
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Accurate estimation of pan evaporation (Epan) is very important in water resources management, irrigation scheduling and water budget of lakes. This study investigates the accuracy of two heuristic regression approaches, multivariate adaptive regression splines (MARS) and M5 model tree (M5Tree) in estimating pan evaporation using only temperature data as input. Monthly minimum temperature, maximum temperature and Epan data from three Turkish stations were used, with month number (periodicity information) added as input to see its effect on estimation accuracy. The models were compared with the calibrated Hargreaves-Samani (CHS), Stephens-Stewart (SS) and multiple linear regression methods. Three different train-test splitting strategies (50%–50%, 60%–40% and 75%–25%) were employed for better evaluation of the applied methods. The results show that the MARS method generally estimated monthly Epan with higher accuracy compared to the M5Tree, CHS and SS methods. When extraterrestrial radiation, calculated from Julian date and latitude information, was used as input to the SS instead of solar radiation, satisfactory estimates were obtained. A positive effect on model accuracy was observed when involving periodicity information in inputs and increasing training data length.
Editor S. Archfield Associate editor N. Verhoest
Introduction
Pan evaporation (Epan) is a key variable in water resources management, water budget of lakes and reservoirs, and crop water requirements. Therefore, exact quantification of Epan is a prerequisite, since it has significant impacts on hydrological processes. Evaporation from water reservoirs will vary depending on several factors, including climate, reservoir characteristics and use practices (Wurbs and Ayala Citation2014). Direct measurement of evaporation using a standard pan evaporimeter is an effective tool for assessing the water cycle of lakes and reservoirs and has been adopted worldwide, as well as being recommended by the World Meteorological Organization (WMO) (Chu et al. Citation2010). When conducted properly, a direct measurement approach can provide an exact and faithful continuous record and will be the best procedure. Indirect estimation of Epan using models is an alternative and attractive tool for providing quantification of evaporation. Several studies worldwide have reported the successful use of various kinds of models for estimating evaporation from surface water, and there are at least two categories of models: (1) physically-based (climate-based models) and (2) artificial intelligence (AI)-based models.
Figure 1. Locations of the stations used in the study.
Figure 2. Structure of the MARS model (after Deo et al. Citation2017).
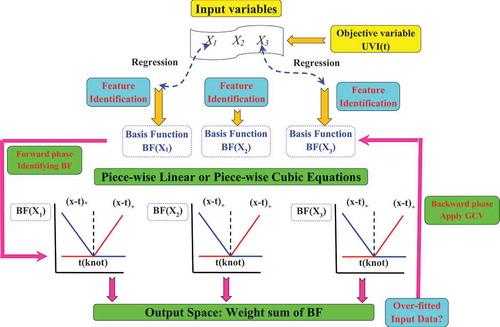
Figure 3. Structure of the M5Tree model (after Deo et al. Citation2017, Sanikhani et al. Citation2018).
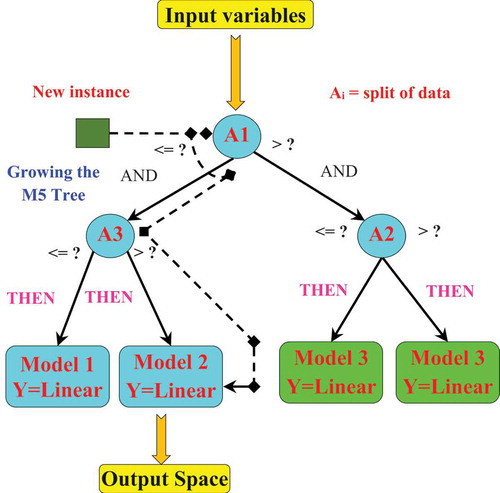
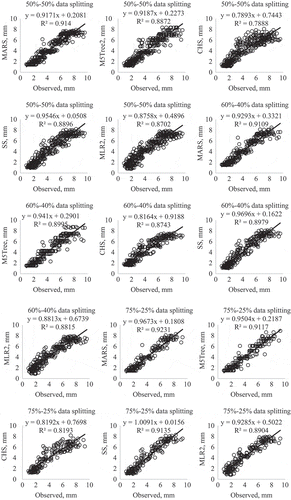
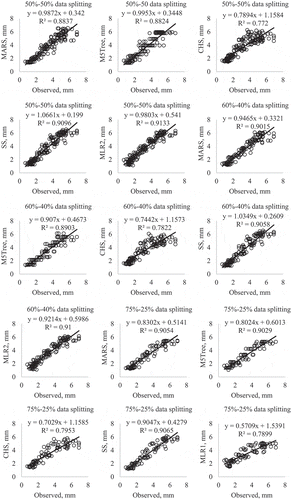
Figure 4. Observed and estimated Epan by the MARS, M5Tree, CHS, SS and MLR methods in the test period – Adana station.
