
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Model averaging (MA) is a modelling strategy where the uncertainty in the configuration of selected variables is taken into account by weight-combining each estimate of the so-called ‘candidate model’. Some studies have shown that MA enables better prediction, even in high-dimensional cases. However, little is known about the model prediction performance at different types of multicollinearity in high-dimensional data. Motivated by calibration of near-infrared (NIR) instruments,we focus on MA prediction performance in such data. The weighting schemes that we consider are based on the Akaike’s information criterion (AIC), Mallows’ Cp, and cross-validation. For estimating the model parameters, we consider the standard least squares and the ridge regression methods. The results indicate that MA outperforms model selection methods such as LASSO and SCAD in high-correlation data. The use of Mallows’ Cp and cross-validation for the weights tends to yield similar results in all structures of correlation, although the former is generally preferred. We also find that the ridge model averaging outperforms the least-squares model averaging. This research suggests ridge model averaging to build a relatively better prediction of the NIR calibration model.
1. Introduction
In a calibration of near-infrared (NIR) instruments, we model the concentrations of chemical compositions as a function of their NIR spectra measured at hundreds or thousands of wavelengths [Citation8]. The main objective of the calibration is to build a model with the best prediction. The spectra data are generally known to have some characteristics that pose a challenge in the modelling: first, the number of variables (wavelengths) far exceeds the number of observations and, second, the variables are highly correlated. When facing these challenges in the modelling, we usually consider a variable selection or model selection method. Some candidate models with different configurations of variables are identified first. One may then consider forward selection, backward selection, Akaike's information criterion (AIC), Mallows' , or cross validation (CV), to arrive at the ‘best’ model. Rather than focusing only on the ‘best’ model, a different approach called model averaging (MA) has been proposed to consider all candidate models. These candidate models are constructed by different subsets of predictors. The prediction is performed by combining predictions from these candidate models, in which higher weights are given to better models. In effect, the configuration of variables is taken into account in the prediction [Citation6]. This MA approach has also been shown to have a good prediction, even in the case of high-dimensional data [Citation2]. We know little, however, whether MA would be advantageous for prediction in the case of high-dimensional and highly correlated data such as the context of a calibration of NIR instruments. Therefore, this study investigates the prediction performance of MA in such a situation and compares it with MA in data with low correlation and ‘block’ correlation within a simulation study.
Just like in any general statistical modelling, there are two main approaches to MA that reflect different schools of thought: Bayesian model averaging (BMA) and frequentist model averaging (FMA). In BMA, we require a prior distribution and compute the posterior probability of each candidate model and use them as weights in the averaging [Citation6,Citation12,Citation15]. On the other hand, the FMA does not require any prior assumption and fully depends on the considered data. Its result, however, is mainly determined by (1) the procedure to construct candidate models, (2) the method to estimate model parameters, and (3) the calculation of weight (for each candidate model). This study focuses only on the FMA and the context is only on high-dimensional data.
With regard to the calculation of candidate model weights, some proposals have been put forward. Buckland et al. [Citation3] proposed the use of the Akaike's information criterion (AIC). Hansen [Citation9] proposed Mallows' and Hansen & Racine [Citation10] later suggested the use of cross-validation (CV) criterion (jackknife MA) for the weights. For the procedure to construct candidate models, Salaki et al. [Citation16] proposed a random partition to select the variables into candidate models. Hansen [Citation9] and Hansen and Racine [Citation10] proposed a nested model set-up, while Ando and Li [Citation2] proposed a marginal correlation of covariate with response variable to construct candidate models. Magnus et al. [Citation13] proposed a separation of focus variables, the ones that must be included in each candidate model, from auxiliary variables in the construction. With the exception of Salaki et al. [Citation16], Zhao et al. [Citation20], and Ando and Li [Citation2], many of literatures do not specifically focus on high-dimensional data when proposing methods for candidate model construction. This point is critical to note since this is related to the methods to estimate model parameters. Unfortunately, most studies restrict themselves to use ordinary least squares (OLS) to estimate model parameters (e.g. [Citation2,Citation10]) even in the context of high-dimensional data. It is well known that OLS estimates tend to be unstable in the presence of correlation between variables and this could negatively affect the model prediction.
