
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Standard latent class modeling has recently been shown to provide a flexible tool for the multiple imputation (MI) of missing categorical covariates in cross-sectional studies. This article introduces an analogous tool for longitudinal studies: MI using Bayesian mixture Latent Markov (BMLM) models. Besides retaining the benefits of latent class models, i.e. respecting the (categorical) measurement scale of the variables and preserving possibly complex relationships between variables within a measurement occasion, the Markov dependence structure of the proposed BMLM model allows capturing lagged dependencies between adjacent time points, while the time-constant mixture structure allows capturing dependencies across all time points, as well as retrieving associations between time-varying and time-constant variables. The performance of the BMLM model for MI is evaluated by means of a simulation study and an empirical experiment, in which it is compared with complete case analysis and MICE. Results show good performance of the proposed method in retrieving the parameters of the analysis model. In contrast, competing methods could provide correct estimates only for some aspects of the data.
1. Introduction
Sociological, psychological and medical research studies are often performed by means of longitudinal designs, and with variables measured on a categorical scale. An example is the LISS (Longitudinal Internet Studies for the Social Sciences) panel study consisting of periodically administered Internet surveys by CentERData (Tilburg University, The Netherlands) to a representative sample of the Dutch population, and covering a broad range of topics such as health, religion, work, and the like.
Different from cross-sectional studies, missing data in longitudinal studies may not only concern partial missingness within a single measurement occasion but may also take the form of complete missing information for certain occasions as a result of missing visits (or complete missingness) or subjects dropping out from the study.Footnote1 When data are missing at random (MAR)Footnote2 and the missingness occurs in the covariates of the analysis model, it is well known that ignoring the missing data (i.e. retaining only the complete cases in the dataset) can lead to biased and inaccurate inferences. While computationally cheap, this method can lead analysts to wrong conclusions under the MAR assumption. Multiple Imputation (MI) is a method developed by [Citation16] which allows separating the missing data handling from the substantive analyses of interest, and moreover takes the additional uncertainty resulting from the missing values into account. Under the MAR assumption, in MI the missing values of a dataset are replaced with M>1 sets of values sampled from the distribution of the missing data given the observed data, . In order to be able to do this, an imputation model is needed. The substantive model of interest is then estimated on each of the M completed datasets, where the M sets of estimates can be pooled through the rules provided by [Citation7,Citation16]. Throughout this paper, we assume the missing data are MAR, and we will deal with methods for incomplete covariates of the analysis model.Footnote3
When imputing missing longitudinal data, the imputation model must fulfill several requirements in order to produce valid imputations. In particular, an imputation model for longitudinal analysis should:
capture dependencies among variables within measurement occasions;
capture overall dependencies between time points resulting from the fact that individuals differ from one another in a systematic way;
capture potential stronger relationships between adjacent time points;
automatically (i.e. without explicit specification) capture complex relationships in the data, such as higher-order interactions and non-linear associations;
respect the measurement scale of the variables (continuous/categorical).
In particular, requirement 4 is motivated by the fact that the imputed datasets could be re-used for several types of analyses, in which different aspects of the data need to be taken into account. An imputation model that can automatically describe all the relevant associations of the data provides datasets that can be re-used in different contexts. Conversely, if an imputation model requires explicit specification of interaction terms and other complex relationships, the imputed datasets are likely to be tailored only for some specific analyses, and the imputation step should be re-performed according to the particular problem under investigation. Furthermore, specifying all the complex interactions that might arise in a dataset can be a difficult and tedious task [Citation23].
One possible approach for the MI of longitudinal categorical data is given by the implementation of the MICE technique [Citation19,Citation20] (a full conditional specification method) with generalized linear models using a logistic link function after converting the data from long to wide format. That is, converting the dataset in such a way that the different time points (the single rows of the dataset in the long format) become columns in the wide format.Footnote4 In such a way, relationships among the variables at different time points can correctly be captured by MICE and reproduced in the imputations [Citation1,Citation26]. This occurs because MICE works by estimating a series of logistic regression models, in which the variables with missing values are treated as outcomes. Each of these outcomes is sequentially regressed on all the other variables present in the dataset; imputation values are then drawn from the resulting models. Despite the advantages and the ease of implementation of the method, MICE is not always guaranteed to work. In the first place, notwithstanding its good performances in simulation studies, convergence to the true distribution of the missing data is not ensured, since the method lacks of theoretical and statistical foundation [Citation23]. Second, conversion from long to wide format causes the number of variables to be imputed (and to be used as predictors) to grow linearly with the number of time points T, slowing down computations and requiring regularization techniques if the sample size is small. Lastly, by default MICE only includes linear main effects into the imputation model. While the routine allows for the specification of more complex relationships when these are needed in the analysis model, it is not always clear at the imputation stage what relationships are needed for future analyses, and thus requirement 4 above might not be always met.
