
ABSTRACT
There are three phonological hypotheses on the Kaytetye segmental inventory. Hypothesis 1 proposes 30 segments: four monophthongs, one diphthong and 25 consonants. Hypothesis 2 proposes 54 segments: two monophthongs and 52 consonants. Hypothesis 3 proposes 55 segments: three monophthongs and 52 consonants. The choice between these three hypotheses has significant implications for models of phonological contrast, phonotactic organization, syllable structure and partial reduplication processes in Kaytetye. We evaluate the three hypotheses against evidence from these domains and find that Hypothesis 1 is the best supported phonological analysis. Companion analysis of the phonetic distribution and functional load of medial Kaytetye monophthong tokens was conducted by phonetically-trained transcribers, and compared with groupings of vowels obtained through unsupervised classification of first and second formant values using finite Gaussian mixture models. Both transcriber-perceived and machine-learnt categorizations agree that none of the four monophthongs are marginal, nor can their qualities be attributed to phonological context effects. These data demonstrate the importance of both phonological and phonetic evidence in evaluating the structure and properties of vowel systems in under-described languages.
1. Introduction
Kaytetye ([kaɪdɪc]) is a language of central Australia, and a member of the Arandic language family, which includes Arrernte and related languages (Koch, Citation2004). All hypotheses on the Kaytetye segmental inventory agree that the inventory contains the two vowels /a/ and /ə/ and the 25 consonantal segments listed in (Koch, Citation1984; Panther, Citation2021; San, Citation2016; Turpin, Citation2005).
Table 1. Kaytetye consonantal inventory (Harvey et al., Citation2015, p. 234).
The hypotheses differ on extension beyond this minimal inventory. The differences arise in the phonological modelling of surface vowel quality oppositions. There is a surface contrast between four monophthongs – [i], [a], [ə], [u] – as illustrated by the minimal pairs in (1).
In addition to these four monophthongs, there is a diphthong [ai].
All hypotheses agree that these vowel quality contrasts are not predictable from surface phonetic structure and that the contrasts must be phonologically specified. Analyses differ as to where the specifications for these quality contrasts are located: whether solely within the vowels themselves, or on both vowels and adjacent consonants. The choice between the various hypotheses has significant implications as the size of the Kaytetye inventory varies from 30 to 55 segments, depending upon which hypothesis is best supported. This paper provides a phonological evaluation of the hypotheses on the Kaytetye segmental inventory.
The structure of the paper is as follows. The theoretical framework assumed in these analyses is introduced in §2. In §3, we detail the hypotheses on the Kaytetye inventory. In §4, we consider phonetic and phonological analyses proposed for the other Arandic languages. There is a high degree of similarity in phonetic and phonological patterns between Arandic languages, including Kaytetye. Consequently, analyses proposed for one language have potential implications for other members of the family. In §6 and §7, we examine phonological analyses of phonetic front and round realizations: the most important domain where the three hypotheses on the Kaytetye segmental inventory differ from one another.
In §8, we consider the mapping between phonological and phonetic analyses of vowels in Kaytetye. When considering the phonological structure of a vowel system, the distribution and frequency of each vowel must also be taken into account, as the functional load could vary greatly across the lexicon (Hall, Citation2012; Hockett, Citation1967). We may consider two hypothetical cases: Lexicon A, in which four vowels are attested, but with large differences in frequency: /a/ 49%, /ə/ 49%, /i/ 1%, /u/ 1%; and Lexicon B, in which all four vowel qualities are equally frequent: /a/ 25%, /ə/ 25%, /i/ 25%, /u/ 25%. In Lexicon A, /i/ and /u/ are clearly highly marginal, and their phonemic status must be carefully reconsidered with multiple sources of evidence. In Lexicon B, where no vowel is any more or less marginal than the others, a four-vowel analysis is robustly supported.
These two hypothetical cases are at quantitative extremes, and the distribution of vowels in any lexicon probably shows some quantitative inequalities in most if not all languages, and this is the case for Kaytetye (§8.4). The essential question is whether the distribution of some vowel realizations may reasonably be described as quantitatively marginal or not. Bearing in mind these issues, a goal of this study is to evaluate different hypotheses about the Kaytetye vowel inventory by taking into account a more comprehensive range of data, including new analyses of phonetic and phonological factors. In §9, we consider the wider typological implications of the phonological analysis of the Kaytetye vowel inventory.
2. Theoretical assumptions
We assume a generative model in which phonological structure is specified in the lexicon, and phonetic forms are realized through a language-specific grammar within a model of the prosodic hierarchy which includes the prosodic word, the syllable and the mora as levels within the hierarchy (Hayes, Citation1989; Kenstowicz, Citation1994; McCarthy & Prince, Citation2017; Selkirk, Citation2004). The analyses presented here do not depend on mechanisms or assumptions specific to any particular framework: they largely address issues of contrast, underlying representation and surface form; the specific mechanisms by which phonetic forms are realized are less relevant than the broad architecture of the system. For example, in §3 we describe how different hypotheses account for the surface forms of Kaytetye consonants and vowels in terms of rules. Each of these hypotheses posit distinctions between underlying phonological representations and surface phonetic realizations and formally specifiable relationships between the underlying representation and the surface realization. However, these relationships could be formally specified in several ways, including through constraint interaction (Prince & Smolensky, Citation2004).
In any analysis of segmental oppositions, it is important to consider whether a contrast is marginal or not (Goldsmith, Citation1995; Hall, Citation2013). Some analyses of Eastern and Central Arrernte propose that /i/ and /u/ are marginal phonemes (§4). To better understand how the vowels of Kaytetye are distributed and how vowel quality interacts with lexical contrast, we present both phonetic and lexical analyses of the vowel system to consider the relative distributions of the vowels and the robustness of the contrast in the lexicon (Renwick & Ladd, Citation2016), and we quantify phoneme co-occurrence rates in key environments (Hall, Citation2012), to examine the phonological status of Kaytetye vowels in new detail.
3. Hypotheses on the Kaytetye inventory
One account of the Kaytetye segmental inventory proposes that all vowel quality specifications are associated solely with vowels. We term this analysis the ‘Vowel Intrinsic’ hypothesis. The Vowel Intrinsic hypothesis proposes four monophthongs – /a/, /ə/, /i/, /u/ – and a diphthong /ai/ (Panther, Citation2021; San, Citation2016).
An alternative analysis proposes that the only quality difference specified for vowels is the height opposition [ ± low] which differentiates /a/ from /ə/; we term this the ‘Vertical Vowel’ hypothesis. Under this analysis, [a] and [ə] are direct realizations of /a/ and /ə/, and all other surface vowel qualities – [i], [u], [ai] – arise from interactions between /ə/ and /a/ and additional phonological features associated intrinsically with consonants (Koch, Citation1984). A third analysis varies only minimally from the Vertical Vowel hypothesis. It proposes that some [i] realizations follow from an underlying /i/ specification, with other [i], [u] and [ai] realizations arising from interactions between /ə/ and /a/ and additional phonological features that are associated intrinsically with consonants (Turpin, Citation2005); we term this the ‘Intermediate’ hypothesis.
These different accounts of vocalic phonology have significant implications for the analysis of the consonant inventory. Under the Vowel Intrinsic hypothesis, the inventory in is the complete consonantal inventory for Kaytetye. Under the other two hypotheses, the consonantal inventory also includes labialized counterparts for 23 of the consonants in , as set out in .
Table 2. Labialized consonant inventory.
These labialized counterparts are complex segments with a place specification for the primary constriction and a labial specification for the release. There are two phonetic implementation rules for the realization of the labial release specification:
As shown in (3), Rule 1 operates when the following vowel is schwa and produces surface [u] realizations. Rule 2 operates when the following vowel is /a/ and produces a surface consonantal sequence [Cw].
Initial versions of the Vertical Vowel hypothesis also included another hypothesis proposing a set of complex consonants with a secondary articulation: the Pre-palatal hypothesis, as set out in (Harvey, Citation2011).
Table 3. Kaytetye pre-palatal hypothesis.
Pre-palatals are distinguished from alveolars by having a secondary palatal articulation attached to the consonantal onset. The phonetic implementation rules under this initial version of the Vertical Vowel hypothesis are set out in (4).
Under the Pre-palatal hypothesis, the phonological representations of the phonetic forms [kitə] ‘firestick’ and [kaitə] ‘edible grub’ are /kəjtə/ and /kajtə/ respectively. However, Harvey (Citation2011) provides evidence that the predictions of the Pre-palatal hypothesis are not supported. The Pre-palatal hypothesis requires that [i] realizations are followed by either alveolar or palatal consonants. However, as Breen (Citation2001) points out, both labials and velars appear following [i] realizations: e.g. [wimpa/r/ə] ‘tree grave’, [aimpə] ‘pouch’, [kika/r/ə] ‘sweet gum’, [maiŋaiŋə] ‘bronzewing pigeon’. Given that its predictions are not supported, we do not consider the Pre-palatal hypothesis further, and analyze phonological representations under the Vertical Vowel hypothesis, as exemplified in (5).
The phonetic implementation rules under this later version of the Vertical Vowel hypothesis are set out in (6).
Analysis of [i] realizations is where the Vertical Vowel and Intermediate hypotheses differ from one another. The Intermediate hypothesis proposes that [iC] realizations arise from an underlying /iC/ specification, provided that /C/ is not a palatal. Consequently, Rule 1 in (6) does not apply under the Intermediate hypothesis, but Rules 2 and 3 do apply.
4. The Arandic languages, phonetic and phonological analyses
The patterns of surface segmental realization in Kaytetye are very similar to those found in the other Arandic languages, see Breen (Citation2001) for a general overview: Antekerrepenh (Breen, Citation1977), Alyawarr (Green, Citation1992; Yallop, Citation1977), Arrernte (Breen & Dobson, Citation2005; Breen & Pensalfini, Citation1999; Breen & Pfitzner, Citation2000; Henderson, Citation2013; Wilkins, Citation1989). Consequently, it is helpful to consider phonetic and phonological analyses of other Arandic languages in evaluating hypotheses on the Kaytetye segmental inventory.
The phonological analyses of inventories in the other Arandic languages are generally Vertical Vowel analyses. Surface [u] vowels are the realizations of the labial release in complex labialized consonants. Surface [i] vowels are usually conditioned by following palatals. The only exception is Yallop’s (Citation1977) analysis of Alyawarr which is essentially a Vowel Intrinsic analysis. As with Kaytetye, there is variation in the analysis of vowel inventories across the other Arandic languages, as set out in . It is important to note that the /i/ and /u/ vowels posited in the three- and four-vowel analyses of Eastern and Central Arrernte are marginal segments. As discussed, most surface [i] and [u] vowels are realizations of features located on adjacent consonants, and these surface [i] and [u] vowels are realizations of /ə/. The /i/ and /u/ segments are posited to account for the small number of cases where [i] and [u] realizations cannot be analyzed in terms of features located on adjacent consonants.