The objective of this study is to investigate how the method to calculate weights of candidate models and the method of parameter estimation affect the prediction performance of MA in modelling high-dimensional data containing different correlation structures: high correlation, low correlation, and ‘blocks’ correlation. We consider three different methods to calculate the weights of candidate models: AIC, Mallows' , and cross validation. For the method to estimate model parameters, we consider both the OLS method and ridge method [Citation11]. Ridge regression is considered to specifically deal with the problem of (high) multicollinearity between variables such as the case in our application. For the method to construct the candidate models, we only consider the marginal correlation between the response variable and predictors as previously done by Ando and Li [Citation2]. They reported that this method to construct candidate models produced better prediction power compared to other methods.
We compare the model performance of MA in the above different situations with those of model selection methods: least absolute shrinkage and selection operators (LASSO) [Citation17] and smoothly clipped absolute deviation (SCAD) [Citation7]. These methods are known and widely used to perform variable selection and parameter estimation simultaneously by imposing a certain penalty on a model fitting criterion. Our simulation study indicates that the prediction performance of MA is determined by the correlation structure of the data, method of parameter estimation, and the calculation method for the weights. In general, we find that MA works better than penalised regression methods in high-dimensional and highly correlated data. In terms of the method of parameter estimation, we also find that ridge regression MA outperforms the least-squares MA as the candidate models contain a larger number of predictors.
The rest of this paper is organised as follows. Section 2 describes the methodology of this study. A simulation study to assess prediction performance of MA in different settings is presented in Section 3, meanwhile, Section 4 describes the results. Section 5 presents the discussion and concluding remarks of this study.
2. Methods
In this section, we describe the MA methodology. Specifically, the setting and notation of the relevant models are defined in Section 2.2. Section 2.3 outlines the MA framework with several different weighting schemes and methods of parameter estimation. However, first, we shall describe the NIR calibration dataset that motivated our study.
2.1. NIR calibration dataset
In this study, we consider two real datasets on the calibration of near-infrared spectrometer. The datasets are spectra from 80 corn specimens measured on two different spectrometers (mp5 and mp6) at 700 wavelengths between 1100 and 2496 nm in 2 nm intervals. Each spectrometer generates a spectra matrix of size 80 × 700. From each corn specimen, moisture, oil, protein and starch concentrations are measured. The average correlation between variables in the corn mp5 and mp6 datasets are 0.997 and 0.982, respectively. The datasets are originally available from http://www.eigenvector.com [Citation1] and the spectra data are presented in Figure (a ,b).
Figure 1. The spectra data involved in this study: (a) corn data using mp5 spectrometer, (b) corn data using mp6 spectrometer. The scale on vertical axis is arbitrary. The lines connect the absorbances of the same experimental specimen across different wavelengths. See the main text in Section 2.1 for more details.
2.2. Models and notation
Let be a vector of response variable, where n is the number of observations and ‘T’ denotes transposition. Let
be vectors of predictors, each of which is an n-vector, and let
be the corresponding model parameters, respectively. The predictors can be summarised in a matrix of predictors
of size
, where of p (the number of predictors) is allowed to exceed n. Consider a linear regression model
(1)
(1)
where
is a p-vector of unknown regression model parameters,
is an n-vector of random error term. We assume that
independently follows a normal distribution with mean zero and variance
, for
. Without loss of generality, we assume that all the variables are centred to have zero mean so that we do not need to worry about the intercept. The objective of model fitting is to estimate
, not only for interpreting the relationship between each predictor and the response variable but also for prediction of future observations.
In the ordinary least-squares (OLS) method, is estimated as
(2)
(2)
which is given by
(3)
(3)
When n<p, Equation (Equation2
(2)
(2) ) is over-parameterised and the estimates in Equation (Equation3
(3)
(3) ) are not attainable. Even when n>p, the estimates in Equation (Equation3
(3)
(3) ) tend to be unstable when high multicollinearity is present in
. To deal with this problem, we usually moderate the objective function in Equation (Equation2
(2)
(2) ) with a penalty function
:
(4)
(4)
for some ‘tuning’ parameter
. Different penalty function
will arrive at different solutions for
. In the ridge regression (RR), the estimates
can be obtained by setting
. It can be shown that the estimates can be written as
(5)
(5)
where
is the identity matrix of the appropriate size. Equation (Equation5
(5)
(5) ) indicates that the estimates
are shrunk towards zero compared to
and the amount of shrinkage depends on λ.