An alternative solution for categorical data is represented by mixture or latent class (LC) models [Citation12], proposed and shown to provide good results as imputation models by [Citation3,Citation23]. Mixture modeling allows for flexible joint-density estimation of the categorical variables in the dataset and requires only the specification of the number of LCs K. When K is set large enough, the model can automatically capture the relevant associations of the joint distribution of the variables [Citation14,Citation23], achieving requirement 4. However, standard LC models are better suited for cross-sectional datasets because they do not account for the longitudinal architecture of the data, and, accordingly, do not satisfy requirement 3 above.
A natural extension of the LC model to longitudinal categorical data, which in addition accounts for unobserved heterogeneity between units, is represented by the mixture Latent Markov (MLM) model [Citation11,Citation21,Citation22]. This model, also known in the literature as mixed Hidden Markov model or random-effects Hidden Markov model, is described more in detail by [Citation13] and [Citation5]. With the MLM model, subjects are clustered at two levels. At the higher level, a time-constant LC variable groups the units with similar time-varying patterns with each other, meeting in this way requirement 2. At the within-subject level, dynamic latent states (LSs; i.e. LCs that can vary over time) are specified for each time point, and -with the first-order Markov assumption- the LS distribution at a specific time point depends only on the LS occupied at the previous time occasion. From an MI point of view, the dynamic LSs help accounting for stronger dependencies across adjacent time points, satisfying requirement 3 above. Furthermore, the distribution of the observed variables at a specific time point depends not only on the time-constant LCs but also on the dynamic LSs, allowing to take dependencies within time points into account, thus meeting requirements 1 and 4. Lastly, the model respects the data scale (requirement 5) by assuming Multinomial distributions for all variables in the measurement model. As a further advantage, the MLM model can produce imputations also for time-constant variables with missing values, when present in the dataset at hand. Note that this imputation model differs from the one proposed in [Citation24], where a Multilevel Latent Class (MLC) model is used to impute multilevel categorical data. In fact, while the time-constant latent classes in the MLM model serve the same purpose as the higher-level classes of the MLC model, the two methods differ for the specification of the lower-level models. On the one hand, the MLC model assumes static latent classes for the lower-level units, which makes it suitable for the imputation and classification of data coming from different populations observed at a specific point in time. On the other hand, the MLM model assumes dynamic latent states for the within-subject observations, which makes this model more fit with data collected across different time points, as auto-correlations are explicitly taken into account by the latent Markov structure of the model. If we were to impute longitudinal data with the MLC model, potential auto-correlations required by the analysis model might be lost or become weaker due to the imputation step, leading in this way to invalid inferences and incorrect conclusions.
While the literature has mainly focused on obtaining unbiased estimates of MLM models in the presence of missing data (e.g. [Citation4] use an event-history extension of the model for situations of informative drop-out), in this article, we investigate the performance of MLM models as an MI tool for missing categorical longitudinal data. The model is implemented under a Bayesian paradigm. The choice of Bayesian modeling in MI is mainly motivated by two arguments: (a) it naturally yields the posterior distribution of the missing data given the observed data; and (b) it automatically takes into account the variability of the imputation model parameter, yielding proper imputations [Citation17].
The outline of the paper is as follows. In Section 2, the model is formally introduced, and the model selection issue is addressed. Sections 3 and 4 describe a simulation and an empirical study evaluating the performance of the Bayesian MLM (BMLM) imputation model. The authors provide final remarks in Section 5.
2. The Bayesian mixture latent Markov model for multiple imputation
Bayesian estimation of the MLM model requires defining the exact data generating model, such as the number of classes for the mixture part and the number of states for the latent Markov chain, as well as the prior distribution of the model parameters. This allows obtaining , the posterior distribution of the unknown model parameters given the observed data
. In MI, the M sets of imputations are obtained from the posterior predictive distribution of the missing data, i.e.
. To achieve this, M parameter values
are first sampled from
, and subsequently the imputations are drawn from
.
2.1. Data generating model and prior distribution
We will assume fixed measurement occasions t () over all subjects and variables. For the ith unit (
),
indicates the value observed for the jth time-varying categorical variable (
) at time t, with
(therefore
represents the number of categories for the jth variable). The J-dimensional vector of observed values for unit i at time t is denoted by
, where
represents a generic pattern, and
is the vector of responses at all time points for unit i.
Often, also time-constant variables (such as the subject's gender) are present in the dataset. When this is the case, is used to denote the value on the pth (
) time-constant variable observed for unit i. Here
and the P-dimensional time-constant pattern observed for i is given by
.
The MLM describes the joint distribution of the data by introducing two types of categorical latent variables: a time-constant LC variable w (
) and a sequence of dynamic LSs
). For the first-order Markov assumption, the distribution of the LSs at time t is dependent on the past only through state at time t−1, that is
. Furthermore, the model assumes local independence for the distribution of both time-constant and time-varying variables conditioned on the latent variables:
and
.
