
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In the design of complex products, some product components can only be chosen from a finite set of options. Each option then corresponds to a multidimensional point representing the specifications of the chosen components. A splitting algorithm that explores the resulting discrete search space and is suitable for optimization problems with simulation-based objective functions is presented. The splitting rule is based on the representation of a convex relaxation of the search space in terms of a minimum spanning tree and adopts ideas from multilevel coordinate search. The objective function is underestimated on its domain by a convex quadratic function. The main motivation is the aim to find—for a vehicle and environment specification—a configuration of the tyres such that the energy losses caused by them are minimized. Numerical tests on a set of optimization problems are presented to compare the performance of the algorithm developed with that of other existing algorithms.
1. Introduction
A new discrete search algorithm for solving design optimization problems with simulation-based objective functions is proposed. The research leading to this article is motivated by the optimization of truck tyres selection (see Lindroth Citation2012; Šabartová et al. Citation2014). The purpose is to enable—for each combination of truck configuration and operating environment—the identification of a tyres configuration that minimizes the energy losses caused by the tyres. The tyres for the individual truck axles are to be chosen from a tyre database. Each tyre is specified by the values of so-called tyre design variables and the truck tyres selection problem involves computationally expensive black-box simulations (Nedělková et al. Citation2016).
A splitting algorithm to explore the multidimensional discrete search space of design points for the tyres selection problem as well as other simulation-based optimization problems with categorical variables is developed and presented. The splitting strategy used in the algorithm developed is inspired by that presented by Fuchs and Neumaier (Citation2010a); it uses only the objective function evaluations and is therefore applicable to simulation-based optimization problems. The strategy exploits the structure of a convex relaxation of the discrete search space, represented by a minimum spanning tree among the edges of a complete graph defined on the design points (see Graham and Hell Citation1985). The use of this knowledge may have significant advantages, since the objective function typically depends more on the selection of the design point rather than on the values of the integer choices stemming from numbering of the design points and not representing any physical entity. The splitting strategy is complemented by a global underestimation of the objective function in order to determine approximate lower bounds along the search tree. The bounds are then used within a multilevel coordinate search (see Huyer and Neumaier Citation1999) to decide on which node of the search tree to split. A pattern search algorithm (see Audet and Dennis Jr Citation2004) is used to obtain a feasible solution from a relaxed solution and also to improve the current smallest objective value.
Utilizing a variety of both artificial and real test problems, differing with respect to both mathematical properties and sizes, the performance of the algorithm developed is compared with that of other existing algorithms that can be used to solve simulation-based optimization problems with categorical variables. It is concluded that the algorithm developed outperforms the other algorithms tested.
1.1. Previous work
In design optimization (see, e.g., Alexandrov and Hussaini Citation1997; Neumaier et al. Citation2007; Fuchs et al. Citation2008) a design choice is typically modelled by a categorical variable, i.e. an integer variable arising from reformulations of discrete multidimensional sets of design points. Depending on the mathematical properties of the objective function and the constraints, the resulting problem falls into one of several classes of mixed integer optimization problems. For each such class identified, algorithms exist that employ splitting of the search space.
For studies of efficient search space splitting methods, see Floudas (Citation1995, Chap. 5) and Nemhauser and Wolsey (Citation1999, Chap. II.4) for mixed integer linear optimization, and Leyffer (Citation1993) and Tawarmalani and Sahinidis (Citation2004) for mixed integer nonlinear optimization. Splitting in simulation-based optimization with continuous variables only is studied in Jones, Perttunen, and Stuckman (Citation1993) and Huyer and Neumaier (Citation1999). For a survey on discrete optimization, including splitting methods, see Parker and Rardin (Citation2014, Chaps 1 and 5).
1.2. Motivation
The present sales tool at Volvo Group Trucks Technology (Volvo GTT) generates a large set of feasible tyres for each truck; these tyres are suitable for their potential utilization and fit the truck dimensionally. The truck tyres selection process is then based on experience and customer input, which can be improved further by means of scientific methodologies. A goal for Volvo GTT is to find an optimal configuration of the tyres for each vehicle configuration and operating environment specification such that the energy losses caused by the tyres are minimized. Each tyre is determined by specific values of tyre design variables (tyre diameter, tyre width, tread depth, and inflation pressure) and an extensive tyre database is available; see Šabartová (Citation2015) for details.
To support the truck tyres selection process, an optimization model has been developed by Nedělková, Lindroth, and Jacobson (Citation2017) with the aim of determining an optimal set of tyres for each vehicle and operation specification. A complex, interacting set of vehicle, tyres and operating environment was modelled in order to evaluate the fuel consumption. Each evaluation of the objective function requires a significant computational effort. One can afford to evaluate the objective function and constraints only for a limited number of sample points (settings of tyre design variables). Moreover, the tyres to be selected are described by a set of discrete variables. Therefore, an efficient optimization algorithm to find the optimal tyres configuration—even for one customer having a specific vehicle configuration and operating environment—is needed.
The algorithm presented in this article can be used to solve any simulation-based optimization problem with categorical variables. Applications include the component selection problem (Carlson Citation1996), vehicle design (Alexandrov and Hussaini Citation1997, 3–21), optimal design of large engineering systems in general (Alexandrov and Hussaini Citation1997, 209–226), surface structure determination for nanomaterials (Zhao, Meza, and Van Hove Citation2006), space system design (Fuchs et al. Citation2008) and the optimization of thermal insulation systems (Abhishek, Leyffer, and Linderoth Citation2010).
1.3. Outline
This article is organized as follows. In Section 2, the design optimization problem with a simulation-based objective function considered is described, as well as basic principles and terminology of the splitting algorithm and a means to underestimate the objective function. The splitting strategy is introduced in Section 3. The local search algorithm used along the search tree is explained in Section 4. The resulting splitting algorithm is described in Section 5. Numerical tests of the suggested algorithm and other competing algorithms are presented in Section 6. Section 7 provides conclusions as well as topics for future research.