In the context of model selection, we can consider the penalty function such that some of the estimates of are estimated to be zero. In effect, a variable selection is performed by negating the contribution of some variables in the prediction. As a comparison to the MA framework, we consider LASSO [Citation17,Citation18], Adaptive LASSO [Citation21], MCP [Citation19], SCAD [Citation7], and Elastic Net [Citation22] to represent model selection methods, although we illustrate here the penalty functions for LASSO and SCAD. To get an estimate based on LASSO, the penalty function is defined as
. This penalty function produces a sparse solution, i.e. some of the parameters are estimated to be zero while the others are estimated to be away from zero. To get estimates based on SCAD, the penalty function is defined such that the first derivative (with regard to
) is given by
for some a>2, where
, and
is an indicator function that equals one if the condition inside the brackets is true and zero otherwise. In our study, the parameter λ in these different estimation methods is estimated using a cross-validation method.
2.3. Model averaging
In this section, we now describe the MA methodology that we consider for our calibration problem. Consider the linear regression model in Equation (Equation1(1)
(1) ) and the set of predictors
that is partitioned into K subsets (described in Section 2.3.1 below). For
, the k-th subset of predictors is considered to construct the design matrix
of the k-th candidate model
. The k-th candidate model
can be written as
(6)
(6)
where
is a matrix of predictors of size
,
is a
-vector of model parameters associated with
, and
is the random error term. The model parameters
are estimated according to different estimation methods as described in Section 2.3.2 below.
Once we obtain the estimates , we define
as a fitted vector based on model
, i.e.
. The fitted vector for MA,
, in model (Equation1
(1)
(1) ) can be written as
(7)
(7)
where
is the weight corresponding to the k-th candidate model,
and
, and is described below in Section 2.3.3. The MA parameter estimate for
, of Equation (Equation1
(1)
(1) ) is calculated by
(8)
(8)
where
is the estimate of
based on the k-th candidate model. Note that, if predictor j is not in the candidate model k, then
for
and
.
2.3.1. Model construction
To construct the candidate models, ,
, we consider the marginal correlation of predictors with the response variable as previously considered in Ando and Li [Citation2]. There are two main reasons behind the adoption of this approach. First, Ando and Li [Citation2] have indicated that this method generally gives better prediction, and second, this method is a common practice in MA to construct candidate models, and we wish our conclusion of this study to be relevant to this common practice. As an alternative method to construct the candidate models, we consider a random partition approach for practical reasons [Citation16]. The main idea is to select the predictors without any prior knowledge of their association with the outcome variable, unlike the marginal correlation approach.
For the marginal correlation approach, recall the response variable and the corresponding design matrix
in Equation (Equation1
(1)
(1) ). By noting that the variables are centred to have zero mean, let
be the (sample) marginal correlation between
and
,
. Based on the absolute values of the observed correlations, all the variables are then ordered in decreasing order to get
.
We assume, without loss of generality, that the set of p predictors can be partitioned exhaustively into K subsets with the same number of predictors v in each subset, i.e. . We then build each of K candidate models by incorporating v predictors from
at a time. The matrix
of model
consists of the first v ordered predictor or
. Similarly,
consists of the second v ordered predictors or
, and so forth until K candidate models are created.
For the random partition approach, we randomly and exhaustively partition p predictors into K subsets with the same number of predictors v in each subset. We then construct the matrices , each of which contains v randomly selected predictors.
