
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Coherent forecasting techniques for count processes generate forecasts that consist of count values themselves. In practice, forecasting always relies on a fitted model and so the obtained forecast values are affected by estimation uncertainty. Thus, they may differ from the true forecast values as they would have been obtained from the true data generating process. We propose a computationally efficient resampling scheme that allows to express the uncertainty in common types of coherent forecasts for count processes. The performance of the resampling scheme, which results in ensembles of forecast values, is investigated in a simulation study. A real-data example is used to demonstrate the application of the proposed approach in practice. It is shown that the obtained ensembles of forecast values can be presented in a visual way that allows for an intuitive interpretation.
1. Introduction
In many fields of application, one is concerned with count time series , i.e. the observations
are non-negative integer values from
, and
denotes the length of the time series. Examples include the daily or weekly numbers of new cases of an infectious disease, or monthly counts of economic events such as strikes or company liquidations [Citation24]. Motivated by such applications, there are also many papers on the forecasting of the underlying count process
. In particular, coherent forecasting techniques have been investigated by many researchers, such as [Citation3,Citation5,Citation7,Citation8,Citation12,Citation16,Citation17,Citation21]. The term coherent forecasting was first used by Freeland and McCabe [Citation5] to express that the computed forecasts of a count process should also be count values themselves. This is achieved by first deriving the full h-step-ahead conditional distribution of
(given the past
), and by then computing
the median or mode of
as a central point forecast (PF);
an extreme (typically upper) quantile of
a finite subset of
Some authors do not derive PFs or PIs from the predictive distribution, but they use the full predictive probability mass function (PMF) itself as the forecast value, see [Citation14,Citation16,Citation17,Citation22,Citation26], for example. While the full forecast PMF is certainly more informative than a PI or PF derived from it, the practitioner might be overtaxed to capture all this information and to draw appropriate conclusions from it. Our main focus is on the widely used PFs and PIs, but the proposed approach is easily adapted to ‘PMF forecasting’ as well, see Section 4 for more details.
In practice, one does not know the true predictive distribution of but has to rely on a fitted model. Thus, the actually computed forecasts (using the estimated model parameters as computed from
) might deviate from the true forecasts (which would have been computed from the true model in the same situation).
Example 1.1
As a simple illustrative example, let us consider the weekly numbers of new cases of the Creutzfeldt–Jakob disease in Germany for the year 2019. The data are offered by the Robert-Koch-Institut at https://survstat.rki.de/ (disease ‘CJK’). These T = 52 counts with mean 1.712 do not exhibit significant autocorrelation (test done on a 5%-level), so we model these data as being independent and identically distributed (i. i. d.) counts. The default candidate for the counts' distribution is the Poisson distribution with mean , denoted by
. The Poisson distribution is characterized by having equidispersion, i.e. the true variance-mean ratio equals 1 for all μ. Since the observed variance-mean ratio 0.833 is not significantly different from the hypothetical value 1 (again on a 5%-level), we conclude that these data are well modeled as i. i. d.
-counts. The maximum likelihood (ML) estimate of μ is equal to the sample mean, so
. If using the ML-fitted model
for forecasting (the true model behind
is not known), we obtain, for example, the median 2 as a central PF, the 95%-quantile 4 as a non-central PF, and the 90%-PI is given by
. However, the considered value 1.712 is just an estimate of the true mean μ. According to the central limit theorem, the ML-estimator
is asymptotically normally distributed with mean μ and approximate variance
. To get an impression of the apparent estimation uncertainty, let us plug-in the observed value 1.712 into this approximate normal distribution. Then, for example, the outer deciles compute as 1.479 and 1.944, respectively. These values delimit a range for
that is even exceeded in 20% of all cases. If we would have used the lower value 1.479 for forecasting, then we would have obtained a different median forecast, namely 1, whereas the upper value 1.944 would have lead to a different 90%-PI, namely
. So we recognize that the actually computed coherent forecasts depend essentially on the calculated estimate of μ.
The effect of estimation uncertainty on coherent forecasts was investigated for selected models by Freeland and McCabe [Citation5], Jung and Tremayne [Citation12], Silva et al. [Citation21], Bisaglia and Gerolimetto [Citation3], and more comprehensively for a large variety of count processes by Homburg et al. [Citation7,Citation8]. The latter authors concluded that the coherent central PFs are usually only slightly affected by estimation error, whereas the non-central and the interval forecasts may suffer a lot from estimated parameters. Since it is impossible to suppress the estimation uncertainty in practice, it is quite natural to ask if, at least, it is possible to account for it in an appropriate way.