2. Design optimization
Design optimization problems typically involve categorical variables. The case when the discrete choice modelled by the categorical variable has a natural ordering that can be associated with integer values is considered, because then a reformulation into an integer optimization problem can be performed.
2.1. Problem formulation
Let be a vector of discrete choice variables, where
, i.e.
is the choice domainFootnote1 of
,
. Then,
is the discrete domain of possible choices of
. Each choice variable
determines the values of the
components of a vector
, where
. The composite vector
denotes the argument of the simulation-based function
. For each
, the so-called table mappingFootnote2
transforms the set
of discrete choices into the multivariate discrete design domain
. The design optimization problem is now formulated as
(1a)
(1a)
(1b)
(1b)
(1c)
(1c)
Example
Consider a heavy vehicle with m=2 axles; then . Each axle is equipped with two identical tyres. For example, if ten tyres feasible for the front axle and five for the rear axle are available, then
and
. The choice of
(
) determines the values of tyre width, tyre diameter, and inflation pressure for the tyres mounted on the front (rear) axle. The resulting vector
with six components is the argument of the objective function F, which represents the fuel consumption for the selected tyre configuration.
2.2. A splitting algorithm for design optimization
A widely used method to solve global optimization problems is branch-and-bound (Horst and Tuy Citation1996, Chap. 4, and Locatelli and Schoen Citation2013, Chap. 5), where the idea is to split the feasible region into smaller subregions and solve what is called a subproblem, i.e. a relaxed (simplified) problem in each subregion. The splitting stops when the best solution found is located in a sufficiently small subregion, such that the prescribed solution accuracy is guaranteed. The splitting is accomplished by adding constraints to the relaxed problem. In order to manage the extra constraints, a search tree is created. This tree is defined by nodes representing subproblems and edges representing the constraints corresponding to the splitting added to define new subproblems. The very first node in the search tree is called the root node. See Nemhauser and Wolsey (Citation1999, Chap. I.3) and Žilinskas (Citation2008) for more details and examples.
In general branch-and-bound algorithms, a lower bound on the optimal value of the objective function over a subregion may be used to indicate the subregions which can be discarded early in the procedure, so that only part of the search tree has to be generated and processed. The bounding procedures are only applicable if enough information about the mathematical properties of the objective function is available, since generally tight and reliable underestimating functions have to be computed. For the simulation-based optimization problems studied in this article, with no known mathematical properties, the lower bounds on the approximation of the objective function can be used only to guide the splitting.
Considering the optimization problem (Equation1(1a)
(1a) ), a splitting algorithm is formulated in which a convex relaxation of problem (Equation1
(1a)
(1a) ) is solved in each subregion. An iteration of the algorithm then processes a node in the search tree, representing a not yet explored subregion of the feasible region. Each iteration of the splitting algorithm corresponds to a node in the search tree and has six main steps, which are detailed in Algorithm 1.

The lower bounds on the objective function value in the subregions are used to choose the next tree node to process. A local search is used to find a feasible design nearest to the solution from step 3 of Algorithm 1 and also to improve it if possible. A feasible design is evaluated if the value of F at that solution is already known. All evaluated feasible designs are stored in an auxiliary list. To select the tree node to process, a multilevel coordinate search (Huyer and Neumaier Citation1999) is used. At the selected node the search tree is branched into two child nodes. Nodes with no child nodes will henceforth be called leaf nodes. The notation to denote the restricted choice domain is also introduced, i.e. the set of feasible choices, for node s.
2.3. A convex underestimation of the objective function
As part of formulating a convex relaxation of problem (Equation1(1a)
(1a) ), its generally non-convex objective function F is approximated and underestimated by a convex quadratic underestimatorFootnote3
, defined as
, over a subset of
. Let
denote the set of symmetric positive semi-definite matrices of dimension
. The coefficients
,
, and
are computed through the solution of the SemiDefinite optimization Problem (SDP, see Wolkowicz, Saigal, and Vandenberghe Citation2012) to
(2a)
(2a)
(2b)
(2b)
(2c)
(2c)
where
is a set of sample points and
is a reference point; see Figure . The function
is called the underestimator of F even though it is guaranteed to underestimate F (i.e.
has lower values than F) only on the sample set
, on which the accuracy of fit and the degree of underestimation is strongly dependent. To guarantee the existence of a solution to optimization problem (Equation2
(2a)
(2a) ), the reference point is chosen as
.
Figure 1. Illustration of the quadratic underestimating function . The objective function F is evaluated at the set of sample points
(illustrated by the dots).
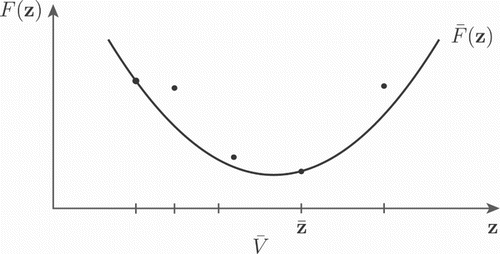
The function is constructed using
sample points through the solution of optimization problem (Equation2
(2a)
(2a) ), having
variables. The sample points are selected from the evaluated feasible designs. If not enough many feasible designs are available, then they are extended with infeasible designs.
Optimization problem (Equation2(2a)
(2a) ) is put into standard form by introducing the notation
and
denoting the trace of a square matrix, and reaching the identity
(see Boyd and Vandenberghe Citation2004, Chap. 4.6.2]) and solved by a standard SDP solver. Furthermore, optimization problem (Equation2
(2a)
(2a) ) can be restricted by utilizing a sparsity pattern for the Hessian of
(Coleman, Garbow, and Moré Citation1985). For the case of a diagonal Hessian, the conditions on positive definiteness reduce to lower bounds on the coefficients A, which means that SDP (Equation2
(2a)
(2a) ) is reduced to a separable linear optimization problem. Note that, even when the underlying objective function F has no sparsity pattern, the use of the underestimator
with a sparse Hessian can still be efficient, as illustrated by the numerical results in Section 6.5.
