to be calibrated.
2.1.3 HMETS
HMETS is a model that uses two reservoirs for the vadose and phreatic zones (Chen et al. Citation2011). HMETS is a Matlab based model which has 21 parameters. The model requires the area of the watershed and the latitude and longitude of the centroid of the basin area as physiographic information. The minimum and maximum temperatures as well as snow and rain are also required as meteorological inputs. HMETS’ structure resembles that of HSAMI as it accounts for snow accumulation, snowmelt and evapotranspiration using the hydrometeorological data available to simulate the streamflow at the outlet. It was fitted with more complex snowmelt and evapotranspiration models than HSAMI, which could improve simulations in the study area.
2.2 Study area
The study area consists of 267 basins covering the province of Québec, Canada. shows the study area and the basin locations. Some basins are nested within others which are included in the study.
Figure 1. Catchment locations in the province of Québec used in this study.
The basins range in size from 30 to 69 191 square kilometres, and cover most of the province of Québec with a total area of 1.6 million square kilometres. A list of 12 catchment descriptors was used in this study according to the compilation by He et al. (Citation2011). Some descriptors, such as soil properties, were not used in this study due to limited availability. The ones that were selected, as well as their statistics, are presented in .
Table 1. Statistics of catchment descriptors used in this study.
2.3 Meteorological and hydrological datasets
The hydrometric data were obtained through a partnership between various province and industry partners who combined their hydrometric data into a single database. The observed climate data were substituted by the Canadian National Land and Water Information Service (NLWIS) 10-km gridded dataset, covering the period 1961–2003. (Hutchinson et al. Citation2009). This choice was made since many catchments have no weather stations within their boundaries, but all the catchments in this study contained at least one NLWIS climate data point. The NLWIS climate dataset was shown to be a good replacement for missing observed data in hydrological applications (Chen et al. Citation2013).
3 Methods
The methodology can be broken down into four main sections: the model calibration approach, the donor basin selection scheme (the regionalization method), the model averaging strategies and the multi-donor aggregation step.
3.1 Model calibration
The first step in this study was to calibrate all the models on all the catchments to obtain parameter sets to be transferred to the ungauged sites. The model calibrations were performed on the first half of the available data, with the other half reserved for validation. All calibrations for the HSAMI and HMETS models were performed using the Covariance-Matrix Adaptation Evolution Strategy (CMAES) (Hansen and Ostermeier Citation1996, Citation2001). CMAES is an evolutionary algorithm for difficult problems, such as those with non-linear, non-convex and non-smooth fitness landscapes. It is an iterative second order method that estimates the positive definite matrix but is free of derivability requirements to estimate gradients. It was shown to outperform other algorithms in calibration for these models (Arsenault et al. Citation2014). Following the same methodology, it was determined that the SCE-UA algorithm (Duan et al. Citation1992, Citation1993, Citation1994) was the better choice for the MOHYSE model. The models were calibrated using three objective functions, namely the Nash-Sutcliffe Efficiency (NSE, Nash and Sutcliffe Citation1970), RSR (RMSE to standard deviation ratio) and Relative Bias (Moriasi et al. Citation2007) metrics. These metrics were selected because they give different emphasis to fitting different parts of the hydrograph and were recommended for continuous streamflow simulation quality evaluation (Moriasi et al. Citation2007).
Lower-scoring basins in calibration are sometimes discarded at this stage in regionalization studies; however they were not removed in this work in order to keep as much information as possible for the regionalization strategies under a multi-model averaging framework.
3.2 Donor basin selection scheme
As was shown in Oudin et al. (Citation2008), a combination of physical similarity and spatial proximity may outperform both approaches taken individually. Therefore, a physical similarity method using spatial distance as one of the catchment characteristics was used.
The physical similarity approach uses catchment descriptors to rank the catchments in similarity to the ungauged one. The strategy involves transferring the parameter sets from the most similar catchments to the ungauged catchment for use in the hydrological models. The similarity between catchments was measured using the similarity index defined by Burn and Boorman (Citation1993):
where k is the catchment descriptor identifier, XG is the catchment descriptor value for the gauged catchment, XU is the catchment descriptor value at the ungauged catchment and ΔX is the range of values taken by XG in the dataset. The catchment that minimizes the difference in similarity index Φ with the ungauged basin is used as the donor catchment. When multiple donors are used, they are selected in ascending order of similarity index value. The catchment descriptors were all used in preliminary testing in this work, but the results were not as good as with small subsets of the descriptors. A one-at-a-time approach allowed showing that only four descriptors were necessary to maximize the performance on almost all the catchments. These are the latitude, longitude, mean annual precipitation and fraction of land cover that is water. These were shown to be optimal or quasi-optimal for the three models by adding one descriptor at a time in descending order of performance increase (see Arsenault and Brissette Citation2014). In doing so, the similarity index is a hybrid of proximity and similarity metrics, thus making it an integrated similarity index. Adding more descriptors to this list only reduced the performance of the models.
It is important to note that all 267 available basins were used during the cross-validation phase as pseudo-ungauged targets, as it would be impossible in a real world scenario to know in advance if a basin would have good calibration efficiency metric values. Then, the catchments whose mean calibration NSE values were less than 0.7 were discarded from the list of possible donor basins. Therefore all basins are considered as ungauged in the cross-validation phase, however the basins which are poorly modelled are not considered as viable donors. This is similar to the approach used by Oudin et al. (Citation2008) and Arsenault and Brissette (Citation2014) which allows for more realistic simulation and validation results.
3.3 Model averaging strategies
3.3.1 Averaging methods description
Four multi-model averaging methods were selected in this work in an attempt to maximize prediction skill.
