Abstract
The purpose of this study is to find a computationally inexpensive calibration method of a hydrologic model for predicting river flows. The approach is called the surrogate model optimization (SMO), which relies on optimizing a surrogate model instead of the original model that requires significantly more computing time. The proposed SMO method combines the Latin hypercube sampling (LHS) method and a statistical approach called the “Design and Analysis of Computer Experiments (DACE)”. To investigate the performance of this approach, the Monte Carlo sampling and LHS results are compared with the results of the proposed SMO. As the case study, the prediction results of WATCLASS hydrologic model over Smokey river watershed using MC, LHS and SMO are presented. The proposed SMO is shown to be significantly faster than traditional calibration methods based on Monte Carlo simulation or other global optimization methods.
Le but de cette étude est de trouver une méthode d’étalonnage (de calibrage) de calcul peu coûteux d’un modèle hydrologique pour prédire les débits fluviaux. L’approche s’appelle l’optimisation du modèle de substitution (OMS) qui repose sur l’optimisation d’un modèle de substitution au lieu du modèle original qui nécessite un temps de calcul beaucoup plus long. La méthode proposée de SMO combine l’échantillonnage hypercube latin (EHL) et une méthode d’approche statistique que l’on appelle la conception et l’analyse d’expériences informatiques. Pour étudier la performance de cette approche, l’échantillonnage Monte Carlo et les résultats EHL sont comparés aux résultats de l’OMS proposé. Le modèle hydrologique choisi WATCLASS s’utilise pour le débit dans la ligne de partage des eaux de la rivière Smoky en Alberta au Canada qui sert d’étude de cas. L’OMS proposé se révèle nettement plus rapide que les méthodesd’étalonnage traditionnelles basées sur la Simulation de Monte Carlo ou d’autres méthodes d’optimisation globale.
Introduction
Calibration of a hydrologic model has been an ongoing active research area in hydrology for decades. The calibration process searches the parameter space in order to find values of parameters that give satisfactory predictions, which is achieved by minimizing an error function. An example error function is the sum of squared deviations of predicted flow values from observed values. Issues that make calibration more complicated than a traditional optimization problem are as follows: The error function is not convex and smooth; the error function is often computationally expensive and requires the simulation of the CPU-time intensive original numerical model for each call of the error function; and the original model has a large number of parameters. In order to calibrate, a variety of optimization techniques have been developed. Global and local optimization methods such as genetic algorithm and its extensions by Gupta et al. (Citation1991), shuffled complex evolution by Duan et al. (Citation1993) and its extension by Chu et al. (Citation2010) and multiple start simplex (MSX) and local simplex methods (Gan and Biftu Citation1996) are among the most commonly used ones. For more information about the comparison of different calibration methods refer to Blasonel, R., H. Madsen, and D. Rosbjerg, Citation2007. Although all of these methods have been shown to work well, they often require many simulations before finding acceptable results as defined later. An alternative category of optimization methods that often need fewer simulations of the original model is the Surrogate Model Optimization (SMO) method. In SMO methods, the parameter space of original model is explored using an approximate function. The search terminates once a region or regions of model space that contain acceptable parameter sets are found. This process may continue until either an optimum is found or a series of near optimal points are found. A new SMO is proposed which combines the Latin hypercube sampling (LHS) method and a statistical approach called the design and analysis of computer experiments (DACE). This paper compares Monte Carlo, LHS and the proposed SMO method for calibrating the 14 parameters of the WATCLASS hydrologic model for simulating flows in the Smoky River. The remainder of this document is organized as follows: a description of the Smoky River Watershed will be followed by an introduction of WATCLASS; the various sampling methods, DACE and the proposed SMO are explained next followed by results and discussion.
Smoky River watershed
Smoky River watershed is a part of Canada’s largest watershed, the Mackenzie River Basin. This basin itself is a part of the Arctic Ocean drainage basin. The Smoky River is a tributary of the Peace River and occupies 3840 km2 drainage area in the foothills of Rocky Mountain. This watershed is mostly alpine forest and is located northwest of Edmonton.
