?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this article, five different formulations for establishing optimal ensembles of metamodels are presented and compared. The comparison is done by minimizing different norms of the residual vector of the leave-one-out cross-validation errors for linear, affine and convex combinations of 10 metamodels. The norms are taken to be the taxicab, the Euclidean and the infinity norm, respectively. The ensemble of metamodels consists of quadratic regression, Kriging with linear or quadratic bias, radial basis function networks with a-priori linear or quadratic bias, radial basis function networks with a-posteriori linear or quadratic bias, polynomial chaos expansion, support vector regression and least squares support vector regression. Eight benchmark functions are studied as ‘black-boxes’ using Halton and Hammersley samplings. The optimal ensembles are established for either one of the samplings and then the corresponding root mean square errors are established using the other sampling and vice versa. In total, 80 different test cases (5 formulations, 8 benchmarks and 2 samplings) are studied and presented. In addition, an established design optimization problem is solved using affine and convex combinations. It is concluded that minimization of the taxicab or Euclidean norm of the residual vector of the leave-one-out cross-validation errors for convex combinations of metamodels produces the best ensemble of metamodels.
Keywords:
1. Introduction
The use of metamodels, such as Kriging in Kleijnen (Citation2009), radial basis function networks in Amouzgar and Strömberg (Citation2017), polynomial chaos expansion in Sudret (Citation2008), support vector machines in Strömberg (Citation2018a) and support vector regression in Yun, Yoon, and Nakayama (Citation2009), for approximating computationally expensive models, such as nonlinear finite element models, in order to perform advanced studies, such as different disciplines of design optimization studied by, for example, Strömberg and Tapankov (Citation2012) and Amouzgar, Rashid, and Strömberg (Citation2013), is today a most established approach in engineering, see for example the review by Wang and Shan (Citation2006). The best choice of metamodel depends strongly on the character of the response, the choice of design of experiments and the definition of best. Therefore, searching for a general best single metamodel valid for all situations is like searching for the holy grail. A more fruitful search is to find the best ensemble of metamodels for a particular problem. This is the topic of the current article. To be more precise, in this article the best linear, affine and convex combinations, respectively, of 10 metamodels are established, where best is defined by the taxicab norm, the Euclidean norm or the infinity norm of the residual vector of the leave-one-out cross-validation errors.
During recent years, initiated by the work of Viana, Haftka, and Steffen (Citation2009) and Acar and Rais-Rohani (Citation2009), the choice of adopting affine combinations of metamodels has emerged to be a standard approach for setting up optimal ensembles of metamodels for design optimization. However, the present author's experience with using affine combinations of metamodels has often been poor. Overfitting and poor generalization of the optimal affine ensemble are frequently observed. Typically, a large positive weight is cancelled out by an almost equally large negative weight. In fact, this issue has already been discussed in Viana, Haftka, and Steffen (Citation2009), but explained to probably depend on the approximation used in the objective function. Furthermore, it was also discussed in this early article whether to introduce a convex constraint in order to overcome this pitfall. Therefore, one might be surprised that so many contributions promote the approach of using affine combinations of metamodels, especially since the pitfalls with affine combinations are well known in machine learning, see for example the textbook by Zhou (Citation2012). In fact, this has already been pointed out by Breiman (Citation1996) when he investigated the ideas of stacked generalization proposed by Wolpert (Citation1992). Breiman clearly states in his article that the proper constraints on the weights of a combination of metamodels are
and
. In conclusion, the ensemble of metamodels should be a convex combination, not an affine combination. Indeed, the investigations done by Strömberg (Citation2018b, Citation2019) support this statement. This is also demonstrated in the following article, where optimal linear, affine and convex combinations are established by minimizing the norm of the residual vector of the leave-one-out cross-validation errors and validating the optimal ensembles of metamodels (OEMs) by calculating the root mean square errors (RMSE) for eight benchmark functions.