The MLM model is composed of four parts:
the latent class probabilities for the time-constant latent clusters, expressed by
;
the latent states probabilities, which represent the distribution of the LSs at each time point; these are given by:
the initial state probabilities, which describe the distribution of the latent states at time t=1, and denoted by
the transition probabilities, the probabilities for a unit to switch from state
the conditional response probabilities of the time-constant variables given the LC w, denoted with
the emission probabilities, which define the probability of the time-varying variables conditioned on the LC w and the LS at time t:
Given the model components above, the MLM model describes the probability of the observed variables as
(1)
(1) where, at the within-subject level,
(2)
(2)
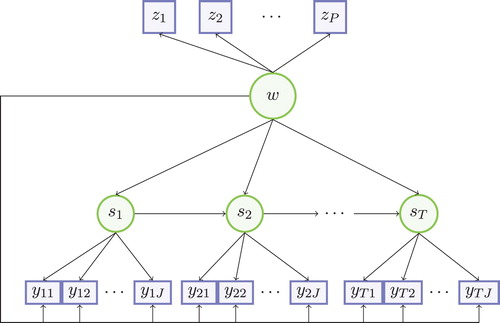
Figure represents the path diagram of the data generating model. The picture stresses the double task executed by the subject-level mixture component w: capturing dependencies among the time-constant variables and overall dependencies between all time points. Figure also shows how the LS at time t affects the distribution of both
and
, capturing dependencies between variables within time point t (by means of the emission probabilities) as well as relationships between adjacent time points (by means of the transition probabilities). With such a model configuration, requirement 2 of Section 1 is satisfied with the time-constant latent variable w, while requirements 1 and 3 are met by means of the latent Markov structure assumed upon the time-varying variables. Importantly, the model can also be implemented in the absence of the time-constant variables, which involves dropping the term
from equation (1) and the nodes representing the time-constant variables
from Figure .
Figure 1. Graphical representation of MLM model. w: time-constant latent class variable; z: time-constant variables; s: dynamic latent variable; y: time-varying variables.
The transition probabilities are stored in T
squared matrices
.
is a stochastic matrix, the rows of which must sum to 1: an entry in row q and column k of the matrix represents the probability for a unit to switch from state q at time t−1 to state k at time t. The qth row of
will be denoted by
.
In order to improve class identification, and to reduce the computational burden during the estimation step, we will assume homogeneous transition and emission probabilities across time points: and
and
, which entails
and
. Thus, the time-identifier subscript will be dropped from the transition and emission probabilities in the remainder of this article, i.e.
and
, and
.
For the Bayesian specification of the model, distributional assumptions must be made for all variables and parameters in model (1)–(2). Since all (latent and observed) variables in the model are categorical, a Multinomial distribution will be adopted for each of them. Formally:
We denote by the whole parameter vector, i.e.
. The conjugate of the Multinomial is the Dirichlet distribution. Hence we will set:
With symmetric Dirichlet priors (i.e. all the hyerparameters are set to the same value for each of the specified Dirichlet), increasing the value of the hyperparameters has the effect of leading to similar posterior modes of the model probabilities (and thus the Multinomial distributions tend to uniformity). Conversely, decreasing this value leads to less uniform Multinomial distributions. Supplemental online material (Section A) offers some guidelines about how to set the priors for MI purposes, and describes what is the effect of varying the hyperparameter values in terms of the allocation of the units to the latent states and classes.
2.2. Model selection
In MI, the imputation model parameters need not be interpreted, and performing imputations with a model that takes into account sample-specific aspects (i.e. a model that overfit the data) is of little concern here [Citation23]. Much more problematic is performing imputations with models that disregard important associations in the data (i.e. models that underfit the data).
Overfitting the data with the BMLM model, and with mixture models in general, means that a number of LCs and LSs (L and K) has been selected for the imputations that is larger than what is needed for the data. When this happens, the BMLM model can carefully capture all relevant associations among the variables as well as sample-specific fluctuations, similar to log-linear imputation models that include non-significant terms [Citation23]. Therefore, to perform imputations a large L and a large K can be chosen. However, it is not always clear whether the selected number of LCs/LSs is large enough; at the same time, too large values might unnecessarily slow down computations, specially with large datasets.
Bayesian modeling offers a simple solution to detect the number of LSs. The method is described by [Citation9], chapter 22 for standard mixture models (i.e. for T=1). Their method consists of preliminarily processing the data by estimating a LC model (by means of the Gibbs sampler) with an arbitrarily large number of classes () and prior distributions for the latent variable parameter that favor the occurrence of empty components (e.g. with
) during the iterations of the Gibbs sampler. Counting the number of latent clusters (at each time point) occupied by the units during every iteration leads to a probability distribution for K (i.e.
) once the Gibbs sampler is terminated. [Citation9], who developed the method for substantive analysis, suggested to use the posterior mode of such distributions to perform inference and obtain interpretable classes. For MI purposes, [Citation25] proposed using the posterior maximum of the resulting posterior distribution. If we denote
the set of all the number of latent classes that have been occupied at least once during the run of the preliminary Gibbs sampler, then the method simply consists of picking
. Once K has been chosen, the mixture model can be re-run (with prior distributions set as described in Section A of the supplemental material) and the imputations can then be performed.
