
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Achievement tests are used to characterize the proficiency of higher-education students. Item response theory (IRT) models are applied to these tests to estimate the ability of students (as latent variable in the model). In order for quality IRT parameters to be estimated, especially ability parameters, it is important that the appropriate number of dimensions is identified. Through a case study, based on a statistics exam for students in higher education, we show how dimensions and other model parameters can be chosen in a real situation. Our model choice is based both on empirical and on background knowledge of the test. We show that dimensionality influences the estimates of the item-parameters, especially the discrimination parameter which provides information about the quality of the item. We perform a simulation study to generalize our conclusions. Both the simulation study and the case study show that multidimensional models have the advantage to better discriminate between examinees. We conclude from the simulation study that it is safer to use a multidimensional model compared to a unidimensional if it is unknown which model is the correct one.
1. Introduction
In different disciplines of studies like statistics, education, psychology, to mention a few, tests might be multidimensional. This means that these tests measure two or more dimensions of ability, also called constructs. The tests consist of several questions, called items. To model such items, a multidimensional item response theory (MIRT) is a widely used tool. The MIRT models are appropriate since these models explain the relationship between two or more latent (unobserved) variables and the probability to correctly answer the particular question by the examinee. The MIRT model has become a popular tool for the analysis of test content, computerized adaptive testing and equating of test calibrations noticed by Reckase (Citation2007).
Generally, MIRT models can be categorized into compensatory and non-compensatory models. More often than not, MIRT models are compensatory allowing the dimensions to interact. As Yang (Citation2007) points out, the literature of educational research is dominated by compensatory model applications (Reckase Citation1979; Drasgow and Parsons Citation1983; Yen Citation1984; Way, Ansley, and Forsyth Citation1988; Reckase and McKinley Citation1991; Kirisci, Hsu, and Yu Citation2001). Our focus remains on compensatory models for this article. For a compensatory model, the high ability, in terms of probability to correctly answer the question in one dimension can compensate for the low ability in another dimension. On the other hand, a non-compensatory model does not permit this. Therefore, one needs to be proficient in each ability to obtain the highest score.
In MIRT models the emphasis has not been to minimize the number of dimensions as is the case in factor analysis. Reckase (Citation1997) analyzed item response data even with 25 or more dimensions. However, most of the recent applications of MIRT have used fewer dimensions either due to the limitations in estimation programs or because it is useful, on other hand, to plot the results but it is difficult to plot more than three dimensions. The usage of unidimensional item response theory (UIRT) models is not new to the disciplines of education and psychology. However, meeting the unidimensionality assumption for ability is difficult in some achievement tests (Reckase Citation1985; Hambleton, Swaminathan, and Rogers Citation1991).
Many researchers (Spencer Citation2004; De La Torre and Patz Citation2005; Yang Citation2007; Kose and Demirtasli Citation2012) have compared unidimensional and multidimensional models. They have demonstrated that the ability and item parameters have less estimation error and provide more precise measurements under MIRT due to the fact that the number of latent traits underlying item performance increase. Moreover, the model-data fit indexes are in the favor of MIRT models. Wiberg (Citation2012) used multidimensional college admission test data to examine the consequences of applying the UIRT models. She discovered from a simulation study that MIRT gives better model fit result compared to UIRT. However, the result of a consecutive UIRT approach is proximate to MIRT. She concluded that if the test had between-item multidimensionality, the use of consecutive UIRT instead of MIRT models is not harmful and it may be easier to interpret logically.
Hooker, Finkelman, and Schwartzman (Citation2009) have highlighted a paradox occuring with MIRT in contrast to UIRT: if the answer of an examinee to an item is changed from correct to wrong, it could happen that the estimated ability decreases in some dimension. Further insights to this potential issue have been given by Finkelman, Hooker, and Wang (Citation2010), Hooker (Citation2010), and Jordan and Spiess (Citation2012, Citation2018). The mentioned references argue for the need to address this issue to avoid unfairness in the test. Other researchers have contrasting views. According to van Rijn and Rijmen (Citation2012), preventing paradoxical results are less relevant as long as one has not a contest perspective on a test. According to van der Linden (Citation2012), the convergence of ability estimates (e.g., the MLE) to the true ability is of main importance; additional information improves estimates even if paradoxical results occur (Reckase and Luo Citation2015). In contrast to this view, Jordan and Spiess (Citation2012) point out that the concept of fairness is an individual concept and refers not to infinite fictitious repetitions like quality of estimates.
The discrimination parameter of the model is a measure of the differential capability of an item. An item is considered valuable if it well discriminates subjects with ability levels in a range of interest for the exam. A larger value of the discrimination parameter demonstrates that the probability to correctly answer a question rapidly increases with the increase in the ability. The high value of discrimination parameter yields a steeper slope of the item characteristic curve (ICC), and the item has then a better possibility to differentiate subjects around the difficulty level of the item. Items with higher discrimination power can therefore contribute more in assessment precision in comparison to items with a low discrimination power, provided that the item-difficulty is in the scope of the exam. So, a feature which is of importance for educationalists is the capability of an item to discriminate between examinees. In UIRT model, items can discriminate subjects on one direction, whereas items in MIRT model differentiate examinees on each dimension.
The objectives of this study are: (1) to show how the question of dimensionality can be explored for an achievement test in higher education, (2) to show how a good model for analysis can be chosen in a real situation and (3) to investigate the impact of the number of dimensions in the chosen model on the discrimination parameter’s estimate.
2. Data of case study
Data used in this paper are acquired from a statistics exam for higher education students. This exam was taken by 238 examinees in March 2015. There were in total 16 questions in this exam which had a mixed-format consisting of 15 multiple-choice items and one free-response item. The first 15 questions Q1 to Q15 offer 5 options and one of them is correct. The responses have been dichotomized with the values 0 (wrong answer) and 1 (correct answer). The last question Q16 offers a maximum of 10 points. We have polychotomized response of this item with the values 0, 1, 2, 3, 4 and 5. The codification 0 represents if the student got 0 points and 1 for and 2 for
in the question, and so on. The characteristics of the exam and the percentage of correct answers are summarized in . Question 1 was easiest and question 12 toughest in the exam for the students according to this percentage. Most of the students were able to get 10 points for the last question. The item questions target different areas of statistics according to the teacher’s intentions, e.g., basic statistics, testing of hypothesis, regression, see .