If the objective function F is convex quadratic or linear, then the convex function is an exact underestimator, thus providing lower bounds on the optimal objective value of problem (Equation1
(1a)
(1a) ). These lower bounds can be used to eliminate portions of the feasible region, thus turning the suggested splitting algorithm into a branch-and-bound algorithm.
3. A convex relaxation based splitting strategy
The splitting strategy for each node s in the search tree, whose feasible region is denoted
, is derived from Fuchs and Neumaier (Citation2010b) and consists of the following three parts.
A convex relaxation of optimization problem (Equation1
(1a)
One choice domain
In the design domain
Fuchs and Neumaier (Citation2010b) approximate the objective function by a linear combination of the function values evaluated and apply a splitting strategy, denoted balanced split and presented in Section 3.1. They also add a penalty term (i.e. a regularization) to the objective function in order to receive a selection of boundary solutions. In contrast, the algorithm developed in this article uses a quadratic approximation of the black-box objective function without any penalty parameters, and a splitting method denoted nearest edge projection, described in Section 3.2.
The relaxation of problem (Equation1(1a)
(1a) ), restricted to a node s, is
(3a)
(3a)
(3b)
(3b)
(3c)
(3c)
(3d)
(3d)
where
is the underestimator of F presented in Section 2.3. The solution to optimization problem (Equation3
(3a)
(3a) ), in terms of
,
, is a convex combination of the designs
,
. The values of the convex combination coefficients
,
,
, are further used to determine the splitting of the choice domain
, where i is chosen to fulfil the inclusion
(4)
(4)
3.1. Balanced splitting strategy
The balanced splitting strategy by Fuchs and Neumaier (Citation2010b) is stated next, for completeness. For each , consider the ith coordinate
. The minimum spanning tree corresponding to the designs
is constructed. For any fixed edge k in the graph of the tree corresponding to
, the set of all designs on the left (right) side of the edge k is denoted by
(
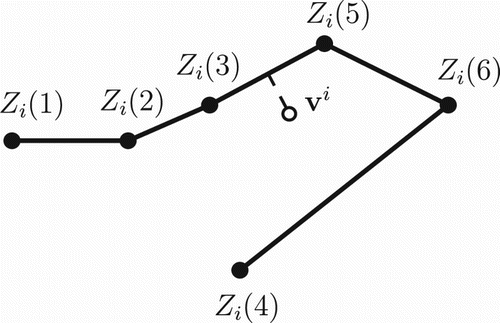
). In Figure , let k be the edge (3–5), then
, and
.
Figure 2. Illustration in of the nearest edge projection splitting strategy. The split is identified across the edge
–
of the minimum spanning tree corresponding to the designs
by projecting (illustrated by the dashed line) the solution to (Equation3
(3a)
(3a) ), in terms of
, onto the tree.
For every edge k in the minimum spanning tree corresponding to , the sums
and
of the weights of all designs in
and
, respectively, are computed as
(5)
(5) In the balanced splitting strategy, the feasible region
is split into two subregions
and
across the edge k, such that the weights
and
are as close as possible to 1/2.
3.2. Nearest edge projection splitting strategy
The optimal solution to optimization problem (Equation3(3a)
(3a) ) is non-unique if the number of evaluated and feasible designs is at least n+2, or if the evaluated designs span a space of dimension at most n. In such a case, no unique edge exists for the balanced splitting strategy. Since it is not clear from Fuchs and Neumaier (Citation2010b) in what sense a balanced split provides an efficient splitting strategy, a more basic splitting strategy is proposed.
The nearest edge projection splitting strategy starts with the construction of the minimum spanning tree corresponding to the designs . The edge defining the split is then identified by projecting the optimal solution to optimization problem (Equation3
(3a)
(3a) ) onto the minimum spanning tree (in terms of Euclidean distance in the z-space); see Figure . In case of ties concerning which edge is closest to the relaxed solution, the first edge in a list of the minimum spanning tree edges is chosen.
The idea of splitting the feasible region in the vicinity of the optimal solution of optimization problem (Equation3
(3a)
(3a) ) is motivated by the fact that the area of convex hull of the two resulting feasible subregions
and
of child nodes will be significantly reduced at the split, which increases the probability of the relaxed solution to optimization problem (Equation3
(3a)
(3a) ) being closer to the optimal solution to problem (Equation1
(1a)
(1a) ).
3.3. Selection of node to split
The choice of tree node to process in the search tree (i.e. step 1 of Algorithm 1) has an impact on the performance of Algorithm 1. Instead of general depth-first or breadth-first strategies (e.g. Nemhauser and Wolsey Citation1999, Chap. II.4]) the strategy presented below is based on the multilevel coordinate search algorithm (Huyer and Neumaier Citation1999).
The idea is to generate a so-called record list (denoted by R) of tree nodes scheduled for future selection of searching and splitting. Once a node is processed, it is removed from the list. When all nodes are processed and the list is empty, a new list is created based on the updated search tree. The record list is computed as follows.
Let N denote the set of all nodes in the tree that are created so far, and let denote the set of leaf nodes, i.e. the nodes that are not yet split. The level
of node
denotes the number of times the node j has been split, where
and
is the maximum number of levels in the tree. The root node, i.e. node 1, belongs to level
and the splitting of a node j results in two child nodes at level
. Let
denote the set of levels containing at least one leaf node and let
denote the set of leaf nodes at level
.Footnote5 Letting
denote the optimal value of optimization problem (Equation3
(3a)
(3a) ) for leaf node
, the record list is then defined as
(6)
(6)
The fact that the leaf nodes at all levels in L are included in the record list ensures a mix of global and local search: the selection of the nodes with the lowest levels constitutes the global search, while the selection of the nodes with the lowest values of ,
, constitute the local search.
4. Local search
In Algorithm 1, a local search is performed when the feasible design that is nearest to the optimal solution of problem (Equation3(3a)
(3a) ) is to be found in each node being processed and also to improve the lowest objective function value in each subproblem. The direct search algorithm pattern search, originating from Box (Citation1957) and described in detail by Audet and Dennis Jr (Citation2004), was implemented because of its simplicity. Within a certain neighbourhood of the current design, it searches for a design with a lower objective value. The finite set of neighbouring design points is determined by a prefixed or random pattern. Pattern search does not require gradient information for the objective function, and the algorithm is robust and flexible (Audet and Dennis Jr Citation2006).
