
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This article presents a novel framework for the multi-objective optimization of offshore renewable energy mooring systems using a random forest based surrogate model coupled to a genetic algorithm. This framework is demonstrated for the optimization of the mooring system for a floating offshore wind turbine highlighting how this approach can aid in the strategic design decision making for real-world problems faced by the offshore renewable energy sector. This framework utilizes validated numerical models of the mooring system to train a surrogate model, which leads to a computationally efficient optimization routine, allowing the search space to be more thoroughly searched. Minimizing both the cost and cumulative fatigue damage of the mooring system, this framework presents a range of optimal solutions characterizing how design changes impact the trade-off between these two competing objectives.
1. Introduction
As the offshore renewable energy sector progresses, it has become increasingly important to ensure that designs simultaneously generate the desired energy, survive in their energetic surroundings for their full lifetime, and remain cost effective. In the quest to satisfy these competing objectives, optimization techniques are now deployed in the design process to identify new design concepts while also aiding the system designer in strategic design decision making. With progressively more offshore renewable energy devices exploring floating solutions, mooring systems have become one of the key subsystems which impacts both the survivability of the device and its costs (Weller et al. Citation2015; Thomsen et al. Citation2018). However, owing to the computational time associated with the simulation of mooring systems, it is not yet commonplace to deploy optimization algorithms in the design cycle. Without the use of numerical optimization methods, the design of mooring systems is limited to an iterative engineering design approach based on experience and engineering judgement. This often leads to innovative mooring designs not being considered, and the deployment of sub-optimal mooring designs (Johanning, Smith, and Wolfram Citation2006). In order to implement optimization techniques in complex engineering design problems, surrogate modelling, the use of simpler low fidelity models which approximate the high fidelity results at a lower computation cost, have emerged as an important technique to improve the computational time associated with these optimization schemes (Won and Ray Citation2005; Voutchkov and Keane Citation2006; Jin Citation2011).
The field of mooring optimization is a relatively nascent field which explores the optimal selection of mooring line materials, lengths and diameters in order to elicit a desired response or minimize the cost associated with a floating system. As mooring systems represent an important component of offshore renewable energy devices which impact not only the motion dynamics of the device, and therefore how it interacts with the resource from which it is extracting energy, but also affects the cost of the overall system and governs the lifetime of the device (Weller et al. Citation2015). In the design of mooring systems, it is therefore common to select designs which minimize the cost or excursions subject to constraints on the tension in the lines, and the fatigue in the mooring system. Given this complex set of design considerations, an optimization approach, and multi-objective optimization in particular, would be appropriate in order to characterize the trade-offs between the competing design objectives and to inform decision making better.
Existing work in the optimal design of mooring systems has explored geometry optimization of the mooring system using a genetic algorithm to minimize the response of the moored vessels and platforms (Carbono, Menezes, and Martha Citation2005; Shafieefar and Rezvani Citation2007; Ryu et al. Citation2007; da Fonesca Monteiro et al. Citation2016; Ryu et al. Citation2016). However, as these studies have focused on vessels and platforms, they may not be the most appropriate optimizer objectives for an offshore renewable energy device. Recent work by Thomsen et al. (Citation2018) has specifically explored the optimization of mooring systems for a wave energy converter considering the minimization of cost; however, the use of single-objective optimization does not fully capture the complexity of the design problem. Offshore renewable energy devices must be both cost effective and achieve a specific device response in order to harness the energy sources effectively. Work by the present authors has, therefore, explored multi-objective optimization of mooring systems for renewable energy platforms in order to highlight potential design trade-offs between the competing objectives that a device designer would face, thereby offering information to allow the system designers to make more informed decisions (Pillai, Thies, and Johanning Citation2017, Citation2018b).
The assessment of mooring system designs is generally achieved through finite element analysis software operating in either the time domain or the frequency domain (Davidson and Ringwood Citation2017). Time domain finite element models are capable of capturing the dynamic behaviour of the mooring lines and therefore play an important role in the design process. However, in order to assess the response of the mooring behaviour effectively, simulations must be executed for each operating condition and for sufficiently long simulations in order adequately to capture the dynamic behaviour during any operational sea state (Thomsen, Eskilsson, and Ferri Citation2017). Previous work by the authors has highlighted the importance of utilizing time domain simulations when designing mooring systems for renewable energy devices, as these devices are characterized by more dynamic motion than vessels or platforms, therefore requiring a simulation domain that can capture these dynamic effects and their impact on the fatigue and design life of the mooring system. Mooring system optimization without surrogate models (Carbono, Menezes, and Martha Citation2005; Shafieefar and Rezvani Citation2007; Ryu et al. Citation2007; da Fonesca Monteiro et al. Citation2016; Ryu et al. Citation2016) tend to rely on frequency domain simulations that are significantly quicker and less computationally demanding than their time domain counterparts. Frequency domain methods, however, are not as effective in capturing the dynamic motion and loading of mooring systems, which may play an important role in selecting appropriate mooring designs for offshore renewable energy applications (Kwan and Bruen Citation1991; Brown and Mavrakos Citation1999; Pillai, Thies, and Johanning Citation2018a).
For many optimization problems, the true objective function(s) are computationally costly. An effective approach to resolve this is to use a simpler objective function, a surrogate, which is correlated to the true objective, but computationally less expensive (Forrester, Sóbester, and Keane Citation2008). Surrogate modelling as a general term includes any model that substitutes for a high fidelity model in order to reduce computational time. These models can therefore attempt to model the underlying science with less detail or can be statistical models built from results using the full model (Forrester, Sóbester, and Keane Citation2007). Traditional forms of surrogate models include decision trees, support vector machines, radial basis functions, and artificial neural networks; however, there are also now many variations and hybrid approaches (Hastie, Tibshirani, and Friedman Citation2009; Forrester, Sóbester, and Keane Citation2008). Recent developments in the field of surrogate modelling in the context of optimization have explored the use of ensembles of surrogates to define and characterize the search space better (Forrester and Keane Citation2009; Forrester, Sóbester, and Keane Citation2007; Chugh et al. Citation2018; Shankar Bhattacharjee, Kumar Singh, and Ray Citation2016). Previous work in this field has focused on the development of generalized strategies that are relevant to a wide range of engineering problems, while the focus of the present article is to demonstrate a specific methodology suitable to the mooring system design and optimization problem. The present work, therefore, focuses on the introduction and demonstration of the applicability of a specific methodology for this specific problem.
Surrogate models built for the assessment of the motions of a moored structure and the tensions in the mooring lines have generally made use of artificial neural networks (de Pina et al. Citation2013, Citation2016; Sidarta et al. Citation2017). The use of surrogate models for mooring system assessment, has, however, not been undertaken in the context of optimizing the mooring system.
This article bridges these two areas of research implementing both a genetic algorithm for the geometry optimization of the mooring system of an offshore renewable energy platform while utilizing a surrogate model built using a machine learning technique in order to reduce the computational complexity of the optimizer evaluation function through a functional approximation architecture. The developed framework represents a pragmatic approach to the design of mooring systems offering a system designer the potential to make more informed decisions regarding the design of the mooring system. Though the optimization and surrogate models deployed are not on their own novel, their integration into a unified framework for the present mooring system design framework represents a novel implementation which is shown to aid the design process and marks an improvement on the present standard approaches.
In the design of mooring systems there are several objectives that are often considered including the cost of the mooring system, the tension in the lines relative to the minimum breaking load (MBL), the excursions of the floating body, or the cumulative fatigue damage. For the presented case study, the optimization routine seeks to minimize the cumulative lifetime fatigue damage in the mooring system and the material cost of the mooring system. These have been selected as they represent two important design criteria for mooring systems and especially for offshore renewable energy developers. Due to increasing challenges in many-objective optimization, the present implementation is as a bi-objective problem, though extensions including further objectives can be explored within the framework in the future in order to consider additional objectives simultaneously during the design process.