Table 4. Proposed vowel inventories for Arandic languages other than Kaytetye.
The consonantal inventories of the other Arandic languages are identical to those proposed for Kaytetye in and . The one exception is the velar approximant /ɰ/ which, apart from Kaytetye, is also proposed for Alyawarr (Green, Citation1992), Mparntwe Arrernte (Wilkins, Citation1989, p. 84), Northern Arrernte (Henderson, Citation2013, pp. 20–21), but not for the other Arandic languages.
Among the Arandic languages, Arrernte is well known for the proposal that the basic syllable type is VC, and that consequently prosodic words are vowel-initial and consonant-final (Breen & Pensalfini, Citation1999). Given the similarity in surface phonetic realization between Arrernte and Kaytetye, the VC analysis is a potential analysis for Kaytetye. However, other proposals argue for a standard CV phonological syllable in Arrernte (Topintzi & Nevins, Citation2017).
Phonetic descriptions of Arrernte report different types of syllable-level interactions between segments. Tabain et al. (Citation2004) report that CV and VC groupings are not differentiated in the degree of control for spectral cues to consonantal place identity in Arrernte. However, this finding also holds for their research on Yanyuwa and Yindjibarndi, and there are no proposals that the phonological syllable is VC in these two languages. Graetzer (Citation2012, pp. 104–108) reports that there was no clear distinction in coarticulation between CV and VC groupings in Arrernte. However, for the three non-Arandic languages she examined – Burarra, Gupapuyngu, Warlpiri – she reports that coarticulation effects were stronger in VC groupings than CV groupings (Graetzer, Citation2012, p. 247).
From a general Australian perspective, there is no direct association between hypotheses on phonological syllable structure and the comparative roles of CV and VC groupings in the implementation of coarticulation. For Arrernte specifically, there is no clear evidence that either anticipatory coarticulation from a consonant into a preceding vowel or carryover coarticulation from a consonant into a following vowel are preferred. As such, the phonetic evidence does not favour a particular direction of phonologically specified coarticulation. The Vertical Vowel and Intermediate hypotheses both involve carryover coarticulation, e.g. /Cwə/ > [Cu]. The Vertical Vowel hypothesis also involves anticipatory coarticulation, e.g. /əjC/ > [iC].
There is one phonetic domain where Arrernte does show a clear differentiation between CV and VC groupings. Singleton consonants are phonetically lengthened before but not after the stressed vowel in Arrernte (Tabain, Citation2016). Overall, for Arrernte, the only phonetic measure which clearly differentiates CV and VC groupings favours the CV grouping, and the analysis of the phonological syllable is unresolved. We do not address the debate on the phonological syllable in the Arandic languages, as this is beyond the scope of this paper. However, given the issues with the VC hypothesis for Arrernte, we present the Kaytetye data organized according to a standard CV syllabification.
The debate over the nature of the syllable raises an important question as to what does and what does not constitute a phonological vowel at the level of the prosodic word, and this is an issue for the analysis of the segmental inventory. Breen and Pensalfini (Citation1999) propose that all words in Arrernte are vowel-initial and consonant-final. They propose that surface realizations involving word-final vowels arise from epenthesis, and that surface realizations involving consonant-initial words arise from the deletion of initial vowels. Henderson (Citation2013, pp. 61–65) argues that in the case of Arrernte, an epenthesis analysis is compatible with the evidence but not strongly supported by it. Koch (Citation1993) proposes an alternative analysis for Kaytetye – that all words have a final non-contrastive vowel, and that words can be underlyingly consonant-initial.
Because the phonemic status of vowels at word boundaries in the Arandic languages including Kaytetye is an unresolved issue, we do not examine vowel realizations in these positions in this study. We focus on word-medial vowel realizations for three reasons: (i) all analyses agree that these are realizations of underlying vowel phonemes; (ii) there is consensus that the tonic vowel in Arandic languages is the first medial vowel (Breen, Citation2001; Breen & Pensalfini, Citation1999; Henderson, Citation2013; Koch, Citation2004); and (iii) medial vowels are less prone to reduction and other prosodic factors which might influence their production. Medial vowels therefore provide the most robust source of information on contrastive vowel realization in Kaytetye.
The inventory of syllable types for Kaytetye varies depending on the analysis of vowels at word boundaries and on the segmental analysis (). Analyses which treat boundary vowels as phonemic vowels require a larger syllable inventory and analyses which do not treat boundary vowels as phonemic vowels require a smaller syllable inventory. Analyses differ as to where they permit complexity. The Vowel Intrinsic analysis permits complex onsets and complex nuclei, but not complex codas. The Vowel Intrinsic hypothesis analyzes [CwV] sequences as realizations of /CwV/ and a syllable boundary precedes the C: i.e. σ[CwV]. The Vowel Intrinsic hypothesis involves a diphthong /ai/ which is a complex nucleus. By contrast, the other two hypotheses do not permit complex onsets or complex nuclei, but they do permit complex codas. These hypotheses analyze sequences such as [aimpa] as /ajm]σ + σ[pa/].
Table 5. Potential Kaytetye syllable inventories.
5. Methods
In this paper we present three analyses of the Kaytetye vowel inventory: (i) phonological analysis of front vowel realizations (§6); (ii) phonological analysis of round vowel realizations (§7); and (iii) an overview of the mapping between phonological categories and phonetic analysis for Kaytetye vowels (§8). The front vowel and round vowel analyses involve a comparison of phonological accounts of the vowels against their proposed realizations and syllable phonotactics. The phonetic analyses of words are based in data collected as part of a long-term joint research programme with the Kaytetye community.
Sections 6 and 7 make use of two datasets: a set of partial reduplication forms used in the analysis of the distribution and realization of the round vowel (§5.1), and a set of phonetic transcriptions of recordings of dictionary headwords produced by Alison Ross (the kPhon corpus; §5.2). This corpus is used in a Gaussian Mixture Model (GMM) analysis of Kaytetye vowel phonetics, as well as two phonotactic analyses of the distribution of Kaytetye vowels (§8).
5.1 Partial reduplication dataset
We designed a set of elicitation sentences making use of 16 verb roots (). Verb roots were chosen to include all four phonetic vowels [a, ə, i, u] and the diphthong [ai] in the penultimate position. Each verb was exemplified in at least one, and up to three different sentences, resulting in a total of 43 elicitation items. The experimental materials also included six example sentences modelling the target construction and six practice sentences for the participant to learn the experimental paradigm. The complete set of elicitation materials are provided in Appendix 1.
Table 6. Verb roots used in the partial reduplication elicitation.
In April 2020, Dr David Moore worked with a middle-aged female native speaker of Kaytetye in Alice Springs. Dr Moore produced each Kaytetye sentence in Appendix 1 to demonstrate a simple verb inflected in past perfective form. The Kaytetye speaker was then prompted to repeat the sentence using a reduplicated counterpart of the same verb. For example, Dr Moore would produce the sentence: [ɭʊnə ɐinən̪ə] ‘(They) ate bread’, where [ɐinən̪ə] is a non-reduplicated form. The Kaytetye speaker then responded: [ɭʊnə ɐinəlpɐinən̪ə] ‘(They) ate bread on the way’, where [ɐinəlpɐinən̪ə] is a reduplicated verb form. Elicitation sessions were recorded on a portable digital audio device for later analysis.
All instances of verb roots and reduplicant containing rounded vowels were transcribed and independently checked for vowel quality. Textgrids were created for all tokens with round vowels to indicate the positions of these vowels in the relevant audio recordings. F1 and F2 values were retrieved using these textgrids using Praat formant measurements. Using 25 ms windows, the mean formant values of the mid 30% of each vowel were used to derive formant measurements for comparison with the kPhon data (§5.2).
5.2 The kPhon phonetic corpus
We conducted a large-scale analysis of Kaytetye vowels in the Kaytetye lexicon. The recordings used in this study were originally created for the purpose of implementing a multimedia Kaytetye to English dictionary, funded by a 2011 University of Queensland New Staff grant.Footnote1 The audio recordings were made in a recording studio in the School of Music at the University of Queensland over three days, 21–23 December 2011. They were recorded on a Roland Portable Recording Unit R-26, with either the R-26 internal microphone or a 106 Sony ECM 44S condenser microphone. Recordings were encoded at a sample rate of 48 kHz in 24-bit WAV format.
Alison Ross,Footnote2 a 41-year-old native speaker of Kaytetye, literate in both Kaytetye and English, read aloud 2,816 headwords from the Kaytetye to English Dictionary (Turpin & Ross, Citation2012), which had just been printed. Two repetitions of each headword were produced. Derived words and reduplicated forms listed in the dictionary, as well as words Ross was unfamiliar with, were not recorded. Myfany Turpin monitored the recording sessions, marking up the print dictionary and turning pages as quietly as possible. As the purpose of the multi-media dictionary was to assist Kaytetye language learning, Ross carefully enunciated words to reflect the orthography. For example, optional word-initial /a/, which is not always written, was produced depending on whether it was present in the orthographic representation. For the purpose of the current study, this could be regarded as a limitation.
Lexical items with at least two medial vowels were randomly selected from the entire lexicon to sample the full range of phonological structures associated with basic word forms in Kaytetye. Some 2,210 unique words were analyzed in this study, representing approximately 47% of the currently known Kaytetye lexicon. We used two different methods to independently determine vowel qualities and examine their distribution: (i) an auditory analysis by phonetically trained transcribers; and (ii) unsupervised classification of first and second formant values using finite GMMs. The results from each method of analysis were compared to provide a maximally informative phonetic characterization of the Kaytetye vowel system, to better inform the phonological analysis.
Two different transcribers produced independent phonetic transcriptions of the vowels in each recording. Transcribers were phonetically-trained, but had no prior knowledge of Kaytetye to ensure that they were naïve to the phonological structure of the language. Because the focus of this study is vowel quality, transcribers were provided with consonantal skeletons to guide transcription. A hypothesized phonological form was automatically generated for each word by converting the orthographic representation to IPA. Vowel and glide (/w/, /j/) symbols were removed from the automatic transcriptions to produce a consonantal skeleton for each word to be transcribed, e.g. arralke-nke (‘yawn-Pres’) → [ɐɾɐlkənkə] → [ɾlknk]. Orthographic forms of the headwords were not available to transcribers, and it was emphasized that the skeletons provided were hypothetical vowel-less approximations. Transcribers were instructed to insert IPA symbols representing the vowels that they heard, and to replace or remove any consonant labels where they disagreed with the automatically generated transcription. Transcribers were also instructed to insert IPA symbols of any glides that they perceived. Transcriptions were conducted using Praat Textgrids, in which annotators transcribed using intervals that also encoded time values, to facilitate phonetic analysis. Textgrids were organized into two tiers: an ‘ipa’ tier for lexical transcriptions, and a ‘vowel’ tier for vowel-level transcriptions. The ‘ipa’ tier demarcated beginning and end of each word, and the ‘vowel’ tier indicated the acoustic interval of each vowel.
