
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The robustness of the t linear mixed model (tLMM) has been proved and exploited in many applications. Various publications emerged with the aim of proving superiority with respect to traditional linear mixed models, extending to more general settings and proposing more efficient estimation methods. However, little attention has been paid to the mathematical properties of the model itself and to the evaluation of the proposed estimation methods. In this paper we perform an in-depth analysis of the tLMM, evaluating a direct maximum likelihood estimation method via an intensive simulation study and investigating some identifiability properties. The theoretical findings are illustrated through an application to a dataset collected from a sleep trial.
1. Introduction
Linear mixed models (LMM) are widely popular for their appealing feature of modeling both the intra- and inter-subject variability with a broad set of possible correlation structures (Laird and Ware Citation1982). However, they rely on normality assumptions, and can be very sensitive to outlying data and heavy tails distributions. The multivariate t distribution (see the publication of Kotz and Nadarajah (Citation2004) for a comprehensive discussion of its characterizations and properties) has been proposed to make linear regression and mixed linear regression robust (Lange, Little, and Taylor Citation1989; Pinheiro, Liu, and Wu Citation2001). In particular, the t linear mixed model (tLMM) is a natural extension of the classical LMM in which the response variable is jointly t distributed (Pinheiro, Liu, and Wu Citation2001). A convenient hierarchical formulation of the tLMM can be derived by mixing the multivariate normal distribution of the response variable with a gamma-distributed latent scaling variable for the covariance matrix (Pinheiro, Liu, and Wu Citation2001). This characteristic makes the tLMM robust to heavy tails distributions of the observed data, and thus more appropriate than the LMM when normality assumptions are violated. Furthermore, the tLMM is a favorable choice over other robust methods because robustness is achieved with only one extra parameter compared to traditional LMMs, and the model structure allows the analysis of random variances.
In fact, many authors have explored applications and extensions of the tLMM, and the related literature is quite broad.
A similar model has been proposed to analyze heterogeneous within-subject variances (Chinchilli, Esinhart, and Miller Citation1995). Here the authors made no distributional assumptions on the random effects, while they imposed a similar hierarchical structure for the residual variances. Chinchilli, Esinhart, and Miller (Citation1995) aimed at studying the within-subject variability of two different laboratory techniques, treated consequently the fixed effects as nuisance parameters, and proposed partial likelihood estimation for a model with only random intercept and no covariates. An extension of this model has been introduced for the analysis of menstrual diary data, where both the mean structure and the mean of the latent variable were assumed to link to some covariates (Lin, Raz, and Harlow Citation1997). The estimation approach proposed here combined quasi-likelihood, pseudolikelihood and method of moments (QL/PL-M) in consecutive steps for the fixed effects, variance components and parameters of the distribution of the latent variable.
First references on tLMMs were focused on making linear mixed models robust against outliers, as an alternative to Gaussian mixture models (Welsh and Richardson Citation1997). They studied the effect of different levels of contamination on the response variable without deriving the marginal distributions or discussing algorithmic details of the estimation. Later, Pinheiro, Liu, and Wu (Citation2001) derived the hierarchical structure and the distribution of random effects and residuals behind the assumption of multivariate t distribution. This work included the description of various expectation maximization (EM) algorithms for maximum likelihood estimation. The model has been later extended by allowing autoregressive residual structures and estimated by using direct maximum likelihood estimation (Lin and Lee Citation2006), EM-type algorithms (Lin Citation2008), and Bayesian methods (Lin and Lee Citation2007). In these publications the authors discussed also the prediction of future values, which is a natural consequence in the Bayesian formulation. Multivariate extensions of the tLMM have been studied in the frequentist and Bayesian frameworks (Wang and Fan Citation2011, Citation2012) and extended by other authors for handling missing values, censored data and heavy tails (Ho and Lin Citation2010; Matos et al. Citation2013; Wang Citation2013a; Wang and Lin Citation2014, Citation2015; Wang, Lin, and Lachos Citation2018; Lin and Wang Citation2019). Besides allowing robust inference, the tLMM enables the detection of outliers, intended as observations that do not comply with normality (and therefore with the LMM) (Pinheiro, Liu, and Wu Citation2001; Lin and Lee Citation2007; Ho and Lin Citation2010; Wang and Fan Citation2011, Citation2012; Matos et al. Citation2013; Wang and Lin Citation2014; Wang Citation2017).
The publications referenced so far focused on applications and extensions of the tLMM, on proposing alternative estimation methods for the tLMM, and on showing the supremacy of the tLMM over the traditional LMM. However, the literature is lacking investigations on the consistency of the proposed estimation methods and the relative estimation error in general settings, as authors seldom include simulation studies. The QL/PL-M estimation approach has been validated through an intensive simulation study (Lin, Raz, and Harlow Citation1997), but the underlying t mixed model included only a random intercept and assumed independence of residuals. Pinheiro, Liu, and Wu (Citation2001) have run a small simulation study focusing on the robustness of the tLMM when compared with the LMM in presence of varying amount of outlying observations, but reported only the relative efficiency. The ML estimation method has never been thoroughly investigated, but has often been employed in the applications that are consistently part of the publications (Lin and Lee Citation2006). Models formulated in their full generality might not be estimable with the data in hand, and fitting is often performed in some particular cases with uncorrelated random intercept and slope (Lin Citation2008), or allowing only either random slope or autoregressive correlation structure (Lin and Lee Citation2006). Furthermore, the standard error of the estimates for the frequentist approaches is based on asymptotic theory (based on the observed/expected Fisher information matrix). Although the authors have recognized that this method might lack accuracy, they have not investigated its reliability in finite-sample settings because of its computational load (Pinheiro, Liu, and Wu Citation2001; Lin and Lee Citation2006; Lin Citation2008). Finally, the common parametrization is not justified and hides possible identifiability issues: all the publications on tLMM make certain choices on the parameters and select parsimonious correlation structures, without giving mathematical explanation for them. Identifiability of the tLMM has never been addressed, while identifiability for LMMs has recently raised much attention. Many authors warned the users of possible misinterpretation of the output given by software capable of fitting LMM (Wang Citation2013b, Wang Citation2017; Samani Citation2014; Janzén et al. Citation2019; Lavielle and Aarons Citation2016). In fact, also when over-parametrization is avoided, the problem might be non-identifiable, and various automatic procedures might return incorrect estimates without warnings.