Early work on ensembles of metamodels can be found in Goel et al. (Citation2007), wherein a weighted average of the metamodels was adopted. Acar (Citation2010) studied various approaches for constructing affine combinations of metamodels using local measures. Xiao, Yi, and Xu (Citation2011) established affine combinations of metamodels with a recursive arithmetic average. Lee and Choi (Citation2014) proposed a new pointwise affine combination of metamodels by using a nearest points cross-validation approach. Shi et al. (Citation2016) proposed efficient affine combinations of radial basis function networks. Most recently, Song et al. (Citation2018) suggested an advanced and robust affine combination of metamodels by using extended adaptive hybrid functions. Two years earlier, Ferreira and Serpa (Citation2016) discussed different variants of least squares approaches, where a formulation including the constraints was mentioned briefly.
The contents of this article are as follows: in the next section, optimal linear, affine and convex combinations are formulated by using the norm of the residual vector of the leave-one-out cross-validation errors. For linear and affine combinations, only the Euclidean norm is considered, but for convex combination the taxicab and the infinity norm are also utilized in order to obtain two linear programming (LP) problems and not only a quadratic one (QP). In addition, in Appendix 1, a symbolic proof is given showing that the established optimal affine formulation presented in Viana, Haftka, and Steffen (Citation2009) is equivalent to minimizing the predicted residual sum of squares (PRESS) for affine combinations. In Section 3, the ensemble of metamodels containing different settings of quadratic regression, Kriging, radial basis function networks (RBFN), polynomial chaos expansion (PCE), support vector regression (SVR) and least squares SVR are presented. In Section 4, the optimal linear, affine and convex combinations of metamodels are compared for eight benchmark functions, by training the metamodels for one particular sampling and then validating the RMSE for another sampling. In addition, a well-known design optimization problem is solved using affine and convex combinations of metamodels. Finally, some concluding remarks are given.
2. Optimal combinations of metamodels
In this work, a new metamodel is defined as a linear combination of an ensemble of metamodels, i.e.
(1)
(1) where M is the total number of metamodels in the ensemble,
are weights and
represents a particular metamodel. In the next section, the basic equations of the 10 metamodels
as implemented in this article are presented.
The leave-one-out cross-validation error at a point of
is given by
(2)
(2) where
represents the metamodel with the kth data point excluded from the sampling set
. If now the leave-one-out cross-validation in (Equation2
(2)
(2) ) is executed for every data point, then the vector of PRESS residuals can be established:
(3)
(3) where
contains
,
is a vector of weights
and
(4)
(4) In order to find the best linear combination of metamodels
, the PRESS can be minimized, i.e.
(5)
(5) The solution to this problem is of course given by the well-known normal equation. Thus, the optimal weights are given by
(6)
(6) The affine constraint
can also be included in (Equation5
(5)
(5) ), i.e.
(7)
(7) The solution to this problem is given by
(8)
(8) where
(9)
(9) Here, and in the following,
represents a column vector of ones of proper size.
It is possible to prove that (Equation8(8)
(8) ) and (Equation9
(9)
(9) ) taken together are equivalent to
(10)
(10) where
(11)
(11) and
(12)
(12) is the leave-one-out cross-validation error for a particular metamodel
. A symbolic proof of this statement is given in Appendix 1. Equation (Equation10
(10)
(10) ) is the normal equation to
(13)
(13) which was suggested by Viana, Haftka, and Steffen (Citation2009). Notice, of course, that the statement of equivalence does not hold for a linear combination. Then, when
is positive definite, the optimal solution to
(14)
(14) is the zero vector, which apparently differs from (Equation6
(6)
(6) ) in general.
In addition, as suggested already by Breiman (Citation1996) and discussed by Viana, Haftka, and Steffen (Citation2009), a natural constraint to include in (Equation7(7)
(7) ) is that
, i.e.
(15)
(15) which, of course, is a QP-problem. Furthermore, by adding this constraint, (Equation1
(1)
(1) ) becomes a convex combination.
Instead of using the Euclidean norm in (Equation15
(15)
(15) ), the taxicab norm
or the infinity norm
can be adopted according to
(16)
(16) where N is the number of sampling points.
