
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Investigating the main determinants of the mechanical performance of metals is not a simple task. Already known physically inspired qualitative relations between 2D microstructure characteristics and 3D mechanical properties can act as the starting point of the investigation. Isotonic regression allows to take into account ordering relations and leads to more efficient and accurate results when the underlying assumptions actually hold. The main goal in this paper is to test order relations in a model inspired by a materials science application. The statistical estimation procedure is described considering three different scenarios according to the knowledge of the variances: known variance ratio, completely unknown variances, and variances under order restrictions. New likelihood ratio tests are developed in the last two cases. Both parametric and non-parametric bootstrap approaches are developed for finding the distribution of the test statistics under the null hypothesis. Finally an application on the relation between geometrically necessary dislocations and number of observed microstructure precipitations is shown.
Abbreviations
AIM; alternating iterative method
EBSD; electron backscatter diffraction
GND; geometrically necessary dislocations
KAM; Kernel average misorientation
LRT; likelihood ratio test
MLE; maximum likelihood estimation
PAVA; pool-adjacentviolators algorithm
1. Introduction
Understanding the intrinsic nature of the mechanical properties of metals is usually not an easy task. In order to get insight into what gives desired mechanical performance to a metal, a deep and detailed analysis of the metal microstructure characteristics is needed. For instance, it is known in literature that dislocations, i.e. line defects in the crystalline arrangement of the atoms [Citation17], play a fundamental role in the mechanical behavior of metal alloys. More specifically, the appearance of geometrically necessary dislocationsFootnote1 (GNDs) during plastic deformation of the material contributes to the hardening of the material. Detecting GNDs from 2D microstructure images is often challenging. One widely accepted way is to use the so-called Kernel average misorientation (KAM) [Citation26]. The KAM, measured in electron backscatter diffraction (EBSD), quantifies the average misorientation around a measurement point with respect to a defined set of a nearest or nearest plus second-nearest neighbor points [Citation8].
In [Citation6,Citation22,Citation31], studies on the relation between GNDs and microstructure properties such as grain size and carbides size are presented. The relation between GNDs and grain size has both theoretical and experimental confirmation and it can be related to the well-known macroscopic physical Hall-Petch relation [Citation15,Citation29]. In fact, the Hall-Petch relation, in its original version, describes the negative dependence of yield stress (mechanical property) on grain size; loosely speaking the smaller grains are, the stronger the material is. More specifically in [Citation18], the authors give as an explanation of the relation between GNDs and grain size that as the grain size decreases the grain boundary layer in which GNDs typically accumulate, occupies a greater volume fraction of the material, therefore it is reasonable to think that the smaller are the grains, the more GNDs will be observed.
Still unclear is, instead, the relation between carbides and GNDs. In fact, since the 1940s, several studies on how carbides affect the mechanical behavior of metals have been conducted. In [Citation30], the authors state that the primary carbides and their distribution have a major influence on the wear resistance and the toughness of the material. However, carbides tend to precipitate along the grain boundaries, that as said before, are the locations in which GNDs typically accumulate. Until now, no direct physical relationship has been found between carbides and GNDs. Therefore, isolating carbides effect and assessing the conjecture on the positive relation between carbides and GNDs is a problem of interest.
In [Citation16], a descriptive statistical analysis with response variable KAM, used as a proxy of GNDs and as explanatory variables the number of grains, the number of carbides and the position of carbides revealed an almost monotone trend of the response variable according to the increments of the explanatories.
Therefore, in order to take into account the already known direction of the physical relation, we want to propose an approach that incorporates this information and a procedure for testing the prementioned conjectures on a new dataset.
In this context, isotonic regression comes to aid. In fact, the idea at the basis of isotonic regression is taking order restrictions into account for improving the efficiency of the statistical analysis by reducing the error or the expected error of estimates and increasing the power of the testing procedures, provided that the hypothesized order restriction actually holds. The first papers about isotonic regression appeared in the 1950's [Citation1,Citation41] and books [Citation2,Citation33] are well-known references for frequentist statistical inference under order restrictions. Isotonic regression proves its power in different fields such as epidemiology in testing the effects of different treatments or in dose-finding [Citation34,Citation40] but also in genetics [Citation23], business [Citation19], biology [Citation3]. There are not many examples of isotonic regression use in Materials Science. Throughout this paper, special attention is given to the peculiar data structure. Nowadays, developments toward multivariate isotonic regression, isotonic regression in inverse and censoring problems [Citation13,Citation14] are ongoing. Also in the Bayesian framework, the problem of estimating and testing under order constraints has been addressed and well developed [Citation7,Citation10,Citation20,Citation21]. But also in the most basic frequentist framework, there is still something missing.