5. Splitting algorithm for simulation-based optimization problems with categorical variables: quadDS
The splitting algorithm for simulation-based optimization problems with categorical variables developed in this article is called ‘quadDS’ (quadratically underestimating discrete search). A flowchart of the algorithm is provided in Figure . The terms used in the flowchart are interpreted below.
Initialize record list. For each node
Select node to process. If the record list
Find the design nearest to the relaxed solution. In each tree node an approximate lower bound on the optimal value of F in (Equation1a
Enough designs for underestimation evaluated? A certain number of designs has to be sampled in order to form the underestimating function
Apply pattern search. The pattern search starts from the evaluated design with a minimum value of F in (Equation1a
Evaluate more designs. Designs that are feasible in the processed node are evaluated through the (computationally expensive) simulations of the objective function F. Form underestimator of F. A quadratic convex approximate underestimating
Minimize underestimator. The function
Split feasible region. The feasible region is split according to the convex relaxation-based splitting strategy, with
Minimize underestimator on each subregion. The function
Convergence. The algorithm is terminated based on a maximum number of evaluations of F. Convergence is, however, guaranteed only when all feasible designs have been evaluated.
Figure 3. Flowchart of the algorithm quadDS.
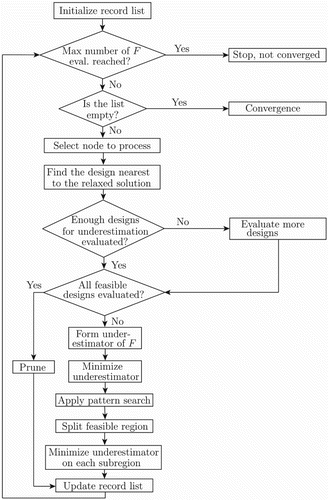
In each iteration of quadDS, one linear optimization problem (LP) (or semidefinite optimization problem [SDP]) and three convex quadratic optimization problems (QPs) are solved. The algorithm quadDS is particularly suitable when the magnitude of the time needed for objective function simulations substantially exceeds the magnitude of the time required to solve these four optimization problems.
6. Computational experiments
This section describes the computational experiments conducted to assess the performance of quadDS, measured by the number of objective function evaluations. The implementation of quadDS is described in Section 6.1. The algorithms used for performance evaluation of quadDS are described in Section 6.2. The test problems used to assess the performance of the algorithms tested are described in Section 6.3. The assessment methodology chosen is introduced in Section 6.4, and the numerical results are presented in Section 6.5.
6.1. Implementation
All experiments were carried out on a laptop computer equipped with Intel Core
i7-5600U 2.60 GHz CPU and 16 GB of RAM, running 64-bit Windows
7 Enterprise. The algorithm quadDS, as described in this article, was implemented in MATLAB
R2015b (The MathWorks Citation2015). To find the convex underestimator
through solving optimization problem (Equation2
(2a)
(2a) ), either the solver for linear and quadratic semi-definite optimization problems SDPT3-4.0 (Toh, Todd, and Tutuncu Citation1999) was used, or the LP solver linprog (Coleman and Zhang Citation2015) from MATLAB's R2015b Optimization Toolbox for the case when the underestimator
has a diagonal Hessian was utilized; see Section 6.5. Quadratic optimization problem (Equation3
(3a)
(3a) ) was solved using the QP solver quadprog (Coleman and Zhang Citation2015) from MATLAB's R2015b Optimization Toolbox. The implementation of quadDS is available upon request.
6.2. Tested algorithms
The considered class of design optimization problem with simulation-based objective functions is in engineering practice often solved using genetic algorithms (Dhingra and Rao Citation1992; Atiqullah and Rao Citation2000; Ryoo and Hajela Citation2004). An alternative is to use a nonlinear optimization algorithm, designed for non-convex optimization problems or simulation-based objective functions, and which can also handle discrete variables. The performance of three variants of quadDS is compared with one genetic algorithm (MATLAB GA)—which is often used and is readily available—and one algorithm developed for simulation-based optimization (NOMAD [nonlinear optimization with the mesh aaptive search algorithm])—which is easy to use.
quadDS
Three variants of quadDS are considered, denoted quadDSLP, quadDSSDP and quadDSFN, respectively. The variants quadDSLP and quadDSSDP both use the nearest edge projection splitting method, but differ in the approach to determining the quadratic underestimator by solving optimization problem (Equation2
(2a)
(2a) ). In quadDSLP, the Hessian of
is diagonal, thus reducing the SDP (Equation2
(2a)
(2a) ) to a separable LP. In quadDSSDP, no assumption on the sparsity of the Hessian of
is made. A complete algorithm has been defined from the techniques described by Fuchs and Neumaier (Citation2010b): quadDSFN, in which the objective function is approximated by a linear combination of the function values at the evaluated designs and the balanced split method is used.
Genetic algorithm solver
The genetic algorithm solver is part of the MATLAB Optimization Toolbox (Coleman and Zhang Citation2015; The MathWorks Citation2015) and solves optimization problems by mimicking the principles of biological evolution, repeatedly modifying a population of individual points using rules based on gene combinations in biological reproduction. The solver contains algorithms for a large variety of optimization problem with continuous, integer or mixed variables. The algorithms within the solver can to some extent be customized to simulation-based optimization problems with categorical variables.
NOMAD
The software application for simulation-based optimization, NOMAD, is based on the Mesh Adaptive Direct Search (MADS) algorithm (Audet and Dennis Jr Citation2006). MADS is an iterative method in which the simulation-based functions are evaluated at trial points lying on a mesh. It can explore a design space efficiently in the search for better solutions for a large spectrum of optimization problem types. Recent implementations of NOMAD can also handle categorical and mixed variables (Audet, Le Digabel, and Tribes Citation2009). To be able to incorporate categorical variables, a definition of neighbourhood has to be supplied. This definition then determines the behaviour of the algorithm. The approach suggested is to solve a reformulation of the problem in which the categorical variables are transformed into discrete variables. NOMAD was allowed to use built-in Latin-hypercube search and variable neighbourhood search in order to improve its performance.