Kisi et al. (Citation2016) compared three machine learning models – classification and regression tree (CRT), chi-squared automatic interaction detector (CHAID) and the multilayer perceptron neural network (MLPNN) – for modelling daily Epan using climatic variables from two weather stations in Turkey. They demonstrated that MLPNN is slightly superior to the two other models. Wang et al. (Citation2017a) conducted a comparative study between six data-driven techniques (DDT) for predicting monthly Epan using large datasets at different climates in China. They selected five meteorological variables – air temperature (Tmean), wind speed (U), sunshine hours (SH), solar radiation (SR) and relative humidity (RH) – and compared the following models: MLPNN, generalized regression neural network (GRNN), fuzzy genetic (FG), least square support vector machine (LSSVM), multivariate adaptive regression spline (MARS), and adaptive neuro-fuzzy inference systems with grid partition (ANFIS-GP). In addition, two standard regression models were used: multiple linear regression (MLR) and the Stephens-Stewart model (SS; Stephens and Stewart Citation1963). According to the results obtained, the MLPNN was broadly more accurate at the majority of the stations. In other studies, Wang et al. (Citation2017b, Citation2017c) compared FG, LSSVM, MARS, the M5 model tree (M5Tree) and the MLR models for predicting daily Epan using Tmean, SH, RH, U and the surface temperature (Ts). They tested two scenarios: local inputs and a cross-validation scenario. According to the results obtained, overall the FG and LSSVM performed best, especially in the case of limited input variables. The high-order response surface method (HORS), a new model for monthly Epan, was introduced by Keshtegar and Kisi (Citation2016) and applied using four meteorological variables (Tmean, SR, RH, U) in Turkey. Compared to the MLPNN, FG and the ANFIS models, the HORS method provided the best accuracy. Keshtegar and Kisi (Citation2017) applied the hybrid response surface function (HRSF), a modified version of the HORS method, for predicting monthly Epan in Turkey. Compared to the second-order response surface method (RSM), ANFIS and M5Tree models, they demonstrated that HRSF and HORS yielded superior results. Malik et al. (Citation2017) compared four machine learning models: (a) co-active neuro-fuzzy inference system (CANFIS), (b) radial basis function neural network (RBFNN), (c) MLPNN and (d) self-organizing map neural network (SOM), for modelling monthly pan evaporation in India. The proposed data-driven models were compared to the climate-based models: the SS model and the Griffith (GF) model. Another of the few studies using the gamma test (GT) for selecting the best input combination of climatic variables for predicting Epan was conducted by Malik et al. (Citation2018), using six climatic variables as inputs – minimum and maximum air temperatures (Tmin and Tmax), morning and afternoon relative humidity (RH1 and RH2), wind speed (U) and sunshine hours (SH). Based on GT results, the RBFNN model with all six variables as inputs gave the best accuracy, the root mean square error (RMSE) of the multiple linear regression model (MLR) was considerably higher than that produced by the RBFNN model. A new data-driven model for daily Epan was recently proposed by Adamala et al. (Citation2018), who compared the generalized higher-order neural network (GHNN) with the generalized first-order neural network (GFNN) and generalized multiple linear regression (GMLR) models. The proposed models were employed for modelling daily Epan in four different climatic regions in India: semi-arid, arid, sub-humid and humid. The researchers concluded and demonstrated the superiority of the GHNN compared to the GFNN and GMLR models.
Deo and Samui (Citation2017) applied four data-driven models – LSSVM, Gaussian process regression (GPR), minimax probability machine regression (MPMR) and genetic programming (GP) – for predicting daily Epan using several climatic variables, e.g. precipitation (P), U, mean solar exposure (St), Tmin, Tmax and daily SR. Comparison of the LSSVM model with GPR, MPMR and GP on the basis of the prediction accuracy showed that the LSSVM model was more accurate and gave a high correlation coefficient for the testing set, whereas the GP model was the worst. More recently, another data-driven model employed for predicting monthly Epan was introduced by Eray et al. (Citation2017): the dynamic evolving neural-fuzzy inference system (DENFIS). Compared to the multi-gene genetic programming (MGGP), based on the use of five climatic variables – Tmax, Tmin, U, SH and RH – collected at two climatic stations in Turkey, the authors demonstrated that the DENFIS performed better at one station, while the MGGP performed better at the second. Arunkumar et al. (Citation2017) selected six daily meteorological variables – Tmin, Tmax, SH, U, RH and dew point temperature (Tdew) – for predicting daily Epan using three AI models: the time-lagged recurrent neural network (TLRN), the M5Tree and the GP model. According to the results obtained, they demonstrated that the GP had the best prediction accuracy, followed by the TLRN model, while the M5Tree gave the lowest accuracy. Pammar and Deka (Citation2017) used the GT method for selecting the best input combination of five meteorological variables – U, P, RH, SH and Tmean – and compared with two DDT for predicting daily Epan in India. They compared the standard support vector regression (SVR) having three different kernel functions and the discrete wavelet transform–support vector regression (DWT-SVR) hybrid models. Based on the results, the authors demonstrated that the DWT-SVR provided the best accuracy compared to the SVR model, and DWT-SVR with radial basis function (RBF) as kernel function had the best prediction accuracy. Ghorbani et al. (Citation2017) proposed a new hybrid model, the multilayer perceptron–firefly algorithm (MLP-FFA), for predicting daily Epan in the arid regions of Iran. Using five meteorological variables – Tmax, Tmin, U, SH and RH – they demonstrated that the MLP-FFA model outperformed the MLPNN and the SVM models.