WATCLASS
WATCLASS is a meso-scale distributed hydrologic model that combines Canadian Land Surface Scheme (CLASS) (Verseghy Citation1991, 1993) and WATFLOOD (Kouwen Citation1988). WATCLASS was developed for the Mackenzie River Basin as part of the Mackenzie GEWEX study (MAGS) (Soulis and Seglenieks Citation2008). This model is specifically designed to consider both the energy and water balance for the Mackenzie River basin using the results of the atmospheric and hydrologic research. Mackenzie River discharges to the Arctic Ocean and its basin occupies an area of 1.8 Million km2. The WATCLASS model was initially developed to create the ability to model continental domain watersheds at short time scale (1 hour) and at small spatial scales (10 km to 25 km). In order to predict stream flows, WATCLASS requires seven inputs, which are precipitation, temperature, humidity, pressure, wind speed, short wave and long wave radiations. These inputs are generated by Environment Canada’s global atmospheric forecast model called the Global Environmental Multiscale (GEM) model that has been in operation since 2006. GEM predicts these inputs using weather satellite information and mathematical equations for modeling the physics and dynamics of the atmosphere. A detailed explanation of CLASS and WATFLOOD can be found in Barlett et al. (2003, 2006) and Stadnyk et al. (Citation2005). The purpose of the development of WATCLASS was to improve the soil-water budget and the cold-water process in CLASS. An update of the recent development in WATCLASS is detailed in Yirdaw et al. (Citation2009).
Monte Carlo simulation
Monte Carlo (MC) simulation is based on conducting repetitive random sampling. We used MC simulation to explore the number of acceptable model parameters that can be obtained by randomly generating sets of model parameter space and their corresponding WATCLASS simulation results. Latin hypercube sampling (LHS) by McKay et al. (Citation1979) is another method of sampling that randomly generates samples from a gridded space of variables. This method belongs to the category of stratified random sampling where the samples are randomly taken from non-overlapping strata.
DACE surrogate model optimization method
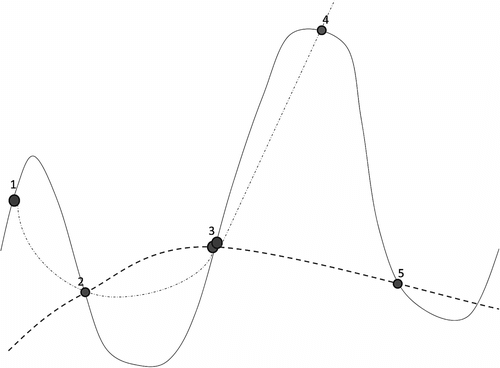
In general, most global optimization algorithms tend to be computationally expensive, sensitive to initial solutions and not easily parallelized. For this reason, in most cases, the direct optimization of computationally expensive models using these algorithms is impractical. As a result, researchers are interested in developing computationally inexpensive strategies to calibrate large-scale models. One such strategy is to optimize a computationally inexpensive ”surrogate” model that is constructed on a limited number of original expensive-model simulations. This technique is called Surrogate Model Optimization (SMO) and refers to optimizing a mathematical or soft computing model called a surrogate model instead of the original costly model. SMO is an iterative process in which, after each iteration, the surrogate model predictions become closer to the predictions of the original model. In order to validate the surrogate model, the solution from the constructed approximate model will be compared with the solution of the original model. If the error is lower than the threshold, the surrogate model is acceptable, otherwise the model is updated and more simulations are needed. Ideally, once the surrogate model becomes validated, its optimum will be very close to the original model optimum. The schematic of SMO process is illustrated in Figure . The original model is shown as a solid line. One surrogate model is constructed based on a set of three points (2, 3 and 5) and is illustrated by a dashed line. In another set of simulation, four points (1, 2, 3 and 4) have been generated and modeled by another surrogate model (light dashed line). In both of these experiments, the minimum of the original model (between points 2 and 3) is missed. Thus, in these stages of the experiment, the model validation will fail and hence more simulated points are needed. By generating points between points 2 and 3 it will be possible to have a fairly accurate model in which the minimum is very close to the original model’s minimum. Therefore, by conducting a smaller number of simulations it is possible to find the minimum of a non-convex model. Jones et al. (Citation1998) adapted the DACE method of Sacks et al. (Citation1989) for global optimization finding the optimum of a computationally expensive model with an approximate model,. This idea has been customized and applied to the variety of engineering problems such as shape optimization (Marsden et al. Citation2004). SMO has been already applied in hydrology domain. Some of the applications are using radial basis function in groundwater (Mugunthan and Shoemaker Citation2006), fuzzy model identification in hydrologic model calibration (Kamali et al. 2005) and rainfall-runoff modeling (Couckuyt et al. 2009).