The first suggestion in this respect is due to [Citation5], who derived an asymptotic approximation for the estimated predictive distribution of the so-called Poi-INAR(1) process (Poisson integer-valued autoregressive; see Appendix 1 for details). While this allows to express the uncertainty of the predictive distribution itself (also see the Bayesian approach proposed by McCabe and Martin [Citation16] as well as the discussion in Section 4), Freeland and McCabe [Citation5] did not transfer their result to express the uncertainty of the PFs and PIs computed thereof. Furthermore, the derived approximation only applies to the particular case of a Poi-INAR(1) data-generating process (DGP), but not to any other type of DGP. Another solution has been proposed by Jung and Tremayne [Citation12], who used a bootstrap approach to capture the effect of the estimated parameters on the computed median forecast. First, they resampled the estimates by using a block bootstrap, which is a non-parametric bootstrap approach that tries to preserve the serial dependence structure of the time series data [Citation15]. Then, they computed the conditional medians corresponding to the resampled estimates, and the mode among all bootstrapped forecast medians was used as the final PF value. Doing this, however, one still ends up with a single forecast value such that the practitioner cannot judge how much it might deviate from the true forecast value. Note that the ‘parametric bootstrap algorithm’ presented by Kim and Hwang [Citation13] is completely different from the works by Freeland and McCabe [Citation5], Jung and Tremayne [Citation12]. Kim and Hwang [Citation13] simulate the 1-step-ahead predictive distribution (given the estimated parameters) and compute the sample median thereof, i.e. they approximate the conditional median by simulation, but they do not account for the estimation uncertainty by their bootstrap approach. Also in [Citation14,Citation22,Citation26], the bootstrap/simulation approach is not used to account for the estimation uncertainty, but for approximately computing the fitted model's predictive distribution.
Inspired by the proposals of [Citation5,Citation12], we suggest and investigate another approach to account for the estimation uncertainty if doing coherent forecasting. Using a resampling technique, we directly approximate the distribution of the coherent forecast value (which is random due to the randomness of the sample ). Here, we consider all three types of forecast values outlined above, i.e. central PFs, non-central PFs, and discrete PIs. Then, instead of providing a single forecast value or forecast interval, the whole ensemble of forecast values (as resulting from the resampling procedure) is presented to the practitioner, to express the effect of the estimation uncertainty. The details of our approach are described in Section 2. Its performance is investigated in Section 3, where results from a comprehensive simulation study are discussed. The real-data example presented in Section 4 illustrates the application of the proposed resampling approach in practice. In particular, it is shown that the presentation of the full ensemble of forecast values need not be done in a tabular form (i.e. as a frequency table of the resampled forecasts), but visual solutions are also possible. The article concludes in Section 5.
2. Resampling of coherent forecasts
Let be the count DGP, the model of which is determined by some parameter vector
, i.e. all distributional as well as dependence parameters are covered by
. Let
be the available time series data that is to be used for computing the coherent forecasts. Parts of our resampling approach for revealing the estimation uncertainty in coherent forecasting follow the ideas of [Citation12]. First, a model is fitted to the data
and the required parameter estimate
is computed. Then, a resampling approach is done to assess the variability of the parameter estimates (details are given below). Finally, the resampled fitted models are used to compute the coherent forecasts (central or non-central PFs, or discrete PIs); we obtain a discrete frequency distribution of forecast values. Jung and Tremayne [Citation12] used the mode of the resampled median forecasts as the final central PF value. By contrast, we shall use the whole frequency distribution of forecast values to incorporate the parameter uncertainty into the coherent forecasting, in analogy to ensemble forecasting in weather prediction [Citation18].
Let us have a more detailed look at the resampling part of the above approach. Jung and Tremayne [Citation12] used a block bootstrap, which is computationally quite demanding and also requires the specification of a nuisance parameter. Since for parameter estimation and for forecasting, a parametric model is assumed anyway, it is not clear why the resampling itself should be based on a model-free approach. Furthermore, it was shown in [Citation10] that the block bootstrap, compared to a parametric bootstrap, performs rather badly under parametric model assumptions. Therefore, we use a parametric resampling scheme in combination with the parametric estimation and forecasting. For a parametric bootstrap in the proper sense, like the parametric INAR bootstrap in [Citation10], it is necessary to generate B times a count time series from the fitted model, and to estimate the model parameters again for each replicate. In this way, one obtains the B bootstrap replicates
of the parameter estimate
. A common choice for the number of bootstrap replicates,
, is B = 500. Although easier to implement than the block bootstrap, also the parametric bootstrap requires a lot of programming work. For each type of DGP being considered, one has to write an individual bootstrap code that executes the actual DGP. Furthermore, it is computationally quite demanding (later in Section 3.2, we report some computing times), because the estimation procedure has to be repeated for each bootstrap replication anew. If computing, for example, the ML estimates
of the model parameters
, a numerical optimization routine has to be run for each bootstrap replication to obtain
. Therefore, we thought of a ‘cheaper’ solution here.