In this paper, starting off with the most basic case, univariate isotonic regression of means under normality assumptions with known variances, we guide the reader into frequentist estimation and testing order restriction assumptions, considering different conditions on the variances.
Three different scenarios are considered. In all three cases, we focus on maximum likelihood as estimation procedure and likelihood ratio test (LRT) as test statistic for hypothesis testing.
The first case is the basic case in which ‘the variances’ are known or unknown but their ratio is known. This instance is considered extensively in [Citation2,Citation33] and results for estimation and testing order restrictions are already known.
The second scenario is from an applications point of view the most common scenario in which the variances are unknown. In [Citation37], the authors derive a two steps estimating procedure for means and variances and interesting results on existence and uniqueness of the maximum likelihood estimates are derived under special conditions. Another iterative method, proposed in [Citation38], is extended to the unknown variances case. The derivation of the test statistic and of its distribution in this scenario is not trivial. In fact, the estimate of the mean under the null hypothesis is also affected by the non-knowledge of the variances. We propose the LRT statistic and two different bootstrap approaches, one parametric and one non-parametric, for obtaining the test statistic distribution.
The last model considers not only the means under order restrictions but also the variances. This case has not often been faced probably because it is not common to have prior knowledge on the order of both means and variances. As in the unknown variances scenario, a two-step procedure for estimating means and variances is derived in [Citation36] and similar results on existence and uniqueness under specific conditions on the empirical variances are given. In [Citation38], an improved algorithm called alternating iterative method (AIM) and more general results about convergence are derived. For testing in this case we derive the LRT taking into account the order of variances also under the null hypothesis and apply a parametric and non-parametric bootstrap approach in line with the one derived in the unknown variance case to obtain approximate p-values.
The paper structure is as follows. In Section 2, we explain the estimation procedure of the isotonic means in the three different cases (Sections 2.1, 2.2, 2.3). In Section 3, the focus is on the LRT. We present it in the three different cases (Sections 3.1, 3.2, 3.3) and in Section 4, we propose both a parametric and non-parametric bootstrap approach for approximating the distribution of the test statistics under the null hypothesis. Finally, in Section 5, we come back to the application and we illustrate step-by-step how to deal with a real problem and more precisely how to perform isotonic regression and test for monotonicity of KAM with respect to the number of carbides. The paper ends with conclusions in Section 6.
2. Estimating restricted means in the normal case
We first introduce isotonic regression and the notation used in the rest of the paper in a more general context. Normality is assumed throughout this section.
Let ,
,
be the jth observation of the response variable
corresponding to the ith level of the explanatory variable
.
We assume to be independent random variables, normally distributed with means
and variances
,
,
.
The log-likelihood is then given by
(1)
(1)
where
is a constant which does not depend on the parameters
and
.
Furthermore, we assume that satisfies
(2)
(2)
A k-dimensional vector
is said to be isotonic if
implies
.
Let D be the set of all the isotonic vectors in ,
(3)
(3)
In this section, we are interested in the maximum likelihood estimator of
, where
is isotonic and
. Depending on the information on
, different MLEs have been derived.
In the following three sections, the three different cases are considered.
2.1. Isotonic regression of means with known variance ratio
This first case constitutes the most basic case in which all variances are either known or unknown but they differ according to some known multiplicative constants . This means that the variance
of the response variable
is given by:
This specific case is already covered in [Citation2,Citation33], but we hereafter report the main results. The problem of maximizing log-likelihood (Equation1
(1)
(1) ) in μ can be rewritten equivalently as solving:
(4)
(4)
where
and
. Note that this objective function does not depend on
. The solution,
, is called the isotonic regression of
with weights
[Citation37]. For obtaining the solution to (Equation4
(4)
(4) ), different algorithms have been proposed in the literature ([Citation2,Citation33]). In this paper, the the intuitive and skilfully implemented ‘Pool-Adjacent Violators Algorithm’ (PAVA) is used ([Citation1,Citation5]).
More details about the algorithm are provided in Appendix 1.
2.2. Isotonic regression of means with unknown variances
In this second case, no assumptions on the variances are made. They are unknown and for obtaining the maximum likelihood estimate of , they need to be estimated as well. In [Citation37], the authors consider this case and interesting results on existence and uniqueness of the MLE are achieved. We hereby recall the main results. The approach is to maximize the log-likelihood (Equation1
(1)
(1) ), with
and
.