2. Mooring system optimization problem
The problem addressed in the present article explores the geometry optimization of a mooring system for an offshore renewable energy device. Offshore renewable energy devices extract energy from natural fluxes which cause some device motion relative to this natural flux, be it the blades of a wind turbine relative to the wind, a tidal turbine's rotor relative to the tidal current, or a wave energy device's active surface relative to the sea surface elevation. As a result of this, it must be ensured that the mooring systems of floating renewable energy devices are designed such that they achieve the desired behaviour while at the same time not adversely impacting the reliability or cost of the overall system. The optimal design of mooring systems must therefore consider the site at which a device is being deployed, the specific device characteristics, the mooring system itself, and the interactions between these elements.
For each of the mooring lines considered in the system, the optimization routine selects the position of the mooring line anchor, the length of the mooring line, the material of each section of the mooring line, and the diameter of each section of the mooring line. These decision variables are given in Table . The optimization routine does not explicitly select the number of mooring lines, but takes this as an input.
Table 1. Description of decision variables.
Though the mooring system is defined using only a few variables for each line, this formulation is efficient in capturing the elements of interest to a mooring designer and can be used to characterize the mooring system for any floating body. In the present work, each line has been limited to consist of a maximum of three sections that can differ in diameter, material or both. This limit has been selected in part because it represents the maximum number of sections often utilized for offshore renewable energy devices, and it allows a significant degree of flexibility to the optimization process. Given the flexibility of the framework, should a designer wish to consider a greater degree of flexibility in the designs then additional sections can easily be considered.
While the variables describing the section lengths and anchor position are continuous variables, the line type is a categorical representing which of the predefined line types is to be deployed. A detailed description of the constraints, and restrictions on the decision variables, follows in Section 2.3.
2.1. Cumulative fatigue damage
Engineering design must consider different failure modes in order to ensure that the design is fit for purpose. This includes the ultimate limit state (ULS), which considers the maximum extreme loads that the system must withstand, as well as the fatigue limit state (FLS), which considers the possible failure as a result of repeated cyclic loading at levels below the ULS (Schijve Citation2009). Offshore renewable energy devices seek to be deployed for a period up to 25 years, which therefore requires reliable systems that can ensure device survival over this lifetime. The first objective explored in this optimization problem is therefore the fatigue damage in the mooring system. The fatigue damage is assessed using simulated tension time-series for each proposed mooring system for each of the anticipated sea states at the installation site. From this, rainflow counting of the tension cycles is done at each point along the lengths of the mooring lines.
Rainflow counting is a methodology used to evaluate fatigue damage for load cycles of varying amplitude. This method operates by identifying and counting the stress ranges corresponding to individual hysteresis loops. This is then used in combination with S-N or T-N curves which define the number of stress (S-N) or tension (T-N) cycles at a specific amplitude required for the material to reach failure. The Palmgren–Miner rule, shown in Equation (Equation1(1)
(1) ), allows the individual contribution of each stress cycle to be summed in order to compute the cumulative fatigue damage (Rychlik Citation1987; Amzallag et al. Citation1994; Schijve Citation2009; Thies et al. Citation2014). The lifetime fatigue damage of the mooring lines is established by carrying out these calculations for each sea state that is expected at the site, and scaling the fatigue contributions based on the relative occurrence of the sea states over the operational lifetime of the device.
(1)
(1) where
is the fatigue damage,
is the number of cycles during time t, and S denotes the stress amplitudes established in the rainflow cycle count. The parameters K and β describe the fatigue properties of the material and are given by the S-N and T-N curves.
The cumulative fatigue damage, is then given by
(2)
(2) where s represents a sea state from
, the set of sea states that are simulated, T is the operational lifetime of the mooring system,
is the simulation duration, and
is the probability of occurrence associated with sea state s. For each mooring line, the cumulative fatigue is computed at each point along the mooring line in order to consider the possible failure anywhere along the line and not exclusively at the fairleads. Though the highest tensions are experienced at the fairleads, the fatigue damage may be higher elsewhere in the system and it is important to consider the possible failure at any position along the mooring lines.
The objective, the minimization of the cumulative fatigue damage, is given explicitly in Equation (Equation4a(4a)
(4a) ) in the full problem formulation.
2.2. Material cost
As cost effective solutions are sought, the second objective explored in the mooring design problem is the minimization of the material cost of the mooring lines. This is computed as a sum over the mooring lines by multiplying the unit cost of each line type (a combination of material and diameter, i.e. MBL) by the length of the line type deployed in the mooring system. In this way, this metric does not include any consideration of the anchors, and in fact the time domain simulations do not affect this objective. This objective, the material cost of the mooring system, is, however, necessary as it represents a key metric that developers must consider when designing and deploying their mooring systems. The mooring system cost is computed using Equation (Equation3(3)
(3) ) and the objective is given in Equation (Equation4b
(4b)
(4b) ) in the problem formulation.
(3)
(3)
2.3. Constraints
In order to model the design problem accurately, it is important to include constraints that limit the search space to feasible solutions and represent the real engineering limitations on the decision variables. Since the decision variables include the line specifications for each line as well as the anchor positions for each line's anchor, the genome is a mixture of various types.
The anchors are defined to be no further than 2500 m away from the floating body, and anchor lines are set to be within 30 of the original orientation defined in the simulation model (Equations (Equation4c
(4c)
(4c) ) and (Equation4d
(4d)
(4d) )). Specific constraints on the anchor positions will be site and project specific and these values have been selected for the present case study to illustrate the capabilities of the tool. The minimization of the mooring line costs will naturally try to limit the mooring footprint by bringing anchors in closer to the floating body, so this upper limit acts to aid the convergence of the optimizer. It is important to note that the present coupling to OrcaFlex® does not simulate or model the anchors or any dynamics at the anchoring points which are assumed to be a fixed points on the seabed.
Equation (Equation4e(4e)
(4e) ) defines the length of the mooring line to be the sum of the line segments and constrains this to be greater than zero to ensure that a mooring line is present, while Equation (Equation4f
(4f)
(4f) ) imposes a constraint that the length of a mooring line cannot exceed the sum of the water depth and the horizontal distance to the anchor in order to ensure that the mooring line is not unrealistically long. Equation (Equation4g
(4g)
(4g) ) limits the tension along the length of the mooring line such that the minimum breaking load (MBL) of the line type at every location of the line is not exceeded. This constraint can optionally include
as a safety factor. Equation (Equation4h
(4h)
(4h) ) ensures that the line type for each line segment of each mooring line is one of those considered in the implementation of the optimization problem. Finally, Equations (Equation4i
(4i)
(4i) ) and (Equation4j
(4j)
(4j) ) define a set of points along each mooring line that are in contact with the seabed during the dynamic simulation and limit these to chain constructions.
2.4. Problem formulation
Given the decision variables, objectives and constraints as described above, the full optimization problem can be formulated as follows:
(4a)
(4a)
(4b)
(4b)
(4c)
(4c)
(4d)
(4d)
(4e)
(4e)
(4f)
(4f)
(4g)
(4g)
(4h)
(4h)
(4i)
(4i)
(4j)
(4j)
where
is the first objective function representing the cumulative fatigue damage,
is the cost objective,
is the decision variable for the section lengths of mooring line l,
is the decision variables for the section constructions of mooring line l,
is the decision variable for the horizontal distance between the platform and mooring line l's anchor, and
is the decision variable for the angle between the platform and mooring line l's anchor.
,
,
and
are the sets representing all the mooring lines, the sea states to examine, the available line constructions, and the line constructions that are chains, respectively. The remaining variables in the above formulation are: s a sea state from the set of sea states, d the cumulative fatigue damage,
the probability of occurrence of sea state s,
the unit cost of a mooring line construction,
the initial orientation of mooring line l,
the minimum breaking load at position a along line l,
the factor of safety on the mooring line tensions, a a position along the line,
the set of nodes along each mooring line that are in contact with the seabed,
the minimum vertical distance between the seabed and node i along mooring line l during the simulation, and h is the water depth.
In this formulation, and
can be evaluated using any relevant model, be it the full dynamic simulations using OrcaFlex or the surrogate model detailed in Section 3.2. In this way, either method takes the same input features (i.e. the genome) and provides estimates of the cumulative fatigue damage and material cost (i.e. the output features).