For common types of count DGPs, the ML estimator behaves in a unique way, see [Citation2,Citation4], for example.
is consistent, and
is asymptotically normally distributed according to
, where
denotes the zero vector, and
the expected Fisher information per observation. The mean observed Fisher information
, in turn, where
is the Hessian of the log-likelihood function, approximates
. This asymptotic distribution can now be used to assess the variability of the parameter estimates, in analogy to [Citation5]. Plugging-in the obtained estimates
in
, we obtain an approximate (multivariate) normal distribution for
. This normal distribution is used to approximate the estimation uncertainty for the parameter
. But it is not clear how to analytically compute the resulting estimation uncertainty for the considered coherent forecasts. Therefore, we sample the replicates
from
, and these are used to compute the corresponding B forecast replicates. The variation among these forecast replicates reflects the estimation uncertainty in forecasting. Note that the resampling is based on the approximate asymptotic normal distribution, i.e. it is neither required to generate the B count time series, nor to apply the estimation approach to them, saving a lot of computing time. Certainly, it is not clear in advance that the proposed asymptotic resampling solution is really able to adequately account for the estimation uncertainty in forecasting. Therefore, it has to be carefully investigated by simulations, also in comparison to an ordinary parametric bootstrap procedure.
3. Simulation study
3.1. Design of simulation study
For the different types of DGP being summarized in Appendix 1, and for several scenarios per DGP, count time series of various lengths T were simulated. For each of these Monte–Carlo replicates, the ML estimates
were computed. Then, we either used the true parameter value
, or the respective estimate
, and computed the following three types of forecasts:
the conditional median as a coherent central PF,
the conditional 95%-quantile as a coherent non-central PF, and
the two-sided discrete PI with nominal coverage 90%.
Comparing the forecasts based on the estimates with the respective true forecast (based on
), we can evaluate the estimation uncertainty in coherent forecasting.
Remark 3.1
Since we are concerned with discretely distributed random variables, generally, neither the computed quantiles nor the computed PIs meet the nominal quantile or coverage level exactly, also see [Citation7,Citation8]. But, given the model used for forecasting (either the true or the estimated one), it is at least ensured that they do not fall below this level. While quantiles are uniquely defined for a given quantile level [Citation7], there is usually more than just one solution for a PI satisfying the coverage requirement. Here, we follow the scheme for two-sided PIs with
in [Citation8], which ensures a PI of minimal length and maximum coverage.
To incorporate the parameter uncertainty into the coherent forecasting, for each Monte–Carlo time series and the corresponding ML estimate , we did a resampling with B = 500 replicates, leading to the resampled estimates
(if using the asymptotic resampling relying on the approximate normality of
) or
(if using the parametric bootstrap), respectively. Then, the forecasting of the Monte–Carlo time series was done by using these replicated estimates, thus leading to an ensemble of replicated forecast values. All tables with simulation results are collected in Appendix 2.
3.2. Poisson INAR(1) DGP
The first type of DGP is the Poi-INAR(1) DGP with marginal mean μ and autocorrelation parameter α, see Appendix 1. Forecasting is done conditioned on the respective last observation in each Monte–Carlo run. The first block of columns in Table (see Appendix 2) shows the numbers of those Monte–Carlo runs, where the respective forecast based on the ML-estimated parameters agrees with the one using the true model parameters. While these numbers improve with increasing sample size T and with increasing α, they become worse with increasing μ (which is equal to the variance of the equidispersed Poisson distribution). These results regarding the effect of estimation uncertainty on the forecasts are in line with the studies by Homburg et al. [Citation7,Citation8]. Now, the question is how to incorporate the parameter uncertainty into the coherent forecasting. Picking up the proposal by Jung and Tremayne [Citation12], one may compute the mode among the resampled forecasts. But for both, the asymptotic resampling and the parametric bootstrap, the numbers of agreement of the mode to the true forecast are nearly the same. The reason for this becomes clear from the second and fourth block of columns in Table : in most cases, the mode among the resampled forecasts just reproduces the original forecast under estimation uncertainty.
Therefore, we recommend to consider the full frequency distribution of resampled forecasts instead (‘ensemble forecasting’). As can be seen from the third and fifth block of columns in Table , apart from very few exceptions, the resampled forecasts cover the true forecasts for all considered scenarios. So if using the ‘blurred’ forecasts resulting from resampling instead of the ‘sharp’ (but often wrong) forecasts based on the individual estimates, we successfully account for the effect of parameter estimation.
Remark 3.2
At this point, let us compare the results stemming from the asymptotic resampling scheme (second and third block of columns in Table ) with those of the parametric bootstrap (fourth and fifth block of columns in Table ). There is an at most very small difference between these numbers, which implies that both resampling approaches lead to nearly the same performance regarding the coherent forecasting. However, there is one big difference between both approaches: the computing time. While the simulations for one scenario in Table took only a few minutes if using the asymptotic resampling, they varied between about 7 hours () and 72 hours (
) for the parametric bootstrap. Therefore, the asymptotic resampling scheme appears to be clearly preferable for practice. In the sequel, no further results regarding the parametric bootstrap are presented.
