
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
As time irreversibility of streamflow is marked for time scales up to several days, while common stochastic generation methods are good only for time-symmetric processes, the need for new methods to handle irreversibility, particularly in flood simulations, has been recently highlighted. From an investigation of the historical evolution of existing stochastic generation methods, which is a useful step before proposing new methods, the strengths and weaknesses of current approaches are located. Following this investigation, a generic solution to the stochastic generation problem is proposed. This is an analytical exact method based on an asymmetric moving-average scheme, capable of handling time irreversibility in addition to preserving the second-order stochastic structure, as well as higher-order marginal statistics, of a process. The method is studied theoretically in its general setting, as well as in its most interesting special cases, and is successfully applied to streamflow generation at an hourly scale.
Editor A. CastellarinAssociate editor not assigned
1 Introduction
Simplicity is the final achievement.
Frédéric Chopin
A recent study (Koutsoyiannis Citation2019b) has investigated the possible existence of time irreversibility in hydrometeorological processes and the related theoretical framework. According to the latter, a simple definition of time reversibility within stochastics is the following, where underlined symbols denote stochastic (random) variables and non-underlined ones denote values thereof or regular variables.
A stochastic process at continuous time t, with nth order distribution function:
is time-symmetric or time-reversible if its joint distribution does not change after reflection of time about the origin, i.e. if for any n, ,
If times are equidistant, i.e.
, the definition can be also written by reflecting the order of points in time, i.e.:
A process that is not time-reversible is called time-asymmetric, time-irreversible or time-directional. Important results related to time (ir)reversibility are the following:
A time-reversible process is also stationary (Lawrance Citation1991).
If a scalar process
is Gaussian (i.e. all its finite-dimensional distributions are multivariate normal) then it is reversible (Weiss Citation1975). The consequences are: (a) a directional process cannot be Gaussian; (b) a discrete-time ARMA process (and a continuous-time Markov process) is reversible if and only if it is Gaussian.
However, a vector (multivariate) process can be Gaussian and irreversible at the same time. A multivariate Gaussian linear process is reversible if and only if its autocovariance matrices are all symmetric (Tong and Zhang Citation2005).
Time asymmetry of a process can be studied through the differenced process, i.e.:
where is the process representation in discrete time τ (denoting the continuous-time interval
), i.e.:
For a stationary stochastic process , the differenced process
has mean zero and variance:
where and
are the variance and lag-one autocovariance, respectively, of
. Then, the time asymmetry is quantified by the skewness coefficient:
where denotes the third moment. Alternatively, it is quantified by the probability of
being negative:
Processes with large or large departure of
from the value 1/2 signify high (positive) time irreversibility. A sketch of a realization of such a process is given in . The graph is characterized by rapid increases followed by gradual decreases. The entire setting in constructing the time series of is nonlinear (the values are obtained by optimization rather than generated by a linear stochastic model), and while the marginal distribution is by construction Gaussian, the multivariate one is not, so there is no conflict with Weiss’s (Citation1975) result mentioned above.
The study by Koutsoyiannis (Citation2019b) has provided evidence that time irreversibility may be profound in the streamflow process at scales of several days or lower. In atmospheric processes irreversibility appears as well, but at much finer time scales. On the other hand, most stochastic simulation methods do not account for irreversibility. In the same study, two methods have been proposed for a stochastic generation that respects irreversibility and reproduces it in a controlled manner, quantifying it by the skewness of the differenced process. After exploring them, one of the two methods proved successful. A disadvantage of that method is that it needs iterations to converge to a solution, in which vector derivatives need to be evaluated.
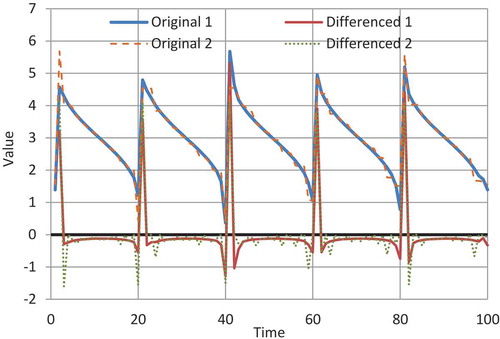
Figure 1. Plot of two synthetic time series generated by maximizing time irreversibility properties of a process restricted to be marginally Gaussian (N(3, 1)) with lag-one autocorrelation 0.5, so that the variance of the differenced process is also 1 (equal to that of the original process). Solution 1 maximizes the skewness of the differenced process. Solution 2 maximizes the frequency that the differenced process has a negative value, without taking into account the skewness. In both series the frequency that the differenced process has negative values is 0.94. The coefficients of skewness of the differenced processes for series 1 and 2 are 4.10 and 3.34, respectively (Source: Koutsoyiannis Citation2019b).
Here we present a simple method that is exact, analytical and direct, and its application is fast avoiding the need for iterations. As far as the general framework related to time’s arrow and time irreversibility of atmospheric and hydrological processes is concerned, the interested reader is referred to the study by Koutsoyiannis (Citation2019b) and its extended list of references. However, in terms of the stochastic synthesis per se, the current paper is a stand-alone study with a detailed presentation, starting from main historical landmarks and ending with proposing a generic method of stochastic synthesis which is entirely new (to the author’s knowledge). In this manner, an earlier study for a generic and parsimonious stochastic modelling scheme (Koutsoyiannis Citation2016) is complemented and extended to time-irreversible processes.
2 Approaches in stochastic synthesis
It is common knowledge that when we want to model the (marginal) distribution of a stochastic variable, we usually fit a model (a distribution such as Gaussian, gamma, generalized extreme value, etc.) using the available data, typically given as a time series . But let us consider for a minute a different tactic: We estimate from the data sufficiently many, say J, moments, and instead of fitting a customary distribution, we approximate the distribution through moments. These moments are
, and their unbiased estimates from the data are
. From the moments we could recover the density function
of the stochastic variable of interest
, in at least two ways:
1.We could exploit the inversion formula (e.g. Papoulis Citation1991, p. 116):
where is the characteristic function of the distribution and
is the imaginary unit, combine it with the moment theorem, according to which the jth derivative of
is:
and then use some type of expansion to approximate and eventually
based on a number J of moment estimates.
2.We could use as an approximation of the maximum entropy distribution conditional on the specified moments, which is (e.g. Papoulis Citation1991, p. 571):
where are constants determined so that the distribution have the specified moments.
This tactic, if implemented in either variant, would have problems, including the following:
Assuming that the number J is not very small, the resulting models would not be parsimonious, as they would include J moments and an equal number of parameters.
The moment estimates beyond second are unreliable for typical sample sizes, despite the fact that unbiasedness is theoretically guaranteed (see the work by Lombardo et al. Citation2014, with the characteristic title “Just two moments”.)
In particular, heavy-tailed distributions would never appear as models, because in these distributions all moments beyond a threshold are infinite, while their sample estimates are finite.
The origin of problems in such a tactic is not actually the approximate character of the specified distribution – after all, any model is an approximation of some real phenomenon. Rather, it is the lack of parsimony and the direct link of the parameters (such as in (11)) with the data, on which their estimation is based. In contrast, the same approximation of the distribution would be valid and not problematic if coefficients
were not model parameters and if they were determined theoretically rather than estimated from the data.
Fortunately, however, this tactic is not commonly implemented. Rather, a parametric model is assumed based, on the one hand, on some theoretical considerations (e.g. central limit theorem, maximum entropy principle, asymptotic theory of distribution of extremes) and on the other hand, on some exploration of the available data.
Strangely enough though, this tactic has been the rule in fitting and applying so-called time-series models – and it is still the norm even today – despite the fact that fitting a stochastic process is more demanding a task than fitting a marginal distribution and, at the same time, the presence of autocovariance increases uncertainty in model fitting. Indeed, time-series models are typically fitted based on estimates of the autocovariance (or autocorrelation) function and even the model formulation (in terms of the multivariate distribution) is determined by the number of the autocorrelation coefficients they are used – similar to what Eq. (11) suggests for the marginal distribution. Apparently, the alternative of fitting a parametric model to the multivariate distribution is valid (Koutsoyiannis Citation2000, Citation2016) but it has not been the norm. The reasons for following such a weird practice in most disciplines whose modelling relies on data, including hydrology, are historical. An attempt to trace their evolution is contained in the next section.