2.3.2. Model estimation
Once the candidate models 's in Equation (Equation6
(6)
(6) ) are constructed, we consider two different estimation methods to estimate the corresponding model parameters
. First, the OLS estimate for
is given by
(9)
(9)
Secondly, the ridge estimate for
is given by
(10)
(10)
To our knowledge, recent studies in MA only consider the OLS estimates, even in the context of high-dimensional data. This is possible because
in the candidate models. Our proposal to also consider the ridge estimate is to deal with high correlation that can still be present in the candidate model's predictors
, as motivated by our NIR calibration problem. In such a situation, even if
, the model parameter estimates generally have very large standard errors. We believe that this can be detrimental to the prediction performance in the context of our application.
In the estimation of parameters of candidate models, we do not consider LASSO or SCAD estimates because in principle they fall in the model selection methodology. The MA does not focus on selection, but rather on incorporating predictors and weighting different plausible (candidate) models in prediction. The prediction performance of the MA, however, will be compared to that of the LASSO and SCAD models in our study. It is currently our active research to investigate the impact of considering model selection within a MA framework and is beyond the scope of this manuscript.
The tuning parameter λ in the ridge regression estimation or model selection methods (LASSO and SCAD) is estimated using a cross-validation method. This cross-validation is separated from cross validation to estimate the candidate model weights (Section 2.3.3) and from that to assess model prediction performance in the simulation study (Section 3.2).To describe this briefly, the observations are randomly split into s subsets or folds, . In our study, we consider s = 5 (i.e. five-fold cross-validation). For each fold, we leave out the fold and fit the model at a given λ on the remaining folds. For each observation in the left-out fold, we calculate the predicted value using the corresponding predictors but using parameter estimates when the model was fitted using the other folds, denoted
. We write the cross validation error as
(11)
(11)
and the optimal λ is estimated as
2.3.3. Weight criteria
One key aspect in the prediction using model averaging methodology is the choice of weight for each candidate model, or 's,
, where
and
. With the constraint that the weights sum up to one, they can be considered as the probability of an associated candidate model to be the best model. In this study, we consider three types of weights: Akaike's information criterion (AIC), Mallows'
, and cross-validation (CV).
Akaike's information criterion (AIC)
The AIC indicates the relative quality of a statistical model given the data. Consider the AIC of a candidate model , denoted as
where
is the log-likelihood of
, and
is effective dimension of the parameter vector fitted in the model. The log-likelihood is given by
where
is a diagonal matrix of the error variance in
, i.e.
. The effective dimension
is equal to
(the number of columns of
) when
is estimated using the OLS method (Equation9
(9)
(9) ), and is equal to [Citation14]
when
is estimated using the ridge estimation (Equation10
(10)
(10) ).
Based on the value of AIC(), Burnham and Anderson [Citation5] proposed to rescale the information criterion as a relative measure for each candidate model called AIC difference, and it is denoted as
where
is the minimum AIC among all candidate models. Therefore, the AIC weights to be assigned in the candidate model
is given by
(12)
(12)
The weights (
's) based on AIC in this case indicate the probability of model
being the best model in the set of considered candidate models [Citation5].
Mallows's
Mallows' model averaging (MMA) was proposed by Hansen [Citation9] and it is based on the well-known Mallows'
criterion in calculating the weights
's. It involves an average of residuals sum of squares and a penalty term for complexity with an unknown
, which has to be estimated. The Mallows'
criterion for MA estimator is given by:
(13)
(13)
where
is a vector of weights for different candidate models,
is the matrix of all residual vectors across K candidate models of size
, Φ is a vector of
's (i.e.
), and
is the number of predictors used in the k-th candidate model,
. Considering this as an estimation problem, the weight vector
is estimated by
(14)
(14)
where
. This is a classical linear programming problem and can be calculated using standard optimisation procedures.
Cross-validation (CV)
Model averaging weights based on the principle of cross-validation (CV) were previously proposed by Hansen and Racine [Citation10]. The idea is that the cross-validation criterion indicates a quality of the model given the data, especially to balance the model fit and model prediction. In our study, we consider the case of leave-one-out cross validation, in which we make a prediction on every i-th observation based on the model parameter estimates in which the i-th row was deleted.