For any fixed , the maximizer
of
over
is the isotonic regression of
with weights
and
.
On the other hand, for any fixed , the maximizer
of
over
is
, where
.
Substituting into (Equation1
(1)
(1) ), we can express the profile log-likelihood of
as
(5)
(5)
where
is the sample variance of the ith normal population and c a constant that does not depend on
. Note that
if
or
. Hence, maximizing l over D is equivalent to maximizing l over a compact subset of D of type
. As l is continuous on
, a maximizer over D exists.
As previously said, the authors in [Citation37] discuss also uniqueness of the MLE of . They state that l is not a concave function in general and that for guaranteeing uniqueness the following condition suffices (see Theorem 2.3 [Citation37]):
Condition 2.1
For ,
.
For finding a maximizer of (Equation5(5)
(5) ), a two-step iterative algorithm based on PAVA has been proposed in [Citation37]. From an initial guess for
, the associated maximizer in
is computed and after that the maximizer in
based on this
and so on. This iterative procedure stops when the maximum difference between the estimated means at step l−1 and at step l is less than an arbitrary small threshold value, e.g.
where m is taken to be equal to 3 in our case. In [Citation38], the authors propose a new algorithm called AIM. The procedure is based on the minimization of a semi-convex function. In particular, restating the problem in terms of
, where
and given
is a convex subset of
and V a convex subset of
,
,
is a semi-convex function because: i)
is defined on
; ii) for any given
,
is strictly convex on V and, for any given
,
is strictly convex on
. The algorithm originally proposed for the simultaneous order restrictions of means and variances can be easily extended to the unknown variance case. The iteration method works in alternating the search of the minimum point,
, of
on a compact subset
and the search of the minimum point,
, of
on V. Proof of the convergence of the algorithm does not require additional conditions [Citation38]. The iterative procedure stops when the difference between the likelihoods at step l−1 and at step l is less than an arbitrary small threshold value:
(6)
(6)
A more detailed version of both algorithms is reported in Appendix A.2.
2.3. Isotonic regression of means and variances simultaneously
We now assume that both mean and variances are restricted by simple orderings. Therefore, in addition to assumption (Equation2(2)
(2) ), we assume also:
(7)
(7)
The reason for taking decreasing order relates to our application considered in Section 5; increasing variances can be dealt with analogously. In [Citation36], maximum likelihood estimation under simultaneous order restrictions on mean and variances from a normal population is studied. Some of the most important results are hereby recalled. The approach is to maximize the log-likelihood (Equation1
(1)
(1) ) with
and
, where
is the closure of
(8)
(8)
This means that the maximizer will have positive
-values if there is variation within the groups. Then, for any fixed
, the maximizer
of
over
is the isotonic regression of
with weights
and
.
Furthermore, for any , the maximizer
of
is the so-called antitonic regression (isotonic regression with reversed order [Citation13]) of
,
, with weights
. Existence is guaranteed noticing that
,
(see [Citation36, Theorem 2.1]).
Uniqueness is proved under the following condition (see Theorem 2.2 [Citation36])
Condition 2.2
For the sample variance
satisfies
, where b and a are the maximal and the minimal means respectively.
As in the unknown variances case, a two-step iterative algorithm is proposed for finding the solution for both means and variances under order restrictions. The proof of the convergence of the algorithm is given under Condition 2.2.
Later, in [Citation38], as mentioned in the previous section, the authors show that restating the problem in terms of , where
Condition 2.2 is not needed for proving that the algorithm converges. In fact, also in this case the proposed AIM algorithm can be employed. Since
has continuous second-order partial derivatives and the Hessian matrix with respect to μ
is a positive definite diagonal matrix for any fixed
,
then by Theorem 4 in [Citation38] the iterative sequence of solutions to
,
converges to the MLE solution and consequently the sequence
as well.
As in the previous case, the alternating iterative procedure is stopped when the maximum difference between the likelihoods at step l−1 and at step l is less than an arbitrary small threshold value (see (Equation6(6)
(6) )).
A pseudo code of the algorithms can be found in Appendix A.3.