6.3. Test problems
An artificial problem
A set of problem instances with cubic objective functions was randomized, according to
(7a)
(7a)
(7b)
(7b)
(7c)
(7c)
where
is a diagonal matrix and the coefficients
and
are uniformly distributed. Two sets with 120 instances, each corresponding to two variants of problem (Equation7
(7a)
(7a) ), were generated. In (i) the sparse artificial problem,
is a diagonal matrix with the elements
uniformly randomly generated. In (ii) fully artificial problem,
is a full matrix with the elements
uniformly randomly generated. The feasible designs are generated using Latin-hypercube sampling (Sóbester et al. Citation2014) with
, where
. The number
of feasible designs in each choice domain
, and the number m of choice domains, are randomized from the integer uniform distribution on the intervals
and
, respectively.
A beam design problem
The second test problem is a relaxation of the stepped beam example in Thanedar and Vanderplaats (Citation1995). A cantilever beam, consisting of five segments with rectangular cross sections, is subjected to an end shear force; see Figure . The height and width of the cross sections constitute the design variables, and in the original setting the optimization problem is to minimize the volume of the beam with constraints on the maximum bending stress and tip displacement. In the relaxation considered, these constraints are dropped and the tip displacement is minimized while penalizing the volume. The beam is modelled using the finite element method utilizing Timoshenko beam theory (Timoshenko and Gere Citation1972, Chap. 5). The beam is subdivided into a set of connected elements with nodes at the ends of the beam. The displacement is assumed to be a piecewise linear function on
.
Figure 4. A stepped cantilever beam with m=5 segments.
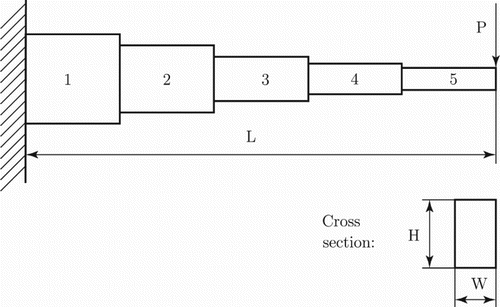
Let k denote the number of elements and q=k+1 the number of nodes. The number of segments corresponds to the length of the vector m of discrete choice variables in Section 2.1. Each segment is composed of p elements, i.e. k=mp. The choices of ,
, determine the composite vector
of widths and heights of the cross sections. Furthermore let
and
denote the stiffness matrix and load vector, respectively, and let
denote the vertical displacements of the beam. With a force P applied to the end tip resulting in the end displacement
, it follows that
and
for
, and the optimization problem is formulated as
(8a)
(8a)
(8b)
(8b)
(8c)
(8c)
(8d)
(8d)
where
denotes the penalty parameter and
is the volume of the beam. The length, the material properties and the load are set according to Thanedar and Vanderplaats (Citation1995).
The number of segments and the number of cross sections available for each segment
, are randomly uniformly generated. For each segment, the cross sections are selected from a discrete set
,
, with heights
and widths
. For the numerical tests, to receive a problem with a known optimal solution,
is set, which implies that the optimal solution can be found by choosing the cross section with both the largest height and the largest width on each segment.
The tyres selection problem
Vehicles with two and three axles, respectively, are considered for the instances of the tyres selection problem introduced in Section 1.2. The operation of the vehicle is varied in order to obtain different optimal tyre configurations, i.e. the optimal tyres to be mounted on the individual axles.
For a vehicle with two axles, i.e. , 35 feasible tyres are available for each axle, resulting in
feasible tyre designs. The choice of the tyre
(
) determines the values of the three design parameters tyre width, tyre diameter, and inflation pressure for the tyres mounted on the front (rear) axle. The resulting vector
thus has six components. For a vehicle with three axles, i.e.
, and 35 feasible tyres per axle, the vector
has nine components and there are
feasible tyre designs.
6.4. Assessment methodology
The measures performance profile and data profile introduced by Moré and Wild (Citation2009) have been utilized to assess the performance of quadDS, the MATLAB GA and NOMAD on the three sets of test problems described in Section 6.3. While performance profiles are used to compare different algorithms, data profiles provide—for each specific algorithm—the average number of function simulations required to solve the test problems.
The following convergence test, commonly used to assess derivative-free solvers (Moré and Wild Citation2009), is employed: a feasible design z fulfils the convergence test if
(9)
(9) holds, where
is a tolerance parameter that represents decrease from the starting value
,
is the initial feasible design, and
is the smallest value of F in (Equation1a
(1a)
(1a) ) obtained by any solver within a given number of function evaluations for a given problem, or the optimal value of F if available. The convergence test requires that the reduction
achieved by
be at least
times the reduction
.
Performance profile
The performance profile for an algorithm originally introduced by Dolan and Moré (Citation2002) is defined in terms of a performance measure; here it is represented by the number of evaluations of the objective function F required to satisfy the convergence test in (Equation9(9)
(9) ). Assuming a set
of algorithms applied to a set
of problems,
is for each
and
defined as the number of function evaluations required to satisfy the convergence test (Equation9
(9)
(9) ). The performance ratio, defined as
relates the performance of algorithm a as applied to the problem p to the best performance of any of the algorithms in the set
. If algorithm a fails to satisfy the convergence test on problem p, then by convention
. An overall assessment of the performance of algorithm a is obtained by defining the probability that the performance ratio is at most α, where
, that is,
The function
is the cumulative distribution function of the performance ratio. A plot of the performance profile for the set of tested algorithms
reveals the major performance characteristics of the algorithms (the relative performance of each solver, the probability of successful solution, and the percentages of problems on which the algorithms perform the best).
