
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper new filters for removing unspecified form of heteroscedasticity are proposed. The filters build on the assumption that the variance of a pre-whitened time series can be viewed as a latent stochastic process by its own. This makes the filters flexible and useful in many situations. A simulation study shows that removing heteroscedasticity before fitting a model leads to efficiency gains and bias reductions when estimating the parameters of ARMA models. A real data study shows that pre-filtering can increase the forecasting precision of quarterly US GDP growth.
1. Introduction
Economic and financial variables often behave in a non-stationary way (Granger Citation1966). They might suffer from seasonality, unit roots, non-linearity and heteroscedasticity that must be dealt with before, or at the same time as estimating a model. The first difference of the logarithm (diff log) of a de-seasonalized series is often used as a standard filter to transform a non-stationary time series into a stationary one (Box and Jenkins Citation1976). Most of the times this is enough for the series to pass unit root tests, but they might still be heteroscedastic – a feature that is frequently neglected among practitioners. This is somewhat surprising since it is well known that ordinary least squares (OLS) estimates are inefficient and no longer best linear unbiased estimators (BLUE) in the presence of heteroscedasticity. This paper offers a way to address this issue by introducing new filters that easily and effectively remove heteroscedasticity of unspecified form.
There are not many ways of removing heteroscedasticity mentioned in the literature. One way is to use a Box-Cox transformation (Box and Cox Citation1964) which include the logarithmic and square root transformations as special cases. However, the Box-Cox transformations only work well when the functional form of the variance does not change throughout the series, rarely a realistic assumption in practice. Stockhammar and Öller (Citation2012) developed a way to remove unspecified form of heteroscedasticity by estimating the standard deviations in a moving lag-window and using a similar idea as in generalized least squares (GLS) to scale the series.
In this paper, new variance stabilizing filters are suggested that improve on the filter suggested by Stockhammar and Öller (Citation2012) in a number of ways. In addition, the properties of the new filters are investigated through both a real data exercise and a simulation study. It is shown that the proposed filters remove different types of heteroscedasticity without changing the autocorrelation structure or other properties of the series. The simulation study shows that stabilizing the series leads to more efficient estimates of the ARMA parameters. The filtering approach proposed in this paper outperforms estimated GARCH models (Bollerslev Citation1986) when the variance follows three different regimes and, interestingly, compare well even for simulated ARMA-GARCH processes. Furthermore, it is shown that the filters does not color white noise and that existing autocorrelation structures are preserved.
In a real data exercise the heteroscedastic and non-normal quarterly diff log US GDP is filtered. After filtering the series is homoscedastic and closer to normal. Also, a pseudo-out-of-sample forecast competition shows that forecast precision is elevated using the filtering approach.
The coming section describes the methodological framework for the filtering and the simulations. Section 3 contains a summary of the results and Section 4 concludes.
2. Methodology
In this section, the methodology is outlined. Specifically, the filtering approaches are explained in detail, the biasedness of autoregressive parameter estimates is discussed and the simulation models and the evaluation procedures are described.
2.1. The filters
2.1.1. The original filter
In the original filter suggested by Stockhammar and Öller (Citation2012) the idea is to divide the time series by a smoothed moving standard deviation observed in the sample. The first step is to make the series stationary by a suitable transformation, the standard deviations are then calculated in a moving lag-window and are further smoothed using a HP-trend, (Hodrick and Prescott Citation1997). The next step is to divide the mean-stationary and mean-corrected series (by the HP-trend to obtain a homoscedastic time series. Finally, the time series is scaled back to have the same mean and variance as the original series.
The filter can be expressed in the following way:
(1)
(1)
where
is the filtered series,
and sy are the mean and standard deviation of the series to be filtered respectively. 2ν + 1 denotes the length of the lag-window and HP(λ) denotes the Hodrick and Prescott filter where λ controls the degree of smoothing. The suggested value for quarterly data λ = 1600 is used in this study. The filter offers a fast and simple way to remove heteroscedasticity of unspecified form. However, because of the smoothed standard deviations, the heteroscedasticity filtering is not efficient in presence of rapidly changing volatility.