The price we have to pay if using the full ensemble of resampled forecasts is a non-unique forecast. Table A2 shows the mean number of different forecasts among the resampled forecasts (so the mean extent of ‘blurredness’), which is larger for the PIs than for the PFs. These mean numbers of different forecasts are quite small if μ is small (implying low dispersion) and if α is large, and increasing the sample size T leads to a further reduction. So, in many cases, we have a rather low level of ambiguity.
To be able to compare the resampled forecasts' distributions with the distribution of the forecasts under estimation uncertainty, we analyze a fixed forecasting scenario, where the predictive distribution is not computed for the respective last observation per Monte–Carlo run, but by conditioning on a unique count value, namely the median of the
marginal distribution. A representative example is given by Figure , referring to the Poi-INAR(1) DGP with
and
. From top to bottom, the sample size increases according to
. The first column refers to the conditional median (‘PF
’), the second column to the 95%-quantile (‘PF
’), and the third column to the 90%-PI (‘PI
’). The respective forecast's distribution under estimation uncertainty (computed from the
Monte–Carlo replicates) is shown by gray dots, whereas the M resampled forecasts' distributions (always computed from the respective B = 500 resampled forecasts) are analyzed by boxplots. It can be seen that the medians of the boxplots are generally close to the gray dots, and the difference between them (expressing the bias of the resampled distributions to the forecast's distribution under estimation uncertainty) gets further reduced for increasing T. In addition, also the size of the boxes decreases with increasing T, indicating the consistency of the resampling scheme. So the resampled forecasts' distributions constitute useful estimates of the true forecast's distribution under estimation uncertainty.
Figure 1. Poi-INAR(1) DGP with ,
, and sample size T. Distribution of forecasts conditioned on value 5: conditional median (‘PF
’, true value: 5), 95%-quantile (‘PF
’, true value: 8), and limits l, u of 90%-PI (‘PI
’, true limits: 2, 8). Distribution under estimation uncertainty as gray dots, and boxplots of resampled distributions.
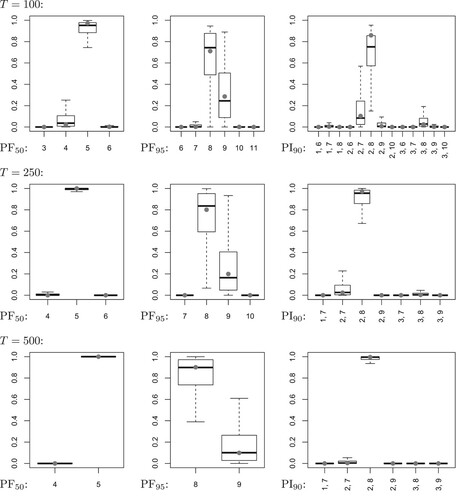
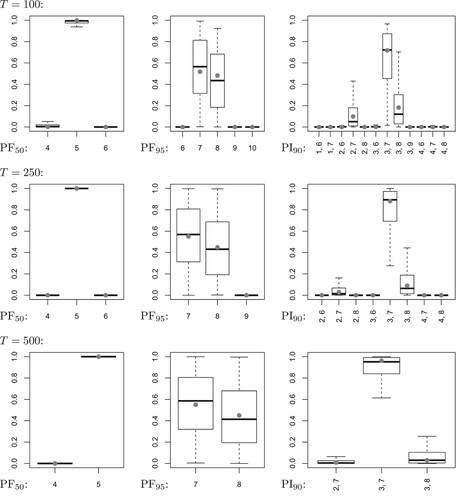
Comparing the boxplots across the different types of forecasts (so across the columns in Figure ), it becomes clear that we have a very small resampling dispersion (‘blurredness’ of forecasts) for the median forecasts, and a rather large one for the 95%-quantile forecast. This goes along with our previous conclusions, as well as with the ones in [Citation7]. The situation might be even worse under different model parametrizations, such as the one in Figure (with instead of
). But here, it is important to note that the root cause for the large resampling dispersion of the 95%-quantile forecasts is a discreteness problem, which affects the true forecast's distribution under estimation uncertainty (nearly a 50:50 distribution on
) in the same way. For
, we have
being very close to 0.95, such that the 95%-quantile is extremely sensitive to estimation error. In contrast, for
, we have
being clearly larger than 0.95, such that the estimated 95%-quantiles equal the true one in the large majority of cases. In fact, this discreteness problem concerning sample quantiles is also observed in more general contexts, see [Citation9] for further details, especially their Theorem 6. While the 95%-quantile forecasts are problematic for
, we again observe consistency for the resampling of the 90%-PIs. It is also worth pointing out that in both Figures and , the range of resampled intervals strongly decreases with increasing T, confirming our conclusions from Table A2.
Figure 2. Poi-INAR(1) DGP with ,
, and sample size T. Distribution of forecasts conditioned on value 5: conditional median (‘PF
’, true value: 5), 95%-quantile (‘PF
’, true value: 7), and limits l, u of 90%-PI (‘PI
’, true limits: 3, 7). Distribution under estimation uncertainty as gray dots, and boxplots of resampled distributions.