Data profile
While performance profiles provide an accurate view of the relative performance of solvers within a given number of function evaluations, they do not provide sufficient information in the case of computationally expensive objective functions, when a more relevant measure is the performance of a solver as a function of the number of expensive function evaluations. The data profile of an algorithm is thus employed, introduced by Moré and Wild (Citation2009) and defined by
which is the proportion of problems that are solved within β function evaluations.
Performance profiles are used to compare different algorithms, while data profiles provide the number of function simulations required to solve any of the problems by each specific algorithm.
6.5. Results
The numerical results are evaluated using the performance measures introduced in Section 6.4. The algorithm set consists of quadDSLP, quadDSSDP, quadDSFN, the MATLAB GA and NOMAD. As benchmark problems, 120 randomly generated instances of each of the four test problems (sparse artificial, fully artificial, beam design and tyres selection) described in Section 6.3 are considered. The tolerance
is used in the inequality (Equation9
(9)
(9) ) used for the convergence test for the artificial and beam problems, and
for the tyres selection problem.
Figures – show the data and performance profiles (Moré and Wild Citation2009) of quadDS (three variants), the MATLAB GA and NOMAD. The three variants of quadDS outperform the competing algorithms, the MATLAB GA and NOMAD, on all the benchmark problems. The variant quadDSLP performs the best on all sets of problems, except for the fully artificial problems. For these problems, quadDSSDP and quadDSFN perform nearly equally well, and significantly better than quadDSLP.
Figure 5. Data profiles and performance profiles
for three variants of quadDS, the MATLAB GA and NOMAD applied to 120 instances of the sparse artificial problem with
.
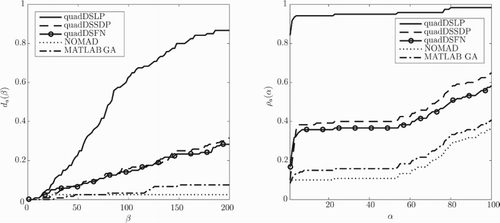
Figure 6. Data profiles and performance profiles
for three variants of quadDS, the MATLAB GA and NOMAD applied to 120 instances of the fully artificial problem with
.
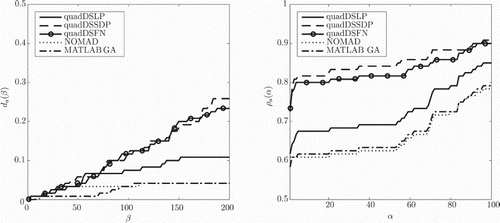
Figure 7. Data profiles and performance profiles
for three variants of quadDS, the MATLAB GA and NOMAD applied to 120 instances of the beam problem with
.
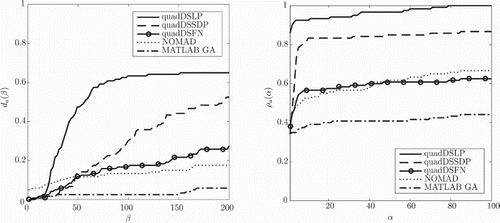
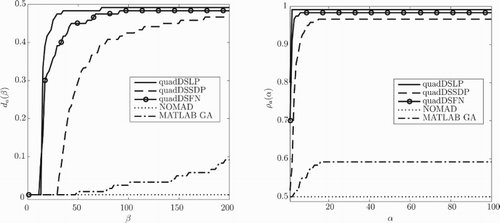
Figure 8. Data profiles and performance profiles
for three variants of quadDS, the MATLAB GA and NOMAD applied to 120 instances of the tyres selection problem with
. Note that
for all values of β and
for all values of α, because NOMAD did not solve any of the instances of the tyres selection problem within the maximum allowed number of objective function evaluations.
For the instances of the sparse artificial problem, quadDSLP performs substantially better than the other algorithms tested, see Figure . The performance of the other algorithms tested improves when the maximum number of allowed objective function evaluations is increased.
When the fully artificial problem is considered, both quadDSSDP and quadDSFN outperform the other algorithms tested, as can be seen in Figure . The underestimator with a sparse Hessian as used within quadDSLP forms an inaccurate approximation of the objective function of the fully artificial problem, resulting in the worse performance of quadDSLP. The performance of NOMAD and the MATLAB GA are almost the same and improve when the maximal number of objective function evaluations is increased.
For the beam problem, quadDSLP outperforms the other algorithms when the maximum number of allowed objective function evaluations exceeds the number of evaluated designs required to form the underestimator, as Figure shows. For fewer evaluated designs, NOMAD would be the best choice.
When the tyre problem is considered, all three variants of quadDS clearly outperform NOMAD and the MATLAB GA, see Figure . The performance of the MATLAB GA improves when the allowed number of function evaluations increases. NOMAD did not solve any of the instances of the tyres selection problem within the maximum allowed number of objective function evaluations.
The number of evaluated designs required to form the underestimator in each of the variants of quadDS influences the performance for low values of β; quadDSLP requires substantially fewer evaluated designs than quadDSSDP to start to iterate (see Enough designs for underestimation evaluated in Figure ). In quadDSFN, no underestimator is created. It is observed that quadDSLP performs better than quadDSSDP on test problems having an objective function with a sparse or even diagonal Hessian. The reason is that the underestimator with a diagonal Hessian formed in quadDSLP approximates the objective function better and requires substantially fewer function evaluations to be formed than an underestimator with a full Hessian (quadDSSDP). Subsequently, more iterations of quadDSLP can also be performed. The objective function of the sparse artificial problem is constructed to have a diagonal Hessian. It is observed that the Hessian of the objective function of the beam problem is indeed sparse and nearly diagonal. The objective function of the tyres selection problem is almost separable with respect to choice domains, resulting in an almost block-diagonal Hessian. For a general optimization problem, for which no information about the sparsity of the objective function can be obtained, quadDSSDP is recommended if sufficiently many function evaluations can be performed, since this algorithm provides tighter lower bounds. If the number of function evaluations allowed is very low, then quadDSLP should be preferred since it requires substantially fewer function evaluations to form the underestimator of the objective function.
7. Conclusions and future research
A discrete search algorithm for design optimization, quadDS, has been developed and implemented. The algorithm is suitable for optimization problems with computationally expensive simulation-based objective functions and categorical variables.