In this paper, we address the possible formulations of the tLMM (cf. Sec. 2) and pin choices of the variance-covariance structure that lead to identifiability issues (cf. Sec. 3). We run a small simulation study to demonstrate the silent risk of converging to the wrong values when the model is not identifiable. Then we choose a popular parametrization of an identifiable model and run an intensive simulation study in Sec. 4. The model we investigate includes various fixed effects, correlated random intercept and slope, and an autoregressive residual correlation structure. We simulate a large number of repeats compared to a relative small number of subjects, a setting that is realistic in various practical situations, but that has rarely been formally analyzed (Lin, Raz, and Harlow Citation1997). The simulations are based on our case study of a sleep trial. We show the accuracy of an extended version of the simple and direct ML estimation method of Lin and Lee (Citation2006) when the fitted model is identifiable and prove that, as expected, the estimation bias decreases substantially when the number of subjects increases. Furthermore, we quantify the error committed in evaluating the estimates’ standard deviation in finite samples when relying on ML asymptotic theory. We also propose a concise overview of the approaches proposed in the literature, and based on the tLMM fit, to identify observations that deviate from the normality of the data. Finally, in Sec. 6 we illustrate the tLMM on a case study from a sleep trial, compare its fit to the fit of the LMM and identify outlying participants. The final section presents a summary and a discussion of the results.
2. Model formulation
The t linear mixed effects model is defined by
(1)
(1)
where
is the vector of Ti observations for subject
and
are known
and
matrices corresponding to the vectors ζ and
of the fixed and random effects respectively, and
is a vector of Ti residuals (Pinheiro, Liu, and Wu Citation2001; Lin and Lee Citation2006; Lin Citation2008). The random effects are assumed to be independent of the residuals conditionally on the latent variable γi
(2)
(2)
(3)
(3)
(4)
(4)
Here G is the covariance matrix for the random effects and
is the residuals correlation matrix. Under the stated distributional assumptions,
is t distributed with α degrees of freedom, mean
and variance-covariance matrix
(Lin, Raz, and Harlow Citation1997; Pinheiro, Liu, and Wu Citation2001).
This parametrization is commonly used in the literature and the choice is motivated by identifiability issues: relaxing the restrictions on the distribution of the latent variable γi leads to
(5)
(5)
(6)
(6)
(7)
(7)
This model is in fact non-identifiable unless α and β have a certain constant ratio (cf. Sec. 3). By taking
one can then show that the two formulations are equivalent.
3. Model identifiability
If we introduce the notation and
for the parameters of the variance-covariance matrix G and consider here a general covariance matrix
with parameters
the set of parameters involved in the t density is
To demonstrate identifiability we need to show that
if and only if
with
defined by
(8)
(8)
and
First note that if is of full rank, then the coefficients for the fixed effects are uniquely determined. For the remainder, we assume that both design matrices
and
are of full rank and that the variance-covariance matrices G and
are positive-definite. Under these assumptions, the problem reduces to identifiability of the matrix
Obviously, identifiability is not met in this general formulation for two reasons. First, α and β can be reparametrized by
and
with some constant c > 0, leading to the same matrix
as the original parametrization, thus we need to fix the ratio
Second, we may rescale
and
and obtain the same matrix
in the original parametrization. To overcome this identifiability issue we assume that
is a correlation matrix, that is,
In this way the scale
represents the residual standard deviation, constant over the dimensions of the multivariate outcome. The set of parameters reduces thus to
where we have changed the residual covariances σrs into the correlations ρrs.
The general variance-covariance matrix of a model with unstructured correlation structure
random intercept and random slope, is given by
(9)
(9)
where we have omitted the elements below-diagonal because of symmetry. Here we denote with
the variance of the random intercept, with
the variance of the random slope and with η the correlation coefficient between random intercept and slope (elements of the covariance matrix G). Furthermore, the random slope is taken with respect to the time points
and ρij denotes the general correlation between observations at time points i and j.
Since is a
symmetric matrix, at maximum it will have N distinct elements, with
(10)
(10)
Therefore identifiability requires the number of parameters in the variance-covariance structure to not exceed N. Also when this condition is satisfied, there may be combinations of G and
that lead to unidentifiability.
To study identifiability of matrix in EquationEq. (9)(9)
(9) , we consider two sets of parameters θ1 and θ2, take
with any c > 0, and consider the system of equations obtained by equating the elements in the two covariance matrices correspondingly. From the diagonal elements we get
(11)
(11)
Substituting these expressions in the off-diagonal elements, we get
(12)
(12)
An unstructured correlation matrix is thus clearly non-identifiable in presence of random effects, because all conditions in EquationEqs. (11)
(11)
(11) and Equation(12)
(12)
(12) can be satisfied by a certain choice of c > 0. Even if we assume that there are no random effects (
) it is possible to define a model with alternative variance-covariance structure that is equivalent to the one of the original model, in which
is replaced by the introduction of random effects. Indeed, if we choose
we create another set of admissible parameters that, together with EquationEq. (12)
(12)
(12) , satisfies EquationEq. (9)
(9)
(9) . In this case the residual variance is being compensated by a random intercept. Strictly speaking thus, this is not an identifiability problem in the sense of the definition because if we start with the parameter set
alone, we are not allowed to increase the parameter set. However, this illustrates how the same variance-covariance structure can be obtained with very different parametrizations.
In the following, we explore how various assumptions on affect conditions in EquationEq. (12)
(12)
(12) , and thus identifiability of the variance-covariance matrix. The results we obtain are for tLMM with random intercept and slope, but the particular case of a tLMM with random intercept only can be obtained by setting
in EquationEq. (9)
(9)
(9) .
3.1. Toeplitz correlation matrix
When is a Toeplitz matrix, it is diagonal-constant
(13)
(13)
This implies the additional constraints on the correlations
These constraints need to hold both for the parameter set θ1 and θ2, together with the conditions in EquationEqs. (11)
(11)
(11) and Equation(12)
(12)
(12) . The Toeplitz correlation structure reduces both the number of parameters and the number of constraints, but it does not induce identifiablity. For example, in case of four repeats we would have the following conditions on the correlation coefficients ρ, γ and w:
and these expressions can clearly be satisfied for a value c other than (but possibly close to) one. Note that the model remains unidentifiable with an increased number of repeats, since it adds one parameter for each repeat. Moreover, reducing the model to a random intercept only does not resolve the identifiability of the parameters ρ, γ and ζ either.