Let be the i-th row of the predictor matrix
in
,
. Let
and
respectively be the predictor matrix
in
and the response variable
where the i-th row (or i-th element in
) is deleted. Furthermore, let
be the prediction on the i-th observation based on the model parameter estimates in which the i-th row was deleted, or (in the case of OLS estimates)
(15)
(15)
In the context of ridge regression estimate, then the estimate on the right-hand side of the above equation is adjusted accordingly.
Let be an n-vector of predicted values from the cross-validation in the k-th candidate model. The CV residual vector of the k-th candidate model is denoted by
. Across K candidate models, the residuals can be summarised into a matrix (of size
) denoted as
. Therefore, the optimal weight based on CV can be calculated by minimising
(16)
(16)
or
(17)
(17)
3. Simulation study
3.1. Simulation setting
To understand the prediction performance of MA methodology in our context of interest, we perform a simulation study where some simulation parameters are varied. In particular, we are interested to understand how the different number of variables included in the candidate models (v), how the model parameter is estimated, and how the candidate model weights ('s) affect the prediction performance in different correlation structures of data.
The simulation data matrix of size
, with n = 300 and p = 1000, is generated according to the multivariate normal distribution with mean zero and covariance matrix
, or
. The way we consider
defines the correlation structure of the simulated data. In this study, we consider different correlation structures as follows. First, we define
as
where
, and 0.95. The value
represents the case of low correlation while the other values represent the case of high correlation. The different values of
in representing high-correlation case is to highlight our attention on the high-correlation data we encounter in the calibration of NIR instruments.
Second, we consider independent block correlation data so that is defined as
(18)
(18)
where
is a sub-matrix of zeros with a corresponding conformable size to that of
, and
. Q here denotes the number of correlation blocks in the data and we consider
so that each
,
, is of size 1000/Q.
Third, we consider correlated-block correlation data so that is defined as
where
is as defined above and
is a sub-matrix that contains the correlation between blocks with elements
.
The simulated response variable is generated as
(19)
(19)
where
for
, and
for
, and the error terms
are sampled from
.
As a summary, for each correlation structure, we vary the following simulation parameters:
The numbers of predictor included in the candidate models v are set at 10, 20, 40, 100, and 200, which correspond to the number of candidate models
100, 50, 25, 10, and 5, respectively.
The methods of constructing candidate models are set to be based on marginal correlation and random partition.
The methods to estimate candidate model parameters are set to be least squares (OLS) and ridge (RR).
The candidate model weights are set to be based on AIC, Mallows'
For each setting, we generated simulated data 500 times and calculate the model prediction performance in terms of root mean square prediction error (RMSEP) as described next. We compare the model prediction performance of MA with those from LASSO, adaptive LASSO, MCP and SCAD models that represent model selection.
3.2. Root mean squared error of prediction (RMSEP)
In order to evaluate the prediction performance of those frameworks over several structures of correlation, we perform five-fold cross-validation by randomly splitting the observations into training set and validation set. While a fold is used as a validation set, the others serve as a training set. Let of the i-th observation that is considered when it falls in the validation set, and let
be the predicted value based on
in the validation set using
from the training set. The root mean squared error of prediction (RMSEP) of a framework π is calculated via this equation,
(20)
(20)
where π represents a framework type or method. This cross validation is separated from cross-validation to estimate λ in ridge regression estimation and from that to estimate candidate model weights.
4. Results
4.1. Simulation results
The results of simulation study are presented in Tables and and Figures and . In Tables and , the root mean squared error of prediction (RMSEP) of different simulation settings across 500 simulated datasets are presented for candidate model construction based on the marginal correlation and random partition, respectively. As a comparison, the RMSEP from model selection methods (LASSO, Adaptive LASSO, MCP, SCAD, and Elastic Net) are also presented in the tables.
Figure 2. RMSEP for several model averaging (MA) frameworks each with five different numbers of predictors in high-correlation simulated data (Corr: 0.95). There are six MA frameworks: MOA, MOM, MOC, MRA, MRM and MRC. The first letter (‘M’) refers to marginal correlation to construct the candidate models, the second letter corresponds to the candidate model parameter estimation (‘O’ for OLS, and ‘R’ for RR), and the third letter corresponds to the weights (‘A’ for AIC, ‘M’ for Mallows' , and ‘C’ for CV). As a comparison, RMSEP from penalised regression are included: LASSO, Adaptive LASSO, MCP, SCAD, and Elastic Net. Figures for RMSEP of MA based on random partition model construction are presented in Figure . Figures for other correlation structures are presented in the Supplementary Material.