For the BMLM model (case T>1), [Citation9]'s method (modified for this kind of model) can be used to determine both L and K (as shown in the simulation study of Section 3 and in the application of Section 4), by setting arbitrarily large initial values for the number of latent classes and states (e.g. for the number of time-constant classes and
for the number of latent states). At this point, the preliminary Gibbs sampler can be run with such large
and large
, and the hyperparameters for the latent classes proportions and transition probabilities can be set equal to
and
. After the run of the Gibbs sampler, the number of clusters to be used for the mixture components can then be chosen to be equal to the posterior maximum of the resulting distribution for L (analogous to what we have seen for the standard Latent Class imputation model). As far as the number of latent states is concerned, the choice of the final K requires evaluating the number of latent states occupied both within each time-constant latent class, and within each time point. In particular, we propose exploring the distribution of K within each time point (conditioned, in turn, on each of the
mixture components). This means that, for the lth latent class, and for the t-th time point, we can find the maximum number of latent states occupied
Here,
denotes the probability of observing k classes occupied at time t within the time-invariant mixture component l. Calculating
for each time point will lead to a vector
for the l-th latent class. From this vector, we can extract the ‘candidate’ number of latent states for class l, denoted by
, as
Note that we select the minimum, rather than the maximum, number of latent states occupied across the various time points. This helps to prevent that some of the latent states are left empty during the imputation stage, which might cause instability in the Gibbs sampler (as explained in the supplemental material, Section A). Last, the above evaluations are performed for all
, which finally leads to the vector
. The final K is then chosen to be the maximum of
; i.e.
.
2.3. Model estimation and imputation step
In the presence of the latent variable w and the dynamic states , model estimation occurs through Gibbs sampling with Data Augmentation schemeFootnote5 [Citation10,Citation15,Citation18]. Section B of the supplemental material reports the Gibbs sampler (Algorithm 1) used to estimate model (1)–(2). For MI, model estimation is performed only on
, as in [Citation23]. During one iteration, units are first allocated to the time-constant classes according to the posterior membership probabilities
and then, conditioned on the sampled w, units are assigned to the states of the LM chain at each time point. For each subject, the sequence
is drawn via multi-move sampling [Citation6,Citation8] through their posterior distribution
. Multi-move sampling requires to store the filtered-state probabilities
for each time point. How to perform multi-move sampling and compute the filtered-state probabilities is reported in Algorithms 2 and 3 of the supplemental material. After units have been allocated to the LSs, the model parameters are updated using subsequent steps of Algorithm 1.
For each subject with missing values, M values of the LCs w and the LSs (for any t in which the subject provided one or more missing values) should be drawn, along with the conditional distribution probabilities and emission probabilities corresponding to the variables with missing information. These draws must be performed during M of the (post-burn-in) Gibbs sampler iterations and should be as spaced from each other as to resemble i.i.d. samples. The sampled values can then be used to perform the imputations:
and
,
and
for
.
3. Simulation study
The performance of the BMLM imputation model was assessed by means of a simulation study and compared with the complete case (CC) analysis and MICE techniques. In the study, we used four time-varying and four time-constant variables, and we included missing visits (typical of multilevel analysis) to make the parameter retrieval more challenging for the missing data routines. In both studies, analyses were carried out with R version 3.3.0.
3.1. Set-up
Population Model. Four time-constant binary predictors were generated from
(3)
(3) For the time-varying variables, we started by defining the predictors of a potential substantive model at time point t=1. Therefore, we generated J=3 binary variables
with the log-linear model:
(4)
(4) For t>1, the binary predictors
and
were generated through auto-regressive (AR) logistic models
(5)
(5) for
and
. In this way, we created predictors that are auto-correlated with each other in time. After generating the 3 predictors, we created at each time point the outcome variable
through the AR logistic model
(6)
(6) Table shows the parameter values chosen for
,…,
, ρ, τ, and
. These parameters were chosen in order to assess how the missing data techniques could capture different aspects of the data:
ρ was used to assess how the models could recover auto-correlations in
τ served to determine whether the models could recover crossed-lagged associations (between
Table 1. Values of the parameters in model (6).
From the population model (3)–(6), we generated N=200 datasets with n=200 units and T=10 time points.
Generating missingness. Missing entries following a MAR mechanism were inserted in ,
,
and
. Defining
equal to 1 when
was missing and 0 otherwise for
, and
equal to 1 when
was missing (
) and 0 when
was observed, missingness was created as follows. For the subject-level variable
,
while for
As far as the time-varying variables are concerned, the mechanisms were specified as follows. For
,
and for
While for
missingness was fully MAR and dependent on the present values of
, for
the missingness mechanism depended on the time indicator t. In particular, at t=1 missing values were entered according to a MCAR mechanism. For t>1, missingness in
was MAR with a probability depending on the value of
. In such a way, we allowed the missingness mechanism to depend also on past values.