The problem in (Equation15(15)
(15) ) with the Euclidean norm switched to the taxicab norm corresponds to the following LP-problem:
(17)
(17) Finally, using the infinity norm, (Equation15
(15)
(15) ) can be rewritten as the following LP-problem:
(18)
(18) In summary, in order to establish optimal ensembles of metamodels, the following optimization problems are considered: LS in (Equation5
(5)
(5) ), LS-A in (Equation7
(7)
(7) ), LS-C in (Equation15
(15)
(15) ), LST-C in (Equation17
(17)
(17) ) and, finally, LSINF-C in (Equation18
(18)
(18) ). In Section 4, these five formulations are used to establish optimal linear, affine and convex combinations of metamodels for eight benchmark functions, which then are validated by calculating the RMSE.
3. Metamodels
A set of sampling data , obtained from design of experiments as mentioned in the previous section, can be represented with an appropriate function, which is called a response surface, a surrogate model or a metamodel. One choice of such a function is the regression model given by
(19)
(19) where
is a vector of polynomials of
, and
contains regression coefficients. By minimizing the sum of square errors, i.e.
(20)
(20) where
and N is the number of sampling points, then optimal regression coefficients are obtained from the normal equation reading
(21)
(21) A quadratic regression model, denoted model Q in the next section, is used as one of the 10 metamodels in the ensemble.
Examples of other useful metamodels, which are included in the ensemble, are Kriging, RBFN, PCE, SVR and least square SVR. The basic equations of these models as implemented in the present author's in-house toolboxFootnote1 are presented below.
3.1. Kriging
The Kriging models are given by
(22)
(22) where the first term represents the global behaviour by a linear (model Kr-L) or quadratic regression model (model Kr-Q) and the second term ensures that the sample data is fitted exactly.
, where
(23)
(23) Furthermore,
is obtained by maximizing the likelihood function
(24)
(24) using a genetic algorithm and establishing
(25)
(25) from the optimality conditions.
3.2. Radial basis function networks
For a particular input , the outcome of the radial basis function network can be written as
(26)
(26) where
and
are constants defined by (Equation29
(29)
(29) ) and (Equation30
(30)
(30) ), or (Equation31
(31)
(31) ) presented below,
(27)
(27) Here,
represents the radial basis function and the second term in (Equation26
(26)
(26) ) is a linear or quadratic bias. Furthermore, for a set of signals, the corresponding outgoing responses
of the network can be formulated compactly as
(28)
(28) where
,
,
and
. If
is given a priori by the normal equation in (Equation21
(21)
(21) ) as
(29)
(29) then
(30)
(30) Two settings of this model are utilized in the ensemble depending on the choice of bias, called model Rpri-L and model Rpri-Q, respectively.
Otherwise, when the bias is unknown, and
are established by solving
(31)
(31) Two settings of this model are also utilized in the ensemble, which are called model Rpost-L and model Rpost-Q.
3.3. Polynomial chaos expansion
Polynomial chaos expansion (model PCE) by using Hermite polynomials can be written as
(32)
(32) where
is the number of terms and constant coefficients
, and
is the number of variables
. The Hermite polynomials are defined by
(33)
(33) For instance, one has
(34)
(34) The unknown constants
are then established by using the normal equation in (Equation21
(21)
(21) ). A nice feature of the polynomial chaos expansion is that the mean of
in (Equation32
(32)
(32) ) for uncorrelated standard normal distributed variables
is simply given by
(35)
(35)
3.4. Support vector regression
The soft nonlinear support vector regression model (model SVR) reads
(36)
(36) where
is the kernel function, and
,
and
are established by solving
(37)
(37) Finally, the corresponding least square support vector regression model (model L-SVR) is established by solving
(38)
(38) where
and
(39)
(39) In summary, the ensemble consists of the following metamodels: Q, Kr-L, Kr-Q, Rpri-L, Rpri-Q, Rpost-L, Rpost-Q, PCE, SVR and L-SVR. In the next section, optimal linear, affine and convex combinations of this ensemble for eight benchmark functions are established.