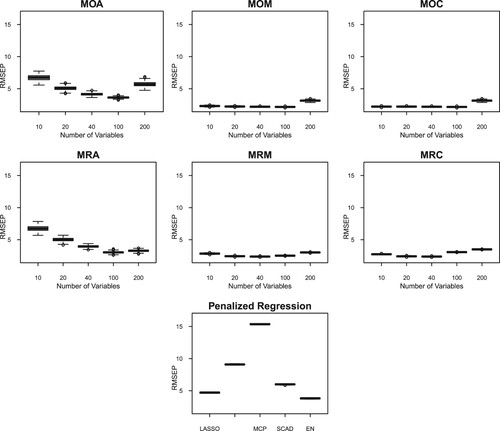
Figure 3. RMSEP for several model averaging (MA) frameworks each with five different numbers of predictors in high-correlation simulated data (Corr: 0.95). There are six MA frameworks: ROA, ROM, ROC, RRA, RRM and RRC. The first letter (‘R’) refers to random partition to construct the candidate models, the second letter corresponds to the candidate model parameter estimation (‘O’ for OLS, and ‘R’ for RR), and the third letter corresponds to the weights (‘A’ for AIC, ‘M’ for Mallows' , and ‘C’ for CV). Figures for RMSEP of MA based on marginal correlation model construction are presented in Figure . Figures for other correlation structures are presented in the Supplementary Material.
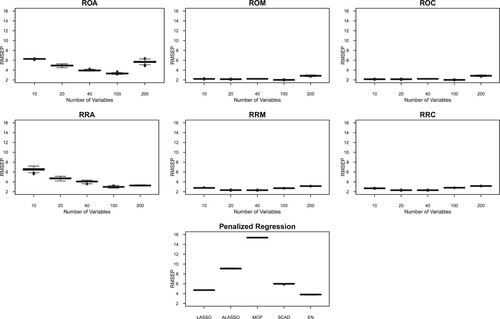
Table 1. Root mean squared error of prediction (RMSEP) from different model averaging (MA) frameworks for different number of variables in the candidate models (v) and in various correlation structures.
Table 2. Root mean squared error of prediction (RMSEP) from different model averaging (MA) frameworks for different number of variables in the candidate models (v) and in various correlation structures.
In Table , there are a few situations in which MA has higher RMSEP than model selection methods. This is true in the case of low correlation, 10 independent block correlation, and 5 independent block correlation. Other than those, MA manages to obtain lower RMSEP than the model selection methods. In Table , MA manages to obtain a lower RMSEP than the model selection methods in all situations, except the low-correlation setting. This is encouraging, considering that the simulation settings considered are relatively challenging with different correlation structures.
In terms of the number of predictors in the candidate models, Tables and indicate that the RMSEP decreases as the number of predictors in the candidate models increases. However, when the model parameters are estimated using OLS, the RMSEP tends to increase again when the number of predictors is 200 in the candidate models. This indication is generally not seen when we consider ridge regression estimates. This is reasonable because when the number of predictors in the candidate models increases to n, then the OLS estimation becomes unstable and the ridge regression estimate is known to be able to deal with this problem. Furthermore, having 100 (n/3) and 200 (2n/3) predictors in the candidate models tends to give optimal predictions when using ridge regression estimates. When the OLS estimation is considered, the general tendency is to consider having 100 predictors in the candidate models for a good prediction. These results indicate that the estimation of model parameters interacts with the number of predictors in the candidate models for an optimal prediction in MA.
In terms of methods to construct candidate models, we find from Tables and that both marginal correlation and random partition methods have comparable performance, except in the case of block correlation with 5 and 10 independent blocks. In these two cases, the tables suggest that random partition is preferable to construct candidate models. In the context of high correlation between variables such as the case in the calibration of NIR instruments, the tables show that the RMSEP is quite similar and they both give lower RMSEP than that from model selection methods. Lastly, in terms of methods to calculate weights for candidate models in MA, Tables and show that the weights based on Mallows' and cross-validation criteria give lower RMSEP than those based on AIC, across different correlation structures of the simulated data.