Several other studies (Kim and Kim Citation2008, Shiri et al. Citation2011, Citation2014, Kim et al. Citation2012) have compared one or more of the AI models reported above, using several meteorological variables at different time steps, and the results obtained have shown that AI models generally provided good accuracy. However, even though the aforementioned studies demonstrated an increased use of AI models, the most important point to note is that, generally speaking, these models require several inputs, i.e. U, RH, SH, Tmean, Tmax and Tmin, and among them the U, RH, SH and SR are the meteorological variables reported as the most significant factors influencing Epan and involved in primary importance. Although Tmax and Tmin were used in several studies focused on modelling Epan, to the best of our knowledge, no study in the literature has used temperature-based data-driven regression models to predict Epan. Hence, this paper makes three main contributions to the related literature. Firstly, in this study, we propose the application of two temperature-based data-driven regression models – the MARS and M5Tree models – using only Tmax and Tmin as input variables, while most of the other studies in the literature used a mix of these two variables and several other meteorological variables. Secondly, for the first time in the SS model, we use extraterrestrial radiation, which is easily obtained from the Julian date and latitude information, instead of solar radiation. Thirdly, we demonstrate the effect of periodicity (month number) as an input variable for Epan estimation using limited climatic inputs. In this study, we apply three different data-splitting strategies, whereas one splitting rule is generally reported in the related literature.
Materials and methods
Case study
The study uses monthly minimum and maximum temperatures (Tmin and Tmax) and pan evaporation (Epan) measured at the stations Adana (37°00′N, 35°19′E; 27 m a.m.s.l.), Antakya (36°33′N, 36°30′E; 100 m a.m.s.l.) and Mersin (36°48′N, 34°38′E; 3 m a.m.s.l.) situated in the Mediterranean region of Turkey. The locations of the stations can be seen in . This region has cool and rainy winters and hot and moderately dry summers. Annual rainfall ranges from 580 to 1300 mm. The Taurus Mountains are close to the coastal area and rain clouds cannot pass these mountains and drop their water on the coastal area (Sensoy et al. Citation2016). The study stations are operated by the Turkish Meteorological Organization. The data periods are 1960–2016, 1962–2015 and 1986–2016 for the Adana, Antakya and Mersin stations, respectively. presents the statistical parameters of the climatic data used in the present study. The extraterrestrial radiation, Ra, of Antakya station has a high negative skewness. The Epan data range of Antakya is higher than that of the Adana and Mersin stations. The correlations between dependent (Tmin, Tmax and Ra) and independent (Epan) variables are smaller for Antakya compared to other two stations ().
Table 1. Statistical parameters of climatic data used in the study. Tmin: minimum temperature; Tmax: maximum temperature; Ra: extraterrestrial radiation; Epan: pan evaporation. xmin, xmax, xmean, Sx and Csx are minimum, maximum, mean, standard deviation and skewness, respectively.
Heuristic regression approaches
Multivariate adaptive regression splines model
The multivariate adaptive regression splines (MARS) model used in this study was developed by Friedman (Citation1991). It has been used recently for suspended sediment load by Yilmaz et al. (Citation2018), analysis of driver lane-keeping behaviour in rain (Ghasemzadeh and Ahmed Citation2018), forecasting natural gas consumption (Ozmen et al. Citation2018), electricity demand forecasting (AL-Musaylh et al. Citation2018), estimation of long-term monthly temperatures (Mehdizadeh Citation2018), mix design method for fly ash geopolymer concrete (Lokuge et al. Citation2018) and damage detection of structures (Ghiasi et al. Citation2018). In the MARS model, the dependent variable is linked to the independent variables in the form of a nonparametric regression formula, and the model is presented by a three terms: (a) the knots, (b) the spline function and (c) the basis functions (BF) (Friedman Citation1991). The main ideas behind the MARS model are as follows: on the one hand, the relationship between the independent and dependent variables does not necessarily have to be well known; on the other hand, the available information in the space of the independent variables is shared (divided) into various regions called knots, and for each knot a regression model is developed using a spline function, itself composed of one or more BFs that replace the original predictors (Abraham et al. Citation2001). The predicted value from the MARS model is based on a linear combination of the BF components involved in the space of the predictors and is summarized as follows:
where βm are unknown coefficients of the model determined during the iterative process, Y is the predicted variable (Epan), BF are the basis functions used to fit the MARS model and composed of the original predictors, i.e. xi (meteorological variables), and M is the total number of BFs (Friedman Citation1991, Ghasemzadeh and Ahmed Citation2018). According to Friedman (Citation1991), the MARS model is built in two stages, a forward (selection) stage and a backward (pruning) stage (see ). The forward stage is governed by a condition: the maximum number of BFs (M in Equation (1)) fixed at the beginning of the learning process must be reached. During the forward stage, an overfitted and very complex model is created taking into account all possible BFs, starting with a constant (BF(x) = 1) and ending with all possible BFs (Ozmen et al. Citation2018). The forward stage is achieved with a model composed of a very high number of BFs, which does not greatly influence the accuracy of the model and the capacity of generalization is not guaranteed. Hence, a second backward stage that eliminates and reduces the BFs with the lowest magnitude is needed in order to obtain an efficient MARS model. During this stage, the BF that least increases the error function is removed from the model and, at each iteration, the effect of the pruning process on prediction accuracy is examined; obviously the final pruned model, based on the backward stage, must still be capable of predicting the test data with high accuracy (Friedman Citation1991, Abraham et al. Citation2001). From a mathematical point of view, the backward pruning stage is realized based on the generalized cross-validation (GCV) (Friedman Citation1991, Abraham et al. Citation2001, Lokuge et al. Citation2018, Ozmen et al. Citation2018):
where N is the number of data, yi is the desired value or the measured Epan, f(xi) is the calculated value of the pattern i, c(M) is the penalty factor, also called a complexity penalty function (Lokuge et al. Citation2018, Yilmaz et al. Citation2018). In this study, the MARS model was employed using the MatLab toolbox ARESLab (Jekabsons Citation2016a).