1. Simple Average Method (SAM)
SAM is the simplest of the tested methods and will be the benchmark by which others are compared. This method is used to determine if simple averaging can perform better than using a single model. The simulated flows from the different models are simply averaged with this method. No weights must be computed as they are de facto equal to the inverse of the number of models.
2. Unconstrained Granger-Ramanathan Averaging (UGRA)
The Unconstrained Granger-Ramanathan Averaging method (Granger and Ramanathan Citation1984) is a simple method that minimizes the RMSE between the simulated and observed variables. As the name implies, the weights are unconstrained. It does not have an explicit bias correction mechanism. Instead, it is implicit in the optimised model parameters, so it is included in the transfer to ungauged catchments.
3. Akaike Information Criterion Averaging (AICA)
The Akaike Information Criterion Averaging method (Akaike Citation1974, Buckland et al. Citation1997, Burnham and Anderson Citation2002, Hansen Citation2008) estimate the likelihood of each member using an average of the log of the error variance of all of the members, to which a penalty term is added for each member. In the AICA method, the penalty term is equal to twice the amount of configurable parameters during the calibration process. For BICA, the amount of configurable parameters multiplied by the natural log of the amount of time steps in the calibration period is used instead.
4. Neural network method (NNM)
The NNM uses a multi-layer feedforward neural network comprising of three layers: The input layer, the output layer, and a central layer called the hidden layer. Each layer has a number of neurons where information is processed. The input layer has one neuron per hydrological model estimated streamflow series, the output layer has only one neuron (the estimated streamflow) and the hidden layer has a user-defined number of neurons. The higher the number of neurons, the better the fit. However, when taken into validation mode, overfitting issues arise if there are too many neurons in the hidden layer. Therefore, keeping the number to a minimum is preferable. In the present study, it was found that the optimal number of neurons in the hidden layer was 3. The different layers are linked together using transfer functions. Input neurons are transferred to the hidden layer neurons using these transfer functions, which can take many shapes. Usually, a non-linear logistic function is used as the activation function (between the input and hidden neurons) and a linear transfer function is used between the hidden and output neurons. The neural network assigns weights to each transfer function to minimize the mean square error between the observed and predicted streamflow values. Many types of NNMs exist, and different approaches using NMMs have been proposed, such as Ensemble NNMs and Non-Linear NN ensemble means (Krasnopolsky and Lin Citation2012). The reader is referred to Shamseldin et al. (Citation1997) for more information on the mathematics and applications of NNM.
3.3.2 Model averaging method application
The multi-model averaging step is the cornerstone of this project. The method will be detailed for one averaging scheme and one objective function, but in the project the process was repeated for each of them. The steps are as follows:
Run the three calibration-optimal hydrological models on the donor catchment and produce three hydrographs.
Apply the weighting schemes to the three hydrographs with the donor basin’s observed hydrograph as the target. This will produce a set of weights, Wk, which do not necessarily add up to one.
Run the hydrological models on the ungauged basin using the donor basin’s parameter set for each model, resulting in three simulated hydrographs on the ungauged basin.
Apply the set of weights Wk (generated in point 2) to the three hydrographs generated in point 3. This produces an averaged hydrograph for the ungauged basin.
Compare the observed and averaged hydrographs on the ungauged basin, or use the averaged hydrograph in a multi-donor framework detailed below, as in Zelelew and Alfredsen (Citation2014).
Multiple donors were used in this framework, so this step was repeated for each of the donor basins. Note that this procedure averages the discharge as simulated by the three models according to the weights that are determined on the donor catchment. Since the three parameter sets are transferred (one per model), it is assumed that the model structural error will be preserved at the target site. Therefore the weights are transferred from the donor to the target basin as-is. Moreover, different combinations of hydrological models were used to determine if any had more impact than any other. Finally, the model weights were analyzed for the AICA and UGRA methods to detect patterns that could explain any differences in their performance.
3.4 Multi-donor averaging
Parajka et al. (Citation2007), amongst others, showed that when multiple donors are used, inverse distance weighting (IDW) outperformed simple arithmetic averaging. Simple linear IDW will thus be used to predict streamflow at an ungauged site when multiple donors are selected (Wi in equation 3). Simply put, the streamflow values produced with the multi-model averaging scheme from each donor were aggregated into a single multi-model, multi-donor streamflow time series. This average is then compared to the observed data to determine the efficiency metric and evaluate the multi-model averaging scheme performance. Furthermore, the distance measure is based not on the spatial distance, but on the physical similarity index distance, which happens to be heavily influenced by spatial distance. This double averaging approach has been shown to be effective in a study by Viney et al. (Citation2009). However, other methods of weighting the donors have been proposed, such as in Reichl et al. (Citation2009) in which prior belief in transferability is used instead of relying on the donor-calibrated weights using a single hydrological model.
4 Results
4.1 Initial model calibration and weighting method evaluation
The hydrological model calibration process was performed on the three models with the NSE, RSR and Relative Bias metrics. However, results are shown only for the NSE metric since the other objective functions had little to no impact on the end results. The few differences obtained with RSR and Relative Bias in regionalization will be addressed in the discussion. Therefore shows the cumulative distribution function for the HSAMI, HMETS and MOHYSE hydrological models when calibrated on the NSE metric.
Figure 2. Cumulative distribution function of initial calibration performance of the three hydrological models calibrated on the NSE metric.