A companion acoustic phonetic analysis of the vowels transcribed by the transcribers was conducted to independently examine their distribution in the acoustic space defined by the first and second formants. Two independent estimates of first and second formant values were automatically obtained for each medial vowel in the dataset, using two different formant trackers: Praat (Boersma & Weenink, Citation2018); and Forest, implemented as part of the wrassp package (Bombien et al., Citation2022) in R (R core team, Citation2022). The clustering analysis uses both the Praat and Forest formant measurements to minimize errors associated with either one of the estimation methods (Appendix 2, Step vii). The acoustic midpoint was located at the mean of the temporally segmented interval corresponding to each vowel token and estimates of F1 and F2 (Hz) were extracted from each formant track at that point in time. Formant values were transformed to z-scores for cross-tracker validation. A data filtering procedure summarized in Appendix 2 was applied to maximize the consistency and reliability of the dataset used for analysis. After data consolidation, 19,007 annotated vowel tokens remained. For the GMM analysis, formant values randomly-sampled from one annotation for each vowel were used: a subset of 9,379 tokens for any one iteration.
6. Front vowel realizations
As discussed in §1, three different hypotheses have been proposed to account for front vowels in Kaytetye. We illustrate these accounts in , by comparing the way that morphemes containing [i] vowels in different contexts would be represented under each hypothesis.
Table 7. Alternative phonological representations of Kaytetye front vowels.
There is a trade-off between the size of the vowel inventories and the complexity of post-lexical implementation among the three hypotheses. The Vertical Vowel theory proposes the smallest inventory, consisting of only two monophthongs /a, ə/, but requires three rules to realize forms containing these vowels, as in (7).
The Intermediate theory requires only Rules 2 and 3 but posits a three-monophthong inventory /i, a, ə/. The Vowel Intrinsic theory proposes a vowel inventory with four monophthongs /i, a, ə, u/ and a diphthong /ai/, but does not require any rules.
All three accounts are descriptively adequate for representing Kaytetye word forms with high front vowels, so evaluation of the three hypotheses depends upon their implications for other domains in Kaytetye phonology. The three theories are not differentiated in terms of the syllable inventories that they propose because all three theories require syllable inventories which include complex rimes, as illustrated in .
Table 8. Representation of complex rimes in Kaytetye.
Kaytetye complex rimes consist of complex nuclei under the Vowel Intrinsic hypothesis, and complex codas under the Intermediate and Vertical Vowel hypotheses. Under the Vertical Vowel hypothesis, complex rimes are a more frequent phenomenon than under the other two hypotheses. The Vertical Vowel hypothesis analyzes [i] before non-palatal consonants as /əj/, whereas the other two hypotheses analyze [i] as /i/ before non-palatal consonants.
6.1 Front vowels and hetero-syllabic consonant sequences
The phonological domain where the three hypotheses have distinct implications is in the analysis of hetero-syllabic consonant sequences. All analyses agree that the inventory of hetero-syllabic consonant sequences includes the sequences in .Footnote3
Table 9. Hetero-syllabic consonant sequences.
Under the Vowel Intrinsic hypothesis, this constitutes the complete inventory of hetero-syllabic consonant sequences in Kaytetye. As shown in , the inventory conforms to the Syllable Contact Law (SCL) as the sonority of the coda C1 is never less than that of the onset C2. Inventories of hetero-syllabic consonant sequence across Australian languages conform to the SCL, and there are recurrent patterns of both place and manner restrictions which further constrain these inventories (Dixon, Citation2002, pp. 553–557; Hamilton, Citation1996). The constraints governing the Kaytetye inventory in conform to these recurrent patterns. There are place constraints – only apicals appear as C1 and apicals do not appear as C2 – as well as manner constraints: approximants do not appear as C1, and [ + continuant] segments do not appear as C2.
These constraints can be motivated in both articulatory and perceptual domains; Hamilton (Citation1996) gives a detailed analysis of these factors, and here we review the principal ideas. There is a preference for the members of hetero-syllabic consonant sequences to involve two distinct articulators. Consequently, sequences of coronals – especially adjacent apicals and adjacent laminals – are dispreferred. In a cluster, C1 lacks CV transition cues and C2 lacks VC transition cues. The principal cues for retroflexes are the VC transition, so these are disfavoured in C2 position but favoured in C1 position (Steriade, Citation2001). Palatals have cues in both VC and CV transitions and so may appear in both C1 and C2 positions (Bundgaard-Nielsen et al., Citation2015). The principal cues for the other places are in the CV transitions and so they are disfavoured in C1 but favoured in C2. Given that most places have significant CV cues, Hamilton (Citation1996, pp. 8–12, 118–125) proposes that articulatory considerations play a central role in determining C1 identity, and that alveolar is preferred for C1 as the unmarked place.
Kawasaki-Fukumori (Citation1992) provides evidence that there is a universal preference for members of hetero-syllabic consonant sequences to show greater rather than lesser acoustic differentiation from one another. She observes that “The results show that some universally rare or unstable phoneme sequences can be explained on the basis of their lack of spectral modulation and/or their spectral similarity to other sequences” (Kawasaki-Fukumori, Citation1992, p. 73). Consequently, sequences of consonants with lesser acoustic differentiation from one another, such as alveolars and dentals or labials and velars, are disfavoured (Bundgaard-Nielsen et al., Citation2015).
Australian languages vary in the degree to which their inventories of hetero-syllabic consonant sequences satisfy these constraints. The minimal inventories satisfy all constraints, as exemplified by the Kalkatungu inventory in (Blake, Citation1979, p. 11). In this inventory, C1 is an apical nasal or lateral, and C2 is a labial/velar stop or nasal. The patterns of expansion from this minimal inventory conform to the place and manner constraints.
Table 10. Kalkatungu hetero-syllabic consonant sequences.
The general principle is that inventories only include clusters violating a greater number of constraints if they also include clusters violating a lesser number of constraints. Thus, an expanded inventory might show lesser satisfaction of place constraints. Comparison of the Kalkatungu and Kaytetye inventories exemplifies this, as Kaytetye permits laminals in C2, whereas Kalkatungu does not. Alternatively, an inventory might show lesser satisfaction of manner constraints, by for example permitting stops and approximants in C1 position: e.g. /tp, tk, ɻp, ɻk/. However, there are no languages attested which permit clusters involving a greater number of violations, e.g. /tt̪, tc, ɻt̪, ɻc/, but not clusters which permit a lesser number of violations: e.g. /nc, lc, rc, tp, tk, ɻp, ɻk/. The articulatory and perceptual constraints therefore offer independent motivations not only for individual inventories but also for the patterning of incremental relations between the most minimal and the most maximal inventories.
A critical difference between the Vowel Intrinsic hypothesis and the other hypotheses lies in the analysis of [ai] phonetic forms. Phonetic diphthongs such as [ai] are widely attested in Australian languages, and their potential phonological analyses are a diphthong /ai/ or a vowel + approximant sequence /aj/ (Dixon, Citation2002, pp. 552–553). Evaluations of the choice between the two analyses agree that the critical factor is how the second component of the phonetic diphthong patterns in relation to phonotactic and prosodic phenomena. If it patterns as a nuclear constituent, then the diphthong analysis is supported, whereas if it patterns as a coda constituent, then the vowel + approximant analysis is better supported (Baker, Citation2008, pp. 63–64, 145; Evans, Citation2003, pp. 75–77; McKay, Citation2011, pp. 22–23).
In the case of Kaytetye, the second component of the diphthong [ai] functions as a nucleus and not as a coda. If this second component is analyzed as a coda, then in addition to the inventory in , the hetero-syllabic consonant sequences in (8) are also required.
These clusters involve significant violations of both the articulatory and perceptual constraints, as C1 is a palatal approximant and the place specification of C2 is unrestricted. Kaytetye does not otherwise permit either approximants or palatals in C1. In other Australian languages, if clusters with palatals in C1 are permitted, then the expanded inventory consists of palatal + labial/dorsal clusters and the palatal is not an approximant: i.e. /ɲp, ɲk, ʎp, ʎk/ (Hamilton, Citation1996, pp. 126–130). Kaytetye does not otherwise permit apicals in C2 and most Australian languages do not permit apicals in C2.
There are no evident acoustic or articulatory factors which would appear to motivate the appearance of /j/ as the sole palatal and the sole approximant in C1. If palatals are permitted in C1, then it is not evident why /ɲ, ʎ/ do not also appear in C1, as nasals and laterals are otherwise permitted in C1 in Kaytetye. If approximants are permitted in C1, then it is not evident why /ɻ/ does not also appear in C1, as apicals are otherwise permitted in C1. If alveolars can appear in C2 preceded by palatals, then it is not evident why they could not be preceded by labials and dorsals: e.g. /mt, ŋt/.
If the consonant sequences in (8) are included in the inventory of Kaytetye hetero-syllabic consonant sequences, then it does not appear possible to account for consonant sequencing preferences motivated by the articulatory and perceptual factors discussed above, as the hetero-syllabic consonant sequence inventory would then be unconstrained. These issues do not arise under the Vowel Intrinsic analysis, as the sequences in (8) are not analyzed as /CC/ sequences, but rather /VC/ structures. The only constraint on /VC/ sequences in Kaytetye is that /ə + palatal/ is not permitted. Otherwise, /VC/ sequences are unconstrained and therefore /i/ may potentially be followed by any consonant, regardless of whether it is a monophthong or the second constituent in the diphthong /ai/.
These data argue that a Vowel Intrinsic hypothesis offers a more satisfactory account of consonant phonotactics in Kaytetye compared to the Intermediate and Vertical Vowel hypotheses, where the organization of hetero-syllabic consonant sequences is not clearly motivated. Under the Vowel Intrinsic hypothesis, the structure of the inventory of hetero-syllabic consonant sequences can be explained with reference to acoustic and articulatory constraints which operate generally across Australian languages.
The Vowel Intrinsic hypothesis does require that nuclei can be complex, but we note that /ai/ is the most commonly occurring diphthong in the world’s languages. /ai/ is the most frequently attested diphthong in the PHOIBLE 2.0 database (Moran & McCloy, Citation2019), and along with /au/, /ai/ occurs more than twice as frequently as any other diphthong in Maddieson’s (Citation1984) survey of inventories. The presence of a diphthong /ai/ in Kaytetye is not therefore surprising from a general typological perspective.
7. Round vowel realizations
As discussed in §1, there are two analyses of round vowels, exemplified in .Footnote4
Table 11. Phonological hypotheses on round vowel realizations.