M5 model tree
The decision tree (DT) algorithm is based on the interaction between two kinds of nodes: a root (primary) node and a secondary node, which together form a tree (Li et al. Citation2018). The DT is a recursive partitioning method, which distributes the input space, containing the input variables, into several homogeneous subsets in terms of dependent variables, and identifies optimal rules called nodes (Hamze-Ziabari and Bakhshpoori Citation2018). The DT works with respect to two conditions: maximize the information and minimize the error in the branches of the tree (Quinlan Citation1992, Wang and Witten Citation1997). The M5 model tree (M5Tree) is inspired by the DT approach (Quinlan Citation1992) and is structured on several multiple linear regression models, each of which is specialized on one subset; the final model is composed of these individual sub-models. The M5Tree model is achieved in three stages (see ): (a) DT induction (the building stage), (b) pruning the tree and (c) smoothing (Quinlan Citation1992, Wang and Witten Citation1997, Hamze-Ziabari and Bakhshpoori Citation2018). During the building stage, the model uses the standard deviation reduction (SDR) as the splitting criterion:
where T represents a set of examples in the dataset that reach the node, and T1, T2 are the sets that result from splitting the node according to the chosen attribute; sd is the standard deviation, and |Ti|/|T | is a criterion for prediction error after splitting the top node (Quinlan Citation1992, Wang and Witten Citation1997, Ranjbar and Mahjouri Citation2018). Over the years, the M5Tree model has become a serious alternative to the traditional artificial neural network (ANN) models and has been used in several applications (e.g. Hamze-Ziabari and Bakhshpoori Citation2018, Li et al. Citation2018, Ranjbar and Mahjouri Citation2018, Sanikhani et al. Citation2018). The majority of these works have demonstrated the robustness of the M5Tree model. In this study, the M5Tree model was employed using the MatLab toolbox M5PrimeLab (Jekabsons Citation2016b).
Empirical equations used
Stephens-Stewart model
The Stephens-Stewart (SS) model, proposed by Stephens and Stewart (Citation1963), is used for Epan estimation using the following relation:
in which Epan is daily pan evaporation (mm/d), R is daily solar radiation (mm/d); a and b are fitting parameters (Al-Shalan and Salih Citation1987, Goyal et al. Citation2014); and Ta is average temperature. In this study, extraterrestrial radiation, Ra, was used in the SS model instead of R.
Hargreaves-Samani model
The Hargreaves-Samani (HS) model provides an estimation of the daily reference evapotranspiration as follows (Hargreaves and Samani Citation1982, Citation1985, Cahoon et al. Citation1991):
where ET0 is reference evapotranspiration; Ra is extraterrestrial radiation (mm/d); and Tmean, Tmax and Tmin are daily mean, maximum and minimum temperature (°C), respectively. In this study, the ET0 was converted to Epan using a calibration procedure on the data used during the training stage of the data-driven models. The calibration must be accomplished using the following linear regression formula, where Epan is the dependent variable and the ET0 is reference evapotranspiration calculated using the HS equation (Cahoon et al. Citation1991, Rahimikhoob Citation2009, Goyal et al. Citation2014):
where a and b are linear regression parameters.
Application and results
Two heuristic regression approaches were utilized in this study to estimate monthly Epan using only temperature data. Data from Adana, Antakya and Mersin stations in Turkey were used for calibration of the methods. The results are compared with those of the empirical HS and SS and multiple linear regression (MLR) methods. In a different approach from those in the literature, we employed three different data-splitting strategies, 50%–50%, 60%–40% and 75%–25%, to better evaluate the applied models. The accuracy of the models was compared with respect to root mean square error (RMSE), mean absolute error (MAE) and Nash-Sutcliffe efficiency (NSE), which can be expressed as:
where N is the number of data, is the mean value of the observed Epan,
is the computed (modelled) Epan, and
is the observed Epan.