4. Examples
In this section, optimal ensembles of the 10 metamodels presented in the previous section are established by using the five formulations presented in Section 2 (LS, LS-A, LS-C, LST-C and LSINF-C). This is done for the eight benchmark functions presented below in (Equation40(40)
(40) ):
(40)
(40) Seven of the eight functions in (Equation40
(40)
(40) ) are well-known test examples, while
is a test function developed by Strömberg (Citation2016, Citation2018a, Citation2018b, Citation2019) in order to evaluate algorithms for reliability-based design optimization. The fourth function
is the well-known peaks function implemented in MATLAB
, where the complete analytical expression can be found easily in the documentation of MATLAB
.
Now, the eight test functions in (Equation40(40)
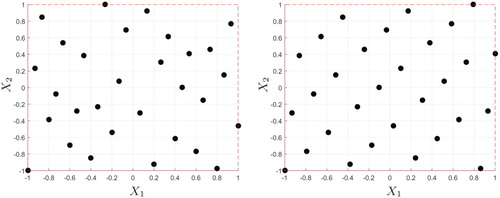
(40) ) are considered to be ‘black-boxes’, which are treated by setting up two different designs of experiments with 30 sampling points; Halton and Hammersley sampling according to Figure are adopted. Thus, in total, 80 optimal ensembles of metamodels are established.Footnote2
Figure 1. Left: Halton sampling. Right: Hammersley sampling.
The performance of each OEM is evaluated by taking the RMSE for the other sampling, i.e. for an OEM established for Halton sampling the RMSE is calculated for Hammersley sampling and vice versa. The RMSE for the OEM established for Halton sampling are presented in Table , and for the Hammersley sampling the RMSE are given in Table . In general, the RMSE are lower for the convex combinations compared to LS and LS-A. Typically, the LS and LS-A have similar values. The LS-C and LST-C have similar values, which, in general, are slightly lower than the values obtained using LSINF-C.
Table 1. RMSE for the five OEMs and all test functions with Halton sampling.
Table 2. RMSE for the five OEMs and all test functions with Hammersley sampling.
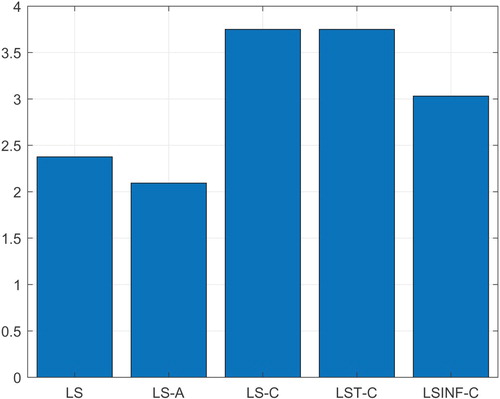
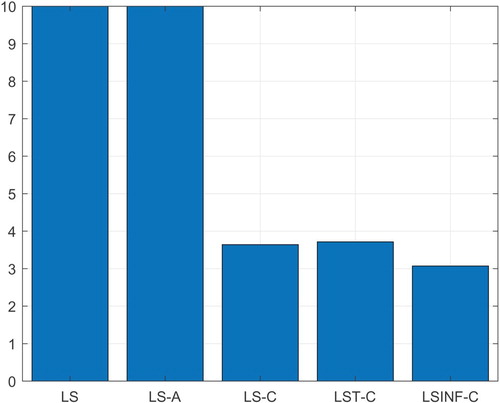
By ranking the OEMs for each test case from 1 (worst) to 5 (best), one obtains the ranking presented in Figure . A clear trend is that LS-C and LST-C have a better performance than the other OEMs.
Figure 2. Ranking of the five formulations for establishing the OEMs.
Not only is a better performance obtained using LS-C or LST-C, but also a smoother behaviour of the OEM compared to the behaviour obtained using a linear or affine combination. This difference appears clearly in Figures , and can be explained by overfitting and the number of metamodels included in the OEM. In general, all 10 metamodels appear in the OEMs of LS and LS-A. For the convex OEMs, three to four metamodels are mostly included in the OEMs. This result is summarized in Figure . Thus, automatic pruning of the metamodels is produced by using convex combinations.