3.3. Comparison to other types of DGP
To analyze if our conclusions drawn for the case of a Poi-INAR(1) DGP transfer to other types of DGP as well, also the remaining count time series models in Appendix 1 have been considered in our simulation study. Certainly, these are (by far) not the only models for count time series, see the surveys by Weiß [Citation24,Citation25]. For example, there are models using different thinning operations, such as the so-called ‘NGINAR(1) model’ by Ristić et al. [Citation19] relying on negative-binomial thinning, and there are also regression-type models for time series consisting of bounded counts, such as the so-called ‘BINARCH models’ by Ristić et al. [Citation20]. Generally, one may also consider models with a non-linear conditional mean, although problems might occur if the log-likelihood function has multiple local maxima, such as for the minification INAR model of [Citation1]. To not make our comparisons unnecessarily complex, we restrict to the models in Appendix 1. The model parametrizations were always chosen such that the mean μ and the ACF at lag 1, , agree across all models. The third model parameter of the NB- and ZIP-INAR(1) model, respectively, was used to ensure that the variance-mean ratio equals
(i.e. 50% overdispersion). The second-order AR parameter of the Poi-INAR(2) model was uniquely chosen as
, and we computed
. Here, forecasting was done conditioned on the respective last two observations
in each Monte–Carlo run. Finally, the possible upper bounds of the BAR(1) model are
, leading to the mean
with the unique choice
. The tabulated results are again collected in Appendix 2, where in each table, always one feature is compared across all types of DGP.
Table A3 provides the numbers of those simulation runs, where the respective forecast based on the estimated parameter values agrees with the one using the true parameter values. Like for the Poi-INAR(1) DGP (first block of columns in Table A3), the forecasts obtained by using estimated parameters often deviate from the true ones also for the remaining models. This deviation is particularly large for the NB- and ZIP-INAR(1) model with their additional overdispersion, and also much larger for the non-central PF and the PI than for the central PF. For the Poi-INARCH(1) DGP, these agreement numbers are more stable across different values of α than for the Poi-INAR(1) DGP. If we would take the modes of the resampled forecasts as the substitutes of the forecasts under estimation uncertainty, then nearly nothing changes because of the modes just reproducing these forecasts most of the times (Table A4).
The full set of resampled forecasts, in contrast, covers the true forecast nearly without exception (Table A5). Only in the presence of additional overdispersion (NB- or ZIP-INAR(1) model) and for the small sample size T = 100, the coverage rate might fall below 99%. Thus, the proposed resampling approach successfully accounts for the effect of parameter estimation for any of the considered DGPs. Finally, let us analyze the mean sizes of the sets of different resampled forecasts (degree of blurredness), see Table . For the Poi-INARCH(1) DGP, these sets typically consist of only 2–4 different forecasts in the mean. These values are more homogeneous than in the Poi-INAR(1) case, i.e. there is less difference between PFs and PIs, and less difference regarding varying values of α. The BAR(1) values resemble those of the Poi-INAR(1) DGP, and also the mean sizes for the central PF are quite similar for all types of DGP. However, the sets of the resampled non-central PFs and, in particular, those of the PIs might become quite large. This can be observed for the Poi-INAR(2) DGP with large mean μ and, in particular, for the NB- and ZIP-INAR(1) DGP (if again μ is large, and if the ACF parameter α is small). Fortunately, these mean sizes get quickly reduced for increasing sample size T. Furthermore, the resampled PIs are strongly overlapping such that a reasonable interpretation is still possible even if the number of different PIs is large. This is illustrated by the example presented in Section 4.
4. Real-data example
To illustrate the application of the resampling approach for coherent forecasting proposed in Section 2, we consider a count time series about the monthly numbers of ‘work stoppages’ (strikes and lock-outs) of workers in the U.S. These numbers are published by the U. S. Bureau of Labor Statistics at https://www.bls.gov/wsp/. A part of these data, the T = 108 counts referring to the period 1994–2002, has already been analyzed by Jung et al. [Citation11], Weiß [Citation23,Citation24] and others. It turned out that these data, which are shown in Figure together with their sample ACF, are well described by a Poi-INARCH(1) model. The corresponding ML estimates (with approximate standard errors in parentheses) are obtained as
(0.593) and
(0.081). This well-established model fit shall now be used as the base for (post hoc) forecasting the counts of the year 2003 (numbered as
, and also taken from the aforementioned website). Thus, we compute the coherent forecasts (again the median as a central PF, the 95%-quantile as a non-central PF, and the 90%-PI) for
after having observed
for
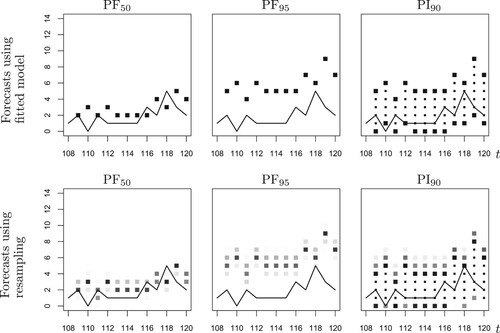
. If these forecasts are computed based on the estimated model, we obtain the unique forecast values shown in the upper panel of Figure (to better highlight their interval nature, the interior points of the PIs are plotted with a smaller point size). This uniqueness, however, could cause the erroneous impression that these forecast values are precise.