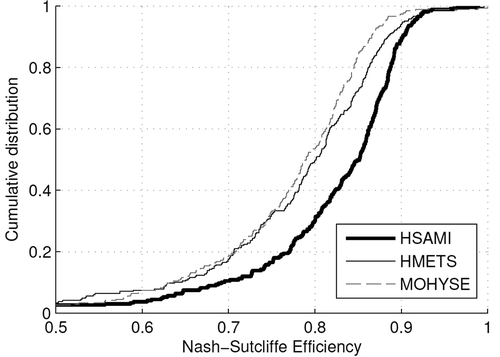
Overall initial calibration of the three hydrological models revealed that the HSAMI model could adapt more easily than the other two models to the various basins in the database. The difference in NSE values between HSAMI and MOHYSE at the 50% probability level, for example, is of 0.07. starts at an NSE value of 0.5 since before that point, all three models are essentially the same.
The weighting methods were then evaluated locally on the gauged basins. The NSE of the best of the three models was pitted against the NSE obtained with the model averaging schemes. shows the results of this evaluation on the validation period, which was equal to the second half of the available data for each given site.
Figure 3. Best single model NSE and model averaging NSE in validation mode for the 4 averaging methods. The diagonal line represents the 1:1 ratio. Markers over (or to the left) of the line indicate basins where the model averaging methods were able to improve upon the best model’s performance.
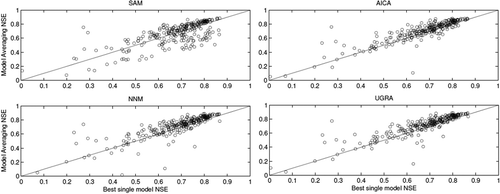
It is clear from that the model averaging methods are usually able to equal or outperform the best model, adding reliability to the simulated streamflow results for gauged catchment applications. There are less than 20% of cases in which model averaging does not equal the best model, with most of these underperforming by a small margin. An exception is the SAM method which is based on equal weights and is not expected to perform as well as the algorithmic methods. This is consistent with the literature (Shamseldin et al. Citation1997, Ajami et al. Citation2006, Diks and Vrugt Citation2010) and is an expected result for local application on gauged basins, but serves as the comparison benchmark for testing in the regionalization mode.
4.2 Regionalization under the multi-model averaging framework
The performance of the multi-model averaging schemes in regionalization was measured by comparing their predictive skill to that of the hydrological models taken individually in a standard mono-model regionalization approach. shows the average NSE values of the 267 ungauged catchments for the four multi-model averaging schemes. Furthermore, the multi-donor aspect of the project is illustrated as up to 15 donors were used to maximize the NSE gain as is the case in mono-model regionalization. Finally, the individual performances of the three models in a mono-model framework were added to for ease of comparison with the multi-model averaging schemes.
Figure 4. Mean NSE value in multi-model regionalization for a varying number of donor basins when the three-model ensemble is used.
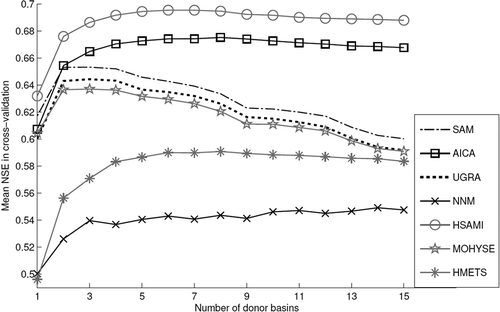
From it is clear that the different model averaging schemes show diverse levels of success. The benchmark (SAM) outperforms all the methods except AICA. The latter often find corner solutions, meaning that weights are attributed in a 0 or 1 fashion. The NNM method is largely the worst, and UGRA shows intermediate performance. It is interesting to note that UGRA and SAM have optimal performances with two donors, whereas AICA is optimal at four to seven donors. The NMM method does not seem to have an optimal number of donors as the performance level shows strong fluctuations. However, and most importantly, no method was able to equal or beat the best single model (HSAMI) used alone in regionalization. Clearly the use of other models with poorer calibration NSE values is lowering the overall score. To give an idea of the regionalization scores on the individual catchments, the best model member’s NSE was plotted against the regionalization NSE using 4 model averaging approaches as shown in . The results in represent the regionalization NSE using 5 donors, but the general trend is similar for 2–15 donors.
Figure 5. Best single model NSE and model averaging NSE in regionalization mode for the 4 averaging methods using 5 donors. The diagonal line represents the 1:1 ratio. Markers over (or to the left) of the line indicate basins where the model averaging methods were able to improve upon the best model’s performance.
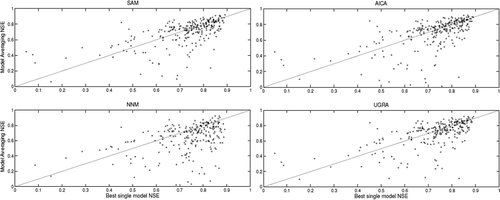
From , it is clear that the model averaging methods are more likely to fail than to succeed in improving upon the best single model. Furthermore, the NSE on failed attempts seems to be significantly more pronounced than what is observed in model averaging on gauged basins.
Another test was performed by reiterating the method with different model ensemble members. shows the behaviour of the model averaging methods when all possible model combinations are used (3x single model, 3x 2 models and 1x 3 models). Each panel in represents a different model averaging technique and each curve represents the mean regionalization NSE value for a given model combination. Note that for the NNM method, the HMETS-MOHYSE ensemble is not shown as its NSE values are too low to properly display.
Figure 6. Mean NSE values in multi-model regionalization depending on the models included in the ensemble. Each panel presents the results for a specific model averaging method. Note than NNM does not show the MOHYSE-HMETS ensemble as the performance is too low to properly display.