For each station, first, various input combinations were tried using MARS and then the results of the optimal MARS were compared with the M5Tree, calibrated HS, SS and MLR models. Error statistics of the MARS models are provided in for the Adana station. It is apparent from that the MARS8 model comprising Tmax, Ra and α inputs has the best accuracy with respect to splitting strategy. It is also clear that the periodicity parameter (α), which indicates the month number and has values from 1 to 12, increases the model accuracy in estimation of Epan. The optimal MARS model (MARS8) is compared with other methods in . For another heuristic regression method, M5Tree, with the same input combination, was used. In MLR, both inputs were considered. According to the average statistics, MARS has lower RMSE and MAE and higher NSE than the M5Tree, CHS, SS and MLR methods. The SS model also performed better than the CHS and MLR models for this station. The accuracy of the applied models generally was increased by including more data in training. For example, the RMSE (0.627 mm) of the MARS model with the 75%–25% train-test strategy is lower than those for the 60%–40% (0.686 mm) and 50%–50% (0.696 mm) strategies (). According to Moriasi et al. (Citation2007), model accuracy can be evaluated according to NSE as: Very Good (0.75 < NSE ≤ 1.00), Good (0.65 < NSE ≤ 0.75), Satisfactory (0.50 < NSE ≤ 0.65), Acceptable (0.40 < NSE ≤ 0.50) and Unsatisfactory (NSE ≤ 0.4). Accordingly, the CHS, SS and MLR2 provided very good results for Adana station (NSE in the ranges 0.785–0.867, 0.882–0.903 and 0.870–881, respectively). The regression trees of the optimal MARS and M5Tree models in the test phase in the 75%–25% train-test scenario are given in and , respectively.
Table 2. Error statistics of various input combinations and data-splitting strategies – Adana station. Tmin, Tmax, Ra and α are minimum and maximum temperatures, extraterrestrial radiation and periodicity (month number), respectively. RMSE, MAE and NSE are root mean square error, mean absolute error and efficiency coefficient, respectively. Bold values indicate the best performance. See Appendix for results of the other two stations.
Table 3. Error statistics of each model for different data-splitting strategies – Adana station. See for explanation of abbreviations and variables.
Table 4. Regression tree of the MARS model in the test phase under the 75%–25% train-test scenario – Adana station.
Table 5. Regression tree of the M5Tree model in the test phase under the 75%–25% train-test scenario – Adana station.
The error statistics of the MARS model for the Antakya station are given in the Appendix (). For this station also the MARS8 model had the best performance in estimating Epan. The positive effect of the periodicity component on model accuracy is also clearly seen from the presented input combinations. The RMSE, MAE and NSE values of the MARS, M5Tree, CHS, SS and MLR methods are compared in . Here also the MARS method outperforms the M5Tree, CHS, SS and MLR methods with respect to three comparison criteria. The superior accuracy of SS over CHS and MLR is clearly seen from the average statistics. For Antakya station also, the accuracy of the methods was increased by the increase in training data length. The model accuracy fluctuated considerably with respect to different train-test strategies. From this, we can say that using only one data-splitting strategy may mislead the modeller; therefore, different splitting rules are needed to obtain more robust results. The regression trees of the optimal MARS and M5Tree models in the test phase under the 75%–25% train-test scenario for Antakya station are given in and .
For Merin station, the error statistics of the MARS models are presented in . Again, the MARS model with the eighth input combination (Tmax, Ra and α) performed the best in all splitting strategies. For this station, including the periodicity component also increased the model accuracy in Epan estimation. compares the five models, again showing the superior accuracy of the MARS models. However, under the 75%–25% data-splitting scenario, the SS model provided better estimates than the MARS and M5Tree models. Here also an increment in training data generally had a positive effect on model accuracy in Epan estimation. According to the average NSE statistics, the MARS, M5Tree and SS models gave very good estimates. Comparison of three stations shows that the model accuracy is lower in estimating Epan for the Antakya station. The main reason for this could be the higher data range and lower correlation between the Tmin/Tmax/Ra and Epan for this station. The regression trees of the optimal MARS and M5Tree models for Antakya station in the test phase, under the 75%–25% train-test scenario, are given in and .
The observed and estimated Epan values obtained by each method in the test period are illustrated in for the Adana station. The figures for Antakya and Mersin stations are given in the Appendix ( and , respectively). Only the best MLR models were included in the scatter plots. It should be noted that all the applied models provided good Epan estimates using only temperature data, except for the CHS and MLR models, which had scattered Epan values in most cases. The MARS models, comprising Tmax, Ra and α inputs, generally had less scattered Epan estimates compared to the other models. The SS model also had less scattered estimates than the CHS and MLR models.
Figure A1. Observed and estimated Epan by the MARS, M5tree, CHS, SS and MLR methods in the test period – Antakya station.
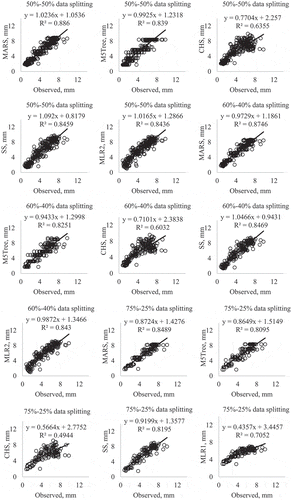
Figure A2. Observed and estimated Epan by the MARS, M5tree, CHS, SS and MLR methods in the test period – Mersin station.