3. LRT: constant μ against monotonicity
We are interested in testing hypotheses of monotonicity in μ under the various assumptions on the variances discussed in Section 2. There exists extensive literature on testing hypotheses on means. In most cases, a standard testing procedure entails testing the hypothesis of equality of means against the hypothesis that they are different. In this paper, we consider the same null hypothesis but the alternative is different: monotonicity of the means. As in the previous section, we consider three different testing frameworks according to the different assumptions on the variances. In all three different scenario, the test statistic of interest is the LRT, an intuitive and powerful tool in hypothesis testing. In both [Citation2] and [Citation33], an entire chapter is dedicated to LRT developments and its use for testing order restrictions hypothesis under the normality assumption and known variance ratio. Using the same notation used in Section 2, we wish to test
against monotonicity of means
(9)
(9)
The LRT for
against
can be defined as:
(10)
(10)
where
,
and
. It rejects the null hypothesis for small values of Λ or alternatively for large values of
. The convenience in using this other form lies on the analogy with the
statistic used to test against the alternative hypothesis
, that not all
's,
, are the same.
In the following sections, more explicit expressions for Λ are given depending on the specific assumptions on means and variances.
3.1. LRT with known variance ratio
As in Section 2.1, let
,
be independent observations, normally distributed with unknown mean
and variances
with
known and
unknown. Under
, the maximum likelihood estimate of
is given by:
(11)
(11)
with
. Under
the MLE of
is
, the isotonic regression of
, with weights
, with respect to the simple order defined in (Equation9
(9)
(9) ).
The LRT for against
, if the variances are known and
boils down to rejecting
for large values of
(12)
(12)
It is easy to check that the test is equivalent to rejecting
for large values of:
(13)
(13)
where
and
is the (known) common value of the variance.
Now, let us consider the more general case, with
known and
unknown. The estimator of
under the null hypothesis is
(14)
(14)
and under
(15)
(15)
The LRT rejects
for small values of
or equivalently, taking
, for large values of
(16)
(16)
An extension to the multivariate case with covariance matrix Σ unknown but common can be found in [Citation28,Citation35].
3.2. LRT with unknown variances
In this second case, no assumptions on the variances are made. They are unknown and possibly unequal. Using the notation of Section 2.2, let ,
,
be independent observations from a univariate normal distribution with unknown mean vector
and completely unknown variances
. Let
be the solution of the isotonic regression of
with weights
,
found used Algorithm (2.2) in Appendix 1.
The first example of testing when all the variances are unknown can be found in [Citation4] and the univariate version of the test proposed by the author is:
(17)
(17)
where
and
. This test is clearly inspired by the LRT but it is not.
Let us consider first the maximum likelihood solution ,
under the null hypothesis. The log-likelihood under the null hypothesis is
(18)
(18)
Differentiating this log-likelihood with respect to μ and
, the following k + 1 score equations in k + 1 unknowns emerge:
(19)
(19)
Substituting
in (Equation18
(18)
(18) ), the profile likelihood of μ is:
(20)
(20)
Theorem 1
A maximizer of (Equation20(20)
(20) ) over
exists and it is contained in
. Moreover, if
then the maximizer is unique.
Proof.
Maximizing profile likelihood of μ (Equation20(20)
(20) ) boils down to maximize the sum of functions
(21)
(21)
Functions of type (Equation21
(21)
(21) ) are unimodal with mode at
and strictly concave on
. As the sum of unimodal functions is decreasing to the right of the rightmost mode (since all terms are decreasing) and from
to the leftmost mode, the sum is increasing (as all of the functions are increasing on that set). Therefore, any maximizer of l, if it exists, belongs to the interval
. As l is continuous on
, existence of a maximizer is guaranteed.
Then if we consider the (possibly empty) interval where all the functions in (Equation21(21)
(21) ) are strictly concave, on that interval the sum is also strictly concave. As for each i the function (Equation21
(21)
(21) ) is strictly concave on
, (Equation20
(20)
(20) ) is strictly concave on
. If
is contained in this intersection, l is strictly concave on
. Hence l has a unique maximizer on
.
Remark 3.1
Remark in a setting with real data, it is easy to check whether and hence to determine whe-ther the maximum is unique.
However, as seen from (Equation19(19)
(19) ), the MLE estimate
has no closed form expression. Therefore, in [Citation11] and [Citation27], two different methods for finding the optimal solution are proposed. The first is an iterative procedure based on the Newton-Raphson method. A reasonable initial value for
is the so-called Graybill-Deal estimator [Citation12]
with
. The convergence speed of the algorithm strongly depends on the initial values. The second method is based on the profile likelihood approach. The authors in [Citation27] propose the bisection method for finding the zero of the profile likelihood with respect to
. Under
we use as estimates of
,
found using the iterative procedure described in Section 2.2.
The LRT when the variances are completely unknown can be expressed as:
Therefore, as in the previous case, the test rejects for small values of
or equivalently for large values of
.