3.2. Banded Toeplitz correlation matrix
A banded Toeplitz matrix is a Toeplitx matrix in which the diagonals outside the bandwidth are equal to zero
(14)
(14)
This means that for time lags larger than the bandwidth, the correlation is zero and there is no correlation coefficient to be estimated. Therefore the off-diagonal elements impose additional conditions that lead to identifiability. For example, take the last element in the first row of EquationEq. (9)
(9)
(9) and equate the expression for two sets of parameters θ1 and θ2,
(15)
(15)
assuming that
due to a bandwidth smaller than Ti. By plugging in the expressions for
in EquationEq. (11)
(11)
(11) , we obtain one unique solution c = 1 which coincides with identifiability. Thus, the model is identifiable as long as the bandwidth is less than or equal to
The same conclusion holds in case the model includes only the random intercept.
3.3. Autoregressive correlation matrix
The elements in the correlation matrix
(16)
(16)
in case of an autoregressive structure can be defined iteratively by
(17)
(17)
(18)
(18)
with
autoregressive coefficients.
AR(1) In case of first order autoregression, EquationEq. (16)(16)
(16) reduces to
where we have dropped the subscript for simplicity of notation (i.e.
). This imposes the additional constraints
for
with the indices 1 and 2 referring to the parameters in the sets θ1 and θ2 respectively. Solving this set of equations leads to c = 1 when there are at least three observations and
Thus the model with an AR(1) correlation structure and random intercept (and possibly random slope) is identifiable with at least three observations.
Note that this holds true also if we replace the power by a distance measure over time, as long as the distances differ from each other. The spatial correlation structure
also makes the model identifiable with at least three observations, both in case of random intercept and slope or random intercept only.
AR(2) In case of AR(2), the elements in matrix EquationEq. (16)(16)
(16) are given by
(19)
(19)
For verifying identifiability we consider thus the additional constraints (EquationEq. 12(12)
(12) ) that reduce to
(20)
(20)
From the first two equations we obtain
and these two expressions plugged in the third equation in EquationEq. (20)
(20)
(20) lead to the only admissible solution c = 1,
Thus already four observations are sufficient to make the tLMM with random intercept and slope and AR(2) correlation structure identifiable. Again, the same conclusion is obtained for the simpler model with random intercept only by setting
AR(3) In case of AR(3), the correlations for time lags (and thus the corresponding elements in matrix (EquationEq. 16
(16)
(16) )) are given by
To make EquationEq. (12)
(12)
(12) explicit in this case, we fill in the expressions above for the autocorrelation corresponding to two sets of parameters θ1 and θ2. The resulting system of equations admits only the solution of equal sets of parameters and c = 1. Thus the tLMM with random intercept and slope and AR(3) correlation structure is identifiable with at least five observations. Similarly, the model with random intercept only is identifiable with the same number of observations. Note that increasing the order of the autoregressive structure increases the complexity of the resulting system of equations. We expect that the tLMM with AR(p) correlation structure is identifiable when the number of observations
but a formal proof is challenging. For AR(3) we had to resort to Mathematica (Wolfram Research, Inc. Citation2019) to solve the set of equations.
4. Model estimation
4.1. A direct ML estimation method
In case an identifiable model is selected, maximum likelihood can be used to estimate the parameters. The log-likelihood function, analogous to the one proposed by Lin and Lee (Citation2006), is given by with
defined in Equation(8)
(8)
(8) , and
To maximize the likelihood, we have chosen the nonlinear optimization procedure NLopt (Johnson Citation2014), named nloptr (Ypma Citation2014) in R (R Core Team Citation2016) using a non-gradient based local search method that performs numerical optimization by using quadratic approximations of the objective function and allows for bound constraints for the variance-covariance components (Powell Citation2008).
To investigate the accuracy of this estimation procedure, we select an identifiable tLMM with a parametrization in line with the literature, namely
with G an unstructured variance-covariance matrix, and
an AR(1) correlation matrix. Note that this formulation is equivalent to EquationEq. (1)
(1)
(1) , with
and
a positive parameter now multiplying only R0. This way, it has the direct interpretation of the residual variance. The response variable conditionally on the latent variable γi has thus variance
(21)
(21)
4.2. Estimation of the standard deviation of the estimates
Under certain regularity conditions, the standard deviation of the estimates can be derived from the observed Fisher information matrix (e.g. Section 5.5 of Van der Vaart Citation1998) with
(22)
(22)
where
denotes the ML-estimator of θ. The Fisher information matrix
is obtained by substituting the ML-estimates
in the derivatives of the log-likelihood function with respect to the parameters. This method has been used by Lin and Lee (Citation2006) and Lin (2008), and with the expected information matrix by Pinheiro, Liu, and Wu (Citation2001).
In the simulation study of an identifiable case, we check the accuracy of this approach via bootstrap analysis (Efron and Tibshirani Citation1994). We compare the asymptotic standard error of the estimates with the ones obtained with the bootstrap approach on 350 samples on the datasets generated in the first setting (). We show the coverage probabilities of these parametric confidence intervals.
Table 1. Simulation settings.
4.3. Outlier identification
“An outlier is an observation that is very different to other observations in a set of data” (Upton and Cook Citation2014). Since traditional LMMs are based on the assumption of normality of the data, they are sensitive to outliers, and maximum likelihood estimates get significantly biased in presence of extreme observations (Pinheiro, Liu, and Wu Citation2001). Therefore, outliers can directly affect statistical inference when modeling relies on normality assumptions. However, excluding extreme observations prior to the analysis is not a solution, as it may delete important information. The (multivariate) tLMM has been shown to be an appropriate tool to perform robust analyses. In fact, the heavier tails of the t distribution can accommodate the effect of outliers. Pinheiro, Liu, and Wu (Citation2001) show that the effect of the outliers on maximum likelihood estimates is bounded in the tLMM, also for larger deviations of the observations, while it is unbounded in the classical LMM.
tLMMs not only allow proper inference by downweighting the effect of outliers, but also enable outlier detection. Outlier identification based on the fit of the tLMM is largely discussed in literature, where outliers are always intended with respect to the Gaussian distribution.