2.1.2. Modifications of the original filter
The modified filters suggested in this subsection all use (in contrast to the original filter) pre-whitening before the smoothed standard deviations are calculated. The reason is that even a mean-stationary process which deviates from zero will only slowly return to steady-state generating a cluster where the squared deviations from zero are high. If no pre-whitening of the series is conducted in beforehand these deviations will be interpreted as an increased variance by the filters. This implies that the variance is scaled in a time window where it actually behaves homoscedastic. On the other hand, if the model is pre-whitened before, the effect from the autocorrelation is accounted for and what is left as increased variance in the pre-whitened series would be isolated to the underlying heteroscedasticity.
Another potential issue with the original approach is the use of the often criticized (see e.g. Hamilton (Citation2017)) HP-filter where the user subjectively chooses a level for the degree of smoothing, λ. A more flexible way is to estimate the degree of smoothing automatically from a time series using the Kalman filter. For this purpose, the local linear trend model (LLTM) is used (see e.g. Durbin and Koopman (Citation2012)).
The LLTM has the following state-space representation:
(2)
(2)
(3)
(3)
(4)
(4)
where the error terms,
and
are independent white noise processes.
and
denote the “local level” and the “local linear trend” respectively and
is the observed time series. Ledolter (Citation2008) shows in a simulation study that this type of smoothing works well compared to for example local polynomial regressions where a moving lag window is used. To achieve a smooth trend it is possible to restrict the variance of the second equation to zero, which is sometimes referred to as “the smooth trend model” (STM). The same effect can be achieved by replacing EquationEquations (3)
(3)
(3) and Equation(4)
(4)
(4) by
in this case we have an integrated random walk (IRW) which together with the extension
has been recommended for modeling trends in state space models (see Durbin and Koopman (Citation2012) and Young et al. (Citation1991)). When the smoothing parameter of the HP-filter λ =
, it is equivalent to the IRW. For completeness, both the case with
=0 and the unrestricted case will be investigated in the coming analysis.
In addition to the original filter of Stockhammar and Öller (Citation2012), we consider three modified heteroscedasticity filters which all build on the pre-whitened, mean-corrected and possibly heteroscedastic series, , which absolute value we denote by
.
“HP variance filter” uses the HP-filter on
to estimate the standard deviation.
“LLTM variance filter” uses the LLTM on
“STM variance filter” uses the STM on
All filters are likely to produce a good degree of smoothing if the volatility smoothly evolves over time. However, if there are jumps or more rapid changes in the variance process, then the LLTM is expected to adjust faster than the others since it does not force smoothness on the states to the same extent.
The filtered version of the original series is obtained by dividing the mean-corrected series by the moving standard deviation. The series is then scaled back to have the same overall variance and mean as . We define
, where
is the low-frequency evolution of the standard deviation estimated by inserting
into (2)–(4). The filtered series is then given by:
(5)
(5)
where
and
are the sample mean and standard deviation of
respectively, and
and
denote the mean and standard deviation of
. If we want to recover the original series we may reverse the filter according to:
(6)
(6)
where we already have the information needed to go back from (5). The same approach can be used to transfer back fitted values with confidence intervals (as is later shown in the real data exercise). In the case of forecasting and forecast intervals, we can proceed in a similar way. The only difference is that we do not have access to
, i.e. future values of the low-frequency volatility, but it might be approximated by simply rolling the Kalman filter forward.
2.2. Biasedness of OLS
It is known that the OLS and ML estimates of AR-coefficients are consistent but biased (e.g. Hamilton Citation1994). When conditioning an AR(1)-process on the whole realization of the series, the bias of the estimator is given by:
(7)
(7)
where
is the AR(1) parameter and
is the error term. The bias of the estimator (7) is non-zero. We may note that
= 0, but the errors are not uncorrelated with the sum in the denominator. Intuitively this can be seen since a high absolute value of the error term today increases the value of
in future periods, thus the bias will be negative for ϕ > 0 and positive for ϕ < 0. This means that the OLS (as well as the conditional likelihood) estimates will be drawn toward zero, but that the bias decrease with the sample size. See e.g. Rai et al. (Citation1995) for a discussion and a simulation study of the bias in small samples. Later, in the results, we will see that filtering has a dampening effect on the attenuation bias in the presence of heteroscedasticity.