The algorithm has been tested utilizing a variety of both artificial and real test problems, and compared with other existing algorithms that can be used to solve the described class of optimization problems. The performance of the algorithms has been assessed using so-called performance and data profiles. The algorithm quadDS outperforms the competing algorithms considered on the selected benchmark problems.
The proposed algorithm enables the efficient solution of the true tyres selection problem for a limited number of customers corresponding to a specific vehicle configuration and operating environment. A technique for finding approximately optimal tyre configurations for many other customers is being developed, based on the forthcoming work by Nedělková et al. (Citation2018).
The algorithm quadDS can be extended to include simple constraints on the discrete choice variables except for those already included. Separable constraints can be handled through a preprocessing of the search domain. Linear constraints can be included in the convex relaxation of the original problem used by the algorithm. To handle more complicated constraints, such as nonlinear and/or simulation-based ones, will require further development. The variant of quadDS presented here is developed for purely categorical variables; continuous and discrete variables can, however, be handled by a simple adjustment of the splitting method.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
Zuzana Nedělková http://orcid.org/0000-0003-1551-9713
Christoffer Cromvik http://orcid.org/0000-0001-5421-7967
Peter Lindroth http://orcid.org/0000-0001-5344-3858
Michael Patriksson http://orcid.org/0000-0001-7675-7454
Ann-Brith Strömberg http://orcid.org/0000-0003-1962-7279
Additional information
Funding
Notes
1. Note that the integer values do not represent any physical entities.
2. The values ,
, are usually provided in an
table,
.
3. A more accurate underestimation would be computationally more expensive to construct and minimize (Nowak and Vigerske Citation2008).
4. The costs of edges are determined by their lengths in terms of Euclidean distance in the -space.
5. It holds that .
References
- Abhishek, K., S. Leyffer, and J. T. Linderoth. 2010. “Modeling without Categorical Variables: A Mixed-Integer Nonlinear Program for the Optimization of Thermal Insulation Systems.” Optimization and Engineering 11 (2): 185–212. doi: 10.1007/s11081-010-9109-z
- Alexandrov, N. M., and M. Y. Hussaini, eds. 1997. Multidisciplinary Design Optimization: State of the Art. Philadelphia, PA: SIAM.
- Atiqullah, M. M., and S. S. Rao. 2000. “Simulated Annealing and Parallel Processing: An Implementation for Constrained Global Design Optimization.” Engineering Optimization 32 (5): 659–685. doi: 10.1080/03052150008941317
- Audet, C., and J. E. Dennis Jr. 2004. “A Pattern Search Filter Method for Nonlinear Programming without Derivatives.” SIAM Journal on Optimization 14 (4): 980–1010. doi: 10.1137/S105262340138983X
- Audet, C., and J. E. Dennis Jr. 2006. “Mesh Adaptive Direct Search Algorithms for Constrained Optimization.” SIAM Journal on Optimization 17 (1): 188–217. doi: 10.1137/040603371
- Audet, C., S. Le Digabel, and C. Tribes. 2009. NOMAD User Guide. Tech. Rep. G-2009-37. Montréal, QC, Canada: Les cahiers du GERAD.
- Box, G. E. P. 1957. “Evolutionary Operation: A Method for Increasing Industrial Productivity.” Journal of the Royal Statistical Society. Series C (Applied Statistics) 6 (2): 81–101.
- Boyd, S., and L. Vandenberghe. 2004. Convex Optimization. Cambridge, UK: Cambridge University Press.
- Carlson, S. E. 1996. “Genetic Algorithm Attributes for Component Selection.” Research in Engineering Design 8 (1): 33–51. doi: 10.1007/BF01616555
- Coleman, T. F., B. S. Garbow, and J. J. Moré. 1985. “Software for Estimating Sparse Hessian Matrices.” ACM Transactions on Mathematical Software 11 (4): 363–377. doi: 10.1145/6187.6190
- Coleman, T. F., and Y. Zhang. 2015. Optimization Toolbox User's Guide, Revised for Version 7.3 (Release 2015b). Natick, MA: The MathWorks, Inc.
- Dhingra, A. K., and S. S. Rao. 1992. “A Neural Network Based Approach to Mechanical Design Optimization.” Engineering Optimization 20 (3): 187–203. doi: 10.1080/03052159208941280
- Dolan, E. D., and J. J. Moré. 2002. “Benchmarking Optimization Software with Performance Profiles.” Mathematical Programming 91 (2): 201–213. doi: 10.1007/s101070100263
- Floudas, Christodoulos A. 1995. Nonlinear and Mixed-Integer Optimization: Fundamentals and Applications. 1st ed. OUP Series on Topics in Chemical Engineering. Don Mills, ON, Canada: Oxford University Press.
- Fuchs, M., D. Girimonte, D. Izzo, and A. Neumaier. 2008. “Robust and Automated Space System Design.” In Robust Intelligent Systems, edited by A. Schuster, 251–272. New York: Springer Science & Businees Media.
- Fuchs, M., and A. Neumaier. 2010a. “A Splitting Technique for Discrete Search Based on Convex Relaxation.” Journal of Uncertain Systems 4 (1): 14–21.
- Fuchs, M., and A. Neumaier. 2010b. “Discrete Search in Design Optimization.” In Complex Systems Design & Management, edited by M. Aiguier, F. Bretaudeau, and D. Krob, 113–122. Berlin-Heidelberg: Springer.
- Graham, R. L., and P. Hell. 1985. “On the History of the Minimum Spanning Tree Problem.” Annals of the History of Computing 7 (1): 43–57. doi: 10.1109/MAHC.1985.10011
- Horst, R., and H. Tuy. 1996. Global Optimization: Deterministic Approaches. New York: Springer.