Figure 3. The modified Brent test function compared to the OEMs by using LS, LS-A and LS-C. Notice the overfitting for LS and LS-A. (a)
in (Equation40
(40)
(40) )—modified Brent, analytic. (b)
in (Equation40
(40)
(40) )—modified Brent, LS, Halton. (c)
in (Equation40
(40)
(40) )—modified Brent, LS-A, Halton. (d)
in (Equation40
(40)
(40) )—modified Brent, LS-C, Halton.
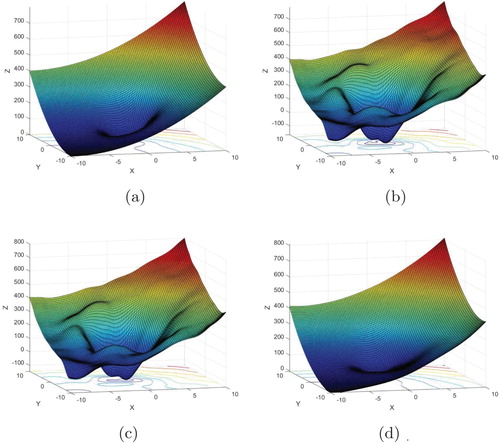
Figure 4. The test function compared to the OEMs by using LS, LS-A and LS-C. Notice the strong overfitting in one of the corners for LS and LS-A. (a)
in (Equation40
(40)
(40) )—analytic. (b)
in (Equation40
(40)
(40) )—LS, Hammersley. (c)
in (Equation40
(40)
(40) )—LS-A, Hammersley. (d)
in (Equation40
(40)
(40) )—LS-C, Hammersley.
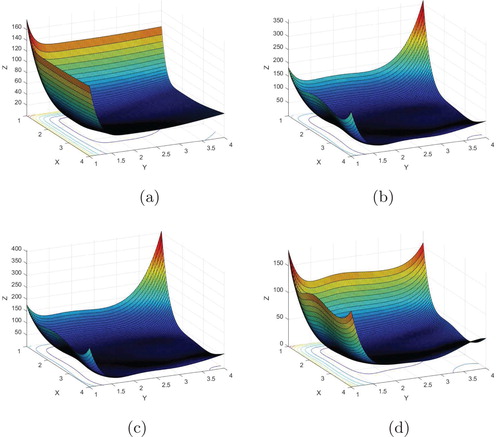
Figure 5. The Hosaki test function compared to the OEMs by using LS, LS-A and LS-C. Notice stronger overfitting along the boundaries for LS and LS-A compared to LS-C. (a)
in (Equation40
(40)
(40) )—Hosaki, analytic. (b)
in (Equation40
(40)
(40) )—Hosaki, LS, Halton. (c)
in (Equation40
(40)
(40) )—Hosaki, LS-A, Halton. (d)
in (Equation40
(40)
(40) )—Hosaki, LS-C, Halton.
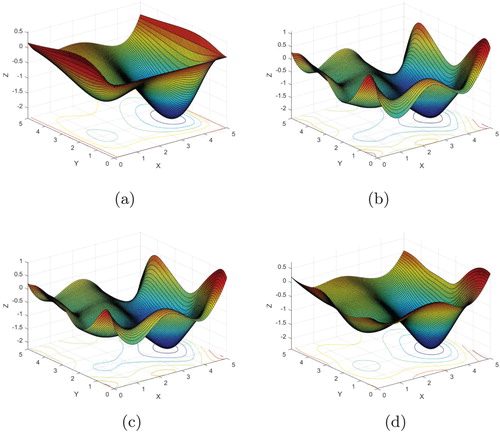
Figure 6. The number of metamodels on average for the OEMs by using the five different formulations.
LS and LS-A also suffer from overfitting. Frequently, a large positive weight is cancelled out by a large negative value on another weight, see for example the optimal weights for the modified Brent test function in Table and the plots in Figure . In this particular test example, the performances of the convex combinations are superior over the performances of the linear and affine combinations. This can be concluded by studying the plots in Figure .