Furthermore, we entered missing visits at each time point by removing for some units simultaneous values of and
with probability equal to 0.05
. These mechanisms yielded about
missing observations in
and
(across the whole dataset and for each time point), about
in
and
, and about
in
and
. Missing data methods. After missingness was generated, we implemented three missing data techniques on the dataset. The first one was CC analysis. The second was the BMLM imputation technique presented in this article. For the selection of L and K, we used [Citation9]'s method described in Section 2.2. Running a preliminary Gibbs sampler for each dataset led to select an average number of LCs equal to L=7.76 and average number number of LSs equal to K=10.54 (starting with
and
, with 3000 iterations for the Gibbs sampler, of which 1000 used for the burn-in). In the online supplemental material (Section A) it is reported how the prior distributions for the BMLM model were set. B=3000 iterations were run for the imputation step, including I=1000 of burn-in. For each dataset, M=20 imputations were performed.
The third missing data technique was the MICE imputation method via logistic regression. For MICE, the datasets were transformed from long to wide format. Notice that, in this case, MICE used an imputation model with JT=40 time-varying variables (plus the 4 time-constant ones). MICE was implemented with its default settings and run for 20 iterations per imputation, with which M=20 imputations were obtained. Outcomes. Bias, stability (in terms of standard deviation of the produced estimates) and coverage rates of the confidence intervals of the parameters in model (6) were used in order to evaluate the performance of each method.
3.2. Results
Results of the simulation study are shown in Table . The BMLM imputation method could, overall, retrieve approximately unbiased parameter estimates not only for the predictors of the time-varying variables, but also for the parameters of the time-constant variables, . CC analysis retrieved unbiased parameter estimates for the main effects parameters of the time-varying variables (as well as the main effects of the subject-specific variables), but retrieved biased intercept and lagged-relationships. The MICE imputation technique could not pick up the estimates of the main and interaction effects of time-varying variables (especially
and
). However, MICE could recover unbiased lagged relationships (ρ and τ) and parameters of the time-constant effects.
Table 2. Simulation study: results observed for the estimates of the AR logistic regression coefficients in model (6) for three missing data methods: CC (complete case analysis), BMLM (Bayesian Mixture Latent Markov model) imputation, MICE imputation.
CC analysis produced the most unstable estimates among the three methods. Estimates yielded by the BMLM technique and MICE had, overall, similar stability for all types of regression coefficients, although the main and interaction effects of time-varying predictors produced by the BMLM model tended to be slightly more unstable. On the other hand, the BMLM method yielded confidence intervals that were rather close to their nominal level. MICE imputation produced confidence intervals for the time-constant and lagged effects whose coverage rates are rather close to their nominal level, but intervals with too low coverage for main and interaction effects of the time-varying items. The confidence intervals computed after CC analysis were close to their nominal coverage level, excluding the intervals of and τ, which resulted in a too low coverage.
4. Empirical study
While in the previous section, the parameters of the BMLM MI method was evaluated using simulated datasets from constructed populations, in this section we focus on a real dataset. More specifically, we make use of the associations as present in a real longitudinal dataset rather than specifying these ourselves, and investigate whether these associations are retained when introducing missing values (including missing visits) and imputing these using the BMLM model. For this application, we create the missing values in the dataset ourselves, in such a way to have a benchmark (the results obtained with the complete data) for the estimates retrieved by the missing-data methods.
We used data collected by CentERData through their LISS panel, which consists of a (representative) sample of Dutch individuals, who participate in monthly Internet surveys. Key topics surveyed once per year include work, education, income, housing, time use, political views, values, and personality.Footnote6 For our experiment, we selected the first 4 yearly waves (T=4, from June 2008 until June 2011) of the Housing questionnaire.
4.1. Study set-up
The data and the analysis model. The original datasets consisted of about a hundred variables (which included survey-specific and background variables) and sample sizes that varied from wave to wave, ranging from 4411 (Wave 3) to 5018 (Wave 4) cases. We merged the datasets coming from the four surveys, retained only those units with complete information for all four waves, and selected only those cases who were owners of the dwellings where they had residence (this was functional to the analysis model we decided to estimate). This resulted in a dataset with sample size of n=257 (and 1028 rows in total for the four time points).
Next, using this dataset, we estimated a Generalized Estimating Equation (GEE) logistic regression model with auto-regressive error (of order 1) for the binarized version of the response variable ‘House Satisfaction’Footnote7; this variable is denoted by in Table . Among the remaining variables, we detected 5 (time-varying) predictors (
in Table ) that were significant at the
level, yielding a total of J=5 variables in the analysis model. Descriptions of these variables, including the time indicator t, are given in Table (top part). Some of these were re-coded (transformed from continuous to categorical) and for others we collapsed some categories (so that their frequencies were not too small).
Table 3. Real-data experiment: variables used in the panel regression model (7) (top part) and to generate missingness (bottom part).