3 A historical overview of stochastic modelling
Current stochastic modelling practices have been influenced by at least three Schools of thought, which will be referred to as (a) the Stochastic School, (b) the Time Series School and (c) the Monte Carlo School. We attempt to trace out the evolution in each of them in the next subsections, while an individual subsection is devoted to hydrology.
3.1 The Stochastic School
Perhaps Ludwig Boltzmann (1844–1906, Universities of Graz and Vienna, Austria, and Munich, Germany) was the first to introduce fundamental concepts related to stochastic process. In particular, Boltzmann (Citation1877) explained the concept of entropy in probability theoretic context and Boltzmann (Citation1884/85) introduced the notion of ergodic systems,Footnote1 which is central in stochastics. Later George D. Birkhoff (1884–1944; Princeton, Harvard, USA) discovered the ergodic theorem (Birkhoff Citation1931) also known as the Birkhoff–Khinchin theorem to give credit to Aleksandr Khinchin (also spelt Khintchine, 1894–1959; Moscow State University, Russia), who gave a purely measure-theoretic proof of the theorem (Khintchine Citation1933). In addition, Khintchine (Citation1934) defined the stationary stochastic processes and introduced a probabilistic setting of the Wiener-Khinchin theorem relating autocovariance and power spectrum.
But it was Andrey N. Kolmogorov (1903–1987; Moscow State University, Russia), the great scientist who founded the stochastic theory. Kolmogorov (Citation1931) introduced the term stochastic process,Footnote2 identifying process with change. He also used the term stationary to describe a probability density function that is unchanged in time. Kolmogorov (Citation1933) defined probability (founded on measure theory) in an axiomatic manner based on three fundamental concepts (a triplet called probability space) and four axioms (non-negativity: normalization, additivity and continuity at zero). Kolmogorov (Citation1937, Citation1938) gave a concise presentation of the concept of a stationary stochastic process and Kolmogorov (Citation1947) defined wide-sense stationarity.
The concept of stationarity (and its negation, nonstationarity) has a central role in stochastics yet is widely misunderstood and broadly misused (Montanari and Koutsoyiannis Citation2014, Koutsoyiannis and Montanari Citation2015). Stationarity is tightly connected to ergodicity, which in turn is a prerequisite to make inference from data, that is, induction. If a system that is modelled in a stochastic framework has deterministic dynamics then it is stationary if it is ergodic and vice versa (Mackey Citation2003, p. 52). Likewise, a nonstationary system is also non-ergodic and vice versa. If the system dynamics is stochastic, then ergodicity and stationarity do not necessarily coincide. However, recalling that a stochastic process is a model (not part of the real world), we can always devise a stationary stochastic process that is ergodic.
It may be useful to include here a reminder of the definitions of the two concepts. Following Kolmogorov (Citation1931, Citation1938) and Khintchine (Citation1934), a process is stationary if its statistical properties are invariant to a shift of time origin, i.e. the processes and
have the same (multivariate) distribution for any t and t΄. Based on the ergodic theorem (Birkhoff Citation1931, Khintchine Citation1933; see also Mackey Citation2003, p. 54), a stochastic process
is ergodic if the time average of any (integrable) function g(x(t)), as time tends to infinity, equals the true (ensemble) expectation, i.e.:
3.2 The Time Series School
Contrary to the theoretical Stochastic School, the Time Series School is more intuitive and empirical, and less rigorous. Its history was written more by economists and less by theoretical mathematicians. Perhaps the first who introduced time-series analysis was the American economist W.M. Persons. In studying the problem “When to buy or sell”, Persons (Citation1919) introduced the study of time series, which he called statistical series, and asserted that they “result from the combination of four elements: secular trend, seasonal variation, cyclical fluctuation, and a residual factor.” He also proposed methods for “Eliminating secular trends” and “Eliminating seasonal variation”. A definition of a time series was given 10 years later by the American statistician Bailey (Citation1929): “A time series is a series of observations taken at different times and recorded with the time at which they were taken.”
Interestingly, Slutsky (Citation1927) demonstrated that what Persons (and other economists) regarded as a cyclical component is nothing but a statistical artefact with no essential meaning (see e.g. Kyun and Kim Citation2006, Barnett Citation2006). Subsequently, the notion of a cyclical component was abandoned but the decomposition of a time series to the remaining three components, trends, seasonal variation and residuals is popular even today.
Yule (Citation1927) and Walker (Citation1931) (both British statisticians), starting from an analysis of sunspot numbers, studied autoregressive processes and in particular their periodogram and autocorrelation properties. But the biggest progress in the Time Series School was made in Uppsala by H.O.A. Wold (a Norwegian-born econometrician and statistician with a career in Sweden) and P. Whittle (a New-Zealand-born mathematician and statistician), who, in their doctoral theses, provided the stochastic foundation of time-series analysis. Wold (Citation1938, Citation1948) proved that a stochastic process (even though he referred to it as a time series) can be decomposed into a regular process (i.e. a process linearly equivalent to a white noise process) and a predictable process (i.e. a process that can be expressed in terms of its past values). Whittle (Citation1951, Citation1952, Citation1953) laid the mathematical foundation of autoregressive and moving-average models in univariate and multivariate setting. Later, in their influential book, Box and Jenkins (Citation1970) named these models with acronyms such as AR(p) (autoregressive models of order p), MA(q) (moving average models of order q), ARMA(p,q) (autoregressive moving-average models) and ARIMA(p,d,q) (autoregressive integrated moving-average models). These became popular under these names and have also been known as Box–Jenkins models (cf. Stigler’s law of eponymy; Stigler Citation2002). A useful extension of these models to apply to processes with long-range dependence was proposed by Hosking (Citation1981). This is done by replacing the integer parameter d in ARIMA(p,d,q) with a real one (fractional differencing) and the models are usually termed ARFIMA(p,d,q).
Despite the wider influence of the Time Series School over the Stochastic School, there are several problems with the former. First, the term time series is ambiguous, sometimes denoting a series of observations, as in the original definition of Bailey (Citation1929) (or, equivalently, a realization of a stochastic process), and at other times denoting the stochastic process per se, as in the aforementioned use by Wold. We emphasize that here the term time series is used with the first meaning, a series of numbers, while for a series of random variables we use the term stochastic process. Second, with the exception of the simplest models of these families, such as the AR(1) and ARMA(1,1), time-series models are too artificial because, being complicated discrete-time models, they do not necessarily correspond to a continuous-time process, while natural processes typically evolve in continuous time. Furthermore, their identification, typically based on the estimation of the autocorrelation function from data, usually neglects estimation bias and uncertainty, which in stochastic processes (as opposed to purely random processes) are often tremendous (Lombardo et al. Citation2014).
Indeed, from their onset, time-series models have been tightly associated with a large number of parameters and they usually become over-parameterized and thus not parsimonious. These parameters are estimated from data, which usually are too few to support a reliable estimation. In Whittle’s (Citation1952) words (emphasis added):
There is, of course, nothing special with the autoregressive scheme; we could equally well graduate with a high-order moving average, and there are many other possibilities. […] In practice, however, the autoregressive graduation has the advantage that the estimated residual sum of squares can be written down directly in terms of the observations […] without the need to solve explicitly for the estimates of the ‘a’ coefficients.
…
It is, of course, not possible to estimate an infinite number of parameters from a finite sample, but the series of a coefficients must converge, and by considering sufficiently many coefficients we should be able to obtain an arbitrarily good approximation to the real process.
This is similar to fitting a distribution function using observations to estimate many moments as described in Sec. 2.