The methods proposed use the Mahalanobis distance and the fact that the posterior distribution of γi is
(23)
(23)
with posterior mean
(24)
(24)
which under normality is equal to one. Here Ti denotes the number of follow-up times for subject i and
is an estimate of the expression in EquationEq. (8)
(8)
(8) , obtained by replacing the parameter values with their estimates. Thus a subject is detected as outlying (with respect to normality) if the values sampled from the posterior distribution are significantly smaller than 1 (Lin and Lee Citation2007), or if the 95% prediction interval for γi does not include 1 (Ho and Lin Citation2010; Wang and Fan Citation2012). Lin and Lee (Citation2007) and Wang and Fan (Citation2011, Citation2012) propose the use of boxplots of posterior samples of γi, drawn from EquationEq. (23)
(23)
(23) to find outlying subjects.
Wang and Lin (Citation2014) and Wang, Lin, and Lachos (Citation2018) complement the approaches above with a quantitative threshold-based method to distinguish outliers, where the threshold is
(25)
(25)
and
is the α quantile of the Beta distribution with parameters
and
(Wang and Lin Citation2014). If the posterior median of the sampled values of γi is less than c, the subject is an outlier. If the upper bound of the
posterior interval is smaller than c, then the subject is an extreme outlier in the population (Wang, Lin, and Lachos Citation2018). The same approach has been proposed to detect outliers in a longitudinal data clustering study (Wang Citation2019), applying formula Equation(25)
(25)
(25) with cluster-specific degrees of freedom (αs). Pinheiro, Liu, and Wu (Citation2001) also introduce a decomposition of the Mahalanobis distance,
(26)
(26)
with
This provides useful diagnostic statistics for understanding how the estimates and
affect the individual weights
and for identifying subjects with outlying observations (Matos et al. Citation2013). In fact, under the Gaussian model
(27)
(27)
and when (one of) these quantities are larger than 1, subject i should be treated as potential outlier at the corresponding level (e.g. random effects or residuals).
4.4. Simulation settings
In this section we introduce the settings of our simulation study to validate the ML estimation method in an identifiable case, and the settings of a smaller simulation study to show the consequence of fitting a model that is not identifiable.
Motivated by the case study (Sec. 6.3), we consider a tLMM including three fixed effects (gender, age and time) and two random effects (intercept and slope),
(28)
(28)
(29)
(29)
(30)
(30)
The coefficients for the fixed effects are set to the values
and the variance of the random intercept to
for all simulations. Furthermore, we choose a set of values for each variance–covariance parameter, and by combining their values we define the simulation settings, identified by the labels in . With the notation introduced in Sec. 2, n is the number of subjects, τ1 is the standard deviation of the random slope, η is the correlation coefficient between random intercept and slope. The remaining parameters are chosen differently for the identifiable and unidentifiable case and specified in the following. Each setting is simulated Nsim = 1000 times to ensure stability.
4.4.1. Unidentifiable case - RIS with Toeplitz correlation structure
To show the risks connected to non-identifiable models described in Sec. 3, we run a small simulation study with a reduced number of repeats n = 50 subjects and a Toeplitz correlation structure with parameters
and
(ensuring the correlation matrix is positive definite). We consider the settings with
α = 5 and α = 15 in , ignoring the last column since ρ is here replaced by the fixed values of
and
This reduces to 24 possible settings. The starting points for the optimization procedure are the linear transformations of the true parameters used in the simulation as given in Sec. 3.1, with c = 2.
4.4.2. Identifiable case - RIS with AR(1) correlation structure
For the identifiable case, we simulate repeats and choose an AR(1) correlation structure with autoregressive coefficient ρ given in . The number of subjects is set to n = 50 in all the 64 cases, while the setting numbers with a star are also simulated with n = 100 subjects. As starting values we give the true values used to simulate the data, and their linear transformations in few cases, for comparison with the unidentifiable case.
5. Results - Model estimation
5.1. Unidentifiable case - RIS with Toeplitz correlation structure
In this section we report the results from the simulation study concerning the unidentifiable case. As visible in , the ML estimates of the fixed effects are reliable. On the other hand, the estimates of the variance-covariance parameters are converging to the starting values (). Thus the bias with respect to the true underlying parameters is very large. The effect of non-identifiability is limited to the variance-covariance matrix, while the fixed parameters can be properly estimated. However, given that this model is often used to compare the inter- and intra-individual variability between groups (Chinchilli, Esinhart, and Miller Citation1995; Lin, Raz, and Harlow Citation1997; Welsh and Richardson Citation1997), estimating variance components accurately is of crucial importance.
Table 2. Statistics of the estimates of the fixed effects.
Table 3. Relative bias in the estimation of the variance–covariance parameters.
5.2. Identifiable case - RIS with AR(1) correlation structure
In this section we report the results from the simulation study on the identifiable case with autoregressive correlation structure. From the results, we can conclude that overall the estimation procedure works well, and it always gets to convergence in a reasonably short amount of time (on average 6 min per simulation). Furthermore, convergence and accuracy are not affected by imposing linear combinations of the true parameters as starting values for the estimation procedure. The fixed effects can be estimated with high accuracy in all the simulated settings, even with a relatively small number of subjects compared with the large number of repeats. In we summarize the results with various statistics. We can conclude that the estimates of the fixed effects are on average equal to the true values, with very little variation across the settings.
Table 4. Statistics of the estimates of the fixed effects.
Also the variance-covariance parameters can be estimated with low bias in most of the settings, although some exceptions exist for the parameters τ0 and especially η (see ).
Table 5. Relative bias in the estimation of the variance–covariance parameters.
Clearly, the increased number of units has a positive effect, reducing relative bias and standard deviation, as we may expect from the asymptotic behavior of ML estimates. To investigate in more detail the bias of the parameters τ0 and η for n = 50, we visualize the relative bias of the individual settings in and . The two lines (continuous and dotted) connect the settings with and
respectively, the two symbols distinguish the different values of η, and the labels on the horizontal axis correspond to the simulation settings defined in .