3.3. LRT with ordered variances
Using the notation of Section 2.3, let ,
,
be independent observations from Normal distributions with mean vector
and variances
. As in the previous case, the first step is the estimation of
under the null hypothesis. In this case, we need to maximize (Equation18
(18)
(18) ) under the restriction
(22)
(22)
Theorem 2
Suppose that for ,
. Then there exists a maximizer of (Equation18
(18)
(18) ) under constraints (Equation22
(22)
(22) ).
Proof.
First consider the situation for fixed with
for all i. Differentiating (Equation18
(18)
(18) ) with respect to μ yields the equation
This shows, that for this
, the (unique) maximizer of (Equation18
(18)
(18) ) in μ is given by the following weighted sum of level-means,
Consequently,
, bounding the set of possible maximizers of (Equation18
(18)
(18) ) in μ irrespective of the precise value of
.
Now, given any , the corresponding optimal
is the solution to the antitonic regression problem
where
,
,
(see [Citation33, Example 1.5.5]). The vector to be projected has elements
. This means, that if μ is restricted to
, the coordinates to be projected all belong to the interval
. So, if μ ranges over
, the optimal
is also contained in a the closed bounded region
. By our assumption that all
, the MLE exists being a maximizer of a continuous function on a compact set in
If we consider this case as a special case of the case considered in [Citation36], the solution is unique if Condition 2.2 holds. Given that the solution is not in a closed form, we use an iterative procedure to approximate the solution. As a starting value , a modified version of the Graybill-Deal estimator of the common mean when the variances are subject to order restrictions proposed in [Citation25] appears to be a good choice:
(23)
(23)
where
is the isotonic regression of
where
,
.
Under we use as estimates of
,
found using the iterative procedure described in Section 2.3.
In contrast with the previous cases, it is not possible to further reduce the expression of the LRT because
does not reduce to a constant. The same holds under
. Therefore, the LRT in this case can be computed by substituting the solutions obtained via the iterative procedure under
and
in the generic expression given in (Equation10
(10)
(10) ):
(24)
(24)
4. Null hypothesis distribution of the test statistics: bootstrap approach
In order to determine the significance of the various test statistics proposed in the previous sections, we need the null hypothesis distribution of the test statistics. The main distributional results concerning and
, the test statistics derived in the known variance ratio case, are contained in [Citation2, Theorems 3.1–3.2]. However, problems related to the value of k can arise in the analytical derivation of the p-values. Numerical approximation can be necessary, especially if k>4 and if the variation in the range of the weights is not ‘moderate’ [Citation32,Citation39].
Furthermore, in the case of completely unknown variances, the null distribution depends on the unknown variances. When analytical derivation of the null distribution is particularly complex or not possible, bootstrap methodology is a good option. Therefore, we propose both a parametric and a non-parametric bootstrap approach that can be easily employed for finding approximate p-values taking into account the different assumptions on the variances. For overcoming the complex derivation when the variances are unknown, bootstrap procedures have been proposed in the literature [Citation4,Citation24].
In particular, in [Citation24], an interesting review of the methods used to approximate the null distribution of the test statistic under and the restrictive normality assumption (with which we will not deal in this paper) is reported. Moreover, the authors propose both a parametric and non-parametric bootstrap approach for the LRT null distribution for one-sided hypothesis testing for means in a multivariate setting [Citation24]. Also in [Citation4], a bootstrap approach to test the homogeneity of order restricted mean vectors when the covariance matrices are unknown is used. In line with those previous approaches, here we propose two general bootstrap procedures, parametric and non-parametric, that can be used for testing the null hypothesis taking into account the various assumptions on the variances.
4.0.1. Parametric bootstrap

4.0.2. Non-parametric bootstrap
The non-parametric version of the bootstrap releases the normality assumption of the bootstrap samples. However, a relatively large sample size is required for the following approach.

5. Application
One of the most common ways for investigating strength and ductility of metallic materials is by performing a tensile test. Loosely speaking, a tensile test is an experiment in which force is applied to the test sample causing deformation of the material, temporarily (elastic behavior), permanently (plastic behavior) and eventually its fracture [Citation9]. Data used in this paper are image data of the microstructure of the material subjected to a plastic strain (deformation) of 0.139 obtained performing a uniaxial tensile test in which force is applied to the test sample with respect to just one specific axis (Figure ).
Figure 1. Tensile testing machine.

At a microstructure level, the deformation of the material corresponds to displacements in the lattice structure and in the possible appearance of GNDs. The material used in this paper is an annealed AISI420 stainless steel with carbides and aim is investigating the carbide effect on the GNDs formation. KAM is used as a proxy of the GNDs. In Figure , the KAM is represented by filaments inside and among grains delimited by solid lines called grain boundaries; carbides are the black dots.