Table 1. Data description.
3. Materials and methods
3.1. Unidimensional item response theory models (UIRT)
Let Uij be the dichotomous response of examinee j to item i
and
the probability of a correct response by examinee j to item i with ability
Commonly used IRT models for dichotomous responses are two- and three-parameter logistic models. However, the four-parameter logistic (4PL) model recently received more attention and some researchers highlighted its potential for practical purposes and from a methodological point of view (Magis Citation2013). The R package catR recently introduced the 4PL model as a baseline IRT model for computerized adaptive test (CAT) generation (Magis and Raîche Citation2012). The 4PL model can be expressed as
(1)
(1)
where
is the ability of examinee j,
is the difficulty of item i (location of the item response function),
is the discrimination of item i that determines the steepness of the item response function,
is the lower asymptotic parameter for the
item response function,
is the upper asymptotic parameter for the
item response function.
The three-parameter logistic (3PL) model is a special case of the 4PL model with The two-parameter logistic (2PL) model is a special case with
and
For the polychotomized free-response item we have used the graded-response (GR) model which was first introduced by Samejima (Citation1969) for ordered categorical responses. This model is a generalization of the 2PL model. The probability of the th examinee to respond the
th out of
categories for the
th item is expressed as
(2)
(2)
where
and
are again discrimination and ability parameter, respectively, and
is a vector of category intercepts for item i.
3.2. Multidimensional item response theory models (MIRT)
In MIRT models, the probability of success is modeled as a function of multiple ability dimensions. Each person has a vector of ability parameter values. Each item has vector of discrimination parameter values
one difficulty parameter
a guessing
and an upper asymptote parameter
(Reckase Citation2009). We can write a four-parameter logistic MIRT model (M4PL) as generalization of the UIRT model Equation(1)
(1)
(1) by replacing
with
where m is the total number of dimensions. The M3PL (or M2PL) is again a special case of the M4PL model by setting
(or
and
). The multidimensional graded response (MGR) model generalizes formula Equation(2)
(2)
(2) by replacing
with
using the vector of category intercepts
for item i, where
3.3. Exploratory and confirmatory MIRT models
The MIRT models are either exploratory or confirmatory depending upon the available information at the model specification step. An exploratory MIRT model is useful to explore the possible structure of a set of test items without preconceived structure on the items, or even when unconstrained solution is seen as a strong test to verify the hypothesized structure of test items. After applying exploratory MIRT model one could identify underlying structure of a set of test items. The confirmatory MIRT models are useful when we have clear hypothesis about structure of set of items in an examination taken by students. In fact, the confirmatory MIRT model needs to have a specified number of latent abilities to explain the pattern of relationships between the items. In confirmatory MIRT the researcher postulates the relationship between items and specific number of latent variables a priori, based on knowledge of the theory, empirical research, or both. This hypothesized structure is statistically tested by the researcher. The confirmatory MIRT models are valuable to measure aspects such as different knowledge structure of examinees, multiple abilities, strategies, satisfaction level and attitudes on which persons differ quantitatively.
It is common that in exploratory analyses a model is used where all ability parameters can influence all items (, middle) called within-item multidimensionality. A typical confirmatory analysis uses models where the different abilities influence disjoint sets of items (, right) denoted as between-item multidimensionality, see Adams, Wilson, and Wang (Citation1997) and Hartig and Höhler (Citation2009). We use a model with between-item multidimensionality later for an exploratory analysis of our case study. The MIRT model with between-item multidimensionality has also been called MIRT model of simple structure or multiunidimensional IRT model; Sheng and Wikle (Citation2007) compare this model with the UIRT model. It has been noted e.g., by Jordan and Spiess (Citation2012) that the model with between-item multidimensionality and with ML estimation avoids the issue of paradoxical results mentioned in the introduction (however, if a Bayesian analysis is used and the dimension is at least 3, paradoxical results still are possible, see Finkelman, Hooker, and Wang (Citation2010)).
Figure 1. The graphical representation of a unidimensional and a multidimensional model with within-item and with between-item multidimensionality. The left panel represents the univariate model. The middle panel depicts a multidimensional model with within-item multidimensionality, and the right panel indicates a multidimensional model with between-item multidimensionality.
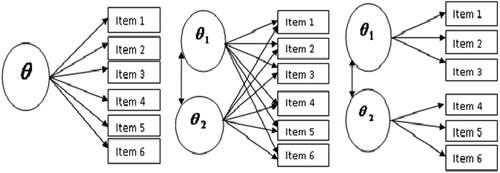
A variant of a MIRT model with between-item multidimensionality is the consecutive UIRT model where the items belonging to one ability are analyzed as separate models. In the right panel of , we remove the arrow between θ1 and θ2 to illustrate the consecutive UIRT.
3.4. The ability parameters in the models
The ability of the examinees is characterized by a single ability parameter in the UIRT or by a multidimensional parameter vector
in the MIRT. We assume that the investigated population has normally distributed ability parameters with standardized variance 1, i.e.,
with covariance matrix C having a diagonal of 1’s, see (Reckase Citation2007; Chalmers Citation2012) and specifically for m = 1, (Baker and Kim Citation2004; Rizopoulos Citation2006). The standardization is important to make the discrimination parameters
in the model well-defined (identifiable) as otherwise dividing all abilities by a factor and multiplying all discrimination parameters by the same factor would lead to the same data fit. We think that this is even more important from an interpretation perspective than from a theoretical perspective: it is beneficial to make discrimination parameters comparable across different analysis models as well as across different examinations.