Figure 1. Relative bias in estimating τ0. The labels on the horizontal axis correspond to the simulation settings as defined in , the line types distinguish the values of ρ and the symbols denote the value of η. Clear dependence on ρ and on η in the cases with
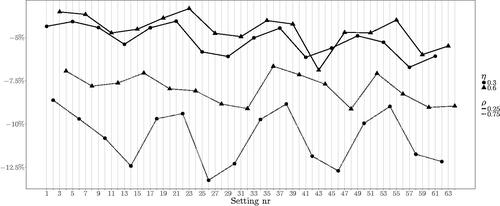
Figure 2. Relative bias in estimating η. The labels on the horizontal axis correspond to the simulation settings as defined in , the line types distinguish the values of ρ and the symbols denote the value of η. Clear dependence on ρ and on η in the cases with
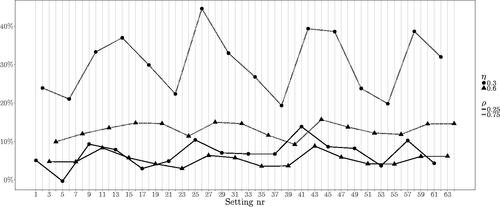
A strong dependence on the autoregressive coefficient ρ is apparent, while ρ itself is always estimated with good accuracy. In particular, higher values of ρ make the estimation of τ0 and η more difficult. Moreover, when we can observe a difference in performance attributable to η, namely small η combined with big ρ causes the most biased estimates of the variance of the random intercept and its correlation with the random slope. When
the relative bias is not large.
Furthermore, we performed a bootstrap analysis on the first simulation setting. We chose a bootstrap sample of B = 350 as this is shown to provide stability in the estimates on the case study (see Supplemental material). In we report the average estimate, the standard error as obtained analytically by exploiting the asymptotic properties of ML estimates, the standard error as obtained from the bootstrap analysis (average over the simulated datasets for the bootstrap standard deviation) and the coverage probabilities of the bootstrap confidence intervals. We observe that the direct derivation from the Fisher information matrix undervalues the standard error of the estimates, since the same values from the bootstrap analysis are overall larger and lead to coverage probabilities close to the nominal ones. Increasing the number of bootstrap samples can probably still improve the coverage for some of these parameters.
6. Case study
Understanding self-reported sleep quality and how it links with measurable data is currently of much interest in sleep medicine, since it has been proved to connect with mental and physical health problems (Åkerstedt et al. Citation1994; Augner Citation2011; Rahe et al. Citation2015). In particular, many references investigated the relationship between heart rate variability and sleep quality, possibly with other factors, such as working conditions and well-being. Although researchers do not agree on the direction of the influence, it is well agreed on the existence of a strong link between sleep and both autonomic and cardiovascular response (Kageyama et al. Citation1998; Burton et al. Citation2010; Michels et al. Citation2013).
Our goal is to assess the influence of physiological values, and in particular of derived heart rate measures on perceived sleep quality using the data from a study on sleep quality. Most of the studies apply traditional linear mixed models, but the observed values are often highly variable both within- and between-subjects, with outlying observations and outlying participants. We propose an alternative approach based on the tLMM to take into account the heterogeneity observed in the data. We estimate the influence of night-averaged heart rate (HR) quantities on perceived sleep quality (PSQ) fitting the same model we used in the simulations.
6.1. The data
The study design involved 50 healthy volunteers, of which 54% were females, aging from 40 to 65 years old, as this was considered the age category with the most stable routine and sleep rhythm. All the participants were chosen according to well defined exclusion criteria (diagnosed neurological, cardiovascular, psychiatric, pulmonary or endocrinological disorder; sleep disorder; using sleep, antidepressant or cardiovascular medications; consuming drugs or excessive alcohol; being pregnant; shift working; crossing more than two time zones in the last 2 months). The protocol involved two weeks of home monitoring plus two days in a sleep laboratory. During the first phase, participants were asked to wear an unobtrusive device and to fill in morning and evening questionnaires, where information of the preceding night and day were collected respectively. In the sleep laboratory, besides the collection of this information, other physiological measurements were taken. For more details on the study setup, refer to Goelema et al. (Citation2017). Due to unreliability of the physiological measurements on 8 participants, and the missingness of all the baseline variables relative to one participant, we remained with a dataset consisting of 41 participants.
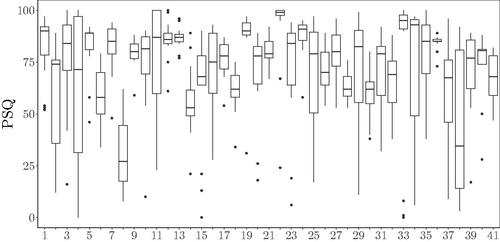
The PSQ, chosen as response variable, was assessed through the morning questionnaire via a visual analog scale ranging from 0 to 100. Being a subjective value, PSQ is highly variable within- and between-participants, with no clear relationship between the level and the variance (see ). Heterogeneity in this variable was checked via the Levene test (F = 3.05 with df = 40 and ).
Figure 3. PSQ per volunteer. Boxplot of the perceived sleep quality reported by each participant across the whole duration of the study.
The heart beats were extracted from the signal measured by the unobtrusive device and then the average heart rate over 30 s-windows was computed. For the aim of this study, we considered only the aggregated values over nights, namely the night average (HRmean) and the night standard deviation (HRsd) of the 30 s window-averages.
6.2. Preprocessing and data imputation
The data collected during the two nights in laboratory settings were excluded as the change in sleeping conditions might have affected sleep quality, resulting in 14 time points per participant. Furthermore, the rate of missingness in the response variable was 11.13%, while it was 11.74% in HR mean and standard deviation. Since the proposed estimation method requires complete datasets, we performed multiple imputation (R package mice, Zhang Citation2016) generating 20 complete datasets using some of the baseline and longitudinal variables.
6.3. The fitted model
We fitted a tLMM with random intercept and slope for time as continuous variable and included age, sex, mean HR, standard deviation HR as covariates for the fixed effects, analogous to the one described in Sec. 4.1. We also fitted a linear mixed model with the same fixed and random effects (MIXED procedure of SAS with maximum likelihood estimation, Littell et al. Citation2007). Note that we used the LMM estimates as starting values for the parameters in the tLMM, together with various initial values for α. Both models were fitted on each imputed dataset separately, and the standard error of the estimates was computed via the bootstrap approach (see Sec. 4.2). Then the final estimates were derived as the mean of the estimates from the analysis of each imputed dataset, and the final standard error of the estimates (combining within- and between-imputed dataset variability) was derived via Rubin’s rule (Rubin Citation2004). For the LMM we used the MIANALYZE procedure of SAS and for the tLMM we implemented the Rubin’s rule in R. After fitting the model, we sampled 1000 values from the posterior distribution of γi (EquationEq. 23(23)
(23) ), and showed their values per subject by means of a boxplot. Analogously to Lin and Lee (Citation2007), we define as outlying the subjects that show extremely small sample values
’s. In fact, a small value of the latent variable indicates that the influence of the corresponding subject (outlier with respect to normality) is downweighted in the estimation of model parameters. To understand better at which level these subjects are outlying (namely in the
or in the
term), we decomposed the Mahalanobis distance following EquationEq. (26)
(26)
(26) , and checked the value of each component divided by its own expected value under the Gaussian model (Pinheiro, Liu, and Wu Citation2001).