Figure 2. Microstructure image showing the KAM at strain level 13.9% (overlapped grid of ).

Modeling the relationship between KAM and carbides and more generally understanding its inhomogeneous distribution over the microstructure is now the main aim and it can be considered a starting point for finding a stochastic model for predicting mechanical properties from 2D microstructure images. We apply estimation procedures and perform tests under order restrictions, solving the three different univariate isotonic regressions problems (2.1, 2.2, 2.3) according to the assumption on the variances.
The first step for obtaining the data in the most suitable form for the analysis is ‘overlaying’ a grid over the image. In Figure , a grid is added to the image. With
, we denote the mean KAM value (expressed in misorientation degree
) of the jth square of the grid of the image taken in which i carbides are observed. The explanatory variable
in all three isotonic regressions is the number of carbides observed in the grid squares. A plot of the data is shown in Figure .
Figure 3. Plot of KAM and number of carbides for the 625 squared areas of Figure .
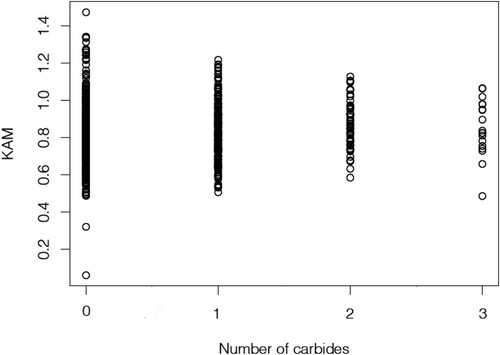
We wish to test the null hypothesis that the expected KAM is the same in all the squares of the gird, regardless the numbers of carbides observed in the grid. The alternative hypothesis
(26)
(26)
represents the idea that KAM tends to be higher in areas where more carbides are observed. Moreover, in the ordered variances case, we assume that
(27)
(27)
This is in accordance with what we see in Figure . In fact, the idea behind this assumption is that in areas in which less carbides are observed GNDs have more freedom to move, resulting in increments in dispersion.
The results of the estimation in the three different scenarios faced in Sections 2.1–2.3 are summarized in Table . The values of ,
and
represent the empirical group mean, group variance and group sample variance respectively. Comparing the solutions of the three different isotonic regression, (1) known variance ratio, (2) unknown variance and (3) variances under order restrictions, just very slightly differences can be noticed.
Table 1. Values of estimated means and variances of the KAM conditioned on the number of carbides visible in a square of a grid according to different order restrictions assumptions (13.9% Strain).
In Table , the results of testing the null hypothesis are shown. For computing and
, the variance ratio is supposed to be known. In the specific case, we assume that the KAM total variance for the whole image is the real-known variance and that
. For computing both the parametric and non-parametric p-values, the two different bootstrap approaches described in Section 4 have been used and M, the number of replications, is taken equal to 20, 000. Independent of the knowledge or assumptions on the variances, the conclusion is the same and leads to the rejection of the null hypothesis.
Table 2. Estimated values for the four different LRT with the corresponding parametric and non-parametric p-values.
6. Conclusions
This paper presents three different models involving order restrictions and within these models the ML estimators and LRTs for the homogeneity of the means against monotonicity are introduced and studied. Prior knowledge given by physical relations or intuition is not often exploited in statistical studies about materials and this can lead to less efficient methods that produce less accurate results. After having described the estimation procedures and highlighted how prior knowledge of the variances influence these, we propose the LRT as test statistic for testing homogeneity of means. In the unknown variances case and the ordered variances case, heteroskedasticity plays a crucial role also under the null hypothesis, leading to different estimates of the common mean under . Results on existence and uniqueness of the maximum likelihood estimates in these last two cases are derived. Furthermore, two different bootstrap approaches are proposed for approximating the null distribution of the test statistic under the different assumptions on the variances. The proposed tests are applied to a real data example from Materials Science, showing evidence that the so-called KAM tends to be higher in regions of the microstructure where more carbides are observed. In fact, incorporating reasonable intuition about the order of means and the variances order in this context helps understanding the evolution of complicated structure of dislocations in metals and its effect on the hardening behavior of the material during deformation.