The decomposition of a time series to components, trends, seasonal variation and residuals is fundamentally problematic, despite being popular. (In particular trend analysis of hydroclimatic processes is more fashionable today than ever before.) However, it should be noted that a meaningful definition of a trend has never been given. Also, for some, including this author, it is hardly conceivable how time per se could be regarded as an explanatory variable in a complex process and what the logical basis is in expressing the statistics of a process as a deterministic function of time. Accumulation of data series with long time spans is revealing that what have been regarded as trends are mostly parts of long-term fluctuations (and in accordance with Slutsky’s work, they could also be regarded as statistical artefacts). Hurst’s (Citation1951) and Kolmogorov’s (Citation1940) works provide a scientific basis to model what has been regarded as trends in the context of stationary stochastic processes. Finally, “deseasonalization” (in Persons’s original terminology “Eliminating seasonal variation”) is a delusion; we can hardly remove seasonality in the multivariate distribution of a stochastic process (what we typically do is in the marginal distribution).
3.3 The Monte Carlo School
The Monte Carlo method is essentially a numerical technique for solving deterministic integrodifferential equations using random sampling. Ideas that could be classified as implementation of the Monte Carlo method are old. Georges Louis LeClerc (Comte de Buffon, French scientist; 1707–1788) became famous for “Buffon’s needle,” a method using needle tosses onto a lined background to estimate π (where, if the line distance is equal to needle length, π is found as twice the inverse of probability that the needle crosses a line).Footnote3 Random sampling is also old. Galton (Citation1890) invented a set of three modified dice to generate samples from a normal distribution. “Student” (the pseudonym of W.S. Gosset), in 1908, performed simulation experiments using 3000 cards (in 750 groups of size 4) to find the distribution of the t-statistic and of the correlation coefficient. Tippett (Citation1927) published a table of random numbers: he took 41 600 digits at random from Census Reports and combined them by fours to give 10 400 numbers. Mahalanobis (Citation1934) published tables of random numbers from normal distribution (208 sets of 50 numbers each). (See more information in Stigler Citation2002.)
The modern Monte Carlo method was conceived by Stanislaw Ulam in 1946.Footnote4 Soon after the method grew to solve neutron diffusion problems by himself and other great mathematicians and physicists in Los Alamos (John von Neumann, Nicholas Metropolis, Enrico Fermi), and was first implemented on the ENIAC computer (Metropolis Citation1989, Eckhardt Citation1989). The “official” history of the method began in 1949 with the publication of a paper by Metropolis and Ulam (Citation1949). One prominent characteristic of the Monte Carlo method as a numerical integration method is that it does not suffer from the well-known curse of dimensionality, unlike the classical (grid-based) numerical integration method, which does suffer. Thus, it is easily shown (e.g. Metropolis and Ulam Citation1949, Niederreiter Citation1992) that for a number of dimensions d > 4, the Monte Carlo integration method (in which the function evaluation points are taken at random) is more accurate (for the same total number of evaluation points) than classical numerical integration, based on a grid representation of the integral space. For large dimensionality, e.g. for d > 20, the classical method is infeasible while the Monte Carlo method is always feasible.
3.4 The onset of stochastic modelling in hydrology
Techniques that could be classified as applications of the Monte Carlo method had appeared in the hydrological literature much earlier than the “official start” of the method in 1949. Hazen (Citation1914), made a pioneering study in which he introduced the reservoir storage-yield-reliability relationship, a concept that would remain unexploited in the western hydrological literature yet constituting the scientific basis of modern reservoir design (Klemes Citation1987). In that study, he proposed an empirical simulation technique and formed a synthetic time series by combining historical flow records of different rivers “spliced” sequentially together. Sudler (Citation1927) extended the work of Hazen by resampling from a sequence of historical river flows using cards, which he shuffled to form new sequences of data. Obviously, this method heavily distorts the time dependence of river flows whose importance was not known at that time. For it was Hurst (Citation1951) who understood that importance, along with the omnipresence in natural processes of a clustering behaviour of similar events in time, a behaviour that is now called long-term persistence (LTP) or long-range dependence (LRD). It is also known as the Hurst-Kolmogorov behaviour, to give also credit to Kolmogorov (Citation1940), who had proposed a mathematical model representing that behaviour before it was verified in natural processes by Hurst. In his attempt to compare natural and random events, Hurst performed physical experiments to generate random numbers. Specifically, he tossed 10 coins (sixpences) simultaneously and repeated this 1025 times (note that 10 binary digits are equivalent to about 3 decimal digits). As he notes, his rate was 100 random numbers per 35 min (while that would be of the order of a microsecond in modern computer environments, even slow ones). He also used another method, shuffling and cutting a pack of 52 cards, in which he improved the rate to 100 random numbers per 20 min.
It would take decades before the hydrological community assimilate Hurst’s discovery of LTP (O’Connell et al. Citation2016), even though some of the pioneering studies appeared towards the end of the 1960s (Mandelbrot and Wallis Citation1969). The initial studies implementing primitive variants of stochastic simulation did not reproduce LTP. Barnes (Citation1954), in designing a reservoir in Australia, used a table of random numbers from normal distribution to generate a 1000-year sequence of synthetic annual data. Thomas and Fiering (Citation1962) generated flows correlated in time, but using only the lag one autocorrelation, obviously neglecting LTP. Beard (Citation1965) and Matalas (Citation1967) generated concurrent flows at several sites. Chow (Citation1969), and Chow and Kareliotis (Citation1970) systematized the use of time-series models (in particular – and using their terminology – moving-average models, sum of harmonics models and autoregression models) and highlighted their value in the economic planning of water supply and irrigation projects. It is evident from the above pioneering studies, as well as of subsequent myriads of studies, that hydrologists have followed (and today still do) the Time Series School rather than the more rigorous Stochastic School.
4 Premises
Before we proceed to the formulation of the simulation scheme, it is necessary to list the main premises on which the scheme is based. These are consistent with the generic procedure in Koutsoyiannis (Citation2016) and are summarized in the following points:
A stochastic model is always required for any stochastic task, such as estimation, testing and synthesis. In stochastics, there cannot be model-free, also known as nonparametric, methods. Nonparametric methods are a delusion caused by an adherence to the classical statistical assumption of independence which, when dealing with natural processes is the ultimate – and most inappropriate – parameterization per se. As an example, Kendall’s rank correlation test (Kendall Citation1938), or its variant for trend detection (Mann Citation1945), is an important and widely used statistical test that is regarded as nonparametric. And indeed it is nonparametric if it is applied on samples that are independent by construction, i.e. obtained by individual and independent experiments. But if the data are time series (consecutive observations in time of a single process) then application of the test needs parameterization of the dependence structure. As usually applied, the test includes in its null hypothesis the sub-hypothesis that autocorrelations for all lags are zero. Thus, the rejection of the null hypothesis could be regarded as rejection of independence, even though the popular interpretation favours the existence of a trend. There exist of course consistent parametric variants of the test, which take the stochastic structure into account (e.g. Hamed Citation2008).
As natural time runs continuously, the model needs to be formulated for continuous time to avoid the risk of making artificial constructs. The discrete-time representation, which is certainly necessary in simulation, should be derived from the continuous time one. Second-order stochastic tools, such as autocovariance and power spectrum, are affected by discretization and the effect should always be accounted for. The climacogram,Footnote5 i.e. the variance
The model needs to be parsimonious in order to be useful (Gauch Citation2003). Inflationary models, while giving an impression of a good fit, in fact entail (often hidden) high uncertainty. An example of a (parametric) parsimonious model is the Filtered Hurst-Kolmogorov process with a generalized Cauchy-type climacogram (FHK-C; Koutsoyiannis Citation2016, Citation2017). This is defined through its climacogram:
where α and λ are scale parameters with dimensions of
Parameter estimation needs to consider statistical bias, which is present in all estimators (Koutsoyiannis Citation2016), including very simple and common ones, such as variance and correlation (a known exception is the mean whose standard estimator is not affected by bias in the presence of dependence; higher order noncentral moments are also unbiased in theory, but suffer from unknowability; Koutsoyiannis Citation2019a).
Awareness of stochastics (the mathematics of stochastic variables and processes), theoretical consistency and logical rigour are always necessary to avoid misleading or erroneous calculations, results and interpretations.