Figure 3. Strikes counts discussed in Section 4: time series plot (left) and sample ACF with time lag k (right).
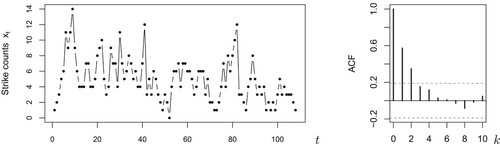
Figure 4. Strikes counts in 2003 (solid line) together with different types of forecasts: conditional median (“PF”), 95%-quantile (“PF
”), and 90%-PI (“PI
”), computed from ML-estimated parameter (upper panel) or based on resampled ML-estimates (lower panel).
To account for the apparent estimation uncertainty, in the way described in Section 2, we first compute the inverse Hessian of the log-likelihood function at its maximum, i.e. at . This is directly offered by the numerical optimization routine used for the ML computation (we used the function optim in R). It leads to the approximate bivariate normal distribution
which is used for simulating the B = 500 replicates
with
(we used mvrnorm in R's MASS package). Then, for
, we compute all forecasts for
again, namely B times based on the replicates
. As an example, the (post hoc) forecasts for
, given that
, are (absolute frequencies shown in parentheses)
PF
PF
PI
So instead of a unique forecast value, we get 3–4 values together with their frequencies; these support lengths are plausible in view of Table , see the values for the Poi-INARCH(1) DGP with and T = 100. Also note that the mode of the resampled forecasts equals the forecast of the fitted model for PF
and PF
, but slightly differs for PI
; recall the discussion of Table A4. The frequency distributions of the resampled PFs are easily visualized by plotting all forecasts as gray dots, where the gray levels are proportional to the respective frequencies (with black=100% and white=0%), see the first two graphs in the lower panel of Figure . So instead of a single dot that leads the viewer to believe in an exact inference, the blurred structure reveals the estimation uncertainty in forecasting and expresses which count values are likely to be the true PF value. Recalling Table A5, we can be rather sure that the respective true PF value is covered by the resampled ones. If, for example, some management decisions rely on PF values regarding the monthly strikes, then these should better use the information about the estimation uncertainty as resulting from resampling, e. g. by using a worst-case strategy.
For the PIs, the situation is slightly more complicated at a first glance, because there is no strict order between the computed sets. However, also recall the comment in the end of Section 3.3, the sets are strongly overlapping. We evaluated the full ensemble of four PIs at t = 109 in the following way. First, we computed the union of all PIs, leading to the set in the present example. Second, for each element in this superset, we computed its absolute frequency as the number of PIs covering this element, leading to 0 (473), 1–3 (500), 4 (488), 5 (234), and 6 (27). These frequencies are then used for computing the gray levels of the dots printed at t = 109 in the last graph of Figure (in addition, the interior points with absolute frequency B = 500 are again plotted with a smaller point size). Note that the superset
is only slightly larger than the PI
of the fitted model, i.e. we have an only small increase of ambiguity in this sense (similar at
, see the last column in Figure ). Furthermore, in view of our simulation results in Table A5 (see the Poi-INARCH(1) DGP with
and T = 100), we can be very confident that the true 90%-PIs are covered by the resampled ones. In addition, we can see that in view of estimation uncertainty, the counts 0–4 are much more likely to be contained in the true PI than the remaining counts 5–6. This refined information is not provided the PI
of the fitted model.
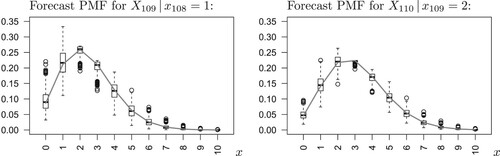
Let us conclude the data application by briefly discussing the task of ‘PMF forecasting’ mentioned in Section 1. As an intermediate step of our resampling approach, we had to compute the forecast PMF for each replicate , because the PMF was used to derive the PFs and PIs. Thus, if a practitioner is interested in the full forecast PMF instead of PFs or PIs, the ensemble of B replicated forecast PMFs can be used to express the actual estimation uncertainty. This is illustrated in Figure , where we compare the forecast PMFs for
and
based on the ML-fitted model (shown as a gray line) with box plots of the B PMF values computed for
, respectively. The box plots clearly indicate where we have to account for how much uncertainty (in a similar spirit, Harris et al. [Citation6] used animated graphics to visualize the effect of estimation uncertainty on forecast densities). The box plots also confirm the above PF and PI computations. For example, the left graph shows that the PMF value for the event
is hardly below 0.05 such that the large majority of two-sided PI
s includes the count 0. For
(right graph), in contrast, the median PMF value 0.047 is slightly below 0.05, and also the PI
based on the ML-fitted model does not include the count 0, recall the upper-right graph in Figure . But the actually realized count is
, i.e. it is erroneously not covered by the fitted model's PI
. This problem does not occur for the resampled PI
s, because 214 out of 500 include the count 0, so it is quite likely that the true PI
would cover the oberserved
.