3.5. Model estimation
First, it is useful to define the response data in the form of an indicator function
Let ψ be the set of all unknown item parameters. The conditional likelihood for the jth
response pattern vector,
can be defined as
where the number of categories ri is set to 2 for dichotomous items (
). Denoting the density of the ability parameter by
(recall that we assume them having a standardized multivariate normal distribution), we integrate them out of the likelihood function. This yields to the marginal likelihood equation of the observed data U (N × n data matrix)
For estimation of the IRT models, the recommended method in case of a small number of dimensions (less than 4) is the expectation maximization (EM) algorithm by using fixed Gauss-Hermite quadrature while the Metropolis-Hastings Robbins-Monro (MH-RM) algorithm and Quasi-Monte Carlo EM (QMCEM) estimation are recommended in case of higher dimensionality or when multidimensional confirmatory model is required (Chalmers Citation2012). For higher dimension, the EM algorithm solution becomes difficult as we require large number of numerical quadrature in the E-step to evaluate high-dimensional integrals in the likelihood function of the item parameters.
3.6. Models comparison criteria
To evaluate the goodness of fit of different competing models, we have used following statistical approaches: Akaike information criterion (AIC), bias corrected AIC (AICc), Bayesian information criterion (BIC) and sample size adjusted BIC (SABIC). These statistics are based on the log-likelihood of a fitted model, sample size and number of parameters estimated as follows:
Here p is the number of item parameters being estimated (= number of item parameters
), LL is the log likelihood of the model, N indicates the number of examinees and m represents number of dimensions. Smaller AIC, AICc, BIC and SABIC values indicate better fit. Like BIC, SABIC places a penalty based on sample size for adding parameters, but the penalty is not as high as for BIC. We note that we use here the above mentioned form of AICc since it is the version implemented in the R package mirt which we use for analysis and since Burnham and Anderson (Citation2002) suggested that this form could be used generally. However, AICc in general is model dependent, see Section 7.4 of Burnham and Anderson (Citation2002).
The likelihood ratio tests were also conducted between the nested models to find out whether a more complicated model fits better than the simple one.
3.7. Determination of number of factors
Standard principal component analysis (PCA) and factor analysis (FA) assume that the analyzed variables are continuous and follow a multivariate normal distribution. With this assumption, the sample covariance matrix is a sufficient statistic and inference can be done based on this matrix. In particular, methods are developed to determine the number of factors for the model which we briefly summarize now.
One starts with computing eigenvalues and eigenvectors of the covariance matrix. We can retain only those factors that have eigenvalues greater than one which is applying the “eigenvalue >1-criterion” or Kaiser-Guttman rule (Guttman Citation1954; Kaiser Citation1960). These factors explain more than the average of the total variance. However, Conway and Huffcutt (Citation2003) summarize ample research findings and say that the Kaiser-Guttman rule “tends to produce too many factors” and “probably should not be relied on”. Gorsuch (Citation1983) proposes that the number of factors is expected to be between and
here n is number of variables. This rule of thumb is even more appropriate when sample size is larger (recommended is at least 100) but when the data has fewer than 40 variables. Horn (Citation1965) proposes another strategy known as parallel analysis which now emerges as one of the strongly recommended techniques for deciding how many factors to retain (Zwick and Velicer Citation1986; Fabrigar et al. Citation1999; Velicer, Eaton, and Fava Citation2000; Hayton, Allen, and Scarpello Citation2004; Peres-Neto, Jackson, and Somers Citation2005; Henson and Roberts Citation2006; Ruscio and Roche Citation2012; Garrido, Abad, and Ponsoda Citation2013). Parallel analysis compares the scree of eigenvalues of the observed data with that of a random data matrix of the same size as that of original. For the factor analysis, any adjusted eigenvalues greater than 0 is retained where the adjustment is given by: Observed
- mean simulated
Here,
observed is the p-th ordered eigenvalue of the observed data (for p = 1 to n), and mean simulated
is the corresponding mean eigenvalue of the iterations number of simulated random data sets. Conway and Huffcutt (Citation2003) have observed that different techniques suggest retaining different number of factors for exploratory factor model, as is reported frequently in literature.
In our MIRT situation with mixed format data consisting of dichotomous and polychotomous items, we cannot use these methods directly. However, these methods can be applied using the poly-choric correlation matrix of the MIRT data, see e.g., (Li, Jiao, and Lissitz Citation2012; Verma and Markey Citation2014). The poly-choric correlation matrix between the items is computed under the assumption that dichotomous and polychotomous items dissect continuous latent variables that follow bivariate normal distributions. In contrast to the situation when the data are multivariate normally distributed, the sample poly-choric correlation matrix is not a sufficient statistic of the data. Hence, some information is lost when principal component analysis is performed based on this correlation matrix and this method is therefore called limited information method. Nevertheless, it is useful in some situations to perform principal component analysis based on poly-choric correlation to obtain a first guidance how many dimensions to use in an MIRT model. Further, this limited information method can provide quite accurate starting values for parameters (Bock, Gibbons, and Muraki Citation1988; Lee and Terry Citation2005) in the algorithms mentioned in the section for model estimation.
Alternatively, we can determine the number of factors in MIRT models with a full information method as follows: we use the full response pattern (not only the sample poly-choric correlation) and compute maximized log likelihood and parameter estimates for several possible number of factors. We decide then about the preferred number of factors by using model comparison criteria or likelihood ratio tests applied to the models with the different number of factors.
In this paper we use the poly-choric correlation matrix and parallel analysis for principal component analysis as limited information method to obtain a prior indication for the dimension. Then, we analyze the IRT model with a full information method as described in the previous paragraph and by this we obtain a recommended number of factors by applying model comparison criteria and by using likelihood ratio tests.