Figure 1 Schematic of surrogate model optimization, see text for more explanation.
Design and analysis of computer experiments
The DACE approach suggests a framework for finding the optimum point of a computationally expensive model. This model is based on the assumption that observations are coming from a model that contains two parts: [1] regression part that explains the general behavior of the data; [2] an error part that covers the small discrepancies between the data and model output. The formula of such model is:
In this equation, n is the number of input data, fh(x) are linear or nonlinear basis functions of x, for example, polynomial basis functions, βh
are the corresponding coefficients of basis functions such as polynomial coefficients, and are errors which are assumed to be normally distributed independent variables. Errors are correlated and have zero mean and σ2
variance. They are spatially related and their correlation is a function of their distances. The correlation between the error of two adjacent points is defined in Equation. 2.
Experiments and results
Decision variables
In this research, we calibrated 14 parameters, which were assumed to be uniformly distributed within their upper and lower bounds. The description and intervals of these parameters are shown in Table .
Table 1 WATCLASS Parameter description.
Experimental process
A Surrogate Model (SM) was employed to model the error function, which is defined to be a measure of the WATCLASS model simulation deviations from the observed results. The error criterion is Nash-Sutcliffe coefficient (Nash and Sutcliffe Citation1970) which is defined by the following equation:
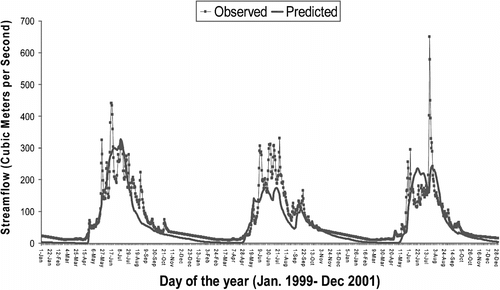
This case study is based on one daily reading of stream flow over a period of 3 years. In this equation Y is the corresponding stream flow and E(Y) is the expectation of observed Y. The NS value will be negative when the prediction of the model is very different from the observed value, and will be close to or equal to one when the model prediction is perfect. Therefore, as NS values become closer to 1, the model prediction becomes closer to the observed values, and the iterations can be terminated once a certain NS value is exceeded. In real-world problems, NS value is rarely close to 1. In order to compare the overall performance of MC, LHS and the approximate model, 10000 random samples using Monte Carlo sampling method were generated and simulated by WATCLASS. The NS value of each simulated result was then computed. The second set of experiments started with 6000 samples from the LHS method, which were simulated using WATCLASS. The third set of experiments had two parts and was focused on the SMO method evaluation. In the first part, 1000 samples from the LHS method were generated on the input space and simulated using WATCLASS and then their corresponding NS values were computed. To increase the concentration of points with acceptable results (higher NS values), 10 best points (that is, best points here means that the points have the highest NS values in the current collection) were selected and in the vicinity of these 10 points 500 LH samples were generated and simulated. In the second part of the third set, a surrogate model was developed using the best 500 points out of the 1500 simulated results. This surrogate model was employed to predict points with NS values higher than 0.70. Subsequently, 10000 LHS samples were generated and their corresponding NS values were predicted using DACE surrogate model. From these 10000, 100 best points were selected. To evaluate the performance of the surrogate model, these best points were simulated using WATCLASS. Deviation of the SMO predicted NS results from the original model NS results were the measure of goodness of the surrogate model. After four iterations (400 sample points / four consecutive iterations of 100 sample points) the surrogate model was evaluated to be satisfactory with reliable predictions. Figure presents flow chart of the third set of experiments. In this flowchart the tinted boxes represent the processes that have taken place in the second part of the third set of experiments. Table represents means and standard deviations of NS values for all processes. Since the outcome of surrogate model construction relies on an entirely random sampling of the points, this experiment is replicated 10 times