Figure 5. Forecast PMFs for strikes counts in Jan./Feb. 2003, computed from ML-estimated parameter (grey line) or based on resampled ML-estimates (box plots).
5. Conclusions
To account for the estimation uncertainty in coherent forecasting of count processes, we proposed an efficient resampling scheme that relies on the asymptotic normal distribution of the DGP's ML estimator, and that generates an ensemble of forecast values instead of a single (and possibly wrong) forecast value. Our resampling approach requires much less computing than if using a traditional parametric bootstrap implementation but shows a very similar performance. It mimics the respective forecast's true sampling distribution and thus describes the actual estimation uncertainty in forecasting. The obtained ensembles of PF or PI values can be represented visually to simplify the interpretation by a practitioner. Our approach is also easily adapted to PMF forecasting. For future research, also other types of discrete-valued processes (such as ordinal processes) should be considered, and one should try to adapt the above forecasting and resampling approaches to such type of data. For count processes, in turn, the forecasting of risk is relevant in some applications. In contrast to the discrete count values themselves, common risk measures for counts are often positively real-valued. It would be interesting to study the effect of parameter estimation on risk forecasts for count processes, and to develop adequate ways of incorporating the resulting estimation uncertainty into such continuous-valued types of forecasts.
Acknowledgments
The authors thank the two referees for their useful comments on an earlier draft of this article. This research was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Projektnummer 394832307.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- M.S. Aleksić and M.M. Ristić, A geometric minification integer-valued autoregressive model, Appl. Math. Model. 90 (2021), pp. 265–280.
- P. Billingsley, Statistical Inference for Markov Processes, University of Chicago Press, Chicago, 1961.
- L. Bisaglia and M. Gerolimetto, Forecasting integer autoregressive processes of order 1: are simple AR competitive? Econ. Bulletin 35 (2015), pp. 1652–1660.
- R. Bu, B. McCabe, and K. Hadri, Maximum likelihood estimation of higher-order integer-valued autoregressive processes, Journal of Time Series Analysis 29 (2008), pp. 973–994.
- R.K. Freeland and B.P.M. McCabe, Forecasting discrete valued low count time series, Int. J. Forecast. 20 (2004), pp. 427–434.
- D. Harris, G.M. Martin, I. Perera, and D.S. Poskitt, Construction and visualization of confidence sets for frequentist distributional forecasts, J. Comput. Graph. Stat. 28 (2019), pp. 92–104.
- A. Homburg, C.H. Weiß, L.C. Alwan, G. Frahm, and R. Göb, Evaluating approximate point forecasting of count processes, Econometrics 7 (2019), 30.
- A. Homburg, C.H. Weiß, L.C. Alwan, G. Frahm, and R. Göb, A performance analysis of prediction intervals for count time series, J. Forecasting. 2020. https://doi.org/https://doi.org/10.1002/for.2729.
- C. Jentsch and A. Leucht, Bootstrapping sample quantiles of discrete data, Ann. Inst. Stat. Math. 68 (2016), pp. 491–539.
- C. Jentsch and C.H. Weiß, Bootstrapping INAR models, Bernoulli 25 (2019), pp. 2359–2408.
- R.C. Jung, G. Ronning, and A.R. Tremayne, Estimation in conditional first order autoregression with discrete support, Stat. Papers 46 (2005), pp. 195–224.
- R.C. Jung and A.R. Tremayne, Coherent forecasting in integer time series models, Int. J. Forecast. 22 (2006), pp. 223–238.
- D.R. Kim and S.Y. Hwang, Forecasting evaluation via parametric bootstrap for threshold-INARCH models, Commun. Stat. Appl. Methods. 27 (2020), pp. 177–187.
- S. Kolassa, Evaluating predictive count data distributions in retail sales forecasting, Int. J. Forecast. 32 (2016), pp. 788–803.
- J.-P. Kreiß and E. Paparoditis, Bootstrap methods for dependent data: A review, J. Korean. Stat. Soc. 40 (2011), pp. 357–378.
- B.P.M. McCabe and G.M. Martin, Bayesian predictions of low count time series, Int. J. Forecast. 21 (2005), pp. 315–330.
- B.P.M. McCabe, G.M. Martin, and D. Harris, Efficient probabilistic forecasts for counts, J. R. Statist. Soc. – Ser. B 73 (2011), pp. 253–272.