5 Simulation method
Let be a stationary stochastic process representing the instantaneous quantity of a certain hydrological or other physical process in continuous time t. For simplicity and without loss of generality we assume that it has zero mean and (instantaneous) variance:
which is arguably (Koutsoyiannis Citation2017) assumed to be finite. The discrete-time representation of the process (Eq. (5)) can also be written as:
where
is the cumulative process, which, if aims to represent a natural processes, should necessarily be nonstationary. Its variance at time t, known as cumulative climacogram, is:
where γ() is the variance of the averaged process. This latter, as a function of time scale k, is called climacogram:
The autocovariance function c(h) of the continuous-time process for time lag h is (Koutsoyiannis Citation2016):
and the power spectrum s(w) for frequency w is the Fourier transform of the autocovariance function, i.e.:
The discrete-time autocovariance for integer time lag η is (Koutsoyiannis Citation2016):
and is related to the discrete-time power spectrum by
where is dimensionless frequency. The power spectrum has some analogies with another stochastic tool, the so-called climacospectrum, which is directly given in terms of the climacogram. Specifically, it is proportional to the difference of the variances of the averaged process at time scales k and 2k:
This tool is useful in the model fitting phase (see Sec. 7).
To simulate we use the generalized moving-average scheme (Koutsoyiannis Citation2000):
where are weights to be calculated from the autocovariance function,
is white noise averaged in discrete-time (and not necessarily Gaussian), also known as innovation process, and J is theoretically infinite, so that in all theoretical calculations we will assume
, while in the generation J is a large integer chosen so that the resulting truncation error be negligible. Here we stress that the above scheme is just the contrary to that suggested by Whittle (Citation1952) in the quotation given in Sec. 3.2. Specifically, (a) we use a purely moving-average scheme instead of the autoregressive scheme favoured by Whittle and (b) we do not relate our scheme with observations, as the observations have been already used in the model fitting phase, which is totally isolated from the generation scheme. Since we do not use the observations, the moving-average scheme has many advantages in calculations.
Writing Eq. (24) for , multiplying it with (24) and taking expected values we find the convolution expression for
:
We need to find the sequence of so that (25) holds true. A known solution (Koutsoyiannis Citation2000) is the symmetric moving average (SMA) scheme in which
. Nonetheless, the problem has infinitely many non-symmetric solutions, which are asymmetric moving average (AMA) schemes. A more common one is the ordinary backward asymmetric moving average (OBAMA) scheme in which
for any
; this latter is typically formulated in a different manner and denoted as simply moving average – MA, but as we study a richer family of schemes, the distinct name OBAMA is necessary.
Here, the following generic solution of the AMA scheme, giving the coefficients , is proposed:
where is any (arbitrary) odd real function (meaning
) and
We prove in Appendix A that the sequence of :
consists of real numbers, despite the expression in Eq. (26) involving complex numbers;
satisfies precisely Eq. (25); and
is easy and fast to calculate using the fast Fourier transform (FFT).
We can now convert this theoretical result into a numerical algorithm. This consists of the following steps:
(i) From the continuous-time stochastic model, expressed through its climacogram , we calculate its autocovariance function in discrete time (assuming time step D):
(ii) We choose an appropriate number of coefficients J that is a power of 2 and perform inverse FFT (using common software) to calculate the discrete-time power spectrum and the frequency function for an array of
:
(iii) We choose (see below) and we form the arrays (vectors)
and
, both of size 2J indexed as
, with the superscripts R and I standing for the real and imaginary part of a vector of complex numbers, respectively:
(iv) We perform FFT on vector (using common software), and get the real part of the result for
, which is precisely the sequence of
.
We note that by choosing J as a power of 2, the vectors and
will have size 2J which is also a power of 2, thus achieving maximum speed in the FFT calculations. More details are contained in a supplementary file which includes numerical examples along with the simple code needed to do these calculations on a spreadsheet.
It may be useful to note the following additional points about the method:
Equation (26) gives not a single solution, but a variety of infinitely many ones, all of which preserve exactly the second-order characteristics of the process.
A particular solution is characterized by the chosen function
Even assuming
The availability of infinitely many solutions enables the preservation of additional statistics, e.g. those related to time asymmetry.
In addition, we always have several options related to the distribution of the white noise
The special case corresponds to the symmetric scheme (SMA), in which:
where we have used the superscript S to denote the symmetric case. Another interesting special case is
(or
): This corresponds to an antisymmetric AMA scheme (ANTAMA) with
where the superscript A denotes the antisymmetric case, is the Dirac delta function, and
with approaching zero as J becomes large. Any other case of constant
(where
) can be expressed in terms of the above two limiting cases through:
(the proof is omitted). In particular, the case (or
) yields the interesting result:
If for some and for
it happens that
, then it can be verified that:
Such a sequence with almost zero coefficients for negative η will be close to the OBAMA scheme. It is interesting to notice that in this approximate solution only depends on the constant
, while for
the coefficients are approximately equal to those in the SMA, multiplied by
.
However, if full accuracy is needed, we must have in mind that a constant θ0 does not give a precise OBAMA. A generic analytical solution that would give a function for OBAMA is not simple (this problem is known as factoring of the power spectrum; see Papoulis Citation1991, p. 402). However, solutions for simple special cases are not too difficult to find (e.g. for rational spectra; Papoulis Citation1991, p. 402–404). In particular, for a Markov process in continuous time (which in discrete-time behaves as an ARMA(1,1) process; see Eq. (39)), as well as for any ARMA(1,1) process (including its special cases AR(1) and MA(1)), the following solution is exact (the proof is omitted):
For stochastic structures with LRD, the OBAMA scheme is difficult to achieve with full precision, but an approximation can be easily found as described in Appendix B.
Figure 2. Illustration of the symmetric (SMA), antisymmetric (ANTAMA) and ordinary-backword (OBAMA) cases of the generic AMA model for (upper) a Markov and (lower) an FHK-C process. The parameter values are α = 10, λ = 1 (in both processes), H = 0.8, M = 0.7, and the number of weights is 2049 (J = 1024 = 210). The panels on the left show the coefficients a and those on the right the autocovariance function.
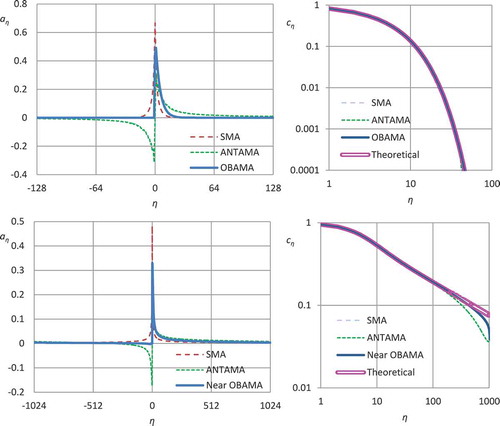
The method is illustrated in using two example processes. The first is the Markov process, whose basic properties are:
The second is the FHK model defined in Eq. (13), which gives its climacogram, whilst all its other properties are evaluated through Eqs. (21)-(22). shows three special cases, SMA (Eq. (32)), ANTAMA (Eq. (33)) and OBAMA for the two processes. For the OBAMA case and the Markov process the exact Eq. (38) is used while for the FHK-C process the coefficients are determined from the approximate equation (B2) in Appendix B (with optimized coefficients of the equation). Some slight (rather invisible) deviations from zero are present in the left-bottom panel, which at a later step will be set to zero and the small resulting effect will be further handled as a truncation error (in the manner described by Koutsoyiannis Citation2016) to obtain an exact OBAMA scheme.
All in all, this simple method of the AMA scheme renders ARMA models unnecessary, particularly because of the generic, analytical and fast solution it offers. Here it is important to stress that, while optimization of coefficients involved in the function could sometimes be necessary as discussed above and specified in Appendix B, it is not necessary in general. Any odd real function
, chosen arbitrarily, will give
that will satisfy Eq. (25) (apart from a truncation error) and thus can directly be used in generation. Even if the sequence of
is constructed at random (e.g. as a sequence of random numbers in the interval [0,1/4]), again Eq. (25) will be satisfied and the resulting
can directly be used in generation. (This case is also implemented on the spreadsheet provided as supplementary information).