2.3. The simulated processes
In this section, 10 000 realizations are simulated from four different processes to evaluate the influence of the above filtering procedures. All of the series are chosen to be of length 200, the approximate length of many quarterly macroeconomic time series. For the ARMA model, two different sample sizes are investigated. The first two series are simulations from homoscedastic white noise- and ARMA processes in order to see that the filters do not change structures intended to be preserved. In addition, two heteroscedastic processes are simulated to see whether the filters can achieve homoscedasticity.
In the first heteroscedastic process, the error term follows the frequently used GARCH structure (Bollerslev Citation1986) and in the second the variance evolves according to three different volatility periods. In both cases, the mean-process will be ARMA(1,1) with arbitrarily chosen parameters, ϕ = 0.7 and θ = 0.5.Footnote1
That is, we simulate from the ARMA-GARCH process given by:
(8)
(8)
which clearly satisfies the conditions for the variance to be positive and finite, see e.g. Tsay (Citation2010).
In the second heteroscedastic process (“the switching variance model”) the volatility changes according to pre-specified regimes:
(9)
(9)
where
denotes an indicator variable which divides the series into three arbitrary chosen volatility periods of different length. It can be seen as a threshold model with three distinct regimes and with time as the regime-controlling variable.
2.4. Evaluation procedure
One of the most important parts of filtering is that it does what it is intended to do without changing other properties of the time series. This is investigated in two ways; first, the filters are tested on simulated white noise to see whether the first four moments remain unchanged. This is done by calculating the means and (empirical) standard deviations for the simulated moments. The series are also tested for non-normality using the Jarque-Bera test (Jarque and Bera Citation1980) and for autocorrelation using the Ljung-Box test (Ljung and Box Citation1978) to make sure that no spurious autocorrelations are imposed.
This is complemented using the probability integral transform (PIT), see e.g. Diebold et al. (Citation1998), which is defined as:
(10)
(10)
where
are realizations of a time series and
is the assumed density. If
is the true density we have
, so deviations from the uniform distribution indicate model misspecification. For the PIT exercises, only one simulated time series of length 10 000 is used.
The outlined tests will be made on the simulated series as well as when the series are run through each of the filters. It is also investigated whether it preserves existing autocorrelations structures in simulated (homoscedastic) ARMA-processes.
After investigations on homoscedastic data, we study whether the filters offer improvements compared to unfiltered ARMA- and the less parsimonious ARMA-GARCH models on heteroscedastic data. The focus is on the efficiency for estimating the ARMA parameters and whether there is remaining heteroscedasticity in the model residuals. We make use of the ARCH-LM test (Engle Citation1982) to test for constancy of the residual variance and an F-test for checking whether the variance is stable in sub-periods of the series (see e.g. Durbin and Koopman (Citation2012), p. 39). Also the probability integral transform is used to graphically see how well the residuals fit a normal distribution.
When evaluating the filter on the log diff US GDP the above tests are complemented with the Ljung-Box test on the squared residuals when testing for heteroscedasticity. The normality tests are complemented with the (Royston Citation1982) extension of the Shapiro-Wilk test (Shapiro and Wilk Citation1965) and the Kolmogorov-Smirnov test (Smirnov Citation1948).
3. Results
This section summarizes the results from the simulation studies and the forecasting competitions of the heteroscedastic US GDP.
3.1. Simulation studies
3.1.1. White noise
shows how the filters affect the properties of white noise in terms of the first four moments, the Jarque-Bera test for normality and the Ljung-Box test for autocorrelation. It is of highest importance that the filters do not impose false autocorrelation structures and/or cause other spurious patterns in the time series.
Table 1. Summary of simulation results for white noise processes.
There is no major distortion of the true white noise process and the first two moments are identical for all filters by construction. The filtered series remain symmetric, however, the kurtosis is somewhat distorted for both the Stockhammar and Öller filter and the HP variance filter (but it is still within two standard deviations from 3).
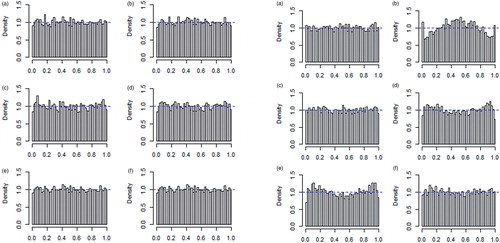
The lower part of shows that normality is rejected less often for the filtered series. The distortion of the normality tests is again worst for the Stockhammar and Öller- and the HP variance filters even though there is a tendency for all filters to make the data more normal. This could be due to that the filters fade out outliers since these are interpreted as increased variance. The distortion of normality is, however, hard to detect from the PITs in in Appendix A.