The Vowel Intrinsic hypothesis proposes that Kaytetye has a round vowel /u/ whose realization is [u]. The Vowel Intrinsic hypothesis also proposes that Kaytetye also permits onset clusters, where C2 is the labial continuant /w/. Consequently, [Cu] is the realization of /C + u/ and [Cwa] is the realization of /C + w + a/.
The key distinction between the Vowel Intrinsic and Vertical Vowel hypotheses is the locus of rounding in /CV/ sequences. Under the Vowel Intrinsic hypothesis, the locus is the vowel and under the Vertical Vowel hypothesis, the locus is the consonant. We compare how rounding is described under the two hypotheses by first considering the implications for analyses of the Kaytetye segmental inventory, phonotactics and syllable structure.
7.1 Implications for segmental representation
The Vertical Vowel hypothesis proposes a phonemic inventory of 25 non-labialized consonants () plus 23 labialized consonants () and two vowels, /a, ə/. The Vowel Intrinsic hypothesis proposes a phonemic inventory of 25 consonants (), four monophthongs, /i, a, ə, u/, and a diphthong /ai/, and requires no post-lexical phonological processes to derive the phonetic forms observed in the lexicon. Unless there are processes or forms that are better described using the more elaborated phonological representations offered by the Vertical Vowel hypothesis, the Vowel Intrinsic hypothesis clearly provides a more parsimonious representation of the sound structure of Kaytetye.
7.2 Implications for syllabification
The Vertical Vowel hypothesis posits a smaller set of syllabic structures because it does not require complex onsets. Under the Vowel Intrinsic hypothesis, complex onsets are posited in syllables of the form /C + w/ (). Cross-linguistically, onsets of this form tend to be structured in accordance with sonority sequencing preferences such that there is maximal sonority dispersion between C1 and C2, with C1 being lower on the sonority hierarchy and C2 being higher on the sonority hierarchy (Clements, Citation1990). In Kaytetye, C2 is /w/ which is a member of the maximally sonorous approximant class, and therefore C1 cannot be more sonorous than C2.
In quantitative terms across the lexicon, /C + w/ clusters in Kaytetye conform to the cross-linguistic preference for maximal sonority dispersion. A standard sonority hierarchy for the Kaytetye consonantal inventory is set out in (Parker, Citation2008).
Table 12. Kaytetye sonority hierarchy.
The only consonant which can appear in C2 position is /w/ which belongs to the maximally sonorous Glide category. Consequently, onset clusters where C2 is less sonorous than C1 do not occur in Kaytetye. The sonority patterns found in the 228 examples of [Cwa] sequences in the Kaytetye lexicon are set out in . Of the 228 sequences, 64% show the maximal dispersion, /Stop + w/. This maximal dispersion class, /Stop + w/, is also the only multi-member sonority class where all possible [C1 + w] sequences are attested. The next most dispersed class, /Nasal + w/, has a 15% frequency. The other classes which involve less dispersion have minimal attestations. The one exception is the [ɭwa] sequence which has an overall 13% frequency. This frequency is unusual not only generally, but also within the lateral class where [ɭwa] sequences constitute 83% of [lateral + w + a] sequences. In none of the other multi-member classes does a single sequence constitute more than 50% of the class frequency.Footnote5
Table 13. Sonority patterns in [Cwa] sequences.
Given that the complex onsets posited under the Vowel Intrinsic hypothesis show prototypical cross-linguistic patterning, the advantage in eliminating them is minimal. This is particularly so when their elimination requires an effective doubling of segmental representations and additional implementation mechanisms, and when there is no other independent evidence for either the additional segmental representations or the additional implementation mechanisms.
7.3 Partial reduplication
Partial reduplication in Kaytetye copies the final disyllable of a verb root, excluding the onset of the first syllable, to produce an auxiliary verb root, as shown in (10) and (11) (Panther & Harvey, Citation2020).
The reduplicated construction in (11) has four morphosyntactic constituents: (i) the verbal root [alarə]; (ii) a ‘participial suffix’ with the phonetic form [lp(ə)] with the meaning ‘during’; (iii) a partial reduplicant [arə] functioning as an auxiliary verb, which conveys a path; and (iv) a tense–aspect–mood suffix. The morpho-syntactic structure of the reduplicated construction is shown in .
Figure 1. A partial reduplication construction in Kaytetye, with morpho-syntactic components labelled
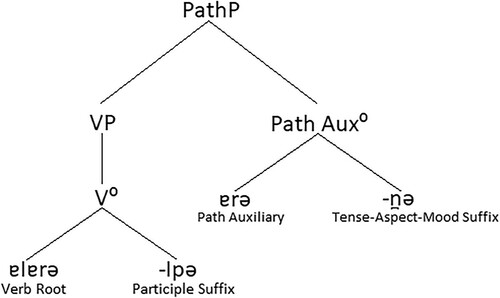
The predictions of the Vowel Intrinsic and Vertical Vowel hypotheses differ in relation to partial reduplications where the final disyllable of the verb is phonetically [CuCV].Footnote6 Under the Vowel Intrinsic hypothesis, the phonological analysis is /CuCV/ and the predicted reduplicant is /uCV/. Under the Vertical Vowel hypothesis, the phonological analysis is /CwəCV/ and the predicted reduplicant is /əCV/. The distinct predictions are illustrated in (12) and (13) with the verb root [jukə] ‘chase’.
As discussed in §5.1, we designed experimental materials targeting V1 in the VCV partial reduplicant to test the predictions of the two hypotheses.
7.3.1 Results
In all materials, the vowel realized in the reduplicated verb form matched the quality of the vowel in the penultimate position in the verbal base. As a result, all four phonetic vowels and the diphthong [ai] attested in the verbal base also appeared in the corresponding position in the reduplicant. Examples of reduplicated vowel forms containing each vowel quality transcribed from the elicitation recordings are shown in .
Table 14. Vowel qualities in partial reduplicants, with the ‘base vowel’ and ‘reduplicant vowel’ highlighted.
The experimental data included eight unique examples of a penultimate [u] vowel, from two verb roots: [jukə] ‘chase (away)’, [ʎukə] ‘light (a fire)’. The elicited data show that in all instances where an [u] occurs in penultimate position in the verbal base, the corresponding vowel in the reduplicant is also a high round vowel, i.e. [u] consistently reduplicates as [u], as illustrated for [jukə] in , and for [ʎukə] in (14), independent of the preceding consonant.
To confirm these transcriptions, we identified F1 and F2 values for each round vowel following the procedure outlined in §5.1. Furthermore, to allow comparative analysis with the kPhon database, we categorized phonetic transcriptions in kPhon into the four vowels that we hypothesize in this paper, by mapping IPA transcriptions to individual vowels. The mappings we use for the purpose of this analysis are provided in Appendix 3. Only cases where both annotators for a given phone had a transcription that mapped to the same vowel were used (e.g. [i] and [ɪ], which both map to /i/, or [u] and [ʊ], which both map to /u/). The Praat F1 and F2 measures were used. Note that this is done only for the purpose of comparison with the reduplication data, and is separate from the phonetic analysis conducted in §8.1. The results are presented in .
Figure 2. Mean F1 and F2 values of mid 30% of reduplicative base vowels (dark blue points) and corresponding reduplication vowels (purple points). Ellipses represent mid-point F1 and F2 values based on stipulated vowel phoneme groupings based on transcriptions in kPhon phonetic corpus: /i/ (red), /ə/ (green), /u/ (light blue), /a/ (yellow).
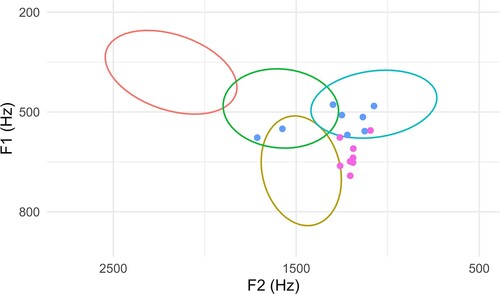
While there are outliers for the reduplicative base vowel formant values, a majority of them fall within the /u/ vowel ellipse. Surprisingly, the evidence shows that while the reduplication vowels have similar F2 values, they typically have a greater F1, meaning that they are lower than the base vowels. While the reduplication vowels do not fall within the /u/ vowel ellipse, the F2 values show they have the same backness as the majority of the reduplicative base vowels.
7.3.2 Discussion
The transcription and phonetic evidence point to the reduplicant being a phonetically round vowel. In the phonetic evidence, F2 shows that the backness of the vowel is identical to a majority of the base vowels, and therefore also the round vowels in the kPhon data. Although the reduplicants show a rise in F1, significantly they do not show a corresponding lowering of F2, which would be evidence of centralization. Consequently, the evidence here points to the reduplicant being a round vowel, like their corresponding base vowels.
Under the Vowel Intrinsic hypothesis, the base vowel is phonologically specified as [ + round] and the [ + round] vowel in the reduplicant follows directly in all standard analyses of reduplication. Under the Vertical Vowel hypothesis, the [ + round] vowel in the reduplication does not follow from default reduplicative principles. Motivations for the [ + round] vowel in the reduplication must therefore derive from other aspects of Kaytetye phonology, under the Vertical Vowel hypothesis.
There are two potential analyses of the [ + round] vowel in the reduplicant under the Vertical Vowel hypothesis. Analysis 1 posits that the surface phonetic [ + round] specification of V1 in the reduplicant results from a post-lexical harmony rule [ə] > [u]/[u](C)C_, which spreads rounding rightwards following the operation of the /Cw + / > [Cu] rule. Analysis 2 is an Overapplication analysis which posits that requirements for maximizing identity between the base and the reduplicant lead to the opaque surface phonetic specification of V1 in the reduplicant as [ + round].
Rounding harmony is attested as a phonetic phenomenon independently of reduplication constructions in Kaytetye. Rightward spread of rounding by one syllable is common, but not consistent, in Kaytetye: e.g. ‘ahead’ can be realized as [aˈrukələ] or as [aˈrukulə]. Rightward harmony only affects a following schwa: e.g. ‘bad’ can only be realized as [ˈmpukarə] and not as [ˈmpukurə]. Our database did not contain examples of rightward spreading of rounding over two syllables. Harold Koch (p.c. 2020) notes that long distance rounding spread can occur in natural speech data, and occasional examples of rounding spreading over two syllables have been noted in Kaytetye audio archives. Two different realizations of verb forms from the root [cuŋəpə-] ‘trick, jest’, one with and one without rounding spread in the third syllable are illustrated in .
Table 15 Rounding harmony across two syllables.
More research is required to better understand the prevalence, domain and constraints on the spread of rounding in Kaytetye. The current data show that there are examples of rightward spread of rounding by one or two syllables, but this spread is not consistent. Consequently, the Vertical Vowel + Harmony analysis cannot account for the fact that the reduplicant consistently shows a round vowel in the reduplication construction.