6.4. Results
After a first analysis of the tLMM, the initially included random slope was left out based on the information criteria (average vs. average
), suggesting that the heterogeneity in the slope was not sufficiently large, and confirmed by the estimate of the variance of the random slope
We thus reduced the model to random intercept only. The estimates for the linear mixed model are shown in , with the corresponding standard errors between brackets.
Table 6. Results of the bootstrap analysis on the datasets from the first setting.
As for the LMM, also for the tLMM the random slope did not improve the fit and thus in we report the estimates of the model with random intercept only, with their standard deviations obtained via the bootstrap approach. The results shown in the table correspond to the starting value
Table 7. Coefficients of the LMM.
The average perceived sleep quality corrected by the mentioned factors is 84.84 ± 6.63, and is negatively affected by an increased mean heart rate over the night (), while it is on average higher for females (
). At the same time, differences in age seem to play no role in the perception of a good night sleep, as well as the fixed effect of the night standard deviation of the heart rate. There is a positive effect of time and a significant difference between participants in overall mean. The residuals have a variance of
with no significant autoregressive structure. Note that both parameters of the gamma distribution are equal to
which justifies the choice of tLMM over traditional LMMs, and this is confirmed by the information criteria (average
against average
). Furthermore, while the estimates do not show extreme differences, the tLMM significantly reduces the standard deviation compared to the LMM. This might be explained by the fact that the heterogeneity affects more the confidence with which we can estimate the parameters than the estimates themselves, and is another observation in favor of the t model over the traditional one.
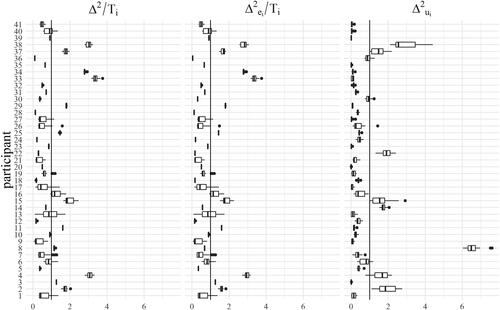
Finally, we used the tLMM fit to identify outlying participants with respect to normality (as discussed in Sec. 4.3), and applied the rule suggested by Lin and Lee (Citation2007). Values ’s substantially lower than 1 indicate a possibly outlying subject. In we show the values sampled from the posterior distribution for each participant via a boxplot. In total each boxplot refers to 1000 values sampled from each of the 20 posterior distributions (20 imputed datasets and relative estimated parameters). We chose to pool the values across imputations because there was no large deviation across imputations. Looking at the plot, we conclude that participants 2, 3, 4, 11, 15, 16, 25, 29, 33, 34, 37 and 38 should be regarded as potential outliers for the LMM fit. It is also interesting to understand at which level the participants are outlying, because even in case their overall behavior is in line with the sample, they may still have outlying behavior at the level of random effects or residuals separately. Following the method of Pinheiro, Liu, and Wu (Citation2001), we plotted the values of the two components of the Mahalanobis distance and the distance itself divided by their own expected value under normality. Cases in which these values are larger than one can be regarded as outliers. In we show these values corresponding to the 20 imputations in our case study: each boxplot collects the values of one of these quantities across the 20 imputed datasets for one single participant. The three plots are for
and
respectively. We can observe that participants 2, 4, 8, 14, 15, 22, 37, 38 are outlying at the
level, while subjects 2, 3, 4, 11, 15, 16, 25, 29, 33, 34, 37, 38 are outlying at the
level. It is worth noticing that participants 8, 14 and 22 are flagged as potential outliers when looking at the components of the Mahalanobis distance, while they would not be detected when looking at the total residuals or at the posterior conditional distribution of the γi’s. The analysis of outlying observations clearly demonstrates the potential of the tLMM over the more common LMM approach.
Figure 4. γi. Boxplot of 1000 sampled γi values per participant. The horizontal line at value 1 separates the bulk of observations from the outlying participants boxplots that are significantly below 1 indicate outlying participants.
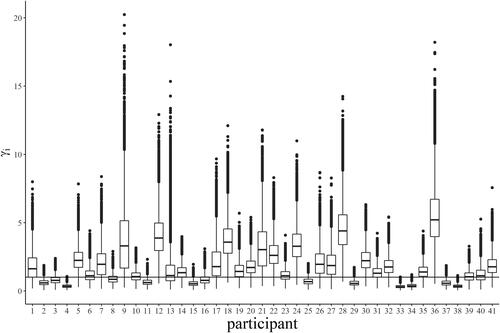
Figure 5. Decomposition of the Mahalanobis distance. (a) (b)
(c)
7. Discussion
In this paper, we presented a thorough analysis of the tLMM, with particular focus on model definition and parameter estimation. For the first part, we provided the mathematical formulation of non-identifiability for tLMMs and gave explanation to the common choice of equal parameters of the gamma distribution, normally not justified. It is worth noticing how different gamma distributions actually end up in the same marginal distribution of the response variable Thus, the same t can have different interpretations.
Identifiability issues that arise in the variance-covariance structure are theoretically shown by comparing the covariance matrix corresponding to two different sets of parameters, illustrating the procedure under some popular assumptions on the variance-covariance structure of random effects and residuals. The effect of unidentifiability on estimation is illustrated via a small simulation study. As expected, the estimates of the fixed effects are still reliable, their standard deviation is slightly higher, but this might be due to the lower number of settings compared with the identifiable case. The main effect of unidentifiability is reflected in the estimation of the variance-covariance parameters, and this is crucial when using the t mixed model for the analysis of variances (Chinchilli, Esinhart, and Miller Citation1995; Lin, Raz, and Harlow Citation1997; Welsh and Richardson Citation1997). Since the method convergences also in this case, identifiability issues are difficult to spot a posteriori and should be checked in the phase of model definition and formulation.