and means and standard deviations are reported. Comparison of the results in the first two rows of Table shows that LHS was slightly more successful in finding points with high NS values than MC sampling (13% of simulated results had acceptable NS in MC sampling versus 15.5% in LHS). Comparably different performances of LHS and MC seemed to be the result of the differences in the spread of the points. In the third row of Table , the results of DACE surrogate model are reported. In this process, total of 1900 points were simulated, of which, 400 of them were based on the DACE surrogate model prediction. Comparison of LHS and DACE (first part) shows that on average, 24% of points have NS values greater than 0.7, whereas in the case of LHS (second row) only 15.5% of points have NS values greater than 0.7. Comparison of the first part and second parts of third set shows that using DACE surrogate model for finding acceptable points was more successful than relying on an entirely random process like LHS for the exploration of the model space. Moreover, the DACE surrogate model could replace the original expensive model as a low cost alternative for further investigations. In the fifth and sixth rows of Table , results that are generated from DACE SMO are selected and reported. The results show that, 36% of the DACE model generated points are above the first threshold, which is 21% more than LHS method explored and are even more promising in the higher thresholds. In general, for finding points with NS values greater than 0.7, the MC method required 10000 original model simulations, the LHS needed 5000 original model simulations, whereas in the DACE SMO method the corresponding number reduced to 1900. A hydrograph that illustrate one of the many good results obtained is shown in Figure ; the WATCLASS model has successfully predicted. the variations of stream flow from Jan. 1999 until Dec. 2001.
Figure 2 The flowchart of the third experiment.
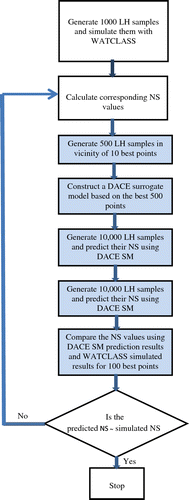
Table 2 Comparison of mean of number of simulations for different methods.
Figure 3 Hydrograph that compares observation and simulated results of calibrated WATCLASS.
This paper illustrates the potential of the SMO in the enhancement of the calibration process of hydrologic models. This approach can help hydrologists to discover the regions of their model that performs well with comparably lower computational cost. The other advantage of the SMO method is the possibility of an inexpensive accurate duplicate of the original model.
Conclusions
The main goal of this paper was to explore and obtain as many parameter sets as possible that have acceptable NS values, usually over the value of 0.7, by using the SMO. DACE is a SMO method that combines the idea of LHS and function approximation. The results showed that the application of DACE reduced the computational cost of calibration process from 2 to 5 times depending upon if one uses the LHS method alone or the MC method. SMO in general and DACE in particular showed a high potential for efficient calibration of large-scale models.
Acknowledgments
We acknowledge with gratitude the critical comments of the reviewers, which improved the presentation significantly. NSERC Discovery grants to second and third authors supported the research reported in this paper. All simulations have been performed using a ”Shared Hierarchal Academic Research Computing Network” (SHARCNET), which is a multi-institutional high performance computing network that spans 16 leading academic institutions in Ontario, Canada. SHARCNET allows the users to conduct hundreds of simulations simultaneously.
Notes
Member of CWRA.
References
- Bartlett , P. A. , McCaughey , J. H. , Lafleur , P. M. and Verseghy , D. L. 2003 . Modelling evapotranspiration at three boreal forest stands using the class: Tests of parameterizations for canopy conductance and soil evaporation . International Journal of Climatology , 23 : 427 – 451 .
- Barlett , P. A. , MacKay , M. D. and Verseghy , D. L. 2006 . Modified snow algorithms in the Canadian Land Surface Scheme: Model runs and sensitivity analysis at three boreal forest stands . Atmosphere - Ocean , 44 ( 3 ) : 207 – 222 .
- Blasonel , R. , Madsen , H. and Rosbjerg , D. 2007 . Parameter estimation in distributed hydrological modelling: comparison of global and local optimisation techniques . Nordic Hydrology , 38 : 451 – 476 .