There are a number of critiques of theoretical constructs specific to base–reduplicant relations such as overapplication (Inkelas & Zoll, Citation2005; Kiparsky, Citation2010). If specific constructs for base–reduplicant relations are supported, then it is important to consider the type of overapplication in the Kaytetye partial reduplication construction. Under the Vertical Vowel hypothesis, the overapplication is that of a post-lexical phonetic implementation rule. The most immediate independent motivation for overapplication would be a general requirement that the surface phonetic realization of the reduplicant should match to the surface phonetic realization of the base. However, there is no general requirement for a surface phonetic match between the base and reduplicant, as shown in (15).
While V1 and C match between the base and reduplicant, V2 does not. The verb root is [ʎʊkə] and V2 has undergone post-lexical rounding harmony in the base, but not in the reduplicant. There do not appear to be candidates for independent phonological factors which might constrain the surface phonetic match more specifically just to V1. The reduplicant does not consistently correspond to any prosodic unit within the base, as illustrated in (16).
There is currently no clear evidence for foot structure in Kaytetye, as there is no clear evidence for secondary stress (Panther, Citation2021; Tabain et al., Citation2014). However, if foot structure should be supported, then the reduplicant would not consistently correspond to a foot in the base, and V1 in the reduplicant would not consistently correspond to the nucleus of a strong syllable in the base.
In the absence of any independent phonological motivation for opaque correspondence in surface phonetic representation between the base and reduplicant, a more specific requirement that the base and reduplicant should match in [round] values for V1 is simply a stipulative re-statement of the descriptive facts. Overall, therefore, the Vertical Vowel hypothesis cannot account for the distribution of rounding in partial reduplication constructions.
8. Mapping between phonetic and phonological vowel categories
In this section we present phonetic evidence that the distribution of Kaytetye vowel qualities is best described as four groupings, corresponding to four vowel phonemes. We show this by conducting an unsupervised GMM analysis of vowels in the kPhon database, followed by a phonotactic analysis. These sources of evidence all support the Vowel Intrinsic hypothesis.
8.1 Distribution of vowel categories
To generate candidate groupings of acoustic vowel categories, we performed unsupervised clustering on the z-normalized mid-point F1 and F2 values from the Praat and Forest formant measurements using finite GMMs, implemented by the mclust R package (v. 5.4.1) (Scrucca et al., Citation2016). GMMs model data as a mixture distribution comprising a finite number of component Gaussian distributions, G, each parameterized by a mean μ and standard deviation σ (e.g. a one-dimensional bimodal distribution could be modelled as a mixture of two component distributions, G1: <μ1, σ1> and G2: <μ2, σ2>, whose two peaks occur at μ1 and μ2, respectively). In the remainder of this section, we denote individual clusters as ‘XGY’, meaning ‘Cluster number Y within a fitted X-component GMM’, e.g. 2G1 refers to the first cluster in the two-cluster model, and 4G2 refers to the second cluster in the four-cluster model.
The distributions of vowel labels provided by annotators grouped into clusters by the z-normalized mid-point F1 and F2 values of the annotated regions by GMMs are shown in . The F1–F2 scatterplot reveals that most low vowels were classified within 2G2, while all other vowels were classified within 2G1. The histograms indicate that these classifications are comparable with IPA labels assigned by human annotators: the two most frequent labels assigned to vowels classified into 2G2 were [ɐ] (51%) and [a] (27%), and for vowels classified into 2G1, the most frequently assigned label was [ə] (42%), followed by [ʊ] (12%) and [i] (11%).
Figure 3. Scatterplots of first and second formant (F1 and F2) values, with optimal two-cluster (upper panel) and three-cluster (lower panel) fits on z-normalized F1 and F2 vowel midpoint values obtained over 10,000 iterations of unsupervised classification using GMMs. Colour and shape represent classification to a given cluster (e.g. 3G2), and size represents classification uncertainty returned by the GMM. Histograms represent within-cluster proportions of IPA label assignment by human annotators.
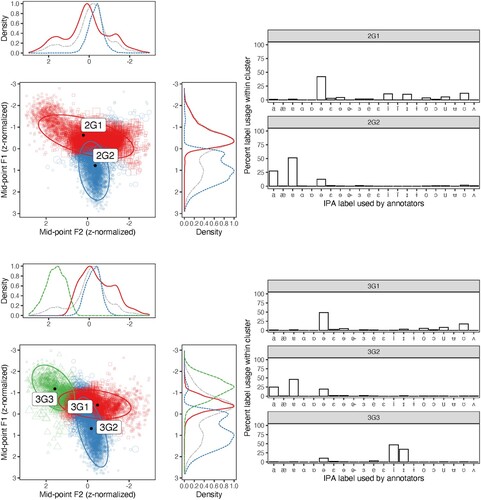
In the three-cluster model, the lower panel in , the majority of front vowels (low F1, high F2) were classified within 3G3. Most low vowels were classified within 3G2, and all other vowels were classified within 3G1. The corresponding histograms show that the most frequently assigned labels within 3G1 were [ə] (49%) and [ʊ] (18%). For vowels within 3G2, the most frequently assigned labels were [ɐ] (46%) and [ə] (20%). In 3G3, the most frequently assigned labels were [i] (47%) and [ɪ] (35%).
The distributions of vowel labels provided by annotators grouped into clusters by the z-normalized mid-point F1 and F2 values of the annotated regions by GMMs are shown in (upper panel: using a four-cluster model; bottom panel: using a five-cluster model). In the four-cluster model, 4G4 largely accounts for round vowels (low F1, low F2), 4G3 for front vowels and 4G2 for low vowels; all other vowels are classified within 4G1. The corresponding histograms reveal that the most frequently assigned label within 4G1 was [ə] (63%). For vowels within 4G2, the most frequently assigned labels were [ɐ] (60%) and [a] (30%). The most frequently assigned labels in 4G3 were [i] (52%) and [ɪ] (36%), and in 4G4: [ʊ] (45%), [u] (21%) and [o] (15%).
Figure 4. Scatterplots of first and second formant (F1 and F2) values, with optimal four-cluster (upper panel) and five-cluster (lower panel) fits on z-normalized F1 and F2 vowel midpoint values obtained over 10,000 iterations of unsupervised classification using GMMs. Colour and shape represent classification to a given cluster (e.g. 4G1), and size represents classification uncertainty returned by the GMM. Histograms represent within-cluster proportions of IPA label assignment by human annotators.
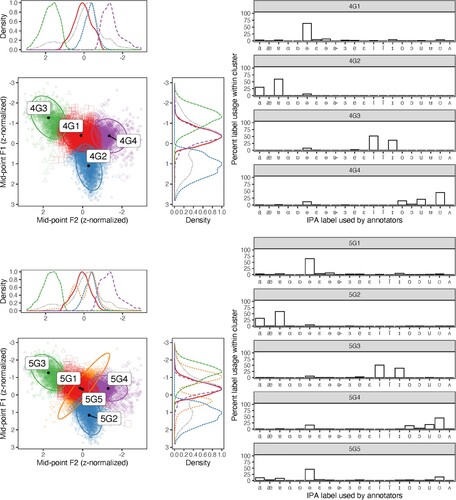
Formant classifications and vowel label distributions in the five-cluster model are shown in (bottom panel). Comparing the four- and five-cluster models, both present highly similar classifications of vowels in the acoustic plane, with the exception of the additional cluster 5G5 (orange, upside down triangles in bottom panel). The 5G5 cluster contained mainly [ə] (45%) along with some round [ʊ] (14%) and low [a] (11%) vowels.
The most frequently assigned phonetic labels associated with vowels in each cluster in optimal GMMs are summarized in . The total number of vowel tokens captured by each grouping, the modal vowel label, and the set of labels assigned to at least 10% of vowel tokens are listed for each cluster. In cluster 2G1, for example, 2,441 (42%) of the 5,789 tokens falling within the cluster were labelled [ə]. Phonological features capturing the set of most-frequently assigned vowel labels for each cluster are listed in the right-most column of .
Table 16. Most frequently assigned IPA labels of vowel tokens classified by separate GMMs. Percent usage within cluster in parentheses. Total number of tokens classified remains constant across all models (N = 9,379).
All models showed some level of mismatch between machine-classified and annotator-perceived vowel categories. Because all transcribers were native or fluent speakers of English, [ə] may have been a preferred label for vowels in non-tonic positions. An analysis of the non-modal [ə] labels revealed that most of these vowels were indeed found in non-tonic positions for all clusters except 5G5. For example, of the 576 [ə] labels captured in 2G2, 55% (316 tokens) originated in a non-tonic position; for 5G5, the majority (56%, 40 tokens) were found in the tonic position. Given differing cluster sizes, label percentages reflect a different number of vowels across models: 22% of 2G2 is 576 [ə] tokens, while 24% of 5G5 is 72 [ə] tokens. The fewest number of non-modal [ə] labels originating in a tonic position was found in the four-cluster model (32 tokens in 4G4).
The five-cluster model appears to over-differentiate the set of vowels given [ + low] labels by annotators. The set of phonetic labels captured by 5G2 and 5G5 are near identical, except for some non-modal [ə] labels within 5G5 (24% of 301 = 72 tokens). Note, however, that this is similar to the number of [ə] labels captured by the low cluster 4G2 in the optimal four-cluster analysis (11% of 722 = 79 tokens). In other words, the combined set of 5G5 and 5G2 is effectively identical to 4G2 (within similar margins of error also found in the four-cluster model), and a four-way categorization of Kaytetye vowel tokens maximizes the agreement between machine-learnt and transcriber-perceived categories.
Crucially, these results establish that the distribution of non-central and non-low vowel categories are far from marginal, whichever grouping of vowel tokens might be best supported phonologically. Under the four-vowel analysis adopted in this paper, non-central and non-low vowel categories account for 25% of the data analyzed (2,437 of 9,379 vowel tokens, in the four-cluster analysis).
8.2 Comparison of all fitted models
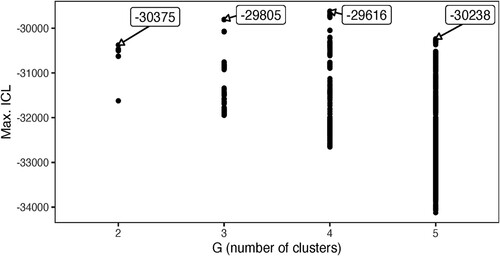
Integrated complete-data likelihood (ICL) values are compared in for GMMs fitted over formant values modelled for different numbers of clusters in the acoustic space defined by the vowel tokens in the data set (Biernacki et al., Citation2000). ICLs are shown for 40,000 fitted models (10,000 iterations × 4 numbers of fitted clusters); text labels indicate the maximum ICL value obtained within a 17 set of n-cluster models (e.g. ICLmax = −30,375 for two-cluster models). Points higher on the y-axis correspond to models with a better fit. Overall, the most optimal fit was found in a four-cluster model (ICL = −29,616). This four-cluster model was marginally a better fit than the most optimal three-cluster model, but considerably better than the most optimal fits for both two- and five-cluster models.