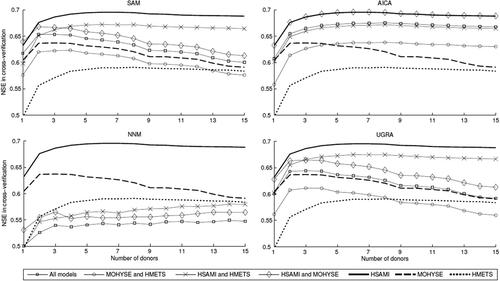
also shows the effects of the different model weighting mechanisms. For instance, AICA offers the same performance as HSAMI when the HMETS model is not used. In this case, the MOHYSE model is never given a weight, leaving HSAMI as the only weighted model with a weight of unity. However, when the HMETS model is used with HSAMI, the performance drops uniformly according to the proportion of times the HMETS model is used in the weighting. Also, the performance of the HSAMI-HMETS ensemble is similar to that of the 3-model ensemble, thus confirming the relative uselessness of MOHYSE when HSAMI is present. This is expected from AICA since the algorithm strongly favours the best model and neglects the other members. In this case, the difference between HSAMI and MOHYSE in terms of relative performance in calibration (as shown in ) is large enough as to render MOHYSE all but unused. In the MOHYSE-HMETS ensemble, AICA is able to beat the individual members by selecting the best model for each case. The difference in performance between HMETS and MOHYSE in calibration was much smaller than with HSAMI, as was seen in . This shows that the level of similarity of the models is important in multi-model regionalization. For the other model averaging methods, the behaviour is different since the multiple models are often allocated non-negligible weights. It can be seen that the HSAMI-HMETS ensemble ranks highest and that the model average follows the same type of performance curve as HSAMI and HMETS. MOHYSE, on the other hand, has an optimum number of donors of two and performance drops quickly thereafter. It can be seen that when the MOHYSE model is part of the ensemble, the model average performance follows the same type of downward trend, thus indicating that the MOHYSE model is often weighted. However, all the averaging methods except AICA are unable to perform at the same level as the single HSAMI model.
4.3 Weights distribution
In order to better understand the model averaging methods properties, the weights that are generated by each method were analyzed. shows the cumulative distribution function of the model weights for the 267 catchments with the 3-member ensemble. The X-axis is the value of the weight and the Y-axis is the frequency probability for that weight value. For example, for the AICA method, the HSAMI member has a weight of 0 for 30% of the basins, a weight between 0 and 1 for approximately 5% of the basins, and a weight of 1 for the remainder (65%). Note that the cumulative distribution function reorders the weight sets in increasing order, thus it is impossible to identify the weights for a given catchment from . For constrained methods with weights bounded from 0 to 1, the weights sum to unity, therefore when one member has a weight of 1 the others are necessarily set to zero.
Figure 7. Cumulative distribution function of the model averaging methods’ calculated weights for the AICA and UGRA weighting schemes for three hydrological models in the ensemble. SAM is not included as the weights are all set to one third, and NNM does not use weights but a neural network transfer function.
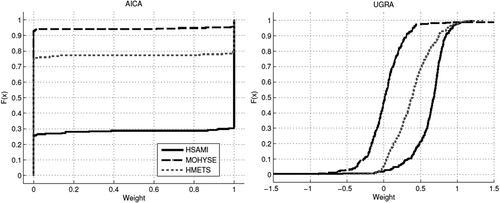
It can be seen in that the AICA method favors corner solutions, in that it gives no weight to the undesirable models and a weight of 1 to the best one. The UGRA method distributes the weights fairly, but it is not bound at 0 or 1. Many solutions therefore use negative and over-unity weights.
5 Analysis and discussion
5.1 Overview of model averaging methods performances
Throughout this study, four model averaging methods were used. While most were able to perform well at some point and in specific conditions, the NNM was unable to compete with the others. Seeing as it does not use weights per se, but rather transfer functions, it is possible that the neural networks are well trained on the gauged basins but are unable to adequately use the inputs from other basins. NNMs have proven time and again that when they are used in the right conditions, they can be powerful tools, such as in classical rainfall–runoff prediction (Shamseldin et al. Citation1997, Krasnopolsky and Lin Citation2012). The number of neurons in the hidden layer was varied from 1 to 10, with 3 neurons returning the best results in validation. The project therefore used 3 neurons for all the tests. This could have biased the results somewhat, but it is doubtful that the end results would change.
Another visible trait is that AICA is able to handle the poorer HMETS model better than the other methods. In and , it scored the highest and maintained a good performance as the number of donors increased. This particularity is due to the way the AICA method computes the weights, often attributing a weight of 1 to the best single model and a weight of 0 to the others, as shown in . This figure also shows that the UGRA method tends to set weights that can be negative or superior to 1. This could produce poor results if the hydrological models are not able to produce reasonable flows on the ungauged basin.