6 Additional methodological issues
6.1 The AMA scheme in forecast mode
It is generally believed that AR models are better suited to forecast as they depend on past variables rather than on multiple innovation variables. According to this logic, among the MA models, only backward schemes would be suitable for forecast, while the generic AMA scheme (including the special case of SMA) would not, because it involves convolutions for both positive and negative lags η. Such beliefs are not quite correct though. Arguably, the forecast problem could be regarded as totally independent of the stochastic model per se, while forecasts can be obtained from any stochastic model, not only from a backward one. Had this not been the case, we would be in a deadlock in providing forecasts even with AR models. To see this, we may consider the case of an AR(p) scheme used to approximate a process with LRD. Because of LRD, the value of p will be large, typically larger than the number (n) of known past observations (. Therefore, the mathematical expression of the AR(p) as a weighted sum of past values could not be applied for forecast because some of the required past values would not be known.
Koutsoyiannis (Citation2000) formulated a simple and general solution of the forecast problem, which can be applied for any type of linear model and hence for AMA. This calculates the prediction for any future time τ combining, on the one hand, any simulation
independent of the observations, and, on the other hand, the observations
, through the equations:
where is a vector containing the observations at the present (
) and past times (
), and
is a vector containing the independently simulated items of the stochastic process at the present and past, whilst
and
are a vector and a matrix of covariances, respectively, with items determined from the chosen stochastic model (again, not estimated from the data).
6.2 Time asymmetry
Time irreversibility can very easily be handled within the AMA framework. Assuming that the white noise (in discrete-time τ) has variance 1 and coefficient of skewness
, we will have:
where and
are the third moment and the coefficient of skewness of process
, respectively.
Time asymmetry is quantified through the skewness of the differenced process , according to Eq. (4), which by virtue of (24) is written as:
with . Thus, its skewness will be:
The ratio:
is independent of and primarily depends on
, which determines the sequence of
. The case
, i.e. the SMA, results in complete time symmetry. However, a constant
(appropriately chosen) can make the ratio
as high as we wish, thus enabling the preservation of time asymmetry.
The above results make it clear that without skewness in the original process (e.g. in the case of Gaussian processes), there cannot be time asymmetry, a result that is consistent with Weiss’s (Citation1975).
7 Application
Here we repeat the application in Koutsoyiannis (Citation2019b) for the streamflow time series but using the new analytical framework. The data are from the database of the US Geological SurveyFootnote6 for the site USGS 01603000 North Branch Potomac River Near Cumberland, Maryland (39°37ʹ18.5”N, 78°46ʹ24.3”W, catchment area: 2271 km2). They cover the period 2013-10-01 to 2018-08-31 for a time step of 15 min, which was aggregated to hourly, while discharge was converted from cubic feet per second to m3/s. Missing values (4% for a total of 172 416 values) were left unfilled. Seasonality is not negligible and was treated by standardizing the values of each month by an appropriate coefficient (see Koutsoyiannis Citation2019b). We note here that this standardization is just a rough modelling approximation, adequate for our aim to investigate time irreversibility, while an approach for operational use would require the construction of a cyclostationary model.
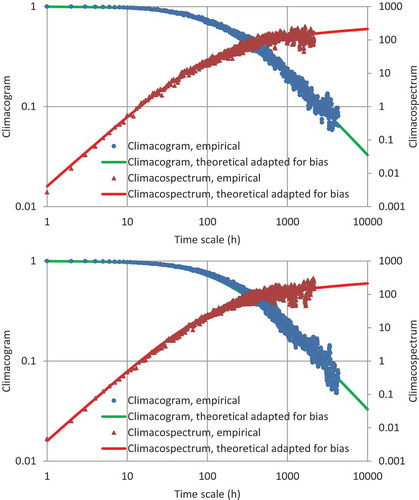
The process is modelled as an FHK-C process; the fitting is impressively good and the parameters are M = 0.56 (indicating a slightly smooth process), H = 0.6 (a persistent process), α = 160 h and λ = γ(0) = 1.01 (for the standardized process). The fitting is shown in in terms of the climacogram, which is good for visualizing the behaviour at large time scales, and the climacospectrum, which provides a better visualization for small time scales.
Figure 3. Comparison with the FHK-C model of the climacogram and climacospectrum of the original series, after standardization for dealing with seasonality (top); and of the generated series (bottom).
Additional parameters, quantifying the state and time asymmetry, are the skewness coefficients of the original and differenced process. The analysis in Koutsoyiannis (Citation2019b) suggested prominent time irreversibility at time scales from 1 h to about 4 d. This is quantified by a skewness coefficient of the differenced process, which is much higher than the skewness of the original process (10.99 for
and 2.98 for
at the hourly scale, a ratio
).
For the application, we use the proposed method with constant and with J = 1024. We note that the SMA case results in zero skewness of the differenced process (time symmetry) while in the ANTAMA case the skewness tends to infinity, which indicates that the method does not have any upper limit of time irreversibility that it can handle. Choosing
, we make the ratio of the skewness of
and
equal to 3.69, as required. The coefficients
determined by direct application of the method are shown in , along with the climacogram and the autocorrelation function of the original process.
Figure 4. Climacogram, autocorrelation and coefficients aη determined by the proposed method.
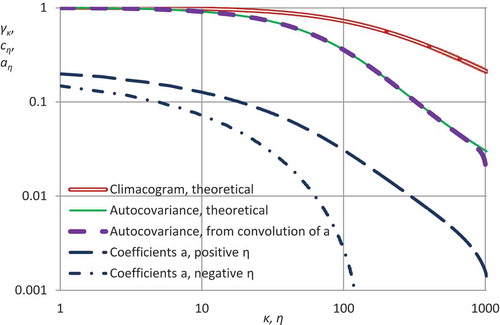
Figure 5. Generated discharge time series (top) (time references are arbitrary) and close-up for a six-month period containing the highest generated discharges (bottom). Plots refer to the “naturalized” (back-transformed) series.
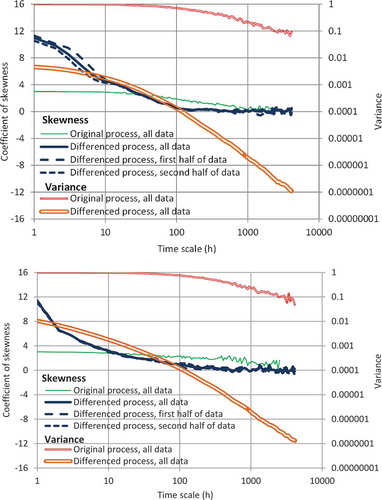
Figure 6. Climacograms and skewness coefficients of the original and differenced time series for: the real-world data (top) and the generated data (bottom). Plots refer to the standardized series.
For the generation of we use lognormal white noise with skewness determined so that the skewness of the original process be 2.98 as required. A time series with length equal to that of the real-world data was derived for the process
using Eq. (24) and was then “naturalized” by applying the inverse seasonal transformation. Plots for the generated time series are shown in , where in the close-up (lower panel) the irreversibility is evident, with steeper rising branches and milder falling ones. Comparisons of the generated time series with the model, as well as with the real-world data, in terms of climacogram and climacospectrum, are shown in . Comparisons of the characteristics related to state and time asymmetry are shown in . It is observed that the generated time series is consistent with the model and the original data in terms of all important statistics, marginal and joint, as well as related to time irreversibility. One slight discrepancy is that the curve related to time asymmetry in , while it captures the skewness of the real-world differenced data for the hourly scale, has a steeper slope for intermediate time scales; however, controlling this slope was not in the scope of this study. All in all, the method seems successful in simulation of streamflow time series even at fine time scales.
8 Conclusions
The main contribution of this article is the introduction of an equation that determines analytically the weights of an asymmetric moving average (AMA) scheme, which can be used in any problem of stochastic simulation of time-irreversible processes. This equation is rewritten here as:
where is the power spectrum of the discrete-time representation of the process of interest and
is any arbitrary odd real function. The same equation can also be used for time-reversible processes, even though in this case it suffices to use the simpler symmetric (SMA) scheme, which can be obtained as a special case of the AMA for
. In this case, the equation simplifies to:
A simple expression can also be obtained for any case where is a constant θ0 multiplied by the sign of ω. Assuming that an adequately large number of weights is used (so that the quantity
be negligible) this expression becomes:
where
is the antisymmetric solution (ANTAMA) of the equation.