4. Results for case study
4.1. Analysis with MIRT model
We start with investigating an appropriate number of dimensions (number of latent factors) based on the poly-choric correlation matrix (limited information matrix). This gives us a rough estimate for the dimensionality in our data set of students result in statistics examination. shows the poly-choric correlation between the pairs of items. We conduct principal component analysis and consider first the eigenvalue-greater-than-one-criterion to determine the appropriate number of factors. depicts that five components meet the rule. The initial two components have eigenvalues (6.54, 1.42) far greater than one, which strongly suggests the multidimensionality in the data. When computing the adjusted eigenvalues greater than 0, the parallel analysis indicates here to retain 3 factors. Parallel analysis is performed using 1000 simulated data. According to Gorsuch’s rule of thumb, we expect our data set to have around 4 factors as we have 16/53 and 16/3
5. While these methods yield somewhat different recommendations for the factors number, our general conclusion is that the data lack unidimensionality and that at least 2 components exist.
Figure 2. Depicts the poly-choric correlations of 16 questions. Assuming that there are latent continuous variables underlying the categorical variables which are normally distributed, poly-choric correlation estimates the correlation between the assumed underlying continuous variables. Blue color squares indicate positive correlation: a darker color means a stronger correlation. Light-pink color squares indicate a weak negative correlation.
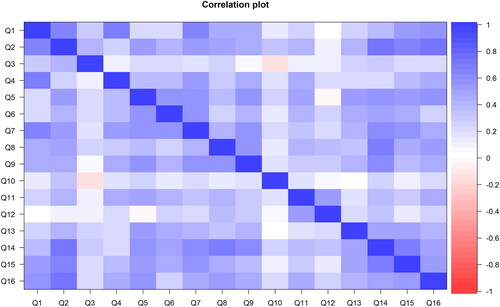
Table 2. Eigenvalue and explained variance for principal component analysis.
Since we have a small number of items (16), we decided to investigate multidimensional item response theory (MIRT) models with up to 3 dimensions as recommended by parallel analysis. We will later choose the most appropriate model in an empirical way using the model comparison approaches described before. However, we simultaneously take a rationalist point of view and consider the content areas for the item () to select the meaningful construct, and an appropriate model for that construct.
We compare three MIRT models, M2PL, M3PL, M4PL, each combined with the MGR model, with respect to their fit to the mixed-format data. The global fit statistics are reported in . Most of them support unidimensionality. They show that the M2PL + MGR model has small AIC, AICc, BIC and SABIC as compared to other models.
Table 3. Global fit statistic for each model up to 3 dimensions.
The likelihood ratio (LR) test is applied to compare nested models. The resulting p-values of the LR tests for nested models are presented in . The block on the left-hand side in the table compares two different models each having a specific dimension. The right-hand side block compares models with different dimensions within each of M2PL + MGR, M3PL + MGR and M4PL + MGR model. These results show that a better model fit is produced with increased dimensionality and complexity of the model. We conclude, therefore, that the unidimensionality assumption has not been met. Based on LR test results, we have observed in this study that the M4PL + MGR model fits better as compared to other models (M2PL + MGR and M3PL + MGR) because it is more complex when we fix the dimension at 2 or 3. In the case of unidimensionality, the LR test favors the 3PL + GR model as compared to other models.
Table 4. P-values for likelihood ratio tests.
We now investigate which model (M2PL + MGR, M3PL + MGR and M4PL + MGR) is better to figure out the construct. shows the structure of the construct for 2 and 3 factor solutions. The groups are made with the questions (items) having higher loading values in the same dimensions. Factor loading expresses the relationship of each item with underlying factor. The items with strongest association to the factor have high value of loading onto that factor. Here, we have observed that complex models with more dimensions are better to form a group of similar kind of questions as compare to other models. Moreover, the factors representing the group of items are more interpretable as compared to the factors representing the group of items in other models. So, the M4PL + MGR model is better in forming groups that are more interpretable and this result remains consistent in the comparison of models by using the LR test. The LR test supports the 3 dimensional, more complex model (M4PL + MGR) and this model is good to figure out the underlying construct of the exam. The Q1, Q3 and Q4 lie in dimension. This dimension represents the students’ ability in basic statistics which include interpretation of a box plot or the definition of the term “range”. The
dimension represents Q5, Q6, Q7, Q11, Q12 and Q13. This dimension evaluates the students’ skill to solve the contingency table and hypothesis testing problem. The
construct is constituted with Q8, Q9, Q10, Q14, Q15, Q16 and Q2. This dimension indicates the students’ ability in probability distribution, regression and chi-square test. The Q2, which is a basic statistics question, is also included in the construct. Its inclusion in this dimension is debatable. One possible reason could be that students have to perform some manual calculations (e.g., calculation of standard deviation for a given sample) to answer the question, which is also required for question Q14, Q15 and Q16.
Table 5. Two- and three-factor solution for each model.