3. Solution approach
3.1. Process overview
Optimization algorithms are methods that seek to identify the best possible solution from those available. To do this, they make use of a search algorithm to explore the possible decision variable values with respect to some objective functions (Burke and Kendall Citation2013). For real-world problems, it is often challenging to formulate these evaluation functions accurately such that the intra-relationships between the decision variables are captured in a time-efficient manner (Jin Citation2005, Citation2011). To overcome this, optimization of real-world problems can opt to replace the complex evaluation function with a simpler, less expensive approximate model: a surrogate model. For these surrogate models to be of use, they need to be able to capture the trends of the full evaluation function, so that, on a relative basis, the results of the surrogate optimization problem can inform the original problem.
For the mooring optimization problem, the full time domain simulations are run using OrcaFlex, an industry standard software package for the time domain analysis of offshore structures. This software package is capable of modelling the tension in mooring lines involving multiple members and materials, as well as the excursions of the moored body (Thomsen, Eskilsson, and Ferri Citation2017). Using these full time domain simulations, the surrogate model is built and trained, allowing proposed mooring systems during the optimization process to be assessed without the use of the full time domain simulations.
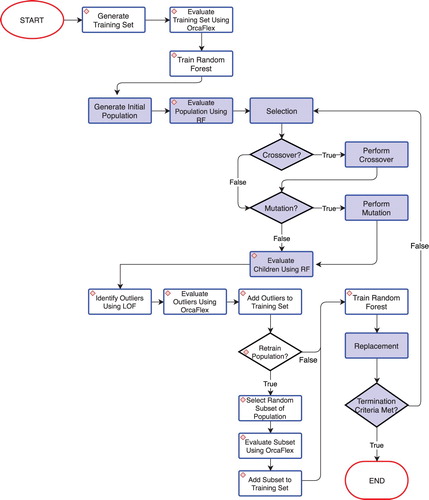
The overall methodology is pictured in Figure and makes use of both a multi-objective genetic algorithm and the machine learning based surrogate model.
Figure 1. Optimization process using a random forest surrogate model. The steps related to the surrogate model are indicated with a diamond in the top left corner, while the core steps of the genetic algorithm are shown by filled shapes.
Machine learning techniques operate according to the principles illustrated in Figure and are generally divided into classification and regression problems. In the case of a classification problem, the output feature represents the classes that the input elements are grouped into, while for a regression problem the output features represent the quantities of interest. Machine learning algorithms are often thought of as black boxes that seek to correlate the output features to the input features without simulating or modelling the underlying physics or engineering principles, being purely statistical models. For any machine learning strategy, a training set, a set of inputs and outputs, is used to calibrate the black box model in order to build these statistical relationships. Machine learning techniques in general, therefore, work best with large training datasets from which the statistical correlations can be built. Furthermore, machine learning algorithms such as a neural network or random forest work best when they are interpolating between values on the training set rather than extrapolating. These algorithms therefore require that the training set cover the extent of the search space thereby allowing interpolation. Some machine learning algorithms such as random forests are capable of extrapolating output features, at a cost, however, in terms of accuracy.
Figure 2. Overview of machine learning estimators. Note that the number of input and output features are not necessarily related, although there are generally fewer output features than there are input features. For the case of a classifier, the output features represent the classes to which each individual belongs, while in the case of regression, the output features represent the values of interest. (a) Classifier, (b) Regressor.
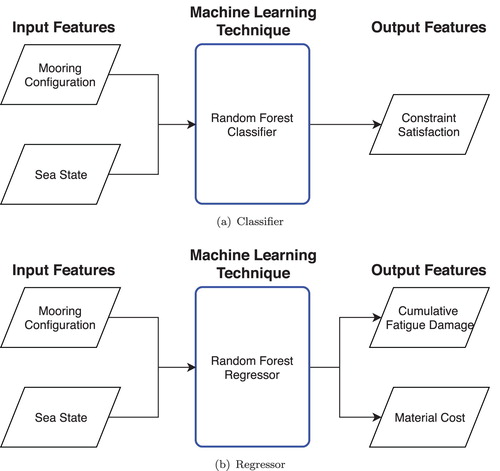
In the present implementation, the input features to the machine learning technique are the decision variables of the optimization problem and the output features are the evaluated objective functions and the mooring system's satisfaction of the constraints. In this scheme, the surrogate model first estimates if the proposed solution will satisfy or violate the constraints, in the event that the model predicts that the constraints will be satisfied, the second phase of the surrogate estimates the objective function values. In effect, this surrogate model, therefore, uses a classifier to determine the constraint satisfaction component of the problem and then a regression method to determine the objective function values. OrcaFlex is therefore only used when training and retraining the learning algorithm and is no longer directly tied to the evaluation functions for the optimization. The full procedure deployed is shown in Figure with the creation of the surrogate model indicated with a diamond in the top left corner. This new methodology follows five basic steps:
build a training set of possible mooring systems;
evaluate the training set using the original full time domain simulation-based evaluation function;
use result from the OrcaFlex model to train the surrogate model;
use the surrogate model to perform optimization using NSGA-II;
retrain the surrogate as required.
A non-dominated sorting genetic algorithm II (NSGA-II) is used to optimize over multiple objective functions. This method and the full methodology deployed in this study are described in greater detail in Section 3.3. Particular care has been taken to avoid premature convergence issues by accurately and consistently implementing both the crossover and mutation operators.
3.2. Random forest
Random forests represent an ensemble learning method that can be used for either classification or regression. In either application, random forests work by constructing several decision trees each from a subset of the training set and its features (Breiman Citation2001).
A decision tree is a basic machine learning technique in which inputs are entered and, as the decision tree is traversed, the features are binned into smaller and smaller sets allowing an output to be determined based on the given input features. From a computational perspective, decision trees are generally implemented as binary trees. Where a single tree may have difficulty in accurately classifying or predicting an output for a complex set of inputs, the use of many trees (i.e. a forest rather than a single tree) can overcome this. Each tree in a random forest uses a subset of the input features and the training set, thereby reducing the biases that may result from using a single tree (James et al. Citation2013; Hastie, Tibshirani, and Friedman Citation2009). The procedure of a random forest is given in Algorithm 1.
The decision variables of the present problem include a categorical variable, representing the line type of the mooring line sections, and continuous variables for the lengths of the mooring lines and the anchor position. The categorical variable () is handled in the surrogate model using one-hot encoding wherein the categorical variable is converted to a binary string in which only one bit can be a one. Using this encoding, there is no assumption of natural ordering of the categories, which improves performance.

(5)
(5)
Once the forest is constructed, subsequent input data can be run through each of the decision trees. The outputs of all the trees are then averaged in order to determine the output of the forest (Equation Equation5(4b)
(4b) ). In machine learning, an ensemble method is any method that uses multiple simpler machine learning techniques in its implementation. In this case, the random forest uses a series of decision trees, thereby operating as an ensemble method (Olaya-Marín, Martínez-Capel, and Vezza Citation2013; Ahmad, Mourshed, and Yacine Citation2017; Bagnall et al. Citation2016). The initial mooring designs used to train the random forest are generated using a Monte Carlo based sampling approach. In order to increase the accuracy of the surrogate, in particular in the regions being explored during the optimization process, further mooring designs are added to the training set and the surrogate is retrained periodically in what is known as the growing set approach (Kourakos and Mantoglou Citation2009).
Though artificial neural networks (ANNs) currently receive much attention in the research literature, there are many problem types where a random forest (RF) is better suited. Prior to building a model, however, it is often difficult to identify which machine learning approach is best suited to a problem a priori (Olaya-Marín, Martínez-Capel, and Vezza Citation2013). Extending the ‘no free lunch theorem’ implies that, although ANNs are effective for solving one particular problem, this does not demonstrate that they will solve all problems efficiently (Wolpert and Macready Citation1997; Wolpert Citation1996; Murphy Citation2012). For the present work, an RF has been deployed, as it is an effective technique for a wide range of problem types with relatively few tunable hyper parameters. This means that, from an implementation perspective, the RF is one of the easiest to set up and get useful results from (Statnikov, Wang, and Aliferis Citation2008; Ahmad, Mourshed, and Yacine Citation2017). Although the RF has been deployed here, the modular nature of the method allows an alternative machine learning method to be implemented with minimal changes to the structure of the tool.