The numerical evaluation of these weights is very easy and fast, as it only needs application of FFT, while the generation of the processes of interest is even easier; both are illustrated in a spreadsheet provided as supplementary information. The applicability of the method has no restrictions and no iterations are needed. Once the process dependence is known through any second-order tool (climacogram, autocovariance, power spectrum, etc.) and the properties related to time reversibility or irreversibility are specified, the method can be readily applied for stochastic generation.
The extended historical review presented in this article reveals that the proposed method is against the current of simulation approaches that were developed since the 1950s. Specifically, the approach proposed (a) uses a purely moving-average scheme, without any autoregressive term, (b) involves innovation terms and weights that extend to both directions of time, and (c) does not link the generation scheme with the observations – rather, the observations are used in the model fitting phase, which is independent of the simulation. Because of the moving-average scheme we are able to easily handle and preserve moments higher than second. Because of the involvement of terms in both directions of time in an asymmetric mode, we can easily reproduce time irreversibility in a controlled manner. And because of the separation of model fitting from the calculation of the weights of the linear model, we are able to handle any type of dependence in time for whatever range (short or long) and fractality (smooth or rough). For the same reason, we are able to make the model as parsimonious as we wish (and as the data allow) without being trapped to involve many parameters in order to preserve, for example, autocovariances of large lags.
The entire framework is so simple and powerful that one can hardly believe that it is presented for the first time. Perhaps it is a reinvention of something already known. Whether it has been invented or not in the past, the fact is that it is not well known (and certainly not known to the author); otherwise, the ARMA models and their variants would not be so popular. Hopefully, this article could contribute to give ARMA-type models a position in the history of stochastics.
Supplemental Material
Download (3.8 MB)Acknowledgements
I thank the eponymous reviewers William Farmer and Alberto Montanari for their extraordinarily constructive comments which encouraged me to broaden, completely restructure and, eventually, substantially improve the initial manuscript. During the preparation of the second version of the manuscript, I had the pleasure to present its content in a seminar in the Sapienza University of Rome as well as in the First Workshop on Control Methods for Water Resource Systems in Delft. I wish to express my gratitude to Francesco Napolitano for inviting and organizing my visit in Rome during September 2019, and Alla Kolechkina and Ronald van Nooyen for the invitation in the Workshop in Delft.
Disclosure statement
No potential conflict of interest was reported by the author.
Supplementary material
Supplemental data for this article can be accessed here.
Additional information
Funding
Notes
1 Boltzmann coined the terms ergode and isodic, both of which are etymologized from Greek words but which ones exactly is uncertain. Most probably, ergodic comes from the Greek ἔργον (ergon = work) and ὁδός (hodos = pathway). According to another interpretation, the second noun is είδος (eidos = form, kind, nature), or the whole word is a transliteration of the Greek adjective ἐργώδης (ergodes = laborious, troublesome; see Mathieu Citation1988).
2 The Greek adjective “stochastic[os/e]” was used by Greek philosophers, including Plato and Aristotle, and was transplanted to the international scientific vocabulary by Jacob Bernoulli (evidently aware of the Greek literature and in particular of Plato’s texts) in his famous book Ars Conjectandi (written in Latin in 1684–89 but published after his death, in 1713). The term was revived by Bortkiewicz (Citation1917; Russian economist and statistician of Polish ancestry) and also by Slutsky (Citation1925, Citation1928a, Citation1928b, Citation1929; Ukrainian/Russian/Soviet mathematical statistician and economist). It appears that the prevalence in USSR of the more sophisticated term “stochastic” (over the rather equivalent term “random”) must have been related to political and ideological reasons (incongruence of randomness with the dialectic materialism: models beyond strict deterministic were considered with a priori suspicion; see Mazliak Citation2018).
3 LeClerc’s Monte Carlo method to calculate π became popular among scientists and his experiment was later repeated by many. There are many other Monte Carlo algorithms to estimate π. However, these are good only for fun, as much faster and much more accurate deterministic algorithms exist to calculate π. Reitwiesner (Citation1950) calculated by a deterministic algorithm, running on the ENIAC computer, the first 2035 decimal digits of π. Metropolis et al. (Citation1950) examined their randomness, an exercise made thereafter many times showing that the digits of π have no apparent pattern and pass tests for statistical randomness. Dodge (Citation1996) promoted an idea opposite to LeClerc’s: that the digits of π form a “Natural Random Number Generator”. Since January 2019, 31.4 trillion digits of π are known (found by the Chudnovsky algorithm); this information, equivalent to ~100 million books of 1000 pages each (note for comparison that the British Library has 25 million books), can serve as a basis for any simulation experiment. However, simple random generators are more economic and convenient.
4 Notably, Ulam conceived the method while playing solitaires during convalescing from an illness, in his attempt to estimate the probabilities of success of the plays. As Ulam describes the story in some remarks later published by Eckhardt (Citation1989), “After spending a lot of time to estimate them by pure combinatorial calculations, I wondered whether a more practical method than ‘abstract thinking’ might not be to lay it out say one hundred times and simply observe and count the number of successful plays.”
5 The term climacogram, from the Greek κλιμακόγραμμα, deriving from κλίμαξ (climax = scale, as well as ladder; pl. κλίμακες) and γράμμα (gramma = written, drawn), was coined by Koutsoyiannis (Citation2010) and could be translated in English as scale(o)gram, but the latter term is used for another concept. Climacogram should not be confused to climatogram which has another meaning related to the climatic regime of temperature and precipitation at a site or area. The latter term, deriving from the noun κλίμα (clima, originally meaning slope; pl. κλίματα), was first used in the Hellenistic period by the astronomer Hipparchus to describe climate (in relationship to the slope of the sun’s rays) and is different from the other derivative noun κλίμαξ. Interestingly though, both κλίμαξ and κλίμα are eventually etymologized from the same verb κλίνειν (klinein = to slope).
6 https://nwis.waterdata.usgs.gov/md/nwis/uv/?site_no = 01603000&agency_cd = USGS, retrieved: 2018-09-16.
Related Research Data
References
- Bailey, A.L., 1929. A summary of advanced statistical methods. US Statistical Bureau. https://babel.hathitrust.org/cgi/pt?id=mdp.39015067991326&view=1up&seq=7.
- Barnes, F.B., 1954. Storage required for a city water supply. The Institution of Engineers, Australia, 26, 198–203.
- Barnett, V., 2006. Chancing an interpretation: Slutsky’s random cycles revisited. The European Journal of the History of Economic Thought, 13 (3), 411–432. doi:10.1080/09672560600875596
- Beard, L.R., 1965. Use of interrelated records to simulate streamflow. Proceedings ASCE, Journal of the Hydraulics Division, 91 (HY5), 13–22.
- Birkhoff, G.D., 1931. Proof of the ergodic theorem. Proceedings of the National Academy of Sciences, 17, 656–660. doi:10.1073/pnas.17.2.656
- Boltzmann, L., 1877. Über die Beziehung zwischen dem zweiten Hauptsatze der mechanischen Wärmetheorie und der Wahrscheinlichkeitsrechnung respektive den Sätzen über das Wärmegleichgewicht. Wiener Ber, 76. 373–435. (in German).
- Boltzmann, L., 1884/85. Über die Eigenschaften monocyklischer und anderer damit verwandter Systeme. Crelles Journal, 98, 68–94.
- Bortkiewicz, L., 1917. Die iterationen — Ein beitrag zur wahrscheinlichkeitstheorie. Berlin: Springer.
- Box, G.E. and Jenkins, G.M., 1970. Time series models for forecasting and control. San Francisco, USA: Holden Day.
- Bracewell, R.N., 2000. The fourier transform and its applications. 3rd Ed. Boston, MA: McGraw-Hill.