As mentioned before, Wang et al. (Citation2017a) employed six different data-driven methods for modelling monthly Epan of different climates in China. They obtained mean R2 values for the temperature based on MLPNN, GRNN, FG, LSSVM, MARS and ANFIS models, using only temperature as input data, of 0.815, 0.809, 0.796, 0.788, 0.808 and 0.756, respectively. Wang et al. (Citation2017c) estimated Epan of six stations in China using three different data-driven methods and obtained mean R2 values for the best temperature-based FG, ANFIS and M5Tree models of 0.835, 0.787 and 0.816, respectively. Malik et al. (Citation2018) applied two different data-driven methods using maximum and minimum temperature (Tmin and Tmax), relative humidity, wind speed and sunshine hours as inputs. They obtained R2 values for the best SOM and RBFNN models of 0.874 and 0.834, respectively. In this study, the mean R2 values of the three stations are 0.873 and 0.825 for the best MARS and M5Tree models, respectively. This comparison suggests the usefulness of these heuristic regression methods in estimating monthly Epan.
Conclusion
This study compared the accuracy of two heuristic regression methods, MARS and M5Tree, in estimating monthly Epan using limited climatic data, minimum and maximum temperatures. The effect of periodicity (month of the year) on the accuracy of the models was also examined. The estimates of the heuristic methods were compared with those of the empirical CHS, SS and MLR methods. Data from three stations in Turkey were used by applying three train-test data-splitting strategies (50%–50%, 60%–40% and 75%–25%). The results may be summarized as follows:
the MARS model generally had better accuracy than the M5Tree, CHS and SS models in estimating monthly Epan using only temperature data;
increasing the proportion of training to test data generally had a positive effect on the accuracy of the applied models;
the estimation performance of the MARS and M5Tree models was increased by including a periodicity component as input;
in the SS models, extraterrestrial radiation was successfully used instead of solar radiation and gave very satisfactory estimates;
the SS model performed better than the CHS and MLR models for all three stations, which showed that the SS model could be used successfully for estimating Epan with only minimum and maximum temperature data; and
based on the application result, one splitting strategy is not recommended: model accuracy fluctuated considerably with respect to the different data-splitting strategies used; therefore, various data-splitting rules are required for better evaluation of the applied models in estimation of Epan.
In this study, we tested the accuracy of two new heuristic approaches in estimating pan evaporation, Epan, using data from three stations in Turkey. In future studies, other data-driven methods (e.g. support vector machine and extreme learning machine) may be tested using more data from other regions for comparison with this study.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Abraham, A., Steinberg, D., and Philip, N.S., 2001. Rainfall forecasting using soft computing models and multivariate adaptive regression splines. IEEE Transactions on Systems, Man, and Cybernetics: Special Issue on Fusion of Soft Computing and Hard Computing in Industrial Applications, 1, 1–6.
- Adamala, S., Raghuwanshi, N.S., and Mishra, A., 2018. Development of generalized higher-order neural network-based models for estimating pan evaporation. In: V. Singh, S. Yadav, and R. Yadava, eds. Hydrologic modeling. Water science and technology library. Vol. 81, Singapore: Springer. 55–71. doi:10.1007/978-981-10-5801-1_5
- AL-Musaylh, M.S., et al., 2018. Two-phase particle swarm optimized-support vector regression hybrid model integrated with improved empirical mode decomposition with adaptive noise for multiple-horizon electricity demand forecasting. Applied Energy, 217, 422–439. doi:10.1016/j.apenergy.2018.02.140
- Al-Shalan, A. and Salih, A.M.A., 1987. Evaporation estimation in extremely arid areas. Journal of Irrigation and Drainage Engineering, 113, 565–574. doi:10.1061/(ASCE)0733-9437
- Arunkumar, R., Jothiprakash, V., and Sharma, K.J., 2017. Artificial intelligence techniques for predicting and mapping daily pan evaporation. Journal of the Institution of Engineers (India): Series A, 98 (3), 219–231. doi:10.1007/s40030-017-0215-1
- Cahoon, J.E., Costello, T.A., and Ferguson, J.A., 1991. Estimating pan evaporation using limited meteorological observations. Agricultural and Forest Meteorology, 55, 181–190. doi:10.1016/0168-1923(91)90061-T
- Chu, C.R., et al., 2010. A wind tunnel experiment on the evaporation rate of Class A evaporation pan. Journal of Hydrology, 381, 221–224. doi:10.1016/j.jhydrol.2011.10.043
- Deo, R.C., Kisi, O., and Singh, V.P., 2017. Drought forecasting in eastern Australia using multivariate adaptive regression spline, least square support vector machine and M5Tree model. Atmospheric Research, 184, 149–175. doi:10.1016/j.atmosres.2016.10.004
- Deo, R.C. and Samui, P., 2017. Forecasting evaporative loss by least-square support-vector regression and evaluation with genetic programming, Gaussian process, and minimax probability machine regression: case study of Brisbane city. ASCE Journal of Hydrologic Engineering, 22 (6), 05017003. doi:10.1061/(ASCE)HE.1943-5584.0001506