- Chu , W. , Gao , X. and Sorooshian , S. 2010 . Improving the shuffled complex evolution scheme for optimization of complex nonlinear hydrological systems: Application to the calibration of the Sacramento soil-moisture accounting model . Water Resources Research , 46 ( 9 ) : W09530 doi: 10.1029/2010WR009224
- Couckuyt, I., D. Gorissen, H. Rouhani, E. Laermans, and T. Dhaene. 2009. “Evolutionary regression modeling with active learning: An application to rainfall runoff modeling.” In Adaptive and Natural Computing Algorithms : 9th International Conference, ICANNGA 2009, Kuopio, Finland, April 2009, Revised Selected Papers, edited by M. Kolehmainen, P. Toivanen and B. Beliczynski, 548–558, New York: Springer.
- Duan , Q. , Gupta , V. and Sorooshian , S. 1993 . A shuffled complex evolution approach for effective and efficient optimization . Journal of Optimization Theory and Applications , 76 : 501 – 521 .
- Gan , T. and Biftu , G. 1996 . Automatic calibration of conceptual rainfall runoff models: Optimization algorithms, catchment conditions, and model structure . Water Resources Research , 32 ( 12 ) : 3513 – 3524 .
- Gupta , H. , Sorooshian , S. and Yapo , P. 1991 . The genetic algorithm and its application to calibrating conceptual rainfall-runoff models . Water Resources Research , 9 : 2467 – 2471 .
- Jones , D. , Schonlau , M. and Welch , W. 1998 . Efficient global optimization of expensive black-box functions . Journal of Global Optimization , 13 : 455 – 492 .
- Kamali, M., K. Ponnambalam, and E. Soulis. 2005. “Hydrologic model calibration using fuzzy TSK surrogate model.” Fuzzy Information Processing Society, Annual Meeting of NAFIPS. 2005: 799–803. doi:10.1109/NAFIPS.2005.1548642.
- Kouwen , N. 1988 . WATFLOOD: A micro-computer based flood forecasting system based on real-time weather radar . Canadian Water Resources Journal , 13 ( 1 ) : 62 – 77 .
- Marsden , A. , Wang , M. , Dennis , J. E. Jr. and Moin , P. 2004 . Optimal aeroacoustic shape design using the surrogate management framework . Optimization and Engineering , 5 : 235 – 262 .
- McKay , M. , Conover , W. and Beckman , R. J. 1979 . A comparison of three methods for selecting values of input variables in the analysis of output from a computer code . Technometrics , 21 : 239 – 245 .
- Mugunthan , P. and Shoemaker , C. 2006 . Assessing the impacts of parameter uncertainty for computationally expensive groundwater models . Water Resources Research , 42 ( 10 ) : W10428 doi: 10.1029/2005WR004640
- Nash , J. and Sutcliffe , J. V. 1970 . River flow forecasting through conceptual models part I: A discussion of principles . Journal of Hydrology , 10 : 282 – 290 .
- Sacks , J. , Welch , W. , Mitchell , T. and Wynn , H. 1989 . Design and analysis of computer experiments . Statistical Science. , 4 : 409 – 423 .
- Soulis , E. D. and Seglenieks , F. 2008 . “ The MAGS integrated modeling system ” . In Cold Regions Atmospheric and Hydrologic Studies: the Mackenzie GEWEX Experience, hydrologic Processes , Edited by: Woo , M. K. Volume 2 , 445 – 473 . Berlin : Springer-Verlag .
- Stadnyk , T. , Amour , N. S. T. , Kouwen , N. , Edwards , T. W. D. , Pietroniro , A. and Gibson , J. J. 2005 . A groundwater separation study in boreal wetland terrain: The WATFLOOD hydrological model compared with stable isotope tracers . Isotopes in Environmental and Health Studies , 41 : 49 – 68 .
- Verseghy , D. L. 1991 . CLASS-A Canadian land surface scheme for GCMs, I soil model . International Journal of Climatology , 11 : 111 – 133 .
- Verseghy , D. L. 1993 . CLASS-A Canadian land surface scheme for GCMs, II vegetation model and coupled runs . International Journal of Climatology , 13 : 347 – 370 .
- Yirdaw , S. , Snelgrove , K. , Seglenieks , F. , Agboma , C. and Soulis , E. 2009 . Assessment of the WATCLASS hydrological model result of the Mackenzie River basin using the GRACE satellite total water storage measurement . Hydrological Processes , 23 : 3391 – 3400 .