5.2 Multi-model averaging in regionalization
According to the results obtained herein, it would not be advisable to use the three same hydrological models in a regionalization context. The model averaging methods are mostly unable to improve upon the best single member in regionalization (as shown in ), which implies that the donors are either too different from the ungauged basins (which limits model performance) or that the transferred weights are not adequate. Since the single HSAMI model is able to generate good results, it follows that the problem lies within the model averaging weights transfer. However, the model averaging methods are able to hedge against the use of a bad model by either ignoring the bad models completely (such as in AICA) or at least weighting them with other models, such as the UGRA and SAM approaches. The results in and suggest that the most sensible approach would be to use the best possible model; however it is not known beforehand which of the models would be the best choice. The calibration score could be used as an approximation but as seen in , the HMETS model scored better in calibration than MOHYSE whereas in regionalization it was found to be the worst. Perhaps the differences between HSAMI and the other models was too large for the model averaging schemes and that finding more similar models would lead to better results, however this would go against the idea of using the strengths of the different models in an averaging framework. It is more likely that the single best model (if known) would be the better option at any stage, as is investigated in section 5.3. It also appears that the AICA method would be the method of choice in this case as it was able to select the best model in each case to improve upon the single models. While this does not guarantee a better NSE value in regionalization, it does reduce the chance of using a model that fails on the ungauged site, therefore reducing some of the uncertainty. In the case at hand, the extra resources required to perform multi-model regionalization do not reap the benefits as expected, especially for the complex neural network method.
The results also demonstrate that the streamflows produced by multi-model averaging can still be improved by using multi-donors, as is the case with single model regionalization. This means the combined hydrographs still contain relevant information with respect to the catchment descriptors and similarity index, even after averaging. Otherwise, the multi-donor averaging would not improve regionalization performance. The rather poor quality of model averaging in this study seems to point to low transferability of the averaging weights, as they are calibrated to minimize errors on the gauged catchments. The assumption of weight transferability behind this project clearly does not hold. Therefore the model weights seem to only compensate for local errors. Future research could attempt to optimize the weights based on transferability criteria independent of the gauged catchment based on prior belief of model parameter transferability such as McIntyre et al. (Citation2005) and Viney et al. (Citation2009) proposed.
5.3 Impacts of objective function selection
This study was conducted three times, once with each of the three objective functions. RSR and Relative Bias were used as objective functions during model calibration, model averaging weighting and regionalization performance analysis in each of these tests. While only the results for NSE were shown, some interesting findings were made with the others. First, RSR, which is the RMSE-to-standard deviation ratio, behaved very similarly to NSE during the project. RSR and NSE are both variants of normalized sum of squares, which could imply that the hydrological models were targeting the same aspects of the hydrographs. The only difference between the results using both objective functions is that NNM scored much worse with RSR than with NSE for which it was already the worse method.
However, the Relative Bias method saw some slight differences in regionalization. First, the HSAMI model was still the best overall method (including against multi-model combinations), but it was closely followed by the individual MOHYSE model. The HMETS model and NNM method shared similar abysmal performance. Between these groups, the SAM method was the best model averaging approach, followed by AICA and finally UGRA. The difference in performance between the NSE and Relative Bias is undoubtedly related to the low-flows, which are more important for the Bias measure than for the NSE metric. Perhaps the bias metric is too vague compared to the NSE, which would render it even less useful to estimate events that are highly dependent on precise climatic events.
In a last test for the Relative Bias metric, HMETS was removed from the ensemble and the results analyzed once again. It was found that the AICA method once again performed practically identically to the best model HSAMI, and surprisingly, when the number of donors climbed over 10, the SAM method was slightly (although not significantly) better than even the best model. In any case, the model averaging schemes either underperform or are approximately equal to the best single model in regionalization for all of the objective functions tested here.
5.4 Model robustness
One of the fundamental aspects of regionalization is the hydrological model’s robustness to different basin characteristics and datasets. The same hydrological models and most of the model averaging schemes used in this work were used in Arsenault et al. (Citation2015). In that paper, it was shown that when the model averaging takes place in simulation mode, the weighting schemes work very well and they almost always score better NSE values than any model taken individually in validation (as is shown in ). The authors also go on to show that even hydrological models that perform poorly are used in the averaging schemes and they contribute to the increase in performance. However, in this current paper we show that in regionalization, models whose robustness is poor cannot be trusted as the transferred parameter sets can make the models produce unrealistic streamflow values which cannot be corrected by the model averaging schemes. This has been noted in Viney et al. (Citation2009), who state that “relative calibration performances of different models in a donor catchment are not necessarily good indicators of how well the models will contribute to prediction in a neighbouring catchment.” Their conclusions are different from the ones presented in this study as they found that multi-model averaging did increase prediction skill in ungauged basins. However they used five models of similar complexity with more similar calibration objective function values than in this study. Furthermore, their weighting algorithm was based on the calibration skill rather than on the reduction of structural error and they used a different objective function. All this adds credibility to the necessity of using the right models to allow the weighting schemes to perform at their best, and also to review the weighting approach according to transferability of the model parameter sets. It is also possible that the climate in the Viney et al. (Citation2009) paper was better suited for model averaging techniques as the warmer and drier conditions of Australia could lead to more uncertainty in the modeled flow, thus allowing room for improvement with the model averaging methods.
A test was devised to verify the robustness of the models in the study when subjected to the parameter transfer process. Each model was run on all the basins using the parameter sets of all the other basins. Therefore basin-1 was run with the parameters from basin-2 to basin-267, basin-2 using parameters from basin-3 to basin-267, and so on. The NSE values obtained were analyzed with their cumulative distribution functions shown in .
Figure 8. Cumulative distribution function of the hydrological models’ performance when parameter sets are blindly transferred to another catchment. The CDFs contain all the possible donor-target combinations.