Figure 5. Maximum ICL values from 40,000 iterations of fitting GMMs onto z-normalized mid-point formant (F1, F2) values. Arrowed text labels annotated the maximum ICL value obtained for a given G, the number of clusters fitted by the GMM.
8.3 Distribution of vowel categories across consonant contexts
The organization of the vowel space suggested by this analysis indicates that the two high vowels – nominally [i] and [u] – are acoustically and perceptually distinct from central [ə]. If vowel quality is purely conditioned by consonant context, we might expect to find that all [ + front] vowel tokens occur adjacent to a palatal, i.e. [c, ɲ, ʎ]. Likewise, [ + round] vowels might occur in the context of a labial consonant, which may condition vowel qualities [u]/[ʊ]/[o]/[ɔ] through rounding assimilation. We consider here only conditioning which is associated with primary consonantal constriction. We do not consider conditioning which is associated with abstract secondary specifications whose principal realization is not associated with primary consonantal construction, such as the proposal for complex labialized consonants discussed in §7.
To investigate the influence of context on vowel quality, labels were assigned to each vowel token describing the place category of each adjacent consonant (e.g. ‘k__n’ → ‘Velar__Alveolar’) and the category of the vowel itself (e.g. ‘u’ → ‘Round’). All tokens where two annotators disagreed on the consonantal category label were discarded, as were tokens where the two annotators disagreed either with each other’s vowel category label or with the label induced from the four-cluster GMM. This ensured that the dataset used for this analysis reflects the most reliable vowel groupings. Some 1,652 tokens were discarded due to these criteria, leaving 7,496 tokens for contextual analysis (80.2% of tokens analyzed in §8.1).
The number of vowel tokens associated with each of the analyzed consonantal context categories is indicated in as a percentage of the total number of vowels in each vowel category (total unique types given in parentheses). For example, within the top-left ‘Round (n = 916)’ panel of , the top-left cell indicates that 1.7% (15 of 916 tokens) of round vowels were associated with the Labial__Labial consonantal context category, and these 15 vowel tokens originated from 13 unique types (headwords).
Figure 6. Distribution of 7,496 vowel tokens from four vowel groups (Round, Central, Front, Low) across 36 consonantal contexts, derived as combinations from six places of articulation (Labial, Dental, Alveolar, Retroflex, Palatal, Velar). Percentages reflect proportion of vowel tokens observed for a given context within the vowel group (e.g. 738 of 3,129 central vowel tokens in ALVEOLAR__ALVEOLAR = 23.6%). Parenthesized numbers indicate types (i.e. unique headwords) contributing to token count. Darker cell-shading indicates higher percentages. Dashed lines indicate expected contexts.
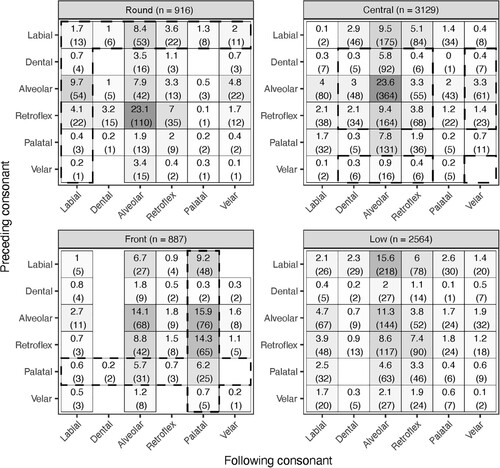
Summed frequencies in the Labial row of the Round panel in reveal that 18% (1.7 + 1 + 8.4 + 3.6 + 1.3 + 2) of round vowels occur after a labial consonant, i.e. in Labial__C context. Summed frequencies in the Labial column reveal that 16.8% (0.2 + 0.4 + 4.1 + 9.7 + 0.7 + 1.7) of round vowels occur before a labial consonant (C__Labial context). Additionally, only 14% of round vowels occurred adjacent to a Velar consonant (14% for C__Velar and Velar__C combined). The context in which round vowels occurred most frequently was Retroflex__Alveolar, accounting for 23.1% of all round vowels. Nearly half of all round vowels occurred before an alveolar consonant (48.2% = 3.4 + 1.9 + 23.1 + 7.9 + 3.5 + 8.4). These data demonstrate that the distribution of round vowels is not deterministically predictable according to the primary place feature of an adjacent consonant.
Summed frequencies in the Palatal row reveal that 13.4% (0.6 + 0.2 + 5.7 + 0.7 + 6.2) of front vowels occurred after a Palatal consonant, (Palatal__C context). Summed frequencies in the Palatal column reveal that nearly half (46.6% = 0.7 + 6.2 + 14.3 + 15.9 + 0.3 + 9.2) of front vowels occurred before a Palatal consonant (C__Palatal context). Therefore, nearly half (46.2% = 100 – (46.6 + 13.4–6.2)) of front vowels occurred in an environment with no adjacent Palatal consonants, i.e. in C__C, where C is non-palatal. Front vowels, therefore, are not deterministically predictable according to the palatal feature of an adjacent consonant.
Summed frequencies in the non-labial and non-palatal rows of the Central panel in reveal that most central vowels (68.3%: summed rows of Dental + Alveolar + Retroflex + Velar) occurred after a non-labial/-palatal consonant, predicted by progressive assimilation. At the same time, summed frequencies in the non-labial and non-palatal columns reveal that most central vowels (87%: summed columns of Dental + Alveolar + Retroflex + Velar) also occurred before a non-labial/-palatal consonant, predicted by regressive assimilation. Taken together with the patterns observed for round and front vowels, none of the three non-low Kaytetye vowel qualities are predictable according to the primary place features of an adjacent consonant, either in terms of distribution or direction (progressive or regressive assimilation).
8.4 Distribution of vowel categories across vowel positions
In many languages, the full set of vowel oppositions is found only in tonic position and non-tonic positions accommodate only a restricted subset of the full vowel inventory (Gordon, Citation2016). We investigated whether this might also be the case for Kaytetye. compares the distribution of vowel categories across the first four medial vowel positions (M1–M4) in the lexical corpus. In 97.8% of our dataset (7,340 of 7,502 tokens), the vowel occupies one of these four positions; vowel positions beyond M4 are not displayed in the figure due to data sparsity. The token total for M1 reveals that nearly half (3,411 of 7,502 = 45.5%) of all observed vowel tokens occurred in the tonic position.
Figure 7. Distribution of four vowel categories (Round, Central, Front, Low) across four medial vowel positions (M1, M2, M3, M4) within Kaytetye words. Bar plots represent proportion of vowel category within a medial position. Figures at top of panels (e.g. M1: 3,411 tokens, 1,948 types) represent total number of types and tokens within position. Figures at the bottom of bars (e.g. M1, Round = 18.1%; 619; 381) represent, respectively, the proportion of vowel category within a medial position and the number of vowel tokens and unique word types.
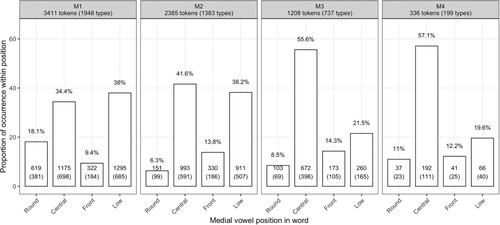
Within each position (M1–M4), low and central vowels comprised the majority of the data. Notably, however, low and central vowels have approximately equal proportions of occurrence within the tonic (M1) and immediate post-tonic (M2) positions. It is only in the non-immediate post-tonic positions (M3–M4), that central vowels occur much more frequently than low vowels. Further, all positions show substantial occurrences of the round and the front vowels.
8.5 Limitations
A limitation of the study is that it samples only one speaker whose aim was to produce audio exemplars of headwords for the Kaytetye Dictionary. As such, the speaker’s pronunciations involved a degree of attention to the gestural and temporal structure of forms produced and the forms produced can be described as monitored speech. Future research targets include a greater range of speakers and unmonitored speech. However, monitored speech has advantages as a database for analyzing segmental inventories. Factors affecting articulation and timing in speech include frequency, information content and predictability in context. High frequency, low information content and high predictability in context may result in reduction of articulatory targets and changes in speech timing (Bybee, Citation2006; Cohen Priva, Citation2017; Zipf, Citation1929). All these factors play a lesser role in the monitored production of individual word forms than in unmonitored continuous speech. Consequently, monitored production is less likely to involve gestural and timing reductions. This is a critical factor in the evaluation of phonological hypotheses on segmental inventories, as gestural and timing reductions in unmonitored continuous speech can blur or nullify phonological distinctions which are maintained in monitored speech, e.g. the realization in English of both /t/ and /d/ in intervocalic positions as a tap [ɾ] in unmonitored speech.
9. Typological implications
The phonological analysis of the Kaytetye vowel inventory is of typological interest, both generally and more specifically within Australia. There is considerable debate over the theoretical status of language universals: whether they are absolute or statistical, unconditional or conditional, or better explained as recurrent patterns arising from other factors and constraints (Bickel, Citation2011; Evans & Levinson, Citation2009; Pullum & Scholz, Citation2009; Rooryck et al., Citation2010).
Crothers (Citation1978, p. 136) proposes a universal that all languages have at least three vowel phonemes, and more specifically that “all languages have /i, a, u/”. The two-vowel /a, ə/ analysis of the Vertical Vowel hypothesis would not be consistent with this proposed universal, either in terms of the number of segments or in the qualities of the proposed segments. The three-vowel /i, a, ə/ analysis of the Intermediate hypothesis is consistent in term of the number of segments, but not in terms of the qualities of the proposed segments. The four-vowel /i, a, ə, u/ analysis of the Vowel Intrinsic hypothesis is consistent with both components of the proposed universal.
Debates over universals are necessarily grounded in typological databases. It is well known that the quality of information in typological databases varies (Everaert et al., Citation2009; Simpson, Citation1999). Particularly, there may be considerable uncertainties about information from lesser-studied languages. Maddieson’s (Citation2013) cross-linguistic typology of vowel quality oppositions samples 564 languages, and only four (0.7%) are analyzed with only two contrasting vowels, and only three (0.09%) of 3,020 inventories in PHOIBLE are analyzed as two-vowel systems (Moran & McCloy, Citation2019). Maddieson (Citation2013) notes that “these are languages in which only the height of the vowel has any distinctive function according to at least one possible interpretation of their phonetic patterns”.
If either the Vertical Vowel or Intermediate hypotheses were supported, then Kaytetye would be one of a very small number of languages which did not conform to Crothers’ proposed universal. As the Vowel Intrinsic hypothesis is the best supported analysis, Kaytetye is not a counterexample to Crothers proposed universal.