Table 3. The optimal weights for the modified Brent test function  . Notice the pruning obtained using LS-C, LST-C and LSINF-C, as well as the appearance of large positive and negative weights cancelling out each other for the LS and LS-A.
. Notice the pruning obtained using LS-C, LST-C and LSINF-C, as well as the appearance of large positive and negative weights cancelling out each other for the LS and LS-A.
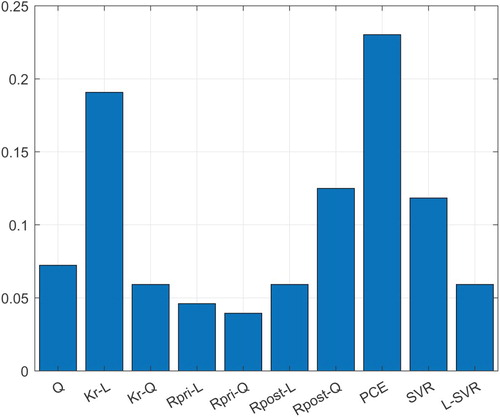
Although automatic pruning is generated using convex combinations, all metamodels appear sometimes in the convex OEMs, see Figure . From this figure one can also see that Kriging-L and PCE are the real workhorses for the examples studied in this article, but also Rpost-Q and SVR appear more frequently than the others.
Figure 7. The frequency of metamodels appearing in the ensemble for LS-C, LST-C and LSINF-C.
Finally, a most established design optimization benchmark is solved using optimal affine (LS-A) and convex (LST-C) combinations of metamodels. The welded beam problem considered by Garg (Citation2014) and Amouzgar and Strömberg (Citation2017) is studied. The governing equations of the problem read
(41)
(41) where the definitions of the shear stress
, normal stress
, displacement
and critical force
can be found in Amouzgar and Strömberg (Citation2017). In addition, the variables are bounded by
and
. The optimal solution obtained by GA and SLP is
. An almost identical solution was presented by Garg (Citation2014). In Amouzgar and Strömberg (Citation2017), this benchmark was solved using screening with a total number of 60 sampling points and radial basis function networks. The solution obtained in their work was (0.4147, 3.926, 6.6201, 0.4147), which violated the first constraint.
In this work, the problem is solved by setting up Halton sampling using 60 points without any screening and establishing optimal affine (LS-A by solving Equation10(10)
(10) ) and convex combinations (LST-C) of the following metamodels: Q, Kr-L, Rpri-Q, Rpost-Q, SVR and L-SVR. The optimal weights for LS-A by solving (Equation10
(10)
(10) ) are presented in Table and the optimal weights for LST-C by solving (Equation17
(17)
(17) ) are presented in Table . The pruning effect using LST-C appears clearly when compared to the solution for LS-A, where no pruning is obtained. The drawback with large positive weights cancelled out by large negative weights using LS-A appears for f and
in Table .
Table 4. The optimal weights for the affine combination (LS-A) defined by (Equation10(10) (10) ). No pruning is observed.
Table 5. The optimal weights for the convex combination (LST-C) defined by (Equation17(17) (17) ). The pruning effect appears clearly.
In Table , the optimal solutions for all metamodels as well as the affine and convex combinations of metamodels are presented. By just studying the objective value f, one obtains the following ranking: Rpri-Q, L-SVR, Rpost-Q, Kr-L, LS-A, Q, LST-C and SVR. It might seem that the performance of LST-C and SVR are poor. However, by studying the corresponding constraints values in Table , one realizes that only the optimal solutions obtained using LST-C and SVR are feasible. All the other metamodels fail; also the affine combination LS-A fails. Thus, the best performance is obtained using LST-C, which in turn is much better than the performance obtained using SVR.
Table 6. The optimal solution using LS-A and LST-C as well as the metamodels of the ensemble taken separately.
Table 7. The corresponding constraint values for the optimal solutions presented in Table . Negative values are feasible.