- Eray, O., Mert, C., and Kisi, O., 2017. Comparison of multi-gene genetic programming and dynamic evolving neural-fuzzy inference system in modeling pan evaporation. Hydrology Research. doi:10.2166/nh.2017.076
- Friedman, J.H., 1991. Multivariate adaptive regression splines. The Annals of Statistics, 19 (1), 1–67. doi:10.1214/aos/1176347963
- Ghasemzadeh, A. and Ahmed, M.M., 2018. Utilizing naturalistic driving data for in-depth analysis of driver lane-keeping behavior in rain: non-parametric MARS and parametric logistic regression modeling approaches. Transportation Research Part C, 90, 379–392. doi:10.1016/j.trc.2018.03.018
- Ghiasi, R., Ghasemi, M.R., and Noori, M., 2018. Comparative studies of metamodeling and AI-Based techniques in damage detection of structures. Advances in Engineering Software, 125, 101–112. doi:10.1016/j.advengsoft.2018.02.006
- Ghorbani, M.A., et al., 2017. Pan evaporation prediction using a hybrid multilayer perceptron-firefly algorithm (MLP-FFA) model: case study in North Iran. Theoretical and Applied Climatology. doi:10.1007/s00704-017-2244-0
- Goyal, M.K., et al., 2014. Modeling of daily pan evaporation in sub-tropical climates using ANN, LS-SVR, Fuzzy logic, and ANFIS. Expert Systems with Applications, 41, 5267–5276. doi:10.1016/j.eswa.2014.02.047
- Hamze-Ziabari, S.M. and Bakhshpoori, T., 2018. Improving the prediction of ground motion parameters based on an efficient bagging ensemble model of M5` and CART algorithms. Applied Soft Computing, 68, 147–161. doi:10.1016/j.asoc.2018.03.052
- Hargreaves, G.H. and Samani, Z.A., 1982. Estimating potential evapotranspiration. Journal of Irrigation and Drainage Engineering (ASCE), 108 (IR3), 223–230.
- Hargreaves, G.H. and Samani, Z.A., 1985. Reference crop evapotranspiration from temperature. Transaction of ASAE, 1 (2), 96–99.
- Jekabsons, G. (2016a). ARESLab adaptive regression splines toolbox for Matlab/Octave ver. 1.13.0. Institute of Applied Computer Systems Riga Technical University, Latvia. Available from: http://www.cs.rtu.lv/jekabsons/Files/ARESLab.pdf
- Jekabsons, G. (2016b). M5PrimeLab: M5ʹ Regression Tree and Model Tree ensemble toolbox for Matlab/Octave ver. 1.7.0. Institute of Applied Computer Systems Riga Technical University, Latvia. Available from: http://www.cs.rtu.lv/jekabsons/Files/M5PrimeLab.pdf.
- Keshtegar, B. and Kisi, O., 2016. A nonlinear modelling-based high-order response surface method for predicting monthly pan evaporation. Hydrology and Earth System Sciences Discussion. doi:10.5194/hess-2016-191
- Keshtegar, B. and Kisi, O., 2017. Modified response-surface method: new approach for modeling pan evaporation. Journal of Hydrologic Engineering ASCE, 22 (10), 04017045. doi:10.1061/(ASCE).HE.1943-5584.0001541
- Kim, S. and Kim, H.S., 2008. Neural networks and genetic algorithm approach for nonlinear evaporation and evapotranspiration modeling. Journal of Hydrology, 351 (3–4), 299–317. doi:10.1016/j.jhydrol.2007.12.014
- Kim, S., Shiri, J., and Kisi, O., 2012. Pan evaporation modeling using neural computing approach for different climatic zones. Water Resources Management, 26, 3231–3249. doi:10.1007/s11269-012-0069-2
- Kisi, O., et al., 2016. Daily pan evaporation modeling using chi-squared automatic interaction detector, neural networks, classification and regression tree. Computers and Electronics in Agriculture, 122, 112–117. doi:10.1016/j.compag.2016.01.026
- Li, Y., et al., 2018. Learning deep generative models of graphs. arXiv:1803.03324. Available from: https://arxiv.org/pdf/1803.03324.pdf
- Lokuge, W., et al., 2018. Design of fly ash geopolymer concrete mix proportions using multivariate adaptive regression spline model. Construction and Building Materials, 166, 472–481. doi:10.1016/j.conbuildmat.2018.01.175
- Malik, A., Kumar, A., and Kisi, O., 2017. Monthly pan-evaporation estimation in Indian central Himalayas using different heuristic approaches and climate based models. Computers and Electronics in Agriculture, 143, 302–313. doi:10.1016/j.compag.2017.11.008
- Malik, A., Kumar, A., and Kisi, O., 2018. Daily pan-evaporation estimation using heuristic methods with gamma test. Journal of Irrigation and Drainage Engineering ASCE, 144 (9), 04018023. doi:10.1061/(ASCE)IR.1943-4774.0001336
- Mehdizadeh, S., 2018. Assessing the potential of data-driven models for estimation of long-term monthly temperatures. Computers and Electronics in Agriculture, 144, 114–125. doi:10.1016/j.compag.2017.11.038
- Moriasi, D.N., et al., 2007. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Transactions of the American Society of Agricultural and Biological Engineers, 50, 885–900. doi:10.13031/2013.23153
- Ozmen, A., Yılmaz, Y., and Weber, G.W., 2018. Natural gas consumption forecast with MARS and CMARS models for residential users. Energy Economics, 70, 357–381. doi:10.1016/j.eneco.2018.01.022
- Pammar, L. and Deka, P.C., 2017. Daily pan evaporation modeling in climatically contrasting zones with hybridization of wavelet transforms and support vector machines. Paddy and Water Environment, 15, 711–722. doi:10.1007/s10333-016-0571-x
- Quinlan, J.R. (1992). Learning with continuous classes. In: Proceedings of the Fifth Australian Joint Conference on Artificial Intelligence (Hobart, Australia, 16-18 November). Singapore: World Scientific, 343–348.