4.2. Analysis using MIRT with between-item multidimensionality
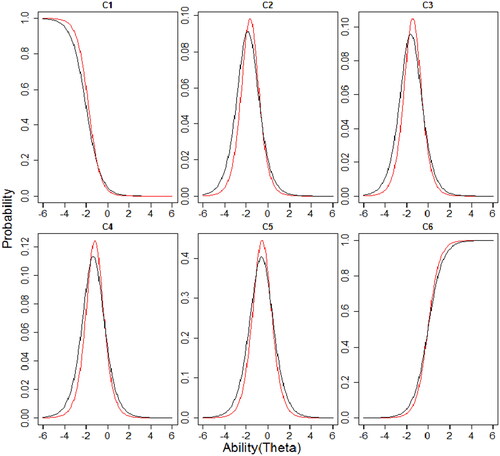
Lastly, using the dimension information from the analysis with the MIRT model before, we run now the M4PL + MGR model with 3 factors and between-item multidimensionality. This model offers the possibility for a simpler interpretation and avoids an issue of paradoxical results. Further, a possibility when using between-item multidimensionality is that we can examine how the M4PL + MGR model item response curve characterizes the items compared to unidimensional 3PL + GR model. The graphs of the item response curves of both models of each item are in to . The item characteristic curve (ICC) of Q1, Q3 and Q4 (factor 1; see ) in the multidimensional model with between-item multidimensionality are steeper as compared to the unidimensional model. The Q3 and Q4 have an upper asymptote parameter smaller than 1 in the M4PL + MGR, while Q1 has an upper asymptote parameter close to 1 in the M4PL + MGR corresponding to the 3PL + GR. Questions Q5, Q6, Q7, Q11, Q12 and Q13 (factor 2; see ) have approximately the same ICC for both models especially if we look at ability level between -2 and 2. Slight differences in guessing parameters are visible in Q5, Q6, Q11 and Q13. While for factor 3 (see ), some ICC differ somewhat due to an upper asymptote estimate < 1 for the M4PL + MGR (Q8, Q9, Q10 and Q14), the most striking difference between the ICCs is also for this factor that the discrimination parameter is higher in the multidimensional model. Also for the graded response item Q16 (see ), all categories show steeper curves for the multidimensional model. As a whole, ICCs from the between-item multidimensionality model has steeper slopes as compare to unidimensional model. This shows that items in the MIRT model with between-item multidimensionality have more discrimination power. The difficulty level of all questions are almost similar in both models except Q1, Q3, Q5, Q6 and Q13 which have a slightly different difficulty level if we look at ICCs of the MIRT model and the UIRT model.
Figure 3. Item characteristic curves (ICCs) for factor 1. The black line represents the item curve of unidimensional 3PL + GR and red line represents the M4PL + MGR model.
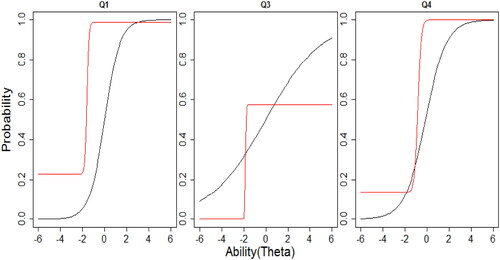
Figure 4. Item characteristic curves (ICCs) for factor 2. The black line represents the item curve of unidimensional 3PL + GR and red line represents the M4PL + MGR model.
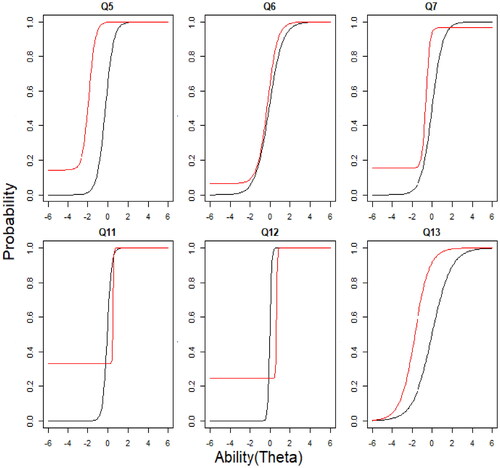
Figure 5. Item characteristic curves (ICCs) for dichotomous items in factor 3. The black line represents the item curve of unidimensional 3PL + GR and red line represents the M4PL + MGR model.
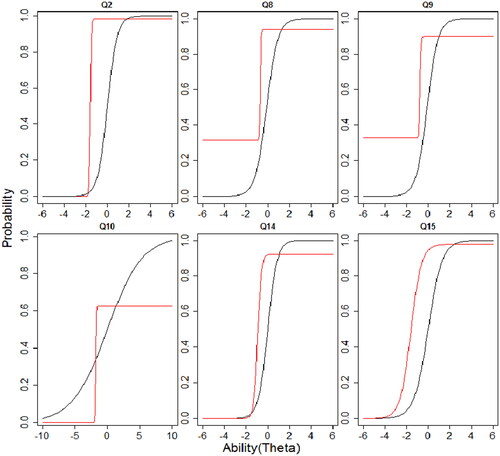
Figure 6. Item characteristic curves (ICCs) for graded response item Q16. The black line represents the item curve of unidimensional 3PL + GR and red line represents the M4PL + MGR model.
5. Simulation study
As observed in the case study in Sec. 4, the estimates for the items’ discrimination parameters are larger for the MIRT compared to the UIRT. We investigate whether this observation is generally valid and carry out a simulation study using a Monte Carlo approach. Motivated by the situation in the case study, a mixed-format data of 16 items have been generated through 300, 500 and 1000 examinees using a unidimensional and a multidimensional model. To avoid the complexity of degree of multidimensionality and to make the simulation study simpler, we have opted to investigate here a two-dimensional model with between-item multidimensionality as representant of the multidimensional models. Further, we considered 2PL models in all cases as we are here not interested in the guessing and upper asymptote parameter. In the multidimensional case we have assumed the situation in the first column of , i.e., the dimension constitutes of items Q11 and Q12 and the
of the other 14 items. In the two-dimensional model, we used the estimated covariance matrix (1, 0.78; 0.78, 1) from the original data as covariance for the simulation. This means that the two latent abilities
and
are correlated with a correlation of 0.78. As true parameter values for the simulation, we used the estimated values we got in the respective models, the 2PL + GR and the M2PL + MGR, in our case study. For data generation we had the described two models and used for data analysis both the 2PL + GR and the M2PL + MGR model for both cases, i.e., we analyzed in each case both with the correct model and the wrong model. The design of simulation study, including data generation process and data analysis method, is illustrated in .
Figure 7. Data generation (simulation model, the true model) and data analysis (fitted model).
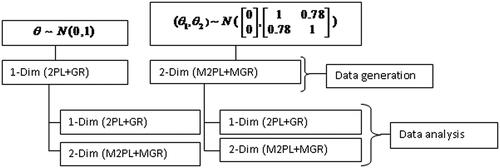
Data were generated and analyzed with R package mirt. For each data generation model and each considered sample size (300, 500, and 1000 students), 1000 simulation runs (repetitions) were done.