Acknowledgments
This research was carried out under project number S41.5.14547b in the framework of the Partnership Program of the Materials innovation institute M2i (www.m2i.nl) and the Technology Foundation TTW (www.stw.nl), which is part of the Netherlands Organization for Scientific Research (www.nwo.nl).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 Dislocations are usually classified into redundant and non-redundant dislocations, respectively, called Statistically Stored Dislocations (SSDs) and Geometrically Necessary Dislocations (GNDs). GNDs are dislocations with a cumulative effect and they allow the accommodation of lattice curvature due to non-homogeneous deformation. They control the work hardening individually by acting as obstacles to slip and collectively by creating a long-range back stress.
References
- M. Ayer, H.D. Brunk, G.M. Ewing, W.T. Reid, and E. Silverman, An empirical distribution function for sampling with incomplete information, Ann. Math. Stat. 26 (1955), pp. 641–647.
- R.E. Barlow and H.D. Brunk, The isotonic regression problem and its dual, J. Am. Stat. Assoc. 67 (1972), pp. 140–147.
- S. Barragán, M.A. Fernández, C. Rueda, and S.D. Peddada, isocir: an R package for constrained inference using isotonic regression for circular data, with an application to cell biology, J. Stat. Softw. 54 (2013), pp. 00–00.
- A. Bazyari, Bootstrap approach to test the homogeneity of order restricted mean vectors when the covariance matrices are unknown, Commun. Stat.-Simul. Comput. 46 (2017), pp. 7194–7209.
- M.J. Best and N. Chakravarti, Active set algorithms for isotonic regression: A unifying framework, Math. Program. 47 (1990), pp. 425–439.
- M.W. Bird, T. Rampton, D. Fullwood, P.F. Becher, and K.W. White, Local dislocation creep accommodation of a zirconium diboride silicon carbide composite, Acta. Mater. 84 (2015), pp. 359–367.
- F. Böing-Messing, M.A. van Assen, A.D. Hofman, H. Hoijtink, and J. Mulder, Bayesian evaluation of constrained hypotheses on variances of multiple independent groups, Psychol. Meth. 22 (2017), pp. 262.
- M. Calcagnotto, D. Ponge, E. Demir, and D. Raabe, Orientation gradients and geometrically necessary dislocations in ultrafine grained dual-phase steels studied by 2D and 3D EBSD, Mater. Sci. Eng.: A 527 (2010), pp. 2738–2746.
- J.R. Davis, Tensile Testing, Materials Park, ASM international, Ohio, 2004.
- M.R. Danaher, A. Roy, Z. Chen, S.L. Mumford, and E.F. Schisterman, Minkowski-Weyl priors for models with parameter constraints: an analysis of the bioCycle study, J. Am. Stat. Assoc. 107 (2012), pp. 1395–1409.
- E.Y. Gökpinar and F. Gökpinar, A test based on the computational approach for equality of means under the unequal variance assumption, Hacettepe J. Math. Stat. 41 (2012), pp. 605–613.
- F.A. Graybill and R.B. Deal, Combining unbiased estimators, Biometrics 15 (1959), pp. 543–550.
- P. Groeneboom and G. Jongbloed, Nonparametric Estimation Under Shape Constraints: Estimators, Algorithms and Asymptotics (Cambridge Series in Statistical and Probabilistic Mathematics). Cambridge University Press, Cambridge, 2014, Vol. 38.
- A. Guntuboyina and B. Sen, Nonparametric shape-restricted regression, Stat. Sci. 33 (2018), pp. 568–594.
- E.O. Hall, The deformation and ageing of mild steel: III discussion of results, Proc. Phys. Soc., B 64 (1951), pp. 747–753.
- J. Hidalgo, M. Vittorietti, H. Farahani, F. Vercruysse, R. Petrova, and J. Sietsma, Influence of large M23C6 carbides on the heterogeneous strain development in annealed 420 stainless steel, preprint (2019).
- D. Hull and D.J. Bacon, Introduction to Dislocations, 4th ed. Butterworth-Heinemann, Oxford, 2001.
- J. Kadkhodapour, S. Schmauder, D. Raabe, S. Ziaei-Rad, U. Weber, and M. Calcagnotto, Experimental and numerical study on geometrically necessary dislocations and non-homogeneous mechanical properties of the ferrite phase in dual phase steels, Acta. Mater. 59 (2011), pp. 4387–4394.
- A. Keshvari and T. Kuosmanen, Stochastic non-convex envelopment of data: applying isotonic regression to frontier estimation, Eur. J. Oper. Res. 231 (2013), pp. 481–491.
- I. Klugkist, O. Laudy, and H. Hoijtink, Inequality constrained analysis of variance: a Bayesian approach, Psychol. Meth. 10 (2005), pp. 477.
- W. Li and H. Fu, Bayesian isotonic regression dose–response model, J. Biopharm. Stat. 27 (2017), pp. 824–833.