Then we investigated the reliability of an existing estimation method in case the model is identifiable. We extended the direct maximum likelihood approach of Lin and Lee (Citation2006) to allow for two correlated random effects and an autoregressive correlation structure of first order. The method is direct, easy to understand, reasonably fast and fully reproducible.
We assessed its performance via an intensive simulation study under the traditional choice of and showed that the fixed effects can be accurately estimated in all the considered settings, also with a relatively small amount of subjects and a large number of repeats. This analysis is quite unique, as previous work on the robustness of estimation methods is limited, and even when it exists, it simulates a small number of observations (Pinheiro, Liu, and Wu Citation2001) or a relatively simple correlation structure (Lin, Raz, and Harlow Citation1997). This is the component that is most difficult to estimate. In fact, we concluded that for some sets of true values the estimation of the variance-covariance parameters is less stable, in particular for η and τ0 when the coefficient of autocorrelation ρ is large. This problem is normally overcome in the literature by employing Bayesian approaches (Lin and Lee Citation2007) or expectation-maximization algorithms (Lin Citation2008), or by avoiding the coupling of both random intercept and slope with autoregressive correlation structures. For example Lin and Lee (Citation2006) explore random intercept with autoregressive correlation, but simplify the correlation structure when including also a random intercept. The choice might be due to their case study, concerning 17 observations on a maximum of 18 participants, which might be very critical for the estimation accuracy. In fact, we showed that thanks to the optimal properties of ML estimation the accuracy can be improved by increasing the number of subjects in the study, which is commonly even larger in panel studies than it was in our simulation study. Furthermore, our study demonstrates that relying on the asymptotic properties of the ML estimates in this case can lead to underestimation of the actual variability in the estimates. Therefore we proposed a bootstrap approach to estimate the standard error of the estimates.
The analysis of sleep data led to conclusions that slightly differ from the literature (Kageyama et al. Citation1998; Michels et al. Citation2013). This might be due to the HR variables that were taken into account, aggregated at night level, or to the novel approach accounting for additional heterogeneity. In fact, even choosing higher starting values for the parameters of the gamma distribution (e.g. ), led to the same estimate of the hyper-parameter, supporting the choice of a model with underlying heavy-tailed distribution. The choice between these assumptions will require further investigation.
Note that the speed and rate of convergence of the estimation method could be increased by choosing an alternative optimization procedure and by providing the gradient of the likelihood function. Furthermore, more research is needed to overcome the limitation of the current method in handling missing values. Also the model could be extended by empowering different heterogeneity factors for the random effects and for the residuals, as already highlighted by Pinheiro, Liu, and Wu (Citation2001). Another extension would involve replacing the gamma distribution with more general exponential probability distributions, and relaxing the hypothesis of conditional independence between random effects and residuals. Finally, future research should focus on deriving specific measures to assess the goodness of fit of the t distribution.
Supplemental Material
Download PDF (107.5 KB)Acknowledgments
This research was performed within the framework of the strategic joint research program on Data Science between TU/e and Philips Electronics Nederland B.V. We thank the anonymous reviewers for carefully reading our manuscript and providing insightful feedback and suggestions, as this resulted in a significant improvement of the manuscript.
Data availability statement
The data that support the findings of this study are available from Philips Research. Restrictions apply to the availability of these data, which were used under license for this study. The codes are available from the corresponding author on request.
Disclosure statement
No potential conflict of interest was reported by the authors.
Table 8. Coefficients of the tLMM.
Related Research Data
References
- Åkerstedt, T., K. Hume, D. Minors, and J. Waterhouse. 1994. The meaning of good sleep: A longitudinal study of polysomnography and subjective sleep quality. Journal of Sleep Research 3 (3):152–8.
- Augner, C. 2011. Associations of subjective sleep quality with depression score, anxiety, physical symptoms and sleep onset latency in students. Central European Journal of Public Health 19 (2):115. doi:https://doi.org/10.21101/cejph.a3647.
- Burton, A., K. Rahman, Y. Kadota, A. Lloyd, and U. Vollmer-Conna. 2010. Reduced heart rate variability predicts poor sleep quality in a case–control study of chronic fatigue syndrome. Experimental Brain Research 204 (1):71–8. doi:https://doi.org/10.1007/s00221-010-2296-1.
- Chinchilli, V. M., J. D. Esinhart, and W. G. Miller. 1995. Partial likelihood analysis of within-unit variances in repeated measurement experiments. Biometrics 51 (1):205–16. doi:https://doi.org/10.2307/2533326.
- Efron, B., and R. J. Tibshirani. 1994. An introduction to the bootstrap. Boca Raton, Florida: CRC Press.
- Goelema, M. S., M. Regis, R. Haakma, E. R. Van Den Heuvel, P. Markopoulos, and S. Overeem. 2017. Determinants of perceived sleep quality in normal sleepers. Behavioral Sleep Medicine 17 (4):388–97. doi:https://doi.org/10.1080/15402002.2017.1376205.
- Ho, H. J., and T.-I. Lin. 2010. Robust linear mixed models using the skew t distribution with application to schizophrenia data. Biometrical Journal 52 (4):449–69. doi:https://doi.org/10.1002/bimj.200900184.
- Janzén, D. L. I., M. Jirstrand, M. J. Chappell, and N. D. Evans. 2019. Three novel approaches to structural identifiability analysis in mixed-effects models. Computer Methods and Programs in Biomedicine 171:141–52. doi:https://doi.org/10.1016/j.cmpb.2016.04.024.
- Johnson, S. G. 2014. The nlopt nonlinear-optimization package.
- Kageyama, T., N. Nishikido, T. Kobayashi, Y. Kurokawa, T. Kaneko, and M. Kabuto. 1998. Self-reported sleep quality, job stress, and daytime autonomic activities assessed in terms of short-term heart rate variability among male white-collar workers. Industrial Health 36 (3):263–72. doi:https://doi.org/10.2486/indhealth.36.263.
- Kotz, S., and S. Nadarajah. 2004. Multivariate t-distributions and their applications. Cambridge, England: Cambridge University Press.
- Laird, N. M., and J. H. Ware. 1982. Random-effects models for longitudinal data. Biometrics 38 (4):963–74. doi:https://doi.org/10.2307/2529876.
- Lange, K. L., R. J. Little, and J. M. Taylor. 1989. Robust statistical modeling using the t distribution. Journal of the American Statistical Association 84 (408):881–96. doi:https://doi.org/10.2307/2290063.