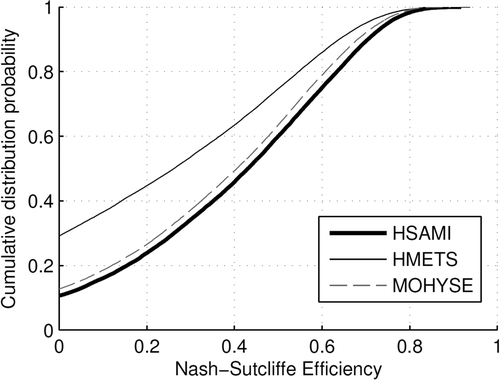
The first obvious trait in is that the HMETS model performs worse than taking the mean of the observed flows in approximately 30% of all cases (NSE<0). HSAMI and MOHYSE have no such problem, with approximately 11% and 14% of bad simulations respectively. The CDFs also show that HSAMI is more robust in that it can simulate better flows on randomly selected catchments compared to the other models, although MOHYSE is not very far behind.
The fact that HMETS is so much poorer than the other two models could explain why it is the worst performing single model in regionalization and why the multi-model regionalization scores are lower than when the HSAMI model is taken alone. If a method such as UGRA gives HMETS a non-negligible weight, it is possible that the predicted streamflow could be unrealistic in cross-validation due to HMETS’ bad transferability properties. AICA is a special case in this regard, as it tends to give a weight of 1 to the best model and 0 to the others. In a case where HSAMI is the best model, the odds of the resulting average streamflow being adequate are good. However if the HMETS model is selected, then the end result could potentially be much poorer. Since HSAMI scores better than HMETS most of the time, AICA is generally the best approach in this scenario.
In light of these results, it seems obvious that the next logical step in the search for optimal regionalization tools resides in the development of hydrological models (or other tools) tailored for robustness in regionalization. One way to investigate this would be to build models with different components and analyze their robustness during parameter transfer. A split-group test could verify the method’s performance in regionalization, as in Singh et al. (Citation2014). Another recent method which eliminates the need to fit rainfall–runoff models to the donor catchments was proposed by Visessri and McIntyre (Citation2015). In their approach, rainfall–runoff indices are transferred and multiple models can be fitted to these indices after they are transferred. It appears that the method is robust, and could be used as a benchmark for future research.
5.5 Multi-donor aspect
Using multiple donor basins has proved to be an excellent way to increase predictive skill in mono-model regionalization. Viney et al. (Citation2009) used multi-donor averaging to further increase their gains on multi-model regionalization. In this work, multi-donor averaging was also found to be very effective in increasing the predictive skill of the multi-model approach. In and it is clear that using donor averaging improved performance for AICA, and even for the other methods, although the latter were generally poorer than AICA in absolute terms. However, the donor averaging skill improvement was similar to that of the HSAMI model. Therefore it was impossible for AICA to surpass the HSAMI model. The optimal number of donors for the method was similar to the optimal number of donors for HSAMI, which was between 4 and 7. Nonetheless, the results show that the use of multiple donors consistently outperforms the single-donor approach. It is thus highly advisable to always use multiple donors when possible.
6 Conclusions
This study aimed at determining if multi-model averaging could be used to improve continuous streamflow prediction in ungauged basins. Four model averaging methods were used in a multi-model, multi-donor regionalization framework based on physical similarity. It was shown that it is good practice to use multiple donors rather than a single donor, as is the case in mono-model regionalization. Every trial performed in this study showed marked gains when using multiple donors.
It was also noted that the performance of the model averaging methods is directly correlated to the robustness of the hydrological models. The HMETS model, when it was used by the model averaging schemes, contributed to lower the overall performance of the method. HSAMI, on the other hand, is more robust and it increased performance when it was used. Accordingly, weighting schemes performances were dependent on the models that were available. If there are non-robust models, the simpler AICA algorithm for optimizing weights is better than more complex methods. It also has the advantage of reducing the chance of failure if multiple good models are available in the ensemble. Overall, in this particular study, it was found that multi-model averaging was not able to consistently perform better than the best single model for regionalization purposes. The results tend to demonstrate that the model averaging techniques correct for errors on local catchments, but that the weights are not transferable in a regionalization framework. More work is needed to better identify which hydrological models are the most robust as to better use the information they can gather on ungauged catchments. The results also show that good performance in model calibration is not a good indicator of regionalization skill in validation. The models can have good calibration skill but poor transferability; therefore they can decrease the overall performance. More research is needed in weighting models on ungauged basins.
Acknowledgements
The authors would like to thank Catherine Guay from IREQ for making the CQ2 measured streamflow database available and Kenjy Demeester from École de technologie supérieure for providing the land cover data for the project. We also thank the anonymous reviewers for their fruitful comments which contributed to considerably improving this paper.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Ajami, N.K., et al., 2006. Multimodel combination techniques for analysis of hydrological simulations: application to distributed model intercomparison project results. Journal of Hydrometeorology, 7, 755–768. doi:10.1175/JHM519.1
- Akaike, H., 1974. A new look at the statistical model identification. IEEE Transactions on Automatic Control, 19 (6), 716–723. doi:10.1109/TAC.1974.1100705
- Arsenault, R. and Brissette, F., 2014. Continuous streamflow prediction in ungauged basins: The effects of equifinality and parameter set selection on uncertainty in regionalization approaches. Water Resour Res, 50 (7), 6135–6153. doi:10.1002/wrcr.v50.7
- Arsenault, R., et al., 2013. Structural and non-structural climate change adaptation strategies for the Péribonka water resource system. Water Resources Management, 27 (7), 2075–2087. doi:10.1007/s11269-013-0275-6
- Arsenault, R., et al., 2014. Comparison of stochastic optimization algorithms in hydrological model calibration. Journal of Hydrologic Engineering, 19 (7), 1374–1384. doi:10.1061/(ASCE)HE.1943-5584.0000938
- Arsenault, R., et al., 2015. A comparative analysis of 9 multi-model averaging approaches in hydrological continuous streamflow simulation. Journal of Hydrology, 529 (3), 754–767. doi:10.1016/j.jhydrol.2015.09.001
- Bárdossy, A., 2007. Calibration of hydrological model parameters for ungauged catchments. Hydrology and Earth System Sciences, 11, 703–710. doi:10.5194/hess-11-703-2007
- Buckland, S.T., Burnham, K.P., and Augustin, N.H., 1997. Model selection: an integral part of inference. Biometrics, 53 (2), 603–618. doi:10.2307/2533961
- Burn, D.H. and Boorman, D.B., 1993. Estimation of hydrological parameters at ungauged catchments. Journal of Hydrology, 143 (3–4), 429–454. doi:10.1016/0022-1694(93)90203-L
- Burnham, K.P. and Anderson, D.R., 2002. Model selection and multi model inference: a practical information-theoretic approach. 2nd ed. New York, NY: Springer-Verlag.