3.3. Genetic algorithms (GAs)
GAs represent a family of biologically inspired population based metaheuristic optimization algorithms that borrow ideas from natural evolution as observed in biological systems (Holland Citation1992). Both genetic algorithms and evolutionary algorithms in general operate on biological analogies based on evolution. As these types of algorithm consider a set of potential solutions in each iteration rather than a single solution, they are further classed as population-based. Evolutionary algorithms are commonly applied to a wide array of engineering optimization problems owing to their generalized form, which allows the same strategy to be applicable to a wide range of different problems. These algorithms are unable to guarantee that the true global optimum is found; however, they generally converge to a high quality solution in an acceptable runtime (Burke and Kendall Citation2013; Rao Citation2009; Mitchell Citation1998). These algorithms are therefore only implemented when the size of the search space or the complexity in the objective space make it infeasible to deploy traditional optimization algorithms.
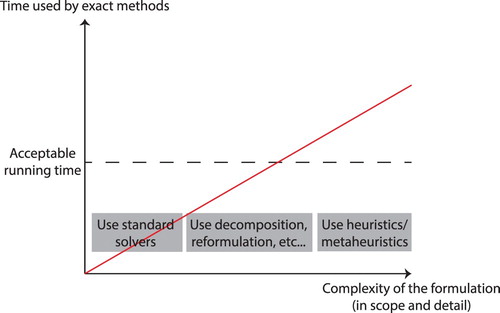
Classical optimization strategies are generally limited to continuous, differentiable objective functions. Due to their complexity, simulation based objective functions such as those relating to real-world engineering optimization problems, e.g. the mooring system optimization problem, are therefore better solved by heuristics and metaheuristic algorithms such as GAs (Rao Citation2009). Figure illustrates the relationship between the time complexity of an optimization problem and the selection of the correct solution approach. As indicated in this figure, as the complexity increases, heuristics and metaheuristics become the algorithms of choice as these allow solutions to be found within acceptable timescales without requiring full enumeration.
Figure 3. Depending on the complexity of the model at hand and the time required to execute the optimization method, different algorithm types can be more appropriate to the problem.
In a GA, the candidate solutions within the population are formulated such that the combination of the decision variables is considered a genome that defines the individual solutions. In keeping with the evolutionary analogy, each solution is assigned a fitness by the evaluation functions, with higher fitness values resulting in a higher probability of contributing genetic material towards new candidate solutions. Poor solutions, as judged by the evaluation functions, are therefore assigned lower fitness scores and therefore are less likely to have traits that are passed on to the next generation. The flowchart in Figure shows the steps of a GA with shaded background. After selecting pairs of individuals among the population to reproduce (i.e. to generate new candidate solutions), the pair undergoes what is referred to as crossover. During crossover, the two parent solutions are combined in such a way that two new solutions are generated, each with approximately 50% of their genome being defined by each parent. In order to ensure that the GA does not prematurely converge to a local solution, a mutation operator is used to alter the child solutions randomly. This process is repeated until the solutions converge, or there is insufficient diversity within the remaining population for the process to continue effectively.
In the present implementation, a uniform crossover operator is deployed with a Gaussian mutation operator. Uniform crossover uses a fixed probability (50% in the present work) to determine which of the parents contributes a given gene to the child solutions. The Gaussian mutation operator uses a Gaussian distribution to alter a given gene if that gene is undergoing mutation (Beyer and Schwefel Citation2002). Uniform crossover is selected as it ensures that the crossover process does not suffer from positional bias (Spears and De Jong Citation1995). The Gaussian mutation operator is one of the simplest to implement, and is generally seen as a quick and effective means of applying mutation (Cazacu Citation2017). This combination of operators, which are commonly deployed in tandem, work as an effective means of ensuring that all possible solutions within the solution space are obtainable during the optimization process regardless of the initialization or the convergence of the algorithm. This helps stave off premature convergence and aids in preserving diversity within the population.
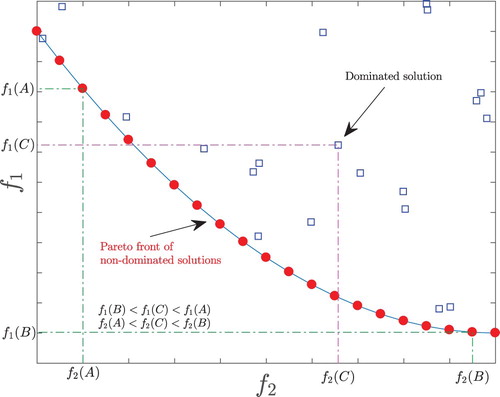
In multi-objective optimization, the optimizer seeks to identify a set of solutions which highlight the trade-off between the competing objectives (Deb Citation2001). Most multi-objective optimization approaches combine the competing objectives in such a way that the problem can be treated as a single-objective problem using traditional approaches; however, in doing so, much of the problem complexity and nuance is often lost. True multi-objective optimization is not simply an extension of single-objective optimization, but requires additional considerations in order to address the various competing objectives simultaneously. In a true non-trivial multi-objective optimization problem with conflicting objectives, there is no single solution that simultaneously optimizes all of the objectives, but a Pareto front which represents the trade-off between the competing objectives (see Figure ). While an optimization algorithm applied to a single-objective optimization problem seeks to identify a single solution representing the global optimum, a multi-objective optimization algorithm seeks instead to identify this Pareto front of potentially an infinite number of solutions. In the event that the objectives do not compete, but rather are complementary, then a Pareto front will not be realized, as from the optimizer perspective, the problem reduces to a single-objective problem.
Figure 4. Illustration of a Pareto front with dominated and non-dominated solutions for a case of two objectives both of which are to be minimized. The non-dominated solutions (circles) are explicitly better in at least one objective and no worse in the others. For example, in this figure solutions A and B lie on the Pareto front, while solution C is dominated by other solutions on the Pareto front and is therefore not a member of the non-dominated set.
NSGA-II, developed by Deb (Citation2001) and Deb, Pratap, and Agarwal (Citation2002), is a multi-objective genetic algorithm (MOGA) which uses a sorting algorithm to identify fronts of non-dominated solutions. NSGA-II is similar to the canonical GA, but differs by using a sorting algorithm to identify fronts of non-dominated solutions which is combined with a diversity preservation measure referred to as the crowding distance. The non-dominated fronts are ranked for use in a tournament selection in which the crowding distance is used as a tie breaker in the event that the two individuals in the tournament have the same non-dominated front (Deb Citation2001; Deb, Pratap, and Agarwal Citation2002; Burke and Kendall Citation2013; Brownlee Citation2011). From here, standard crossover and mutation operations are used. The full NSGA-II methodology is well described in Deb, Pratap, and Agarwal (Citation2002) and Deb (Citation2001). In the present implementation of NSGA-II, the parameters given in Table are used. In this implementation, two crossover and mutation rates are applied. The first set, those for the entire genome, reflect the probability that the individual is subjected to crossover or mutation respectively, while the second set, those for an individual gene (i.e. decision variable), reflect the probability, given that crossover or mutation occurs, that an individual decision variable is crossed-over or mutated.
Table 2. Genetic algorithm parameters.
The parameters used in the present implementation, which are given in Table , have been selected using a combination of recommendations from Grefenstette (Citation1986), from Deb, Pratap, and Agarwal (Citation2002) and from preliminary tuning of the algorithm. The current parameters are found to work well for the present problem, and as they are in line with general rules of thumb for GA parameters, they will probably be suitable for a wide range of problems; however, the parameters will be impacted by the specific problem at hand and should be tuned for the specific implementation and problem instance.
3.4. Anomaly detection and retraining the surrogate model
In order to ensure that the surrogate model remains relevant to the region of the search space being explored by the optimizer, additional solutions are added to the training set (the growing set approach) and the model is periodically retrained (Kourakos and Mantoglou Citation2009; Ong, Nair, and Keane Citation2003). Often, retraining of surrogates is done to augment the training set with solutions in the area of interest (i.e. near the Pareto front) in order to improve the quality of solutions in this region of the search space. Alternatively, however, retraining can be done to improve the surrogate's performance more evenly across the entire search space by using samples across the space when growing the training set. In the present work, increasing the size of the training set was done with two goals in mind: (1) increasing the surrogate's accuracy across the entire search space and (2) increasing the applicability of the surrogate by adding designs to the mooring system to ensure that the surrogate is always interpolating and not extrapolating.