- Rahimikhoob, A., 2009. Estimating daily pan evaporation using artificial neural network in a semi-arid environment. Theoretical and Applied Climatology, 98, 101–105. doi:10.1007/s00704-008-0096-3
- Ranjbar, A. and Mahjouri, N., 2018. Development of an efficient surrogate model based on aquifer dimensions to prevent seawater intrusion in anisotropic coastal aquifers, case study: the Qom aquifer in Iran. Environmental Earth Sciences, 77, 418. doi:10.1007/s12665-018-7592-2
- Sanikhani, H., et al., 2018. Non-tuned data intelligent model for soil temperature estimation: a new approach. Geoderma, 330, 52–64. doi:10.1016/j.geoderma.2018.05.030
- Sensoy, S., Demircan, M., and Ulupinar, Y. (2016). Climate of Turkey, Turkish State Meteorological Service, Ankara, Turkey. https://www.researchgate.net/publication/296597022_Climate_of_Turkey.
- Shiri, J., et al., 2011. Estimating daily pan evaporation from climatic data of the State of Illinois, USA using adaptive neuro-fuzzy inference system (ANFIS) and artificial neural network (ANN). Hydrology Research, 42 (6), 491–502. doi:10.2166/nh.2011.020
- Shiri, J., Marti, P., and Singh, V.P., 2014. Evaluation of gene expression programming approaches for estimating daily evaporation through spatial and temporal data scanning. Hydrological Processes, 28, 1215–1225. doi:10.1002/hyp.9669
- Stephens, J.C. and Stewart, E.H., 1963. A comparison of procedures for computing evaporation and evapotranspiration. General Assembly of Berkeley, 123–133: IAHS Publ. no. 62.
- Wang, L., et al., 2017a. Pan Evaporation modeling using six different heuristic computing methods in different climates of China. Journal of Hydrology, 544, 407–427. doi:10.1016/j.jhydrol.2016.11.059
- Wang, L., et al., 2017b. Pan evaporation modeling using four different heuristic approaches. Computers and Electronics in Agriculture, 140, 203–213. doi:10.1016/j.compag.2017.05.036
- Wang, L., et al., 2017c. Evaporation modelling using different machine learning techniques. International Journal of Climatology, 37 (S1), 1076–1092. doi:10.1002/joc.5064
- Wang, Y. and Witten, I.H., 1997. Induction of model trees for predicting continuous lasses. In: Proceedings of the Poster Papers of the European Conference on Machine Learning. Prague: University of Economics, Faculty of Informatics and Statistics. doi:10.1007/s11269-013-0440-y
- Wurbs, R.A. and Ayala, R.A., 2014. Reservoir evaporation in Texas, USA. Journal of Hydrology, 510, 1–9. doi:10.1016/j.jhydrol.2013.12.011
- Yilmaz, B., et al., 2018. Estimating suspended sediment load with multivariate adaptive regression spline, teaching learning based optimization, and artificial bee colony models. Science of the Total Environment, 639, 826–840. doi:10.1016/j.scitotenv.2018.05.153
Appendix
Table A1. Error statistics of various input combinations and data-splitting strategies – Antakya station. Tmin, Tmax, Ra and α are minimum and maximum temperatures, extraterrestrial radiation, and periodicity (month number), respectively. RMSE, MAE and NSE are root mean square error, mean absolute error and efficiency coefficient, respectively. Bold values indicate the best performance.
Table A2. Error statistics of each model for different data splitting strategies – Antakya station. See for explanation of abbreviations and variables.
Table A3. Regression tree of the MARS model in the test phase under the 75%–25% train-test scenario – Antakya station.
Table A4. Regression tree of the M5Tree model in the test phase under the 75%–25% train-test scenario – Antakya station.
Table A5. Error statistics of various input combinations and data-splitting strategies – Mersin station. See for explanation of abbreviations and variables. Bold values indicate the best performance.
Table A6. Error statistics of each model for different data-splitting strategies – Mersin station. See for explanation of abbreviations and variables.
Table A7. Regression tree of the MARS model in the test phase under the 75%–25% train-test scenario – Mersin station.
Table A8. Regression tree of the M5Tree model in the test phase under the 75%–25% train-test scenario – Mersin station.