- P.D. Littlewood, T.B. Britton, and A.J. Wilkinson, Geometrically necessary dislocation density distributions in Ti-6Al-4V deformed in tension, Acta. Mater. 59 (2011), pp. 6489–6500.
- R. Luss, S. Rosset, and M. Shahar, Efficient regularized isotonic regression with application to gene-gene interaction search, Ann. Appl. Stat. 6 (2012), pp. 253–283.
- A.T. Minhajuddin, W.H. Frawley, W.R. Schucany, and W.A. Woodward, Bootstrap tests for multivariate directional alternatives, J. Stat. Plan. Inference. 137 (2007), pp. 2302–2315.
- N. Misra and E.C. van der Meulen, On estimation of the common mean of k(≥2) normal populations with order restricted variances, Stat. Probab. Lett. 36 (1997), pp. 261–267.
- C. Moussa, M. Bernacki, R. Besnard, and N. Bozzolo, Statistical analysis of dislocations and dislocation boundaries from EBSD data, Ultramicroscopy 179 (2017), pp. 63–72.
- H.T. Mutlu, F. Gökpinar, E. Gökpinar, H.H. Gül, and G. Güven, A new computational approach test for one-way ANOVA under heteroscedasticity, Commun. Statist.-Theor. Meth. 46 (2017), pp. 8236–8256.
- M.D. Perlman, One-sided testing problems in multivariate analysis, Ann. Math. Stat. 40 (1969), pp. 549–567.
- N.J. Petch, The cleavage strength of polycrystals, J. Iron Steel Instit. 174 (1953), pp. 25–28.
- E. Pippel, J. Woltersdorf, G. Pöckl, and G. Lichtenegger, Microstructure and nanochemistry of carbide precipitates in high-speed steel S 6-5-2-5, Mater. Charact. 43 (1999), pp. 41–55.
- C. Revilla, B. López, and J.M. Rodriguez-Ibabe, Carbide size refinement by controlling the heating rate during induction tempering in a low alloy steel, Mater. Des. 62 (2014), pp. 296–304.
- T. Robertson and F.T. Wright, On approximation of the level probabilities and associated distributions in order restricted inference, Biometrika 70 (1983), pp. 597–606.
- T. Robertson, F. Wright, and R.L. Dykstra, Order Restricted Statistical Inference, New York, Wiley, 1988.
- G. Salanti and K. Ulm, Multidimensional isotonic regression and estimation of the threshold value, Ph.D. diss., 2001.
- S. Sasabuchi, More powerful tests for homogeneity of multivariate normal mean vectors under an order restriction, Sankhy?: The Indian J. Stat. 69 (2007), pp. 700–716.
- N.Z. Shi, Maximum likelihood estimation of means and variances from normal populations under simultaneous order restrictions, J. Multivar. Anal. 50 (1994), pp. 282–293.
- N.Z. Shi and H. Jiang, Maximum likelihood estimation of isotonic normal means with unknown variances, J. Multivar. Anal. 64 (1998), pp. 183–195.
- N.Z. Shi, G.R. Hu, and Q. Cui, An alternating iterative method and its application in statistical inference, Acta Mathematica Sinica 24 (2008, English Series), pp. 843–856.
- M.J. Silvapulle and P.K. Sen, Constrained Statistical Inference: Inequality, Order and Shape Restrictions, 1st ed. John Wiley & Sons, Hoboken, NJ, 2005.
- M. Stylianou and N. Flournoy, Dose finding using the biased coin up and down design and isotonic regression, Biometrics 58 (2002), pp. 171–177.
- C. Van Eeden, Note on two methods for estimating ordered parameters of probability distributions, Indagationes Mathematicae (Proceedings); North-Holland; 1957, Vol. 60, pp. 506–512.
Appendix 1
A.1. ALGORITHM 2.1
Let
and
Is
Replace
A.2. ALGORITHM 2.2
A.2.0.1 Two steps Iterative procedure
Let
Is
Use Step 1.2 Algorithm 2.1 to compute
Compute
Go back to QUESTION 1 using
Repeat until
A.2.0.2 Alternating Iterative Method
Let
Repeat (1)-(2) until
A.3. ALGORITHM 2.3
A.3.0.3 Two steps Iterative procedure
Let
Is
Use Step 1.2 Algorithm 2.1 to compute
Compute
Is
Replace
Go back to QUESTION 1 using
Repeat until
A.3.0.4 Alternating Iterative Method
Let
Arxiv Preprint: arXiv:2002.00993