The estimated discrimination parameter was compared with the true parameter used in data generation. Root mean square error (RMSE), absolute bias (AB) and bias have then been computed for each item in each simulation run. The mean and the standard deviation of RMSE, AB and bias of the 16 items in the 1000 simulation runs was computed and is shown in .
Table 6. Simulation results for discrimination parameter (mean RMSE, AB and bias over 16 items and 1000 simulation runs) and AIC (mean over 1000 simulation runs).
In the block of , data were generated from the unidimensional 2PL + GR model and analyzed with 2PL + GR and confirmatory M2PL + MGR. The estimated discrimination parameters of all items are positively biased and bias reduces as the sample size increases. For each sample size the values of RMSE, AB and Bias values for M2PL + MGR model are higher compared to 2PL + GR, i.e., we obtain as expected, better values when estimating with the correct model compared to the overspecified two-dimensional model.
In the block of , data were generated from the two-dimensional confirmatory M2PL + MGR model and analyzed with 2PL + GR and confirmatory M2PL + MGR. When analyzed with the wrong unidimensional model, the estimated discrimination parameters for the items are negatively biased. Their absolute value decreases with the increase in sample size. When analyzed with the correct two-dimensional model, the estimated discrimination parameters for the items are positively biased, decreasing with the increase in sample size. For each sample size the values of RMSE, AB and the absolute value of the mean bias are higher for the 2PL + GR model compared to M2PL + MGR, i.e., we have again better values when estimating with the correct model compared to the wrong unidimensional model.
In both the and
block of , the bias for each sample size is lower for the unidimensional model as compared to the multidimensional model. This highlights that we get higher estimated discrimination parameter in the multidimensional case as compared to unidimensional. Hence, this simulation study supports the finding of our case study that items have a higher discrimination capability in multidimensional model as compared to unidimensional model. Why is this case? When using the MIRT and considering a specific item, we obtain first a discrimination parameter estimate for each dimension. We focus then on the dimension which has the highest discrimination capacity. This means that the discrimination estimate we consider in the MIRT case is a maximum out of several estimates. It is the value which seems to belong to the ability-dimension connected to this item. Therefore, the estimate based on MIRT is larger compared to the UIRT no matter which of the models is the true one.
We have focused so far on the discrimination parameter. Looking at the results for the difficulty parameter, the results of RMSE, AB and Bias () show only small difference between unidimensional and multidimensional. This indicates that the degree of multidimensionality seems to have no greater effect on the estimation of difficulty parameters. This result confirms the findings of Childs and Oppler (Citation1999) and Yang (Citation2007).
Table 7. Simulation results for difficulty parameter (mean RMSE, AB and bias over 16 items and 1000 simulation runs).
In an actual study in contrast to this simulation study, we do not know if the true model is unidimensional or multidimensional. Applying the multidimensional model, even though the true is unidimensional, is safer since items can discriminate the students better and model estimated discrimination parameter are close to actual parameter, especially for large sample size as suggested by the simulation study result. Furthermore, model fit criterion AIC is only a little higher when analyzing the wrong multidimensional model when the true is unidimensional ( block in ). On the other hand, if we apply the wrong unidimensional model in the multidimensional case (
block in ), the AIC is increased with a larger amount. The negative bias of estimated discrimination parameters is not reduced when sample size is increased to 1000. We observe, based on these results, that the violation of unidimensionality assumption may seriously bias ability and estimated item parameters which is in accordance with statements by Reckase (Citation1979) and Harrison (Citation1986).
6. Discussion and conclusion
In some situations, it is possible to build the model by first conducting an exploratory factor analysis and then – with new data – confirm this model. While an approach to confirm with new data would lead to strong certainty about the proposed model, we have not this possibility here: the data are too small to be split into subgroups for exploration and confirmation and due to the nature of examination in higher education, the exam will not be repeated with the same questions for new students such that no new data with the same items will be obtained in the future. In order to obtain a meaningful model in a situation like ours, we recommend to choose the model using purely data driven criteria in combination with knowledge about groups of items suspected to belong to the same factor. Models with factor structure corresponding to the areas in are preferable. Nevertheless, it is important to carefully consider unexpected results and reflect possible explanations; in our case study, the placement of item Q2 within another factor than it’s group Q1 to Q4 could be explained. This approach aims to facilitate a meaningful interpretation of our model but we point out that the resulting model still needs to be seen as exploratory.
Instead of performing a confirmatory analysis which here is difficult or impossible, we propose to conduct analyses similar to ours for several exams from different occasions (i.e., with different questions) and to look out for results which are supported from several different analyses. Based on interpretation supported by independent analyses, exams from higher education can be improved. For example, low discriminating items or items which discriminate in an ability range which is not of interest for the exam can be avoided.
The sample size in the case study appears low in the context of the applied models (e.g., 4PL) where recommendations usually require higher numbers. However, the sample size is common in higher education. Our approach described before tries to gain insights from the analysis in this challenging situation while acknowledging that results needs to be taken with care.
As we have seen in the case and simulation study, the estimates for the discrimination parameter were higher when an MIRT was used as compared to an UIRT. This effect which we explained in Sec. 5 has not found much attention in the literature yet. The estimate based on MIRT is larger compared to the UIRT no matter which of the models is the true one. This effect is important to keep in mind when working with both types of models: when one is used to a certain range of discrimination parameter estimates from UIRT analyses, one can expect a higher range when the analysis model is switched to MIRT.
An implicit assumption we made in this article is that high discriminating items are preferable. In a situation like considered here, an achievement test in higher education, it is intuitively reasonable to strive for a set of several well discriminating items with difficulties spread over a range of interest. However, in general it is not clear if high discrimination is preferable. Buyske (Citation2005) mentions reasons to use low discriminating items in the beginning of a computerized adaptive test. To investigate a general situation in detail, we need explicitly define the objective. Then optimal design methods can formally determine the optimal item parameters, see e.g., Berger and Wong (Citation2005).