Following each generation of the GA, the solutions estimated by the surrogate model are analysed using a local outlier factor (LOF) method which identifies potential outliers in a dataset based on a local density measure (Breunig et al. Citation2000; Chandola, Banerjee, and Kumar Citation2009). LOF is a proximity-based anomaly detection algorithm which operates by comparing the local deviation of a sample with respect to its neighbours (Breunig et al. Citation2000). LOF operates by comparing the distance between a sample and its nearest neighbours in order to establish a density, samples which have substantially lower densities than their neighbours are classed as outliers. In this case, the density is defined by the local reachability density () of a point. The reachability distance (
) and the
are given by Equations (Equation6
(4c)
(4c) ) and (Equation7
(4d)
(4d) ), respectively:
(6)
(6)
(7)
(7) These metrics are then combined to compute the LOF of a sample:
(8)
(8) where
is the distance from o to its kth nearest neighbour,
is the true distance between p and o,
is the set of nearest neighbours to p,
represents the reachability distance. LOF values of approximately one indicate that a sample is comparable to its neighbours, while values below one represent inliers, and values above one represent the outliers.
Individuals classed as potential outliers are added to the training set and the surrogate model is retrained. In this way, as the GA proceeds, the training set from which the surrogate model is built continues to grow and covers an increasing portion of the search space. This ensures that the surrogate model is interpolating rather than extrapolating, thereby reducing potential errors. Though the surrogate will still struggle with outliers, and solutions surrounding the limits of the surrogate, the use of retraining should keep these to a minimum.
Furthermore, every five generations, 10% of the population is selected at random for inclusion in the training set, ensuring that not only is the extent of the model improving through the inclusion of outliers, but the surrogate also improves across the entire search space. A random subset of the population rather than those closest to the Pareto front are selected as this ensures that the surrogate has an equal probability of improving throughout the search space rather than intensifying the search only in one particular region of the space, potentially leading to premature convergence to a local solution.
Retraining the model in this way comes at increased computational expense as additional solutions must be assessed using OrcaFlex and the training itself must also be completed at regular intervals. A preliminary sensitivity study in the development stages of this methodology found that, without the retraining, the final solutions were inferior unless a much larger initial training set was used. The net computational cost to achieve solutions of similar quality was therefore similar; however, using retraining allowed the algorithm to select solutions to include in the training set adaptively, thereby providing the maximum gain.
4. Case study
4.1. Case description
Continuing with the case study used in Pillai, Thies, and Johanning (Citation2017, Citation2018b), the Offshore Code Comparison and Collaboration Continuation (OC4) semi-submersible designed for offshore wind turbines is modelled for deployment at Wave Hub, a renewable energy test site located off the south west coast of the United Kingdom. The OC4 semi-submersible is defined in Robertson, Jonkman, and Masciola (Citation2014) and the hydrodynamic data is distributed as part of NREL's FAST software package. A schematic of the OC4 semi-submersible is shown in Figure . The conditions at Wave Hub are defined by long term measurements in Pitt, Saulter, and Smith (Citation2006) and are shown in Table . Using extracts from the DTOcean Database, a range of chains and polyester ropes between 24 and 200 mm were provided to the OrcaFlex model and the optimizer (see Table ). These represent the materials and sizes likely to be deployed for offshore renewable energy applications (JRC Ocean Citation2016; Weller et al. Citation2014).
Figure 5. DeepCwind floating wind system used as part of the Offshore Code Comparison Collaboration Continuation (OC4) project (Robertson, Jonkman, and Masciola Citation2014).
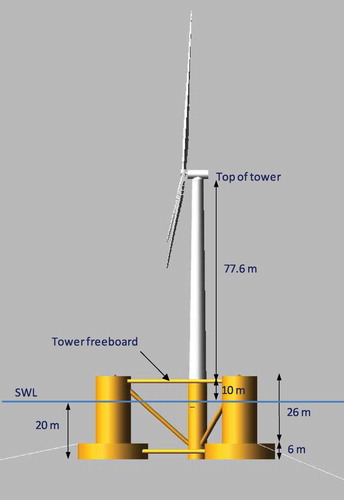
Table 3. Available line types—data from JRC Ocean (Citation2016).
Table 4. Wave scatter table for Wave Hub site – data from Pitt, Saulter, and Smith Citation2006).
To demonstrate the capabilities of this optimization framework, relatively small training sets of 500 feasible mooring designs and approximately 2000 infeasible mooring designs were used to train the classification and regression forests. Based on Oshiro, Perez, and Baranauskas (Citation2012) the forests were designed to contain between 64 and 128 trees. A standard cross-validated grid search was deployed to determine the optimal number of trees in the forest on each occasion that the random forest was trained (Rao Citation2009; Müller and Guido Citation2016). In general, the greater the number of trees in the forest, the better the quality of the fit; however, this comes at the cost of an increase in the processing time required to construct the random forest estimator and to use the forest to estimate. Sensitivity studies into the number of trees in a random forest have found that, for a range of problems, implementing beyond 128 trees offers diminishing returns (Oshiro, Perez, and Baranauskas Citation2012).
4.2. Results
The final generation of feasible solutions from execution of the surrogate-model based multi-objective genetic algorithm are shown in Figure with solutions of interest highlighted. These solutions of interest, the minimum cumulative fatigue damage, minimum cost, and a compromise solution are described in Tables , respectively. Figure explores the knee of this curve showing the solutions that simultaneously best minimize both solutions representing an equal priority between the two objectives.
Figure 6. Feasible solutions following final generation of optimization showing the trade-off between the mooring system cost and the cumulative fatigue damage; minimum cost and minimum fatigue solutions are highlighted.
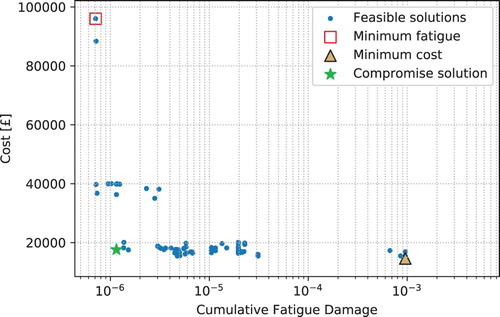
Figure 7. Focus on solutions at the knee of the trade-off curve after the final generation of the optimization, highlighting the wide range of cost levels for any given fatigue level.
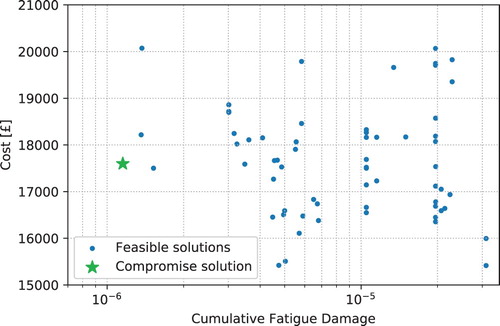
Table 5. Numerical results—minimum fatigue damage.
Table 6. Numerical results—minimum cost.
Table 7. Numerical results—knee.
Following 50 generations of the optimization, the surrogate models had classification ROC AUC of 0.862 and an outright accuracy of 0.998. The regression model had an of 0.915. These results indicate that the use of this hybrid surrogate model achieves high accuracy results for both constraint satisfaction and the output feature values.
Although metrics such as the mean averaged error (MAE) and root mean squared error (RMSE) are commonly used, the present authors use the root mean square logarithmic error (RMSLE) here (see ), which is given by Equation (Equation9(4f)
(4f) ):
(9)
(9) where there are n samples,
is the true value of sample i and
is the predicted value of sample i using the surrogate model. The RMSLE (Tables and ) differs from the RMSE in that the RMSLE applies the natural logarithm to both the predicted and true values prior to computing the root mean square error. This is done to balance the impact of both big and small predictive errors. Especially given the different scales on which the output features operate, it was felt that using the MAE or RMSE would cause any errors in the cost estimate to dominate the error function and therefore give a biased measure of the error. The RMSLE avoids this and allows the error to convey greater meaning on the performance of the surrogate. Even in the event that all the output features are normalized to similar scales, the RMSLE still has the advantage over the MAE and RMSE in that it is not biased by the sizes of the errors.