5. Concluding remarks
In this article, a general framework for generating optimal linear, affine and convex combinations of metamodels by minimizing the PRESS using the taxicab, Euclidean or infinity norm are presented and studied. Thus, the formulation proposed by Viana, Haftka, and Steffen (Citation2009) is not the starting point in this article, but instead derived symbolically as a special case for affine combinations using the Euclidean norm. It is concluded from the study that convex combinations are preferable over linear as well as the established affine combinations. The risk of overfitting is less and automatic pruning of metamodels is obtained. In conclusion, it is suggested that the optimal weights of the convex combinations of metamodels be established by minimizing the Euclidean norm or the taxicab norm of the residual vector of the leave-one-out cross-validation errors, where the former formulation implies a QP-problem and the latter one is an LP-problem to be solved. For future work, it is suggested to study the performance of these two formulations for large problems, in order to establish if the QP-problem is preferable over the LP-problem or vice versa.
Disclosure statement
No potential conflict of interest was reported by the author(s).
ORCID
Niclas Strömberg http://orcid.org/0000-0001-6821-5727
Notes
1 MetaBox, http://www.fema.se
2 The optimal weights for the OEMs for all test functions in (Equation40(40)
(40) ) can be obtained from the author upon request by sending an e-mail to [email protected]
References
- Acar, E. 2010. “Various Approaches for Constructing An Ensemble of Metamodels Using Local Measures.” Structural and Multidisciplinary Optimization 42: 879–896. doi:10.1007/s00158-010-0520-z
- Acar, E., and M. Rais-Rohani. 2009. “Ensemble of Metamodels with Optimized Weight Factors.” Structural and Multidisciplinary Optimization 37: 279–294. doi:10.1007/s00158-008-0230-y
- Amouzgar, K., A. Rashid, and N. Strömberg. 2013. “Multi-Objective Optimization of a Disc Brake System by Using SPEA2 and RBFN.” In Proceedings of the 39th Design Automation Conference. New York: ASME.
- Amouzgar, K., and N. Strömberg. 2017. “Radial Basis Functions As Surrogate Models with a Priori Bias in Comparison with a Posteriori Bias.” Structural and Multidisciplinary Optimization 55: 1453–1469. doi:10.1007/s00158-016-1569-0
- Breiman, L. 1996. “Stacked Regressions.” Machine Learning 24: 49–64. doi:10.1007/BF00117832
- Ferreira, W. G., and A. L. Serpa. 2016. “Ensemble of Metamodels: The Augmented Least Squares Approach.” Structural and Multidisciplinary Optimization 53: 1019–1046. doi:10.1007/s00158-015-1366-1
- Garg, H. 2014. “Solving Structural Engineering Design Optimization Problems Using An Artificial Bee Colony Algorithm.” Journal of Industrial and Management Optimization 10 (3): 777–794. doi:10.3934/jimo.2014.10.777
- Goel, T., R. T. Haftka, W. Shyy, and N. V. Queipo. 2007. “Ensemble of Surrogates.” Structural and Multidisciplinary Optimization 33: 199–216. doi:10.1007/s00158-006-0051-9
- Kleijnen, J. P. C. 2009. “Kriging Metamodeling in Simulation: A Review.” European Journal of Operational Research 192 (3): 707–716. doi:10.1016/j.ejor.2007.10.013
- Lee, Y., and D.-H. Choi. 2014. “Pointwise Ensemble of Meta-Models Using ν Nearest Points Cross-Validation.” Structural and Multidisciplinary Optimization 50: 383–394. doi:10.1007/s00158-014-1067-1
- Shi, R., L. Liu, T. Long, and J. Liu. 2016. “An Efficient Ensemble of Radial Basis Functions Method Based on Quadratic Programming.” Engineering Optimization 48: 1202–1225. doi:10.1080/0305215X.2015.1100470
- Song, X., L. Lv, J. Li, W. Sun, and J. Zhang. 2018. “An Advanced and Robust Ensemble Surrogate Model: Extended Adaptive Hybrid Functions.” Journal of Mechanical Design 140 (4): Article ID 041402. doi:10.1115/1.4039128
- Strömberg, N. 2016. “Reliability-Based Design Optimization by Using a SLP Approach and Radial Basis Function Networks.” In Proceedings of the 2016 International Design Engineering Technical Conferences & Computers and Information in Engineering Conference (IDETC/CIE). New York: ASME.