4.2. NIR calibration data
The results of the MA on real NIR calibration data are presented in Table . The table shows the RMSEP on the two NIR datasets across different numbers of predictors in the candidate models (v). The numbers of predictors tested in the real data are n/4, n/3, and n/2. This is based on a ratio over n that gives the optimal RMSEP in the simulation study of approximately n/3. The table indicates that in the Corn (mp5) data, the MA gives lower RMSEP than the model selection methods in all outcome variables. However, in the Corn (mp6) data, MA only gives lower RMSEP when the outcome variable is oil content. For the other outcome variables, MA gives a higher RMSEP than the model selection methods.
Table 3. RMSEP's of the calibration models in the NIR datasets under the different frameworks of model averaging (MA) in comparison with model selection methods (LASSO, Adaptive LASSO, MCP, SCAD, and Elastic Net).
Table indicates that MA frameworks with ridge estimation produce less RMSEP than those with OLS estimates. This reflects the situation that we observed previously in the simulation study. It is also interesting to note that the application of MA on real datasets indicates that the choice of weights is less crucial. The lowest RMSEP within each outcome variable in the MA framework can be obtained by weights based on AIC, Mallows' , and cross validation. Although, it is important to note that all these minimums are achieved only when the parameters are estimated using ridge regression.
5. Discussion and concluding remarks
We have investigated the impact of different numbers of predictors, parameter estimation methods, and weighting schemes on prediction within the MA frameworks. Our investigation indicates that increasing the number of predictors in the candidate model is expected to better the prediction performance in general. However, this is consistent when we consider the ridge regression to estimate the candidate models' parameters. When we consider OLS estimates, the prediction starts to be negatively affected when the number of predictors is getting closer to the number of observations. This is a main result that is important to note as all known studies in MA, to our knowledge, have consistently utilised only the OLS estimation method. With the ridge estimates, our simulation study has indicated a stable performance in prediction.
The results of the simulation study also indicated that the Mallows' and CV weights are more beneficial for prediction compared to the AIC weights. Overall, the Mallows'
is generally preferred, as this is shown to be consistent across different correlation structures of simulated data. The advantage of MA compared to the model selection methods (LASSO, Adaptive LASSO, MCP, SCAD, and Elastic Net) is visible in all correlation structures within the simulated data, except in the case of lower correlation setting. In the context of ten and five independent block correlation, MA still has the advantage compared to the model selection methods when we construct the candidate models using random partition, but not when using marginal correlation. In the different settings of high-correlation simulated data, such as the case in the calibration of NIR instruments, we find that the MA is generally better than the model selection methods. These simulation results are important to guide researchers on whether to consider MA or model selection approach in prediction. In particular, many areas such as molecular biology, medicine, and social sciences usually deal with clusters of variables in their data. So, a careful check on the correlation structure of data is necessary when considering which approach to use.
The principles that we learned from the simulation study, to much extent, are also seen in the real data application. The ridge model averaging is shown to be generally superior compared to the more common OLS MA. The ridge MA also produces lower RMSEP than the model selection methods in the Corn (mp5) data. In the Corn (mp6) data, the ridge MA only produces lower RMSEP than the model selection methods when the outcome variable is oil. This suggests that, in the context of calibration of NIR instruments with correlated high-dimensional data, we still consider the MA approach to be a preferred alternative.
For the number of predictors in the candidate models v, we find from the simulation study that n/3 is generally preferable to achieve an optimal prediction for both OLS and ridge regression estimation in the MA framework. This should be considered as a rule of thumb rather than a prescription. In the real data application where v is set to be n/4, n/3 and n/2, MA managed to achieve better RMSEP than the model selection methods in the majority of outcome variables.