Kaytetye is not the only potential counterexample to this universal. Crothers’ database included one language, Kabardian, which has been analyzed as having fewer than three vowel phonemes. There has been considerable debate about the phonemic constituency of Kabardian (Kiparsky, Citation2018, pp. 90–94). Earlier reference grammars proposed seven vowel phonemes /ə, ɐ, ɑː, iː, uː, eː, oː/, while recent analyses propose smaller inventories whose constituents have contextual allophones arising from coarticulation (Choi, Citation1991). Although the structure of the phonological vowel inventory remains contested, instrumental studies have provided more clarity on the number of surface phonetic oppositions in Kabardian: five long vowels [iː, eː, aː, oː, uː] and two short vowels [ə, ɐ] (Gordon & Applebaum, Citation2006, Citation2010). However, there has been no detailed assessment of the implications of the various analyses of the vowel inventory across the full range of the phonology of Kabardian, including the consonantal phonology.
While the vowel inventory under the Vowel Intrinsic hypothesis is not a counterexample to Crothers’ universal, it is still of typological interest, at least in terms of Australian vowel inventories. In Australia, four-vowel systems are a minority phenomenon, and all other reported examples involve a mid vowel, i.e. either /a, e, i, u/ or /a, i, o, u/ (Busby, Citation1979, pp. 33–41; Fletcher & Butcher, Citation2014, pp. 91–94). The Kaytetye four-vowel inventory /a, ə, i, u/ is a previously undescribed subtype within the minority class of four vowel systems.
10. Conclusion
We have examined the phonological and phonetic properties of Kaytetye vowels in new detail, using a larger dataset than has previously been considered, to shed more light on the structure and behaviour of the vowel system, and to evaluate the different hypotheses proposed to account for it. Large-scale analysis of the acoustic distribution of Kaytetye citation-form monophthongs reveals four phonetically and perceptually distinct vowel qualities [i–a–ə–u]. Analysis of the frequencies and distributions of these vowels shows that none of these vowels are marginal, and none of the contrastive vowel qualities can be explained merely as allophony arising from contextual influences.
The most parsimonious account of these data is that Kaytetye uses a four-vowel system /i–a–ə–u/ (Panther, Citation2021; San, Citation2016). The primary advantage of this Vowel Intrinsic hypothesis is a direct mapping between vowel phonemes and their realization, such that no post-lexical phonological processes are required to account for the phonetic forms of vowels. Furthermore, no additional series of labialized consonant phonemes () is required to account for rounded vowels. We propose instead that Kaytetye syllables may contain a complex onset in which the second consonant is the labial approximant, and have demonstrated that the organization of syllable onsets and hetero-syllabic consonant sequences under this analysis are entirely consistent with general principles of sonority sequencing, and with the general phonotactic preferences in Australian languages.
We have presented new data on Kaytetye partial reduplication showing that rounded vowels are produced in reduplicant forms, and that these data are consistent with the Vowel Intrinsic hypothesis, but difficult to motivate under alternative approaches, where there is no independent motivation for the appearance of a [ + round] feature in the reduplicant that is not intrinsically associated with the vowel.
These data suggest that Kaytetye does not pose a challenge to the proposed universal that all languages have /i, a, u/ as vowel phonemes (Crothers, Citation1978). This is the case whether the universal is interpreted in absolute or quantitative terms, as we have shown that /i/ and /u/ do not have marginal frequencies in the Kaytetye lexicon. Finally, our analysis provides evidence that if proposals for small vowel inventories involve specification on consonants, then evaluation across the broader range of phonological phenomena relating to consonants within a language is important.
Acknowledgements
We wish to acknowledge all the Kaytetye speakers who have contributed to our research on the Kaytetye language, in particular Amy Nambulla, the late Alison Nangala Ross and the late Tommy Kngwarraye Thompson. We thank their families for permission to reproduce their names following their passing, and to use their recordings for Kaytetye language research. We also thank David Moore who undertook additional field work for this article.
Data availability statement
The data that support the findings of this study are available on request from the authors. The authors are planning to deposit the data in a public repository.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Mark Harvey
Mark Harvey is a Conjoint Associate Professor in Linguistics at the University of Newcastle. He has worked with speakers of Australian languages in the Darwin region since 1980. The morphosyntax of Australian languages is one of his principal research interests. His other research interests include phonetics, phonology, historical linguistics, kinship, ethnobiology and indigenous spatial heritage.
Nay San
Nay San is a PhD candidate in the Department of Linguistics at Stanford University. He has worked on pre-stopping in Arabana and Warlpiri lexicography. More broadly, he is interested in the use of quantitative and computational methods in language documentation and description.
Michael Proctor
Michael Proctor is Associate Professor in Linguistics at Macquarie University. His research focuses on phonetics, phonology and morphophonology, and methods for analyzing and describing sound systems, with a special interest in under-described languages.
Forrest Panther
Forrest Panther is a post-doctoral fellow at the New Zealand Institute of Language, Brain & Behaviour. His research focuses on the grammar of Te Reo Māori, and the phonology and morpho-syntax of Kaytetye.
Myfany Turpin
Myfany Turpin is a linguist and ethnomusicologist at the University of Sydney. She has been involved in language and music documentation with Aboriginal communities in central Australia since 1994. Her research focuses on describing the Kaytetye language, Aboriginal song-poetry, and the relationship between language and music. Her research on the Kaytetye language has resulted in a co-authored encyclopaedic dictionary, picture dictionary and collection of stories with the late Kaytetye speaker Alison Nangala Ross. She has written scholarly articles in the areas of lexicography, music, phonology, anthropological linguistics, and ethnobiology. She supports school language and culture programmes in central Australia and works with local organizations to produce resources for Aboriginal people to maintain their cultural and linguistic survival.
Notes
1 The multi-media dictionary called Yerrampe was released in 2016. It is a web-based locally hosted database with source code developed by Nay San, James McElvenny and Ben Foley, and compiled by Myfany Turpin and Alison Nangala Ross.
2 Alison Nangala Ross passed away on 27 March 2020. Her name is reproduced here with permission from her children.
3 The sequences given in are the heterorganic, hetero-syllabic sequences. Kaytetye also has homorganic hetero-syllabic sequences of nasal+stop and lateral+stop. However, these homorganic sequences are not subject to the same constraints as heterorganic sequences and it is the constraints on heterorganic sequences that are relevant to the evaluation of hypotheses on the vowel inventories. Consequently, we do not consider the homorganic sequences.
4 As discussed in §3, there are three hypotheses on the Kaytetye vowel inventory: Vowel Intrinsic, Vertical Vowel, Intermediate. The Vertical Vowel and Intermediate hypotheses posit the same analysis of round vowel realizations, and this analysis is a Vertical Vowel analysis with specifications on consonants and not on vowels. Consequently, we refer only to the Vertical Vowel hypothesis in the analysis of round vowel realizations.
5 It seems likely that the aberrant frequency of [ɭwa] sequences has a historical explanation in lexicalization. The term for ‘eye’ in Kaytetye is [iɭwa] and it appears a number of synchronically unanalyzable forms involving [ɭwa] derive historically from compounds involving ‘eye’.
6 In the Partial Reduplication Elicitation Transcription, the round vowel is frequently realized as [ʊ] rather than [u]; this vowel is consistently referred to as [u] in the text.
References
- Baker, B. (2008). Word structure in Ngalakgan. CSLI.
- Bickel, B. (2011). Statistical modeling of language universals. Linguistic Typology, 15(2). https://doi.org/10.1515/lity.2011.027
- Biernacki, C., Celeux, G., & Govaert, G. (2000). Assessing a mixture model for clustering with the integrated completed likelihood. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(7), 719–725. https://doi.org/10.1109/34.865189
- Blake, B. J. (1979). A Kalkatungu grammar. Dept. Of Linguistics, Research School of Pacific Studies. Australian National University.
- Boersma, P., & Weenink, D. (2018). Praat: Doing phonetics by computer (6.0.26).
- Bombien, L., Winkelmann, R., & Scheffers, M. (2022). Wrassp: An R wrapper to the ASSP Library. (1.0.2).
- Breen, G. (1977). Andegerebenha vowel phonology. Phonetica, 34(5), 371–391. https://doi.org/10.1159/000259909
- Breen, G. (2001). The wonders of Arandic phonology. In J. Simpson, D. Nash, M. Laughren, P. Austin, & B. Alpher (Eds.), Forty years on: Ken Hale and Australian languages (pp. 45–69). Pacific Linguistics.
- Breen, G., & Dobson, V. (2005). Central Arrernte. Journal of the International Phonetic Association, 35(2), 249–254. https://doi.org/10.1017/S0025100305002185
- Breen, G., & Pensalfini, R. (1999). Arrernte: A language with No syllable onsets. Linguistic Inquiry, 30(1), 1–25. https://doi.org/10.1162/002438999553940
- Breen, G., & Pfitzner, J. C. (2000). Introductory dictionary of western Arrernte. IAD Press. c2000.
- Bundgaard-Nielsen, R. L., Baker, B., Kroos, C. H., Harvey, M., & Best, C. T. (2015). Discrimination of multiple coronal stop contrasts in Wubuy (Australia): A natural referent consonant account. PLOS ONE, 10(12), e0142054. https://doi.org/10.1371/journal.pone.0142054
- Busby, P. A. (1979). A classificatory study of phonemic systems in Australian aboriginal languages [Masters]. The Australian National University.
- Bybee, J. (2006). From usage to grammar: The mind’s response to repetition. Language, 82(4), 711–733. https://doi.org/10.1353/lan.2006.0186
- Choi, J. D. (1991). An acoustic study of Kabardian vowels. Journal of the International Phonetic Association, 21(1), 4–12. https://doi.org/10.1017/S0025100300005958
- Clements, N. (1990). The role of the sonority cycle in core syllabification. In J. Kingston, & M. E. Beckman (Eds.), Papers in laboratory phonology I: Between the grammar and physics of speech (pp. 283–333). Cambridge University Press. https://doi.org/10.1017/CBO9780511627736.017
- Cohen Priva, U. (2017). Informativity and the actuation of lenition. Language, 93(3), 569–597. https://doi.org/10.1353/lan.2017.0037
- Crothers, J. (1978). Typology and universals of vowel systems in phonology. In J. Greenberg, C. Ferguson, & E. Moravcsik (Eds.), Universals of human language (Vol. 2 (pp. 93–152). Stanford University Press.
- Dixon, R. M. W. (2002). Australian languages: Their nature and development (1st ed.). Cambridge University Press. https://doi.org/10.1017/CBO9780511486869
- Evans, N. (2003). Bininj Gunwok: A pan-dialectal grammar of Mayali, Kunwinjku and Kune. Pacific Linguistics.