Table 8. Surrogate model RMSLE.
4.3. Comparison to direct optimization
The surrogate assisted optimization methodology developed in this article seeks to offer an improved means of optimizing the mooring designs of offshore renewable energy devices. In order to demonstrate the value of this approach, a comparison against direct optimization using NSGA-II has been completed (see ).
Figure 8. Comparison of feasible solutions identified by direct optimization and surrogate assisted optimization routines.
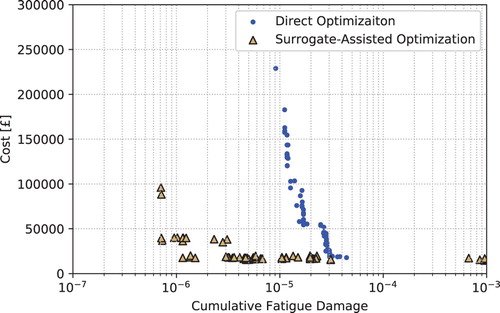
The final Pareto front from executing the surrogate assisted optimization routine as described above is shown again against the results following nine generations of direct optimization. Unfortunately, owing to the increased computational complexity incurred when executing the direct optimization, it was not possible to execute the optimization for the same number of generations within a sensible time frame. From these results it can be seen that, in a fraction of the time (see Table ), the surrogate model can evaluate significantly more mooring systems, identifying a superior Pareto front. Furthermore, the best solutions with respect to fatigue damage are an order of magnitude lower when using the surrogate assisted model as a result of the more complete optimization that can be achieved for a given computational effort. As the surrogate assisted solutions dominate the direct optimization results, the surrogate assisted results will be of greater value with respect to aiding decision making.
Table 9. Time complexity of surrogate model.
5. Discussion
The presented work has detailed a new time efficient approach for the multi-objective optimization of mooring systems for renewable energy systems. This implementation of a trained random forest to replace the time-intensive time domain simulations generally used in the design process reduces the average time required to evaluate a single mooring design (including time spent retraining the surrogate) from 692.2 to 6.1 s running on an Intel® Xeon® E5440 rated at 2.83 GHz with 16 GB of RAM, representing a time reduction on the order of 114. This is a marked improvement over the traditional design approaches, especially considering the high level of accuracy in both the classifier's ability to identify if solutions are compliant with respect to the constraints, and the regressor's ability to determine the cost and cumulative fatigue damage. In fact, without implementation of the surrogate assisted framework, a direct NSGA-II based optimization routine exceeds 30 h in evaluating and evolving each generation of solutions, while the surrogate assisted framework requires on average approximately 15 min.
In Figure , the minimum cost solution and minimum fatigue solution are both highlighted. These solutions represent the extents of the Pareto front and can be thought of as the solutions to single-objective optimization problems along either of these objectives. From the shape of the curve, it is apparent that the two objectives are indeed competing; however, there is a high density of solutions near the knee of the curve that may potentially represent a good compromise solution between the two extremes. In fact, though the minimum cost solution coincides with the maximum fatigue damage solution, there are many solutions with similar cost values at significantly lower fatigue levels.
Figure highlights the solutions of the final population located at the knee of the Pareto front. This figure shows more solutions than just the Pareto front, highlighting the fact that there is a wide range of cost levels for a given fatigue level. This is important information for a decision maker as it indicates that the overall cost of the mooring system can be changed. However, if the high fatigue lines or components are not altered, this design change may not impact the overall cumulative fatigue damage.
The results described in Table minimize the fatigue loading by increasing the length of the heavily loaded line, line 2, utilizing a long catenary chain thereby reducing the fatigue damage by reducing the tension experienced relative to the MBL. Furthermore, compared to the lower cost solutions, greater lengths of polyester are used throughout the mooring system and a much larger mooring footprint is required as a result of the longer catenary moorings.
Exploring the other extreme, the minimization of the system's material cost as shown in Table reduces the use of polyester lines in favour of chain constructions. Furthermore, the mooring lines are shorter, and anchors have moved closer to the platform for a smaller footprint. Though this significantly reduces the cost, the fatigue levels are also significantly increased.
The ‘compromise’ solution detailed in Table represents an attempt at trying to balance the two objectives. In this case, the knee of the curve is targeted trying to find a solution which most equally balances the two objectives. This solution is similar to the low cost solution, however, and makes use of mooring lines in order to reduce the fatigue with limited impact on the cost. If the relevant mooring system designer had a different prioritization of the objectives, then an alternative design from the non-dominated front would prove to be more important; however, this is specific to the relative importance placed on the objectives by the mooring system designer.
Although the RF has been deployed to develop the present surrogate, the present framework can be used in future work to benchmark different machine learning algorithms for this specific application allowing the most suitable surrogate to be deployed.
6. Conclusion
The results presented indicate that, for the present case study, the surrogate assisted optimization methodology is an effective means of mapping the design space and subsequently of optimizing the mooring system with a reduction of the time required on the order of 114 times. The surrogate model can in this case accurately estimate the features of interest to sufficient accuracy to provide useful information to the optimization process. The use of two separate models, one for the classification of solutions as feasible or infeasible had an outright accuracy of 0.998, indicating high reliability of the classifier. The use of both a classifier and a regression model ensures that the regression is only done for valid solutions, and the deployment of an anomaly detection algorithm helps in the identification of outliers that should be added to the training set to improve the performance of the surrogate. This works to orient the surrogate so that it has a relevant scope for interpolation and is not forced to extrapolate predictions, which has helped the regression model achieve an RMSLE across all output features of 1.87.
The multi-objective approach implemented here does not identify a single optimum for the given problem, but aids in decision making by presenting the trade-off between competing objectives. The results from using this methodology must then be assessed by a decision maker in order to determine where along the proposed Pareto front they wish to operate. The case study presented therefore only presents a series of solutions that, from an optimization perspective, are of equal value.
Although a large training set is used and significant time is required to generate this training set, once this information is compiled for a given device and site, the optimization process simply augments this. As a result, though there could be further improvements with regards to the time efficiency of the overall procedure, the present methodology does demonstrate how a random forest based surrogate model could be integrated with a genetic algorithm in order to aid in the design and optimization of mooring systems for floating offshore renewable energy devices.
Future work using this framework can directly aid in the design of mooring systems for prototype devices considering deployment at test facilities such as FaBTest, Wave Hub, or EMEC. Furthermore it can be used to explore the impact of novel mooring line materials that have been designed for offshore renewable energy applications. It should also be noted that the results presented here represent the outputs from a single run in order to establish the capabilities and applicability of the developed methodology. Given the reduction in computational time through the deployment of this methodology, it is reasonable to expect that, when utilizing this methodology for real design problems, multiple runs or a larger population size would be used in order to avoid any seeding bias of either the GA or the surrogate's training set.
Nomenclature
| β | = | Material fatigue parameter derived from S-N or T-N curve |
| = | Simulation duration | |
| = | Cumulative fatigue damage | |
| = | Fatigue damage during time t | |
| d | = | True distance between two points |
| = | Distance to kth nearest neighbour | |
| = | Reachability distance | |
| = | True value of sample i | |
| = | Estimated value of sample i | |
| K | = | Material fatigue parameter derived from S-N or T-N curve |
| = | Local outlier factor | |
| = | Local reachability distance | |
| = | Number of stress cycles | |
| = | Set of nearest neighbours to p | |
| n | = | Number of samples |
| S | = | Stress amplitudes established in the rainflow cycle count |
| T | = | Expected operational lifetime of the mooring system |
| z | = | Target output features |
Acknowledgements
The authors would like to thank Jason Jonkman at NREL, who provided the hydrodynamic data for the OC4 semi-submersible, and Orcina Ltd. for providing OrcaFlex.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
Ajit C. Pillai http://orcid.org/0000-0001-9678-2390
Philipp R. Thies http://orcid.org/0000-0003-3431-8423
Lars Johanning http://orcid.org/0000-0002-3792-3373
Additional information
Funding
References
- Ahmad, Muhammad Waseem, Monjur Mourshed, and Rezgui Yacine. 2017. “Trees vs Neurons: Comparison between Random Forest and ANN for High-Resolution Prediction of Building Energy Consumption.” Energy and Buildings 147: 77–89. doi:10.1016/j.enbuild.2017.04.038
- Amzallag, C., J. P. Gerey, J. L. Robert, and J. Bahuaud. 1994. “Standardization of the Rainflow Counting Method for Fatigue Analysis.” International Journal of Fatigue 16 (4): 287–293. doi:10.1016/0142-1123(94)90343-3
- Bagnall, Anthony, Jason Lines, Aaron Bostrom, and James Large. 2016. “The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms. Extended Version.” https://arxiv.org/abs/1602.01711.