- Chow, V.T., 1969. Stochastic analysis of hydrologic systems. Final Report. Urbana, IL: University of Illinois. https://www.ideals.illinois.edu/bitstream/handle/2142/90345/Chow_1969.pdf?sequence=2.
- Chow, V.T. and Kareliotis, S.J., 1970. Analysis of stochastic hydrologic systems. Water Resources Research, 6 (6), 1569–1582. doi:10.1029/WR006i006p01569
- Dimitriadis, P. and Koutsoyiannis, D., 2015. Climacogram versus autocovariance and power spectrum in stochastic modelling for Markovian and Hurst–Kolmogorov processes. Stochastic Environmental Research & Risk Assessment, 29 (6), 1649–1669. doi:10.1007/s00477-015-1023-7
- Dimitriadis, P. and Koutsoyiannis, D., 2018. Stochastic synthesis approximating any process dependence and distribution. Stochastic Environmental Research & Risk Assessment, 32 (6), 1493–1515. doi:10.1007/s00477-018-1540-2
- Dodge, Y., 1996. A natural random number generator. International Statistical Review, 64 (3), 329–344. doi:10.2307/1403789
- Eckhardt, R., 1989. Stan Ulam, John von Neumann and the Monte Carlo method. In: N.G. Cooper, ed. From cardinals to chaos. NY: Cambridge University, 131–136.
- Galton, F., 1890. Dice for statistical experiments. Nature, 42, 13–14. doi:10.1038/042013a0
- Gauch, H.G., Jr., 2003. Scientific method in practice. Cambridge, UK: Cambridge University Press.
- Hamed, K.H., 2008. Trend detection in hydrologic data: the Mann–Kendall trend test under the scaling hypothesis. Journal of Hydrology, 349 (3–4), 350–363. doi:10.1016/j.jhydrol.2007.11.009
- Hazen, A., 1914. Storage to be provided in impounding reservoirs for municipal water supply. Transactions of the American Society of Civil Engineers, 77, 1539–1640.
- Hosking, J.R.M., 1981. Fractional differencing. Biometrika, 68 (1), 165–176. doi:10.1093/biomet/68.1.165
- Hurst, H.E., 1951. Long term storage capacities of reservoirs. Transactions of the American Society of Civil Engineers, 116, 776–808.
- Kendall, M.G., 1938. A new measure of rank correlation. Biometrika, 30 (1/2), 81–93. doi:10.1093/biomet/30.1-2.81
- Khintchine, A., 1933. Zu Birkhoffs Lösung des Ergodenproblems. Mathematische Annalen, 107, 485–488. doi:10.1007/BF01448905
- Khintchine, A., 1934. Korrelationstheorie der stationären stochastischen Prozesse. Mathematische Annalen, 109 (1), 604–615. doi:10.1007/BF01449156
- Klemes, V., 1987. One hundred years of applied storage reservoir theory. Water Resources Management, 1 (3), 159–175. doi:10.1007/BF00429941
- Kolmogorov, A.N., 1931. Uber die analytischen Methoden in der Wahrscheinlichkcitsrechnung. Mathematische Annalen, 104, 415–458. (English edition: Kolmogorov, A.N., 1992. On analytical methods in probability theory. Selected Works of A. N. Kolmogorov - Volume 2, Probability Theory and Mathematical Statistics, A. N. Shiryayev, ed., Kluwer, Dordrecht, The Netherlands, pp. 62-108). doi:10.1007/BF01457949
- Kolmogorov, A.N., 1933. Grundbegriffe der Wahrscheinlichkeitsrechnung (Ergebnisse der Mathematik und Ihrer Grenzgebiete). Berlin: Springer. (2nd English Edition: Foundations of the Theory of Probability, 84 pp. Chelsea Publishing Company, New York, 1956).
- Kolmogorov, A.N., 1937. Ein vereinfachter Beweis der Birkhoff-Khintchineschen Ergodensatzes. Matematicheskii Sbornik, 2, 367–368.
- Kolmogorov, A.N., 1938. A simplified proof of the Birkhoff-Khinchin ergodic theorem. Uspekhi Matematicheskikh Nauk, 5. 52–56. (English edition: Kolmogorov, A.N., 1991, Selected Works of A. N. Kolmogorov - Volume 1, Mathematics and Mechanics, Tikhomirov, V. M. ed., Kluwer, Dordrecht, The Netherlands, pp. 271-276).
- Kolmogorov, A.N., 1940. Wienersche Spiralen und einige andere interessante Kurven im Hilbertschen Raum. Doklady Akademii Nauk SSSR, 26. 115–118. (English edition: Kolmogorov, A.N., 1991. Wiener spirals and some other interesting curves in a Hilbert space. Selected Works of A. N. Kolmogorov - Volume 1, Mathematics and Mechanics, Tikhomirov, V. M. ed., Kluwer, Dordrecht, The Netherlands, pp. 303-307).
- Kolmogorov, A.N., 1947. Statistical theory of oscillations with continuous spectrum. In: Collected papers on the 30th anniversary of the Great October Socialist Revolution. Vol. 1. Moscow-Leningrad: Akad. Nauk SSSR, 242–252. (English edition: Kolmogorov, A.N., 1992. Selected Works of A. N. Kolmogorov - Volume 2, Probability Theory and Mathematical Statistics, A. N. Shiryayev ed., Kluwer, Dordrecht, The Netherlands, pp. 321-330).
- Koutsoyiannis, D., 2000. A generalized mathematical framework for stochastic simulation and forecast of hydrologic time series. Water Resources Research, 36 (6), 1519–1533. doi:10.1029/2000WR900044
- Koutsoyiannis, D., 2010. A random walk on water. Hydrology and Earth System Sciences, 14, 585–601. doi:10.5194/hess-14-585-2010
- Koutsoyiannis, D., 2016. Generic and parsimonious stochastic modelling for hydrology and beyond. Hydrological Sciences Journal, 61 (2), 225–244. doi:10.1080/02626667.2015.1016950
- Koutsoyiannis, D., 2017. Entropy production in stochastics. Entropy, 19 (11), 581. doi:10.3390/e19110581
- Koutsoyiannis, D., 2019a. Knowable moments for high-order stochastic characterization and modelling of hydrological processes. Hydrological Sciences Journal, 64 (1), 19–33. doi:10.1080/02626667.2018.1556794
- Koutsoyiannis, D., 2019b. Time’s arrow in stochastic characterization and simulation of atmospheric and hydrological processes. Hydrological Sciences Journal, 64 (9), 1013–1037. doi:10.1080/02626667.2019.1600700
- Koutsoyiannis, D. and Montanari, A., 2015. Negligent killing of scientific concepts: the stationarity case. Hydrological Sciences Journal, 60 (7–8), 1174–1183. doi:10.1080/02626667.2014.959959
- Kyun, K. and Kim, K., 2006. Equilibrium business cycle theory in historical perspective. International Statistical Review.
- Lawrance, A.J., 1991. Directionality and reversibility in time series. International Statistical Review, 59 (1), 67–79. doi:10.2307/1403575
- Lombardo, F., et al., 2014. Just two moments! A cautionary note against use of high-order moments in multifractal models in hydrology. Hydrology and Earth System Sciences, 18, 243–255. doi:10.5194/hess-18-243-2014
- Mackey, M.C., 2003. Time’s arrow: the origins of thermodynamic behavior. Mineola, NY: Dover, 175.
- Mahalanobis, P.C., 1934. Tables of random samples from a normal population. Sankya, 1, 289–328.
- Mandelbrot, B.B. and Wallis, J.R., 1969. Computer experiments with fractional gaussian noises: part 1, averages and variances. Water Resources Research, 5, 228–241. doi:10.1029/WR005i001p00228
- Mann, H.B., 1945. Nonparametric tests against trend. Econometrica, 13 (3), 245–259. doi:10.2307/1907187
- Matalas, N.C., 1967. Mathematical assessment of synthetic hydrology. Water Resources Research, 3 (4), 937–945. doi:10.1029/WR003i004p00937
- Mathieu, M., 1988. On the origin of the notion ‘Ergodic Theory’. Expositiones Mathematicae, 6, 373–377.