- Evans, N., & Levinson, S. C. (2009). The myth of language universals: Language diversity and its importance for cognitive science. Behavioral and Brain Sciences, 32(5), 429–448. https://doi.org/10.1017/S0140525X0999094X
- Everaert, M., Musgrave, S., & Dimitriadis, A. (Eds.). (2009). The Use of databases in cross-linguistic studies. Mouton de Gruyter. https://doi.org/10.1515/9783110198744
- Fletcher, J., & Butcher, A. (2014). Sound patterns of Australian languages. In H. Koch, & R. Nordlinger (Eds.), The languages and linguistics of Australia: A comprehensive guide (pp. 91–138). Walter de Gruyter.
- Goldsmith, J. (1995). Phonological theory. In J. Goldsmith (Ed.), The handbook of phonological theory (pp. 1–23). Blackwell.
- Gordon, M., & Applebaum, A. (2006). Phonetic structures of Turkish Kabardian. Journal of the International Phonetic Association, 36(2), 159–186. https://doi.org/10.1017/S0025100306002532
- Gordon, M., & Applebaum, A. (2010). Acoustic correlates of stress in Turkish Kabardian. Journal of the International Phonetic Association, 40(1), 35–58. https://doi.org/10.1017/S0025100309990259
- Gordon, M. K. (2016). Phonological typology. Oxford University Press. https://doi.org/10.1093/acprof:oso/9780199669004.001.0001
- Graetzer, S. (2012). An acoustic study of coarticulation: Consonant-vowel and vowel-to-vowel coarticulation in four Australian languages. University of Melbourne.
- Green, J. (1992). Alyawarr to English dictionary. Institute for Aboriginal Development.
- Hall, K. C. (2012). Phonological relationships: A probabilistic model. McGill Working Papers in Linguistics, 22(1).
- Hall, K. C. (2013). A typology of intermediate phonological relationships. The Linguistic Review, 30(2). https://doi.org/10.1515/tlr-2013-0008
- Hamilton, P.J. (1996). Phonetic constraints and markedness in the phonotactics of Australian aboriginal languages [PhD Thesis]. University of Toronto. https://twpl.library.utoronto.ca/index.php/twpl/article/view/6520/3491
- Harvey, M. (2011). Prepalatals in Arandic. Australian Journal of Linguistics, 31(1), 79–110. https://doi.org/10.1080/07268602.2011.532858
- Harvey, M., Lin, S., Turpin, M., Davies, B., & Demuth, K. (2015). Contrastive and Non-contrastive Pre-stopping in Kaytetye. Australian Journal of Linguistics, 35(3), 232–250. https://doi.org/10.1080/07268602.2015.1023170
- Hayes, B. (1989). The prosodic hierarchy in meter. In P. Kiparsky, & G. Youmans (Eds.), Rhythm and meter (pp. 201–260). Elsevier. https://doi.org/10.1016/B978-0-12-409340-9.50013-9
- Henderson, J. (2013). Topics in eastern and central Arrernte grammar. Lincom Europa.
- Hockett, C. F. (1967). The quantification of functional load. Word, 23(1–3), 300–320. https://doi.org/10.1080/00437956.1967.11435484
- Inkelas, S., & Zoll, C. (2005). Reduplication: Doubling in morphology (1st ed.). Cambridge University Press. https://doi.org/10.1017/CBO9780511627712
- Kawasaki-Fukumori, H. (1992). An acoustical basis for universal phonotactic constraints. Language and Speech, 35(1–2), 73–86. https://doi.org/10.1177/002383099203500207
- Kenstowicz, M. J. (1994). Phonology in generative grammar. Blackwell.
- Kiparsky, P. (2010). Reduplication in stratal OT. In L. Uyechi, & L.-H. Wee (Eds.), Reality, exploration and discovery: Pattern interaction in language and life (pp. 125–142). CSLI Publications.
- Kiparsky, P. (2018). Formal and empirical issues in phonological typology. In L. M. Hyman, & F. Plank (Eds.), Phonological typology (pp. 54–106). De Gruyter. https://doi.org/10.1515/9783110451931-003
- Koch, H. (1984). The category of ‘associated motion’. Language in Central Australia, 1(1), 23–34.
- Koch, H. (1993). Review of J. Green “Alyawarr to English dictionary”. Aboriginal History, 17(2), 167–169.
- Koch, H. (2004). The Arandic subgroup of Australian languages. In C. Bowern, & H. Koch (Eds.), Current issues in linguistic theory (Vol. 249, pp. 143–168). John Benjamins Publishing Company. https://doi.org/10.1075/cilt.249.10koc
- Maddieson. (1984). Patterns of sounds (1st ed.). Cambridge University Press. https://doi.org/10.1017/CBO9780511753459
- Maddieson, I. (2013). Vowel quality inventories. In M. Dryer, & M. Haspelmath (Eds.), The world atlas of language structures online. Max Planck Institute for Evolutionary Anthropology.
- McCarthy, J. J., & Prince, A. S. (2017). Prosodic morphology. In A. Spencer, & A. M. Zwicky (Eds.), The handbook of morphology (pp. 281–305). Blackwell Publishing Ltd. https://doi.org/10.1002/9781405166348.ch14
- McKay, G. (2011). Rembarrnga, a language of central Arnhem Land. Lincom Europa.
- Moran, S., & McCloy, D. (Eds.). (2019). PHOIBLE 2.0. Max Planck Institute for the Science of Human History. http://phoible.org.
- Panther, F. (2021). Topics in Kaytetye phonology and morpho-syntax [PhD]. University of Newcastle.
- Panther, F., & Harvey, M. (2020). Associated path in Kaytetye. Australian Journal of Linguistics, 40(1), 74–105. https://doi.org/10.1080/07268602.2019.1703644
- Parker, S. (2008). Sound level protrusions as physical correlates of sonority. Journal of Phonetics, 36(1), 55–90. https://doi.org/10.1016/j.wocn.2007.09.003
- Prince, A., & Smolensky, P. (2004). Optimality theory: Constraint interaction in generative grammar (1st ed.). Wiley. https://doi.org/10.1002/9780470759400
- Pullum, G. K., & Scholz, B. C. (2009). For universals (but not finite-state learning) visit the zoo. Behavioral and Brain Sciences, 32(5), 466–467. https://doi.org/10.1017/S0140525X09990732
- R core team. (2022). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/.
- Renwick, M. E. L., & Ladd, D. R. (2016). Phonetic distinctiveness vs. Lexical contrastiveness in Non-robust phonemic contrasts. Laboratory Phonology, 7(1), 19. https://doi.org/10.5334/labphon.17
- Rooryck, J., Smith, N. V., Liptak, A., & Blakemore, D. (2010). Editorial introduction to the special issue of lingua on Evans & Levinson’s “The myth of language universals”. Lingua, 120(12), 2651–2656. https://doi.org/10.1016/j.lingua.2010.04.012
- San, N. (2016). A quantitative analysis of vowel variation in Kaytetye [M.Res]. Macquarie University.
- Scrucca, L., Fop, M., Murphy, T.,. B., & Raftery, A. E. (2016). Mclust 5: Clustering, classification and density estimation using Gaussian finite mixture models. The R Journal, 8(1), 289. https://doi.org/10.32614/RJ-2016-021
- Selkirk, E. (2004). The prosodic structure of function words. In J. J. McCarthy (Ed.), Optimality theory in phonology (pp. 464–482). Blackwell Publishing Ltd. https://doi.org/10.1002/9780470756171.ch25
- Simpson, A. (1999). Fundamental problems in comparative phonetics and phonology: Does UPSID help to solve them? Proceedings of the 14th International Congress of Phonetic Sciences, 349–352.
- Steriade, D. (2001). Directional asymmetries in place assimilation: A perceptual account. In E. Hume, & K. Johnson (Eds.), The role of speech perception in phonology (pp. 219–250). Academic Press.
- Tabain, M. (2016). Aspects of Arrernte prosody. Journal of Phonetics, 59, 1–22. https://doi.org/10.1016/j.wocn.2016.08.005
- Tabain, M., Breen, G., & Butcher, A. (2004). VC vs. CV syllables: A comparison of Aboriginal languages with English. Journal of the International Phonetic Association, 34(2), 175–200. https://doi.org/10.1017/S0025100304001719
- Tabain, M., Fletcher, J., & Butcher, A. (2014). Lexical stress in Pitjantjatjara. Journal of Phonetics, 42, 52–66. https://doi.org/10.1016/j.wocn.2013.11.005
- Topintzi, N., & Nevins, A. (2017). Moraic onsets in Arrernte. Phonology, 34(3), 615–650. https://doi.org/10.1017/S0952675717000306
- Turpin, M. (2005). Form and meaning of Akwelye: A Kaytetye woman’s song series of Central Australia [PhD]. University of Sydney.
- Turpin, M., & Ross, A. (2012). Kaytetye to English dictionary. IAD Press.
- Wilkins, D. (1989). Mparntwe Arrernte (Aranda): Studies in the structure and semantics of grammar [Ph.D. thesis]. Australian National University. https://openresearch-repository.anu.edu.au/handle/1885/9908
- Yallop, C. (1977). Alyawarra: An Aboriginal language of central Australia. Australian Institute of Aboriginal Studies, p. 1977.
- Zipf, G. K. (1929). Relative frequency as a determinant of phonetic change. Harvard Studies in Classical Philology, 40, 1–95. https://doi.org/10.2307/310585
Appendix 1: Reduplication elicitation forms
Appendix 2: kPhon data validation and consolidation procedure
The initial dataset of kPhon phonetic transcriptions contained 35,798 unique vowel tier annotations across all word tokens and annotators. The following procedure was used to consolidate these data:
Transcriptions that contained only a consonant (e.g. [ɹ̩]) were removed, along with vowel tier annotations whose mid-point was outside of the corresponding IPA tier word transcription boundaries; 421 vowel tier annotations were removed through this process.
Word tokens containing [ərə] were removed. Epenthetic vowels were frequently perceived before trills, but were inconsistently identified as vowels by the annotators, so could not be reliably analyzed; 486 word tokens were removed according to this criterion.
Vowel realizations at word boundaries are not considered in this analysis, so vowel tier annotations located on word edges were removed; 10,890 vowel tier tokens were removed according to this criterion.
Vowel tier annotations consisting of more than one IPA symbol (e.g. [iə]) were removed; these cannot be robustly characterized within this procedure and may be associated with non-stationary F1 and/or F2 trajectories which cannot be reliably estimated at a single time point; 726 vowel tier annotations were removed according to this criterion.
Tokens in which an annotator transcribed a consonant in the vowel tier were removed; 711 vowel tier annotations were removed according to this criterion.
Tokens in which annotators disagreed on the number of vowel tier annotations were removed, so that the analysis dataset consisted only of items in which there was a high degree of inter-annotator reliability about phonological structure and vowel placement within the word; 2,845 vowel tier annotations were removed according to this criterion.
Outlier removal of vowel tier annotations with F1 and F2 values with a Praat or Forest Z score of < −3 or > 3 was conducted, removing 642 vowel tier annotations.
The resulting dataset consisted of 19,007 vowel tier annotations for analysis.