The GEE logistic model we estimated was
(7)
(7) The response covariance matrix assumed by the model takes the form
, where σ is a scale parameters that allows for overdispersion,
is a diagonal matrix with elements
, and
is the correlation matrix of
. The correlation matrix
will be assumed to specify an auto-regressive model of order 1 (AR(1)), which implies:
The values of the model parameters
, and ρ estimated on the complete data are reported in the first columns of Table , along with their standard errors. All predictor effects were significant at
level as highlighted, except for
, one of the variables yielding the significant interaction term
.
Table 4. Real-data experiment: results for the parameters in model 7. Est. = point estimate. S.E. = standard error.
Generating missingness. Apart from the variables , we used the time-constant variable gender denoted with
in Table , to generate MAR missingness in the variable
(
was thus also included in the imputation models as a time-constant variable). In particular, by denoting the missingness of
with
, we created missing values for
with the logistic model
Furthermore, we entered MAR missingness in
– conditioned on
– with the logistic model
where
is defined in a way similar to
. The parameters of both logistic models were chosen in such a way to obtain marginal missingness rates of about
for each of these two variabes.
Furthermore, we generated missing visits in the dataset; thus, for some units, we removed the observations for all the time-varying variables with increasing probability at each time point. If
is the indicator equal to 1 for those units with missing visits at time t and equal to 0 otherwise, the mechanism we used was
which generated missing visits for about
of the cases at the first wave, and for about
of the cases at the fourth wave.
Overall, all the time-varying variables had a marginal (i.e. across all time points) rate of missingness equal to about , except for
and
, which had a marginal rate of missingness roughly equal to
.
Missing data methods. As done for Section 3, we compared the performance of three missing data methods to retrieve the parameters of model 7: CC analysis, BMLM MI and MICE.
With CC analysis we estimated model 7 on the dataset with only complete observations, i.e. excluding all cases with missing data. This left a dataset with 619 rows, with sample sizes ranging from n=153 at wave four to n=157 at wave two.
For the BMLM model, we performed model selection with [Citation9] 's method reported in Section 2.2. We ran the preliminary Gibbs sampler with and
, and the same number of iterations as the previous case. This led us to choose L=15 and K=9. In the subsequent step, M=50 imputations were performed during 10000 iterations (plus 5000 iterations for the burn-in).
Lastly, MICE was implemented with its default settings, and its algorithm was run for 50 iterations for each of the M=50 produced imputations.
Outcomes. We compared the results provided by each missing data method with the results observed for the complete-data case. In particular, we focused on the point estimates of all parameters in model 7 as well as the standard errors for the fixed effects (). We also examined which fixed effect estimates were significant at a
level.
4.2. Results
The results are reported in Table . Both CC analysis and the two versions of the BMLM imputation model retrieved point estimates of the fixed effects rather close to those of the complete-data analysis. Exceptions for the CC analysis were the main effects and
and the cross-lagged term
, which were slightly different from the corresponding values obtained with the complete data. Some of the standard errors yielded by CC analysis were inflated because of the limited sample size exploited by this method, which made some parameter estimates no longer significant at the
level (in Table , some fixed and cross-lagged effects are no longer marked with a ‘*’). Conversely, despite a couple of values being slightly off (the intercept
and the fixed effect
), BMLM could exploit the original sample size, causing the standard errors to be only slightly larger than those of complete-data analysis (reflecting in this way the imputation step uncertainty). As a result, all parameters that were significant with the full data were also significant after imputing the missing values with the BMLM model. The MICE method did also a good job at retrieving most of the model point estimates; however, coefficients such as the intercept
and the main effects
,
, and
were off the estimates of the complete-data condition. The standard errors observed after imputing the data with MICE were close to the BMLM MI estimates. Lastly, all parameters that were significant with the complete data, were also significant after MICE imputation.
Concerning the parameters of the variance component of the model, all missing data techniques could retrieve good estimates for the variances of the scale parameter σ. The auto-regressive coefficient ρ, on the other hand, was well retrieved by all MI techniques, but overestimated by CC analysis.
5. Discussion
We introduced the use of the BMLM model for the MI of missing categorical longitudinal covariates. The model is flexible enough to automatically recover relationships arising between time-varying and time-constant variables, as well as lagged relationships and auto-correlations. Furthermore, the model reflects the correct (categorical) scale with which the variables are measured.
The performance of BMLM-based MI approach was evaluated and compared with other two missing data methods, CC analysis and MICE, by means of a simulation study and an empirical experiment. In the simulation study, the analysis model used was a logistic model including an auto-regression term and a crossed-lagged relationship coefficient, as well as main effects of time-constant predictors. Despite the acceptable results produced by MICE imputation and CC analysis, especially when retrieving parameter estimates of main effects (CC analysis) or interaction and cross-lagged relationships (MICE), these two methods could not fully do an adequate job for all the type of dependencies present in the data. The BMLM model, on the other hand, though not uniformly overperforming the other methods, it could retrieve unbiased estimates for all types of parameters specified in the substantive models, the coverage rates of their confidence intervals being never too small w.r.t. to their nominal level. The good performance of MI via BMLM showed that the model can also cope with missing visits when these are present at any time point.