- Beyer, Hans-Georg, and Hans-Paul Schwefel. 2002. “Evolution Strategies—A Comprehensive Introduction.” Natural Computing 1 (1): 3–52. doi:10.1023/A:1015059928466
- Breiman, Leo. 2001. “Random Forests.” Machine Learning 45 (1): 5–32. doi: 10.1023/A:1010933404324
- Breunig, Markus M., Hans-Peter Kriegel, Raymond T. Ng, and Jörg Sander. 2000. “LOF: Identifying Density-Based Local Outliers.” In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, 93–104. New York, NY: ACM.
- Brown, D. T., and S. Mavrakos. 1999. “Comparative Study on Mooring Line Dynamic Loading.” Marine Structures 12 (3): 131–151. doi: 10.1016/S0951-8339(99)00011-8
- Brownlee, Jason. 2011. Clever Algorithms—Nature-Inspired Programming Recipes. http://www.cleveralgorithms.com.
- Burke, Edmund K., and Graham Kendall. 2013. Search Methodologies. 2nd ed. Boston, MA: Springer US.
- Carbono, Alonso J. Juvinao, Ivan F. M. Menezes, and Luiz Fernando Martha. 2005. “Mooring Pattern Optimization Using Genetic Algorithms.” Paper presented at the 6th World Congresses of Structural and Multidisciplinary Optimization, Rio de Janeiro, Brazil, May 30–June 3.
- Cazacu, Razvan. 2017. “Comparative Study between the Improved Implementation of 3 Classic Mutation Operators for Genetic Algorithms.” Procedia Engineering 181: 634–640. doi: 10.1016/j.proeng.2017.02.444
- Chandola, Varun, Arindam Banerjee, and Vipin Kumar. 2009. “Anomaly Detection: A Survey.” ACM Computing Surveys 41 (3): Article No. 15. doi:10.1145/1541880.1541882.
- Chugh, Tinkle, Yaochu Jin, Kaisa Miettinen, Jussi Hakanen, and Karthik Sindhya. 2018. “A Surrogate-Assisted Reference Vector Guided Evolutionary Algorithm for Computationally Expensive Many-Objective Optimization.” IEEE Transactions on Evolutionary Computation 22 (1): 129–142. doi: 10.1109/TEVC.2016.2622301
- da Fonesca Monteiro, Bruno, Aline Aparecida de Pina, Juliana Souza Baioco, Carl Horst lbrecht, Beatriz Souza Leite Pires de Lima, and Breno Pinheiro Jacob. 2016. “Towards a Methodology for the Optimal Design of Mooring Systems for Floating Offshore Platforms Using Evolutionary Algorithms.” Marine Systems & Ocean Technology 11 (3-4): 55–67. doi:10.1007/s40868-016-0017-8.
- Davidson, Josh, and John V. Ringwood. 2017. “Mathematical Modelling of Mooring Systems for Wave Energy Converters—A Review.” Energies 10 (5): Article ID 666. http://www.mdpi.com/1996-1073/10/5/666.
- de Pina, Aline Aparecida, Bruno da Fonseca Monteiro, Carl Horst Albrecht, Beatriz Souza Leite Pires de Lima, and Breno Pinheiro Jacob. 2016. “Artificial Neural Networks for the Analysis of Spread-Mooring Configurations for Floating Production Systems.” Applied Ocean Research 59: 254–264. doi:10.1016/j.apor.2016.06.010
- de Pina, Aloísio Carlos, Aline Aparecida de Pina, Carl Horst Albrecht, Beatriz Souza Leite Pires de Lima, and Breno Pinheiro Jacob. 2013. “ANN-Based Surrogate Models for the Analysis of Mooring Lines and Risers.” Applied Ocean Research 41: 76–86. doi: 10.1016/j.apor.2013.03.003
- Deb, Kalyanmoy. 2001. Multi-Objective Optimization Using Evolutionary Algorithms. Chichester, UK: Wiley.
- Deb, Kalyanmoy, Amrit Pratap, and Sameer Agarwal. 2002. “A Fast and Elitist Multiobjective Genetic Algorithm: NSGA-II.” IEEE Transactions on Evolutionary Computation 6 (2): 182–197. doi:10.1109/4235.996017
- Forrester, Alexander I. J., and Andy J. Keane. 2009. “Recent Advances in Surrogate-Based Optimization.” Progress in Aerospace Sciences 45 (1-3): 50–79. doi: 10.1016/j.paerosci.2008.11.001
- Forrester, Alexander I. J., Andráas Sóbester, and Andy J. Keane. 2007. “Multi-Fidelity Optimization via Surrogate Modelling.” Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences 463 (2088): 3251–3269. doi: 10.1098/rspa.2007.1900
- Forrester, Alexander, András Sóbester, and Andy Keane. 2008. Engineering Design via Surrogate Modelling. 1st ed. Chichester, UK: Wiley.
- Grefenstette, John J. 1986. “Optimization of Control Parameters for Genetic Algorithms.” IEEE Transactions on Systems, Man, and Cybernetics 16 (1): 122–128. doi:10.1109/TSMC.1986.289288
- Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2009. The Elements of Statistical Learning. 2nd ed. New York: Springer Science+Business Media.
- Holland, John H. 1992. “Genetic Algorithms.” Scientific American 267 (1): 66–72. doi: 10.1038/scientificamerican0792-66
- James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2013. An Introduction to Statistical Learning, with Applications in R. Vol. 103 of the book series Springer Texts in Statistics. New York: Springer. doi:10.1007/978-1-4614-7138-7.
- Jin, Y. 2005. “A Comprehensive Survey of Fitness Approximation in Evolutionary Computation.” Soft Computing 9 (1): 3–12. doi:10.1007/s00500-003-0328-5
- Jin, Yaochu. 2011. “Surrogate-Assisted Evolutionary Computation: Recent Advances and Future Challenges.” Swarm and Evolutionary Computation 1 (2): 61–70. doi:10.1016/j.swevo.2011.05.001
- Johanning, L., G. H. Smith, and J. Wolfram. 2006. “Mooring Design Approach for Wave Energy Converters.” Proceedings of the Institution of Mechanical Engineers, Part M: Journal of Engineering for the Maritime Environment 220 (4): 159–174. doi:10.1243/14750902JEME54
- JRC Ocean. 2016. “DT Ocean Suite—DTOcean Database 1.0.0.” https://setis.ec.europa.eu/dt-ocean/.
- Kourakos, George, and Aristotelis Mantoglou. 2009. “Pumping Optimization of Coastal Aquifers Based on Evolutionary Algorithms and Surrogate Modular Neural Network Models.” Advances in Water Resources 32 (4): 507–521. doi:10.1016/j.advwatres.2009.01.001
- Kwan, C. T., and F. J. Bruen. 1991. “Mooring Line Dynamics: Comparison of Time Domain, Frequency Domain, and Quasi-Static Analyses.” Proceedings of the 23rd Annual Offshore Technology Conference (OTC), 6–9 May 1991, Houston, Texas. doi:10.4043/6657-MS.
- Mitchell, Melanie. 1998. An Introduction to Genetic Algorithms. 1st ed. Cambridge, MA: The MIT Press.
- Müller, Andreas C., and Sarah Guido. 2016. Introduction to Machine Learning with Python, a Guide for Data Scientists. Sebastopol, CA: O'Reilly Media.
- Murphy, Kevin P. 2012. Machine Learning: A Probabilistic Perspective. Cambridge, MA: The MIT Press.