- Lavielle, M., and L. Aarons. 2016. What do we mean by identifiability in mixed effects models? Journal of Pharmacokinetics and Pharmacodynamics 43 (1):111–22. doi:https://doi.org/10.1007/s10928-015-9459-4.
- Lin, T.-I. 2008. Longitudinal data analysis using t linear mixed models with autoregressive dependence structures. Journal of Data Science 6:333–55.
- Lin, T. I., and J. C. Lee. 2006. A robust approach to t linear mixed models applied to multiple sclerosis data. Statistics in Medicine 25 (8):1397–412. doi:https://doi.org/10.1002/sim.2384.
- Lin, T. I., and J. C. Lee. 2007. Bayesian analysis of hierarchical linear mixed modeling using the multivariate t distribution. Journal of Statistical Planning and Inference 137 (2):484–95. doi:https://doi.org/10.1016/j.jspi.2005.12.010.
- Lin, T.-I., and W.-L. Wang. 2019. Multivariate-t linear mixed models with censored responses, intermittent missing values and heavy tails. Statistical Methods in Medical Research 0:1–17. doi:https://doi.org/10.1177/0962280219857103.
- Lin, X., J. Raz, and S. D. Harlow. 1997. Linear mixed models with heterogeneous within-cluster variances. Biometrics 53 (3):910–23. doi:https://doi.org/10.2307/2533552.
- Littell, R. C., G. A. Milliken, W. W. Stroup, R. D. Wolfinger, and O. Schabenberger. 2007. SAS for mixed models. Cary, North Carolina: SAS Institute.
- Matos, L. A., M. O. Prates, M.-H. Chen, and V. H. Lachos. 2013. Likelihood-based inference for mixed-effects models with censored response using the multivariate-t distribution. Statistica Sinica 23 (3):1323–45. doi:https://doi.org/10.5705/ss.2012.043.
- Michels, N., E. Clays, M. D. Buyzere, B. Vanaelst, S. D. Henauw, and I. Sioen. 2013. Children's sleep and autonomic function: low sleep quality has an impact on heart rate variability. Sleep 36 (12):1939–46. doi:https://doi.org/10.5665/sleep.3234.
- Pinheiro, J. C., C. Liu, and Y. N. Wu. 2001. Efficient algorithms for robust estimation in linear mixed-effects models using the multivariate t distribution. Journal of Computational and Graphical Statistics 10 (2):249–76. doi:https://doi.org/10.1198/10618600152628059.
- Powell, M. J. 2008. Developments of NEWUOA for minimization without derivatives. IMA Journal of Numerical Analysis 28 (4):649. doi:https://doi.org/10.1093/imanum/drm047.
- R Core Team. 2016. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing.
- Rahe, C., M. E. Czira, H. Teismann, and K. Berger. 2015. Associations between poor sleep quality and different measures of obesity. Sleep Medicine 16 (10):1225–8. doi:https://doi.org/10.1016/j.sleep.2015.05.023.
- Rubin, D. B. 2004. Multiple imputation for nonresponse in surveys, vol. 81. Hoboken, New Jersey: John Wiley & Sons.
- Samani, E. B. 2014. Sensitivity analysis for the identifiability with application to latent random effect model for the mixed data. Journal of Applied Statistics 41 (12):2761–76. doi:https://doi.org/10.1080/02664763.2014.929641.
- Upton, G., and I. Cook. 2014. A dictionary of statistics 3e. Oxford, UK: Oxford University Press.
- Van der Vaart, A. W. 1998. Asymptotic statistics, vol. 3. Cambridge, England: Cambridge University Press.
- Wang, W.-L. 2013. Multivariate t linear mixed models for irregularly observed multiple repeated measures with missing outcomes. Biometrical Journal 55 (4):554–71. doi:https://doi.org/10.1002/bimj.201200001.
- Wang, W.-L. 2019. Mixture of multivariate t nonlinear mixed models for multiple longitudinal data with heterogeneity and missing values. TEST 28 (1):196–222. doi:https://doi.org/10.1007/s11749-018-0612-4.
- Wang, W.-L., and T.-H. Fan. 2011. Estimation in multivariate t linear mixed models for multiple longitudinal data. Statistica Sinica 21 (4):1857–80. doi:https://doi.org/10.5705/ss.2009.306.
- Wang, W.-L., and T.-H. Fan. 2012. Bayesian analysis of multivariate t linear mixed models using a combination of IBF and Gibbs samplers. Journal of Multivariate Analysis 105 (1):300–10. doi:https://doi.org/10.1016/j.jmva.2011.10.006.
- Wang, W.-L., and T.-I. Lin. 2014. Multivariate t nonlinear mixed-effects models for multi-outcome longitudinal data with missing values. Statistics in Medicine 33 (17):3029–46. doi:https://doi.org/10.1002/sim.6144.
- Wang, W.-L., and T.-I. Lin. 2015. Bayesian analysis of multivariate t linear mixed models with missing responses at random. Journal of Statistical Computation and Simulation 85 (17):3594–612. doi:https://doi.org/10.1080/00949655.2014.989852.
- Wang, W.-L., T.-I. Lin, and V. H. Lachos. 2018. Extending multivariate-t linear mixed models for multiple longitudinal data with censored responses and heavy tails. Statistical Methods in Medical Research 27 (1):48–64. doi:https://doi.org/10.1177/0962280215620229.
- Wang, W. 2013. Identifiability of linear mixed effects models. Electronic Journal of Statistics 7 (0):244–63. doi:https://doi.org/10.1214/13-EJS770.
- Wang, W. 2017. Checking identifiability of covariance parameters in linear mixed effects models. Journal of Applied Statistics 44 (11):1938–46. doi:https://doi.org/10.1080/02664763.2016.1238050.
- Welsh, A., and A. Richardson. 1997. Approaches to the robust estimation of mixed models. Handbook of Statistics 15:343–84.
- Wolfram Research, Inc. 2019. Mathematica, version 12.0. Champaign, IL: Wolfram Research, Inc.
- Ypma, J. Introduction to nloptr: An R interface to NLopt. Technical report, Technical report. 2014.
- Zhang, Z. 2016. Multiple imputation with multivariate imputation by chained equation (MICE) package. Annals of Translational Medicine 4 (2):30. doi:https://doi.org/10.3978/j.issn.2305-5839.2015.12.63.