In the empirical experiment, we estimated a GEE logistic regression model using data from the LISS panel. The model included main and interaction fixed effects, along with crossed-lagged relationships and an auto-regressive term. Furthermore, the variance of the response was also described by an overdispersion parameter. When creating missingness on this data, we also included cases with missing visits in the LISS dataset as a further challenge for the missing data methods. The results confirmed the good performance of the BMLM model when compared to complete-data condition estimates. In particular, the same conclusions (i.e. the same terms were statistically significant) were drawn for the complete-data case and the BMLM imputation method. This did not happen with the CC technique, which nevertheless yielded good results for most of the parameters considered in the study. Lastly, imputing the data with the MICE method also led to valid inferences of the GEE model, although some of the parameter estimates obtained with MICE were a bit farther from the complete-data estimates than the values obtained with the BMLM model.
Importantly, it should be noted that throughout the paper, we have assumed MAR data on the covariates of the analysis model. This is known to lead to invalid inferences when ignoring the missing data (i.e. when CC analysis is applied), as the simulation studies of this article have shown. In this respect, the imputation models used in this paper were favored over CC analysis, due to the implied assumptions. However, in practical analyses, it is difficult to determine whether the missing data mechanism is missing at random or completely at random (MCAR). When the data are MCAR, CC analysis can produce valid inferences while providing a computationally cheap method to deal with missing data (as no action is taken to handle them, nor is an imputation model required). Therefore, when data are known to be MCAR, performing CC analysis is a valid method to proceed.
In light of the results of the studies carried out in this article, we recommend the applied researcher that needs to deal with missing longitudinal categorical data to consider the BMLM model as a possible MI tool. Nevertheless, some issues still need to be better investigated in future research. For instance, whereas in this article, we aimed to introduce the use of the BMLM model for MI purposes, some more extensive simulation experiments (in which the model is tested with different sample size and missingness conditions, such as systematic drop-out) should be performed in future studies. In addition, while we showed that our model can deal with MAR missing data, a version of the BMLM model for missing not at random data (MNAR; i.e. the distribution of the missingness depends on the unobserved data), which are likely to occur in longitudinal analysis, should be developed in future research. While we focused on unobserved predictor variables of the analysis model, future studies should also investigate the behavior of such imputation model when missingness occurs also in the response variable.
Furthermore, the proposed imputation model itself can be extended in various useful ways. Firstly, while we dealt with categorical (both ordinal and nominal) variables, the BMLM model can be extended to accommodate mixed types of data, i.e. it can be implemented on datasets containing both categorical and continuous variables. This can be achieved, for instance, by specifying mixtures of univariate Normal and Multinomial distributions. Second, the BMLM model we proposed for the imputations can be seen as a Hidden Markov Model with discrete random effect. An alternative to such model can be obtained by specifying a continuous random effect, as proposed by [Citation2]. The continuous random effect might lead to more precise inferences, for instance, when a continuous random effect is required in the analysis model. Future research should investigate this model for MI. Third, although we assumed the BMLM model to have a Markov chain of order 1, it is possible to consider lags of higher orders by conditioning the distribution of the dynamic LSs at time t on the configuration of the states at earlier time points, e.g. , etc., if these kinds of lags are needed in the substantive analysis. Fourth, when the measurement may occur at different continuous time points rather than at fixed discrete occasions, imputations of the missing data can be provided by assuming a continuous-time latent Markov chain for the distribution of the LSs. Last, for applications in which the subjects observed across time are coming from different groups (e.g. patients coming from different hospitals), the model can be moved towards a multilevel framework, for instance, by adding a further LC variable at the group-level.
Supplemental_Material.pdf
Download PDF (254.1 KB)Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
1 In the first case (missing visits), subjects fail or refuse to provide information for all variables at one or more time occasions. In the second case (drop-out), a subject stops providing information for all variables from a specific time point until the end of the study. Even though this paper generally deals with partial missingness, we will also test the performance of the proposed method in the presence of missing visits by means of a simulation study and an empirical experiment. In the latter, few cases of drop-out are also present in the dataset.
2 That is, the probability of missingness depends exclusively on the observed data.
3 Note that, in case of missing visits, values can be unobserved also for the response of the analysis model.
4 In this way, each row in the wide format corresponds to a single unit of analysis.
5 In Data Augmentation units are assigned to the LCs in a first step, and – accordingly – model parameters are updated in the subsequent step. These two main steps are then iterated.
6 More information about the LISS panel can be found at www.lissdata.nl.
7 The name of the variable was cd08a001 in the original dataset. We binarized this variable (which originally was categorical with four categories), so that we could enable the estimation of the GEE logistic regression model with the LISS dataset.
Related Research Data
References
- P.D Allison, Missing data, in The SAGE Handbook of Quantitative Methods in Psychology, R.E. Millsap and A. Maydeu-Olivares, eds., Sage, Thousand Oaks, CA, 2009, pp. 72–89.