When it comes to the autocorrelation tests the rejection rates look similar to those of the true processes for all but the filter of Stockhammar and Öller. This means that the newly proposed filters do not impose false autocorrelation structures.
3.1.2. ARMA processes
shows a summary of the simulation study where 10 000 ARMA processes were simulated for two different time series lengths. Each of these series were filtered and the parameters were estimated using an ARMA model.
Table 2. Summary of simulation results for ARMA processes.
Contrary to the Stockhammar and Öller filter, the modified filters seem to preserve the underlying autocorrelation structure. In addition, the LLTM- and the STM filters have equally low standard errors as the true unfiltered ARMA for the sample size of 200. For the sample size of 80, there are only slight differences. The PITs look close to identical to those in the white noise case and are therefore not included (but are available from the authors upon request).
3.1.3. ARMA-GARCH processes
shows the results from 10000 simulated series from the ARMA-GARCH(1,1)(1) model, see EquationEquation (8)(8)
(8) .
Table 3. Summary of simulation results for ARMA-GARCH processes.
As judged by the ARCH-LM tests it appears that when the time series follow a GARCH process the filters are not able to fully clean out the heteroscedasticity. A plausible reason for this is that the volatility is switching too rapidly such that the smoothing filters do not react fast enough. However, the LLTM filter does a decent job and the null hypothesis of homoscedasticity is typically rejected in less than 10% of the simulations. Looking at the F-tests for constancy of the variance over sub-periods we can see that the three modified filters effectively remove this type of heteroscedasticity. This is not the case for the other approaches, not even for the GARCH model which generated the data.
Looking at the parameter estimates we can see that, compared to the standard ARMA model, the filters reduce the bias of the AR-coefficient in all cases except for the filter of Stockhammar and Öller. The moving average estimates are close to the true in all cases. In addition, all specifications except for the original filter produce smaller standard errors for the parameters compared to the unfiltered series.
in Appendix A shows that the residuals of the true model, the Stockhammar and Öller- and the STM filter are close to normally distributed whereas the errors from the unfiltered approach are leptokurtic. The residuals from the HP- and LLTM filters seem to be slightly platykurtic.
3.1.4. Switching variance model
In the simulated processes are created with three different variance regimes. In the first regime (observations 1–40), σ = 2, in the second regime (41–140) σ = 1 and in the third regime (141–200) σ = 4, see EquationEquation (9)(9)
(9) .
Table 4. Summary of simulation results for switching variance processes.
It is clear that also under this form of heteroscedasticity the modified filtering approaches offers both bias reductions and efficiency gains compared to regular ARMA models. The filtered models also yield lower standard deviations of the empirical distribution (and smaller bias) than the GARCH model, which in turn is still to prefer compared to the ARMA.Footnote2
The LLTM filter succeeds best in eliminating ARCH effects while the HP variance filter most efficiently even out the variance according to the F-test. The original filter does not perform particularly well and the GARCH model works fairly well for ARCH effects but not according to the F-test.
3.1.5. Bias reduction
According to the simulations, the filtering appears to give less biased estimates for the AR-parameters than the non-filtered approach for heteroscedastic data. This phenomenon is further investigated in this section. In Section 2 it was shown that the estimates of autoregressive components are biased toward zero. The size of the bias is determined by the correlation between the error term and the sum of squares, which violates the least squares assumption of strict exogeneity.
The switching volatility model from (9) will be used to evaluate the effect of filtering on the estimation bias. 10 000 time series are simulated for a grid of sample sizes ranging from 25 to 500. For each sample size, the empirical means and standard deviations of the estimated AR coefficients are calculated for the unfiltered series and the ones filtered using the LLTM. The results are illustrated in .
Figure 1. Average point estimates (left panel) and empirical standard deviations (right panel) for ϕ in the 10 000 draws. The dashed blue lines show the results from the LLTM filtered series and the solid black lines from the unfiltered ARMA.