- Chen, J., et al., 2011. Uncertainty of downscaling method in quantifying the impact of climate change on hydrology. Journal of Hydrology, 401 (3–4), 190–202. doi:10.1016/j.jhydrol.2011.02.020
- Chen, J., et al., 2013. Finding appropriate bias correction methods in downscaling precipitation for hydrologic impact studies over North America. Water Resources Research, 49, 4187–4205. doi:10.1002/wrcr.20331
- Diks, C.G.H. and Vrugt, J.A., 2010. Comparison of point forecast accuracy of model averaging methods in hydrologic applications. Stochastic Environmental Research and Risk Assessment, 24 (6), 809–820. doi:10.1007/s00477-010-0378-z
- Duan, Q., Sorooshian, S., and Gupta, V.K., 1992. Effective and efficient global optimization for conceptual rainfall runoff models. Water Resources Research, 24 (7), 1163–1173. doi:10.1029/WR024i007p01163
- Duan, Q., Sorooshian, S., and Gupta, V.K., 1993. A shuffled complex evolution approach for effective and efficient optimization. Journal of Optimization Theory and Applications, 76 (3), 501–521. doi:10.1007/BF00939380
- Duan, Q., Sorooshian, S., and Gupta, V.K., 1994. Optimal use of the SCE-UA global optimization method for calibrating watershed models. Journal of Hydrology, 158, 265–284. doi:10.1016/0022-1694(94)90057-4
- Duan, Q., et al., 2006. Model Parameter Estimation Experiment (MOPEX): an overview of science strategy and major results from the second and third workshops. Journal of Hydrology, 320, 3–17. doi:10.1016/j.jhydrol.2005.07.031
- Fortin, V., 2000. Le modèle météo-apport HSAMI: historique, théorie et application, 68p. Institut de Recherche d’Hydro-Québec, Varennes, Canada.
- Fortin, V. and Turcotte, R., 2007. Le modèle hydrologique MOHYSE (bases théoriques et manuel de l’usager). Note de cours pour SCA7420, Département des sciences de la terre et de l’atmosphère 17p. Université du Québec à Montréal, Montréal, Canada.
- Goswami, M., O’Connor, K.M., and Bhattarai, K.P., 2007. Development of regionalisation procedures using a multi-model approach for flow simulation in an ungauged catchment. Journal of Hydrology, 333 (2–4), 517–531. doi:10.1016/j.jhydrol.2006.09.018
- Granger, C.W.J. and Ramanathan, R., 1984. Improved methods of combining forecasts. Journal of Forecasting, 3 (2), 197–204. doi:10.1002/for.3980030207
- Hansen, B.E., 2008. Least-squares forecast averaging. Journal of Econometrics, 146 (2), 342–350. doi:10.1016/j.jeconom.2008.08.022
- Hansen, N. and Ostermeier, A., 1996. Adapting arbitrary normal mutation distributions in evolution strategies: the covariance matrix adaptation. In: Proceedings of the 1996 IEEE international conference on evolutionary computation, 312–317.
- Hansen, N. and Ostermeier, A., 2001. Completely derandomized self-adaptation in evolution strategies. Evolutionary Computation, 9 (2), 159–195. doi:10.1162/106365601750190398
- He, Y., Bárdossy, A., and Zehe, E., 2011. A review of regionalisation for continuous streamflow simulation. Hydrology and Earth System Sciences, 15, 3539–3553. doi:10.5194/hess-15-3539-2011
- Hrachowitz, M., et al., 2013. A decade of predictions in ungauged basins (PUB)—a review. Hydrological Sciences Journal, 58 (6), 1198–1255. doi:10.1080/02626667.2013.803183
- Hutchinson, M.F., et al., 2009. Development and testing of Canada-wide interpolated spatial models of daily minimum-maximum temperature and precipitation for 1961–2003. Journal of Applied Meteorology and Climatology, 48, 725–741. doi:10.1175/2008JAMC1979.1
- Krasnopolsky, V.M. and Lin, Y. 2012. A neural network nonlinear multimodel ensemble to improve precipitation forecasts over continental US. Advances in Meteorology, 2012, 11p, Article ID 649450. doi:10.1155/2012/649450
- McIntyre, N., et al., 2005. Ensemble predictions of runoff in ungauged catchments. Water Resources Research, 41 (12).doi:10.1029/2005WR004289
- Merz, R. and Blöschl, G., 2004. Regionalisation of catchment model parameters. Journal of Hydrology, 287, 95–123. doi:10.1016/j.jhydrol.2003.09.028
- Minville, M., et al., 2009. Adaptation to climate change in the management of a Canadian water-resources system exploited for hydropower. Water Resources Management, 23 (14), 2965–2986. doi:10.1007/s11269-009-9418-1
- Minville, M., Brissette, F., and Leconte, R., 2008. Uncertainty of the impact of climate change on the hydrology of a Nordic watershed. Journal of Hydrology, 358 (1–2), 70–83. doi:10.1016/j.jhydrol.2008.05.033
- Minville, M., et al., 2010. Behaviour and performance of a water resource system in Québec (Canada) under adapted operating policies in a climate change context. Water Resources Management, 24, 1333–1352. doi:10.1007/s11269-009-9500-8