- R. Altman, Mixed hidden Markov models: An extension of the hidden Markov model to the longitudinal data setting, J. Am. Stat. Assoc. 102 (2007), pp. 201–210. doi: 10.1198/016214506000001086
- S. Bacci and F. Bartolucci, A multidimensional finite mixture structural equation model for nonignorable missing responses to test items, Struct. Equ. Model: Multidiscip. J. 22 (2015), pp. 352–365. doi: 10.1080/10705511.2014.937376
- F. Bartolucci and A. Farcomeni, A discrete time event-history approach to informative drop-out in mixed latent Markov models with covariates, Biometrics 71 (2015), pp. 80–89. doi: 10.1111/biom.12224
- F. Bartolucci, A. Farcomeni, and F. Pennoni, Latent Markov Models for Longitudinal Data, Chapman and Hall/CRC, Boca Raton, 2013.
- S. Chib, Calculating posterior distributions and modal estimates in Markov mixture models, J. Econom. 75 (1996), pp. 79–97. doi: 10.1016/0304-4076(95)01770-4
- C. Enders, Applied Missing Data Analysis, Guildford, New York, 2010.
- S. Fruhwirth-Schnatter, Finite Mixture and Markov Switching Models, 1st ed., Springer-Verlag, New York, 2006.
- A. Gelman, J.B. Carlin, H.S. Stern, and D.B. Rubin, Bayesian Data Analysis, 3rd ed., Chapman and Hall, London, 2013.
- S. Geman and D. Geman, Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images, IEEE Trans. Pattern Anal. Mach. Int. 6 (1984), pp. 721–741. doi: 10.1109/TPAMI.1984.4767596
- R. Langeheine and F. van de Pol, Discrete-time mixed Markov latent class models, in Analyzing Social and Political Change: A Casebook of Methods, A. Dale and R. B. Davies, eds., Sage Publications, London, 1994, pp. 171–197.
- P.F Lazarsfeld, The logical and mathematical foundation of latent structure analysis, in Measurement and Prediction, S.A. Stouffer, L. Guttman, E.A. Suchman, P.F. Lazarsfeld, S.A. Star and J.A. Clausen, eds., Princeton University Press, Princeton, NJ, 1950, pp. 361–412.
- A. Maruotti, Mixed hidden Markov models for longitudinal data: An overview, Int. Stat. Rev. 79 (2011), pp. 427–454. doi: 10.1111/j.1751-5823.2011.00160.x
- G.J. McLachlan and D. Peel, Finite Mixture Models, Wiley, New York, 2000.
- S. Richardson and P. Green, On bayesian analysis of mixtures with an unknown number of components (with discussion), J. R. Stat. Soc. Ser. B 59 (1997), pp. 731–792. doi: 10.1111/1467-9868.00095
- D.B. Rubin, Multiple Imputation for Nonresponse in Surveys, Wiley, New York, 1987.
- J.L. Schafer and J.W. Graham, Missing data: Our view of the state of the art, Psychol. Methods. 7 (2002), pp. 147–177. doi: 10.1037/1082-989X.7.2.147
- A.M. Tanner and W.H. Wong, The calculation of posterior distributions by data augmentation, J. Am. Stat. Assoc. 82 (1987), pp. 528–540. doi: 10.1080/01621459.1987.10478458
- S. Van Buuren and K Groothuis-Oudshoorn, Multivariate imputation by Chained equations: MICE V.1.0 User's manual. Toegepast Natuurwetenschappelijk Onderzoek (TNO) Report PG/VGZ/00.038, Leiden, The Netherlands, 2000.
- S. Van Buuren and C Oudshoorn, Flexible multivariate imputation by MICE Tech. rep. TNO/VGZ/PG 99.054. TNO Preventie en Gezondheid, Leiden, The Netherlands, 1999.
- F. van de Pol and R. Langeheine, Mixed Markov latent class models, Sociol. Methodol. 20 (1990), pp. 213–247. doi: 10.2307/271087
- J.K Vermunt, Longitudinal research using mixture models, in Longitudinal Research with Latent Variables, V.K. Montfort, J. Oud. and A. Satorra, eds., Springer, Verlag, Berlin, 2010, pp. 119–152. 2010.
- J.K. Vermunt, J.R. Van Ginkel, L.A. Van der Ark, and K. Sijtsma, Multiple imputation of incomplete categorical data using latent class analysis, Sociol. Methodol. 38 (2008), pp. 369–397. doi: 10.1111/j.1467-9531.2008.00202.x
- D. Vidotto, J. Vermunt, and K. van Deun, Bayesian multilevel latent class models for the multiple imputation of nested categorical data, J. Educ. Behav. Stat. 43 (2018), pp. 511–539.
- D. Vidotto, J.K. Vermunt, and K. van Deun, Bayesian latent class models for the multiple imputation of categorical data, Methodology 14 (2018), pp. 56–68. doi: 10.1027/1614-2241/a000146
- I.R. White, P. Royston, and A.M. Wood, Multiple imputation using chained equations: issues and guidance for practice, Stat. Med. 30 (2011), pp. 377–399. doi: 10.1002/sim.4067