- Olaya-Marín, E. J., F. Martínez-Capel, and P. Vezza. 2013. “A Comparison of Artificial Neural Networks and Random Forests to Predict Native Fish Species Richness in Mediterranean Rivers.” Knowledge and Management of Aquatic Ecosystems no. 409: Article ID 07. doi:10.1051/kmae/2013052.
- Ong, Yew S., Prasanth B. Nair, and Andrew J. Keane. 2003. “Evolutionary Optimization of Computationally Expensive Problems via Surrogate Modeling.” AIAA Journal 41 (4): 687–696. doi: 10.2514/2.1999
- Oshiro, Thais Mayumi, Pedro Santoro Perez, and Jose Augusto Baranauskas. 2012. “How Many Trees in a Random Forest?” International Workshop on Machine Learning and Data Mining in Pattern Recognition, 154–168. doi:10.1007/978-3-642-31537-4_13.
- Pillai, Ajit C., Philipp R. Thies, and Lars Johanning. 2017. “Multi-Objective Optimization of Mooring Systems for Offshore Renewable Energy.” In Proceedings of the 12th European Wave and Tidal Energy Conference (EWTEC), 27 August–1 September 2017, Cork, Republic of Ireland. http://hdl.handle.net/10871/29194.
- Pillai, Ajit C., Philipp R. Thies, and Lars Johanning. 2018a. “Comparing Frequency and Time Domain Simulations for Geometry Optimization of a Floating Offshore Wind Turbine Mooring System.” Proceedings of the 1st ASME International Offshore Wind Technical Conference (IOWTC2018), 4–7 November 2018, San Francisco, CA. http://hdl.handle.net/10871/33363.
- Pillai, Ajit C., Philipp R. Thies, and Lars Johanning. 2018b. “Development of a Multi-Objective Genetic Algorithm for the Design of Offshore Renewable Energy Systems.” In Advances in Structural and Multidisciplinary Optimization: Proceedings of the 12th World Congress of Structural and Multidisciplinary Optimization (WCSMO12), 5–9 June 2017, Braunschweig, Germany, edited by Axel Schumacher, Thomas Vietor, Sierk Fiebig, Kai-Uwe Bletzinger, and Kurt Maute, 2013–2026. Cham, Switzerland: Springer International Publishing.
- Pitt, E. G., A. Saulter, and H. Smith. 2006. “The Wave Power Climate at the Wave Hub Site.” Technical Report November 2006. Applied Wave Research report to the South West of England Regional Development Agency (SWRDA).
- Rao, Singiresu S. 2009. Engineering Optimization: Theory and Practice. 4th ed. Hoboken, NJ: Wiley.
- Robertson, A., J. Jonkman, and M. Masciola. 2014. “Definition of the Semisubmersible Floating System for Phase II of OC4.” Technical Report NREL/TP-5000-60601NREL, National Renewable Energy Laboratory (NREL), US Department of Energy Office of Energy Efficiency & Renewable Energy, Golden, CO, 38.
- Rychlik, I. 1987. “A New Definition of the Rainflow Cycle Counting Method.” International Journal of Fatigue 9 (2): 119–121. doi:10.1016/0142-1123(87)90054-5
- Ryu, Sam, Arun S. Duggal, Caspar N. Heyl, and Zong Woo Geem. 2016. “Cost-Optimized FPSO Mooring Design Via Harmony Search.” Journal of Offshore Mechanics and Arctic Engineering 138 (6): Article ID 061303. http://offshoremechanics.asmedigitalcollection.asme.org/article.aspx?doi=10.1115/1.4034374.
- Ryu, Sam, Caspar N. Heyl, Arun S. Duggal, and Zong Woo Geem. 2007. “Mooring Cost Optimization via Harmony Search.” Proceedings of the 26th AMSE International Conference on Offshore Mechanics and Arctic Engineering, Paper No. OMAE2007-29334, 355–362. doi:10.1115/OMAE2007-29334.
- Schijve, Jaap. 2009. Fatigue of Structures and Materials. 2nd ed. Dordrecht, The Netherlands: Springer Science+Business Media.
- Shafieefar, Mehdi, and Aidin Rezvani. 2007. “Mooring Optimization of Floating Platforms Using a Genetic Algorithm.” Ocean Engineering 34 (10): 1413–1421. doi: 10.1016/j.oceaneng.2006.10.005
- Shankar Bhattacharjee, Kalyan, Hemant Kumar Singh, and Tapabrata Ray. 2016. “Multi-Objective Optimization with Multiple Spatially Distributed Surrogates.” Journal of Mechanical Design 138 (9): Article ID 091401. doi: 10.1115/1.4034035
- Sidarta, Djoni E., Johyun Kyoung, Jim O'Sullivan, and Kostas F. Lambrakos. 2017. “Prediction of Offshore Platform Mooring Line Tensions Using Artificial Neural Network.” In ASME 2017 36th International Conference on Ocean, Offshore and Arctic Engineering – Volume 1: Offshore Technology, Paper No. OMAE2017-61942. New York: ASME.
- Spears, William M., and Kenneth A. De Jong. 1995. “On the Virtues of Parameterized Uniform Crossover.” Technical Report DTIC ADA293985. Naval Research Laboratory, Washington, DC. https://archive.org/details/DTIC_ADA293985.
- Statnikov, Alexander, Lily Wang, and Constantin F. Aliferis. 2008. “A Comprehensive Comparison of Random Forests and Support Vector Machines for Microarray-Based Cancer Classification.” BMC Bioinformatics 9: Article ID 319. doi:10.1186/1471-2105-9-319.
- Thies, Philipp R., Lars Johanning, Violette Harnois, Helen C. M. Smith, and David N. Parish. 2014. “Mooring Line Fatigue Damage Evaluation for Floating Marine Energy Converters: Field Measurements and Prediction.” Renewable Energy 63: 133–144. http://dx.doi.org/10.1016/j.renene.2013.08.050
- Thomsen, Jonas Bjerg, Claes Eskilsson, and Francesco Ferri. 2017. “Assessment of Available Numerical Tools for Dynamic Mooring Analysis, WP1.2 & M1.” Technical Report DCE 220. Aalborg University. http://vbn.aau.dk/en/publications/assessment-of-available-numerical-tools-for-dynamic-mooring-analysis(bd127ad6-caa6-4a5e-9ac9-e6fa8da11436).html.
- Thomsen, Jonas, Francesco Ferri, Jens Kofoed, and Kevin Black. 2018. “Cost Optimization of Mooring Solutions for Large Floating Wave Energy Converters.” Energies 11 (1): Article ID 159. http://www.mdpi.com/1996-1073/11/1/159. doi: 10.3390/en11010159
- Voutchkov, I., and A. J. Keane. 2006. “Multi-Objective Optimization Using Surrogates.” In Proceedings of the 7th International Conference on Adaptive Computing in Design and Manufacture 2006 (ACDM 2006), 167–175. http://eprints.soton.ac.uk/37984/.
- Weller, Sam, Jon Hardwick, Lars Johanning, Madjid Karimirad, Boris Teillant, Alex Raventos, and Stephen Banfield, et al. 2014. “A Comprehensive Assessment of the Applicability of Available and Proposed Offshore Mooring and Foundation Technologies and Design Tools for Array Applications.” Optimal Design Tools for Ocean Energy Arrays, DTOcean Consortium. http://www.dtocean.eu/Deliverables-Documentation/Deliverable-4.1.
- Weller, Sam D., Philipp R. Thies, Tessa Gordelier, and Lars Johanning. 2015. “Reducing Reliability Uncertainties for Marine Renewable Energy.” Journal of Marine Science and Engineering 3: 1349–1361. doi: 10.3390/jmse3041349
- Wolpert, D. H. 1996. “No Free Lunch Theorems for Search.” Technical Report SFI-TR-95-02-010, The Santa Fe Institute, Santa Fe, NM, 1–38. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.47.7505*rep=rep1*type=pdf.
- Wolpert, D. H., and W. G. Macready. 1997. “No Free Lunch Theorems for Optimisation.” IEEE Transactions on Evolutionary Computation 1 (1): 67–82. doi: 10.1109/4235.585893
- Won, Kok Sung, and Tapabrata Ray. 2005. “A Framework for Design Optimization Using Surrogates.” Engineering Optimization 37 (7): 685–703. doi: 10.1080/03052150500211911