We demonstrated in our simulation study that if it is unknown whether the UIRT or the MIRT is the underlying model it is safer to use the MIRT. We found there that if the MIRT model is used for analysis, estimated discrimination parameters are quite close to the true parameters especially for large sample size.
Based on our analysis of real data and on simulations with realistic parameter choices, we pointed out advantages of MIRT compared to UIRT. How our conclusions depend on parameter values, e.g., on the correlation between the abilities, was not in our focus here and should be investigated in future research.
Data availability
The data that support the findings of this study are available from the corresponding author (Ul Hassan) upon reasonable request.
Related Research Data
References
- Adams, R. J., M. Wilson, and W.-C. Wang. 1997. The multidimensional random coefficients multinomial logit model. Applied Psychological Measurement 21 (1):1–23. doi:10.1177/0146621697211001.
- Baker, F. B., and S.-H. Kim. 2004. Item response theory: Parameter estimation techniques. CRC Press.
- Berger, M. P. F., and W.-K. Wong. 2005. Applied optimal designs. West Sussex: John Wiley & Sons.
- Bock, R. D., R. Gibbons, and E. Muraki. 1988. Full-information item factor analysis. Applied psychological measurement 12 (3):261–80. doi:10.1177/014662168801200305.
- Burnham, K. P., and D. R. Anderson. 2002. Model selection and multimodel inference – a practical information-theoretic approach. New York: Springer.
- Buyske, S. 2005. Optimal designs in educational testing. In Applied optimal designs, eds. M. P. F. Berger and W. K. Wong. Chichester, UK: John Wiley & Sons, Ltd.
- Chalmers, R. P. 2012. mirt: A multidimensional item response theory package for the R environment. Journal of Statistical Software 48 (6):1–29. doi:10.18637/jss.v048.i06.
- Childs, R. A., and S. H. Oppler. 1999. Practical implications of test dimensionality for item response theory calibration of the medical college admission test. MCAT Monograph. Washington, DC: ERIC.
- Conway, J. M., and A. I. Huffcutt. 2003. A review and evaluation of exploratory factor analysis practices in organizational research. Organizational Research Methods 6 (2):147–68. doi:10.1177/1094428103251541.
- De La Torre, J., and R. J. Patz. 2005. Making the most of what we have: A practical application of multidimensional item response theory in test scoring. Journal of Educational and Behavioral Statistics 30 (3):295–311. doi:10.3102/10769986030003295.
- Drasgow, F., and C. K. Parsons. 1983. Application of unidimensional item response theory models to multidimensional data. Applied Psychological Measurement 7 (2):189–99. doi:10.1177/014662168300700207.
- Fabrigar, L. R., D. T. Wegener, R. C. MacCallum, and E. J. Strahan. 1999. Evaluating the use of exploratory factor analysis in psychological research. Psychological Methods 4 (3):272–99. doi:10.1037//1082-989X.4.3.272.
- Finkelman, M., G. Hooker, and Z. Wang. 2010. Prevalence and magnitude of paradoxical results in multidimensional item response theory. Journal of Educational and Behavioral Statistics 35 (6):744–61. doi:10.3102/1076998610381402.
- Garrido, L. E., F. J. Abad, and V. Ponsoda. 2013. A new look at Horn’s parallel analysis with ordinal variables. Psychological Methods 18 (4):454–74. doi:10.1037/a0030005.
- Gorsuch, R. L. 1983. Factor analysis. 2nd ed. London: Lawrence Erlbaum Associates.
- Guttman, L. 1954. Some necessary conditions for common-factor analysis. Psychometrika 19 (2):149–61. doi:10.1007/BF02289162.
- Hambleton, R. K., H. Swaminathan, and H. J. Rogers. 1991. Fundamentals of item response theory. Newbury Park, CA: Sage Publications.
- Harrison, D. A. 1986. Robustness of IRT parameter estimation to violations of the unidimensionality assumption. Journal of Educational Statistics 11 (2):91–115. doi:10.3102/10769986011002091.
- Hartig, J., and J. Höhler. 2009. Multidimensional IRT models for the assessment of competencies. Studies in Educational Evaluation 35 (2/3):57–63. doi:10.1016/j.stueduc.2009.10.002.
- Hayton, J. C., D. G. Allen, and V. Scarpello. 2004. Factor retention decisions in exploratory factor analysis: A tutorial on parallel analysis. Organizational Research Methods 7 (2):191–205. doi:10.1177/1094428104263675.
- Henson, R. K., and J. K. Roberts. 2006. Use of exploratory factor analysis in published research common errors and some comment on improved practice. Educational and Psychological Measurement 66 (3):393–416. doi:10.1177/0013164405282485.
- Hooker, G. 2010. On separable test, correlated priors, and paradoxical results in multidimensional item response theory. Psychometrika 75 (4):694–707. doi:10.1007/s11336-010-9181-5.
- Hooker, G., M. Finkelman, and A. Schwartzman. 2009. Paradoxical results in multidimensional item response theory. Psychometrika 74 (3):419–42. doi:10.1007/s11336-009-9111-6.
- Horn, J. L. 1965. A rationale and test for the number of factors in factor analysis. Psychometrika 30 (2):179–85. doi:10.1007/BF02289447.
- Jordan, P., and M. Spiess. 2012. Generalization of paradoxical results in multidimensional item response theory. Psychometrika 77 (1):127–52. doi:10.1007/s11336-011-9243-3.
- Jordan, P., and M. Spiess. 2018. A new explanation and proof of the paradoxical scoring results in multidimensional item response models. Psychometrika 83 (4):831–46. doi:10.1007/s11336-017-9588-3.
- Kaiser, H. F. 1960. The application of electronic computers to factor analysis. Educational and Psychological Measurement 20 (1):141–51. doi:10.1177/001316446002000116.