- Strömberg, N. 2018a. “Reliability-Based Design Optimization by Using Support Vector Machines.” In Proceedings of ESREL—the European Safety and Reliability Conference. London: CRC Press. doi:10.1201/9781351174664.
- Strömberg, N. 2018b. “Reliability-Based Design Optimization by Using Metamodels.” In Proceedings of the 6th International Conference on Engineering Optimization (EngOpt 2018). Cham, Switzerland: Springer International Publishing. doi:10.1007/978-3-319-97773-7.
- Strömberg, N. 2019. “Reliability-Based Design Optimization by Using Ensemble of Metamodels.” In Proceedings of the 3rd International Conference on Uncertainty Quantification in Computational Sciences and Engineering (UNCECOMP 2019). Athens: UNDECOMP.
- Strömberg, N., and M. Tapankov. 2012. “Sampling- and SORM-based RBDO of a Knuckle Component by Using Optimal Regression Models.” In Proceedings of the 14th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference. Reston, VA: AIAA. doi:10.2514/6.2012-5439.
- Sudret, B. 2008. “Global Sensitivity Analysis Using Polynomial Chaos Expansions.” Reliability Engineering & System Safety 93 (7): 964–979. doi:10.1016/j.ress.2007.04.002
- Viana, F. A. C., R. T. Haftka, and V. Steffen Jr. 2009. “Multiple Surrogates: How Cross-Validation Errors Can Help Us to Obtain the Best Predictor.” Structural and Multidisciplinary Optimization 39: 439–457. doi:10.1007/s00158-008-0338-0
- Wang, G. G., and S. Shan. 2006. “Review of Metamodeling Techniques in Support of Engineering Design Optimization.” Journal of Mechanical Design 129 (4): 370–380. doi:10.1115/1.2429697
- Wolpert, D. H. 1992. “Stacked Generalization.” Neural Networks 5: 241–259. doi:10.1016/S0893-6080(05)80023-1
- Xiao, Jian Zhou, Zhong Ma Yi, and Fang Li Xu. 2011. “Ensembles of Surrogates with Recursive Arithmetic Average.” Structural and Multidisciplinary Optimization 44: 651–671. doi:10.1007/s00158-011-0655-6 doi: 10.1007/s00158-011-0652-9
- Yun, Y., M. Yoon, and H. Nakayama. 2009. “Multi-Objective Optimization Based on Meta-modeling by Using Support Vector Regression.” Optimization and Engineering 10: 167–181. doi:10.1007/s11081-008-9063-1
- Zhou, Z.-H. 2012. Ensemble Methods, Foundations and Algorithms. New York: Chapman and Hall/CRC. doi:10.1201/b12207
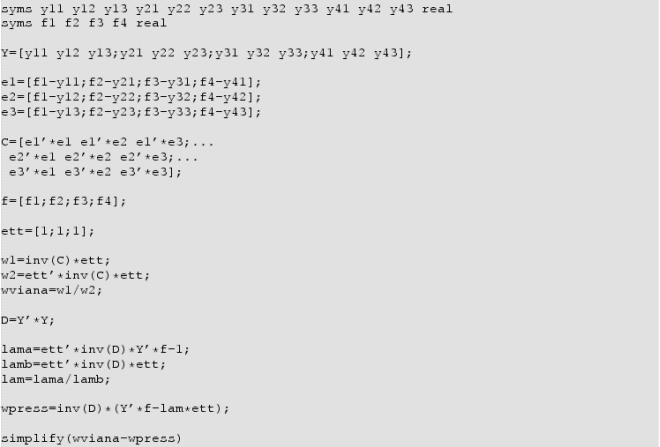
Appendix 1. Symbolic proof
Below, in this appendix, the MATLAB code for a symbolic proof showing that the optimal weights for an affine combination by minimizing the PRESS in (Equation8
(8)
(8) ) and (Equation9
(9)
(9) ) are identical to the optimal weights (Equation10
(10)
(10) ) by using the formulation by Viana, Haftka, and Steffen (Citation2009) is given.