- T.N. Palmer, The economic value of ensemble forecasts as a tool for risk assessment: from days to decades, Q. J. R. Meteorolog. Soc. 128 (2002), pp. 747–774.
- M.M. Ristić, H.S. Bakouch, and A.S. Nastić, A new geometric first-order integer-valued autoregressive (NGINAR(1)) process, J. Stat. Plan. Inference. 139 (2009), pp. 2218–2226.
- M.M. Ristić, C.H. Weiß, and A.D. Janjić, A binomial integer-valued ARCH model, Int. J. Biostatist. 12 (2016), 20150051.
- N. Silva, I. Pereira, and M.E. Silva, Forecasting in INAR(1) model, REVSTAT 24 (2009), pp. 171–176.
- R.D. Snyder, J.K. Ord, and A. Beaumont, Forecasting the intermittent demand for slow-moving inventories: A modelling approach, Int. J. Forecast. 28 (2012), pp. 485–496.
- C.H. Weiß, The INARCH(1) model for overdispersed time series of counts, Commun. Statist. – Simul. Comput. 39 (2010), pp. 1269–1291.
- C.H. Weiß, An Introduction to Discrete-Valued Time Series, John Wiley & Sons Inc., Chichester, 2018.
- C.H. Weiß, Stationary count time series models, WIREs Comput. Stat. 13 (2021), e1502.
- T.R. Willemain, C.N. Smart, and H.F. Schwarz, A new approach to forecasting intermittent demand for service parts inventories, Int. J. Forecast. 20 (2004), pp. 375–387.
Appendices
Appendix 1.
Summary of considered count DGPs
In what follows, we summarize those count time series models, which were used as a DGP in our simulation studies. More details and references on these and further count time series models can be found in the book by Weiß [Citation24], or in the survey article by Weiß [Citation25]. The INAR(1) model is defined by the recursive scheme
(A1)
(A1)
where the innovations
are i. i. d. count random variables, and where ‘°’ denotes the binomial thinning operator. The latter is defined by a conditional binomial distribution,
, and it is executed independently of the innovations and of already available observations. Important special cases are the
Poi-INAR(1) model, where
NB-INAR(1) model, where
ZIP-INAR(1) model, where
With denoting the means,
the variances, and
the autocorrelation function (ACF), it holds that
The conditional distribution of
is a convolution of the thinning's binomial distribution,
, and the distribution of
. A second-order extension of (EquationA1
(A1)
(A1) ), the INAR(2) model, is obtained by the recursion
(A2)
(A2)
where all thinnings are executed independently. The distribution of
is a convolution of
,
, and the distribution of
. The ACF satisfies
, and
for
.
A modification of (EquationA1(A1)
(A1) ) for counts having the bounded range
with some
, the binomial AR(1) model, is defined by
(A3)
(A3)
Here, the model parameters are
and
, and we define the thinning probabilities as
and
. The BAR(1) process (EquationA3
(A3)
(A3) ) has the marginal distribution
, the ACF
, and the conditional distribution of
is a convolution of
and
.
Another modification of (EquationA1(A1)
(A1) ) is the Poi-INARCH(1) model (where ‘CH’ abbreviates ‘conditional heteroskedasticity’), which follows the recursion
(A4)
(A4)
Mean, variance, and ACF, respectively, are given by
Appendix 2.
Tables with simulation results for Section 3
Table A1. Coherent forecasting of Poi-INAR(1) DGP: conditional median (‘PF’), 95%-quantile (‘PF
’), and 90%-PI (‘PI
’), computed from true parameter, ML-estimated parameter, or based on resampled ML-estimates.
Table A2. Coherent forecasting of Poi-INAR(1) DGP based on resampled ML-estimates: conditional median (‘PF’), 95%-quantile (‘PF
’), and 90%-PI (‘PI
’). Mean number of different forecasts obtained from resampling.
Table A3. Coherent forecasting of different count DGPs: conditional median (‘PF’), 95%-quantile (‘PF
’), and 90%-PI (‘PI
’), computed from true parameter, ML-estimated parameter, or based on resampled ML-estimates. Numbers of agreement of true and estimated forecasts.
Table A4. Coherent forecasting of different count DGPs: conditional median (‘PF’), 95%-quantile (‘PF
’), and 90%-PI (‘PI
’), computed from true parameter, ML-estimated parameter, or based on resampled ML-estimates. Numbers of agreement of estimated forecasts and modes of resampled forecasts.
Table A5. Coherent forecasting of different count DGPs: conditional median (‘PF’), 95%-quantile (‘PF
’), and 90%-PI (‘PI
’), computed from true parameter, ML-estimated parameter, or based on resampled ML-estimates. Numbers of cases, where true forecasts covered by resampled forecasts.
Table A6. Coherent forecasting of different count DGPs: conditional median (‘PF’), 95%-quantile (‘PF
’), and 90%-PI (‘PI
’), computed from true parameter, ML-estimated parameter, or based on resampled ML-estimates. Mean lengths of support of resampled forecasts.