- Huyer, W., and A. Neumaier. 1999. “Global Optimization by Multilevel Coordinate Search.” Journal of Global Optimization 14 (4): 331–355. doi: 10.1023/A:1008382309369
- Jones, D. R., C. D. Perttunen, and B. E. Stuckman. 1993. “Lipschitzian Optimization without the Lipschitz Constant.” Journal of Optimization Theory and Applications 79 (1): 157–181. doi: 10.1007/BF00941892
- Leyffer, S. 1993. “Deterministic Methods for Mixed Integer Nonlinear Programming.” PhD diss., University of Dundee, UK.
- Lindroth, P. 2012. “TyreOpt—Fuel Consumption Reduction by Tyre Drag Optimisation.” [In Swedish]. Project number: P34882-1. Swedish Energy Agency, Stockholm. Accessed 14 April 2017. http://www.energimyndigheten.se/forskning-och-innovation/projektdatabas/.
- Locatelli, M., and F. Schoen. 2013. Global Optimization: Theory, Algorithms, and Applications. Philadelphia, PA: SIAM.
- Moré, J. J., and S. M. Wild. 2009. “Benchmarking Derivative-Free Optimization Algorithms.” SIAM Journal on Optimization 20 (1): 172–191. doi: 10.1137/080724083
- Nedělková, Z., P. Lindroth, and B. Jacobson. 2017. “Modelling of Optimal Tyres Selection for a Certain Truck and Transport Application.” International Journal of Vehicle Systems Modelling and Testing 12 (3–4): 284–303. doi: 10.1504/IJVSMT.2017.089998
- Nedělková, Z., P. Lindroth, M. Patriksson, and A.-B. Strömberg. 2018. “Efficient Solution of Many Instances of a Simulation-Based Optimization Problem Utilizing a Partition of the Decision Space.” Annals of Operations Research 265 (1): 93–118. doi:10.1007/s10479-017-2721-y.
- Nedělková, Z., P. Lindroth, A.-B. Strömberg, and M. Patriksson. 2016. “Integration of Expert Knowledge into Radial Basis Function Surrogate Models.” Optimization and Engineering 17 (3): 577–603. doi: 10.1007/s11081-015-9297-7
- Nemhauser, G. L., and L. A. Wolsey. 1999. Integer and Combinatorial Optimization. 1st ed. Vol. 55 of the Wiley Series Discrete Mathematics and Optimization. Hoboken, NJ: Wiley.
- Neumaier, A., M. Fuchs, E. Dolejsi, T. Csendes, J. Dombi, B. Bánhelyi, Z. Gera, and D. Girimonte. 2007. Application of Clouds for Modeling Uncertainties in Robust Space System Design, Final Report. Tech. Rep. ACT Ariadna Research ACT-RPT-05-5201, European Space Agency. http://www.esa.int/gsp/ACT/doc/ARI/ARI%20Study%20Report/ACT-RPT-INF-ARI-055201-Clouds.pdf.
- Nowak, I., and S. Vigerske. 2008. “LaGO: A (Heuristic) Branch and Cut Algorithm for Nonconvex MINLPs.” Central European Journal of Operations Research 16 (2): 127–138. doi: 10.1007/s10100-007-0051-x
- Parker, R. G., and R. L. Rardin. 2014. Discrete Optimization. 2nd ed. Elsevier Series on Computer Science and Scientific Computing. Cambridge, MA: Elsevier.
- Ryoo, J., and P. Hajela. 2004. “Decomposition-Based Design Optimization Method Using Genetic Co-Evolution.” Engineering Optimization 36 (3): 361–378. doi: 10.1080/03052150410001657587
- Šabartová, Z. 2015. “Mathematical Modelling for Optimization of Truck Tyres Selection.” Lic. thesis, Chalmers University of Technology and Department of Mathematical Sciences, University of Gothenburg.
- Šabartová, Z., A.-B. Strömberg, M. Patriksson, and P. Lindroth. 2014. “An Optimization Model for Truck Tyres Selection.” In Engineering Optimization IV. Proceedings of the International Conference on Engineering Optimization (ENGOPT 2014), edited by H. C. Rodrigues, José Herskovits, C. M. Mota Soares, J. M. Guedes, Aurelio L. Araújo, J. O. Folgado, F. Moleiro, and J. F. A. Madeira, 561–566. Leiden, The Netherlands: CRC Press/Balkema.
- Sóbester, A., A. I. J. Forrester, D. J. J. Toal, E. Tresidder, and S. Tucker. 2014. “Enginering Design Applications of Surrogate-Assisted Optimization Techniques.” Optimization and Engineering 15 (1): 243–265. doi: 10.1007/s11081-012-9199-x
- Tawarmalani, M., and N. V. Sahinidis. 2004. “Global Optimization of Mixed-Integer Nonlinear Programs: A Theoretical and Computational Study.” Mathematical Programming 99 (3): 563–591. doi: 10.1007/s10107-003-0467-6
- Thanedar, P. B., and G. N. Vanderplaats. 1995. “Survey of Discrete Variable Optimization for Structural Design.” Journal of Structural Engineering 121 (2): 301–306. doi: 10.1061/(ASCE)0733-9445(1995)121:2(301)
- The MathWorks. 2015. MATLAB
- Timoshenko, Stephen, and James M. Gere. 1972. Mechanics of Materials. Boston, MA: Van Nostrand Reinhold.
- Toh, K. C., M. J. Todd, and R. H. Tutuncu. 1999. “SDPT3—A MATLAB Software Package for Semidefinite Programming.” Optimization Methods and Software 11 (1-4): 545–581. doi:10.1080/10556789908805762.
- Wolkowicz, H., R. Saigal, and L. Vandenberghe. 2012. Handbook of Semidefinite Programming: Theory, Algorithms, and Applications. Springer International Series on Operations Research & Management Science. New York: Springer Science & Business Media.
- Zhao, Z., J. C. Meza, and M. Van Hove. 2006. “Using Pattern Search Methods for Surface Structure Determination of Nanomaterials.” Journal of Physics: Condensed Matter 18 (39): 86–93.
- Žilinskas, J. 2008. “Branch and Bound with Simplicial Partitions for Global Optimization.” Mathematical Modelling and Analysis 13 (1): 145–159. doi: 10.3846/1392-6292.2008.13.145-159