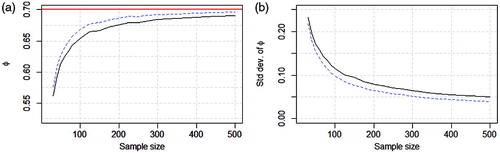
It is clear that the LLTM approach (represented by the blue dashed line) is both less biased and has smaller standard errors than the unfiltered (solid black line). This is true for all sample sizes investigated even though the numerical differences get smaller as the sample size increases.
3.2. A real data study
In this section, the filtering approach is applied to the heteroscedastic quarterly diff log US GDP series 1947Q2-2017Q1. No matter which filtering method used, the heteroscedasticity is removed after the filtering, see in Appendix B. It is investigated how the filtering affect the statistical properties as well as the forecast accuracy when modeling the series.
A benefit of being able to recover the original scale from the filtered series is illustrated by calculating 95% confidence intervals for the filtered series and transfer them back to the original scale. shows how the properties of the intervals are improved.
Figure 2. Diff log US GDP (red solid), fitted values of ARMA(2,1) (black solid) and 95% confidence intervals (blue dashed). Unfiltered series (left panel) and LLTM-filtered series (right panel).
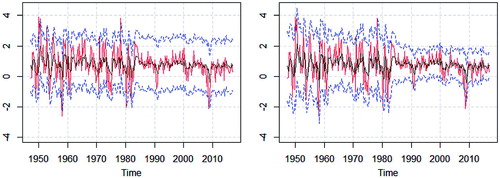
The filtering approach lets the width of the confidence bands to vary over time which improves the coverage rates in both the first and second half of the sample. In this example with an intended coverage rate of 95%, the unfiltered approach yields a coverage of 93% for the full sample while the filtered approach yields a 95% coverage. If the full sample is divided into two halves the regular approach yields 87% and 99% coverage respectively for the first and second half, while the filtering approach generates a 95% and 96% coverage.
For the data study, we first fit the best ARIMA model which is identified by minimizing the AIC and BIC while the conditions that we have no unit root and no remaining autocorrelation in the residuals hold. This approach showed that the best fit was accomplished by an AR(1) for the unfiltered series and an ARMA(2,1) model for both the STM- and LLTM variance filters. The best GARCH model was GARCH(1,1) with an ARMA(1,1) part.
in Appendix B shows that the filters remove the heteroscedasticity of the diff log US GDP series and brings the residuals closer to normality.
To further assess the usefulness of the filters a forecast competition was conducted between the unfiltered-, STM, LLTM, and ARMA-GARCH approach. The comparison was constructed such that the data was divided into a training period (first half of the sample) and an evaluation period (second half). For the training period, the best ARMA model was identified in the same way as for the full sample above. When the best model was identified (which turned out to be ARMA(2,1) for the mean equation for all models) recursive pseudo out of sample forecasts where calculated in three different settings. First, an expanding estimation window was used such that one observation at a time was added after each forecast during the evaluation period. In the second and third setting, rolling windows of size 50 and 100 observations were used to estimate the models. Each time the window rolled forward new forecasts and root mean squared forecast errors (RMSFE) for 1-12 quarter ahead were calculated. The RMSFEs relative to those of a random walk benchmark are shown in .
Table 5. RMSFEs of the real data forecasting comparison.
According to the Diebold and Mariano (Citation1995) test, all models perform significantly better (in both statistical and practical sense) on most forecast horizons than the naive forecast. For small samples (n = 50) the modeling of the variance stabilized series, and especially those from the STM, yield smaller RMSFEs than the unfiltered ARMA at all forecast horizons and in some cases significantly better. When the sample size becomes larger the advantage of the filtering somewhat declines although both STM and LLTM still produce smaller RMSFEs at most horizons using a rolling window with 100 observations.
4. Conclusion/discussion
This paper suggests a new way of removing unspecified form of heteroscedasticity from time series. A simulation study shows that the local linear trend- and smooth trend filters reduce or completely remove heteroscedasticity which yields more efficiently estimated parameters. It is also found that the well-known bias in the autoregressive coefficients is reduced by first filtering the time series. The filtering approach compares well with an ARMA-GARCH in terms of both efficiency and for removing heteroscedasticity from the model residuals.
In a real data exercise, we find that if the diff log US GDP series, which is significantly heteroscedastic and non-normal, is filtered it turns homoscedastic and gets closer to normality. In addition, in small samples, the pseudo out of sample forecast precision of the US GDP growth is typically significantly improved using the filtering approach.