- Moriasi, D.N., et al., 2007. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Transactions of the ASABE, 50 (3), 885–900. doi:10.13031/2013.23153
- Nash, J.E. and Sutcliffe, J.V., 1970. River flow forecasting through conceptual models part I — a discussion of principles. Journal of Hydrology, 10 (3), 282–290. doi:10.1016/0022-1694(70)90255-6
- Neuman, S.P., 2003. Maximum likelihood Bayesian averaging of uncertain model predictions. Stochastic Environmental Research and Risk Assessment (SERRA), 17 (5), 291–305. doi:10.1007/s00477-003-0151-7
- Oudin, L., et al., 2008. Spatial proximity, physical similarity, regression and ungaged catchments: a comparison of regionalization approaches based on 913 French catchments. Water Resources Research, 44 (3). doi:10.1029/2007WR006240
- Parajka, J., et al., 2013. Comparative assessment of predictions in ungauged basins – part 1: runoff hydrograph studies. Hydrology and Earth System Sciences Discussions, 10, 375–409. doi:10.5194/hessd-10-375-2013
- Parajka, J., Blöschl, G., and Merz, R., 2007. Regional calibration of catchment models: Potential for ungauged catchments. Water Resources Research, 43, W06406. doi:10.1029/2006WR005271
- Parajka, J., Merz, R., and Blöschl, G., 2005. A comparison of regionalisation methods for catchment model parameters. Hydrology and Earth System Sciences, 9, 157–171. doi:10.5194/hess-9-157-2005
- Poulin, A., et al., 2011. Uncertainty of hydrological modelling in climate change impact studies in a Canadian, snow-dominated river basin. Journal of Hydrology, 409 (3–4), 626–636. doi:10.1016/j.jhydrol.2011.08.057
- Raftery, A.E., Gneiting, T., and Bakabdaoui, F., 2005. Using Bayesian model averaging to calibrate forecast ensembles. Monthly Weather Review, 133 (5), 1155–1174. doi:10.1175/MWR2906.1
- Raftery, A.E. and Zheng, Y., 2003. Discussion: performance of Bayesian model averaging. Journal of the American Statistical Association, 98 (464), 931–938. doi:10.1198/016214503000000891
- Razavi, T. and Coulibaly, P., 2013. Streamflow prediction in ungauged basins: review of regionalization methods. Journal of Hydrologic Engineering, 18 (8), 958–975. doi:10.1061/(ASCE)HE.1943-5584.0000690
- Reichl, J.P.C., et al., 2009. Optimization of a similarity measure for estimating ungauged streamflow. Water Resources Research, 45, W10423. doi:10.1029/2008WR007248
- Shamseldin, A., O’Connor, K., and Liang, G., 1997. Methods for combining the outputs of different rainfall–runoff models. Journal of Hydrology, 197, 203–229. doi:10.1016/S0022-1694(96)03259-3
- Singh, R., Archfield, S.A., and Wagener, T., 2014. Identifying dominant controls on hydrologic parameter transfer from gauged to ungauged catchments – a comparative hydrology approach. Journal of Hydrology, 517, 985–996. doi:10.1016/j.jhydrol.2014.06.030
- Sivapalan, M., et al., 2003. IAHS decade on predictions in ungauged basins (PUB), 2003-2012: shaping an exciting future for the hydrological sciences. Hydrological Sciences Journal, 48, 857–880. doi:10.1623/hysj.48.6.857.51421
- Smith, M.B., et al., 2004. The distributed model intercomparison project (DMIP): motivation and experiment design. Journal of Hydrology, 298, 4–26. doi:10.1016/j.jhydrol.2004.03.040
- Velázquez, J.A., Anctil, F., and Perrin, C., 2010. Performance and reliability of multi-model hydrological ensemble simulations based on seventeen lumped models and a thousand catchments. Hydrology and Earth System Sciences, 14, 2303–2317. doi:10.5194/hess-14-2303-2010
- Viney, N.R., et al., 2009. Comparison of multi-model and multi-donor ensembles for regionalisation of runoff generation using five lumped rainfall-runoff models, 18th World IMACS Congress and MODSIM09 International Congress on Modelling and Simulation, Cairns, Australia.
- Visessri, S. and McIntyre, N., 2015. Regionalisation of hydrological responses under land use change and variable data quality. Hydrological Sciences Journal. doi:10.1080/02626667.2015.1006226
- Vrugt, J.A. and Robinson, B.A., 2007. Treatment of uncertainty using ensemble methods: comparison of sequential data assimilation and Bayesian model averaging. Water Resources Research, 43, W01411. doi:10.1029/2005WR004838
- Zelelew, M.B. and Alfredsen, K., 2014. Transferability of hydrological model parameter spaces in the estimation of runoff in ungauged catchments. Hydrological Sciences Journal, 59 (8), 1470–1490. doi:10.1080/02626667.2013.838003
- Zhang, Y. and Chiew, F.H.S., 2009. Relative merits of different methods for runoff predictions in ungauged catchments. Water Resources Research, 45 (7). doi:10.1029/2008WR007504