As an idea for extension, we can consider e.g. a model selection approach for each candidate model within the MA framework. This is currently our active research and is beyond the scope of this manuscript. There are some complications to consider in this ‘hybrid’ approach. However, we believe that this research is still necessary to arrive at a MA framework that potentially improves further its prediction ability in data with different correlation structures. Lastly, it is important to note that in the calibration of NIR instruments, it is common to have multivariate outcomes such as in our datasets. In this case, we can consider the MA framework in a multivariate response setting, although we did not consider that in this study. Overall, we feel that MA provides an opportunity for better prediction in the calibration problem compared to model selection methods, despite some remaining issues for future works.
Supplemental Material
Download PDF (215.9 KB)Acknowledgments
The first author (DTS) would like to thank the School of Mathematics, University of Leeds, UK, for hosting her research visit.
Additional information
Funding
References
- Eigenvector Research, Inc. NIR of Corn Samples for Standardization Benchmarking, 2021. Available at https://www.eigenvector.com/data/Corn/, accessed 2 May 2021.
- T. Ando and K.C. Li, A model-averaging approach for high dimensional regression, J. Am. Stat. Assoc. 109 (2014), pp. 254–265.
- S.T. Buckland, K.P. Burnham, and N.H. Augustin, Model selection: an integral part of inferences, Biometrics 53 (1997), pp. 603–618.
- P. Buhlmann and S. Van de Geer, Statistics for High-Dimensional Data, Spinger-Verlag, Berlin, 2011.
- K.P. Burnham and D. Anderson, Model Selection and Multimodel Inference: A Practical Information-Theoritic Approach, Spinger-Verlag, Berlin, 2002.
- G. Claeskens and N. Hjort, Model Selection and Model Averaging, Cambridge University, New York, 2008.
- J. Fan and R. Li, Variable selection via nonconcave penalized likelihood and its oracle properties, J. Am. Stat. Assosiation 96 (2001), pp. 1348–1360.
- A. Gusnanto, Y. Pawitan, J. Huang, and B. Lane, Variable selection in random calibration of near infrared instruments: ridge regression and partial least squares regression settings, J. Chemom. 17 (2003), pp. 174–185.
- B.E. Hansen, Least squares model averaging, Econometrica 75 (2007), pp. 1175–1189.
- B.E. Hansen and J. Racine, Jackknife model averaging, J. Econom. 167 (2012), pp. 34–38.
- A.E. Hoerl and R.W. Kennard, Ridge regression: biased estimation for nonorthogonal problems, Technometrics 12 (1970), pp. 55–67.
- Q. Liu, R. Okui, and A. Yoshimura, Generalized Least Squares Model Averaging, SSRN Working Paper, Kyoto University, Kyoto, 2014.
- J. Magnus, O.R. Powell, and P. Prufer, A comparison of two model averaging techniques with application to growth empiric, J. Econom. 154 (2010), pp. 139–153.
- Y. Pawitan, In All Likelihood: Statistical Modelling and Inference Using Likelihood, Oxford University Press, New York, 2013.
- A. Raftery, D. Madigan, and J. Hoeting, Bayesian model averaging for linear regression models, J. Am. Stat. Assoc. 92 (1997), pp. 179–191.
- D.T. Salaki, A. Kurnia, A. Gusnanto, I.W. Mangku, and B. Sartono, Model averaging in calibration model, IJSRSET 4 (2018), pp. 189–195.
- R. Tibhsirani, Regression shrinkage and selection via the lasso, J. R. Stat. Soc. Ser. B 58 (1996), pp. 267–288.
- R. Tibhsirani, The lasso problem and uniqueness, Electron. J. Stat. 7 (2013), pp. 1456–1490.
- C.H.. Zhang, Nearly unbiased variable selection under minimax concave penalty, Ann. Stat. 38 (2010), pp. 894–942.
- S. Zhao, J. Zhou, and H. Li, Model averaging with high-dimensional dependent data, Econ. Lett. 146 (2016), pp. 68–71.
- H. Zou, The adaptive lasso and its oracle properties, J. Am. Stat. Assoc. 101 (2006), pp. 1418–1429.
- H. Zou and T. Hastie, Regularization and variable selection via the elastic net, J. R. Stat. Soc. Ser. B67 (2005), pp. 301–320.