In this paper, the effects of removing heteroscedasticity has only been investigated for univariate specifications. This does not imply that pre-filtering cannot be useful before multivariate modeling and co-movement studies. In multivariate modeling the dimensionality quickly becomes a problem and a parsimonious model is even more important than in the univariate case. If the series can be stabilized and normalized before joint modeling with other series, complex volatility models are not needed to the same extent. Since the model residuals can be made normal and homoscedastic, relationships between e.g. economic variables and evaluation of theories can be done more credible if the filters suggested in this paper are used. The filtering techniques proposed in this paper may thus be used as a standard tool for analysts, practitioners, policy makers etc. no matter the application and the properties of the time series data.
Notes
1 Similar results are obtained with other parameter values.
2 The PITs (available from the authors upon request) look similar to those of the ARMA-GARCH.
References
- Bollerslev, T. (1986). generalized autoregressive conditional heteroskedasticity. Journal of econometrics, 31(3): 307–327.
- Box, G., and D. Cox. 1964. An analysis of transformations. Journal of the Royal Statistical Society. Series B (Methodological) 26(2):211–52.
- Box, G., and G. Jenkins. 1976. Time series analysis: Forecasting and control, revised ed. Holden-Day.
- Diebold, F., and R. Mariano. 1995. Comparing predictive accuracy. Journal of Business & Economic Statistics 13(3):253–63.
- Diebold, F., T. Gunther, and A. Tay. 1998. Evaluating density forecasts with applications to financial risk management. International Economic Review 39(4):863–83.
- Durbin, J., and S. Koopman. 2012. Time series analysis by state space methods. 2nd ed. Oxford: Oxford University press..
- Engle, R. 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica: Journal of the Econometric Society 50(4):987–1007.
- Granger, C. 1966. The typical spectral shape of an economic variable. Econometrica: Journal of the Econometric Society 34(1):150–61.
- Hamilton, J. 1994. Time series analysis. (Vol. 2). Princeton: Princeton university press.
- Hamilton, J. 2017. Why you should never use the Hodrick-Prescott filter. Review of Economics and Statistics.
- Hodrick, R., and E. Prescott. 1997. Postwar US business cycles: an empirical investigation. Journal of Money, Credit, and Banking 29(1):1–16.
- Jarque, C., and A. Bera. 1980. Efficient tests for normality, homoscedasticity and serial independence of regression residuals. Economics Letters 6(3):255–9.
- Ledolter, J. 2008. Smoothing time series with local polynomial regression on time. Communications in Statistics—Theory and Methods 37(6):959–71.
- Ljung, G., and G. Box. 1978. On a measure of lack of fit in time series models. Biometrika 65(2):297–303.
- Rai, S., B. Abraham, and S. Peiris. 1995. Analysis of short time series with an Ovesr-Dispersion Model. Communications in Statistics – Theory and Methods 24(2):335–48.
- Royston, J. 1982. An extension of Shapiro and Wilk's W test for normality to large samples. Applied Statistics 31(2):115–24.
- Shapiro, S., and M. Wilk. 1965. An analysis of variance test for normality (Complete samples). Biometrika 52(3/4):591–611.
- Smirnov, N. 1948. Table for estimating the goodness of fit of empirical distributions. The Annals of Mathematical Statistics 19(2):279–81.
- Stockhammar, P., and L.-E. Öller. 2012. A simple heteroscedasticity removing filter. Communications in Statistics-Theory and Methods 41(2):281–99.
- Tsay, R. 2010. Analysis of financial time series. New York: Wiley.
- Young, P., C. Ng, K. Lane, and D. Parker. 1991. Recursive forecasting, smoothing and seasonal adjustment of Non-Stationary environmental data. Journal of Forecasting 10(1-2):57–89
Appendix A. List of figures
Figure A1: Histograms of the probability integral transform when the true underlying process is white noise (left panel) and ARMA-GARCH (right panel) for; (a) a GARCH-process, (b) white noise process, (c) S&Ö filtered series, (d) HP-filtered series, (e) LLTM filtered series and (f) STM filtered series.
Appendix B. List of tables
Table B1. P-values of diagnostics tests.