- Mazliak, L., 2018. The beginnings of the Soviet encyclopedia. The utopia and misery of mathematics in the political turmoil of the 1920s. Centaurus, 60 (1–2), 25–51. doi:10.1111/cnt.2018.60.issue-1-2
- Metropolis, N., 1989. The beginning of the Monte Carlo method. In: N.G. Cooper, ed.. From cardinals to chaos. NY: Cambridge University, 125–130.
- Metropolis, N., Reitwiesner, G., and von Neumann, J., 1950. Statistical treatment of values of first 2,000 decimal digits of e and of π calculated on the ENIAC. Mathematical Tables and Other Aids to Computation, 4, 109–112. doi:10.2307/2002776
- Metropolis, N. and Ulam, S.M., 1949. The Monte Carlo method. Journal of the American Statistical Association, 44, 335–341. doi:10.1080/01621459.1949.10483310
- Montanari, A. and Koutsoyiannis, D., 2014. Modeling and mitigating natural hazards: stationarity is immortal! Water Resources Research, 50 (12), 9748–9756. doi:10.1002/2014WR016092
- Niederreiter, Η., 1992. Random number generation and quasi-Monte Carlo methods. Philadelphia: Society for Industrial and Applied Mathematics.
- O’Connell, P.E., et al., 2016. The scientific legacy of Harold Edwin Hurst (1880 – 1978). Hydrological Sciences Journal, 61 (9), 1571–1590. doi:10.1080/02626667.2015.1125998
- Papoulis, A., 1991. Probability, Random Variables and Stochastic Processes. 3rd Ed. New York: McGraw-Hill.
- Persons, W.M. 1919. Measuring and forecasting general business conditions. Harvard University & American Institute of Finance. https://babel.hathitrust.org/cgi/pt?id=hvd.32044018749697
- Reitwiesner, G., 1950. An ENIAC Determination of π and e to more than 2000 Decimal Places. Mathematical Tables and Other Aids to Computation, 4, 11–15. doi:10.2307/2002695
- Slutsky, E., 1927. Slozhenie sluchainykh prichin, kak istochnik tsiklicheskikh protsessov. Voprosy Kon”yunktury, 3. 34–64. [English edition: Slutsky, E., 1937. The summation of random causes as the source of cyclic processes. Econometrica: Journal of the Econometric Society, 105-146].
- Slutsky, E., 1928a. Sur ùn critérium de la convergence stochastique des ensembles des valeurs éventuelles). Comptes Rendus De l’Académie Des Sciences, 187, 370.
- Slutsky, E., 1925. Über stochastische Asymptoten und Grenzwerte. Metron, 5 (3), 3–89.
- Slutsky, E., 1928b. Sur les fonctions éventuelles continues, intégrables et dérivables dans le sens stochastiques. Comptes Rendus Des Séances De l’Académie Des Sciences, 187, 878.
- Slutsky, E., 1929. Quelques propositions sur les limites stochastiques éventuelles. Comptes Rendus Des Séances De l’Académie Des Sciences, 189, 384.
- Stigler, S.M., 2002. Statistics on the table: the history of statistical concepts and methods. Cambridge, MA: Harvard University Press.
- Sudler, C., 1927. Storage required for the regulation of streamflow. Transactions of the American Society of Civil Engineers, 91, 622–660.
- Thomas, H.A. and Fiering, M.B., 1962. Mathematical synthesis of streamflow sequences for the analysis of river basins by simulation. In: A. Maass, et al., eds.. Design of water resource systems. Cambridge, MA: Harvard University Press, 459–493.
- Tippett, L.H.C., 1927. Random sampling numbers. London: Cambridge University Press, Tracts for Computers No. XV.
- Tong, H. and Zhang, Z., 2005. On time-reversibility of multivariate linear processes. Statistica Sinica, 15 (2), 495–504.
- Walker, G., 1931. On periodicity in series of related terms. Proceedings of the Royal Society of London, Series A, 131, 518–532. doi:10.1098/rspa.1931.0069
- Weiss, G., 1975. Time-reversibility of linear stochastic processes. Journal of Applied Probability, 12 (4), 831–836. doi:10.2307/3212735
- Whittle, P., 1951. Hypothesis testing in times series analysis. PhD thesis, Almqvist & Wiksells, Uppsala.
- Whittle, P., 1952. Tests of fit in time series. Biometrika, 39 (3/4), 309–318. doi:10.1093/biomet/39.3-4.309
- Whittle, P., 1953. The analysis of multiple stationary time series. Journal of the Royal Statistical Society B, 15 (1), 125–139.
- Wold, H.O., 1938. A study in the analysis of stationary time-series. PhD thesis, Almquist and Wicksell, Uppsala.
- Wold, H.O., 1948. On prediction in stationary time series. The Annals of Mathematical Statistics, 19 (4), 558–567. doi:10.1214/aoms/1177730151
- Yule, G.U., 1927. On a method of investigating periodicities in disturbed series, with special reference to Wolfer’s sunspot numbers. Philosophical Transactions of the Royal Society of London A, 226, 267–298. doi:10.1098/rsta.1927.0007
Appendix A
Proof of the basic properties of the AMA solution
To show point (a) below Eq. (27), we observe that the sequence of is the finite Fourier transform of:
We recall that the power spectrum is an even function, and so are
and
. Besides
is also even, while
is odd, given that
is odd. Consequently,
has even real part and odd imaginary part. Hence, its Fourier transform is real (Bracewell Citation2000, p. 13), which proves that
is real. It can also be written as a real expression:
To show point (b), we observe that is the inverse finite Fourier transform of
, i.e.
Besides, the inverse finite Fourier transform of the quantity is
where is the conjugate of
, equal to
. Consequently,
where we have utilized the definition of in (27). Hence, the Fourier transform of
equals the power spectrum, which means that
is identical to the autocovariance function
.
Now, coming to point (c), the calculation of the sequence of coefficients , and hence the generation of the required time series, we first note that, unlike in the above theoretical derivations, summation is in practice made for a finite number of terms, i.e. for
, where J if finite. The coefficients
will decrease with increasing η and will be negligible beyond an appropriately chosen, adequately large, J. Possible truncation errors can be handled as described by Koutsoyiannis (Citation2016 – even though that solution was for the SMA scheme). For the numerical part, since we know the frequency functions
(from the power spectrum) and
(appropriately or even arbitrarily or randomly chosen), for an array of frequencies
, we are able to write Eqs. (30)–(31) and complete the algorithm described in steps (i)-(iv) in Sec. 5.
Appendix B
The OBAMA scheme and other cases requiring optimization
If the process exhibits LRD and for some reason an OBAMA scheme is desired, one option would be to generalize Eq. (38) to the form:
where are coefficients to be optimized numerically, so that the deviation from zero of all
(quantified e.g. by the mean square error) be minimal. Continuity at 0 of
is not necessary, but if required it can be achieved setting
.
A second option, which was found quite satisfactory in numerical explorations, is to define as the smooth minimum of two rational functions of frequency,
with first degree polynomials, i.e.:
where are coefficients with values to be optimized and
a big negative number, say,
. Optimizing each
, without using parametric relationships, is another option but in the LRD case the frequencies of interest
will be numerous and, therefore, an expression such as (B1) or (B2), whose coefficients are optimized, may be an advantage.
We can use the same expressions for other tasks. For example, if for some reason we need an ordinary-backward scheme of ARMA type, again the framework provided can directly convert itself into an ARMA scheme. Thus, to convert AMA to an ARMA model, for which
for
and
for
and for some appropriate β, we can form the objective function (representing the cumulative departure of the achieved sequence of coefficients from those of an ARMA
model):
minimize it finding the vector of coefficients , and reformulate the generating Eq. (24) as:
so that a limited number of previous noise variables and the latest process variable
are only needed. This case is also implemented in the spreadsheet provided as supplementary information. The same spreadsheet file contains also other cases, such as the conversion into an AR(q) model or to the sum of three AR(1) models, where the algorithms used are hopefully self-explanatory.