- Kirisci, L., T.-C. Hsu, and L. Yu. 2001. Robustness of item parameter estimation programs to assumptions of unidimensionality and normality. Applied Psychological Measurement 25 (2):146–62. doi:10.1177/01466210122031975.
- Kose, I. A., and N. C. Demirtasli. 2012. Comparison of unidimensional and multidimensional models based on item response theory in terms of both variables of test length and sample size. Procedia - Social and Behavioral Sciences 46:135–40. doi:10.1016/j.sbspro.2012.05.082.
- Lee, S., and R. Terry. 2005. MDIRT-FIT: SAS macros for fitting multidimensional item response. Paper presented at the SUGI 31st Conference, Cary.
- Li, Y., H. Jiao, and R. W. Lissitz. 2012. Applying multidimensional item response theory models in validating test dimensionality: An example of k–12 large-scale science assessment. Journal of Applied Testing Technology 13 (2):1–27.
- Magis, D. 2013. A note on the item information function of the four-parameter logistic model. Applied Psychological Measurement 37 (4):304–15. doi:10.1177/0146621613475471.
- Magis, D., and G. Raîche. 2012. Random generation of response patterns under computerized adaptive testing with the r package catr. Journal of Statistical Software 48 (8):1–31. doi:10.18637/jss.v048.i08.
- Peres-Neto, P. R., D. A. Jackson, and K. M. Somers. 2005. How many principal components? Stopping rules for determining the number of non-trivial axes revisited. Computational Statistics & Data Analysis 49 (4):974–97. doi:10.1016/j.csda.2004.06.015.
- Reckase, M. D. 1979. Unifactor latent trait models applied to multifactor tests: Results and implications. Journal of Educational Statistics 4 (3):207–30. doi:10.3102/10769986004003207.
- Reckase, M. D. 1997. High dimensional analysis of the contents of an achievement test battery: Are 50 dimensions too many? Paper presented at the meeting of the Society for Multivariate Experimental Psychology, Scottsdale, AZ.
- Reckase, M. D. 2007. Multidimensional item response theory. In: Handbook of statistics 26: Psychometrics, ed. C. R. Rao and S. Sinharay, 607–42. Amsterdam, Netherlands: Elsevier.
- Reckase, M. D. 2009. Multidimensional item response theory. Springer, New York.
- Reckase, M., and X. Luo. 2015. A paradox by another name is good estimation. In Quantitative psychology research. Springer proceedings in mathematics & statistics, R. Millsap, D. Bolt, L. van der Ark, and W. C. Wang, vol. 89, 465–86. Cham: Springer.
- Reckase, M. D., and R. L. McKinley. 1991. The discriminating power of items that measure more than one dimension. Applied Psychological Measurement 15 (4):361–73. doi:10.1177/014662169101500407.
- Reckase, M. D. 1985. Models for multidimensional tests and hierarchically structured training materials. Technical report, American Coll Testing Program IOWA city IA test development div.
- Rizopoulos, D. 2006. ltm: An R package for latent variable modeling and item response theory analyses. Journal of Statistical Software 17 (5):1–25. doi:10.18637/jss.v017.i05.
- Ruscio, J., and B. Roche. 2012. Determining the number of factors to retain in an exploratory factor analysis using comparison data of known factorial structure. Psychological Assessment 24 (2):282–92. doi:10.1037/a0025697.
- Samejima, F. 1969. Estimation of latent ability using a response pattern of graded scores. Psychometrika Monograph Psychometrika 34 (4):100. doi:10.1007/BF03372160.
- Sheng, Y., and C. K. Wikle. 2007. Comparing multiunidimensional and unidimensional item response theory models. Educational and Psychological Measurement 67 (6):899–919. doi:10.1177/0013164406296977.
- Spencer, S. G. 2004. The strength of multidimensional item response theory in exploring construct space that is multidimensional and correlated. Ph. D. thesis., Doctoral Dissertation, Brigham Young University-Provo.
- van der Linden, W. J. 2012. On compensation in multidimensional response modeling. Psychometrika 77 (1):21–30. doi:10.1007/s11336-011-9237-1.
- van Rijn, P. W., and F. Rijmen. 2012. A note on explaining away and paradoxical results in multidimensional item response theory. Technical report, Princeton, New Jersey: Educational Testing Service. doi:10.1002/j.2333-8504.2012.tb02295.x.
- Velicer, W. F., C. A. Eaton, and J. L. Fava. 2000. Construct explication through factor or component analysis: A review and evaluation of alternative procedures for determining the number of factors or components. In Problems and solutions in human assessment, 41–71. Boston: Springer.
- Verma, N., and M. K. Markey. 2014. Item response analysis of Alzheimer’s disease assessment scale. In Engineering in medicine and biology society (EMBC), 2014 36th annual international conference of the IEEE, 2476–2479. Chicago: IEEE.
- Way, W. D., T. N. Ansley, and R. A. Forsyth. 1988. The comparative effects of compensatory and noncompensatory two-dimensional data on unidimensional IRT estimates. Applied Psychological Measurement 12 (3):239–52. doi:10.1177/014662168801200303.
- Wiberg, M. 2012. Can a multidimensional test be evaluated with unidimensional item response theory? Educational Research and Evaluation 18 (4):307–20. doi:10.1080/13803611.2012.670416.
- Yang, S. 2007. A comparison of unidimensional and multidimensional RASCH models using parameter estimates and fit indices when assumption of unidimensionality is violated. Ph. D. thesis, doctoral dissertation, The Ohio State University.
- Yen, W. M. 1984. Effects of local item dependence on the fit and equating performance of the three-parameter logistic model. Applied Psychological Measurement 8 (2):125–45. doi:10.1177/014662168400800201.
- Zwick, W. R., and W. F. Velicer. 1986. Comparison of five rules for determining the number of components to retain. Psychological Bulletin 99 (3):432–42. doi:10.1037//0033-2909.99.3.432.